

Привет, меня зовут Павел Мурзаков, я – разработчик в команде Features в Badoo. Нам важно, чтобы наши сервисы потребляли как можно меньше ресурсов, поскольку каждый дополнительный сервер стоит денег. Поэтому мы часто профилируем и оптимизируем код. Часть наших демонов написана на Go, с оптимизацией кода на котором мне пришлось работать в последнее время. Благо в стандартной библиотеке Go есть множество готовых инструментов для этого.
Недавно мне попалась эта статья, в которой собрана информация о многих инструментах и на конкретном примере показано, как начать ими пользоваться. Кроме того, в ней есть несколько хороших рецептов по написанию эффективного кода. Эта информация будет полезна любому начинающему Go-разработчику (более продвинутые тоже смогут найти что-то для себя), поэтому я сделал для вас перевод. Enjoy!
Go имеет мощный встроенный профайлер, который поддерживает профилирование CPU, памяти, горутин и блокировок.
Подключение профайлера
Go предоставляет низкоуровневый API для профилирования runtime/pprof, но если вы разрабатываете демон, то удобнее работать с высокоуровневым пакетом net/http/pprof.
Всё, что вам нужно для подключения профайлера, – импортировать net/http/pprof; необходимые HTTP-обработчики будут зарегистрированы автоматически:
package main
import (
"net/http"
_ "net/http/pprof"
)
func hiHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hi"))
}
func main() {
http.HandleFunc("/", hiHandler)
http.ListenAndServe(":8080", nil)
}Если ваше веб-приложение использует собственный URL-роутер, необходимо вручную зарегистрировать несколько pprof-адресов:
package main
import (
"net/http"
"net/http/pprof"
)
func hiHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hi"))
}
func main() {
r := http.NewServeMux()
r.HandleFunc("/", hiHandler)
// Регистрация pprof-обработчиков
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
http.ListenAndServe(":8080", r)
}Вот и всё. Запустите приложение, а затем используйте pprof tool:
go tool pprof [binary] http://127.0.0.1:8080/debug/pprof/profileОдним из самых больших преимуществ pprof является то, что благодаря низким накладным расходам он может использоваться в продакшне без каких-либо заметных потерь производительности.
Но прежде чем углубляться в подробности работы pprof, рассмотрим на реальном примере, как можно выявить и решить проблемы с производительностью в Go.
Пример: микросервис left-pad
Предположим, вы разрабатываете совершенно новый микросервис, который заданными символами дополняет заданную строку с левого края до заданной длины:
$ curl "http://127.0.0.1:8080/v1/leftpad/?str=test&len=10&chr=*"
{"str":"******test"}Сервис должен собирать статистику: количество входящих запросов и продолжительность каждого запроса. Предполагается, что все собранные данные отправляются в агрегатор метрик (например, StatsD). Кроме того, сервису необходимо логировать параметры запроса: URL, IP-адрес и User Agent.
Начальный вариант реализации нашего примера можно найти на GitHub.
Компилируем и запускаем приложение:
go build && ./goprofexИзмерение производительности
Нам нужно определить, сколько запросов в секунду может обслуживать наш микросервис. Это можно сделать с помощью ab – Apache benchmarking tool:
ab -k -c 8 -n 100000 "http://127.0.0.1:8080/v1/leftpad/?str=test&len=50&chr=*"
# -k Включить постоянное HTTP-соединение (KeepAlive)
# -c Количество одновременных запросов
# -n Количество запросов, которое будет делать abНеплохо, но может быть быстрее:
Requests per second: 22810.15 [#/sec] (mean)
Time per request: 0.042 [ms] (mean, across all concurrent requests)Примечание: измерение проводилось на MacBook Pro Late 2013 (2,6 ГГц Intel Core i5, 8 Гб, 1600 МГц DDR3, macOS 10.12.3) с использованием Go 1.8.
Профилирование CPU
Снова запускаем Apache benchmarking tool, но уже с большим количеством запросов (1 млн должно быть достаточно). И одновременно запускаем pprof:
go tool pprof goprofex http://127.0.0.1:8080/debug/pprof/profileПрофайлер CPU по умолчанию работает в течение 30 секунд. Он использует выборку, чтобы определить, какие функции тратят большую часть процессорного времени. Рантайм Go останавливает выполнение каждые десять миллисекунд и записывает текущий стек вызовов всех работающих горутин.
Когда pprof перейдёт в интерактивный режим, введите top, чтобы увидеть список функций, которые в процентном соотношении больше всего присутствовали в полученной выборке. В нашем случае все эти функции из стандартной библиотеки и библиотеки времени выполнения (runtime), что для нас неинформативно:
(pprof) top
63.77s of 69.02s total (92.39%)
Dropped 331 nodes (cum <= 0.35s)
Showing top 10 nodes out of 78 (cum >= 0.64s)
flat flat% sum% cum cum%
50.79s 73.59% 73.59% 50.92s 73.78% syscall.Syscall
4.66s 6.75% 80.34% 4.66s 6.75% runtime.kevent
2.65s 3.84% 84.18% 2.65s 3.84% runtime.usleep
1.88s 2.72% 86.90% 1.88s 2.72% runtime.freedefer
1.31s 1.90% 88.80% 1.31s 1.90% runtime.mach_semaphore_signal
1.10s 1.59% 90.39% 1.10s 1.59% runtime.mach_semaphore_wait
0.51s 0.74% 91.13% 0.61s 0.88% log.(*Logger).formatHeader
0.49s 0.71% 91.84% 1.06s 1.54% runtime.mallocgc
0.21s 0.3% 92.15% 0.56s 0.81% runtime.concatstrings
0.17s 0.25% 92.39% 0.64s 0.93% fmt.(*pp).doPrintfЕсть более наглядный способ, который позволяет решить эту проблему – команда web. Она генерирует граф вызовов в формате SVG и открывает его в веб-браузере:
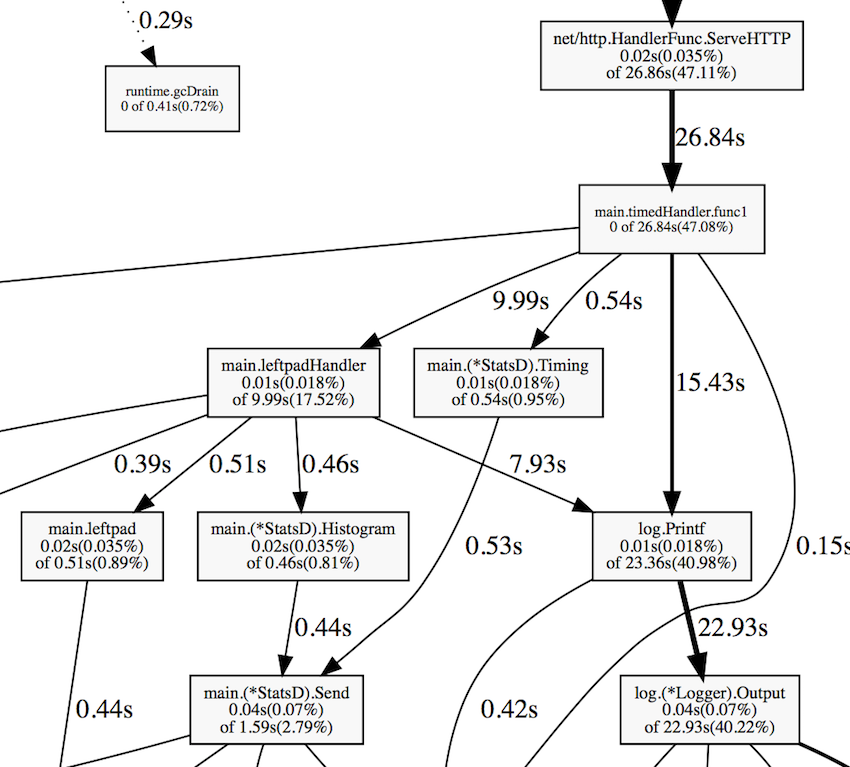
Из этого графа видно, что заметную часть процессорного времени приложение затрачивает на ведение лога и сбор метрик. Ещё некоторое время тратится на сборку мусора.
С помощью команды list можно подробно исследовать каждую функцию, например, list leftpad:
(pprof) list leftpad
ROUTINE ================= main.leftpad in /Users/artem/go/src/github.com/akrylysov/goprofex/leftpad.go
20ms 490ms (flat, cum) 0.71% of Total
. . 3:func leftpad(s string, length int, char rune) string {
. . 4: for len(s) < length {
20ms 490ms 5: s = string(char) + s
. . 6: }
. . 7: return s
. . 8:}Для тех, кто не боится смотреть на дизассемблированный код, pprof включает команду disasm, выводящую фактические инструкции процессора:
(pprof) disasm leftpad
ROUTINE ======================== main.leftpad
20ms 490ms (flat, cum) 0.71% of Total
. . 1312ab0: GS MOVQ GS:0x8a0, CX
. . 1312ab9: CMPQ 0x10(CX), SP
. . 1312abd: JBE 0x1312b5e
. . 1312ac3: SUBQ $0x48, SP
. . 1312ac7: MOVQ BP, 0x40(SP)
. . 1312acc: LEAQ 0x40(SP), BP
. . 1312ad1: MOVQ 0x50(SP), AX
. . 1312ad6: MOVQ 0x58(SP), CX
...Профилирование кучи
Запустите профайлер кучи:
go tool pprof goprofex http://127.0.0.1:8080/debug/pprof/heapПо умолчанию он показывает объём используемой памяти:
(pprof) top
512.17kB of 512.17kB total ( 100%)
Dropped 85 nodes (cum <= 2.56kB)
Showing top 10 nodes out of 13 (cum >= 512.17kB)
flat flat% sum% cum cum%
512.17kB 100% 100% 512.17kB 100% runtime.mapassign
0 0% 100% 512.17kB 100% main.leftpadHandler
0 0% 100% 512.17kB 100% main.timedHandler.func1
0 0% 100% 512.17kB 100% net/http.(*Request).FormValue
0 0% 100% 512.17kB 100% net/http.(*Request).ParseForm
0 0% 100% 512.17kB 100% net/http.(*Request).ParseMultipartForm
0 0% 100% 512.17kB 100% net/http.(*ServeMux).ServeHTTP
0 0% 100% 512.17kB 100% net/http.(*conn).serve
0 0% 100% 512.17kB 100% net/http.HandlerFunc.ServeHTTP
0 0% 100% 512.17kB 100% net/http.serverHandler.ServeHTTPНо нас больше интересует количество размещённых в куче объектов. Запустим pprof с опцией -alloc_objects:
go tool pprof -alloc_objects goprofex http://127.0.0.1:8080/debug/pprof/heapПочти 70% всех объектов были созданы двумя функциям – leftpad и StatsD.Send. Изучим их подробнее:
(pprof) top
559346486 of 633887751 total (88.24%)
Dropped 32 nodes (cum <= 3169438)
Showing top 10 nodes out of 46 (cum >= 14866706)
flat flat% sum% cum cum%
218124937 34.41% 34.41% 218124937 34.41% main.leftpad
116692715 18.41% 52.82% 218702222 34.50% main.(*StatsD).Send
52326692 8.25% 61.07% 57278218 9.04% fmt.Sprintf
39437390 6.22% 67.30% 39437390 6.22% strconv.FormatFloat
30689052 4.84% 72.14% 30689052 4.84% strings.NewReplacer
29869965 4.71% 76.85% 29968270 4.73% net/textproto.(*Reader).ReadMIMEHeader
20441700 3.22% 80.07% 20441700 3.22% net/url.parseQuery
19071266 3.01% 83.08% 374683692 59.11% main.leftpadHandler
17826063 2.81% 85.90% 558753994 88.15% main.timedHandler.func1
14866706 2.35% 88.24% 14866706 2.35% net/http.Header.cloneДругими полезными параметрами для решения проблем с памятью являются:
• -inuse_objects, показывающий количество объектов в памяти;
• -alloc_space, показывающий, сколько памяти было выделено с момента запуска программы.
Автоматическое управление памятью – вещь удобная, но в мире, увы, нет ничего бесплатного. Выделение памяти на куче не только значительно медленнее, чем выделение на стеке, но ещё и косвенно влияет на производительность. Каждый фрагмент памяти, который вы выделяете в куче, добавляет работы сборщику мусора и заставляет использовать больше ресурсов процессора. Единственный способ заставить приложение тратить меньше времени на сборку мусора – сократить количество аллокаций.
Escape-анализ
Всякий раз, когда вы используете оператор & для получения указателя на переменную или выделяете память для нового значения с помощью make или new, они не обязательно размещаются в куче:
func foo(a []string) {
fmt.Println(len(a))
}
func main() {
foo(make([]string, 8))
}В приведённом выше примере make([]string, 8) выделяет память в стеке. Go использует escape-анализ, чтобы определить, можно ли безопасно выделить память в стеке вместо кучи. Вы можете добавить опцию -gcflags=-m, чтобы увидеть результаты escape-анализа:
5 type X struct {v int}
6
7 func foo(x *X) {
8 fmt.Println(x.v)
9 }
10
11 func main() {
12 x := &X{1}
13 foo(x)
14 }
go build -gcflags=-m
./main.go:7: foo x does not escape
./main.go:12: main &X literal does not escapeКомпилятор Go достаточно умён, чтобы в некоторых случаях вместо выделения памяти в куче использовать стек. Но ситуация ухудшается, когда вы начинаете работать, например, с интерфейсами:
// Пример 1
type Fooer interface {
foo(a []string)
}
type FooerX struct{}
func (FooerX) foo(a []string) {
fmt.Println(len(a))
}
func main() {
a := make([]string, 8) // make([]string, 8) escapes to heap
var fooer Fooer
fooer = FooerX{}
fooer.foo(a)
}
// Пример 2
func foo(a interface{}) string {
return a.(fmt.Stringer).String()
}
func main() {
foo(make([]string, 8)) // make([]string, 8) escapes to heap
}В статье Дмитрия Вьюкова Go Escape Analysis Flaws описаны и другие случаи, когда escape-анализ недостаточно хорош, чтобы понять, безопасно ли выделять память в стеке.
Вообще для небольших структур, которые вам не нужно изменять, предпочтительно использовать передачу по значению, а не по ссылке.
Примечание: для больших структур дешевле передать указатель, чем скопировать всю структуру и передать её по значению.
Профилирование горутин
При запуске профайлера горутин получаем их стек вызова и количество работающих горутин:
go tool pprof goprofex http://127.0.0.1:8080/debug/pprof/goroutine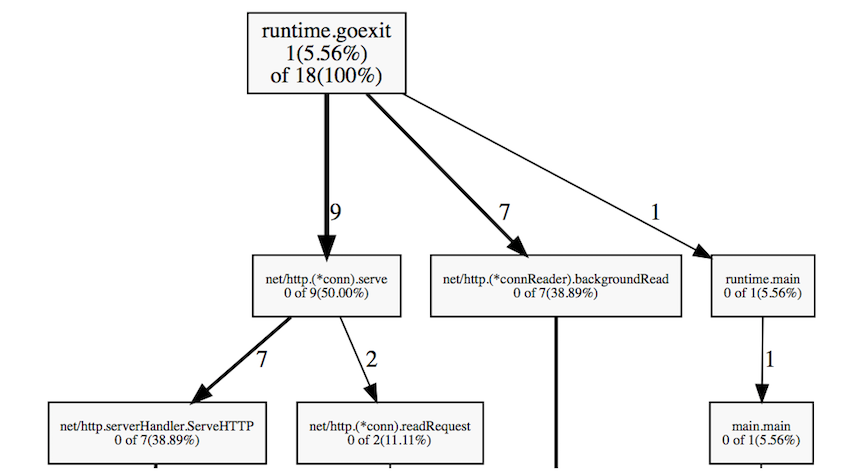
На графе отображено только 18 активных горутин, что очень мало. Нередко можно встретить тысячи запущенных горутин без существенного ухудшения производительности.
Профилирование блокировок
Профайлер блокировок показывает, где в программе происходят задержки из-за блокировок, вызванных такими объектами синхронизации, как мьютексы и каналы.
Перед запуском профайлера блокировок необходимо с помощью функции runtime.SetBlockProfileRate установить уровень профилирования. Вы можете добавить её вызов в свою функцию main или init.
go tool pprof goprofex http://127.0.0.1:8080/debug/pprof/block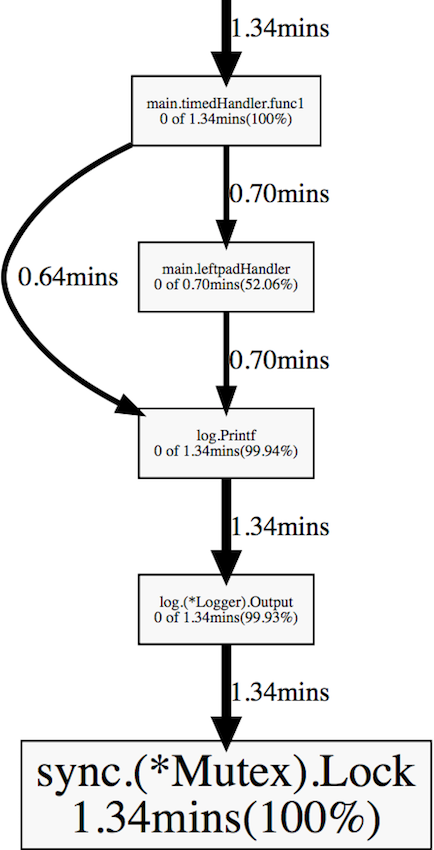
timedHandler и leftpadHandler тратят много времени на мьютексы внутри log.Printf. Причина в том, что реализация пакета log использует мьютекс, чтобы синхронизировать доступ к файлу, совместно используемому несколькими горутинами.
Бенчмаркинг
Как отмечалось выше, самыми большими нарушителями с точки зрения производительности являются функции пакетов log, leftpad и StatsD.Send. Мы нашли узкое место. Но прежде чем приступать к оптимизации, необходимо разработать воспроизводимый способ измерения производительности интересующего нас кода. Такой механизм включён в пакет testing. Нужно создать функцию вида func BenchmarkXxx(*testing.B) в тестовом файле:
func BenchmarkStatsD(b *testing.B) {
statsd := StatsD{
Namespace: "namespace",
SampleRate: 0.5,
}
for i := 0; i < b.N; i++ {
statsd.Incr("test")
}
}Также можно с использованием пакета net/http/httptest провести бенчмаркинг всего HTTP-обработчика:
func BenchmarkLeftpadHandler(b *testing.B) {
r := httptest.NewRequest("GET", "/v1/leftpad/?str=test&len=50&chr=*", nil)
for i := 0; i < b.N; i++ {
w := httptest.NewRecorder()
leftpadHandler(w, r)
}
}Запускаем бенчмарк:
go test -bench=. -benchmemОн показывает время, занимаемое каждой итерацией, а также объём и количество выделений памяти:
BenchmarkTimedHandler-4 200000 6511 ns/op 1621 B/op 41 allocs/op
BenchmarkLeftpadHandler-4 200000 10546 ns/op 3297 B/op 75 allocs/op
BenchmarkLeftpad10-4 5000000 339 ns/op 64 B/op 6 allocs/op
BenchmarkLeftpad50-4 500000 3079 ns/op 1568 B/op 46 allocs/op
BenchmarkStatsD-4 1000000 1516 ns/op 560 B/op 15 allocs/opПовышение производительности
Логирование
Хороший, но не всегда очевидный способ сделать приложение быстрее – заставить его меньше работать. За исключением случаев отладки, строка log.Printf("%s request took %v", name, elapsed) не обязательно должна присутствовать в нашем сервисе. Перед развёртыванием приложения в продакшне все ненужные логи должны быть удалены из кода или отключены. Эта проблема может быть решена с помощью одной из многочисленных библиотек для логирования.
Ещё одна важная вещь, связанная с логированием (и вообще со всеми операциями ввода-вывода), – использование по возможности буферизованного ввода-вывода, что позволяет сократить количество системных вызовов. Обычно нет необходимости записывать в файл каждый вызов логгера – для реализации буферизованного ввода-вывода используйте пакет bufio. Мы можем просто обернуть передаваемый логгеру объект io.Writer в bufio.NewWriter или bufio.NewWriterSize:
log.SetOutput(bufio.NewWriterSize(f, 1024*16))leftpad
Снова обратимся к функции leftpad:
func leftpad(s string, length int, char rune) string {
for len(s) < length {
s = string(char) + s
}
return s
}Конкатенация строк в цикле – не самая умная вещь, потому что каждая итерация цикла приводит к размещению в памяти новой строки. Лучшим способом построения строки является использование bytes.Buffer:
func leftpad(s string, length int, char rune) string {
buf := bytes.Buffer{}
for i := 0; i < length-len(s); i++ {
buf.WriteRune(char)
}
buf.WriteString(s)
return buf.String()
}В качестве альтернативы мы можем использовать string.Repeat, что позволяет немного сократить код:
func leftpad(s string, length int, char rune) string {
if len(s) < length {
return strings.Repeat(string(char), length-len(s)) + s
}
return s
}StatsD
Следующий фрагмент кода, который нам нужно изменить, – функция StatsD.Send:
func (s *StatsD) Send(stat string, kind string, delta float64) {
buf := fmt.Sprintf("%s.", s.Namespace)
trimmedStat := strings.NewReplacer(":", "_", "|", "_", "@", "_").Replace(stat)
buf += fmt.Sprintf("%s:%s|%s", trimmedStat, delta, kind)
if s.SampleRate != 0 && s.SampleRate < 1 {
buf += fmt.Sprintf("|@%s", strconv.FormatFloat(s.SampleRate, 'f', -1, 64))
}
ioutil.Discard.Write([]byte(buf)) // TODO: Write to a socket
}Вот несколько возможных улучшений:
Функция
sprintfудобна для форматирования строк. И это прекрасно, если вы не вызываете её тысячи раз в секунду. Она тратит процессорное время на разбор входящей форматированной строки и размещает в памяти новую строку при каждом вызове. Мы можем заменить её наbytes.Buffer+Buffer.WriteString/Buffer.WriteByte.
Функция не должна каждый раз создавать новый экземпляр
Replacer, он может быть объявлен ??как глобальная переменная или как часть структурыStatsD.
- Замените
strconv.FormatFloatнаstrconv.AppendFloatи передайте ему буфер, выделенный в стеке. Это предотвратит дополнительное выделение памяти в куче.
func (s *StatsD) Send(stat string, kind string, delta float64) {
buf := bytes.Buffer{}
buf.WriteString(s.Namespace)
buf.WriteByte('.')
buf.WriteString(reservedReplacer.Replace(stat))
buf.WriteByte(':')
buf.Write(strconv.AppendFloat(make([]byte, 0, 24), delta, 'f', -1, 64))
buf.WriteByte('|')
buf.WriteString(kind)
if s.SampleRate != 0 && s.SampleRate < 1 {
buf.WriteString("|@")
buf.Write(strconv.AppendFloat(make([]byte, 0, 24), s.SampleRate, 'f', -1, 64))
}
buf.WriteTo(ioutil.Discard) // TODO: Write to a socket
}
Это уменьшает количество выделений памяти с 14 до одного и примерно в четыре раза ускоряет вызов Send:
BenchmarkStatsD-4 5000000 381 ns/op 112 B/op 1 allocs/opИзмерение результата
После всех оптимизаций бенчмарки показывают очень хороший прирост производительности:
benchmark old ns/op new ns/op delta
BenchmarkTimedHandler-4 6511 1181 -81.86%
BenchmarkLeftpadHandler-4 10546 3337 -68.36%
BenchmarkLeftpad10-4 339 136 -59.88%
BenchmarkLeftpad50-4 3079 201 -93.47%
BenchmarkStatsD-4 1516 381 -74.87%
benchmark old allocs new allocs delta
BenchmarkTimedHandler-4 41 5 -87.80%
BenchmarkLeftpadHandler-4 75 18 -76.00%
BenchmarkLeftpad10-4 6 3 -50.00%
BenchmarkLeftpad50-4 46 3 -93.48%
BenchmarkStatsD-4 15 1 -93.33%
benchmark old bytes new bytes delta
BenchmarkTimedHandler-4 1621 448 -72.36%
BenchmarkLeftpadHandler-4 3297 1416 -57.05%
BenchmarkLeftpad10-4 64 24 -62.50%
BenchmarkLeftpad50-4 1568 160 -89.80%
BenchmarkStatsD-4 560 112 -80.00%Примечание: для сравнения результатов я использовал benchcmp.
Запускаем ab ещё раз:
Requests per second: 32619.54 [#/sec] (mean)
Time per request: 0.030 [ms] (mean, across all concurrent requests)Теперь веб-сервис может обрабатывать около 10 000 дополнительных запросов в секунду!
Советы по оптимизации
- Избегайте ненужных выделений памяти в куче.
- Для небольших структур используйте передачу параметров по значению, а не по ссылке.
- Заранее выделяйте память под maps и slices, если вам известен размер.
- Не логируйте без необходимости.
- Используйте буферизованный ввод-вывод, если выполняете много последовательных операций чтения или записи.
- Если ваше приложение широко использует JSON, то подумайте об использовании парсеров/ сериализаторов (лично я предпочитаю easyjson).
- В горячих местах любая операция может привести к значительному снижению производительности.
Вывод
Иногда узким местом может оказаться не то, что вы ожидаете. Поэтому профилирование является лучшим (а иногда – единственным) способом узнать реальную производительность вашего приложения.
Вы можете найти полные исходники нашего примера на GitHub. Первоначальная версия помечена как v1, а оптимизированная – как v2. Вот ссылка для сравнения двух версий.
kamilsk
В статье упомянули кастомный URL-роутер, но пример настройки не полный (хотя по тексту дальше используют конкретные профили). Для heap, goroutine,… :
lu4e3ar
В статье приведены примеры для Mux из стандартного net/http.
Ему не нужны дополнительные роуты для goroutine, threadcreate и остальных, потому что они будут обслужены в Index хендлере: https://golang.org/src/net/http/pprof/pprof.go?s=6486:6536#L207
Ваше замечание будет полезно для тех, кто использует нестандартные Mux. Спасибо.