
Добрый день! В этой статье я хотел бы вкратце рассказать о решении которое принесло мне первое место на конкурсе по машинному обучению ML Boot Camp III от mail.ru.
Представлюсь, меня зовут Карачун Михаил, я являюсь так же победителем и предыдущего конкурса mail.ru. Мое прошлое решение описано здесь и иногда я буду на него ссылаться.
Участникам конкурса было предложено на основании выборки данных спрогнозировать вероятность того, что игрок игравший в онлайн-игру покинет ее. Выборка содержала некоторые данные об активности игроков за две недели, в качестве метрики был выбран logloss, подробное описание задачи на сайте конкурса.
Каждый конкурс по машинному обучению имеет свою специфику, которая зависит от выборки данных предложенной участникам. Это может быть огромная таблица сырых логов которые нужно чистить и преобразовывать в признаки. Это может быть целая база данных с различными таблицами из которой так же нужно генерировать признаки. В нашем случае данных было очень мало (25k строк и 12 колонок), они были без пропусков и ошибок. Исходя из этого были сделаны следующие предположения:
То есть это должен был быть конкурс в котором сложно найти хорошую зависимость в данных и лучшее решение скорее будет состоять из ансамбля моделей, нежели из одной единственной. Так и вышло.
Небольшое лирическое отступление. Большинство победных решений конкурсов по машинному обучению не подходят для реальных систем. Взять хотя бы известный случай с Netflix, они заплатили 1 миллион $ за решение которое не смогли внедрить. Поэтому финальные модели в таких конкурсах напоминают мне про один роман. Вторая часть его названия «Современный Прометей» — тот самый который принес людям огонь и знания. Первая часть, конечно, «Франкенштейн».
В качестве базового решения я использовал xgboost который после оптимизации параметров через hyperopt сразу выдал результат на лидерборде 0.3825. Далее я перешел к feature engineering.
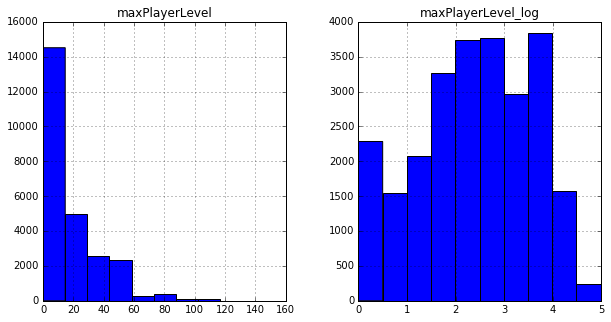
Например, было замечено, что распределения многих признаков напоминают логарифмические, поэтому к базовым колонкам я добавил их логарифмы (а точнее log(x+1)).
Дальше я генерировал различные функции от всех возможных сочетаний двух колонок и проверял как они влияют на результат. В рамках данной задачи мне показалось бессмысленным придумывать некоторые «интерпретируемые» признаки, ведь намного быстрее было бы их просто перебрать, благо объем данных позволяет. Хороший результат, например, дали разности различных признаков, что позволило получить на том же xgboost 0.3819.
Об оптимизации параметров и отборе колонок можно почитать в моей предыдущей статье.
При проверке решений уже в самом начале чемпионата оказалось что изменение оценки на лидерборде достаточно плохо соответствует изменению локальной оценки. При генерации новых колонок логлосс на локальной кросс-валидации стабильно уменьшался, а на лидерборде — рос, причем никакие изменения параметров локального разбиения выборки для проверки не помогали. Наблюдая за общим чатом конкурса, можно было заметить что с этой проблемой столкнулось очень много участников, вне зависимости от средних и дисперсий локальных оценок. Это был еще один знак в пользу создания ансамбля моделей.
На том же наборе колонок (на этот момент у меня их получилось 70) я создал еще два ансамбля градиентных деревьев, но из других библиотек — sklearn и lightgbm. Обучение происходило следующим образом — сначала я настраивал каждую модель по отдельности на лучший результат, потом брал среднее, сохранял результаты всех моделей и настраивал каждую по очереди, но уже не на собственный лучший результат, а на лучший результат в ансамбле из трех моделей. Это дало на лидерборде примерно 0.3817.
Несмотря на то что даже разные реализации одних и тех же алгоритмов при усреднении в ансамбле дают лучший результат, намного эффективней соединять вместе разные алгоритмы.
Так в общий ансамбль были добавлена логистическая регрессия. Модель строилась так же как и прошлые — генерируем все возможные признаки, рекурсивно отбираем и оставляем лучшие. Здесь меня ждало разочарование. Локальной регрессия показывала результат лучше чем xgboost! На лидерборде оценка была сильно хуже: 0.383. Я достаточно долго боролся с этим, выбрасывал признаки у которых распределение на тренировочной и тестовой выборках отличаются, пробовал различные методы нормализации, пробовал разбивать признаки на интервалы — ничего не помогало. Но даже при таком результате добавление регрессии в ансамбль оказалось полезным — результат примерно 0.3816
Раз линейная регрессия показала хороший результат, то стоит попробовать и нейронные сети. На них я потратил достаточно времени, так как применение стандартных алгоритмов гипероптимизации к структуре нейрононй сети дает очень слабый результат. В итоге была найдена неплохая конфигурация которая давала на лидерборде примерно столько же сколько и регрессия. Для реализации использовалась библиотека keras, здесь саму структуру приводить не буду, вы можете найти ее в итоговом файле, приведу лишь небольшой пример кода который мне достаточно помог. На кроссвалидации было видно что результат модели сильно зависит от количества эпох обучения. Можно снизить learning rate — но это ухудшало результат, настроить decay у меня не получилось — так же ухудшение результата. Тогда я просто решил изменить learning rate один раз в середине обучения.
Результат после добавления в ансамбль — результат примерно 0.3815.
Все вышеописанные модели были построены на примерно одних и тех же колонках — сгенерированных на основании базовых признаков и их логарифмов. Так же я попробовал генерировать признаки на основании базовых колонок и их квадратных корней. Это тоже помогло — было добавлено еще два ансамбля градиентных деревьев. Такой набор и стал окончательным: регрессия, нейронная сеть и пять ансамблей градиентных деревьев. Результат примерно 0.3813
Важным дополнением ансамбля стало небольшое изменение общего результата модели перед отправкой. Обнаружилось что в обучающей выборке есть большие группы строк с абсолютно одинаковыми признаками. А так как логлосс призывает нас оптимизировать вероятность то логично было бы заменить результаты модели на этих группах средним рассчитанным на обучающей выборке. Так и было сделано для групп размером более 50 элементов. Результат примерно 0.3809
Стэкинг. При таком большом количестве моделей кажется что можно придумать лучшую функцию для их усреднения, нежели простое арифметическое среднее. Можно, например, поместить их результаты в еще одну модель. От этой идеи я отказался потому что локальные результаты сильно не совпадали с лидербордом, причем не работал даже простейший вид стекинга — взвешенное среднее.
Ручное изменение результатов. На обучающей выборке встречались подгруппы чьи результаты были строго 1 или строго 0, например, все игроки игравшие 14 дней. Тут конечно стоило помнить о том, как сильно логлосс наказывает за такие значения, в случае использования можно было потерять не одну сотню мест.
Так же до последнего момента среди моделей был еще random forest, но в итоге на основании public score я его исключил, хотя, как потом оказалось, на privat score модель с ним показывала лучший результат.
В итоге очень хочется поблагодарить организаторов! Вот здесь можно посмотреть исходный код решения.
Представлюсь, меня зовут Карачун Михаил, я являюсь так же победителем и предыдущего конкурса mail.ru. Мое прошлое решение описано здесь и иногда я буду на него ссылаться.
Условия
Участникам конкурса было предложено на основании выборки данных спрогнозировать вероятность того, что игрок игравший в онлайн-игру покинет ее. Выборка содержала некоторые данные об активности игроков за две недели, в качестве метрики был выбран logloss, подробное описание задачи на сайте конкурса.
Вступление
Каждый конкурс по машинному обучению имеет свою специфику, которая зависит от выборки данных предложенной участникам. Это может быть огромная таблица сырых логов которые нужно чистить и преобразовывать в признаки. Это может быть целая база данных с различными таблицами из которой так же нужно генерировать признаки. В нашем случае данных было очень мало (25k строк и 12 колонок), они были без пропусков и ошибок. Исходя из этого были сделаны следующие предположения:
- Генерировать и перебирать гипотезы эффективней, чем их придумывать, так как объем данных очень мал.
- Скорее всего в выборке нет какой-то одной очень крутой скрытой зависимости которая в итоге все решит (killer feature).
- Скорее всего борьба будет за n-нный знак после запятой и топ-10 будет очень плотный.
То есть это должен был быть конкурс в котором сложно найти хорошую зависимость в данных и лучшее решение скорее будет состоять из ансамбля моделей, нежели из одной единственной. Так и вышло.
Небольшое лирическое отступление. Большинство победных решений конкурсов по машинному обучению не подходят для реальных систем. Взять хотя бы известный случай с Netflix, они заплатили 1 миллион $ за решение которое не смогли внедрить. Поэтому финальные модели в таких конкурсах напоминают мне про один роман. Вторая часть его названия «Современный Прометей» — тот самый который принес людям огонь и знания. Первая часть, конечно, «Франкенштейн».
Базовое решение
В качестве базового решения я использовал xgboost который после оптимизации параметров через hyperopt сразу выдал результат на лидерборде 0.3825. Далее я перешел к feature engineering.
Например, было замечено, что распределения многих признаков напоминают логарифмические, поэтому к базовым колонкам я добавил их логарифмы (а точнее log(x+1)).
Дальше я генерировал различные функции от всех возможных сочетаний двух колонок и проверял как они влияют на результат. В рамках данной задачи мне показалось бессмысленным придумывать некоторые «интерпретируемые» признаки, ведь намного быстрее было бы их просто перебрать, благо объем данных позволяет. Хороший результат, например, дали разности различных признаков, что позволило получить на том же xgboost 0.3819.
Об оптимизации параметров и отборе колонок можно почитать в моей предыдущей статье.
Первые неприятности
При проверке решений уже в самом начале чемпионата оказалось что изменение оценки на лидерборде достаточно плохо соответствует изменению локальной оценки. При генерации новых колонок логлосс на локальной кросс-валидации стабильно уменьшался, а на лидерборде — рос, причем никакие изменения параметров локального разбиения выборки для проверки не помогали. Наблюдая за общим чатом конкурса, можно было заметить что с этой проблемой столкнулось очень много участников, вне зависимости от средних и дисперсий локальных оценок. Это был еще один знак в пользу создания ансамбля моделей.
Больше деревьев …
На том же наборе колонок (на этот момент у меня их получилось 70) я создал еще два ансамбля градиентных деревьев, но из других библиотек — sklearn и lightgbm. Обучение происходило следующим образом — сначала я настраивал каждую модель по отдельности на лучший результат, потом брал среднее, сохранял результаты всех моделей и настраивал каждую по очереди, но уже не на собственный лучший результат, а на лучший результат в ансамбле из трех моделей. Это дало на лидерборде примерно 0.3817.
Регрессия
Несмотря на то что даже разные реализации одних и тех же алгоритмов при усреднении в ансамбле дают лучший результат, намного эффективней соединять вместе разные алгоритмы.
Так в общий ансамбль были добавлена логистическая регрессия. Модель строилась так же как и прошлые — генерируем все возможные признаки, рекурсивно отбираем и оставляем лучшие. Здесь меня ждало разочарование. Локальной регрессия показывала результат лучше чем xgboost! На лидерборде оценка была сильно хуже: 0.383. Я достаточно долго боролся с этим, выбрасывал признаки у которых распределение на тренировочной и тестовой выборках отличаются, пробовал различные методы нормализации, пробовал разбивать признаки на интервалы — ничего не помогало. Но даже при таком результате добавление регрессии в ансамбль оказалось полезным — результат примерно 0.3816
Нейронные сети
Раз линейная регрессия показала хороший результат, то стоит попробовать и нейронные сети. На них я потратил достаточно времени, так как применение стандартных алгоритмов гипероптимизации к структуре нейрононй сети дает очень слабый результат. В итоге была найдена неплохая конфигурация которая давала на лидерборде примерно столько же сколько и регрессия. Для реализации использовалась библиотека keras, здесь саму структуру приводить не буду, вы можете найти ее в итоговом файле, приведу лишь небольшой пример кода который мне достаточно помог. На кроссвалидации было видно что результат модели сильно зависит от количества эпох обучения. Можно снизить learning rate — но это ухудшало результат, настроить decay у меня не получилось — так же ухудшение результата. Тогда я просто решил изменить learning rate один раз в середине обучения.
from keras.callbacks import Callback as keras_clb
class LearningRateClb(keras_clb):
def on_epoch_end(self, epoch, logs={}):
if epoch ==300:
self.model.optimizer.lr.set_value(0.01)
Результат после добавления в ансамбль — результат примерно 0.3815.
Больше моделей богу моделей
Все вышеописанные модели были построены на примерно одних и тех же колонках — сгенерированных на основании базовых признаков и их логарифмов. Так же я попробовал генерировать признаки на основании базовых колонок и их квадратных корней. Это тоже помогло — было добавлено еще два ансамбля градиентных деревьев. Такой набор и стал окончательным: регрессия, нейронная сеть и пять ансамблей градиентных деревьев. Результат примерно 0.3813
Анализ выборки
Важным дополнением ансамбля стало небольшое изменение общего результата модели перед отправкой. Обнаружилось что в обучающей выборке есть большие группы строк с абсолютно одинаковыми признаками. А так как логлосс призывает нас оптимизировать вероятность то логично было бы заменить результаты модели на этих группах средним рассчитанным на обучающей выборке. Так и было сделано для групп размером более 50 элементов. Результат примерно 0.3809
Идеи от которых я отказался
Стэкинг. При таком большом количестве моделей кажется что можно придумать лучшую функцию для их усреднения, нежели простое арифметическое среднее. Можно, например, поместить их результаты в еще одну модель. От этой идеи я отказался потому что локальные результаты сильно не совпадали с лидербордом, причем не работал даже простейший вид стекинга — взвешенное среднее.
Ручное изменение результатов. На обучающей выборке встречались подгруппы чьи результаты были строго 1 или строго 0, например, все игроки игравшие 14 дней. Тут конечно стоило помнить о том, как сильно логлосс наказывает за такие значения, в случае использования можно было потерять не одну сотню мест.
Так же до последнего момента среди моделей был еще random forest, но в итоге на основании public score я его исключил, хотя, как потом оказалось, на privat score модель с ним показывала лучший результат.
В итоге очень хочется поблагодарить организаторов! Вот здесь можно посмотреть исходный код решения.
Поделиться с друзьями