
Больше изоленты!
У меня есть друг, его профессия связана с электромонтажом. Когда он был моложе и циничнее, он любил травить байки про электриков, которые работали на необесточенных сетях. Конец всегда был занимательный, но печальный для главного героя. С компонентной архитектурой так же: где-нибудь не изолируешь один функционал от другого, «ударит током» и тебя, и того, кто будет после тебя. Разница в том, что изоляция в IT пока более затратное удовольствие, чем в электрике.

В предыдущей статье мы уже делали первые инженерные оценки объема функционала нового решения для Сбербанка – Единой Фронтальной Системы. Мы делали упор на количественные оценки объема функционала, на способы его производства и развития. Пора поговорить о его связанности и способах изоляции функционала.
В первую очередь мы изолировали друг от друга системный, прикладной и интеграционный функционал. По факту, это разные «электрические цепи», с разным «напряжением» и режимом эксплуатации. Получилась метамодель допустимых зависимостей, как на рисунке ниже:
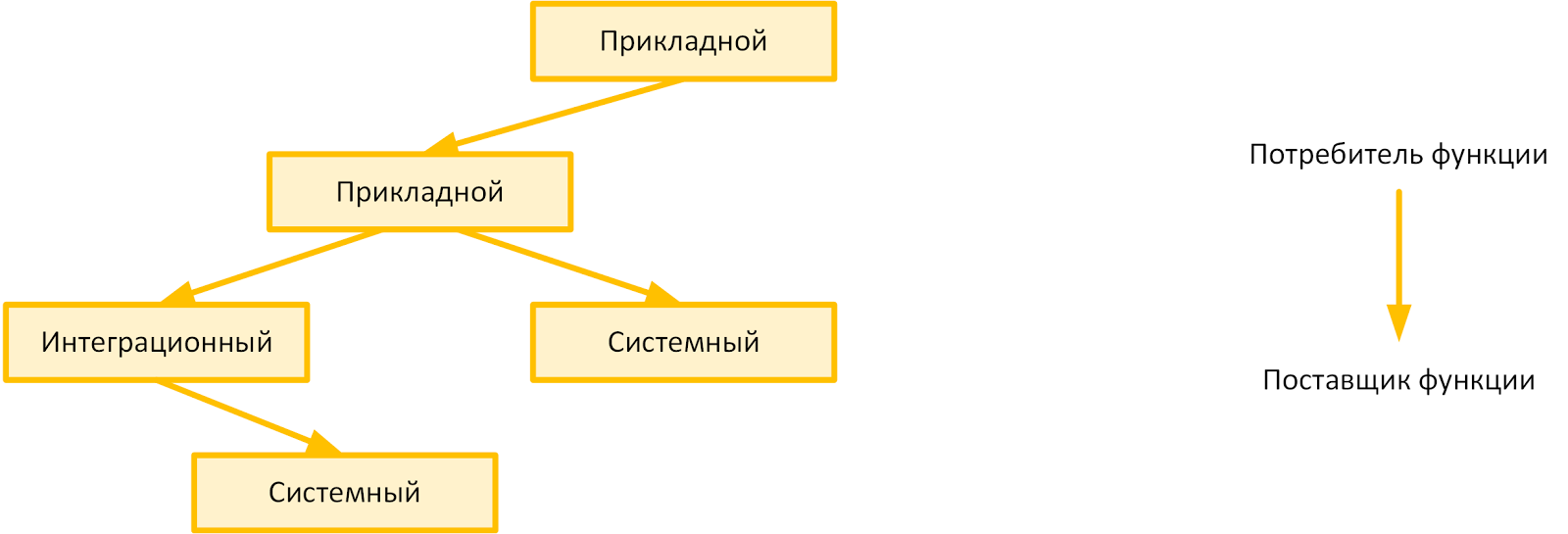
Естественно, в масштабах Сбербанка преобладающим является прикладной функционал. Поэтому про него поговорим отдельно.
Аналогом «нелинейной электрической цепи» для фронтальной банковской системы является фронтальный сценарий обслуживания клиента. Точно так же, как и цепи, фронтальные сценарии могут быть разветвленными и включать в себя множество подпроцессов. Естественным желанием каждого архитектора, который уже работал на «необесточенных сетях», является желание гранулировать процессы как можно сильнее, чтобы любые изменения приводили к меньшему регрессу.
Аналогом «линейной электрической цепи» для Единой Фронтальной Системы является любая state-less логика, вызываемая со стороны фронтальных сценариев. В отличие от самих сценариев, у нее свой жизненный цикл. В Сбербанке он подчинен общей программе замены legacy-функционала на решения на базе собственной перспективной платформы автоматизации back- и middle-офисного банковского функционала.
Продолжая аналогию, отдельные электрические цепи мы обмотали изолентой и ввели понятие «модуля» — группы прикладного функционала, сильно связанного внутри и слабо связанного с другим функционалом. После реализации в коде — это обычный jar-файл и pom-артефакт.
Хотя мы старались ограничиться небольшим унифицированным количеством правил для гранулизации прикладного функционала, нам все равно понадобилось очень много изоленты. На серверной стороне целевое количество модулей >= 104. Вот эти правила:
- разделение state-less и state-full логики по разным модулям;
- разделение логики над сущностями разных доменов по разным модулям;
- вынесение в отдельные модули любого публичного API;
- разделение по разным модулям продуктово-специфичной и канало-специфичной логики;
- выделение модулей для концентрации зависимостей.
Получилась приблизительно следующая метамодель модульной концентрации прикладного функционала, изолированного друг от друга:
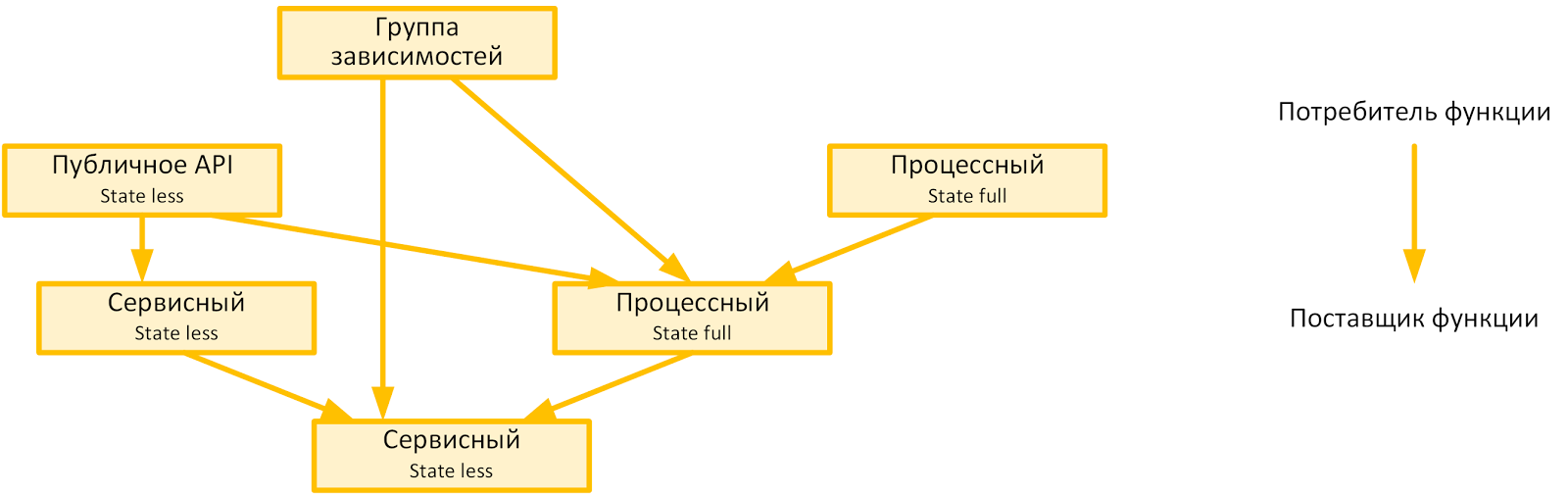
Пределы грануляции определены устойчивостью API модуля (сервисного API и API вызова отдельного подпроцесса) при:
- изменениях требований регулятора и представлении заказчика о целевом функционале к автоматизации;
- изменении системного или интеграционного функционала, которому ЕФС делегирует state-less логику;
- изменении последовательности state-full цепочек обработки.
Размер отдельного модуля — 20-50 java-классов.
Пока всего 5% модулей менялись реже одного раза в квартал, и в будущем эта тенденция сохранится. Значит, для соблюдения архитектурной техники безопасности требуется добавить изоленты непосредственно в сами модули. Хорошо, что до нас уже придумали такие паттерны, как мостики, адаптеры и фасады. Все это и стало естественной изолентой внутри самих модулей.
Общая типовая архитектура для самых распространенных прикладных модулей показана на рисунке ниже. Естественно, акцент сделан не на том, что там происходит, а на том, как это изолировано друг от друга.
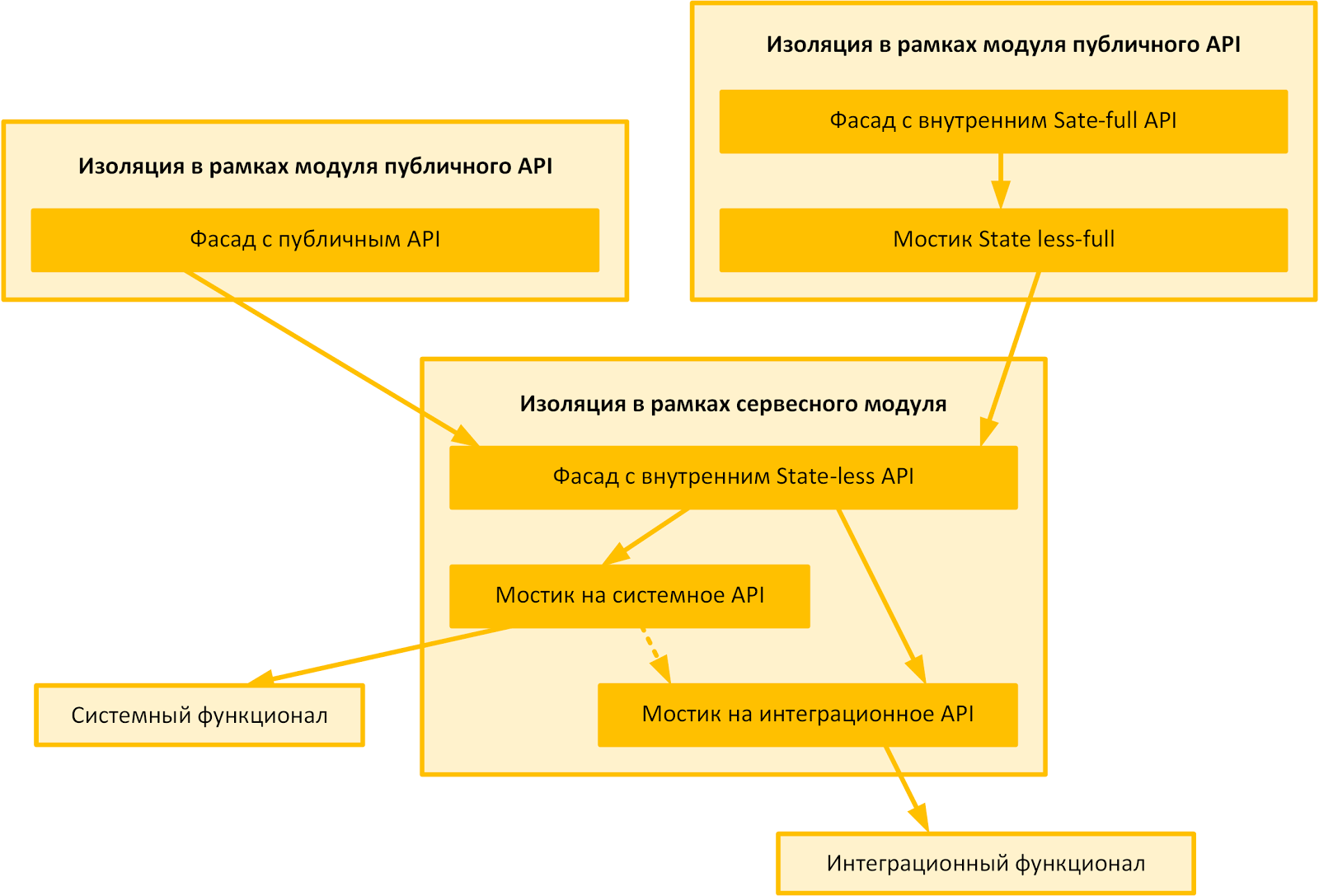
По характеру грануляции функционала, с точки зрения исполняющего потока, архитектура отдельных модулей больше всего соответствует layered architecture. С точки зрения конечного приложения, включающего по зависимости целую группу прикладных модулей, – process driven architecture.
Гранулизация и обилие изоляции, кроме приведенных плюсов, имеет еще и следующие:
- все формы взаимодействия хорошо разделяются на типовые, и для их участников можно использовать или абстракции, или маркерные интерфейсы;
- несколько независимых команд разработчиков могут править один и тот же модуль несколько месяцев, и он каким-то чудесным образом сохраняет работоспособность;
- мостики, адаптеры и фасады являются удачными местами для концентрации «костылей», которые появляются на той или иной стадии «недозрелости» или «перезрелости» кода;
- легкий верхнеуровневый контроль архитектурных нарушений. Достаточно глянуть в pom-файл и сверить фактические зависимости с проектными;
- поскольку системного функционала всегда не хватает, его ранние прообразы легко изолировать на уровне отдельных прикладных модулей, а возникающая избыточная связанность не «растекается», «отравляя код».
Среди существенных недостатков:
- высокая трудоемкость поддержания высокой гранулярности. Собственно, мостики, адаптеры, фасады и огромное количество кода по перекладке одной структуры данных в другую требуют реализации;
- необходимо наличие развитого функционала управления версиями и impact-анализа, чтобы не погрузить все решение в jar hell;
- сквозные кросс-модульные изменения кода требуют синхронного переключения с ветки на ветку для связанной группы модулей, а pull-request-ы должны приниматься с учетом межмодульных зависимостей.
Микросервисно-монолитный дуализм
Среди известных лабораторных работ по физике для первокурсников есть эксперименты с фотонами, которые одновременно ведут себя и как частицы (корпускулы), и как волна. Эти опыты используют для иллюстрации непостижимых на бытовом уровне свойств корпускулярно-волнового дуализма. У Единой Фронтальной Системы Сбербанка очень схожее поведение.
У ЕФС есть два требования, каждое из которых само по себе безобидно:
- «Корпускулярное требование»: изменение любого прикладного функционала должно предполагать минимальный регресс смежного, включая аналогичный функционал в других каналах. Вся ЕФС никогда не должна попадать под сквозной регресс. Кроме того, «корпускулярность» ЕФС неизбежна из-за большого количества команд, разрабатывающих независимо прикладной функционал.
- «Волновое требование»: изменение логики обслуживания клиента должно проводиться сразу по всем каналам обслуживания. Это как раз основная идея, отраженная в названии «Единая Фронтальная Система», — минимизировать канало-специфичные затраты на вывод продукта в каждый канал.
В целом оба требования противоречивы и заставляют задуматься об «интерференции и дифракции» в архитектуре. Первое требование хорошо реализуется в микросервисной архитектуре, второе – в монолитной.
Решение проблемы -в управлении зависимостями. У нас должны быть зависимости одного рода, железобетонно гарантирующие минимальный регресс и прозрачные, с точки зрения требования внедрения продуктов по всем каналам. И наоборот, иметь группу зависимостей «прозрачных», с точки зрения объемов регресса, и железобетонных — для изменения продуктов.
Первую группу зависимостей, удовлетворяющих этим требованиям, можно создать, опираясь на практики Domain-driven design и общее понимание автоматизируемой банковской области. Если проводить аналогии с ядерной физикой, достаточно выделить элементарные стабильные
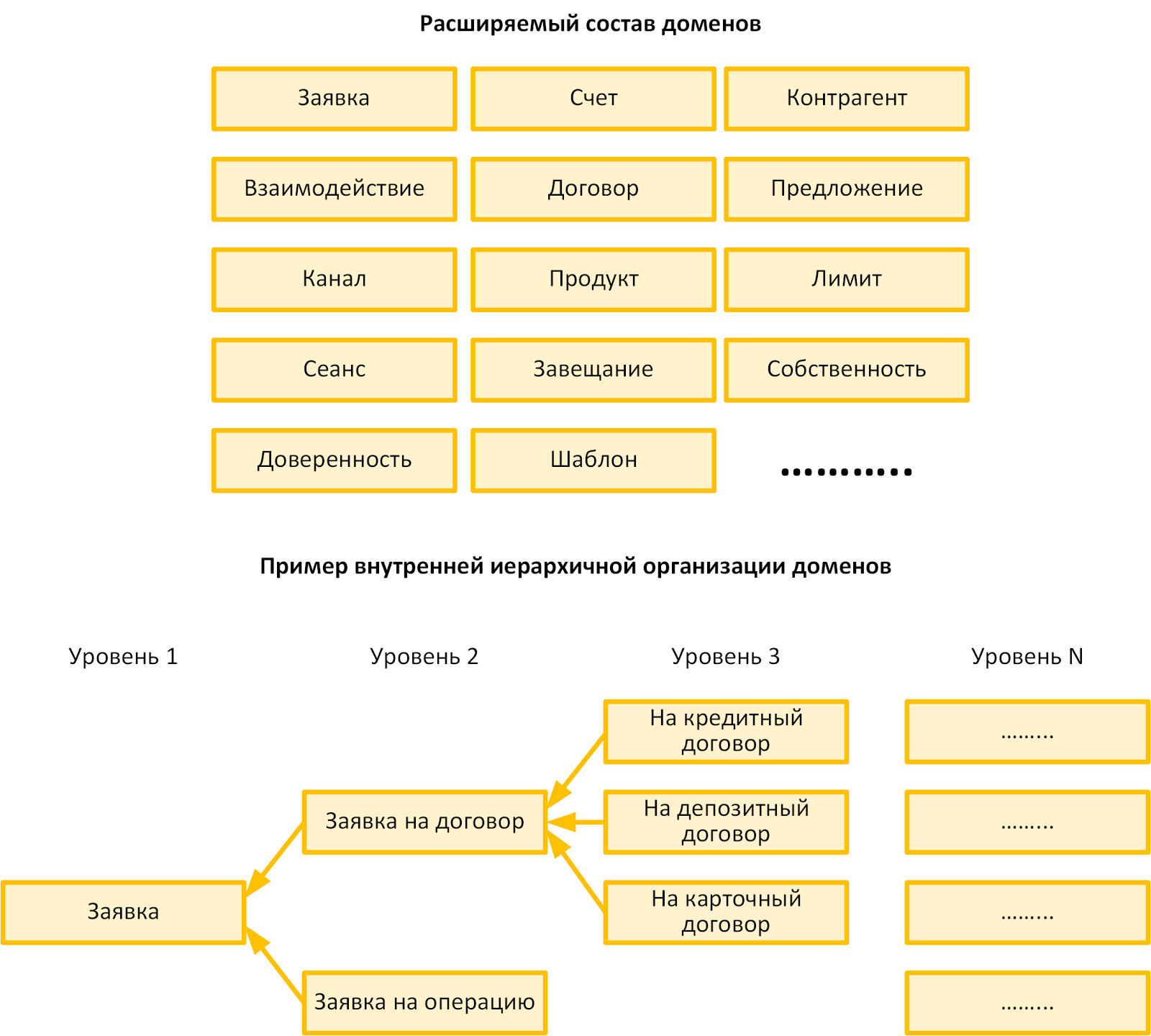
Ниже приведена иллюстративная карта использованных нами доменов. Ни один из модулей, относящихся к конкретному домену, не должен непосредственно зависеть от модуля другого домена, если не находится наверху цепочки зависимостей.
У отдельных доменов есть своя иерархическая структура. Для них можно выделять отдельные поддомены, между которыми прямые зависимости также будут запрещены.
Вторую группу «корпускулярно-волновых» зависимостей можно создать, разделив функционал на кросс-канальный и канало-специфичный. Функционал первой группы будет продуктовым функционалом, а функционал второй — вспомогательным. Тогда, изолировав продуктовый функционал от специфичного для канала способа построения презентационной логики, авторизации пользователя, идентификации клиента и т.д., можно построить схему, отраженную на рисунке ниже.
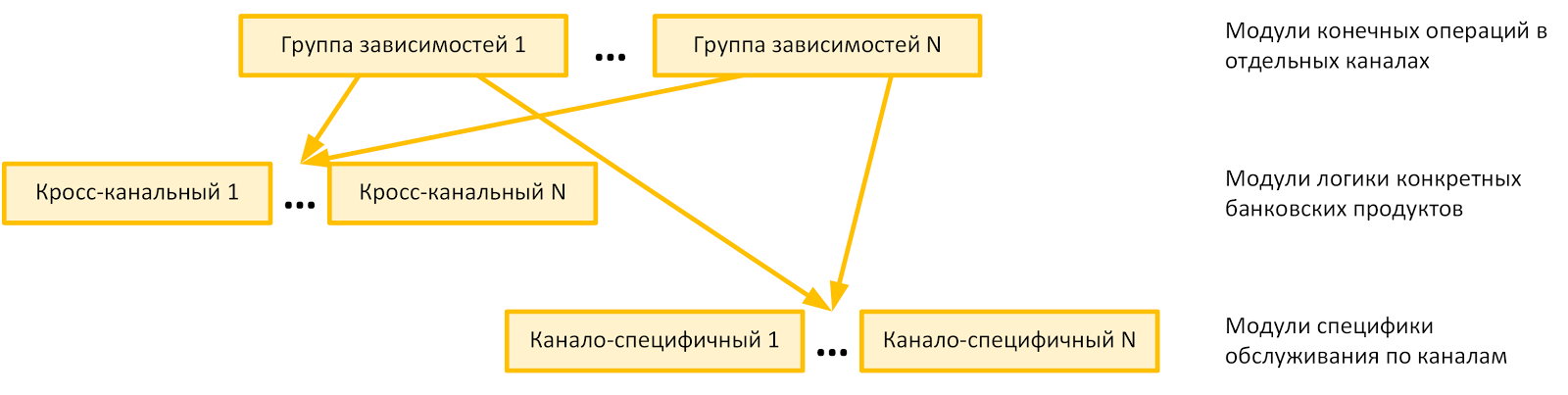
Обратите внимание:
- если меняются требования регулятора относительно специальных процедур взаимодействия с клиентом по каналу, изменения в коде вступят в силу для всех продуктов канала;
- если меняется понимание бизнеса относительно самого продукта, все изменения становятся доступными для всех каналов.
По нашему опыту, чтобы последняя приведенная схема работала, важно соблюдать следующие требования:
- необходим развитый системный кросс-канальный функционал для абстракции прикладного сценария обслуживания клиента от конкретного способа взаимодействия с клиентом;
- нужна строгая бизнес-архитектура, классифицирующая конечный функционал и унифицирующая взаимодействие с потребителем.
Теперь у тебя, уважаемый читатель, есть все для самостоятельного понимания уравнения Шредингера. ;)
Если любишь – отпусти
Так что же нам делать с количеством модулей? Напомню, в целевом виде модулей >= 104. Да еще у заказчика есть ожидание, что весь функционал можно заменить целиком не реже, чем раз в квартал.
Несмотря на то, что основных паттернов проектирования типового прикладного функционала меньше двух десятков, для каждой автоматизируемой операции необходимо выполнять следующее:
- помодульная декомпозиция функционала;
- компоновка модулей по приложениям;
- проектирование бизнес-сущностей и API;
- фиксация внутри модульных зависимостей и изоляции.
Потянет на несколько архитектурных решений. Все осложняется тем, что заложенные требования на повторное использование кода требуют знания содержания прикладных модулей.
Практика показала, что один архитектор, проектирующий компонентную структуру прикладного функционала, в состоянии помнить содержание ~ 100 модулей. Значит, нам достаточно иметь ~100 архитекторов для управления всем прикладным функционалом. Но это уже такое количество специалистов, при котором сами архитекторы не будут знать друг про друга. Значит, у проблемы нет административного решения.
К счастью, ранее Габриэль Гарсиа Маркес предложил «контрадминистративное» решение проблемы, вынесенное в заголовок раздела. Сейчас мы «отпускаем» прямое проектирование архитектуры прикладного функционала, так как удержать его на целевых масштабах невозможно.
Мы собираемся ничего не знать про каждый модуль и переходим только к контролю:
- качества проектируемых новых модулей, сравнивая их количественные характеристики с типовыми значениями статистически удачных решений;
- характера вносимых изменений в коде через reverse engineering;
- и обеспечиваем контент для автоматизации поиска модулей для повторного использования.
Здесь важно, что сведение архитектуры IT к большим числам (в частности, к большому количеству типовых компонент) — это решение, хорошее тем, что позволяет на достаточно большом количестве частных случаев выработать общее решение.
Хроника событий:
- все началось с 20 прикладных модулей;
- когда модулей стало 50, была получена оценка целевого количества прикладных модулей и построена предварительная метамодель зависимостей;
- 100 модулей было достаточно для того, чтобы стабилизировать модульную компонентную архитектуру и поставить вопрос об автоматизации «производства» прикладных модулей;
- 300 модулей стало достаточно, чтобы количественно выявить «золотое сечение» идеальных и приемлемых по качеству прикладных модулей.
Сейчас у нас на ряде проектов отрабатывается промежуточное решение, которое позволяет выполнять внутреннее проектирование прикладных модулей по функциональной конфигурации, об инструменте для которой мы рассказывали в прошлой публикации. Архитектор вручную решает только одну задачу – «размечает» функционал для генерации по разным прикладным модулям, позиционирует модули в конечной иерархии по зависимостям.
Может быть, эти новые методы формирования прикладной архитектурой даже назовут как-нибудь по-умному. Например, Statistic driven application architecture. Как вам? ;)
Технически мы готовы к полной автоматизации процесса прикладного проектирования. И важно, что, в отличие от Габриэля Гарсиа Маркеса, мы знаем, что такое reverse engineering, который нам позволит держать нашу любимую прикладную архитектуру «на поводке» и контролировать ручную доработку автоматически сгенерированного кода. Но, кажется, это уже что-то из Дарьи Донцовой.
В заключение замечу следующее. Есть расхожее мнение, что любого творца (и Гарсиа Маркеса, и Донцову) по-настоящему оценят только потомки. В IT, и особенно в ЕФС, это не так. Мы готовы рассматривать новые идеи и технологические решения. Присоединяйтесь к нашему технологическому конкурсу «Продвижение»!
Комментарии (13)
VolCh
18.04.2017 19:55+2Сейчас мы «отпускаем» прямое проектирование архитектуры прикладного функционала, так как удержать его на целевых масштабах невозможно.
Мы собираемся ничего не знать про каждый модуль и переходим только к контролю:
качества проектируемых новых модулей, сравнивая их количественные характеристики с типовыми значениями статистически удачных решений;
характера вносимых изменений в коде через reverse engineering;
и обеспечиваем контент для автоматизации поиска модулей для повторного использования.Ощущение, что зря потратил время на чтение. Большое вступление и "решение" на один абзац, без всякой детализации, даже без пояснений кто это "мы" будет контролировать и кого? Команда Q&A будет контролировать решения сотни архитекторов через метрики и реверс-инженеринг?

slekenitchs
18.04.2017 21:35Спасибо за обратную связь, поясню.
В данной публикации мы обозначили тему, которую раскроем в нескольких статьях. В следующем материале, речь пойдет про интеграцию Eclipse Modeling Framework в инструменты DevOps. И никаких электриков, архитекторов и представителей Q&A :)
Сегодня, мы поделились с Вами общей проблематикой управления компонентной архитектурой в крупном корпоративном приложении. Но связывая этот текст с предыдущей публикацией и анонсируя будущую, конкретизирую:
- Мы автоматизировали процесс создания отдельных компонент (выше по тексту — модули), осуществляя прямую генерацию самих компонент и всех слоев изоляции внутри модулей, непосредственно из самой функциональной конфигурации (см. предыдущую публикацию)
- Реализовано на базе EMF с созданием собственной Model2Model трансформации и далее Model2Java трансформации.
- Важно что все конфигурации в рабочем места аналитика заранее валидируются на M2M генерацию с поддержкой приведенных в статье шаблонов проектирования для типового функционала фронт-офиса.
- Естественно, любой код может быть доработан руками. Требуется проверять изменения на нарушения по зависимостям модулей, да и вообще использования типовых паттернов.
- Для этого мы строим JavaModel кода (выполняем reverse) и выполняем трансформацию в модель, аналогичную исходной, из которой шла генерация кода.
- Сравниваем, 2 модели, ищем расхождения. Допустимые включаются в модель (пока в полу ручном режиме). Не допустимые фиксируются в отчете и отправляются в команду, вносившую изменения в сгенерированный код.
Но это же так скучно ;)Ares_ekb
19.04.2017 10:52А как вы строите Java-модель? С помощью JaMoPP?
На каком языке описываете преобразования модель-модель?slekenitchs
19.04.2017 11:04Добрый день. Мы явно используем API JavaModel. В части типов, атрибутов, операций (методов) оно достаточно похоже на uml2, так что выявлять различия в коде и исходной модели удобно без дополнительных инструментов.
Ares_ekb
19.04.2017 12:18Если я правильно понял, то у вас
1) исходная модель на языке UML2
2) затем она преобразуется в промежуточную модель (с помощью Model2Model преобразования, написанного на Java)
3) промежуточная модель преобразуется в Java-код (генератор кода тоже на Java)
И в обратную сторону:
1) Получаем объектную модель Java-кода с помощью JavaModel
2) Генерим промежуточную модель
3) Сравниваем эту промежуточную модель с промежуточной моделью, которую сгенерили из UML2 (см. выше) (сравнивалка написана на Java)
Всё правильно?slekenitchs
19.04.2017 12:27Добрый день. Точно:
- Первая модель — это модель исходных функциональных элементов (формы, процессы, точки интеграции). Она совсем оторвана от языка, на котором будет генерироваться исходный код. Вводная по ней была в предыдущей статье.
- Вторая модель — это модель типовых паттернов, на базе компонентной модели, описанной в данной статье. Она уже ближе к фактической реализации и предполагает генерацию кода на ООП.
- Ну и в конце-концов — исходный код на Java
Преобразования в обратную сторону также идут, как Вы указали.Ares_ekb
19.04.2017 12:52Мы тоже делаем подобные штуки с помощью EMF. Описываем на UML систему, для которой будет генериться код. И генерим Java, XSLT, XPath и т.п. Только все преобразования описаны на языке QVTo (стандарт, реализация Eclipse и моя статья с простыми примерами).
А парсинг или генерацию кода мы вообще не реализуем, это делается автоматически средствами EMFText (статья 1, статья 2).
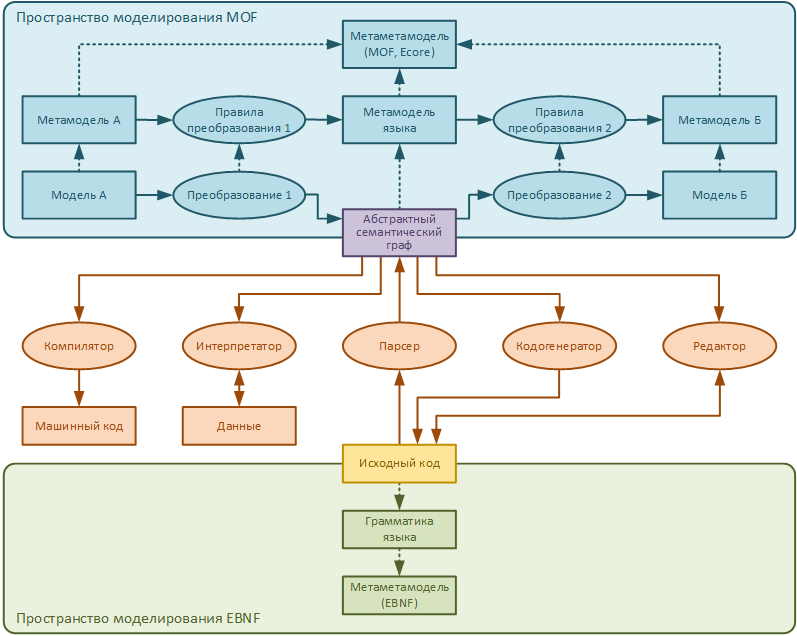
Вот, мозговыносная картинка из статьи, как оно у нас работает. Прямой путь — по стрелкам от модели А до исходного кода. И обратный — по стрелкам от исходного кода до модели Б. Парсер и кодогенератор мы не пишем, генерим их с помощью EMFText. А «преобразование 1» и «преобразование 2» пишем на QVTo.
lostpassword
А можно несколько примеров баек про электриков?
slekenitchs
В качестве байки можно привести любой «анекдот про Вовочку», где имя собственное «Вовочка», заменить на обезличенное «электрик»… или «архитектор» :)