

Одним из способов улучшения производительности и уменьшения латентности в системах хранения данных (СХД) является использование алгоритмов, анализирующих входящих трафик.
С одной стороны, кажется, что запросы к СХД сильно зависят от пользователя и, соответственно, мало предсказуемы, но на деле это не так.
Утро практически любого человека одинаково: мы просыпаемся, одеваемся, умываемся, завтракаем, едем на работу. Рабочий день же, в зависимости от профессии, у всех разный. Также и загрузка СХД изо дня в день одинакова, а вот рабочий день зависит от того, где используется СХД и какая у неё типичная нагрузка (workload).
Для того, чтобы нагляднее представить наши идеи, мы воспользовались образами персонажей из детских рассказов о Николая Носова. В данной статье основными действующими лицами выступят Незнайка (случайное чтение) и Знайка (последовательное чтение).

Случайное чтение (random read) — Незнайка. C Незнайкой никто не хочет иметь дело. Его поведение не поддается логике. Хотя некоторые алгоритмы все-таки пытаются предсказать его поведение, например, изощренные алгоритмы упреждающей выборки из памяти типа C-Miner (о нем будет подробнее рассказано ниже). Это алгоритмы машинного обучения – значит, они требовательны к ресурсам СХД и не всегда успешны, но в связи с колоссальным развитием вычислительных мощностей процессоров в дальнейшем будут использоваться все больше и больше.
Если в СХД приходят одни Незнайки, то лучшим решением будет СХД на базе SSD (All-Flash Storage).

Последовательное чтение (sequential read) — Знайка. Строг, педантичен и предсказуем. Благодаря такому поведению его можно считать лучшим другом для СХД. Существуют алгоритмы упреждающего чтения (read ahead), которые умеют хорошо работать со Знайкой, они заранее помещают нужные данные в оперативную память, сводя латентность запроса к минимуму.
Блендер-эффект
Последовательное чтение предсказуемо, но читатель может возразить: «А как же блендер-эффект <рис. 1>, который делает из последовательных запросов случайные в результате перемешивания траффика?».
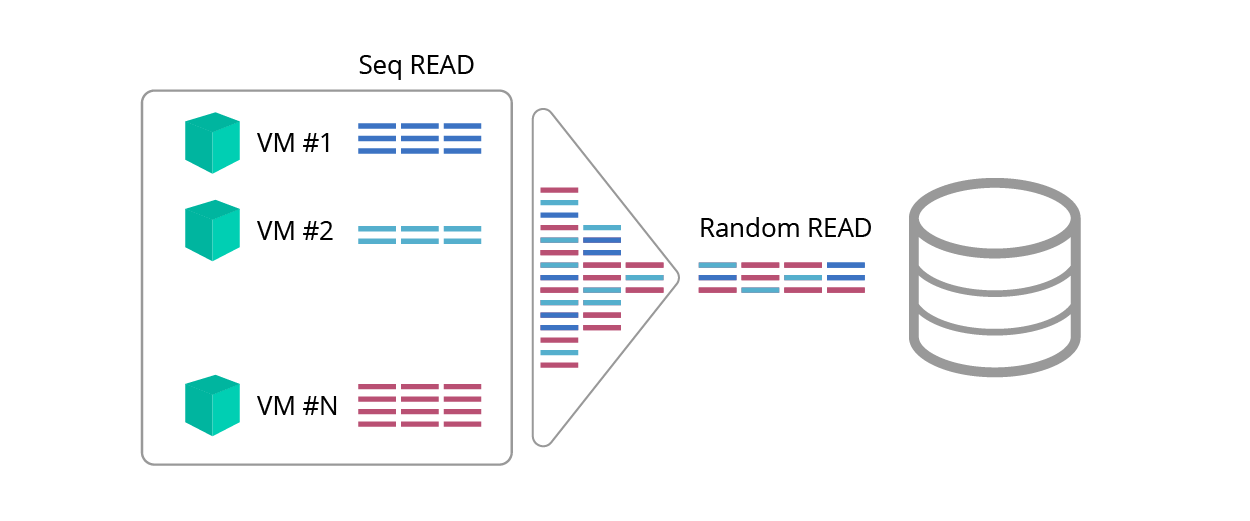
Рис. 1. Блендер-эффект
Неужели Знайки в результате такой неразберихи станут Незнайками?

На помощь Знайке приходят алгоритм упреждающего чтения и детектор, который умеет идентифицировать разные типы запросов.
Упреждающее чтение
Одним из главных способов оптимизации, призванных сократить время доступа и повысить пропускную способность, является применение технологии упреждающего чтения (read ahead). Технология позволяет на основании уже запрошенных данных предугадывать, какие данные будут запрошены следующими, и переносить их с более медленных носителей информации (например, с жёстких дисков) на более быстрые (например, оперативная память и твёрдотельные накопители) до того, как к этим данным обратятся (рис. 2).
В большинстве случаев упреждающее чтение применяется при последовательных операциях.
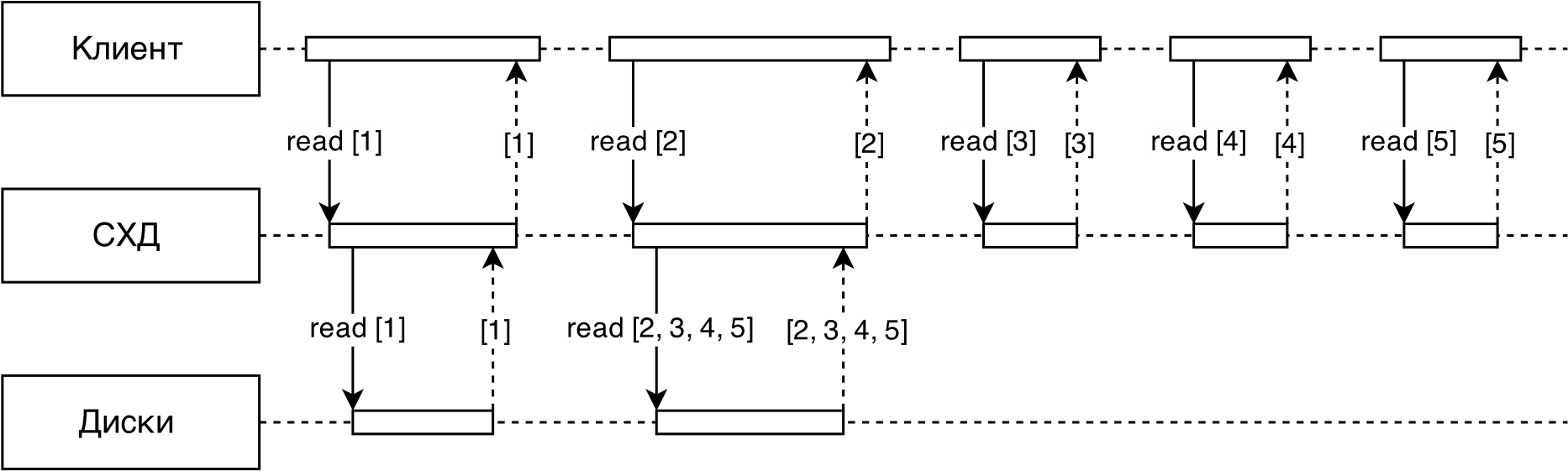
Рис. 2. Упреждающее чтение
Работу алгоритма упреждающего чтения принято разделять на два этапа:
- обнаружение запросов последовательного чтения в потоке всех запросов;
- принятие решения о необходимости считывать данные наперёд и объёмах считывания.
Реализация детектора в RAIDIX
Алгоритм упреждающего чтения в RAIDIX основан на понятии диапазонов, соответствующих связным интервалам адресного пространства.
Диапазоны обозначаются парами (), что соответствует адресу и длине запроса, и отсортированы по . Они разделяются на случайные, длина которых меньше некоторого порога, и последовательные. Одновременно отслеживается до случайных диапазонов и до последовательных.
Алгоритм детектора работает следующим образом:
1. Для каждого приходящего запроса на чтение производится поиск ближайших диапазонов в радиусе strideRange.
1.1. Если таковых не нашлось, создаётся новый случайный диапазон с адресом и длиной, соответствующим характеристикам запроса. При этом один из существующих диапазонов может быть вытеснен по LRU.
1.2. Если нашёлся один диапазон, запрос добавляется в него с расширением интервала. Случайный диапазон при этом может быть преобразован в последовательный.
1.3. Если нашлось два диапазона (слева и справа), они объединяются в один. Получившийся в результате этой операции диапазон также может быть преобразован в последовательный.
2. В случае, если запрос оказался в последовательном диапазоне, для этого диапазона может быть произведено упреждающее чтение.
Параметр упреждающего чтения может меняться в зависимости от скорости потока и размера блока.
На рисунке 3 схематично представлен алгоритм адаптивного упреждающего чтения, реализованный в RAIDIX.

Рис.3. Схема упреждающего чтения
Все запросы к СХД от клиента сначала попадают в детектор, его задача выделить последовательные потоки (отличить последовательные запросы от случайных).
Далее для каждого последовательного потока определяется его скорость и размер — средний размер запроса в потоке (обычно в потоке все запросы одинакового размера).
Каждый поток сопоставляется с параметром упреждающего чтения .
Таким образом, с помощью алгоритма упреждающего чтения мы справляемся c эффектом «I/O блендера» и для последовательных запросов гарантируем пропускную способность и latency, сопоставимую с параметрами оперативной памяти.
Таким образом Знайка побеждает Незнайку!

Производительность случайного чтения
Как же можно поднять производительность случайного чтения?
Для этих целей разработчики Винтик и Шпунтик предлагают использовать более быстрые носители, а именно SSD и гибридное решение (тиринг или SSD-кэш).

Также можно воспользоваться ускорителем случайных запросов — алгоритмом упреждающего чтения С-Miner.
Основная задача всех этих методов — посадить Незнайку на «быстрый» автомобиль :-) Проблема в том, что автомобилем надо уметь управлять, а у Незнайки уж слишком непредсказуемый характер.

C-Miner
Одним из наиболее интересных алгоритмов, используемых для упреждающего чтения при случайных запросах, является C-Miner, основанный на поиске корреляций между адресами последовательно запрашиваемых блоков данных.
Этот алгоритм обнаруживает семантические связи между запросами, такими как запрос метаданных файловой системы перед чтением соответствующих им файлов или поиск записи в индексе СУБД.
Работа C-Miner состоит из следующих этапов:
- В последовательности адресов запросов ввода-вывода обнаруживаются повторяющиеся короткие подпоследовательности, ограниченные окном некоторого размера.
- Из полученных подпоследовательностей извлекаются суффиксы, которые затем комбинируются в соответствии с частотой встречаемости.
- На основе извлечённых суффиксов и цепочек суффиксов генерируются правила вида {a > b, a > c, b > c, ab > c}, описывающие, каким блокам данных предшествуют запросы по адресам из коррелирующей области.
- Полученные правила ранжируются в соответствии с их надёжностью.
Алгоритм C-Miner хорошо подходит для систем хранения, данные в которых редко обновляются, но запрашиваются часто и небольшими порциями. Такой сценарий использования позволяет составить набор правил, который не устареет долгое время, а также не замедлит выполнение первых запросов (появившихся до создания правил).
В классической реализации зачастую возникает множество правил с низкой надежностью. В связи с этим алгоритмы упреждающего чтения довольно плохо справляются со случайными запросами. Гораздо эффективнее использовать гибридное решение, в рамках которого наиболее популярные запросы попадают на более производительные накопители, например, SSD- или NVME-диски.
SSD-кэш или SSD-тиринг?
Возникает вопрос, какую технологию лучше выбрать: SSD-кэш или SSD-тиринг? Ответить на этот вопрос поможет детальный анализ рабочей нагрузки.
SSD-кэш схематично изображен на рисунке 4. Здесь запросы сначала попадают в оперативную память, а далее, в зависимости от типа запроса, могут быть вытеснены в SSD-кэш или в основную память.
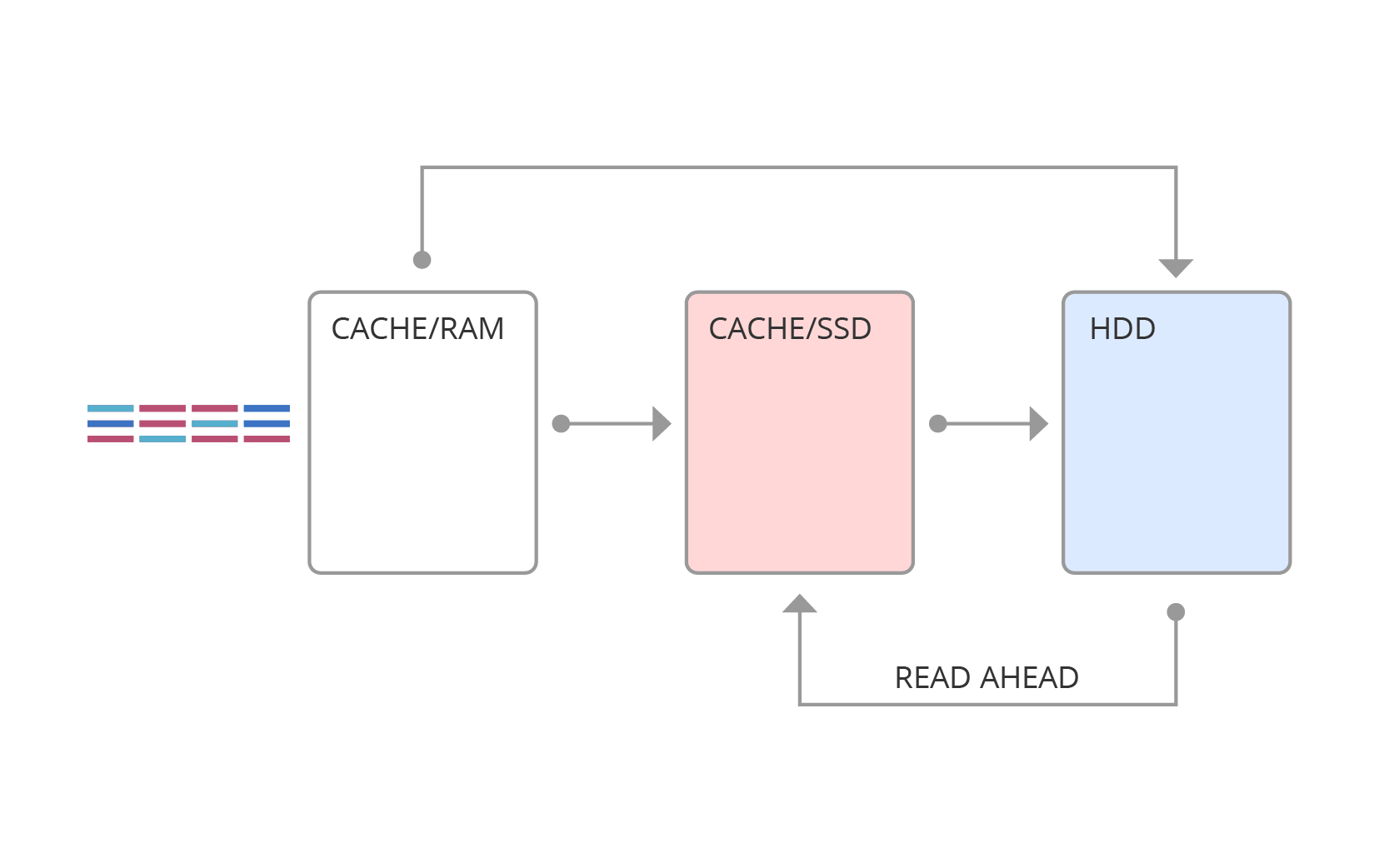
Рис. 4. SSD-кэш
SSD-тиринг имеет другую структуру (рис. 5). При тиринге ведется статистика горячих областей, и в фиксированные моменты времени горячие данные переносятся на более быстрый носитель.

Рис. 5. SSD-тиринг
Основное отличие SSD-кэша от SSD-тиринга заключается в том, что данные в тиринге не дублируются в отличие от SSD-кэша, в котором «горячие» данные хранятся как в кэше, так и на диске.
В таблице ниже приведены некоторые критерии выбора того или иного решения.
| Тиринг | Кэш | |
|---|---|---|
| Метод исследования | Предсказание будущих значений | Выявление локальностей в данных |
| Нагрузка (workload) | Предсказуемая. Слабо меняющаяся | Динамичная, непредсказуемая. Требует мгновенной реакции |
| Данные | Не дублируются (диск) | Дублируются (буфер) |
| Миграция данных | Offline-алгоритм, окно релокации (relocation window). Есть временной параметр перемещения данных | Online-алгоритм, данные вытесняются и попадают в кэш на лету. |
| Способы исследования | Регрессионные модели, модели предсказания, долговременная память | Кратковременная память, алгоритмы вытеснения |
| Взаимодействие | HDD-SSD | RAM-SSD, взаимодействие с SSD через алгоритмы упреждающего чтения |
| Блок | Большой (например, 256 МБ) | Маленький (например, 64 КБ) |
| Алгоритм | Функция, зависящая от времени переноса и статистических характеристик адресов памяти | Алгоритмы вытеснения и заполнения кэша |
| Чтение/запись | Случайное чтение | Любые запросы, в том числе на запись, за исключением последовательного чтения (в большинстве случаев) |
| Девиз | Чем сложнее, тем лучше | Чем проще, тем лучше |
| Ручной режим переноса нужных данных | Возможен | Не возможен — противоречит логике кэша |
В основе любого гибридного решения, так или иначе, лежит предсказание будущей нагрузки. В тиринге мы пытаемся по прошлому предсказать будущее, в SSD-кэше считаем, что вероятность использования недавних и частотных запросов выше, чем давно используемых и низкочастотных. В любом случае в основе алгоритмов лежит исследование «прошлой» нагрузки. Если характер нагрузки меняетcя, например, начинает работать новое приложение, то нужно время, чтобы алгоритмы адаптировались к изменениям.
Незнайка не виноват (характер у него такой — случайный), что гибридное решение плохо управляется в неизвестной новой местности!

Но даже при правильном «предсказании» производительность гибридного решения будет невысокой (значительно ниже максимальной производительности, которую может выдать SSD-диск).
Почему? Ответ ниже.
Сколько IOPS ожидать от SSD-кэша?
Допустим, что у нас есть SSD-кэш размером 2ТБ, а кэшируемый том имеет размер 10ТБ. Мы знаем, что какой-то процесс читает случайным образом весь том с равномерным распределением. Также знаем, что из SSD-кэша мы умеем читать со скоростью 200К IOPS, а из некэшированной области со скоростью 3К IOPS. Предположим, что кэш уже наполнился, и в нём лежат 2ТБ из 10 читаемых. Сколько IOPS мы получим? На ум приходит очевидный ответ: 200К * 0,2 + 3К * 0,8 = 42,4К. Но так ли всё просто на самом деле?
Давайте попробуем разобраться, применив немного математики. Наши расчеты несколько отклоняются от реальной практики, но вполне допустимы в целях оценки.
ДАНО:
Пусть x% читаемых данных (или даже запросов) лежат (обрабатываются) в кэше SSD.
Считаем, что SSD-кэш обрабатывает запросы со скоростью u IOPS. А запросы, идущие на HDD, обрабатываются со скоростью v IOPS.
РЕШЕНИЕ:
Для начала рассмотрим случай, когда iodepth (глубина очереди запросов) = 1.
Примем размер всего читаемого пространства за 1. Тогда доля данных (запросов), находящихся (обрабатываемых) в кэше составит x/100.
Пусть за 1 секунду обрабатывается запросов. Тогда из них обработаются в кэше, а остальные пойдут на HDD. Это верно вследствие того, что чтение происходит с равномерным распределением.
Примем за общее время, потраченное на те запросы, которые пошли в SSD, а за время, потраченное на запросы к HDD.
Так как сейчас рассматриваем всего одну секунду, то (сек).
Имеем такое равенство (1): . С использованием единиц измерения: IOPS * сек + IOPS * сек = IO.
Также имеем следующее (2): . Выразим I: .
Подставим в (1) полученное из (2) I: . Выразим , учитывая, что .
Знаем , тогда знаем и .
Получили времена и , теперь можем их подставить в (1): .
Упрощаем равенство: .
Отлично! Теперь мы знаем количество IOPS при iodepth = 1.
Что же будет при iodepth > 1? Эти выкладки станут неверными, а точнее, не совсем верными. Можно попробовать рассмотреть несколько параллельных потоков, для каждого из которых iodepth = 1, или придумать иной способ, однако при достаточной длительности теста эти неточности сгладятся, и картина окажется такой же, как и при iodepth = 1. Полученный результат всё равно будет отражать реальную картину.
Итак, отвечая на вопрос «а сколько же будет IOPS?», применяем формулу:
ОБОБЩЕНИЕ
А что, если у нас не равномерное распределение, а какое-нибудь более близкое к жизни?
Возьмём, например, распределение Парето (правило 80/20 — к 20% самых «горячих» данных идёт 80% запросов).
В этом случае полученная формула также работает, т. к. мы нигде не опирались на размер пространства и размер SSD. Нам лишь важно знать, сколько % запросов (в данном случае – именно запросов!) обработается в SSD.
Если размер SSD-кэша составляет 20% от всего читаемого пространства и вмещает в себя эти 20% самых «горячих» данных, то 80% запросов будет идти в SSD. Тогда по формуле I(80, 200000, 3000) ? 14150 IOPS. Да, скорее всего, это меньше, чем вы думали.
Давайте построим график I(x) при u = 200000, v = 3000.
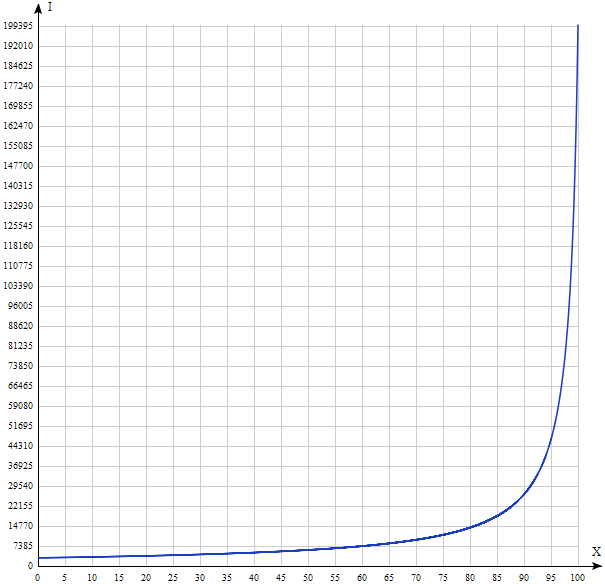
Результат существенно отличается от интуитивно понятного. Таким образом, вручая Незнайке ключи от быстрого автомобиля, мы не всегда можем ускорить производительность системы. Как видно из графика выше, только All-Flash решение (где все диски — твердотельные) может реально ускорить случайное чтение до максимума, «выжимаемого» из SSD-диска. Виноват в этом не Незнайка и, конечно, не разработчики систем хранения данных, а простая математика.
Комментарии (9)

NeZnaika3
10.05.2017 12:35Какие-нибудь полезные цифры при работе разных алгоритмов
Также разными типами RAID, если был подобный анализ.
Скорее всего в завершении «а простая математика.» имеется ввиду именно это? Или какая ещё математика?
ПС.Мне кажется Вы несколько недочитали Н.Носова. Незнайка, не так однозначен, как просто любитель рандомных поступков. Например, именно он принял решение по спасению в кризисе на воздушном шаре. Хотя отчасти сам к нему имел отношение.
Не случайно, дальнейшая трилогия полностью посвящена именно этому персонажу, с девизом, зачем что-то делать, если назавтра делать ровно обратное. А ведь в «Незнайка на Луне» описано почти пост-капиталистическое о-во, т.е. наша реальность. Как тогда относиться к персонажу в широкой синей шляпе и желтых штанах?raidixteam
10.05.2017 14:11Посмотрите ответ на предыдущий комментарий, полагаю, что там может быть ответ на интересующий вас вопрос.
«Простая математика» охватывает именно представленные в статье расчеты.
Мы не утверждаем, что Незнайка однозначен и «рандомен». Мы взяли некоторые характерные его черты и использовали их в качестве иллюстрации (то же самое со Знайкой). Что же касается рассуждений о пост-капиталистических реалиях, то это, пожалуй, выходит за пределы наших профессиональных компетенций :)
NeZnaika3
10.05.2017 20:40Да, спасибо. Понятно. Тесты проводились лишь при RAID6. Почему не RAID10, вроде показатели могли бы лучшими.
Скажем так, один LUN на весь массив — не типичный случай. Также не понятно, какая зависимость от снижения количества дисков.
Какая зависимость при использовании упр.чтения в количестве неустранимых ошибок чтения. Т.е. эта зависимость и возможное снижение обусловлена лишь дисками, кэшом или увеличением потоков
Ещё вопрос. Где больше ошибок на SSD или SAS. Почему-то об URE вообще ничего.raidixteam
11.05.2017 12:45При операциях последовательного чтения суммарные производительности RAID 10 и RAID 6 незначительно отличаются. Более того, наш RAID 6 часто работает быстрее. Это получается в связи с тем, что у нас есть такая функция, как Advanced Reconstruction.
Работает это так: на все чанки в стайпе (Пусть, он будет размером 10+2) отправляются запросы на чтение. Дождавшись первые 10 чанков мы восстанавливаем оставшиеся по контрольным суммам. Делается это со скоростью доступа к RAM, алгоритм восстанавливает со скоростью 35 ГБ/с на ядро. В десятке же мы будем ждать самого медленного.
Периодическое возникновение ошибок чтения при тех-же параметрах никак не влияет на производительность по тем же причинам. Мы не ждем, пока диск попытается перечитать область или вернет ошибку. Мы просто восстанавливаем чанк по контрольным суммам и забываем про него.
Все хуже, если чтение не полнострайповое. В этом случае при возникновении ошибки нужно дочитать страйп и восстановить данные чанка. А это-дополнительные IO и задержки. Но на нормальных дисках вероятность ситуации ничтожно мала и никак не повлияет на средний результат и все же, адаптивный Read Ahead сделан в первую очередь для полнострайповых чтений.NeZnaika3
11.05.2017 21:30Но на нормальных дисках
Нормальные — это HP или Seagate?
По практике наших СХД летят почти одинаково. Разница лишь в полном дизэйбле.
На Seagate сразу в красный, а HP ещё с месяц по-желтеет.
Вообще странно, что «производительности RAID 10 и RAID 6 незначительно отличаются»
Из статьи не понял. Допустим один LUN 30Tb. Сколько в % SSD и SAS.ildarz
12.05.2017 11:48Вообще странно, что «производительности RAID 10 и RAID 6 незначительно отличаются»
Чего же тут странного, когда речь идет о чтении? У RAID 5/6 нет никакого специфического оверхеда в этом случае.
NeZnaika3
12.05.2017 21:11Чего же тут странного, когда речь идет о чтении?
Если упомянут IOPS, то по факту это операция ввода\вывода.
Оценивать работу СХД одним чтением, сложно найти параллели.
Тем более, RAID 6 — как мне известно не самая быстродействующая технология.
Но этот вопрос уходит чуть в сторону. По нашей практике, главное в СХД — минимум ошибок, быстрое восстановление\замена дизэйблов, полное восстановление или перенос. Лишь после этого можно рассмотреть быстродействие.
Не понятно, как начальное условие будет обеспечено при SSD-кэш + SAS-массив. Хотя наверное, технология упреждающего чтения — это рабочий вариант, а восстановление с отключением read ahead.
rPman
Какие-нибудь полезные цифры при работе разных алгоритмов упреждающего чтения, на реальных данных и нагрузках, вы можете предоставить?
raidixteam
Алгоритм упреждающего чтения для последовательных потоков по умолчанию включен в наше решение. Его можно выключить, но в «реальных» условиях этого никто не делает. Поэтому сравнительных цифр с «полей» мы не получаем. Ниже проведен тест с использованием бенчмарки FIO c включенным и выключенным read ahead.
Параметры системы: в дисковой корзине 24 HDD, RAID6, LUN развернут на всем рэйде. Кэш рэйда — 16 гигабайт. Инициатор подключен по Infiniband напрямую к таргету. Конфиг для 1 потока: [global], direct=1, ioengine=libaio, iodepth=32, runtime=180, blocksize=1M, rw=read, filename=/dev/sdc.
Показатели чтения с выключенным read ahead: 1369 MB/sec
Показатели чтения с включенным read ahead: 2940 MB/sec
При этом максимум пропускной способности в этой конфигурации будет чуть ниже 3240 MB/sec (т.к. есть нечитаемые данные с контрольных сумм).