

В современном мире наблюдается экспоненциальный рост объемов данных. Перед вендорами СХД возникает целый ряд задач, связанных с колоссальными объемами информации. Среди них — защита пользовательских данных от потери и максимально быстрое восстановление данных в случае выхода из строя сервера или диска.
В нашей статье будет рассмотрена задача быстрой реконструкции. Казалось бы, оптимальным решением для защиты данных является репликация, однако объем служебной информации при этом сценарии составляет 100% и более. Выделить такой объем возможно не всегда. Следовательно, нужно искать компромисс между избыточностью и скоростью восстановления.
Широко известным подходом, обеспечивающим меньший объем служебной информации, являются коды с локальной четностью (LRC) и регенерирующие коды. Эти решения работают как для распределенных систем, так и для локальных дисковых массивов.
В этой статье мы рассмотрим особенности применения LRC-кодов для дисковых массивов и предложим сценарии ускоренного восстановления данных отказавшего диска.
Тестирование производительности мы проводили одновременно и для LRC, и для регенерирующих кодов, но о последних мы более подробно расскажем в одной из следующих статей.
Доступность данных
Технология RAID (Redundant Array of Independent Disks) применяется в системах хранения данных для обеспечения высокой скорости доступа к данным и отказоустойчивости. Высокая скорость достигается за счет распараллеливания процессов чтения и записи данных на диски, а отказоустойчивость — за счет применения помехоустойчивого кодирования.
С течением времени требования к объему и надежности систем хранения увеличивались. Это привело к появлению новых уровней RAID (RAID-1...6, RAID-50, RAID-60, RAID-5E и т.д.) и применению разных классов помехоустойчивых кодов, как MDS (Maximum distance separable — коды с максимальным кодовым расстоянием), так и не-MDS.
Мы рассмотрим, как влияет размещение данных при определенном способе кодирования на скорость восстановления отказавшего диска, и, как следствие, на доступность данных дискового массива.
Availability (доступность) — это вероятность того, что система будет доступна по запросу. Высокая доступность достигается, в частности, за счет кодирования, т.е. часть дискового пространства системы отводится не под пользовательские данные, а для хранения контрольных сумм. В случае отказа дисков системы утраченные данные могут быть восстановлены с помощью этих контрольных сумм — тем самым обеспечивается доступность данных. Как правило, availability рассчитывается по формуле:
MTTF — Mean Time To Failure (средняя наработка до отказа), MTTR — Mean Time To Repair (среднее время восстановления). Чем меньше время, необходимое для восстановления определенного компонента системы, в данном случае – диска или кластерного узла, тем выше доступность данных.
Скорость восстановления компонента зависит от:
- скорости записи восстановленных данных;
- скорости чтения;
- количества прочитанных данных, необходимых для восстановления;
- производительности алгоритма декодирования.
Каждый из вариантов организации хранения данных и расчета контрольных сумм имеет свои преимущества и недостатки. Например, коды Рида-Соломона (RS codes) обеспечивают высокую отказоустойчивость. RS-коды являются кодами с максимальным кодовым расстоянием (MDS) и представляются оптимальными с точки зрения избыточного места под хранение контрольных сумм. Недостаток RS-кодов состоит в том, что они достаточно сложны с точки зрения кодирования и требуют очень много чтений для восстановления отказа.
Среди других возможных решений — модифицированные Rotated RS-коды или WEAVER codes (разновидность XOR-кодов). Последние достаточно просты с точки зрения кодирования и требуют очень мало чтений для восстановления отказа. Однако при этом способе кодирования под контрольные суммы требуется выделить гораздо больший, чем при MDS-кодах, объем хранилища.
Хорошим решением указанных выше проблем стало появление LRC (Local Reconstruction Codes). В работе «Erasure Coding in Windows Azure Storage» проводится детальное описание этих кодов, которые, по сути, являются преобразованием RS-кодов в не-MDS. В этой же работе проводится сравнение LRC с другими кодами и показаны преимущества LRC. В данной статье мы рассмотрим, как влияет расположение блоков LRC-страйпов на скорость восстановления.
Проблемы использования LRC в RAID
Далее мы кратко опишем идеологию LRC, рассмотрим возникающие проблемы и возможные пути их решения. Рассмотрим последовательность блоков, хранящихся на дисках, образующих один страйп. В дальнейшем, если не указано иное, будем понимать страйп как множество блоков, находящихся на разных дисках и объединенных общей контрольной суммой.
Если данные этого страйпа закодированы RS кодом, как это, например, делается в RAID-6 с двумя контрольными суммами, то кодовую информацию содержат два блока страйпа. На рис. 1 сверху представлен страйп из 19 блоков, среди которых 2 блока и — контрольные суммы. При отказе диска, содержащего, например, блок с номером 2, для восстановления этого блока необходимо будет прочитать 17 блоков из каждого страйпа (16 не отказавших и одну контрольную сумму).
Коды локальной реконструкции в данном случае потребуют разбиения страйпа на несколько локальных групп, для каждой из которых рассчитывается локальная контрольная сумма (local syndrome). Для всех блоков данных также рассчитывается глобальная контрольная сумма. На рис. 1 рассмотрен пример, в котором блоки разбиты на 3 локальные группы размером 5. Для каждой из них рассчитаны локальные контрольные суммы , а также рассчитана одна глобальная контрольная сумма G.
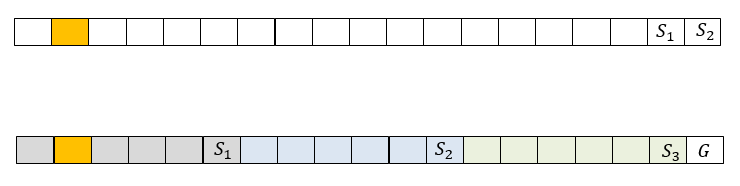
Рис. 1. Пример представления страйпа RAID6 и страйпа LRC
Локальные контрольные суммы вычисляются как XOR блоков данных, от которых они зависят. Глобальных контрольных сумм может быть несколько, они вычисляются как контрольные суммы RS кодов. В данном случае для восстановления блока с номером 2 необходимо прочитать 6 блоков. Это в 3 раза меньше по сравнению с предыдущим случаем, но на хранение контрольных сумм здесь потребуется больше места. Следует отметить, что в случае отказа 2 дисков одной группы, LRC легко преобразуется в классический RS при сложении (XOR) всех 3 локальных контрольных сумм.
Использование LRC может отлично решить проблему количества чтений, необходимых для восстановления одного диска. Тем не менее, если все страйпы располагать на дисках или кластерных узлах одинаковым образом и не менять в них последовательность блоков, то получится, что при изменении данных в любом блоке локальной группы всегда будет пересчитываться локальная контрольная сумма этой группы и глобальная контрольная сумма страйпа. Таким образом, компоненты с контрольными суммами будут подвержены большим нагрузкам и износу. Следовательно, производительность такого массива будет ниже. Классически такая проблема в RAID решается циклическим сдвигом страйпов на дисках, см. рис. 2.
Чтобы при восстановлении данных скорость восстановления не ограничивалась скоростью записи на один компонент системы хранения, в каждый страйп может быть добавлен так называемый Empty Block (E), как это делается в RAID-5E и RAID-6E. Таким образом, восстановленные данные в каждом страйпе записываются на свой empty block, а значит, и на отдельный диск. Наличие empty block в страйпе необязательно. В дальнейших наших рассуждениях мы будем рассматривать страйпы с таким блоком для полноты картины.
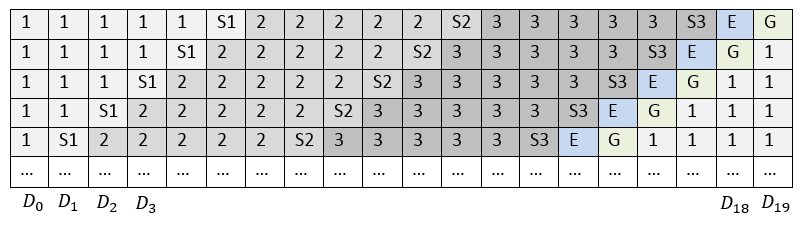
Рис. 2. Расположение блоков страйпа со сдвигом
Таким образом, при использовании циклического сдвига и наличии empty block расположение страйпов по дискам примет вид как на рис. 2.
Использование LRC также накладывает незначительное ограничение по количеству дисков, на которых может быть расположен страйп. Так, если количество локальных групп равно , размер одной локальной группы равен , количество глобальных контрольных сумм равно и наличествует empty block, то общий размер страйпа будет равен . Если число дисков отличается от длины страйпа, то возможны два варианта:
- Создавать локальные группы разного размера. В таком случае некоторые локальные контрольные суммы будут чаще обновляться при изменении данных страйпа, что может привести к более медленной записи.
- Не размещать каждый страйп на все диски, а там, где заканчивается один страйп, сразу начинать второй, см. рис. 3. Такой подход приводит к тому, что все локальные группы могут быть одинакового размера, и циклическое смещение вносится автоматически сообразно расположению страйпов. Если длина страйпа совпадает с количеством дисков, то для каждого страйпа выполняется циклический сдвиг, как это делается для RAID-6.
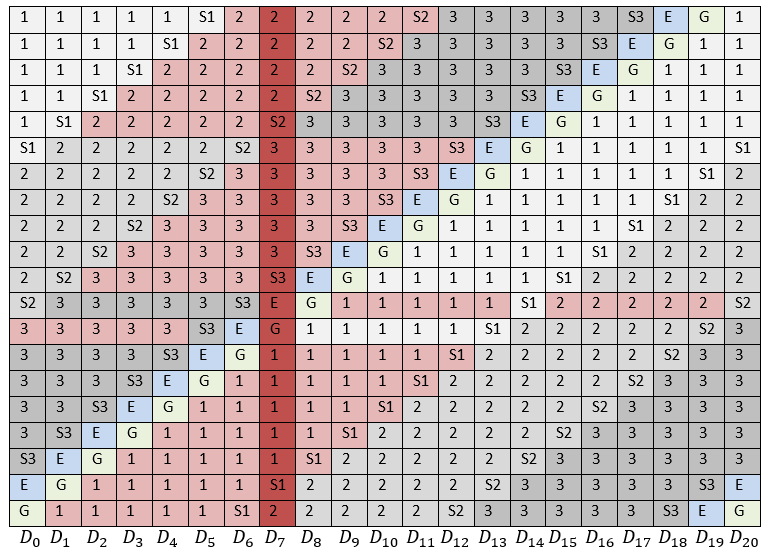
Рис. 3. Блоки, необходимые для восстановления одного отказавшего диска
На рис. 3 рассмотрен случай отказа одного диска — . Розовым цветом обозначены все блоки, которые необходимо прочитать, чтобы восстановить его.
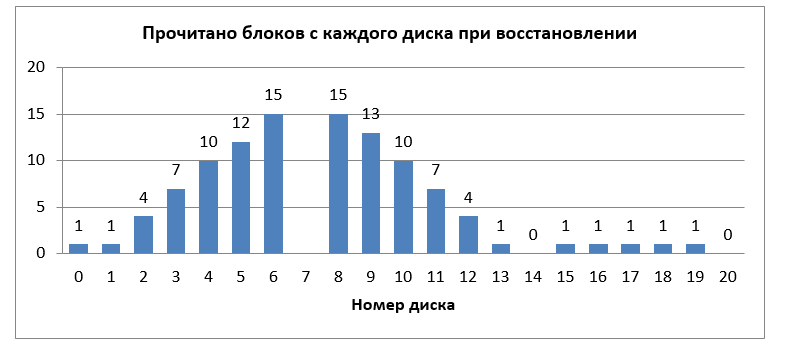
Рис. 4. Количество блоков, прочитанное с каждого диска для восстановления одного отказавшего диска
Всего потребовалось прочитать 105 блоков. Если бы вместо LRC использовался RAID-6, то необходимо было бы 340 прочитанных блоков. Чтобы понять, является ли такое расположение блоков оптимальным, посчитаем количество прочитанных с каждого диска блоков, см. рис. 4.
Можно заметить, что диски, располагающиеся ближе к отказавшему, будут гораздо больше нагружены по сравнению с остальными. Таким образом, при восстановлении данных в случае отказа именно эти наиболее загруженные диски станут узким местом. Однако, расположение блоков LRC-страйпа, когда сперва идут блоки первой локальной группы, затем второй, затем третьей, не является жестким ограничением. Таким образом, наша задача состоит в определении такого расположения блоков, при котором нагрузка на все диски в случае отказа была бы минимальной и равномерной.
Рандомизированные алгоритмы для дисков большого объема
Оставляя в стороне различные способы решения аналогичной проблемы для RAID-6, рассмотрим возможный сценарий в случае с LRC:
- Для каждого LRC-страйпа берем классическое расположение блоков (аналогично рис. 1). Используем номер выбранного страйпа в качестве инициализирующего значения (seed) для генератора случайных чисел. Для всех страйпов используется один и тот же генератор случайных чисел, но с разным seed.
- Используя инициированный генератор случайных чисел и исходное расположение блоков, получим случайное расположение блоков в текущем страйпе. В нашем случае был применен алгоритм Fisher–Yates shuffle.
- Такую процедуру выполняем для каждого страйпа.
При таком подходе каждый страйп будет иметь некоторую случайную структуру, которая однозначно определяется его номером. Поскольку в данной задаче не требуется криптографическая стойкость генератора случайных чисел, то мы можем использовать достаточно простой и быстрый его вариант. Таким образом возможно оценить математическое ожидание средней загрузки каждого диска в случае отказа.
Введем обозначения: — объем каждого диска в массиве, — размер одного блока страйпа, — длина одного страйпа, — количество дисков, — размер локальной группы. — количество локальных групп, — количество глобальных контрольных сумм. Тогда математическое ожидание средней загруженности каждого диска будет рассчитываться следующим образом:
Располагая такой оценкой и зная скорость чтения блоков с диска, можно сделать приблизительную оценку времени восстановления одного отказавшего диска.
Тестирование производительности
Для тестирования производительности мы создавали RAID из 22 дисков с различными схемами размещения. RAID-устройство создавалось при помощи модификации device-mapper, которая меняла адресацию блока данных по определенному алгоритму.
На RAID записывались данные, для которых выполнялся расчет контрольных сумм в целях последующего восстановления. Выбирался отказавший диск. Выполнялось восстановление данных либо на соответствующие empty blocks, либо на hot spare disk.
Мы сравнили следующие схемы:
- RAID-6 — классический RAID-6 с двумя контрольными суммами; восстановление данных на hot spare disk;
- RAID-6E — RAID6 c empty блоком в конце страйпа; восстановление данных на empty blocks соответствующих страйпов;
- Classic LRC+E — LRC-схема, в которой локальные группы идут последовательно и заканчиваются контрольной суммой (см рис. 3); восстановление на empty block;
- LRC rand — для генерации каждого LRC-страйпа, его номер используется в качестве ядра генератора случайных числе, восстановление данных на empty block.
Для тестирования использовались 22 диска со следующими характеристиками:
- MANUFACTURER: IBM
- PART NUMBER: ST973452SS-IBM
- CAPACITY: 73GB
- INTERFACE: SAS
- SPEED: 15K RPM
- SIZE FORM FACTOR: 2.5IN
При тестировании производительности большую роль играет размер блоков страйпа. Чтение с дисков при восстановлении данных ведется по возрастающим адресам (последовательно), но из-за декластеризации в случайных схемах расположения некоторые блоки пропускаются. Это значит, что при работе с блоками малого размера позиционирование магнитной головки диска будет производиться очень часто, что пагубно скажется на производительности.
Поскольку конкретные значения скорости восстановления данных могут зависеть от модели жестких дисков, производителя, RPM и др., мы представили полученные результаты в относительных величинах. На рис 5. продемонстрирован прирост производительности в рассматриваемых схемах (RAID6 c empty блоком, Classic LRC, LRC rand) в сравнении с классическим RAID-6.
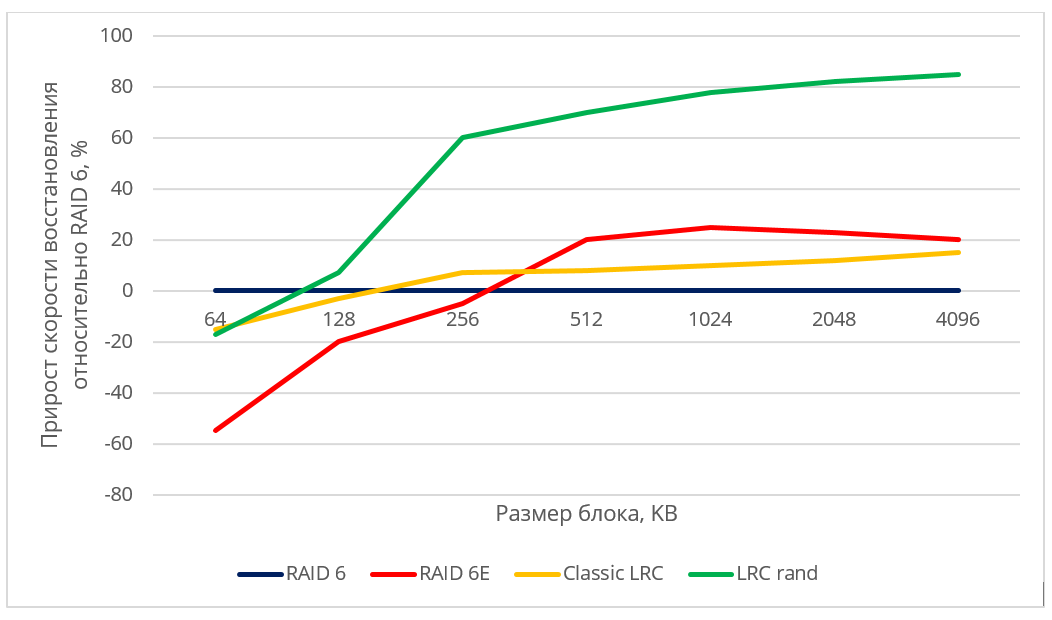
Рис. 5. Относительная производительность различных алгоритмов размещения
При восстановлении данных на hot spare диск скорость восстановления ограничивалась скоростью записи на диск для всех схем, использующих hot spare. Можно заметить, что рандомизированная LRC-схема дает достаточно высокий прирост скорости восстановления по сравнению с неоптимальной схемой и RAID-6.
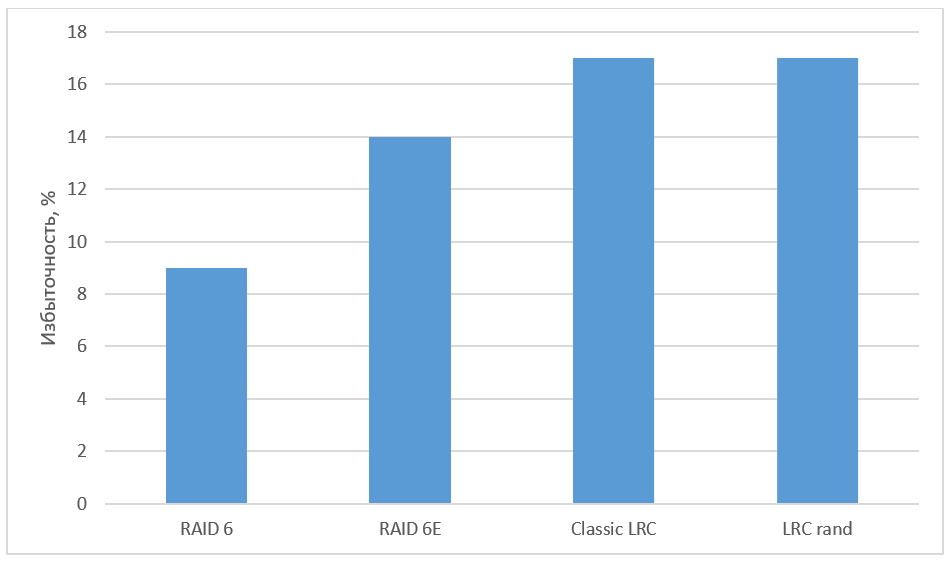
Рис. 6. Избыточность различных алгоритмов
Заключение
Мы привели возможные варианты расположения блоков, а также провели тестирование различных схем и увидели заметный прирост в скорости восстановления. Благодаря высокой масштабируемости LRC-кодов данный подход может использоваться также при построении массивов из большого количества дисков, с помощью увеличения количества локальных групп. Повышение надежности может достигаться за счет увеличения числа глобальных контрольных сумм.
Помехоустойчивое кодирование при помощи LRC способствует существенному снижению избыточности в хранилище по сравнению с репликацией. Схемы кодирования, отличающиеся от кодов Рида-Соломона, на практике чаще всего исследуются в контексте LRC. Xorbas — реализация LRC в HDFS — потребовала увеличения избыточности на 14% по сравнению с RS-кодированием. Скорость восстановления при этом увеличилась на 25-45%. Количество чтений и пересылок по сети также значительно сократилось. Для дальнейшего изучения оптимальных LRC советуем обратиться к работе «A Family of Optimal Locally Recoverable Codes» (Itzhak Tamo, Alexander Barg).
Использованные источники:
- Hafner, J. L., WEAVER Codes: Highly Fault Tolerant Erasure Codes for Storage Systems, FAST-2005: 4th Usenix Conference on File and Storage Technologies
- Khan, O., Burns, R., Plank, J. S., Pierce, W., Huang, C. Rethinking Erasure Codes for Cloud File Systems: Minimizing I/O for Recovery and Degraded Reads, FAST-2012: 10th Usenix Conference on File and Storage Technologies
- Huang, C., Simitci, H., Xu, Y., Ogus, A., Calder, B., Gopalan, P., Li, J., Yekhanin, S., Erasure Coding in Windows Azure Storage, USENIX Annual Technical Conference
- M. Sathiamoorthy, M. Asteris, D. Papailiopoulos, A. G. Dimakis, R. Vadali, S. Chen, and D. Borthakur. XORing Elephants: Novel Erasure Codes for Big Data. In Proceedings of the VLDB Endowment, volume 6, pages 325–336. VLDB Endowment, 2013.
- Itzhak Tamo, Alexander Barg. A Family of Optimal Locally Recoverable Codes. arXiv preprint arXiv: 1311.3284, 2013.
Поделиться с друзьями
Комментарии (3)

basilbasilbasil
08.06.2017 18:35а есть ли аппаратные решения на LRC?
raidixteam
09.06.2017 10:34В рамках нашего (софтверного) направления, LRC реализуется вполне успешно.
Что касается, аппаратных решений, то у нас нет сведений о таких продуктах. Но, вероятнее всего, это не имеет широкого распространения, ввиду гибкости и сложности конфигурации LRC.
kat_djonson
Круто!