
Постепенная информатизация медицины связана со сбором очень разных данных. Они добываются совершенно непохожими способами и почти всегда имеют уникальную структуру. Откуда, как и зачем их стоит собирать? В своём докладе руководитель разработки сервиса Яндекс.Здоровье Михаил Tomcat Пайсон рассказывает об основных путях развития современной медицины и о технологических проблемах, которые перед ней стоят.
Под катом — расшифровка доклада и слайды.
Меня зовут Михаил Пайсо?н, я занимаюсь разработкой Яндекс.Здоровья, фактически руковожу ей. В своем докладе я расскажу про космические корабли, которые бороздят просторы. Но не Большого театра, потому что Большой театр довольно далеко, а эти близкие просторы, которые находятся где-то рядом и уже скоро станут реальностью. Это будет доклад по верхам, очень неглубокий. Я постараюсь максимальное количество областей затронуть, где могут использоваться большие данные, машинное обучение.
Почему я здесь? Мы занимаемся Яндекс.Здоровьем, пока мы находимся очень близко к пользователю, то есть решаем какие-то совершенно практические задачи: запись к врачу, хранение результатов приема и т. д. Поэтому то, о чем буду говорить, — максимально практические вещи, которые, наверное, хотелось бы и использовать сейчас, и ввести в промышленность, а не просто оставлять в научных исследованиях.
Начнем с раздела о том, какие большие данные у нас могут быть в медицине, над которыми можно какое-то условное машинное обучение встраивать или искусственный интеллект.
Первый самый большой блок данных, которые накопились в индустрии, — неструктурированные данные.
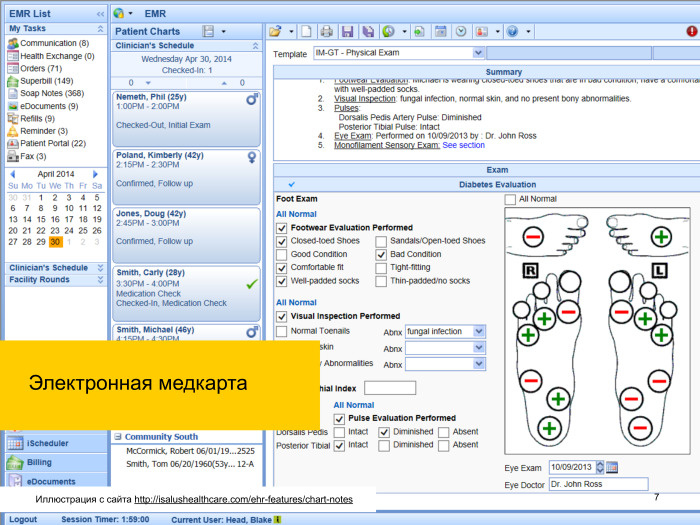
Что это такое? Например, электронная медкарта. Сейчас активно развивается во многих областях, применяется во многих клиниках. Уже есть проекты, где-то в США это уже очень давно стало обязательным. В России внедряется, кажется, больше с постоянным успехом, нежели с переменным. Тем не менее, есть такие данные. Все это хранится, сохраняется, где-то есть база, в Америке она централизованная, у нас, надеюсь, тоже скоро будет централизованной.
Это неструктурированные данные. Это данные, в которых нет четкого разделения на поля, четкого выделения каких-то терминов или ключевых слов. То есть есть какой-то массив, из него надо майнить нужную информацию.
Следующее — запись телемедицинского приема. Тоже хороший пример, когда пациент и врач удаленно общаются. Пациент что-то говорит, врач что-то отвечает. Это все — аудио, видео — можно распознавать, и это тоже неструктурированные данные как пример того, что может пригождаться.
Фото и сканы документов. Тут тоже есть некие проблемы, особенно если вспомнить, как замечательно у нас врачи… Пациент точно не может распознать то, что они написали. Меня всегда удивляет, как провизор в аптеке, когда ему отдаешь рецепт, может понять, что там написано. Тем не менее, это тоже большой кусок для анализа, то есть мы тоже можем анализировать эти данные, мы тоже можем находить там структуру и получать оттуда какие-то инсайты.
Есть еще форумы, блоги. Блоги бывают разные, форумы тоже бывают разные. Некоторые немножко хуже, некоторые лучше, но это тоже источник данных, которые мы можем брать и над которыми можем работать.

Есть такая штука — IBM Watson. Кто слышал про Watson? Ого! Здорово. Кажется, про Watson слышали практически все. Сейчас это не какая-то одна технология, а скорее набор технологий, плюс платформа, на которых она работает. Сравнительно недавно они купили британскую компанию, которая занимается обработкой изображений. У них там сейчас свой Deep Learning и т. д. Но в целом они начинали с того, что взяли электронный архив медкарт, плюс формы, блоги специализированные, полностью их проиндексировали, накинули на них natural language processing и сделали на их основе алгоритмы правильного поиска, matching. Потом начали использовать для диагностики. Начали они с обработки неструктурированной информации, то есть информации из медкарт.
Стоит упомянуть известный гугловский DeepMind Health. Как у всех нормальных живых врачей, у Watson и у DeepMind есть хобби. Watson играет в свою американскую игру Jeopardy и всех побеждает, то есть он в свое время являлся чемпионом Америки по «Своей игре». А DeepMind увлекается го, и AlphaGo — это тот самый DeepMind, который сейчас используется в медицине. Это что касается неструктурированных данных.
Неструктурированных данных много, их надо майнить, их можно майнить. Понятно, как. Люди так уже делают в промышленности. Тот же самый Watson уже вовсю используется, они его предлагают как систему в поддержке принятия решений, и даже вполне успешно предлагают.
Данные с носимых устройств — тоже большой кусок данных, которые сейчас еще активно не обрабатываются, но, кажется, все вот-вот начнется.
Какие бывают носимые устройства? Для начала, речь идет о неких профессиональных устройствах. Хороший пример — холтеровский мониторинг. Что такое профессиональные устройства? Это устройства, которые стоят больших денег, тысячи долларов, и которые покупает клиника. Человек приходит, надевает это устройство, некоторое время носит, и потом они получают данные с этого устройства.
Что такое холтеровский мониторинг, думаю, многие знают. Это штука, которую надевают на день и которая мониторит состояние сердца. Большие-большие данные, которые за день человек собрал, он потом приносит к врачу и как-то размечает: «В это время я делал одно, в это время делал другое». Потом по полученной разметке он сейчас в полуавтоматическом режиме анализирует, и врач, в свою очередь, делает какие-то выводы.
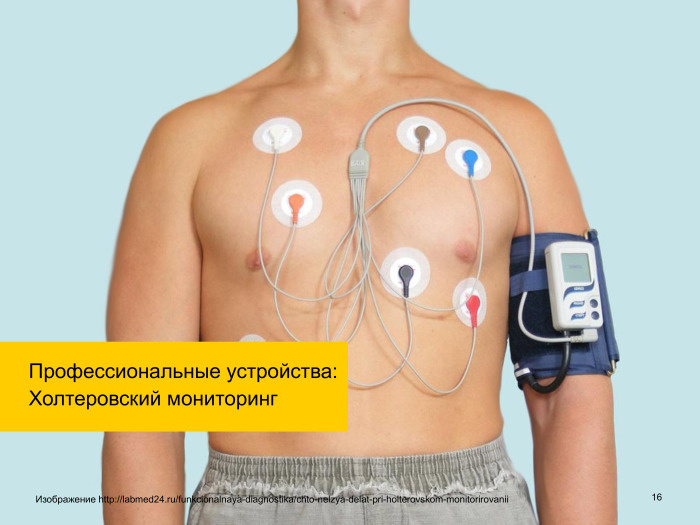
Все, наверное, кто с этим сталкивался, привыкли примерно к такому виду холтеровского мониторинга, а на самом деле он сейчас уже примерно вот такой.
То есть это штука, которая вшивается. Видите, как сильно уже продвигается наука. Это штука, которая на какую-нибудь док-станцию по Wi-Fi или Bluetooth постоянно отправляет данные, которые в реальном времени могут идти на пульт врача, и т. д. То есть это уже сегодня используется. И данных много, они большие по определению. Если ЭКГ за целый день снимать с человека, то там очень серьезный объем данных, он требует обработки, и можно делать разные выводы.
Следующий шаг — потребительская электроника. Что это такое? Смартфоны, Mi Band, браслеты. У кого прямо сейчас на руке какой-нибудь Mi Band, браслетик надет, шагомер? В принципе, уже достаточное количество, процентов 10 зала.
Тот самый Mi Band, который сейчас активно рекламируется — штука, с которой тоже можно брать много-много разных данных. Фактически, пульс плюс число шагов и так далее. Поставить по этим данным диагноз, когда они сами по себе, может быть сложно. Но когда они падают в хранилище, где до этого лежали данные из других источников — та же медкарта, — процесс начинает обретать смысл. Над указанными данными тоже уже можно строить какие-то алгоритмы.
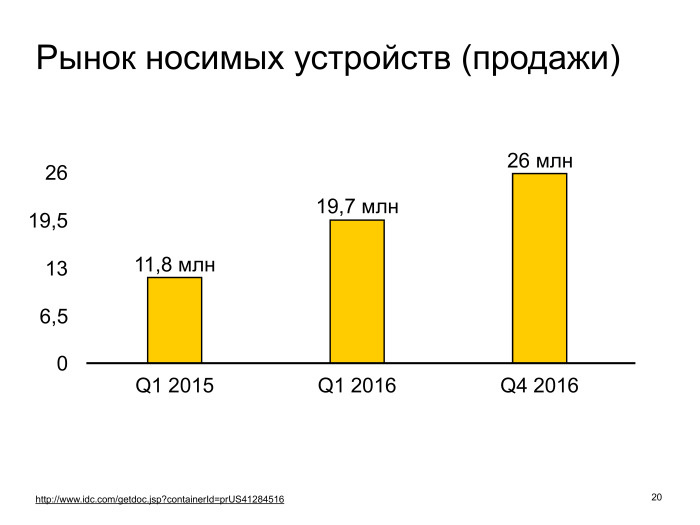
К вопросу про рынок носимых устройств. По статистике с хорошего аналитического сайта, приведенного внизу, мы видим рост более чем в два раза с начала 2015-го и условно до конца 2016-го — потому что данных за 2017-й у них еще не было. Это довольно много. Кажется, рано или поздно примерно у всех будет такая носимая электроника, тот же смартфон, который измеряет шаги.

Есть еще такой промежуточный вариант — специализированные устройства, которые может позволить купить себе человек, то есть необязательно забирать их в медицинском учреждении. При этом они более-менее продвинутые. Например, электронный стетоскоп. Он не сам делал аускультацию, но он получает данные и может, например, отправить их врачу. Или — это же большие данные, мы про науку и про космические корабли — почему бы не делать это автоматически, почему бы не слушать звук сердца, звук дыхания, и на основе обработки звукового сигнала почему бы не делать какие-то выводы?
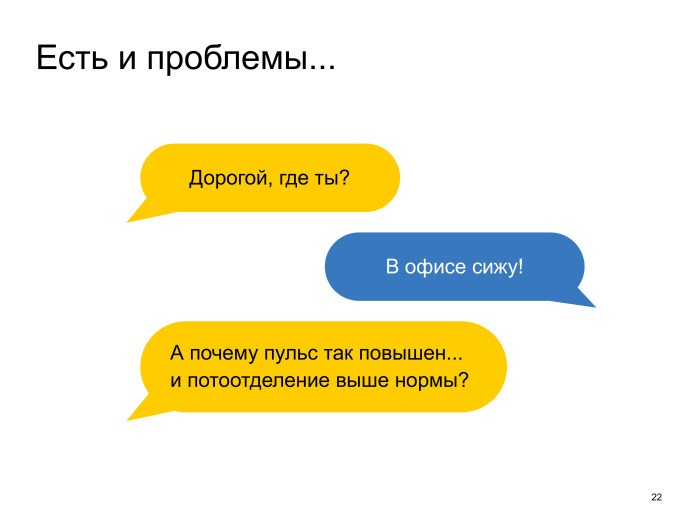
С носимой электроникой есть большие проблемы. Это скорее про защиту персональных данных, о которой Дмитрий после меня будет рассказывать. Но в целом, когда мы говорим том, что у нас будет много-много данных про всяких пользователей, мы должны думать, где они будут храниться, куда отправляться. Потому что в принципе даже сейчас известны случаи, когда Apple где-то у себя хранит маршруты людей, то, как они в течение дня двигаются и куда. И это не очень нравится тем, за кем Apple следит.
Дальше. Вот мой самый любимый кусочек, потому что он про rocket science. Если до сих пор все было более-менее понятно и приближенно, то это прямо очень крутая область, где есть море интересного.
Генетическая информация тоже в очень многих областях может использоваться, и речь не только про само секвенирование. Кусочки генома уже сейчас понемногу расшифровывают, либо сейчас уже есть аппарат, который расшифровывает большой кусочек, но с потерей точности. Но речь здесь и не только про расшифровку самого генома — хотя это огромный кладезь для знаний и данных. На самом деле можно расшифровывать геномы братьев наших меньших, которые у нас во всяких потаенных уголках тела живут и на основе которых тоже можно получить много информации о нас.
Для примера — уже сейчас активно и замечательно работает диагностика генетических заболеваний. Это уже промышленность, реальность. В эту область уже сейчас можно прийти. Наверное, слышали эпическую историю про Анджелину Джоли, как она сделала себе мастэктомию, потому что у нее оказался очень высокий риск рака груди? Можно сказать, что эта штука уже спасла ей жизнь, вполне возможно. Или, по крайней мере, сильно улучшила качество.
Второе — поиск патогенов.
Про секвенирование микробиоты сегодня будет отдельный доклад. Очень хочу его послушать.
Поиск патогенов. Мы смотрим на ДНК, которое нарезали из маленьких кусочков, и видим, что там что-то не то. Там какой-то нехороший ДНК затесался какого-то зловреда, и мы видим, что это за зловред, и уже можем точечно назначать лечение.
На самом деле, я призываю сходить по этой ссылке. У нас целый семинар был, Data & Science, в рамках этого же курса. Замечательные докладчики, там целых четыре часа, но не пожалеете, тем более что можно в YouTube ускорить в два раза.
Наверное, самое распространенное, самое первое, что бросается в глаза и что приходит в голову, — изображения. Понятно, что в глаза бросаются именно изображения. Тут тоже много чего можно найти.
Например, рентгеновские изображения. По ним можно автоматически обрабатывать и детектировать много нарушений, каких-то заболеваний и т. д.
То же самое МРТ, автоматическая обработка, КТ. Скажем, есть такая ОКТ — примерно то же самое, что УЗИ, только на оптических волнах. Я, может быть, не очень точно с медицинской точки зрения говорю, а просто чтобы было понимание.
И изображения с электронных микроскопов — тоже огромный кусок данных, которые тоже можно анализировать. Мы сейчас говорим про обработку изображений, автоматический анализ, распознавание образов и т. д.
Вот примеры. Их два, оба примерно одинаковые, но тем не менее. Для начала, Google недавно выпустил статью, там Джефф Дин, про то, как они научились локализовывать опухолевые клетки. Понятно, есть рак груди, есть метастазы в соседних лимфоузлах, и их нужно найти.
Есть такая штука — гигапиксельные изображения. В них миллиарды пикселей. Если примерно посчитать, то порядок такой. Если его с нормальным разрешением распечатать, то размер полотна — примерно 30 на 30 метров. Понятно, что врачу, когда он смотрит на это изображение, глазами довольно сложно понять, что там происходит, детектировать маленькие очаги и т. д. Но если на все это натравить алгоритм — допустим, ту же нейронку, как это сделали ребята из Google, — то можно довольно точно детектировать наличие, скажем, опухолевых клеток. По результатам исследований они примерно 89% точности показали против 73% у обычного живого, серьезного и хорошего врача. Кажется, это уже тоже продвижение.
Следующее — примерно то же самое. Тут, как мне кажется, уже более интересно. Ребята определяли разный тип рака легких. Есть плоскоклеточный рак, а есть аденокарцинома. Они немножко по-разному выглядят и, самое главное, лечатся разной химиотерапией. Соответственно, по изображению с микроскопа они могут с большой долей вероятности отличать первый от второго. И системы поддержки принятия решений — ведь все равно все решения принимает человек — уже могут с изрядной долей уверенности сказать, что, скорее всего, здесь этот рак.
Чем указанный пример отличается от предыдущего? Кажется, они очень похожи, разница в деталях. В предыдущем на гигапиксельные изображения просто накидывалась нейросеть — обученная, может быть, на ImageNet, на котиках и собачках (это была шутка). Здесь же они просто обрабатывают изображение, выделяют эти клеточки и уже по изображениям клетки делают замер, считают порядка 200 фич. В этой статье есть прямо Excel-таблица, где указано, какие конкретно фичи они считают. И уже на основании этих фич они классифицируют опухоль. Кажется, они просто там SVM делают сверху.
Дальше, еще один пример про изображения. Понятно, что про них можно говорить очень много. Там есть огромное количество применений не только для детектирования типов онкологии и т. д. Поле непаханое.
Сейчас я немножко даже не пофантазирую, а сделаю некое подведение итогов.
Где можно прямо сейчас использовать большие данные?

Фактически, для врача это в основном диагностика систем поддержки принятия решений. То есть мы прямо сейчас еще, кажется, боимся сказать, что мы диагностировали на 100%, что у пациента эта штука, лечите вот так, врач не нужен, делаем автоматически. Сейчас мы пока не готовы, как разработчики алгоритмов, принимать такие решения. Но уже сейчас алгоритмы с большой долей вероятности могут дать правильное решение, и диагностировать более точно.
Что такое точная медицина? Это медицина, которая при диагностике учитывает не только текущий анамнез человека, но и огромное количество информации о нем, в частности генетический код и все те данные, которые я вначале описывал. В эту сторону тоже все будет двигаться, потому что чем больше мы о человеке знаем, тем точнее можем понять, чем человек болеет и как его лечить.
Третий пункт, упрощение ежедневной работы, — уже исключительно приземленный. Например, распознавание голоса, кажется, очень актуально сейчас для врачей, потому что в определенных случаях — когда руки, например, заняты манипуляциями — писать очень неудобно. Здесь может помочь хорошее распознавание голоса, которое, скажем, берет и транслирует все, что врач проговаривает, в ту же электронную медкарту.

Теперь про пациента. Для начала — предсказание заболеваний. Что это значит? Это значит — пациент приходит, как сейчас, сдает кусочек слюны или капельку крови, ему по ДНК секвенируют и находят потенциальные проблемы. Это очень круто, позволяет заранее узнать о том, о чем узнать не получается. Еще раз говорю: все штуки, связанные с ДНК, секвенированием, алгоритмом обработки этих последовательностей, тоже очень интересные, там очень сильная математика. Я отсылаю к той самой ссылке, которую давал с десяток слайдов назад. Послушайте, посмотрите — очень круто.
Дальше предсказания. Дальше — рекомендация обследования, примерно на этом же уровне. Если мы понимаем, что у человека повышенный риск какого-то определенного заболевания, то ему можно рекомендовать обследование, например. Можно УЗИ молочной железы сделать или сдать на какие-то маркеры.
Рекомендации по здоровому образу жизни. Ровно так же, когда тебе коробочка или смартфон — что скорее всего — будет говорить: «Так, что-то все плохо, что-то ты долго и много бегал. Давай-ка отдохни». Или: «Что-то в последнее время пульс как-то странно себя ведет. Надо поесть морковки», — условно.
Мониторинг состояния здоровья — это больше для хроников. Я пролистнул слайд с пластырем, который измеряет уровень глюкозы. Сейчас уже, например, Apple вовсю это делает. Кажется, неинвазивные методы замера глюкозы станут следующим огромным прорывом. Это тоже очень важно, потому что человек колет себе палец много раз на дню, особенно если это хроник с диабетом. Это неприятно, противно. Если такой пластырь будет просто где-то на руке наклеен — по-моему, это сильно повысит вероятность того, что он не станет игнорировать эти процедуры.
Поговорил про хорошее, теперь немножко про плохое.
Для начала — объемы выборки. Возвращаясь к тому, что мы все-таки имеем в виду большие данные, скажу: с объемом выборки все плохо. Если читать много современных исследований, это 200-300 измерений. Не сказать, что это большие данные. Обучить какой-то нормальный классификатор на 200-300 измерениях — сомнительное удовольствие, все-таки надо больше данных. И получить большие данные, просто так их взять и сказать: «Я хочу заниматься большими данными в медицине. Дайте мне данные, я их поанализирую», тоже не получается. В основном все исследования, на которые даются ссылки и про которые говорится, что они на переднем крае науки, проводятся через партнерство с каким-то крупным лечебным учреждением. Google партнерится с Королевским колледжем в Лондоне, берет у них данные постоянно. Тот же IBM получил доступ к единой медкарте в Америке. Нужно очень много дипломатических усилий, особенно в России.
Что в России? Самое, кажется, интересное, что у нас будет в ближайшее время, — электронная медкарта. Она сейчас пока разрабатывается, внедряется. Как я уже сказал, внедряется с условно переменным успехом. Кажется, скорее с успехом, нежели без него. Но про реализацию есть некие опасения. Они говорят: «Давайте мы все сотни тысяч клиник, фельдшерских пунктов и прочего покроем единой сетью и структурой». То есть с ней, как и с любой большой государственной инициативой, возникает много проблем в части совпадения данных, форматов и т. д. Проблемы даже чисто технические — я уже не говорю про организационные. Плюс дальше они постулируют, что доступ к этим данным будет, но, возвращаясь к предыдущему слайду, не у всех и не сразу. То есть я не удивлюсь, если надо вносить себя в реестр организаций, имеющих доступ к обезличенным медицинским данным. В общем, бюрократия тут будет изрядная. Судя по тому, что сейчас есть, данных там будет достаточно мало, и самое интересное не всегда будет доступно.
Про качество заполнения — не хочу никого обидеть, но это вопрос компьютерной грамотности. Понятно, что человеку в отдаленном фельдшерском пункте, где-нибудь в селе, тяжело заполнять электронную медицинскую карту c надлежащим качеством. И, скорее всего, там будет не то, что хотелось бы видеть при анализе данных.
Про изображения тоже не все так хорошо. Я только что руками махал, какие Google хорошие, как они на гигапиксельных изображениях все здорово анализируют и детектируют. Проблема в чем? Чтобы сделать гигапиксельное изображение, нужна дорогая техника. Чтобы это был не точечный эксперимент, когда мы написали статью, защитили диссертацию и «Ура», а действительно промышленное решение — к сожалению, должно пройти много времени. Причина в том, что на закупки такой техники… Со временем она будет все дешевле и дешевле, как 30-40 лет назад мы не могли представить, что в каждом лечебном учреждении будут стоять компьютеры и все они будут между собой связаны. Но есть проблемы с внедрением. Оно тоже появится не сразу — в будущем, нежели сейчас.
Про будущее. Погрустили — надо продолжить на оптимистичной ноте.

В состоянии здоровья видится единая структурированная история болезни с открытым доступом. Очень хочется такое. Оно рано или поздно будет. Конечно, открытый доступ — это не то, что я прихожу и говорю: «Мне, пожалуйста, про Иванова Федора Михайловича все данные дайте», и они мне дадут. Конечно, нет, все будет обезличено. Большой объем данных будет пригоден для анализа. В принципе, уже сейчас определенные колледжи выкладывают свои дата-сеты на различные соревнования а-ля Kaggle. Условно говоря, это некие соревнования между командами, которые занимаются анализом данных, машинным обучением. И уже на реальных данных от различных пациентов — но, конечно, обезличенных — можно тренироваться. Но хочется, чтобы я приехал откуда-нибудь из региона, пришел к врачу, мне говорят: «Ага, у тебя пять лет назад в течение дня наблюдался повышенный пульс — твой браслетик об этом нам написал в карту».
Дальше. Здесь тоже немножко про космические корабли, про полное и мгновенное секвенирование генома. Сейчас это занимает некоторое время. Хочется, чтобы секвенирование было быстрое и полное. Пришел я, плюнул на ладошку… Кстати, здесь мы возвращаемся к азам: раньше, в начале какого-нибудь XII века, сидела обвешанная талисманами бабуля, ей плевали на ладошку, она говорила результат. Кажется, все это повторяется, но с немножко более научной основой, и немножко более достоверно. То есть речь идет о мгновенном анализе. Не менее важны общая база данных по генетическим заболеваниям, расшифрованный геном и т. д.
Третье — непрерывный трекинг активности, причем это не только шаги, пульс, но и, например, сердечная деятельность, уровень сахара и т. д. Этого тоже очень-очень хочется, и, наверное, когда-то оно станет реальностью.
Четвертое — специализированные микроимпланты. Они больше про хроников. Мы все постепенно превращаемся в киборгов. Самые первые киборги — это, наверное, люди со слуховым аппаратом, дальше с сердечным стимулятором и т. д. Кажется, все это будет происходить и дальше. И та штука, которая уже мелькала на слайде, и та, которая для холтеровского мониторинга, и та, которая для мониторинга сахара, и много чего другого. Они уже будут имплантироваться. Для хроников это особенно важно. Причем на основе этого будут автоматически приниматься какие-то решения. Хорошо бы. То есть все, сахар скакнул — надо что-то делать. Инсулиновая помпа, условно.

И — автоматизированная диагностика. Мы огромное-огромное количество данных, наверное, научимся собирать рано или поздно. Но над этим огромным количеством, конечно же, нужно будет писать алгоритмы и автоматизировать диагностику. Снова речь про будущее. Кажется, вся диагностика рано или поздно будет скорее машинно обученная, скорее компьютерная, нежели представленная в виде живого человека. Пока на первом этапе она уже постепенно уходит в помощь, но заменит она диагностов или нет — кажется, покажет время. Но я верю, что она их все-таки заменит, потому что мощности несравнимы с человеческим мозгом, даже гениальным.
Дальше — определение аномалий в реальном времени с моментальным принятием решений. Увидели, что у нас с глюкозой непорядок — инсулиновая помпа сработала, автоматом ввела дозу. Человек радуется. С изображениями — ровно то же самое. Кажется, что профессия рентгенолога скоро будет требовать образования в области анализа больших данных и компьютерного зрения — потому что этот кусочек уже ближе всего. Когда появятся нормальные рентген-аппараты, которые дают достаточное разрешение для анализа, анализ дефектов на изображениях станет очень-очень близок. Речь не про дефекты изображений, а про дефекты человека.

Отдельно упомяну о самом важном — об аппарате для автоматического надевания бахил в поликлиниках. Я его уже видел, встречал — не буду говорить, где. Но это очень круто, за этим будущее. Не болейте!
Под катом — расшифровка доклада и слайды.
Меня зовут Михаил Пайсо?н, я занимаюсь разработкой Яндекс.Здоровья, фактически руковожу ей. В своем докладе я расскажу про космические корабли, которые бороздят просторы. Но не Большого театра, потому что Большой театр довольно далеко, а эти близкие просторы, которые находятся где-то рядом и уже скоро станут реальностью. Это будет доклад по верхам, очень неглубокий. Я постараюсь максимальное количество областей затронуть, где могут использоваться большие данные, машинное обучение.
Почему я здесь? Мы занимаемся Яндекс.Здоровьем, пока мы находимся очень близко к пользователю, то есть решаем какие-то совершенно практические задачи: запись к врачу, хранение результатов приема и т. д. Поэтому то, о чем буду говорить, — максимально практические вещи, которые, наверное, хотелось бы и использовать сейчас, и ввести в промышленность, а не просто оставлять в научных исследованиях.
Начнем с раздела о том, какие большие данные у нас могут быть в медицине, над которыми можно какое-то условное машинное обучение встраивать или искусственный интеллект.
Первый самый большой блок данных, которые накопились в индустрии, — неструктурированные данные.
Что это такое? Например, электронная медкарта. Сейчас активно развивается во многих областях, применяется во многих клиниках. Уже есть проекты, где-то в США это уже очень давно стало обязательным. В России внедряется, кажется, больше с постоянным успехом, нежели с переменным. Тем не менее, есть такие данные. Все это хранится, сохраняется, где-то есть база, в Америке она централизованная, у нас, надеюсь, тоже скоро будет централизованной.
Это неструктурированные данные. Это данные, в которых нет четкого разделения на поля, четкого выделения каких-то терминов или ключевых слов. То есть есть какой-то массив, из него надо майнить нужную информацию.
Следующее — запись телемедицинского приема. Тоже хороший пример, когда пациент и врач удаленно общаются. Пациент что-то говорит, врач что-то отвечает. Это все — аудио, видео — можно распознавать, и это тоже неструктурированные данные как пример того, что может пригождаться.
Фото и сканы документов. Тут тоже есть некие проблемы, особенно если вспомнить, как замечательно у нас врачи… Пациент точно не может распознать то, что они написали. Меня всегда удивляет, как провизор в аптеке, когда ему отдаешь рецепт, может понять, что там написано. Тем не менее, это тоже большой кусок для анализа, то есть мы тоже можем анализировать эти данные, мы тоже можем находить там структуру и получать оттуда какие-то инсайты.
Есть еще форумы, блоги. Блоги бывают разные, форумы тоже бывают разные. Некоторые немножко хуже, некоторые лучше, но это тоже источник данных, которые мы можем брать и над которыми можем работать.
Есть такая штука — IBM Watson. Кто слышал про Watson? Ого! Здорово. Кажется, про Watson слышали практически все. Сейчас это не какая-то одна технология, а скорее набор технологий, плюс платформа, на которых она работает. Сравнительно недавно они купили британскую компанию, которая занимается обработкой изображений. У них там сейчас свой Deep Learning и т. д. Но в целом они начинали с того, что взяли электронный архив медкарт, плюс формы, блоги специализированные, полностью их проиндексировали, накинули на них natural language processing и сделали на их основе алгоритмы правильного поиска, matching. Потом начали использовать для диагностики. Начали они с обработки неструктурированной информации, то есть информации из медкарт.
Стоит упомянуть известный гугловский DeepMind Health. Как у всех нормальных живых врачей, у Watson и у DeepMind есть хобби. Watson играет в свою американскую игру Jeopardy и всех побеждает, то есть он в свое время являлся чемпионом Америки по «Своей игре». А DeepMind увлекается го, и AlphaGo — это тот самый DeepMind, который сейчас используется в медицине. Это что касается неструктурированных данных.
Неструктурированных данных много, их надо майнить, их можно майнить. Понятно, как. Люди так уже делают в промышленности. Тот же самый Watson уже вовсю используется, они его предлагают как систему в поддержке принятия решений, и даже вполне успешно предлагают.
Данные с носимых устройств — тоже большой кусок данных, которые сейчас еще активно не обрабатываются, но, кажется, все вот-вот начнется.
Какие бывают носимые устройства? Для начала, речь идет о неких профессиональных устройствах. Хороший пример — холтеровский мониторинг. Что такое профессиональные устройства? Это устройства, которые стоят больших денег, тысячи долларов, и которые покупает клиника. Человек приходит, надевает это устройство, некоторое время носит, и потом они получают данные с этого устройства.
Что такое холтеровский мониторинг, думаю, многие знают. Это штука, которую надевают на день и которая мониторит состояние сердца. Большие-большие данные, которые за день человек собрал, он потом приносит к врачу и как-то размечает: «В это время я делал одно, в это время делал другое». Потом по полученной разметке он сейчас в полуавтоматическом режиме анализирует, и врач, в свою очередь, делает какие-то выводы.
Все, наверное, кто с этим сталкивался, привыкли примерно к такому виду холтеровского мониторинга, а на самом деле он сейчас уже примерно вот такой.
То есть это штука, которая вшивается. Видите, как сильно уже продвигается наука. Это штука, которая на какую-нибудь док-станцию по Wi-Fi или Bluetooth постоянно отправляет данные, которые в реальном времени могут идти на пульт врача, и т. д. То есть это уже сегодня используется. И данных много, они большие по определению. Если ЭКГ за целый день снимать с человека, то там очень серьезный объем данных, он требует обработки, и можно делать разные выводы.
Следующий шаг — потребительская электроника. Что это такое? Смартфоны, Mi Band, браслеты. У кого прямо сейчас на руке какой-нибудь Mi Band, браслетик надет, шагомер? В принципе, уже достаточное количество, процентов 10 зала.
Тот самый Mi Band, который сейчас активно рекламируется — штука, с которой тоже можно брать много-много разных данных. Фактически, пульс плюс число шагов и так далее. Поставить по этим данным диагноз, когда они сами по себе, может быть сложно. Но когда они падают в хранилище, где до этого лежали данные из других источников — та же медкарта, — процесс начинает обретать смысл. Над указанными данными тоже уже можно строить какие-то алгоритмы.
К вопросу про рынок носимых устройств. По статистике с хорошего аналитического сайта, приведенного внизу, мы видим рост более чем в два раза с начала 2015-го и условно до конца 2016-го — потому что данных за 2017-й у них еще не было. Это довольно много. Кажется, рано или поздно примерно у всех будет такая носимая электроника, тот же смартфон, который измеряет шаги.
Есть еще такой промежуточный вариант — специализированные устройства, которые может позволить купить себе человек, то есть необязательно забирать их в медицинском учреждении. При этом они более-менее продвинутые. Например, электронный стетоскоп. Он не сам делал аускультацию, но он получает данные и может, например, отправить их врачу. Или — это же большие данные, мы про науку и про космические корабли — почему бы не делать это автоматически, почему бы не слушать звук сердца, звук дыхания, и на основе обработки звукового сигнала почему бы не делать какие-то выводы?
С носимой электроникой есть большие проблемы. Это скорее про защиту персональных данных, о которой Дмитрий после меня будет рассказывать. Но в целом, когда мы говорим том, что у нас будет много-много данных про всяких пользователей, мы должны думать, где они будут храниться, куда отправляться. Потому что в принципе даже сейчас известны случаи, когда Apple где-то у себя хранит маршруты людей, то, как они в течение дня двигаются и куда. И это не очень нравится тем, за кем Apple следит.
Дальше. Вот мой самый любимый кусочек, потому что он про rocket science. Если до сих пор все было более-менее понятно и приближенно, то это прямо очень крутая область, где есть море интересного.
Генетическая информация тоже в очень многих областях может использоваться, и речь не только про само секвенирование. Кусочки генома уже сейчас понемногу расшифровывают, либо сейчас уже есть аппарат, который расшифровывает большой кусочек, но с потерей точности. Но речь здесь и не только про расшифровку самого генома — хотя это огромный кладезь для знаний и данных. На самом деле можно расшифровывать геномы братьев наших меньших, которые у нас во всяких потаенных уголках тела живут и на основе которых тоже можно получить много информации о нас.
Для примера — уже сейчас активно и замечательно работает диагностика генетических заболеваний. Это уже промышленность, реальность. В эту область уже сейчас можно прийти. Наверное, слышали эпическую историю про Анджелину Джоли, как она сделала себе мастэктомию, потому что у нее оказался очень высокий риск рака груди? Можно сказать, что эта штука уже спасла ей жизнь, вполне возможно. Или, по крайней мере, сильно улучшила качество.
Второе — поиск патогенов.
Про секвенирование микробиоты сегодня будет отдельный доклад. Очень хочу его послушать.
Поиск патогенов. Мы смотрим на ДНК, которое нарезали из маленьких кусочков, и видим, что там что-то не то. Там какой-то нехороший ДНК затесался какого-то зловреда, и мы видим, что это за зловред, и уже можем точечно назначать лечение.
На самом деле, я призываю сходить по этой ссылке. У нас целый семинар был, Data & Science, в рамках этого же курса. Замечательные докладчики, там целых четыре часа, но не пожалеете, тем более что можно в YouTube ускорить в два раза.
Наверное, самое распространенное, самое первое, что бросается в глаза и что приходит в голову, — изображения. Понятно, что в глаза бросаются именно изображения. Тут тоже много чего можно найти.
Например, рентгеновские изображения. По ним можно автоматически обрабатывать и детектировать много нарушений, каких-то заболеваний и т. д.
То же самое МРТ, автоматическая обработка, КТ. Скажем, есть такая ОКТ — примерно то же самое, что УЗИ, только на оптических волнах. Я, может быть, не очень точно с медицинской точки зрения говорю, а просто чтобы было понимание.
И изображения с электронных микроскопов — тоже огромный кусок данных, которые тоже можно анализировать. Мы сейчас говорим про обработку изображений, автоматический анализ, распознавание образов и т. д.
Вот примеры. Их два, оба примерно одинаковые, но тем не менее. Для начала, Google недавно выпустил статью, там Джефф Дин, про то, как они научились локализовывать опухолевые клетки. Понятно, есть рак груди, есть метастазы в соседних лимфоузлах, и их нужно найти.
Есть такая штука — гигапиксельные изображения. В них миллиарды пикселей. Если примерно посчитать, то порядок такой. Если его с нормальным разрешением распечатать, то размер полотна — примерно 30 на 30 метров. Понятно, что врачу, когда он смотрит на это изображение, глазами довольно сложно понять, что там происходит, детектировать маленькие очаги и т. д. Но если на все это натравить алгоритм — допустим, ту же нейронку, как это сделали ребята из Google, — то можно довольно точно детектировать наличие, скажем, опухолевых клеток. По результатам исследований они примерно 89% точности показали против 73% у обычного живого, серьезного и хорошего врача. Кажется, это уже тоже продвижение.
Следующее — примерно то же самое. Тут, как мне кажется, уже более интересно. Ребята определяли разный тип рака легких. Есть плоскоклеточный рак, а есть аденокарцинома. Они немножко по-разному выглядят и, самое главное, лечатся разной химиотерапией. Соответственно, по изображению с микроскопа они могут с большой долей вероятности отличать первый от второго. И системы поддержки принятия решений — ведь все равно все решения принимает человек — уже могут с изрядной долей уверенности сказать, что, скорее всего, здесь этот рак.
Чем указанный пример отличается от предыдущего? Кажется, они очень похожи, разница в деталях. В предыдущем на гигапиксельные изображения просто накидывалась нейросеть — обученная, может быть, на ImageNet, на котиках и собачках (это была шутка). Здесь же они просто обрабатывают изображение, выделяют эти клеточки и уже по изображениям клетки делают замер, считают порядка 200 фич. В этой статье есть прямо Excel-таблица, где указано, какие конкретно фичи они считают. И уже на основании этих фич они классифицируют опухоль. Кажется, они просто там SVM делают сверху.
Дальше, еще один пример про изображения. Понятно, что про них можно говорить очень много. Там есть огромное количество применений не только для детектирования типов онкологии и т. д. Поле непаханое.
Сейчас я немножко даже не пофантазирую, а сделаю некое подведение итогов.
Где можно прямо сейчас использовать большие данные?
Фактически, для врача это в основном диагностика систем поддержки принятия решений. То есть мы прямо сейчас еще, кажется, боимся сказать, что мы диагностировали на 100%, что у пациента эта штука, лечите вот так, врач не нужен, делаем автоматически. Сейчас мы пока не готовы, как разработчики алгоритмов, принимать такие решения. Но уже сейчас алгоритмы с большой долей вероятности могут дать правильное решение, и диагностировать более точно.
Что такое точная медицина? Это медицина, которая при диагностике учитывает не только текущий анамнез человека, но и огромное количество информации о нем, в частности генетический код и все те данные, которые я вначале описывал. В эту сторону тоже все будет двигаться, потому что чем больше мы о человеке знаем, тем точнее можем понять, чем человек болеет и как его лечить.
Третий пункт, упрощение ежедневной работы, — уже исключительно приземленный. Например, распознавание голоса, кажется, очень актуально сейчас для врачей, потому что в определенных случаях — когда руки, например, заняты манипуляциями — писать очень неудобно. Здесь может помочь хорошее распознавание голоса, которое, скажем, берет и транслирует все, что врач проговаривает, в ту же электронную медкарту.
Теперь про пациента. Для начала — предсказание заболеваний. Что это значит? Это значит — пациент приходит, как сейчас, сдает кусочек слюны или капельку крови, ему по ДНК секвенируют и находят потенциальные проблемы. Это очень круто, позволяет заранее узнать о том, о чем узнать не получается. Еще раз говорю: все штуки, связанные с ДНК, секвенированием, алгоритмом обработки этих последовательностей, тоже очень интересные, там очень сильная математика. Я отсылаю к той самой ссылке, которую давал с десяток слайдов назад. Послушайте, посмотрите — очень круто.
Дальше предсказания. Дальше — рекомендация обследования, примерно на этом же уровне. Если мы понимаем, что у человека повышенный риск какого-то определенного заболевания, то ему можно рекомендовать обследование, например. Можно УЗИ молочной железы сделать или сдать на какие-то маркеры.
Рекомендации по здоровому образу жизни. Ровно так же, когда тебе коробочка или смартфон — что скорее всего — будет говорить: «Так, что-то все плохо, что-то ты долго и много бегал. Давай-ка отдохни». Или: «Что-то в последнее время пульс как-то странно себя ведет. Надо поесть морковки», — условно.
Мониторинг состояния здоровья — это больше для хроников. Я пролистнул слайд с пластырем, который измеряет уровень глюкозы. Сейчас уже, например, Apple вовсю это делает. Кажется, неинвазивные методы замера глюкозы станут следующим огромным прорывом. Это тоже очень важно, потому что человек колет себе палец много раз на дню, особенно если это хроник с диабетом. Это неприятно, противно. Если такой пластырь будет просто где-то на руке наклеен — по-моему, это сильно повысит вероятность того, что он не станет игнорировать эти процедуры.
Поговорил про хорошее, теперь немножко про плохое.
Для начала — объемы выборки. Возвращаясь к тому, что мы все-таки имеем в виду большие данные, скажу: с объемом выборки все плохо. Если читать много современных исследований, это 200-300 измерений. Не сказать, что это большие данные. Обучить какой-то нормальный классификатор на 200-300 измерениях — сомнительное удовольствие, все-таки надо больше данных. И получить большие данные, просто так их взять и сказать: «Я хочу заниматься большими данными в медицине. Дайте мне данные, я их поанализирую», тоже не получается. В основном все исследования, на которые даются ссылки и про которые говорится, что они на переднем крае науки, проводятся через партнерство с каким-то крупным лечебным учреждением. Google партнерится с Королевским колледжем в Лондоне, берет у них данные постоянно. Тот же IBM получил доступ к единой медкарте в Америке. Нужно очень много дипломатических усилий, особенно в России.
Что в России? Самое, кажется, интересное, что у нас будет в ближайшее время, — электронная медкарта. Она сейчас пока разрабатывается, внедряется. Как я уже сказал, внедряется с условно переменным успехом. Кажется, скорее с успехом, нежели без него. Но про реализацию есть некие опасения. Они говорят: «Давайте мы все сотни тысяч клиник, фельдшерских пунктов и прочего покроем единой сетью и структурой». То есть с ней, как и с любой большой государственной инициативой, возникает много проблем в части совпадения данных, форматов и т. д. Проблемы даже чисто технические — я уже не говорю про организационные. Плюс дальше они постулируют, что доступ к этим данным будет, но, возвращаясь к предыдущему слайду, не у всех и не сразу. То есть я не удивлюсь, если надо вносить себя в реестр организаций, имеющих доступ к обезличенным медицинским данным. В общем, бюрократия тут будет изрядная. Судя по тому, что сейчас есть, данных там будет достаточно мало, и самое интересное не всегда будет доступно.
Про качество заполнения — не хочу никого обидеть, но это вопрос компьютерной грамотности. Понятно, что человеку в отдаленном фельдшерском пункте, где-нибудь в селе, тяжело заполнять электронную медицинскую карту c надлежащим качеством. И, скорее всего, там будет не то, что хотелось бы видеть при анализе данных.
Про изображения тоже не все так хорошо. Я только что руками махал, какие Google хорошие, как они на гигапиксельных изображениях все здорово анализируют и детектируют. Проблема в чем? Чтобы сделать гигапиксельное изображение, нужна дорогая техника. Чтобы это был не точечный эксперимент, когда мы написали статью, защитили диссертацию и «Ура», а действительно промышленное решение — к сожалению, должно пройти много времени. Причина в том, что на закупки такой техники… Со временем она будет все дешевле и дешевле, как 30-40 лет назад мы не могли представить, что в каждом лечебном учреждении будут стоять компьютеры и все они будут между собой связаны. Но есть проблемы с внедрением. Оно тоже появится не сразу — в будущем, нежели сейчас.
Про будущее. Погрустили — надо продолжить на оптимистичной ноте.
В состоянии здоровья видится единая структурированная история болезни с открытым доступом. Очень хочется такое. Оно рано или поздно будет. Конечно, открытый доступ — это не то, что я прихожу и говорю: «Мне, пожалуйста, про Иванова Федора Михайловича все данные дайте», и они мне дадут. Конечно, нет, все будет обезличено. Большой объем данных будет пригоден для анализа. В принципе, уже сейчас определенные колледжи выкладывают свои дата-сеты на различные соревнования а-ля Kaggle. Условно говоря, это некие соревнования между командами, которые занимаются анализом данных, машинным обучением. И уже на реальных данных от различных пациентов — но, конечно, обезличенных — можно тренироваться. Но хочется, чтобы я приехал откуда-нибудь из региона, пришел к врачу, мне говорят: «Ага, у тебя пять лет назад в течение дня наблюдался повышенный пульс — твой браслетик об этом нам написал в карту».
Дальше. Здесь тоже немножко про космические корабли, про полное и мгновенное секвенирование генома. Сейчас это занимает некоторое время. Хочется, чтобы секвенирование было быстрое и полное. Пришел я, плюнул на ладошку… Кстати, здесь мы возвращаемся к азам: раньше, в начале какого-нибудь XII века, сидела обвешанная талисманами бабуля, ей плевали на ладошку, она говорила результат. Кажется, все это повторяется, но с немножко более научной основой, и немножко более достоверно. То есть речь идет о мгновенном анализе. Не менее важны общая база данных по генетическим заболеваниям, расшифрованный геном и т. д.
Третье — непрерывный трекинг активности, причем это не только шаги, пульс, но и, например, сердечная деятельность, уровень сахара и т. д. Этого тоже очень-очень хочется, и, наверное, когда-то оно станет реальностью.
Четвертое — специализированные микроимпланты. Они больше про хроников. Мы все постепенно превращаемся в киборгов. Самые первые киборги — это, наверное, люди со слуховым аппаратом, дальше с сердечным стимулятором и т. д. Кажется, все это будет происходить и дальше. И та штука, которая уже мелькала на слайде, и та, которая для холтеровского мониторинга, и та, которая для мониторинга сахара, и много чего другого. Они уже будут имплантироваться. Для хроников это особенно важно. Причем на основе этого будут автоматически приниматься какие-то решения. Хорошо бы. То есть все, сахар скакнул — надо что-то делать. Инсулиновая помпа, условно.
И — автоматизированная диагностика. Мы огромное-огромное количество данных, наверное, научимся собирать рано или поздно. Но над этим огромным количеством, конечно же, нужно будет писать алгоритмы и автоматизировать диагностику. Снова речь про будущее. Кажется, вся диагностика рано или поздно будет скорее машинно обученная, скорее компьютерная, нежели представленная в виде живого человека. Пока на первом этапе она уже постепенно уходит в помощь, но заменит она диагностов или нет — кажется, покажет время. Но я верю, что она их все-таки заменит, потому что мощности несравнимы с человеческим мозгом, даже гениальным.
Дальше — определение аномалий в реальном времени с моментальным принятием решений. Увидели, что у нас с глюкозой непорядок — инсулиновая помпа сработала, автоматом ввела дозу. Человек радуется. С изображениями — ровно то же самое. Кажется, что профессия рентгенолога скоро будет требовать образования в области анализа больших данных и компьютерного зрения — потому что этот кусочек уже ближе всего. Когда появятся нормальные рентген-аппараты, которые дают достаточное разрешение для анализа, анализ дефектов на изображениях станет очень-очень близок. Речь не про дефекты изображений, а про дефекты человека.
Отдельно упомяну о самом важном — об аппарате для автоматического надевания бахил в поликлиниках. Я его уже видел, встречал — не буду говорить, где. Но это очень круто, за этим будущее. Не болейте!
Поделиться с друзьями
Psychosynthesis
Ну да, как обычно. Очень круто про всё это читать, очень круто что всё это вот прямо сейчас есть, что над этим работают и т.д. и т.п.
Но по настоящему круто будет только когда я приду к поликлинику, не тогда когда мне назначат, а когда мне будет удобно. Зайду к врачу, он спросит, например, номер моего ОМС, данные с моих «носимых» устройств автоматом загрузятся к нему в компьютер и он сразу изложит свои предположения касательно причины моего визита.
Хотя… что-то я расфантазировался. Для начала будет круто уже даже если они хотя бы перестанут терять мою мед.карту стабильно каждые два года.
kloppspb
Зато — высокие технологии плюс интернет :)
Просто покажу как выглядит одна из нужных страниц, если на неё продраться:
darthunix
Вы не можете записаться на удобное вам время просто потому, что денег нет. ТФОМС раз в год выдаёт план задание — обязательство каждому медучреждения оплатить N медицинских услуг, не больше и не меньше. И медучреждение обязано их сделать ровно столько, сколько выдал в виде плана ТФОМС. Меньше сделаешь — урежут в следующем году план, больше — не заплатят. Проблема в том, что ТФОМС обязуется оплатить количество услуг в несколько раз меньшее, чем реально нужно населению. Медучреждение планирует этот минимум помесячно, чтобы не выполнить весь годовой план за пару месяцев. Услуг не хватает, а что есть разлетается как горячие пирожки. Денег на ОМС медицину у государства нет, поэтому развивается только платный сегмент. А с учётом полной импортозависимости по реагентам, расходникам и оборудованию, а так же с учётом курса, платная медицина будет только дорожать.
frees2
Большие данные придут когда датчики станут дешёвыми, в смартфонах и так далее. Сейчас даже пульс не измеряют как надо. Температуру тела не могут снять. Точнее, могут но датчики в разработке.
Применение.
Выявление эпидемий, ухудшение отопления в районе, даже предотвращение терроризма, если зафиксируется каким нибудь ватсоном нестандартное изменение данных у группы в локальном районе.
hungry_ewok
/цинично/
… и фраза «ректальный зонд от гугла» перестанет быть гиперболой.
kloppspb
Да. Её просто нет, и в этом основная проблема. Поищите "монитор холтера", например. А потом сравните с тем, что даёт якобы достоверную информацию по мнению гуглплея или аппстора :)
lxsmkv
Не знаю, немецкие врачи даже анализы не берут если их об этом не попросить. А если ты за прием платишь сам, а не страховка, то они сделают любые анализы вплоть до ДНК.
Зачем им высокие технологии, если они и без них нормально могут принимать решения. Назначаешь лечение, если не помогло — придет еще раз, а если не придет, то, либо помогло, либо кони двинул.
2PAE
Первое впечатление, что Яндекс хочет ворваться на рынок платных мед услуг и совместно с минздрав россии вытеснить лечение по ОМС. :(
Ну хотя бы интерфейс будут хороший. Не те дерьмовые, не работающие, высоко бюджетные поделки что есть сейчас. Всякие самозаписи и прочее…