

Расскажем о том, как устроен поиск похожих треков среди всех аудиозаписей ВКонтакте.
Зачем всё это надо?
У нас действительно много музыки. Много — это больше 400 миллионов треков, которые весят примерно 4 ПБ. Если загрузить всю музыку из ВКонтакте на 64 ГБ айфоны, и положить их друг на друга, получится башня выше Эйфелевой. Каждый день в эту стопку нужно добавлять еще 25 айфонов — или 150 тысяч новых аудиозаписей объёмом 1.5 ТБ.
Конечно, далеко не все эти файлы уникальны. У каждого аудио есть данные об исполнителе и названии (опционально — текст и жанр), которые пользователь заполняет при загрузке песни на сайт. Премодерации нет. В результате мы получаем одинаковые песни под разными названиями, ремиксы, концертные и студийные записи одних и тех же композиций, и, конечно, совсем неверно названные треки.
Если научиться достаточно точно находить одинаковые (или очень похожие) аудиозаписи, можно применять это с пользой, например:
- не дублировать в поиске один трек под разными названиями;
- предлагать прослушать любимую композицию в более высоком качестве;
- добавлять обложки и текст ко всем вариантам песни;
- усовершенствовать механизм рекомендаций;
- улучшить работу с жалобами владельцев контента.
Пожалуй, первое, что приходит в голову — это ID3-теги. У каждого mp3-файла есть набор метаданных, и можно принимать во внимание эту информацию как более приоритетную, чем то, что пользователь указал в интерфейсе сайта при загрузке трека. Это самое простое решение. И оно не слишком хорошее — теги можно редактировать вручную, и они совсем не обязательно соответствуют содержимому.
Итак, вся ассоциированная с файлом информация, которая у нас есть, человекозависима и может быть недостоверна. Значит, нужно приниматься за сам файл.
Мы поставили перед собой задачу определять треки, которые одинаковы или очень похожи на слух, анализируя при этом только содержимое файла.
Кажется, кто-то уже это делал?
Поиск похожих аудио — довольно популярная история. Ставшее уже классическим решение используется всеми подряд, от Shazam’а до биологов, изучающих вой волков. Оно основано на акустических отпечатках.
Акустический отпечаток — это представление аудиосигнала в виде набора значений, описывающих его физические свойства.
Проще говоря, отпечаток содержит в себе некую информацию о звуке, причем эта информация компактна — её объём сильно меньше, чем у исходного файла. Композиции, похожие на слух, будут иметь одинаковые отпечатки, и наоборот, у отличных по звучанию песен отпечатки не будут совпадать.
Мы начали с попытки использовать одно из готовых решений на C++ для генерации акустических отпечатков. Прикрутили к нему свой поиск, протестировали на реальных файлах и поняли, что для значительной части выборки результаты плохие. Один и тот же трек успешно «маскируется» эквалайзером, добавлением фонового шума или джинглов, склейкой с фрагментом другого трека.
Вот как это выглядит (в сравнении с исходным треком):
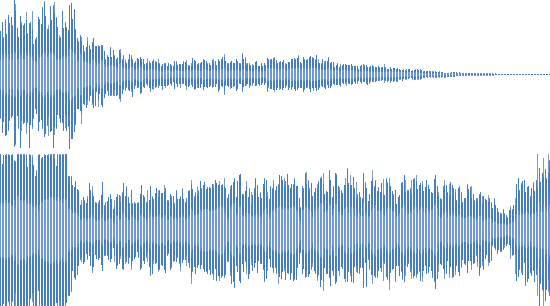
Лайв-исполнение
Эхо

Ремикс
Во всех этих случаях человек легко поймёт, что это одна и та же композиция. У нас много файлов с подобными искажениями, и важно уметь получать хороший результат и на них. Стало ясно, что нам нужна собственная реализация генератора отпечатков.
Генерация отпечатка
Что ж, у нас есть аудиозапись в виде mp3-файла. Как превратить его в компактный отпечаток?
Нужно начать с декодирования аудиосигнала, который в этот файл упакован. MP3 представляет собой цепочку фреймов (блоков), в которых содержатся закодированные данные об аудио в формате PCM (pulse code modulation) — это несжатый цифровой звук.
Чтобы получить PCM из MP3, мы использовали библиотеку libmad на С и собственную обертку для неё на Go. Позднее сделали выбор в пользу прямого использования ffmpeg.
Так или иначе, в результате мы имеем аудиосигнал в виде массива значений, описывающих зависимость амплитуды от времени. Можно представить его в виде такого графика:
Аудиосигнал
Это тот звук, который слышит наше ухо. Человек может воспринимать его как одно целое, но на самом деле звуковая волна представляет собой комбинацию множества элементарных волн разной частоты. Что-то вроде аккорда, состоящего из нескольких нот.
Мы хотим знать, какие частоты есть в нашем сигнале, а особенно — какие из них наиболее «характерны» для него. Прибегнем к каноническому способу получения таких данных — быстрое преобразование Фурье (FFT).
Подробное описание математического аппарата выходит за рамки этой статьи. Узнать больше о применении преобразования Фурье в области цифровой обработки сигналов Вы можете, например, в этой публикации.
В нашей реализации используется пакет GO-DSP (Digital Signal Processing), а именно github.com/mjibson/go-dsp/fft — собственно FFT и github.com/mjibson/go-dsp/window — для оконной функции Ханна.
На выходе получаем набор комплексных чисел, которые, будучи перенесенными на плоскость, называются спектрограммой.
Спектрограмма — это визуальное представление всех трёх акустических измерений: времени, частоты и амплитуды сигнала. Она выражает значение амплитуды для определённого значения частоты в определённый момент времени.
Например:
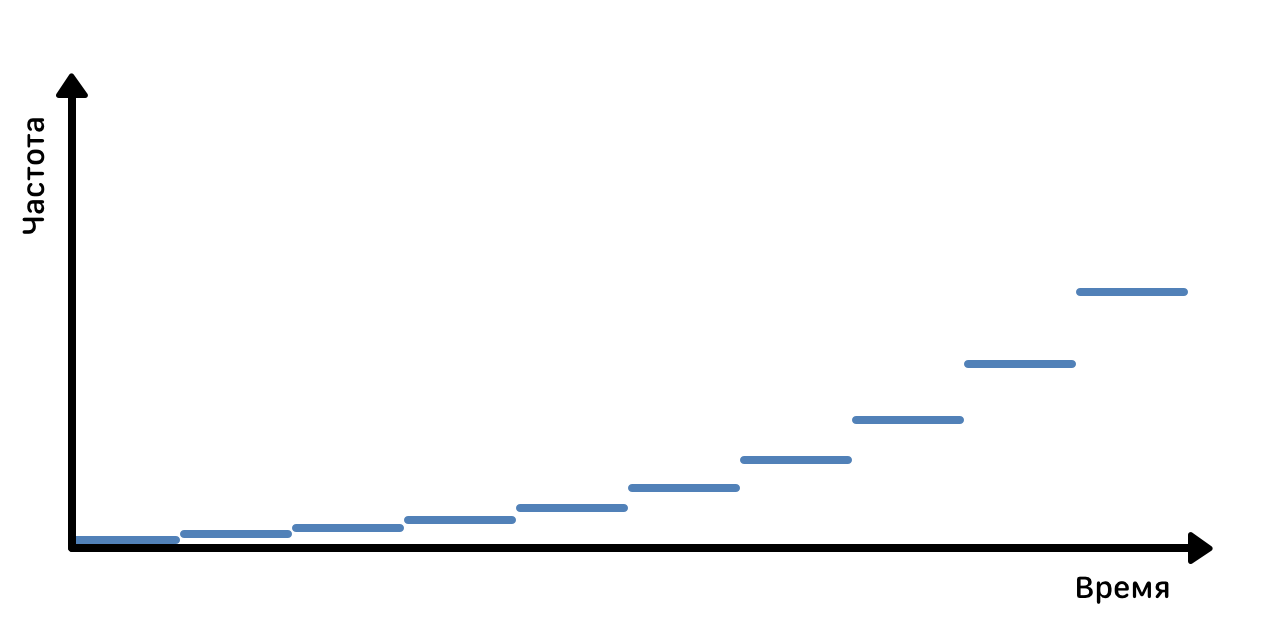
Спектрограмма эталонной дорожки
По оси X отсчитывается время, ось Y представляет частоту, а значение амплитуды обозначается интенсивностью цвета пикселя. На иллюстрации приведена спектрограмма для «эталонного» сигнала с равномерно повышающейся частотой. Для обычной песни спектрограмма выглядит, например так:

Спектрограмма обычной дорожки
Это довольно подробный «портрет» аудиодорожки, из которого можно (с определённой аппроксимацией) восстановить исходный трек. С точки зрения ресурсов, хранить такой «портрет» полностью невыгодно. В нашем случае это потребовало бы 10 ПБ памяти — в два с половиной раза больше, чем весят сами аудиозаписи.
Мы выбираем ключевые точки (пики) на спектрограмме, основываясь на интенсивности спектра, чтобы сохранять только самые характерные для этого трека значения. В результате объём данных сокращается примерно в 200 раз.

Ключевые значения на спектрограмме
Осталось собрать эти данные в удобную форму. Каждый пик однозначно определяется двумя числами — значениями частоты и времени. Добавив все пики для трека в один массив, получим искомый акустический отпечаток.
Сравнение отпечатков
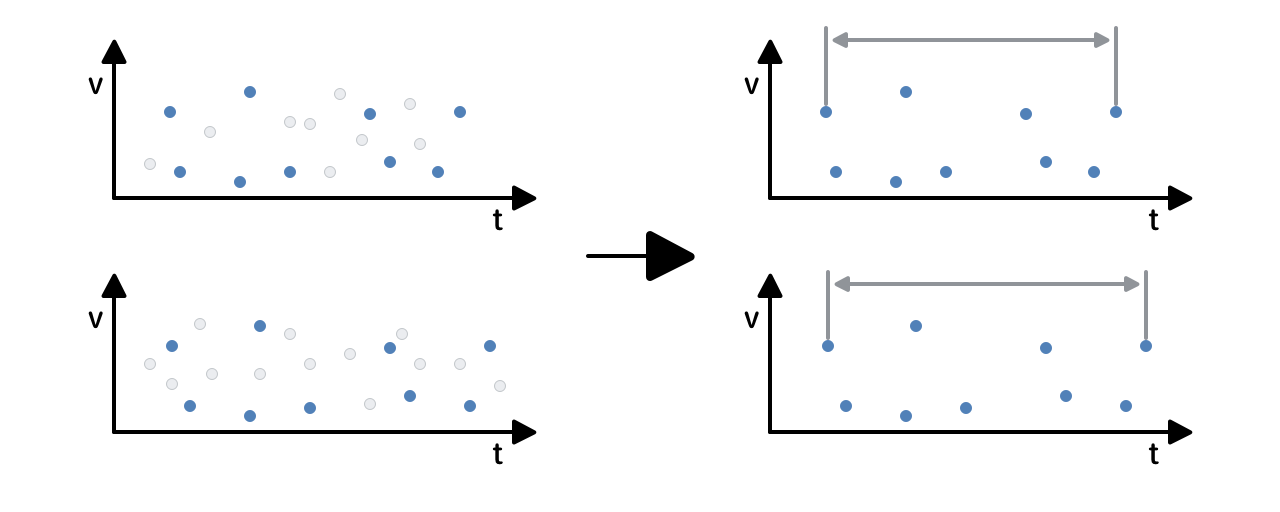
Допустим, мы проделали всё вышеописанное для двух условных треков, и теперь у нас есть их отпечатки. Вернёмся к исходной задаче — сравнить эти треки с помощью отпечатков и выяснить, похожи (одинаковы) они или нет.
Каждый отпечаток — массив значений. Попробуем сравнивать их поэлементно, сдвигая треки по временной шкале относительно друг друга (сдвиг нужен, например, чтобы учесть тишину в начале или в конце трека). На одних смещениях совпадений в отпечатках будет больше, на других — меньше. Выглядит это примерно так:
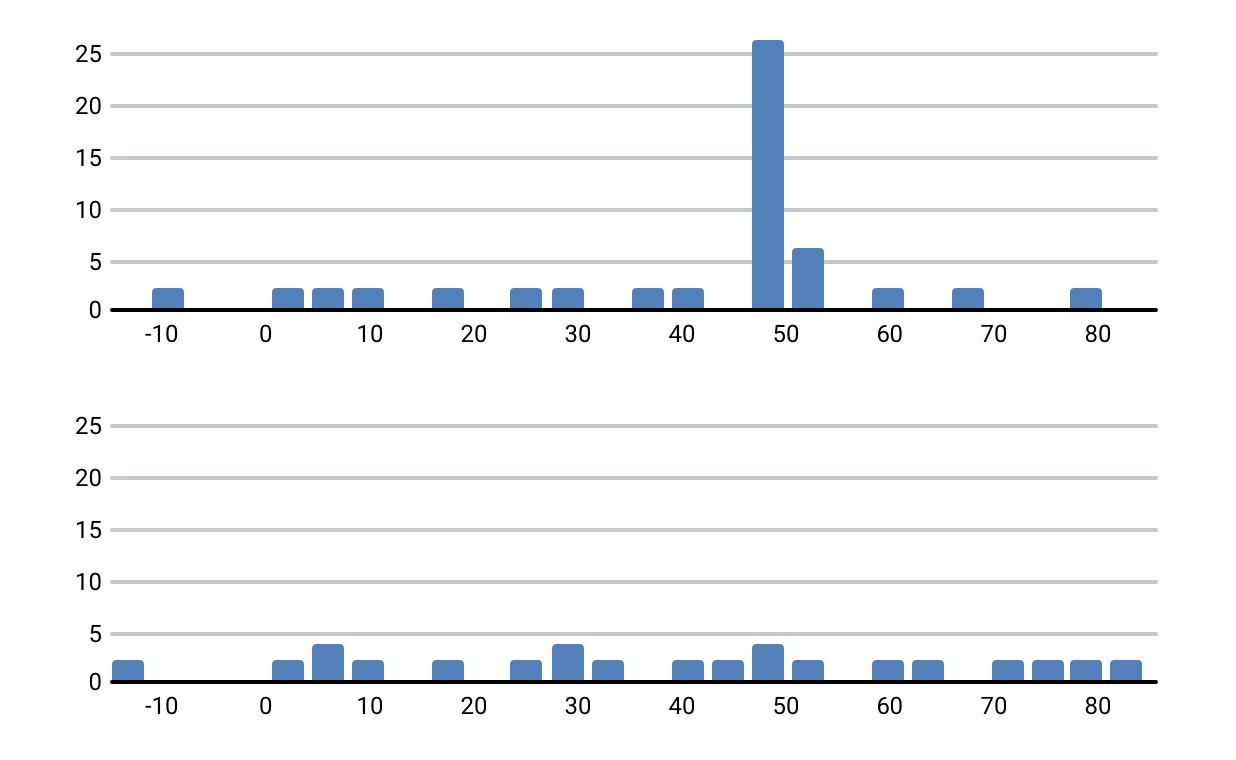
Треки с общим фрагментом и разные треки
Похоже на правду. Для треков с общим фрагментом этот фрагмент нашелся и выглядит как всплеск числа совпадений на определённом временном смещении. Результат сравнения — «коэффициент сходства», который зависит от числа совпадений с учетом смещения.
Программная реализация Go библиотеки для генерации и сравнения отпечатков доступна на GitHub. Вы можете увидеть графики и результаты для собственных примеров.
Теперь надо встроить всё это в нашу инфраструктуру и посмотреть, что получится.
Архитектура
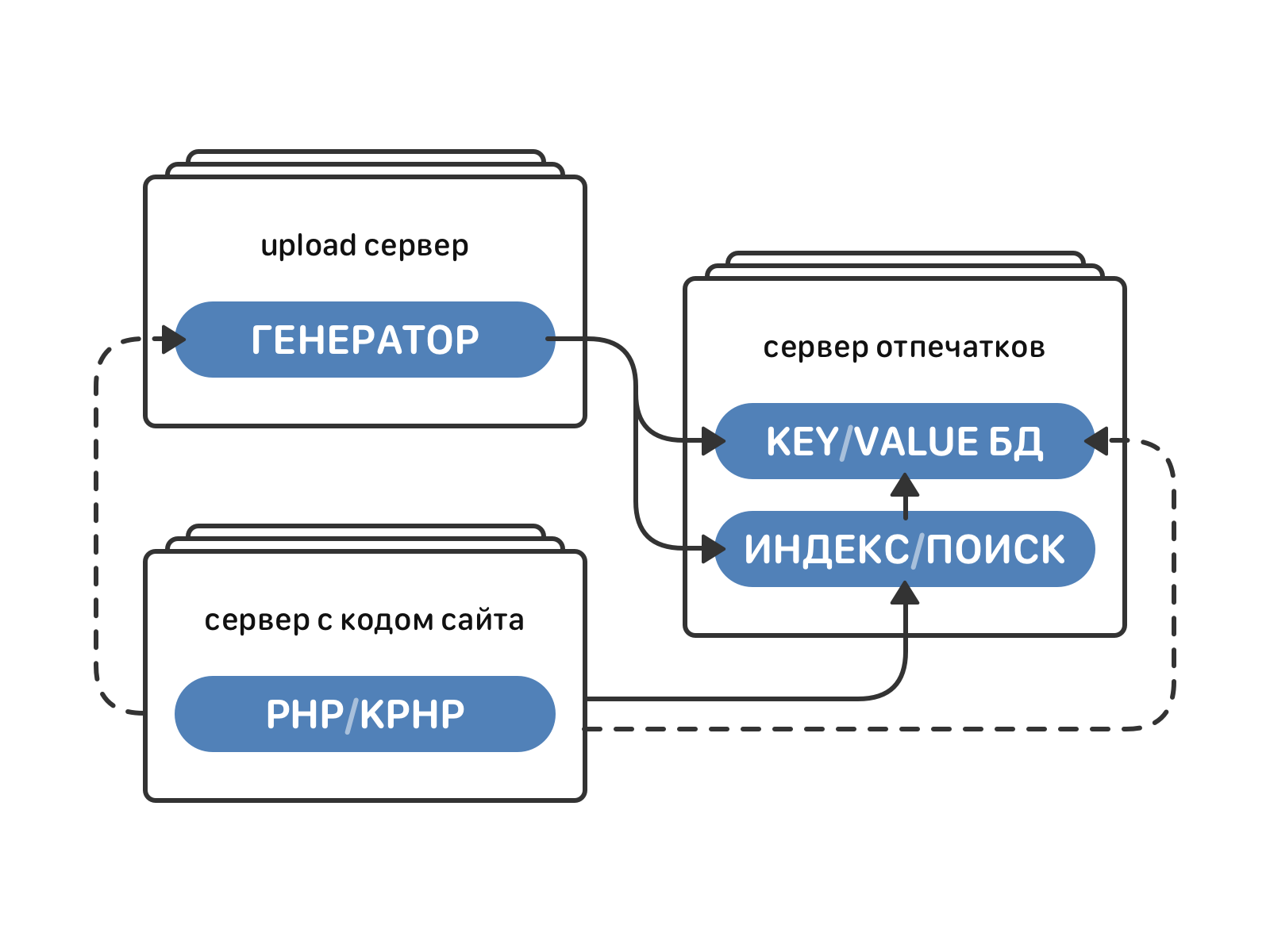
Движки генерации отпечатков и индексирования/поиска в архитектуре ВК
Движок для генерации отпечатков работает на каждом сервере для загрузки аудио (их сейчас около 1000). Он принимает на вход mp3-файл, обрабатывает его (декодирование, FFT, выделение пиков спектра) и выдаёт акустический отпечаток этого аудио.
Нагрузка распараллеливается на уровне файлов — каждый трек обрабатывается в отдельной горутине. Для средней аудиозаписи длительностью 5-7 минут обработка занимает 2-4 секунды. Время обработки линейно растет с увеличением длительности аудио.
Акустические отпечатки всех треков, хоть и с некоторой потерей точности, займут около 20 ТБ памяти. Весь этот объём данных нужно где-то хранить и уметь быстро к нему обращаться, чтобы что-нибудь в нём найти. Эту задачу решает отдельный движок индексирования и поиска.
Он хранит данные об отпечатках в виде обратных (инвертированных) индексов:
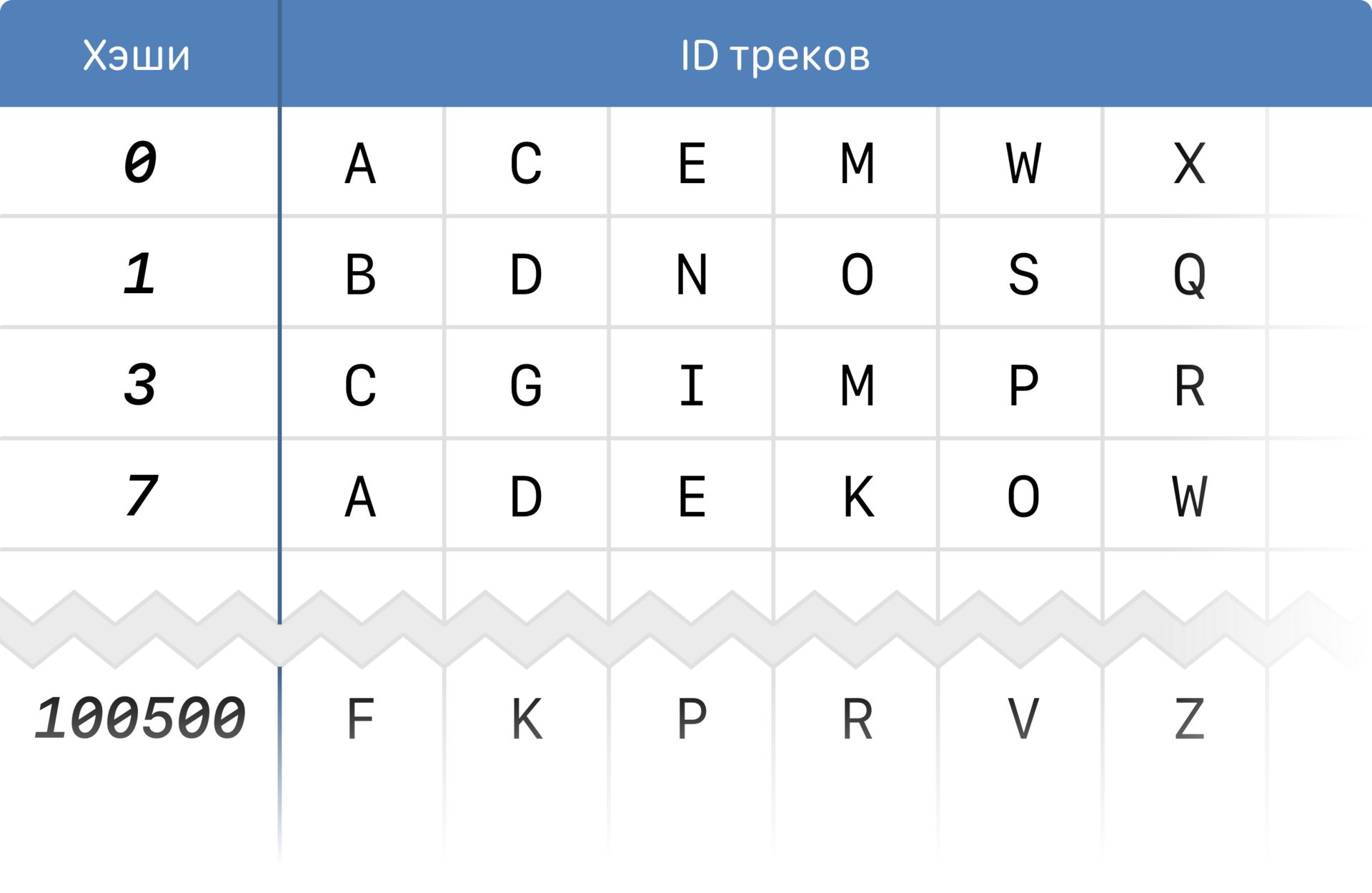
Обратный индекс
Чтобы добиться быстродействия и сэкономить на памяти, мы используем преимущества структуры самого отпечатка. Отпечаток — это массив, и мы можем рассматривать отдельные его элементы (хэши), которые, как Вы помните, соответствуют пикам спектра.
Вместо того, чтобы хранить соответствие «трек» > «отпечаток», мы разбиваем каждый отпечаток на хэши и храним соответствие «хэш» > «список треков, в отпечатках которых он есть». Индекс прореженный, и 20 ТБ отпечатков в виде индекса займут около 100 ГБ.
Как это работает на практике? В движок поиска приходит запрос с аудиозаписью. Нужно найти похожие на неё треки. Из хранилища скачивается отпечаток для этого аудио. В индексе выбираются строчки, содержащие хэши этого отпечатка. Из соответствующих строк выбираются часто встречающиеся треки, для них скачиваются отпечатки из хранилища. Эти отпечатки сравниваются с отпечатком исходного файла. В результате возвращаются самые похожие треки с соответствующими совпавшими фрагментами и условным «коэффициентом сходства» для этих фрагментов.
Движок индексирования и поиска работает на 32 машинах, написан на чистом Go. Здесь по максимуму используются горутины, пулы внутренних воркеров, параллелится работа с сетью и глобальным индексом.
Итак, вся логика готова. Давайте соберем отпечатки всей музыки, проиндексируем и начнём с ними работать. Кстати, сколько времени это займёт?
Мы запустили индексацию, подождали пару дней и оценили сроки. Как оказалось, результат будет примерно через год. Такой срок неприемлем — нужно что-то менять.
Внедрение sync.Pool везде, где только можно, выкроило 2 месяца. Новый срок: 10 месяцев. Это всё ещё слишком долго. Надо лучше.
Оптимизируем тип данных — выбор треков по индексу был реализован слиянием массива. Использование container/heap вместо массива обещает сэкономить половину времени. Получаем 6 месяцев выполнения. Может, можно ещё лучше?
Затачиваем container/heap под использование нашего типа данных вместо стандартных интерфейсов, и выигрываем ещё месяц времени. Но нам и этого мало (то есть много).
Правим stdlib, сделав собственную реализацию для container/heap — ещё минус 2 месяца, итого остаётся 3. В четыре раза меньше первых оценок!
И, наконец, обновление версии Go с 1.5 на 1.6.2 привело нас к финальному результату. 2.5 месяца потребовалось в итоге на создание индекса.
Что получилось?
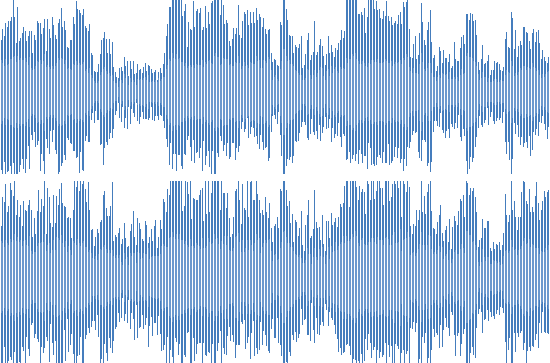
Продакшн-тестирование выявило несколько кейсов, которые мы не учли изначально. Например, копия трека с немного изменённой скоростью воспроизведения:
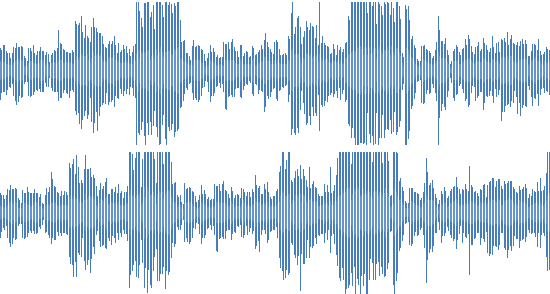
Ускоренная дорожка
Для слушателя это практически одно и то же, небольшое ускорение не воспринимается как существенное отличие. К сожалению, наш алгоритм сравнения отпечатков считал такие треки совсем разными.
Чтобы это исправить, мы добавили немного преобработки. Заключается она в поиске наибольшей общей подпоследовательности (Longest Common Subsequence) в двух отпечатках. Ведь амплитуда и частота не меняются, меняется в этом случае только соответствующее значение времени, а общий порядок следования точек друг за другом сохраняется.
LCS
Нахождение LCS позволяет определить коэффициент «сжатия» или «растяжения» сигнала по шкале времени. Дальше дело за малым — сравниваем отпечатки как обычно, применив к одному из них найденный коэффициент.
Применение алгоритма поиска LCS значительно улучшило результаты — многие треки, которые прежде не находились по отпечатку, стали успешно обрабатываться.
Еще один интересный случай — совпадение по фрагментам. Например, минус какой-то популярной песни с записанным поверх него любительским вокалом.
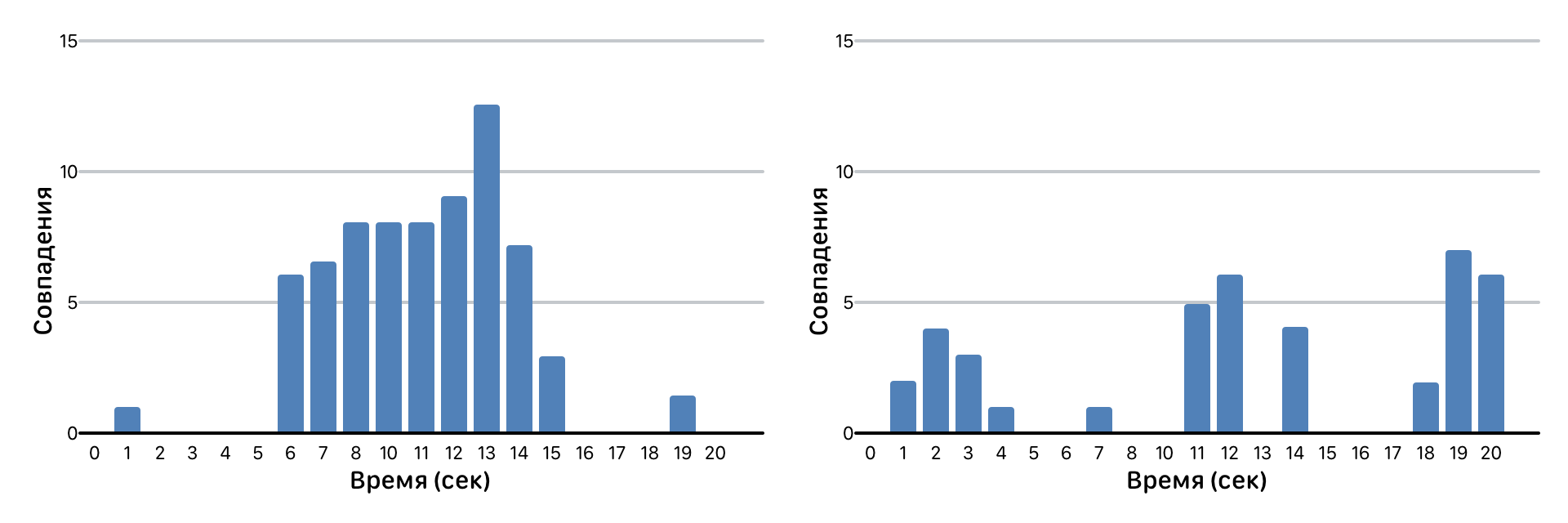
Совпадения фрагментов треков
Мы раскладываем результат сравнения по времени и смотрим на число совпадений для каждой секунды трека. На картинке выше как раз пример любительской записи поверх минуса в сравнении с исходным треком этого минуса. Интервалы с отсутствием совпадений — вокал, пики совпадений — молчание (т.е. чистый минус, который аналогичен исходной дорожке). В такой ситуации мы считаем число фрагментов с совпадениями и вычисляем условный «коэффициент сходства» по числу самих совпадений.
После кластеризации похожих треков отдельные кластеры оказались значительно больше остальных. Что там? Там — интересные ситуации, в которых не очень понятно, чем их правильно считать. Например, всем известная Happy Birthday to You. У нас есть несколько десятков вариантов этой песни, которые отличаются только именем поздравляемого. Считать их разными или нет? То же касается и версий трека на разных языках. Эти искажения и их сочетания стали серьёзной проблемой на этапе запуска.
Нам пришлось изрядно доработать механизм с учётом этих и других не вполне обычных ситуаций. Сейчас система работает должным образом в том числе и на таких сложных кластерах, и мы продолжаем совершенствать её, встречаясь с новыми неординарными преобразованиями. Мы умеем находить песни под вымышленными названиями, ускоренные, с врезками джинглов и без вокала. Поставленная задача была выполнена, и, несомненно, ещё не раз пригодится в дальнейшей работе по развитию сервиса рекомендаций, поиска по музыке и аудиораздела в целом.
P.S. Это первая статья из цикла давно обещанных нами историй про техническую сторону ВКонтакте.
Помимо Хабра, мы будем публиковать их в своём блоге на русском и английском языках. Задать вопрос авторам статей тоже можно не только здесь, но и в отдельном сообществе ВК.
Комментарии (86)

domix32
19.06.2017 18:41+1Мне интересно почему до сих пор при загрузке трека с текстом песен в ID3 тэгах он не попадает автоматически в соотвествующее поле на сайте?

AterCattus
19.06.2017 19:05Можно чуть подробнее (в личку, к примеру)?

IvaYan
19.06.2017 21:51А, я понял. Почему при загрузке трека с текстом песен, вшитом в ID3, этот текст не извлекается загрузчиком и не помещается в соответствующее поле? Если этого действительно не происходит.

Otanim
19.06.2017 19:05Кажется ссылки на github репозитории нерабочие.
AterCattus
19.06.2017 19:05+3Если речь про github.com/mjibson/go-dsp/fft и соседнюю, то это и не ссылки, а именно имена go пакетов.
Это уже парсер Хабра принял их за ссылки и подсветил…

BuriK666
19.06.2017 19:22+4Видео с HighLoad++janitor
19.06.2017 19:45+1Практически то же самое, что и здесь — https://habrahabr.ru/company/yandex/blog/181219/ и https://habrahabr.ru/company/wunderfund/blog/275043/. Ну и echonest/echoprint-server аналогично работает

ZoomLS
19.06.2017 22:35+3А почему блокируются некоторые треки, например в США? Замечу, что треки под лицензией Creative Commons.
Hixon10
19.06.2017 23:02+1Спасибо за статью!
Конечно, это не какой-то прорыв, не rocket science. Однако крайне приятно осознавать, что кому-то везёт, и он на работе может делать такие решения (пускай, и свой велосипед).
А ещё приятно, что в статье упомянут поиск LCS. На это место статьи можно сразу слать всех людей, кто утверждает, что алгоритмы не нужны, всё уже давно написано, а олимпиадное программирование никогда не пригодится.
Прочитал на одном дыхании. Как будто вернулся в свой университет.
8bitjoey
19.06.2017 23:14+1Возможны ли коллизии при таком способе нахождения отпечатка?
Что если некий трек заблокирован по требованию правообладателя, а отпечаток трека который я хочу загрузить волшебным образом с ним совпал, смогу ли я загрузить его?AterCattus
19.06.2017 23:56В этом случае стоит писать в ТП.
Но все примеры, какие я сейчас могу вспомнить, связаны с жалобами про «авторские» записи под минусовку чужой песни :) От того, что поверх минуса наложена какая-то речь, фоновая музыка своего владельца не меняет.8bitjoey
20.06.2017 00:00Но все же коллизии возможны, или вам о таких случаях ничего не известно? (кроме «минусовок»)
Дело даже не в авторских правах, есть и другие проблемы тогда. Вот пишете, что используете отпечаток для отображения обложки, текста, рекомендаций. Получается, что они могут бы неправильными, т.е. относиться к другой песне имеющей тот же отпечаток.

Psychosynthesis
20.06.2017 00:14+10Это всё, конечно, прикольно…
Только вот поиск по аудио у вас до сих пор невероятно тупой. Достаточно одной буквой ошибиться, чтобы он не понимал чего от него хотят:
Screenshot
grieverrr
20.06.2017 15:43-9то есть вы не в состоянии правильно написать название песни, а тупой — поиск?
Psychosynthesis
20.06.2017 16:06+6Начнём с того, что это был просто пример, коих ещё с пяток можно привести.
А вообще, это вполне нормальная ситуация, у меня в коллекции больше 2к треков, я не в состоянии точно запомнить названия всех. И да, внезапно, людям свойственно ошибаться.

pavelkolodin
21.06.2017 17:05Правописание не является функцей логики, поэтому утверждение о тупости любого опечатавшегося не особо-то истинно.

saluev
20.06.2017 17:56Это не по теме статьи. Текстовый поиск — другая история.
Psychosynthesis
20.06.2017 18:21+3По «теме статьи» — если это делается не для того, чтобы потом выпилить весь раздел в платное приложение, а сугубо для удобства пользователей — конечно авторы всячески молодцы. Вот только мы живём в таком мире, что я скорее поставлю на первый вариант.
agentx001
20.06.2017 01:05+1Вот и все что нужно знать про ВКонтакте — статьи пишут для галочки, свои опен сорс продукты не обновляют по три года.

jtiq
20.06.2017 01:22А вы использовали golang до этого ещё где то или только в индексации аудиозаписей? Не думаете полностью перейти на этот ЯП?
AterCattus
20.06.2017 01:23Go у нас кроме этой задачи используется еще и во всяких разных других.
Переходить — нет конечно, каждому ЯП свои задачи.jtiq
20.06.2017 01:27Как давно начали использовать его (golang)? И в каких сервисах используется?
Если трек обрезать спереди на 5 секунд и сзади на 5 секунд, то найдет ли соответствие с оригиналом?AterCattus
20.06.2017 01:33Как давно начали использовать его (golang)? И в каких сервисах используется?
С 2014 для всяких пушей, вот этих отпечатков, сбора access логов, голосовых сообщений, умных проксей, кое-какого api… в общем, это отдельная тема :)
Если трек обрезать спереди на 5 секунд и сзади на 5 секунд, то найдет ли соответствие с оригиналом?
Конечно. Оно выдерживает значительно более сильные искажения.jtiq
20.06.2017 01:37Спасибо. А почему выбрали go, а не C++?
P.S. Очень хотелось бы подробнее узнать конечно же про golang в вк :) Но если это отдельная тема, то будет ли еще что нибудь про то как его использовали в проекте, и конечно же исходники?AterCattus
20.06.2017 01:46+3C/C++ используются для одних задач, Go — для других. Смотря что нужно сделать.
Ну, в теории, можно сделать отдельный пост про то, что есть на Go, если будет спрос на такую довольно специфическую тему)
Просто выложить исходники не достаточно. Они еще должны быть востребованы, как решающие какую-то распространенную задачу. С теми проектами, гду у нас сейчас Go, с этим не очень хорошо.jtiq
20.06.2017 01:48Например, про умные прокси и кое-какого api :)
AterCattus
20.06.2017 01:53Про то-самое-кое-какое-api, возможно, скоро будет что-нибудь публичное ;-)
Прокси используются в крайне специфичных задачах, вряд ли что интересное.

hose314
20.06.2017 09:43+1По поводу ускорения и замедления трека, при каком макс. коэффициенте растяжения / сжатия ваш алгоритм продолжает работать? Вот тут достаточно интересный подход.
И самый интересный вопрос, на сколько устойчив ваш алгоритм к тому, что кто-нибудь сделает хитрое преобразования трека, при котором восприятие его не изменится, но при этом алгоритм сфейлится?
AterCattus
20.06.2017 12:43при каком макс. коэффициенте растяжения / сжатия ваш алгоритм продолжает работать
Сколько зададим в параметрах работы
кто-нибудь сделает хитрое преобразования трека
Зависит от «хитроты». Не возможно добиться 100% корректной работы на любой неизвестной выборке и без ложно-положительных срабатываний.hose314
20.06.2017 12:52Мне кажется это интересный вопрос. Возможно ли создать иной алгоритм с бОльшей обобщающей способностью? (может что-то с CNN)
Кажется, что умельцев всегда будет хватать, которые будут шаманить с аффинными преобразованиями над звуковой дорожкой.
Minusator
20.06.2017 12:40-5Скажите как так получается, загружаешь Вконтакте, перекодированный из допустим wav в mp3 формат без всяких метаданных, аудиофайл, а на следующий день он уже удален по просьбе правообладателей. К сведению музыка не голосовая, т.е. голосом никто не поет, исполнитель вряд ли мог найти данную запись и еще на следующий день после публикации. Название файла — Неизвестное. Как Карл?
lgorSL
20.06.2017 12:48аудиосигнал в виде массива значений, описывающих зависимость амплитуды от времени.
На приведённой картинке точно не амплитуда, так как амплитуда не может быть отрицательной.
helender
20.06.2017 13:36В нашей реализации используется пакет GO-DSP (Digital Signal Processing), а именно github.com/mjibson/go-dsp/fft — собственно FFT и github.com/mjibson/go-dsp/window — для оконной функции Ханна.
Ссылки на репозитории не рабочие.
А так статья очень даже интересная.

Itachi261092
20.06.2017 14:17+3А что вы будете делать, если кто то импортнёт альбом одной последовательной дорожкой, как например, FLAC иногда делают с CD, одним файлом. когда будет общий трек на 70 минут из разных песен, как алгоритм будет искать совпадения?
AterCattus
21.06.2017 01:38Мы умеем находить фрагменты в склейке. Понятно, что похожесть будет ниже, чем у отдельного трека, но она будет.
Itachi261092
21.06.2017 12:11А что будет, если на 15 минут закинуть один 3-минутный трек запрещённый лицензией, а остальное время забить не запрещёнными?
AterCattus
21.06.2017 12:57Будет запрет.

markoffko
21.06.2017 17:59А если диджейский микс? Как у них с правами? Что если в если в «оригинальном» (вся музыка своя) миксе используется небольшой фрагмент «запрещенного» трека?

OksikOneC
20.06.2017 14:52+1Интересная статья, спасибо! А применяются ли какие-то алгоритмы для создания «отпечатков» видео контента? Т.е. все тоже самое, но на видео ролике — работает как-то уже? Можно ли загрузив источник, сделав какой-то с него отпечаток, и после — найти содержимое, но уже в других роликах? Или это фантастика? У меня просто любопытство распирает :)
AterCattus
21.06.2017 01:38Если коротко — то да. Не уверен, что могу про это рассказывать)
OksikOneC
21.06.2017 09:32Спасибо за ответ! Я просто в последнее время стал замечать интересное наблюдение, когда многие пытаются обмануть правообладателей видео-контента и пишут оригинальное название на латинице, или просто бессвязно, надеясь на то, что система определяет идентичность по каким-то ключевым словам в названии файла. И очень быстро, такой контент все равно банится. Я тогда и предположил, что скорее всего, люди написавшие такую систему, явно не с мороза пришли.
И еще один вопрос, если позволите! Сами понимаете, когда появляется один из разработчиков вк, нужно успеть спросить все!
Объясните пожалуйста, или отрепостите кому-нибудь кто может объяснить, если это возможно. ПОЧЕМУ в 2017 году я, как пользователь вк, который кажется в оном уже более 10 лет, до сих пор не могу увидеть все мои написанные комментарии в одном месте? Когда у вк был какой-то юбилей, то количество написанных комментариев даже показывалось. У меня их было что-то вроде 10к. Т.е. у вас явно вся эта информация по пользователю хранится, но почему же она не выводится нигде в интерфейсе пользователя??? Кроме того, я чутка мониторю вашу официальную страницу, которую «просматривают разработчики», и там тоже частенько такой вопрос поднимается на доработку/изменение. Я вот, даже с точки здравого смысла, никак не пойму, почему я, написатель собственных комментариев, даже спустя 10 лет, не могу их централизованно увидеть? Я же их автор, ну почему я не могу их посмотреть? При этом, у вас там публиковались какие-то лайф-хаки, которые позволяли в группе искать чужие комментарии. Мне просто со стороны, это кажется каким-то эпичным маразмом :) Ну т.е. официальные люди из вк пишут на официальной странице как можно поискать чужие комментарии в группе, но как поискать свои вообще везде — это табу! С чем это связано? Я так полагаю, инфа 100% — не с технической реализацией? А с чем тогда? Вот можно как-то это вопрос просветить настолько возможно, насколько это допустимо? Я нигде ответа не нашел.
Спасибо!AterCattus
21.06.2017 11:08Интересует список своих комментов в конкретной группе или все комменты везде по сайту? )
OksikOneC
21.06.2017 16:24Интересует список своих комментов везде по сайту. Т.е. я хочу натурально видеть, что и где я кому писал :)
Кстати, если вы знаете вменяемый способ поиска своих комментов в конкретной группе — был бы вам премного благодарен. Я, после прочтения официального мана, сейчас юзаю мной изобретенный лайф-хак: добавляю некий хвост в каждое свое сообщение, индентификатор меня, (типа ооо_1), и по нему ищу в группе. Только так, я могу видеть все свои комменты в группе. Может я изобрел колесо, фик его знает, но другой способ мне не известен. Но сами понимаете, другие участники группы, часто спрашивают: 000_1 — это что за фигня, парень?

Maccimo
21.06.2017 20:20Что же тут непонятного?
Вдруг вы лет 10 назад написали комментарий, оскорбляющий чувства выдуманных существ?
Летающего Макаронного Монстра, к примеру.
Если у вас будет список всех ваших комментариев, то вы сможете утаить еретические мысли от Святой Макаронной Инквизиции, а без списка даже и не вспомните, что что-то такое писали.
А вотSELECT * FROM ... WHERE userName = ...помнит всё.

JDTamerlan
20.06.2017 15:05Спасибо Вам за интересную и полезную (демонстрирует код, который делает возложенные на него обязательства как хотелось) публикацию!

4c74356b41
20.06.2017 16:01+2а много ложно положительных срабатываний? скажем у меня есть мой любимый концертник, а вы его замените альбомной записью?
пс. вообще не пользуюсь vk, но интересноAterCattus
20.06.2017 17:38Нет, такое не заменяется форсированно.
И вопрос, что считать ложно-положительным: концертная запись и должна матчиться (с меньшей степенью, но должна).
Ложно положительное — это именно разные записи, которые взяли и совпали. Мне такие примеры сейчас не известны, все хорошо.4c74356b41
20.06.2017 19:28тогда я не понимаю в чем смысл, зачем вы обрабатываете записи но ничего с ними не делаете. в чем тогда смысл? и концертная запись не должна совпадать, ибо там СОВСЕМ другой звук.

ivan386
20.06.2017 20:15+2- не дублировать в поиске один трек под разными названиями;
- предлагать прослушать любимую композицию в более высоком качестве;
- добавлять обложки и текст ко всем вариантам песни;
- усовершенствовать механизм рекомендаций;
- улучшить работу с жалобами владельцев контента.
AterCattus
21.06.2017 01:41Вот ivan386 правильно привел пример: мы можем подставить треку оригинальную обложку или текст песни, предложить лучшее качество, и т.п.
Но не форсированно заменять вашу песню на другую.
Larick
20.06.2017 16:14+6Увы, «поиск по музыке» иногда приводит к тому, что система удаляет cover-версии, несмотря что они законны.
ponkin
20.06.2017 17:39А как вы выбирали ключевые точки (пики) на спектрограмме?
AterCattus
20.06.2017 17:40Это локальные максимумы. В своей небольшой окрестности отфильтровываются через два прохода (вперед и назад) по спектрограмме.
dmitry_dvm
20.06.2017 20:38+2А теперь запилите возможность искать только оригиналы треков в наилучшем качестве без всяких тошных недоремиксов.
mrrouter
20.06.2017 22:07-5Лучше бы вместо всей этой возни назначили меня верховным модератором фонотеки, чтобы я мог очистить её от всяких недоремиксов, на которые тут жалуются. Заодно и от проблем с правообладателями избавились бы, я-то знаю, как правильно послать их. А то надоело, что чуть ли не каждый второй трек заблокирован. Вам самим-то не стыдно было так прогнуться? Нам в очередной раз продлили санкции, собираются ввести новые, постоянно обваливают цены на нефть, а вы о чём-то договариваетесь с ними и послушно выполняете их противоправные требования. Тьфу, противно!
И мой комментарий из предыдущей темы, который остался без ответа.
Есть альбом: https://vk.com/album296339984_212813665 Его автор удалила свою страницу. Ссылку нашёл в какой-то теме, где прикрепили часть фотографий из него. Остальные просмотреть не могу. Залейте, пожалуйста, весь альбом архивом на файлообменник.

grozaman
21.06.2017 22:56Я так понял можно грузить к вам треки «задом наперед», сделать клиенты и дополнения к браузерам, которые будут играть их нормально и система ничего не заметит.

billionaire
21.06.2017 23:421. Применялся ли список эталонных песен (mp3-файлы), относительно которого вёлся поиск дубликатов песен?
2. Как определить какая песня является оригинальной (эталонной), а остальные копии? Например, если в базе ВК есть 1 уникальная песня в двух экземплярах, которые отливаются только продолжительностью звучания (одна со скоростью X, а другая ускоренная на 5%). Если я правильно понял содержание статьи, хэши у них будут разные, но при этом алгоритм определит, что одна песня является дублем другой.
3. Хэш каждой песни сравнивается с каждой песней в БД?
Благодарю за статью.AterCattus
22.06.2017 14:36У нас есть некий пополняемый список эталонов, но часто они появляются на сайте позже «модификаций».
Да, каждая новозагруженная песня ищется по всей базе (конечно же не fullscan'ом).
ProgM
22.06.2017 14:47Посмотрел код здесь. В match.go есть допустимые коэффициенты масштабирования, а вот где вы Longest Common Subsequence ищите, не пойму. Есть там этот код?
AterCattus
22.06.2017 14:49Увы, я не могу выложить весь код. Это все, что могу + будет обновление еще этой версии в ближайшее время.






astudent
Есть же масса научных статей на тему audio fingerprinting, оптимальные алгоритмы отпечатков уже давно известны человечеству. Зачем вы переизобрели свое да и похоже не очень качественно?
AterCattus
Мы в 2015 рассматривали некоторые доступные варианты (не только вскользь упомянутое), они не подошли под наши требования.
Часто задача заканчивается или на уровне «найти зашумленный кусок» или вообще по точному совпадению (не считая перекодирования).
С нашими аудио записями, когда пользователю льют просто невообразимое разнообразие всевозможных вариантов, все несколько сложнее.
Ну и вопросы масштабирования realtime поиска по всему объему записей…
webmasterx
Присоединясь. Я когда смотрел их доклад на Highload, тоже задался этим вопросом. Ребята похоже не рассматривали никакие научные статьи по этой теме
640509-040147
Потому что у них куча чемпионов мира по спортивному программированию, которых нужно чем-то занять. Ну не использовать же известные алгоритмы, ей богу!
AterCattus
Сишники у нас занимаются другими задачами)
pavelkolodin
Более скучными?
AterCattus
Про бОльшие нагрузки. А эту задачу мы своими силами backend'а сделали.
JDTamerlan
Многие говорят «все уже давно написано», но когда пробуешь использовать это в своей ситуации, а оно работает криво или вовсе не работает, вот тогда и встает выбор — разбираться с «чужим мерседесом и снимать два колеса» или сделать свой самокат, который делает именно то, что хочется.
astudent
Если сначала разобраться с чужим мерседесом, то свой самокат получится гораздо лучше!