
В большинстве проектов по внедрению Siebel, так или иначе, приходится сталкиваться с проблемами качества данных. В этой части Oracle предлагает интересное решение – Enterprise Data Quality с возможностью интегрирования в Siebel (что нас собственно и привлекло). В данном материале я вкратце расскажу о самом продукте, его архитектуре, а также покажу, как можно создать простой процесс повышения качества данных.
EDQ ? продукт, позволяющий управлять качеством информации. Основой для анализа EDQ могут служить разные источники данных, такие как:
EDQ позволяет анализировать данные, находить в них неточности, пробелы и ошибки. Можно совершать корректировки, трансформировать и преобразовывать информацию для улучшения ее качества. Можно интегрировать правила контроля качества данных в ETL-средства, тем самым предотвращая появление неконсистентной информации. Большим плюсом при использовании EDQ является интуитивно понятный интерфейс, а также простота изменения и расширения правил валидации и трансформации. Немаловажный инструмент EDQ – информационные панели (Dashboards), которые позволяют бизнес-пользователям отслеживать тенденции в качестве данных. Например, как на скриншоте ниже:

EDQ ? это веб-приложение Java, в котором используется Java Servlet Engine, графический интерфейс пользователя Java Web Start и СУБД для хранения данных.
EDQ предоставляет ряд клиентских приложений, которые позволяют управлять системой:
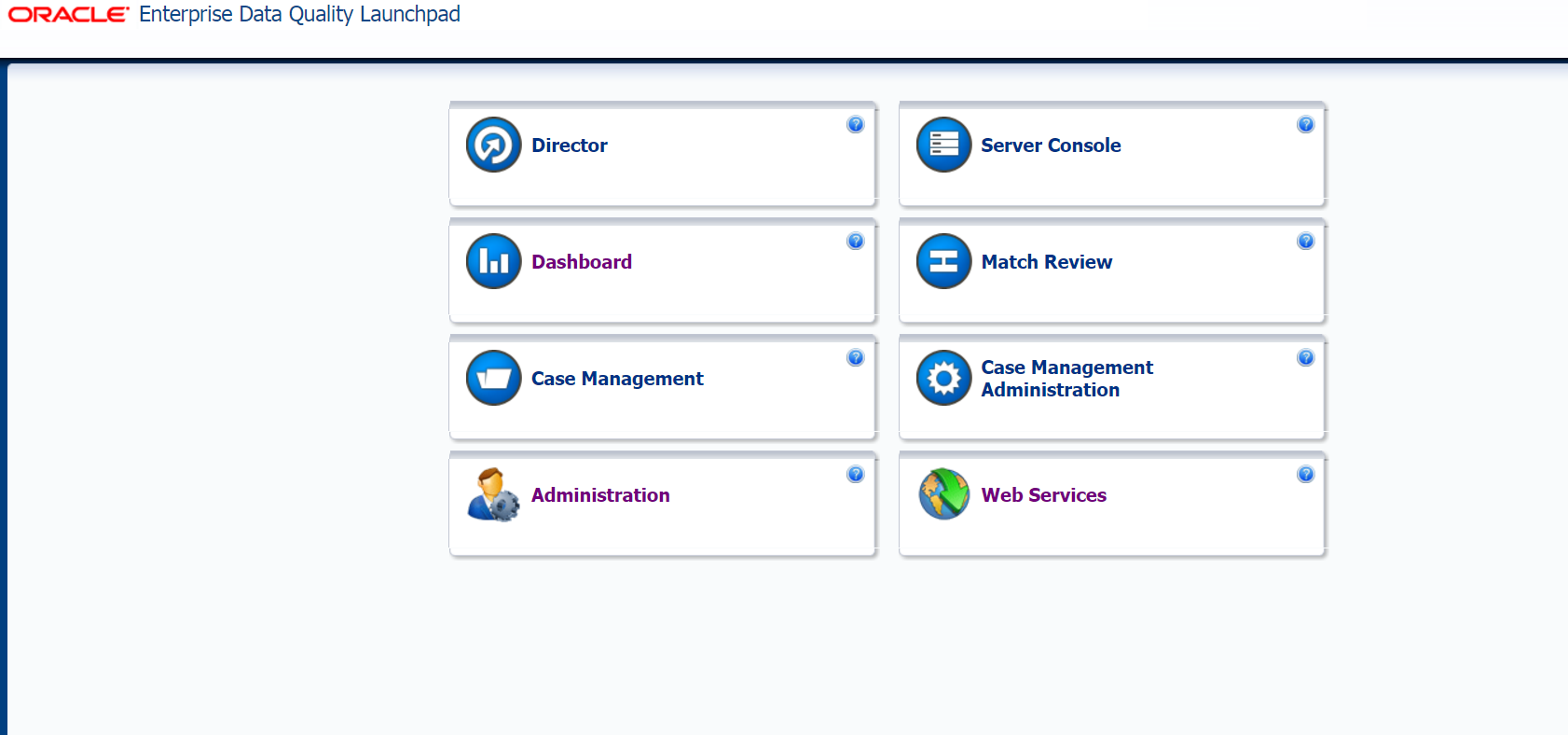
При посещении страницы Enterprise Data Quality Launchpad можно увидеть данные приложения, например, Director, отвечающий за проектирование и обработку информации. При нажатии на кнопку нам предлагается сохранить файл:

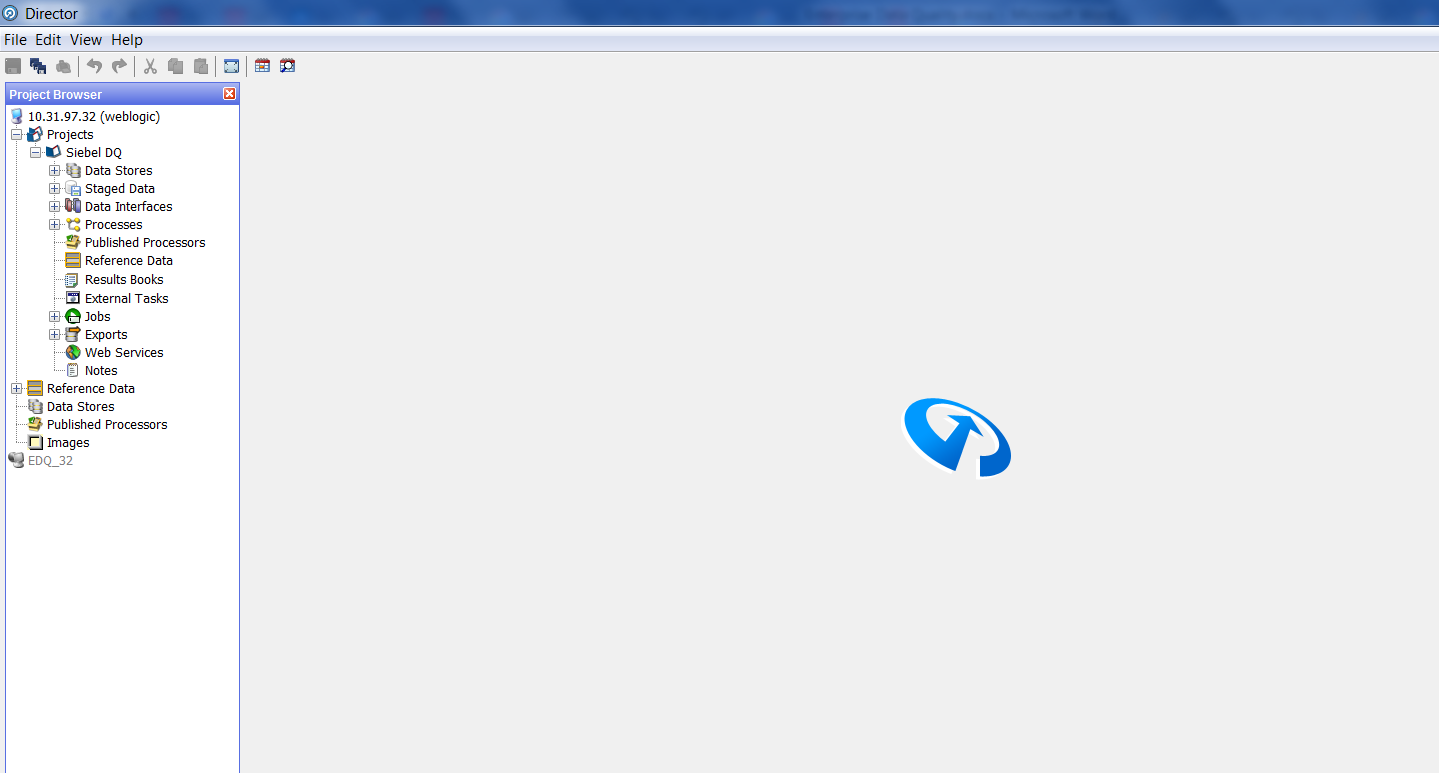
Открыв его, мы попадаем в основной интерфейс проектирования:
Слепки данных, обработанная информация и необходимые метаданные хранятся на сервере EDQ. Клиентские машины хранят только пользовательские настройки. EDQ использует репозиторий, который хранится в двух схемах БД – в конфигурационной и в схеме результатов.
В конфигурационной схеме хранится информация о настройках EDQ, а в схеме результатов – слепки информации (промежуточные итоги обработки и конечные результаты выполнения процессов).
Примеры задач, решаемых с помощью EDQ:
На основе подключений к разным источникам данных создаются так называемые «Staged Data» ? слепки информации для последующего анализа.
EDQ имеет множество процессоров, с помощью которых можно трансформировать исходный слепок информации.
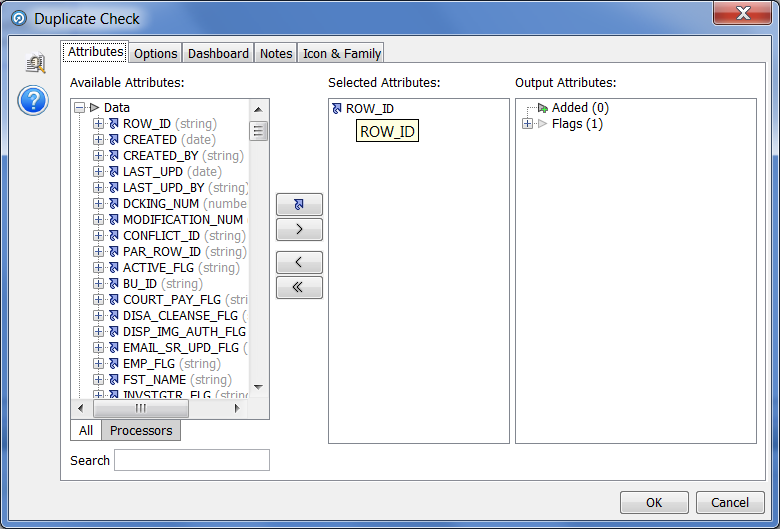
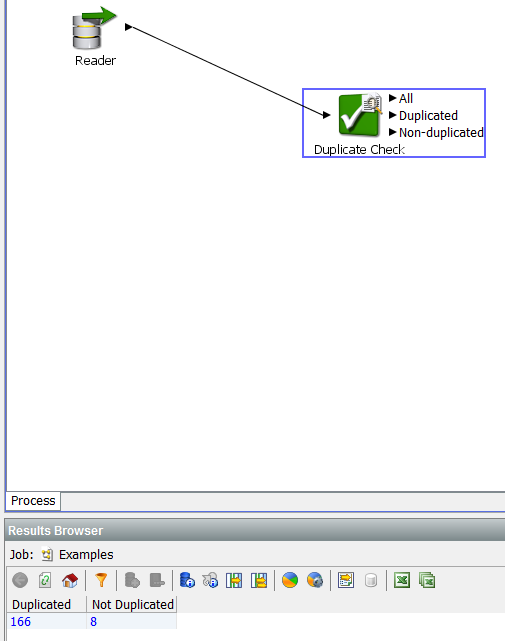
Часто встречающаяся проблема при использовании информации – наличие дубликатов. Как говорилось выше, EDQ позволяет ее решить. Для исключения дубликатов можно воспользоваться процессором «Duplicate Check», в его настройках необходимо выбрать поле, по которому будет производиться группировка информации:
Этот процессор позволяет отобрать для дальнейшего анализа очищенные от дубликатов данные:
Для слияния повторяющихся строк можно использовать процессор «Group and Merge». На примере рассмотрим его функционал.
Поместив процессор в рабочее пространство и соединив его с процессором, отбирающим исходную информацию, необходимо зайти в настройки «Group and Merge».
Данный процессор имеет три подпроцессора:
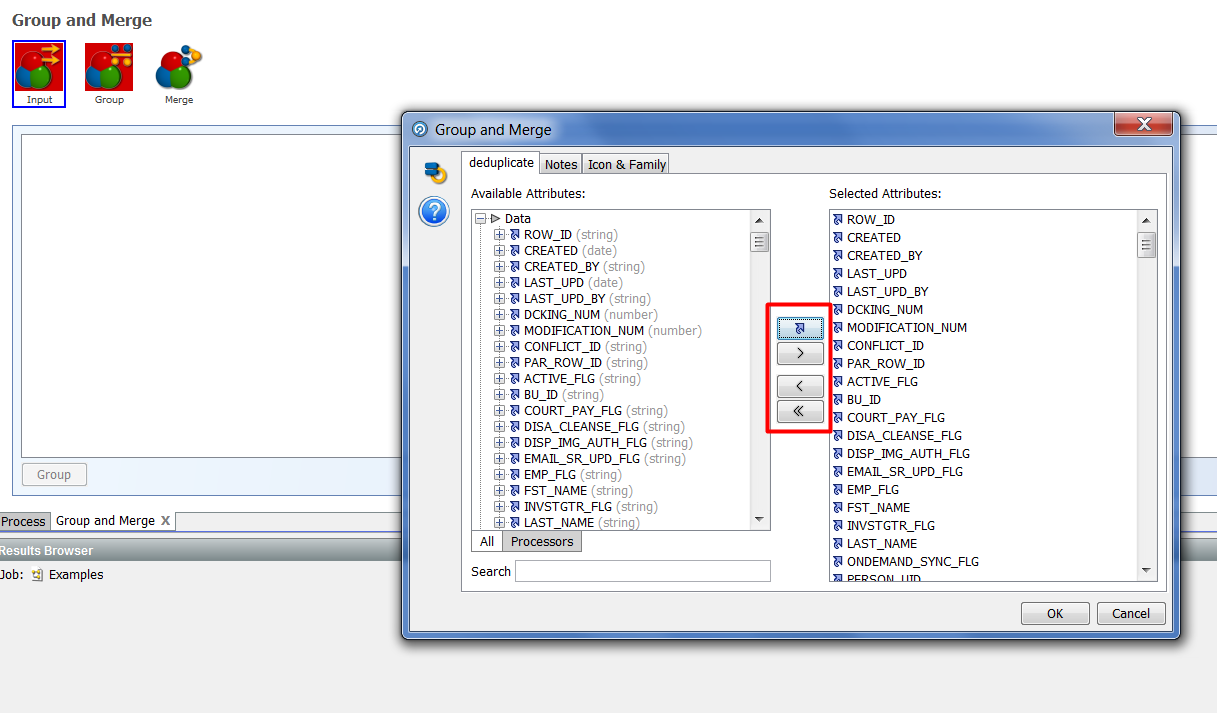
Inputs – позволяет из исходного набора данных выбрать те поля, которые необходимо преобразовать. Перетаскиваем нужные колонки с помощью кнопок:
На основе выбранных атрибутов мы выберем поле или поля, на основе которых будет производиться группировка.
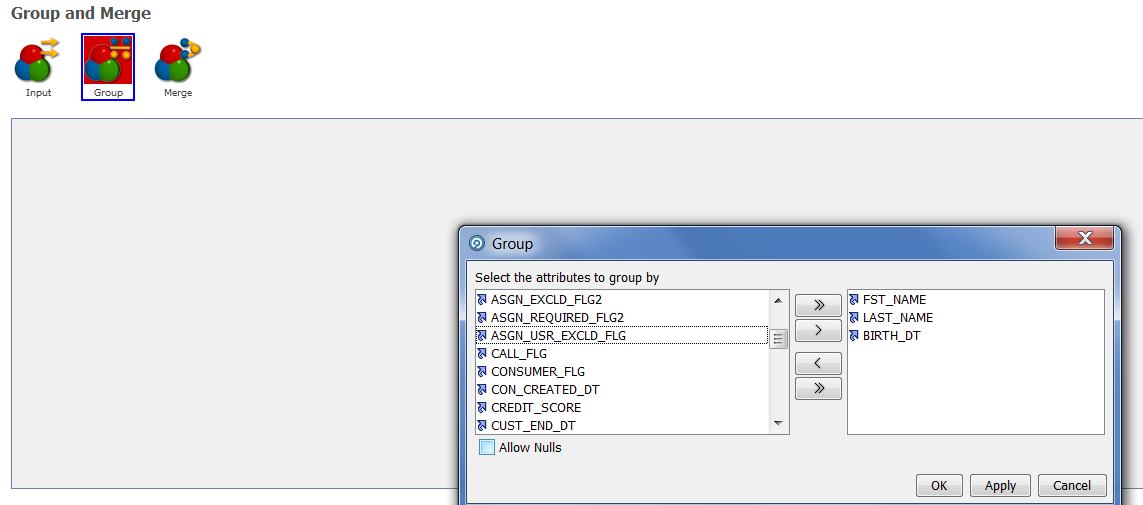
Group – в данном процессоре необходимо выбрать поля, на основе которых будут сгруппированы исходные данные:
И последний подпроцессор – Merge, позволяющий настроить правила для слияния каждого атрибута:
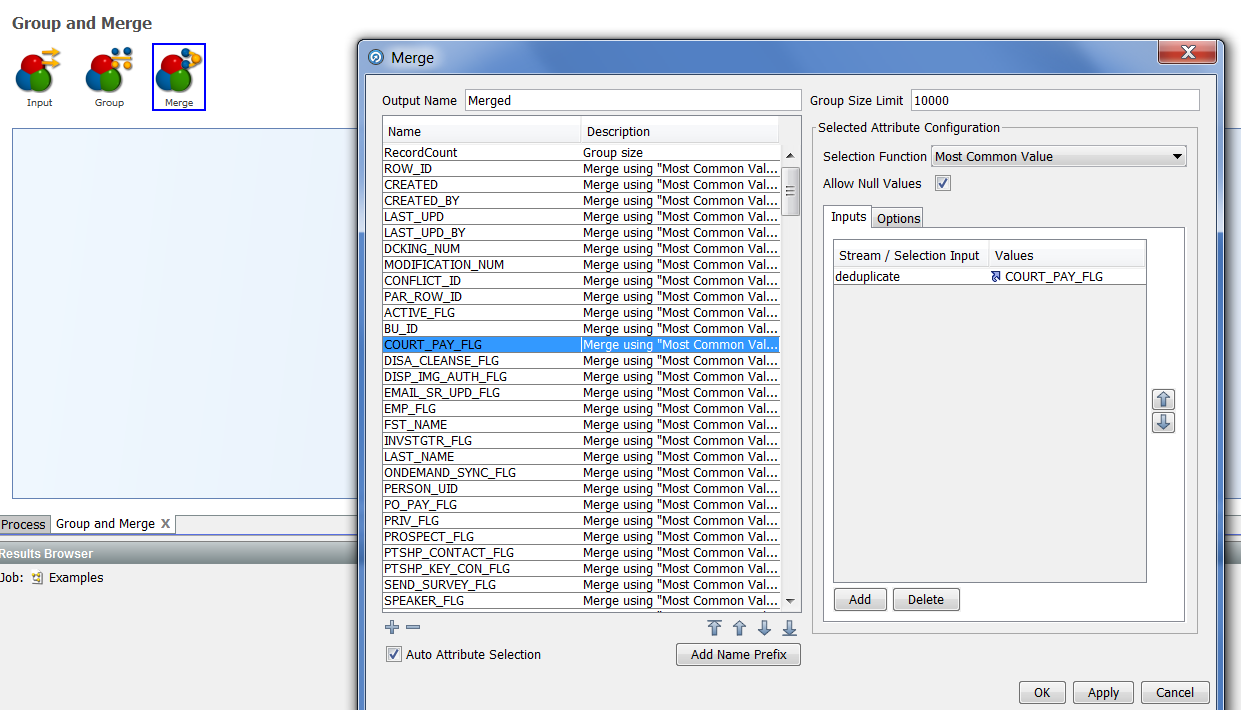
По умолчанию значение правила установлено в «Most Common Value», но это значение при необходимости можно заменить на подходящие из списка:

После настройки и запуска процессора мы видим результат его работы:

В исходном же наборе было другое количество данных:

Эти преобразования выполняются на уровне слепка данных в EDQ и не затрагивают данные в базе. Для того чтобы отобразить полученную очищенную информацию в базе данных, необходимо совершить еще несколько шагов. На основе полученной информации из процессора «Group and Merge» нужно создать новый слепок информации, который впоследствии мы загрузим в БД. Выбираем процессор «Writer»:
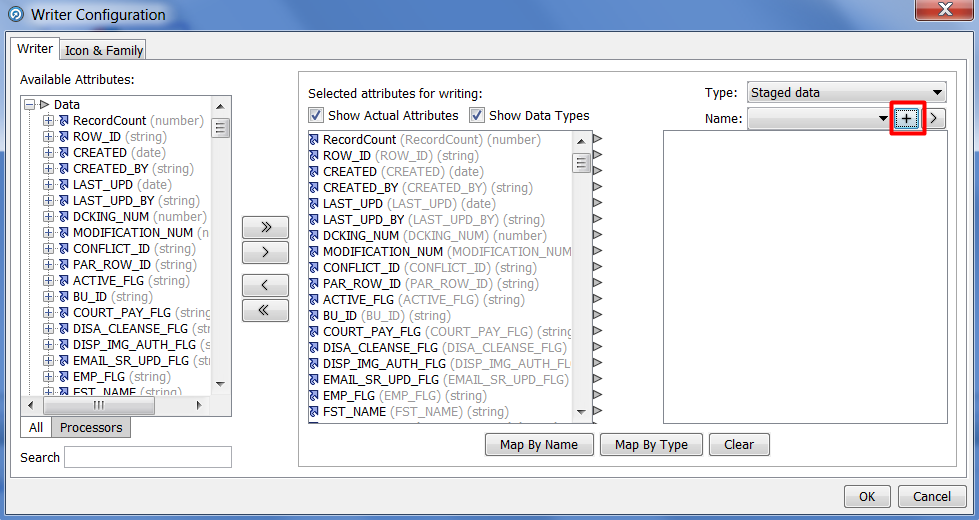
И нажимаем кнопку New Staged Data. Далее предлагается создать новый слепок на основе полученной информации после дедупликации. Итоговый экран должен выглядеть следующим образом:

Также можно использовать уже существующие слепки, которые будут перезаписаны после запуска процесса.
После записи дедуплицированой информации нужно создать новый экспорт, который запишет наши изменения в базу данных:

В интерфейсе выше предлагается выбрать подготовленный слепок данных и таблицу, в которую планируется его загрузка. По умолчанию этот процесс будет производить удаление существующих данных и вставку новых, но его можно настроить. Для этого требуется создать новый Job.
В рабочую область перетащить созданный процесс:
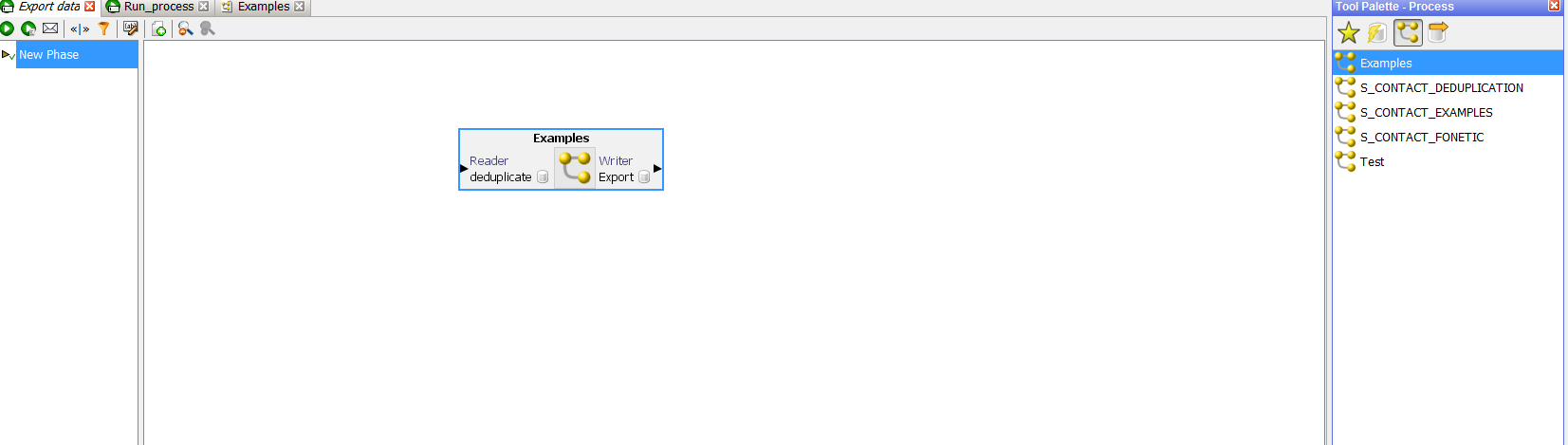
И созданный экспорт данных:
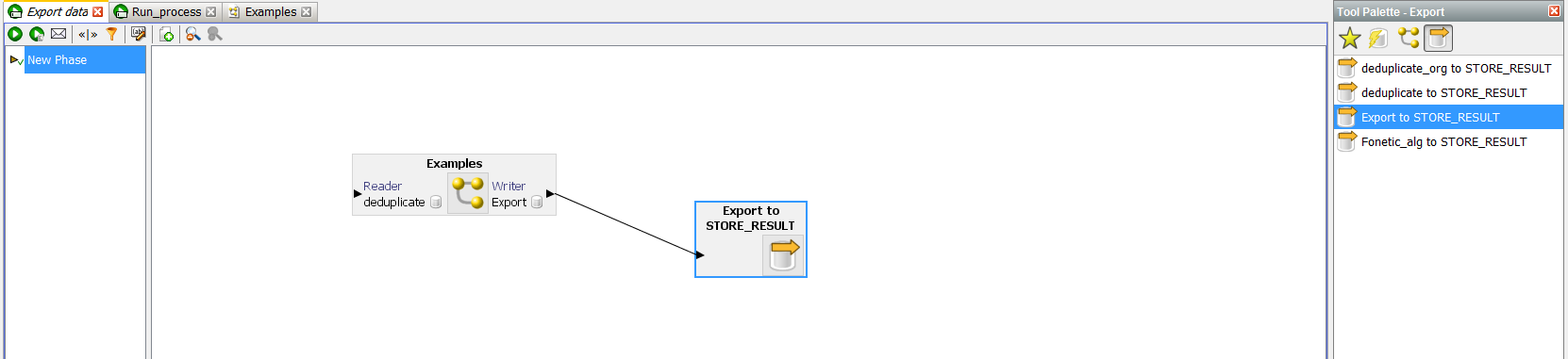
После чего можно настроить экспорт. Двойным щелчком вызываем меню:
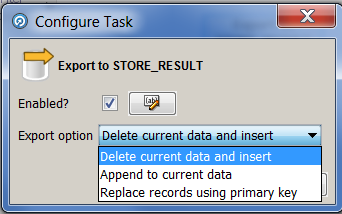
Выбрав нужное значение, запускаем задачу в работу и проверяем результат в БД.
EDQ предоставляет пользователю большой спектр инструментов, но есть, как говорится, некоторые нюансы. Например, к таковым можно отнести отсутствие преднастроенных шаблонов обработки информации. Ведь большинство проблем, связанных с качеством данных, типичны для многих проектов. Стоит сказать, что некоторые готовые процессы все же можно найти и интегрировать в свой проект. Собственно этим мы и планируем заняться – подготовить пакет процессов, которые можно использовать на разных проектах.
Для использования фонетических алгоритмов, представленных в EDQ, подходит только латиница, но всегда можно использовать транслитерацию и преднастроить свои данные для этих алгоритмов.
Еще одна, так скажем, не вполне удобная особенность, которую мы заметили, ? это не совсем прозрачный процесс выгрузки результатов обработки в базу. Если использовать как источник таблицы БД, то проще было бы при получении результата сразу иметь возможность заменить исходную информацию очищенной.
Как было сказано в начале, большинство проектов, которые используют хранилища данных, так или иначе «страдают» от качества информации, хранящейся в них. EDQ может помочь в решении проблем не только дедупликации, о которой мы тут говорили, но и многих других. Большой плюс данного продукта – наличие готовых к использованию разнообразных процессоров. А информационные панели с простым интерфейсом помогут бизнес-пользователям принимать активное участие в контроле качества данных.
В следующих статьях мы постараемся рассмотреть на примере процесс стандартизации адресов по ФИАС и создание информационных панелей, а также интеграцию с Oracle Siebel.Следите за обновлениями.
Антон Акиньшин, разработчик центра внедрения бизнес-систем компании «Инфосистемы Джет». Пожалуйста, обращайтесь с вопросами в комментариях.
Коротко о продукте
EDQ ? продукт, позволяющий управлять качеством информации. Основой для анализа EDQ могут служить разные источники данных, такие как:
- базы данных (Oracle, Postgres, DB2, MySql и т.д.),
- текстовые файлы,
- XML-файлы,
- MS Office файлы,
- системные файлы и прочее.
EDQ позволяет анализировать данные, находить в них неточности, пробелы и ошибки. Можно совершать корректировки, трансформировать и преобразовывать информацию для улучшения ее качества. Можно интегрировать правила контроля качества данных в ETL-средства, тем самым предотвращая появление неконсистентной информации. Большим плюсом при использовании EDQ является интуитивно понятный интерфейс, а также простота изменения и расширения правил валидации и трансформации. Немаловажный инструмент EDQ – информационные панели (Dashboards), которые позволяют бизнес-пользователям отслеживать тенденции в качестве данных. Например, как на скриншоте ниже:
EDQ ? это веб-приложение Java, в котором используется Java Servlet Engine, графический интерфейс пользователя Java Web Start и СУБД для хранения данных.
EDQ предоставляет ряд клиентских приложений, которые позволяют управлять системой:
При посещении страницы Enterprise Data Quality Launchpad можно увидеть данные приложения, например, Director, отвечающий за проектирование и обработку информации. При нажатии на кнопку нам предлагается сохранить файл:
Открыв его, мы попадаем в основной интерфейс проектирования:
Слепки данных, обработанная информация и необходимые метаданные хранятся на сервере EDQ. Клиентские машины хранят только пользовательские настройки. EDQ использует репозиторий, который хранится в двух схемах БД – в конфигурационной и в схеме результатов.
В конфигурационной схеме хранится информация о настройках EDQ, а в схеме результатов – слепки информации (промежуточные итоги обработки и конечные результаты выполнения процессов).
Какие задачи решает EDQ
Примеры задач, решаемых с помощью EDQ:
- дедупликация и консолидация информации,
- приведение информации к единому виду (написание названия одной страны разными способами и др.),
- идентификация информации, внесенной не в то поле,
- парсинг адресов,
- разбиение полей, в которых закодирована информация о нескольких атрибутах.
На основе подключений к разным источникам данных создаются так называемые «Staged Data» ? слепки информации для последующего анализа.
EDQ имеет множество процессоров, с помощью которых можно трансформировать исходный слепок информации.
Часто встречающаяся проблема при использовании информации – наличие дубликатов. Как говорилось выше, EDQ позволяет ее решить. Для исключения дубликатов можно воспользоваться процессором «Duplicate Check», в его настройках необходимо выбрать поле, по которому будет производиться группировка информации:
Этот процессор позволяет отобрать для дальнейшего анализа очищенные от дубликатов данные:
Простой процесс дедупликации
Для слияния повторяющихся строк можно использовать процессор «Group and Merge». На примере рассмотрим его функционал.
Поместив процессор в рабочее пространство и соединив его с процессором, отбирающим исходную информацию, необходимо зайти в настройки «Group and Merge».
Данный процессор имеет три подпроцессора:
- Inputs
- Group
- Merge
Inputs – позволяет из исходного набора данных выбрать те поля, которые необходимо преобразовать. Перетаскиваем нужные колонки с помощью кнопок:
На основе выбранных атрибутов мы выберем поле или поля, на основе которых будет производиться группировка.
Group – в данном процессоре необходимо выбрать поля, на основе которых будут сгруппированы исходные данные:
И последний подпроцессор – Merge, позволяющий настроить правила для слияния каждого атрибута:
По умолчанию значение правила установлено в «Most Common Value», но это значение при необходимости можно заменить на подходящие из списка:
После настройки и запуска процессора мы видим результат его работы:
В исходном же наборе было другое количество данных:
Эти преобразования выполняются на уровне слепка данных в EDQ и не затрагивают данные в базе. Для того чтобы отобразить полученную очищенную информацию в базе данных, необходимо совершить еще несколько шагов. На основе полученной информации из процессора «Group and Merge» нужно создать новый слепок информации, который впоследствии мы загрузим в БД. Выбираем процессор «Writer»:
И нажимаем кнопку New Staged Data. Далее предлагается создать новый слепок на основе полученной информации после дедупликации. Итоговый экран должен выглядеть следующим образом:
Также можно использовать уже существующие слепки, которые будут перезаписаны после запуска процесса.
После записи дедуплицированой информации нужно создать новый экспорт, который запишет наши изменения в базу данных:
В интерфейсе выше предлагается выбрать подготовленный слепок данных и таблицу, в которую планируется его загрузка. По умолчанию этот процесс будет производить удаление существующих данных и вставку новых, но его можно настроить. Для этого требуется создать новый Job.
В рабочую область перетащить созданный процесс:
И созданный экспорт данных:
После чего можно настроить экспорт. Двойным щелчком вызываем меню:
Выбрав нужное значение, запускаем задачу в работу и проверяем результат в БД.
Заключение
EDQ предоставляет пользователю большой спектр инструментов, но есть, как говорится, некоторые нюансы. Например, к таковым можно отнести отсутствие преднастроенных шаблонов обработки информации. Ведь большинство проблем, связанных с качеством данных, типичны для многих проектов. Стоит сказать, что некоторые готовые процессы все же можно найти и интегрировать в свой проект. Собственно этим мы и планируем заняться – подготовить пакет процессов, которые можно использовать на разных проектах.
Для использования фонетических алгоритмов, представленных в EDQ, подходит только латиница, но всегда можно использовать транслитерацию и преднастроить свои данные для этих алгоритмов.
Еще одна, так скажем, не вполне удобная особенность, которую мы заметили, ? это не совсем прозрачный процесс выгрузки результатов обработки в базу. Если использовать как источник таблицы БД, то проще было бы при получении результата сразу иметь возможность заменить исходную информацию очищенной.
Как было сказано в начале, большинство проектов, которые используют хранилища данных, так или иначе «страдают» от качества информации, хранящейся в них. EDQ может помочь в решении проблем не только дедупликации, о которой мы тут говорили, но и многих других. Большой плюс данного продукта – наличие готовых к использованию разнообразных процессоров. А информационные панели с простым интерфейсом помогут бизнес-пользователям принимать активное участие в контроле качества данных.
В следующих статьях мы постараемся рассмотреть на примере процесс стандартизации адресов по ФИАС и создание информационных панелей, а также интеграцию с Oracle Siebel.Следите за обновлениями.
Антон Акиньшин, разработчик центра внедрения бизнес-систем компании «Инфосистемы Джет». Пожалуйста, обращайтесь с вопросами в комментариях.
Поделиться с друзьями
ALIron
Всё так, только поиск дублей вести лучше в связке с MDM, если данных хоть сколько нибудь ощутимое количество.
Поиск дублей сравнением «каждый с каждым» — тупиковый путь на больших объемах, особенно для хранилищ.
Merge в EDQ — работает, но жестко настроен, при тонкой работе (например клиенты) приходилось использовать внешний обработчик.
В остальном отличный инструмент, рабочий.