
В этом посте речь пойдет о тестировании серверного ПО, которое обслуживает огромную сеть банковских терминалов в России и за рубежом. Название банка мы раскрыть не можем, некоторые строчки конфигов скрыты.
Итак, мы занимаемся разработкой данного ПО, используя современный CI/CD подход, чем обеспечивается высокая скорость поставки фич, хотфиксов и релизов в продакшн. В начале года нам была предложена задача обеспечить нагрузочным тестированием разрабатываемое решение и продемонстрировать заказчику способность встраивать в CI/CD любые подзадачи и шаги.
Помимо общих слов, хотелки сводились к следующему: необходимо обеспечить автоматический деплой ПО на нагрузочный стенд, придумать легкий способ генерации данных, внедрить автоматический и полуавтоматический способ запуска тестов, снабдить тесты автоматическим триггером старта и остановки по событию, подключить механику НТ к трекеру задач для короткого репортинга, подключить систему тестирования к доступной системе аналитики НТ, создать возможность “покраски” плохих и хороших релизов для дальнейших действий в workflow (выкатить или отправить репорт). Требования, надо признать, абсолютно адекватные и понятные.
Начнем издалека. Мы постоянно слышим одно и то же: “Автоматизировать нагрузочное тестирование банковского и финансового ПО невозможно! У нас слишком много взаимосвязей! Мы очень сложные!”. Этот вызов только усиливал азарт решения задачи. Нам всегда хотелось проверить сложность на конкретном примере.
Помните замечательную картинку про тестирование в виде пирамидки и рожка с мороженым? Пирамидка – это когда у вас много дешевых автоматических Unit-тестов и мало дорогих UI. Рожок с мороженным – наоборот. Рожок – это дорого, неповоротливо и не масштабируется, пирамидка – дешево и гибко.
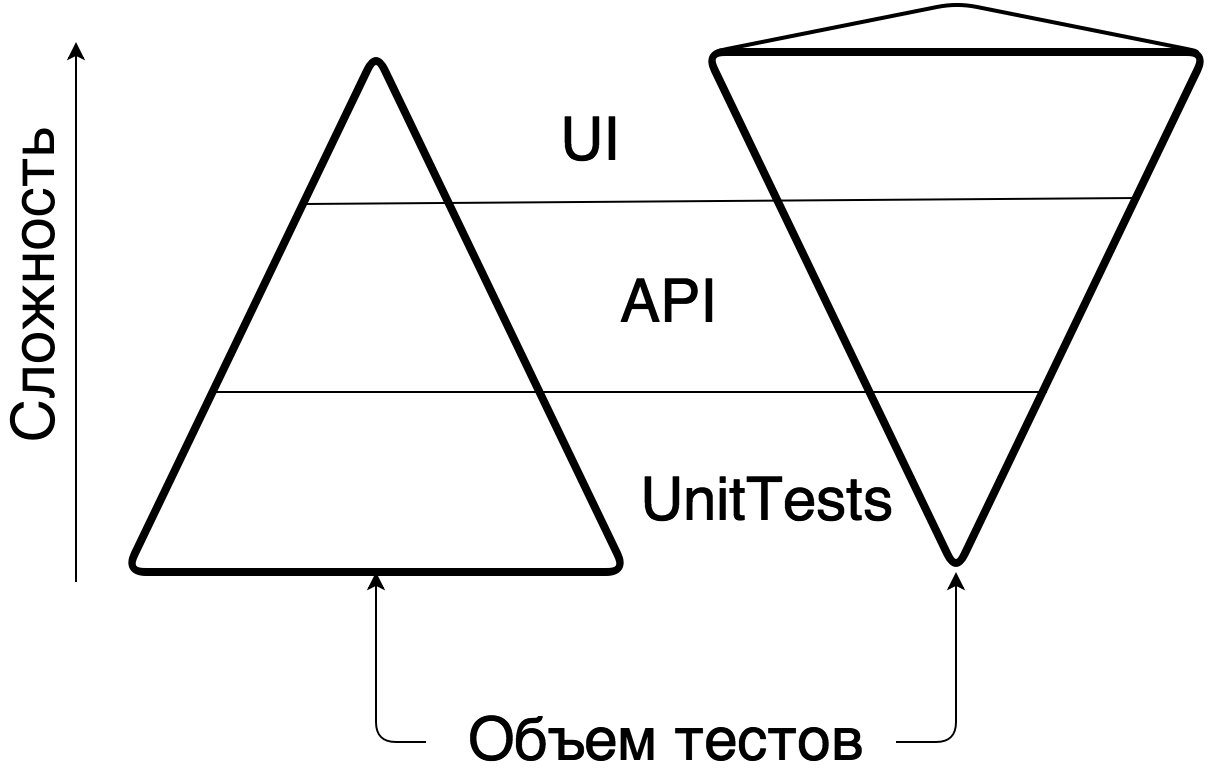
Вместо того, чтобы заниматься нагрузочным тестированием ПО на уровне взаимодействий систем, в секторе банковского ПО традиционно все тестируют через UI, как повелось со времен неразъемных систем и приложений. На это уходит много времени и сил, что делает разработку банковского ПО медленной, некачественной и нетехнологичной. Мы в компании “Инфосистемы Джет” были избавлены от этих стереотипов — разработчики сами писали юнит-тесты на свой код, функциональные тестировщики прекрасно программировали UI-тесты через Selenium+Cucumber. Осталось только встроить в процесс дополнительную стадию нагрузочного тестирования.
В самом начале мы решили отказаться от взаимосвязей, которые усложняют и размывают ответ на вопрос, насколько производительный и надежный код мы разрабатываем. Например, авторизация и выдача токенов на проведение операций — это функциональность сторонней системы, исследовать производительность которой в рамках задачи было бы избыточно. Помимо этого мы сразу отказались от интеграции с несколькими back-office системами, сделав заглушку, отвечающую нашей системе с определенной задержкой (все мы знаем, как опасно тестировать систему на сверхбыстрых моках).
Но самое значительное изменение в парадигме тестирования ? это отказ от нагрузочного тестирования UI-терминала. До сих пор это кажется странным, но до нас данное серверное ПО нагрузочно тестировали именно через UI ATM. Происходило это следующим образом: эмулировался некоторый средний пользователь, который проходил какой-то пул сценариев с набором средних пауз (paсing, think time), а нагрузочный инструмент был вынужден создавать нагрузку, которая состоит из длительных и “холодных” сценариев с нескольких лоад-генераторов HP Loadrunner, в то время как результирующая нагрузка на одну ноду API-сервера составляла всего около сотни(!) транзакций в секунду. (Оставим за скобками безумную картину, когда тысячи граждан пытаются нажимать на контролы одного банковского терминала). В итоге из стенда было выброшено практически все, что не имело отношения к производительности бэкенда ATM.

После проектирования и осмотра оставшейся инфраструктуры стало примерно понятно, как будет выстроен процесс, какие бенефиты будут получены, и нужно было приступать к созданию самого процесса НТ.
Код ПО выкладывается во внутреннем git-репозитории (GitLab). После коммита по специальному триггеру Jenkins вытаскивает код на сборочную машину и пытается собрать релиз с прогоном всех заведенных Unit-тестов. После успешной сборки с помощью скриптов собранный билд инсталлируется в два тестовых окружения ? НТ и ФТ ? и делает рестарт тестинга. После подъема бэкенда Jenkins прогоняет друг за другом ФТ, UI и ИФТ-тесты. Нагрузочное тестирование запускается отдельной задачей, но про это стоит рассказать отдельно.
Как всем известно, классический инструмент нагрузочного тестирования состоит из трех “столпов”: генератора тестовых данных, лоад-генератора и анализатора полученных результатов. Поэтому задачу мы решали в трех направлениях.
Чтобы собрать релевантный запрос к API и не переписывать каждый раз XML под изменяющуюся спецификацию, мы пошли другим путем ? мы “грабим” TOP-10 основных платежных сценариев в момент прогона UI-тестов. Для этого на тестовом стенде мы развернули tshark, из дампа которого и собираем XML (его впоследствии будем отправлять в API). Это позволяет экономить кучу времени и сил на подготовку тестовых данных.
В качестве лоад-генератора мы использовали самый популярный инструмент на Open Source рынке ? JMeter, но в качестве обвязки к нему использовали Yandex.Tank. Мощности JMeter для отправки 100 транзакций в секунду на одну ноду хватает с лихвой, а Tank дает нам удобство в автоматизации и несколько полезных фич ? автостопы, интерактивные графики, возможность использования других генераторов нагрузки без перекраивания процесса НТ и т.д.
Самое сложное на этапе конструирования НТ ? это аналитическая часть. Так как на рынке пока нет отдельных решений по созданию своей аналитики для тестирования производительности, мы решили использовать Overload от Яндекса. Overload – это сервис для хранения и анализа результатов нагрузочных тестов. Нагрузку вы создаете со своих лоад-генераторов, а результаты загружаете на сервис и наблюдаете их там в виде графиков. Сейчас сервис находится в публичной бете, а для “Инфосистемы Джет” Яндекс создал пилотный приватный инстанс.
Все данные с нашего JMeter поступают в Overload в агрегированном виде и не содержат никакой персональной информации о платежах и клиентах ? пользователь видит только графическое представление тестов производительности.
После того как билд попадает на нагрузочный стенд, посредством скриптов в Jenkins запускается специальная задача для нагрузочного тестирования. Задача настроена классическим способом, через shell-скриптинг и параметризацию.
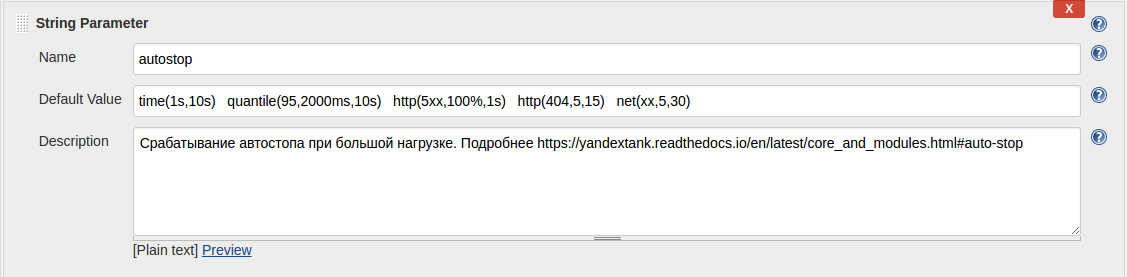
Например, так можно конфигурировать автостопы:
Так выглядит конфиг Yandex.Tank:
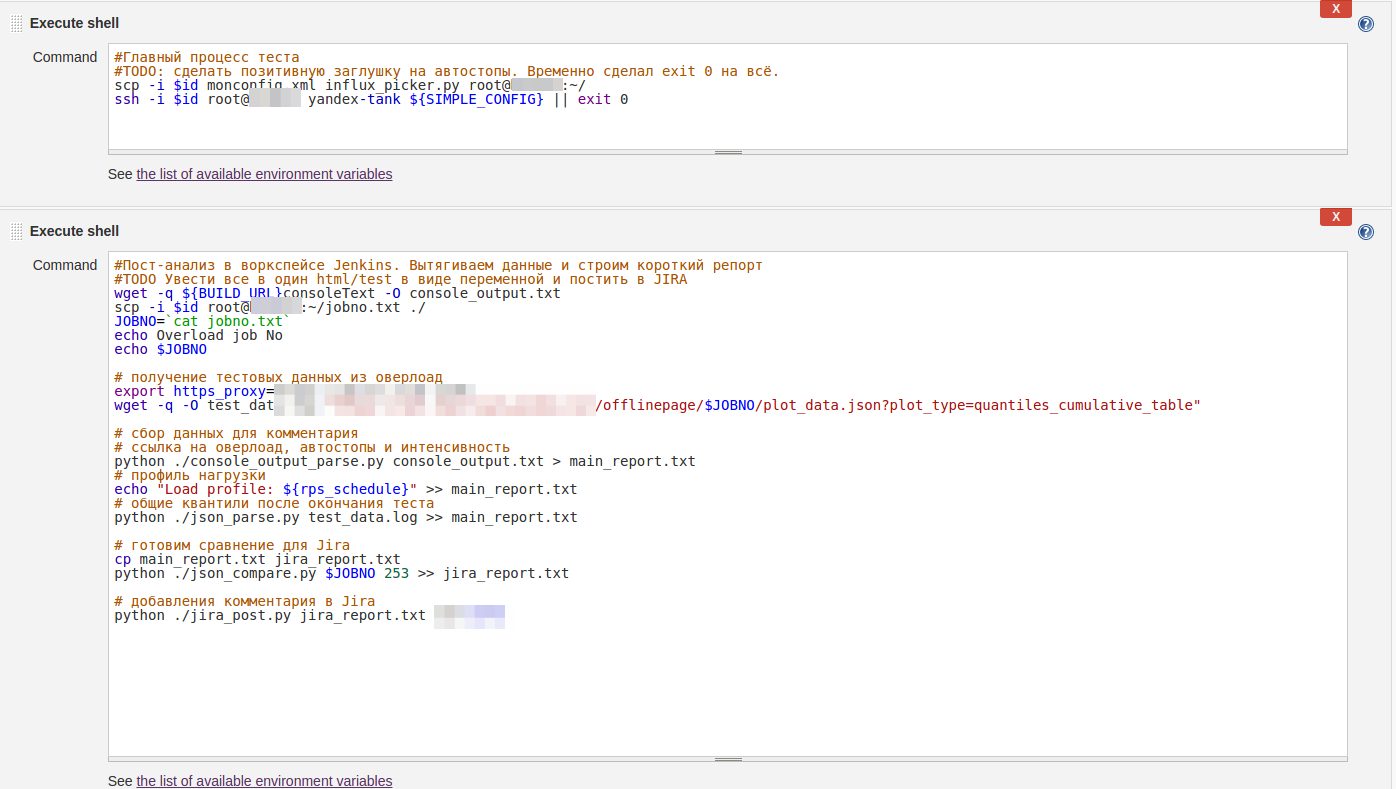
А так выглядит пример shell-script запуска всего процесса НТ:
Как видите, все настройки достаточно примитивны. При автоматическом запуске джоба дефолтные параметры применяются автоматически, при ручном же запуске вы можете конфигурировать стрелялку параметрами Jenkins, не разбираясь в документации и не копаясь на Linux-машинке и перебирая необходимые конфиги.
Режим “Запуск по кнопке” для разработчика выглядит так:
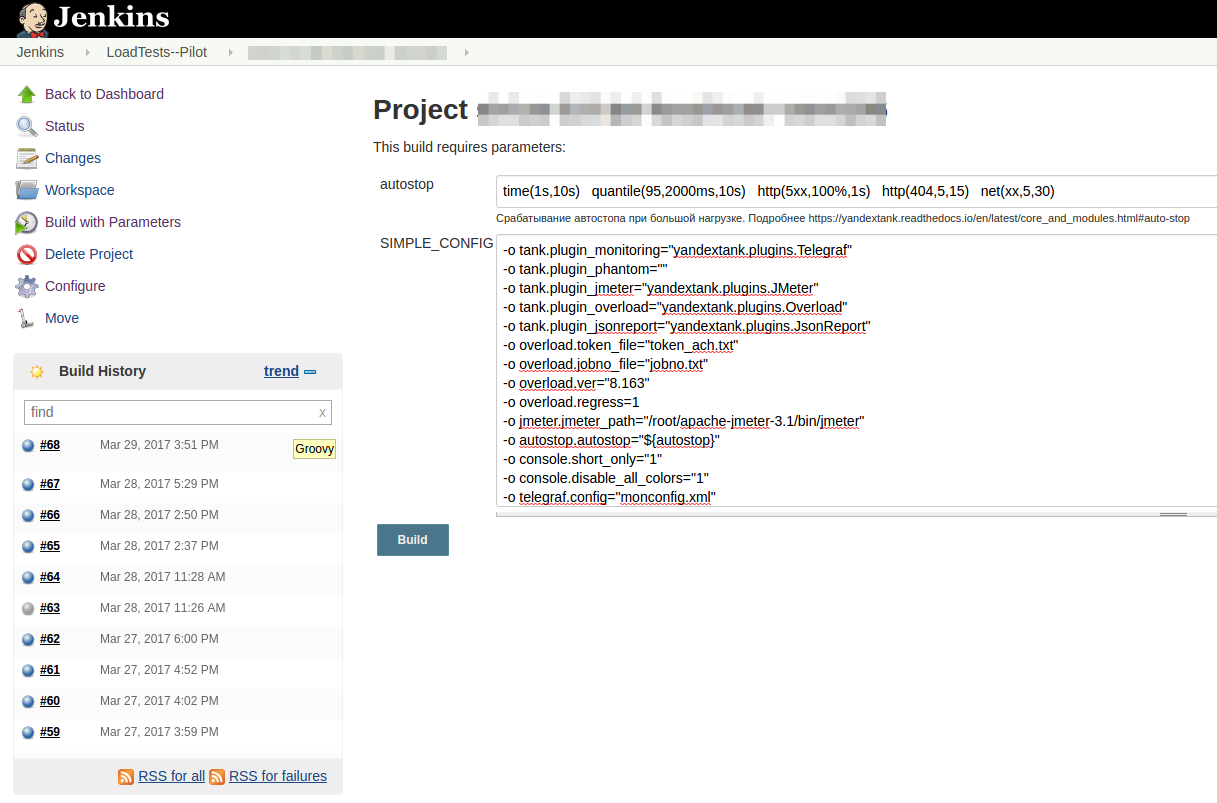
После запуска теста вы получаете ссылку в Console View Jenkins и Telegram, перейдя по которой можно наблюдать нагрузочный тест в реальном времени:

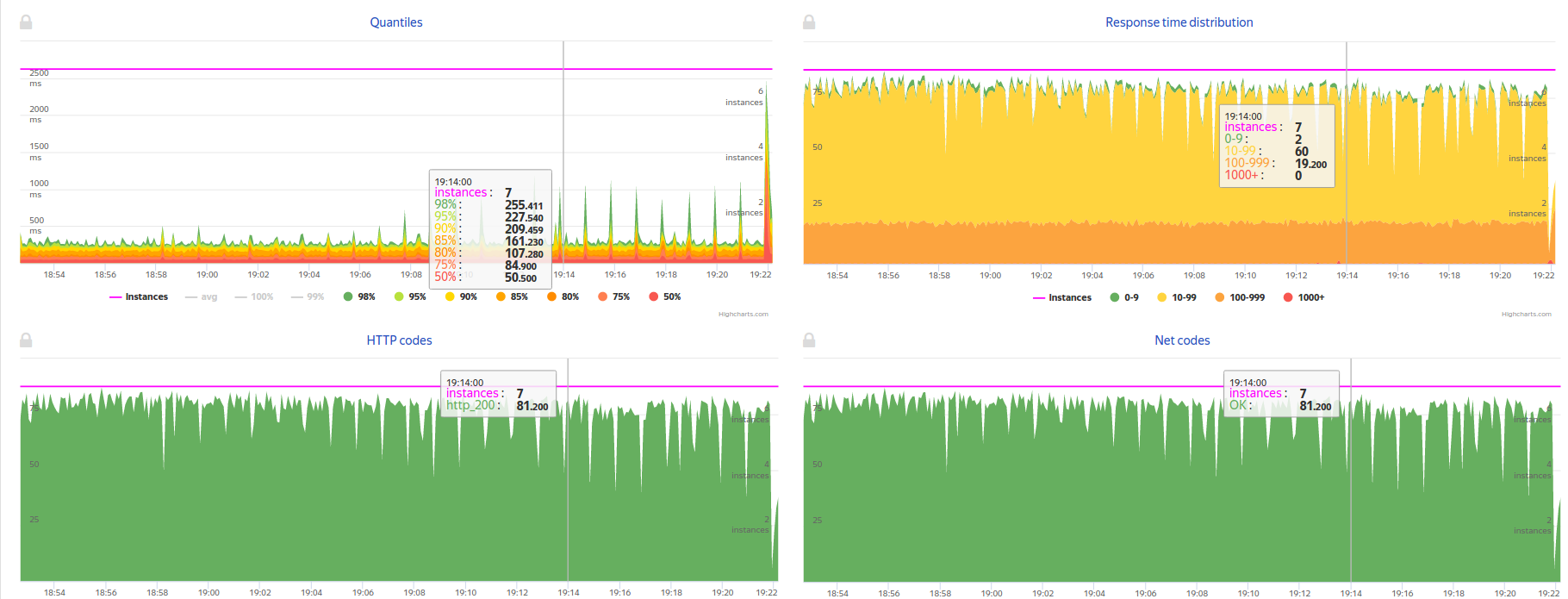
Если результаты теста вышли за пределы SLA, то тест автоматически останавливается и вы получаете репорт в Telegram, почту и JIRA о проблемах с релизом. Если же результат хороший, то после репорта релиз получает статус SUCCESS и готов для деплоя на нагруженную среду, в продакшн.
Скрин с экрана Telegram:

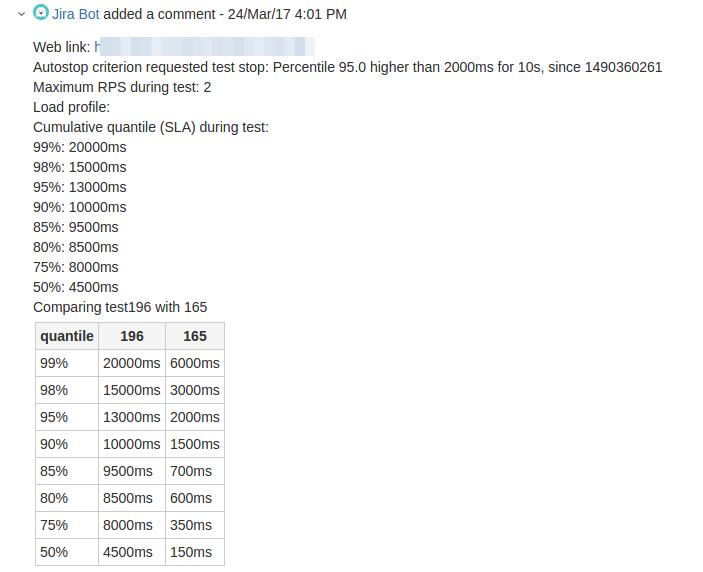
А так бот репортит результаты в JIRA:
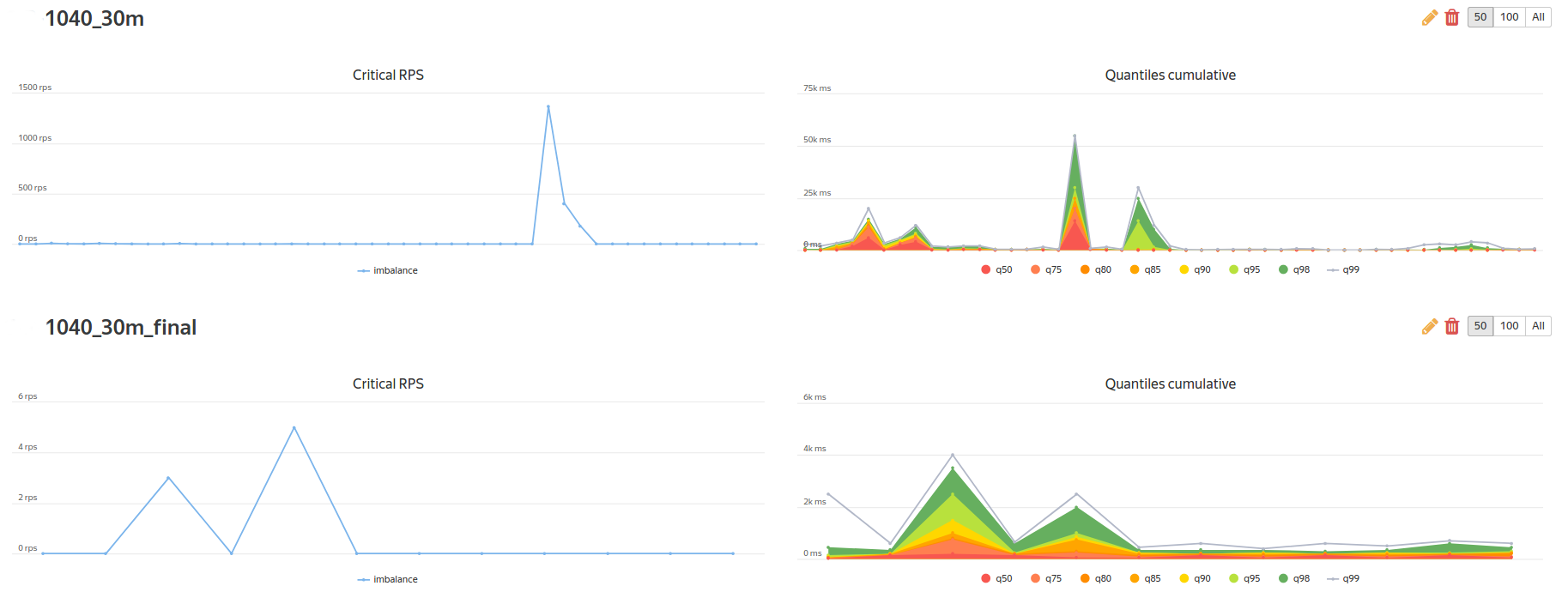
В качестве корпоративной “плюшки” от Яндекса мы получили доступ к сравнению тестов:

и доступ к построению регрессионных отчетов по KPI-метрикам:
Данный рассказ был бы неполным, если бы мы не описали несколько граблей, на которые наткнулись в процессе своей работы.
Мониторинг. Очевидно, что при нагрузочном тестировании вы обязаны использовать средства не только бизнес-мониторинга (валидация транзакций, размер очереди, скорость прохождения), но и системного мониторинга (потребление процессора, объем памяти, число дисковых операций, метрики, которые вы придумали сами и т.д.). Хорошо, когда у вас вся инфраструктура построена на Linux ? использование встроенного решения на telegraf поверх ssh решает эту задачу ? все данные автоматически заливаются в бэкенд статистики и строятся синхронно с агрегатами бизнес-метрик. Но что делать, если у вас часть тестового окружения построена на Windows-платформе?
Мы обсуждали разные варианты и пришли к такому:
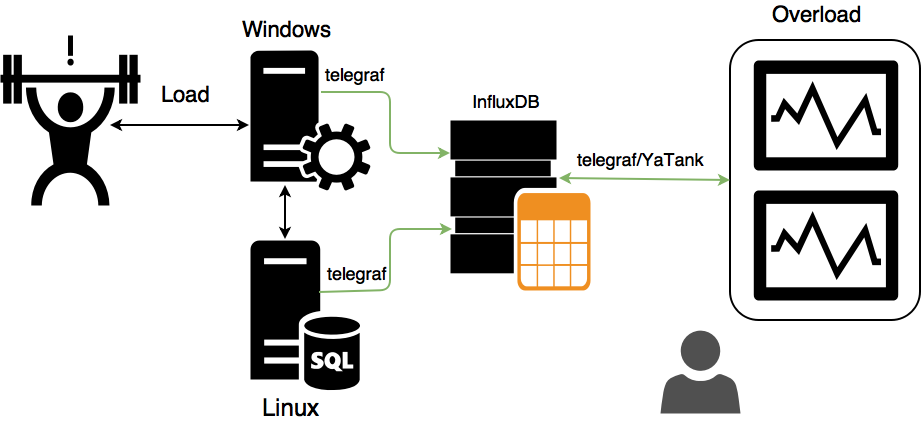
В данном случае, все метрики с серверов и load-генераторов пишутся в InfluxDB локальными агентами telegraf, а мониторинг Яндекс.Танка уже извлекает данные из InfluxDB простейшим скриптом и пушит данные в Overload. Такой подход позволяет отказаться от поддержки всего зоопарка операционных систем со стороны Яндекс.Танка и избежать необходимости коннекта “от одного ко всем”.
Написав простейший скрипт, вроде:
Мы можем заставить Яндекс.Танк собирать Custom-метрики из InfluxDB таким конфигом мониторинга:
В результате получаем такие графики в Overload:
Репортинг. Мы использовали два вида репортинга результатов.
Краткий отчет ? небольшой объем метаинформации с распределением времен и сообщением от автостоп-плагина ? отправлялся в виде сообщения в Telegram-чат, на который были подписаны разработчики, архитектор, менеджер и тестировщики.
Регрессионный отчет ? расширенный отчет, где к краткой информации добавлялось сравнение с эталонными результатами ? отправлялся в виде комментария в JIRA.
Для этого мы использовали скрипт на Groovy для Telegram и простенькую либу (подробнее на https://pypi.python.org/pypi/jira/) для провязки c API JIRA.
Как можно заметить, данная задача не из разряда Rocket Science, и вы могли читать подобные статьи здесь, здесь и даже смотреть видео здесь. Под капотом лежат обычные скрипты и сервисы ? мы всего лишь хотели продемонстрировать, что на самом деле к эре “Devops” и повальной автоматизации финансовый сектор готов уже давно, просто нужно иметь смелость и политическую волю внедрять современные и быстрые процессы.
Какие бенефиты мы можем получить от автоматизации?
В следующих статьях мы расскажем про наши эксперименты с InfluxDB с точки зрения производительности и оптимизации движка. Следите за новостями!
Команда нагрузочного тестирования компании “Инфосистемы Джет”.
Итак, мы занимаемся разработкой данного ПО, используя современный CI/CD подход, чем обеспечивается высокая скорость поставки фич, хотфиксов и релизов в продакшн. В начале года нам была предложена задача обеспечить нагрузочным тестированием разрабатываемое решение и продемонстрировать заказчику способность встраивать в CI/CD любые подзадачи и шаги.
Помимо общих слов, хотелки сводились к следующему: необходимо обеспечить автоматический деплой ПО на нагрузочный стенд, придумать легкий способ генерации данных, внедрить автоматический и полуавтоматический способ запуска тестов, снабдить тесты автоматическим триггером старта и остановки по событию, подключить механику НТ к трекеру задач для короткого репортинга, подключить систему тестирования к доступной системе аналитики НТ, создать возможность “покраски” плохих и хороших релизов для дальнейших действий в workflow (выкатить или отправить репорт). Требования, надо признать, абсолютно адекватные и понятные.
Автоматизация
Начнем издалека. Мы постоянно слышим одно и то же: “Автоматизировать нагрузочное тестирование банковского и финансового ПО невозможно! У нас слишком много взаимосвязей! Мы очень сложные!”. Этот вызов только усиливал азарт решения задачи. Нам всегда хотелось проверить сложность на конкретном примере.
Помните замечательную картинку про тестирование в виде пирамидки и рожка с мороженым? Пирамидка – это когда у вас много дешевых автоматических Unit-тестов и мало дорогих UI. Рожок с мороженным – наоборот. Рожок – это дорого, неповоротливо и не масштабируется, пирамидка – дешево и гибко.
Вместо того, чтобы заниматься нагрузочным тестированием ПО на уровне взаимодействий систем, в секторе банковского ПО традиционно все тестируют через UI, как повелось со времен неразъемных систем и приложений. На это уходит много времени и сил, что делает разработку банковского ПО медленной, некачественной и нетехнологичной. Мы в компании “Инфосистемы Джет” были избавлены от этих стереотипов — разработчики сами писали юнит-тесты на свой код, функциональные тестировщики прекрасно программировали UI-тесты через Selenium+Cucumber. Осталось только встроить в процесс дополнительную стадию нагрузочного тестирования.
Проектирование инфраструктуры
В самом начале мы решили отказаться от взаимосвязей, которые усложняют и размывают ответ на вопрос, насколько производительный и надежный код мы разрабатываем. Например, авторизация и выдача токенов на проведение операций — это функциональность сторонней системы, исследовать производительность которой в рамках задачи было бы избыточно. Помимо этого мы сразу отказались от интеграции с несколькими back-office системами, сделав заглушку, отвечающую нашей системе с определенной задержкой (все мы знаем, как опасно тестировать систему на сверхбыстрых моках).
Но самое значительное изменение в парадигме тестирования ? это отказ от нагрузочного тестирования UI-терминала. До сих пор это кажется странным, но до нас данное серверное ПО нагрузочно тестировали именно через UI ATM. Происходило это следующим образом: эмулировался некоторый средний пользователь, который проходил какой-то пул сценариев с набором средних пауз (paсing, think time), а нагрузочный инструмент был вынужден создавать нагрузку, которая состоит из длительных и “холодных” сценариев с нескольких лоад-генераторов HP Loadrunner, в то время как результирующая нагрузка на одну ноду API-сервера составляла всего около сотни(!) транзакций в секунду. (Оставим за скобками безумную картину, когда тысячи граждан пытаются нажимать на контролы одного банковского терминала). В итоге из стенда было выброшено практически все, что не имело отношения к производительности бэкенда ATM.
После проектирования и осмотра оставшейся инфраструктуры стало примерно понятно, как будет выстроен процесс, какие бенефиты будут получены, и нужно было приступать к созданию самого процесса НТ.
CI/CD процесс и программное обеспечение
Код ПО выкладывается во внутреннем git-репозитории (GitLab). После коммита по специальному триггеру Jenkins вытаскивает код на сборочную машину и пытается собрать релиз с прогоном всех заведенных Unit-тестов. После успешной сборки с помощью скриптов собранный билд инсталлируется в два тестовых окружения ? НТ и ФТ ? и делает рестарт тестинга. После подъема бэкенда Jenkins прогоняет друг за другом ФТ, UI и ИФТ-тесты. Нагрузочное тестирование запускается отдельной задачей, но про это стоит рассказать отдельно.
Как всем известно, классический инструмент нагрузочного тестирования состоит из трех “столпов”: генератора тестовых данных, лоад-генератора и анализатора полученных результатов. Поэтому задачу мы решали в трех направлениях.
Чтобы собрать релевантный запрос к API и не переписывать каждый раз XML под изменяющуюся спецификацию, мы пошли другим путем ? мы “грабим” TOP-10 основных платежных сценариев в момент прогона UI-тестов. Для этого на тестовом стенде мы развернули tshark, из дампа которого и собираем XML (его впоследствии будем отправлять в API). Это позволяет экономить кучу времени и сил на подготовку тестовых данных.
В качестве лоад-генератора мы использовали самый популярный инструмент на Open Source рынке ? JMeter, но в качестве обвязки к нему использовали Yandex.Tank. Мощности JMeter для отправки 100 транзакций в секунду на одну ноду хватает с лихвой, а Tank дает нам удобство в автоматизации и несколько полезных фич ? автостопы, интерактивные графики, возможность использования других генераторов нагрузки без перекраивания процесса НТ и т.д.
Самое сложное на этапе конструирования НТ ? это аналитическая часть. Так как на рынке пока нет отдельных решений по созданию своей аналитики для тестирования производительности, мы решили использовать Overload от Яндекса. Overload – это сервис для хранения и анализа результатов нагрузочных тестов. Нагрузку вы создаете со своих лоад-генераторов, а результаты загружаете на сервис и наблюдаете их там в виде графиков. Сейчас сервис находится в публичной бете, а для “Инфосистемы Джет” Яндекс создал пилотный приватный инстанс.
Все данные с нашего JMeter поступают в Overload в агрегированном виде и не содержат никакой персональной информации о платежах и клиентах ? пользователь видит только графическое представление тестов производительности.
Самое интересное
После того как билд попадает на нагрузочный стенд, посредством скриптов в Jenkins запускается специальная задача для нагрузочного тестирования. Задача настроена классическим способом, через shell-скриптинг и параметризацию.
Например, так можно конфигурировать автостопы:
Так выглядит конфиг Yandex.Tank:
А так выглядит пример shell-script запуска всего процесса НТ:
Как видите, все настройки достаточно примитивны. При автоматическом запуске джоба дефолтные параметры применяются автоматически, при ручном же запуске вы можете конфигурировать стрелялку параметрами Jenkins, не разбираясь в документации и не копаясь на Linux-машинке и перебирая необходимые конфиги.
Режим “Запуск по кнопке” для разработчика выглядит так:
После запуска теста вы получаете ссылку в Console View Jenkins и Telegram, перейдя по которой можно наблюдать нагрузочный тест в реальном времени:
Если результаты теста вышли за пределы SLA, то тест автоматически останавливается и вы получаете репорт в Telegram, почту и JIRA о проблемах с релизом. Если же результат хороший, то после репорта релиз получает статус SUCCESS и готов для деплоя на нагруженную среду, в продакшн.
Скрин с экрана Telegram:
А так бот репортит результаты в JIRA:
В качестве корпоративной “плюшки” от Яндекса мы получили доступ к сравнению тестов:
и доступ к построению регрессионных отчетов по KPI-метрикам:
Проблемы и решения
Данный рассказ был бы неполным, если бы мы не описали несколько граблей, на которые наткнулись в процессе своей работы.
Мониторинг. Очевидно, что при нагрузочном тестировании вы обязаны использовать средства не только бизнес-мониторинга (валидация транзакций, размер очереди, скорость прохождения), но и системного мониторинга (потребление процессора, объем памяти, число дисковых операций, метрики, которые вы придумали сами и т.д.). Хорошо, когда у вас вся инфраструктура построена на Linux ? использование встроенного решения на telegraf поверх ssh решает эту задачу ? все данные автоматически заливаются в бэкенд статистики и строятся синхронно с агрегатами бизнес-метрик. Но что делать, если у вас часть тестового окружения построена на Windows-платформе?
Мы обсуждали разные варианты и пришли к такому:
В данном случае, все метрики с серверов и load-генераторов пишутся в InfluxDB локальными агентами telegraf, а мониторинг Яндекс.Танка уже извлекает данные из InfluxDB простейшим скриптом и пушит данные в Overload. Такой подход позволяет отказаться от поддержки всего зоопарка операционных систем со стороны Яндекс.Танка и избежать необходимости коннекта “от одного ко всем”.
Написав простейший скрипт, вроде:
from inflow import Client
import sys
try:
connect = Client(sys.argv[1])
try:
query_string = "SELECT LAST(" + sys.argv[4] + ") FROM " + sys.argv[3] + " WHERE host='" + sys.argv[2] + "';"
result = connect.query(query_string)
print (result[0]["values"][0]["last"])
except:
print ("Bad request or something wrong with DB. See logs on " + sys.argv[1] + " for details.")
except ValueError:
print("Something wrong with parameters. "
"Usage: python ./influx_picker <http://db_host:port/dbname> <target_host> <group> <metric>")
except IndexError:
print("Usage: python ./influx_picker <http://db_host:port/dbname> <target_host> <group> <metric>")
Мы можем заставить Яндекс.Танк собирать Custom-метрики из InfluxDB таким конфигом мониторинга:
<Monitoring>
<Host address="localhost" interval="5">
<Custom diff="0" measure="call" label="cpu_sys">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_system</Custom>
<Custom diff="0" measure="call" label="cpu_usr">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_user</Custom>
<Custom diff="0" measure="call" label="cpu_iowait">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_iowait</Custom>
<Custom diff="0" measure="call" label="mem_free_perc">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host mem available_percent</Custom>
<Custom diff="0" measure="call" label="mem_used_perc">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host mem used_percent</Custom>
<Custom diff="0" measure="call" label="diskio_read">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host diskio read_bytes</Custom>
<Custom diff="0" measure="call" label="diskio_write">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host diskio write_bytes</Custom>
</Host>
</Monitoring>
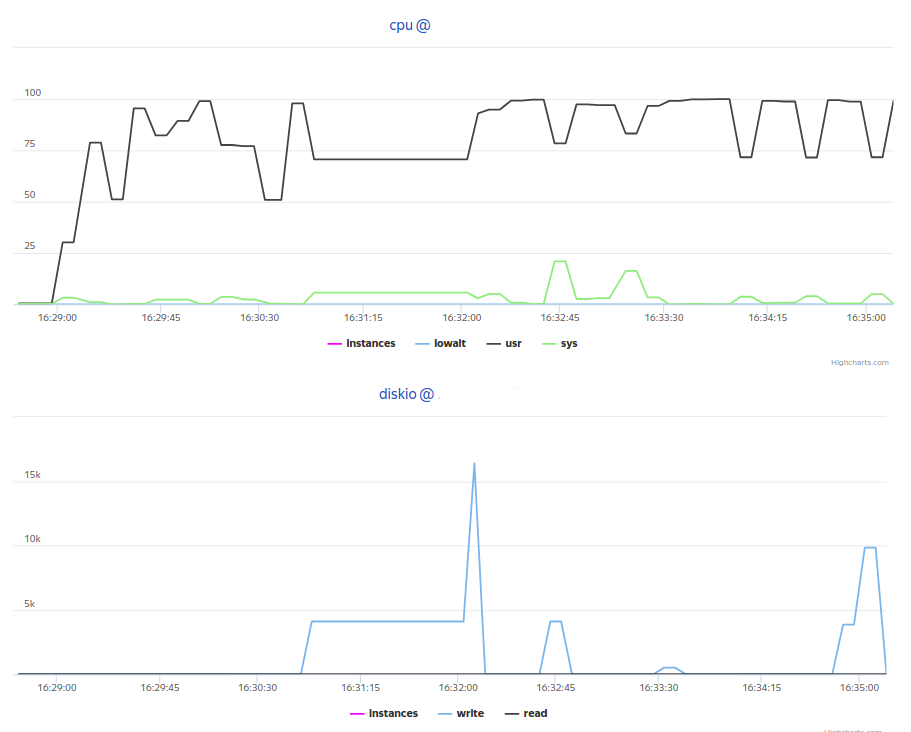
В результате получаем такие графики в Overload:
Репортинг. Мы использовали два вида репортинга результатов.
Краткий отчет ? небольшой объем метаинформации с распределением времен и сообщением от автостоп-плагина ? отправлялся в виде сообщения в Telegram-чат, на который были подписаны разработчики, архитектор, менеджер и тестировщики.
Регрессионный отчет ? расширенный отчет, где к краткой информации добавлялось сравнение с эталонными результатами ? отправлялся в виде комментария в JIRA.
Для этого мы использовали скрипт на Groovy для Telegram и простенькую либу (подробнее на https://pypi.python.org/pypi/jira/) для провязки c API JIRA.
Заключение
Как можно заметить, данная задача не из разряда Rocket Science, и вы могли читать подобные статьи здесь, здесь и даже смотреть видео здесь. Под капотом лежат обычные скрипты и сервисы ? мы всего лишь хотели продемонстрировать, что на самом деле к эре “Devops” и повальной автоматизации финансовый сектор готов уже давно, просто нужно иметь смелость и политическую волю внедрять современные и быстрые процессы.
Какие бенефиты мы можем получить от автоматизации?
- Выигрыш в скорости тестирования: мы получаем результаты максимум через 2 часа после коммита, в то время как при ручном тестировании на это уходит порядка недели-двух.
- Выигрыш в использовании мощностей: 3 виртуальных сервера против порядка десяти физических серверов(!).
- Выигрыш в стоимости лицензий: Jmeter против Loadrunner, Telegraf против Sitescope/Tivoli и высокая вендор-независимость.
В следующих статьях мы расскажем про наши эксперименты с InfluxDB с точки зрения производительности и оптимизации движка. Следите за новостями!
Команда нагрузочного тестирования компании “Инфосистемы Джет”.
Поделиться с друзьями
atpshnik
Коллеги, привет. Я к НТ имею некоторое отношение, но далеко не специалист в этом деле. Скорее (да так и есть) я разгребаю дефекты НТ и провожу какие-то оптимизации. Меня сильно зацепила фраза «все мы знаем, как опасно тестировать систему на сверхбыстрых моках». Вот я не знаю насколько это опасно и почему, но у нас задержек на заглушках нет. Поделитесь сокровенными знаниями, и быть может мне удастся сделать частичку этого мира лучше.
doctornkz
Привет. При нулевых таймингах заглушек вы можете не столкнуться с такими проблемами как: нехватка воркеров, которые окажутся занятыми долгими соединениями, нехватка самих соединений при обращении к бэкенду, утечками памяти, если воркеры пытаются положить данные в очередь, ожидая свободного сокета. В данном случае мы не могли этим фактором пренебречь, так как отклик от бэкенда иногда составлял единицы, а то и десятки секунд.