

Как и обещал, рассказываю о том, как мы мигрировали свой бэкенд на Go и смогли уменьшить объем бизнес логики на клиенте более, чем на треть.
Для кого: небольшим компаниям, Go и мобильным разработчикам, а также всем, кто в тренде или просто интересуется данной тематикой.
О чем: причины перехода на Go, с какими сложностями столкнулись, а также инструкции и советы по улучшению архитектуры мобильного приложения и его бэкенда.
Уровень: junior и middle.
Долгое время наша команда мобильной аутсорс разработки работала над сторонними проектами, у которых были свои бэкенд разработчики, а мы выступали в роли подрядчика для конкретного продукта. Несмотря на то, что в договоренностях всегда было четко оговорено, что именно мы, как мобильные девелоперы, диктуем музыку и API, далеко не всегда это помогало.

Настолько не всегда, что недавно я сделал небольшой сборник травмирующих душу ситуаций, который выложил в одной из своих прошлых статей.
Так получилось, что у нас тогда в команде был довольно сильный Java(Spring) разработчик, и мы решили каждому новому заказчику твердо объявлять: мы сами пишем бэкенд, либо ищите кого-нибудь другого. Поначалу боялись, что такая принципиальная позиция будет отпугивать, а мы в итоге останемся голыми на хлебе и воде. Но как оказалось, что если мы уже понравились кому-то на этапе переговоров и с нами хотят работать, то практически обо всем можно договориться. Даже когда у клиента в команде уже есть свои люди, которых он изначально планировал задействовать. Тогда-то мы узнали такое умное слово как микросервисы, и что можно делать отдельный сервак с бизнес логикой, выполняющий задачи строго для мобильного приложения. Не буду спорить, что такой подход не везде уместен, но речь дальше пойдет не об этом.
Причины перехода на Go
После нескольких успешных проектов Java оказалась слишком тяжелой для нас. Много времени уходило на рутину, чтобы сделать все максимально удобно для приложения.
Не хочу сказать ничего плохого о Spring и Java в целом, это удивительный инструмент под серьезные задачи, как огромный толстопузый испанский галеон. А мы искали что-то больше похожее на легковесный пиратский клипер.
Нам надо было быстро внедрять фичи, легко их менять и не греть голову в поисках самого оптимального решения в каждой ситуации. Знаете, как это бывает, когда долго гуглишь на предмет типового решения твоей задачи, чтобы оно было наиболее подходящим, потом оказывается, что из 10 из них 5 уже устарели. А потом еще тратишь полчаса на выбор названия для переменной.
У Go такой проблемы нет. От слова совсем. Иногда даже через слишком: сидишь, ищешь идеальное решение, а StackOverflow тебе на это отвечает: 'Ну да, просто циклом for, а ты чего ждал?'
Со временем к этому привыкаешь и перестаешь гуглить всякие мелочи по пустякам, а начинаешь включать голову и просто писать код.
Какие возникли сложности
Начнем с того, что там нет наследования. Поначалу это просто выносило мозг. Приходится ломать все свое представление об ООП и привыкать к утиной типизации. Формулируя простыми словами: если это выглядит как утка, плавает как утка и крякает как утка, то это, возможно, и есть утка.
По сути, есть только интерфейсное наследование.
А во-вторых, из существенных минусов, — малое количество готовых инструментов, но зато много багов. Многие вещи нельзя сделать привычным способом, а кое-что вообще отсутствует как класс. Например, нет нормального фреймворка для IoC (инверсия зависимостей). Опытные гоферы скажут, что есть либа от Facebook. Но может я просто не умею ее готовить, либо все-таки ее удобство на самом деле оставляет желать лучшего. Оно просто не может сравниться со Spring и потому приходится много работать руками.
Еще из небольших ограничений Go в целом, например, нельзя сделать API вида:
/cards/:id
/cards/somethingТак как для существующего http роутера — это взаимоисключающие запросы. Он путается между wildcard переменной и конкретным адресом something. Глупое ограничение, но приходится с этим жить. Если же кто-то знает решение, то буду рад услышать.
Также отсутствует hibernate или более менее адекватные аналоги. Да, есть множество ORM, но все они пока довольно слабые. Лучшее, что я встретил за время разработки на Go — это gorm. Ее главное преимущество — это удобнейший маппинг ответа от базы в структуру. А запросы придется писать на голом sql, если не хотите провести долгие часы за отладкой сомнительного поведения.
P.S. Хочу отдельно поделиться workaround-ом, который возник в процессе работы с этой либой. Если вам нужно записать id после insert в какую-то переменную с помощью gorm, а не в структуру как обычно, то поможет следующий костыль. На уровне запроса переименовываем результат returning на любой другой, отличный от id:
... returning id as valueС последующим сканом в переменную:
... Row().Scan(&variable)Оказывается, дело в том, что поле 'id' воспринимается gorm-ом как конкретное поле объекта. И чтобы развязаться, нужно на уровне запроса ее переименовать во что-нибудь другое.
Плюсы или почему мы все-таки пишем на Go
Хочется начать с порога вхождения: он минимален. Вспоминая какой скрежет вызывал в освоении тот же Spring, то Go, по сравнению с ним, можно преподавать в младших классах, настолько он прост.
И эта простота заключается не только в языке, но и в окружении, которое он за собой несет. Вам не нужно читать долгие маны по gradle и maven, не потребуется писать длиннющие конфиги, чтобы все хотя бы просто один раз запустилось. Здесь все обходится парой команд, а достойный сборщик и профилировщик уже является частью языка и не требует глубокого исследования для старта.
Как говорится: easy to learn, hard to master. Это то, чего мне всегда лично не хватало в современных технологиях: их как будто делают не для людей.
Из этого же следует скорость разработки. Язык был сделан для одной цели:

По сути, это backend язык для бизнеса. Он быстр, он прост и позволяет решать сложные задачи понятными способами. Насчет сложных задач и понятности — это отдельная тема для разговора, потому что в Go есть такая классная вещь как горутинки и каналы. Это удобнейшая многопоточность с минимальной возможностью для выстрела себе в ногу.
Архитектура
Web
В качестве web framework остановили свой выбор на Gin. Есть еще Revel, но нам он показался слишком узким и непоколебимо диктующим свою парадигму. Мы же предпочитаем чуть больше развязанные руки, чтобы можно было быть гибкими.
Gin соблазнил удобным API и отсутствием лишних сложностей. Порог вхождения у него просто приторно низкий. Настолько, что стажеры разбирались в нем буквально за день. Там просто негде запутаться. Весь нужный функционал как на ладони.
Конечно, и он не без проблем. Некоторые решения, например, кэш, сделаны третьей стороной. И происходит конфликт импортов, если вы у себя привыкли использовать import через github, а у них сделано через gopkg и наоборот. В итоге два плагина могут быть просто взаимоисключающими.
Если кто-то знает решение этой проблемы, то напишите, пожалуйста, в комментариях.
Менеджер зависимостей
Долго писать не буду, а сразу скажу, что это без сомнений Glide. Если вы работали с gradle или maven, то вам наверняка знакома парадигма объявлений зависимостей в неком файле с последующим их задействованием по необходимости. Так вот Glide — это хомячий Gradle, с решением конфликтов и прочими плюшками.
Кстати, если у вас возникнут проблемы при тестировании, когда go test лезет в папку vendor, жадно тестируя каждую либу, то проблема решается элементарно:
go test $(glide novendor)Этот параметр исключает папку vendor из тестирования. В сам репозиторий достаточно положить glide.yaml и glide.lock файлы.
Мобильной разработке это все никак не поможет, но просто, чтобы вы знали)
ORM и Realm
Это будет объемный раздел о передаче и хранении данных с бэкенда на клиент. Начнем с Go, плавно переходя на мобильную платформу.
Если вы никогда не сталкивались с Realm и не понимаете о чем речь, то правильно раскрыли спойлер.
Realm — это мобильная база, которая облегчает работу с синхронизацией данных на протяжении всего приложения. В ней нет таких проблем как в CoreData, где постоянно приходится работать в контекстах, даже когда объект еще никуда не сохранен. Легче соблюдать консистентность.
Достаточно просто создать сущность и работать с ней как с обычным объектом, передавая между потоками и жонглируя ею как душе угодно.
Множество операций она делает за вас, но, конечно, и у нее есть косяки: отсутствует не привязанный к регистру поиск, в целом поиск не доделан нормально, потребляет памяти как не в себя (особенно на android), отсутствует группировка как в FRC, и так далее.
Мы посчитали, что стоит мириться с этими проблемами и оно того стоит.
Чтобы не повторяться, коротко скажу, что мы в качестве orm используем Gorm и дам пару рекомендаций:
- Пишите SQL запросы руками, не ленитесь. Заодно выучите SQL, если еще этого не сделали.
- Старайтесь делать запросы в рамках одной транзакции, по возможности.
- Выбирайте из базы минимум необходимых вам полей.
- Обязательно маппите все в структуры. Чем меньше промежуточных переменных, тем лучше.
Наверное, это все применимо к любой технологии, тут я немного скапитанил, но все же. Лишний раз напомнить не повредит, это важно.
Теперь, что касается мобильного приложения. Ваша основная задача — сделать так, чтобы поля, возвращаемые в запросах, имели одинаковые названия с соответствующими им на клиенте. Этого можно легко добиться с помощью так называемых тегов:

Убедитесь, что тег json имеет правильное название. И желательно, чтобы у него был установлен флаг omitempty, как в примере. Это позволяет избежать захламления ответа пустующими полями.
У вас может справедливо возникнуть вопрос: при чем тут вообще Go, если одинаковые названия можно сделать в любом языке? И будете правы, но одним из преимуществ Go является легчайшее форматирование чего угодно через рефлексию и структуры. Пусть рефлексия есть во многих языках, но в Go с ней работать проще всего.
Кстати, если вам нужно спрятать из ответа пустую структуру, то наилучший способ — это перегрузить метод MarshalJSON у структуры:
// Допустим, надо скрыть пустое поле Pharmacy у объекта Object
func (r Object) MarshalJSON() ([]byte, error) {
type Alias Object
var pharmacy *Pharmacy = nil
// Если id != 0, то используем значение. Если нет - ставим nil
if r.Pharmacy.ID != 0 {
pharmacy = &r.Pharmacy
}
return json.Marshal(&struct {
Pharmacy *Pharmacy `json:"pharmacy,omitempty"`
Alias
}{
Pharmacy: pharmacy,
Alias: (Alias)(r),
})
}Многие не заморачиваются и сразу пишут в структурах указатель вместо значения, но это не Go way. Go вообще не любит указатели там, где они не нужны. Это лишает его возможности оптимизировать ваш код и использовать весь свой потенциал.
Кроме названий полей еще обратите внимание на их типы. Числа должны быть числами, а строки строками (спасибо, кэп). В том, что касается дат, то удобнее всего использовать RFC3339. На сервере дату можно отформатировать также через перегрузку:
func (c *Comment) MarshalJSON() ([]byte, error) {
type Alias Comment
return json.Marshal(&struct {
CreatedAt string `json:"createdAt"`
*Alias
}{
CreatedAt: c.CreatedAt.Format(time.RFC3339),
Alias: (*Alias)(c),
})
}А на клиенте это делается через форматирование даты по следующему шаблону:
"yyyy-MM-dd'T'HH:mm:ssZ"Еще одним преимуществом RFC3339 является то, что он выступает форматом даты по умолчанию для Swagger. И сама по себе отформатированная таким образом дата, довольно читаема для человека, особенно по сравнению с posix time.
На клиенте же (пример для iOS, но на Android аналогично), при идеальном совпадении названий всех полей и отношений класса, сохранение можно сделать одним генерик методом:
func save(dictionary: [String : AnyObject]) -> Promise<Void>{
return Promise {fulfill, reject in
let realm = Realm.instance
// Если у вас есть дата в словаре, то здесь надо ее отформатировать перед записью.
// Так как реалм не умеет сохранять дату в виде строго.
try! realm.write {
realm.create(T.self, value: dictionary, update: true)
}
fulfill()
}
}Для массивов ситуация аналогичная, но сохранение придется гонять уже в цикле. Часто неопытные разработчики допускают ошибку и заворачивают в цикл целиком блок записи:
array.forEach { object in
try! realm.write {
realm.create(T.self, value: object, update: true)
}
}Что просто в корне неверно, потому что так вы открываете новую транзакцию на каждый объект, вместо того, чтобы сохранить все скопом. А если у вас подключены еще уведомления для обновлений, то все становится еще 'веселее'. Правильнее сделать следующим образом, вынося транзакцию на уровень выше:
try! realm.write {
array.forEach { object in
realm.create(T.self, value: object, update: true)
}
}Как вы могли заметить, у нас полностью отвалился промежуточный слой, отвечающий за маппинг. Когда данные достаточно подготовлены, их можно сразу лупить в базу без дополнительной обработки. И чем лучше у вас бэкенд, тем меньше этой дополнительной обработки потребуется. В идеале только дату сконвертировать в объект. Все остальное должно быть сделано заранее.
Кстати, немного отходя от темы. Если вам не нужно иметь персистентную базу данных на клиенте, то это не повод отказываться от Realm. Он позволяет работать с собой строго в оперативной памяти, сбрасывая свое наполнение по первому требованию.
Такой подход позволяет использовать все преимущества реактивной базы данных и вышеописанный маппинг.
Еще хочу добавить для особо внимательных к мелочам: здесь нет утверждения, что Go — это единственно верное решение и панацея для мобильной разработки. Каждый может решать эту задачу по-своему. Мы выбрали этот путь.
Структура Go проекта
Сейчас пойдет много кода для Go разработчиков. Если вы мобильный девелопер, то можете свободно пролистать к следующему разделу.
Теперь мы подошли к самому интересному, если вы Go разработчик. Допустим, вы пишите бэкенд для некоего типового приложения: у вас есть слой с REST API, некая бизнес логика, модель, логика работы с базой данных, утилиты, скрипты миграции и конфиг с ресурсами. Вам как-то все это надо увязать у себя в проекте по классам и папочкам, соблюсти принципы SOLID и, желательно, не сойти с ума при этом.
Пока накидаем абстрактно, не погружаясь слишком глубоко, но так, чтобы была понятна общая структура. Если будет интересно, то посвящу этому полноценный отдельный материал. Все-таки сейчас речь идет о мобильном приложении в связке с Go.
Сразу оговорюсь, что не претендую на догматичность своих высказываний, каждый волен работать в своем проекте как считает нужным.
Начнем со скриншота нашей структуры:
(До чего милые в Intellij Idea хомячки, не правда ли? Каждый раз умиляюсь)
В неразвернутых директориях содержатся сразу Go файлы, либо файлы ресурсов. Проще говоря, все раскрыто так, чтобы видеть максимальное погружение.
В этой статьей расскажу только о том, что отвечает за бизнес логику: api, сервисы, работа с базой и как все это зависит друг от друга. Если вы, уважаемая публика, проявите интерес к этой теме, то потом распишу и остальное, потому как информации там слишком много для одной статьи.
Итак, по порядку:
Web
В вебе хранится все, что отвечает за обработку запросов: байндеры, фильтры и контроллеры — а вся их спайка происходит в api.go. Пример такого склеивания:
regions := r.Group("/regions")
regions.GET("/list", Cache.Gin, rc.List)
regions.GET("/list/active", Cache.Gin, regionController.ListActive)
regions.GET("", binders.Coordinates, regionController.RegionByCoord)Там же происходит инициализация контроллеров и инъекция зависимостей. По сути весь api.go файл состоит из метода Run, где формируется и стартуется роутер, и кучи вспомогательных методов по созданию контроллеров со всеми зависимостями и их групп.
Web.Binders
В папке binders располагаются биндеры, которые парсят параметры из запросов, конвертируют в удобный формат и закидывают в контекст для дальнейшей работы.
Пример метода из этого пакета. Он берет параметр из query, конвертирует в bool и кладет в контекст:
func OpenNow(c *gin.Context) {
openNow, _ := strconv.ParseBool(c.Query(BindingOpenNow))
c.Set(BindingOpenNow, openNow)
}Самый простой вариант без обработки ошибок. Просто для наглядности.
Web.Controllers
Обычно на уровне контроллеров делают больше всего ошибок: напихают лишней логики, забудут про интерфейсы и изоляцию, а потом вообще скатятся к функциональному программированию. Вообще в Go контроллеры страдают от той же болезни, что и в iOS: их постоянно перенагружают. Поэтому сразу определим, какие задачи они должны выполнять:
- получать параметры запроса;
- вызывать соответствующий метод сервиса;
- отправлять ответ об успехе или ошибке с изменением форматирования по необходимости.
Необходимость — это, например, когда сервис логично возвращает числом id некоего объекта, нет ничего криминального в том, что контроллер обернет его в map перед отправкой:
c.IndentedJSON(http.StatusCreated, gin.H { "identifier": m.ID })
Возьмем какой-нибудь пример типового контроллера.
Класс, если опускать импорты, начинается с интерфейса контроллера. Да-да, соблюдаем букву 'D' в слове SOLID, даже если у вас всегда будет только одна реализация. Это значительно облегчает тестирование, давая возможность подменять сам контроллер на его mock:
type Order interface {
PlaceOrder(c *gin.Context)
AroundWithPrices(c *gin.Context)
}Далее у нас идет сама структура контроллера и его конструктор, принимающий в себя зависимости, который мы будем вызывать при создании контроллера в api.go:
// С маленькой буквы, чтобы наружу ничего не вываливалось
type order struct {
service services.Order
}
func NewOrder(service services.Order) Order {
return &order {
service: service,
}
}И, наконец, метод, обрабатывающий запрос. Так как мы успешно прошли слой с биндингом, то можем быть уверены, что все параметры у нас гарантировано есть и мы можем получить их с помощью MustGet, не боясь панических атак:
func (o order)PlaceOrder(c *gin.Context) {
m := c.MustGet(BindingOrder).(*model.Order)
o.service.PlaceOrder(m)
c.IndentedJSON(http.StatusCreated, gin.H {
"identifier": m.ID,
})
}С опциональными параметрами та же история, но только на уровне биндера стоит заложить некое нулевое значение, которое вы будете проверять в контроллере, подставляя в него дефолтное при отсутствии, или просто игнорируя.
Services
Ситуация с сервисами во многом идентична, они так же начинаются с интерфейса, структуры и конструктора с последующим набором методов. Акцент хочется сделать на одной детали — это принцип работы с базой.
Конструктор сервиса должен принимать в себя набор репозиториев, с которыми он будет работать, и фабрику транзакций:
func NewOrder(repo repositories.Order, txFactory TransactionFactory) Order {
return &order { repo: repo, txFactory: txFactory }
}Фабрика транзакций — это просто класс, генерирующий транзакции, здесь ничего сложного:
type TransactionFactory interface {
BeginNewTransaction() Transaction
}type TransactionFactory interface {
BeginNewTransaction() Transaction
}
type transactionFactory struct {
db *gorm.DB
}
func NewTransactionFactory(db *gorm.DB) TransactionFactory {
return &transactionFactory{db: db}
}
func (t transactionFactory)BeginNewTransaction() Transaction {
tx := new(transaction)
tx.db = t.db
tx.Begin()
return tx
}А вот на самих транзакциях остановиться стоит. Начнем с того, что это вообще такое. Транзакция представляет из себя тот же интерфейс с реализацией, который содержит методы для старта транзакции, завершения, отката и доступа к реализации движка уровнем ниже:
type Transaction interface {
Begin()
Commit()
Rollback()
DataSource() interface{}
}type Transaction interface {
Begin()
Commit()
Rollback()
DataSource() interface{}
}
type transaction struct {
Transaction
db *gorm.DB
tx *gorm.DB
}
func (t *transaction)Begin() {
t.tx = t.db.Begin()
}
func (t *transaction)Commit() {
t.tx.Commit()
}
func (t *transaction)Rollback() {
t.tx.Rollback()
}
func (t *transaction)DataSource() interface{} {
return t.tx
}Если с begin, commit, rollback все должно быть понятно, то Datasource — это просто костыль для доступа к низкоуровневой реализации, потому что работа с любой БД в Go устроена так, что транзакция является просто копией акссессора к базе со своими измененными настройками. Он нам понадобится позже при работе в репозиториях.
Собственно, вот и пример работы с транзакциями в методе сервиса:
func (o order)PlaceOrder(m *model.Order) {
tx := o.txFactory.BeginNewTransaction()
defer tx.Commit()
o.repo.Insert(tx, m)
}Начали транзакцию, выполнили доступ к базе, закоммитили или откатили, как больше нравится.
Конечно, все преимущество транзакций особенно раскрывается при нескольких операциях, но и даже если у вас всего одна, как в примере, хуже от этого не будет.
Знаю, что нет управления уровнями изоляции.
Если нашли еще какие косяки — пишите в комментах.
В качестве дополнительного совета юниорам, хочу сказать, что транзакция должна быть открыта минимально возможное время. Постарайтесь подготовить все данные так, чтобы на период между begin и commit приходилось минимальное количество логики и вычислений.
Бывает, что транзакцию открывают и идут курить, отправляя, например запрос в гугл. А потом удивляются, почему это с дедлоком зафакапилось все.
Интересный факт
Во многих современных базах данных, deadlock определяется максимально просто: по таймауту. При большой нагрузке сканировать ресурсы на предмет определения блокировки — дорого. Поэтому часто вместо этого используется обычный таймаут. Например, в mysql. Если не знать эту особенность, то можно подарить себе чудеснейшие часы веселой отладки.
Repositories
Тоже самое: интерфейс, структура, конструктор, который, как правило, уже без параметров.
Просто приведу пример операции Insert, которую мы вызывали в коде сервиса:
func (order)Insert(tx Transaction, m *model.Order) {
db := tx.DataSource().(*gorm.DB)
query := "insert into orders (shop_id) values (?) returning id"
db.Raw(query, m.Shop.ID).Scan(m)
}Получили из транзакции низкоуровневый модификатор доступа, составили запрос, выполнили его. Готово.
Всего этого вполне должно хватить, чтобы не угробить архитектуру. По крайней мере слишком быстро. Если возникли вопросы или возражения, то пишите в комментариях, буду рад обсудить.
Приложение
Ладно, суслики это мило, но как теперь с этим работать на клиенте?
Начнем, как и в случае с Go, с нашего стека. Вообще, мы активно используем реактив практически везде, но сейчас расскажу про более щадящий вариант архитектуры, чтобы так сразу не травмировать ничью психику.
Стек
Сетевой слой:
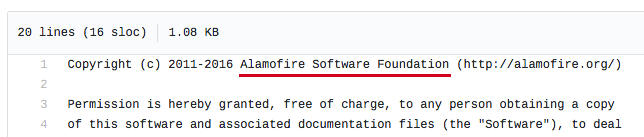
Alamofire для Swift проектов и AFNetworking для Objective-C.
Кстати, а вы знали, что Alamofire — это и есть AFNetworking? Префикс AF значит Alamofire, в чем можно убедиться, заглянув в лицензию AFNetworking:
Замыкания:
Многие в качестве callback-ов для бизнес логики передают в параметры запросов блоки для успеха/провала или лепят один на все. В итоге в параметрах каждого метода бизнес логики висит толстенное замыкание или даже не одно, что не сказывается положительно на читаемости проекта. Иногда блок отдают в качестве возвращаемого значения, что тоже неудобно.
Есть такая замечательная вещь как промисы. Реализация iOS: PromiseKit. Простыми словами — вместо кучи блоков, передаваемых в метод, вы возвращаете объект, который потом можно развернуть не только в success/failure замыкания, но еще и некий always, вызывающийся всегда, независимо от успеха/провала метода. Их также можно чередовать, объединять и делать множество приятных вещей.
Как по мне, так ключевое преимущество — это именно последовательное применение. Можно разделить flow бизнес логики на маленькие операции, вызываемые друг за другом. В итоге, например, метод получения детализации для некого товара, будет выглядеть так:
func details(id: Int) -> Promise<Void> {
return getDetails(id)
.then(execute: parse)
.then(execute: save)
}А так внутренний метод getDetails, просто делающий запрос на конкретный адрес:
func getDetails(id: Int) -> Promise<DataResponse<Any>> {
return Promise { fulfill, reject in
Alamofire.request(NetworkRouter.drugDetails(id: id)).responseJSON { fulfill($0) }
}
}Не самый чистый код, но для копипасты подойдет. Прячу под кат, потому что код реально трэш. Постараюсь обновить, когда руки дойдут. Уже даже стыдно за легаси, кочующий из проекта в проект.
func parseAsDictionary(response: DataResponse<Any>) -> Promise<[String:AnyObject]> {
return Promise {fulfill, reject in
switch response.result {
case .success(let value):
let json = value as! [String : AnyObject]
guard response.response!.statusCode < 400 else {
let error = Error(dictionary: json)
reject(error)
return
}
fulfill(json)
break
case .failure(let nserror):
let error = Error(error: nserror as NSError)
reject(error)
break
}
}
}
// Выше этот метод уже был, но продублриюу
func save(items: [[String : AnyObject]]) -> Promise<Int> {
return Promise {fulfill, reject in
let realm = Realm.instance
try! realm.write {
items.forEach { item in
// Замените на свой класс или сделайте generic
realm.create(Item.self, value: item, update: true)
}
}
fulfill(items.count)
}
}А в самом контроллере, если вы используете MVC, все максимально просто:
_ = service.details().then {[weak self] array -> Void in
// Success. Do w/e you like.
}База данных
Вопрос про хранение данных описывал выше, когда говорил про работу с ORM на Go-side, поэтому повторяться не буду, только добавлю ссылку на то как получать уведомления об обновлениях базы в том же контроллере. По сути если в БД что-то добавилось, то контроллер асинхронно об этом узнает. Это гораздо удобнее, чем каждый раз мучиться с подсчетом datasource при каждом малейшем движении. А если еще и эти изменения могут произойти не только из одного места, то вообще швах.
Сюда перетаскивать кусок кода из гайда по fine-grained notifications не буду, дабы не плодить копипасту.
class ViewController: UITableViewController {
var notificationToken: NotificationToken? = nil
override func viewDidLoad() {
super.viewDidLoad()
let realm = try! Realm()
let results = realm.objects(Person.self).filter("age > 5")
// Observe Results Notifications
notificationToken = results.addNotificationBlock { [weak self] (changes: RealmCollectionChange) in
guard let tableView = self?.tableView else { return }
switch changes {
case .initial:
// Results are now populated and can be accessed without blocking the UI
tableView.reloadData()
break
case .update(_, let deletions, let insertions, let modifications):
// Query results have changed, so apply them to the UITableView
tableView.beginUpdates()
tableView.insertRows(at: insertions.map({ IndexPath(row: $0, section: 0) }),
with: .automatic)
tableView.deleteRows(at: deletions.map({ IndexPath(row: $0, section: 0)}),
with: .automatic)
tableView.reloadRows(at: modifications.map({ IndexPath(row: $0, section: 0) }),
with: .automatic)
tableView.endUpdates()
break
case .error(let error):
// An error occurred while opening the Realm file on the background worker thread
fatalError("\(error)")
break
}
}
}
deinit {
notificationToken?.stop()
}
}Взаимодействие внутри проекта
Многие разработчики болеют гигантоманией, которая вызывает у них желание запихнуть всю бизнес логику в один файл с названием ApiManager.swift. Или есть более латентные формы, когда этот файл делят на много других, где каждый — это extension от ApiManager, что на самом деле совсем не лучше.
Получается перегруженный божественный класс и к тому же singleton, отвечающий просто за все. Я сам раньше так работал, когда занимался мелкими приложениями, но на крупном проекте это здорово аукнулось.
Лечится это с помощью SOA (service oriented architecture). Есть отличное видео от Rambler, где подробнейшим образом разбирается, что это такое и с чем его едят, но я постараюсь на пальцах дать инструкцию по внедрению в проект.
Вместо одного менеджера делаем несколько сервисов. Каждый сервис — это отдельный класс без состояния с набором методов по вышеописанному принципу. Сервисы также могут вызывать друг друга, это нормально. А чтобы использовать сервис в контроллере, то просто передаете ему нужный объект в конструкторе или создаете во viewDidLoad. Конечно, второй вариант хуже, но для начала сойдет. Иногда бывает, что прямо здесь и сейчас надо срочно подключить еще один сервис в контроллер, а разгребать всю эту цепочку зависимостей, проверять каждое место, где контроллер используется, нет никакого желания.
Пример таких сервисов в одном из проектов:

Где в каждом сервисе находится ограниченный набор методов, за которые он отвечает и с которыми работает. Желательно, чтобы сервис не превышал 200-300 строк. Если он перевалил за этот объем, то значит бедняга выполняет совсем не одну задачу, которая ему предназначена.
В итоге, вся ваша логика на клиенте сводится к следующему: запрос на сервер, парсинг в контейнер и сохранение в базу. Все, никаких промежуточных действий.
Заключение
Подытожу. Хорошо подготовленные данные на бэкенде в связке с Realm-ом на mobile-side дают возможность практически целиком отказаться от дополнительной бизнес логики на клиенте, сводя все к работе с интерфейсом. Можно не согласиться, но по-моему, так и должно быть. Ведь любой клиент, пусть даже и такой классный как iOS или Android, — это в первую очередь вью вашего продукта!
А перед тем как закончить, хотелось бы поделиться наболевшим. Многие в комментариях к моим статьям выказывают недовольство, что я рассказываю очевидные вещи и вообще капитаню, а кое-кто даже не стесняется минус в карму зарядить за это.
Но вот что я хочу сказать. Своей работой я стараюсь подтянуть общий уровень разработчиков в сообществе.
Вы можете сказать, что это чересчур смело. Но знаете, как становится грустно, когда на собеседование приходит человек, считающий себя классным специалистом или, по крайней мере, сильным мидлом, но при этом даже не знающий простейших вещей? Который путается между MVP и MVVM и похоже, что вообще разрабатывает интуитивно.
Из серии, когда заглядываешь человеку в код, видишь там несуразную лютую жесть и спрашиваешь его: “Вася, почему ты так сделал?” А он отвечает: “Хз, иначе не работало.”
Про архитектуру даже не заикаюсь.
Что ж, надеюсь, было полезно. И как всегда, буду рад услышать любые вопросы, критику и предложения.
P.S. Прикладываю опрос. Стоит ли делать в будущих статьях титульную информацию с кратким сюжетом и целевой аудиторией? Нигде такого не видел, но мне кажется, могло бы быть полезно. Да, есть тэги, но они, на мой взгляд, недостаточно заметны и не раскрывают сути.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (96)

Wolfie
01.07.2017 15:43func (t *transaction)Commit() { t.tx.Commit() }
Вам все равно, успешно ли прошел коммит? Как вы возвращаете/обрабатываете ошибки?
Mehdzor
01.07.2017 15:47Если возникла ошибка, то она обрабатывается на уровне конкретной query, а потом делается rollback.
Приведу пример из гайда по Gorm, так будет понятнее:
func CreateAnimals(db *gorm.DB) err { tx := db.Begin() // Note the use of tx as the database handle once you are within a transaction if err := tx.Create(&Animal{Name: "Giraffe"}).Error; err != nil { tx.Rollback() return err } if err := tx.Create(&Animal{Name: "Lion"}).Error; err != nil { tx.Rollback() return err } tx.Commit() return nil }
Если рассматривать в нашей архитектуре, то репозиторий возвращает ошибку, а сервис уже будет решать, что с ней делать.
Mehdzor
01.07.2017 15:50Я не опускался до деталей в статье, потому что получилось уже и так слишком много информации. Если интересно, то потом посвящу отдельный материал этой теме.

MariyaSafonova
01.07.2017 16:12А когда будете более направлено освящать iOS?
зы Хомяк на картинке особенно удался!Mehdzor
01.07.2017 18:40Как оказалось, это суслик, а не хомяк)
В следующей статье. У iOS слишком узкая аудитория, хочется охватывать побольше.


ozkriff
01.07.2017 16:32Это же суслик, а не хомяк.
Mehdzor
01.07.2017 16:42Даже задумался на минуту. Если верить официальному блогу, то это не хомяк и не суслик, а гофер — неизвестное науке животное. Так что, можно называть его как угодно)
ozkriff
01.07.2017 16:45https://www.multitran.ru/c/m.exe?s=суслик
https://www.multitran.ru/c/m.exe?s=gopher
Чего это "gopher" не суслик?
Mehdzor
01.07.2017 16:51+1Поменял в статье везде. Спасибо, что открыли глаза)

postromantic
01.07.2017 23:53гофер — не суслик. это отдельный вид североамериканских грызунов: https://ru.wikipedia.org/wiki/Гоферовые

Legion21
01.07.2017 18:05gorm это вещь, особенно радует возможно переопределения событий create,insert…
Legion21
01.07.2017 18:07А вот по поводу gin, меня очень убивает его работа с роутингом… хочу regexp в параметрах роута))))


TViT
01.07.2017 18:32-2В качестве лирического отступления. Сколько не читал подобных статей. Все время крутится в голове вопрос, для чего выпускают эти новые языки, для чего вообще в принципе весь этот зоопарк языков с различным синтаксисом если они все делают примерно все одинаково исходя из принципа работы процессора.
Уже давно пора просто общаться с компьютером как будто пишешь письмо — Создать окно с надписью в заголовке «Моя программа», взять данные вида и размера окна моей программы и объектов на нем из файл.xml
При нажатии на кнопку один с надписью «расчет» вывести в текстовое поле результат произведения их двух текстовых полей «поле1» и «поле2»
…
Ну ей Богу наплодили языков и тем как сейчас узких специалистов, к пуговицам есть претензии, нет? Тогда вам туда…Mehdzor
01.07.2017 18:35Программы не умеют видеть будущее и знать зачем они созданы, от этого многое зависит. Особенность языков для бэкенда, например, тот же garbage collector, который в отличие от ARC, рассчитан на долговременное использование программы.
Есть еще много логических деталей, которые нельзя предусмотреть типовым решением. А то что можно, выносится во framework-и.
TViT
01.07.2017 23:43-2Не соглашусь. Программам и не нужно видеть будущее это за них делает программист (они же не ИИ и построены на простой логике, не на нейронных сетях где требуется самостоятельное обучение без учителя или генетические алгоритмы многократных итераций). Всякие сборщики мусора есть в интерпретируемых языках типа Python. А синтаксис любого языка это тот же самый язык просто укороченные инструкции, что размазывает понимание работы если вы не знаете синтаксис и названий функций что делается и что возвращается. Что человеку знать в принципе и не нужно. Поскольку человек решает глобальную задачу, а не тонкости языка и функций из сторонних библиотек.
Поэтому по сути чтобы создать универсальный человеческий язык препроцессор-интерпретатор-компилятор нужно всего лишь что-то типа IBM- Watson который будет понимать логику чего хочет человек, причем это будет проще чем отвечать на вопросы в разных играх где он всех обыграл. Поскольку синтаксис будет заменен жесткой логикой и функцией. Вместо написания цикла или функции например Преобразования Фурье, достаточно будет написать — построить спектр звукового файла и вывести в окно в область под названием изображение (или потока с USB зависит что делаете от задачи) и механизм разбора логики сам подставит все циклы библиотеки и функции с переменными судя из логики того что требуется. Ну накрайняк можно в генерируемом файле перед компиляцией все проверить и дописать вручную. Хотя ошибки при мощном аналитическом алгоритме и системах типа Watson исключены. Их быстрее программист допустит как в синтаксисе, так и при опечатках или логических ошибках типа сравнения в Си ==.
Nikon_NLG
02.07.2017 01:56+3Дяденька, я не настоящий сварщик, поэтому спрошу прямо — если Вы такой умный — чего ж сами язык не напишете который будет сам всё делать по описанию «Создать окно с надписью»?
И, кстати, что программа должна делать когда окно создать не получается?TViT
02.07.2017 12:01-2Дяденька ответ очевиден. Я не Google, у меня нет столько ресурсов. Так или иначе к этому в любом случае все придет. Так же как появились после перфокарт — ассемблер и интерпретаторы языки типа Питона.
Тем более любой программист пишет и так словами укороченными инструкциями программу поэтому разница не сильно большая. Нужно просто интерпретировать правильно. Понять контекст ответить что именно требуется что нужно сделать. Так же как это делает IBM Watson. Поэтому препроцессор-интерперетатор можно на ИИ сделать который будет обучаться понимать контекст с задачей максимально эффективно использовать память и максимизировать скорость выполнения программы. И потом связывать с именами переменных и вызываемыми функциями.
А если окно создать не получается будет делать то что напишет программист. Хошь месагу гневную выкинь с выгрузкой приложения из памяти. Хошь просто заверши все процессы треды и очисти память если не предполагается в реализиции компилятора автоматически все это делать. Все как при написании обычным языком программирования.

Dethrone
02.07.2017 02:50Потому что каждый язык заточен под разные юзкейси, не??
TViT
02.07.2017 12:15А что меняется? Проблема разве простыми словами описать логику что пишется на том или ином ЯП. Вопрос только в понимании препроцессором-интерпретатором что требуется. А здесь уже нужен аналитический инструмент типа нейронных сетей или IBM Watson.
Dethrone
02.07.2017 14:07+1Дело не просто в том что бы описать логоку, а в том какие гарантии тебе дает язык(например в Rust невозможно словить data-race, а в си можно, но в си ненадо замарачиваься с borrow checker за счет которого Rust предотвращает data-race), какой тулинг возможно построить вокруг него (например Go генерит быстрый код, и генерит его быстро, что уникально если не брать в расчет Ocaml, но недостаток Ocamla в том что в нем нету поддержки параллелизма, зато Gc с очень низкой latency, и присутствуют HKT), я уже не говорю о том что если тебе нужно бытро разрабатывать то тебе подойдет Python, Ruby, JS, Clojure, но никак не Rust, C++, etc.… и самое главное что таких ньюансов сотни, и для каждой конкретной задачи один язык(и его экосистема) будет лучше другого.
TViT
02.07.2017 15:17-2Вы привели специфический пример. Поскольку к языку описания это не имеет отношения тут работа самого компилятора. Какие механизмы предоставляет для отлова исключений переполнений гонок и т.д. Ну и конечно это проблемы программиста. Нюансов конечно много в различных сферах применения. Но это отпечаток усложнения теорема Геделя. Понятно что казусы периодические плавающие ошибки будут только возрастать с усложнением. Будет требоваться все больше сил их отловить и подходов их предотвратить. Поэтому это лишь накладывает дополнительную строгость к языку к стандартам оформления библиотек функций вызовов и к программисту, но никак не к синтаксису самих языков. Поскольку циклы везде одинаковые и ветвления тоже. Тогда вопрос почему бы это не писать простым языком, будет растянуто, но не потребуется знать зоопарк, а сосредоточится на задаче. Так же к библиотекам и функциям для различных платформ и архитектур как и ОС будет просто применяться дополнительный критерий универсальности. IDE разработки тоже должна подсказывать прогнозировать возможные проблемы в выполнении кода. Я думаю это будет неизбежно в скором будущем. Тем более на любом этапе можно исправить руками исходник перед компиляцией или виртуальной машиной.
Dethrone
03.07.2017 17:56+1Поскольку к языку описания это не имеет отношения тут работа самого компилятора
Как раз к языку это имеет самое непосредственное отношение, поскольку какой компилятор для си ты не пиши, а предотвращения data-race во время компиляции как у Rust или скорости компиляции как у Go ты не получишь ну НИКАК, потому что для этого нужно поменять дизайн языка. А на Ruby ты никак не определишь data-layout, потому что язык не предоставляет никаких средств для этого. Haskell позволяет трекать все сайд эффекты в системе типов за счет ленивости+purity.
TViT
02.07.2017 15:17-2А если добавить нейронные сети и какой-то минимальный ИИ то приведенные вами ошибки будут через сеть сопоставляться с различными подходами у разных программистов и вырабатываться решение, которое и будет подставляться при программировании как опробованное и эффективное. Тут конечно уже распределенная сеть получится глобальная, вы просто пишете что нужно она генерирует код запускаете и тестируете. Не понравилось пишите дополнительные предложения на чем сконцентрировать внимание препроцессора или пишите сами вручную на Си например.

TheShock
02.07.2017 16:57+3А если добавить нейронные сети и какой-то минимальный ИИ то приведенные вами ошибки будут через сеть сопоставляться с различными подходами у разных программистов и вырабатываться решение
Я так понимаю, что вас «нейтронные сети» равносильно «неведомой магии, которую достаточно добавить и все будет просто заебись»TViT
02.07.2017 17:50-3Вы… ни о чем. Причем тут неведомая магия. Это то как я бы сделал. И то как у меня распознавание на микроконтроллере работает. Поэтому не вижу сложностей для google или подобных компаний с большими ресурсами.
RidgeA
03.07.2017 16:13+1Вы думаете, что компании с большими ресурсами не хотя что бы у разработчиков было 2 кнопки — «Реализовать фичу» и «Исправить все баги» что бы программисты работали/гребли в разы эффективнее?
Видимо не все так просто с IBM Watson, ИИ и т. п. в средствах разработки программного обеспечения. И IBM Watson, как и любой ИИ не способны решать широкий круг задач, а только то, под что они заточены.
Поэтому по сути чтобы создать универсальный человеческий язык препроцессор-интерпретатор-компилятор нужно всего лишь что-то типа IBM- Watson
Подумашеь, какая мелочь, надо каждому программисту поставить по суперкомпьютеру.
https://en.wikipedia.org/wiki/Watson_(computer)#HardwareTViT
03.07.2017 19:41-2Никто про легкость и не говорит. Я то уверен в скором будущем все к этому и придет. Это лишь вопрос времени причем небольшого. Поскольку сейчас просматривается тренд распиарить новый язык привлечь внимание и получить выгоду со своего детища. А потом этот язык кое как живет и то ощущение что исключительно из-за опенсорс. За редким исключением где признана его эффективность и универсальность проверенная годами. Я то хочу больше узнать может были попытки внедрить подобное, обсуждения такой возможности. Поскольку синтаксис языка не имеет значения циклы ветвления везде одинаковые и завязаны на машинные инструкции. А раз так в чем проблема простым языком описывать требуемые действия. Хотите на более высоком уровне типа Питона, если проблем будет куча для Си подобного языка. И на каждом этапе смотреть и контролировать исходники.
khim
03.07.2017 22:22А потом этот язык кое как живет и то ощущение что исключительно из-за опенсорс.
Существует масса языков не имеющих опенсорс-реализаций. Тот же язык 1С.TViT
03.07.2017 23:36-1Пример не корректный. Поскольку язык по сути создан для одной задачи и поддерживается в бух учете. И то многие крупные компании не используют 1С. И кому этот язык будет нужен если исчезнет 1С? Никому, может будет жить и поддерживаться небольшим сообществом если станет опенсорс.
Вот МайкроСофт нашел новость создает универсальную систему на ИИ — DeepCoderkhim
05.07.2017 01:20-1И кому этот язык будет нужен если исчезнет 1С?
А кому будут нужны все эти компьютеры, если вдруг с лица Земли исчезнет человек? Все эти Clarionы, Delphi и Pickи оказываются достаточно живучими для того, чтобы использоваться десятилетиями — срок за который множество языков с опенсорс-реализациями успевают появиться, завоевать популярность и умереть.
Dethrone
03.07.2017 17:59+2А если добавить нейронные сети и какой-то минимальный ИИ то приведенные вами ошибки будут через сеть сопоставляться с различными подходами у разных программистов и вырабатываться решение, которое и будет подставляться при программировании как опробованное и эффективное.
В то время когда космические корабли бороздили просторы вселенной…
pawlo16
01.07.2017 20:23+11) sqlx лучше чем gorm, в нём нет магии. Если писать sql самостоятельно (а это следует делать, да), то gorm не даёт вообще ни каких бонусов в сравнении sqlx, только усложнения
2) rest api на хттп — устаревший подход. Рекомендую использовать вебсокет в качестве транспорта — это модно, меньше трафик, проще архитектура приложения
3) DI в Гоу не нужно. В Гоу в отличие от java и C# нет проблем с явной инициализвцией зависимостей в нужных местах кода. Понимаю, трудно принять этот тезис после опыта с java, в которой DI и SOLID превратились в карго культ и применяются бездумно. Рекомендую к прочтению по этому поводу если не знакомы https://www.sandimetz.com/blog/2016/1/20/the-wrong-abstraction и https://en.wikipedia.org/wiki/KISS_principle
4) в качестве web фреймворка по ряду причин лучше использовать chi — более лёгкий и идеоматичный, чем gin. Для обработки хттп сессии он использует стандартный для net/http
func(w http.ResponseWriter, r *http.Request)
5) Glide — OMG, зачем? для прикладных программ в Гоу используется вендоринг.
MariyaSafonova
01.07.2017 20:56+2Вебсокет это клево, но если только мобильное устройство всегда на зарядке, или вашим приложением пользуются не более 10-15 секунд в день. К сожалению, в современных мобильных устройствах заряд батареи не позволяет заменить rest api на вебсокет. Как только аккумулятор будет держать заряд не 2 дня, а хотя бы неделю (при интенсивном использовании телефона), тогда можно говорить о том. что rest api устарел.
pawlo16
01.07.2017 21:30вы правы с точностью до наоборот. Для экономии заряда батареи вебсокет и асинхронный веб — это то, что доктор прописал. Вебсокет не расходует трафик на служебные пакеты для поддержания соединения. Клиент не поллит сервер и получает только те данные, которые ему требуются. При этом трафик не палится на бесполезные хттп хэдеры.
MariyaSafonova
01.07.2017 22:37+3На деле же вебсокет — постоянно поддерживает связь с сервером, не давая уснуть CPU и WiFi. Мне кажется, Ваши познания о работе вебсокета на мобильном устройстве только теоретические.Поищите в интернете — какие приложения больше всего садят батарейку на мобильном устройстве? А так же, почему?
На практике: приложение, на вебсокете разряжает батарейку мобильного устройства за час работы (навигаторы, мессенджеры).pawlo16
01.07.2017 23:50Мои познания на уровне разработчика full stack веб приложений. Потребление батарейки зависит от сценарий работы приложения, а не от выбора транспортного протокола. С таким же успехом батарею можно разрядить за счёт тупого поллинга сервера хттп запросами на т.н. rest api.
поддерживает связь с сервером
ещё раз, при нормальной асинхронной архитектуре клиентского приложения ни какой пингпонг не нужен и ни каких служебных пакетов от клиента к серверу не приходит.
приложение, на вебсокете разряжает батарейку мобильного устройства за час работы (навигаторы, мессенджеры).
так вот если бы они использовали хттп с тем же объёмом данных, батарея садилась бы на порядок быстрее

bitver
02.07.2017 11:12Пинг понг фреймы не стандарт, но используются повсеместно и их не видно и не получится использовать в js. Откройте Wireshark и узрейте истину.
pawlo16
02.07.2017 18:37не получится использовать в js
как напишите код, так и будут работать программа в плане отправки/не отправки пингпонгов. Если вы сами не пингуете сервер, браузер этого делать тоже не будет, я гарантирую это :-)
Откройте Wireshark и узрейте истину.
для своих приложений открывал и зрел, чужие в этом плане меня мало интересуют.
bitver
03.07.2017 13:26А не, я ошибся, пинг/понг фреймы стандарт , но не обязательны, но на пинг обязательно надо ответить понг иначе закрывается соединение. Последние Хром и Сафари откликиваются на пинг сервера, что вы там у себя смотрели совершенно не ясно.
pawlo16
03.07.2017 15:42+1бинго! с третьего раза вы поняли половину истины — пингпонги не обязательны. Уверен, если ещё раз 5 вам повторить, то до вас таки дойдёт, что и серверу совершенно не обязательно пинговать клиентов.
что вы там у себя смотрели совершенно не ясно.
я смотрел сетвые пакеты своего приложения )
Mehdzor
01.07.2017 22:22Прокомментирую второй пункт:
Попробуйте разрабатывать на мобильные платформы. Может быть socket соединение без пинг-понга и идейно лучше, но все, прямо совсем все, все случаи прерывания соединения, обработку сессии, условия для восстановления и так далее, придется делать р-у-к-а-м-и. Совсем руками. Жестковато.pawlo16
01.07.2017 22:36Код, о который вы имеете ввиду, при нормальной организации клиентского приложения будет достаточно тривиальными и утилитарным. Клиент асинхронный и ведущий, поэтому никакой "сессии" он не процессит — это делает сервер.Всё, что требуется от клиентского кода — кеширование запросов на сервер с дублированием в случае реконнекта и собственно реконнект с линейным таймаутом.
EvilFox
02.07.2017 01:28+14) в качестве web фреймворка по ряду причин лучше использовать chi — более лёгкий и идеоматичный, чем gin. Для обработки хттп сессии он использует стандартный для net/http func(w http.ResponseWriter, r *http.Request)
Зато более тормознутый.

Hixon10
01.07.2017 21:17А во-вторых, из существенных минусов, — малое количество готовых инструментов, но зато много багов.
А можете, пожалуйста, рассказать, какие баги вы поймали?Mehdzor
01.07.2017 21:36Навскидку могу припомнить косяк с роутером, о котором писал уже, отвратительно медленно работающий regexp (условно не баг, но фичей это трудно назвать). Еще у gorm есть проблемы с каскадами, которые никак не отключишь, даже способом из документации, и тп.

vaniaPooh
01.07.2017 21:38нельзя сделать API вида
Можно, но сторонними библиотеками типа такой: https://github.com/gorilla/mux В стандартной библиотеке, действительно, просто сделать нельзя.

akzhan
02.07.2017 04:03+2Отличная статья, ибо опыт расписан. Про роутеры вам рассказали уже :)
Когда выйдет Crystal, попробуйте его, вам понравится. Что плохо у Golang, — он слишком много требует писать руками.

Avvero
02.07.2017 08:31Причины перехода на Go
Вот Вы написали, а люди прочитают и поверят.
как огромный толстопузый испанский галеон. А мы искали что-то больше похожее на легковесный пиратский клипер
И то и это инструмент, как молоток и зубило, можно джавой писать просто и не использовать спринг. Так дойдет и до того, что «нет джавы кроме спринга».
Я это к чему. Сам давно пишу на джаве и недавно на го стал пописывать, но после «вау-как-тут-просто в го, на джаве бы я написал сложнее» стал приходить к той мысли, что и в джаве то можно писать так же просто, БЕЗ СПРИНГА. Я вот сейчас не пошутил.
ps: каналы и горутины конечно молодцы, упрощают многое. Но не справдливо начать считать джаву страшным ентепрайзом
yarric
02.07.2017 19:21StackOverflow тебе на это отвечает: 'Ну да, просто циклом for, а ты чего ждал?'
В Java нет простых циклов for?
Mehdzor
02.07.2017 19:51В Java есть, а вот в Go нет ничего, кроме цикла for)
yarric
02.07.2017 21:19+1Я когда-то тоже думал "зачем придумывать какие-то классы, шаблоны и прочее, ведь в чистом C всё так просто и понятно".
Mehdzor
02.07.2017 21:48+2Вот чего, а генериков в Go сильно не хватает. Он не настолько примитивен как C, но и разных лямбд в нем нет.
pawlo16
02.07.2017 22:09-3Какие контейнеры кроме slice и map вы используете каждый день? Эти два встроенных в Go контейнера позволяют работать с произвольными типами. Остальные используются настолько редко, что не составляет никакого труда написать их кастомную реализацию под требуемый тип данных, которую затем обобщить с помощью вот этой замечательной библиотеки https://github.com/clipperhouse/gen
Mehdzor
02.07.2017 23:08+1Вы про генерики говорите? Если да, то они не только для контейнеров применимы. Например, для унификации решений, для создания сложных интерфейсов. Чтобы не надо было проверять тип через switch)
pawlo16
02.07.2017 23:18-3Не понимаю о чём вы. можно пример? мне никогда не приходилось проверять тип через switch в Гоу и ни чего подобного я не видел в многочисленных best practices за исключением низкоуровневого обобщённого кода с рантайм рефлексией
Mehdzor
02.07.2017 23:25+1Допустим, у вас есть абстрактный класс животного с методом 'родить', который является генериком. В зависимости от класс реализующего интерфейс, родиться может яйцо, котенок, икра и тп.
Когда вы работаете без генериков, то после рождения вам надо сделать длиннющий switch, чтобы точно понять с каким зверем вы работаете. Либо явно приводить типы на свой страх и риск.
Если без кошечек с собачками, то для конструкторов генерики особенно удобны. Когда достаточно в одном месте реализовать типовое поведение, а не в каждом классе копипастить.pawlo16
03.07.2017 07:25-1и что мне мешает по вашему мнению использовать интерфейс Гоу в качестве абстракции животного ?
Когда достаточно в одном месте реализовать типовое поведение, а не в каждом классе копипастить.
для этого в Гоу есть интерфейсы
TheShock
02.07.2017 23:47+2можно пример?
Да запросто. Я вам сейчас несколько практических примеров подкину.
Ну вот как сейчас в Go парсится JSON? Как-то так:
func(r *http.Request) my.HttpResult { var identity types.Identity var err = json.NewDecoder(r.Body).Decode(&identity) if err != nil { return my.JsonParseError(err) } return my.IdentityResponce(identity) }
И все, вы никак не сократите это существенно. Будь дженерики — при помощи простого фреймворка можно было бы сделать так. И сам фреймворк уже бы занимался проверкой на валидность JSON, возвращением ошибки и так далее.
А еще как очень приятный бонус — никакой рефлексии, как в оригинале, полная статическая типизация.
func(input *my.Request<types.Identity>) my.HttpResult { return my.IdentityResponce(input.data) }
Или вот другой пример. У нас с сервера приходят такие данные:
{ pageCount: number, currentPage: number, items: [] }
И вот items может быть абсолютно любой — одна страница тем на форуме, или новостей, или чего угодно.
Как это сделать с дженериками? Да как-то так:
type JsonPage<ItemType> { pageCount: number, currentPage: number, items: ItemType[] }
Использование:
func (page *JsonPage<Article>) { page.items[0]. }
Ну или вот вы пишете сервер игры. У вас есть юнит, а у него есть абилки — ездить, стрелять и так далее. И каждый юнит может иметь или не иметь неограниченное количество таких абилок. Вот как такое реализовать на C#:
tank.AddAbility(new AttackAbility()); var attackAbility = tank.GetAbility<AttackAbility>();
В результате у вас будет в переменной сразу правильный тип.
Остальные используются настолько редко
Вы ошибаетесь очень сильно.pawlo16
03.07.2017 09:29-1Ну вот как сейчас в Go парсится JSON? Как-то так:
Нет, не так. Вариантов много, зависит от сценария. У вас — мягко говоря странный, поскольку
- инфрмация об ошибке засунута в тип с данными, что ни как не соответсвует best practices Golang
- данные копируются, что в общем случае ни куда не готится вообще.
Вот пример идеоматичного кода
func(r http.Request) (r types.Identity, e error) {
r := &types.Identity{}
e = json.NewDecoder(r.Body).Decode®
return
}
Требуют ли эти три строчки кода обощения? Не думаю.
Про JsonPage не понял пример использования. Из того, что items может быть абсолютно любой, совершенно не следует, что его тип нужно обощать.
Вот как такое реализовать на C#:
а вот как такое реализовать на Гоу
tank.AddAbility(&AttackAbility{}) attackAbility = tank.GetAttackAbility()
ни малейшего профита от джененриков С# в данном примере в упор не вижу
Вы ошибаетесь очень сильно.
Ок. Приведите пожалуйста пример такого контейнера.
Повторю пожелание — хотелось бы увидеть примеры из практики, где без дженериков никуда. Желательно со ссылками на исходники. Подсказать, чем практика отличается от теории?
TheShock
03.07.2017 09:55+2У вас — мягко говоря странный
Увы, но взят из официальной документации, на которую ведет ссылка отсюда:
var v map[string]interface{} if err := dec.Decode(&v); err != nil { log.Println(err) return }
Вашего способа там нету.
Требуют ли эти три строчки кода обощения? Не думаю.
Так разверните дальше. Бизнес-требования такие. У вас есть api, которое получает на вход JSON и на выходе тоже должно отдать JSON ответ «Ok» или стандартную ошибку «JsonParseError», если Json неверен. Псевдокод:
route '/foo' => types.JsonFoo { return types.JsonFooResponce } route '/bar' => types.JsonBar { return types.JsonBarResponce } route '/qux' => types.JsonQux { return types.JsonQuzResponce }
С Дженериками я бы смог это написать как-то так:
route("/foo", func (json Input<types.JsonFoo>) { return Ok( prepareFoo(json.data) ) } route("/bar", func (json Input<types.JsonBar>) { return Ok( prepareBar(json.data) ) } route("/qux", func (json Input<types.JsonQux>) { return Ok( prepareQux(json.data) ) }
Обратите внимание, в бизнес-коде только обработка успешного ответа.
Однотипный парсинг JSON, а также обработка однотипных ошибок теперь выполняется фреймворком.
И таких ендпоинтов, скажем, 50.
Напишите эту логику на Go.
а вот как такое реализовать на Гоу
tank.AddAbility(&AttackAbility{}) attackAbility = tank.GetAttackAbility()
Ох какой вы шустрый! Вы решили убрать композицию и заменить ее говнокодом?
А если абилок сотня — все методы вручную прописывать?
А если некоторые из них может иметь не только танк, но и самолет?
И откуда у него вообще может взяться метод GetAttackAbility? Если абилки — это вообще другой неймспейс. Ну вот представьте — я хочу создать игровой движок, чтобы каждый мог его взять — написать пару своих абилок и с легкостью их подключить. И ему для этого нужно будет лезть в самое ядро движка? Очень «мудрое» решение.
Видели как это в Юнити сделано?
gameObject.GetComponent<Image>();
И этот компонент может быть написан пользователем и добавлен через интерфейс, ему не нужно менять исходники Юнити для того, чтобы заставить лампочку мигать.pawlo16
03.07.2017 11:19-1на всякий случай я слегка откорректирую код, там какая то ерунда с маркапом была
func(r *http.Request) (r * types.Identity, e error) { r = &types.Identity{} e = json.NewDecoder(r.Body).Decode( r ) return }
По поводу первого примера — этот код не имеет ничего общего с вашим, и там написано
Here's an example program that reads a series of JSON objects from standard input, removes all but the Name field from each object, and then writes the objects to standard output:
это не имеет отношения к вашему примеру — извлечение информации из жсон-хттп с обработкой ошибок.
Обратите внимание, в бизнес-коде только обработка успешного ответа.
Так это не правильно в корне. Фремворк не может адекватно хэндлить ни битый жсон, ни ошибки в данных. Это прикладной код должен решать как поступить в случае ошибки жсон, а не фреймворк. В зависимости от сценария может потребоваться всё что угодно — откат транзакции, ответ с ошибкой, повтор запроса, panic и т.д. Кроме того эти ваши
Ok( prepareXXX(json.data) )— точно такой же бойлерплейт, короче на одну строчку, но более костыльной, поскольку навязывает вызывающему коду монаду Result, при чём на практике асинхронную (prepareXXX также может фэйлится). В языке без do-нотаций плакать хочестся от такого кода.
А если абилок сотня — все методы вручную прописывать?
смотря что у вас представляет из себя AttackAbility. из вашего примера это ни разу не очевидно.
А если некоторые из них может иметь не только танк, но и самолет?
я хочу создать игровой движок, чтобы каждый мог его взять — написать пару своих абилок и с легкостью их подключитьв таком случае танк и самолёт в Гоу реализуют интерфейсы, соответствущие вашим абилкам. Это не просто, а очень просто в Гоу в отличии от пародии на интерфейсы в C#, где их нужно явно перечислять для каждого класса, где они реализуются.
Видели как это в Юнити сделано?
нет. Но кто сказал, что юнити — это приемлемое решение с т.з. дизайна апи? Из того факта, что юнити как-то работает, не следует, что её архитектура заслуживает повторения в вашем коде :-) Игры глючат и тормозят же безбожно :-)
компонент может быть написан пользователем и добавлен через интерфейс
Это прерасно имхо. В Гоу можно и нужно делать именно так. Вот только в Гоу проще использовать интерфейсы, чем в C#.
TheShock
03.07.2017 18:00+2это не имеет отношения к вашему примеру — извлечение информации из жсон-хттп с обработкой ошибок.
Это пример перевода строки с JSON в Go-объект. Какая разница для данной локальной задачи, какой у нее источник и куда этот объект потом пойдёт?
Так это не правильно в корне
Давайте начнем с того, что вы покажите свой гуру-код решения этой задачи. Как бы это решалось в Го?
в таком случае танк и самолёт в Гоу реализуют интерфейсы, соответствущие вашим абилкам
Ну не изменяются все объекты, которые могут использовать абилку когда вы пишете абилку. Абилки пишутся десятками, а то и сотнями. Если я хочу добавить абилку какому-то юниту — я не должен ВООБЩЕ лезть в код юнита, даже «просто добавить один интерфейс».
Вот помните ВарКрафт третий? Там на любого юнита могла повесится куча самых разных эффектов. Ну или Герои третьи. Замедление, слепота, благословление, каменная кожа. Вы предлагаете мне делать для каждого из эффектов отдельный метод? Вместо такого:
stoneSkin := squad.GetEffect<StoneSkin>()
Это прерасно имхо. В Гоу можно и нужно делать именно так. Вот только в Гоу проще использовать интерфейсы, чем в C#.
Через ЮИ-интерфейс, интерфейс редактора. В коде не нужно добавлять наследование core-классу.
Игры глючат и тормозят же безбожно :-)
У меня ничего не глючит и не тормозит безбожно. Работает вполне на уровне всех остальных современных движков, так что я не понимаю о чем вы говорите.
pawlo16
04.07.2017 10:50-1Это пример перевода строки с JSON в Go-объект.
Нет. Задача — получить полезную информацию из внешнего источника. Способ десериализация из жсон — это детали реализации, зависящие от котнтекста.
Давайте начнем с того, что вы покажите свой гуру-код решения этой задачи. Как бы это решалось в Го?
На Го я бы не стал обобщать результаты обращений к апи, поскольку, как уже было сказано, две-три строчки кода, десериализующие данные из жсон и проверяющие ошибку — это не то, что требует обощения или заворачивания в абстракцию. Типичная же ошибка джуниоров — наворачивать сложность на пустом месте. В моём коде на Гоу данные используются мною по назначению в том месте, где они получены и десериализованы. Например, так:
// схема запроса к апи type ApiRequest struct { ReqFoo *ReqFoo `json:",omitempty"` ReqBar *ReqBar `json:",omitempty"` // и т.д. } router.Get("/api", func(w http.ResponseWriter, httpRequest *http.Request) { var apiRequest ApiRequest if e := json.NewDecoder(httpRequest.Body).Decode(&apiRequest); e!= nil { handleError(w, r, e ) return } if (apiRequest.ReqFoo != nil ){ handleFoo(w, apiRequest.ReqFoo) return } if (apiRequest.ReqBar != nil ){ handleBar(w, apiRequest.ReqBar) return } // и так далее handleUnknownRequest(w, r ) return }
Как видите, ни каких танцев с бубнами в виде джененриков и монады Result не требуется.
Ну не изменяются все объекты, которые могут использовать абилку когда вы пишете абилку.
Дело в том, что в Гоу не требуется изменять тип для того, чтобы он удовлетворял внешнему интерфейсу. Достаточно всего лишь написать реализацию интерфейса для данного типа. Было бы проще, если бы вы дали себе труд ознакомится с концепцией интерфейсов в Гоу. Очень вероятно, что в этом случае у вас за одно возникнет желание забить на C# с кучей бессмысленных мозгодробильных абстракций и магии, и перейти на Гоу :-) Огромное количество игровых серверов уже перешли на Гоу, ещё больше в процессе перехода. В ближайшем будущем судя по всему доля Гоу в этом сегменте бизнеса будет близка к 100%.
Вы предлагаете мне делать для каждого из эффектов отдельный метод?
Вы так говорите, будто бы для меня должно быть очевидно, что из себя у вас предсавляет "эффект". У каждого гэймдева своё виденеие таких вещей. ПокАжите продовый код — постараюсь дать конкретные рекомендации по переводу его на Гоу с указанием конкретных бонусов. А в общем случае я это вижу как-то так
type Effect struct{ Apply func (*Unit) // что там ещё ээфект должен делать // ... } type Unit struct { hitpoints int resistance int effects [] *Effect // ... } func (x *Unit) ApplyEffect( eff *Effect){ x.effects = append(x.effects, eff) eff.Apply(x) } func (x *Unit) HasEffect( eff *Effect) bool { for _,xEff := range x.effects{ if xEff == eff { return true } } return false } var stoneSkinn = &Effect{ Apply : func (x *Unit) { x.resistance += 100500 }, } var squad = &Unit{ hitpoints : 100, resistance : 50, } squad.ApplyEffect(stoneSkinn) //... squad.HasEffect(stoneSkinn) // true
Пойнт в том, чтобы описывать какждый отдельный эффект не в виде класса, как навязывают нам упоротые теоретики ООП, а в виде объекта. По такому принципу постоены НАСТОЯЩИЕ шедевры гэйминдустрии — Fallout-ы, Baldurs's Gate-ы и т.п. В этом случае нет нужды в джененриках для управления эффектами инрового объекта.
TheShock
04.07.2017 16:38+1Например, так:
Что-то вы бизнес-требования переписали. Я ж явно указал три разных роута. Это принципиально, уж простите:
route '/foo' => types.JsonFoo { return types.JsonFooResponce } route '/bar' => types.JsonBar { return types.JsonBarResponce } route '/qux' => types.JsonQux { return types.JsonQuzResponce }
монады Result не требуется.
У меня в примере Ok — не от монады Result, а от http-заголовка «200 OK». Ну то есть что-то типа такого:
if loggedIn return Ok(resp1) else return AccessDenied(resp2)
Было бы проще, если бы вы дали себе труд ознакомится с концепцией интерфейсов в Гоу
Я обязательно почитаю в этом направлении внимательнее, спасибо.
забить на C# с кучей бессмысленных мозгодробильных абстракций и магии, и перейти на Гоу
C# мой далеко не первый язык и я им пользуюсь (стараюсь по крайней мере) без мозгодробильных абстракций и магии. Дженерики — явно далеки от магии и коду только помогают. Уж явно менее магические, чем рефлексия.
В ближайшем будущем судя по всему доля Гоу в этом сегменте бизнеса будет близка к 100%.
Смешно, молодец)
squad.ApplyEffect(stoneSkinn)
Миленько. А если эффект параметризированный и вычисляется от кучи разных входных данных — баффов и дебаффов?
squad.ApplyEffect(new StoneSkinn(20))pawlo16
05.07.2017 11:16-1Я ж явно указал три разных роута. Это принципиально, уж простите:
Подобные требования (схема маршрутов сервера, формат сериализации данных, транспортный протокол, способ передачи ошибок) программист обычно выдвигает себе сам, либо разрабатываются коллегиально на скрамах. Потому пример с туевой хучей роутов на каждый чих — он довольно искусственный, технически не обоснованный, устаревший и идёт от худших практик. Гуманитарщина иными словами. Впрочем любой каприз за ваши деньги:
// схема запроса к апи type ApiRequest struct { ReqFoo *ReqFoo `json:",omitempty"` ReqBar *ReqBar `json:",omitempty"` // и т.д. } //ApiRoute - просто кортеж type ApiRoute struct { pred func(*ApiRequest) bool // проверка формы запроса handler func(http.ResponseWriter, *ApiRequest) // ваша бизнес логика } //маршруты к апи var apiRoutes = map[string]ApiRoute{ "/foo": ApiRoute{ func(r *ApiRequest) bool { return r.ReqFoo != nil }, handleFoo, }, "/bar": ApiRoute{ func(r *ApiRequest) bool { return r.ReqBar != nil }, handleBar, }, // ... } //инициализация маршрутов апи for path, _ := range apiRoutes { router.Get(path, handleAPI) } func handleAPI(w http.ResponseWriter, httpRequest *http.Request) { var apiRequest ApiRequest if e := json.NewDecoder(httpRequest.Body).Decode(&apiRequest); e != nil { handleError(w, httpRequest, e) return } x, ok := apiRoutes[httpRequest.RequestURI] if ok && x.pred(&apiRequest) { x.handler(w, &apiRequest) } else { handleUnknownRequest(w, httpRequest) } return }
У меня в примере Ok — не от монады Result, а от http-заголовка «200 OK».
Хттп-ответ — та самя трихомонада, только не правильная и неудобная в использовании :-) Ваша
prepareBar(json.data)может фэйлиться при анализеjson.data, и в этом случае у вас будет что-то вродеOk (BadRequest(resp1)), что на самом делеBadRequest(resp1). В Гоу не надо задумываться о таких вещах, соответственно ошибиться невозможно: если существует возможность ошибки вычислений, то функция возвращает два значения — полезные данные и ошибку. Вообще функции в гоу могут возвращать произвольное количество значений, а не одно, как в C#.
И это я ещё молчу про то, что на практике
prepareBar(json.data)— асинхроннная, то есть код куда сложнее, чем тот, что вы привели. А в Гоу асинхронщина не нужна, соответсвенно там нет уродливых обёрток на подобиеTask<T>
Дженерики — явно далеки от магии и коду только помогают.
Господин Брэд Фитцпатрик обещал джененрики в Гоу 2.0. Не думайте, что дженереки — это бесплатная фича. Расплата за дженереки в С# — это снижение скорости копиляции/сборки/jit-компиляции, усложнение структур данных, доп. когнитивная нагрузка, разрастание скомпилированных бинарников. И только в паре процентов случаев использование generic’ов дает реальный выигрыш в качестве кода. В 99% случаев это стандартный набор контейнеров и алгоритмов для произвольных типов данных. В Гоу их не добавляют не потому, что гоферы упоротые, просто пока ещё не нашли способа сделать это безболезненно.
Уж явно менее магические, чем рефлексия.
я практически не использую рефлексию в прикладном коде и крайне редко встречаю такие случаи на практике. Во всех гайдлайнах по Гоу особо подчёркивается, что как правило рефлексия нужна лишь в низкоуровневом коде обощённых библиотек
Смешно, молодец)
Посмотрим, кто будет смеятсья, когда вам выдадут ТЗ на разработку бэкенда к игре на Гоу :-) Go идеально подходит для сервера многопользовательской игры по следующим причинам:
- простая и эффективная работы с сетью. Не нужно никаких мозгодробильных epoll’ов с лапшой из калбэков на конечных автоматах;
- один сервер может с легкостью держать десятки или даже сотни тысяч клиентов. При этом каждый клиент обрабатывается простым линейным кодом в отдельном наборе горутин, а не притянутыми за уши акторам с многослойными бесполезными абстракциями, затрудняющими понимание кода;
- Задержки gc в последних версиях go не превышают 0.1 мс, в то время, как в C# они достигают нескольких сотен миллисекунд. С такими задержками в C# можно писать лишь сервера для пошаговых стратегий.
А если эффект параметризированный и вычисляется от кучи разных входных данных — баффов и дебаффов?
значит объекты баффов и дебаффов будут применены для модификации объекта stoneSkinn (или squad). Логично?
TheShock
05.07.2017 17:50программист обычно выдвигает себе сам, либо разрабатываются коллегиально на скрамах
В моем случае так исторически сложилось, что апи уже есть и я под него просто должен реализовать сервер. Потому, увы, ваше решение с ApiRequest не подходит, вы понимаете?
Да даже если бы это была просто абстрактная ситуация — то, что так сильно вы меняете API, чтобы оно подходило под возможность написать на Го заставляет усомниться в хорошести языка. Можете показать пример, как сделать, чтобы в разные роуты приходили разные объекты? А не так — что сделать один супер-объект, в который будет парситься json? При этом API менять нельзя — это ведь абстрактные бизнес-требования. Ну то есть так:
var apiRoutes = map[string]ApiRoute{ "/foo": ApiRoute{ func(r *FooRequest) bool { ... }, handleFoo, }, "/bar": ApiRoute{ func(r *BarRequest) bool { ... }, handleBar, }, // ... }
Хттп-ответ — та самя трихомонада, только не правильная и неудобная в использовании
Я не буду спорить, потому что там был просто псевдокод, который, к сожалению, оказался недостаточно понятным.
Посмотрим, кто будет смеятсья, когда вам выдадут ТЗ на разработку бэкенда к игре на Гоу
Мы с вами и прям сейчас — я прям уже имею ТЗ на разработку сервера на Гоу. Но я сам захотел, меня не заставляли — интересно понять и разобраться. Мне пока все нравится кроме отсутствия Дженериков.
С такими задержками в C# можно писать лишь сервера для пошаговых стратегий.
Я напомню, что сейчас вполне пишутся игры на Юнити, которые выдают 60 fps и GC этому не помеха.
значит объекты баффов и дебаффов будут применены для модификации объекта stoneSkinn (или squad). Логично?
Ну тогда это должен быть отдельный инстанс для каждого Юнита. Потому что у одного юнита абилка «Каменная кожа эффективнее в $уровень$ раз» зависимо от уровня абилки, а у другого юнита висит дебаф «Ближайшие 30 секунд вся накладываемая магия — вдвое слабее». А в момент, когда каменная кожа накладывается — она должна наложится вдвое слабее.pawlo16
05.07.2017 19:16ваше решение с ApiRequest не подходит, вы понимаете?
то, что так сильно вы меняете API, чтобы оно подходило под возможность написать на Го заставляет усомниться в хорошести языка.стоп… я вам привёл же код для много роутов, нет так ли?
Не вижу в этом смысле каких-то ограничений для Гоу. Просто надо же понимать, что апи — не законы шариата, вбитые в святые скрижали. Его можно и нужно рефакторить — читай, выкидывать на помойку и делать новое
Можете показать пример, как сделать, чтобы в разные роуты приходили разные объекты? А не так — что сделать один супер-объект, в который будет парситься json?
у меня вроде так и есть — в разные роуты приходят объекты с оригинальной структурой. Никакого, как вы выразились, суперобъекта я в упор там не вижу. тот факт, что типы объектов входят в композицию одной и той же служебной структуры, для меня лично является всего лишь деталью реализации.
Мне пока все нравится кроме отсутствия Дженериков.
О, это быстро проходит. Через 3-4 месяца программирования на Гоу вас будет тошнить от дженериков в C# :-)
cейчас вполне пишутся игры на Юнити, которые выдают 60 fps и GC этому не помеха.
да, такое можно и в джаве если что. Но какой ценой это достигается? — гигабайты ОЗУ, 100%ная загрузка GPU и CPU и вынос жёсткого диска. В бэкенде это не допустимо.
Ну тогда это должен быть отдельный инстанс для каждого Юнита.
имхо это уже детали. пойнт в том, что без дженериков дизайн проще
TheShock
02.07.2017 23:59+1которую затем обобщить с помощью вот этой замечательной библиотеки
И как оно поддерживается IDE?
кастомную реализацию под требуемый тип данных
А если их может быть огромное множество?
Да и дженериками реализуются не только коллекции.pawlo16
03.07.2017 17:52-1И как оно поддерживается IDE?
как и любой другой код на Гоу — прекрасно поддерживается
А если их может быть огромное множество?
тогда на основе работающего кода делаем шаблон для кодогенерации — и генерируем кастомные типы с помощью go generate.
TheShock
03.07.2017 18:23+2как и любой другой код на Гоу — прекрасно поддерживается
А оно поддерживается до запуска генерации по мета-данным или уже после того, как такой сгенерировался?pawlo16
04.07.2017 13:07-1разумеется после. Как уже было сказано, это весьма мало и редко востребованная опция, и утяжелять ею плагины для ide нет ни какого смысла
TheShock
04.07.2017 16:21+1Тогда это имеет смысла не больше, чем копипаста — поддержка такого кода все-равно неудобная.
pawlo16
05.07.2017 12:20в чём именно заключается неудобство поддержки?
TheShock
05.07.2017 17:54Я считаю, что сложность приложения растет в первую очередь от количества кода, которую программисту необходимо (есть возможность) читать. То есть пока этот код в несгенерированном виде — он 100 строк, а потом его на 10 разных видов сгенерировали — получилось 1000 строк. Сложность выросла в 10 раз.
Мне не сложно написать код (скопипастив его с уже существующего класса). Значительно сложнее потом его поддерживать. Даже если он каждый раз перегенерируется вручную.
То есть я всегда стремлюсь уменьшить код, который я читаю, даже если мне придется в 2 раза увеличить количество кода, который я пишу (например раз за разом рефакторя какую-то штуку).
В долгосрочной перспективе код на 50 000 кода поддерживается значительно легче, чем код на 500 000 кода.khim
05.07.2017 18:16Я считаю, что сложность приложения растет в первую очередь от количества кода, которую программисту необходимо (есть возможность) читать.
«Необходимо» и «есть возможность» — это совершенно разные вещи. У нас в проекте есть автогенерённй файл размером чуть не в миллион строк — но никому и в голову не приходит его читать.
В долгосрочной перспективе код на 50 000 кода поддерживается значительно легче, чем код на 500 000 кода.
Зависит от того что там в этих 50 000 кода. В погоне за уменьшением размера можно нагенерить такого, что 50 000 строк будет сложнее поддерживать, чем 5 000 000 строк.
А вообще — с таким подходом вам прямая дорога в Forth, где какой-нибудь ассемблер может занимать 1000 строк (против GNU Assembler'а в 100'000 строк с, фактически, такой же функциональностью). Вы не поверите сколько можно убрать строк кода за счёт активного применения GIGO.TheShock
05.07.2017 18:33Но ведь это не просто файл, который там где-то лежит, а файл, с которым работает автодополнение, ссылку на которого ты указываешь в коде, то есть активно с ним взаимодействуешь.
khim
05.07.2017 18:44-1И это прекрасно! Как человек, активно использующий метапрограммирование в C++ хочу сказать что в подавляющем большинстве случаев я бы предпочёл видеть все эти инстунциорованные шаблоны в каком-нибудь файле, чем пытался бы по косвенным признакам понять — что и где пошло не так.
То что при этом кода, на который бы мне пришлось смотреть стало бы больше — не так ужасно, как то, что мне иногда приходится в ассемблер смотреть чтобы понять — что и как там инстанциировалось…
В результате у нас даже некоторые вещи, которые можно было бы сделать на шаблонах реализованы кодогенератором, потому что так — удобнее.

arzonus
04.07.2017 10:51func (order)Insert(tx Transaction, m *model.Order) { db := tx.DataSource().(*gorm.DB) query := "insert into orders (shop_id) values (?) returning id" db.Raw(query, m.Shop.ID).Scan(m) }
Правильно я понимаю, что у вас есть 2 метода всегда, 1 с транзакцией, а другой без?
У вас есть возможность такого?Mehdzor
04.07.2017 13:17Один метод сервиса, который создает транзакцию и определяет какие методы в ней будут. И есть методы репозитория, которые принимают в себя транзакцию.
Если надо из одного сервиса вызвать другой в той же транзакции, то придется делать подметод в сервисе, чтобы он принимал транзакцию. Делать state у сервиса не неправильно будет, а других способов передавать транзакцию не вижу.
Можно попробовать как-то поколдовать с инжекцией общей фабрики, чтобы управление было единым на два сервиса, но это опять же тащить за собой state.
Я бы делал именно через промежуточный метод, который принимает в себя транзакцию.

asvechkar
06.07.2017 00:32Не сочтите за дерзость, но возник вопрос: был ли какой то анализ перед выбором Go для бэкенд сервиса?
Если у Вас в компании пишутся в основном мобильные приложения, то у Вас уже есть специалисты по Java, ObjC, Swift. Хорошо, отмели Java как медленный для бэкенда. Остаются C и Swift. Оба могут использоваться для бэкенд сервиса. Ну даже если и они не подошли, есть же проверенный node.js + sequelize + 100500 npm пакетов.
Просто в данном случае выбор Go получился как «модно, стильно, молодежно».Mehdzor
06.07.2017 01:30-1Разрабатывать на С чрезвычайно трудоемко)
Что касается Swift для бэкенда, то он не приспособлен для него, даже с учетом наличия соответствующих инструментов: отсутствует garbage collector (важный атрибут для long running задач), мало инструментов для бэкенда, неудобно работать со стримами данных и прочее. Язык в первую очередь ориентирован на приложения и самого начала задумывался для них.
Насчет node.js/ruby/python/php, у меня лично немного предвзятое отношение к интерпретируемым языкам для бэкенда. Я понимаю, лет восемь назад просто не было альтернатив. Выбор стоял между java и сишником, либо ruby/python/php. Java сама по себе не самый удобный язык для бизнес разработки, даже если рассматривать Play/Gwt помимо Spring, а про Си даже говорить ничего не нужно.
Ruby и Python никогда не создавались как языки для чего-то нагруженного, просто они удобные и их использовали и используют за неимением адекватных альтернатив. Можно спросить — откуда у вас, плебеев, что-то нагруженное? Отвечу, что ситуация обратная. Требуется постоянно ютиться на микро-инстансах амазона, чтобы не высовываться за определенные лимиты. Поэтому прожорливость — довольно серьезный мотиватор.
Про NodeJS сказать нечего. Обычный инструмент, может с определенными ограничениями, как и любой. Тут уже каждый выбирает на вкус и цвет.
А писать надо на том в чем шаришь, так быстрее)
Mehdzor
06.07.2017 04:20-1Вспомнил еще один сильный минус бэкенда на Swift — это любой крэш является фатальным, кладущий сервак целиком.
RidgeA
Почему не Dep? Он хоть и сыр, но со временем обещают его внедрить в go tool
И что использовали для управления конфигами?
Мне надо было пакет, который умеет читать и мержить между собой несколько файлов конфигов, в зависимости от переменной окружения. Не нашел такого в свое время…
Mehdzor
Еще использовал дефолтный менеджер пакет) Dep выглядит сыроватым, документация не очевидная и пугает лейбл Alpha. В итоге определился в сторону Glide, где с порога освящаются основные кейсы использования и все подробно расписано.