

Известно, что практически ни одно мобильное приложение не обходится без бэкенда.
Если вы мобильный разработчик, то наверняка сталкивались с такими бородатыми дядями, которые меланхолично тянут логику на перле и вечно что-то пишут в консоли. Или может это был сутулый анимешник с длинными волосами, всосавший php с молоком матери.
Так или иначе, большинство из них ни разу не сталкивалось с мобильной разработкой, а кое-кто считает себя при этом гуру.
Специально для таких случаев, я подготовил список вредных советов о том как угробить бэкенд вашего приложения.
Приятного чтения.
Итак, если вы серверный разработчик:
- Не обращайте внимания на строение приложения, вам абсолютно не должно быть дело до того, как будет выглядеть продукт для пользователя. Ведь вы не хипстер, чтобы задумываться о таких вещах. Если данные для одного экрана надо получать через 10 разных запросов, это проблемы дизайнера, который рисовал интерфейс, не согласовывая его с вашим API. В следующий раз пусть не думает об удобстве пользователя, все-таки в проекте есть вещи поважнее.
- Ни в коем случае не пишите документацию. Простого вордовского файла на дропбоксе будет достаточно. В конце концов ваша работа — это струящиеся потоки данных, элегантные и высокопроизводительные. Пусть беспомощные мобильные разработчики почаще обращаются к вам за разъяснениями. Простого списка запросов без малейших примеров и описания им будет вполне достаточно. Ведь всегда можно заглянуть в ваш код и посмотреть все параметры и аргументы.
- Не заморачивайтесь с названиями полей. Это нормально, что одна и та же сущность в разных местах называется по-разному, пусть поле, обозначающее количество объектов, в одном месте будет count, а в другом koli4estvo_kek. И так понятно, неужели не распарсят?
И в смысле приходит разный тип данных? Ну да, в одном случае число, а в другом строка. Что не так? - Меняйте логику без предупреждения. Если вас озарило, то не медлите — срочно внедряйте. Не задумывайтесь о совместимости, не торопитесь обсуждать, просто делайте. И обязательно выкатывайте в релиз, дальше сами разберутся. Документацию тоже обновлять не обязательно, это все суррогат.

- Ни в коем случае не пишите тесты и не проверяйте собственное API. Помните, вы не допускаете ошибок, это в приложениях вечно едут экранчики и что-то вылетает. Да и потом, понять, что найденная проблема находится все-таки на бэкенде — дело пары минут.
- Не присылайте пояснения к ошибкам. Во-первых, они случаются крайне редко. Все должно идти идеально. Во-вторых, всем и так понятно почему что-то пошло не так. Простого http 400 или 500 (вишенка на торте) должно быть достаточно.
- Отдавайте ответы в разных форматах. Пусть где-то будет json, а в другом месте xml. В конце концов, природа любит разнообразие.
Цитата замечательных людей: 'А тут тоже в json ответ нужен что ли?' - Для авторизации используйте только cookie. Вас так вас в институте учили, когда вы делали свой первый интернет магазин. Ведь Android и iOS — это просто еще один браузер, не нужно преувеличивать их сложность.
- Запомните: никаких тестовых данных, пусть разработчики руками генерируют весь контент. И не забывайте при этом каждый день очищать базу, это только добавляет азарта в работу.
- Будьте бунтарем: принимайте параметры в POST через URL, ведь это тот же GET, только другой. Дайте волю воображению. И игнорируйте любые мольбы коллег привести все к стандартному виду, они просто не могут мыслить нестандартно.
- Выносите максимальное количество логики на клиент. Сервер должен быть настолько легковесным, насколько возможно. Надо сделать рассылку по расписанию? На клиент, пусть крутит у себя таймер. Агрегация данных из трех разных источников? Туда же. У вас тут вообще-то нет фонового потока, который можно безнаказанно нагружать.
Когда показывал эту статью коллегам, то многие бэкенд разработчики тоже решили поделиться парой наболевших моментов:
- Не читайте документацию, всегда проще и быстрее спросить у коллеги. Даже если вас пятнадцать человек, он будет рад каждому объяснить еще раз.

(Может быть, им просто одиноко и не с кем поговорить?)
- Прося коллегу что-то переделать в API, не объясняйте причину. Если для него это не очевидно, то и объяснять бессмысленно, все равно не поймет.
Полезные рекомендации
Вместе посмеяться над знакомыми ситуациями — это здорово, но кроме этого хотелось бы поделиться еще действенными практиками, которые мы используем у себя. Даже когда приходится работать с внешними мобильными разработчиками, они всегда благодарят нас за исключительно удобное API и профессионализм.
Все дальнейшие советы относятся к бэкенду, но если вы мобильный разработчик, то вам тоже будет интересно и полезно это прочитать. Ведь в первую очередь именно вы заинтересованы в изменениях.
Документация
Это интерфейс для мобильного разработчика. Она должна быть не просто информативна, но еще легко читаться и быть приятной глазу. Звучит странно, но чем легче воспринимается документ, тем быстрее и проще с ним работать, и тем меньше возникает к вам вопросов в процессе.
Самый простой и удобный вариант — это использовать Swagger. Хоть его изначальный внешний вид и оставляет желать лучшего:
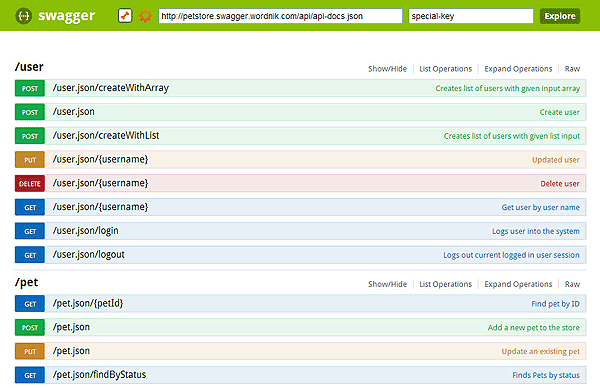
Но его можно без проблем облагородить с помощью форматтера:

Получается симпатично и удобно. В качестве альтернатив можно использовать Apiary, но придется разделять код и документацию, что нежелательно, либо заморачиваться с рендерингом.
Единообразие
В мобильной разработке есть сложность — многие решения и фреймворки крайне неповоротливы. Нельзя просто взять и поменять формат для какого-то одного конкретного запроса, либо это предельно сложно. Как и нельзя изменить название определенного поля только для определенного случая: бедный девелопер будет орать в голосину, пытаясь воткнуть под это костыль.
Все должно быть целостно: везде одинаковые названия, один формат взаимодействия (предпочтительно JSON), и тп.
Особенно хорошо, если названия параметров в запросе и ответе идеально совпадают с полями соответствующих классов в мобильном приложении. Звучит странно, но это настолько упрощает жизнь разработчикам, что они будут вам за это шоколадки таскать из магазина.
В некоторых местах упрощение доходит до абсурда: например, сохранение в Realm (мобильная база данных) может быть произведено практически сразу из json. Если будет интересно, то отдельно расскажу о том, как мы избавлялись от middleware в мобильном приложении.
Пример кода по сохранению любых пришедших объектов на iOS:

Один generic метод на любую запись в базу с сервера. Классно, правда?
Тоже самое касается и изображений. Лучше всего, когда на картинку сразу приходит ссылка, которую не нужно 'доделывать'. И по тому же правилу — название ссылки должно быть везде одинаковым.
У нас был случай, когда нужно было искать изображения в гугле для определенных информационных блоков в мобильном приложении. В итоге мы просто сделали псевдо-ссылку на картинку, к которой приложение обращается, а внутри сервак ищет подходящее изображение в гугле и делает на нее редирект. А для приложения это выглядит как самая обыкновенная пикча, которая просто немного дольше соображает.
Достаточность
Когда работаешь над сервером, то привычно, что все находится в едином scope запроса, где достаточно просто открыть транзакцию на запись и в нее последовательно протолкнуть данные. Все изолированно, предсказуемо и линейно.
В мобильном приложении такого нет. Все крутится асинхронно, а если требуется соблюсти целостность данных из разных запросов, то это выливается в сложнейшие манипуляции с многопоточностью, злющими критическими секциями и распределением приоритетов, чтобы не было и намека на тормоза. Не зря вопрос про синхронизацию потоков в собеседовании на мобильного разработчика задают одним из первых.
Теперь понимаете, почему мобильные девелоперы стараются, чтобы все приходило в едином запросе? От этого зависит, уйдут они сегодня домой или нет)
И конечно, если какие-то данные нужно загрузить асинхронно, то не надо их пихать в общую кучу, это надо понимать.
В конце концов, не поленитесь открыть дизайн приложения и посмотреть из чего состоит экран для которого вы делаете API. Посоветуйтесь с вашими мобильными коллегами, определите как лучше вам отдавать им данные и какие последующие запросы будут от них зависеть. Может быть, в данном конкретном запросе нужно выдать чуть больше информации, чем кажется достаточным. Но зато это сделает последующую работу удобнее и приятнее на клиенте. Помогая в таких мелочах, вы надолго запомнитесь. И потом будут вспоминать с теплотой всю их профессиональную жизнь.
В этот же пункт хочется отнести отладочную информацию. Если вы сделали запрос для получения списка комментариев, то озаботьтесь, чтобы эти комментарии там были. Вам накопипастить однотипных данных — дело одной минуты, а для напарника из мобильного отдела — это целый выдох облегчения.
Стабильность
Просто архиважный пункт на который хочется отдельно обратить внимание. Всегда проверяйте свое API, а еще лучше — пусть тесты делают это за вас. Каждый баг на бэкенде равен десяти на клиенте. Ведь между сервером и пользователем находится множество уровней абстракций, которые надо исключить перед тем, как винить сервер.
Каждый баг тратит время пользователя, тестировщика, мобильного разработчика и только потом — вас. На вас возложена наибольшая ответственность, и ваши ошибки обходятся компании дороже всего.
В качестве бонуса хочется добавить, что здорово, когда есть pretty print, хотя бы на время разработки. Бывает, что надо разобраться с тем, что пришло от сервера, не заглядывая в документацию.
А что приятнее читать, такое:
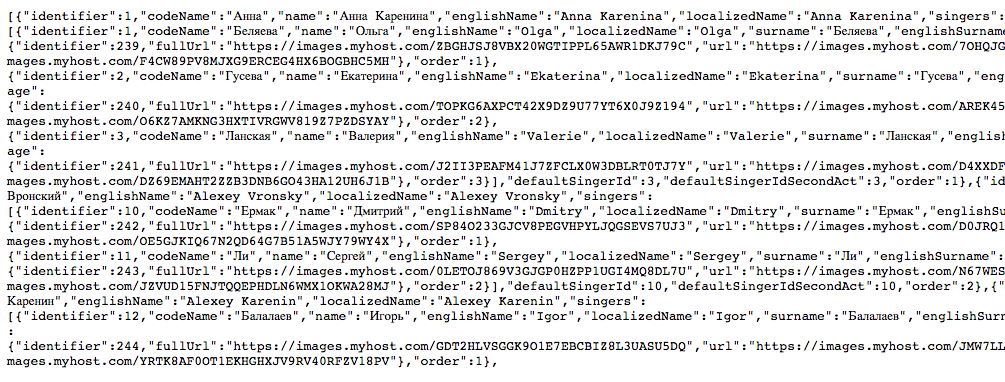
Или такое:

Разница, мне кажется, на лицо.
Главное, не забудьте отключить Pretty Print на боевом сервере, поскольку ресурсов он жрет как не в себя.
Заключение
Хочется всем просто сказать, что правило на самом деле одно и довольно простое — не заставляйте коллег скрежетать зубами от вашей работы.
В следующий раз планирую рассказать о том, как мы переезжали на Go и избавились от огромного куска бизнес логики на клиенте, сократив бинарник приложения больше, чем на треть.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (117)


DSolodukhin
22.06.2017 17:22+3Если дизайнер должен согласовывать API с разработчиком, то у вас явная проблема в тех. процессе. Для определения того, как должен выглядеть API есть архитекторы и аналитики. Если дизайнеру не хватает чего-то в апи, он идет к архитектору и аргументированно объясняет, что ему не хватает вот таких методов. Дальше сформированное ТЗ спускается разработчику, который его реализует.

Mehdzor
22.06.2017 17:26+2Это была ирония про дизайн и API =\
Дизайнер в принципе не себе техническую архитектуру клиент-серверного взаимодействия в большинстве случаев.
И, к сожалению, далеко не все и не всегда могут работать по ТЗ. Часто требования к проекту меняются быстрее, чем может быть написано ТЗ.zenkz
22.06.2017 18:47Одним из решений, особенно хорошо применимых для API является замены ТЗ на каталог фич. Т.е. это Excel таблица с описанием всех фич, которые нужно реализовать. Любое изменение фичи начинается с изменения этого документа и он же используется для Acceptance-теста и написания пользовательской документации
Получается менее формальный, но более «живой» документ

x07
23.06.2017 12:04+1А зачем дизайнеру вообще что-то знать про бекенд? Какие методы могут потребоваться дизайнеру от архитектора?

frees2
22.06.2017 17:30В json можно вставлять куски скриптов. К примеру, пользователя интересуют имена, он нажимает и получает скрипт подгружаемый.
Равно и место экономить
«channelTitle»: «НТВ»,
«tags»: [
«NTV»,
«НТВ»,
«прямой эфир»,
«LIVE»,
«прямой эфир НТВ»,
«НТВ LIVE»
],

svoksiv
22.06.2017 18:32-2Я просто оставлю это здесь: grpc и grpc-gateway
le1ic
22.06.2017 21:22+2- У них постоянно коммиты с фиксами утечек памяти. В частности полгода — год назад фиксили утечку, которая вела к покаррапченным фреймам! И это проект которому хрен знает сколько лет и уже носит гордо взрослую версию «3.0».
- Позиционируется как полноценный rpc, но в протоколе нет поддержки такой примитивной вещи как keep-alive.
- полная неразбериха с кодами ошибок (хотя это частично беда google apis, которые его используют)
maribartim
22.06.2017 18:35+1Спасибо за статью, с юмором и по делу! Воспринимается на ура) пишите еще
Movimento5Litri
22.06.2017 18:43+1О, да вы описали проект над которым сейчас работаю!
Особенно первый пункт!
Там вообще мрак, бекенда ещё вообще нет а АПИ уже нарисовали.
Куча ненужных полей, нету нужных,ебстранная структура.
Единственный клиент данного АПИ — моё приложение.
Прошу сделать по человечески — не, мы так привыкли.
И это при том что бекенд уже 2 месяца как должен быть готов а его даже не начали.
Наболело, простите.
el777
23.06.2017 12:10бекенда ещё вообще нет а АПИ уже нарисовали.
Так именно этому и учит swagger!
То есть вначале договорились об АПИ, а потом пошли его параллельно реализовывать.

NoFearJoe
22.06.2017 18:46+1Ты еще забыл про то, что надо что бы ни случилось, присылать только 200 Ok (а также включать в этот ответ не только запрашиваемую сущность, но и ошибку).
Ну и про изменение API не меняя версию методов, когда приложение в продакшене.
fukkit
22.06.2017 20:53+4Сводить бизнес-коды ошибок к кодам http на сервере, а потом двухуровнево парсить их на клиенте — конечно тру, но не всегда удобно и оправданно, зато всегда — дополнительная сложность ( время разработки и возможности для ошибок), потому 200 Ок + сквозной код реальной ошибки на жизнь вполне имеет право, хоть конечно и будет проклят снобами и высокомерными сектантами.

Envek
22.06.2017 23:21+2На самом деле всё делать 200-м кодом — зло. Нужно хотя бы отличать успешные ответы от неуспешных (чтобы и в браузерных DevTools сразу видеть, если что не так, и curl'ом тыкать было удобнее).
Ну т.е. 200 для успешных, 400 — если клиент портачит и 500 — если сервер. Хотя бы.
А лучше примерно так:
- 400 — ты дурак, см. тело ответа для ошибки
- 401 — сначала токен покажи, потом проходи
- 403 — куда прёшь?
- 404 — здесь рыбы нет
- 422 — ты прислал какую-то дичь, см. тело ответа для ошибки
Ну а в теле сообщения уже использовать специфичные для приложения коды ошибок.
Mehdzor
23.06.2017 00:31Чем 400 и 422 отличаются? На практике с 422 не сталкивался. Это, видимо, битый какой-то запрос должен быть.

SerafimArts
23.06.2017 01:48+2422 — это зачастую ошибка валидации. Например "какого хрена у почты нет символа собаки" или "число, кажется, не может содержать буквы, но это не точно".
Envek
23.06.2017 09:59422 (Unprocessable Entity) — это нестандартный код ошибки, но популярный среди, например, разработчиков на Ruby on Rails. Смысл: синтаксически твой запрос правильный, но данные невалидные в нём или не хватает их.
А в 400 идут все некорректные запросы: синтаксически некорректный JSON, или вы отправили Form URL Encoded POST туда, где сервер ожидает JSON, или структура JSON'а кривая…
mayorovp
23.06.2017 09:10+1Возможно, я несколько отстал от жизни, но успешные ответы идут с тэгом Body, а неуспешные — с тэгом Fault. А еще у них разные Action. Зачем их еще как-то дополнительно различать?..
Mehdzor
23.06.2017 09:53+1Это неудобно на уровне клиента обрабатывать. Большинство сетевых мобильных инструментов сделано так, что критерием вызова callback-а ошибки является http код.
mayorovp
23.06.2017 10:22-3Очевидно, чтобы работать с SOAP — нужно не "большинство инструментов", а один, который работает с SOAP. И он, внезапно, не будет смотреть на http код...
Vladymyr_Artemenko
23.06.2017 10:12Какие бизнес-коды ошибок нельзя отдавать с помощю ошибки http, запихнув всю необходимую инфу в тело шибки ??? А?
Как мобильному разработчику, в 80-90% проектах приходиться иметь дело с бекендом на стороне заказчика. И в основном это реальная боль. БООООЛь!
Был не так давно проект, над которым именно я работал, и там «северник» и в принципе, заказчик считали так же.
«Это, не ошибка сервера, это ошибка бизнес логики» говорили они мне. И вообще рвзговор сводился к разговору глухого и немого.
Да, не так сложно оказалось реализовать поддержку такого подхода, но только при условии, что ошибки единообразно структурированы (а тут мне пришлось попотеть). Дико раздражает, что например при запросе валидации данных пользователя на сервер, он отдает тебе 200OK. И приходится еще проверять, а 200 это точно все хорошо, или тут ошибок,с*ка,бизнес логики еще натыкали.
В общем, если этот коммент прочтет дядька, который пилит Бэк, пожалуйста, не будь безразличен к людям использующим твое АПИ. Потому что, как минимум, они тебя не будут уважать. У меня часто возникают вопросы, а люди которые пилят бек, это вообще люди? Где их берут таких криворуких, что приходит тебе строка, о потом, false, а иногда даже, массив!!! Зовите экзоциста! =)
Нет, ну серьезно, не нужно так!fukkit
23.06.2017 11:51+1В общем случае http статус вторичен и показывает лишь класс ошибки, но не её суть. Т.е. его можно установить в целях дополнительного информирования разработчика клиентской части (особенно, если известно, что он — истеричка).
Сам же код клиентской части легко может его игнорировать, обрабатывая только признак успешности, а затем собственно реальную ошибку уровня приложения.
Фактическое отсутствие стандарта классификации бизнес-ошибок по http статусам (да и откуда ему взяться) и соответствующая самопальная каша в кодерских головах — дополнительная причина полюбить 200 Ок.
Neikist
24.06.2017 08:37А еще может быть так что на некоторые запросы фреймворк перехватывает обработку и отдает свои странички ошибок с соответствующими кодами, и в таком случае получится каша, когда на половину ошибок запрос возвращает статус не 200 + текст формат и состав которого задать невозможно, а на дргугую половину статус 200, но ошибку в теле. Серьезно, такая путаница убивает, поэтому пусть лучше будут под статусом 200 только успешные запросы. Также в некоторых случаях используются нестандартные методы сжатия трафика, которые не сжимают странички с ошибками которые выдает платформа, и от кода статуса еще будет зависеть нужно ли нам функцию распаковки ответа дергать или нет.

ZaEzzz
23.06.2017 12:02+1С кодом 200 нужно возвращать подобный ответ:
{ success: false, error: null }
А данные обязательно передавать так:
data: { rub: 101, usd: "2,02" }

velvetcat
22.06.2017 19:35+3Когда работаешь над сервером, то привычно, что все находится в едином scope запроса, где достаточно просто открыть транзакцию на запись и в нее последовательно протолкнуть данные. Все изолированно, предсказуемо и линейно.
Вы, похоже, никогда не занимались бэкендом.
Всегда проверяйте свое API
На кого рассчитана Ваша статья?
Mehdzor
22.06.2017 20:01Даже не знаю, что вам ответить. Статья, очевидно, для тех, о ком она написана.
velvetcat
22.06.2017 23:16+4Типичный бэкенд — это, в том числе, и работа с другими API. Поэтому именно бэкендеры не узнают из Вашей статьи ничего нового.
Что же до ее технического уровня, то даже "Спасибо, Кэп" не за что сказать.
Один generic метод на любую запись в базу с сервера. Классно, правда?
Вообще-то это печально.
Mehdzor
23.06.2017 00:27+2Господи, это же не туториал, а юмореска с базовыми рекомендациями тем, кто допускает простейшие ошибки.
P.S. Когда пишешь серьезные технические вещи, то внимание к ним гораздо меньше приковано. Слишком сложно тоже плохо.
Envek
22.06.2017 23:25Если вы думаете, что если вы тестируете и документируете свой API, то и все другие делают так же, то у меня есть новости для вас!
Mehdzor
23.06.2017 00:30У меня был случай, когда человек на позицию руководителя разработки на полном серьезе утверждал, что документацию надо писать только, когда есть время свободное на это. И типа и без нее сойдет.
Поддерживаемость? Нет, не слышали.Movimento5Litri
23.06.2017 10:42+1Ну строго говоря много где хорошим тоном является так называемый self-explanatory и self-documented код…


zharikovpro
22.06.2017 20:00> Как написать максимально хреновый бэкенд для мобильного приложения
Использовать BaaS :)
le1ic
22.06.2017 21:34+3А почему не упоминается про самый частый и самый страшный косяк мобильных разработчиков — ретраить без пауз, устраивая тем самым мощнейший DDoS? Пишешь-пишешь мануалы, документации, рассказываешь про exponential backoff, а все равно ретрай в цикле — наше все )
Mehdzor
22.06.2017 21:47Мои соболезнования вашему серверу) Я с таким хардкорищем не встречался, но спасибо за опыт.

hoefling
25.06.2017 13:53Рейт-лимиты, если уговоры не помогают. И уведомление по емейлу вместе с временным баном.
kulakoff83
22.06.2017 21:46Как всегда круто написано! Надеюсь много похожих на героев этой статьи это прочтут и прислушаются.

arvitaly
22.06.2017 23:20+1Это к вопросу. зачем нужна стандартизация и GraphQL, например.

SPAHI4
23.06.2017 05:25Согласен. Половину вопросов из статьи он решает. Например, строение и документацию.

MOTORIST
23.06.2017 16:10Когда последний раз им интересовался там не все понятно было с ошибками, особенно с ошибками валидации.
Да и backend щиков заставляет попотеть =)

bogolt
23.06.2017 00:56+3Не очень понял причем тут мобильная разработка. Обычные советы для любого типа бекенда сгодятся. Или сейчас просто «программирование == программы для мобилок»? — тогда да, тогда понятно. Примерно как десять лет назад «программист — значит сайты делает».
getmaxx
23.06.2017 01:32+7а как написать максимально хреновое мобильное приложения для вашего бекенда будет?

yorick_kiev_ua
23.06.2017 09:43-1>Если данные для одного экрана надо получать через 10 разных запросов, это проблемы дизайнера, который рисовал интерфейс, не согласовывая его с вашим API.
А в чём проблема? И что вы предлагаете взамен?Mehdzor
23.06.2017 09:57Проектировать API так, чтобы объединение данных было на сервере, а не на клиенте.
Дизайнер же не должен задумываться об архитектуре, но думать о сложности реализации ему все таки надо. У нас макет проходит через команду разработчиков перед финальным согласованием, чтобы отмести какие-то совсем нереальные фичи.yorick_kiev_ua
23.06.2017 11:08-21. Вы не ответили на вопрос «в чём проблема». Какая вообще разница, какое количество запросов будет послано на сервер?
2. Для бекенда «приложение» — это фронтенд, причём. И как именно будут показываться данные, кто с чем и по какому принципу будет объединяться — эти вопросы бекенд не волнуют вообще. API должно предоставлять набор простых «атомарных» методов, без объединений и прочей шелухи.
А вот «объединяя данные на сервере» мы получим bad design с бредовыми методами типа «дай нам список заказов, информацию когда закончится премиум аккаунт. И какая цветовая схема у пользователя выбрана еще». При этом если добавляется новый комонент, то дизайнер который «не должен задумываться об архитектуре»(ему всего-то надо добавить компонент на форму и послать 11-й запрос) внезапно начинает о ней задумываться и требовать, что бы к метод GetOrdersAndAccountExiredAndUserColourSchemaSettings возвращал еще и расписание автобусов(и, видимо, переименовался в GetOrdersAndAccountExiredAndUserColourSchemaSettingsAndPublicTransportSchedule). При этом бекенд намертво прибивается гвоздями к какой-то конкретной форме. Это при том, что бекенд не то, что о конкретной форме — он даже не должен знать, дёргает его «мобильное приложение», другой сервис или десктоп-клиент.
Эти все проблемы были окончательно решены лет 30 назад, в начале 90-х. Примерно тогда устаканилось такое семейство патернов, MV*** называется. Рекомендую ознакомиться, это сильно вам поможет.Mehdzor
23.06.2017 11:25+11. Неудобно объединять результат на клиенте + лишняя нагрузка на сервер.
2. Есть парадигма — backend для клиента, а не наоборот. Насчет названий — запрос в случае сложных форм называется как экран на клиенте (условно). Может быть это будет getUserSettings.
Что плохого, если есть методы для конкретной формы? Потребуется для не конкретной, будет еще один endpoint.
Что касается 'он не должен знать, дергает его приложение или что-то еще' — вот об этом и писал статье. В итоге получается API неудобное ни приложению, ни сервису, ни десктопу. И которое долбят в 10 раз больше, чем надо. Классно.yorick_kiev_ua
23.06.2017 12:32Да, это «классно», это провереное временем решение. У вас, повторяюсь, типичный bad design, когда бекенд знает о фронтенде, логика представления размазана на везде и малейшее изменение во view требует изменения сервера.
>>Что плохого, если есть методы для конкретной формы?
Тем, что из(форм) мношго, они могут меняться/создаваться вообще людьми, о которых вы не имеете представления.
«Дорогой Гугл, я тут пишу страничку, не мог бы метод, возвращающий по координатам информацию о трафике дополнительно сообщать историю погоды за 100 лет в NY, курс валют, адрес ближайшей пиццерии и пропушеные звонки в G+».Mehdzor
23.06.2017 12:45Если делаем публичный API, то ничего не мешает прислушиваться к пользователям. Когда многим надо, чтобы был запрос на историю погоды на 100 лет с курсом валют, то почему нет?
Но в данном конкретном обсуждении мы говорим вовсе не о публичных API. Вы же своих разработчиков не считаете незнакомыми?
И вообще, API — это view сервера, на минуточку. Если изменилось view продукта, то почему бы не измениться и view сервака? Вы же затачиваете свое решение для конкретного случая, а не сферических коней делаете.yorick_kiev_ua
23.06.2017 14:05+2" Насчет названий — запрос в случае сложных форм называется как экран на клиенте (условно). "
Ага. Вот есть у нас Form1 и API для него — GetForm1Data.
Потом что-то добавили, что-то убрали. Серверное API обзоведётся в API набором функций GetForm1Data1, GetForm1Data2… GetForm1DataN — на каждое изменение ФОРМЫ.
Удачи.
>Когда многим надо, чтобы был запрос на историю погоды на 100 лет с курсом валют, то почему нет?
Потому что вы не сможете это поддерживать. Вообще достаточно взглянуть на любой распространённый API(от того же гугла или любой друго) что бы понять кто прав.

alexevil
23.06.2017 11:40+2Я конечно не автор, но:
- не надо насиловать процессоры телефона и сеть передачи данных лишний раз.
- сервер может лечь от количества запросов с клиентов. Если у вас мобильных клиентов миллион, то сервер должен обработать 10 млн. запросов, только для того, чтобы показать экран. А если это все придет одновременно? :)
yorick_kiev_ua
23.06.2017 12:19-2Это чепуха и экономия на спичках. В 99% основным узким местом у вас будет БД. Вторым — сеть.
Передать 10М данных за один запрос и 10Х1М — оверхед минимален. В случае, если мы гоняем всё через tcp — я не уверен, что он будет вообще.
С «другой стороны» всё то же самое: принять 10М за раз и принять за 10 раз — разницы никакой.Mehdzor
23.06.2017 12:31+1БД, кстати, тяжелее всего придется, когда 10 запросов вместо 1.
По трафику все таки разница есть: всякие хидеры, мета инфа и тп на каждый запрос. Пусть и немного, но все же зависит от ситуации.
Разница может доходить до 2x, когда мета инфа занимает столько же, сколько сам полезный ответ.
Но еще нельзя забывать про время. Каждый запрос — это минимум 30мс дополнительного ожидания на установку соединения и передачу данных. А 10 запросов — это уже 0.3 секунды. Это же получается, что каждый третий экран создает задержку в секунду. Не круто ли?
Давайте сюда же запишем дополнительные действия сервера для обработки подключения: авторизация, фильтры различные, да что угодно. Все это будет выполняться в 10 раз больше, чем нужно.
И оно вам надо?yorick_kiev_ua
23.06.2017 13:16-4>БД, кстати, тяжелее всего придется, когда 10 запросов вместо 1.
Извините, но это фейспалм. Потому что их будет 10 в любом случае.
>По трафику все таки разница есть: всякие хидеры, мета инфа и тп на каждый запрос.
«всякие хидеры, мета инфа и тп» — это сотни байт, ну единицы килобайт. Оверхед в «типичном» приложении — сотые доли процента, на уровне погрешности.
>Каждый запрос — это минимум 30мс дополнительного ожидания на установку соединения и передачу данных. А 10 запросов — это уже 0.3 секунды.
Ну вы же шутите, правда?
>Все это будет выполняться в 10 раз больше, чем нужно.
Выполняться в 10 раз дольше оно будет на идеальном канале в случае, если сервер не делает вообще ничего(шлём пустые запросы — получаем пустые ответы) причём сервер однопоточный и держит строго одно соединение.
Это, скажем так, несколько оторваный от практики случай.Mehdzor
23.06.2017 13:38Дальше спорить не вижу смысла, прокомментирую только одну фразу.
> Извините, но это фейспалм. Потому что их будет 10 в любом случае.
Транзакции и материализация данных значительно облегчают нагрузку.yorick_kiev_ua
23.06.2017 14:08Вам нужно, условно говоря, сделать 10 select к десяти разным DB view.
Как вы сделаете это одним запросом и при чём тут транзакции вообще?
michael_vostrikov
23.06.2017 22:15+3«всякие хидеры, мета инфа и тп» — это сотни байт, ну единицы килобайт. Оверхед в «типичном» приложении — сотые доли процента, на уровне погрешности.
А тело ответа у вас значит не единицы килобайт? В «типичном» приложении ответы по 10 мегабайт и выше?)
Dionis_mgn
23.06.2017 13:24Именно для решения всех этих проблем и существуют backend-программисты. Не пытайтесь учить их работать. Если Вы считаете, что описанная yorick_kiev_ua ситуация хоть и утрирована, но нормальна… У меня для Вас плохие новости.
Проблема, описанная в статье должна решаться, например, батчингом запросов. В итоге и запрос всего один и API остаётся красивым, логичным, выверенным. А не смесью говна, палок, котлет и мух.

DarthVictor
23.06.2017 16:35+31. Вы не ответили на вопрос «в чём проблема». Какая вообще разница, какое количество запросов будет послано на сервер?
Самая очевидная проблема — ошибка несогласованных данных. Данные по одной карточке банка пришли до транзакции перевода, данные по другой перед. Итог — у пользователя впечатление, что у него исчезли деньги. Некоторые интернет-банки этим страдают. Этакое неповторяющееся чтение, несмотря на наличие нормальных транзакций на сервере. Чтобы этого избежать нужно чтобы у клиента были данные о связях между компонентами, что когда в одном окошке выполнили перевод нужно обновить две карточки счетов в другом, причем обязательно одновременно. Или можно просто прислать новые данные обеих карт в качестве ответа на перевод денег.

deNULL
25.06.2017 22:24+1Непонятно, о чём спор. Не нужно делать десятки запросов на один экран и не нужно делать методы типа GetOrdersAndAccountExiredAndUserColourSchemaSettings.
Достаточно же просто сделать один метод batch, который будет уметь принимать массив любых других методов и возвращать такой же массив результатов от них. Многие крупные API так и делают.

virtual_hack2root
23.06.2017 12:46Вот это правильно: Не обращайте внимания на строение приложения. Кто не понял, тот поймёт
dmitry_dvm
23.06.2017 13:29+1А еще присылайте каждый ответ в разном корневом объекте. Тут response, тут data, тут item. Мы же любим под каждый запрос свою модель пилить.
Imrahil
23.06.2017 13:31Что бы делать качественно back-end мне не западло было освоить фронт) знания ни по яве ни по обжектив с мне ещё никогда не мешали) да я не гуру в мобильной разработке но основы бриджа API — Backend обязан знать, так я считаю)

UporotayaPanda
23.06.2017 13:39Добрый день!
Благодарен вам за труд, статься вышла отличной!
Прочитал, вынес некоторые нюансы для себя и в ближайшее время надеюсь избавиться от этих вредных привычек.
Хочу выразить благодарность и за две предыдущие статьи!
Но возникает вопрос, зачем пользоваться этим «модным» способом давать именно вредные статьи? Почему писать статью именно полезных советов с приведением примеров? Ведь это бы облегчило чтение, и можно было бы использовать как памятку для себя, или выдать как инструкцию для новичков?Mehdzor
23.06.2017 13:41> Но возникает вопрос, зачем пользоваться этим «модным» способом давать именно вредные статьи?
Целью было не создать инструкцию, а поделиться наболевшим и дать пару советов.
> Ведь это бы облегчило чтение, и можно было бы использовать как памятку для себя, или выдать как инструкцию для новичков?
Задумаюсь над вашим предложением.
MOTORIST
23.06.2017 14:08Разработка вообще должна идти через frontend программиста. Сделал прототип с сервисами и фейковыми данными, дальше отдал backend-щику со словами «Сделай мне так» и нет никаких проблем.
Dionis_mgn
23.06.2017 14:44Т.е. тормозящее и неподдерживаемое нечто, получившееся в результате такого подхода — это не проблема? Согласитесь, глупо ожидать от фронтендера, что он учтёт все тонкости бэкенда.
mayorovp
23.06.2017 14:57Можете пояснить механизм возникновения тормозов и лагов при таком подходе?
Dionis_mgn
23.06.2017 15:05+1Запросто. Интерфейс может оказаться недружелюбным к различного рода кешам, требовать выполнения забавных, неоптимальных запросов к БД (именно требовать, да). Можно вспомнить про распределённость данных и необходимость их собирать с разных шард, сложность этих задач сильно разнится в зависимости от данных. Это всё будет отлично работать на фейковых и небольших наборах данных. А вот в продакшене — выстрелит. Сталкивался с таким.
И про неподдерживаемость не забывайте.
БОльшая часть проблем, описанных в статье (если не все), вытекает из отсутствия взаимодействия в команде. API должно разрабатываться всей командой. backend и frontend ДОЛЖНЫ работать сообща, иначе у них получится говно будь даже каждый из них гением в своём деле.

potan
23.06.2017 14:11+1Хорошо, когда документация генерируется по исходнику, возможно с аннотациями. И содержать информацию о типах — что этот 'id' не просто строка, а идентификатор сущности такого-то типа.
Я слышал несколько докладов на разных конференциях, на разных языках, от Scala до Haskell, про то, как это сделать. Сам пока не смог повторить, но надежду не теряю.

springimport
23.06.2017 20:05С помощью Swagger (codepen) можно генерировать как клиенты так и серверы для API для множества языков. Например, я использую сгенерированный php-клиент для magento 2.
А для проверки работы API рекомендую великолепное приложение Insomnia.
Надеюсь, это поможет облегчить нелегкую работу с API :)
Mehdzor
23.06.2017 20:10Сравнивали Postman с Insomnia?
springimport
23.06.2017 20:28Не пользовался Postman. Как я понял, оба инструмента похожи. Postman с уклоном в тестирование API.


vintage
25.06.2017 09:39Не обращайте внимания на строение приложения, вам абсолютно не должно быть дело до того, как будет выглядеть продукт для пользователя. Ведь вы не хипстер, чтобы задумываться о таких вещах. Если данные для одного экрана надо получать через 10 разных запросов, это проблемы дизайнера, который рисовал интерфейс, не согласовывая его с вашим API.
Такой подход возможен, когда клиент всего один. Но сейчас это уже крайне редкий случай. Как правило клиентов несколько (веб + мобильные приложения), экраны у них разные, экранов гораздо больше, чем бизнес-сущностей, и к тому же экраны эти без конца меняются. Если у вас бэкенд будет подстраиваться под фронтенд, то вы огребаете следующие проблемы:
Огромный API. Тысячи похожих методов со своими параметрами и выдаваемыми данными. Вы не сможете быстро развивать бэкенд, так как нужно будет вносить синхронные изменения во все эти методы. В их реализации будет куча копипасты. А число багов пропорционально объёму кода. Чтобы разгребать это болото вам потребуется куча бэкендеров.
Медленная разработка. Вам приходится писать типовой код запроса и обработки ответа для каждого экрана. А на каждый чих нужно дождаться изменений бэкенда. Это от пары часов, до пары дней времени. Наличие нормализованного API позволяет изменять клиент очень быстро, не теребонькая бэкендеров по пустякам. Кроме того, это позволяет выделить всё общение с сервером в модель — попробуйте, это крайне удобно.
- Невозможность кеширования. Разные сущности обновляются с разной частотой. Степень актуальности разных сущностей нам нужна разная. Часть данных у нас может оставаться после предыдущих запросов и даже предыдущего запуска приложения. Правильная реализация Модели, позволит вам даже не запрашивать те данные, что у вас уже есть. Если же для каждого экрана у вас свой метод в API, который возвращает все данные для этого экрана, то вы тратите кучу ресурсов впустую (как на бэкенде, вытягивая их, так и на клиенте — обрабатывая их снова, ну и трафик, конечно же).
Для авторизации используйте только cookie. Вас так вас в институте учили, когда вы делали свой первый интернет магазин. Ведь Android и iOS — это просто еще один браузер, не нужно преувеличивать их сложность.
А в чём проблема мобильному приложению посылать заголовок Cookie? Или вы предпочитаете посылать токен в URL и светить им в логах сервера?
Запомните: никаких тестовых данных, пусть разработчики руками генерируют весь контент.
Что ж это за разработчики такие, что не могут автоматизировать столь простую задачу? :-) Но да, лучше не стирать базу, а тестировать на копии прода.
Будьте бунтарем: принимайте параметры в POST через URL, ведь это тот же GET, только другой. Дайте волю воображению. И игнорируйте любые мольбы коллег привести все к стандартному виду, они просто не могут мыслить нестандартно.
Нет никаких POST и GET параметров. Есть URL и есть Body. У GET запроса не может быть Body, у POST — может. Через что передавать тот или иной параметр зависит от сути параметра. Например, идентификатор сущности имеет смысл передавать через URl, а вот её новое состояние — через PATCH (а не POST). Для многих, к сожалению, является сюрпризом, что кроме POST есть более подходящие методы.
Самый простой и удобный вариант — это использовать Swagger.
Нет, самый простой — описать бизнес-сущности и универсальный протокол работы с ними. Клиент один раз реализует протокол и далее работает с бизнес-сущностями через модель. Красивая документашка по http-ручкам тут уже не нужна. А "Простого вордовского файла на дропбоксе будет достаточно".
Пример формального описания сущностейskeddy_model OTriggered created string \iso8601 changed string \iso8601 skeddy_person skeddy_model - пользователь сервиса id unique string \text full_ame lucene string \text description string \text karma double \[-1,+1] is_admin notunique boolean avatar link-list \skeddy_image mail link-set \skeddy_mail phone link-set \skeddy_phone token link-set \skeddy_token meeting link-set \skeddy_meeting profession link-set \skeddy_profession refer_to link \skeddy_person refer_from link \skeddy_person manager link \skeddy_person worker link-list \skeddy_person service link-set \skeddy_service salon_manage link-set \skeddy_salon salon_work link-set \skeddy_salon assessment_from link-set \skeddy_assessment assessment_to link-set \skeddy_assessment image link-list \skeddy_image album link-set \skeddy_album favorite link-set \skeddy_person fan link-set \skeddy_person notification link-set \skeddy_notification place link-set \skeddy_place social link-set \skeddy_social schedule json \[{from,to,period}] payment_to link-set \skeddy_payment payment_from link-set \skeddy_payment team link-set \skeddy_team skeddy_mail skeddy_model - электронная почта id unique string \text value unique string \text confirmation string \text person link \skeddy_person skeddy_phone skeddy_model - номер телефона id unique string \text value unique string confirmation string \char[6] person link \skeddy_person salon link \skeddy_salon skeddy_social skeddy_model - информаця из социальной сети id unique string \text identity unique string \text profile string \url phone string \text country string \text city string \text mail string \text provider string \text photo string \url name_first string \text name_last string \text name_nick string \text birthday string \iso8601 sex string \male|female person link \skeddy_person skeddy_token skeddy_model - аутентификационный токен id unique string \text value unique string description string expires string device_id string \char64 person link \skeddy_person application link-set \skeddy_application skeddy_application skeddy_model - зарегистрированное клиентское приложение id unique string \text push_service string \apn|gcm|c2dm|wns private_key string \text certificate string \text token link-set \skeddy_token skeddy_profession skeddy_model - основная профессия мастера id unique string \text title lucene string \text master link-set \skeddy_person skeddy_service skeddy_model - предоставляемая мастером услуга id unique string \text title lucene string \text description string \text duration string \iso8601 period string \iso8601 price decimal master link \skeddy_person meeting link-set \skeddy_meeting assessment link-set \skeddy_assessment image link-list \skeddy_image facet notunique link-list \skeddy_facet skeddy_meeting skeddy_model - встреча мастера и клиента id unique string \text from string \iso8601 to string \iso8601 price decimal status string \suggested|booked|planned|completed|cancelled payed boolean is_suggested boolean description string \text service link \skeddy_service master link \skeddy_person customer link \skeddy_person place link \skeddy_place assessment link-set \skeddy_assessment payment link-set \skeddy_payment skeddy_assessment skeddy_model - отзыв о прошедшей встрече id unique string \text comment string strength double from link \skeddy_person to link \skeddy_person meeting link \skeddy_meeting service link \skeddy_service skeddy_message skeddy_model - сообщение одного пользователя другому id unique string \text value string \text from link \skeddy_person to link \skeddy_person skeddy_album skeddy_model - альбом с фотографиями id unique string \text title string \text description string \text person link \skeddy_person image link-list \skeddy_image skeddy_image skeddy_model - мета информация о фотографии id unique string \text small string big string width integer height integer person link \skeddy_model album link-set \skeddy_album service link-set \skeddy_service skeddy_notification skeddy_model - уведомления с гарантированной доставкой id unique string \text status string \pending|sended|readed type string \text title string \text message string \text start string \iso8601 link string \uri sender string \uri recipient link \skeddy_person skeddy_place skeddy_model - адрес оказания услуг id unique string \text title string \text description string \text address string \text longitude double latitude double master link-set \skeddy_person skeddy_track skeddy_model - собираемые координаты пользователя id unique string \text longitude double latitude double accuracy double time string \iso8601 token link-set \skeddy_token skeddy_payment skeddy_model - входящий платёж id unique string \text amount decimal status string \await|completed|rejected reason string acquire_id string from link \skeddy_person to link \skeddy_person meeting link \skeddy_meeting skeddy_article skeddy_model - вики статья id unique string \text title lucene string \text content string \text image link-list \skeddy_image skeddy_banner skeddy_model - рекламный блок id unique string \text title string \text description string \text link string \uri image link \skeddy_image skeddy_team skeddy_model - группа пользователей id unique string \text title string \text member link-set \skeddy_person skeddy_aspect skeddy_model - критерий кластеризации услуг id unique string \text title lucene string \text description string \text image link-list \skeddy_image facet_sub link-list \skeddy_facet facet_super link-set \skeddy_facet skeddy_facet skeddy_model - значение критерия кластеризации id unique string \text title lucene string \text description string \text image link-list \skeddy_image aspect_super link \skeddy_aspect aspect_sub link-list \skeddy_aspect service link-set \skeddy_service skeddy_salon skeddy_model - салон, где работают мастера id unique string \text title string \text manager link-set \skeddy_person worker link-set \skeddy_person phone link-set \skeddy_phone
Blumfontein
25.06.2017 11:00-1>> Если у вас бэкенд будет подстраиваться под фронтенд, то вы огребаете следующие проблемы
А если ваш бекенд не подстраивается под фронтенд, то вы огребаете другую проблему: при изменениях бизнес-процессов придется обновлять клиент. И если сервер можно обновить в любое время, то тысячи клиентов обновить совсем непросто. Уж по мне лучше гемороиться с огромным бекендом с кучей методов под разные клиенты, чем сидеть и думать, как нам скрыть вот эту кнопку только для пользователей Андроида на планшетах (пример утрированный).vintage
25.06.2017 14:23+1Клиент в любом случае придётся обновлять. Если, конечно, у нас не тонкий терминальный клиент. Но такие клиенты для мобилок плохо подходят из-за нестабильного коннекта.
Blumfontein
26.06.2017 08:38>> Клиент в любом случае придётся обновлять
Вы это бизнесу обоснуйте) То ли дело 10 раз обновить, то ли 2-3 раза
У нас раньше так и было: клиенты дергали модельки из АПИ, потом по состоянию моделек показывали те или иные ЮИ-элементы. Тут были 2 большие проблемы: 1) Фронтенд команд как правило 3 (js, android, ios), трудно всем объяснить как выглядит бизнес процесс; 2) Клиент становится слишком умный, чтобы изменить поведение каких-то элементов надо либо перезаливать клиент, либо вставлять какие-то жуткие костыли в АПИ с подменой данных модели под конкретные версии. Затем мы стали делать так чтобы клиент спрашивал у сервера какие (значимые) элементы на экране показывать и в каком виде, а какие нет. Плюсы: вся логика с клиента переехала на сервер (легче изменять поведение клиента и объяснять бизнес процессы нужно только серверным программистам). Минусы: сервер стал толще, потому что писать АПИ надо под каждый экран.vintage
26.06.2017 09:31У вас вся клиентская логика заключалась в том показывать или нет тот или иной элемент? :-) Ну, модели "Отчёт" и "Дашборд" — могут быть такими же бизнес сущностями, как и все остальные. Если у вас куча похожих экранов, то грех не реализовать их через один параметризируемый экран, конфиг для которого получать с сервера.
Mehdzor
25.06.2017 14:17+11. По опыту, проект на 5 клиентских платформ (веб, android, ios, macos, windows), не заметил, чтобы документация раздулась. Для регулярных случаев с вебом и двумя мобилками, все по дефолту хорошо.
2. Каждый запрос, при достойной архитектуре, делается за 20 минут максимум. У нас бэкенд всегда идет впереди клиента по скорости работы, хотя людей там, как правило, в двое меньше, чем на каждой клиентской платформе. С учетом всех тестов, документирования и тп.
3. Не очень понял. Почему не кэшировать по максимуму? Ведь эта проблема будет так же, если не делать индивидуальные API под каждый чих.
> В чем проблема присылать cookie?
Плохая управляемость. Во-первых, система сама решает, цеплять этот куки к запросу или нет. Если решила, не цеплять, то счастливой отладки всем.
Во-вторых, кроме как удалить/прицепить — ничего больше не сделаешь. Понятия обновления токена нет. А дальше придется капчу приложению проходить?)
> Нет никаких POST и GET параметров. Есть URL и есть Body. У GET запроса не может быть Body, у POST — может.
Согласен, в статье упрощенное представление.
> Нет, самый простой — описать бизнес-сущности и универсальный протокол работы с ними.
Swagger не исключает бизнес-сущности, а требует их. Но не везде нужна полная сущность, например. Не присылать же целиком сущности же?
> Сквозное именование — классная штука, но важно, чтобы имена эти определялись бизнес-доменом.
Согласен, но это немного другой уровень.
Теперь про ссылки:
1. «Для смены хоста вам придётся перезапросить все данные с сервера.»
В принципе, при смене хоста придется все нафиг перевыпустить. Желательно, чтобы домен был статичным.
2. «Серверу надо знать по какому хосту вы обращались к апи „
Не вижу сложности. Все веб серверы умеют передавать Host.
3. “Раздувание объёма данных на ровном месте»
Ну не, как-то из пальца совсем уж. Сколько должно быть регулярно гуляющих ссылок, чтобы реально оказать влияние на объем.
4. «Нужны отдельные поля для картинок в разных размерах — усложнение API»
Согласен. Правда, не всегда применимо использовать композитные адреса. Представьте, что вконтакте можно было бы получить любые изображения любого человека, просто правильно составив ссылку? Но в целом, почему нет.
> то не так уж сложно запилить её самому на основе сопрограмм
Вы не разрабатывали приложения. Просто нечего сказать. Люблю такое, когда бэкенд разработчики говорят, что почему вы просто не сделаете ассемблерные вставки, например? Типа, могу хоть сейчас скинуть код.
На рынке многие разработчики не знают даже про простейший gcd, а вы говорите про инкапсуляции в библиотеку…vintage
25.06.2017 16:01По опыту, проект на 5 клиентских платформ (веб, android, ios, macos, windows), не заметил, чтобы документация раздулась. Для регулярных случаев с вебом и двумя мобилками, все по дефолту хорошо.
Конкретных цифр не будет? Сколько уникальных серверных ручек в API? Сколько лет проекту?
Каждый запрос, при достойной архитектуре, делается за 20 минут максимум. У нас бэкенд всегда идет впереди клиента по скорости работы, хотя людей там, как правило, в двое меньше, чем на каждой клиентской платформе. С учетом всех тестов, документирования и тп.
Если 20 минут — это написание клиентского кода, то это слишком долго. С полноценной моделью (которая генерируется по общей с сервером схеме) вам потребуется 0 минут.
Не очень понял. Почему не кэшировать по максимуму? Ведь эта проблема будет так же, если не делать индивидуальные API под каждый чих.
Потому что к разным типам ресурсов разные требования по актуальности. От "балланс нельзя кешировать — он должен запрашиваться при каждом заходе на страницу", до "статистика обновляется по ночам, обновлять её в течении дня нет смысла".
Плохая управляемость. Во-первых, система сама решает, цеплять этот куки к запросу или нет. Если решила, не цеплять, то счастливой отладки всем.
Что значит "сама"? У вас там куки Шрёддингера? :-) Телепат во мне подсказывает, что она попросту протухает.
Во-вторых, кроме как удалить/прицепить — ничего больше не сделаешь. Понятия обновления токена нет.
В чём проблема установить новую куку?
Нет, самый простой — описать бизнес-сущности и универсальный протокол работы с ними.
Swagger не исключает бизнес-сущности, а требует их. Но не везде нужна полная сущность, например. Не присылать же целиком сущности же?Стандартизированный fetch-plan позволяет указать какие поля и в каком объёме нужно возвращать. Зачем это описывать для каждого ресурса отдельно?
В принципе, при смене хоста придется все нафиг перевыпустить. Желательно, чтобы домен был статичным.
Зачем перевыпускать? В чём проблема серверу прислать событие "используй для картинок теперь такую-то базовую ссылку"? А клиенту резолвить урл в момент запроса, а не в момент получения ответа.
Не вижу сложности. Все веб серверы умеют передавать Host.
Это не тот хост, к которому обращался клиент, а тот, по которому обратились к вашему сервису. Одинаковыми они будут только если клиент обратился напрямую к вашему хосту, без посредников с другими именами.
Ну не, как-то из пальца совсем уж. Сколько должно быть регулярно гуляющих ссылок, чтобы реально оказать влияние на объем.
Согласен. Правда, не всегда применимо использовать композитные адреса. Представьте, что вконтакте можно было бы получить любые изображения любого человека, просто правильно составив ссылку? Но в целом, почему нет.
Из ВК и так кто угодно может получить ссылку на вашу аватарку :-)
https://api.vk.com/method/users.get?user_ids=1&fields=photo_max
Вы не разрабатывали приложения. Просто нечего сказать. Люблю такое, когда бэкенд разработчики говорят,
Я — преимущественно фронтенд-разработчик.
что почему вы просто не сделаете ассемблерные вставки, например? Типа, могу хоть сейчас скинуть код.
Тут не нужны ассемблерные вставки. Всё уже вставили за вас.
На рынке многие разработчики не знают даже про простейший gcd, а вы говорите про инкапсуляции в библиотеку…
Так пусть идут в школу и учатся.
dmitry_dvm
25.06.2017 20:49Нет никаких POST и GET параметров.
Я думаю речь о пост-запросах на урл типа ***/api/items/1?id=123&user=sdfs — то есть когда пост-запрос требует передачи query strings. И это абсолютно идиотское использование REST. За такую реализацию надо как минимум штрафовать.
Или вы предпочитаете посылать токен в URL и светить им в логах сервера?
Для этого есть хедеры. А куки в restapi — это рудимент, который должен отвалиться как можно скорее.vintage
26.06.2017 05:52-1Я думаю речь о пост-запросах на урл типа ***/api/items/1?id=123&user=sdfs — то есть когда пост-запрос требует передачи query strings. И это абсолютно идиотское использование REST. За такую реализацию надо как минимум штрафовать.
А обосновать сможете?
Для этого есть хедеры. А куки в restapi — это рудимент, который должен отвалиться как можно скорее.
А куки через астрал передаются или через что?
mayorovp
26.06.2017 10:11Поддержка кук предполагает, что кука может быть установлена сервером в ответ на любой запрос, после чего клиент обязан ее запомнить и передавать при последующих запросах. Частичная реализация этого механизма ("мы сохраняем только куку token и только полученную в ответ на запрос login") будет противоречить стандарту. Часть реализации, кончено же, возьмет на себя клиентская библиотека — но реализовывать хранение кук на диске придется самостоятельно.
В то же время, при передаче токена в заголовке Authorization или в нестандартном заголовке никто не мешает использовать самую простейшую схему управления токеном — он возвращается в ответ на запрос аутентификации и прикладывается ко всем остальным запросам.
Кроме того, если клиент работает в браузере, то отказ от использования кук автоматически устраняет XSRF-уязвимость без дополнительных телодвижений.
vintage
26.06.2017 14:20Токен, конечно же, никогда не протухает и никогда не отзывается?
Сам по себе отказ от кук — уже дополнительное телодвижение.
mayorovp
26.06.2017 14:56Ну пусть токен протухает и отзывается. И что с того? Это ничем не сложнее для реализации чем протухшая или отозванная кука.
Отказ от кук является дополнительным телодвижением только если клиент работает на платформе, которая из коробки обеспечивает хранение кук (= в браузере), для всех остальных видов клиентов это не так.
И даже в браузере обратиться к api, использующему токены авторизации, ничуть не сложнее чем обратиться к api, использующему анти-XSRF токены.
vintage
26.06.2017 15:12-1Ну пусть токен протухает и отзывается. И что с того? Это ничем не сложнее для реализации чем протухшая или отозванная кука.
О чём и речь.
Отказ от кук является дополнительным телодвижением только если клиент работает на платформе, которая из коробки обеспечивает хранение кук (= в браузере), для всех остальных видов клиентов это не так.
Для всех остальных — монописуально.
Mehdzor
25.06.2017 17:43> Из ВК и так кто угодно может получить ссылку на вашу аватарку :-)
И что в итоге этот метод возвращает? Правильно, полную ссылку)
> Это не тот хост, к которому обращался клиент, а тот, по которому обратились к вашему сервису.
Он пробрасывается, как правило, чтобы иметь значение исходного хоста. По крайней мере везде, где я сталкивался с цепочкой проксирования.
> Так пусть идут в школу и учатся.
Дело говорите, но только больше годных спецов от этого не становится)
> Зачем перевыпускать? В чём проблема серверу прислать событие «используй для картинок теперь такую-то базовую ссылку»
Потому что сложно. Какое-то состояние дополнительное за которым надо следить. Везде, где я сталкивался с подобным поведением, было огромная куча багов из-за этого. Да, можно сказать, идите в школу учиться прогать, но лучше сейчас от этого не станет.
> Стандартизированный fetch-plan позволяет указать какие поля и в каком объёме нужно возвращать. Зачем это описывать для каждого ресурса отдельно?
Вы такого хорошего мнения о среднем уровне разработчиков на рынке) Там же не просто один запрос, которому надо передать список полей.
> В чём проблема установить новую куку?
Проблема следить за ней и в том, что она неуправляема на уровне приложения практически. Это действительно осложняет жизнь значительно.
> Конкретных цифр не будет? Сколько уникальных серверных ручек в API? Сколько лет проекту?
Полтора года, около 40.
В общем, все можно сделать офигенно по уму, с классной логикой, но когда у тебя штат состоит из сильнейших девов, которые никуда не разбегутся, платят им выше среднего и вообще у вас гугл. Но много ли где так?vintage
26.06.2017 06:07И что в итоге этот метод возвращает? Правильно, полную ссылку)
С тем же успехом ссылка могла бы быть и не полная.
Он пробрасывается, как правило, чтобы иметь значение исходного хоста. По крайней мере везде, где я сталкивался с цепочкой проксирования.
Ок, прилетел вам
Host: localhost:8080. Какой сервис на вашем IP обработает этот запрос?
Дело говорите, но только больше годных спецов от этого не становится)
Достаточно иметь одного грамотного архитектора в команде, который научит этих негодников уму-разуму. :-)
Потому что сложно. Какое-то состояние дополнительное за которым надо следить. Везде, где я сталкивался с подобным поведением, было огромная куча багов из-за этого.
Не вижу тут сложности. Я же описал вам весь алгоритм действий: изменять значение одной глобальной переменной, когда приходит событие от сервера, и резолвить ссылки перед запросом относительно значения этой переменной. Всё.
Вы такого хорошего мнения о среднем уровне разработчиков на рынке) Там же не просто один запрос, которому надо передать список полей.
Если он разобрался в хоть каком-нибудь языке программирования, то разобраться в тривиальном
?fetch=first_name,last_name,ageи подавно сможет.
Проблема следить за ней и в том, что она неуправляема на уровне приложения практически. Это действительно осложняет жизнь значительно.
Под iOS приложение не может читать и устанавливать куки?
Полтора года, около 40.
У вас 40 экранов суммарно на 5 приложений? Что ж вы там полтора года делали? :-)
medvoodoo
Адекватность заказчика. Обычно ужас-ужас работы и пространства имен образуется из того, что требования сто раз меняются в процессе разработки. И с этим ничего не поделаешь, все сразу предусмотреть невозможно. При большом опыте работы я не знаю как сделать, чтобы коллеги не скрежетали зубами. Имхо, только постоянный рефакторинг и документирование, а главное выделение на них времени, спасает от скрежета зубовного коллег, каюсь, в 90% случаев у нас на это просто нет времени.
P.S. Топ моих болей в работе со сторонними апи:
Mehdzor
'Адекватность заказчика' — это вообще тема для отдельной статьи.