
Наталья Гараханова, директор по маркетингу в агентстве Black Engine и аспирант курса «Управление продуктом», развенчивает мифы в области Big Data.
Big Data в последнее время стали трендом. Но что это такое, понятно не всем.
Многие думают, что большие данные — это либо просто огромный массив данных, либо простой и дешевый способ их хранения.
Большие данные вовсе не предмет, а совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов. Это технологии, которые помогают решать важные задачи для бизнеса и науки. Из-за непонимания сути технологии возникли мифы, которые я попыталась развенчать в этой статье.

Миф основан на статистике, которая говорит, что около 80% рабочих задач можно автоматизировать. Это большая проблема с точки зрения образования: огромному количеству кадров надо будет переучиваться на другие профессии. В чем-то этот миф прав. Многим людям придется отказаться от текущей деятельности. Но кардинальной безработицы не будет.
Например, если мы станем проектировать систему эффективной таргетированной рекламы с использованием Big Data, то потребуется специалист в новой области знаний на пересечении математики и маркетинга. Именно он будет следить за работой системы и исправностью механизма. Сейчас на рынке уже начинают появляться такие люди на позиции «Data Management Platform Operator».
Не стоит бояться, что люди останутся без работы. Появятся другие профессии, как это было много раз в истории человечества. Ведь и печатный станок когда-то изменил историю книгопечатания и сделал ненужной перепись книг.
Необходимость обучения алгоритмов ведет к тому, что появляются компании и сервисы, которые агрегируют данные в одном месте. Это может вызвать проблемы с безопасностью и доступом к пользовательской информации.
Агрегация данных для обучения искусственного интеллекта, алгоритмов и машин уже перестала быть настолько важной, как прежде. Сейчас корпорации вроде Google и Apple активно работают над тем, чтобы сделать свои устройства частью распределенной сети машинного обучения.
Google по своим устройствам имеет одну сеть, которая работает одновременно. Apple идет по его стопам в области новых технологий на основе больших данных. Например, в патенте Google «Federated Learning» все построено на распределенном обучении. Данные с телефона не утекают в определенный Data-центр, а приезжает модель, обучается и начинает коммуницировать с другими моделями мобильных телефонов или через общий хаб. Таким образом сохраняется приватность.
Модель — это алгоритм, который может быть сложным или простым, но на выходе будет получен ответ на интересующий нас вопрос. Его можно задать математически формулами или словами. В принципе, даже наши юридические законы — это модель, которая позволяет классифицировать действия человека на приемлемые (ненаказуемые) и неприемлемые (наказуемые).
Моделью может быть набор формул для описания физического феномена, а могут быть правила языка, делящие многообразия слов и словосочетаний на корректные (грамотные) и некорректные (безграмотные). Если обобщить, не прибегая к строгим математическим формулировкам, то модель — это формализуемый критерий, который мы получаем на основе тренировки на имеющихся данных.
Есть области знаний, где приходится сталкиваться с большим количеством данных для обработки. Но не всегда Big Data дают ощутимый результат.
Компания Gartner провела исследования, какие кейсы наиболее популярны в различных индустриях. Все данные были представлены в виде тепловой карты кейсов, реализованных в бизнесе. Чем краснее квадратик (чем больше процент), тем больше из опрошенных компаний реализовали кейсы на основе Big Data у себя в бизнесе.
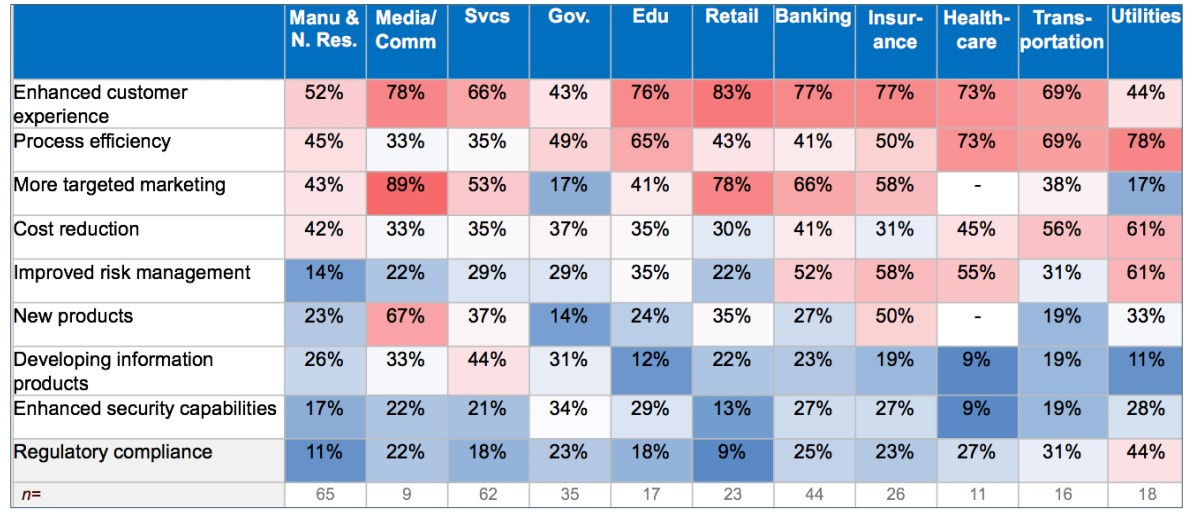
Как видно из исследования, больше всех кейсов реализовано в области маркетинга, таргетирования и customer experience. То есть в самой актуальной области клиентской аналитики и работы с клиентами — в сфере продаж b2c. Меньше всего кейсов реализовали в государственном секторе, но область эффективности процессов для этого сектора наиболее актуальна. Сфера новых продуктов пока остается для этого сектора не существенной.
А вот такой опрос проводил Tech Pro Research:
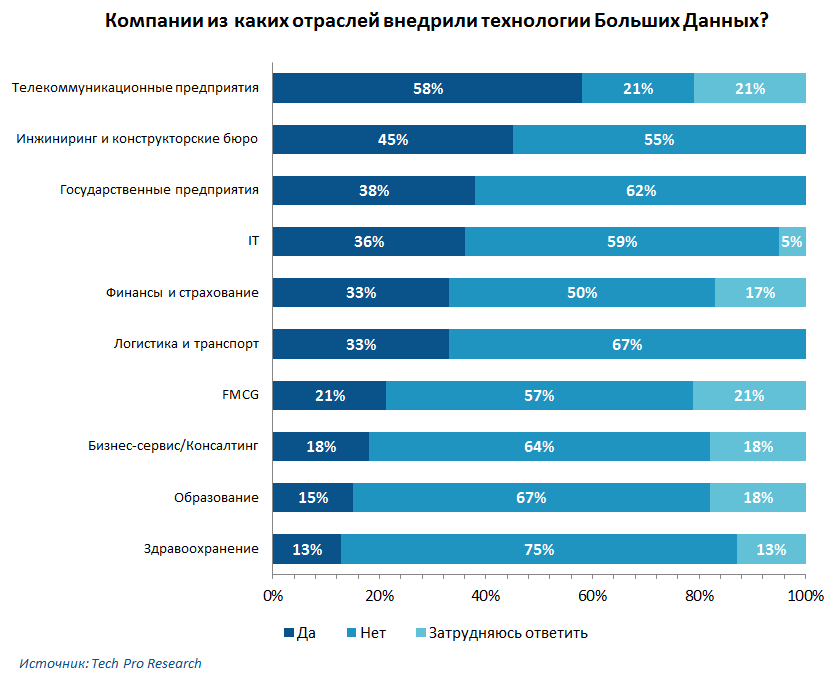
Интересно, что в области образования и здравоохранения большие данные оказались не так популярны. А вот финансовые и государственные структуры, инжиниринг и ИТ активно пользуются этими методами. Причем телеком — самая популярная сфера для внедрения технологий Big Data.
Big Data не нужны, если в вашей компании:
Еще один миф, с успехом развенчанный показательными успешными кейсами. Он основан на том, что в сфере среднего или малого бизнеса сам сбор данных может стать проблемой.
Такие системы, как Google Analytics или Яндекс.Метрика используются исключительно для оценки посещаемости ресурса, и никаких дополнительных отчетов с их помощью не формируется. Многие компании до сих пор хранят свои данные в старом добром Excel, и понятно, что в этом случае говорить об использовании методов Big Data пока рано. В российском ИТ в основном все ссылаются на те же Google Analytics, простейшую систему с использованием больших данных, но эффективную для сбора и систематизации данных. Некоторые успешно пользуются Retail Rocket — платформой для мультиканальной персонализации интернет-магазинов на основе Big Data.
Также для жаждущих попробовать высокие технологии существуют биржи данных, где даже небольшие компании могут себе позволить приобретать данные, вокруг которых можно строить бизнес или улучшать организационные и маркетинговые процессы.
На Западе эта тема более активно обсуждается. В пример приводятся сервисы Followerwonk, YouTube Analytics и Tweriod. Некоторые представители малого и среднего бизнеса успешно пользуются облачными решениями, например, платформой Amazon, построенной специально для вычислений на основе Big Data.
Есть компании, которые идут еще дальше и заводят собственные инфраструктуры, например, Hadoop — проект с открытым исходным кодом, который выступает как хранилищем петабайт данных, так и используется для надежных, масштабируемых и распределенных вычислений.
Если малый и средний бизнес хочет расширить объемы задач в исследовательских и производственных целях, то использование Big Data позволит не только систематизировать данные, но и увеличить скорость их обработки.
Этот миф часто встречается, когда необходимо построить модель из распределенной файловой системы. Поставщики решений утверждают, что «все данные должны быть обработаны». Здесь кроется противоречие. Между количеством обработанной информации и результатом работы нет взаимосвязи. Увеличение объема обработанных данных не влияет на увеличение точности итоговой модели.
Общеизвестная теория, построенная на математических исчислениях, показала, что лучшие результаты мы получаем, когда строим модели из небольших сегментов, специально подобранных под цель назначения модели.
С точки зрения математики каждый объект выборки имеет равную вероятность попасть в случайную подвыборку для обучения модели. И её точность будет зависеть не от количества элементов, а от качества выборки. Из нескольких тысяч ответов на некий опрос, получается построить очень точный прогноз по всему результату.
Реальная значимость Big Data не в том, чтобы обработать как можно больше данных, а в том, чтобы весь объем данных был сегментирован и разбит на кластеры, и в построении большого количества моделей для небольших кластеров.
Этот миф распространен в компаниях, которые только начинают использовать большие данные. Недостаточно только рассчитать рекомендацию, например, какой продукт на кого таргетировать, или какой продукт с каким нужно поставить. Важно уметь делать саму расстановку. На этом шаге многие проекты останавливаются.
С Big Data необходимо много работать. Это подразумевает создание сложного проекта, сбор данных, создание инфраструктуры, проектирование модели и затем поиск необходимых данных, которые помогут улучшить процессы.
Это всего лишь малая часть суеверий и заблуждений о больших данных. Big Data — не волшебная палочка. Это инструмент, который в руках умелого аналитика поможет правильно выстроить ваши бизнес-процессы.
Нетология проводит набор на курсы по Big Data:
Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
Формат занятий: онлайн.
Подробности по ссылке > http://netolo.gy/dAZ
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
Подробности по ссылке > netolo.gy/dA0
Big Data в последнее время стали трендом. Но что это такое, понятно не всем.
Многие думают, что большие данные — это либо просто огромный массив данных, либо простой и дешевый способ их хранения.
Большие данные вовсе не предмет, а совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов. Это технологии, которые помогают решать важные задачи для бизнеса и науки. Из-за непонимания сути технологии возникли мифы, которые я попыталась развенчать в этой статье.
Миф 1. Машины на основе Big Data заменят людей
Миф основан на статистике, которая говорит, что около 80% рабочих задач можно автоматизировать. Это большая проблема с точки зрения образования: огромному количеству кадров надо будет переучиваться на другие профессии. В чем-то этот миф прав. Многим людям придется отказаться от текущей деятельности. Но кардинальной безработицы не будет.
Новые области знаний рождают новые профессии.
Например, если мы станем проектировать систему эффективной таргетированной рекламы с использованием Big Data, то потребуется специалист в новой области знаний на пересечении математики и маркетинга. Именно он будет следить за работой системы и исправностью механизма. Сейчас на рынке уже начинают появляться такие люди на позиции «Data Management Platform Operator».
Контролировать и мониторить процессы всегда должен человек.
Не стоит бояться, что люди останутся без работы. Появятся другие профессии, как это было много раз в истории человечества. Ведь и печатный станок когда-то изменил историю книгопечатания и сделал ненужной перепись книг.
Миф 2. Данные нужно собирать в одном месте
Необходимость обучения алгоритмов ведет к тому, что появляются компании и сервисы, которые агрегируют данные в одном месте. Это может вызвать проблемы с безопасностью и доступом к пользовательской информации.
Агрегация данных для обучения искусственного интеллекта, алгоритмов и машин уже перестала быть настолько важной, как прежде. Сейчас корпорации вроде Google и Apple активно работают над тем, чтобы сделать свои устройства частью распределенной сети машинного обучения.
Google по своим устройствам имеет одну сеть, которая работает одновременно. Apple идет по его стопам в области новых технологий на основе больших данных. Например, в патенте Google «Federated Learning» все построено на распределенном обучении. Данные с телефона не утекают в определенный Data-центр, а приезжает модель, обучается и начинает коммуницировать с другими моделями мобильных телефонов или через общий хаб. Таким образом сохраняется приватность.
Модель — это алгоритм, который может быть сложным или простым, но на выходе будет получен ответ на интересующий нас вопрос. Его можно задать математически формулами или словами. В принципе, даже наши юридические законы — это модель, которая позволяет классифицировать действия человека на приемлемые (ненаказуемые) и неприемлемые (наказуемые).
Моделью может быть набор формул для описания физического феномена, а могут быть правила языка, делящие многообразия слов и словосочетаний на корректные (грамотные) и некорректные (безграмотные). Если обобщить, не прибегая к строгим математическим формулировкам, то модель — это формализуемый критерий, который мы получаем на основе тренировки на имеющихся данных.
Миф 3. Big Data нужны всем
Есть области знаний, где приходится сталкиваться с большим количеством данных для обработки. Но не всегда Big Data дают ощутимый результат.
Компания Gartner провела исследования, какие кейсы наиболее популярны в различных индустриях. Все данные были представлены в виде тепловой карты кейсов, реализованных в бизнесе. Чем краснее квадратик (чем больше процент), тем больше из опрошенных компаний реализовали кейсы на основе Big Data у себя в бизнесе.
Как видно из исследования, больше всех кейсов реализовано в области маркетинга, таргетирования и customer experience. То есть в самой актуальной области клиентской аналитики и работы с клиентами — в сфере продаж b2c. Меньше всего кейсов реализовали в государственном секторе, но область эффективности процессов для этого сектора наиболее актуальна. Сфера новых продуктов пока остается для этого сектора не существенной.
А вот такой опрос проводил Tech Pro Research:
Интересно, что в области образования и здравоохранения большие данные оказались не так популярны. А вот финансовые и государственные структуры, инжиниринг и ИТ активно пользуются этими методами. Причем телеком — самая популярная сфера для внедрения технологий Big Data.
Big Data не нужны, если в вашей компании:
- сотрудники в состоянии обработать и автоматизировать данные по клиентам с помощью обычных CRM-систем;
- планирование, учет и контроль бизнес-процессов вполне реализуем с помощью ERP-систем;
- раньше объединяли данные из различных источников информации, обрабатывали их, оценивали полученный результат с помощью BI-систем и не испытывали со всем вышеперечисленным никаких трудностей.
Миф 4. Big Data подходят только большим компаниям
Еще один миф, с успехом развенчанный показательными успешными кейсами. Он основан на том, что в сфере среднего или малого бизнеса сам сбор данных может стать проблемой.
Такие системы, как Google Analytics или Яндекс.Метрика используются исключительно для оценки посещаемости ресурса, и никаких дополнительных отчетов с их помощью не формируется. Многие компании до сих пор хранят свои данные в старом добром Excel, и понятно, что в этом случае говорить об использовании методов Big Data пока рано. В российском ИТ в основном все ссылаются на те же Google Analytics, простейшую систему с использованием больших данных, но эффективную для сбора и систематизации данных. Некоторые успешно пользуются Retail Rocket — платформой для мультиканальной персонализации интернет-магазинов на основе Big Data.
Также для жаждущих попробовать высокие технологии существуют биржи данных, где даже небольшие компании могут себе позволить приобретать данные, вокруг которых можно строить бизнес или улучшать организационные и маркетинговые процессы.
На Западе эта тема более активно обсуждается. В пример приводятся сервисы Followerwonk, YouTube Analytics и Tweriod. Некоторые представители малого и среднего бизнеса успешно пользуются облачными решениями, например, платформой Amazon, построенной специально для вычислений на основе Big Data.
Есть компании, которые идут еще дальше и заводят собственные инфраструктуры, например, Hadoop — проект с открытым исходным кодом, который выступает как хранилищем петабайт данных, так и используется для надежных, масштабируемых и распределенных вычислений.
Если малый и средний бизнес хочет расширить объемы задач в исследовательских и производственных целях, то использование Big Data позволит не только систематизировать данные, но и увеличить скорость их обработки.
Миф 5. Все данные должны быть обработаны
Этот миф часто встречается, когда необходимо построить модель из распределенной файловой системы. Поставщики решений утверждают, что «все данные должны быть обработаны». Здесь кроется противоречие. Между количеством обработанной информации и результатом работы нет взаимосвязи. Увеличение объема обработанных данных не влияет на увеличение точности итоговой модели.
Общеизвестная теория, построенная на математических исчислениях, показала, что лучшие результаты мы получаем, когда строим модели из небольших сегментов, специально подобранных под цель назначения модели.
С точки зрения математики каждый объект выборки имеет равную вероятность попасть в случайную подвыборку для обучения модели. И её точность будет зависеть не от количества элементов, а от качества выборки. Из нескольких тысяч ответов на некий опрос, получается построить очень точный прогноз по всему результату.
Больше не значит лучше.
Реальная значимость Big Data не в том, чтобы обработать как можно больше данных, а в том, чтобы весь объем данных был сегментирован и разбит на кластеры, и в построении большого количества моделей для небольших кластеров.
Миф 6. Big Data дают мгновенный и волшебный результат
Этот миф распространен в компаниях, которые только начинают использовать большие данные. Недостаточно только рассчитать рекомендацию, например, какой продукт на кого таргетировать, или какой продукт с каким нужно поставить. Важно уметь делать саму расстановку. На этом шаге многие проекты останавливаются.
С Big Data необходимо много работать. Это подразумевает создание сложного проекта, сбор данных, создание инфраструктуры, проектирование модели и затем поиск необходимых данных, которые помогут улучшить процессы.
Главная задача — встроить модели в бизнес-процессы в продакшене и выгодно использовать найденные решения.
Это всего лишь малая часть суеверий и заблуждений о больших данных. Big Data — не волшебная палочка. Это инструмент, который в руках умелого аналитика поможет правильно выстроить ваши бизнес-процессы.
От редакции Нетологии
Нетология проводит набор на курсы по Big Data:
1. Программа «Big Data: основы работы с большими массивами данных»
Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
- введение в историю и основы технологии;
- способы сбора больших данных;
- типы данных;
- основные и продвинутые методы анализа больших данных;
- основы программирования, архитектуры хранения и обработки для работы с большими массивами данных.
Формат занятий: онлайн.
Подробности по ссылке > http://netolo.gy/dAZ
2. Программа «Data Scientist»
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
- экспресс-обучение основным инструментам, Hadoop, кластерные вычисления;
- деревья решений, метод k-ближайших соседей, логистическая регрессия, кластеризация;
- уменьшение размерности данных, методы декомпозиции, спрямляющие пространства;
- введение в рекомендательные системы;
- распознавание изображений, машинное зрение, нейросети;
- обработка текста, дистрибутивная семантика, чатботы;
- временные ряды, модели ARMA/ARIMA, сложные модели прогнозирования.
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
Подробности по ссылке > netolo.gy/dA0
Поделиться с друзьями
nick1990spb
Простите, но это самая бесполезная статья на хабре с тэгом «big data»…