
Чему уже научились сверточные искусственные нейронные сети (ИНС) и как они устроены?
1. Предисловие
Такие статьи принято начинать с экскурса в историю, дабы описать кто придумал первые ИНС, как они устроены и налить прочую, бесполезную, по большей части, воду. Скучно. Опустим это. Скорее всего вы представляете, хотя бы образно, как устроены простейшие ИНС. Давайте договоримся рассматривать классические нейронные сети (типа перцептрона), в которых есть только нейроны и связи, как черный ящик, у которого есть вход и выход, и который можно натренировать воспроизводить результат некой функции. Нам не важна архитектура этого ящика, она может быть очень разной для разных случаев. Задачи, которые они решают — это регрессия и классификация.
2. Прорыв
Что же такого произошло в последние годы, что вызвало бурное развитие ИНС? Ответ очевиден — это технический прогресс и доступность вычислительных мощностей.
Приведу простой и очень наглядный пример:
2002:

Earth Simulator – один из самых быстрых в мире вычислительных комплексов. Он был построен в 2002 году. До 2004 года эта машина оставалась самым мощным вычислительным устройством в мире.
Стоимость: $350.000.000.
Площадь: четыре теннисных корта,
Производительность: 35600 гигафлопс.
2015:

NVIDIA Tesla M40/M4: GPU для нейронных сетей
Стоимость: $5000
Площадь: помещается в карман,
Производительность: До 2,2 Терафлопс производительности в операциях с одинарной точностью с NVIDIA GPU Boost
Итогом такого бурного роста производительности стала общедоступность ресурсоемких математических операций, что позволило испытать давно зародившиеся теории на практике.
3. Операция свертки.
Одной из ресурсоемких в реализации теорий, а точнее методом, который требует очень больших мощностей, является операция свертки.
Что же это такое? Попробуем разложить всё по полочкам:
Котики
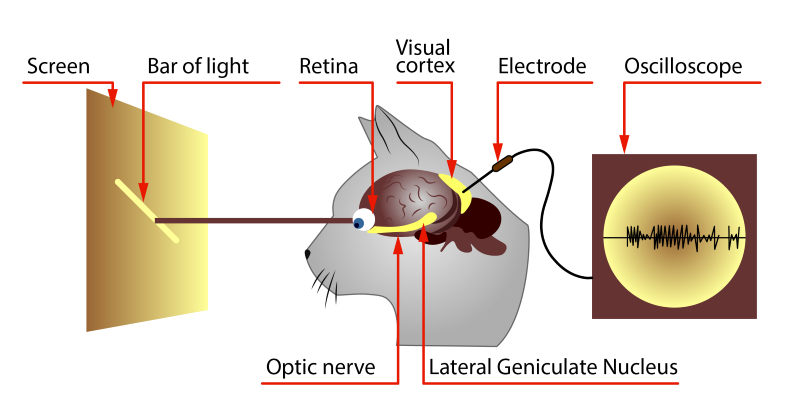
Экспериментируя на животных, David Hubel и Torsten Wiesel выяснили, что одинаковые фрагменты изображения, простейшие формы, активируют одинаковые участки мозга. Другими словами, когда котик видит кружочек, то у него активируется зона “А”, когда квадратик, то “Б”. И это сподвигло ученых написать работу, в которой они изложили свои идеи по принципам работы зрения, а затем они это подтвердили опытами:
Вывод был примерно такой:
В мозгу животных существует область нейронов, которая реагирует на наличие определенной особенности у изображения. Т.е. перед тем как изображение попадает в глубины мозга, оно проходит так называемый фича-экстрактор.
Математика

Графические редакторы давно используют математику для изменения стиля изображения, но как оказалось, те же самые принципы можно применить и в области распознавания образов.
Если мы рассмотрим картинку как двумерный массив точек, каждую точку — как набор значений RGB, а каждое значение — это просто 8-ми битовое число, то получим вполне себе классическую матрицу. Теперь возьмем и придумаем свою, назовем её Kernel, матрицу, и будет она такой:

Попробуем пройтись по всем позициям, от начала и до конца матрицы изображения и перемножить наш Kernel на участок с таким же размером, а результаты сформируют выходную матрицу.
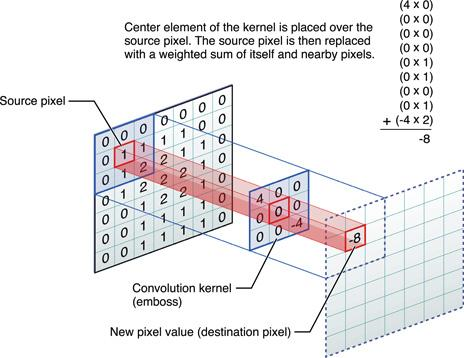
Вот что мы получим:

Взглянув на секцию Edge Detection мы увидим, что результатом являются грани, т.е. мы легко можем подобрать такие Kernel, которые на выходе будут определять линии и дуги разной направленности. И это именно то что нам нужно — фичи изображения первого уровня. Соответственно, можно предположить, что применив те же действия еще раз, мы получим комбинации фич первого уровня — фичи второго уровня (кривые, окружности и т.п.) и это можно было бы повторять очень много раз, если бы мы не были ограничены в ресурсах.
Вот пример наборов Kernel матриц:


А вот так выглядит фича-экстрактор от слоя к слою. На пятом слое уже формируются очень сложные фичи, например глаза, образы животных и прочего вида объекты, на которые и натренирован экстрактор.

Сначала разработчики пытались сами подобрать Kernel, но вскоре выяснилось, что его можно получить обучением, и это намного эффективнее.
Подводные камни
Поняв, как работают мозги котов и как применить математический аппарат, мы решили создать свой фича-экстрактор! Но… подумав сколько фич нужно извлекать, сколько уровней извлечения нам надо и, прикинув, что для нахождения сложных образов мы должны анализировать сочетания фич “каждая с каждой” мы поняли, что памяти для хранения этого всего нам точно не хватит.
На помощь вновь пришли математики и придумали операцию объединения (pooling). Суть ее проста — если в определенной области присутствует фича высокого уровня, то можно откинуть другие.

Такая операция не только помогает экономить память, но и избавляет от мусора и шумов на изображении.
На практике чередуют слои свертки и объединения несколько раз.
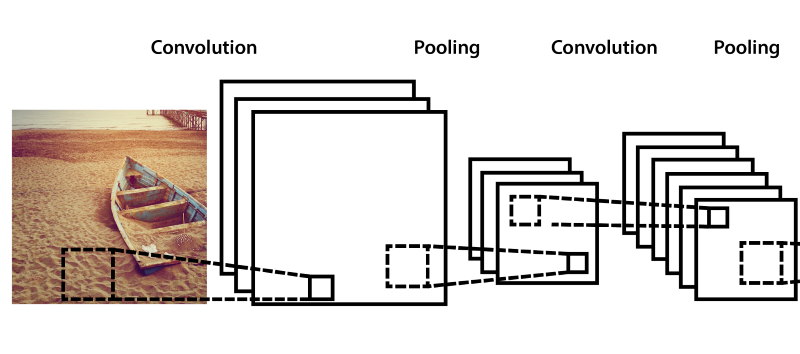
Финальная архитектура
Применив всё, что описано выше, можно получить вполне рабочую архитектуру фиче-экстрактора, не хуже, чем у кошки в голове, более того, в настоящее время точность распознавания компьютерного зрения достигает в отдельных случаях >98%, а, как подсчитали ученые, точность распознавания образа человеком составляет в среднем 97%. Будущее пришло, Скайнет наступает!
Вот примеры нескольких схем реальных фича-экстракторов:
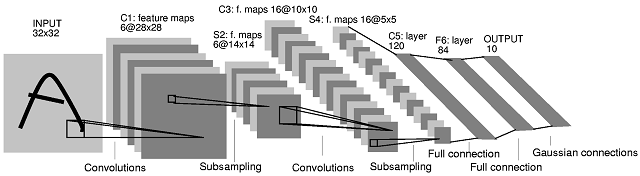

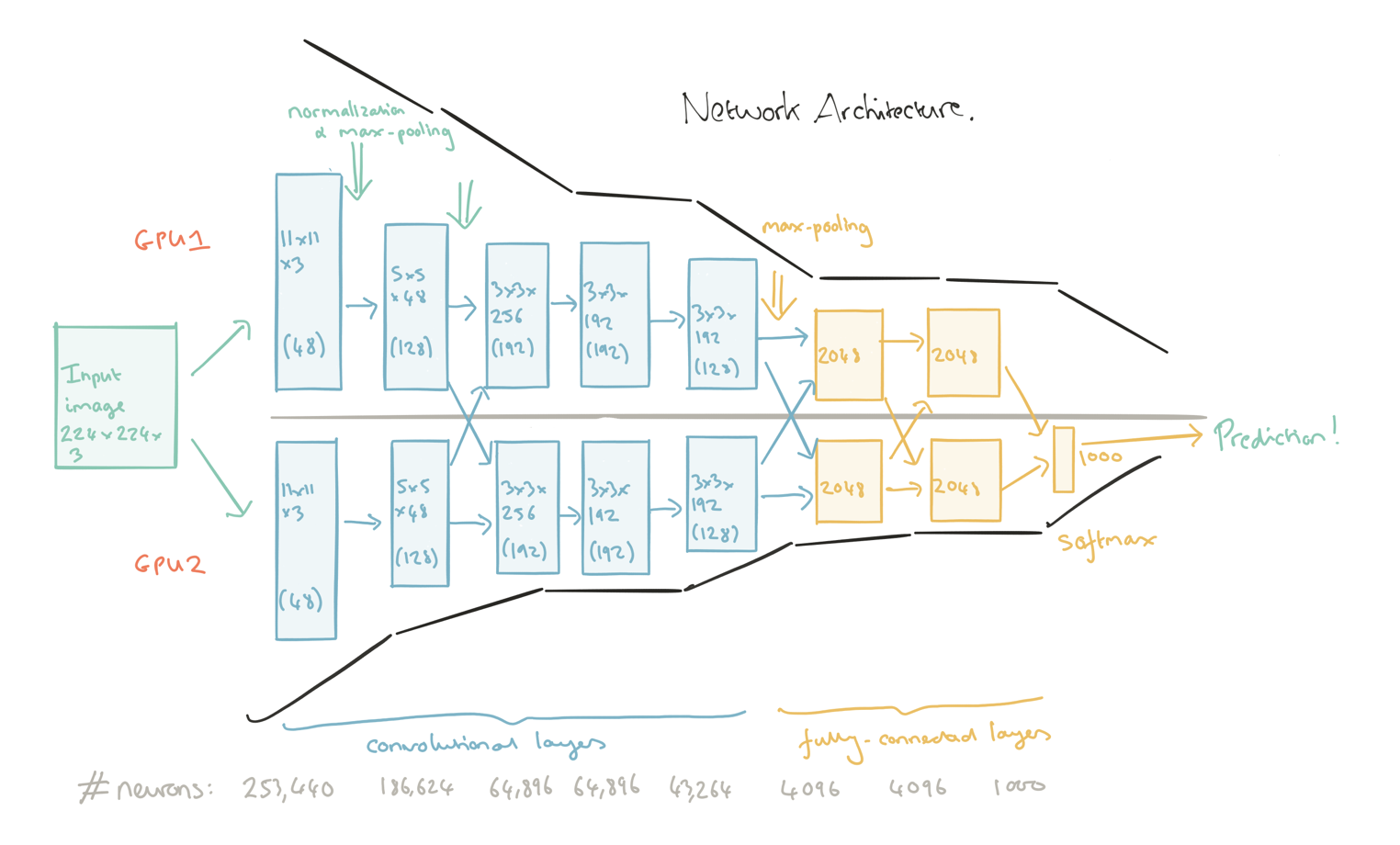
Как вы видите, на каждой схеме в конце присутствуют еще 2-3 слоя нейронов. Они не являются частью экстрактора, они — наш черный ящик из предисловия. Только вот на вход ящика при распознавании, подаются не просто цвета пикселей, как в простейших сетях, а факт наличия сложной фичи, на которую тренировали экстрактор. Ну вам же тоже проще определить что перед вами, например, лицо человека, если вы видите нос, глаза, уши, волосы, чем если бы вам назвали по отдельности цвет каждого пикселя?
Это видео просто шикарно демонстрирует как работают фича-экстракторы:
4. Кто всем заправляет?
1. Tensorflow
Свободная программная библиотека для машинного обучения. Практически всё, что делает сервисы Google такими умными использует эту библиотеку.
Пример того, что дает Inception-v3 (классификатор изображений от Google, построенный на Tensorflow) и натренированный на ImageNet наборе изображений:

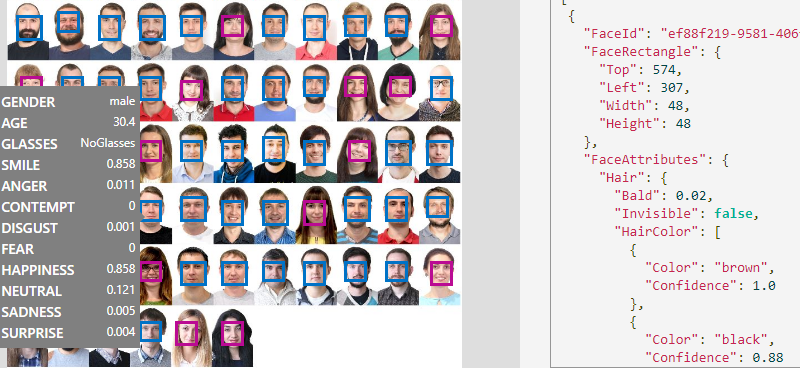
2. MS Cognitive Services (The Microsoft Cognitive Toolkit)
Компания Microsoft пошла другой дорогой, она предоставляет готовые API, как за деньги, так и бесплатно, с целью ознакомления, но лимитируя количество запросов. API — очень обширные, решают десятки задач. Это всё можно попробовать прямо на их сайте.
Можно, конечно, использовать MSCT так же как и TF, там даже синтаксис и идея очень похожи, оба описывают графы с заглушками, но ведь зачем тратить время, когда можно использовать уже обученные модели?
3. Caffe (Caffe2)
Открытая библиотека, фрэймворк на котором можно построить любые архитектуры. До недавнего времени был самым популярным. Существует множество готовых (натренированных) бесплатных моделей сетей на этом фрэймворке.
Яркий пример применения Caffe:
Rober Bond, используя натренированную на распознавание котов сеть, соорудил автоматизированную прогонялку котов с его газона, которая при обнаружении кота на видео, поливает его водой.

Существует еще много разных, популярных в свое время библиотек, оберток, надстроек: BidMach, Brainstorm, Kaldi, MatConvNet, MaxDNN, Deeplearning4j, Keras, Lasagne(Theano), Leaf, но лидером считается Tensorflow, в силу своего бурного роста за последние два года.
5. Области применения (вместо заключения)
В конце статьи хочу поделиться некоторыми яркими примерами использования сверточных сетей:
| Область применения | Коментарии | Ссылки |
|---|---|---|
| Распознавание рукописного текста | Точность человека — 97.5% CNN — 99.8% | Визуализация образов натренированной сети в TF, JS интерактивная визуализация работы свертки, MNIST |
| Компьютерное зрение | CNN распознает не только простые объекты на фото, но и эмоции, действия, а еще анализирует видео для автопилотов (семантическая сегментация). | Эмоции, Семантическая сегментация, Skype Caption бот, Google Image поиск |
| 3D реконструкция | Создание 3D моделей по видео | Deep stereo |
| Развлечение | Стилизация и генерация картинок | Deep dream, Deep style, Перенос стиля на видео, Генерация лиц, Генерация различных объектов |
| Фото | Улучшение качества, оцветнение | Face Hallucination, Colorizing |
| Медицина | Создание лекарств | |
| Безопасность | Обнаружение аномального поведения (Свертка + Реккурентрость) | Пример 1, 2, 3 |
| Игры | В итоге сеть играет круче профессионала, выбивая дырку и специально загоняя туда шар. | Atari Breakout |
Комментарии (20)

mwizard
21.07.2017 03:12+4В статье нет ни слова о копировании человеческого мозга.

verych
21.07.2017 11:06Разве операция свертки это не копирование принципов работы мозга?

rprokop
21.07.2017 15:37+3«копирование мозга» в заголовке воспринимается как клонирование. Лучше написать моделирование, имитация и т.д.
sasha1024
21.07.2017 19:53+1Тоже подумал про копирование в смысле переноса сознания, а не в смысле подражания в некоторых аспектах (потом решил, что, наверное, специально сделали такой броский заголовок просто для привлечения внимания).

SADKO
21.07.2017 20:29+1Не разу, кроме того ЕМНИП свёртки и сопутствующий мат аппарат придумали за долго до того как начали извлекать полезные знания из мозга котиков :-) И практически применять эти знания для «машинного зрения» тоже начали за долго до, в СССР даже специальная лампа для этого была, я об этом как-нибудь напишу историю…
Вы правы в том, что вычислительные мощности подогрели интерес к ИНС, но я бы не назвал это развитием, а скорее масштабированием, которое расширяет возможности но не решает принципиальных проблем.
Nakosika
21.07.2017 10:44+2"Поняв, как работают мозги котов" ох, если бы все было так просто...

Steely
21.07.2017 18:28ничего сложного, нейронная сеть залезла в коробку
Nakosika
21.07.2017 20:20Да-да, конечно. А потом она взяла и научилась ходить, мяукать, вылизываться, метить территорию, бояться веника, ловить мышей и приносить их котятам, сидеть в засаде, переворачиваться при падении, узнавать хозяев, ластиться, бояться воды, плавать, орать по ночам, ссать в ботинки обидчикам и т.п. И все это без обучения — с первого раза. По мне так слишком много для сети, пусть и самой мощной.
sasha1024
21.07.2017 21:16+1Как по мне, так половина из того, что Вы назвали — врождённое.
Nakosika
21.07.2017 21:24А что значит врожденное? Как оно работает? А почему человек не может бегать на третьей неделе со своим мегамозгом а котам даже родителей видеть не нужно? Тут вопросов гораздо больше чем у науки есть ответов, а теории о нейросетях, уж извините, не объясняют вообще ничего.
sasha1024
21.07.2017 21:46Ну то есть проявляться-то инстинкты могут по-разному (тюнинг — приобретённое), но сами акценты в развитии навыков (орать, бегать, прыгать, метить, ловить — надо; рыть нору, летать и строить карту звёздного неба — не надо), а во многих случаях даже частично и сами способы проявления — захарокожены (причём в некоторых случаях вполне себе с hardware'ными костылями).
То, что теории о нейросетях что-то объясняют, я и не говорил (а, ну да, вот теперь мне стал понятнее посыл Вашего исходного сообщения).
Про человека — отдельная тема. Во-первых, у человека, AFAIK, гораздо меньше захардкожено (по крайней мере, тех навыков, которые полезны в современной жизни; возможно, держаться за мамину шерсть, бегать на четвереньках и бояться змей как раз закардкожено — да вот толку; а вот у котов даже частично ходьба захардкожена). Во-вторых, человек, возможно, дольше достигает относительной зрелости (то есть, допустим, даже если предположить, что ходьба на двух ногах в нас захардкожена — что не так — то кости, мышцы и вестибюлярный аппарат готовы к этому далеко не сразу; ну и коты, собственно, тоже не с первого дня ходят, глаза даже не сразу открываются).


{kind=link}
{kind=link}
{kind=link}
devalone
21.07.2017 18:53+2в настоящее время точность распознавания компьютерного зрения достигает в отдельных случаях >98%, а, как подсчитали ученые, точность распознавания образа человеком составляет в среднем 97%
Да кем себя возомнили эти железки? Часто бывает, что гуглокапча, где нужно распознавать образы, мне не верит, когда я прохожу её правильно, но отмечаю в том числе и те квадраты, где попал лишь небольшой кусочек машины.
TrueZarathustra
24.07.2017 09:23Спасибо, как раз начал разбираться с этой темой и уровень понимания примерно на уровне возможности чтения данной статьи. Никак не мог понять, откуда берутся первые фильтры. В статье увидел:
Сначала разработчики пытались сами подобрать Kernel, но вскоре выяснилось, что его можно получить обучением, и это намного эффективнее.
может кто-то пояснить чуть подробнее? Такой Kernel можно собрать универсальный или под каждую задачу собирается свой? Если это базовые примитивы, то зачем им каждый раз обучаться? Или их слишком много, чтобы они подходили под все задачи и под каждую задачу лучше выбрать свое подмножество?
И еще, если такой комплект фильтров получается при обучении, то как достигается, что все они запоминают разные примитивы? Почему не получается, что все фильтры обучились распознавать, условно, только вертикальные линии?verych
24.07.2017 09:48Когда я сделал свою первую сеть на Tensorflow, она была корявой, но на 10 классах изображений я смог добиться 50% точности распознавания (было примерно по 1000 образов на класс). Тогда мне стало интересно визуализировать первый слой фича-экстрактора. Сделал. Там было что-то похожее на шумы. Я задумался, почему же там нет таких красивых картинок как в примерах? Стал искать инфу, оказалось что те примеры и были сгенерены человеком, а при обучении всего лишь немного видоизменяется рандомно инициализированная матрица. Тогда я поставил эксперимент, применив к первому уровню фильтры со второй картинки Kernel в статье. Результат остался примерно таким же. Может только скорость обучения немножечко выросла.
Я сделал для себя вывод:
не стоит пытаться подбирать кернелы, это занимает много моего времени, к тому же их размер очень сильно зависит от размера входа. При размере 28*28 — это матрица 3*3 или 5*5, при 256*256 — лучше работает 7*7. Можно, конечно иметь разные заготовленые размеры, но зачем? На скорость обучения это хоть и влияет, но не так чтоб прям сильно. Да и для каждой задачи лучше подбирать оптимальное количество кернелов. Для MNIST достаточно 16-ти, а то и 8-ми, для сложных образов 32 и выше.
Если не хочется тратить время на это, а хочется взять что-то готовое, то как вариант взять Inception-v3, её фича экстрактор очень даже хорош, и добавить нужных классов без переобучения экстрактора, такой метод называется fine-tuning.
Вот линка на инструкцию:
https://www.tensorflow.org/tutorials/image_retraining
Dron_Dronych
24.07.2017 09:23+1В целом спасибо за статью. Неплохо было бы все-таки написать свое определение операции свертки. А то оно как-то размылось по тексту и выводы, которые читатель делает после прочтения, могут оказаться неверными.
novoselov
Не совсем корректное сравнение Earth Simulator помимо вычислительной мощности в 36 TFLOPS включал 10 TB памяти, 700 TB дискового пространства, 1.6 PB на лентах и сеть с пропускной способностью 10 TB/s и это в 2002 году!

Сравнивать стоит с чем-то хоть отдаленно похожим, например с персональным суперкомпьютером NVidia DGX Station
Включает 4X Tesla V100 мощностью 480 TFLOPS с 64 GB GPU и 256 GB DDR4, 1.92 TB SSD и стоимостью $69 000 :)
P.S. на картинке кстати Earth Simulator 2, а Earth Simulator выглядит как-то так
babylon
Господа, включите мозг — статья это только ПЕРЕВОД. Жду проприетарных рассуждений на тему градуальности, бэктрекинга, отсечений, ритмов, то бишь циклов и… свёрток. Короче, Prolog — в студию!