

Краткий экскурс в генетику. Если вдруг вы помните, в 2003 г. было сделано сенсационное заявление: ученые, наконец, расшифровали геном человека. Геном построен из ДНК, а ДНК – это исходный код организма. ДНК представляет собой двойную цепочку, состоящую из 4-х видов нуклеотидов, которые повторяются в геноме человека порядка 3 млрд. раз. Так же, как в битах зашифрована вся информация на вашем компьютере, в нуклеотидах зашифрована инструкция о сборке всех белков человеческого тела. То есть зная, в какой последовательности расположены нуклеотиды в ДНК, мы теоретически можем собрать все необходимые белки и получить модель человека. Так вот в стандартном понимании ученые не расшифровали ДНК, а просто перевели химическую последовательность в набор нулей и единиц на компьютере. Что делать с этим дальше – отдельный разговор. Например, на данный момент нам ясна функция лишь 5% всего массива генома (это кодирование белков). Чем занимаются остальные 95%, можно только предполагать.
В 2003 году стоимость секвенирования ДНК человека составляла около 100 млн долларов. С течением времени эта цифра уменьшалась и сейчас она приближается к тысяче долларов. Вы платите, вашу ДНК секвенируют и отдают вам жесткий диск с 3 ГБ информации – вашим геномом в цифровом виде.
Сегодня на рынке представлено три основных секвенатора. Самый производительный, Hiseq, и его приемник NovaSeq, обеспечивает самое дешевое (флуоресцентное) секвенирование. Один его запуск длится несколько дней, и за это время обрабатываются геномы сразу нескольких человек. Однако сам запуск стоит около десятка тысяч долларов. К слову, и сам прибор стоит порядка $1 млн, а, поскольку устаревает он примерно за 3 года, для того, чтобы он окупился, он должен приносить вам $1000 в день.
Второй прибор появился на рынке буквально прошлым летом. Он называется Nanopore и базируется на очень интересной технологии, когда ДНК секвенируется путем пропускания через нанопору. Самый дешевый вариант Nanopore позиционируется как одноразовый домашний секвенатор и стоит $1000.
Третий прибор – PGM, полупроводниковый секвенатор, который стоит $50 000 у себя на родине и около 10 млн рублей (с доставкой, растаможиванием и т. д.) в России. Процесс секвенирования на нем занимает порядка нескольких часов.
Что ж, десяти миллионов у меня не было, а PGM захотелось. Пришлось сделать самому. Сначала вкратце о том, как происходит полупроводниковое секвенирование. Вся цепочка ДНК делится на фрагменты длиной по 300-400 нуклеотидов, называемые ридами. Затем риды прикрепляются к маленьким сферам и многократно копируются – в итоге на каждой сфере «висит» целый пучок одинаковых фрагментов ДНК. Копирование нужно для усиления сигнала от каждого конкретного рида. Набор разных сфер называется библиотекой ДНК.
Сердцем PGM является одноразовый чип – матрица, похожая на матрицу в фотокамере, только вместо пикселей, реагирующих на свет, здесь pH-транзисторы, реагирующие на изменение кислотно-щелочного баланса. Полученная библиотека ДНК загружается на чип, содержащий 10 млн лунок, на дне каждой из них находится pH-транзистор. В лунку умещается только одна сфера и, следовательно, риды только одного типа (с одной определенной последовательностью нуклеотидов). Далее на чип подаются реагенты таким образом, чтобы ДНК начала себя копировать. А копируется она линейно, то есть нуклеотиды прикрепляются к вновь создаваемой цепочке в том порядке, в котором они стоят в материнской цепочке. Поэтому на чип подается один тип нуклеотидов – и тут же фиксируется изменение pH в некоторых лунках (это значит, что в них произошло присоединение данного нуклеотида). Далее подается другой тип нуклеотидов и фиксируется изменение pH в лунках и т. д. Таким образом, подавая на чип все 4 типа нуклеотидов много раз, мы можем получить информацию о последовательности нуклеотидов в каждом риде. Затем математическими способами прочитанные короткие отрезки собираются на компьютере в единую цепочку. Чтобы собрать ее более-менее уверенно, каждый рид нужно прочесть примерно по 100 раз.
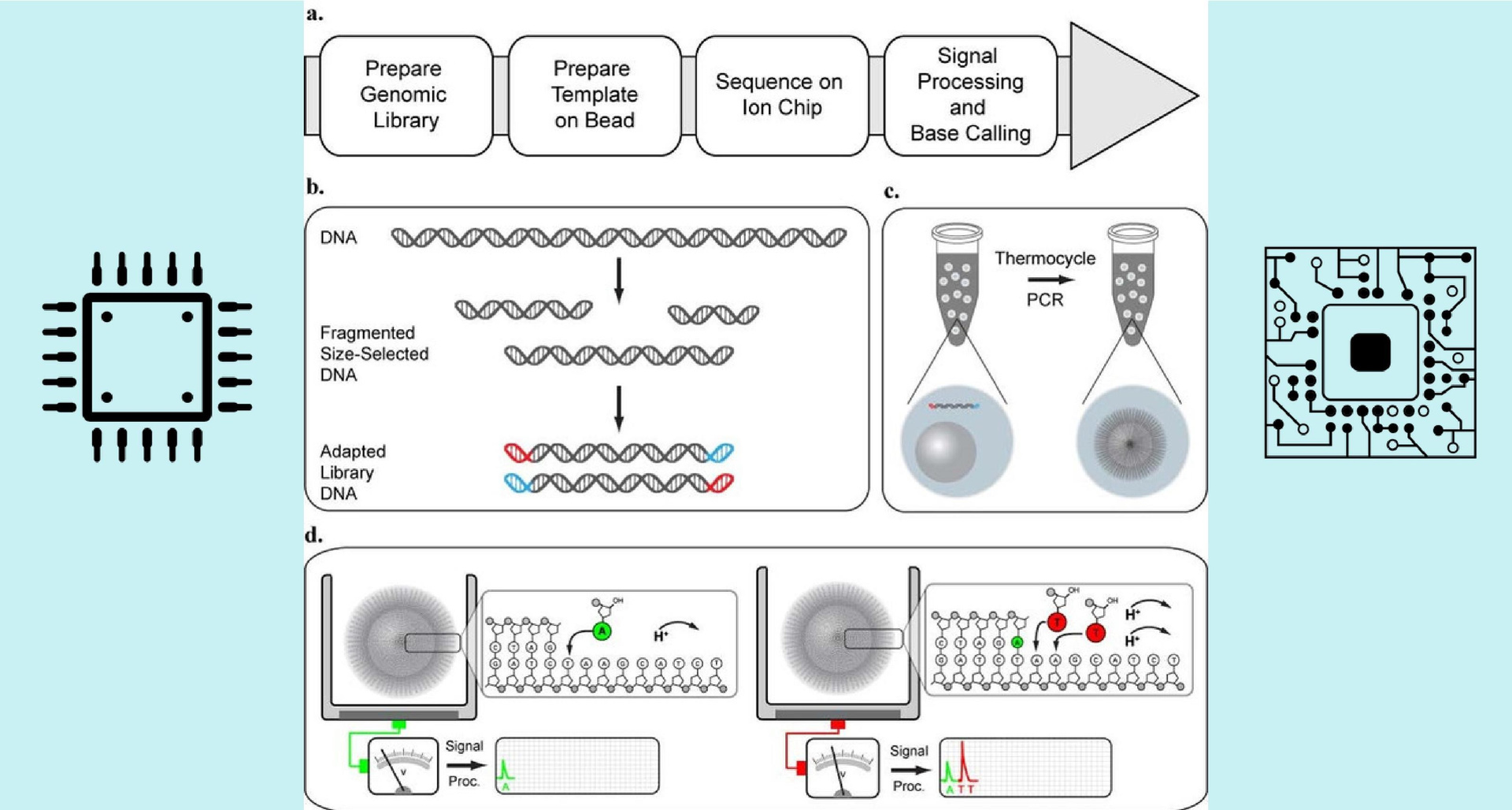
Рис.1. Полупроводниковое секвенирование
Теперь разберемся, из чего состоит сам прибор. Имеется, как мы уже знаем, чип, а также система подачи реагентов и материнская плата. Все секвенирование ведется именно на чипе – остальной аппарат только передает на него определенные сигналы, подает реагенты, считывает с него аналоговые сигналы, оцифровывает их и гонит полученный поток информации на компьютер, где данные накапливаются и обрабатываются.
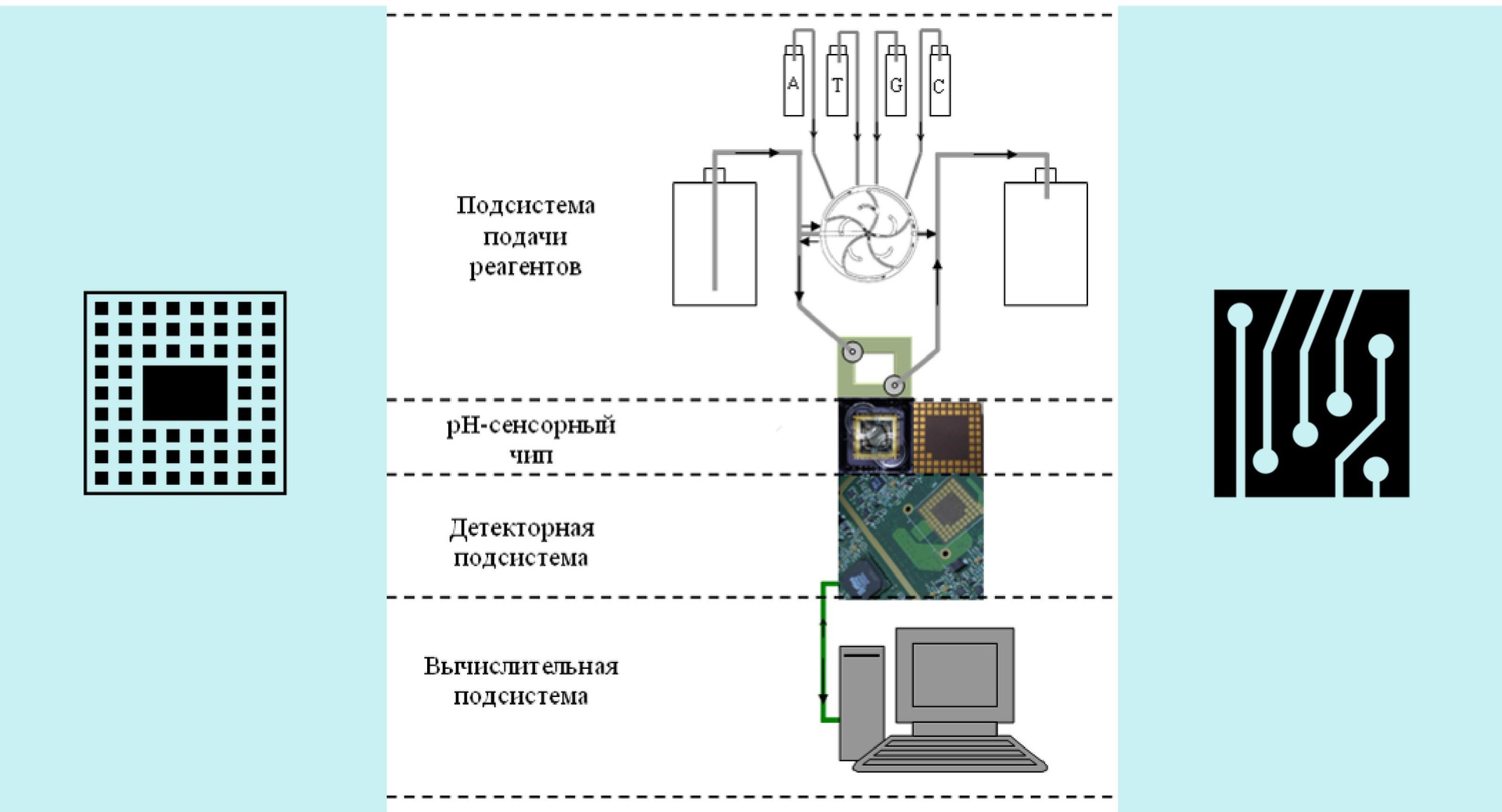
Рис. 2. Устройство секвенатора
Чип позиционируется как одноразовый и после использования выкидывается. Соответственно, там, где работает PGM, такие чипы можно достать бесплатно в любом количестве. Зачем их доставать, спросите вы? Дело в том, что чип мне уже удалось использовать многократно. По сути он вечен: достаточно хорошо промывать его – и можно применять вновь и вновь. По точности работы он ничем не будет отличаться от нового. Сама моя идея заключалась в том, чтобы сделать прибор под этот условно бесплатный чип.
Итак, передо мной встала задача реверс-инжиниринга чипа. Разумеется, никакой документации на заветную микросхему найти было нельзя – производитель не собирался делиться секретами производства, а хотел спокойно продавать свои приборы за $50 000. Для начала я сделал самое очевидное и простое: прозвонил контакты тестером. Стало ясно, где расположены цифровые и аналоговые входы-выходы, питание и прочее. Кое-какую информацию удалось почерпнуть из патентов на чип. Но всего этого, понятно, было недостаточно для создания полноценного продукта. Я еще повозился с чипом, проверял разные свои догадки, поэкспериментировал с подачей сигналов, но никуда принципиально не продвинулся. Пришлось поставить проект на паузу.

Рис. 3. Прозвонка чипа
А затем внезапно на Habrahabr мне попалась статья известного блоггера BarsMonster о том, как он делает реверс-инжиниринг чипов! Воодушевился, написал ему, написал другим энтузиастам, отправил запрос в Киев, где занимались фотографированием чипов. Из Киева ответили, что полировать по слоям они не умеют, могут только отснять верхний слой, а так как мой чип – многослойный, будет не понятно, куда идут дорожки от контактов. Потом познакомился с одним американцем, который тоже занимается реверс-инжинирингом чипов, послал ему свои микросхемы, но и тут дальше фотографирования верхнего слоя дело не пошло. Затем наткнулся в интернете на статью про тех, кто смог отреверсить чип Sony PlayStation и пр. («Слава героям!» и вот это все, если кто в курсе). Решил написать им с вопросами, нашел их ники – и тут же понял, что один из них мне знаком. Недавно товарищ свел меня со своим другом, который «тоже занимается генетикой на любительском уровне», мы пообщались с этим другом в Skype и на этом диалог закончили. И вот я понимаю, что мой новый приятель – мегакрутой мастер реверс-инжиниринга чипов. Тут же написал ему. Однако выяснилось, что, хоть помочь он и готов, у него нет микроскопа. Снова тупик.
А через несколько месяцев нужный микроскоп нашелся в соседней лаборатории! Правда, встроенная в него камера была ужасной, я фотографировал на мобильный телефон через окуляр и получал снимки вот такого качества:

Рис. 4. Чип под микроскопом
Затем на последний Новый год отличный микроскоп за 130 тыс. появился у меня на работе (я – специалист по квантовой криптографии). Мечты сбываются. Наконец, я смог нормально сфотографировать чип сверху.
Рис. 5. Мой рабочий микроскоп
А потом… Потом мне все-таки пришлось самому освоить технику его полировки. Трудность полировки заключается в том, чтобы снимать слои металла толщиной порядка 1 микрона – при этом ширина чипа составляет 1 сантиметр. Для сравнения скажу, что это примерно то же, что допустить на 1 км погрешность не более 10 см. Я очень старался. Результаты моих трудов представлены на следующем фото:

Рис. 6. Реверс-инжиниринг под оптическим микроскопом
Довольно хорошо видны нижний кремниевый слой, верхний слой с транзисторами, первый, второй, третий и четвертый слои металла.
Чип состоит из повторяющихся зон (типа сдвиговых регистров), и по таким картинкам было очень удобно его анализировать: сразу становилось ясно, что происходит на разных слоях. Я «отреверсил» самые «нафаршированные» участки с обилием логики, которые многократно повторялись. Но самым сложным оказалось отследить трассы, идущие по всему чипу, понять, какой внешний контакт к чему относится. С новогодних праздников до конца февраля, я, вооружившись новым прекрасным микроскопом, корпел над этой задачей – сидел на работе до десяти ночи, «реверсил», думал. И тут произошло новое чудо: товарищ смог организовать бесплатную фотосъемку чипа по слоям на электронном микроскопе в МИРЭА. «Фотосессия» крохи в 1 кв. см представляла собой 50 ГБ черно-белых фотографий.
Теперь все эти отдельные фотографии нужно было каким-то образом объединить в одну целую картинку. Чуть ли не в тот же день я написал на «питоне» программу, которая генерировала HTML-файл – при его открытии в браузере я получал требуемое. (Кстати, самая старая 10-я Opera справилась с этим лучше всего, рекомендую!) Затем на javascript написал еще одну программу, позволяющую сравнивать слои, плавно переходить между ними, выравнивать их, подбирать масштаб и т. д. Наконец, в моих руках были все инструменты для решения главных задач. Я отследил трассы, пронизывающие чип, и восстановил всю его структуру до последнего транзистора.
Еще одна фотография среза чипа, сделанная под рентгеном (в МИРЭА):
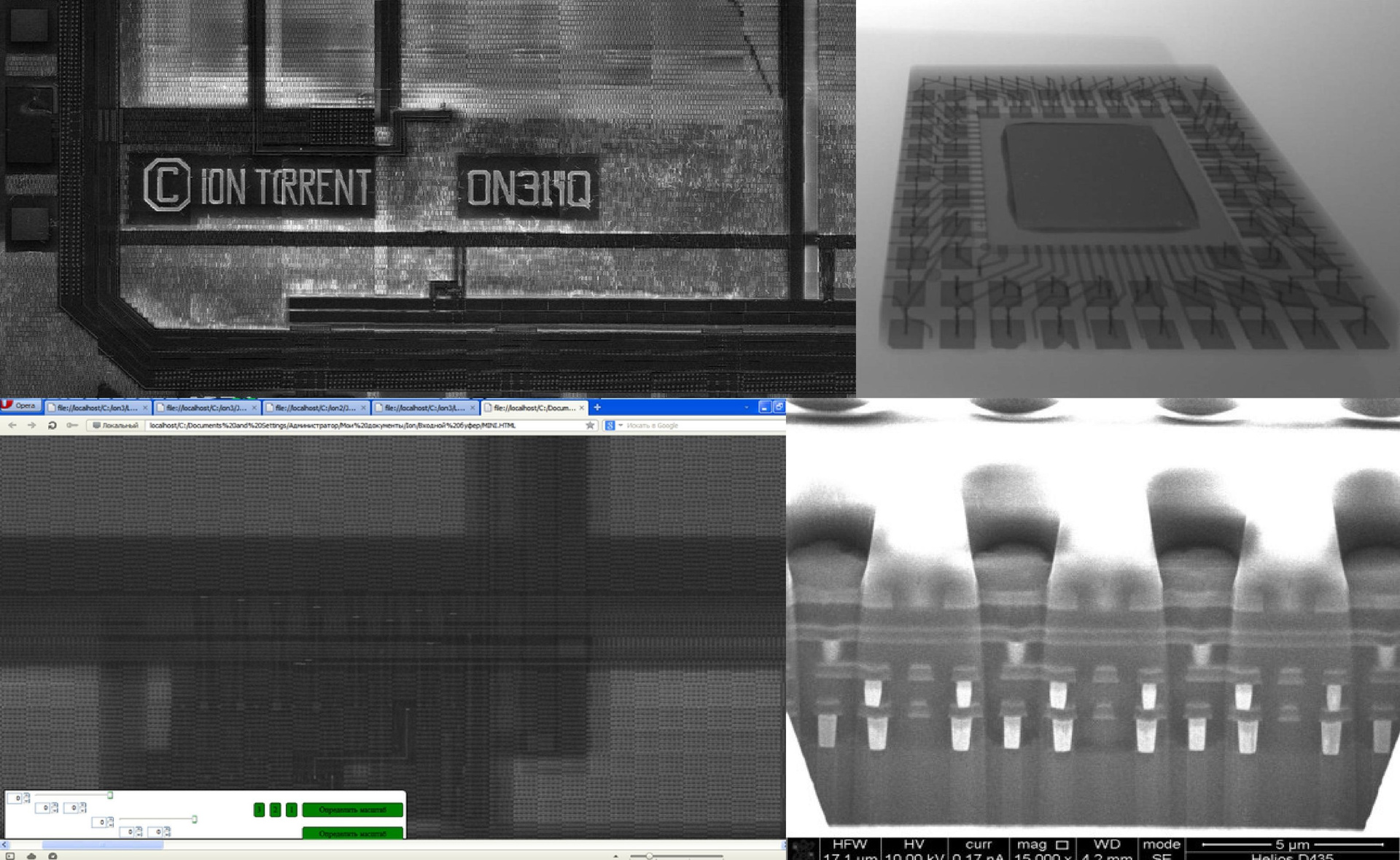
Рис. 7. Съемка под электронным микроскопом
Хорошо видны лунки, куда попадают сферы с ридами. Ниже располагаются три слоя металла, а еще ниже – слой с транзисторами.
Следующим этапом борьбы за светлое будущее стало создание под чип материнской платы. Спроектировал ее и отправил заказ на производство. А пока суд да дело использовал для работы с чипом плату «Марсоход-2» с FPGA. (FPGA – это, грубо говоря, массив из 10 000 универсальных логических элементов; программируя FPGA, мы можем получать любую логическую схему, легко обрабатывающую гигабитные потоки информации.) Прошивку для FPGA я написал сам, а кроме того, для динамического управления системой написал софт, который задает всю конфигурацию для FPGA. Потом вновь образовался полугодовой перерыв (я разводился, ездил в командировку на Байкал, готовил в лаборатории установку, которую демонстрировали Путину). Но в конце концов звезды сошлись: у меня появилось время, приехали готовые платы – и я собрал свою систему.
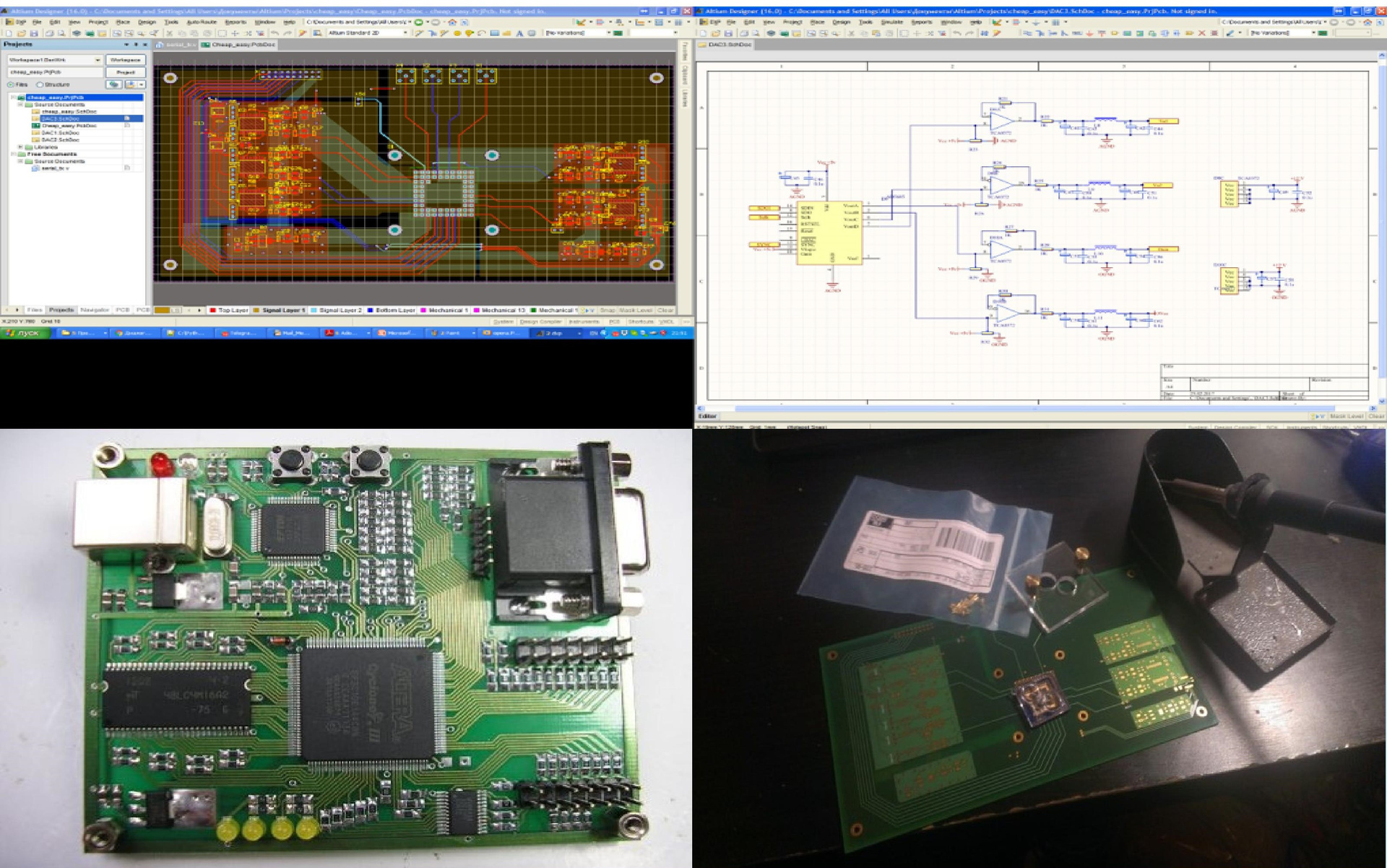
Рис. 8. Создание «железа»
Подал все необходимые сигналы и – о, чудо! – увидел на осциллографе сигнал с чипа. (Осциллограф я купил когда-то за 6 000 рублей на eBay, еще 1 000 стоила прошивка к нему.) На картинке хорошо видны пятна – капельки какого-то реагента.
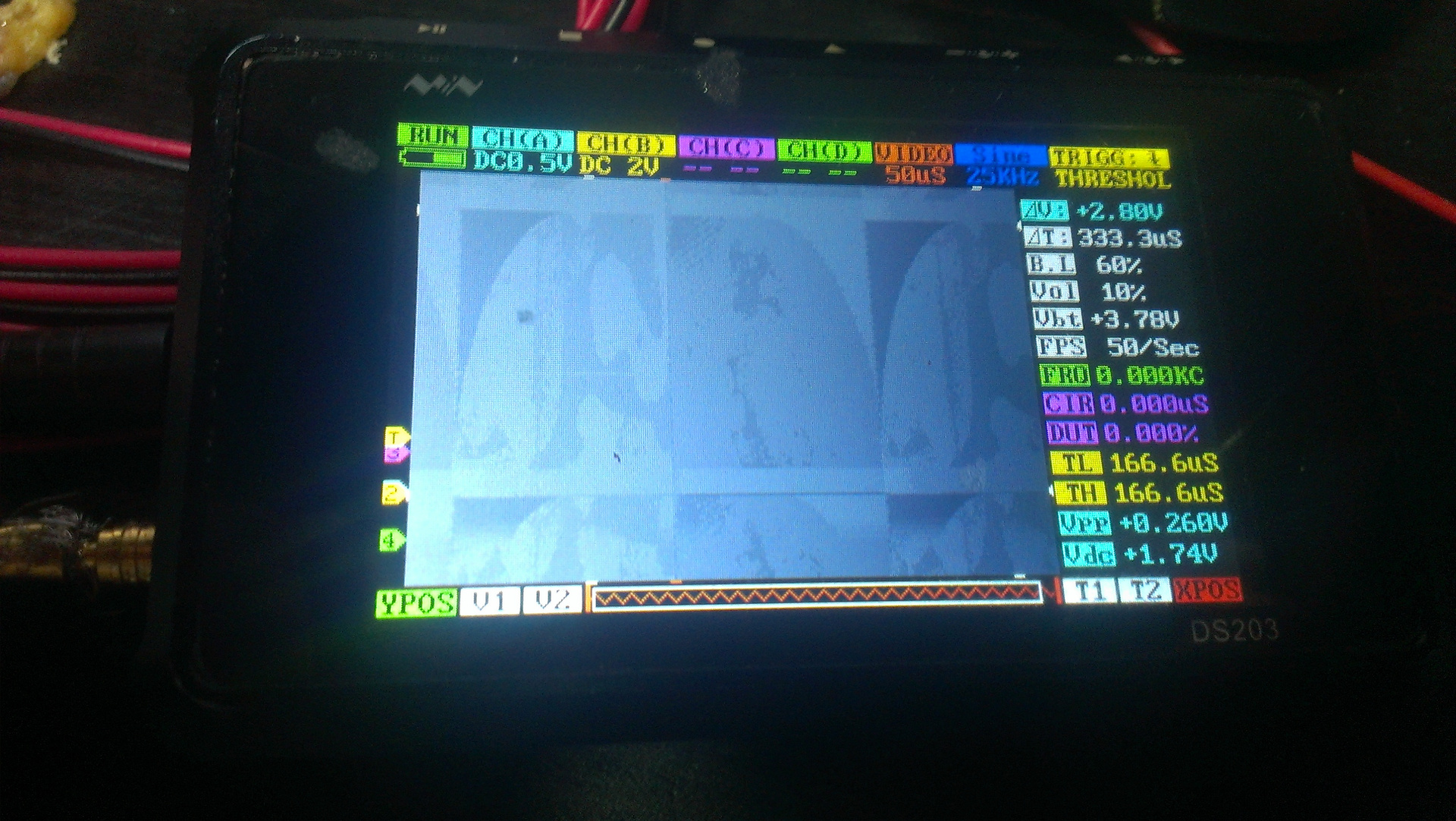
Рис. 9. Сигнал с чипа на осциллографе
Теперь мне нужно было придумать, как оцифровать эту картинку и передать ее на компьютер. Я собрал вот такую установку:
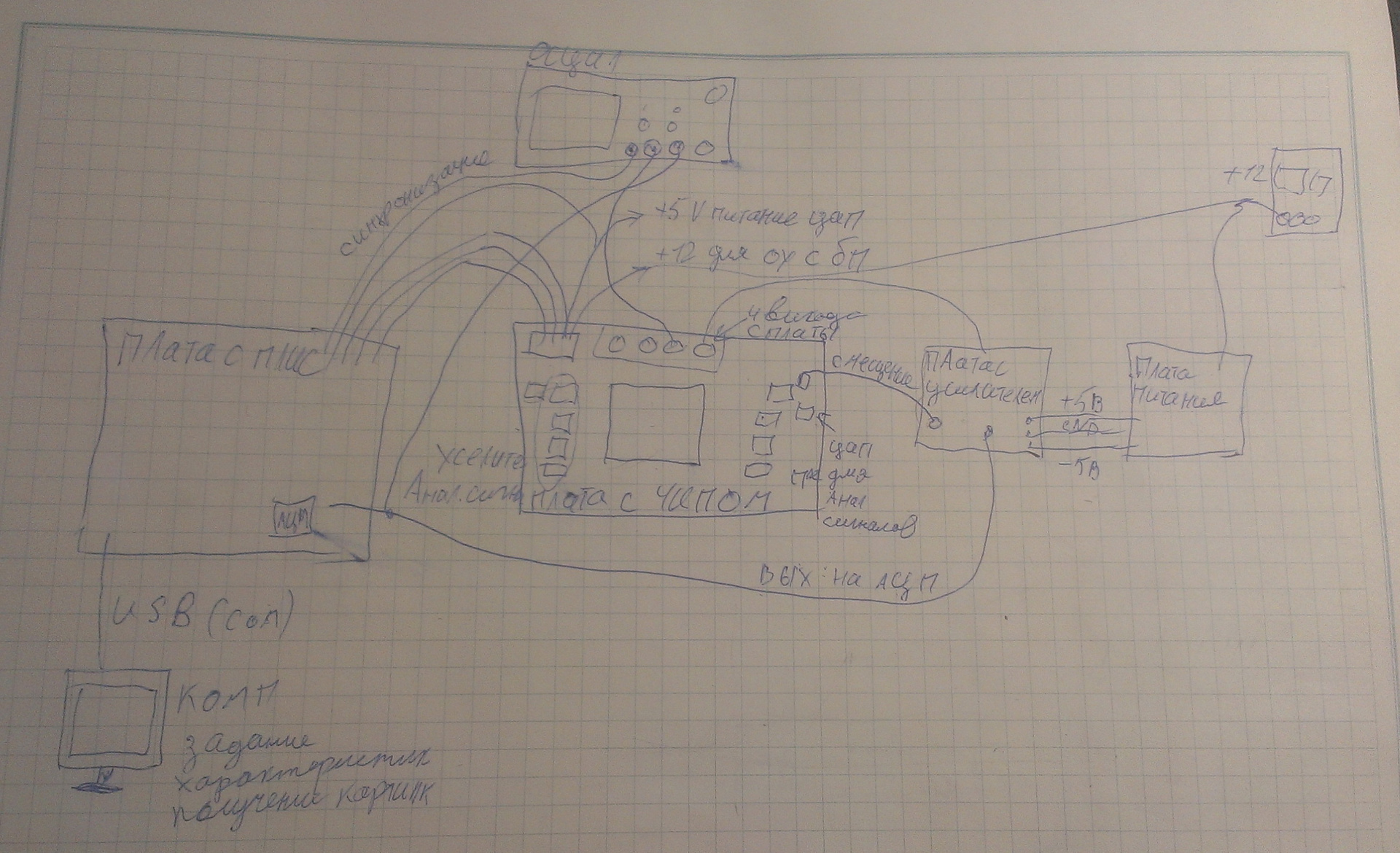
Рис.10. Схема прибора

Рис. 11. Готовая установка
Есть компьютер, который подает данные управления на плату с FPGA. Плата генерирует цифровые сигналы и отправляет их на чип. Сигнал с чипа идет на усилитель, далее – на АЦП на плате, оцифровывается и передается через COM-порт на компьютер. Вообще, пропускная способность COM-порта невелика: 15 килобит в секунду (т. к. в одном чипе находится от 1 млн до 10 млн «пикселей», а максимальная скорость передачи – 115200 бод). Тем не менее картинка на компьютер в итоге попадает.

Рис. 12. Обработанный сигнал на компьютере.
На фото выше видно, что, когда на использованный б/у-шный чип подается библиотека ДНК, чип заполняется неравномерно: по краям – в меньшей степени. Разные цвета обусловлены разным напряжением на pH-транзисторах. То есть мы можем ясно различить те лунки, куда попали сферы с ридами – впоследствии это поможет нам контролировать промывку чипа.
Соответственно, следующей задачей стала промывка чипа. Нужно было добиться, чтобы он стал, как новый. К счастью, у меня имелся совершенно новый чип в качестве референсного образца. На илл. А видно, что в активной области такой чип практически одного цвета (вертикальные повторяющиеся полосы – это просто шумы, наводки).

Рис. 13. Промывка чипа
На рис. 13 B неудачно промытый чип – он разноцветный. На рис.13 D – использованный, но хорошо промытый чип. Видно, что градиент по краям исчез. Тем не менее стоило бы еще доказать, что он действительно чистый и может использоваться повторно.
Поскольку библиотеки ДНК прикрепляются к танталовому покрытию чипа в кислой среде и открепляются – в щелочной (то есть при высоком pH), то чип промывается с помощью специальных полуавтоматических пипеток растворами с разными pH. На сегодняшний день мне удалось добиться практически полной очистки чипа.
У меня интересовались, почему, когда я полностью разобрался в структуре чипа, я не стал заказывать его изготовление, а предпочел по-прежнему искать и доставать б/у-шные, возиться с их промывкой и т. п. Да потому, что разработка микросхемы стоит огромных денег, миллионы долларов, и солидная часть этой суммы уходит на физическую отладку полученного продукта: подгонку, настройку всех параметров транзисторов и т. д. То есть просто скопировать логическую схему – недостаточно. Поэтому я беру условно бесплатную, уже готовую – спроектированную, изготовленную, отлаженную – микросхему и таким образом экономлю значительные средства, серьезно удешевляю проект.
Следующей моей задачей было собрать более продвинутый прибор, который позволял бы быстрее передавать информацию на компьютер и при этом не состоял бы из огромного количества отдельных плат.
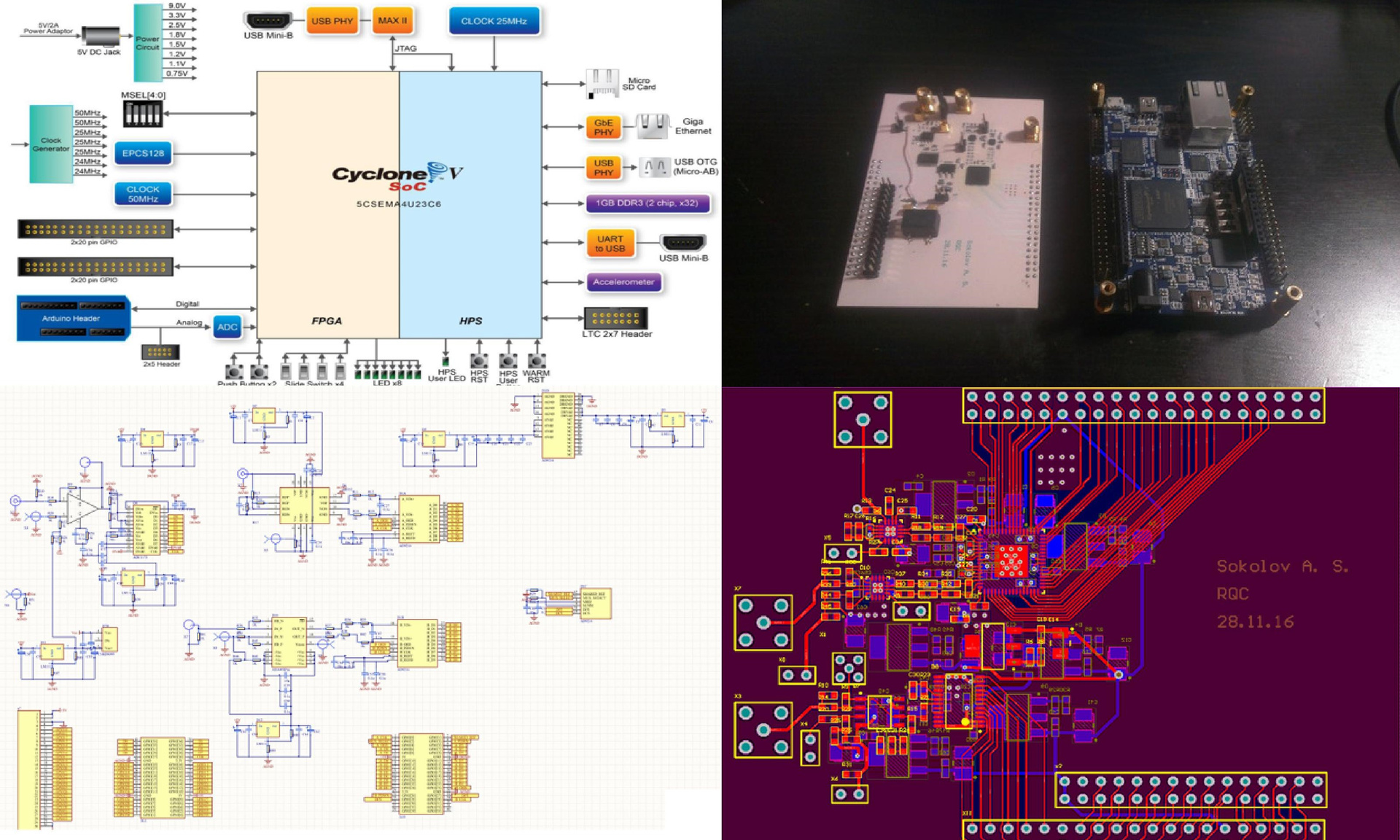
Рис.14 Разработка следующей версии прибора
Я взял новую плату с FPGA – на том же кристалле здесь было 2 ARM-ядра с Linux, имелся Gigabit Ethernet и прочие «плюшки», но зато, в отличие от предыдущего варианта, не было АЦП. Позже спроектировал еще одну плату, с высокоскоростными АЦП и всеми другими необходимыми элементами. Запустил – все заработало.
Что осталось сделать для появления финального прибора? Всего три вещи.
Первое. Нужен гигабитный интернет, быстрая передача данных на компьютер. Это я реализовал буквально вчера.
Второе. Система подачи реагентов. Проектирование специального клапана уже в процессе.
Третье. Софт для обработки информации с чипа. С ПО пока есть вопросы, поэтому приглашаю к сотрудничеству программистов.
Финальный прибор стоит 10 млн рублей. Себестоимость секвенирования составляет несколько тысяч долларов. Чипы обходятся от 100 до 1000 долларов – в зависимости от количества «пикселей» в них. (К слову, восстановление чипов само по себе может стать неплохим заработком, особенно учитывая, что для промывки нужно сделать лишь пару кликов.) Реагенты тоже покупаются, но в перспективе будут создаваться и они.
В общем все это очень интересно, но главное – за этим будущее. Сегодня биотехнологии занимают в мировом научно-техническом прогрессе то же место, что компьютерные технологии в 80-х гг. прошлого века. При этом секвенирование – одно из ключевых направлений для современной биологии и медицины. Ну и, конечно, биотехнологии – это очень прибыльно.
В последнее время на рынке появился полупроводниковый секвенатор S5, и в ближайшее будущие я планирую переключиться на него.
Буду рад пообщаться со всеми, кто захочет тем или иным образом поучаствовать в развитии этого проекта!
Проект был бы не возможен, без теоретической подготовки Владимира Зубова. Выражаю ему свою благодарность.
Спасибо за внимание!
Комментарии (171)


neochapay
31.07.2017 17:32+19Вы просто хардкорный маньяк в лучшем смысле этого слова… так на раз-два отреверсить спаять спроектировать… это ж какой объём знаний в голове держать то надо?

AlexanderS
01.08.2017 10:47+4Это при чтении так кажется, так как всё сжато. А вы внимательно посмотрите сколько у автора это заняло времени. Очень упорный труд, который достойно вознаградился. Уважаю.
neochapay
01.08.2017 11:21+3Да даже у людей знакомых с квантовой механикой и микробиологией с микроэволюцией это всё равно звучит как «Сейчас мы возьмём кусок адамантия потрём его криптонитом, смажем электролитом из грузинских конденсаторов...» и тыды…


frees2
31.07.2017 17:45-34Бизнес на этом, продают «ген мухаммеда» и «ген еврея», притом один и тот же. Лет пять назад стало модно «ген национальности» продавать. Расценки удивительны, прайслисты. В последнее время стихло или не так рекламируется.
Кроме этих фейков можно как то практически применять?


igorkozinov
31.07.2017 17:58+5А потом производители отреверсенной железки его засудят… Патаму чта их права нарушелесь!!!

UA3MQJ
01.08.2017 11:13+1Либо использовать б/у как-то запретят

amarao
01.08.2017 16:30Если бы я был мудаком-копирастом, то я бы просто выжигал чип в оригинальном устройстве. Как минимум, проблему б/у это решит.

Halt
04.08.2017 09:04С учетом того, что чип отреверсили, вполне могут появиться китайские аналоги.

vvzvlad
04.08.2017 21:02Эм. Реверс восстанавливает как бы только логическую схему. Для производства такого же чипа надо еще пилить и пилить — по затратам будет чуть меньше, чем с нуля разрабатывать. Если бы китайцы видели в этом смысл, они бы уже давно купили чип и скопировали его сами)



nikosias
31.07.2017 18:24-11Вы не пробовали через нейросеть пропускать данные?
Не могли бы поподробнее рассказать как формируются данные?AllexIn
31.07.2017 21:46+19Что значит «прогнать через нейросеть»?
Сеть на что должна быть обучена? И каким образом?
Часто вижу эту фразу «попробуй прогнать через нейросеть». Каждый раз ощущение, что написавшией её сичтает нейросеть некой крутой универсальной штукой, которая автоматически выдаст интересный результат на любых исходных данных.
Это не так. Сеть должна быть обучена. И только тогда она может что-то анализировать.vedenin1980
31.07.2017 22:01-5Это не так. Сеть должна быть обучена. И только тогда она может что-то анализировать.
Не совсем так, можно просто скормить сети данные и она построит какие-то группы (задача кластеризации). Например, разделит долгожителей и остальных или тех у кого талант к музыки и у кого нет. Анализируя полученные группы в теории можно тоже получить интересные результаты.
Можно например скармливать сети как геном, так болезни, увлечения, профессии и таланты, в теории она может сама найти интересные связи, даже если ее ничему реально не учить, просто отдавать сырые данные (любые вплоть до любви к огурцам).
Кстати, удивительно что никто не пытается сети скарвливать все данные о челевеке и геном, чтобы посмотреть результат.AllexIn
31.07.2017 22:05+9Необученная — это с коэфициентами от балды?
Честно говоря первый раз слышу, что случайные коэфициенты могут делать какую-то полезную работу.
Звучит как бред… Впрочем, не возьмусь утверждать. Пойду курить актуальные материалы.
Спасибо за правку.
Garbage in - garbage out
vedenin1980
31.07.2017 22:17+1Обучение без учителя (самообучение, спонтанное обучение) — один из способов машинного обучения, при котором испытуемая система спонтанно обучается выполнять поставленную задачу без вмешательства со стороны экспериментатора. С точки зрения кибернетики, это является одним из видов кибернетического эксперимента. Как правило, это пригодно только для задач, в которых известны описания множества объектов (обучающей выборки), и требуется обнаружить внутренние взаимосвязи, зависимости, закономерности, существующие между объектами.
случайные коэфициенты могут делать какую-то полезную работу.
Они настраиваются, через определенное время они уже не случайныAllexIn
31.07.2017 22:18+5А. Вот вы о чём. Ну так это просто один из способов обучения.
vedenin1980
31.07.2017 22:24-1Ну так это просто один из способов обучения
В данном случае есть просто получает некий набор сырых данных, и должна найти какие-то связи, при этом ей не говорят что она должна искать и не показывают примеры. В данном случае это именно «прогнать через сеть данные». Она, конечно, должна обучиться (то есть иметь какой-то достаточно большой набор данных), но это просто вопрос статистики, так как машинное обучение иметь смысл при достаточной выборке.
KiloLeo
31.07.2017 23:41+4Начнём с того, что этих данных у автора просто нет. Чтобы сделать то, о чём Вы пишете, надо иметь набор данных: Геном (3Гб), продолжительность жизни (т.е. брать геном надо у трупа), наличие таланта к музыке,… пр. И желательно на несколько сот тысяч человек. Ага. Автору пока есть чем заняться :-)
vedenin1980
01.08.2017 00:10-1В данном случае, я отвечал не на предложение автору использовать машинное обучение, а на то что сети должны быть только «обученные» (то есть, что не может быть сети, которая обучится совсем сама).
К тому же, конечно ставить глобальные цели вроде расшифровки всего генома при такой выборки бессмысленно, а вот если делать много анализов генома у сотен больных с определенной генетической болезнью (например, если это требуется по работе) и у сотен здоровых людей, то всего лишь загнав данные в систему машинного обучения — есть шанс найти корреляции генов и данной болезни, что может быть полезным (даже при том что корреляция еще не означает следствия). То есть глобальные цели — так не достичь, а локальные на медицинскую статью — вполне можно.
stychos
03.08.2017 14:08Вот и тема для стартапа: сделать библиотеку бесплатных днк-библиотек, openDNA.

Kriminalist
04.08.2017 16:18Бренд занят — http://opendna.ai/, а идея давно не стартап — https://www.openhumans.org

BelerafonL
01.08.2017 12:28+1Автору нужно из сигнала матрицы «фотокамеры» получить кусочки ДНК длиной 300 нуклеотидов — «риды». Здесь и речи не идет о получении целого ДНК человека. Хорошо если вирус получится прочитать за несколько заходов.
Нейросеть можно было бы обучить анализировать сигнал этой матрицы и собирать из них эти «риды», но для этого нужно точно знать, какой кусок ДНК там секвенируется априори для «обучения с учителем». И сделать скажем 10000 таких опытов с разными «точно известными» ридами, набрать базу обучения и тогда можно попробовать дать это нейросети.
Судя по описанию, что чтобы прочитать один (один!) нуклеотид одного рида нужно капать на матрицу реагент нужного типа, а потом его смывать (судя по описанной технологии PGM), потом капать другой… то в домашних условиях получить такую выборку не видится возможным.
nikosias
01.08.2017 11:15Я имел ввиду, что можно пред очищать данные если я праельно понял то данных с чипа идет много часть из них повторяется часть из за того что чип не совсем хорошо очищен может быть искажена. И с помощью нейросетей которые хорошо работают с искаженными данными, попытаться их вытащить.
Для того чтобы развить свою мысль и попросил уточнить в каком виде приходят данные.

barbanel
02.08.2017 14:43+3Что значит «прогнать через нейросеть»?
Пффф! Очень просто!
«Посмотреть в компьютере» же надо!

kgbplus
01.08.2017 11:20+1Мне кажется, вы не представляете какой там объем данных. Там SVM годы будет работать…
carpaccio
31.07.2017 18:24+22Вы сделали классическую работу целого советского НИИ в одиночку, очень круто. Единственная проблема в том, что надо сделать validation на большом количестве последовательностей чтобы быть уверенным в том, что полученные результаты достаточно точны. А когда и если вы решите эту проблему, то окажется, что сделанный прибор сильно устарел, и на рынке есть горздо более эффективные решения. Но проект замечательный!
sintech
31.07.2017 19:00+7Не согласен. На выходе НИИ была бы технология производства аналогов таких чипов в промышленных масштабах. А сейчас автор при всем к нему уважении, зависим от отходов коммерческих секвенаторов. Производители которых могут в любой момент сделать так, чтобы чипы нельзя было использовать повторно. Но к сожалению таков капитализм.
carpaccio
31.07.2017 19:12+7Чипы использовать повторно крайне чревато. В отличие от заправки картриджей косяки тут глазом увидеть невозможно.

redpax
07.08.2017 13:37Почему же? Многократное сравнение с результатами с нового чипа вполне себе даст понимание точности на БУ чипах при рассмотрении одинакового материала.

NiTr0_ua
01.08.2017 01:50+2Ну ок, 2/3 работы — по спецификациям/схемам/послойным шаблонам сделать чип-клон таки намного проще, чем имея чип (без какой-либо обвязки) получить схему и разводку слоев, а также — протокол управления.
AlexanderS
01.08.2017 10:54+3Вы слишком гипертрофируете. У меня на работе тоже каждый человек ведёт свою часть работы, которые в советские времена делало по доброй половине НИИ. А за пару месяцев мы делаем больше, чем раньше целые почтовые ящики пилили годами)
Автор молодец, всё это способствует прокачиванию понимания многих вещей и вообще — когда узнаёшь что-то новое и делаешь сам — это чертовски интересно! Я понимаю — сам немножко такой)

censor2005
31.07.2017 18:24+15Для меня эта статья подобна «Как собрать термоядерный реактор в чулане за 100$». Звучит просто невероятно!
Куча вопросов родилась. Сколько времени ушло на реверс-инжиниринг чипа по фото? Делали это вручную, или есть какие то программы облегчающие построение схемы? И сколько элементов примерно в микросхеме? Насколько точным будет секвенирование ДНК в б.у. чипе? Спасибо большое!
Navij
31.07.2017 19:25+4Ну так-то не в чулане, у автора был доступ к лабораторному оборудованию всё-таки. Что, впрочем, не умаляет невероятной крутости того, что он сделал.

robo2k
31.07.2017 18:26+22Как подается биоматериал на анализ? Как ДНК извлекается из ядра? Как ДНК делится на сегменты? Так много вопросов, и так мало ответов. Да и вообще, чувствую себя пещерным человеком на лекции в ВУЗе.

BlessYourHeart
31.07.2017 18:45+6В этой технологии чип — одна из главных деталей, и один из самых дорогих расходников.
Как принтер, в котором картридж стоит относительно дорого.
Собственно и промывка чипов похожа на перезаправку картриджей — для частных лиц и отдельных способов применения промывка подойдет, но ни одна лицензированная лаборатория не будет использовать отмытые чипы в своей деятельности.Garbus
31.07.2017 19:26К принтерам производители «догадались» приспособить СНПЧ, и тут со временем наладят промывку и повторное использование. Вычислительные мощности ныне позволяют вытягивать информацию порой из отвратительных исходников. Путь чип станет не вечным, а на десяток-другой циклов — уже приятное удешевление.
BlessYourHeart
31.07.2017 19:53+1Все же это гораздо более узкий рынок, чем принтеры.
Опять же вопрос в том, что для данного вида чипов автор подобрал промывку, а как промывать чипы со специфическими антителами, и не будет ли это дороже, чем покупать новые?.. Это тоже ставит вопросы о том, насколько этот рынок мытых чипов широк.
Garbus
31.07.2017 21:06Ну не рассказывать же о том, как бизнес «ленится», став монополистом? Может некоторый стимул, в виде призрачных недорогих наборов для промывки, заставит выпустить более удобное и недорогое решение пораньше. Думаю рынок пока далек от насыщения, наверняка использование сильно сдерживает цена.
BlessYourHeart
31.07.2017 23:53+4Недорогие наборы для промывки подойдут для энтузиастов, для "домашнего" применения, для некоторых видов исследований. Это относительно маленький рынок дня технологии, ну просто потому, что энтузиастов разного рода мало, для "домашнего" применения надо придумать прикладные задачи (это крайне сложно для такой узкоспециализированной системы), а исследователи обычно могут позволить себе покупать оригинальные расходники.
Повторюсь, что в медицинское применение "отмытых" чипов я не верю, так как это крайне зарегулированная сфера.
А сам пост автора меня наводит на мысли о жутком разрыве между возможностями современных технологий, их доступности и сложностью их осознания и понимания их возможностей. Одни люди разбираются в домашних условиях с, буквально, нуклеотидами, а другие боятся ГМО и верят в заговор учёных...
Garbus
01.08.2017 04:02+2Думаю потенциальный рынок «домашних» исследований все же не мал. Селекционеров любителей и профессионалов хватает, неужели они откажутся от недорогого и удобного прибора, пусть даже с «китайским» уклоном? Правда нужно хорошее ПО и информационная база, но уже проще в развитии, когда есть что анализировать.
Ну или другие исследования, прорабатываем теорию на дешевых расходниках, а подтверждаем на оригинальных. Тоже ведь неплохая экономия.
AllexIn
31.07.2017 21:48+4Почему узкий-то? Определение генетических заболеваний — это очень востребованная штука.
Впрочем я и 1000 готов заплатить за это. А если будет 100$ — рынок значительно вырастет. ИМХОBlessYourHeart
31.07.2017 22:40+1Я к сожалению не знаком с применением секвенирования для прямого определения генетических заболеваний.
Насколько я знаю, сейчас используются маркерные методы, а расшифровка днк даёт только некоторую вероятность и/или склонность к заболеваниям, что, согласитесь, от диагностических методов далеко.
А рынок любопытствующих, которые готовы заплатить за свой профиль и знать свои особенности, включая склонность к патологиям, по моему мнению сейчас достаточно покрыт существующими компаниями, вроде того же Атласа.
golf2109
31.07.2017 19:32максимальная скорость передачи – 115200 бод
921600 уже давно широко применяетсяя

kablag
31.07.2017 19:36+1Александр, Вы с этой идеей в компанию Синтол не обращались? Российский секвенатор по Сэнгеру они уже сделали совместно с Институтом аналитического приборостроения РАН — может и на полногеномный замахнутся.
read2only
31.07.2017 20:06+10Пожалуй, это самый интересный и, к сожалению, крайне редкий теперь вид публикаций на Geektimes.
Удачи вам Александр!

Valerij56
31.07.2017 20:16+2Мне тоже кажется, что автор где-то не там работает. Думаю, его уже взяли а карандаш хэдхнтеры.
И, да, Александр, это неимоверно круто. Удачи вам, и хватит изобретать велосипеды!

ra3vdx
31.07.2017 20:18+4Даа, впечатляет! Это не LM317 исследовать)
Всё же правы биологи — мы живём в самой лавине третьей — геномной — революции. Осталось научиться интерпретировать все данные (или хотя бы бОльшую часть). Поскольку знаем мы сегодня крайне мало о регуляторных последовательностях и о межгенном взаимодействии.
А вот видео, где Фёдор Кондрашов про эту технологию рассказывает, кому интересно (с меткой времени):

NeoCode
31.07.2017 20:28+2Вот оно будущее!
Восхищаюсь проделанной вами работой и огромное спасибо за статью!
Нечто подобное делали когда-то давно, когда техника была простая. Сами собирали компьютеры из рассыпухи, писали любительские ОС,… Теперь кажется что подобное уже невозможно, что сложность технологий давно превзошла тот порог, когда еще был возможен индивидуальный хакинг, кажется что сейчас для чего-то серьезного нужны огромные человеческие ресурсы и куча денег…
А вы доказываете что это не так. Невероятно…
А что вы планируете с этим делать дальше? Какие пути развития проделанной работы видите?
alexhott
31.07.2017 20:51+2Да мне тоже интересно узнать как разделять ДНК на РИДы, копировать их и прикреплять к сферам
и где брать сферы.
А так после почти запущенного в гараже электронно микроскопа, уже перестаешь таким вещам как ревер инженеринг ИС удивляться.
Возможностей все больше и лабораторные методы становятся доступными.
Вот таким людям как автор надо доступ напрямую ко всему такому "богатству". И возможно не сбежит за границу и чегонибудь тут изоьбретет.

ferreto
31.07.2017 21:07+2Для меня это была, пожалуй, лучшая статья на гиктаймсе за последнее время, читал, как приключенческий детектив. Даже страшно подумать, что Вы там показывали Путину, если у Вас такое хобби. С разводом тоже понятно: редкая женщина оценит такое хобби мужа. Мне только непонятно, почему Ваш прибор стоит 10 миллионов. И да, этот прибор тоже стоит показать Путину. Государство просто обязано этим заняться...
NeoCode
31.07.2017 21:09+19Государство просто обязано этим заняться...
Запретить исследования в области генной инженерии без кучи разрешений и допусков?
Простите вырвалось:(AlexanderS
01.08.2017 11:05+1Ага, и вообще — а чем это там сотрудник занимается в рабочее время на нашем оборудовании? Ещё и поздно уходит, режим работы нарушает — непорядок! =)
AlexanderS
01.08.2017 11:03+3Давайте не будем про развод — мы не знаем ничего. Со стороны кажется, что у ребенка был бы отличный папа) А как оно там в семье, кто виноват и что делать — это их дело.
Хотя доля правды есть — современные девушки, по крайней мере те, с котороыми я знакомился, абсолютно не впечатляются и по достоинству не оценивают серьёзные хобби мужчин. Может оно им кажется как игра в кубики (возится там со своими мЫкросхемами как дитё — нет чтобы деньги зарабатывать и BMW купить) и следует вывод о «недоросшем» мужчине — фиг его знает)

lonelymyp
31.07.2017 23:15Подозреваю что производители чипов в курсе того что их чипы многоразовые, но вероятно на данном этапе выгодней отсутствие системы очистки в аппарате.
И вот такие публикации очевидно приближают момент когда производители оборудования согласятся встраивать систему очистки в своё оборудование, радикально снизив тем самым стоимость секвенирования.kablag
31.07.2017 23:23+3Одноразовые шприцы они тоже, теоретически, многоразовые. Дело не всегда в жадности производителя, но и в риске получения неправильного результата. Чем меньше манипуляций возложено на пользователя, тем он ниже.
А так, в молекулярной биологии раньше у нас и носики для дозаторов мыли. Застал ещё такие времена, может и сейчас где моют.
SADKO
31.07.2017 23:45Ну, ИМХО в случае с чипом, качество отмывки можно проконтролировать, и потом, как мне видится тут заложена большая избыточность, для решения ситуаций когда в кодоне подряд идут одинаковые нуклеотиды…
А большая ли она, а достаточная-ли, и будет ли промытый чип менее достоверным это ещё и не факт.
tormozedison
01.08.2017 07:00Так раз промытый чип ничего не стоит, их можно сразу несколько использовать, результаты объединить.
lonelymyp
01.08.2017 00:13+1Если речь идёт о диагностике заболевания живого человека то вероятно дешевле сделать один раз правильно, но если речь идёт о сотне другой лабораторных мышей над которыми ставятся опыты, возможно дешевле будет заморить лишний десяток мышей по ошибке и сэкономить пару сотен тыщ баксов на секвенировании.

semen-pro
01.08.2017 22:43+1радикально снизив тем самым стоимость секвенирования.
Я бы сказал — прикрыв лазейку с повторным использованием чипов. Но тогда, я бы на их месте поменял все проданные аппараты на новые. И прекратил выпуск расходников к старым.
SADKO
01.08.2017 00:03Интересно было бы по изучать статистическое распределение уровней сигнала с оных чипов в разном состоянии (новый\засраный\отмытый) дабы понимать, где шумы аналогового тракта, где косяки техпроцесса чипа, а где полезный сигнал, как выглядят переходные процессы…
… и насколько качественная нужна отмывка, может быть по аналогии с видео сенсорами, калибровка решает!
… а если отмывку интегрировать в процесс считывания, загрязнения\дефекты будут лишь замедлять процесс но не влиять на достоверность результата ИМХО
Kopart
01.08.2017 00:26-1Есть подозрение, что процесс отмывки уже должен использоваться для калибровки, отбраковки новых чипов производителем. Обычные методы проверки цифровых/аналоговых чипов не гарантируют итогового качества, а вот эталонные процедуры как в статье автора и потом промывка с проверкой чистоты чипа вполне подойдет.
Aquahawk
01.08.2017 00:19Я правильно понимаю что собрать это на компьютере мы можем только потому что большой объём генного материала разорвётся на разные риды и потом, т.к. они будут пересекаться можно будет собрать полную цепочку?
И для сколько-нибудь качественного сканирования потребуется секвентировать пару раз и запустить это дело на паре разных бу чипах. Тогда можно будет говорить о достоверности результата? Поддержать проект готов только финансово, будучи клиентом, когда будете готовы к приёму заказов пишите. Сколько это, кстати, примерно будет стоить?SADKO
01.08.2017 11:33Правильно, да не совсем… Если коротко, то новый или абсолютно промытый чип, даёт возможность секвенции более длинных цепей. Промывка автора, не вполне абсолютна, и перед тем как говорить о каком-либо результате, нужно попробовать прочесть что-нибудь коротенькое и известное, что бы понять масштабы явления, в смысле новый чип в среднем читает столько-то кодонов на пиксель, промытый столько-то.
Ибо чем длиннее цепи, тем больше вероятность того, что из них сложится что-то путное, и я так понимаю что если амплификация используется в оригинальном девайсе, то вопрос объективной необходимости именно новых чипов не праздный…
Грубо говоря, если у нас есть куча копий текста, разорванных по нескольким строкам, мы можем сложить целую книгу опираясь на взаимно пересекающиеся фрагменты, но если книга разорвана на отдельные слова, мы не соберём её никогда.

reactos
01.08.2017 00:45+13Очень интересно!
Я здесь про микроскоп не писал уже месяца два (уезжал по работе) но вот эта статья сильно мотивирует писать продолжение.
dfgwer
01.08.2017 01:16Насколько полно идет мойка? Может быть так что остаток предыдущего теста повлияет на тест? Может быть, надо на двух разных чипах проводить тест и выкидывать неповторяющиеся фрагменты, это также должно значительно уменьшить требования к качеству мойки и теста.

uvelichitel
01.08.2017 01:35-7Третье. Софт для обработки информации с чипа. С ПО пока есть вопросы, поэтому приглашаю к сотрудничеству программистов.
Так и вижу blockchain нейросетей построенный на qubit вычислителях. Всегда готов, где записываться?
EighthMayer
01.08.2017 07:38+6Не забудьте использовать Internet of Things умный дом из квадрокоптера, инвестируемый через краудфандинг. С ним всё становится лучше.
uvelichitel
01.08.2017 13:15-6Не верю.
К. С. Станиславский
По моему разумению статья fake, вброс. Ни одного комментария автора. Литературно красиво, убедительно. Сомневаюсь, что описаное было исполнено.
s0ko1ok
01.08.2017 14:27+8Привет -) Заезжай в гости -)
uvelichitel
02.08.2017 16:27Я не могу просто запросто заехать — я живу в Крыму(лучше Вы к нам). Откройте repo на github, попробуйте поставить ТехЗадание. Если вы действительно сделали то о чем пишете готов писать код на волонтерских/opensource условиях потому, что интересно. Я квалифицированный разработчик, у меня есть открытый код который можно посмотреть. Думаю я не один такой, тема интересна, но есть недоверие.
EighthMayer
01.08.2017 14:57-3Согласен, заявленные навыки реверс-инженеринга и работы с FPGA рядом с неспособностью отличить килобиты от килобайтов смотрится достаточно подозрительно. Но люди разные бывают, так что не берусь ничего утверждать.
EighthMayer
01.08.2017 20:59У несогласных действительно есть что возразить, или это просто стадное чувство заставляет жалких животных действовать в едином порыве, могущественно тыкая в минус?
megabrain
01.08.2017 08:44+1Желаю вам продолжать с той же увлеченностью. Результаты поражают.
Оставлю здесь ссылку для читателей на страницу ещё одного увлеченного инженера: https://simplifier.neocities.org/
Увлекательное чтение. Он в гараже работает над самодельными вакуумными диодами, триодами, создаёт солнечные батареи и т.д. Все только по делу, кратко, со схемами, графиками.

Impuls
01.08.2017 09:39+11Как же скучно я живу. Один микроскоп в гараже собирает, второй ДНК секвенирует. Снимаю шляпу господа.
AlexanderS
01.08.2017 11:08+2Это всё безобидно — пускай делают. Я только радуюсь, когда такие статьи читаю. Некоторые вообще пытаются сделать дома ядерный реактор-размножитель.
DmitrySpb79
01.08.2017 11:14+5Спасибо, читается интересно.
Но во-первых, не очень понятно где здесь собственно «домашние условия» и «на коленке». Из текста можно понять, что для работы использовалась аппаратура ценой не один миллион.
Во-вторых, все написанное имеет смысл, если по соседству случайно оказалась днк-лаборатория, которая ежедневно выбрасывает старые чипы :) Вероятность можно прикинуть самостоятельно.
В-третьих, между строк прочиталось что проект таки позиционируется как коммерческий, хотя тут может и ошибаюсь.s0ko1ok
01.08.2017 14:32+2Из оборудования у меня было: Осцил ds-203 (на фото), микроскоп Биомед металлургический (можно было использовать и более простой), ну и паяльная станция. Работа помогла только микроскопом.
Лабораторий таких, по крайней мере в Москве, довольно много.
Kriminalist
01.08.2017 11:28+5O___O!!!
Несколько вопросов:
— Где планируете брать расходники (неспецифические и праймеры)?
— Как планируете накапливать ДНК (есть ли у вас амплификатор)?
— Есть ли механизм подачи/отмывки реагентов на чип?
— Какую длину рида планируете достичь?
— Какую скорость чтения планируете достичь?
Да не забросают меня помидорами, но этот метод секвенирования тупиковый в плане гаражного самодельства — самого секвенатора недостаточно, и если амплификатор сейчас уже не редкость, праймеры в любом случае придется покупать у производителя. Да и ряд принципиальных ограничений (длина рида, скорость) — не выглядят внушающими оптимизма.
Строго говоря, отмывка чипа может быть и не идеальной, достаточно программно метить грязные лунки как «битые пиксели», это снизит эффективность конечно, но пусть даже вдвое по сравнению с новым — для ваших целей это непринципиально.
Как по мне, для частных лиц оптимальный вариант на сегодня — miniION от Oxford Nanopore. Стартовый набор тысячу USD, там прибор и два картриджа, один тестовый и один рабочий, при заказе картриджей оптом цена падает до 500 за шт. Длина рида — десятки тысяч нуклеотидов, не нужно никаких специфичных реагентов, подключил к ноуту и секвенируй, сколько памяти хватит. Плюс комьюнити. https://nanoporetech.com/products/minion
SADKO
01.08.2017 12:16Таки грязная ячейка — короткая ячейка? Там и так-то длинна не фонтан и нужна большая избыточность (амплификация и до фига ячеек), а тут ещё грязные. (хотя опять же без конкретных данных об этом трудно судить, но я чисто по картинкам, на глазок) Может никакая амплификация уже не поможет, тут собрать что-либо достоверное.
С нанопорами, да было бы интересней, они вроде то-же не вечные и это возможно то-же как-то лечится…Kriminalist
01.08.2017 12:47+4Грязная ячейка — не отмытая, там уже сфера со старым куском ДНК. Ее просто нужно маркировать, и не принимать во внимание.
Смысл такого секвенирования просто автор немного не раскрыл, необходим значительный объем пробоподготовки. Т.е. грубо: берем образец (кровь) — лизируем (разрушаем) клетки — отмываем ДНК — рубим ДНК на куски — добавляем праймеры (затравочные фрагменты, в данном случае они закреплены на микросферах) — проводим ПЦР в амплификаторе — получаем библиотеку ДНК — вносим ее на чип — запускаем реакцию (последовательное добавление чистых нуклеотидов и их смывание) — накапливаем данные, обрабатываем их.
Т.е. на секвенатор в данном случае подается ДНК уже предварительно порубленная на кусочки до 300 нуклеотидов длиной примерно, и в каждой лунке идет анализ своего фрагмента. Чем больше лунок — тем производительнее система. Так что «грязные» лунки просто ухудшают мощность чипа.
SADKO
01.08.2017 13:33То есть нужны ячейки отмытые под чистую? Но на D мы их практически не видим!
Есть-ли возможность того, что «ОК у нас есть в ячейке некоторое дерьмо, мы примем его за 0 и продолжим» по аналогии с видео сенсорами?Kriminalist
01.08.2017 13:49Да, нужны ячейки отмытые полностью. Сигнал с грязной ячейки скорее всего приходить вообще не будет, я сомневаюсь, что после отмывания там осталось значимое количество реактоспособной ДНК, а если будет, то мы будем секвенировать старый образец. Нам нужно быть уверенными, что в ячейке сфера с теми ДНК, которые мы амплифицировали, а ячейка вмещает только одну сферу.
s0ko1ok
01.08.2017 14:38Несколько вопросов:
— Где планируете брать расходники (неспецифические и праймеры)?
— Как планируете накапливать ДНК (есть ли у вас амплификатор)?
— Есть ли механизм подачи/отмывки реагентов на чип?
— Какую длину рида планируете достичь?
— Какую скорость чтения планируете достичь?
1) По началу использовать родные. Праймеры не проблема синтезировать, последовательности известны.
2) Есть самодельный амплификатор.
3) Система подачи реагентов разрабатывается
4,5) Все как у родного прибора.Kriminalist
01.08.2017 15:44+1Праймеры не проблема синтезировать
А разве в вашем случае один из праймеров не должен быть на сфере закреплен, если я правильно понимаю?
Хотя после «Самодельный амплификатор» я вас верю :).
Psychopompe
03.08.2017 15:55Коллеги (англоязычные) спрашивают, каким образом производится амплификация.

dlinyj
01.08.2017 11:35+2Посмотрите мои публикации на хабре и гиктаймс, может я чем-то смогу вам помочь. Мой поклон!

madf
01.08.2017 12:27-4Ничего непонятно, что за чип? В смысле: какой сенсор? Какая основа анализа/структура? Складывается такая каша мола, что вы выбрали какой-то сумасшедший, длинный и сложный путь.
А данные в комп надо было передавать через FT245, там легко 8-10МБ/сек передача на слабом железе, а так и больше...
Ruslikk
01.08.2017 13:21Здорово, что вы умеете делать такие сложные вещи. Но вот секвенатор… Первый автоматический секвенатор я видел ровно 20 лет назад, а сейчас юзаный секвенатор стоит на Ебее от 400 долларов. Да, я видел в вашей статье цены на секвенаторы новых поколений, но там скорость и длина рида совсем другие, чем у вашего прибора, разве нет?
kablag
01.08.2017 20:34Импортозамещение!

Greendq
03.08.2017 09:35На отреверсенных технологиях? Уже было, проходили. Ничего хорошего у СССР не получилось.
kablag
03.08.2017 09:57+2Если серьёзно, то научиться повторять удачные вещи — это уже неплохо. Но проблема российского биотеха, не в секвенаторах, а в банальных расходниках: пробирки, наконечники к пипеткам, перчатки. Научиться бы делать такие вещи хорошо. Но это скучно — вот сделать секвенатор — это да!
Продолжая аналогию с СССР: делать космические корабли, когда нет производства холодильников.
vedenin1980
03.08.2017 09:57Во-первых, у СССР много что получалось, например в космос слетать или ядерную бомбу сделать на отреверсенных технологиях, СССР развалился не из-за технологий, а скорее из-за организации. Во-вторых, у Китая эта тактика работает.
Импортозамещение в основном проваливается потому что РФ, увы, не СССР и не Китай.
AlexanderS
01.08.2017 13:22+2s0ko1ok, а какая ПЛИСовая реализация управления чипом? Интересно как ПЛИСовику. Чип конфигурируется через SPI (т.е. регистры какие-то и вы реверснули логику)? Какой-то свой параллельный интерфейс? Или там просто тактируешь чип какой-то частотой, а он тебе данные на этих тактах обратно сыпет, ну может ещё какой-то энейбл есть — по сути-то это же необычный, но ЦАП как я понимаю?
Кстати, а что изображено на осциллографе? Как такая картинка получилась, или это уже какая-то математика с пары щупов?
Поздравляю с новым микроскопом!
У нас-то старенький)
Afterk
01.08.2017 14:20Круто.
Насчёт обработки данных, если задача хорошо распараллеливается, надо бы глянуть в сторону OpenCL на GPU. Производительность можеть быть на порядок (или более) чем на хорошем CPU. Ещё можно наращивать мощность подключая множество карт.
exot1c
01.08.2017 14:20+1Спасибо за статью, было довольно интересно! Поражает количество проделанной работы, а также потраченного времени (считаю, что оно не было потрачено впустую)
REALpredatoR
01.08.2017 14:20Так почему финальный прибор ТСа стоит 10 миллионов? 9,99 миллиона — это чип?

Sekira
03.08.2017 01:03Первая мысль после прочтения была такая же, фраза вводит в заблуждение, но имелось ввиду, как и в начале статьи, что аналогичный прибор стоит 10 млн., а не создаваемый.

alexey_public
01.08.2017 14:21Софт для обработки информации с чипа. С ПО пока есть вопросы, поэтому приглашаю к сотрудничеству программистов
С этим могу помочь, пишите на почту, проект интересный :-)
dmsp
01.08.2017 14:21Интересно, насколько повторяем результат?
Ну если два раза заказать жесткий диск с геномом, то данные будут совпадать до бита?
А вообще, здорово!AndrewRo
01.08.2017 16:41До бита — нет, конечно. Ошибки будут в любом случае.
В википедии есть примерные данные по точности.kablag
01.08.2017 20:37Если делать два раза пробоподготовку с нуля, то данные точно не совпадут. И дело не в сиквенсе, а в предыдущих этапах — получатся разные библиотеки для сиквенса.

Tavrid
01.08.2017 14:41+1На выходе получается Ion Personal Genome Machine (PGM) + Ion Torrent Server (для обработки)?
Не проще ли строго в научных целях взять ПО из имеющегося сервера, там ведь Torrent Suite Software v5.х.х на Ubuntu 10.4.
Появление S5 и S5 XL больше похоже на маркетинг, 4 вида чипов, много наборов… делают маркетинг из науки.
Проект интересен, если найти стабильный выход на б/у чипы. Не будет ли потом как с картриджами в принтерах — чипы внедренные в чип, дабы остановить заправщиков (чистильщиков)?
В любом случае проект очень интересен, а для меня очень важен, т.к. ищу лекарство от дегенерации сетчатки глаз (ВМД), на данный момент анализ делал NGS Next Generation Sequencing (v11 RD chips 5040 primer sets duplicated on two chips) на 280 генов (теоретически смутировали ~8 генов, 2 с высокой вероятностью).
texder
01.08.2017 14:41+2Слушал Ваше выступление на митапе в mail_ru по этой теме. Это просто замечательно!

Firelander
01.08.2017 14:59+3Мда, работа проделана сумасшедшая. Причём в совершенно разных областях. Особенно реверс-инженеринг чипа. К сожалению, из-за огромного масштаба проекта, статья получилась очень беглой. Хотелось бы почитать подробнее про каждый аспект. Я так понимаю, полностью результат реверсинга автор выкладывать в публичный доступ не хочет. Но хотя бы отдельную статью про это с фотографиями и разбором каких-то конкретных элементов чипа очень хотелось бы.
И про биотехнологию тоже почитать интересно. Я представляю себе в общих чертах как работает пцр, но здесь понятны не все аспекты. Например как ДНК делится на риды. Сферы все одинаковые и на них цепляется рандомный кусок днк (а что если нескольно разных?) или они содержат что-то типа праймеров?Kriminalist
01.08.2017 15:54Например как ДНК делится на риды. Сферы все одинаковые и на них цепляется рандомный кусок днк (а что если нескольно разных?) или они содержат что-то типа праймеров?
Сферы разные. Для порезки ДНК надо два праймера — они ограничивают фрагмент, который будем ПЦРить. Один из праймеров на сфере закреплен, второй свободный. Комбинация праймеров дает предполагаемый участок ДНК. Для полногеномного секвенирования это слабо подходит, это такое целевое по предполагаемым мишеням.Firelander
01.08.2017 16:12Ага, вижу коммент автора выше. То есть сферы в любом случае расходник, их надо закупать уже готовыми, или покупать чистые и «обмазывать» праймерами собственного производства. Не уверен, можно ли, и имеет ли смысл их отмывать. С учетом количества требуемых разных участков (сотни? тысячи?) процесс выходит довольно веселым.

shadrap
01.08.2017 15:03+1Что сказать, восхитительно, уважительно и прочее — ительно!)
А софт надо новый писать ..., тут можно и програмно сужать область чтения, когда часть лунок будет «невымываема» и перестраивать под чтение каких-то более простых геномов. Так сказать деградируемый чип.)
Александр, а какой процент ошибок вы думаете будет в среднем у «свежего чипа»?
AndrewRo
01.08.2017 16:42Поймите меня правильно, это очень круто. Но всё же, это называется пиратством.
shadrap
01.08.2017 17:26Пиратством чего? Принципа генотипирования на чипах? Я точно не уверен, но помоему сам принцип не зафиксирован ни за кем. Как работает чип? Можно почитать и в доступной литературе…
Обвязку автор делает свою, принципы получения ридов, свои. Я так понимаю софт со сборками то ж будет свой.
AndrewRo
01.08.2017 17:34Я не юрист, но мне не кажется, что делать свою обвязку под чужое оборудование — это законно. У реверс-инжиниринга тоже довольно сомнительный правовой статус.
shadrap
01.08.2017 17:39Вы считаете, если я перепаял свой старый смартфон самсунг под сигнализацию, я нарушил что-то?
kablag
01.08.2017 20:40У технологий секвенирования есть патенты.
В вашей аналогии, если из смартфона собрать сигнализации по патентованной технологии и продавать, то нарушили.shadrap
01.08.2017 21:03По тому что я прочитал принципы никто и не нарушает, в лунках чипа лежат фирменные бусинки, комплиментарные определенным основаниям и нарезанные «хвосты» ДНК клеятся к ним, а чувствительные рН транзисторы определяют что за кусочек там сидит. Человек взял и прочитал данные из фирменного чипа, который был куплен повидимому официально и использовал вторично, со своей методикой прочтения. Чип, главная сложная технологически деталь, ее никто не трогал.
Аналогия с катриджами довольно четкая. Если я катридж приобрел, он мой, я волен собрать из него «микроволновку» или что еще мне вздумается.
AndrewRo
01.08.2017 20:55+1Я погуглил поподробнее, вопрос спорный.
С одной стороны, реверс-инжиниринг для создания совместимого продукта в США легален (например, Sega vs Accolade).
С другой, он может быть нелегален в случае наличия такого пункта в EULA или если протокол обмена между чипом и секвенатором запатентован.
С третьей стороны, первый пункт относится к США, а в России я прецедентов не нашёл. Лопатить же законодательство мне лень.
Так что, возможно, я не прав.
Whiteha
01.08.2017 21:47+2Статье место на хабре, для гт слишком круто.
AlexanderS
02.08.2017 06:27+1Вот, кстати, вопрос — если статья подходит «туда» и «туда», то можно её опубликовать и на хабре и на гиктаймс? От НЛО по шапке не прилетит?
Потому что есть те, что сидит на хабре и редко на gt лазит, а есть ноборот. Но и тем и другим было бы интересно.

n1tra
03.08.2017 22:30+1А на хабре ей что делать? Там же одни фреймворки да облака. К тому же принцип деления материалов идет по тематике, а не по «крутости».
Каким образом этот кхм… «DIY проект»(да простит меня автор!) относится к такой мега-профессиональной области как обсасывание очередного модного языка погромирования?
HEKOT
02.08.2017 03:04+3Читающий коллега попросил опубликовать его коментарий. Возможно, он окажется полезным:
Проделанная автором работа впечатляет и заслуживает всяческих похвал. Однако, как это зачастую бывает с работами талантливых инженеров, практический «выхлоп» от этого ре-инжиниринга пока невелик.
Использование, и даже многоразовое использование фирменных картриджей, на руку их производителю. С ходу назову две причины:
1. Как и производители мешков для пылесосов, картриджей для принтеров и Неспрессо-кофе и т.п., даже несанкционированное повторное использование оригинальных картриджей «льёт воду на колесо» продаж производителя. Пускай даже обладатель самодельного анализатора и не купит сам прибор, но при активной работе сколько-то картриджей он всё-равно потребит. Опять же, это косвенный промоушен определённого бренда в пику другим производителям аналогичных товаров и услуг.
2. Потребитель картриджей «сидит на крючке» производителя и не представляет для него ни конкуренции ни угрозы. Так, в своё время, Стив Балмер из Майкрософта публично благодарил пиратов за распространение их ОС, потому как вторую другую ОС на тот же компьютер, за редким исключением, никто не устанавливал. Так и с картриджами. Собственно, с их продаж производители и расчитывают получать главную прибыль. Копируя что-то можно только всё время догонять оригинального производителя, но никогда его не превзойти. Собственно говоря, ре-инжиниринг ценен именно тем, что даёт понимание как сделать по-другому и лучше.
Как бы в такой ситуации действовал Западный предприниматель?
1. Изучил оригинальный патент,
2. сравнил его с результатами ре-инжиниринга,
3. разработал альтернативу «в обход» патента,
4. запатентовал свою разработку,
5. наладил производство с качеством не хуже и по меньшей цене,
6. начал вовсю использовать свой продукт сам, и уже затем
7. предложил пользователям оригинального продукта. Только на этом этапе оригинальный производитель может «увидеть» конкурента. Тут и потребуются «мускулы» стоящей за спиной юридическо-бюрократической системы для защиты интеллектуальной собственности.
Конечно, это не под силу одному, даже очень талантливому человеку. Для этого существуют Инновационные Инкубаторы и т.п. За ними стоят или государство, или большие деньги, или и то и другое. За примерами далеко ходить не нужно имея под боком опыт технологического взлёта Китая. Опять же, существует немало российских хай-тек фирм, разработки которых успешно реализуются Западными корпорациями по вышеописанной схеме.
На этом остается завершить пост и пожелать автору Здоровья и Удачи!

paceholder
02.08.2017 11:59Вся цепочка ДНК делится на фрагменты длиной по 300-400 нуклеотидов, называемые ридами.
А как вы планируете получить эти риды? Существуют какие-то специальные реагенты для разделения цепи ДНК? Можно где-то почитать про это?shadrap
02.08.2017 12:25+2Есть много разных способов нарезать фрагменты ДНК. Фермент DNASa режет, например, произвольным образом, есть ферменты которые ориентированы на нарезку в определенных местах. Процесс «резки» естественно химический. Фермент рестрикции, который отрежет в определенном месте, не знаю, как у нас, а на западе можно купить по интернету, как и многие другие реагенты для энтого дела… )
Единой ссылки, где про это почитать наверное нет. Если вы программист, то довольно сжатый курс на ресурсах биоинформатики присутствует.kablag
02.08.2017 19:46Произвольным образом режет, например, ультразвук, а ДНКаза имеет небольшую специфичность к последовательности.
Ферменты рестрикции у нас можно прекрасно купить по интернету. Возможно Вы удивитесь, но часть ферментов, которые продают на западе открыли и делают у нас.
Kriminalist
02.08.2017 13:58+2http://molbiol.ru/protocol/ и если непонятно http://molbiol.ru/forums/lofiversion/index.php/f1.html
http://www.appropedia.org/Open-source_Lab
Ну и немного устаревшая но в целом адекватная обзорно-популярная статья http://www.vokrugsveta.ru/vs/article/7872/

CheatEx
02.08.2017 12:08+2А где у нас квантовой криптографией занимаются? Работаете над математикой/алгоритмами или железками?

Xakki
02.08.2017 20:58+1Потрясающе. Начните компанию по краудфандингу, а лучше найдите надежного партнера (чтоб не отвлекаться) который будет заниматься этим и всей остальной бюрократией.
PerlPower
03.08.2017 01:10Статья оставляет вопросы.
— Судя по фото условия далеко не стерильные — частицы попавшие на него могут дать непредсказуемые помехи. И это при том, что мы до конца не знаем, насколько эффективна промывка, и вообще работает ли чип второй раз также как в первый. «Лунки» чипа могут забиваться частицами, имеющими pH недостаточный для срабатывания транзистора, но при этом не дающим ридам попасть в лунку.
— В условиях, в которых вы паяете, опять же судя по фото, мне удавалось убивать статикой, перегревом и загрязнением и куда менее тонкие микросхемы.
— Химическая часть и вообще подготовка тестовых образцов расписана чуть менее чем никак.
— Вы разбираетесь в FPGA, создали систему для формирования сырого сигнала, но просите у программистов помощи для его интерпретации? Мне кажется это самая простая часть задачи, и более того только вы как владелец прибора сможете ее выполнить, подсовывая тестовые риды. Ведь это же у вас есть реверс-инжениринг чипа и вы можете примерно понять что приходит от транзисторов и куда.
— Без обид, но картинки выглядят так будто бы кто-то пытался изобразить работу ученого. Отлично для репортажа ОРТ, но слабо для статьи такого уровня для гиктаймса.
— Режет глаза упоминание Путина и того-чувака-который-реверсировал чип для Playstation, и ваше имя на схеме платы.
— Предлагаете зарабатывать промывкой чипов, серьезно?
Я очень хочу чтобы люди вашего ума и способностей существовали, и чтобы они при этом существовали в России. Но статья выглядит как минимум очень неполной, хотя и производит впечатление.
redpax
07.08.2017 13:43Если аппарат будет работать не хуже оригинала, я сделаю автора разработки очень богатым причем без необходимости налаживать производство данного аппарата. Меня лишь интересует вопрос пропускной способность аппарата с учетом очистки чипа. Сколько времени занимает полный цикл получения цифровой версии ДНК?
ABsurDdeMaraZm
08.08.2017 22:38Я вообще мимо прохрдил, и многое не понял но статья захватила, было очень интересно читать, рад что есть такие достойные люди двигающие прогресс, какой я жалкий((
dyezepchik
08.08.2017 22:42Да ладно!
Ничесебе, читать это было увлекательнее, чем что-либо за последнее время!
Я в восторге, если это правда =)
Самому проделать такую работу — это МегаКруто

antonsosnitzkij
08.08.2017 22:50javascript, Python, программирование под FPGA и SoC системы — и это все только хобби… Подскажите, пожалуйста, где такому учат? Или все это тоже выросло из собственных увлечений и это самообразование?

dimchik_b
08.08.2017 22:55Жму Вашу руку! С удовольствием присоединился бы к Вам, если бы было время :)!








DROS
Как скучно я живу. Удачи, даже не знаю в чем, да во всем вообще. Ваша энергия пошла в нужном русле. как мне кажется. Это нереально круто. Ждем продолжения.