

Не так давно мы рассказали о запуске нашей новой облачной услуги – объектного хранилища Техносерв Cloud, совместимого с S3. Сегодня мы хотим перейти к конкретным техническим моментам в работе с нашей услугой, а в частности к настройкам системы резервного копирования для работы с S3-совместимым хранилищем. Сейчас практически все современные СРК имеют встроенную поддержку протокола S3 API, но не все об этом знают и, соответственно, не в полной мере используют функциональность систем.
Недавнее исследование Taneja Group определило приоритеты в использовании объектных хранилищ среди пользователей, согласно которому хранение резервных копий занимает первое место. В качестве примера для сегодняшнего поста мы взяли СРК Commvault. Подробнее об исследовании, о Commvault и настройке подключения облака к системе в нашем новом материале.
Поскольку объемы накапливаемых компаниями данных растут более чем на 50% в год, а свыше 80% — это неструктурированные данные, объектное хранение приобретает несомненную ценность. Это единственная технология, которая позволяет поспевать за увеличивающейся емкостью хранилищ, оставаясь в рамках бюджета.

Согласно результатам исследования, резервное копирование файлов и архивное хранение – наиболее типичные задачи (их отметили 57% респондентов). Причина, вероятно, кроется в высоком спросе на масштабируемое резервное копирование файлов и архивирование документов, а также экономически эффективное долгосрочное хранение данных в целях соблюдения нормативных требований. Объектное хранилище идеально подходит для крупномасштабного хранения неструктурированных данных, поскольку оно легко наращивается по емкости (до петабайт и выше) простым добавлением узлов хранения. Такой подход устраняет узкое место в производительности, которое ограничивает одно- и двуконтроллерные архитектуры традиционных файловых хранилищ. Кроме того, объектное хранение обеспечивает независимость от аппаратной платформы, поэтому компании могут увеличить емкость за счет добавления оборудования.
На втором месте — хранение объектов (Storage as a service), ее выделили 44% опрошенных. Хранилище объектов предоставляет поставщикам услуг экономичный способ управления резервными копиями с использованием надежной, масштабируемой и многоарендной архитектуры. И поскольку это «услуга», компании экономят на расходах на персонал, оборудование и центры обработки данных. ИТ-администратор просто арендует пространство для хранения на основе стоимости за гигабайт и затрат на передачу данных.
Третье место по популярности занимает аналитика больших данных (35% респондентов). Объектное хранилище предназначено для больших наборов данных, что делает его идеальным для задач аналитики больших данных. В недавнем опросе выяснилось, что около 30% респондентов накапливают 100 ТБ или более «больших данных», причем объем этих данных каждый месяц существенно увеличивается. Тем не менее, для поддержки большой аналитики данных и искусственного интеллекта для корреляции и интерпретации данных нужно тесно интегрировать объектное хранилище с хранилищем с низкой задержкой и системами высокопроизводительных вычислений.
Наконец, еще один распространенный вариант применения объектного хранилища — безопасное совместное использование файлов (его также указали 35% респондентов).
| Amazon Infrequent Access | Google Nearline | Amazon Glacier | Google Coldline | |
|---|---|---|---|---|
| Durability | 99,999999999% | 99,999999999% | 99,99% | 99,999999999% |
| Availability SLA | 99,9% | 99,9% | N/A | 99% |
| Access Time | Milliseconds | Milliseconds | 5 min-12 hrs | Milliseconds |
| Minimum Time | 30 | 30 | 90 | 90 |
| Amazon S-3 Standard | Google Multiregional | Amazon Reduced Redundancy | Google Regional | |
|---|---|---|---|---|
| Durability | 99,999999999% | 99,999999999% | 99,99% | 99,999999999% |
| Availability SLA | 99,95% | 99,95% | 99% | 99% |
| Access Time | Milliseconds | Milliseconds | Milliseconds | Milliseconds |
| Minimum Time | None | None | None | None |
Большинство объектных хранилищ также предлагают очень высокую отказоустойчивость с защитой от отказов сайта, узла и нескольких дисков.
Поэтому сегодня речь пойдет именно о таком направлении применения объектных хранилищ как хранение резервных копий, а в качестве примера системы резервного копирования, как уже было отмечено, мы выбрали Commvault как одного из лидеров в данном сегменте и самое популярное решение среди корпоративных клиентов.

Лидеры в сегменте решений резервного копирования для ЦОД (Gartner, июль 2017 г.).
Немного о Commvault
Commvault – это масштабируемая программная платформа для РК баз данных, приложений, файлов, виртуальных машин и ОС.

Cистемы резервного копирования, поддерживающие S3.
Сегодня практически все современные системы резервного копирования имеют встроенную поддержку протокола S3 API, но не все об этом знают и, соответственно, не в полной мере используют функциональность системы.
Система Commvault поддерживает резервное копирование в облако Amazon S3 и другие S3-совместимые хранилища. А ядро облачного хранилища Техносерв Cloud не только построено с использованием технологий S3, но и поддерживает все команды S3 API, что гарантирует совместимость с приложениями клиента — как сейчас, так и в будущем.
Далее на примере нашего облака покажем, как выполнять резервное копирование из Commvault в S3-совместимое хранилище. Данная инструкция применима к любому S3-совместимому хранилищу.
Настройка подключения хранилища Техносерв Cloud к системе резервного копирования Commvault
Для подключения облачного хранилища Техносерв Cloud к системе резервного копирования Commvault необходимо выполнить три простых шага.
1.Войти в консоль управления облачными ресурсами (https://storage.technoserv.cloud) и создать контейнер для хранения данных. Для этого необходимо перейти на вкладку «Корзины и объекты», затем ввести название корзины в поле «Корзина» и выбрать «Создать», а остальные поля оставить заполненными по умолчанию.
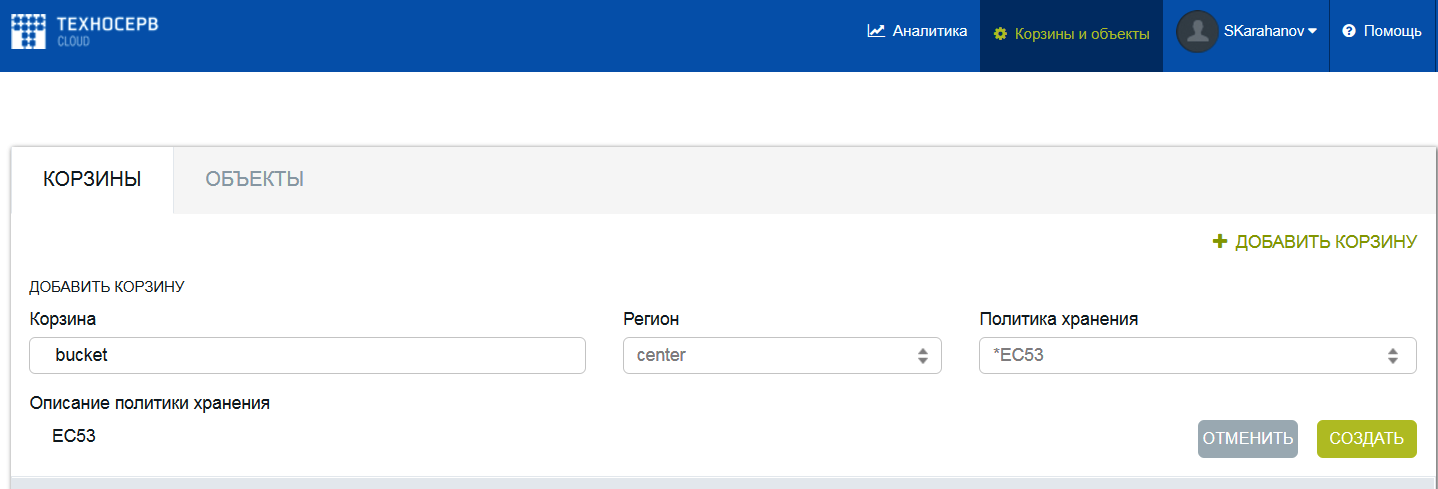
В данном примере мы назвали корзину «bucket».
2.После этого необходимо узнать ключ доступа и пароль к облачному хранилищу. Для этого нужно перейти на вкладку «Управление паролями».
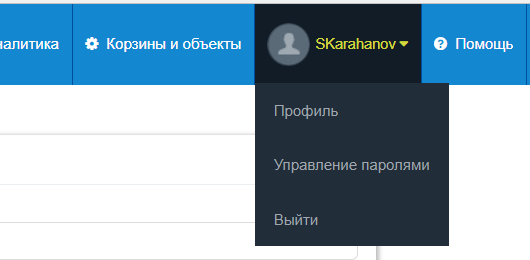
В открывшемся окне будет указана информация, необходимая для подключения облачного хранилища к системе резервного копирования, а именно:
• информация о сервисе (Service Host);
• ключ доступа (Access Key ID);
• и секретный ключ (Secret Access Key).

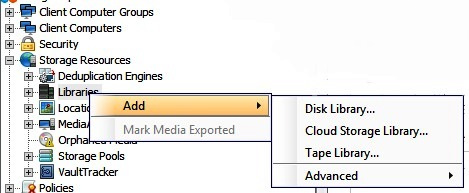
3.Теперь нужно создать облачную библиотеку в системе резервного копирования Commvault. Для этого необходимо в консоли Commcell нажать правой кнопкой мыши на вкладке Libraries и выбрать Add -> Cloud Storage Library.
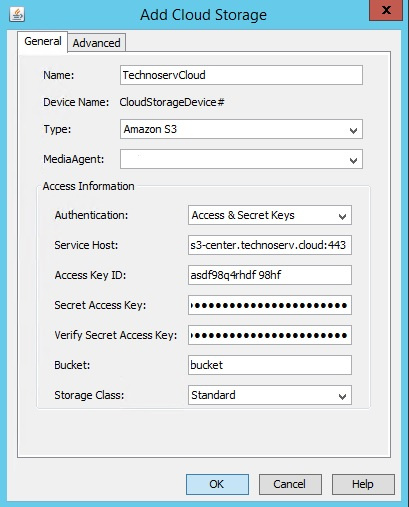
В открывшемся окне во вкладке «General» следует заполнить все поля:
• Name — указать название создаваемой облачной библиотеки;
• Type — из выпадающего списка выбрать Amazon S3;
• MediaAgent — выбрать медиа-сервер, который будет подключаться к облачному хранилищу;
• Access Information — указать упомянутые выше адрес сервера, ключ доступа и пароль. В поле Bucket указать название созданной ранее корзины.
Если для подключения к интернету используется прокси-сервер, то нужно перейти на вкладку «Advanced» и указать параметры прокси-сервера.
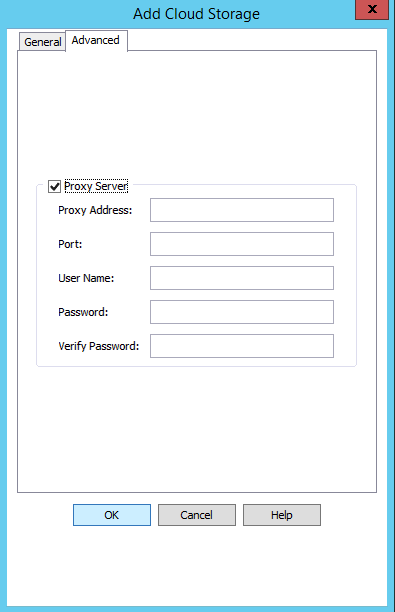
Вот, собственно, и все. На этом интеграция облачного хранилища Техносерв Cloud с системой Commvault завершена.
Для отправки резервных копий в облачное хранилище необходимо в консоли системы резервного копирования задать политику хранения, в которой указать созданную облачную библиотеку. После этого остается назначить политику хранения заданию резервного копирования и запустить его.

Использование объектных облачных хранилищ системой Commvault.
Вот таким, как видите, простым путём мы подключили свое облачное хранилище к системе резервного копирования Commvault, когда запускали услугу резервное копирование в облаке.
Таким образом, можно быстро реализовать преимущества резервного копирования данных в облако, используя его как расширение вашей ИТ-инфраструктуры. В числе преимуществ такого решения:
• Быстрое и надежное резервное копирование и восстановление данных.
• Нет необходимости в дорогостоящих шлюзах и сложных промежуточных решениях.
• Можно заменить ленту облачным хранилищем.
• Можно использовать облако для аварийного восстановления.
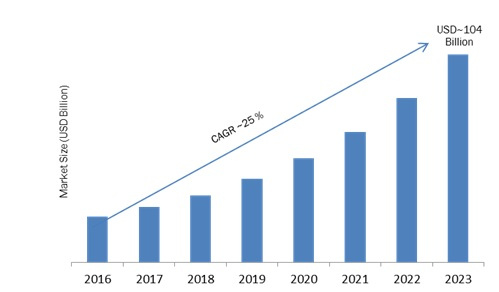
По прогнозу IDC, мировой рынок облачного хранения (Cloud Storage) будет расти на 25% в год.
А что думаете вы? Нам интересно ваше мнение: был ли материал полезен? Нужна ли подобная инструкция по резервному копированию из другой системы? Из какой именно? Ждем ваших комментариев!
Комментарии (6)
Dmitry88
09.08.2017 19:16А вопрос иной плоскости. Как лицензируется комволт? Если по месту, то как подсчитывается облачное хранение?
Для системы РК — это же фактически некий /dev/S3 и какая магия в компрессии и дедупликации ей неведомо.

TS_Cloud Автор
09.08.2017 21:46Dmitry88, Commvault Simpana имеет несколько вариантов лицензирования вплоть до подписки на определенное время (месяц, полгода, год и т.д).
Некоторое время назад (года 3-4 назад) наиболее востребованным способом было лицензирование по агентам, т.е. на каждый компонент приобреталась отдельная лицензия. В данном случае хранилище лицензировалось либо по объему, либо по количеству слотов (для устройств с возможностью отчуждения накопителей, например, ленточных библиотек).
В данный момент распространены и применяются в основном типы лицензирования основанные на FE (Front End) метриках, т.е. на исходных «данных».
Такими «данными» могут являться объем либо количество процессов в серверах \ пользователей \ почтовых ящиков и т.д.
А в данных политиках не лицензируется конечный объем хранимых копий.
К примеру, в компании есть 10ТБ данных, покупается лицензия CV Simpana на 10 ТБ исходных данных, и компания может хранить хоть 5, хоть 50 копий, главное чтобы у него хватило аппаратных ресурсов на это.
Конечно, есть еще и разные типы таких объемных лицензий, но общий подход описан выше.
В случае с CV Simpana, подключение к S3 хранилищам не производится на уровне ОС и не формируется некий псевдодевайс /dev/ S3, подключение формируется и управляется из самой системы РК. Это позволяет ПО Simpana самой управлять потоками и какие данные на него пойду. Если говорить об дедупликации, то она производится на программном уровне СРК и в хранилище уже направляются дедуплицированные данные.
Dmitry88
09.08.2017 22:30> сли говорить об дедупликации, то она производится на программном уровне СРК и в хранилище уже направляются дедуплицированные данные.
То есть, S3 воспринимается, как блочное устройство, то есть этакая смесь объектного хранения посылаемых блоков? Или я запутался
TS_Cloud Автор
09.08.2017 23:49Да, запутаться тут можно из-за многообразия конфигураций. Попробуем объяснить. S3 тут не воспринимается как блочное устройство. Оно является внешним хранилищем к которому обращаются по S3 с запросами по размещению или получению объекта, прощу файла. CV Simpana в своем функционала имеет возможность дедупликации и компрессии на программном уровне. Проще говоря, это происходит так. На серверах СРК хранится БД дедупликации, в которой хранится информация какие блоки есть в системе. Когда производится РК ПО Simpana проверяет весь поток данных на нахождение аналогичных блоков в системе и на повторяемость блоков в рамках потока. Все повторяющие блоки исключаются, вернее заменяются на ссылки на уже существующие в системе. Таким образом, поток дедуплицируется. Уже дедуплицированный поток формируется в специальные контейнеры, фактически файлы содержащие новые уникальные блоки данных и дополнительную мету информацию. Как раз такие контейнеры отправляются в хранилище S3. Весть этот процесс происходит inline, т.е. «на лету» в ОЗУ сервера и не требует промежуточного хранилища для размещения недедуплицированных данных или проведения дедупликации на блочном устройстве.
CV Simpana довольно гибкий продукт, в нем можно сразу «лить» резервные копии на S3 хранилище, либо сначала делать копии на локальные блочные хранилища, Ю а потом по специальному рассписанию переносить в S3 хранилище и множество других комбинаций.
Предугадывая логичный вопрос — БД дедупликации не слияет на сохранность дедуплицированных данных. Даже если она будет потеряно (преднамеряно или по аварии), восстановление данных из дедуплицированного виде возможна без нее, т.к. вся необходимая мета информация для восстановления хранится в контейнерах. БД дедупликации нужна для оперативного процесса дедупликации, как раз из-за нее и возможно проведения процесса «на лету».
Dmitry88
И какие скорости на download/upload? Скажем так можно ли 1-2 террабайта за ночь в облако скинуть, чтобы в окно РК влезть( какой канал нужен)?
TS_Cloud Автор
Dmitry88, расчет канала каждый раз проводится индивидуально, так как зависит от нескольких факторов.
Основными являются степень компрессии и дедупликации и скорость конечного S3 хранилища.
Объектное хранилище Техносерв Cloud является горизонтально масштабируемым и на текущий момент имеет возможность гарантированной обработки до 10 Gbps суммарного потока и возможность его увеличения. В связи с этим конечное устройство не будет являться ограничением.
Степень дедупликации и компрессии всегда разное и имеет прямую зависимость от типа и структуры данных. Поскольку мы рассматриваем объем в 1-2 ТБ то можем предположить, что данные будут разнородными (с разной степенью эффективности компрессии и дедупликации). По нашему опыту (в рамках СРК Техносерв Cloud и локальных инсталляций наших заказчиков), первичная степень (первая полная копия) в среднем равна 2,5 (100% данных дедуплицируется в 40% конечного объема копий), вторичная степень (вторая и последующие полные копии) в среднем равны 5 (100% данных дедуплицируется в 40% конечного объема копий) при условии изменений с момента предыдущего полного РК не более 40-45%.
Предположим, что окно резервного копирования составляет 8 часов.
Таким образом, расчет требуемого канала будет следующим:
2 ТБ первая полная копия:
(2048*0,4)/(8*60*60)*8*1024 что равно ~233 Mbps
1 ТБ первая полная копия:
(1024*0,4)/(8*60*60)*8*1024 что равно ~116,5 Mbps
2 ТБ последующие полные копии:
(2048*0,2)/(8*60*60)*8*1024 что равно ~116,5 Mbps
1 ТБ последующие полные копии:
(1024*0,2)/(8*60*60)*8*1024 что равно ~58,25 Mbps
Данный расчет ориентировочный и является предварительной оценкой, так как в каждом отдельном случае требуется произвести отдельный анализ и расчет или опытное тестирование.
Вообще, мы обычно рекомендуем делить полные копии по сегментам, чтобы поделить нагрузку и трафик по дням недели. К примеру, часть систем делают полное РК в понедельник, другие во вторник и т.д. Этот подход позволяет значительно снизить нагрузку к каналам.