
Продолжаем рассказывать об успешных примерах использования Kubernetes в production. Новый кейс — совсем свежий. Подробная информация о нём появилась только вчера. А что ещё более значимо, речь пойдёт про крупный онлайн-сервис, с которым наверняка так или иначе работает каждый читатель хабры, — GitHub.
О том, что GitHub занимается внедрением Kubernetes в своём production, стало впервые публично известно месяц назад из Twitter-аккаунта SRE-инженера компании Aaron Brown. Тогда он кратко сообщил:
То есть: «если вы ходите по страницам GitHub сегодня, то вас может заинтересовать тот факт, что с этого дня весь веб-контент отдаётся с помощью Kubernetes». В последующих ответах уточнялось, что трафик на Docker-контейнеры, управляемые Kubernetes, был переключён для веб-фронтенда и сервиса Gist, а приложения API находились в процессе миграции. Контейнеризация в GitHub затронула только stateless-приложения, потому что дела со stateful-продуктами обстоят сложнее и «[для обслуживания] MySQL, Redis и Git у нас [в GitHub] уже налажена обширная автоматизация». Выбор в пользу Kubernetes был назван оптимальным для сотрудников GitHub с примечанием, что «Mesos/Nomad ни хуже ни лучше — они просто другие».
Информации было мало, но инженеры GitHub обещали рассказать о подробностях в скором времени. И вот вчера Jesse Newland, старший SRE в компании, опубликовал долгожданную заметку «Kubernetes at GitHub», а буквально за 8 часов до этой публикации на хабре уже упомянутый Aaron Brown выступал на запоздалом праздновании 2-летия Kubernetes в Apprenda с соответствующим докладом:

Цитата из доклада Аарона: «„Мечтаю проводить больше времени за настройкой хостов“, — никакой инженер, никогда»
До недавних событий основное приложение GitHub, написанное на Ruby on Rails, мало менялось за последние 8 лет с его создания:
По мере роста GitHub (сотрудников, количества возможностей и сервисов, пользовательских запросов) возникали сложности, а в частности:
Инженеры и разработчики начали совместный проект по решению этих проблем, который привёл к изучению и сравнению существующих платформ оркестровки контейнеров. Оценивая Kubernetes, они выделили несколько преимуществ:
Для организации деплоя основного Ruby-приложения GitHub с использованием инфраструктуры на базе Kubernetes была создана так называемая «оценочная лаборатория» (Review Lab). Она состояла из следующих проектов:
Итог — интерфейс на базе чата для развёртывания приложения GitHub по любому pull request:
Реализация лаборатории зарекомендовала себя отлично, и к началу июня весь деплой GitHub перешёл на новую схему.
Следующим этапом внедрения Kubernetes стало построение очень требовательной к производительности и надёжности инфраструктуры для главного сервиса компании в production — github.com.
Базовая инфраструктура GitHub — так называемое metal cloud (облако, запущенное на физических серверах в собственных дата-центрах). Разумеется, Kubernetes требовалось запускать с учётом имеющейся специфики. Для этого инженеры компании снова реализовали ряд вспомогательных проектов:
Итог — кластер Kubernetes на железных серверах, который проходил внутренние тесты и менее чем через неделю начал использоваться для миграции с AWS. После создания дополнительных подобных кластеров инженеры GitHub запустили копию боевого github.com на Kubernetes и (с помощью GLB) предложили своим сотрудникам кнопку для переключения между оригинальной инсталляцией приложения и версией в Kubernetes. Архитектура сервисов выглядела следующим образом:
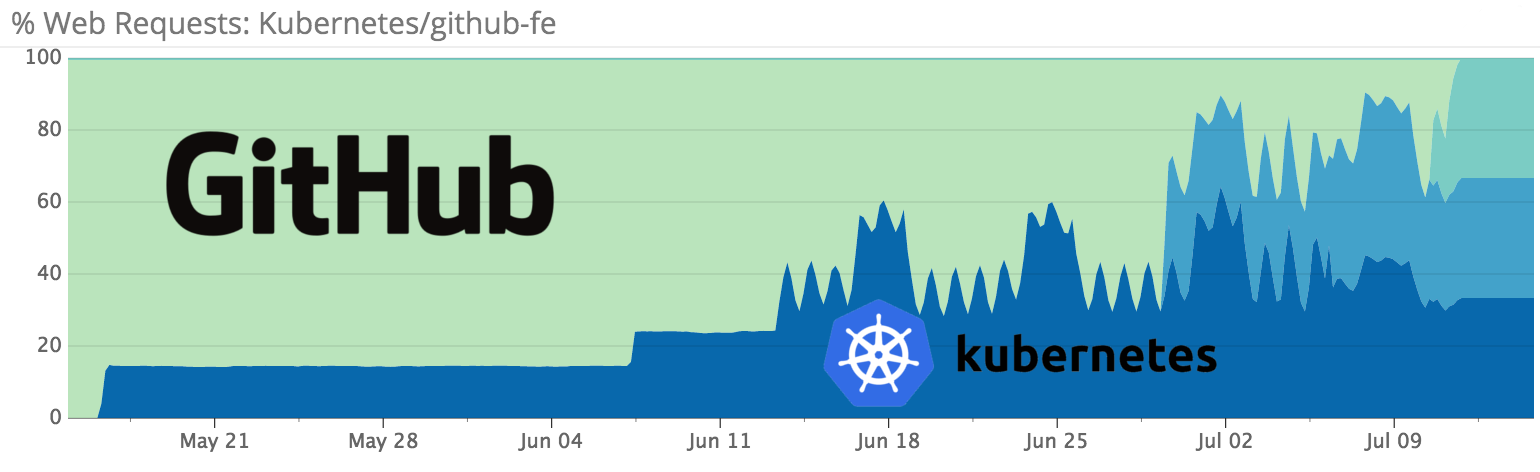
После исправления обнаруженных сотрудниками проблем началось постепенное переключение пользовательского трафика на новые кластеры: сначала по 100 запросов в секунду, а затем — 10 % всех запросов на github.com и api.github.com.
Переходить от 10 % до 100% трафика не спешили. Тесты с частичной нагрузкой показали неожиданные результаты: отказ одного узла Kubernetes apiserver оказывал негативное влияние на доступность имеющихся ресурсов в целом — причина, «по всей видимости», оказалась связана со взаимодействием между разными клиентами, подключающимися к apiserver (calico-agent, kubelet, kube-proxy, kube-controller-manager), и особенностями поведения внутреннего балансировщика нагрузки во время падения узла apiserver. Поэтому в GitHub решили запускать основное приложение на нескольких кластерах в разных местах и перенаправлять запросы с проблемных кластеров на рабочие.
К середине июля этого года 100% production-трафика GitHub было перенаправлено на инфраструктуру на базе Kubernetes.
Одна из оставшихся проблем, со слов инженера компании, заключается в том, что иногда во время сильных нагрузок на некоторых узлах Kubernetes возникает kernel panic, после чего они перезагружаются. Хотя внешне для пользователей это никак не заметно, у SRE-команды высокий приоритет на выяснение причин такого поведения и их устранения, а в тесты, проверяющие отказоустойчивость, уже был специально добавлен вызов kernel panic (через
Первые сведения
О том, что GitHub занимается внедрением Kubernetes в своём production, стало впервые публично известно месяц назад из Twitter-аккаунта SRE-инженера компании Aaron Brown. Тогда он кратко сообщил:
То есть: «если вы ходите по страницам GitHub сегодня, то вас может заинтересовать тот факт, что с этого дня весь веб-контент отдаётся с помощью Kubernetes». В последующих ответах уточнялось, что трафик на Docker-контейнеры, управляемые Kubernetes, был переключён для веб-фронтенда и сервиса Gist, а приложения API находились в процессе миграции. Контейнеризация в GitHub затронула только stateless-приложения, потому что дела со stateful-продуктами обстоят сложнее и «[для обслуживания] MySQL, Redis и Git у нас [в GitHub] уже налажена обширная автоматизация». Выбор в пользу Kubernetes был назван оптимальным для сотрудников GitHub с примечанием, что «Mesos/Nomad ни хуже ни лучше — они просто другие».
Информации было мало, но инженеры GitHub обещали рассказать о подробностях в скором времени. И вот вчера Jesse Newland, старший SRE в компании, опубликовал долгожданную заметку «Kubernetes at GitHub», а буквально за 8 часов до этой публикации на хабре уже упомянутый Aaron Brown выступал на запоздалом праздновании 2-летия Kubernetes в Apprenda с соответствующим докладом:
Цитата из доклада Аарона: «„Мечтаю проводить больше времени за настройкой хостов“, — никакой инженер, никогда»
Зачем вообще Kubernetes в GitHub?
До недавних событий основное приложение GitHub, написанное на Ruby on Rails, мало менялось за последние 8 лет с его создания:
- На серверах с Ubuntu, конфигурируемых с помощью Puppet, менеджер процессов God запускал веб-сервер Unicorn.
- Для деплоя использовался Capistrano, который подключался по SSH к каждому фронтенд-серверу, обновлял код и перезапускал процессы.
- Когда пиковая нагрузка превышала имеющиеся мощности, SRE-инженеры добавляли новые фронтенд-серверы, используя в своём рабочем процессе gPanel, IPMI, iPXE, Puppet Facter и PXE-образ Ubuntu (подробнее об этом можно почитать здесь).
По мере роста GitHub (сотрудников, количества возможностей и сервисов, пользовательских запросов) возникали сложности, а в частности:
- некоторым командам требовалось «извлекать» из больших сервисов малую часть их функциональности для отдельного запуска/деплоя;
- рост числа сервисов приводил к необходимости поддержки множества схожих конфигураций для десятков приложений (больше времени уходило на поддержку серверов и provisioning);
- деплой новых сервисов (в зависимости от их сложности) занимал дни, недели или даже месяцы.
Со временем стало очевидно, что такой подход не обеспечивает наших инженеров гибкостью, которая была необходима для создания сервиса мирового уровня. Нашим инженерам была нужна платформа самообслуживания, которую они могли бы использовать для экспериментирования с новыми сервисами, их деплоя и масштабирования. Кроме того, было нужно, чтобы эта же платформа удовлетворяла требованиям основного приложения на Ruby on Rails, чтобы инженеры и/или роботы могли реагировать на изменения в нагрузке, выделяя дополнительные вычислительные ресурсы за секунды, а не часы, дни или более долгие сроки.
Инженеры и разработчики начали совместный проект по решению этих проблем, который привёл к изучению и сравнению существующих платформ оркестровки контейнеров. Оценивая Kubernetes, они выделили несколько преимуществ:
- активное Open Source-сообщество, поддерживающее проект;
- позитивный опыт первого запуска (на первый деплой приложения в маленьком кластере потребовалось всего несколько часов);
- обширная информация об опыте авторов Kubernetes, который привёл их к имеющейся архитектуре.
Деплой с Kubernetes
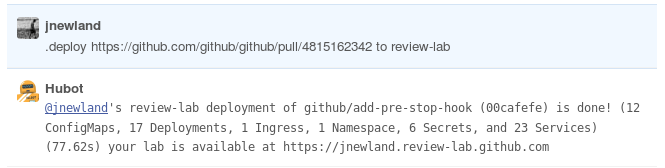
Для организации деплоя основного Ruby-приложения GitHub с использованием инфраструктуры на базе Kubernetes была создана так называемая «оценочная лаборатория» (Review Lab). Она состояла из следующих проектов:
- Кластер Kubernetes, запущенный в облаке AWS VPC и управляемый с помощью Terraform и kops.
- Набор интеграционных тестов на Bash, выполняющих проверки на временных кластерах Kubernetes, которые активно использовались в начале проекта.
-
Dockerfileдля приложения. - Улучшения у внутренней платформы непрерывной интеграции (CI) для поддержки сборки контейнеров и их публикации в реестре.
- YAML-представления 50+ ресурсов, используемых в Kubernetes.
- Улучшения во внутреннем приложении для деплоя для «проброса» ресурсов Kubernetes из репозитория в пространство имён Kubernetes и создания секретов Kubernetes (из внутреннего хранилища).
- Сервис на базе HAProxy and consul-template для перенаправления трафика из подов с Unicorn в существующие сервисы.
- Сервис, пересылающий аварийные события из Kubernetes во внутреннюю систему учёта ошибок.
- Сервис kube-me, который совместим с chatops-rpc и предоставляет пользователям чата ограниченный доступ к командам kubectl.
Итог — интерфейс на базе чата для развёртывания приложения GitHub по любому pull request:
Реализация лаборатории зарекомендовала себя отлично, и к началу июня весь деплой GitHub перешёл на новую схему.
Kubernetes для инфраструктуры
Следующим этапом внедрения Kubernetes стало построение очень требовательной к производительности и надёжности инфраструктуры для главного сервиса компании в production — github.com.
Базовая инфраструктура GitHub — так называемое metal cloud (облако, запущенное на физических серверах в собственных дата-центрах). Разумеется, Kubernetes требовалось запускать с учётом имеющейся специфики. Для этого инженеры компании снова реализовали ряд вспомогательных проектов:
- В качестве сетевого провайдера выбрали Calico, который «из коробки предоставлял необходимую функциональность для быстрого развёртывания кластера в режиме
ipip». - Многократное («не менее дюжины раз») чтение Kubernetes the hard way помогло собрать несколько вручную обслуживаемых серверов во временный кластер Kubernetes, который с успехом прошёл интеграционные тесты, использовавшиеся для имевшихся кластеров на базе AWS.
- Создание небольшой утилиты, генерирующей CA и конфигурацию для каждого кластера в формате, распознаваемым используемым Puppet и системами хранения секретов.
- Puppet'изация конфигурации двух ролей (Kubernetes node и Kubernetes apiserver).
- Создание сервиса (на языке Go), собирающего логи контейнеров, добавляющего к каждой строке метаданные в формате ключ-значение и отправляющего их в syslog для хоста.
- Добавление поддержки Kubernetes NodePort Services в сервисе балансировки нагрузки (GLB).
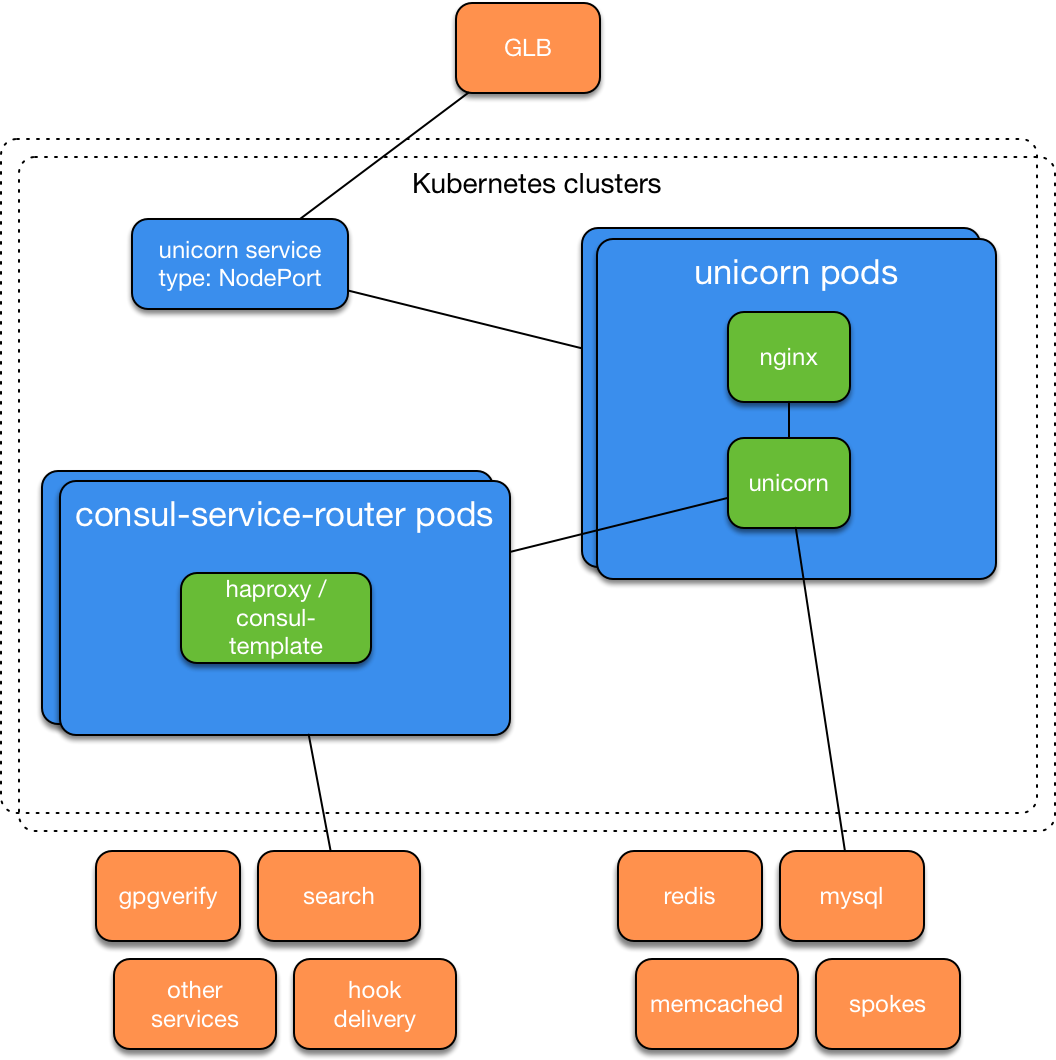
Итог — кластер Kubernetes на железных серверах, который проходил внутренние тесты и менее чем через неделю начал использоваться для миграции с AWS. После создания дополнительных подобных кластеров инженеры GitHub запустили копию боевого github.com на Kubernetes и (с помощью GLB) предложили своим сотрудникам кнопку для переключения между оригинальной инсталляцией приложения и версией в Kubernetes. Архитектура сервисов выглядела следующим образом:
После исправления обнаруженных сотрудниками проблем началось постепенное переключение пользовательского трафика на новые кластеры: сначала по 100 запросов в секунду, а затем — 10 % всех запросов на github.com и api.github.com.
Переходить от 10 % до 100% трафика не спешили. Тесты с частичной нагрузкой показали неожиданные результаты: отказ одного узла Kubernetes apiserver оказывал негативное влияние на доступность имеющихся ресурсов в целом — причина, «по всей видимости», оказалась связана со взаимодействием между разными клиентами, подключающимися к apiserver (calico-agent, kubelet, kube-proxy, kube-controller-manager), и особенностями поведения внутреннего балансировщика нагрузки во время падения узла apiserver. Поэтому в GitHub решили запускать основное приложение на нескольких кластерах в разных местах и перенаправлять запросы с проблемных кластеров на рабочие.
К середине июля этого года 100% production-трафика GitHub было перенаправлено на инфраструктуру на базе Kubernetes.
Одна из оставшихся проблем, со слов инженера компании, заключается в том, что иногда во время сильных нагрузок на некоторых узлах Kubernetes возникает kernel panic, после чего они перезагружаются. Хотя внешне для пользователей это никак не заметно, у SRE-команды высокий приоритет на выяснение причин такого поведения и их устранения, а в тесты, проверяющие отказоустойчивость, уже был специально добавлен вызов kernel panic (через
echo c > /proc/sysrq-trigger). Несмотря на это, авторы в целом довольны полученным опытом и собираются провести больше миграций на подобную архитектуру, а также начать эксперименты с запуском stateful-сервисов в Kubernetes.