
Детектирование и регистрация особенностей изображений имеет много приложений в робототехнике, видео компрессии и т.д. Быстрая и аккуратная регистрация — пока недостижимая мечта многих программистов и пользователей. Она или быстрая, или аккуратная…
Я довольно давно (около 17 лет ), работаю над обработкой изображений, в том числе реконструирования 3D mesh из видео и даже есть своя компания продающая такой продукт. Однако решил часть разработки и ключевую идею выложить в открытый доступ без патентного блокирования
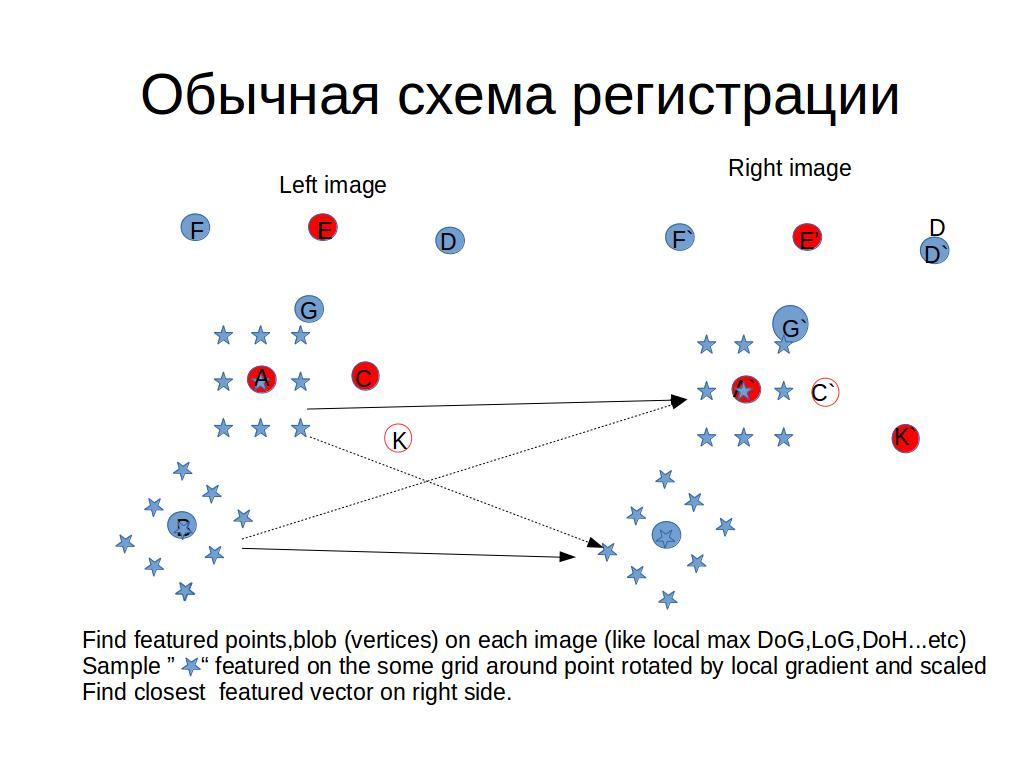
Общая идея существующих относительно быстрых алгоритмов следующая:
Предлагаемая схема регистрации следующая.
Для каждой картинки (detect):

Для регистрации (bind):
Результат:
для ФуллХД на i7-6900K using single core
Для примерно 10000 точек на каждое изображение
detect 29.0556 ms /per image
bind 10.46563 ms /per pair
Достоинства: быстрый, надежный при малых перспективных искажениях (малое количество неверно связанных точек), простой код, не закрыт патентами(насколько мне известно).


Собственно исходный код
На базе этой схемы сейчас пишу заготовку для Raspberry Pi SLAM, в свободное от работы время.
Я довольно давно (около 17 лет ), работаю над обработкой изображений, в том числе реконструирования 3D mesh из видео и даже есть своя компания продающая такой продукт. Однако решил часть разработки и ключевую идею выложить в открытый доступ без патентного блокирования
Общая идея существующих относительно быстрых алгоритмов следующая:
- (Feature detection) Найти какие либо особые точки на каждой картинке, желательно с субпиксельной точностью.
- (Feature description) Построить некий массив признаков для каждой точки, полностью или частично удовлетворяющий следующим требованиям:
- Инвариантность к:
- (Физика) шумы, изменения выдержки(яркость и контраст), артефакты сжатия
- (Геометрия 2D) поворотам, сдвигам, масштабированию
- (Геометрия 3D) проекционным искажениям
- Компактность (меньше памяти, быстрее сравнение)
- Разновидности (Около выделенной точки в некоем предопределенном паттерне):
- Гистограмма градиентов, яркости, цветов. (SIFT,SURF ...)
- Инвариантность к:
- Считывание значений и нормализация уровня.(ORB,BRIFF...)
- Для пары картинок найти соответствия точек с помощью минимального расстояния (сумма абсолютных разностей (L1) или сумма квадратов разностей (L2)) между массивами признаков, асимптотическая сложность данного шага О(N^2), где N — число особых точек.
- (Необязательно): Проверить геометрическую совместимость пар с помощью например RANSAC и повторить шаг 3
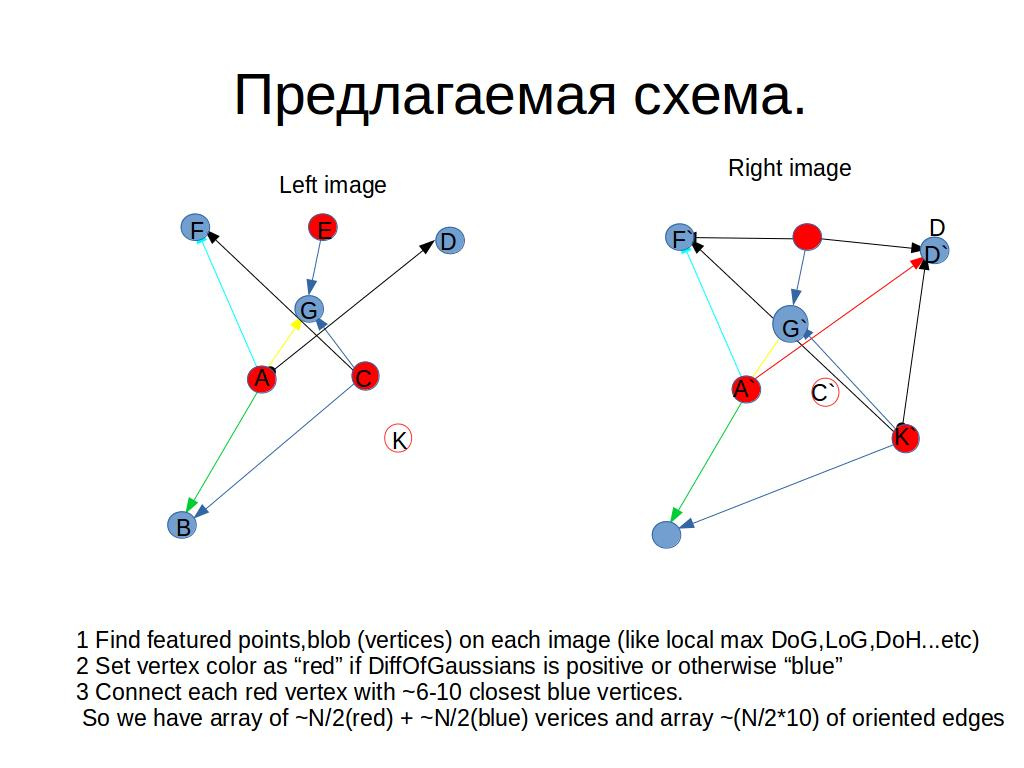
Предлагаемая схема регистрации следующая.
Для каждой картинки (detect):
- Найти особые точки
- Разделить особые точки на 2 группы по признаку знака разницы (DoG) между значением в точке и среднего в малой окрестности.
- Для каждой точки из первой группы найти примерно десяток соседей.
На данном этапе мы имеем биграф из ~N/2*10 ориентированных ребер - Для каждого ребра семплируем в точках паттерна масштабированного и повернутого вместе с ребром
- Строим битовый (~26 бит) hash c помощью сравнения отсчетов
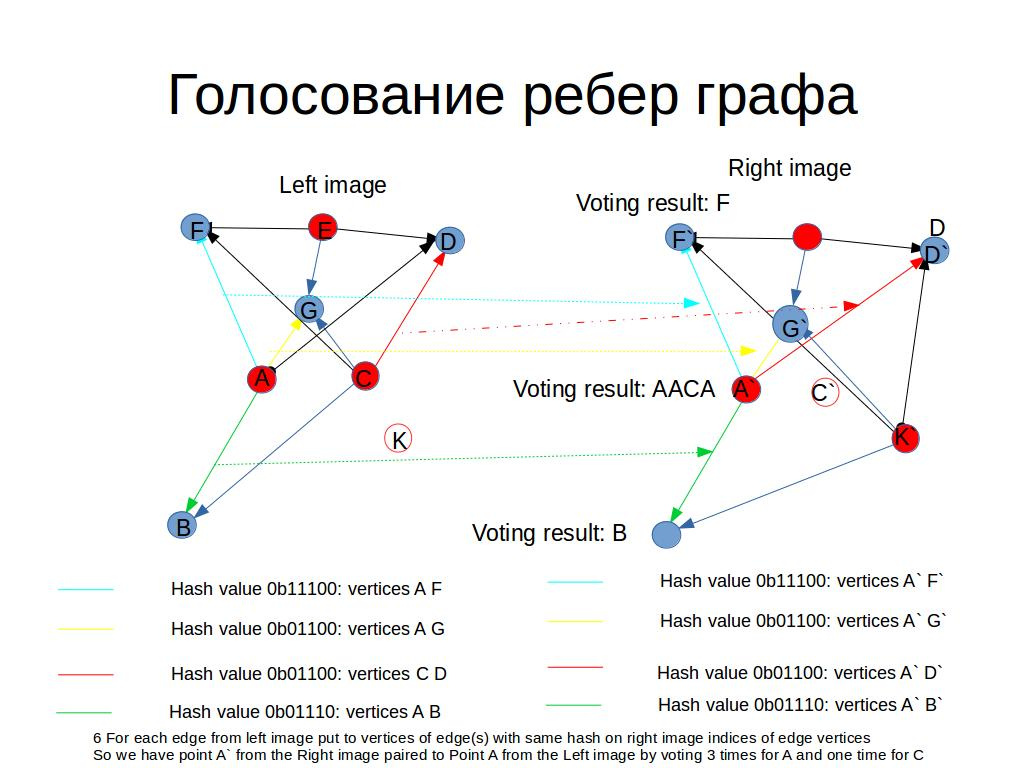
Для регистрации (bind):
- Строим LUT из ребер правой картинки по hash значению
- Для каждого ребра из левой картинки ищем О(1) ребро(ребра) с тем же hash в LUT
- Дописываем 2 индекса точек из левого ребра в 2 индекса точек из правого
- Проходим по всем точкам правой картинки и подсчитываем число голосов
Результат:
для ФуллХД на i7-6900K using single core
Для примерно 10000 точек на каждое изображение
detect 29.0556 ms /per image
bind 10.46563 ms /per pair
Достоинства: быстрый, надежный при малых перспективных искажениях (малое количество неверно связанных точек), простой код, не закрыт патентами(насколько мне известно).
Собственно исходный код
На базе этой схемы сейчас пишу заготовку для Raspberry Pi SLAM, в свободное от работы время.
Комментарии (8)

0dyssey
29.08.2017 17:32Большое спасибо за то, что поделились идеей! Мне эта тема очень интересна, как будет время, попробую детальнее разобраться в подходе.
Если не возражаете, небольшой субъективный совет по коду.
Немного псевдокода.Выражения вида:
for (...) { if (condition_1) { ... if (condition_2) { ... } } }
Могут быть легко представлены в следующем виде (при этом сохраняется функциональность и, на мой взгляд, повышается читабельность):
for (...) { if (!condition_1) continue; ... if (!condition_2) continue; ... }Sdima1357 Автор
29.08.2017 17:45Спасибо. Ну не люблю я «continue». Впрочем и «break» тоже :) Впрочем я не настаиваю…
Код набросан копипастой за день. Я его не вылизывал, а только набросал в качестве сопровождения к статье, хотя он вполне рабочий и достаточно быстрый.
Sdima1357 Автор
29.08.2017 17:55Кстати там есть куски и похуже. Например кривая инициализация класса Detector или не очевидная упаковка индекса и счетчика голосов в одну переменную и тд
Alexander_vrn
Большое спасибо за статью. Я лишь поверхностно знаком с этой темой, но интересуюсь давно, как пользователь. Немного не хватает в заключении аналогичных цифр для других алгоритмов, чтобы было сразу понятно, насколько предлагаемый алгоритм лучше. Ну, например, сколько мс потребуется на те же 10000 точек при использовании широко известных в узких кругах Bundler/PMVS2/CMVS, там ведь тоже SIFT используется?
А своя компания, это, часом, не Agisoft?
Sdima1357 Автор
Sift на том же железе -приблизительно 5-6 мс на 500 точек (связывание ) но с увеличением числа точек время растёт с квадратичной зависимостью. Детекцию sift выгоднее делать на графической карте.
Нет не agisoft. Они вроде видео не занимались…
Alexander_vrn
Спасибо, действительно, я как-то совсем подзабыл, что SIFT на GPU обычно делается. Увидел теперь ваш продукт, надо было сразу на github зайти :)
Sdima1357 Автор
Да вообщем-то продукт тут непричем, не о нем речь Сам алгоритм <моя прелесть> можно применить для очень многих приложений. За счёт схемы голосования у него очень низкий процент outliers (не знаю русского эквивалента) Самый простой вариант-стабилизация видео, или поиск подвижных объектов(non rigid) на сцене.
Alexander_vrn
Да, очень интересный материал. Спасибо еще раз, что поделились!