
 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и спполучить базу. В общем, страсти в этих ваших Интернетах еще те. Недавно я наткнулся на статью, где без всяких нейросетей на устройстве делают очень даже хорошую сегментацию. Для сегментации от пользователя требуется дать алгоритму несколько подсказок, но с помощью dlib и opencv такие подсказки легко автоматизируются. В качестве бонуса мы так же сгладим вырезанное лицо и перенесем на какого-нибудь рандомного человека, тем самым поймем, как работают маски во всех этих снапчятах и маскарадах. В общем, классика еще жива, и если вы хотите немного окунуться в классическое компьютерное зрение на питоне, то добро пожаловать под кат.
Алгоритм
Кратко опишем алгоритм, а затем перейдем к его реализации по шагам. Допустим, у нас есть некоторое изображение, мы просим пользователя нарисовать на изображении две кривых. Первая (синий цвет) должна полностью принадлежать объекту интереса. Вторая (зеленый цвет) должна касаться только фона изображения.

Далее делаем следующие шаги:
- строим плотности распределения цветов точек для фона и для объекта;
- для каждой точки вне штрихов вычисляется вероятность принадлежности к фону и к объекту;
- используем эти вероятности для вычисления "расстояния" между точками и запускаем алгоритм поиска кратчайших расстояний на графе.
В итоге точки, которые ближе к объекту, относим к нему и, соотвественно, те, что ближе к фону, относим к фону.
Дальнейший материал будет разбавляться вставками кода на питоне, если вы планируете выполнять его по мере чтения поста, то вам понадобятся следующие импорты:
%matplotlib inline
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("dark")
plt.rcParams['figure.figsize'] = 16, 12
import pandas as pd
from PIL import Image
from tqdm import tqdm_notebook
from skimage import transform
import itertools as it
from sklearn.neighbors.kde import KernelDensity
import matplotlib.cm as cm
import queue
from skimage import morphology
import dlib
import cv2
from imutils import face_utils
from scipy.spatial import DelaunayАвтоматизируем штрихи
 Идея того, как автоматизировать штрихи была навеяна приложением FaceApp, которое якобы использует нейросети для трансформации. Как мне кажется, они если и используют сети где то, то только в детектировании особых точек на лице. Взгляните на скриншот справа, они предлагают выровнять свое лицо по контуру. Вероятно, алгоритм детекции обучен примерно на таком масштабе. Как только лицо попадает в контур, сама рамка контура исчезает, значит особые точки вычислились. Позвольте вам представить сегодняшнего подопытного, а так-же напомнить, что из себя представляют эти самые особые точки на лице.
Идея того, как автоматизировать штрихи была навеяна приложением FaceApp, которое якобы использует нейросети для трансформации. Как мне кажется, они если и используют сети где то, то только в детектировании особых точек на лице. Взгляните на скриншот справа, они предлагают выровнять свое лицо по контуру. Вероятно, алгоритм детекции обучен примерно на таком масштабе. Как только лицо попадает в контур, сама рамка контура исчезает, значит особые точки вычислились. Позвольте вам представить сегодняшнего подопытного, а так-же напомнить, что из себя представляют эти самые особые точки на лице.
img_input = np.array(Image.open('./../data/input2.jpg'))[:500, 400:, :]
print(img_input.shape)
plt.imshow(img_input)
Теперь воспользуемся возможностями бесплатного программного обеспечения с открытым исходным кодом и найдем рамку вокруг лица и особые точки на лице, всего их 68.
# инстанцируем класс для детекции лиц (рамка)
detector = dlib.get_frontal_face_detector()
# инстанцируем класс для детекции ключевых точек
predictor = dlib.shape_predictor('./../data/shape_predictor_68_face_landmarks.dat')
# конвертируем изображение в много оттенков серого
img_gray = cv2.cvtColor(img_input, cv2.COLOR_BGR2GRAY)
# вычисляем список рамок на каждое найденное лицо
rects = detector(img_gray, 0)
# вычисляем ключевые точки
shape = predictor(img_gray, rects[0])
shape = face_utils.shape_to_np(shape)img_tmp = img_input.copy()
for x, y in shape:
cv2.circle(img_tmp, (x, y), 1, (0, 0, 255), -1)
plt.imshow(img_tmp)
Оригинальная рамка на лице слишком мелкая (зеленый цвет), нам понадобится рамка, которая полностью содержит в себе лицо с некоторым зазором (красный цвет). Коэффициенты расширения рамки получены эмпирическим путем с помощью анализа нескольких десятков селфи разного масштаба и разных людей.
# оригинальная рамка
face_origin = sorted([(t.width()*t.height(),
(t.left(), t.top(), t.width(), t.height()))
for t in rects],
key=lambda t: t[0], reverse=True)[0][1]
# коэффициенты расширения рамки
rescale = (1.3, 2.2, 1.3, 1.3)
# расширение рамки, так чтобы она не вылезла за края
(x, y, w, h) = face_origin
cx = x + w/2
cy = y + h/2
w = min(img_input.shape[1] - x, int(w/2 + rescale[2]*w/2))
h = min(img_input.shape[0] - y, int(h/2 + rescale[3]*h/2))
fx = max(0, int(x + w/2*(1 - rescale[0])))
fy = max(0, int(y + h/2*(1 - rescale[1])))
fw = min(img_input.shape[1] - fx, int(w - w/2*(1 - rescale[0])))
fh = min(img_input.shape[0] - fy, int(h - h/2*(1 - rescale[1])))
face = (fx, fy, fw, fh)img_tmp = cv2.rectangle(img_input.copy(), (face[0], face[1]),
(face[0] + face[2], face[1] + face[3]),
(255, 0, 0), thickness=3, lineType=8, shift=0)
img_tmp = cv2.rectangle(img_tmp, (face_origin[0], face_origin[1]),
(face_origin[0] + face_origin[2], face_origin[1] + face_origin[3]),
(0, 255, 0), thickness=3, lineType=8, shift=0)
plt.imshow(img_tmp)

Теперь у нас имеется область, которая точно не относится к лицу — всё, что вне красной рамки. Выберем оттуда некоторое количество случайных точек и будем считать их штрихами фона. Также у нас имеются 68 точек, которые точно расположены на лице. Для упрощения задачи я выберу 5 из них: по одной на уровне глаз на краю лица, по одной на уровне рта на краю лица и одну внизу посередине подбородка. Все точки внутри этого пятиугольника будут принадлежать только лицу. Опять же для простоты будем считать, что лицо вертикально расположено на изображении и потому мы можем отразить полученный пятиугольник по оси , тем самым получив восьмиугольник. Все, что внутри восьмиугольника будем считать штрихом объекта.
# выбираем вышеописанные пять точек
points = [shape[0].tolist(), shape[16].tolist()]
for ix in [4, 12, 8]:
x, y = shape[ix].tolist()
points.append((x, y))
points.append((x, points[0][1] + points[0][1] - y))
# я не особо в прототипе запариваюсь над производительностью
# так что вызываю триангуляцию Делоне,
# чтобы использовать ее как тест на то, что точка внутри полигона
# все это можно делать быстрее, т.к. точный тест не нужен
# для прототипа :good-enough:
hull = Delaunay(points)
xy_fg = []
for x, y in it.product(range(img_input.shape[0]), range(img_input.shape[1])):
if hull.find_simplex([y, x]) >= 0:
xy_fg.append((x, y))
print('xy_fg%:', len(xy_fg)/np.prod(img_input.shape))
# вычисляем количество точек для фона
# примерно равно что бы было тому, что на лице
r = face[1]*face[3]/np.prod(img_input.shape[:2])
print(r)
k = 0.1
xy_bg_n = int(k*np.prod(img_input.shape[:2]))
print(xy_bg_n)
# накидываем случайные точки
xy_bg = zip(np.random.uniform(0, img_input.shape[0], size=xy_bg_n).astype(np.int),
np.random.uniform(0, img_input.shape[1], size=xy_bg_n).astype(np.int))
xy_bg = list(xy_bg)
xy_bg = [(x, y) for (x, y) in xy_bg
if y < face[0] or y > face[0] + face[2] or x < face[1] or x > face[1] + face[3]]
print(len(xy_bg)/np.prod(img_input.shape[:2]))img_tmp = img_input/255
for x, y in xy_fg:
img_tmp[x, y, :] = img_tmp[x, y, :]*0.5 + np.array([1, 0, 0]) * 0.5
for x, y in xy_bg:
img_tmp[x, y, :] = img_tmp[x, y, :]*0.5 + np.array([0, 0, 1]) * 0.5
plt.imshow(img_tmp)
Нечеткое разделение фона и объекта
Теперь у нас есть два набора данных: точки объекта и точки фона .
points_fg = np.array([img_input[x, y, :] for (x, y) in xy_fg])
points_bg = np.array([img_input[x, y, :] for (x, y) in xy_bg])Посмотрим на распределение цветов по RGB каналам в каждом из множеств. Первая гистограмма — для объекта, вторая — для фона.
fig, axes = plt.subplots(nrows=2, ncols=1)
sns.distplot(points_fg[:, 0], ax=axes[0], color='r')
sns.distplot(points_fg[:, 1], ax=axes[0], color='g')
sns.distplot(points_fg[:, 2], ax=axes[0], color='b')
sns.distplot(points_bg[:, 0], ax=axes[1], color='r')
sns.distplot(points_bg[:, 1], ax=axes[1], color='g')
sns.distplot(points_bg[:, 2], ax=axes[1], color='b')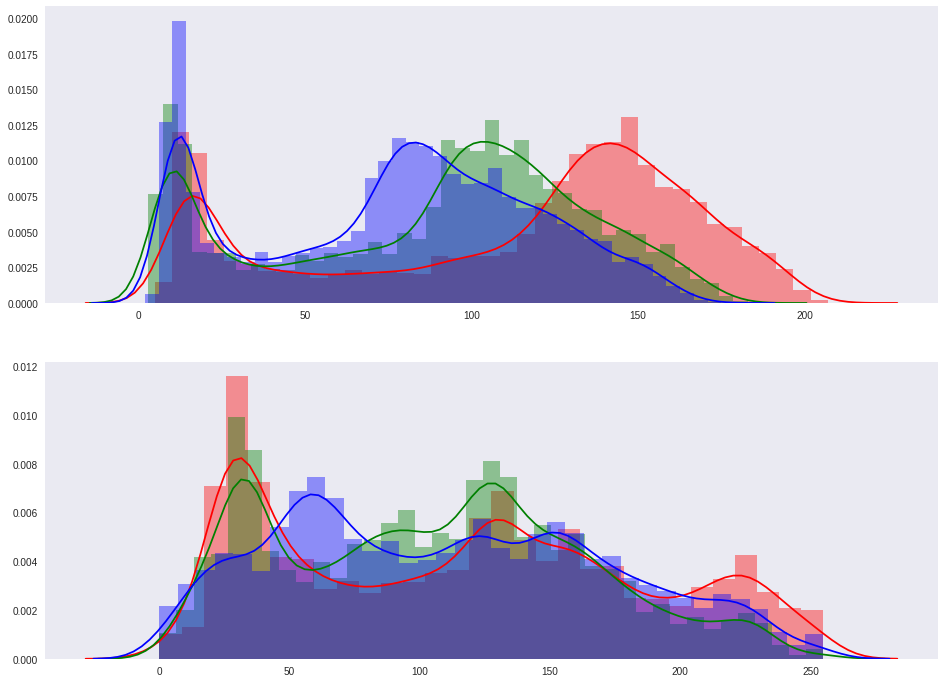
Радует, что распределения отличаются. Это значит, что если мы сможем получить функции, оценивающие вероятность принадлежности точки к нужному распределению, то мы получим нечеткие маски. И оказывается такой способ есть — kernel density estimation. Для заданного набора точек, можно построить функцию оценки плотности для новой точки следующим образом (для простоты пример для одномерного распределения):
где:
- — параметр сглаживания
- — некоторое ядро
Мы для простоты будем использовать Гауссово ядро:
Хотя для скорости Гауссово ядро не лучший выбор и если взять ядро Епанечникова, то все будет считаться быстрее. Так же я буду использовать KernelDensity из sklearn, что в итоге выльется в 5 минут скоринга. Авторы этой статьи утверждают, что замена KDE на оптимальную реализацию сокращает расчеты на устройстве до одной секунды.
# инстанцируем классы KDE для объекта и фона
kde_fg = KernelDensity(kernel='gaussian',
bandwidth=1,
algorithm='kd_tree',
leaf_size=100).fit(points_fg)
kde_bg = KernelDensity(kernel='gaussian',
bandwidth=1,
algorithm='kd_tree',
leaf_size=100).fit(points_bg)
# инициализируем и вычисляем маски
score_kde_fg = np.zeros(img_input.shape[:2])
score_kde_bg = np.zeros(img_input.shape[:2])
likelihood_fg = np.zeros(img_input.shape[:2])
coodinates = it.product(range(score_kde_fg.shape[0]),
range(score_kde_fg.shape[1]))
for x, y in tqdm_notebook(coodinates,
total=np.prod(score_kde_fg.shape)):
score_kde_fg[x, y] = np.exp(kde_fg.score(img_input[x, y, :].reshape(1, -1)))
score_kde_bg[x, y] = np.exp(kde_bg.score(img_input[x, y, :].reshape(1, -1)))
n = score_kde_fg[x, y] + score_kde_bg[x, y]
if n == 0:
n = 1
likelihood_fg[x, y] = score_kde_fg[x, y]/nВ итоге у нас есть несколько масок:
score_kde_fg— оценка вероятности быть точкой объектаscore_kde_bg— оценка вероятности быть точкой фонаlikelihood_fg— нормализированная вероятность быть точкой объекта1 - likelihood_fgнормализированная вероятность быть точкой фона
Посмотрим на следующие распределения.
sns.distplot(score_kde_fg.flatten())
plt.show()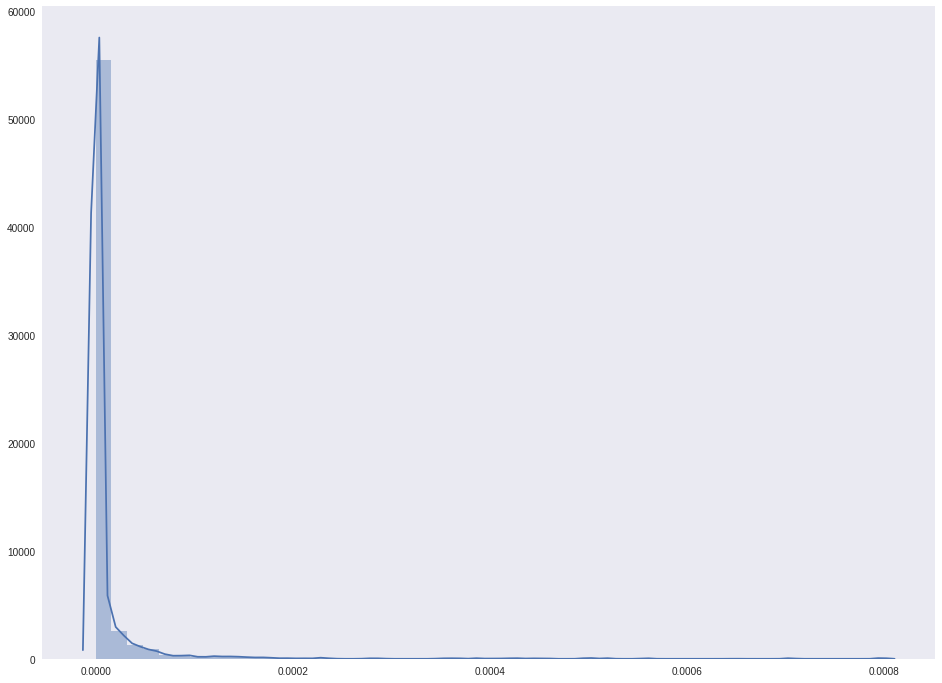
sns.distplot(score_kde_bg.flatten())
plt.show()
Распределение значений likelihood_fg:
sns.distplot(likelihood_fg.flatten())
plt.show()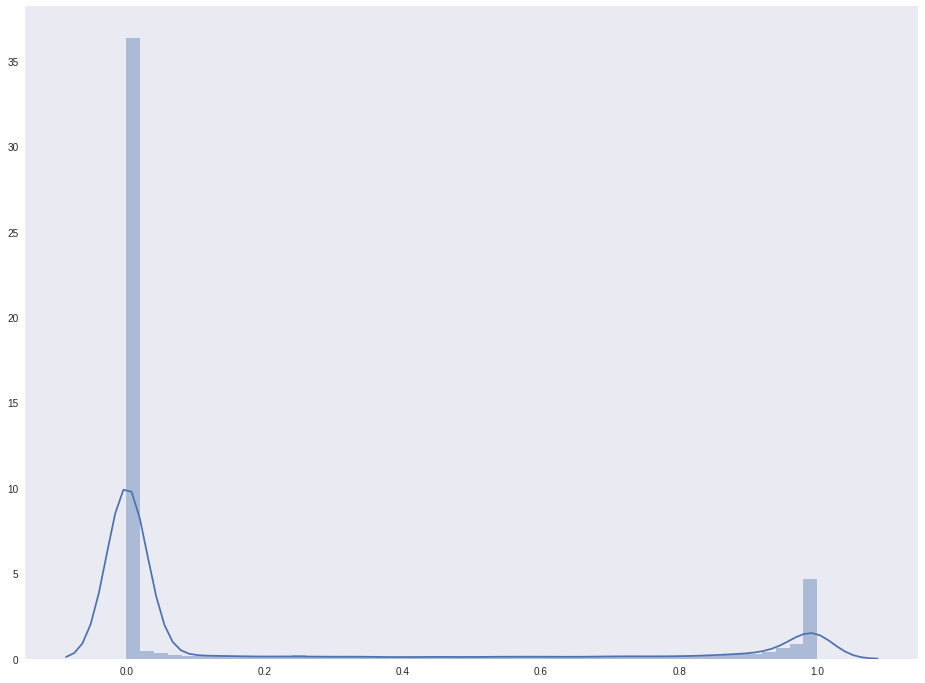
Вселяет надежду то, что на есть два пика, и количество точек, принадлежащих лицу, явно не меньше, чем фоновых точек. Нарисуем полученные маски.
plt.matshow(score_kde_fg, cmap=cm.bwr)
plt.show()
plt.matshow(score_kde_bg, cmap=cm.bwr)
plt.show()
plt.matshow(likelihood_fg, cmap=cm.bwr)
plt.show()
plt.matshow(1 - likelihood_fg, cmap=cm.bwr)
plt.show()
К сожалению, часть косяка двери получилась частью лица. Хорошо, что косяк далеко от лица. Этим-то свойством мы и воспользуемся в следущей части.
Бинарная маска объекта
Представим изображение как граф, узлами которого являются пиксели, а ребрами соединены точки сверху и снизу от текущей точки, а так же справа и слева от неё. Весами ребер будем считать абсолютное значение разницы вероятностей принадлежности точек к объекту или к фону:
Соответственно, чем вероятности ближе к друг другу, тем меньше вес ребра между точками. Воспользуемся алгоритмом Дейкстры для поиска наикратчайших путей и их расстояний от точки до всех остальных. Алгоритм мы вызовем два раза, подав на вход все вероятности принадлежности в объекту и затем вероятности принадлежности точек к фону. Понятие расстояния зашьем сразу в алгоритм, а расстояние между точками, принадлежащими одной группе (объекту или фону), будет равно нулю. В рамках алгоритма Дейкстры мы можем поместить все эти точки в группу посещенных вершин.
def dijkstra(start_points, w):
d = np.zeros(w.shape) + np.infty
v = np.zeros(w.shape, dtype=np.bool)
q = queue.PriorityQueue()
for x, y in start_points:
d[x, y] = 0
q.put((d[x, y], (x, y)))
for x, y in it.product(range(w.shape[0]), range(w.shape[1])):
if np.isinf(d[x, y]):
q.put((d[x, y], (x, y)))
while not q.empty():
_, p = q.get()
if v[p]:
continue
neighbourhood = []
if p[0] - 1 >= 0:
neighbourhood.append((p[0] - 1, p[1]))
if p[0] + 1 <= w.shape[0] - 1:
neighbourhood.append((p[0] + 1, p[1]))
if p[1] - 1 >= 0:
neighbourhood.append((p[0], p[1] - 1))
if p[1] + 1 < w.shape[1]:
neighbourhood.append((p[0], p[1] + 1))
for x, y in neighbourhood:
# тут вычисляется расстояние
d_tmp = d[p] + np.abs(w[x, y] - w[p])
if d[x, y] > d_tmp:
d[x, y] = d_tmp
q.put((d[x, y], (x, y)))
v[p] = True
return d
# вызываем алгоритм для двух масок
d_fg = dijkstra(xy_fg, likelihood_fg)
d_bg = dijkstra(xy_bg, 1 - likelihood_fg)plt.matshow(d_fg, cmap=cm.bwr)
plt.show()
plt.matshow(d_bg, cmap=cm.bwr)
plt.show()
А теперь относим к объекту все те точки, от которых расстояние до объекта меньше чем расстояния до фона (можно добавить некоторый зазор).
margin = 0.0
mask = (d_fg < (d_bg + margin)).astype(np.uint8)
plt.matshow(mask)
plt.show()
Можно отправить себя в космос.
img_fg = img_input/255.0
img_bg = (np.array(Image.open('./../data/background.jpg'))/255.0)[:800, :800, :]
x = int(img_bg.shape[0] - img_fg.shape[0])
y = int(img_bg.shape[1]/2 - img_fg.shape[1]/2)
img_bg_fg = img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :]
mask_3d = np.dstack([mask, mask, mask])
img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :] = mask_3d*img_fg + (1 - mask_3d)*img_bg_fg
plt.imshow(img_bg)
Сглаживание маски
Вы наверняка заметили, что маска слегка рваная на краях. Но это легко исправить методами математической морфологии.

Допустим, у нас есть структурный элемент (СЭ) типа "диск" — бинарная маска диска.
- эрозия: прикладываем к каждой точке объекта на оригинальном изображении СЭ так, чтобы совпадал центр СЭ и точка на изображении; если СЭ полностью принадлежит в объекту, то такая точка объекта остается; получается, что удаляются детали, которые меньше чем СЭ, и объект "худеет"; в примере из синего квадрата сделали голубой
- наращивание (dilation): на каждую точку объекта накладывается СЭ, и недостающие точки дорисовываются; таким образом закрашиваются дырки меньшие чем СЭ, а объект в целом "толстеет"; на примере из синего квадрата сделали голубой, углы получились закругленные
- размыкание (opening): сначала эрозия, потом наращивание тем же СЭ
- замыкание (closing): сначала наращивание, потом эрозия тем же СЭ
Мы воспользуемся размыканием, что сначала удалит "волосатость" по краям, а потом вернет первоначальный размер (объект "похудеет" после эрозии).
mask = morphology.opening(mask, morphology.disk(11))
plt.imshow(mask)
После применения такой маски результат станет поприятнее:
img_fg = img_input/255.0
img_bg = (np.array(Image.open('./../data/background.jpg'))/255.0)[:800, :800, :]
x = int(img_bg.shape[0] - img_fg.shape[0])
y = int(img_bg.shape[1]/2 - img_fg.shape[1]/2)
img_bg_fg = img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :]
mask_3d = np.dstack([mask, mask, mask])
img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :] = mask_3d*img_fg + (1 - mask_3d)*img_bg_fg
plt.imshow(img_bg)
Накладываем маску
Возьмем случайную фотку из интернетов для эксперимента по переносу лица.
img_target = np.array(Image.open('./../data/target.jpg'))
img_target = (transform.rescale(img_target, scale=0.5, mode='constant')*255).astype(np.uint8)
print(img_target.shape)
plt.imshow(img_target)
Найдем на подопытном все 68 колючевые точки лица, напомню, что они будут в том же порядке как и на любом другом лице.
img_gray = cv2.cvtColor(img_target, cv2.COLOR_BGR2GRAY)
rects_target = detector(img_gray, 0)
shape_target = predictor(img_gray, rects_target[0])
shape_target = face_utils.shape_to_np(shape_target)Чтобы перенести одно лицо на другое, нужно первое лицо отмасштабировать под новое, повернуть и передвинуть, т.е. применить некоторое аффинное преобразование к первому лицу. Оказывается, что и аффинное преобразование не некоторое, а вполне конкретное. Оно должно быть таким, которое переводит 68 точки первого лица в 68 точки второго лица. Получается, что для получения оператора аффинного преобразования нам необходимо решить задачу линейной регрессии.
Данное уравнение легко решается с помощью псевдообратной матрицы:
Так и сделаем:
# добавим справа к матрицам колонку единиц,
# иначе будет только масштабирование и поворот, без переноса
X = np.hstack((shape, np.ones(shape.shape[0])[:, np.newaxis]))
Y = np.hstack((shape_target, np.ones(shape_target.shape[0])[:, np.newaxis]))
# учим оператор
A = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
# выбираем точки лица по искомой маске
X = np.array([(y, x, 1) for (x, y) in
it.product(range(mask.shape[0]),
range(mask.shape[1])) if mask[x, y] == 1.0])
# вычисляем новые координаты маски на целевом изображении
Y = np.dot(X, A).astype(np.int)img_tmp = img_target.copy()
for y, x, _ in Y:
if x < 0 or x >= img_target.shape[0] or y < 0 or y >= img_target.shape[1]:
continue
img_tmp[x, y, :] = np.array([0, 0, 0])
plt.imshow(img_tmp)
img_trans = img_target.copy().astype(np.uint8)
points_face = {}
for ix in range(X.shape[0]):
y1, x1, _ = X[ix, :]
y2, x2, _ = Y[ix, :]
if x2 < 0 or x2 >= img_target.shape[0] or
y2 < 0 or y2 >= img_target.shape[1]:
continue
points_face[(x2, y2)] = img_input[x1, y1, :]
for (x, y), c in points_face.items():
img_trans[x, y, :] = c
plt.imshow(img_trans)
Заключение
В качестве домашней работы вы можете самостоятельно сделать следующие улучшения:
- добавить прозрачности по краям, чтобы был плавный переход маски в целевое изображение (matting);
- пофиксить перенос на изображения большего размера — точек оригинального лица не хватит, чтобы покрыть все точки целевого лица, таким образом, образуются пропуски между точками; исправить это можно увеличением размера исходного лица;
- сделать какую-либо маску, например бурундука Дейла, нанести вручную 68 точки и осуществить перенос (вот вам и маскарад);
- использовать какой-нибудь модный нейросетевой детектор точек, который умеет искать большее количество точек.
{kind=link}
Ноутбук с исходниками находится тут. Приятного времяпрепровождения.
Как обычно спс bauchgefuehl за редактуру.
Комментарии (21)

napa3um
11.09.2017 15:04+2Адепты нейросетей часто считают само по себе использование нейросетей достаточным условием для получения хороших результатов, даже без формализации модели, параметры которой они этой сетью оптимизируют. Результаты получаются либо случайно, либо применением типовых архитектур нейросетей для типовых задач (без особых размышлений над тем, почему они работают). Интересно, что почти тот же мотив приводит и к противоположным подходам — считая нейросети костылём для тех, кто не способен сам сформулировать модель, адепты «алгоритмических» решений полностью строят модель и аналитически, «руками» ограничивают её параметры.
А Истинный Путь, как водится, лежит посередине. Нейросети не освобождают разработчика от понимания прикладной области и формулирования математической модели, но позволяют некоторые параметры этой модели не фиксировать, оставлять свободными, отдавая их подбор на откуп автоматическим алгоритмам оптимизации.
Неправильно противопоставлять «нейросетевые» алгоритмы и «ручные», для решения прикладной задачи без модели не обойтись, и именно эти модели и являются самым важным аспектом решения, а вопрос в способе фиксации свободных параметров в этой модели, в общем-то, вторичен (а для математика он вообще не принципиален, он фиксирует саму принципиальную решаемость задачи :)).
mephistopheies Автор
11.09.2017 16:12нейросети захватят мир, на самом деле, но вы правы в чем-то — захватят, но не сегодня

sergehog
11.09.2017 15:14+1Про Виолу-Джонс что-то не вспомнили совсем. Чтоб вам сразу не воспользоваться альфа-маттингом? Получили 62 точки, гарантированно на морде лица, по-бокам бэкраунд — и вперед, альфаматить. Современные методы вытворяют чудеса www.alphamatting.com
mephistopheies Автор
11.09.2017 16:09>CVPR 2009
ну не очень современный, но вообще про то и речь, да

shebanoff
11.09.2017 19:59+1Альфа маттинг сейчас это общий термин, который подразумевает разделение картинки на фон и передний план с учетом частичной прозрачности переднего плана.
Давать ссылки можно, например, на это arxiv.org/abs/1703.03872
salisbury-espinosa
12.09.2017 04:30+1а есть имплементации этой white paper?
(нашел лишь github.com/Joker316701882/Deep-Image-Matting но там статус еще — «в процессе»)marten_de
12.09.2017 12:44+1а Segnet это не из той же оперы? mi.eng.cam.ac.uk/projects/segnet
salisbury-espinosa
13.09.2017 14:07+2угумс — это сегментация.
для картинки из статьи результат такой:

проектов то в целом много — вот например github.com/facebookresearch/deepmask, но вот нормально оно не работает ничего…
есть только более-менее норм github.com/tensorflow/models/tree/master/object_detection
но, там не по пикселям, а в box просто объекты заворачиваются…
IamG
11.09.2017 19:26+1а не подскажете эффективное решение такой задачи «первый кадр- статичный фон, потом на нём появляется человек и прорамма заменяет фон на произвольный» именно в real-time на видео потоке?
mephistopheies Автор
11.09.2017 19:47я видел статьи как отделять движущийся объект от фона, таких много, но вот хз на сколько они риал тайм; могу посоветовать зайти к нам в слак, там есть канал по компьютерному зрения и там думаю вам помогут; щас кину им туда ссылку может кто комент оставит
marten_de
12.09.2017 12:43+1Дай вам Бог здоровьечка, сходным путем шел для сегментации монет на фото, проблема была как раз улучшить после первичного разделения фона и объекта.

mclander
12.09.2017 12:45+1Спасибо. Редко когда приятно читать статью в которой не понимаешь деталей)
Кстати, выглядит так, что ключевые точки на лице визуально меняют ориентацию подопытного…mephistopheies Автор
12.09.2017 13:10стоп стоп, ориентация меняется в самом конце моего прошлого поста habrahabr.ru/company/ods/blog/322514

ZlodeiBaal
12.09.2017 14:57+2Так. Детекция лиц в актуальном dlib уже cnn сделана. Где-то с пол года назад они собирались переделывать и поиск точек под cnn. Уверены, что там ещё не вставили их и чистый AAM идёт?:)
mephistopheies Автор
12.09.2017 15:16вот это поворот =) честно говоря я хз что там, я же просто import face detector from dlib
ну вообще для текущей задачи не так важно качество детектирования точек, так что в принципе пофиг; я тут сотрудничая с одной конторой видел у них детектор точек просто деревянный регрессор на фичах хаара, ну и качество такое же (ну если оценивать на глаз)
marten_de
12.09.2017 16:00+1Сегментация там на HOG. А вот points of interest может быть.
ZlodeiBaal
12.09.2017 16:21+4Хм? Вот блог.

16 октября 2016 года там уже был CNN Face Detection. Сейчас он в основной ветке. Работает, в принципе неплохо, но я и более хорошие видел.
Сейчас там на CNN уже детектор произвольных объектов.
salisbury-espinosa
интересно отделять какие то предметы от background, а не только лица )

вот с ходу получилось найти полуработающее решение на tensorflow:
с OpenCv получается хуже (если не только с лицом работать)
mephistopheies Автор
ну так тензорфлоу жеж, нейросетоньки