

В предыдущей статье «SDAccel – первое знакомство» я попытался описать основы применения OpenCL на ПЛИС Xilinx. Теперь настало время поделиться результатами экспериментов по передаче данных на модуле ADM-PCIe-KU3. Проверяется передача данных в обоих направлениях. Исходный код программ размещён на GitHub: https://github.com/dsmv/sdaccel
Аппаратура
Все эксперименты выполнены на модуле ADM-PCIe_KU3 компании Alpha-Data

Центральным элементом является ПЛИС Xilinx Kintex UltraScale KU060
К ПЛИС подключены два модуля SODIMM DDR3-1600; Ширина памяти 72 бита, это даёт возможность использовать контроллер памяти с коррекцией ошибок.
Существует возможность подключения двух QSFP модулей. Каждый QSFP модуль это четыре двунаправленные линии со скоростью передачи до 10 Гбит/с. Это даёт возможность использовать 1G, 10G, 40G Ethernet, в том числе реализовать Low-Latency Network Card. Также есть интересное свойство – ввод секундной метки от GPS приёмника. Но в данной работе всё это не используется.
Сервер NIMBIX
Сервер NIMBIX предоставляет разные вычислительные услуги, в том числе среду разработки SDAccel и что более важно – выполнение программы на выбранном аппаратном модуле.
Модель вычислителя
Хочу напомнить, что из себя представляет система OpenCL.
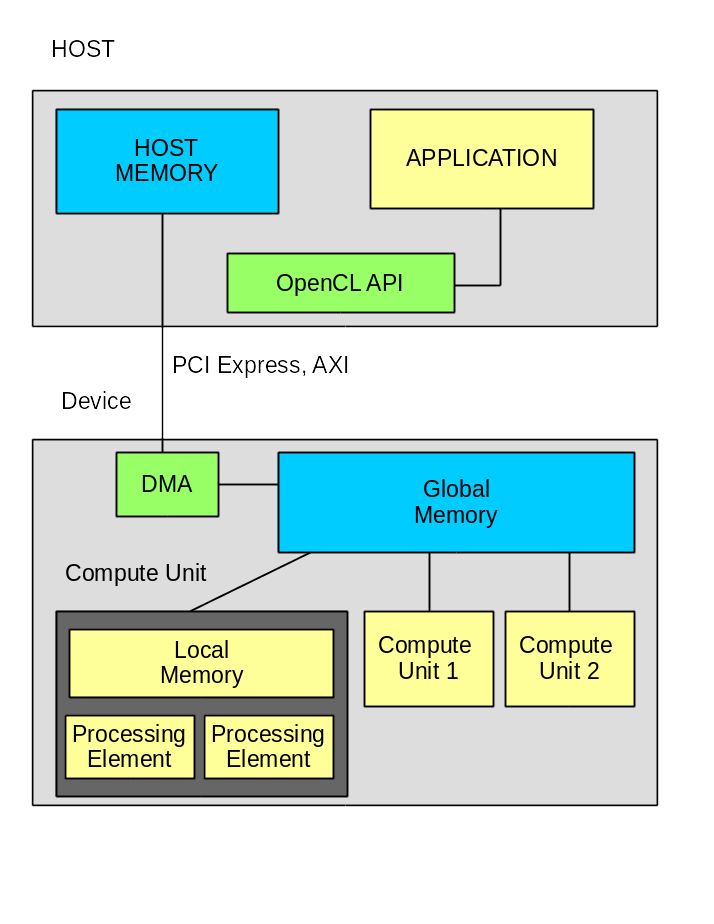
Система состоит из HOST компьютера и вычислителя, которые связаны между собой по шине. В данном случае это PCI Express v3.0 x8;
Прикладное программное обеспечение состоит из двух частей:
- Программа HOST компьютера.
- Одна или несколько функций для работы на вычислителе.
Обмен данными идёт только через глобальную память, в данном случае это два модуля SODIMM.
Для работы прикладного ПО требуется инфраструктура, которую должен кто-то предоставить. В данном случае — компания Xilinx. В состав инфраструктуры входят:
- библиотека opencl — реализация функций стандарта OpenCL.
- драйвер модуля — обеспечивает взаимодействие с модулем.
- пакет DSA. Это основа для разработки собственной прошивки ПЛИС.
Пакет DSA содержит базовую прошивку, в состав которой входят контроллеры для PCI Express, динамической памяти и возможно для других узлов. В составе базовой прошивки есть элемент, который называется OpenCL Region. Вот внутри именно этого элемента и будут реализованы все функции OpenCL kernels. Загрузка прошивки внутрь OpenCL Regions производится через PCI Express с использованием технологии частичной перезагрузки (Partial Reconfiguration). Надо отметить, что Xilinx сильно продвинулся в скорости загрузки. Если в предыдущих версиях загрузка занимала несколько минут, то что сейчас около 5 секунд. А в версии 2017.2 объявлено что можно вообще не проводить повторную загрузку прошивки.
На данный момент для модуля ADM-PCIe-KU3 в составе пакета SDAccel доступно два пакета:
- xilinx:adm-pcie-ku3:2ddr:3.3
- xilinx:adm-pcie-ku3:2ddr-xpr:4.0
Оба пакета имеют поддержку двух контроллеров памяти и PCI Express v3.0 x8; Обратите внимание на суффикс -xpr. Это достаточно важное различие. Вариант без xpr фиксирует положение DDR контроллеров и PCI Express. Вариант с xpr фиксирует только положение PCI Express, а контроллеры DDR участвуют в трассировке прикладных функций OpenCL. Это различие приводит и к различиям в результатах. Вариант без xpr разводится быстрее, а вариант с xpr может получить более оптимальную трассировку. Для данного проекта получилось 1 час 11 минут для варианта без xpr и 1 час 32 минуты для варианта xpr. Логи здесь.
Кстати, в состав каждого DSA пакета входит свой драйвер.
Программа CHECK_TRANSFER
Программа предназначена для проверки непрерывной передачи данных в трёх режимах:
- Из ПЛИС в SODIM и в компьютер
- Из компьютера в SODIMM и в ПЛИС
- Одновременная передача в двух направлениях
На мой взгляд проверка скорости работы без проверки данных особого смысла не имеет. Поэтому я с помощью OpenCL реализовал на ПЛИС узел генератора тестовой последовательности и узел проверки тестовой последовательности.
Стандарт OpenCL предусматривает обмен между устройством и компьютером только через глобальную память устройства. Обычно это динамическая память на SODIMM. И здесь возникает очень интересный вопрос о возможности передачи данных с предельными скоростями. На модуле ADM-PCIe-KU3 применены два SODIM DDR3-1600. Скорость обмена для одного SODIMM около 10 Гбайт/с. Скорость обмена по шине PCI Express v3.0 x8 – около 5 Гбайт/с (пока получилось намного меньше). Т.е. существует возможность записывать в память один блок поступающий от PCI Express и одновременно считывать второй блок для обработки внутри ПЛИС. А что делать если надо ещё возвращать результат? PCI Express обеспечивает двунаправленный поток на высокой скорости. Но у памяти шина одна, и скорость будет делиться между чтением и записью. Вот здесь и нужен второй SODIMM. У нас существует возможность указать в каком именно модуле будет размещён буфер для обработки.
Операционная система
SDAccel может работать только под некоторыми системами Linux. В списке доступных систем CentOS 6.8, CentOS 7.3, Ubuntu 16.04, RedHat 6.8, RedHat 7.3; Первые эксперименты я начинал на CentOs 6.7; Далее попробовал использовать Ubuntu 16.04, но там не всё заработало. На данный момент я использую CentOS 7.3 и очень доволен этой системой. Однако при настройке SDAccel есть ряд тонкостей. Главная проблема – по умолчанию сетевой интерфейс имеет имя “enp6s0”. Такое имя не понимает сервер лицензий Xilinx. Ему требуется обычный “eth0”.
Настройка здесь: https://github.com/dsmv/sdaccel/wiki/note_04---Install-CentOS-7-and-SDAccel-2017.1
Qt 5.9.1 устанавливается но не работает. Для него требуется более новый компилятор gcc и git. Это тоже решается, подробности здесь: https://github.com/dsmv/sdaccel/wiki/note_05---Install-Qt-5.9.1-and-Git-2.9.3
Системы разработки
Для разработки я использую две системы:
- SDAccel 2017.1 – для разработки kernel и небольших тестовых программ HOST
- Qt 5.9.1 – для разработки более сложных программ. Qt используется только для разработки программ HOST.
Организация проекта на GitHub
Репозитарий dsmv/sdaccel предназначен для разработки примеров для SDAccel. В данный момент там есть только одна программа check_transfer. Для проекта используются ряд возможностей GitHub:
- README.md – первый файл, который виден посетителю.
- WiKi – описание программы
- Development Notes – заметки по ходу разработки
- Issues – список задач
- Projects – управление проектом
- А также есть документация на программу сформированная Doxygen
Основные каталоги программы
- useful – полезные скрипты для настройки системы
- qt – каталог для исходников Qt
- sdx_wsp/check_transfer — рабочий каталог SDAccel
В данном проекте исходные тексты для Qt и SDAссel одни и те же, хотя и находятся в разных каталогах. Однако предполагается, что на Qt будут разрабатываться намного более сложные программы.
Два режима вывода
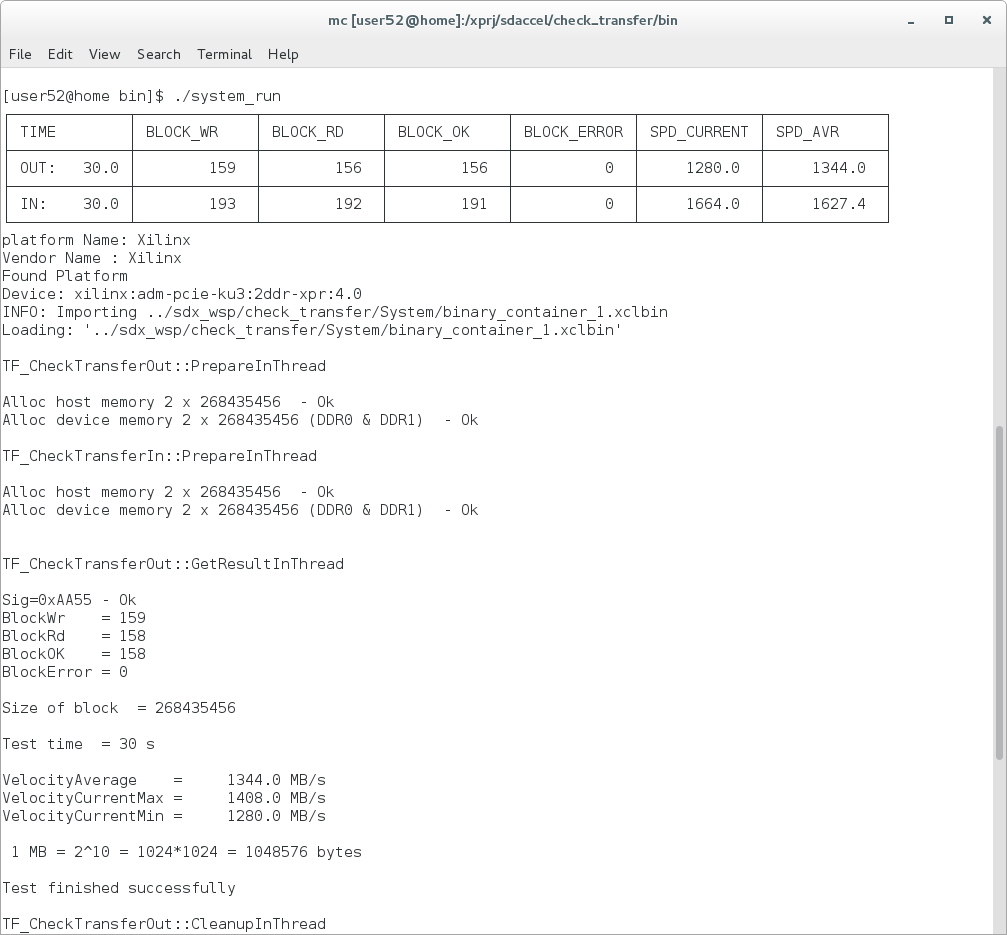
(Нажмите на картинку для увеличения)
На рисунке показан внешний вид терминала во время работы программы. Обратите внимание на таблицу. Это таблица с выводом текущего состояния теста. Во время работы очень интересно узнать, а что собственно происходит. Тем более что предусмотрен режим без ограничения по времени. Таблица очень помогает. К сожалению, есть проблемы. SDAccel сделан на основе Eclipse. Мне не удалось научиться запускать программу из среды во внешнем терминале. А во встроенном терминале таблица не работает. Пришлось сделать режим запуска без таблицы. Кстати система Nsight Eclipse Edition для программирования устройств NVIDIA тоже не умеет запускать программы во внешнем терминале. Или может я что-то не знаю?
Мегабайты или Мебибайты ?
Я отношусь к тем людям, которые точно знают что 1 килобайт это 1024 байта (а также предполагают что в 1 километре 1024 метра). Но это уже незаконно. Что бы избежать путаницы программа может измерять в обоих режимах и текущий режим отображается в логе.
Давайте рассмотрим некоторые фрагменты кода программы.
Kernel gen_cnt
Код ядра gen_cnt() очень простой. Функция заполняет массив заданного размера тестовым блоком данных.
__kernel
__attribute__ ((reqd_work_group_size(1,1,1)))
void gen_cnt(
__global ulong8 *pOut,
__global ulong8 *pStatus,
const uint size
)
{
uint blockWr;
ulong8 temp1;
ulong8 checkStatus;
ulong8 addConst;
checkStatus = pStatus[0];
temp1 = pStatus[1];
addConst = pStatus[2];
blockWr = checkStatus.s0 >> 32;
__attribute__((xcl_pipeline_loop))
for ( int ii=0; ii<size; ii++)
{
pOut[ii] = temp1;
temp1.s0 +=addConst.s0;
temp1.s1 +=addConst.s1;
temp1.s2 +=addConst.s2;
temp1.s3 +=addConst.s3;
temp1.s4 +=addConst.s4;
temp1.s5 +=addConst.s5;
temp1.s6 +=addConst.s6;
temp1.s7 +=addConst.s7;
}
blockWr++;
checkStatus.s0 = ((ulong)blockWr)<<32 | 0xAA56;
pStatus[0] = checkStatus;
pStatus[1] = temp1;
}Переменная temp1 имеет тип ulong8. Это стандартный тип OpenCL который представляет собой вектор из восьми 64-х разрядных чисел. Обращаться к элементам вектора можно по именам s0..s7 или так temp1.s[ii]. Это достаточно удобно. Ширина вектора 512 бит. Это соответствует ширине внутренней шины для контроллера SODIMM. Одним из элементов оптимизации как раз и заключается в обмене с памятью только 512 битными данными. По указателю pStatus находится блок со статусной информацией, из него считывается текущее значение и константы. Для каждого 64-х битного поля используется своя константа. Это позволяет сделать не только простой счётчик но и что то более сложное. Хотя пока что программа делает только простой счётчик. В конце функции производится запись текущего значения данных и число заполненных блоков.
check_cnt_m2a и check_read_input
Для реализации проверки я написал две функции, одна check_read_input — читает данные из динамической памяти и записывает их в pipe. Вторая – check_cnt_m2a – читает данные из pipe и проверяет их. Наверное в данном случае разделение на два kernel и их связь через pipe является избыточным. Но мне было интересно проверить эту технологию.
Код здесь
Структура программы HOST
Программа основана применении виртуальных классов TF_Test и TF_TestThread; На основе этих классов разработаны два класса тестирования
- TF_CheckTransferOut — проверка передачи от устройства в компьютер
- TF_CheckTransferIn – проверка передачи из компьютера в устройство
Базовый класс TF_Test содержит функции:
| Название | Назначение |
|---|---|
| Prepare() | Подготовка |
| Start() | Запуск |
| Stop() | Останов |
| StepTable() | Шаг отображения таблицы |
| isComplete() | Работа теста завершена |
| GetResult() | Вывод результата |
Функция main() создаёт по одному экземпляру каждого класса и начинает выполнение.
Каждый класс тестирования создаёт свой поток выполнения, в котором происходит обмен с модулем. Функция main вызывает Prepare() для каждого класса. Внутри этой функции как раз и создаётся поток, выделяется память и проводится вся подготовка. После того как оба класса готовы вызывается старт, что приводит к запуску главного цикла тестирования. При нажатии Ctrl-C или при окончании заданного времени тестирования вызывается Stop(). Классы останавливают работу и с помощью функции isComplete() информируют об этом main(). После остановки вызывается GetResult() для получения результата. В процессе выполнения теста функция main() вызывает StepTable каждые 100 мс для обновления таблицы. Это позволяет обновлять статусную информацию без вмешательства в обмен данными.
Такой подход оказался очень удобным для построения тестовых программ. Здесь все тесты строятся по одинаковому шаблону. В результате их можно запускать параллельно, а можно и поодиночке. В данной программе легко организуется режим как одиночного запуска одного из тестов, так и одновременный запуск.
Режимы выполнения OpenCL программы
Система SDAccel предоставляет три режима выполнения программы:
- Emulation-CPU — всё выполняется на HOST процессоре
- Emulation-HW — функции OpenCL выполняются на симуляторе Vivado
- System — работа на реальной аппаратуре.
Более подробно — в предыдущей статье.
Интересно сравнить скорости работы в трёх средах. Сравнение очень показательное:
| Emulation-CPU | Emulation-HW | System |
|---|---|---|
| 200 МБ/с | 0.1 МБ/с | 2000 МБ/с |
Числа я округлил что бы лучше видеть порядок. Собственно разница в скорости между Emulation-CPU и Emulation-HW показывает что в разработке прошивок ПЛИС надо переходить на C/C++ или что-то аналогичное. Выигрыш на четыре порядка это очень много, это перекрывает все недостатки С++. При этом надо отметить, что разработка на VHDL/Verilog не исчезнет, и эти языки скорее всего придётся применять для достижения предельных характеристик. Очень перспективным выглядит возможность создания OpenCL kernel на VHDL/Verilog, это позволит сочетать высокую скорость разработки и предельные характеристики ПЛИС. Но это уже тема отдельного исследования и отдельной статьи.
Результат трассировки
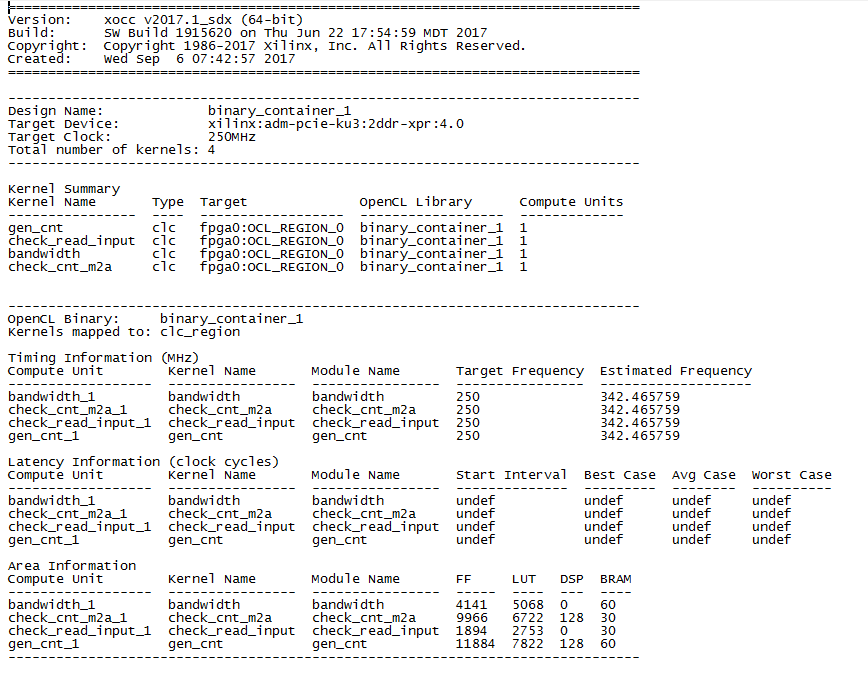
Вот что получилось. Обратите внимание на количество DSP для gen_cnt. Для реализации восьми 64-х разрядных счётчиков потребовалось 128 DSP блоков. Это по 16 блоков на счётчик. Скорее всего это результат работы оптимизатора по раскрытию цикла.
Различия в методах оптимизации для FPGA и GPU
Для достижения предельных результатов должны применяться разные методы оптимизации. GPU имеет фиксированную структуру. Если условно говоря один процессорный элемент GPU может выполнять одну операцию, то что бы параллельно выполнить 100 операций надо задействовать 100 процессорных элементов. А вот в ПЛИС это не является единственным вариантом. Да, мы можем написать один kernel и разместить несколько экземпляров в ПЛИС. Но это приводит к большим накладным расходам. Xilinx рекомендует использовать не более 16 kernel, а точнее портов памяти. Зато внутри одного элемента нет ограничений на распараллеливание. Собственно пример gen_cnt это и показывает. Там сразу в коде записаны восемь 64-х разрядных сумматоров. Кроме того сработал оптимизатор и развернул цикл. Для GPU этот пример надо написать по другому, например сделать один kernel для получения 64-х разрядного отсчёта и запустить сразу восемь экземпляров.
Что может показать Emulation-HW
Этот режим может показать что происходит на шинах доступа к памяти. На картинке показан процесс чтения данных из памяти функцией check_read_input().
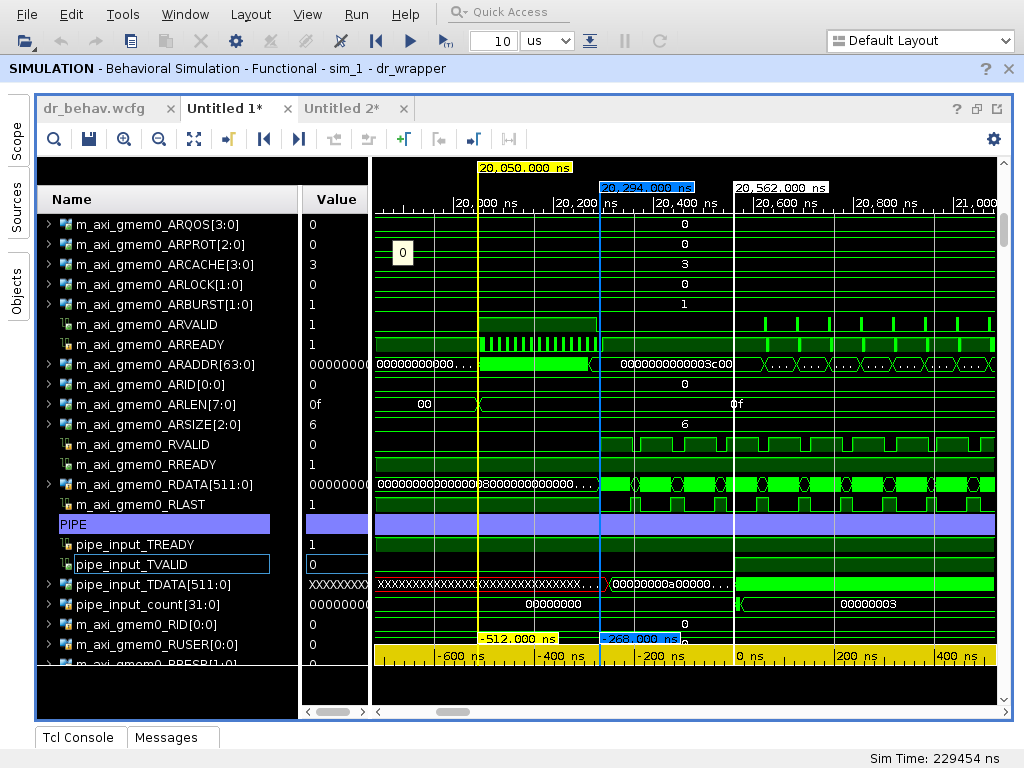
(Нажмите что бы увеличить)
Во первых здесь видно с какой большой задержкой приходят данные. Задержка от первого запроса до появления первых данных 512 нс. Во вторых видно что чтение идёт блоками по 16 слов (размером 512 бит). При разработке на VHDL я бы использовал больший размер блока. Но видимо контроллер умеет объединять блоки и это не приводит к замедлению. В третьих видно что есть разрывы в получении данных. Они тоже объяснимы. Частота работы OpenCL 250 МГц, частота шины памяти для SODIMM DDR3-1600 составляет 200 МГц. Разрывы точно соответствуют переходу от шины 200 МГц к шине 250 МГц.
Результаты
Результаты интересные, но я ожидал достичь более высоких скоростей.
Одиночные тесты
| Компьютер | Ввод [MiB/s] | Вывод [MiB/s] |
|---|---|---|
| Intel Core-i5, PCIe v2.0 x8 | 2048 | 1837 |
| Intel Core-i7, PCIe v3.0 x8 | 2889 | 2953 |
Двунаправленный тест
| Компьютер | Ввод [MiB/s] | Вывод [MiB/s] |
|---|---|---|
| Intel Core-i5, PCIe v2.0 x8 | 1609 | 1307 |
| Intel Core-i7, PCIe v3.0 x8 | 2048 | 2057 |
Для сравнения, на нашем модуле с аналогичной ПЛИС рекордная скорость ввода составила 5500 MiB/s, хотя по ряду причин пришлось её снизить до 5000. Так что возможности для увеличения скорости обмена есть.
Что дальше
Работа будет продолжаться.
- Исследование возможностей SDAccel 2017.2
- Реализация узла свёртки на основе библиотеки FPFFTK от Александра Капитанова ( capitanov )
- Разработка собственных DSA пакетов, в том числе с поддержкой 10G Ethernet
- И главное — разработка собственного модуля, название уже есть — DSP135P
P.S. Хочу выразить благодарность Владимиру Каракозову за помощь в разработке шаблона программы тестирования.
tronix286
Чет я не пойму, вы на ней не майните чтоле?
dsmv2014 Автор
Нет
Sdima1357
А что ещё на ней делать? Карточка получается дорогая, обмен заметно (раз в 6) медленнее gpu, производительность openCl где то такая же, обмен с локальной памятью тоже медленнее. Так зачем «это» нужно?
nerudo
Вам могут рассказать, но после этого лет 5 придется наслаждаться исключительно курортами краснодарского края ;)
Sdima1357
Спасибо, мне в Израиле хорошо.
На моих задачах реконструкции ст картинки, gpu быстрее чем fpga раз в десять, правда там много float32 и обмена с памятью. Просто стало интересно, а зачем люди вообще использую fpga в таком форм- факторе. Ну если секрет, то и ладно
dsmv2014 Автор
По утверждению Xilinx, вычислитель на FPGA потребляет примерно в 7 раз меньше чем GPU. По моим осторожным подсчётам в масштабах среднего Data центра с потреблением в 20 МВт может получиться экономия порядка 100 миллионов рублей в год. А это перекрывает все затраты. По слухам, всё крупные компании, тип Google, Amazon, Microsoft, IBM двигаются в направлении применения FPAG в крупных Data центрах.
А такой форм-фактор позволяет установить плату в тонкий сервер. Тонкий именно по высоте, размер 1U.
Sdima1357
«В 7 раз меньше» и на каких вычислениях? У Вас линк есть? Я что то не нашёл :(
«По слухам» — как только рынок такого рода будет достаточно велик, добавят в gpu нужную операцию в железе и конец истории. Все таки fpga -это мелкосерийные задачи
dsmv2014 Автор
Точный линк не нашёл. Можно вот это посмотреть: www.xilinx.com/products/design-tools/software-zone/sdaccel.html
Да, если какая то функция станет массовой, как например тот же bitcoin, это сделают в железе, но скорее всего не в GPU а в ASIC. С bitcoin так и произошло.
А FPGA так и останется — как платформа для перепрограммируемых решений.
Sdima1357
Зато я нашел:
Не в 7, а по утверждению самого Xilinx:
NVidia Tesla P4 209 GOP/s/W (INT8)
Xilinx Virtex® UltraScale+™ 277 GOP/s/W (INT8)
www.xilinx.com/support/documentation/white_papers/wp492-compute-intensive-sys.pdf
итого в 277/209 — 1.32 раза
Причем NVIDIA считает, что и них 22 TOPS (INT8) /75-Watt = 293 GOP/s/W
images.nvidia.com/content/pdf/tesla/184457-Tesla-P4-Datasheet-NV-Final-Letter-Web.pdf
Хотя безусловно ПЛМ имеют свою нишу применения и поддержка ими OpenCL сокращает время разработки.
dsmv2014 Автор
Ссылку я пока не нашёл. Но вот есть такая статья: www.bertendsp.com/pdf/whitepaper/BWP001_GPU_vs_FPGA_Performance_Comp
Но в любом случае мне нужен собственный опыт сравнения GPU и FPGA. Но это будет позднее.
Sdima1357
Я её видел, но статья не слегка устарела.NVidia так просто рынок не уступит, о чём собственно я и говорил. Да и левое это исследование.
Int8 — собственно нужен для NN приложений и НВ его не упустит.
Впрочем НВ тоже хорошо лажают со своими карточками для критических по надежности приложений, я бы не стал с ними связываться… И суппорт у них так себе. Впрочем я работаю и с FPGA и GPU. Пока GPU выигрывает, по скорости и цене
dsmv2014 Автор
Статья устарела, там нет серии Kintex UltraScale.
INT8 меня не сильно интересует.
Я собираюсь применить библиотеку FP23FFTK, там используется плавающая точка размером 23 бита.