
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория
Часть 5. Первое приложение (настоящая статья)
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами
Часть 8. Работа с прерываниями
При начале работы с контроллерами, принято мигать светодиодами. Я нарушу эту традицию.
Во-первых, это банально надоело. Во-вторых, светодиоды потребляют слишком большой ток. Не спешите думать, что я экономлю каждый милливатт, просто по ходу работ, нам эта экономия будет крайне важна. Опять же, то, что мы увидим ниже — на светодиодах увидеть практически невозможно.
Итак, пока нет генератора проектов, берём проект по-умолчанию для своей макетной платы и своего любимого компилятора (я взял ...\maksRTOS\Compilers\STM32F4xx\MDK-ARM 5\Projects\Default) и копируем его под иным именем (у меня получилось ...\maksRTOS\Compilers\STM32F4xx\MDK-ARM 5\Projects\Test1) . Также следует снять со всех файлов атрибут «Только для чтения».
Каталог файлов проекта весьма спартанский.
DefaultApp.cpp
DefaultApp.h
main.cpp
MaksConfig.h
Файл main.cpp относится к каноническому примеру, файлы DefaultApp.cpp и DefaultApp.h описывают пустой класс-наследник от Application. Файл MaksConfig.h мы будем использовать для изменения опций системы.
Если открыть проект, то окажется, что к нему подключено огромное количество файлов операционной системы.
В свойствах проекта также имеется бешеное количество настроек.
Так что не стоит даже надеяться создать проект «с нуля». Придётся смириться с тем, что его надо или копировать из пустого проекта по умолчанию, или создавать при помощи автоматических утилит.
Для дальнейшего изложения, я разрываюсь между «правильно» и «читаемо». Дело в том, что правильно — это начать создавать файлы для задач, причём — отдельно заголовочный файл, отдельно — файл с кодом. Однако, читатель запутается в том, что автор натворит. Такой подход хорош при создании видеоуроков. Поэтому я пойду другим путём — начну добавлять новые классы в файл DefaultApp.h. Это в корне неверно при практической работе, но зато код получится более-менее читаемым в документе.
Итак. Мы не будем мигать светодиодами. Мы будем изменять состояние пары выводов контроллера, а результаты наблюдать — на осциллографе.
Сделаем класс задачи, которая занимается этим шевелением. Драйверы мы использовать пока не умеем, поэтому будем обращаться к портам по-старинке. Выберем пару свободных портов на плате. Пусть это будут PE2 и PE3. Что они свободны, я вывел из следующей таблицы, содержащейся в описании платы STM32F429-DISCO:
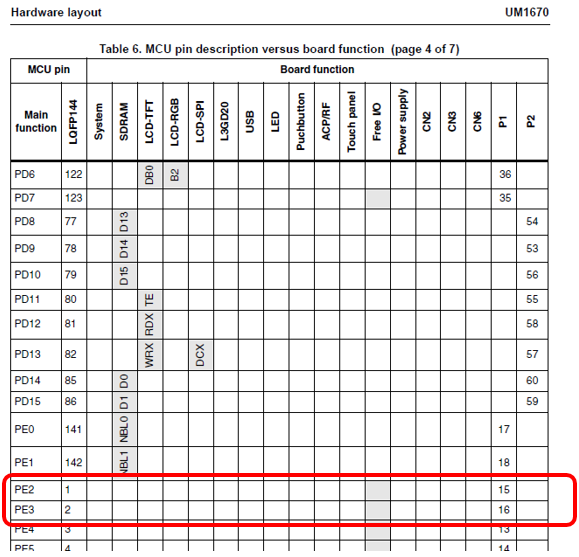
Сначала сделаем класс, шевелящий ножкой PE2, потом — переделаем его на шаблонный вид.
Идём в файл DefaultApp.h (как мы помним, это неправильно для реальной работы, но зато наглядно для текста) и создаём класс-наследник от Task. Что туда нужно добавить? Правильно, конструктор и функцию Execute(). Прекрасно, пишем (первая и последняя строки оставлены, как реперные, чтобы было ясно, куда именно пишем):
#include "maksRTOS.h"
class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<2);
GPIOE->BSRR = (1<<(2+16));
}
}
};
class DefaultApp : public ApplicationЗадача, дёргающая PE2 готов. Но теперь надо
- Включить тактирование порта E;
- Подключить задачу к планировщику.
Где это удобнее всего делать? Правильно, мы уже знаем, что это удобнее всего делать в функции
void DefaultApp::Initialize()благо заготовка уже имеется. Пишем что-то, вроде этого:
void DefaultApp::Initialize()
{
/* Начните код приложения здесь */
// Включили тактирование порта E
RCC->AHB1ENR |= RCC_AHB1ENR_GPIOEEN;
// Линии PE2 и PE3 сделали выходами
GPIOE->MODER = GPIO_MODER_MODER2_0 | GPIO_MODER_MODER3_0;
// Подключили поток к планировщику
Task::Add (new Blinker ("Blink_PE2"));
}Шьём в в пла… Ой, а в проекте по умолчанию используется симулятор.
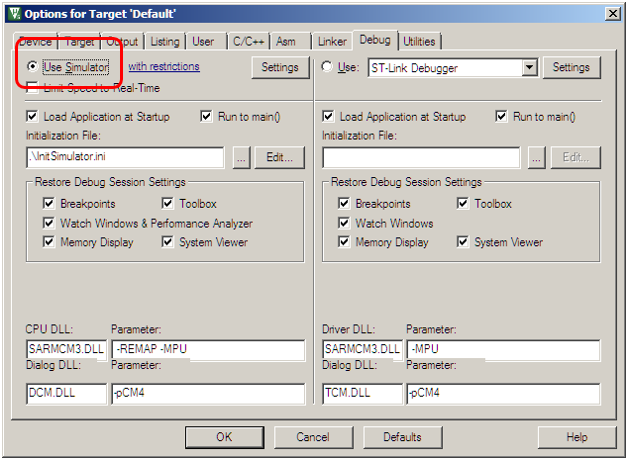
Хорошо, переключаемся на JTAG адаптер (в случае платы STM32F429-DISCO — на ST-Link).
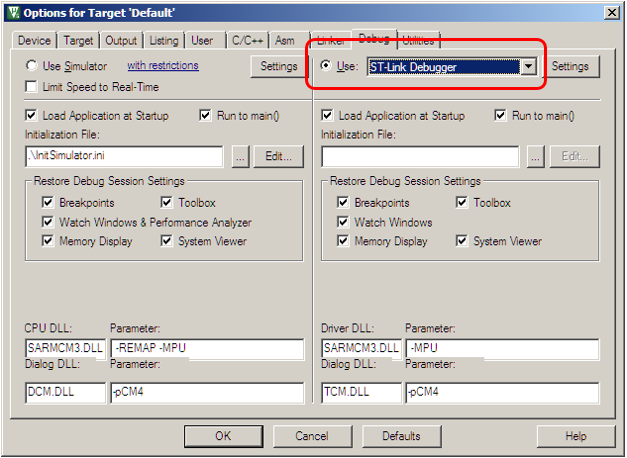
Теперь всё можно залить в плату. Заливаем, подключаем осциллограф к линии PE2, наблюдаем…
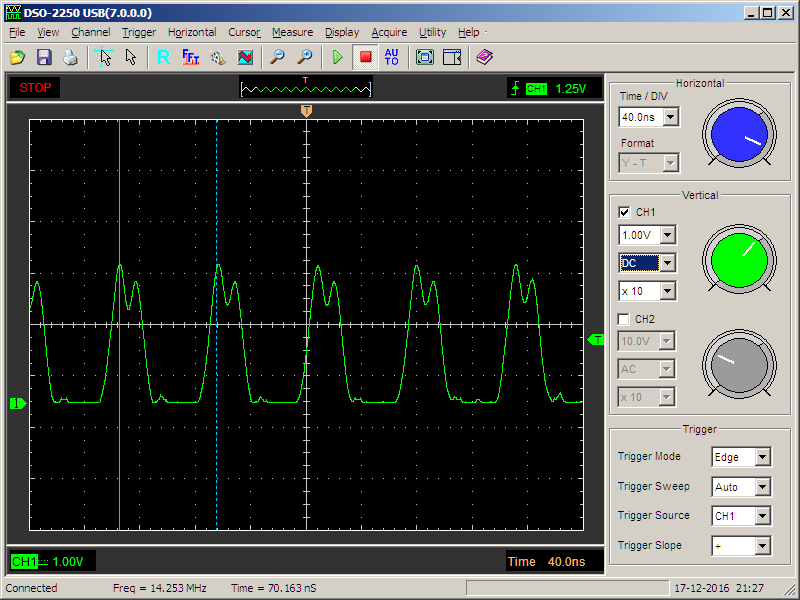
Красота! Только быстродействие какое-то низковатое.
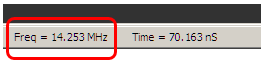
Заменяем оптимизацию с уровня 0 на уровень 3

И… Всё перестаёт работать вообще

Пытаемя трассировать — по шагам прекрасно работает. Что за чудо? Ну, это не проблемы ОС, это проблемы микроконтроллера, ему не нравятся рядом стоящие команды записи в порт. Разгадка этого эффекта – в настройках тока выходных транзисторов. Выше ток – больше звон, но выше быстродействие. По умолчанию, все выходы настроены на минимальном быстродействии. А у нас оптимизатор всё хорошо умял:
0x08004092 6182 STR r2,[r0,#0x18]
0x08004094 6181 STR r1,[r0,#0x18]
0x08004096 E7FC B 0x08004092Можно, конечно, поднять быстродействие выхода на этапе настройки порта
// Максимальный ток выходных транзисторов
GPIOE->OSPEEDR |= (3<<(2*2))|(3<<(3*2));
Но у сигнала будет явно неправильная скважность (Вверх, затем – вниз, затем – задержка на переход). Для улучшения сигнала поправим код основного цикла следующим образом:

virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<2);
asm {nop}
GPIOE->BSRR = (1<<(2+16));
}
}
};Здесь получается вверх, затем – задержка на NOP, затем – вниз, затем – задержка на переход, что обеспечивает скважность, близкую к 50% (в комментариях ниже было точно вычислено, что реально 3 такта в единице и 5 тактов в нуле, но это ближе к 50%, чем 1 к 5, да и на имеющемся осциллографе разницу в верхней и нижней частях импульсов всё равно практически невозможно заметить). И быстродействия выхода уже хватает даже в малошумящем режиме. Частота выходного сигнала стала 168/(3+5) = 21 МГц.
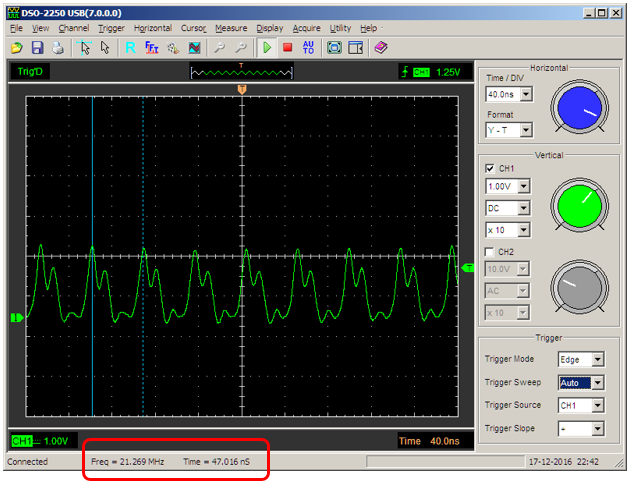
Правда, на другом масштабе нет-нет, да и проскочат вот такие чёрные провалы
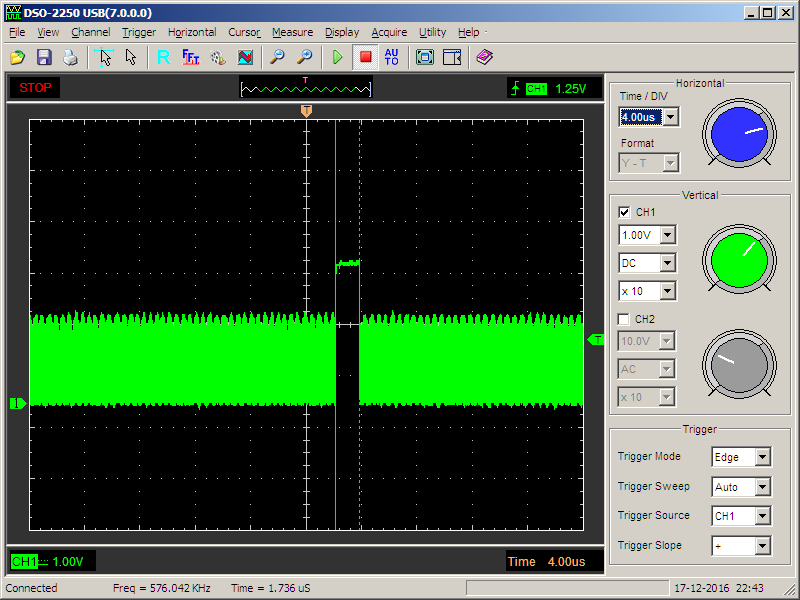
Это мы наблюдаем работу планировщика. Задача у нас одна, но периодически у неё отбирают управление, чтобы проверить, нельзя ли передать его кому-то другому. При наличии отсутствия других задач, управление возвращается той единственной, которая есть. Что ж, добавляем вторую задачу, которая будет дёргать PE3. Поместим номер бита в переменную-член класса, а настраивать его будем через конструктор

class Blinker : public Task
{
int m_nBit;
public:
Blinker (int nBit,const char * name = nullptr) : Task (name),m_nBit(nBit){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<m_nBit);
GPIOE->BSRR = (1<<(m_nBit+16));
}
}
};А добавление задач в планировщик — вот так:
void DefaultApp::Initialize()
{
/* Начните код приложения здесь */
// Включили тактирование порта E
RCC->AHB1ENR |= RCC_AHB1ENR_GPIOEEN;
// Линии PE2 и PE3 сделали выходами
GPIOE->MODER = GPIO_MODER_MODER2_0 | GPIO_MODER_MODER3_0;
// Подключили поток к планировщику
Task::Add (new Blinker (2,"Blink_PE2"));
Task::Add (new Blinker (3,"Blink_PE3"));
}Подключаем второй канал осциллографа к выводу PE3. Теперь иногда идут импульсы на одном канале
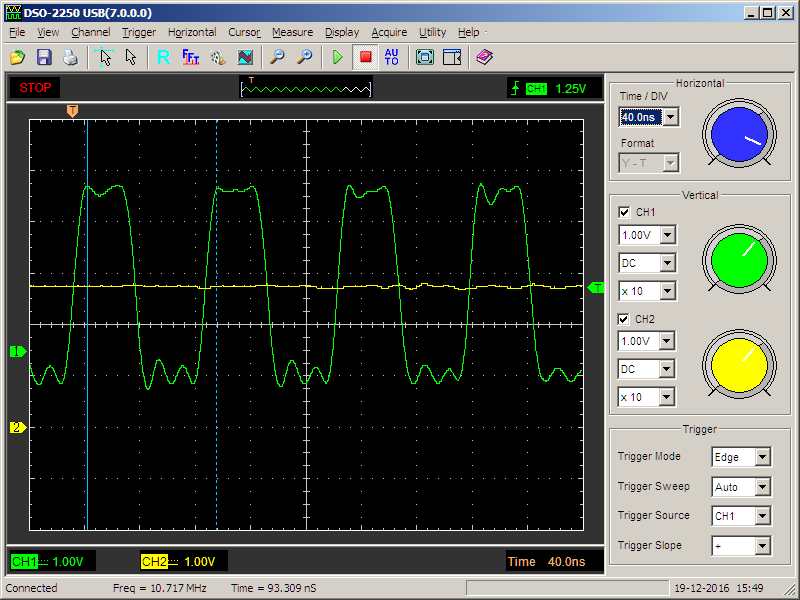
Ой какая частота низкая… Нет, фальстарт. Перепишем задачу на шаблонах…

template <int nBit>
class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<nBit);
asm {nop}
GPIOE->BSRR = (1<<(nBit+16));
}
}
};И её постановку на планирование — вот так:

Task::Add (new Blinker<2> ("Blink_PE2"));
Task::Add (new Blinker<3> ("Blink_PE3"));Итак. Теперь иногда импульсы (с правильной частотой) идут на одном канале:
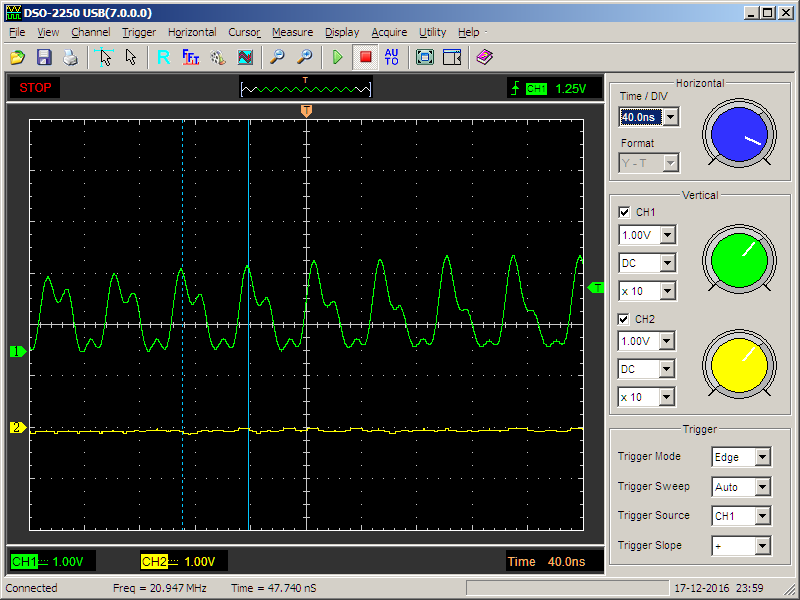
А иногда — на другом
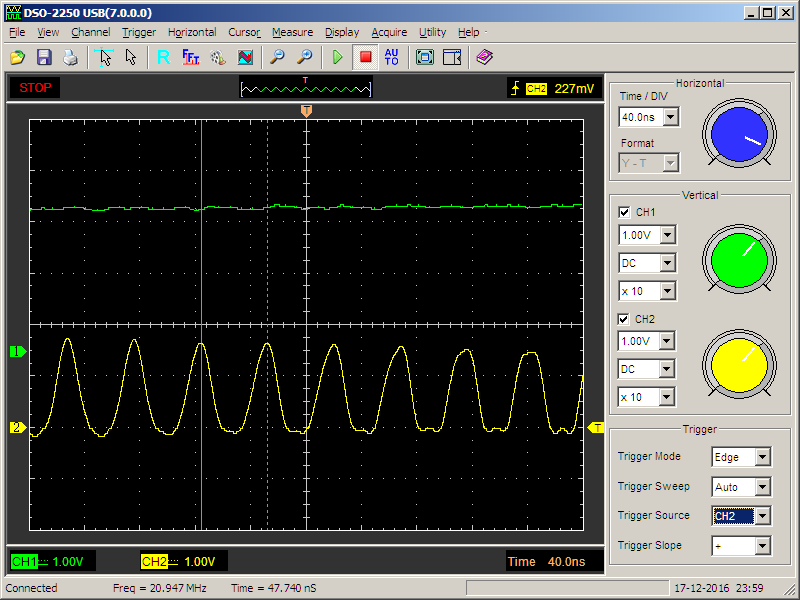
Можно выбрать масштаб, на котором видны кванты времени. Заодно произведём замер и убедимся, что один квант действительно равен одной миллисекунде (с точностью до масштаба экрана осциллографа)
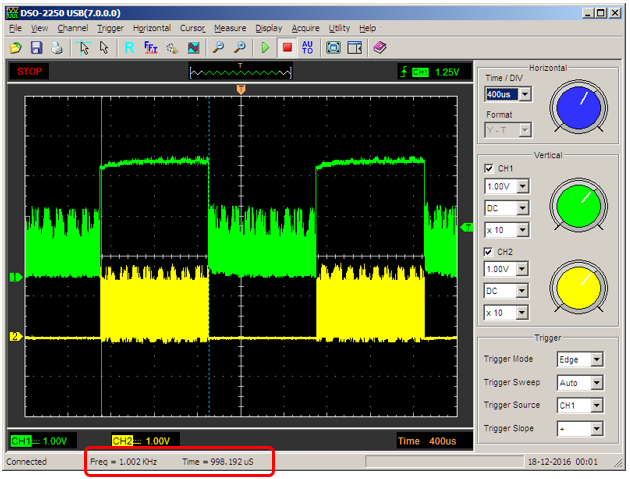
Можно убедиться, что планировщику всё так же нужно время для переключения задач (причём больше, чем в те времена, когда задача была одна)
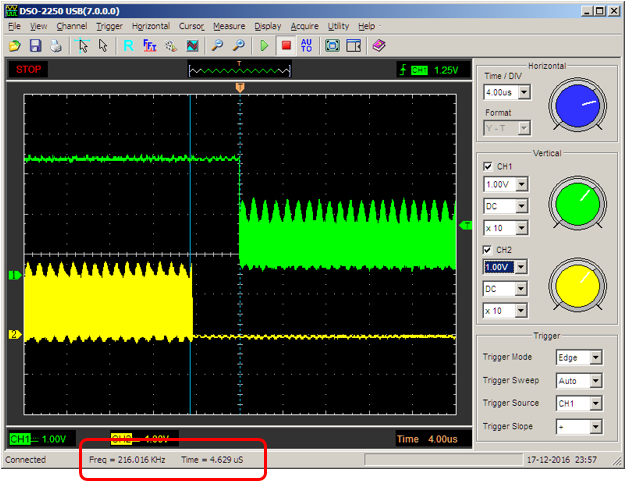
Теперь давайте рассмотрим работу потоков с разными приоритетами. Добавим забавную задачу, которая «то потухнет, то погаснет»
public:
Funny (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
Delay (5);
CpuDelay (5);
}
}
};И добавим её в планировщик с более высоким приоритетом

Task::Add (new Blinker<2> ("Blink_PE2"));
Task::Add (new Blinker<3> ("Blink_PE3"));
Task::Add (new Funny ("FunnyTask"),Task::PriorityHigh);Эта задача половину времени выполняет задержку без переключения контекста. Так как её приоритет выше остальных, то управление не будет передано никому другому. Половину времени задача спит. То есть, находится в заблокированном состоянии. То есть, в это время будут работать потоки с нормальным приоритетом. Проверим?
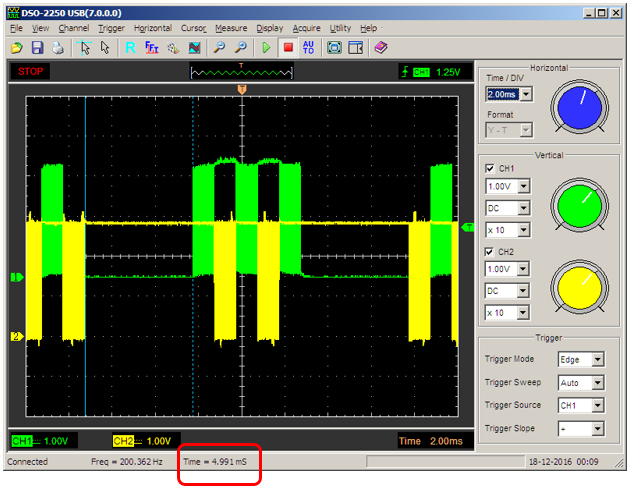
Собственно, что и требовалось доказать. Пауза равна пяти миллисекундам (выделено курсорами), а во время работы нормальных задач, контекст успевает 5 раз переключиться между ними. Вот другой масштаб, чтобы было видно, что это не случайность, а статистика
Убираем работу этой ужасной задачи. Продолжать будем с двумя основными
Task::Add (new Blinker<2> («Blink_PE2»));
Task::Add (new Blinker<3> («Blink_PE3»));
Наконец, переведём дёрганье порта из режима «Совсем дёрганный» в более реальный. До светодиодного доводить не будем. Скажем, сделаем период величиной в 10 миллисекунд

class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
GPIOE->BSRR = (1<<nBit);
Delay (5);
GPIOE->BSRR = (1<<(nBit+16));
Delay (5);
}
}
};Тепрерь подключаем амперметр. Для платы STM32F429-DISCO надо снять перемычку JP3 и включить прибор вместо неё, о чём сказано в документации:

Измеряем ток, потребляемый данным вариантом программы

Идём в файл MaksConfig.h и добавляем туда строку:
#define MAKS_SLEEP_ON_IDLE 1
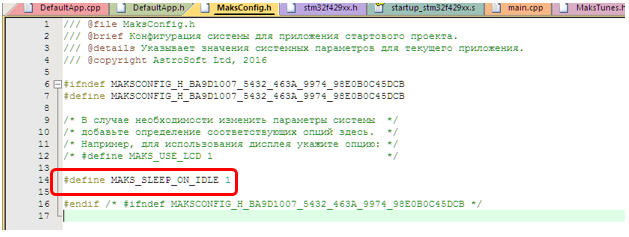
Собираем проект, «прошиваем» результат в плату, смотрим на амперметр:

Таааак, ещё одну теоретическую вещь проверили на практике. Тоже работает. А вот если бы мы мигали светодиодом, то он бы то потреблял, то не потреблял 10 мА, что на фоне измеренных значений — вполне существенно.
Ну, и напоследок заменим многозадачность на кооперативную. Для этого добавим конструктор к классу приложения

class DefaultApp : public Application
{
public:
DefaultApp() : Application (false){}
private:
virtual void Initialize();
};И сделаем так, чтобы задачи после трёх импульсов в порт передавали друг другу управление. Также добавим задержки, чтобы на осциллографе задержка планировщика не уводила бы изображение другой задачи за экран.
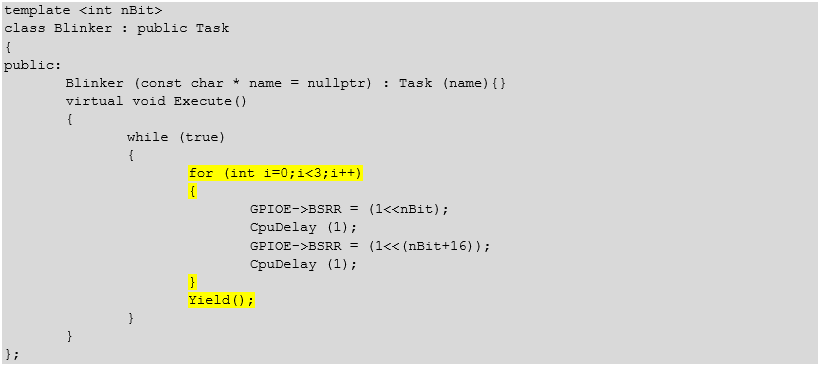
template <int nBit>
class Blinker : public Task
{
public:
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
while (true)
{
for (int i=0;i<3;i++)
{
GPIOE->BSRR = (1<<nBit);
CpuDelay (1);
GPIOE->BSRR = (1<<(nBit+16));
CpuDelay (1);
}
Yield();
}
}
};Что там на осциллографе?
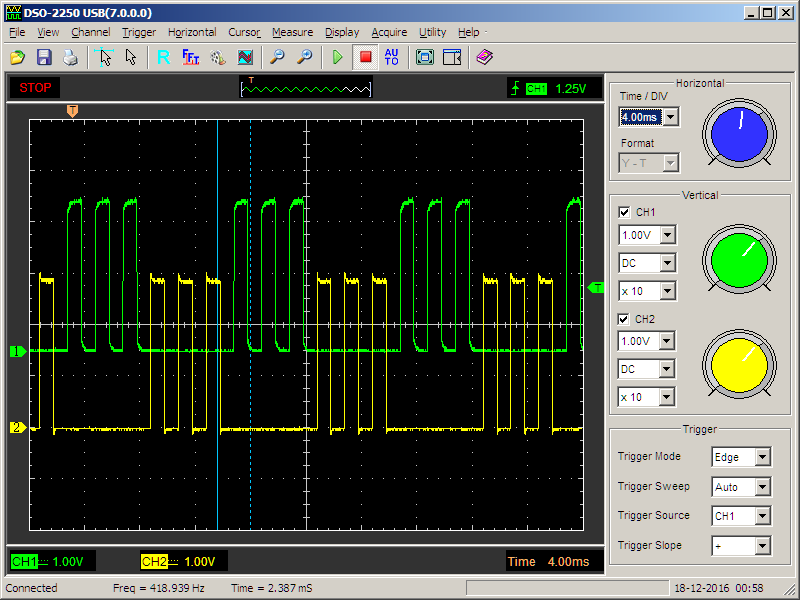
Собственно, мы хотели тройки импульсов — мы их получили.
Ну, и наконец, добавим виртуальную функцию

class DefaultApp : public Application
{
public:
DefaultApp() : Application (true){}
virtual ALARM_ACTION OnAlarm(ALARM_REASON reason)
{
while (true)
{
volatile ALARM_REASON r = reason;
}
}
private:
virtual void Initialize();
};и попробуем вызвать какую-либо проблему. Например, создадим критическую секцию в задаче с обычным уровнем привилегий.
Blinker (const char * name = nullptr) : Task (name){}
virtual void Execute()
{
CriticalSection cs;
while (true)
{
GPIOE->BSRR = (1<<nBit);
Delay (5);
GPIOE->BSRR = (1<<(nBit+16));
Delay (5);
}Запускаем проект на отладку, ставим точку останова на следующую строку

после чего запускаем на исполнение (F5). Моментально получаем останов (если не сработало — щёлкаем по пиктограмме «Stop»).
В строке, на которой произошёл останов, наводим курсор на переменную reason. Получаем следующий результат:

Ну что же, проверку первых основных теоретических выкладок мы завершили, можно переходить к следующему большому сложному разделу.
Комментарии (18)

no111u3
21.09.2017 19:45Ну насчёт отсутствия светодиодов вы это зря, их там аж целых 4. Второй момент, это то что работа с портами ввода — вывода, если у них правильно настроена скорость реакции то они работают с частотой шины на которой они «сидят» — AHB, а это внимание 168 МГц. То есть дело скорее в том что вы не совсем верно настроили периферию. Ну и наконец третий момент: слишком много параметров которые можно было бы по хорошему оптимизировать, поручив это грамотной системе сборки. А так хотелось бы посмотреть побольше кода и преимущества данной ОС перед другими: например стабильность планировщика, отказоустойчивость и многое другое.

EasyLy Автор
21.09.2017 20:13-1Четыре светодиода на STM32F4-Discovery. А на STM32F429-DISCO (которая с экранчиком)… Хм. Сейчас проверил — да, два есть. Но только два. Я почему-то всё время только один находил. И всё равно, на них то, что показано на осциллографе — не покажешь. Тем не менее, про число — уберу.
Насчёт частоты — похоже, не правы ни Вы, ни я в тексте. Возможно, надо будет переделать. Нашёл в даташите именно на 429-й чип:
3.37 General-purpose input/outputs (GPIOs)
Each of the GPIO pins can be configured by software as output (push-pull or open-drain,
with or without pull-up or pull-down), as input (floating, with or without pull-up or pull-down)
or as peripheral alternate function. Most of the GPIO pins are shared with digital or analog
alternate functions. All GPIOs are high-current-capable and have speed selection to better
manage internal noise, power consumption and electromagnetic emission.
The I/O configuration can be locked if needed by following a specific sequence in order to
avoid spurious writing to the I/Os registers.
Fast I/O handling allowing maximum I/O toggling up to 90 MHz.
Надо будет попробовать не NOPы добавлять, а выход переключить на самый быстрый. Проверю в ближайшее время.
По остальным вопросам — данная публикация является «художественным руководством» по работе с ОС. Серьёзные и занудные вещи, что-то доказывающие надо будет рассматривать в другой публикации. Всё в одном — не смешать.no111u3
21.09.2017 20:22Это да, то насколько быстро способны меняться сигналы на вводе-выводе, а так периферия работает на частоте системной шины. Тут согласен не увидите.
EasyLy Автор
21.09.2017 20:43-1Проверил. На максимальном токе выходов заработало на частоте 28 МГц. С плохой скважностью. Начинаю думать, как бы это в текст вставить, чтобы не сильно его покрушить. NOP скважность хорошую обеспечивал. С одной стороны — он, с другой — переход. То на то и выходило. Сейчас буду думать, как и ляп в тексте убрать, и не сильно его менять.
Если что — с проверки настройки PLL я начал. Там всё по максимуму настроено (ну, по такому максимуму, на котором USB работает, разумеется, а так — можно и шустрее, я в курсе)
28 МГц — это именно частота выходного сигнала, то есть, порт шевелится быстрее, разумеется.no111u3
21.09.2017 22:05Просто тут такой вопрос что оно реально на выходе даёт 90 МГц — так как для работы ULPI (Physic Layer USB 2.0 HS) нужно 60 МГц на вводе — выводе. Там конечно могут другие факторы накладываться, но факт остаётся фактом.
EasyLy Автор
21.09.2017 22:25-1Скажу прямо. Раздел про флэш перечитал много раз, не всё понял. Понял только, что на трёх вольтах и частотах ядра от 150 до 180 МГц, Latency должно быть равно пяти. У меня оно равно пяти.
Все аппаратные блоки работают внутри себя (это касается и упомянутого Вами блока для работы с ULPI). Ядро — если Вы научите меня считать точные цифры — я буду рад. Точно знаю, что все настройки выставлены верно, а точную цифру рассчитать пока не смог, на какой частоте всё это обязано работать.
Сейчас я вижу, что когда крутятся 4 команды — частота сигнала на выходе равна 21 МГц, когда три команды — 28 МГц. Это я вижу по приборам. И я никогда не доверял прямому управлению через GPIO в критичных к скорости вещах, предпочитая аппаратные блоки.no111u3
21.09.2017 22:38Хм, очень интересно, у меня просто нет в наличие именно этого процессора, А вообще проверить частоту которая на выходе из ФАПЧ достаточно несложно — берём эту частоту, запускаем для таймера делитель равный нулю (что даёт частоту кратную той что приходит на таймер) (учитывая делители для шин AHB и APBx(где х это та шина на которой висит таймер). Далее заполняем для таймера регистр перезагрузки в значение 1000, а для регистра совпадения — 500, выставляем режим — шим, и получается таймер будет аппаратно переключать с частотой не более 180 кГц. Это и будет частота на которую вы настроили ФАПЧ (PLL).
EasyLy Автор
21.09.2017 23:29-1// Настроим ножку PA2 на выход ШИМа GPIOA->MODER = (2<<(2*2)); GPIOA->AFR[0] = (1<<(2*4)); // На скорую руку настроим таймер RCC->APB1ENR |= RCC_APB1ENR_TIM2EN; TIM2->PSC = 0; TIM2->ARR = 1000; TIM2->CCR3 = 500; TIM2->CCMR2 |= TIM_CCMR2_OC3M_2 | TIM_CCMR2_OC3M_1; TIM2->CCER |= TIM_CCER_CC3E; TIM2->CR2 = 0; TIM2->CR1 = TIM_CR1_CEN;
Получаем 84 КГц
При том, что
RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1; RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV4; RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2;
Согласно описанию STM32F4, если делитель APB не равен одному, то частота на таймеры удваивается. Получем (168/4)*2 = 84. Дальше делитель таймера 1000, итого 84 КГц. Тут всё верно.
Так что проблема работы с GPIO не в настройке PLL. Где-то ещё возникает деление на два. Потому что 21*4 = 28 * 3 = 84. Всё работает на 84 МГц. Можно было бы сказать, что перед нами такт на выборку и такт на запись, но все книжки говорят про Гарвардскую архитектуру…
В общем, в тексте моего руководства, вроде, особых ляпов больше нет, я там убрал неверное утверждение. Но задачку Вы задали интересную. Если разберусь, то напишу.
EasyLy Автор
22.09.2017 02:40-1А ларчик просто открывался. Ну, или почти просто…
8.2 GPIO main features
…
• Fast toggle capable of changing every two clock cycles
Запись в GPIO у STM32F4 требует двух тактов. Тогда понятно, что в описании команды STR срабатывает оговорка:
STR Rx,[Ry,#imm] is always one cycle. This is because the address generation is performed in the initial cycle, and the data store is performed at the same time as the next instruction is executing. If the store is to the write buffer, and the write buffer is full or not enabled, the next instruction is delayed until the store can complete. If the store is not to the write buffer, for example to the Code segment, and that transaction stalls, the impact on timing is only felt if another load or store operation is executed before completion.
Почему «почти просто » — команда NOP не должна исполняться два такта. Но спишем это на какие-то особенности, вытекающие из выше сказанного, с учётом гарвардской архитектуры. Тем более, что реально скважность не строго 50%, как выяснилось при снижении частоты шины (я много экспериментировал сейчас). Тем не менее — кажущиеся глобальные странности разрешены. И они не относятся ни к проблемам ОС, ни к проблемам повествования. Просто я нашёл ссылки на официальные документы, говорящие, что это — совершенно нормальное поведение программы. Теперь можно спать спокойно.
EasyLy Автор
22.09.2017 03:15-1Вообще, эти ARMы всех запутать хотят. Перечитал процитированное ранее. Не очень убедительно. Но ниже они пишут
•Other instructions cannot be pipelined after STR with register offset. STR can only be pipelined when it follows an LDR, but nothing can be pipelined after the store. Even a stalled STR normally only takes two cycles, because of the write buffer.
И в другой таблице — чётко пишут, что 2 цикла и всё тут.
Все описания касаются именно Cortex M4. То есть, обсуждаемой архитектуры.
EasyLy Автор
22.09.2017 04:25-1Нет, не могу уснуть. Провел ещё одно исследование, которое несколько подмывает официальные документы, но зато никак не противоречит моему основному трактату. Итак. Чтобы сделать красивые фронты на моём осциллографе, делим частоту на 16. 168000000/16=10500000, один такт примерно 95.2 нс.
Переписываем программу вот так
while (true) { GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); }
Получаем вот такие импульсы

Один, один, один такт на состояние! Чушь какая-то!
Тем не менее, видны вот такие чёткие пачки

у которых провал равен пяти тактам. Один такт на состояние и четыре — на ветвление. В целом, не противоречит документу, где сказано 1+P, P зависит от Pipeline, и может быть до трёх. То есть, 1+3 = 4. Оставляем один переброс на итерацию, провал как был, так и есть пять тактов

Получаем одно подтверждение (ветвление 4 такта) и одно противоречие (GPIO работает за один такт). Возвращаем частоту на 168 МГц

1 такт равен 5.95 нс. У нас явно два такта! Два, два, два! А поменяна только частота. Вернее, делитель частоты. И ничего больше. В нуле находится 5 тактов. Я измерял на более крутом стационарном осциллографе.
Получается, что запись идёт 2 такта, но если буфер занят (две записи подряд) — ждём, если свободен (после записи идёт ветвление) — продолжаем работать. Но всё это — только на предельной частоте.
В общем, спишем это всё на то, что система как-то определяет, что работает на высокой частоте и добавляет лишний такт при записи в порт. Иного объяснения я не вижу. Возможно, это касается только отдельных чипов, так как я уже ловил несоответствие моего F429 более новым. Там DWT по умолчанию по-разному настроен, знаменитая ошибка с приёмом младшего бита в SPI по-разному проявляется/не проявляется. Может и тут что-то такое.
Но как видим, это — практическое поведение чипа, а не грубый ляп в моём повествовании. Надеюсь.no111u3
22.09.2017 08:54Тут запись идёт в ODR, но сути не меняет, как бы человек получил 84 МГц на выходе из пинов ввода — вывода:
vjordan.info/log/fpga/stm32f4-bare-metal-start-up-and-real-bit-banging-speed.htmlEasyLy Автор
22.09.2017 09:51-1Не вижу никаких противоречий. Он писал много раз на итерацию, как и я в ночном эксперименте. В основном же примере, я пишу 1 раз на итерацию, и 4 такта каждый раз тратится на переход. Ну, потому что у меня немного другая задача, мне надо показать, как работает ОС, а не как добиться максимальной частоты. Хотя, факты катастрофической просадки «ниоткуда» я и отмечаю.
Чтобы закрыть тему окончательно и бесповоротно (судя по оценкам, она нравится не всем), я сделал следующее: Как и ночью, увеличил делитель частоты на 16, чтобы попасть в область точных измерений моего осциллографа. Убедился, что тратится 8 тактов на итерацию.
Дальше, модифицировал код следующим образом:
while (true) { GPIOE->BSRR = (1<<nBit); GPIOE->BSRR = (1<<(nBit+16)); GPIOE->BSRR = (1<<nBit); asm{nop} GPIOE->BSRR = (1<<(nBit+16)); }
Получил следующую осциллограмму в чёткой области работы осциллографа:
Напомню, 1 такт равен примерно 95.2 нс. Здесь чётко видно, что сначала имеем взлёт на 1 такт (запись единицы), затем — падение на 1 такт (запись нуля). Затем — взлёт на 3 такта (запись единицы + NOP), затем — падение на 5 тактов (запись нуля + ветвление).
Итого, в примере из моего основного текста имеем взлёт (1) NOP (ничего не знаю, чётко видно, что 2), падение (1), ветвление (4). 1 + 2 + 1 + 4 = 8. 168/8 = 21. Всё сходится.
Если писать много раз за итерацию — да, будет почти 84. До первого ветвления, которое у автора по ссылке не попало на экран (тем более, что он пишет, что осциллограф ловит сигнал, уже поделённый в ПЛИС, как именно он там делится — не говорит).
EasyLy Автор
22.09.2017 10:28Поправка: Перечитал. Автор говорит, как делит частоту. Но зато ещё он говорит, что осциллограф работает почти на пределе частотного диапазона. А я после этой ночи чего-то перестал доверять показаниям китайских осциллографов на высоких пределах. Я вёл проверку сразу двумя. У обоих полоса 250 МГц, дискретизация — у одного 1ГГц, у второго — целых 2 ГГц (разумеется, прямая, а не стробоскоп). Но похоже, там АЦП в таком режиме работает, что лучше конкретные импульсы было не измерять…
В общем, на уменьшенных частотах всё у меня сошлось (8 тактов с NOP, 6 тактов без NOP дают 21 и 28 МГц соответственно), а у автора по ссылке всё может оказаться не строго 84 МГц, так как RIGOL — тоже китайская марка. И он работает без курсоров, на предельных частотах этого осциллографа… Но чем больше записей в порты на итерацию, тем ближе будет частота именно к 84 МГц. Однако, к обсуждаемому тексту, это уже не имеет никакого отношения.
khvostovets
22.09.2017 16:49+1А можно как-то это пощупать руками? Если да, то где можно скачать и сколько это стоит?
EasyLy Автор
22.09.2017 16:54Бесплатно (тестовая версия). В планах, ходят слухи, сделать ядро бесплатным и для коммерческого использования. Скачать можно на официальном сайте.
saw_tooth
Боюсь спросить, какой результирующий размер «мигалки», при наличии стольких зависимостей?
ЗЫ. Боюсь, потому что очевидно что он будет огромен. Заранее говорю, что это не попытка упрекнуть в Вашей RTOS, просто интересно.
EasyLy Автор
Ну, там же оптимизатор всё неиспользуемое выкидывает, так что зависимостей бояться не стоит.
Эта книга писалась в ноябре прошлого года. Сейчас собрал проект именно этой мигалки, привязанный к ОС тех времён — получилось 18000 байт кода (я сам удивился столь круглому числу). Скорее всего, сегодня получилось бы меньше — за прошедший период был рефакторинг. Но именно этот пример именно с той версией ОС, для которой он был сделан — чуть меньше 18К занял.
И понятно, что мигалку ради мигалки лучше делать без ОС. Но демонстрировать практические опыты проще именно на мигалке.