
Публикую последнюю статью из первого тома «Книги знаний» ОСРВ МАКС. Надеюсь, это неформальное руководство поможет вам, коллеги, в случае, если придется работать с этой RTOS.
Предыдущие статьи:
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами
Часть 8. Работа с прерываниями (настоящая статья)
Преподаватели информатики очень любят рассказывать о том, что существует работа по опросу, а также — по прерыванию, после чего обычно приводят небольшой примерчик обработки прерываний и забывают о теме. Дальше, при реальном программировании, приходится постигать основы этого дела не собственной шкуре.
При программировании в однозадачных системах, очень часто удаётся «выкрутиться» за счёт работы с оборудованием по опросу. В многозадачных системах это становится всё труднее.
Рассмотрим простейший пример. Пусть идёт приём из последовательного порта с ужасно низкой скоростью 9600 БОД. Реальные скорости давно находятся в районе 250 КБОД, но чтобы не возникало желания просто снизить скорость для решения проблемы, давайте рассмотрим именно сверхмедленный вариант.
В последовательном порту один байт — это при моей любимой настройке порта 10 бит (8 битов данных, а также стартовый и стоповый). Итого, приходит 960 байт в секунду. Округлим до 1000. Это 1 байт в миллисекунду. Разместим события на оси времени.
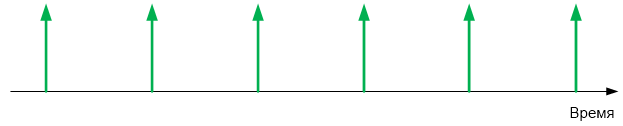
Если в типовом контроллере не успеть обработать очередной байт до прихода следующего, он будет затёрт новым пришедшим из линии значением. Рассмотрим суть этого на схеме из описания контроллера STM32.

По умолчанию, задачи переключаются 1 раз в 1 миллисекунду. Разместим на оси времени случай последовательного переключения пяти задач.

Пусть COM порт опрашивается в задаче 1. Совместим два рисунка…
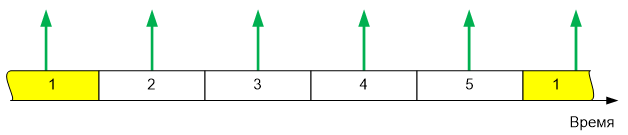
Как видно, 4 байта из последовательного порта придут, когда задача, ожидающая их, неактивна. Имеются контроллеры с большой аппаратной очередью. Например, ESP8266 может принять 128 байт в аппаратный буфер. Таким контроллерам рассмотренная ситуация нипочём — задача 1 получит данные, накопленные аппаратурой. Но, например, у всех STM32 входной буфер может принять не более одного байта. И для них работа с последовательным портом в многозадачной среде по опросу смерти подобна даже на таких «смешных» скоростях, как 9600 бит в секунду.
Правильным решением будет пришедшие байты складывать в буферную память, чтобы обрабатывающая задача взяла всё, что накоплено, оптом. Как вариант, производить какую-то предобработку (например, первичный разбор пакетов, если это возможно без особых задержек) и передавать в обрабатывающую задачу уже предобработанные параметры.
Разумеется, пример с последовательным портом был выбран, как наиболее близкий большинству читателей. На самом деле, имеется намного больше случаев, где опрос даже в однозадачной среде слабо приемлем, а в многозадачной — невозможен. Первое, что приходит на ум — поддержание оборотов двигателя. Реальный случай — двигатель вращается на скорости до 5 тысяч оборотов в минуту, от него приходит два импульса обратной связи на оборот.
Один из типовых алгоритмов измерения частоты вращения, требует измерить при помощи таймера период следования этих импульсов. То есть, требуется снять показания таймера на момент прихода, а затем — перезапустить таймер для нового измерения. Если от момента прихода импульса до момента снятия показаний будет проходить случайное время — точность измерения существенно упадёт. Чаще всего — не просто существенно, а неприемлемо упадёт.
Прикинем нашу ситуацию — 10000 импульсов обратной связи в минуту. Делим на 60 — получаем 167 Гц. 1 импульс в 5 миллисекунд, который надо обработать как можно ближе к моменту его возникновения, чтобы не потерять точность измерений. Время прихода импульса подгадать невозможно — двигатель вращается так, как нравится ему. При пяти задачах, время возможного ожидания передачи управления следящей задаче составляет более половины периода следования импульсов. Например, вот такая ситуация:
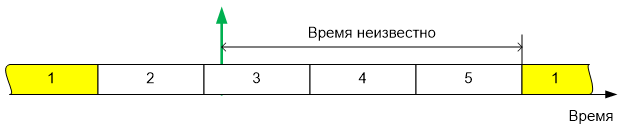
Сколько времени прошло от прихода импульса до активации задачи, производящей опрос — неизвестно. Как видно, и здесь реализовать сколь-либо разумную обработку данных можно только по прерываниям. Импульс пришёл, время его прихода было запомнено, а уже обрабатывающая задача может этим временем воспользоваться когда угодно.
Из всего вышесказанного следует, что
При работе с ОСРВ МАКС, прерывания допускается обрабатывать двумя способами — «удобным» и «быстрым». Рассмотрим сначала тот, который считается основным вариантом («удобный»).
В рамках ОС разрабатывается обычная задача, но она должна наследоваться не от Task, а от TaskIrq. Этой задаче ставится высокий приоритет, так как она должна будет вытеснить все остальные задачи, как только возникнет прерывание. Класс TaskIrq содержит виртуальную функцию IrqHandler(), которую следует перекрыть, разместив там все действия, связанные с обработкой прерывания.
Во время инициализации, прерывание следует разрешить через программирование контроллера прерывания (я сам пугаюсь, сколько раз слово «прерывание» было сказано в последних двух абзацах, но увы, без этого никак). При постановке задачи на планирование, так как она унаследована от особого класса, следует в виде параметра указать номер запроса на прерывание, который она обрабатывает.
Идеологически, вызов данной задачи можно представить следующим образом:
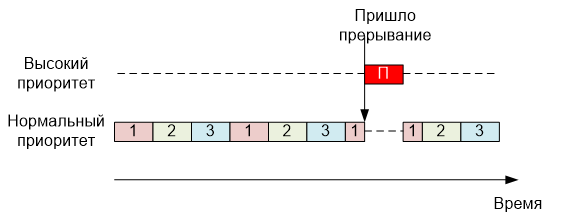
Именно поэтому её приоритет должен быть высоким — она ничем не отличается от остальных задач, поэтому обязана их вытеснить, а это делается именно при помощи приоритета. Теперь рассмотрим практический пример. Вот типичная задача — обработчик радиомодуля, подключённого к последовательному порту. Как видим, она действительно унаследована от TaskIrq, и в ней действительно перекрыта функция IrqHandler().

Вот так эта задача добавляется:
Настройку NVIC для примера радиомодуля вынесем за пределы этого раздела. На мой взгляд, в этом примере она не очень иллюстративна. Чисто для иллюстрации покажем, как настраивается NVIC для конкретного обработчика в другом примере (специально выбран вариант с изменением приоритета, хотя можно приоритет и не изменять).
Итак. Задача описана, её функция TaskIrq перекрыта, задача добавлена в планировщик, что дальше? А дальше — забота ОС. Когда возникнет прерывание, внутренний обработчик прерывания самостоятельно вызовет планировщик. Тот — активирует задачу. Здесь важно, чтобы у задачи был высокий приоритет, чтобы она гарантированно вытеснила другие задачи. Ну, и через некоторое время (требуемое на переключение задач), функция IrqHandler() получит управление. Что разместить в теле данной функции — проблемы прикладного программиста (в следующей части документа будут описаны типовые решения для случаев работы через драйверы нижнего уровня).
Стандартные решения:
Простенький пример обработчика прерывания:
Все возможные проблемы от использования основного механизма обработки прерываний связаны с одним: для пробуждения задачи-обработчика требуется переключить контекст задач. На это требуется время. При практической работе в системе с двумя задачами, на осциллограмме мы видели, что переключение происходило за 4.7 микросекунды. В целом, время зависит от опций сборки, от количества задач, от прочих условий. Возьмём за основу для дальнейших прикидок достаточно реальное и достаточно круглое значение 10 микросекунд.
Давайте рассмотрим несколько типовых сценариев работы оборудования, обслуживаемого микроконтроллером. Начнём с простого. Станок с ЧПУ, получающий команды G-CODE через последовательный порт на скорости 250 килобит. Как уже говорилось, в последовательном порту байт — это 10 бит (8 бит данных, плюс стартовый и стоповый биты). Итого, частота прихода байтов составляет 25 КГц. Один байт в 40 микросекунд. И на переключение контекста уходит 10 микросекунд.
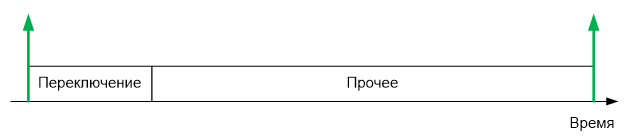
Четверть времени работы микроконтроллера (мощного 32 битного микроконтроллера) будет уходить только на переключение контекста, так как строки G-Code идут одна за одной, достаточно плотным потоком. Приемлемо ли это? Скорее нет, чем да.
Дальше, работа с шаговым двигателем, требующим 200 шагов на миллиметр на 3D принтере, печатающем со скоростью 150 мм/с требует работы на частоте 30 КГц. Это уже даже больше четверти.
G-Code принимается тем же контроллером, который управляет шаговыми двигателями. Итого, на вход в прерывание требуется уже более половины процессорного времени.
Само собой, такой вариант неприемлем.
Но с другой стороны. Возьмём тот же последовательный порт, на той же самой скорости, но подключим к нему радиомодуль, с которого приходят 32-байтные пакеты 4 раза в секунду. Таким образом, нагрузка на процессор будет повышаться на участках длиной 1200 микросекунд, а за секунду такие периоды пиковой нагрузки будут возникать в течение 4800 микросекунд. Это 4.8% времени. Приемлемо? Чаще да, чем нет. То есть, считаем, что этот вариант для обработки стандартным способом приемлем.
Точно так же можно прикинуть, что уже упомянутый механизм определения скорости вращения двигателя по сигналам обратной связи будет неприемлем — показания таймера надо снимать как можно ближе к моменту прихода сигнала. А снятие показаний с датчика влажности — вполне приемлемо. В то же время, обработка данных с последовательного порта на скорости 921 килобит в секунду займёт 100% времени на переключение задач, поэтому неприемлема… Ну, и так далее. В игру «приемлемо-неприемлемо» можно играть долго. Давайте сформулируем общие принципы.
Если прерывания приходят редко — вариант приемлем.
Если прерывания приходят так часто, что на переключение контекста уйдёт 100 и боле процентов времени — вариант неприемлем
Если на переключение контекста уйдёт высокий процент времени, но это будет происходить достаточно редко и достаточно короткими пачками — вариант приемлем.
Если переключение с высокой частотой будет постоянным — вариант неприемлем.
Какую же замену можно предложить? Конечно, прямую обработку прерываний.
Вы можете спросить: «А почему не предложить прямую обработку прерываний во всех случаях?». Я задал точно такой же вопрос разработчикам ОСРВ МАКС. Увы, их ответ был категоричен: есть причины, по которым стандартная обработка всё-таки удобнее.
Начнём с простого. Имена обработчиков прерываний. Даже в пределах семейств ARM они разные. Приведём наиболее яркие различия между семействами STM32 и «Миландр»
При миграции, их потребуется переписывать. При основном механизме, имена обработчиков — это забота ОС. Они скрыты от прикладного программиста (жаль только, что имена векторов всё-таки не скрыты, но без этого уже не обойтись).
Далее, при использовании стандартного обработчика, вызывается обычная задача. Настоящий обработчик прерываний скрыт от глаз прикладного программиста. Он всего лишь пробуждает задачу-обработчик и сообщает планировщику, что следует переключить контекст. Всё остальное — это обычная задача. А вот с прерываниями — там всё иначе. Если посмотреть описание любой ОС (хоть реального времени, хоть даже и Windows), то будет видно, что очень многие механизмы не работают в обработчике прерываний. Бегло осмотрим механизмы ОСРВ МАКС.
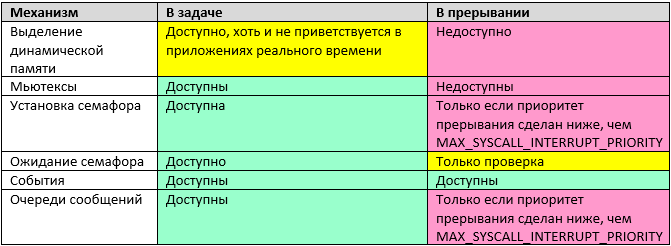
Давайте разберёмся, почему пара записей, казалось бы, могла быть жёлтой (ведь при некоторых условиях механизм доступен), но отмечена красным. При реализации указанных механизмов, требуется исключить возможность повторного входа в функцию. Для этого, в ней размещается критическая секция, которая, как мы помним, блокирует все прерывания, приоритет которых ниже, чем MAX_SYSCALL_INTERRUPT_PRIORITY. Собственно, этим всё сказано. Прерывания временно запрещаются. То есть, мы не получаем преимуществ от прямой обработки прерываний. С другой стороны, мы теряем все удобства, имеющиеся в основном механизме обработки прерываний. В общем, в ситуациях, ради которых отказываются от основного механизма обработки прерываний в пользу прямого, семафоры устанавливать нельзя и очередями сообщений пользоваться нельзя. Поэтому в таблице они отмечены красным.
При прямой обработке прерываний, скорость реакции определяется только возможностями микроконтроллера. Перечень обработчиков прерываний удобно брать из файла startupXXXX.s, имеющегося в каждом проекте. В демонстрационном приложении PinListAndTimerDemo обрабатывается прерывание от таймера 2, давайте рассмотрим, как быстро найти имя его обработчика.
 0
0
Зная имя обработчика, его очень просто сделать, пользуясь следующими правилами:
Таким образом, в уже упомянутом примере, обработчик прерывания от таймера 2 в стартовом коде именован так:
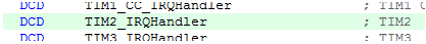
А функция обработки, соответственно,
Важно помнить, что обработчик такого прерывания должен исполняться максимально быстро. Пока программа находится в обработчике, не работают все остальные задачи, а также заблокированы прерывания с меньшим приоритетом.
Обработчик прерываний должен быстро принять данные, положить их для дальнейшей обработки и тут же прекратить свою работу. Никаких сложных вычислений, никакой другой лишней работы в обработчике прерываний располагаться не должно.
Удобным механизмом для связи прерываний с основными задачами является кольцевой буфер. Прерывание помещает принятые данные в него по мере их прихода, а какая-либо задача — изымает и использует, не заботясь о скорости обработки.
Библиотека mcucpp Константина Чижова, используемая в качестве вспомогательной, уже содержит реализацию кольцевых буферов. О самой библиотеке много будет говориться в следующей части документа, а пока рассмотрим файл ring_buffer.h.
Класс RingBuffer использует в своей работе оператор new для добавления каждого элемента, поэтому в приложениях реального времени (и, тем более, в прерываниях) использован быть не может. Но этот же заголовочный файл содержит класс RingBufferPO2 — кольцевой буфер, размер которого кратен степени двойки. Данный класс не только работает с заранее предвыделенным буфером, но и ещё настолько потокобезопасен для схемы «один писатель, один читатель», насколько это позволяет система команд микроконтроллера (опасные счётчики записываются через класс атомарного доступа, и безопасность определяется уже тем классом).
Определяется класс следующим образом:
template<size_t SIZE, class T, class Atomic = VoidAtomic>
class RingBufferPO2
SIZE — количество элементов. Должно быть кратно степени двойки, в противном случае, компилятор выдаст ошибку.
T — тип хранимых данных. Допускаются как скаляры, так и структуры.
Atomic — класс для обеспечения атомарности операций (если не указан — атомарность не обеспечивается).
Пример объявления для буфера байтов, принятых из COM порта (на 64 символа):
если результат равен false, то данные не были помещены, так как буфер переполнен.
Обычно для получения данных используется функция, которая попутно выталкивает их из очереди. Для случая скалярных величин, это оправдано, но для случая структур — выполняется лишняя операция копирования — данные копируются на новое место, так как из старого они будут удалены. Скорее всего, для предотвращения копирования, автор библиотеки mcucpp пошёл несколько другим путём. Данные из очереди не выталкиваются, а считываются (получается ссылка на них). Для удаления данных, используется отдельная функция.
Основной функцией чтения данных можно назвать следующую:
const T& front()const
T& back()
Как видим, она возвращает ссылку на данные, то есть, не выполняет копирования.
Можно получить ссылку на самый последний элемент в очереди:
const T& back()const
T& front()
Можно даже работать с очередью по индексу:
const T& operator[] (size_type i)const
T& operator[] (size_type i)
Ну, и когда в элементе отпала нужда, его следует удалить из очереди при помощи функции:
bool pop_front()
Если очередь пустая, функция вернёт false.
Имеются также вспомогательные функции проверки очереди на переполненность и пустоту:
bool full()const
bool empty()const
Можно узнать, сколько конкретно элементов находится в настоящий момент в очереди:
size_type size()const
Наконец, можно узнать ёмкость очереди (правда, она равна константе и задаётся на этапе разработки программы, но для совместимости с динамическими буферами, эти функции могут оказаться полезны):
size_type max_size()
size_type capacity()
Давайте проверим, насколько плох подход вызова двух функций вместо одной. Чтобы получить хорошие реперы, обрамим фрагмент кода чётко выраженными вызовами (соответствующие строки зачеркнём).

Соответствующий ассемблерный код выглядит так:

Как видно, оптимизатор не стал делать вызовы функций, а разместил всё линейно. И качество кода таково, что будь тут одна или две функции — разницы не будет. Как не будет и копирования в случае использования структур.
Собственно, пример прост. Рассмотрим его на примере буферизации данных, приходящих из COM-порта. В третьей части документа постараемся рассмотреть работу с COM-портом и его прерываниями более подробно. Объявляем буфер на 64 элемента (я интуитивно принял решение, что такой буфер точно не переполнится, если будут обрабатываться строки со средней длиной 30 символов).
В обработчике прерываний помещаем данные в буфер:
А в одной из задач, среди прочих вещей, выполняем какие-либо действия, например, такие:
не опасаясь за то, что данные будут затёрты (само собой разумеется, размер очереди должен быть достаточным, чтобы она не переполнилась). Ну, и производим некие действия с полученным символом ch. Если очередь пуста, вход в указанный цикл просто не произойдёт.
Чтобы вас не запутать, начнём с простой фразы: всё, что необходимо для начала работы с прерываниями, уже было описано. Всё остальное — уже высший пилотаж. Наверное, самое правильное — сначала освоить две крайности (медленно и удобно, а также быстро и не очень удобно), а затем — уже вернуться к чтению этой части раздела.
Существует смешанный способ обработки прерывания. Сначала переписывается обработчик, в его начале выполняются критически важные действия, а затем — из него активируется обычная высокоприоритетная задача. В частности, для случая измерения частоты — в этом обработчике может быть получено фактическое значение таймера в момент прихода прерывания от ножки, затем — таймер запущен на следующее измерение, после чего — проблема обработки полученного с таймера значения делегирована обычной задаче. Ну, и любые другие вещи. Если важна мгновенная реакция, а то, что переключение контекста займёт время — не критично, то можно использовать данный метод.
Итак, мы создали задачу, порождённую от TaskIrq, мы создали собственный обработчик прерывания, в нём мы выполнили критичные ко времени действия… Что дальше?
А дальше следует вызвать функцию MaksIrqHandler (). Эта функция инициирует переключение контекста и передачу управления функции, связанной с прерыванием.

И, наконец, рассмотрим механизм, который не относится непосредственно к прерываниям, но связан с ними. Этот механизм просто предоставляет программисту дополнительные выразительные сведения, не являясь обязательным к использованию.
При создании задачи, классу-наследнику от TaskIRQ можно присвоить реально несуществующий номер прерывания. Он должен быть больше, чем значение FIRST_VIRT_IRQ (для архитектуры ARM это значение равно 0x100, но для других архитектур может оказаться иным).
Такая задача не связывается ни с одним реальным прерыванием и никогда не будет активирована ядром автоматически. Но программист всегда может вызвать функцию:
void ProceedIrq(int irq_num);
после чего произойдёт активация задачи по всем принципам активации задачи, связанной с прерыванием. Зачем? Варианты возможны самые фантастические. Например, можно вызывать несколько разных задач-обработчиков из одного физического обработчика прерываний, если на одном векторе «висит» несколько устройств (как ни велик диапазон линий IRQ, а уже даже на нём разработчики контроллеров умудряются объединять вызовы). В целом, как объяснил один из разработчиков ОС: «Механизм достался даром, почему бы не воспользоваться?». Функция ProceedIrq() в любом случае, необходима для внутренних нужд системы.
На этом, рассмотрение ядра можно считать начерно законченным. Впереди — драйверы, но про них — во втором томе руководства.
Предыдущие статьи:
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами
Часть 8. Работа с прерываниями (настоящая статья)
Почему прерывания жизненно необходимы
Преподаватели информатики очень любят рассказывать о том, что существует работа по опросу, а также — по прерыванию, после чего обычно приводят небольшой примерчик обработки прерываний и забывают о теме. Дальше, при реальном программировании, приходится постигать основы этого дела не собственной шкуре.
При программировании в однозадачных системах, очень часто удаётся «выкрутиться» за счёт работы с оборудованием по опросу. В многозадачных системах это становится всё труднее.
Рассмотрим простейший пример. Пусть идёт приём из последовательного порта с ужасно низкой скоростью 9600 БОД. Реальные скорости давно находятся в районе 250 КБОД, но чтобы не возникало желания просто снизить скорость для решения проблемы, давайте рассмотрим именно сверхмедленный вариант.
В последовательном порту один байт — это при моей любимой настройке порта 10 бит (8 битов данных, а также стартовый и стоповый). Итого, приходит 960 байт в секунду. Округлим до 1000. Это 1 байт в миллисекунду. Разместим события на оси времени.
Если в типовом контроллере не успеть обработать очередной байт до прихода следующего, он будет затёрт новым пришедшим из линии значением. Рассмотрим суть этого на схеме из описания контроллера STM32.
По умолчанию, задачи переключаются 1 раз в 1 миллисекунду. Разместим на оси времени случай последовательного переключения пяти задач.
Пусть COM порт опрашивается в задаче 1. Совместим два рисунка…
Как видно, 4 байта из последовательного порта придут, когда задача, ожидающая их, неактивна. Имеются контроллеры с большой аппаратной очередью. Например, ESP8266 может принять 128 байт в аппаратный буфер. Таким контроллерам рассмотренная ситуация нипочём — задача 1 получит данные, накопленные аппаратурой. Но, например, у всех STM32 входной буфер может принять не более одного байта. И для них работа с последовательным портом в многозадачной среде по опросу смерти подобна даже на таких «смешных» скоростях, как 9600 бит в секунду.
Правильным решением будет пришедшие байты складывать в буферную память, чтобы обрабатывающая задача взяла всё, что накоплено, оптом. Как вариант, производить какую-то предобработку (например, первичный разбор пакетов, если это возможно без особых задержек) и передавать в обрабатывающую задачу уже предобработанные параметры.
Разумеется, пример с последовательным портом был выбран, как наиболее близкий большинству читателей. На самом деле, имеется намного больше случаев, где опрос даже в однозадачной среде слабо приемлем, а в многозадачной — невозможен. Первое, что приходит на ум — поддержание оборотов двигателя. Реальный случай — двигатель вращается на скорости до 5 тысяч оборотов в минуту, от него приходит два импульса обратной связи на оборот.
Один из типовых алгоритмов измерения частоты вращения, требует измерить при помощи таймера период следования этих импульсов. То есть, требуется снять показания таймера на момент прихода, а затем — перезапустить таймер для нового измерения. Если от момента прихода импульса до момента снятия показаний будет проходить случайное время — точность измерения существенно упадёт. Чаще всего — не просто существенно, а неприемлемо упадёт.
Прикинем нашу ситуацию — 10000 импульсов обратной связи в минуту. Делим на 60 — получаем 167 Гц. 1 импульс в 5 миллисекунд, который надо обработать как можно ближе к моменту его возникновения, чтобы не потерять точность измерений. Время прихода импульса подгадать невозможно — двигатель вращается так, как нравится ему. При пяти задачах, время возможного ожидания передачи управления следящей задаче составляет более половины периода следования импульсов. Например, вот такая ситуация:
Сколько времени прошло от прихода импульса до активации задачи, производящей опрос — неизвестно. Как видно, и здесь реализовать сколь-либо разумную обработку данных можно только по прерываниям. Импульс пришёл, время его прихода было запомнено, а уже обрабатывающая задача может этим временем воспользоваться когда угодно.
Из всего вышесказанного следует, что
прерывания в многозадачной среде являются не только мощным, но зачастую и единственно возможным механизмом работы с аппаратурой.
Основной механизм обработки прерываний в ОСРВ МАКС
При работе с ОСРВ МАКС, прерывания допускается обрабатывать двумя способами — «удобным» и «быстрым». Рассмотрим сначала тот, который считается основным вариантом («удобный»).
В рамках ОС разрабатывается обычная задача, но она должна наследоваться не от Task, а от TaskIrq. Этой задаче ставится высокий приоритет, так как она должна будет вытеснить все остальные задачи, как только возникнет прерывание. Класс TaskIrq содержит виртуальную функцию IrqHandler(), которую следует перекрыть, разместив там все действия, связанные с обработкой прерывания.
Во время инициализации, прерывание следует разрешить через программирование контроллера прерывания (я сам пугаюсь, сколько раз слово «прерывание» было сказано в последних двух абзацах, но увы, без этого никак). При постановке задачи на планирование, так как она унаследована от особого класса, следует в виде параметра указать номер запроса на прерывание, который она обрабатывает.
Идеологически, вызов данной задачи можно представить следующим образом:
Именно поэтому её приоритет должен быть высоким — она ничем не отличается от остальных задач, поэтому обязана их вытеснить, а это делается именно при помощи приоритета. Теперь рассмотрим практический пример. Вот типичная задача — обработчик радиомодуля, подключённого к последовательному порту. Как видим, она действительно унаследована от TaskIrq, и в ней действительно перекрыта функция IrqHandler().
Текстом
class PortRadioTask : public TaskIrq
{
public:
PortRadioTask() : TaskIrq("Radio") {}
virtual void IrqHandler();
};
Вот так эта задача добавляется:
const int Radio_IrqNumber = EXTI15_10_IRQn;
...
result = TaskIrq::Add(radio_task = new PortRadioTask, Radio_IrqNumber, Task::PriorityRealtime);Настройку NVIC для примера радиомодуля вынесем за пределы этого раздела. На мой взгляд, в этом примере она не очень иллюстративна. Чисто для иллюстрации покажем, как настраивается NVIC для конкретного обработчика в другом примере (специально выбран вариант с изменением приоритета, хотя можно приоритет и не изменять).
NVIC_EnableIRQ(EXTI9_5_IRQn);
NVIC_SetPriority(EXTI9_5_IRQn,1);Итак. Задача описана, её функция TaskIrq перекрыта, задача добавлена в планировщик, что дальше? А дальше — забота ОС. Когда возникнет прерывание, внутренний обработчик прерывания самостоятельно вызовет планировщик. Тот — активирует задачу. Здесь важно, чтобы у задачи был высокий приоритет, чтобы она гарантированно вытеснила другие задачи. Ну, и через некоторое время (требуемое на переключение задач), функция IrqHandler() получит управление. Что разместить в теле данной функции — проблемы прикладного программиста (в следующей части документа будут описаны типовые решения для случаев работы через драйверы нижнего уровня).
Стандартные решения:
- можно принять данные, предобработать их, поставить в очередь сообщений для задачи с нормальным приоритетом,
- а можно — взвести семафор для задачи с нормальным приоритетом
Простенький пример обработчика прерывания:
Semaphore s_sema_radio_irq(0, 1); // семафор разблокируется в обработчике прерывания радиомодуля
void PortRadioTask::IrqHandler() {
s_sema_radio_irq.Signal();
}Возможные проблемы при использовании основного механизма
Все возможные проблемы от использования основного механизма обработки прерываний связаны с одним: для пробуждения задачи-обработчика требуется переключить контекст задач. На это требуется время. При практической работе в системе с двумя задачами, на осциллограмме мы видели, что переключение происходило за 4.7 микросекунды. В целом, время зависит от опций сборки, от количества задач, от прочих условий. Возьмём за основу для дальнейших прикидок достаточно реальное и достаточно круглое значение 10 микросекунд.
Давайте рассмотрим несколько типовых сценариев работы оборудования, обслуживаемого микроконтроллером. Начнём с простого. Станок с ЧПУ, получающий команды G-CODE через последовательный порт на скорости 250 килобит. Как уже говорилось, в последовательном порту байт — это 10 бит (8 бит данных, плюс стартовый и стоповый биты). Итого, частота прихода байтов составляет 25 КГц. Один байт в 40 микросекунд. И на переключение контекста уходит 10 микросекунд.
Четверть времени работы микроконтроллера (мощного 32 битного микроконтроллера) будет уходить только на переключение контекста, так как строки G-Code идут одна за одной, достаточно плотным потоком. Приемлемо ли это? Скорее нет, чем да.
Дальше, работа с шаговым двигателем, требующим 200 шагов на миллиметр на 3D принтере, печатающем со скоростью 150 мм/с требует работы на частоте 30 КГц. Это уже даже больше четверти.
G-Code принимается тем же контроллером, который управляет шаговыми двигателями. Итого, на вход в прерывание требуется уже более половины процессорного времени.
Само собой, такой вариант неприемлем.
Но с другой стороны. Возьмём тот же последовательный порт, на той же самой скорости, но подключим к нему радиомодуль, с которого приходят 32-байтные пакеты 4 раза в секунду. Таким образом, нагрузка на процессор будет повышаться на участках длиной 1200 микросекунд, а за секунду такие периоды пиковой нагрузки будут возникать в течение 4800 микросекунд. Это 4.8% времени. Приемлемо? Чаще да, чем нет. То есть, считаем, что этот вариант для обработки стандартным способом приемлем.
Точно так же можно прикинуть, что уже упомянутый механизм определения скорости вращения двигателя по сигналам обратной связи будет неприемлем — показания таймера надо снимать как можно ближе к моменту прихода сигнала. А снятие показаний с датчика влажности — вполне приемлемо. В то же время, обработка данных с последовательного порта на скорости 921 килобит в секунду займёт 100% времени на переключение задач, поэтому неприемлема… Ну, и так далее. В игру «приемлемо-неприемлемо» можно играть долго. Давайте сформулируем общие принципы.
Если прерывания приходят редко — вариант приемлем.
Если прерывания приходят так часто, что на переключение контекста уйдёт 100 и боле процентов времени — вариант неприемлем
Если на переключение контекста уйдёт высокий процент времени, но это будет происходить достаточно редко и достаточно короткими пачками — вариант приемлем.
Если переключение с высокой частотой будет постоянным — вариант неприемлем.
Какую же замену можно предложить? Конечно, прямую обработку прерываний.
Почему не стоит отказываться от основного механизма
Вы можете спросить: «А почему не предложить прямую обработку прерываний во всех случаях?». Я задал точно такой же вопрос разработчикам ОСРВ МАКС. Увы, их ответ был категоричен: есть причины, по которым стандартная обработка всё-таки удобнее.
Начнём с простого. Имена обработчиков прерываний. Даже в пределах семейств ARM они разные. Приведём наиболее яркие различия между семействами STM32 и «Миландр»
| STM32 | «Миландр» |
| USART1_IRQHandler | UART1_IRQHandler |
| TIM1_UP_TIM10_IRQHandler | Timer1_IRQHandler |
| TIM2_IRQHandler | Timer2_IRQHandler |
При миграции, их потребуется переписывать. При основном механизме, имена обработчиков — это забота ОС. Они скрыты от прикладного программиста (жаль только, что имена векторов всё-таки не скрыты, но без этого уже не обойтись).
Далее, при использовании стандартного обработчика, вызывается обычная задача. Настоящий обработчик прерываний скрыт от глаз прикладного программиста. Он всего лишь пробуждает задачу-обработчик и сообщает планировщику, что следует переключить контекст. Всё остальное — это обычная задача. А вот с прерываниями — там всё иначе. Если посмотреть описание любой ОС (хоть реального времени, хоть даже и Windows), то будет видно, что очень многие механизмы не работают в обработчике прерываний. Бегло осмотрим механизмы ОСРВ МАКС.
Давайте разберёмся, почему пара записей, казалось бы, могла быть жёлтой (ведь при некоторых условиях механизм доступен), но отмечена красным. При реализации указанных механизмов, требуется исключить возможность повторного входа в функцию. Для этого, в ней размещается критическая секция, которая, как мы помним, блокирует все прерывания, приоритет которых ниже, чем MAX_SYSCALL_INTERRUPT_PRIORITY. Собственно, этим всё сказано. Прерывания временно запрещаются. То есть, мы не получаем преимуществ от прямой обработки прерываний. С другой стороны, мы теряем все удобства, имеющиеся в основном механизме обработки прерываний. В общем, в ситуациях, ради которых отказываются от основного механизма обработки прерываний в пользу прямого, семафоры устанавливать нельзя и очередями сообщений пользоваться нельзя. Поэтому в таблице они отмечены красным.
Итак, если есть возможность пользоваться всеми возможностями ОС, то лучше и проще ими пользоваться, а переходить к прямой обработке прерываний только если в этом есть крайняя необходимость.
Прямая обработка прерываний
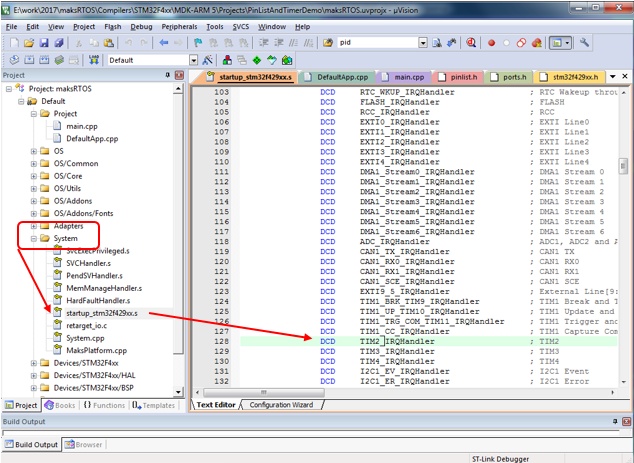
При прямой обработке прерываний, скорость реакции определяется только возможностями микроконтроллера. Перечень обработчиков прерываний удобно брать из файла startupXXXX.s, имеющегося в каждом проекте. В демонстрационном приложении PinListAndTimerDemo обрабатывается прерывание от таймера 2, давайте рассмотрим, как быстро найти имя его обработчика.
0Зная имя обработчика, его очень просто сделать, пользуясь следующими правилами:
- Если он размещается в файле cpp (код C++), обязательно следует добавить префикс extern «C». Без этого, имя функции будет сформировано по правилам С++ и система не поймёт, что мы подменяем обработчик прерывания.
- Возвращаемый тип — void.
- Аргументов – нет.
Таким образом, в уже упомянутом примере, обработчик прерывания от таймера 2 в стартовом коде именован так:
А функция обработки, соответственно,
extern "C" void TIM2_IRQHandler (void)
{
...Важно помнить, что обработчик такого прерывания должен исполняться максимально быстро. Пока программа находится в обработчике, не работают все остальные задачи, а также заблокированы прерывания с меньшим приоритетом.
Обработчик прерываний должен быстро принять данные, положить их для дальнейшей обработки и тут же прекратить свою работу. Никаких сложных вычислений, никакой другой лишней работы в обработчике прерываний располагаться не должно.
Удобным механизмом для связи прерываний с основными задачами является кольцевой буфер. Прерывание помещает принятые данные в него по мере их прихода, а какая-либо задача — изымает и использует, не заботясь о скорости обработки.
Кольцевой буфер из библиотеки mcucpp
Библиотека mcucpp Константина Чижова, используемая в качестве вспомогательной, уже содержит реализацию кольцевых буферов. О самой библиотеке много будет говориться в следующей части документа, а пока рассмотрим файл ring_buffer.h.
Класс RingBuffer использует в своей работе оператор new для добавления каждого элемента, поэтому в приложениях реального времени (и, тем более, в прерываниях) использован быть не может. Но этот же заголовочный файл содержит класс RingBufferPO2 — кольцевой буфер, размер которого кратен степени двойки. Данный класс не только работает с заранее предвыделенным буфером, но и ещё настолько потокобезопасен для схемы «один писатель, один читатель», насколько это позволяет система команд микроконтроллера (опасные счётчики записываются через класс атомарного доступа, и безопасность определяется уже тем классом).
Определяется класс следующим образом:
template<size_t SIZE, class T, class Atomic = VoidAtomic>
class RingBufferPO2
SIZE — количество элементов. Должно быть кратно степени двойки, в противном случае, компилятор выдаст ошибку.
T — тип хранимых данных. Допускаются как скаляры, так и структуры.
Atomic — класс для обеспечения атомарности операций (если не указан — атомарность не обеспечивается).
Буфер для хранения данных является переменной-членом класса. Поэтому объект класса следует помещать в тот пул, в котором имеется достаточно свободного места (стек, куча, глобальная память, специально заданный пул памяти и т.п.)
Пример объявления для буфера байтов, принятых из COM порта (на 64 символа):
Mcucpp::Containers::RingBufferPO2<64, uint8_t, Mcucpp::Atomic> bufFromUart;
Для помещения данных в буфер, используется функция
<b>bool push_back(const T& value)</b>если результат равен false, то данные не были помещены, так как буфер переполнен.
Обычно для получения данных используется функция, которая попутно выталкивает их из очереди. Для случая скалярных величин, это оправдано, но для случая структур — выполняется лишняя операция копирования — данные копируются на новое место, так как из старого они будут удалены. Скорее всего, для предотвращения копирования, автор библиотеки mcucpp пошёл несколько другим путём. Данные из очереди не выталкиваются, а считываются (получается ссылка на них). Для удаления данных, используется отдельная функция.
Основной функцией чтения данных можно назвать следующую:
const T& front()const
T& back()
Как видим, она возвращает ссылку на данные, то есть, не выполняет копирования.
Можно получить ссылку на самый последний элемент в очереди:
const T& back()const
T& front()
Можно даже работать с очередью по индексу:
const T& operator[] (size_type i)const
T& operator[] (size_type i)
Ну, и когда в элементе отпала нужда, его следует удалить из очереди при помощи функции:
bool pop_front()
Если очередь пустая, функция вернёт false.
Имеются также вспомогательные функции проверки очереди на переполненность и пустоту:
bool full()const
bool empty()const
Можно узнать, сколько конкретно элементов находится в настоящий момент в очереди:
size_type size()const
Наконец, можно узнать ёмкость очереди (правда, она равна константе и задаётся на этапе разработки программы, но для совместимости с динамическими буферами, эти функции могут оказаться полезны):
size_type max_size()
size_type capacity()
Давайте проверим, насколько плох подход вызова двух функций вместо одной. Чтобы получить хорошие реперы, обрамим фрагмент кода чётко выраженными вызовами (соответствующие строки зачеркнём).
Текстом
txtOuter.ShowSymbol('A');
txtOuter.ShowSymbol(bufFromUart.front());
bufFromUart.pop_front();
txtOuter.ShowSymbol('B');Соответствующий ассемблерный код выглядит так:
Текстом
00025c 2141 MOVS r1,#0x41 ;288
00025e a801 ADD r0,sp,#4 ;288
000260 f7fffffe BL _ZN9TextOuter10ShowSymbolEwb ; TextOuter::ShowSymbol(wchar_t, bool)
000264 484b LDR r0,|L4.916|
000266 2201 MOVS r2,#1 ;290
000268 f8901044 LDRB r1,[r0,#0x44] ;290
00026c f001013f AND r1,r1,#0x3f ;290
000270 5c09 LDRB r1,[r1,r0] ;290
000272 a801 ADD r0,sp,#4 ;290
000274 f7fffffe BL _ZN9TextOuter10ShowSymbolEwb ;
000278 f3bf8f4f DSB ;290
00027c 4845 LDR r0,|L4.916|
00027e 6c02 LDR r2,[r0,#0x40] ;290
000280 6c41 LDR r1,[r0,#0x44] ;290
000282 428a CMP r2,r1 ;290
000284 d001 BEQ |L4.650|
000286 1c49 ADDS r1,r1,#1 ;290
000288 6441 STR r1,[r0,#0x44] ;290
|L4.650|
00028a 2201 MOVS r2,#1 ;293
00028c 2142 MOVS r1,#0x42 ;293
00028e a801 ADD r0,sp,#4 ;293
000290 f7fffffe BL _ZN9TextOuter10ShowSymbolEwb ; Как видно, оптимизатор не стал делать вызовы функций, а разместил всё линейно. И качество кода таково, что будь тут одна или две функции — разницы не будет. Как не будет и копирования в случае использования структур.
Пример использования кольцевого буфера
Собственно, пример прост. Рассмотрим его на примере буферизации данных, приходящих из COM-порта. В третьей части документа постараемся рассмотреть работу с COM-портом и его прерываниями более подробно. Объявляем буфер на 64 элемента (я интуитивно принял решение, что такой буфер точно не переполнится, если будут обрабатываться строки со средней длиной 30 символов).
#include <ring_buffer.h>
#include <atomic.h>
...
Mcucpp::Containers::RingBufferPO2<64, uint8_t, Mcucpp::Atomic> bufFromUart;В обработчике прерываний помещаем данные в буфер:
bufFromUart.push_back (Buf[i]);
А в одной из задач, среди прочих вещей, выполняем какие-либо действия, например, такие:
while (!bufFromUart.empty())
{
char ch = bufFromUart.front();
bufFromUart.pop_front();
...не опасаясь за то, что данные будут затёрты (само собой разумеется, размер очереди должен быть достаточным, чтобы она не переполнилась). Ну, и производим некие действия с полученным символом ch. Если очередь пуста, вход в указанный цикл просто не произойдёт.
Смешанный способ обработки прерываний
Чтобы вас не запутать, начнём с простой фразы: всё, что необходимо для начала работы с прерываниями, уже было описано. Всё остальное — уже высший пилотаж. Наверное, самое правильное — сначала освоить две крайности (медленно и удобно, а также быстро и не очень удобно), а затем — уже вернуться к чтению этой части раздела.
Существует смешанный способ обработки прерывания. Сначала переписывается обработчик, в его начале выполняются критически важные действия, а затем — из него активируется обычная высокоприоритетная задача. В частности, для случая измерения частоты — в этом обработчике может быть получено фактическое значение таймера в момент прихода прерывания от ножки, затем — таймер запущен на следующее измерение, после чего — проблема обработки полученного с таймера значения делегирована обычной задаче. Ну, и любые другие вещи. Если важна мгновенная реакция, а то, что переключение контекста займёт время — не критично, то можно использовать данный метод.
Итак, мы создали задачу, порождённую от TaskIrq, мы создали собственный обработчик прерывания, в нём мы выполнили критичные ко времени действия… Что дальше?
А дальше следует вызвать функцию MaksIrqHandler (). Эта функция инициирует переключение контекста и передачу управления функции, связанной с прерыванием.
Текстом
extern "C" {
extern void MaksIrqHandler ();
void EXTI15_10_IRQHandler()
{
if (EXTI_GetITStatus(EXTI_Line13) != RESET) {
/* Clear interrupt flag - существенно, что в конце! */
EXTI_ClearITPendingBit(EXTI_Line13);
// переключение в задачу обработки прерывания
MaksIrqHandler ();
}
}
}
Виртуальные прерывания
И, наконец, рассмотрим механизм, который не относится непосредственно к прерываниям, но связан с ними. Этот механизм просто предоставляет программисту дополнительные выразительные сведения, не являясь обязательным к использованию.
При создании задачи, классу-наследнику от TaskIRQ можно присвоить реально несуществующий номер прерывания. Он должен быть больше, чем значение FIRST_VIRT_IRQ (для архитектуры ARM это значение равно 0x100, но для других архитектур может оказаться иным).
Такая задача не связывается ни с одним реальным прерыванием и никогда не будет активирована ядром автоматически. Но программист всегда может вызвать функцию:
void ProceedIrq(int irq_num);
после чего произойдёт активация задачи по всем принципам активации задачи, связанной с прерыванием. Зачем? Варианты возможны самые фантастические. Например, можно вызывать несколько разных задач-обработчиков из одного физического обработчика прерываний, если на одном векторе «висит» несколько устройств (как ни велик диапазон линий IRQ, а уже даже на нём разработчики контроллеров умудряются объединять вызовы). В целом, как объяснил один из разработчиков ОС: «Механизм достался даром, почему бы не воспользоваться?». Функция ProceedIrq() в любом случае, необходима для внутренних нужд системы.
На этом, рассмотрение ядра можно считать начерно законченным. Впереди — драйверы, но про них — во втором томе руководства.