
Современные компьютерные сети, предложив дешёвый трафик, высокий профит, суперстабильность и божественную конвергентность, лишились таких притягательных качеств старых технологий, как возможность определять путь трафика и обеспечить качество канала от начала до конца.
Однако сеть linkmeup выросла до размеров федерального оператора. Возможность управления трафиком и быстрого восстановления сервисов стали очень важным требованием в MPLS-сети.
Пора внедрять Traffic Engineering.

Зачем вообще может понадобиться инжиниринг трафика?
Приведу простой пример.
Конвергентная сеть мобильного оператора.

Два типа трафика:
Левое плечо — широкий оптический канал 10G. Правое — резерв через арендованную линию — 1G.
Общий объём трафика — 2,5 Гб/с, мобильного: 800 Мб/с.
В случае разрыва основного канала, нужно переключить на резервный только мобильный трафик и сделать это за 50мс.
Подумайте, можем ли мы сделать это стандартными средствами? Разделить трафик разных сервисов разными VPN, безусловно, можем, но направить разными маршрутами — нет.
Без использования ТЕ весь трафик перенаправится в правое плечо, а там, кто бы мог предположить, не хватает пропускной способности — начнутся отбрасывания.
Кроме того, скорость сходимости OSPF или ISIS даже при использовании BFD исчисляется десятками мс, но после этого ещё и транспортные LSP должны перестроиться. В наши дни это уже не пройдёт незамеченным для абонентов.
Какие же функции по управлению трафиком предоставляет MPLS Traffic Engineering?
Базовые механизмы работы MPLS TE были рассмотрены в выпуске СДСМ 10, куда я вас и шлю за подробным рассмотрением. А здесь приведу лишь короткую сводку.
С точки зрения передачи данных TE несколько отличается от LDP. Жирным выделены отличия:
А вот в плане управления отличия гораздо более значительные. C ними всю оставшуюся дорогу и будем разбираться.
И его место занимает RSVP-TE — наследник отвергнутого стеком TCP/IP протокола RSVP.
TE работает в тесном симбиозе с IGP. Хотя правильнее это называть паразитизмом. Он вынуждает их (OSPF или IS-IS) служить себе: переносить нужную ему информацию и тем самым наполнять TEDB.
Процесс выглядит следующим образом:
Всё это подробно и в красках в статье СДСМ10. А ещё там же самый простой пример на практике.
Далее мы будем ходить вокруг да около вот этой схемы:
У нас есть L3VPN-клиент, офисы которого подключены к Linkmeup_R1 и Linkmeup_R4.
В отличие от LDP LSP, по которым трафик бежит по умолчанию и так, в TE-туннели трафик нам нужно направить.
И есть для этого следующие способы:
Самый простой в понимании и самый сложный в обслуживании способ.
По сути тот же статический маршрут.
Этот способ наиболее распространённый и поддерживается почти всеми производителями.
Маршрутизатор рассматривает туннель, как виртуальный интерфейс. И через этот интерфейс удалённые маршрутизаторы словно бы непосредственно подключены к локальному, а не находятся в десятках хопов. Этакая телекоммуникационная червоточина. Она и называется — shortcut — сокращённый путь.

Червоточина Фламма
Но протоколы IGP по умолчанию не хотят этого видеть и используют для отправки трафика физический интерфейс.
С помощью IGP Shortcut (в цисконародье AutoRoute Announce) мы вынуждаем протокол маршрутизации на Ingress LSR рассматривать туннель как обычную линию — Egress LSR будто бы подключен непосредственно. А соответственно и все сети, находящиеся за Egress LSR, будут доступны через туннель.
Таким образом всё, чьей точкой назначения является этот маршрутизатор, или узлы за ним, будет отправлено в туннель. В том числе и VPN-пакеты.

Таким образом туннель становится обычным интерфейсом, и, как у любого другого интерфейса у него должна быть метрика.
Во-первых, есть два типа метрик:
Метрика IGP — хорошо известная нам из курса базовой маршрутизации метрика интерфейсов.
Метрика TE — та метрика, которая будет использована при расчёте метрики TE-туннеля.
Во-вторых, у нас есть следующие способы управления метрикой туннеля:
*Этот способ зависит от производителя — у кого-то есть, у кого-то нет.
Tunnel-policy применяется для перенаправления исключительно трафика VPN в туннели.
То есть в режиме настройки VPN (не важно, L2 или L3) указывается какой туннель должен быть использован.
Существует две возможности:
У джуна зачастую свой подход (ещё сегодня в этом убедитесь). Так у него существует несколько таблиц маршрутизации:
При помещении VPN-маршрутов в таблицу IP-маршрутизации BGP сверяется с таблицей MPLS inet.3. Если в ней он находит LSP до Next Hop'а маршрутра VPN, то автоматически трафик загоняется в этот LSP. Никаких дополнительных действий не требуется.
Это в некотором смысле похоже на микс Tunnel-Policy и IGP Shortcut, только автоматически.

Всё та же сеть, но с ограничениями по пропускной способности.
Нам нужно обеспечить L3VPN клиенту.
У клиента есть требования: 8 Мб/с. Вынь да положь.
Направляем трафик в туннель через Auto-Route.
Итак, начнём с того, что никакого LDP — только RSVP-TE. То есть LSP нет, пока мы не настроим туннель.
Хоть мы всё это уже и делали в прошлый раз, но начнём настройку сначала.
Сейчас путь от R1 до R4 выглядит так: R1->R5->R2->R6->R3->R4 — всё из-за этих чёртовых ограничений.
Теперь начинаем баловаться.
Попробуем разорвать наш рабочий линк R3->R4, пока длится непрерывный пинг.

LSP перестроился на R1->R5->R2->R6->R3->R7->R4 с потерей одного пакета. Это время может значительно увеличиться, если физического падения линии не будет на маршрутизаторах.
Например, выключим линию R2-R5 и наблюдаем падения TE-туннеля на R1 без его дальнейшего восстановления.
Если линк R3->R4 восстановится, туннель перестроится обратно?
Да. Но не скоро. Пролетит много пакетов, прежде чем Ingress PE шевельнёт своим RSVP. (На самом деле зависит от производителя)
Это называется переоптимизацией туннелей (Tunnel reoptimization). С некоторой периодичностью Ingress PE заставляет CSPF проверить, а не появилось ли более оптимальных маршрутов.
То есть сначала он строит новый RSVP LSP, пускает туда трафик и только потом ломает старый. Этот механизм называется Make-Before-Break, о котором в конце.
Итак, у нас достаточно способов, как повлиять на путь трафика с помощью TE:
Первый самый очевидный способ — это метрики интерфейсов.
Как мы помним есть IGP-метрики, а есть TE-метрики. Вторые по умолчанию равны первым.
TE-метрика на линковых интерфейсах не только влияет на метрику туннеля с точки зрения IGP Shortcut, но и учитывается при построении LSP.
Чтобы указать туннелю, какую учитывать метрику:
Значение по умолчанию:
Конкретный туннель:
Cisco подробно про метрики.
На практике мы познакомились с базовой функцией TE — возможностью строить MPLS туннели с резервированием ресурсов на всём протяжении LSP.
Но не беспокоит ли вас вот эта идея с Bandwidth? Не возвращаемся ли мы в каменный век, когда не было переподписки. Да и как вообще определять величину этого ограничения? А что делать с тем, что она плавает в течение суток на порядки?
Метод, когда мы настраиваем статическое значение требуемой полосы, называется Offline Bandwidth.
Идея в том, что есть некая программа стоимостью в трёшку на Патриарших прудах, которая по каким-то алгоритмам вычисляет для вашего трафика одну цифру, которую вам и нужно настроить на туннеле.
Полосу можно настроить для всего туннеля, как мы делали это выше на практике:
А можно для конкретного RSVP LSP:
Это значение может отличаться от того, что указано для туннеля и имеет более высокий приоритет.
При этом для другого LSP (path-option 2, например), значение может отличаться — мол, если уж не получается зарезервировать 8 Мб/с, давай хотя бы 5 попробуем?
У Offline Bandwidth есть два существенных минуса:
— Ручная работа, которой хороший инженер старается избегать.
— Неоптимальное использование ресурсов. Ну, назначим мы полосу в 300 Мб/с клиенту, зарезервируем на каждой линии, а на деле ему надо-то от силы 30. И только в пике, когда у него бэкапятся БД, нужно 300. Неаккуратненько.
Этот вариант практиковался на заре появления TE. Существует он и сейчас.
Однако, следуя в ногу со временем, нужно быть более гибким и податливым.
А Autobandwidth молодец.
Этот механизм отслеживает загрузку туннеля в течение определённого периода и потом адаптирует резервирование.
Например, Adjust Interval у нас 2 часа. Текущее значение зарезервированной полосы пропускания — 90 Мб/с.
Adjust Threshold — 20 Мб/с.
В первом интервале всплеск 119 Мб/с (до 119 Мб/с) — больше порога. Значит RSVP-TE пытается построить новый туннель с новыми значениями для полосы пропускания.
Во втором — 23Мб/с (до 142) — опять больше порога. Обновляем резервирование по возможности.
В третьем максимальное значение падает до 137 Мб/с — разница только 5. Ничего не происходит.
В четвёртом всплеск падает до 116 (разница 21) — RSVP сигнализирует новый LSP с пониженными требованиями по полосе.
Так, каждые два часа будет происходить проверка и, возможно, перестроение туннелей.
Чем короче Adjust Interval, тем, соответственно, чаще будет обновляться резервирование и более рационально использоваться доступная полоса пропускания.
Примерно так при двухчасовом интервале будет выглядеть 24-часовое поведение auto-bandwidth.

Уже заметили проблему?
Возьмём типичный профиль утреннего трафика:

И такая дребедень целый день.
Вот измерили мы в 8 утра всплеск — 200 Мб/с. И два часа держится это значение для туннеля. А за это время на работу уже пришёл народ и запустил ютуб — средняя скорость уже 240, а всплески до 300. До 10 утра будет происходить тихая деградация. Тихая, потому что ни туннель, ни Auto-Bandwidth о ней не знают. А вот пользователи знают и их ИТшник тоже знает, уж поверьте.
Если же сильно уменьшать интервал юстировки, то на сети будут постоянно пересигналзироваться новые LSP.
Для решения этой и других проблем существуют механизмы Overflow и Underflow. Первый — для слежения за ростом трафика, второй — за снижением.
Если разница между текущим резервированием и всплесками трафика превосходит порог Overflow несколько раз подряд, RSVP TE будет пробовать построить новый LSP, не дожидаясь истечения Adjust Interval.
То же и для Underflow — RSVP-TE будет пересегнализировать LSP с более низкими требованиями, если заметил тенденцию к уменьшению объёма трафика.
И остаётся только одна, но серьёзная проблема.
Так уж устроен наш мир, что когда растёт трафик у одного абонента, обычно растёт и у другого. И может так статься, что когда придёт время снова увеличить резервирование, увеличить его будет уже некуда — всё занято. И тогда, если нет других путей, удовлетворяющих новым условиям, будет использоваться старый. И никому не будет дела до того, что его уже не хватает, что пакеты начали теряться, что клиент ищет номер директора, чтобы найти инженера, которому можно оторвать что-нибудь лишнее.
Мы с этим будем бороться с помощью приоритезации туннелей, о которой ниже.
Для включения функции AutoBandwidth глобально и одновременно настройки Adjust Interval:
Далее для каждого туннеля отдельно нужно активировать AutoBandwidth. При этом можно задать другое значение для Adjust Interval, а также установить минимально и максимально возможные значения для резервируемой полосы.
Для настройки Overflow:
Подробнее о Auto-Bandwidth можно почитать в очень честном документе.
Это механизм, который приоритезирует туннели: какой из них важнее. Он применим, как для случая Auto-Bandwidth в частности, так и для любого построения RSVP LSP вообще.
Всё предельно логично:
Setup Priority — приоритет установки RSVP LSP.
Hold Priority — приоритет удержания RSVP LSP.
Если полосы пропускания не хватает на узле, и у нового туннеля приоритет установки выше, чем приоритет удержания у старого, новый будет построен — старый сломан.
Оба имеют 8 значений: от 0 до 7. Для обоих 0 — это наивысший, 7 — наинизший.
Например, у нас есть туннель LSP1, у которого Hold priority 4.
Тут приходит запрос от RSVP-TE на LSP2 с Setup Priority 6 и Hold Priority тоже 6. Если полосы пропускания достаточно, то он просто построится. Если нет — то маршрутизатор не даст этого сделать — потому что уже существующий туннель приоритетнее нового (4>6).
Допустим, полосы достаточно и оба туннеля поднялись нормально.
И тут приходит новый запрос на LSP3 с Setup/Hold Priority 5. Это выше, чем у LSP2, но ниже, чем у LSP1. И ему полосы уже не хватает. LSP1 точно не будет тронут, потому что его Hold приоритет до сих пор самый высокий. И тогда есть два варианта:
Касательно значений — обычно выбираются одинаковые для Setup и Hold. И не стоит настраивать Hold ниже, чем Setup. Во-первых это не логично. Во-вторых, может случиться ситуация, когда два туннеля войдут в петлю, когда они будут постоянно перебарывать друг друга — как только установится один, второй его сломает и построится сам, потом первый сломает второй итд.
Существует два режима замещения туннелей:
Hard preemption — LSP с более высоким приоритетом просто замещает LSP с низким. Даже если потом LSP с низким приоритетом найдёт новый путь, часть трафика будет потеряна.
Soft preemption — применяется механизм Make-Before-Break. Маршрутизатор через RSVP-TE сообщает Ingress LSR низкоприоритетного LSP, что нужно искать новый путь. LSP с высоким приоритетом ожидает, пока трафик низкоприоритетного LSP переключится на новый LSP.
При этом, если путь найти не удалось в течение некоторого времени, низкоприоритетный LSP всё равно ломается и строится высокоприоритетный.
Данные о приоритетах замещения передаются в RSVP-TE PATH и учитываются при резервировании ресурсов на промежуточных узлах.
Если вы обратили внимание, то после настройки tunnel mpls traffic-eng badnwidth на туннельном интерфейсе, в конфигурации автоматически появляется строка tunnel mpls traffic-eng priority 7 7.
Дело в том, что без требований по полосе приоритеты не имеют никакого значения — через один узел можно проложить сколько угодно туннелей — ведь полоса не резервируется — и команды нет.
Но, как только появилось требование, по полосе, приоритеты начинают играть роль.
7 — это значение по умолчанию — наименьшее.
Давайте на Linkmeup_R1 настроим новый туннель до 4.4.4.4 с более высоким приоритетом?
Необходимая полоса всего 4Мб/с. Поэтому туннель должен пройти по пути R1->R2->R3->R4.
Так и есть, вот его трассировка:

С Tunnel4 у них только один общий линк R3->R4, но его полоса пропускания только 10. А двум туннелям нужно 8+4=12.
Tunnel42 с приоритетом установки 4 выдавливает Tunnel4 с приоритетом удержания 7.
И тому приходится искать новый путь.
И он находится:

Сначала удаляется старый RSVP LSP Tunnel4 и сигнализируется новый по доступному пути

Потом RSVP-TE сигнализирует LSP для Tunnel42.


В этот момент вернёмся к Autobandwidth. Именно связка Tunnel priority + Autobandwidth даёт элегантное решение.
Одним ранним утром было трафика мало, autobandwidth подсчитал сколько именно его в каждом туннеле, и TE везде хватило пропускной способности.
Потом ближе к обеду трафик подрос, autobandwidth адаптировался, перерезервировал новые полосы — всё ещё хватает.
К вечеру один за другим туннели начинают вылетать, потому что TE не может зарезервировать новую полосу.
И тут важно, чтобы туннели жирных клиентов, IP-телефонии и канал для МВД никогда не падали. Тогда задаём для этих туннелей Hold priority выше, чем Setup priority других.
— При попытке низкоприоритетных зарезервировать новую полосу на интерфейсе, где её уже не хватает, он обломится.
— Высокоприоритетный наоборот вытеснит низкоприоритетный и займёт освободившуюся полосу.
Получается, что
Идея Explicit-Path более чем полно была раскрыта в 10-м выпуске СДСМ.
Как вы помните, CSPF вычисляет кратчайший путь с учётом ограничений. Далее этот путь трансформируется в объект ERO (Explicit Route Object) сообщения RSVP-TE PATH, который явно сообщает, по какому пути этот PATH нужно передать.
Так вот если, вы хотите, чтобы какие-то узлы обязательно присутствовали или наоборот отсутствовали в этом пути, можно это явно указать в Explicit-Path, который станет одним из входных ограничений для CSPF.
Итак, мы вручную задаём, через какие узлы должен пролечь LSP, а через какие не должен.
RSVP-TE просит CSPF рассчитать маршрут с учётом Explicit-Path и других ограничений туннеля.
Если одно входит в противоречие с другим — беда, не будет LSP.
1) Создание самого explicit-path с ограничениями:
2) Примение его к path-option на туннеле:
SRLG — Shared Risk Link Group. Ещё один способ повлиять на LSP и отличная идея против плоских колец.
Задача этой функции предотвратить построение основного и резервного LSP через линии, которые могут повредиться одновременно.
Например, два волокна, которые физически проходят в одном кабеле, наверняка порвутся одним и тем же ковшом экскаватора.
SRLG-группа — группа интерфейсов, которые «разделяют риск». О! Группа риска.
Вручную (конечно, а как иначе маршрутизатор узнает, что это физически идентичные линии) настраиваются интерфейсы, которые являются членами одной SRLG-группы.
Информация о SRLG распространяется по сети вместе с анонсами IGP, как и доступная полоса или значение Attribute-Flag, и помещается потом в TEDB.
Далее CSPF должен учитывать эту информацию при расчёте кратчайших маршрутов.
Имеется два режима:
Force Mode заставляет CSPF учитывать данные SRLG обязательно — если иного пути нет, то резервный LSP не будет построен вообще.
Preffered Mode допускает построение запасных туннелей через SRLG-линии, если нет иных возможностей.
Режим задаётся на Ingress LSR.
Для добавления интерфейсов в одну группу риска на любых узлах вводится команда:
А на Ingress PE включить проверку SRLG:
Что это за команда, поговорим в разделе FRR.
Вот сейчас должно стать страшно. Мне страшно.
Итак, к данному моменту мы узнали про четыре инструмента управления трафиком:
RFC3630 для OSPF, а для ISIS определяют TLV для Administrative Group, который передаётся IGP вместе с другими характеристиками линиями.
Но, новая связка — удивительное спасение, которое решит все наши проблемы, просто нажмите кнопку «сделать хорошо».
Идея в том, что каждый интерфейс мы помечаем определёнными цветами.
А потом говорим, что вот этот туннель может идти по красным и фиолетовым линиям, но не может по зелёным, жёлтым и коричневым.
Marketing Bullshit! Непонятно? Мне тоже.
Итак.
Administrative Group (у Juniper: admin-group, у Cisco: Attribute-Flag) — это атрибут физического интерфейса, который может описать 32 его дискретных характеристики.
Какой бит из 32 за что отвечает решает оператор самостоятельно.
Раз уж примеры у нас в консоли Cisco, то далее буду использовать термин Attribute-Flag наравне с Administrative group, что не совсем правильно.
Affinity и маска — это требования туннеля к своему пути.
Какие отношения могут сложиться в этом треугольнике {Affinity, Mask, Attribute-Flag}?
Если это равенство выполняется, туннель можно строить через этот интерфейс.
Рассмотрим на примере.
У нас есть 32 бита и политика — за что отвечает каждый из них (возьмём пример выше).
В Mask мы указываем, какие характеристики канала нас интересуют. Например, для туннеля с трафиком 2G важно
Поэтому в маске выставляем 1 там, где важно, что стоит:
Mask: 0100 0110
Взяли только первые 8 бит для простоты.
Заметьте, что это Wildcard Mask.

В Affinity мы указываем, что именно нам нужно.
Affinity: 0000 0100.

Выполняем операцию и получаем: 0000 0100.

Теперь возьмём для примера три интерфейса.
То есть при построении LSP на каждом линке будет учитываться значение Attribute-Flag.
По умолчанию значение Attribute-Flag на интерфейсе — 0x0. И в некотором смысле — это прискорбно — ведь результат операции «И» с маской будет отличаться от результата с Affinity, а значит мы должны настроить Attribute-Flag на всех интерфейсах.
Соответственно, в пределах компании можно выработать политики, как помечать интерфейсы и как управлять трафиком. Можно возложить эту задачу даже на систему управления, чтобы работа инженера сводилась к расстановке галочек в графическом интерфейсе, а конфигурация затем применялась бы автоматически.
Но в любом случае это не умаляет человеческого фактора с одной стороны и просто непостижимой сложности отладки и обслуживания с другой.
Однако случаи комплексного внедрения Administrative Group даже на сетях российиских операторов имеются.
Другим примеров использования могли бы быть коды регионов или стран. Тогда можно было бы задавать через какую географию пропускать трафик.
В этом свете 32 бита оказывается очень мало, поэтому RFC 7308 определяет расширенные административные группы, количество бит в которых ограничено естественым пределом LSA или вообще MTU.
Парень на пальцах разжёвывает Affinity и в рот стопочкой складывает.
Очень очень короткая. Просто посмотрим, что работает. Короткая, потому что применение Affinity требует настройки Attribute-Flag на всех узлах и всех интерфейсах. А это то, чего меньше всего хочется, если честно.

Продолжаем с последней конфигурации, где у нас два туннеля.
Файл конфигурации.
Tunnel42 идёт по пути R1-R2-R3-R4. С ним и поиграем.
Значение Attribute-Flag по умолчанию 0x0. Поэтому его и возьмём в качестве Affinity — то есть все интерфейсы у нас подпадают под условие. Кроме R3-R4, на котором мы настроим Attribute-Flag 0x1. Поскольку равенство не выполнится — CSPF не сможет строить кратчайший путь через этот линк.
И наблюдаем, как туннель пошёл в обход этого линка.

Однако при этом благополучно развалился Tunnel4. Значение Affinity по-умолчанию тоже 0x0, но маска 0xFFFF. Поэтому он тоже не вписался в перенастроенный линк R3-R4.
Но, мы могли бы настроить на нём маску 0x0 — не учитывать никакие биты Affinity и Attribute-Flag:
И тогда туннель поднимется, не учитывая эти ограничения.
На практике мы уже видели, что перестроение туннеля в случае поломки занимает несколько секунд. Что ж, не так уж и плохо было во времена моего деда.
Вся история развития компьютерных сетей — это история борьбы с авариями, борьбы за скорость сходимости, за уменьшение времени перерыва.
Что у нас есть на вооружении?
IP хорош, но сходится за секунды, а то и минуты.
MPLS TE предлагает две опции для повышения стабильности и уменьшения времени прерывания сервисов.

Первая реализует защиту на уровне всего LSP, вторая — на уровне линка или узла — и она называется FRR — Fast ReRoute.
При настройке туннеля мы можем указать, сколько и каких LSP мы хотим построить.

Protection — это не только и не столько про восстановление сервиса, сколько про скорость этого восстановления.
В этом ключе понятное дело, что non-standby совсем не дело. Опираясь на IGP, RSVP-TE сначала ждёт обновления маршрутной информации, потом сам должен отработать — счёт на секунды. Сигналом является уведомление от RSVP-TE или BFD, что LSP больше не живой, либо информация от IGP об изменении топологии.
Для случая Standby строится одновременно основной RSVP LSP и резервный. Соответственно, как только Ingress LSR фиксирует разрывшаблона основного LSP, трафик сразу переключается на запасной — нам грозит потеря только тех пакетов, которые были посланы ровно до момента, как авария была зафиксирована.
А вот FRR — Fast Reroute — позволяет спасти даже те машинки, которые прямо сейчас уже стремятся к назначению, не подозревая ещё, что там мост обвалился. То есть FRR — это как объезд на участке трассы, где ведутся ремонтные работы, а Backup LSP — это другая трасса.
FRR использует обходные пути и описан в RFC4090 Среднее время переключения после детектирования аварии — 50мс.
Это вещь, которая просто включается, а дальше работает автоматически. То есть с точки зрения конфигурации выглядит элементарно.
Как это обычно и бывает, вещи которые просто настраиваются, скрывают под пальто нечто интересное.
Итак, у FRR есть две функции:
Поэтому он и называется Local Protection — не следит за всем LSP, а проверяет доступность только ближайшего линка или узла.

Когда случается страшное, он просто уводит пакеты в обходной туннель.

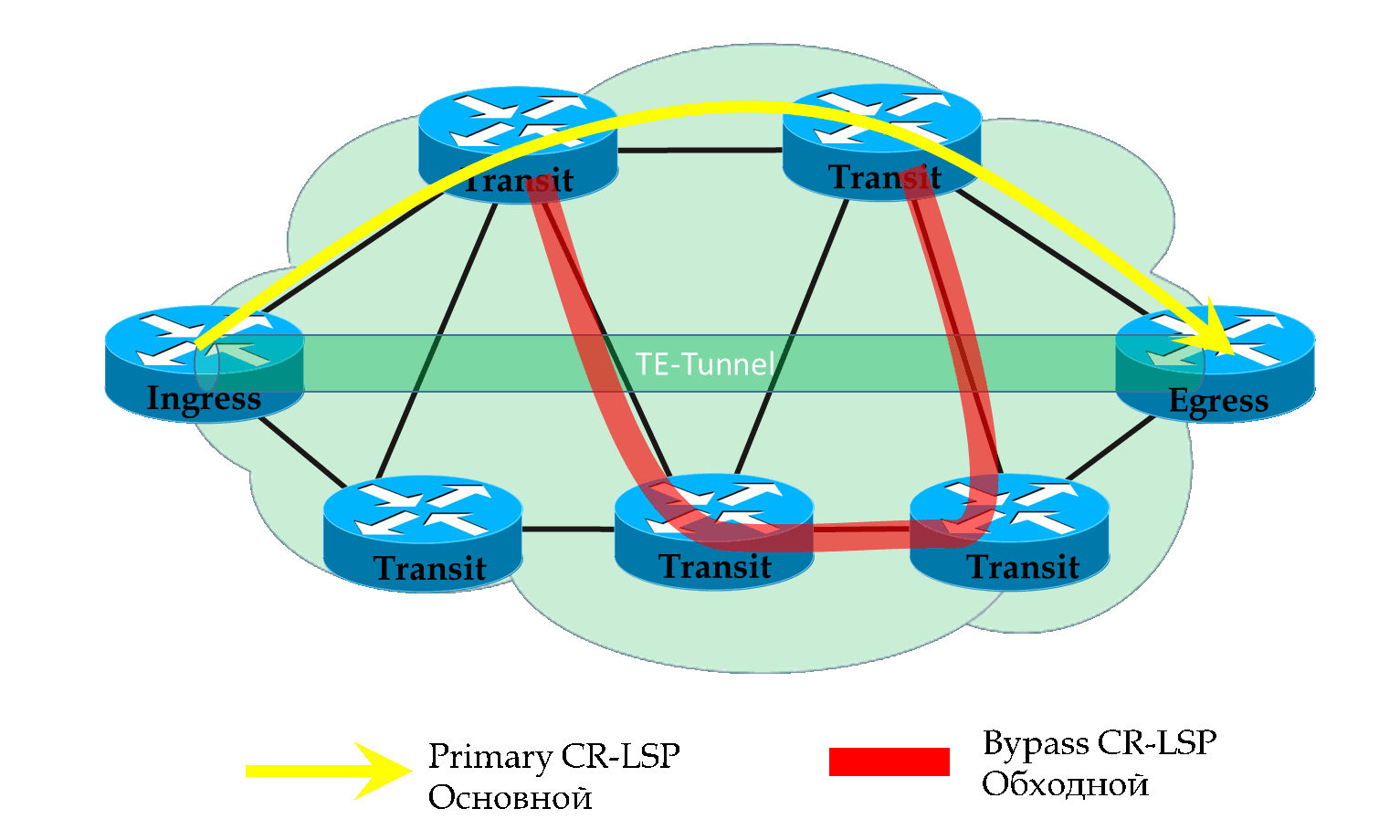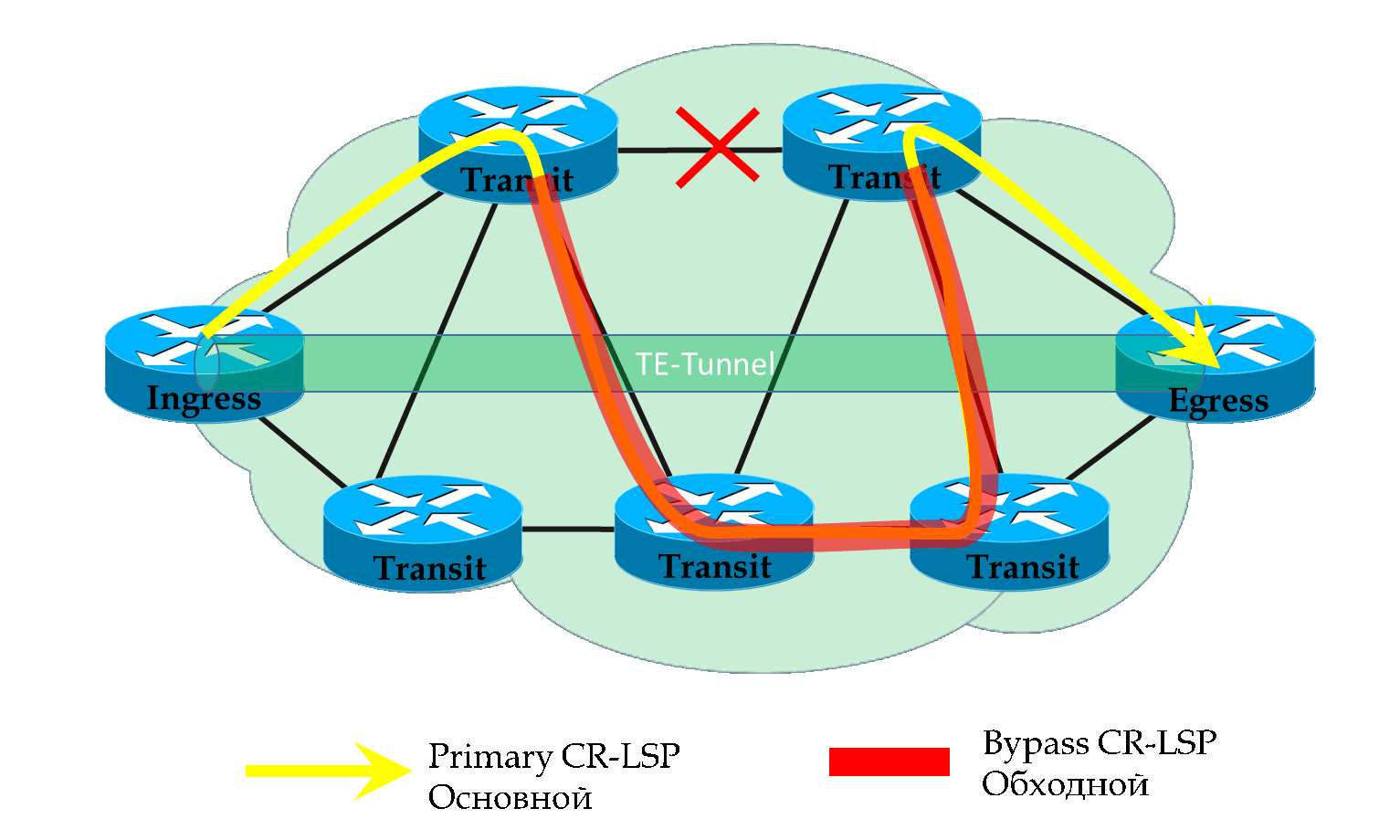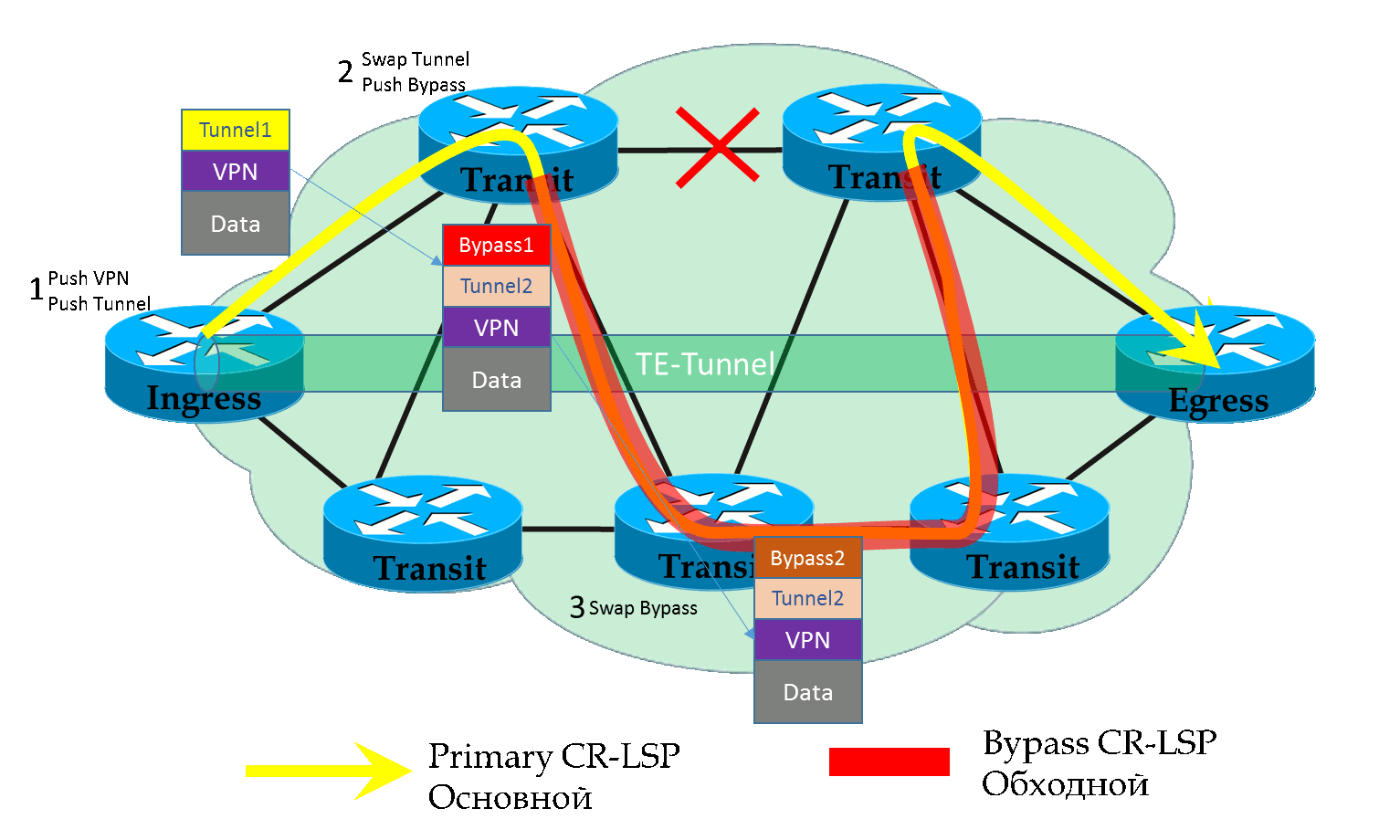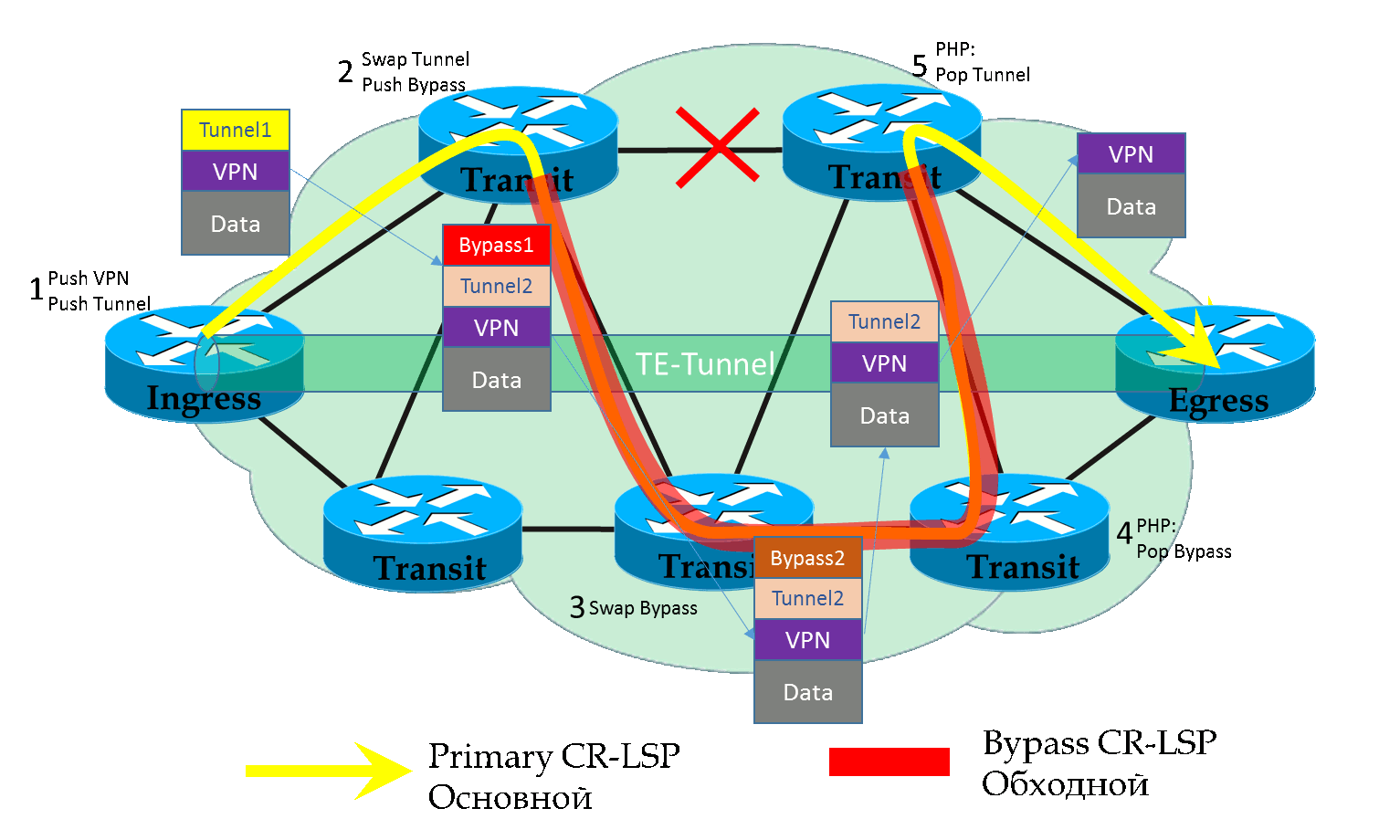
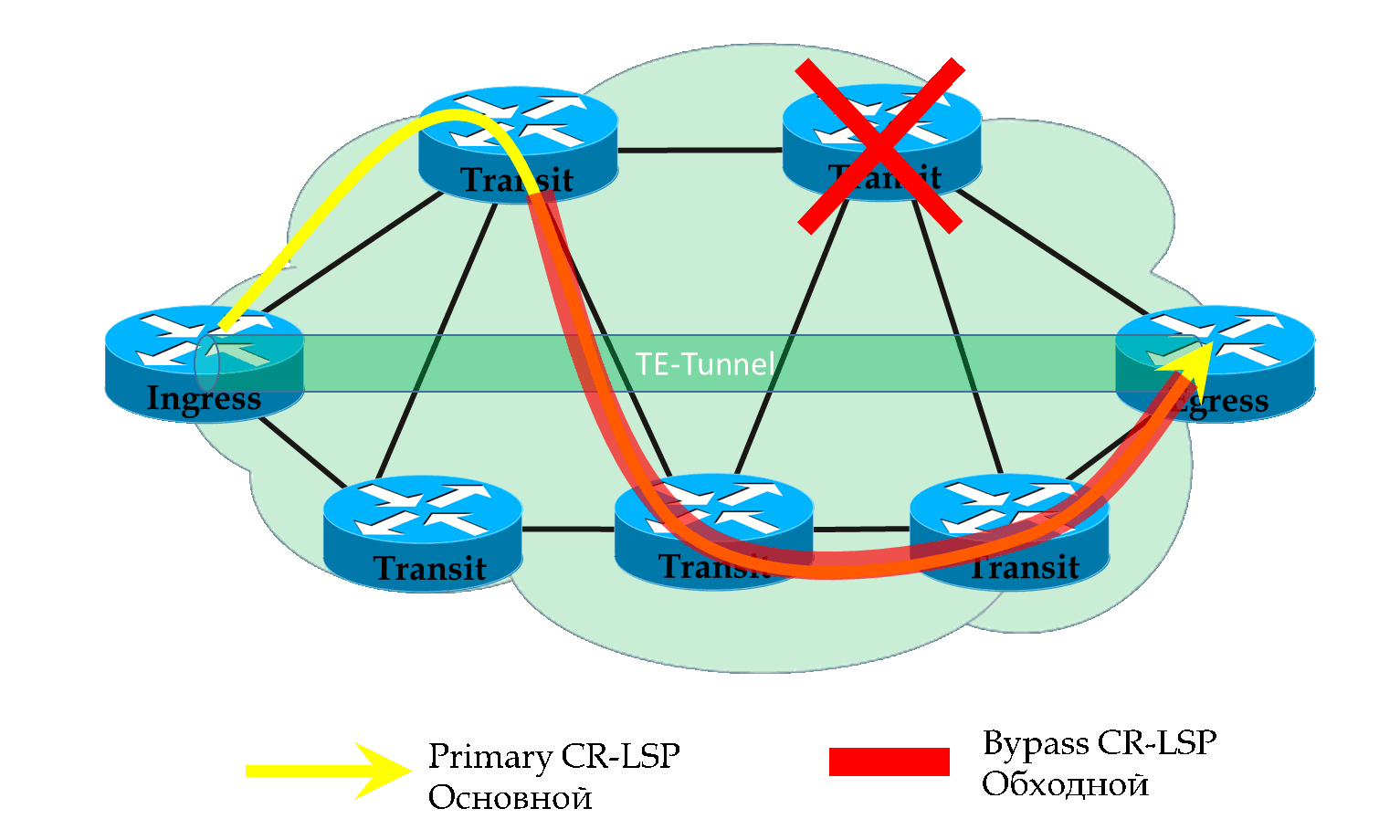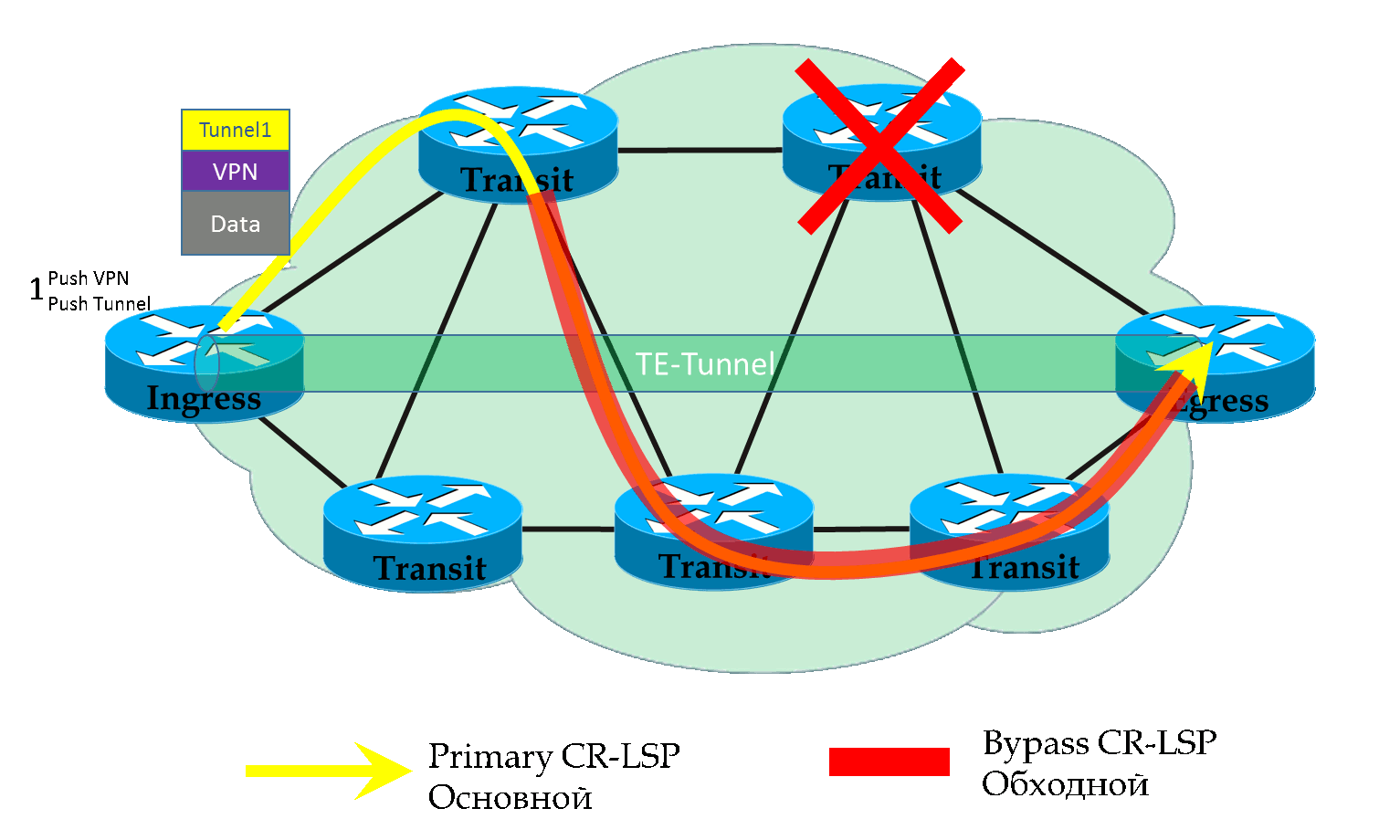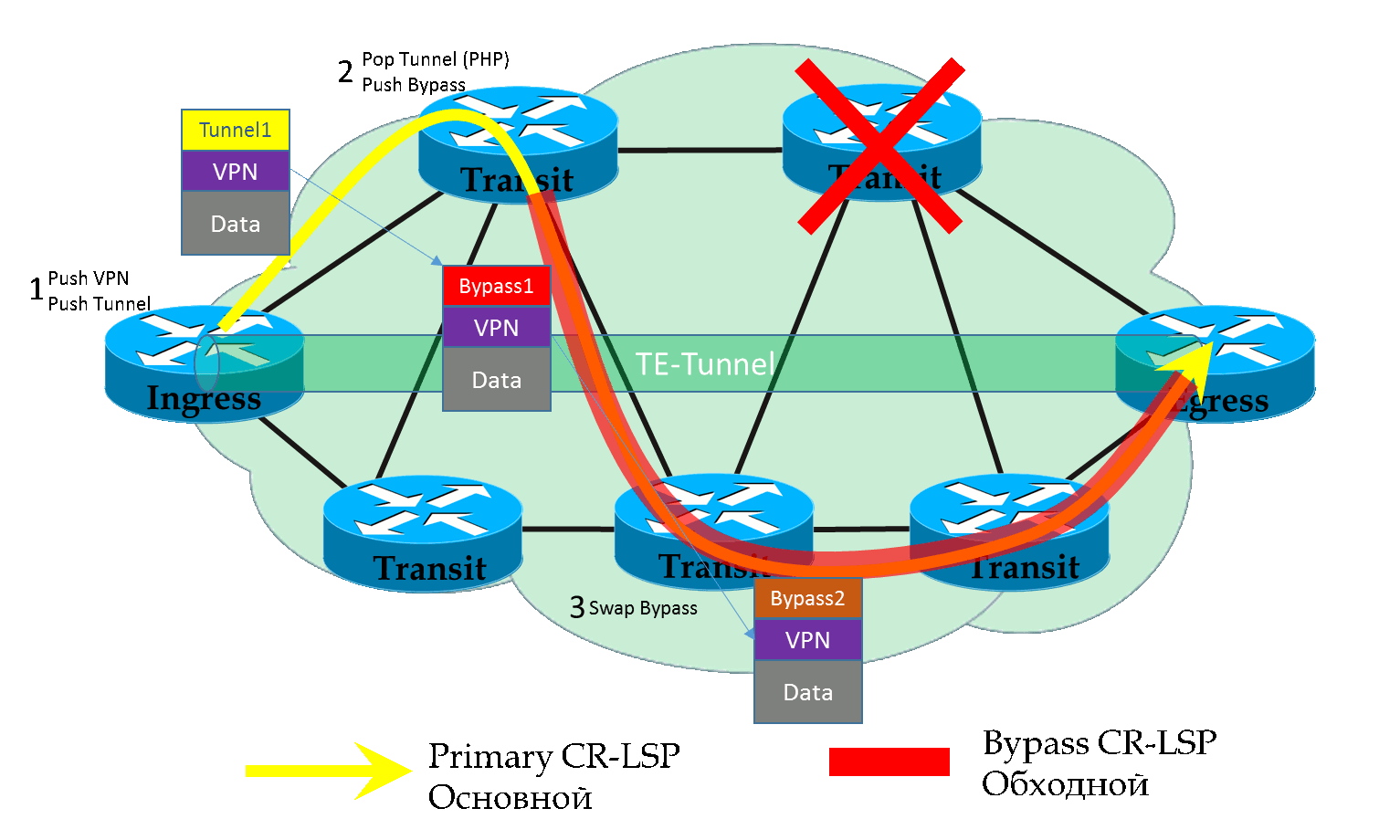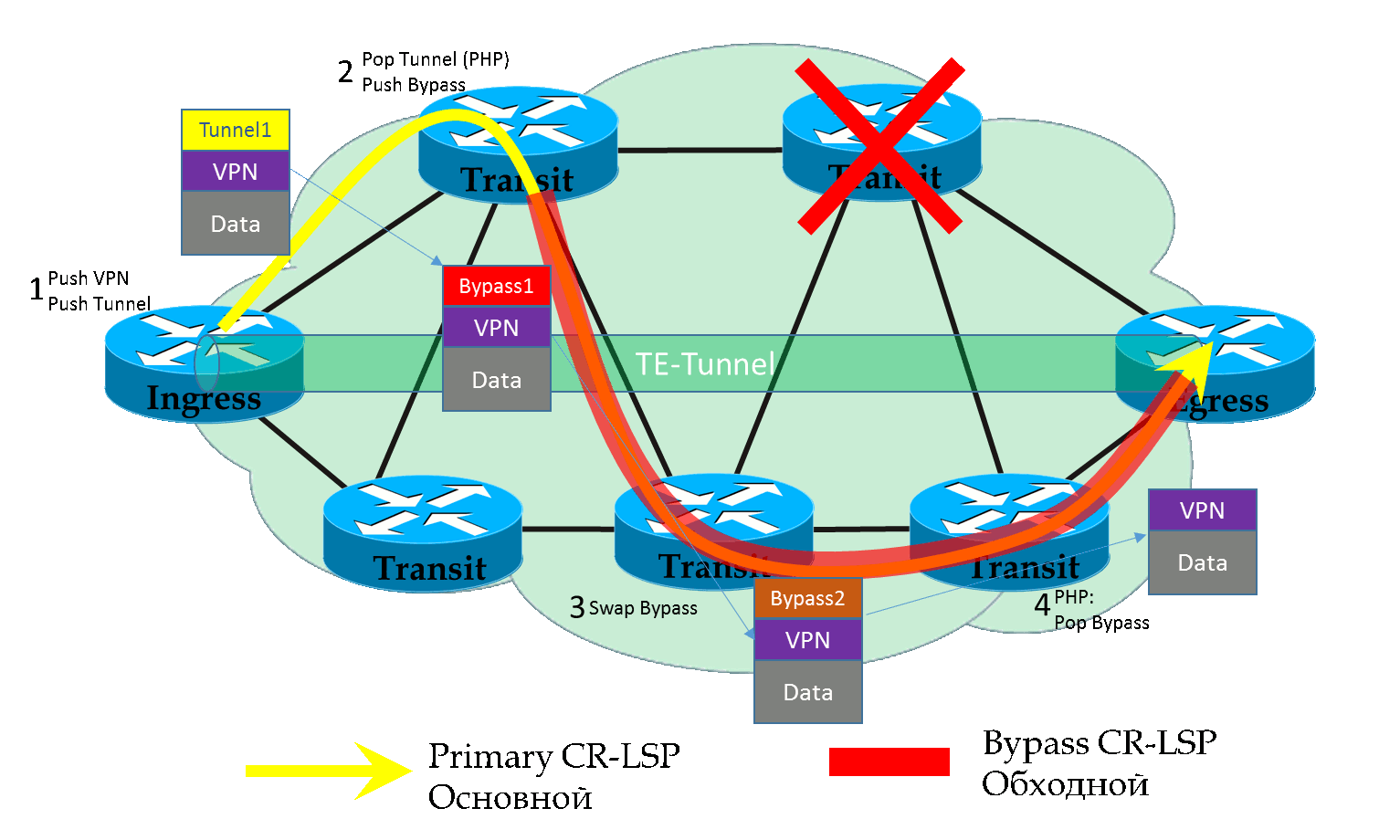
На иллюстрации а) показана защита линии. На б) — защита узлов.
Берём LSP от R1 до R4. Каждый узел по пути, кроме R4, будет пытаться строить свои обходные пути.
Так R1 для защиты линии R1-R2 выберет путь R1->R5->R2. А для защиты от падения узла R2: R1->R5->R6->R3.
R2 должен защитить линию R2-R3 и узел R3.
ИТД.
Задача FRR — спасти те пакетики, которые летят прямо в пропасть рухнувшего линка, уведя их на этот самый Bypass LSP.
Когда PLR замечает, что линия, через которую лежит транзитный LSP, упала, он мгновенно перенаправляет трафик. Заметьте, что не Ingress PE этим занимается, а именно тот узел, на котором произошёл обрыв. Падение линка фиксируется по падению интерфейса или BFD-сессии.
Можно сравнить FRR со стрелкой на железнодорожных путях.
Чтобы так быстро перенаправить пакеты, Bypass LSP должен быть построен заранее. Так и происходит.
Каждый узел по ходу Primary LSP ищет, как обойти падение следующего линка и падение следующего хопа.
То есть он запускает полный механизм построения LSP:
Туннели строятся автоматически и не отображаются в конфигурации. Но в остальном это обычные туннели, по которым можно посмотреть информацию или потрассировать их.
— как в этот Bypass LSP поместить пакеты из Primary LSP.
— Как на MP понять, что с полученным счастьем делать.
Всё очень просто — FRR LSP — это обычный туннель. То есть нам достаточно туннелировать наш предыдущий туннель на участке от PLR до MP, а это значит, добавить ещё одну MPLS-метку в каждый пакет. Итого их будет 3: VPN, Tunnel, FRR.
Итак, когда пакет приходит на PLR во время аварии, тот сначала делает обычный SWAP внешней метки, словно бы он должен был выйти через старый (в данный момент сломанный интерфейс) и ещё он знает, что надо передать его в FRR туннель — добавляет ещё одну метку.
Далее пакет коммутируется по Bypass LSP по стандартным правилам — меняется внешняя (FRR) метка, а две внутренние остаются неизменными.
На предпоследнем узле внешняя метка снимается — PHP и до MP пакет идёт с изначальными двумя.
MP получает пакет, смотрит на транспортную метку и далее коммутирует пакет, словно бы ничего и не происходило.


Всё абсолютно то же самое за исключением транспортной метки — PLR должен знать какую метку ждёт NNHOP.
Туннель теперь строится не до следующего узла, а через один — NNHOP. В этом помогает атрибут сообщения RSVP — LRO (Label Request Object). Будучи в RSVP PATH он просит узлы по пути выделять метки.
А в RSVP RESV Label Object содержит эти самые выделенные метки.


При сигнализации Bypass LSP возникает вопрос: а резервировать ли ресурсы.
Если да, то это уже называется Bandwidth Protection.
При этом обычно нет смысла два раза резервировать ресурсы для одного и того же туннеля. Ну действительно — от того, что мы увели трафик из Primary в Bypass ведь не следует, что ресурсы будут использоваться дважды на PLR и MP? Тем более, что свободной полосы вообще может не хватить. Поэтому вводится понятие SE (Shared Explicit). Если в изначальном RSVP PATH будет установлен этот атрибут, ресурсы не будут резервироваться дважды — промежуточные узлы буду знать, что это не совсем независимый LSP — это старый задумал что-то.
Итак, процедура следующая:
Режимы FRR.
Единственный вопрос, который стоит ещё обсудить про FRR — какие LSP собственно перенаправлять? Он же не один всё-таки, наверно, проходит через этот PLR?
Тут есть два варианта:
Первый вариант предпочтителен, поскольку использует ресурсы более рационально. Всё, что было выше именно про режим Facility.
One-to-One вводит пару новых терминов:
Detour LSP — запасной туннель. Тот же Backup LSP, но Detour защищает только один Primary LSP,
DMP — Detour Merge Point — Тот же MP.
Этот метод очень похож на Facility, но есть одно существенное отличие. В режиме Facility существующие LSP туннелировались в Bypass LSP, получая третью метку в стек. В режиме One-to-One при обходе препятствия в стеке останется две метки, то есть это будет выглядеть и работать, как самый обычный LSP.
PLR при обнаружении аварии, полученные пакеты старых LSP будет отправлять по новому пути, просто выполнив обычный Swap транспортной метки. Но метка и выходной интерфейс будут новыми — от Detour LSP.
DMP также выполняет обычный Swap транспортной метки. Вместо метки Detour LSP он подставляет старую от Primary LSP и отправляет дальше.


Я разобрал подробно режим Facility, потому что он наиболее часто используемый.

Продолжаем всё с той же сетью и с того момента, на котором мы остановились (если не считать affinity).
Файл конфигурации.
Добавим Standby LSP с более низкими требованиями полосы пропускания: 3 Мб/с.

Путь защитного туннеля лёг следующим образом:

Во-первых, на линии R1-R2 4 Мб/с из 5 уже занял Tunnel42. Поэтому для запасного LSP Tunnel4 не осталось полосы.
Во-вторых, основной и резервный LSP используют обычно метод резервирования полосы Shared Explicit (SE), что означает, что для одного и того же туннеля не будет полоса резервироваться дважды. Поэтому через 10 Мб/с линк R1-R5 удалось проложить и основной LSP (8 Мб/с) и резервный (3 Мб/с).
В-третьих, вы можете видеть, что резервный LSP на участке R6-R4 он выбрал тот же путь, что и основной. Поэтому использование Explicit-path иногда вполне может быть оправдано.
Для удовольствия и удовлетворения можете дёрнуть линк R2-R5 и убедится, что трафик абонентов почти не прерывался.
1) Включаем FRR на туннеле
Логично сделать это и на другом конце
Сразу после этого RSVP сигнализировал новый атрибут вдоль LSP

Он сообщил, что для этого LSP нужна защита линка.
Но туннелей пока не появляется.
2) Теперь нужно включить возможность построения туннелей автоматически:
Что делает эта команда? Проверяет, какие интерфейсы используются под туннели, требующие Local-protection, и пытается защитить линк и следующий узел, поэтому на каждом узле (где может) строит необходимые туннели.
Например, на Linkmeup_R2 будет 4:

Обратите внимание на то, что защитные туннели строятся без какого-либо учёта полосы пропускания, пока об этом отдельно не будет сказано.

Так, теперь я хочу разорвать линию R2->R6.
По идее для защиты этой линии у нас есть Tunnel65436 (R2->R5->R6). Но тогда полный путь будет выглядеть немного странно: R1->R5->R2->R5->R6-R3->R4 — то есть по линии R5-R2 трафик пройдёт дважды — туда и обратно. Поэтому R2 ненадолго включает интеллект и выбирает Tunnel65437, который напрямую ведёт к R3.
Тогда на участке R2-R3 мы должны увидеть две метки в стеке — VPN и туннельную. Метка bypass не будет вставляться, потому что PHP.
Если хочется, увидев все три метки, убедиться, что FRR работает, введите на R2 команду
Она заставит R2 использовать тот самый странный путь.
Смотрим на VPN и транспортную метки R1:


PUSH VPN — 16
PUSH Tunnel — 26
Смотрим таблицу меток на R5:

SWAP Tunnel 26->16
Смотрим FRR на R2:


SWAP Tunnel 16->27 (метка, которую ждёт NHOP)
PUSH Bypass Implicit Null — то есть реально метку не вставляем.
Метки на R3:

PHP: POP Tunnel 27 (дождался).
Смотрим дамп на участке — 2 метки (implicit null не был реально добавлен):

Прекрасно!
Ну и напоследок пара лёгких тем без практики.
Теме QoS будет посвящён отдельный выпуск. Готовьтесь. Но не поговорить немного об этом сейчас было бы непростительно.
Итак, MPLS TE использует парадигму IntServ QoS — предварительное резервирование ресурсов по всему пути.
То есть мы изначально уверены, что необходимая полоса (и другие требования) будет предоставлена сервису. При этом пакеты внутри туннеля (LSP) все равнозначны.
Однако, такое случается, что трафик у клиента растёт. Может, в какой-то момент его объём превосходит статически настроенный порог, а свободной полосы больше нет, или Autobandwidth ещё не успел отработать повышение скорости.
Так или иначе — пакеты начинают отбрасываться, причём безо всякого разбора — важные они или нет.
То есть идея IntServ в реализации MPLS TE сама по себе ещё не гарантирует, что на каждом отдельном узле проблем не возникнет.
А кто у нас там отвечает за Per-Hop Behavior? Напомните? DiffServ? А не объединить ли нам эти две прекрасные парадигмы?
Ведь в заголовке MPLS имеется поле EXP, которое планировалось Expериментальным, но уже давно официально используется для задания приоритета пакетов и называется Traffic class. Вот только по старой привычке его и сейчас продолжат называть EXP,
Это называется MPLS DiffServ-aware Traffic Engineering — MPLS DS-TE.
Идея, вообще говоря, заключается в том, чтобы MPLS-пакетам предоставить то качество сервиса, которое ожидали оригинальные пакеты. То есть в идеале нужно сделать соответствие 1 к 1. Но EXP — это всего лишь 3 бита, то есть 8 значений приоритета, тогда как DSCP — 6 бит (64 значения) — как ни крути, но детализация при такой архивации теряется.
Таким образом, существует два подхода:
E-LSP — EXP-Inferred LSP. Забить и радоваться тому, что имеем.
L-LSP — Label-Inferred LSP. Кодировать приоритет связкой EXP+метка.
Для случая, когда изначально имеем дело с полем DSCP — мы переносим в MPLS EXP только три наиболее значимых (левых) бита DSCP.
И да, мы смиряемся с потерей деталей.
Когда PDU приходит на Ingress LSR, мы помещаем его в туннель и задаём приоритет в поле EXP.
Ну например, в одном туннеле у нас пойдут данные ШПД и фиксированной телефонии. Естественно, телефонии мы дадим приоритет 5, а всему остальному 0.
Тогда даже если внутри одного туннеля случится затор, первыми будут умирать слабые.
В этом случае данные QoS кодируются в связку Метка+EXP. Предполагается, что метка задаёт механизм обработки в очередях, а метка — приоритет отбрасывания пакета.
Информация о PHB должна быть сигнализирована в процессе установки LSP.
Каждый L-LSP несёт только один тип сервиса.
На сегодняшний день операторы в большинстве своём определяют четыре класса трафика: BE, AF, EF и CS. E-LSP более чем достаточно для этого, поэтому L-LSP не только практически не используется, но и более того, не у всех вендоров реализован. Поэтому останавливаться далее на сравнении методов я даже не буду.
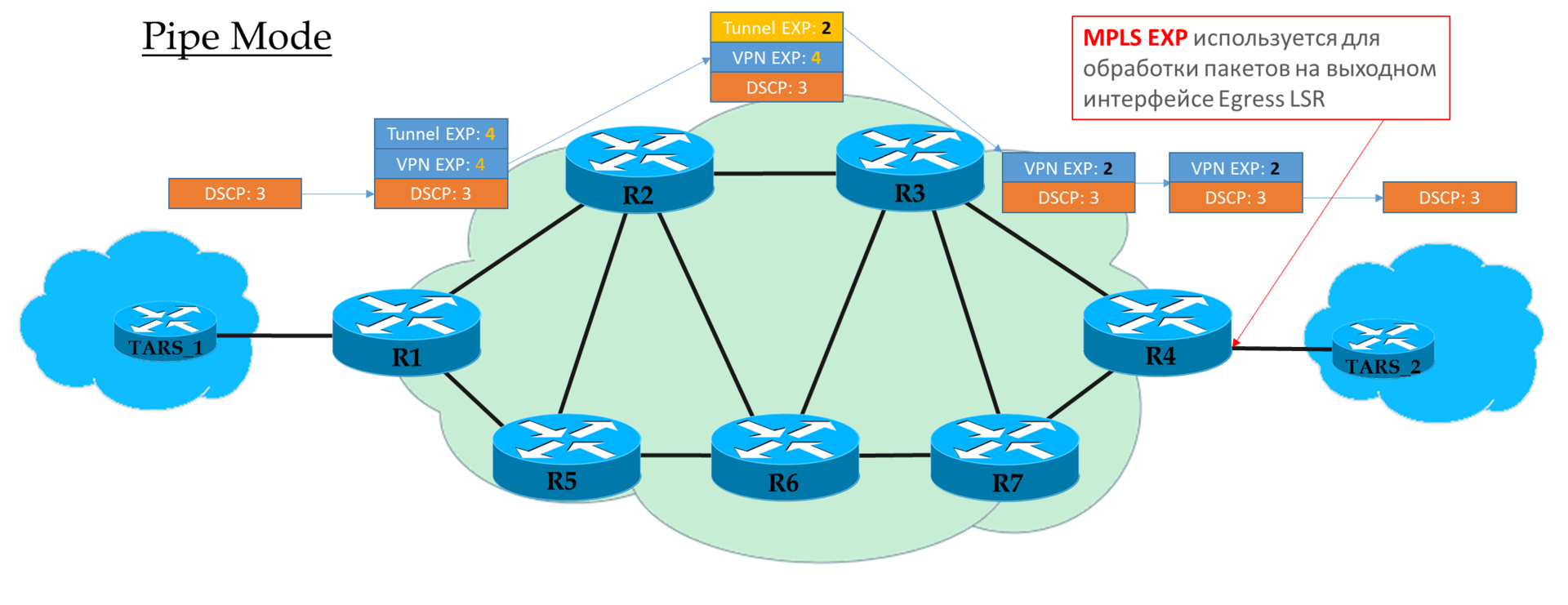
А вот что интересно, так это какому всё-таки полю CoS доверять на каждом узле: IP DSCP, Tunnel EXP или VPN EXP?
Есть три режима:
Помните, уже сталкивались с такими понятиями при разборе TTL в MPLS L3VPN? Что-то похожее и тут.
Это плоская модель End-to-End.
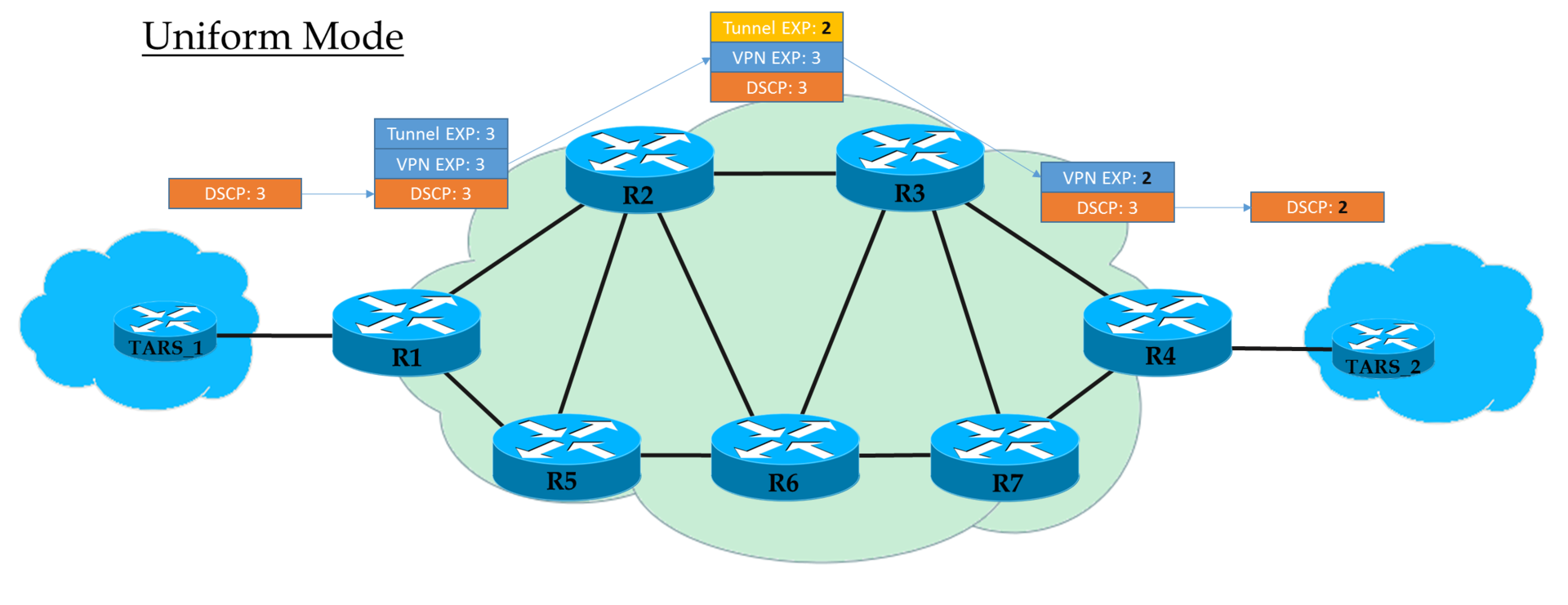
На Ingress PE мы доверяем IP DSCP и копируем (строго говоря, отображаем, но для простоты будем говорить «копируем») его значение в MPLS EXP (как туннельный, так и VPN заголовки). На выходе с Ingress PE пакет уже обрабатывается в соответствии со значением поля EXP верхнего заголовка MPLS.
Каждый транзитный P тоже обрабатывает пакеты на основе верхнего EXP. Но при этом он может его поменять, если того хочет оператор.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в VPN-заголовок. Не важно, что там стояло — в режиме Uniform, происходит копирование.
Egress PE снимая метку VPN, тоже копирует значение EXP в IP DSCP, даже если там записано другое.
То есть если где-то в середине значение метки EXP в туннельном заголовке изменилось, то это изменение будет унаследовано IP-пакетом.
Если же на Ingress PE мы решили не доверять значению DSCP, то в заголовки MPLS вставляется то значение EXP, которое пожелает оператор.
Но допустимо и копировать те, что были в DSCP. Например, можно переопределять значения — копировать всё, вплоть до EF, а CS6 и CS7 маппировать в EF.
Каждый транзитный P смотрит только на EXP верхнего MPLS-заголовка.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в заголовок VPN.
Egress PE сначала производит обработку пакета, опираясь на поле EXP в заголовке MPLS, и только потом его снимает, при этом не копирует значение в DSCP.
То есть независимо от того, что происходило с полем EXP в заголовках MPLS, IP DSCP остаётся неизменным.
Такой сценарий можно применять, когда у оператора свой домен Diff-Serv, и он не хочет, чтобы клиентский трафик как-то мог на него влиять.
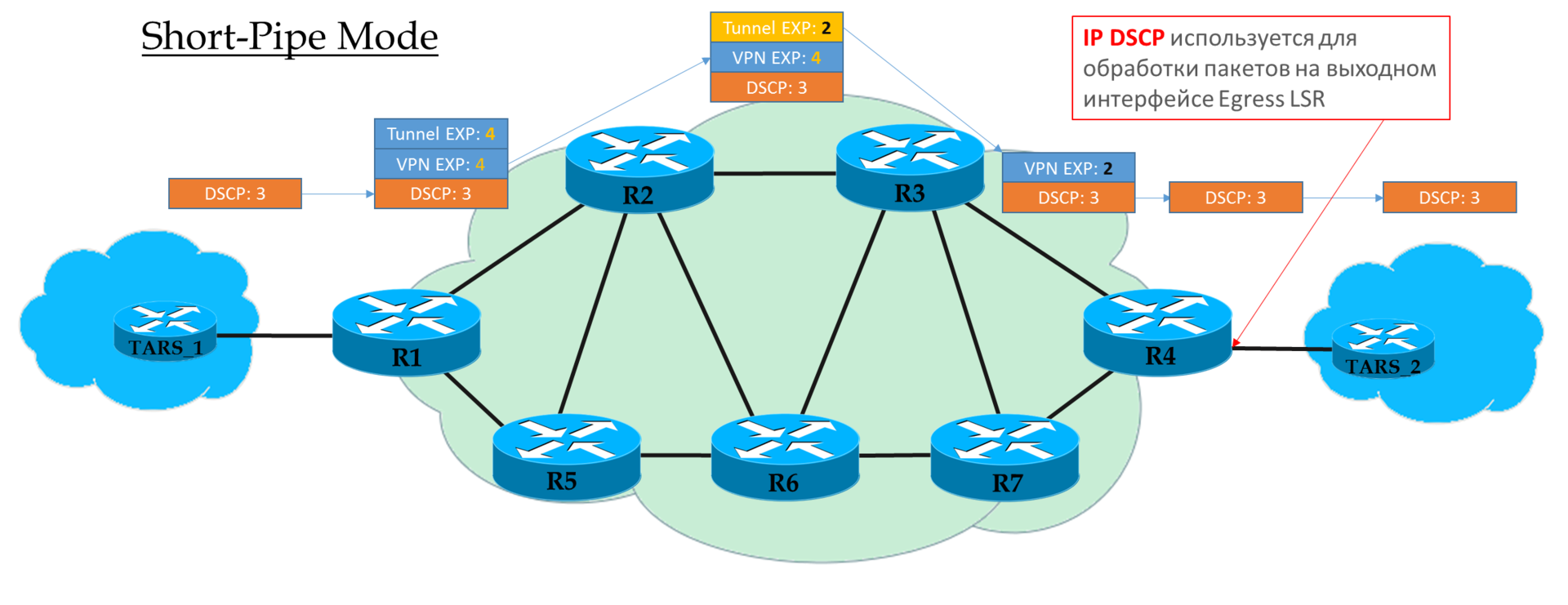
Этот режим вы можете рассматривать вариацией Pipe-mode. Разница лишь в том, что на выходе из MPLS-сети пакет обрабатывается в соответствие с его полем IP DSCP, а не MPLS EXP.
Это означает, что приоритет пакета на выходе определяется клиентом, а не оператором.
Ingress PE не доверяет IP DSCP входящих пакетов. Транзитные P смотрят в поле EXP верхнего заголовка. Предпоследний P снимает транспортную метку и копирует значение в VPN-метку.
Egress PE сначала снимает метку MPLS, потом обрабатывает пакет в очередях.
Объяснение от cisco.
В типичной операторской сети для масштабирования и снижения нагрузки сейчас разворачиваются L3/L2VPN на основе BGP с функцией Auto-Discovery и выделенными BGP Route Reflector.
Если в качестве транспорта используются LDP LSP, то туннели MPLS у нас автоматически образуют полносвязную топологию.
В таких условиях добавление нового PE требует настройки только этого нового PE и RR.
Однако ситуация совсем иная, если на транспорте RSVP-TE. Если узлов PE много, то может стать головной болью настроить туннели между всеми нужными парами маршрутизаторов.
Есть два подхода, которые позволяют избежать этого конфиграционного безумия.
Этот подход не требует нового функционала. Вводят иерархию — в неком неизменном ядре сети поднимается полносвязная система TE-туннелей между P-маршрутизаторами.
Делается это один раз и никогда уже не меняется.
А обычные PE маршрутизаторы друг к другу строят LDP LSP.

В стеке пакета MPLS, движущегося в ядре сети, получится три метки — VPN, LDP, RSVP-TE.
То есть LDP LSP, как бы туннелируются в RSVP LSP.

Иллюстрация с сайта www.nexthop.me
На, назовём это, сегменте доступа у нас удобный и уютный LDP, а в ядре сети (это может быть междугородней магистралью) при этом есть возможность управлять трафиком.
Это маленькая, но крайне полезная импрувизация, позволяющая автоматизировать настройку туннелей.
Как только в TEDB появляется новое PE-устройство, с ним моментально строятся прямые и обратные туннели.
Какая конфигурация применяется? Заранее создаётся шаблон настройки туннельного интерфейса.
Как узнать, что новый узел — это PE? В шаблоне указывается ACL, который определяет с кем можно строить.
Например, мы берём за правило, что у PE узлов интерфейс Loopback 127 будет 10.127.127.0/24, и анонсируем его в IGP.
Простейшая конфигурация будет выглядеть так:
Хотелось бы подвести краткий итог одной фразой: всё, что было описано в данной статье, в самом деле встречается на белом свете и вовсе не замки на песке.
Поэтому кратко повторим:
MPLS TE использует RSVP-TE, как протокол распределения меток и резервирования ресурсов. А тот в свою очередь опирается на LS IGP:
Управлять тем, как построится RSVP LSP, мы можем следующими способами:
IGP распространяет и заносит в TEDB информацию о:
При расчёте кратчайших маршрутов CSPF берёт требования из конфигурации TE-Туннеля, а ограничения из TEDB.
Требования туннеля:
RSVP-TE в своих сообщениях передаёт:
Направить трафик в туннель мы можем двумя основными способами:
Make-Before-Break:
Это широко используемая концепция в MPLS TE — сперва добейся! Прежде, чем сломать что-то, что уже работает, построй новый LSP.
Применяется при:
Shared Explicit или Fixed Filter:
Тесно связанные с MBB понятия.
Shared Explicit (SE) — два разных резервирования (LSP) для одного туннеля рассматриваются связанными и полоса полоскания не будет резервироваться дважды.
Fixed Filter (FF) — различные LSP от одного и того же отправителя всегда рассматриваются независимыми и полоса для них резервируются отдельно.
Режим SE очень удобен в механизме MBB, и зачастую в режиме FF отключаются вообще возможности FRR и переоптимизации.
Защита туннелей:
Приоритет туннелей:
Каждый туннель имеет два значения:
Обычно они равны.
0 — наивысший, 7 — низший.
Туннель с более высоким значением Setup Priority вытеснит установленный туннель с более низким Hold Priority.
Механизмы упрощения настройки:
Правила обработки полей CoS в MPLS DS-TE:
Все аббревиатуры, использованные в статье, вы можете найти в глоссарии linkmeup.
Благодарности
Андрею Глазкову, Александру Клипперу и Александру Фатину за вычитку материала и комментарии.
Артёму Чернобаю за иллюстрацию.
Моей жене и детям, что терпели лишения, но позволили закрыть тему MPLS.
Однако сеть linkmeup выросла до размеров федерального оператора. Возможность управления трафиком и быстрого восстановления сервисов стали очень важным требованием в MPLS-сети.
Пора внедрять Traffic Engineering.
Содержание выпуска:
- Предпосылки появления MPLS TE
- Принципы работы MPLS TE
- Способы направления трафика в TE-туннели
- Способы управления туннелями
- Метрики
- Ограничения по полосе пропускания
- Приоритеты туннелей
- Explicit-Path
- SRLG
- Affinity и Attribute-Flag
- Обеспечение надёжности и сходимость
- Path Protection
- Local Protection — Fast ReRoute
- MPLS QoS
- MPLS TE IntServ
- MPLS TE DiffServ
- Режимы работы MPLS QoS
- Упрощение настройки туннелей
- Заключение
- Полезные ссылки
Зачем вообще может понадобиться инжиниринг трафика?
Приведу простой пример.
Конвергентная сеть мобильного оператора.
Два типа трафика:
- Мобильный
- ШПД
Левое плечо — широкий оптический канал 10G. Правое — резерв через арендованную линию — 1G.
Общий объём трафика — 2,5 Гб/с, мобильного: 800 Мб/с.
В случае разрыва основного канала, нужно переключить на резервный только мобильный трафик и сделать это за 50мс.
Подумайте, можем ли мы сделать это стандартными средствами? Разделить трафик разных сервисов разными VPN, безусловно, можем, но направить разными маршрутами — нет.
Без использования ТЕ весь трафик перенаправится в правое плечо, а там, кто бы мог предположить, не хватает пропускной способности — начнутся отбрасывания.
Кроме того, скорость сходимости OSPF или ISIS даже при использовании BFD исчисляется десятками мс, но после этого ещё и транспортные LSP должны перестроиться. В наши дни это уже не пройдёт незамеченным для абонентов.
Принципы работы MPLS Traffic Engineering
Какие же функции по управлению трафиком предоставляет MPLS Traffic Engineering?
- Расширяет возможности стандартных IGP, позволяя маршрутизировать трафик разных классов разными способами.
- Передаёт трафик через сеть, используя коммутацию MPLS, что означает поддержку всяческих VPNов.
- При построении маршрута учитывает заданные ограничения, например, какие ресурсы необходимы этому классу трафика и сколько их доступно на всех узлах и линиях по пути, или по каким линиям нельзя строить туннели.
- Быстрое перестроение путей в соответствии с требованиями в случае аварии.
- Периодическая оптимизация путей.
Базовые механизмы работы MPLS TE были рассмотрены в выпуске СДСМ 10, куда я вас и шлю за подробным рассмотрением. А здесь приведу лишь короткую сводку.
Data Plane
С точки зрения передачи данных TE несколько отличается от LDP. Жирным выделены отличия:
- В TE-туннель трафик нужно поместить насильно, тогда как в LDP он попадает автоматически
Juniper здесь — исключение.
- Первый маршрутизатор навешивает внешнюю MPLS-метку (PUSH LABEL)
- Транзитные маршрутизаторы смотрят на какой интерфейс поступил пакет и значение метки и, поменяв её на новую согласно таблице меток, отправляют её в выходной интерфейс (SWAP LABEL)
- Предпоследний маршрутизатор снимает транспортную метку (POP LABEL, PHP — зависит от реализации и настроек)
- В случае обрыва на пути трафик можно спасти путём перенаправления пакетов в заранее подготовленный туннель.
Control Plane
А вот в плане управления отличия гораздо более значительные. C ними всю оставшуюся дорогу и будем разбираться.
Итак, MPLS TE хочет строить LSP с учётом требуемых ресурсов и пожеланий оператора, поэтому столь простой LDP с его лучшим маршрутом тут не у дел.Терминология
LSP — Label Switched Path — вообще говоря, любой путь через сеть MPLS, но порой подразумевают LDP LSP. Однако мы не будем столь категоричны — при необходимости я буду указывать, что имею в виду именно LDP LSP.
RSVP LSP — соответственно LSP, построенный с помощью RSVP TE с учётом наложенных ограничений. Может также иногда называться CR-LSP — ConstRaint-based LSP.
Туннелем мы будем называть один или несколько MPLS LSP, соединяющих два LSR-маршрутизатора. Метка MPLS — это по сути туннельная инкапсуляция.
В случае LDP — каждый LSP — это отдельный туннель.
В случае RSVP туннель может состоять из одного или нескольких LSP: основной, резервный, best-effort, временный.
Говоря TE-туннель, мы будем подразумевать уже конкретно MPLS Traffic Engineering туннель, построенный RSVP-TE.
TEDB — Traffic Engineering Data Base — тот же LSDB протоколов IS-IS/OSPF, но с учётом ресурсов сети, которые интересны модулю TE.
CSPF — Constrained Shortest Path First — расширение алгоритма SPF, которое ищет кратчайший путь с учётом наложенных ограничений.
И его место занимает RSVP-TE — наследник отвергнутого стеком TCP/IP протокола RSVP.
TE работает в тесном симбиозе с IGP. Хотя правильнее это называть паразитизмом. Он вынуждает их (OSPF или IS-IS) служить себе: переносить нужную ему информацию и тем самым наполнять TEDB.
Процесс выглядит следующим образом:
- IGP собирает со всей сети информацию:
— о линиях и сетях,
— о метриках,
— о доступных ресурсах,
— о характеристиках линий.
И заполняет TEDB, где всё это отражено.
- Когда RSVP-TE хочет построить LSP до какого-то узла, он просто обращается к CSPF и говорит: «Хочу кратчайший маршрут до точки G с вот этими ограничениями». Ограничения могут быть следующими:
— требуемая полоса пропускания,
— определённый путь или линии,
— характеристики линии.
- Из запроса RSVP-TE CSPF берёт ограничения, а из TEDB — реальную информацию о сети. И выдаёт маршрут… или не выдаёт, если ограничения удовлетворить не удалось.
- Когда маршрут получен, RSVP-TE отправляет RSVP PATH в эту точку G с запросом на резервирование ресурсов.
- А точка G возвращает RSVP RESV — так резервируются ресурсы на всём пути. И если RESV вернулся с хорошими новостями, RSVP LSP/туннель поднимается.
Всё это подробно и в красках в статье СДСМ10. А ещё там же самый простой пример на практике.
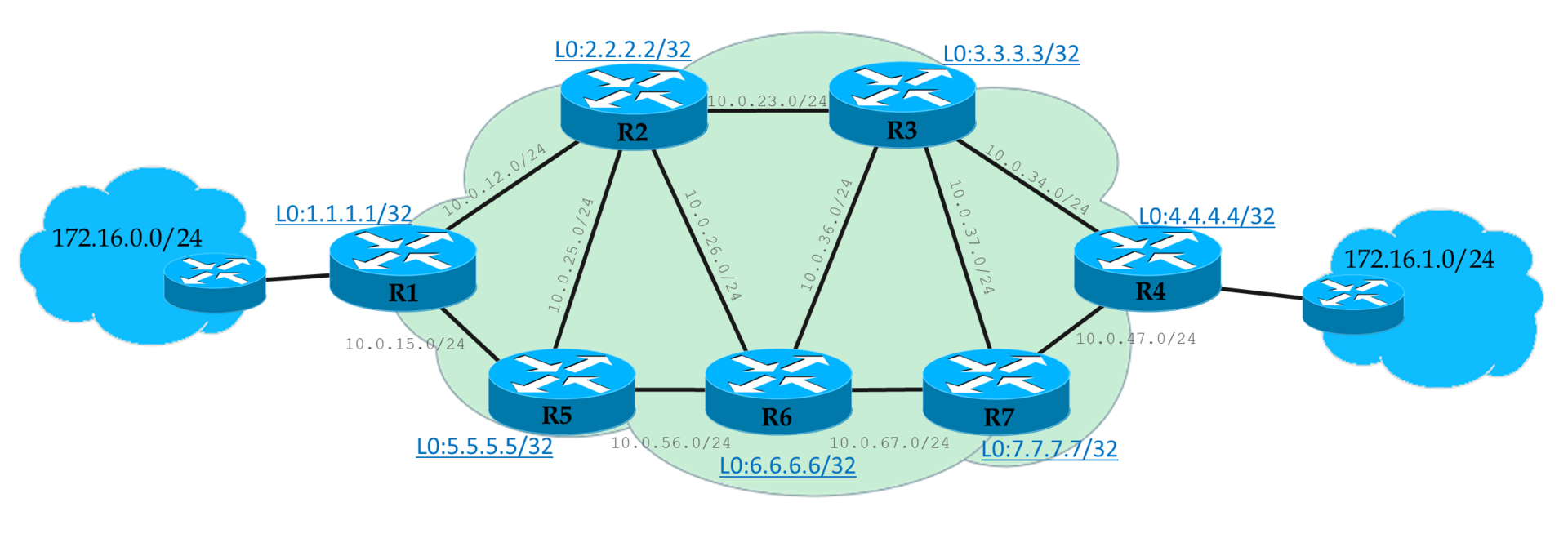
Далее мы будем ходить вокруг да около вот этой схемы:
У нас есть L3VPN-клиент, офисы которого подключены к Linkmeup_R1 и Linkmeup_R4.
Способы направления трафика в TE-туннель
В отличие от LDP LSP, по которым трафик бежит по умолчанию и так, в TE-туннели трафик нам нужно направить.
И есть для этого следующие способы:
- Статический маршрут
- PBR
- IGP Shortcut
- Tunnel-policy*
- Или всё-таки автоматом в туннель попадёт?*
Статический маршрут
Самый простой в понимании и самый сложный в обслуживании способ.
Linkmeup_R1(config) ip route 4.4.4.4 255.255.255.255 Tunnel 4PBR
По сути тот же статический маршрут.
Linkmeup_R1(config) ip access-list extended lennut
Linkmeup_R1(config-ext-nacl)) permit ip 172.16.0.0 0.0.0.255 172.16.1.0 0.0.0.255
Linkmeup_R1(config) route-map lennut permit 10
Linkmeup_R1(configconfig-route-map) match ip address lennut
Linkmeup_R1(config-route-map) set interface Tunnel4
Linkmeup_R1(config) interface Ethernet0/3
Linkmeup_R1(config-if) ip policy route-map lennutIGP Shortcut
Этот способ наиболее распространённый и поддерживается почти всеми производителями.
Маршрутизатор рассматривает туннель, как виртуальный интерфейс. И через этот интерфейс удалённые маршрутизаторы словно бы непосредственно подключены к локальному, а не находятся в десятках хопов. Этакая телекоммуникационная червоточина. Она и называется — shortcut — сокращённый путь.
Червоточина Фламма
Но протоколы IGP по умолчанию не хотят этого видеть и используют для отправки трафика физический интерфейс.
С помощью IGP Shortcut (в цисконародье AutoRoute Announce) мы вынуждаем протокол маршрутизации на Ingress LSR рассматривать туннель как обычную линию — Egress LSR будто бы подключен непосредственно. А соответственно и все сети, находящиеся за Egress LSR, будут доступны через туннель.
Таким образом всё, чьей точкой назначения является этот маршрутизатор, или узлы за ним, будет отправлено в туннель. В том числе и VPN-пакеты.
Таким образом туннель становится обычным интерфейсом, и, как у любого другого интерфейса у него должна быть метрика.
Метрика туннеля
Во-первых, есть два типа метрик:
Метрика IGP — хорошо известная нам из курса базовой маршрутизации метрика интерфейсов.
Метрика TE — та метрика, которая будет использована при расчёте метрики TE-туннеля.
- По умолчанию, TE=IGP.
- По умолчанию, используется TE.
- По умолчанию, метрика туннеля равна сумме TE-метрик всех линий от Ingress до Egress по кратчайшему IP-пути (а не по тому, по которому туннель идёт). То есть метрики обычных IP-маршрутов и маршрутов через туннель будут одинаковыми, даже если туннель фактически намного длиннее.
Почему выбирается по кратчайшему пути? Логично, чтобы метрика туннеля должна перебить метрику лучшего IP-пути. - При равенстве метрик маршрутизатор выберет именно туннель, поскольку IGP shortcut именно это и подразумевает.
Если есть IP-пути, которые не имеют общих сегментов с туннельным LSP, и при этом их метрики равны, будет иметь место балансировка.
Во-вторых, у нас есть следующие способы управления метрикой туннеля:
- Изменить значение метрики TE на физических интерфейсах.
- Указать MPLS TE использовать IGP метрику вместо TE.
- Соответственно, изменить IGP метрику физического интерфейса.
- Настроить непосредственно метрику туннельного интерфейса:
Вот человек очень доступно объясняет, как работают метрики.Ну и вообще рекомендую ресурс: labminutes.com/video/sp
Forwarding adjacencies
Forwarding adjacencies — штука сходной c IGP Shortcut природы с той лишь (существенной) разницей, что туннель теперь будет анонсироваться Ingress LSR IGP-соседям, как обычный линк. Соответственно, все окружающие маршрутизаторы будут учитывать его в своих расчётах SPF.
IGP Shortcut же влияет только на таблицу маршрутизации на Ingress LSR, и окружающие соседи про этот туннель не знают.
Tunnel-policy*
*Этот способ зависит от производителя — у кого-то есть, у кого-то нет.
Tunnel-policy применяется для перенаправления исключительно трафика VPN в туннели.
То есть в режиме настройки VPN (не важно, L2 или L3) указывается какой туннель должен быть использован.
Существует две возможности:
- Tunnel binding mode. В зависимости от Egress PE выбирать конкретный туннель. Применимо только к RSVP LSP.
- Select-Seq mode. Тунель будет выбираться в порядке, указанном в конфигурации. Это может быть TE-туннель, LDP-туннель, с балансировкой или без.
Особенности Juniper
У джуна зачастую свой подход (ещё сегодня в этом убедитесь). Так у него существует несколько таблиц маршрутизации:
- IP routing table (inet.0)
- MPLS routing table (inet.3)
- MPLS forwarding table (mpls.0).
При помещении VPN-маршрутов в таблицу IP-маршрутизации BGP сверяется с таблицей MPLS inet.3. Если в ней он находит LSP до Next Hop'а маршрутра VPN, то автоматически трафик загоняется в этот LSP. Никаких дополнительных действий не требуется.
Это в некотором смысле похоже на микс Tunnel-Policy и IGP Shortcut, только автоматически.
Практика
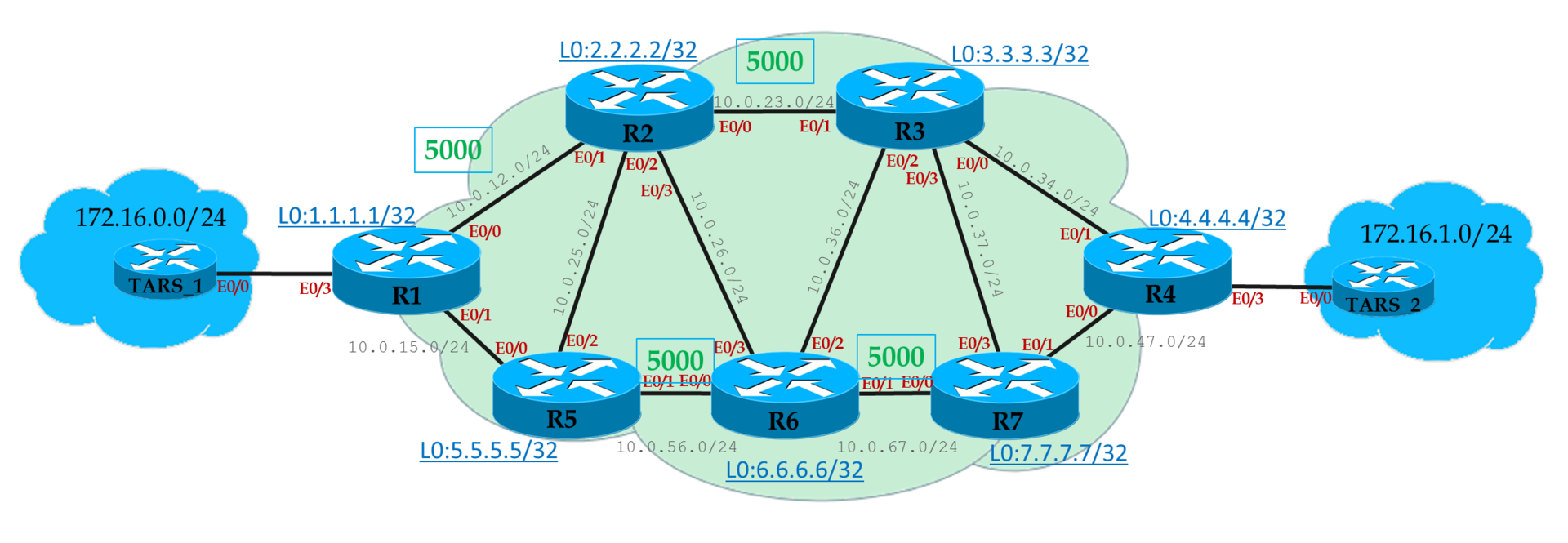
Всё та же сеть, но с ограничениями по пропускной способности.
Нам нужно обеспечить L3VPN клиенту.
У клиента есть требования: 8 Мб/с. Вынь да положь.
Направляем трафик в туннель через Auto-Route.
В лаборатории ограничение интерфейса — 10000 кб/с. Поэтому при задании требований туннеля и доступных полос, отталкиваемся исключительно от этой цифры.Поехали!
Итак, начнём с того, что никакого LDP — только RSVP-TE. То есть LSP нет, пока мы не настроим туннель.
Хоть мы всё это уже и делали в прошлый раз, но начнём настройку сначала.
- Базовая конфигурация уже имеется (IP+IGP)
Файл конфигурации.
- Включаем возможности TE
Linkmeup_R1(config) mpls traffic-eng tunnels
И заодно на всех интерфейсах сразу настроим ограничение по полосе пропускания
Router(config-if) ip rsvp bandwidth значение_ограничения
При указании требования по полосе для туннеля данная команда является обязательной — полосу нужно задать явно, иначе IGP эту информацию не анонсирует, а CSPF соответственно не будет учитывать эту линию и не вычислит путь под требования туннеля.
На схеме выше я обозначил, какие из интерфейсов имеют ограничение в 5Мб/с. Если не подписано, то ограничения нет — ставим 10.
Следует всегда помнить, что это только референсное значение для расчёта пути TE, и фактически команда никак не ограничивает реальную скорость TE-трафика, через интерфейс.
Linkmeup_R1(config) interface FastEthernet 0/0 Linkmeup_R1(config-if) mpls traffic-eng tunnels Linkmeup_R1(config-if) ip rsvp bandwidth 5000 Linkmeup_R1(config) interface FastEthernet 0/1 Linkmeup_R1(config-if) mpls traffic-eng tunnels Linkmeup_R1(config-if) ip rsvp bandwidth 10000
Обратите внимание, что команда ip rsvp bandwidth указывает полосу только в одном направлении. То есть если мы настроили её на интерфейсе E0/0 в сторону Linkmeup_R2, то это означает, что в 5Мб/с ограничена полоса только для исходящего трафика.
Чтобы ограничить в другую сторону, нужно настроить интерфейс E0/1 со стороны Linkmeup_R2.
Конфигурация других узлов
Linkmeup_R2(config) mpls traffic-eng tunnels Linkmeup_R2(config) interface FastEthernet 0/0 Linkmeup_R2(config-if) mpls traffic-eng tunnels Linkmeup_R2(config-if) ip rsvp bandwidth 5000 Linkmeup_R2(config) interface FastEthernet 0/1 Linkmeup_R2(config-if) mpls traffic-eng tunnels Linkmeup_R2(config-if) ip rsvp bandwidth 10000 Linkmeup_R2(config) interface FastEthernet 0/2 Linkmeup_R2(config-if) mpls traffic-eng tunnels Linkmeup_R2(config-if) ip rsvp bandwidth 10000 Linkmeup_R2(config) interface FastEthernet 0/3 Linkmeup_R2(config-if) mpls traffic-eng tunnels Linkmeup_R2(config-if) ip rsvp bandwidth 10000 <hr> Linkmeup_R3(config) mpls traffic-eng tunnels Linkmeup_R3(config) interface FastEthernet 0/0 Linkmeup_R3(config-if) mpls traffic-eng tunnels Linkmeup_R3(config-if) ip rsvp bandwidth 10000 Linkmeup_R3(config) interface FastEthernet 0/1 Linkmeup_R3(config-if) mpls traffic-eng tunnels Linkmeup_R3(config-if) ip rsvp bandwidth 10000 Linkmeup_R3(config) interface FastEthernet 0/2 Linkmeup_R3(config-if) mpls traffic-eng tunnels Linkmeup_R3(config-if) ip rsvp bandwidth 10000 Linkmeup_R3(config) interface FastEthernet 0/3 Linkmeup_R3(config-if) mpls traffic-eng tunnels Linkmeup_R3(config-if) ip rsvp bandwidth 10000 <hr> Linkmeup_R4(config) mpls traffic-eng tunnels Linkmeup_R4(config) interface FastEthernet 0/0 Linkmeup_R4(config-if) mpls traffic-eng tunnels Linkmeup_R4(config-if) ip rsvp bandwidth 10000 Linkmeup_R4(config) interface FastEthernet 0/1 Linkmeup_R4(config-if) mpls traffic-eng tunnels Linkmeup_R4(config-if) ip rsvp bandwidth 10000 <hr> Linkmeup_R5(config) mpls traffic-eng tunnels Linkmeup_R5(config) interface FastEthernet 0/0 Linkmeup_R5(config-if) mpls traffic-eng tunnels Linkmeup_R5(config-if) ip rsvp bandwidth 10000 Linkmeup_R5(config) interface FastEthernet 0/1 Linkmeup_R5(config-if) mpls traffic-eng tunnels Linkmeup_R5(config-if) ip rsvp bandwidth 5000 Linkmeup_R5(config) interface FastEthernet 0/2 Linkmeup_R5(config-if) mpls traffic-eng tunnels Linkmeup_R5(config-if) ip rsvp bandwidth 10000 Linkmeup_R5(config) interface FastEthernet 0/3 Linkmeup_R5(config-if) mpls traffic-eng tunnels Linkmeup_R5(config-if) ip rsvp bandwidth 10000 <hr> Linkmeup_R6(config) mpls traffic-eng tunnels Linkmeup_R6(config) interface FastEthernet 0/0 Linkmeup_R6(config-if) mpls traffic-eng tunnels Linkmeup_R6(config-if) ip rsvp bandwidth 10000 Linkmeup_R6(config) interface FastEthernet 0/1 Linkmeup_R6(config-if) mpls traffic-eng tunnels Linkmeup_R6(config-if) ip rsvp bandwidth 10000 Linkmeup_R6(config) interface FastEthernet 0/2 Linkmeup_R6(config-if) mpls traffic-eng tunnels Linkmeup_R6(config-if) ip rsvp bandwidth 10000 Linkmeup_R6(config) interface FastEthernet 0/3 Linkmeup_R6(config-if) mpls traffic-eng tunnels Linkmeup_R6(config-if) ip rsvp bandwidth 10000 <hr> Linkmeup_R7(config) mpls traffic-eng tunnels Linkmeup_R7(config) interface FastEthernet 0/0 Linkmeup_R7(config-if) mpls traffic-eng tunnels Linkmeup_R7(config-if) ip rsvp bandwidth 10000 Linkmeup_R7(config) interface FastEthernet 0/1 Linkmeup_R7(config-if) mpls traffic-eng tunnels Linkmeup_R7(config-if) ip rsvp bandwidth 10000 Linkmeup_R7(config) interface FastEthernet 0/3 Linkmeup_R7(config-if) mpls traffic-eng tunnels Linkmeup_R7(config-if) ip rsvp bandwidth 10000
- Настраиваем IS-IS на возможность сбора и передачи TE данных
Linkmeup_R1(config) router isis Linkmeup_R1(config-router) metric-style wide Linkmeup_R1(config-router) mpls traffic-eng router-id Loopback0 Linkmeup_R1(config-router) mpls traffic-eng level-1
Команда metric-style wide — обязательна, напоминаю. Дело в том, что TE использует новые TLV с расширенными метками, а по умолчанию ISIS генерирует только короткие.
Поскольку конфигурация полностью одинаковая, для других узлов не привожу.
- Настраиваем TE-туннель.
Linkmeup_R1(config) interface Tunnel4 Linkmeup_R1(config-if) description To Linkmeup_R4 Linkmeup_R1(config-if) ip unnumbered Loopback0 Linkmeup_R1(config-if) tunnel mode mpls traffic-eng Linkmeup_R1(config-if) tunnel destination 4.4.4.4 Linkmeup_R1(config-if) tunnel mpls traffic-eng bandwidth 8000 Linkmeup_R1(config-if) tunnel mpls traffic-eng path-option 1 dynamic
Здесь мы указали, что туннель строим до узла 4.4.4.4, требуется 8 Мб/с, а LSP строится динамически (без Explicit-Path)
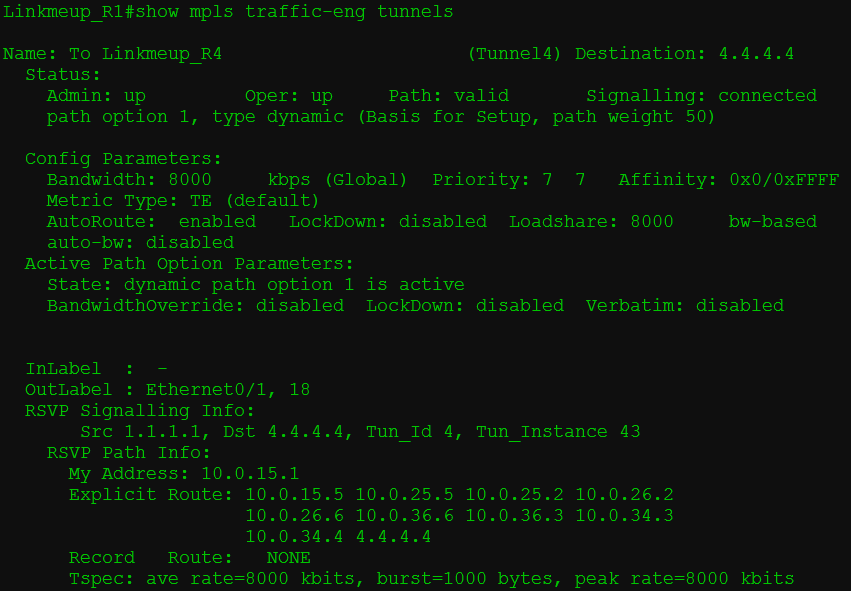
Сразу после этого видим, что туннель поднялся.

То есть CSPF рассчитал маршрут с учётом нашего ограничения, RSVP PATH успешно сигнализировал путь, а RSVP RESV зарезервировал ресурсы на всём пути.
Трассировка показывает, что путь проложен ровно так, как мы этого хотели.
То же самое на обратной стороне:

А в сообщении RSVP PATH можно увидеть, что он несёт информацию о требуемой полосе.
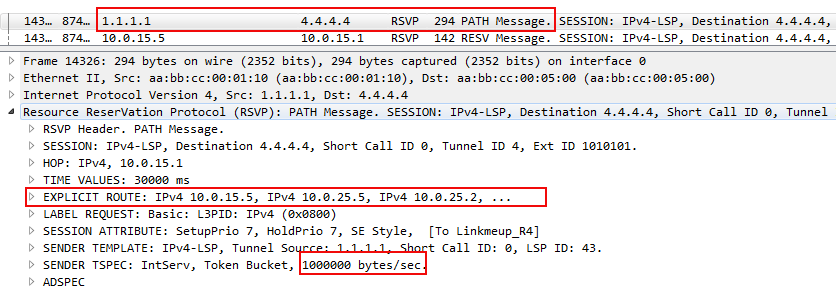
В дампе вы можете видеть начало объекта ERO с перечислением всех узлов по пути будущего RSVP LSP и запрос резервирования полосы пропускания.
Здесь стоит 1000000 Байтов в секунду или ровно 8 Мегабит в секунду (если мы не путаем Мега с Меби). Величина эта дискретная и меняется с некоторым шагом. В случае данной лабы — это 250 кб/с.
Можете поиграться с параметрами и увидеть, как туннель реагирует на изменения в сети.
Linkmeup_R4(config) interface Tunnel1 Linkmeup_R4(config-if) description To Linkmeup_R1 Linkmeup_R4(config-if) ip unnumbered Loopback0 Linkmeup_R4(config-if) tunnel mode mpls traffic-eng Linkmeup_R4(config-if) tunnel destination 1.1.1.1 Linkmeup_R4(config-if) tunnel mpls traffic-eng bandwidth 8000 Linkmeup_R4(config-if) tunnel mpls traffic-eng path-option 1 dynamic
- Создаём VPN (см. как)
Linkmeup_R1(config) ip vrf TARS Linkmeup_R1(config-vrf) rd 64500:200 Linkmeup_R1(config-vrf) route-target export 64500:200 Linkmeup_R1(config-vrf) route-target import 64500:200 Linkmeup_R1(config-vrf) interface Ethernet0/3 Linkmeup_R1(config-if) description To TARS_1 Linkmeup_R1(config-if) ip vrf forwarding TARS Linkmeup_R1(config-if) ip address 172.16.0.1 255.255.255.0 Linkmeup_R1(config-if) router bgp 64500 Linkmeup_R1(config-router) neighbor 4.4.4.4 remote-as 64500 Linkmeup_R1(config-router) neighbor 4.4.4.4 update-source Loopback0 Linkmeup_R1(config-router) address-family vpnv4 Linkmeup_R1(config-router-af) neighbor 4.4.4.4 activate Linkmeup_R1(config-router-af) neighbor 4.4.4.4 send-community both Linkmeup_R1(config-router) address-family ipv4 vrf TARS Linkmeup_R1(config-router-af) redistribute connected
Настройка на Linkmeup_R4
Linkmeup_R4(config) ip vrf TARS Linkmeup_R4(config-vrf) rd 64500:200 Linkmeup_R4(config-vrf) route-target export 64500:200 Linkmeup_R4(config-vrf) route-target import 64500:200 Linkmeup_R4(config-vrf) interface Ethernet0/3 Linkmeup_R4(config-if) description To TARS_2 Linkmeup_R4(config-if) ip vrf forwarding TARS Linkmeup_R4(config-if) ip address 172.16.1.1 255.255.255.0 Linkmeup_R4(config-if) mpls traffic-eng tunnels Linkmeup_R4(config-if) router bgp 64500 Linkmeup_R4(config-router) neighbor 1.1.1.1 remote-as 64500 Linkmeup_R4(config-router) address-family vpnv4 Linkmeup_R4(config-router-af) neighbor 1.1.1.1 activate Linkmeup_R4(config-router-af) neighbor 1.1.1.1 send-community both Linkmeup_R4(config-router-af) address-family ipv4 vrf TARS
Если сейчас попробуем пропинговать, то облом — ничего не будет.
Обратите внимание, что BGP распространил маршруты VPN вместе с их метками, но нет передачи данных.
Это потому, что пока нет привязки к транспортному LSP, а без этого нет никакого смысла и в метках VPN.
- Направляем в него трафик через IGP Shortcut.
Для этого достаточно одной команды на обоих PE:
Linkmeup_R1(config) interface Tunnel4 Linkmeup_R1(config-if) tunnel mpls traffic-eng autoroute announce
Linkmeup_R4(config) interface Tunnel1 Linkmeup_R4(config-if) tunnel mpls traffic-eng autoroute announce
При необходимости можно также настроить метрику туннельного интерфейса:
Linkmeup_R1(config-if) tunnel mpls traffic-eng autoroute metric relative -5
Linkmeup_R4(config-if) tunnel mpls traffic-eng autoroute metric relative -5



- Есть пинг, есть счастье!

Итак, что произошло?
- Сначала мы настроили базовую поддержку TE,
а) Включили поддержку TE в глобальном режиме,
б) Включили функцию TE на магистральных интерфейсах,
г) Указали доступную пропускную способность физических интерфейсов,
д) Заставили IGP анонсировать данные TE.
На этом шаге IGP уже составил TEDB.
- Создали туннель (прямой и обратный):
а) Указали точку назначения,
б) Режим работы — TE,
в) Указали требуемую полосу,
г) Разрешили строить LSP динамически.
На этом шаге сначала CSPF вычисляет список узлов, через которые нужно проложить LSP. Выхлоп этого процесса помещается в объект ERO. потом RSVP-TE с помощью сообщений PATH и RESV резервирует ресурсы и строит LSP.
Но этого ещё недостаточно для практического использования туннеля.
- Настроили L3VPN (см. как).
Когда MP-BGP обменялся маршрутными данными VRF, Next Hop'ом для этих маршрутов стал Loopback адрес удалённого PE.
Однако маршруты из таблицы BGP не инсталлируются в таблицу маршрутизации данного VRF, поскольку трафик в LSP мы пока не запустили.
- Заставили IGP рассматривать TE-туннель, как возможный выходной интерфейс.
Это не влечёт никаких изменений в других частях сети — исключительно локальное действие — IGP только меняет таблицу маршрутизации этого узла.
Теперь LoopBack удалённого PE стал доступен через туннель, а маршруты добавились в таблицу маршрутизации VRF.
То есть когда IP-пакет приходит от клиента,
а) он получает метку VPN (16).
б) из FIB VRF TARS ему известно, что для данного префикса пакет должен быть отправлен на адрес 4.4.4.4
в) До 4.4.4.4 есть TE-туннель (Tunnel 4) и известна его пара выходной интерфейс/метка — Ethernet0/1, 18 — она будет транспортной.
На этой иллюстрации решительно нечего выделить — всё абсолютно прекрасно — вся информация о TE-туннеле в одной команде.

Сейчас путь от R1 до R4 выглядит так: R1->R5->R2->R6->R3->R4 — всё из-за этих чёртовых ограничений.
Теперь начинаем баловаться.
Попробуем разорвать наш рабочий линк R3->R4, пока длится непрерывный пинг.
LSP перестроился на R1->R5->R2->R6->R3->R7->R4 с потерей одного пакета. Это время может значительно увеличиться, если физического падения линии не будет на маршрутизаторах.
Что при этом происходило?Если у нас не останется путей, удовлетворяющих заданным условиям — беда — LSP не будет.
- Сначала R1 через сообщение RSVP PATH ERROR узнал о том, что линия испорчена.
- R1 отправил RSVP PATH TEAR по направлению к 4.4.4.4, а обратно идущий RSVP RESV TEAR удалил LSP.
- Тем временем на R1 CSPF рассчитал новый маршрут в обход сломанного линка.
- Потом RSVP-TE сигнализировал новый LSP R1->R5->R2->R6->R3->R7->R4

Например, выключим линию R2-R5 и наблюдаем падения TE-туннеля на R1 без его дальнейшего восстановления.
Переоптимизация туннелей
Если линк R3->R4 восстановится, туннель перестроится обратно?
Да. Но не скоро. Пролетит много пакетов, прежде чем Ingress PE шевельнёт своим RSVP. (На самом деле зависит от производителя)
Это называется переоптимизацией туннелей (Tunnel reoptimization). С некоторой периодичностью Ingress PE заставляет CSPF проверить, а не появилось ли более оптимальных маршрутов.
- CSPF находит новый путь, удовлетворяющий всем условиям. В нашем случае R1->R5->R2->R6->R3->R4.
- Ingress PE сигнализирует новый RSVP LSP, отправляя RSVP PATH.
- Получив RSVP RESV, он понимает, что новый LSP готов.
- Отправляет RSVP PATH TEAR, чтобы сломать старый LSP.
- Когда RSVP RESV TEAR возвращается — всё закончено.
То есть сначала он строит новый RSVP LSP, пускает туда трафик и только потом ломает старый. Этот механизм называется Make-Before-Break, о котором в конце.
Способы управления туннелями
Итак, у нас достаточно способов, как повлиять на путь трафика с помощью TE:
- Метрика пути MPLS TE
- Ограничение по полосе пропускания
- Explicit-Path
- SRLG
- Administrative Groups/Affinity
Метрика пути MPLS TE
Первый самый очевидный способ — это метрики интерфейсов.
Как мы помним есть IGP-метрики, а есть TE-метрики. Вторые по умолчанию равны первым.
TE-метрика на линковых интерфейсах не только влияет на метрику туннеля с точки зрения IGP Shortcut, но и учитывается при построении LSP.
Для чего может понадобиться настраивать TE-метрику отличной от IGP?Используется для этого команда
Например, есть линия с высоким значением задержки. Ей задаём бОльшее значение TE-метрики.
Тогда:
При построении туннелей для голосового трафика будем использовать TE-метрику,
В туннелях для прочих данных — IGP.
Router(config-if) mpls traffic-eng administrative-weight значение TE-метрикиЧтобы указать туннелю, какую учитывать метрику:
Значение по умолчанию:
Router(config) mpls traffic-eng path-selection metric {igp | te}Конкретный туннель:
Router(config-if) tunnel mpls traffic-eng path-selection metric {igp | te}Cisco подробно про метрики.
Ограничение по полосе пропускания
На практике мы познакомились с базовой функцией TE — возможностью строить MPLS туннели с резервированием ресурсов на всём протяжении LSP.
Но не беспокоит ли вас вот эта идея с Bandwidth? Не возвращаемся ли мы в каменный век, когда не было переподписки. Да и как вообще определять величину этого ограничения? А что делать с тем, что она плавает в течение суток на порядки?
Offline Bandwidth
Метод, когда мы настраиваем статическое значение требуемой полосы, называется Offline Bandwidth.
Идея в том, что есть некая программа стоимостью в трёшку на Патриарших прудах, которая по каким-то алгоритмам вычисляет для вашего трафика одну цифру, которую вам и нужно настроить на туннеле.
Полосу можно настроить для всего туннеля, как мы делали это выше на практике:
Router(config-if) tunnel mpls traffic-eng bandwidth значение требуемой полосыА можно для конкретного RSVP LSP:
Router(config-if) tunnel mpls traffic-eng path-option 1 dynamic bandwidth значение требуемой полосыЭто значение может отличаться от того, что указано для туннеля и имеет более высокий приоритет.
При этом для другого LSP (path-option 2, например), значение может отличаться — мол, если уж не получается зарезервировать 8 Мб/с, давай хотя бы 5 попробуем?
У Offline Bandwidth есть два существенных минуса:
— Ручная работа, которой хороший инженер старается избегать.
— Неоптимальное использование ресурсов. Ну, назначим мы полосу в 300 Мб/с клиенту, зарезервируем на каждой линии, а на деле ему надо-то от силы 30. И только в пике, когда у него бэкапятся БД, нужно 300. Неаккуратненько.
Этот вариант практиковался на заре появления TE. Существует он и сейчас.
Однако, следуя в ногу со временем, нужно быть более гибким и податливым.
Auto-Bandwidth
А Autobandwidth молодец.
Этот механизм отслеживает загрузку туннеля в течение определённого периода и потом адаптирует резервирование.
Ближе к телу.Терминология
Adjust Interval — время, в течение которого маршрутизатор наблюдает за трафиком и отслеживает пики.
Adjust Threshold — порог, после которого RSVP перезапрашивает резервирование.
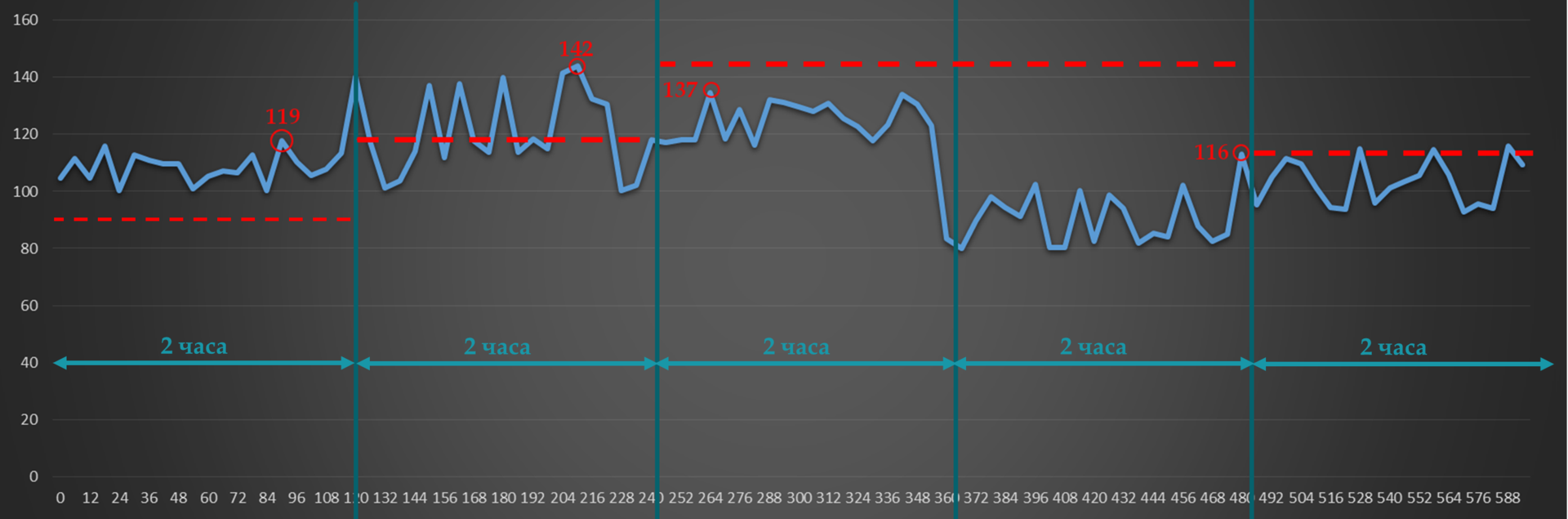
Например, Adjust Interval у нас 2 часа. Текущее значение зарезервированной полосы пропускания — 90 Мб/с.
Adjust Threshold — 20 Мб/с.
В первом интервале всплеск 119 Мб/с (до 119 Мб/с) — больше порога. Значит RSVP-TE пытается построить новый туннель с новыми значениями для полосы пропускания.
Во втором — 23Мб/с (до 142) — опять больше порога. Обновляем резервирование по возможности.
В третьем максимальное значение падает до 137 Мб/с — разница только 5. Ничего не происходит.
В четвёртом всплеск падает до 116 (разница 21) — RSVP сигнализирует новый LSP с пониженными требованиями по полосе.
Так, каждые два часа будет происходить проверка и, возможно, перестроение туннелей.
Чем короче Adjust Interval, тем, соответственно, чаще будет обновляться резервирование и более рационально использоваться доступная полоса пропускания.
Примерно так при двухчасовом интервале будет выглядеть 24-часовое поведение auto-bandwidth.
Уже заметили проблему?
Возьмём типичный профиль утреннего трафика:
И такая дребедень целый день.
Вот измерили мы в 8 утра всплеск — 200 Мб/с. И два часа держится это значение для туннеля. А за это время на работу уже пришёл народ и запустил ютуб — средняя скорость уже 240, а всплески до 300. До 10 утра будет происходить тихая деградация. Тихая, потому что ни туннель, ни Auto-Bandwidth о ней не знают. А вот пользователи знают и их ИТшник тоже знает, уж поверьте.
Если же сильно уменьшать интервал юстировки, то на сети будут постоянно пересигналзироваться новые LSP.
Для решения этой и других проблем существуют механизмы Overflow и Underflow. Первый — для слежения за ростом трафика, второй — за снижением.
Если разница между текущим резервированием и всплесками трафика превосходит порог Overflow несколько раз подряд, RSVP TE будет пробовать построить новый LSP, не дожидаясь истечения Adjust Interval.
То же и для Underflow — RSVP-TE будет пересегнализировать LSP с более низкими требованиями, если заметил тенденцию к уменьшению объёма трафика.
И остаётся только одна, но серьёзная проблема.
Так уж устроен наш мир, что когда растёт трафик у одного абонента, обычно растёт и у другого. И может так статься, что когда придёт время снова увеличить резервирование, увеличить его будет уже некуда — всё занято. И тогда, если нет других путей, удовлетворяющих новым условиям, будет использоваться старый. И никому не будет дела до того, что его уже не хватает, что пакеты начали теряться, что клиент ищет номер директора, чтобы найти инженера, которому можно оторвать что-нибудь лишнее.
Мы с этим будем бороться с помощью приоритезации туннелей, о которой ниже.
Для включения функции AutoBandwidth глобально и одновременно настройки Adjust Interval:
Router(config) mpls traffic-eng auto-bw timers frequency [sec]Далее для каждого туннеля отдельно нужно активировать AutoBandwidth. При этом можно задать другое значение для Adjust Interval, а также установить минимально и максимально возможные значения для резервируемой полосы.
Router(config) tunnel mpls traffic-eng auto-bw max-bw Значение min-bw ЗначениеДля настройки Overflow:
Router(config) tunnel mpls traffic-eng auto-bw [overflow-limit количество раз overflow-threshold Процент изменения]Подробнее о Auto-Bandwidth можно почитать в очень честном документе.
Приоритеты туннелей
Это механизм, который приоритезирует туннели: какой из них важнее. Он применим, как для случая Auto-Bandwidth в частности, так и для любого построения RSVP LSP вообще.
Всё предельно логично:
Setup Priority — приоритет установки RSVP LSP.
Hold Priority — приоритет удержания RSVP LSP.
Если полосы пропускания не хватает на узле, и у нового туннеля приоритет установки выше, чем приоритет удержания у старого, новый будет построен — старый сломан.
Оба имеют 8 значений: от 0 до 7. Для обоих 0 — это наивысший, 7 — наинизший.
Например, у нас есть туннель LSP1, у которого Hold priority 4.
Тут приходит запрос от RSVP-TE на LSP2 с Setup Priority 6 и Hold Priority тоже 6. Если полосы пропускания достаточно, то он просто построится. Если нет — то маршрутизатор не даст этого сделать — потому что уже существующий туннель приоритетнее нового (4>6).
Допустим, полосы достаточно и оба туннеля поднялись нормально.
И тут приходит новый запрос на LSP3 с Setup/Hold Priority 5. Это выше, чем у LSP2, но ниже, чем у LSP1. И ему полосы уже не хватает. LSP1 точно не будет тронут, потому что его Hold приоритет до сих пор самый высокий. И тогда есть два варианта:
- Если сломать LSP2, полосы хватает для LSP3. В этом случае Setup приоритет LSP3 выше, чем Hold LSP2. Ingress PE LSP2 узнаёт, что его LSP вероломно разломали и будет искать новый путь — его удача, если он найдёт.
- Если сломать LSP2, полосы всё равно не хватит для LSP3. LSP1 маршрутизатор не отдаст. И тогда LSP1 и LSP2 остаются, а Ingress PE LSP3 будет искать другие возможности для самореализации.
Касательно значений — обычно выбираются одинаковые для Setup и Hold. И не стоит настраивать Hold ниже, чем Setup. Во-первых это не логично. Во-вторых, может случиться ситуация, когда два туннеля войдут в петлю, когда они будут постоянно перебарывать друг друга — как только установится один, второй его сломает и построится сам, потом первый сломает второй итд.
Существует два режима замещения туннелей:
Hard preemption — LSP с более высоким приоритетом просто замещает LSP с низким. Даже если потом LSP с низким приоритетом найдёт новый путь, часть трафика будет потеряна.
Soft preemption — применяется механизм Make-Before-Break. Маршрутизатор через RSVP-TE сообщает Ingress LSR низкоприоритетного LSP, что нужно искать новый путь. LSP с высоким приоритетом ожидает, пока трафик низкоприоритетного LSP переключится на новый LSP.
При этом, если путь найти не удалось в течение некоторого времени, низкоприоритетный LSP всё равно ломается и строится высокоприоритетный.
Данные о приоритетах замещения передаются в RSVP-TE PATH и учитываются при резервировании ресурсов на промежуточных узлах.
Практика
Если вы обратили внимание, то после настройки tunnel mpls traffic-eng badnwidth на туннельном интерфейсе, в конфигурации автоматически появляется строка tunnel mpls traffic-eng priority 7 7.
Дело в том, что без требований по полосе приоритеты не имеют никакого значения — через один узел можно проложить сколько угодно туннелей — ведь полоса не резервируется — и команды нет.
Но, как только появилось требование, по полосе, приоритеты начинают играть роль.
7 — это значение по умолчанию — наименьшее.
Давайте на Linkmeup_R1 настроим новый туннель до 4.4.4.4 с более высоким приоритетом?
Linkmeup_R1(config) interface Tunnel42
Linkmeup_R1(config-if) ip unnumbered Loopback0
Linkmeup_R1(config-if) tunnel mode mpls traffic-eng
Linkmeup_R1(config-if) tunnel destination 4.4.4.4
Linkmeup_R1(config-if) tunnel mpls traffic-eng priority 4 4
Linkmeup_R1(config-if) tunnel mpls traffic-eng bandwidth 4000
Linkmeup_R1(config-if) tunnel mpls traffic-eng path-option 1 dynamicНеобходимая полоса всего 4Мб/с. Поэтому туннель должен пройти по пути R1->R2->R3->R4.
Так и есть, вот его трассировка:
С Tunnel4 у них только один общий линк R3->R4, но его полоса пропускания только 10. А двум туннелям нужно 8+4=12.
Tunnel42 с приоритетом установки 4 выдавливает Tunnel4 с приоритетом удержания 7.
И тому приходится искать новый путь.
И он находится:
Сначала удаляется старый RSVP LSP Tunnel4 и сигнализируется новый по доступному пути
Потом RSVP-TE сигнализирует LSP для Tunnel42.
В этот момент вернёмся к Autobandwidth. Именно связка Tunnel priority + Autobandwidth даёт элегантное решение.
Одним ранним утром было трафика мало, autobandwidth подсчитал сколько именно его в каждом туннеле, и TE везде хватило пропускной способности.
Потом ближе к обеду трафик подрос, autobandwidth адаптировался, перерезервировал новые полосы — всё ещё хватает.
К вечеру один за другим туннели начинают вылетать, потому что TE не может зарезервировать новую полосу.
И тут важно, чтобы туннели жирных клиентов, IP-телефонии и канал для МВД никогда не падали. Тогда задаём для этих туннелей Hold priority выше, чем Setup priority других.
— При попытке низкоприоритетных зарезервировать новую полосу на интерфейсе, где её уже не хватает, он обломится.
— Высокоприоритетный наоборот вытеснит низкоприоритетный и займёт освободившуюся полосу.
Получается, что
- без Autobandwidth мы либо настраиваем требования полосы вручную на всей сети, либо вообще не делаем этого, пуская на самотёк,
- без Autobandwidth мы никогда не знаем, сколько реально трафика в туннеле,
- без Autobandwidth мы никак не можем его ограничить,
- без Tunnel priority мы не можем сказать наверняка, какие туннели пострадают.
Explicit-Path
Идея Explicit-Path более чем полно была раскрыта в 10-м выпуске СДСМ.
Как вы помните, CSPF вычисляет кратчайший путь с учётом ограничений. Далее этот путь трансформируется в объект ERO (Explicit Route Object) сообщения RSVP-TE PATH, который явно сообщает, по какому пути этот PATH нужно передать.
Так вот если, вы хотите, чтобы какие-то узлы обязательно присутствовали или наоборот отсутствовали в этом пути, можно это явно указать в Explicit-Path, который станет одним из входных ограничений для CSPF.
Итак, мы вручную задаём, через какие узлы должен пролечь LSP, а через какие не должен.
RSVP-TE просит CSPF рассчитать маршрут с учётом Explicit-Path и других ограничений туннеля.
Если одно входит в противоречие с другим — беда, не будет LSP.
Explicit-Path — это строго локальное ограничение — только Ingress LSR о нём знает и не передаёт ни в анонсах IGP, ни в сообщениях RSVP-TE.Настройка Explicit-path выполняется в два этапа:
1) Создание самого explicit-path с ограничениями:
Router(config) ip explicit-path name Имя
Router(cfg-ip-expl-path) next-address IP-адрес
Router(cfg-ip-expl-path) exclude-address IP-адрес
...2) Примение его к path-option на туннеле:
Router(config-if) tunnel mpls traffic-eng path-option 1 explicit name ИмяSRLG
SRLG — Shared Risk Link Group. Ещё один способ повлиять на LSP и отличная идея против плоских колец.
Задача этой функции предотвратить построение основного и резервного LSP через линии, которые могут повредиться одновременно.
Например, два волокна, которые физически проходят в одном кабеле, наверняка порвутся одним и тем же ковшом экскаватора.
SRLG-группа — группа интерфейсов, которые «разделяют риск». О! Группа риска.
Вручную (конечно, а как иначе маршрутизатор узнает, что это физически идентичные линии) настраиваются интерфейсы, которые являются членами одной SRLG-группы.
Информация о SRLG распространяется по сети вместе с анонсами IGP, как и доступная полоса или значение Attribute-Flag, и помещается потом в TEDB.
Далее CSPF должен учитывать эту информацию при расчёте кратчайших маршрутов.
Имеется два режима:
Force Mode заставляет CSPF учитывать данные SRLG обязательно — если иного пути нет, то резервный LSP не будет построен вообще.
Preffered Mode допускает построение запасных туннелей через SRLG-линии, если нет иных возможностей.
Режим задаётся на Ingress LSR.
Для добавления интерфейсов в одну группу риска на любых узлах вводится команда:
Router(config-if) mpls traffic-eng srlg номер группыА на Ingress PE включить проверку SRLG:
Router(config) mpls traffic-eng auto-tunnel backup srlg exclude force/prefferedЧто это за команда, поговорим в разделе FRR.
Administrative Groups или Affinity
Вот сейчас должно стать страшно. Мне страшно.
Итак, к данному моменту мы узнали про четыре инструмента управления трафиком:
- Метрика MPLS TE.
- Требования к полосе пропускания канала и приоритет замещения.
- Explicit-path.
- SRLG.
RFC3630 для OSPF, а для ISIS определяют TLV для Administrative Group, который передаётся IGP вместе с другими характеристиками линиями.
Пока вы не согнулись под тяжестью знаний, расскажу вам такую историю.Каждый раз, настраивая туннель, учитывать в Explicit Path все эти детали — с ума можно сойти.
Огромнейшая сеть linkmeup. Своя оптика, свои РРЛ пролёты, куски лапши, доставшиеся от купленных домонетов, куча арендованных каналов у разных операторов. И через всё это хозяйство MPLS, хуже того — TE-туннели.
И для разных сервисов важно, чтобы они шли определённым путём.
Например, трафик 2G ни в коем случае не должен идти через РРЛ-пролёты — проблемы с синхронизацией нас съедят.
Трафик ШПД нельзя пускать через линии Балаган Телеком, потому что эти паразиты из 90-х берут деньги за объём пропущенного трафика.
Разрешать строить туннели через сети доступа вообще запрещено категорически.
И с этим нужно что-то делать.
Но, новая связка — удивительное спасение, которое решит все наши проблемы, просто нажмите кнопку «сделать хорошо».
Идея в том, что каждый интерфейс мы помечаем определёнными цветами.
А потом говорим, что вот этот туннель может идти по красным и фиолетовым линиям, но не может по зелёным, жёлтым и коричневым.
Marketing Bullshit! Непонятно? Мне тоже.
Итак.
Administrative Group (у Juniper: admin-group, у Cisco: Attribute-Flag) — это атрибут физического интерфейса, который может описать 32 его дискретных характеристики.
Какой бит из 32 за что отвечает решает оператор самостоятельно.
Раз уж примеры у нас в консоли Cisco, то далее буду использовать термин Attribute-Flag наравне с Administrative group, что не совсем правильно.
Например,
считаем с наименее значимых битов (с конца):
первый бит в 1 означает, что это оптика
второй бит в 1 означает, что это РРЛ
третий бит в 0 означает, что это линия в сторону сети доступа, а 1 — магистральный интерфейс.
четвёртый бит в 1 означает, что это аренда
пятый бит в 1 означает, что это Балаган-Телеком
шестой бит в 1 означает, что это Филькин-Сертификат
седьмой бит в 1 означает, что это канал через интернет без гарантий.
…
десятый бит в 1 означает, что полоса пропускания меньше 500 Мб/с
итд. я так могу все 32 утилизировать.
Affinity и маска — это требования туннеля к своему пути.
Какие отношения могут сложиться в этом треугольнике {Affinity, Mask, Attribute-Flag}?
(AFFINITY && MASK) == (ATTRIBUTE && MASK)Если это равенство выполняется, туннель можно строить через этот интерфейс.
Рассмотрим на примере.
У нас есть 32 бита и политика — за что отвечает каждый из них (возьмём пример выше).
В Mask мы указываем, какие характеристики канала нас интересуют. Например, для туннеля с трафиком 2G важно
- РРЛ это или нет
- Магистральная линия или в сторону сегмента доступа
- Канал через интернет или нет
Поэтому в маске выставляем 1 там, где важно, что стоит:
Mask: 0100 0110
Взяли только первые 8 бит для простоты.
Заметьте, что это Wildcard Mask.
В Affinity мы указываем, что именно нам нужно.
- Чтобы это не был РРЛ (0)
- Чтобы это был магистральный линк (1)
- Канал не через интернет (0)
Affinity: 0000 0100.
Выполняем операцию и получаем: 0000 0100.
Теперь возьмём для примера три интерфейса.
- Attribute-Flag 0000 0100 — Не РРЛ, магистральный и не через Интернет. Attribute-Flag && Mask = 0000 0100 = Affinity && Mask — сюда можно пускать трафик.

- Attribute-Flag 0100 0000 — Не РРЛ, но в сторону сегмента доступа, да ещё и через интернет. Attribute-Flag && Mask = 0100 0000 ? Affinity && Mask — сюда нельзя пускать трафик.

- Attribute-Flag 0000 0101 — Оптика, не РРЛ, магистральный и не через Интернет. Attribute-Flag && Mask = 0000 0100 = Affinity && Mask — сюда можно пускать трафик. Не важно, оптика или нет — результат тот же.

То есть при построении LSP на каждом линке будет учитываться значение Attribute-Flag.
По умолчанию значение Attribute-Flag на интерфейсе — 0x0. И в некотором смысле — это прискорбно — ведь результат операции «И» с маской будет отличаться от результата с Affinity, а значит мы должны настроить Attribute-Flag на всех интерфейсах.
Соответственно, в пределах компании можно выработать политики, как помечать интерфейсы и как управлять трафиком. Можно возложить эту задачу даже на систему управления, чтобы работа инженера сводилась к расстановке галочек в графическом интерфейсе, а конфигурация затем применялась бы автоматически.
Но в любом случае это не умаляет человеческого фактора с одной стороны и просто непостижимой сложности отладки и обслуживания с другой.
Однако случаи комплексного внедрения Administrative Group даже на сетях российиских операторов имеются.
Другим примеров использования могли бы быть коды регионов или стран. Тогда можно было бы задавать через какую географию пропускать трафик.
В этом свете 32 бита оказывается очень мало, поэтому RFC 7308 определяет расширенные административные группы, количество бит в которых ограничено естественым пределом LSA или вообще MTU.
Парень на пальцах разжёвывает Affinity и в рот стопочкой складывает.
Практика
Очень очень короткая. Просто посмотрим, что работает. Короткая, потому что применение Affinity требует настройки Attribute-Flag на всех узлах и всех интерфейсах. А это то, чего меньше всего хочется, если честно.
Продолжаем с последней конфигурации, где у нас два туннеля.
Файл конфигурации.
Tunnel42 идёт по пути R1-R2-R3-R4. С ним и поиграем.
Значение Attribute-Flag по умолчанию 0x0. Поэтому его и возьмём в качестве Affinity — то есть все интерфейсы у нас подпадают под условие. Кроме R3-R4, на котором мы настроим Attribute-Flag 0x1. Поскольку равенство не выполнится — CSPF не сможет строить кратчайший путь через этот линк.
Linkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) tunnel mpls trafаic-eng affinity 0x0 mask 0x1Linkmeup_R3(config) interface e0/0
Linkmeup_R3(config-if) mpls trafаic-eng attribute-flags 0x1И наблюдаем, как туннель пошёл в обход этого линка.
Однако при этом благополучно развалился Tunnel4. Значение Affinity по-умолчанию тоже 0x0, но маска 0xFFFF. Поэтому он тоже не вписался в перенастроенный линк R3-R4.
Но, мы могли бы настроить на нём маску 0x0 — не учитывать никакие биты Affinity и Attribute-Flag:
Linkmeup_R1(config) interface Tunnel4
Linkmeup_R1(config-if) tunnel mpls trafаic-eng affinity 0x0 mask 0x0И тогда туннель поднимется, не учитывая эти ограничения.
Надёжность и сходимость
На практике мы уже видели, что перестроение туннеля в случае поломки занимает несколько секунд. Что ж, не так уж и плохо было во времена моего деда.
Вся история развития компьютерных сетей — это история борьбы с авариями, борьбы за скорость сходимости, за уменьшение времени перерыва.
Что у нас есть на вооружении?
- Защита на физическом уровне. Например, APS в SONET или LAG в Ethernet.
- IP — решение всех проблем. IGP, BGP, VRRP итд.
- Набор технологий в MPLS.
Если бы эволюция строила людей по этому принципу, мы бы умирали преимущественно от старости (вторая причина по числу смертей была бы «погиб под собственным весом»).Защита на физическом уровне обычно предоставляет время сходимости в ±50 мс.
IP хорош, но сходится за секунды, а то и минуты.
MPLS TE предлагает две опции для повышения стабильности и уменьшения времени прерывания сервисов.
- Path Protection
- Local Protection
Первая реализует защиту на уровне всего LSP, вторая — на уровне линка или узла — и она называется FRR — Fast ReRoute.
Path Protection
При настройке туннеля мы можем указать, сколько и каких LSP мы хотим построить.
- Primary — это основной LSP, который и будет использоваться для передачи трафика.
- Secondary — запасной LSP. Если Ingress PE узнаёт от падении основного — он переводит трафик на запасной.
Последний в свою очередь тоже может быть:
- Standby — всегда наготове: путь заранее вычислен и LSP сигнализиован. То есть он сразу готов подхватить трафик. Может также называться Hot-standby.
- Non-standby — путь заранее вычислен, но LSP не сигнализирован. При падении основного LSP Ingress LSP сначала с помощью RSVP-TE строит запасной, потом пускает в него трафик. Зато полоса не простаивает зарезервированная. Может называться Ordinary.
- Standby — всегда наготове: путь заранее вычислен и LSP сигнализиован. То есть он сразу готов подхватить трафик. Может также называться Hot-standby.
- Best Effort — если основной и запасной пути сломались или не могут быть удовлетворены условия, то RSVP-TE построит хоть как-нибудь без резервирования ресурсов.
Protection — это не только и не столько про восстановление сервиса, сколько про скорость этого восстановления.
В этом ключе понятное дело, что non-standby совсем не дело. Опираясь на IGP, RSVP-TE сначала ждёт обновления маршрутной информации, потом сам должен отработать — счёт на секунды. Сигналом является уведомление от RSVP-TE или BFD, что LSP больше не живой, либо информация от IGP об изменении топологии.
Для случая Standby строится одновременно основной RSVP LSP и резервный. Соответственно, как только Ingress LSR фиксирует разрыв
Local Protection (FRR)
А вот FRR — Fast Reroute — позволяет спасти даже те машинки, которые прямо сейчас уже стремятся к назначению, не подозревая ещё, что там мост обвалился. То есть FRR — это как объезд на участке трассы, где ведутся ремонтные работы, а Backup LSP — это другая трасса.
FRR использует обходные пути и описан в RFC4090 Среднее время переключения после детектирования аварии — 50мс.
Это вещь, которая просто включается, а дальше работает автоматически. То есть с точки зрения конфигурации выглядит элементарно.
Как это обычно и бывает, вещи которые просто настраиваются, скрывают под пальто нечто интересное.
Итак, у FRR есть две функции:
- Защитить линию — Link Protection.
- Защитить один узел — Node Protection.
Поэтому он и называется Local Protection — не следит за всем LSP, а проверяет доступность только ближайшего линка или узла.
Когда случается страшное, он просто уводит пакеты в обходной туннель.
На иллюстрации а) показана защита линии. На б) — защита узлов.
Берём LSP от R1 до R4. Каждый узел по пути, кроме R4, будет пытаться строить свои обходные пути.
Так R1 для защиты линии R1-R2 выберет путь R1->R5->R2. А для защиты от падения узла R2: R1->R5->R6->R3.
R2 должен защитить линию R2-R3 и узел R3.
ИТД.
Давайте сначала с Link Protection разберёмся?Терминология
PLR — Point of Local Repair — точка расхода. Это узел, который инициирует защиту линии или узла. Может быть Ingress PE или любой транзитный P, но не Egress PE
MP — Merge Point — точка схода, куда приземляется защитный туннель. Любой транзитный P или Egress PE, но не Ingress PE.
Primary LSP или Protected LSP — исходный LSP, который требует защиты.
Bypass LSP — защитный LSP.
NHOP — Next Hop — следующий после PLR узел в Primary LSP.
NNHOP — Next Next Hop — соответственно следующий узел после Next Hop.
FRR Link Protection
Задача FRR — спасти те пакетики, которые летят прямо в пропасть рухнувшего линка, уведя их на этот самый Bypass LSP.
Когда PLR замечает, что линия, через которую лежит транзитный LSP, упала, он мгновенно перенаправляет трафик. Заметьте, что не Ingress PE этим занимается, а именно тот узел, на котором произошёл обрыв. Падение линка фиксируется по падению интерфейса или BFD-сессии.
Можно сравнить FRR со стрелкой на железнодорожных путях.
Чтобы так быстро перенаправить пакеты, Bypass LSP должен быть построен заранее. Так и происходит.
Каждый узел по ходу Primary LSP ищет, как обойти падение следующего линка и падение следующего хопа.
То есть он запускает полный механизм построения LSP:
- CSPF до MP (NHOP для случая падения линка и NNHOP для случая падения узла)
- Отправляет по просчитанному пути RSVP PATH с запросом резервирования.
- Поулчает RSVP RESV, если резервирование удалось.
Туннели строятся автоматически и не отображаются в конфигурации. Но в остальном это обычные туннели, по которым можно посмотреть информацию или потрассировать их.
Технически, голый FRR требует ручной настройки всех Bypass-туннелей. То есть оператор сам должен предусмотреть все места, где может что-то сломаться и настроить резервирование.Теперь нужно решить две задачи —
Ага. Так и представляю себе, как инженеры настраивают тысячи защитных туннелей.
Но мы бы с вами не работали в телекоме, если бы нельзя было автоматизировать рутинные операции.
Поэтому давно существует механизм AutoTunnel, который инструктирует каждый узел на пути Primary LSP самостоятельно и автоматически рассчитывать Bypass-туннели.
Включается он на Ingress LSR командой глобального режима:
Router(config) mpls traffic-eng auto-tunnel backup
Идея auto-tunnel значительно глубже, чем только автоматические FRR-туннели. Читать об этом тут.
— как в этот Bypass LSP поместить пакеты из Primary LSP.
— Как на MP понять, что с полученным счастьем делать.
Всё очень просто — FRR LSP — это обычный туннель. То есть нам достаточно туннелировать наш предыдущий туннель на участке от PLR до MP, а это значит, добавить ещё одну MPLS-метку в каждый пакет. Итого их будет 3: VPN, Tunnel, FRR.
Итак, когда пакет приходит на PLR во время аварии, тот сначала делает обычный SWAP внешней метки, словно бы он должен был выйти через старый (в данный момент сломанный интерфейс) и ещё он знает, что надо передать его в FRR туннель — добавляет ещё одну метку.
Далее пакет коммутируется по Bypass LSP по стандартным правилам — меняется внешняя (FRR) метка, а две внутренние остаются неизменными.
На предпоследнем узле внешняя метка снимается — PHP и до MP пакет идёт с изначальными двумя.
MP получает пакет, смотрит на транспортную метку и далее коммутирует пакет, словно бы ничего и не происходило.
Важно, что всё это работает, только если используется глобальный пул меток, а не специфичный по интерфейсам. Так MP не учитывает, с какого интерфейса пришёл пакет с данной меткой.
FRR Node Protection
Всё абсолютно то же самое за исключением транспортной метки — PLR должен знать какую метку ждёт NNHOP.
Туннель теперь строится не до следующего узла, а через один — NNHOP. В этом помогает атрибут сообщения RSVP — LRO (Label Request Object). Будучи в RSVP PATH он просит узлы по пути выделять метки.
А в RSVP RESV Label Object содержит эти самые выделенные метки.
Bandwidth Protection
При сигнализации Bypass LSP возникает вопрос: а резервировать ли ресурсы.
Если да, то это уже называется Bandwidth Protection.
При этом обычно нет смысла два раза резервировать ресурсы для одного и того же туннеля. Ну действительно — от того, что мы увели трафик из Primary в Bypass ведь не следует, что ресурсы будут использоваться дважды на PLR и MP? Тем более, что свободной полосы вообще может не хватить. Поэтому вводится понятие SE (Shared Explicit). Если в изначальном RSVP PATH будет установлен этот атрибут, ресурсы не будут резервироваться дважды — промежуточные узлы буду знать, что это не совсем независимый LSP — это старый задумал что-то.
Итак, процедура следующая:
- При настройке туннеля мы указываем, что хотим FRR и набор атрибутов этого туннеля:
- Запись меток — RSVP TE будет передавать метки по всему пути LSP — так транзитные маршрутизаторы будут знать, какую метку ждёт NNHOP.
- Защита с требованием по полосе (если необходимо).
- Стиль SE — надо/не надо.
- Ingress LSR устанавливает Primary LSP.
- PLR строит Bypass LSP для защиты линка и NHOP. Ему для этого нужно знать:
- LSR ID узла MP (NHOP для защиты линка и NNHOP для защиты NHOP).
- Транспортную метку, которую MP выделил для данного FEC.
- Учитывать ли требования по полосе пропускания или нет.
- Если ответ на предыдущий вопрос «да», то в каком режиме: SE или нет.
Далее он определит
- Выходной интерфейс Bypass LSP.
- Его выходную метку.
- PLR обнаруживает аварию
- В случае защиты линии, он видит её по падению физической линии или BFD на интерфейсе.
- В случае защиты узла, он может обнаружить физическое падение линии, BFD для RSVP или интерфейса или отсутствие RSVP Hello.
- PLR осуществляет переключение мгновенно после обнаружения аварии. Для каждого приходящего от Ingress LSR пакета:
- меняет оригинальную транспортную метку на ту, которую ждёт MP.
- добавляет сверху новую Bypass метку.
- отправляет пакет в выходной интерфейс Bypass LSP.
- сообщает Ingress PE о факте переключения через сообщение RSVP — на случай, если тот ещё сам этого не обнаружил и не переключился на резервный LSP.
- Пакеты передаются по Bypass LSP, доходят до предпоследнего узла Bypass LSP, где снимается Bypass метка (PHP).
- MP получает MPLS пакет в таком виде, в каком и должен был, только, скорее всего, с другого интерфейса.
- Дальше всё происходит так, словно FRR и не работал.
- После переключения Ingres LSR будет постоянно пытаться восстановить Primary LSP, используя механизм Make-Before-Break.
Когда ему это удастся, новый LSP будет называться Modified LSP.
Заметьте, что MP особо ничего и не делал — только вначале поучаствовал в построении LSP — он даже не знал, что это какой-то там Bypass LSP — для него это было обычный запрос со стороны RSVP TE.
Режимы FRR.
Единственный вопрос, который стоит ещё обсудить про FRR — какие LSP собственно перенаправлять? Он же не один всё-таки, наверно, проходит через этот PLR?
Тут есть два варианта:
- Many-to-One (или Facility mode). Соответственно — все полетят через один туннель.
- One-to-One. То есть для каждого транзитного LSP будет построен свой личный обходной туннель.
Первый вариант предпочтителен, поскольку использует ресурсы более рационально. Всё, что было выше именно про режим Facility.
One-to-One вводит пару новых терминов:
Detour LSP — запасной туннель. Тот же Backup LSP, но Detour защищает только один Primary LSP,
DMP — Detour Merge Point — Тот же MP.
Этот метод очень похож на Facility, но есть одно существенное отличие. В режиме Facility существующие LSP туннелировались в Bypass LSP, получая третью метку в стек. В режиме One-to-One при обходе препятствия в стеке останется две метки, то есть это будет выглядеть и работать, как самый обычный LSP.
PLR при обнаружении аварии, полученные пакеты старых LSP будет отправлять по новому пути, просто выполнив обычный Swap транспортной метки. Но метка и выходной интерфейс будут новыми — от Detour LSP.
DMP также выполняет обычный Swap транспортной метки. Вместо метки Detour LSP он подставляет старую от Primary LSP и отправляет дальше.
Я разобрал подробно режим Facility, потому что он наиболее часто используемый.
Теперь, когда более менее разобрались с концепцией FRR, добро пожаловать в болото деталей.Вот и всё, что нужно знать об FRR.
Как это водится, когда мы погружаемся слишком глубоко, в игру вступают квантовые законы, а технологии теряют свою вендоронезависимость.
Например, в терминологии Juniper, One-to-One режим называется Fast Reroute — да вот так странно и называется. Разработчиков как-то не напрягает пересечение с FRR в более высокой ступени иерархии. Ну хоть link и link-node protection вторым названием имеют Facility mode.
Потом, Cisco не поддерживает режим One-to-One, поэтому для реализации FRR важно, чтобы MPLS-маршрутизаторы использовали глобальный пул меток, а не по интерфейсам. Да и ладно — не очень-то и хотелось.
Зато Cisco обладает гибким механизмом, какие LSP туннелировать и для каких нужно резервировать полосу. Подробнее.
Если говорить про Huawei, то по умолчанию режим Facility предполагает ручную настройку туннелей на PLR. Но есть режим Auto-FRR — тогда всё будет работать автоматически.
Как говорится, чем дальше в сельву, тем злее гаучо.
Cisco.
Juniper.
Практика
Продолжаем всё с той же сетью и с того момента, на котором мы остановились (если не считать affinity).
Файл конфигурации.
Path-Protection
Добавим Standby LSP с более низкими требованиями полосы пропускания: 3 Мб/с.
Linkmeup_R1(config) interface tunnel4
Linkmeup_R1(config-if) tunnel mpls traf path-option protect 1 dynamic bandwidth 3000Обратите внимание, что Preference (1) должен быть таким же, как и у Primary LSP.
Путь защитного туннеля лёг следующим образом:
Во-первых, на линии R1-R2 4 Мб/с из 5 уже занял Tunnel42. Поэтому для запасного LSP Tunnel4 не осталось полосы.
Во-вторых, основной и резервный LSP используют обычно метод резервирования полосы Shared Explicit (SE), что означает, что для одного и того же туннеля не будет полоса резервироваться дважды. Поэтому через 10 Мб/с линк R1-R5 удалось проложить и основной LSP (8 Мб/с) и резервный (3 Мб/с).
В-третьих, вы можете видеть, что резервный LSP на участке R6-R4 он выбрал тот же путь, что и основной. Поэтому использование Explicit-path иногда вполне может быть оправдано.
Для удовольствия и удовлетворения можете дёрнуть линк R2-R5 и убедится, что трафик абонентов почти не прерывался.
Если в текущей конфигурации у вас пинг прекратился и не восстанавливается, попробуйте понять почему.
Local-Protection (FRR)
Если вы всё ещё дёргаете линк R2-R5, пожалуйста, перестаньте и верните его в состояние Up.Итак, мы хотим настроить FRR для этого Tunnel4.
Кроме того, для наглядности работы FRR, придётся убрать Path-Protection.
Файл конфигурации
1) Включаем FRR на туннеле
Linkmeup_R1(config) interface tunnel4
Linkmeup_R1(config-if) tunnel mpls traffic-eng fast-rerouteЛогично сделать это и на другом конце
Linkmeup_R4(config) interface tunnel1
Linkmeup_R4(config-if) tunnel mpls traffic-eng fast-rerouteСразу после этого RSVP сигнализировал новый атрибут вдоль LSP
Он сообщил, что для этого LSP нужна защита линка.
Но туннелей пока не появляется.
2) Теперь нужно включить возможность построения туннелей автоматически:
Linkmeup_R1(config) mpls traffic-eng auto-tunnel backupЧто делает эта команда? Проверяет, какие интерфейсы используются под туннели, требующие Local-protection, и пытается защитить линк и следующий узел, поэтому на каждом узле (где может) строит необходимые туннели.
Например, на Linkmeup_R2 будет 4:
- для защиты линка R2->R6 (R2->R5->R6).

- для защиты от падения узла R6: R2->R6->R3 (R2->R3).

- для защиты линка R2->R5 (R2->R6->R5)

- для защиты от падения узла R5: R2->R5->R1 (R2->R1).

Обратите внимание на то, что защитные туннели строятся без какого-либо учёта полосы пропускания, пока об этом отдельно не будет сказано.
Так, теперь я хочу разорвать линию R2->R6.
По идее для защиты этой линии у нас есть Tunnel65436 (R2->R5->R6). Но тогда полный путь будет выглядеть немного странно: R1->R5->R2->R5->R6-R3->R4 — то есть по линии R5-R2 трафик пройдёт дважды — туда и обратно. Поэтому R2 ненадолго включает интеллект и выбирает Tunnel65437, который напрямую ведёт к R3.
Тогда на участке R2-R3 мы должны увидеть две метки в стеке — VPN и туннельную. Метка bypass не будет вставляться, потому что PHP.
Если хочется, увидев все три метки, убедиться, что FRR работает, введите на R2 команду
Linkmeup_R2(config) mpls traffic-eng auto-tunnel backup nhop-onlyОна заставит R2 использовать тот самый странный путь.
Здесь нужно быть аккуратным. Я на это попался.
Дело в том, что у нас нет реального бешеного трафика, на котором можно было бы заметить переключение с Bypass-туннеля FRR на заново построенный Primary.
Я хочу сказать, что Primary LSP успевает восстановиться в промежутке между двумя ICMP-запросами. И тогда в дампе вы увидите не Bypass LSP, а перестроенный Primary LSP, а соответственно, не три метки, а две.
И в этой нелёгкой учебной ситуации нам помогает полоса пропускания — Primary LSP не сможет перестроиться через линию R2->R3 из-за недостатка свободной полосы, а Bypass LSP, не учитывающий этого, сможет.
Таким образом переключения с Bypass на Primary не произойдёт, и мы можем наслаждаться долгоживущим Bypass.
Смотрим на VPN и транспортную метки R1:
PUSH VPN — 16
PUSH Tunnel — 26
Смотрим таблицу меток на R5:
SWAP Tunnel 26->16
Смотрим FRR на R2:
SWAP Tunnel 16->27 (метка, которую ждёт NHOP)
PUSH Bypass Implicit Null — то есть реально метку не вставляем.
Метки на R3:
PHP: POP Tunnel 27 (дождался).
Смотрим дамп на участке — 2 метки (implicit null не был реально добавлен):
Прекрасно!
Ну и напоследок пара лёгких тем без практики.
MPLS QoS
Теме QoS будет посвящён отдельный выпуск. Готовьтесь. Но не поговорить немного об этом сейчас было бы непростительно.
MPLS TE IntServ
Итак, MPLS TE использует парадигму IntServ QoS — предварительное резервирование ресурсов по всему пути.
То есть мы изначально уверены, что необходимая полоса (и другие требования) будет предоставлена сервису. При этом пакеты внутри туннеля (LSP) все равнозначны.
Однако, такое случается, что трафик у клиента растёт. Может, в какой-то момент его объём превосходит статически настроенный порог, а свободной полосы больше нет, или Autobandwidth ещё не успел отработать повышение скорости.
Так или иначе — пакеты начинают отбрасываться, причём безо всякого разбора — важные они или нет.
То есть идея IntServ в реализации MPLS TE сама по себе ещё не гарантирует, что на каждом отдельном узле проблем не возникнет.
MPLS TE DiffServ
А кто у нас там отвечает за Per-Hop Behavior? Напомните? DiffServ? А не объединить ли нам эти две прекрасные парадигмы?
Ведь в заголовке MPLS имеется поле EXP, которое планировалось Expериментальным, но уже давно официально используется для задания приоритета пакетов и называется Traffic class. Вот только по старой привычке его и сейчас продолжат называть EXP,
Это называется MPLS DiffServ-aware Traffic Engineering — MPLS DS-TE.
Идея, вообще говоря, заключается в том, чтобы MPLS-пакетам предоставить то качество сервиса, которое ожидали оригинальные пакеты. То есть в идеале нужно сделать соответствие 1 к 1. Но EXP — это всего лишь 3 бита, то есть 8 значений приоритета, тогда как DSCP — 6 бит (64 значения) — как ни крути, но детализация при такой архивации теряется.
Таким образом, существует два подхода:
E-LSP — EXP-Inferred LSP. Забить и радоваться тому, что имеем.
L-LSP — Label-Inferred LSP. Кодировать приоритет связкой EXP+метка.
E-LSP
Для случая, когда изначально имеем дело с полем DSCP — мы переносим в MPLS EXP только три наиболее значимых (левых) бита DSCP.
И да, мы смиряемся с потерей деталей.
Когда PDU приходит на Ingress LSR, мы помещаем его в туннель и задаём приоритет в поле EXP.
Ну например, в одном туннеле у нас пойдут данные ШПД и фиксированной телефонии. Естественно, телефонии мы дадим приоритет 5, а всему остальному 0.
Тогда даже если внутри одного туннеля случится затор, первыми будут умирать слабые.
L-LSP
В этом случае данные QoS кодируются в связку Метка+EXP. Предполагается, что метка задаёт механизм обработки в очередях, а метка — приоритет отбрасывания пакета.
Информация о PHB должна быть сигнализирована в процессе установки LSP.
Каждый L-LSP несёт только один тип сервиса.
На сегодняшний день операторы в большинстве своём определяют четыре класса трафика: BE, AF, EF и CS. E-LSP более чем достаточно для этого, поэтому L-LSP не только практически не используется, но и более того, не у всех вендоров реализован. Поэтому останавливаться далее на сравнении методов я даже не буду.
Режимы QoS
А вот что интересно, так это какому всё-таки полю CoS доверять на каждом узле: IP DSCP, Tunnel EXP или VPN EXP?
Есть три режима:
- Uniform Mode
- Pipe Mode
- Short-Pipe Mode
Помните, уже сталкивались с такими понятиями при разборе TTL в MPLS L3VPN? Что-то похожее и тут.
Uniform Mode
Это плоская модель End-to-End.
На Ingress PE мы доверяем IP DSCP и копируем (строго говоря, отображаем, но для простоты будем говорить «копируем») его значение в MPLS EXP (как туннельный, так и VPN заголовки). На выходе с Ingress PE пакет уже обрабатывается в соответствии со значением поля EXP верхнего заголовка MPLS.
Каждый транзитный P тоже обрабатывает пакеты на основе верхнего EXP. Но при этом он может его поменять, если того хочет оператор.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в VPN-заголовок. Не важно, что там стояло — в режиме Uniform, происходит копирование.
Egress PE снимая метку VPN, тоже копирует значение EXP в IP DSCP, даже если там записано другое.
То есть если где-то в середине значение метки EXP в туннельном заголовке изменилось, то это изменение будет унаследовано IP-пакетом.
Pipe Mode
Если же на Ingress PE мы решили не доверять значению DSCP, то в заголовки MPLS вставляется то значение EXP, которое пожелает оператор.
Но допустимо и копировать те, что были в DSCP. Например, можно переопределять значения — копировать всё, вплоть до EF, а CS6 и CS7 маппировать в EF.
Каждый транзитный P смотрит только на EXP верхнего MPLS-заголовка.
Предпоследний узел снимает транспортную метку (PHP) и копирует значение EXP в заголовок VPN.
Egress PE сначала производит обработку пакета, опираясь на поле EXP в заголовке MPLS, и только потом его снимает, при этом не копирует значение в DSCP.
То есть независимо от того, что происходило с полем EXP в заголовках MPLS, IP DSCP остаётся неизменным.
Такой сценарий можно применять, когда у оператора свой домен Diff-Serv, и он не хочет, чтобы клиентский трафик как-то мог на него влиять.
Short-Pipe Mode
Этот режим вы можете рассматривать вариацией Pipe-mode. Разница лишь в том, что на выходе из MPLS-сети пакет обрабатывается в соответствие с его полем IP DSCP, а не MPLS EXP.
Это означает, что приоритет пакета на выходе определяется клиентом, а не оператором.
Ingress PE не доверяет IP DSCP входящих пакетов. Транзитные P смотрят в поле EXP верхнего заголовка. Предпоследний P снимает транспортную метку и копирует значение в VPN-метку.
Egress PE сначала снимает метку MPLS, потом обрабатывает пакет в очередях.
Объяснение от cisco.
Упрощение настройки туннелей
В типичной операторской сети для масштабирования и снижения нагрузки сейчас разворачиваются L3/L2VPN на основе BGP с функцией Auto-Discovery и выделенными BGP Route Reflector.
Если в качестве транспорта используются LDP LSP, то туннели MPLS у нас автоматически образуют полносвязную топологию.
В таких условиях добавление нового PE требует настройки только этого нового PE и RR.
Однако ситуация совсем иная, если на транспорте RSVP-TE. Если узлов PE много, то может стать головной болью настроить туннели между всеми нужными парами маршрутизаторов.
Есть два подхода, которые позволяют избежать этого конфиграционного безумия.
- LDP over TE
- RSVP Auto-Mesh
LDP over TE
Этот подход не требует нового функционала. Вводят иерархию — в неком неизменном ядре сети поднимается полносвязная система TE-туннелей между P-маршрутизаторами.
Делается это один раз и никогда уже не меняется.
А обычные PE маршрутизаторы друг к другу строят LDP LSP.
В стеке пакета MPLS, движущегося в ядре сети, получится три метки — VPN, LDP, RSVP-TE.
То есть LDP LSP, как бы туннелируются в RSVP LSP.
Иллюстрация с сайта www.nexthop.me
На, назовём это, сегменте доступа у нас удобный и уютный LDP, а в ядре сети (это может быть междугородней магистралью) при этом есть возможность управлять трафиком.
RSVP Auto-Mesh/Auto-Tunnel
Это маленькая, но крайне полезная импрувизация, позволяющая автоматизировать настройку туннелей.
Как только в TEDB появляется новое PE-устройство, с ним моментально строятся прямые и обратные туннели.
Какая конфигурация применяется? Заранее создаётся шаблон настройки туннельного интерфейса.
Как узнать, что новый узел — это PE? В шаблоне указывается ACL, который определяет с кем можно строить.
Например, мы берём за правило, что у PE узлов интерфейс Loopback 127 будет 10.127.127.0/24, и анонсируем его в IGP.
Простейшая конфигурация будет выглядеть так:
- Знакомой командой включаем возможность Auto-tunnel в режиме Mesh:
Router(config) mpls traffic-eng auto-tunnel mesh
- Определяем потенциальные PE в ACL:
Router(config) ip access-list standard 1 Router(config-std-nacl) permit source 10.127.127.0 0.0.0.255
- Заводим шаблон конфигурации:
Router(config) interface auto-template 1 Router(config-if) ip unnumbered Loopback127 Router(config-if) tunnel mode mpls Router(config-if) tunnel mpls traffic-eng autoroute announce Router(config-if) tunnel mpls traffic-eng priority 4 4 Router(config-if) tunnel mpls traffic-eng auto-bw Router(config-if) tunnel mpls traffic-eng path-option 4 dynamic Router(config-if) tunnel destination access-list 1
Заключение
Хотелось бы подвести краткий итог одной фразой: всё, что было описано в данной статье, в самом деле встречается на белом свете и вовсе не замки на песке.
Поэтому кратко повторим:
MPLS TE использует RSVP-TE, как протокол распределения меток и резервирования ресурсов. А тот в свою очередь опирается на LS IGP:
- OSPF с его Opaque LSA
- IS-IS с TLV
Управлять тем, как построится RSVP LSP, мы можем следующими способами:
- Метрика (IGP или TE)
- Требования к ресурсам
- Explicit-path
- SRLG
- Administrative Groups/Affinity
IGP распространяет и заносит в TEDB информацию о:
- Состоянии линий
- Метриках
- Свободных ресурсах с учётом приоритетов удержания (Hold Priority)
- SRLG
- Attribute-Flag/Administrative Group
При расчёте кратчайших маршрутов CSPF берёт требования из конфигурации TE-Туннеля, а ограничения из TEDB.
Требования туннеля:
- Требуемая полоса и приоритет установки
- Affinity/Administrative Group
- Explicit-Path
RSVP-TE в своих сообщениях передаёт:
- Требуемую полосу для резервирования с приоритетом установки и удержания
- Режим резервирования — SE или FF
- ERO — список узлов для прокладывания LSP
- RRO — реальный список узлов и меток на каждом участке
- Информацию о необходимости FRR
Направить трафик в туннель мы можем двумя основными способами:
- Статический маршрут или PBR
- IGP Shortcut (или Forwarding Adjacencies)
- Вендорозависимые механизмы: автоматически на Juniper или Tunnel-policy на Huawei/HP
Make-Before-Break:
Это широко используемая концепция в MPLS TE — сперва добейся! Прежде, чем сломать что-то, что уже работает, построй новый LSP.
Применяется при:
- Переоптимизации туннелей
- FRR
- Важный туннель пытается вытеснить менее важный.
Shared Explicit или Fixed Filter:
Тесно связанные с MBB понятия.
Shared Explicit (SE) — два разных резервирования (LSP) для одного туннеля рассматриваются связанными и полоса полоскания не будет резервироваться дважды.
Fixed Filter (FF) — различные LSP от одного и того же отправителя всегда рассматриваются независимыми и полоса для них резервируются отдельно.
Режим SE очень удобен в механизме MBB, и зачастую в режиме FF отключаются вообще возможности FRR и переоптимизации.
Защита туннелей:
- Когда ломается линия/узел, в первые 50 мс отрабатывает FastReRoute, спасая те пакеты, что уже идут в LSP.
- Потом Ingress LSR узнаёт о проблемах с основным LSP и перенаправляет трафик в резервный LSP — так уже спасаются все последующие пакеты.
- Далее Ingress LSR пытается восстановить основной LSP в обход проблемного участка, если это возможно.
Приоритет туннелей:
Каждый туннель имеет два значения:
- Setup Priority
- Hold Priority.
Обычно они равны.
0 — наивысший, 7 — низший.
Туннель с более высоким значением Setup Priority вытеснит установленный туннель с более низким Hold Priority.
Механизмы упрощения настройки:
- LDP over TE
- RSVP Auto-Mesh/Auto-tunnel
Правила обработки полей CoS в MPLS DS-TE:
- Uniform. На всём пути оператор обрабатывает трафик на основе значения поля CoS изначального PDU и полем может быть переписано им.
- Pipe. Значение поля CoS изначального PDU не меняется. Egress PE обрабатывает пакет на основе заголовка MPLS.
- Short-pipe. Значение поля CoS изначального PDU не меняется. Egress PE обрабатывает пакет на основе изначального поля CoS PDU.
Полезные ссылки
- Три документа от cisco на тему MPLS TE. Длинно и по делу:
- Cisco же об FRR: MPLS Traffic Engineering. Traffic Protection using Fast Re-route (FRR)
- На практике об Autobandwidth: Deploying MPLS Traffic Engineering
- MPLS TE Affinity
- DiffServ Tunneling Modes for MPLS Networks
- Отличный подбор видео об MPLS: labminutes.com
Также напоминаю, что список лучших книг по сетям сейчас тут.Кто-то скажет: СДСМ становится всё более и более странным. Вы отрываетесь от реальности.
И будет неправ: в следующий раз всё-таки вернёмся к животрепещущим темам — QoS. Долгожданный, многообещанный, и насколько сложный, настолько же и бесполезный.
Будет так же треш и угар на 140к знаков, но про то, с чем вы каждый день работаете.
Все аббревиатуры, использованные в статье, вы можете найти в глоссарии linkmeup.
Благодарности
Андрею Глазкову, Александру Клипперу и Александру Фатину за вычитку материала и комментарии.
Артёму Чернобаю за иллюстрацию.
Моей жене и детям, что терпели лишения, но позволили закрыть тему MPLS.
Все выпуски СДСМ...
12. Сети для самых матёрых. Часть двенадцатая. MPLS L2VPN
11.1. Сети для самых маленьких. Микровыпуск №6. MPLS L3VPN и доступ в Интернет
11. Сети для самых маленьких. Часть Одиннадцатая. MPLS L3VPN
10. Сети для самых маленьких. Часть десятая. Базовый MPLS
9. Сети для самых маленьких. Часть девятая. Мультикаст
8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
11.1. Сети для самых маленьких. Микровыпуск №6. MPLS L3VPN и доступ в Интернет
11. Сети для самых маленьких. Часть Одиннадцатая. MPLS L3VPN
10. Сети для самых маленьких. Часть десятая. Базовый MPLS
9. Сети для самых маленьких. Часть девятая. Мультикаст
8.1 Сети для Самых Маленьких. Микровыпуск №3. IBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
sir_Maverick
Не планируете в книжном формате это все оформить?
eucariot Автор
После каждой статьи мне задают этот вопрос :) С каждым разом ответ всё более и более утвердительный. Однако серия ещё не завершена.
Skerrigan
Эм… я помню начало этой эпопеи с 2013-го года. Не сочтите за грубость, но кажется, что когда будет «все, конец, пора в тираж», можно будет часть переписывать из-за устаревания.
eucariot Автор
Базовые технологии ещё долго никуда не денутся.
IPv4 канет в лету, да, эту часть, возможно придётся переделать. Это если, конечно, хватит сил довести до бумаги.