
Одним из нововведений в Go 1.9 было добавление в стандартную библиотеку нового типа sync.Map, и если вы ещё не разобрались что это и для чего он нужен, то эта статья для вас.
Для тех, кому интересен только вывод, TL;DR:
если у вас высоконагруженная (и 100нс решают) система с большим количеством ядер процессора (32+), вы можете захотеть использовать sync.Map вместо стандартного map+sync.RWMutex. В остальных случаях, sync.Map особо не нужен.

Если же интересны подробности, то давайте начнем с основ.
Тип map
Если вы работаете с данными в формате "ключ"-"значение", то всё что вам нужно это встроенный тип map (карта). Хорошее введение, как пользоваться map есть в Effective Go и блог-посте "Go Maps in Action".
map — это generic структура данных, в которой ключом может быть любой тип, кроме слайсов и функций, а значением — вообще любой тип. По сути это хорошо оптимизированная хеш-таблица. Если вам интересно внутреннее устройство map — на прошлом GopherCon был очень хороший доклад на эту тему.
Вспомним как пользоваться map:
// инициализация
m := make(map[string]int)
// запись
m["habr"] = 42
// чтение
val := m["habr"]
// чтение с comma,ok
val, ok := m["habr"] // ok равен true, если ключ найден
// итерация
for k, v := range m { ... }
// удаление
delete(m, "habr")Во время итерации значения в map могут изменяться.
Go, как известно, является языком созданным для написания concurrent программ — программ, который эффективно работают на мультипроцессорных системах. Но тип map не безопасен для параллельного доступа. Тоесть для чтения, конечно, безопасен — 1000 горутин могут читать из map без опасений, но вот параллельно в неё ещё и писать — уже нет. До Go 1.8 конкурентный доступ (чтение и запись из разных горутин) могли привести к неопределенности, а после Go 1.8 эта ситуация стала явно выбрасывать панику с сообщением "concurrent map writes".
Почему map не потокобезопасен
Решение делать или нет map потокобезопасным было непростым, но было принято не делать — эта безопасность не даётся бесплатно. Там где она не нужна, дополнительные средства синхронизации вроде мьютексов будут излишне замедлять программу, а там где она нужна — не составляет труда реализовать эту безопасность с помощью sync.Mutex.
В текущей реализации map очень быстр:
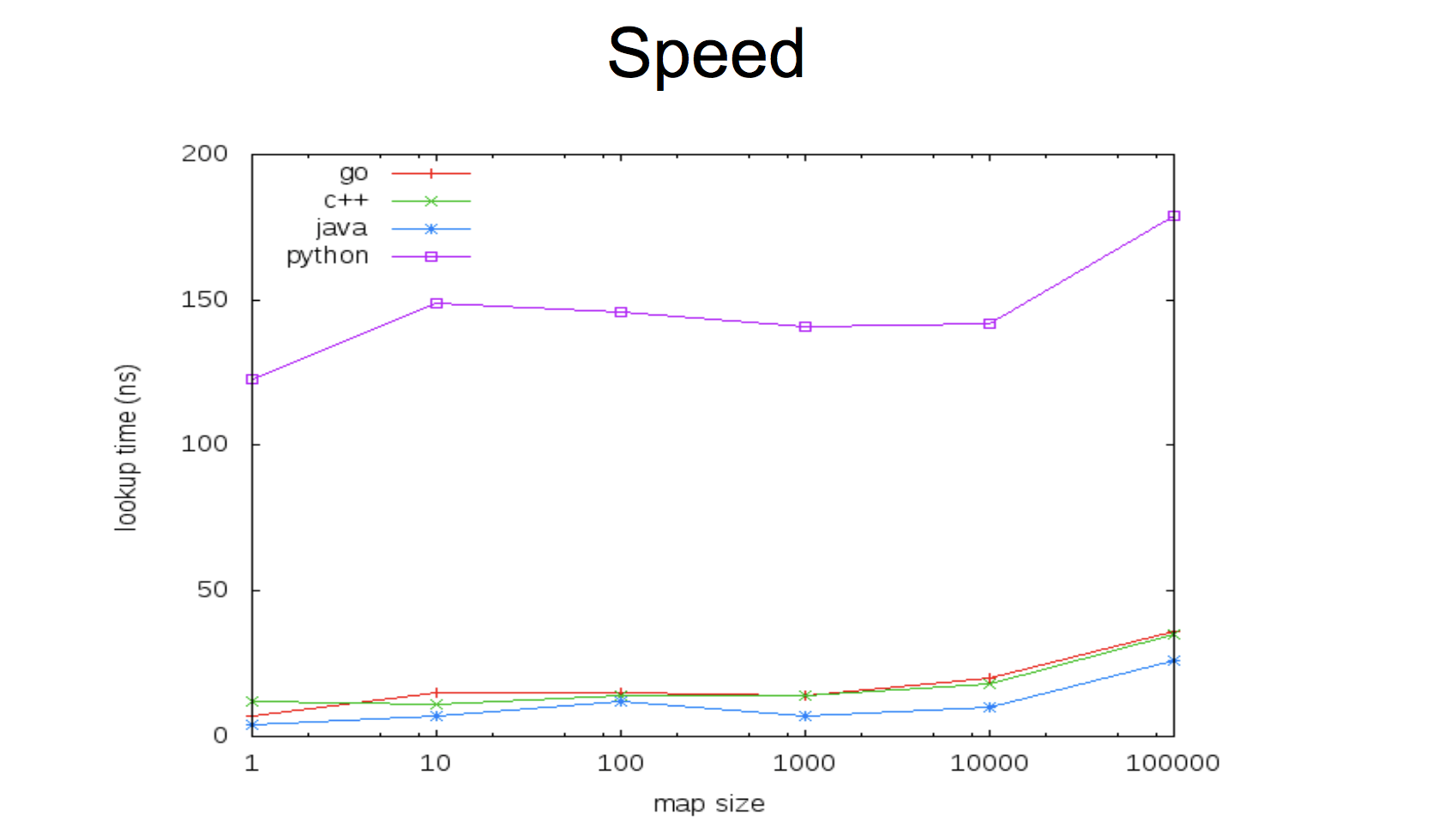
Такой компромисс между скоростью и потокобезопасностью, при этом оставляя возможность иметь и первый и второй вариант. Либо у вас сверхбыстрый map безо всяких мьютексов, либо чуть медленнее, но безопасен для параллельного доступа. Важно тут понимать, что в Go использование переменной параллельно несколькими горутинами — это не далеко единственный способ писать concurrent-программы, поэтому кейс этот не такой частый, как может показаться вначале.
Давайте, посмотрим, как это делается.
Map + sync.Mutex
Реализация потокобезопасной map очень проста — создаём новую структуру данных и встраиваем в неё мьютекс. Структуру можно назвать как угодно — хоть MyMap, но есть смысл дать ей осмысленное имя — скорее всего вы решаете какую-то конкретную задачу.
type Counters struct {
sync.Mutex
m map[string]int
}Мьютекс никак инициализировать не нужно, его "нулевое значение" это разлоченный мьютекс, готовый к использованию, а map таки нужно, поэтому будет удобно (но не обязательно) создать функцию-конструктор:
func NewCounters() *Counters {
return &Counters{
m: make(map[string]int),
}
}Теперь у переменной типа Counters будет метод Lock() и Unlock(), но если мы хотим упростить себе жизнь и использовать этот тип из других пакетов, то будет также удобно сделать функции обёртки вроде Load() и Store(). В таком случае мьютекс можно не встраивать, а просто сделать "приватным" полем:
type Counters struct {
mx sync.Mutex
m map[string]int
}
func (c *Counters) Load(key string) (int, bool) {
c.mx.Lock()
defer c.mx.Unlock()
val, ok := c.m[key]
return val, ok
}
func (c *Counters) Store(key string, value int) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key] = value
}Тут нужно обратить внимание на два момента:
deferимеет небольшой оверхед (порядка 50-100 наносекунд), поэтому если у вас код для высоконагруженной системы и 100 наносекунд имеют значение, то вам может быть выгодней не использоватьdefer- методы
Get()иStore()должны быть определены для указателя наCounters, а не наCounters(тоесть неfunc (c Counters) Load(key string) int { ... }, потому что в таком случае значение ресивера (c) копируется, вместе с чем скопируется и мьютекс в нашей структуре, что лишает всю затею смысла и приводит к проблемам.
Вы также можете, если нужно, определить методы Delete() и Range(), чтобы защищать мьютексом map во время удаления и итерации по ней.
Кстати, обратите внимание, я намеренно пишу "если нужно", потому что вы всегда решаете конкретную задачу и в каждом конкретном случае у вас могут разные профили использования. Если вам не нужен Range() — не тратьте время на его реализацию. Когда нужно будет — всегда сможете добавить. Keep it simple.
Теперь мы можем легко использовать нашу безопасную структуру данных:
counters := NewCounters()
counters.Store("habr", 42)
v, ok := counters.Load("habr")В зависимости, опять же, от конкретной задачи, можно делать любые удобные вам методы. Например, для счётчиков удобно делать увеличение значения. С обычной map мы бы делали что-то вроде:
counters["habr"]++а для нашей структуры можем сделать отдельный метод:
func (c *Counters) Inc(key string) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key]++
}
...
counters.Inc("habr")Но часто у работы с данными в формате "ключ"-"значение", паттерн доступа неравномерный — либо частая запись, и редкое чтение, либо наоборот. Типичный случай — обновление происходит редко, а итерация (range) по всем значениям — часто. Чтение, как мы помним, из map — безопасно, но сейчас мы будем лочиться на каждой операции чтения, теряя без особой выгоды время на ожидание разблокировки.
sync.RWMutex
В стандартной библиотеке для решения этой ситуации есть тип sync.RWMutex. Помимо Lock()/Unlock(), у RWMutex есть отдельные аналогичные методы только для чтения — RLock()/RUnlock(). Если метод нуждается только в чтении — он использует RLock(), который не заблокирует другие операции чтения, но заблокирует операцию записи и наоборот. Давай обновим наш код:
type Counters struct {
mx sync.RWMutex
m map[string]int
}
...
func (c *Counters) Load(key string) (int, bool) {
c.mx.RLock()
defer c.mx.RUnlock()
val, ok := c.m[key]
return val, ok
}Решения map+sync.RWMutex являются почти стандартом для map, которые должны использоваться из разных горутин. Они очень быстрые.
До тех пор, пока у вас не появляется 64 ядра и большое количество одновременных чтений.
Cache contention
Если посмотреть на код sync.RWMutex, то можно увидеть, что при блокировке на чтение, каждая горутина должна обновить поле readerCount — простой счётчик. Это делается атомарно с помощью функции из пакета sync/atomic atomic.AddInt32(). Эти функции оптимизированы под архитектуру конкретного процессора и реализованы на ассемблере.
Когда каждое ядро процессора обновляет счётчик, оно сбрасывает кеш для этого адреса в памяти для всех остальных ядер и объявляет, что владеет актуальным значением для этого адреса. Следующее ядро, прежде чем обновить счётчик, должно сначала вычитать это значение из кеша другого ядра.
На современном железе передача между L2 кешем занимает что-то около 40 наносекунд. Это немного, но когда много ядер одновременно пытаются обновить счётчик, каждое из них становится в очередь и ждёт эту инвалидацию и вычитывание из кеша. Операция, которая должна укладываться в константное время внезапно становится O(N) по количеству ядер. Эта проблема называется cache contention.
В прошлом году в issue-трекере Go была создана issue #17973 на эту проблему RWMutex. Бенчмарк ниже показывает почти 8-кратное увеличение времени на RLock()/RUnlock() на 64-ядерной машине по мере увеличения количества горутин активно "читающих" (использующих RLock/RUnlock):

А это бенчмарк на одном и том же количестве горутин (256) по мере увеличения количества ядер:
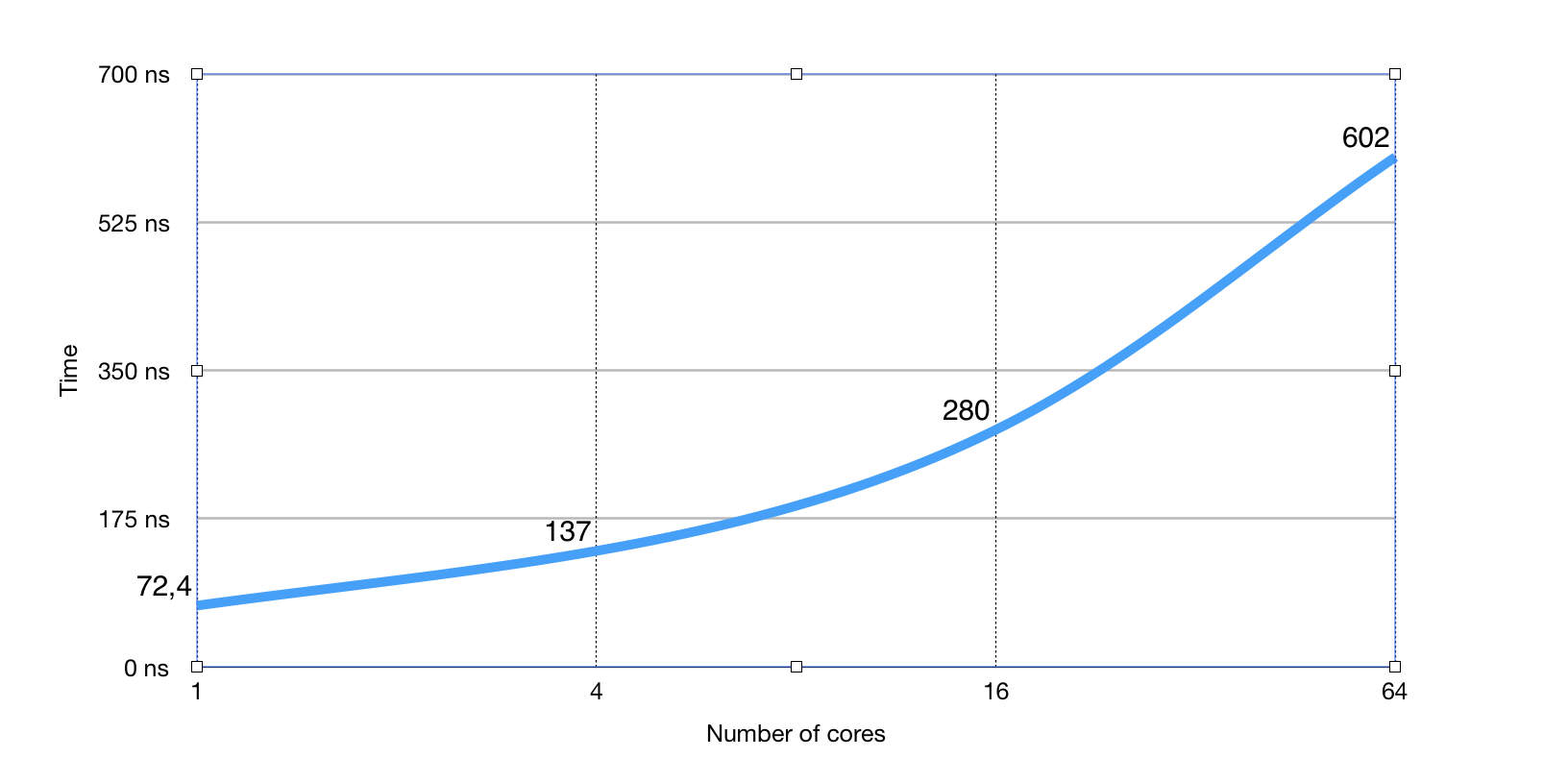
Как видим, очевидная линейная зависимость от количества задействованных ядер процессора.
В стандартной библиотеке map-ы используются довольно много где, в том числе в таких пакетах как encoding/json, reflect или expvars и описанная проблема может приводить к не очень очевидным замедлениям в более высокоуровневом коде, который и не использует напрямую map+RWMutex, а, например, использует reflect.
Собственно, для решения этой проблемы — cache contention в стандартной библиотеке и был добавлен sync.Map.
sync.Map
Итак, ещё раз сделаю акцент — sync.Map решает совершенно конкретную проблему cache contention в стандартной библиотеке для таких случаев, когда ключи в map стабильны (не обновляются часто) и происходит намного больше чтений, чем записей.
Если вы совершенно чётко не идентифицировали в своей программе узкое место из-за cache contention в map+RWMutex, то, вероятнее всего, никакой выгоды от sync.Map вы не получите, и возможно даже слегка потеряете в скорости.
Ну а если все таки это ваш случай, то давайте посмотрим, как использовать API sync.Map. И использовать его на удивление просто — практически 1-в-1 наш код раньше:
// counters := NewCounters() <--
var counters sync.MapЗапись:
counters.Store("habr", 42)Чтение:
v, ok := counters.Load("habr")Удаление:
counters.Delete("habr")При чтении из sync.Map вам, вероятно также потребуется приведение к нужному типу:
v, ok := counters.Load("habr")
if ok {
val = v.(int)
}Кроме того, есть ещё метод LoadAndStore(), который возвращает существующее значение, и если его нет, то сохраняет новое, и Range(), которое принимает аргументом функцию для каждого шага итерации:
v2, ok := counters.LoadOrStore("habr2", 13) counters.Range(func(k, v interface{}) bool {
fmt.Println("key:", k, ", val:", v)
return true // if false, Range stops
})API обусловлен исключительно паттернами использования в стандартной библиотеке. Сейчас sync.Map используется в пакетах encoding/{gob/xml/json}, mime, archive/zip, reflect, expvars, net/rpc.
По производительности sync.Map гарантирует константное время доступа к map вне зависимости от количества одновременных чтений и количества ядер. До 4 ядер, sync.Map при большом количестве параллельных чтений, может быть существенно медленнее, но после начинает выигрывать у map+RWMutex:
Заключение
Резюмируя — sync.Map это не универсальная реализация неблокирующей map-структуры на все случаи жизни. Это реализация для конкретного паттерна использования для, преимущественно, стандартной библиотеки. Если ваш паттерн с этим совпадает и вы совершенно чётко знаете, что узкое место в вашей программе это cache contention на map+sync.RWMutex — смело используйте sync.Map. В противном случае, sync.Map вам вряд ли поможет.
Если же вам просто лень писать map+RWMutex обертку и высокая производительность совершенно не критична, но нужна потокобезопасная map, то sync.Map также может быть неплохим вариантом. Но не ожидайте от sync.Map слишком многого для всех случаев.
Так же для вашего случая могут больше подходить други реализации hash-таблиц, например на lock-free алгоритмах. Подобные пакеты были давно, и единственная причина, почему sync.Map находится в стандартной библиотеке — этого его активное использование другими пакетами из стандратной библиотеки.
Ссылки
Комментарии (26)

claygod
26.09.2017 08:21+4Только вчера искал что-нибудь про sync.Map (очень уж смущала фраза в официальной документации про «стабильность»), и тут по подписке готовый и разжеванный ответ! Спасибо за разъяснение.
При прочтении статьи закралась мысль, а не может ли оказаться так, что вместо map+RWMutex лучше себя проявит map+Mutex в ситуации cache contention или близкой к ней?
divan0 Автор
26.09.2017 14:46You're welcome!
При прочтении статьи закралась мысль, а не может ли оказаться так, что вместо map+RWMutex лучше себя проявит map+Mutex в ситуации cache contention или близкой к ней?
Ну, для этого
(*sync.Mutex).Lock() + чтение из map + (*sync.Mutex).Unlock()должны быть быстрее, чем трансфер значения из L2 кеша между ядрами CPU на данной архитектуре. Несложно замерить, впрочем.
nikitadanilov
26.09.2017 18:06+2Mutex.Lock() гарантировано содержит атомарную операцию, т.е. cache transfer там точно будет.

SirEdvin
26.09.2017 11:11+1Простите, а можно ли ссылку на бенчмарк, с которого взят график скорости для python? Не думал что он настолько медленный, интересно посмотреть, почему так.
А, кажется это можно найти тут. Итого, мы сравниваем (если я правильно понял): "Java openjdk 1.8.0 java.util.HashMap, c++11 gcc 4.8.4 unordered_map, -O2. Python 2.7.6".
Что ж такую новую версию питона взяли, а не какой-то python 2.3? Уверен, результаты были бы еще более шокирующими.
wing_pin
26.09.2017 11:24+1Как показывает практика, производительность Python 3 немного ниже производительность Python 2. Такие дела.
SirEdvin
26.09.2017 11:31Если верить вот этим бенчмаркам, основанным на python/performance, то зависит от того, что использовать.
Тот же pickle_dict проходит быстрее, следовательно, вполне возможно, что сам dict в python3.6 в целом работает быстрее, чем в python 2.7.6.
И даже если забить на это, почему нельзя было использовать последнюю версию python 2.7?
khim
26.09.2017 18:00-1И даже если забить на это, почему нельзя было использовать последнюю версию python 2.7?
Потому что бенчмарки эти делались, в первую очередь, для того, чтобы принять решения. И была использована последняя доступная версия python2. То что она оказалась несколько… старше, чем фанатам бы хотелось — ну что ж тут поделать. Зато это то, что реально используется в проде.
По этой же принчине использовался gcc 4.8.4, а не gcc 7, OpenJDK 8 и так далее.
Переписывать миллионы строк на python 3 ради копеечного ускорения никто не будет. Вот если бы python3 был сравним с go или java — тогда другой вопрос, а так — разница вместо стократной станет, если повезёт, десятикратной. И то вряд ли. Если уж переписывать, то стоит взять другой язык и получить-таки стократное ускорение…SirEdvin
26.09.2017 18:19Ну так не переписывайте. Вот я взял и провел бенчмарк из этого комментария для 2.7.13. Получил аналогичные результаты стандартным %timeit, то есть 35-40 ns.
Страшные циферки из графика у меня получилось получить только низким количеством прогонов, а следовательно, реальное отставание от лидеров у python всего в 2-3 раза, что не так плохо.
Ну и да, это какое-то странное лукавство, сравнивать "реальные версии, которые есть в дистрибутиве" и новый релиз go.
Если же на python 2.7.6 в самом деле все так плохо, то уж обновить пакет ради прироста производительности то можно, я думаю.

homm
26.09.2017 17:24Тоже заинтересовали цифры. Проверил:
$ ipython Python 3.5.3 (default, Apr 22 2017, 00:00:00) Type 'copyright', 'credits' or 'license' for more information IPython 6.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: m = dict(enumerate('abcdefghij')) In [2]: %timeit m[4] 38.1 ns ± 0.247 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) In [4]: m = dict((v, v) for v in 'abcdefghij') In [5]: %timeit m['c'] 35.6 ns ± 0.346 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
Интересно, в каки условиях могло получиться 150 ns.
SirEdvin
26.09.2017 18:10-2А потому что нужно делать вот так:
Python 3.6.2 (default, Jul 20 2017, 03:52:27) Type 'copyright', 'credits' or 'license' for more information IPython 6.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: m = dict(enumerate('abcdefghij')) ...: In [2]: %timeit -n 15 m[4] 265 ns ± 43.7 ns per loop (mean ± std. dev. of 7 runs, 15 loops each)
Можно попрогонять так раз 20 и получить совершенно фантатические результаты, от 36.3 до 265.

anjensan
26.09.2017 18:57Я думаю все немного проще. Можно потестировать так
In [1]: m = dict(enumerate('abcdefghij')) In [2]: %%timeit x = 0 x = x + 7 if x > 9: x = 0 m[x] 10000000 loops, best of 3: 58.7 ns per loop
А можно и так
In [3]: import random In [4]: %%timeit m[random.randint(0, 9)] 1000000 loops, best of 3: 708 ns per loop
Сами по себе хеш-таблицы в Python очень быстрые, что вполне логично для языка, где любой объект по сути хеш таблица. Думюа в Python они побыстрее, нежели в Go.
Но вот обвязочка медленная. Скажем банальный вызов random.randint добавляет еще одно чтение из хеш-таблицы random и т.п. Поэтому все подобные «бенчмарки» без исходников не стоят и выеденного яйца.
homm
26.09.2017 19:19+1Можно попрогонять так раз 20 и получить совершенно фантатические результаты, от 36.3 до 265.
Я получаю либо 0, либо 63ns. Если посмотреть
time.get_clock_info('clock'), будет видно, что разрешение таймера 1e-06 секунд, то есть 1000 наносекунд. Проверяем:
In [35]: (time.clock() - time.clock()) * 1e9 Out[35]: -1000.000000139778
1000ns / 15 раз = 66.6ns. Так что замерять время выполнения таких быстрых операций отдельно или даже по 15 штук нет никакого смысла — время выполнения меньше разрешения таймера.
divan0 Автор
26.09.2017 18:29-1График взят из доклада Keith Randall, упоминаемого в статье: docs.google.com/presentation/d/1CxamWsvHReswNZc7N2HMV7WPFqS8pvlPVZcDegdC_T4/edit
anjensan
26.09.2017 12:55В текущей реализации map очень быстр
Но медленнее Java примерно на 15-40% (на глаз по графику)? Было инетересно взглянуть на бенчмарки.
quasilyte
26.09.2017 16:22Есть ещё вот такой открытый issue:
runtime: working with small maps is 4x-10x slower than in nodejs.anjensan
26.09.2017 16:52Ну для nodejs там результаты ожидаемые — идет внутренняя оптимизация для объектов с целочисленными индексами. В комментариях это упоминается github.com/golang/go/issues/19495#issuecomment-289293859
Хотя выигрыш PyPy в этом бенчмарке выглядит забавно :)
Ситуация для Java иная — хеш таблицы не имеют поддержки на уровне языка и реализованы как часть стандартной библиотеки. По идее реализация на уровне языка (go) должна быть побыстрее… Поэтому и интересно было бы взглянуть на бенчмарки.

sondern
26.09.2017 14:39Есть глупый вопрос автору. В статье «ядро» это поток или физическое ядро. Intel i7 4 ядра с гипертрейдингом это 8 потоков или 8 ядер?
divan0 Автор
26.09.2017 14:41Это «поток» — тоесть то значение количества CPU, которое видно операционной системе. runtime.NumCPU(), другими словами.
Bonart
26.09.2017 16:27Интересно, а есть ли возможность прикрепить пул горутин к одному потоку ОС?
В этом случае синхронизация внутри такого пула не нужна по построению.divan0 Автор
26.09.2017 16:35+1Пул вроде нет, а конкретную горутину — да: golang.org/pkg/runtime/#LockOSThread
Bonart
26.09.2017 17:03Это слишком сурово, особенно с учетом
Until the calling goroutine exits or calls UnlockOSThread, it will always execute in that thread, and no other goroutine can.
Хочется провернуть фокус, который легко доступен, скажем, с файберами на Windows — IO параллелизм без синхронизации.

QtRoS
26.09.2017 23:36А затраты на приведение типа (из interface{} в конкретный) учитывались при подсчете разницы во времени между map[...]… и sync.Map?
divan0 Автор
27.09.2017 02:27-3Да, если вы про график вначале статьи, то там учтены (он из статьи по ссылкам в разделе Ссылки).
Оверхед от конвертации в и из интерфейсом можно померять бенчмарками из стандартной библиотеки:
go test -test.run none -bench Conv runtime
У меня вот такой результат выдает (T — type, I — interface, E — empty interface):
$ go test -test.run none -bench Conv runtime goos: darwin goarch: amd64 pkg: runtime BenchmarkConvT2ESmall-4 500000000 3.50 ns/op BenchmarkConvT2EUintptr-4 500000000 3.49 ns/op BenchmarkConvT2ELarge-4 50000000 26.3 ns/op BenchmarkConvT2ISmall-4 500000000 3.44 ns/op BenchmarkConvT2IUintptr-4 500000000 3.43 ns/op BenchmarkConvT2ILarge-4 50000000 25.5 ns/op BenchmarkConvI2E-4 2000000000 1.12 ns/op BenchmarkConvI2I-4 200000000 9.91 ns/op BenchmarkConvT2Ezero/zero/16-4 500000000 3.53 ns/op BenchmarkConvT2Ezero/zero/32-4 500000000 3.53 ns/op BenchmarkConvT2Ezero/zero/64-4 500000000 3.42 ns/op BenchmarkConvT2Ezero/zero/str-4 500000000 3.35 ns/op BenchmarkConvT2Ezero/zero/slice-4 500000000 3.33 ns/op BenchmarkConvT2Ezero/zero/big-4 20000000 99.7 ns/op BenchmarkConvT2Ezero/nonzero/16-4 100000000 14.2 ns/op BenchmarkConvT2Ezero/nonzero/32-4 100000000 15.0 ns/op BenchmarkConvT2Ezero/nonzero/64-4 100000000 17.6 ns/op BenchmarkConvT2Ezero/nonzero/str-4 50000000 30.4 ns/op BenchmarkConvT2Ezero/nonzero/slice-4 50000000 36.3 ns/op BenchmarkConvT2Ezero/nonzero/big-4 20000000 93.4 ns/op PASS ok runtime 38.947s
bat
вот бы подробностей что там под капотом
Blooderst
Вот тут все подробно описано: golang.org/src/sync/map.go