
«Нельзя просто так взять и написать классный тест. Один тест написать можно, но сделать, так чтобы по мере того, как количество этих классных тестов росло, как количество людей, которые пишут эти классные тесты, и вы не теряли ни в скорости, ни во времени...»
Эта мысль красной нитью пойдет сквозь материал под катом, и она, пожалуй, требует пояснения. Статья основана на докладе Николая Алименкова, к которому он подошёл не просто прогретым, а горящим после дискуссии с Алексеем Виноградовым о подходах к написанию тестов: методом прямого кода или при помощи паттернов. Нужны ли какие-то еще паттерны, кроме PageElement, Steps, PageObject?! С чего кто-то решил, что паттерны усложняют код, заставляют нас тратить время на создание ненужных (?) boilerplate-простыней? SOLID вам не угодил? А ведь все они создавались с учётом всего накопленного опыта сообщества разработчиков и они знали, что делают.
Николай xpinjection Алименков – известный Java-разработчик, Java техлид и delivery-менеджер, основатель XP Injection. В настоящее время является независимым разработчиком и консультантом, Agile/XP коучем, спикером и организатором различных конференций
Автоматизация тестирования имеет собственный набор задач, так что существует и набор полезных паттернов проектирования для этой области. В докладе Николай рассказывает обо всех известных паттернах и подробно описывает их с практическими примерами.
В основу этого материала легло выступление Николая Алименкова на конференции Heisenbug 2017 Piter под названием «Паттерны проектирования в автоматизации тестирования». Слайды здесь.
Дизайн-паттерны – достаточно спорная тема. Если погуглить этот вопрос, найдется множество других примеров дизайн-паттернов в автоматизации проектирования, которых нет в этой презентации. В этом материале хотелось бы собрать все паттерны, накопленные за 13 лет личной практики, с которыми пришлось сталкиваться лично. В презентацию не включены паттерны, которые автор считает сомнительными, не полезными или с которыми он не сталкивался. В то же время эта презентация со временем расширяется новыми примерами.
Но сначала – краткое определение паттернов проектирования.
Что такое дизайн-паттерн (Design Pattern), зачем эта штука существует?
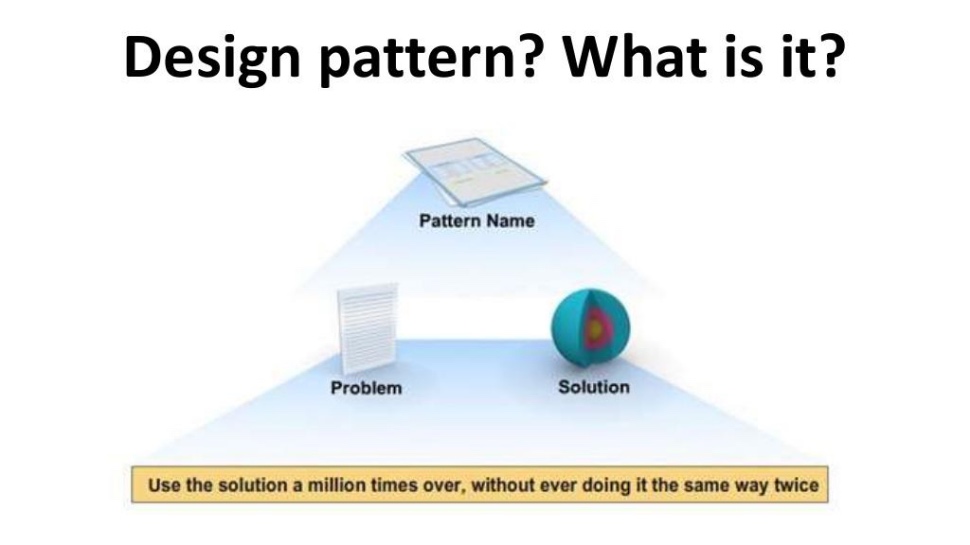
Не существует такого понятия как «хороший дизайн-паттерн», «плохой дизайн-паттерн». Сам термин «дизайн-паттерн» был придуман в качестве формулировки проблемы и предложенного решения. Поэтому для каждого встреченного вами паттерна – в разработке, в тестировании, еще в чем-то, если вы не разделяете проблему, для которой он был придуман – это не значит, что он плохой или «вышел из моды», просто он для вас не подходит. Если ваша проблема каким-то образом совпадает и накладывается на этот дизайн-паттерн, значит, вам стоит его рассмотреть.
Таким образом важно не просто приносить дизайн-паттерны в свой проект только потому, что вы о них услышали, важно понимать их назначение, проблематику, как и чем они могут вам помочь.
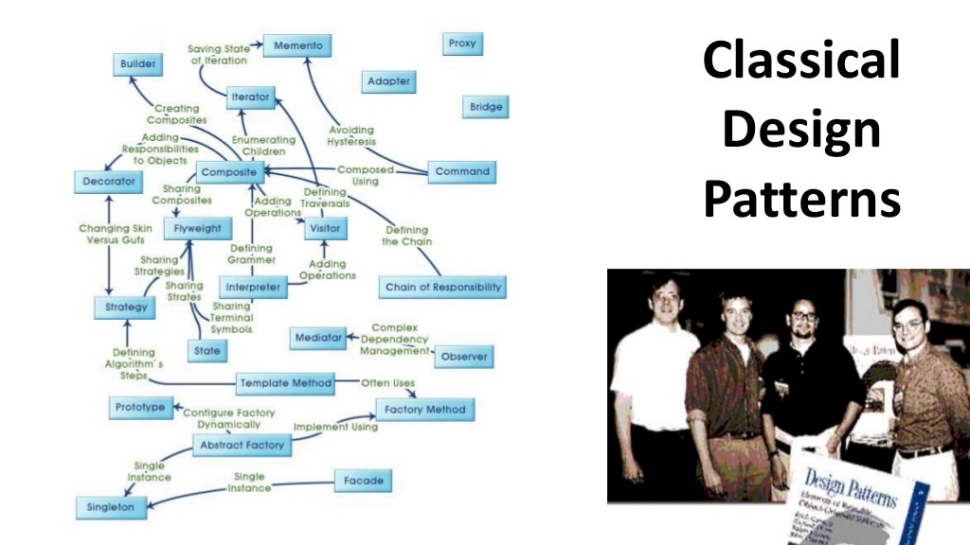
Проблем в автоматизации проектирования и разработке множество, и сталкиваясь с этими проблемами, люди формулировали паттерны. Изначально классические паттерны были сформулированы давным-давно четверкой, которая выпустила книгу Design Patterns.
В книге сформулированы все паттерны, с которыми они сталкивались в то время в объектно-ориентированном мире. Есть проблема – есть ее решение, и долгое время эта концепция дизайн-паттернов росла и развивалась, пополняясь новыми паттернами.
Сегодня просматривается тенденция появления подобных паттернов в других областях, в которых накопилась проблематика.

Основными драйверами практически всех паттернов в автоматизации тестирования являются факторы на слайде выше: надежность, понятность, гибкость, поддерживаемость, стабильность и другие подобные факторы, которые вам важны в ваших тестах.
Большая часть этих факторов находится под влиянием разделения концепции: в любом вашем тесте – функциональном, интеграционном, unit-тесте — всегда присутствует три компонента: тестовая логика, тестовые данные и application driver, или technical details, technical parts – часть, отвечающая за непосредственное взаимодействие с вашим приложением, вашим кодом (вызов функций, клики на экран и т. п.).
Если эти части хорошо разделены, ваши тесты начинают хорошо попадать в выше упомянутые факторы, потому что в этом случае ими гораздо проще манипулировать, гораздо проще их понимать и поддерживать.
Все паттерны я разделил на несколько групп.
Структурные паттерны – Structural Patterns
Первая группа – это cтруктурные паттерны, основная задача которых сводится к структурированию кода наших тестов — чтобы упростить поддержку, избежать дубликатов и проблем с запутанностью. Таким образом, тестовым инженерам, работающим с теми же проблемами, будет проще понять их и изменить, и проще поддерживать.

Первая группа таких паттернов – это Page Object. Зачем он нужен, какова проблематика?
Первая часть проблематики: у нас есть логическая структура нашего приложения, и когда мы пишем тесты в коде, мы не совсем понимаем, где именно мы сейчас находимся – мы же не видим UI непосредственно со своим тестом. Где я нахожусь после шага 15, на какой странице, какие действия могу там сделать, могу ли, например, после 15 шага вновь вызвать log in?
Вторая часть проблематики: я бы хотел разделить технические детали (в данном случае, говоря про web, это элементы в браузере, элементы, выполняющие ту или иную функциональность), разнести и унести их из логики своих тестов, чтобы логика тестов осталась чистой и прозрачной, а эта информация хранилась где-то в другом месте.
Наконец, последний фактор: я хотел бы впоследствии многократно использовать тот код, который я вынес в эти страницы. Потому что если множество сценариев проходит через одни и те же страницы, то будет вполне логично, если я, написав этот код один раз, больше никогда в жизни не буду писать этот код самостоятельно руками, я его буду вызывать, что, соответственно, значительно упростит написание моих тестов.
Вот три проблемы, которые помогает решать Page Object. Если у вас только пара тестов, у вас нет этой проблемы – просто нет масштаба, на который вы можете это применить. Если у вас пять – десять – пятнадцать тестов, у вас эта проблема может быть и может не быть. Поэтому вы должны понимать, соответствует ли этот паттерн тому, что вы делаете.

Давайте быстро «пробежимся» по Page Object. У нас есть какая-то страница с какими-то элементами, неважно, чем вы их помечаете (в данном примере с помощью аннотаций @FindBy). Вы можете использовать любые аннотации, которые вам нравятся. Я вынес все элементы этой логической страницы в одно отдельное место, снабдив ее дополнительно доменными методами, которые теперь выглядят таким образом:
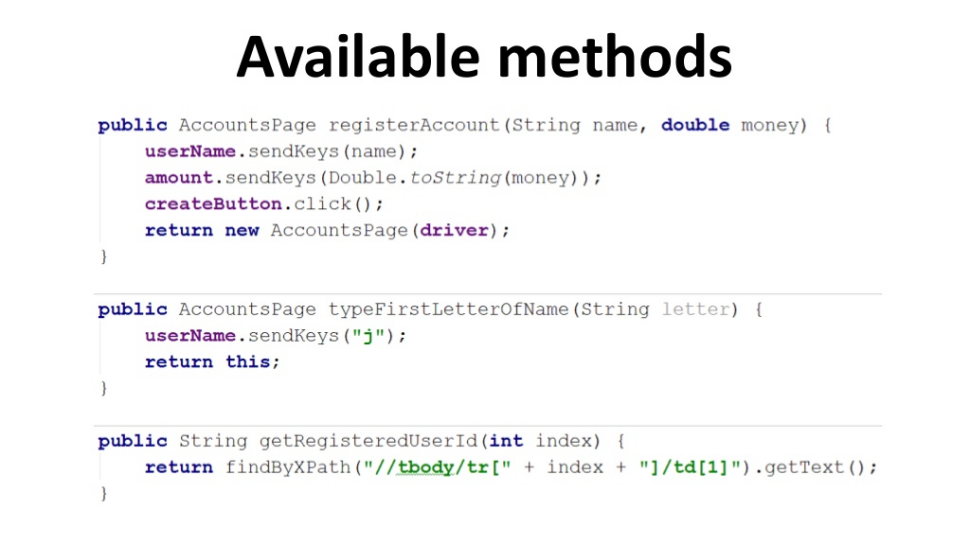
Например, теперь у меня есть доменный метод registerAccount, я приведу туда userName и количество денег (amount), и благодаря этому в одно поле я ввожу имя, в другое поле ввожу количество денег, нажимаю кнопку и у меня создаётся новый аккаунт. Или, например, ввести первую букву имени (пример ниже).
Таким образом, тест выглядит очень просто, в тесте всего этого нет, оно вынесено, тестовая логика очистилась. Мы получили то, ради чего этот паттерн был придуман.
Это самый простой паттерн. Идем дальше.
Fluent/Chain of invocations
Следующая проблематика, которую вы хотите решить – когда вы вызываете что-нибудь, например, на login page. Можете ли вы далее вызвать что-нибудь на login page или нет? Вы не знаете.
Теперь представьте себе, что на какой-то странице у вас есть, например, 50 методов. И вы не понимаете, могут ли они все сразу вызваться, или можно вызывать только некоторые из них, а потом уже другие. К примеру, могу ли я работать с диалогом показа имен, если я еще не ввел никакой буквы и не вывалилась автоподсказка? Наверно, нет, потому что этого диалога пока как бы не существует.
Эта проблематика важна, когда у вас начинает накапливаться количество страниц, количество элементов, количество методов внутри, и вы хотели бы выстраивать определенный поток ваших действий. Каждый раз, когда вы хотели бы сделать следующее действие, у вас бы появлялась автоподсказка, и все было бы понятно.

Поэтому, вместо кода, где вы говорите «accountsPage, введите первую букву, accountsPage, подожди подсказок, accountsPage, выбери первое имя» — заметьте, здесь я спокойно могу менять их местами, и ничто не подскажет мне, что я пишу что-то неправильно, ошибку сделать достаточно просто.
Вместо этого предлагается использовать вот такой подход, где каждый раз, когда вы выполняете какое-то действие, вам возвращают контекст, в котором вы находитесь. Это может быть та же страница, перегруженная страница, другая страница, логический компонент или еще что-то.
Обычно, если вы хотите прервать эту цепочку, в этом методе вы даете какое-либо значение, например, строку, число или что-то еще, тем самым намекая, что дальше двигаться нельзя. То есть это является конечной, терминальной операцией, после которой цепочку продолжать нельзя, и дальше вы должны подумать, куда хотите дальше идти, и сделать это действие руками.
Реализуется это очень просто – в своих page objects или других местах, где можно применить этот паттерн, вы используете возвращаемое значение, которое может быть this или любой другой объект, с которым вы дальше хотите продолжить работу.
Код не то чтобы становится мега-компактным – из него убираются некоторые дубликаты (в данном случае, убирается кусочек, где каждый раз говорится на какой странице вы находитесь), и он становится более понятным и прозрачным.

Factory/Page Factory
Следующий паттерн – это Page Factory, или просто Factory, потому что он может применяться не только к страницам. Возник этот паттерн потому, что иногда, чтобы инициализировать вашу страницу, необходимо сделать больше действий, чем просто сказать «new page» или open, или еще что-то. То есть у вас в этой странице скрыта еще какая-то дополнительная логика, и вы хотите ее куда-то зарегистрировать, инициализировать ее элементы и так далее.
В этот случае вам бы хотелось, чтобы эта информация была скрыта от того, кто создает эту страницу, чтобы она была спрятана – это техническая информация, которая никому не важна.
Именно здесь применяется подход Factory. В данном случае у меня действует такой подход: я говорю «new MainPage», передаю туда драйвер и потом говорю «страница, откройся». Если бы я хотел сделать что-то дополнительное на этом открытии, мне нужно было бы либо занести это в метод open, который стал бы factory-методом, потому что он открывал бы эту страницу, инициализируя ее и делая ее новой, либо мне нужно было бы внести это в конструктор, что может быть тоже не очень хорошо.
Поэтому есть альтернативный подход – когда вы просто указываете вашу фабрику (я для примера привел здесь классическую Page Factory, которая есть в Java для web-драйвера), вы можете просто заказать Page Factory, Init elements, и у вас на выходе получится экземпляр класса этой страницы со всеми инициализированными элементами, которые есть в этой странице.
Дополнительный фактор, который будет здесь работать – это инициализация всех элементов. Я могу открыть так любую страницу, и мне не обязательно начинать с главной страницы.
«Фабрики» есть разные. Вы можете написать свои, можете использовать фабричные методы – важно понимать суть, для чего это делается.
Page Element/Composite List of Items Link Menu Panel Checkbox

Любое важное веб-или десктоп-приложение состоит из повторяющихся элементов, к которым вы снова и снова пишете логику ваших в ваших тестах. Когда вы начинаете работать с табличкой, у нас всегда есть меню, чекбоксы. Когда мы работаем с нашими тестами, вряд ли мы думаем об этих верхних ссылках как о живущих в своей отдельной реальности и не связанных друг с другом. Мы все понимаем, что это меню, мы понимаем, что это панель с расположенными на ней элементами, ссылка, список элементов и так далее.
Благодаря этому пониманию мы можем существенно сократить затраты коммуникацию с элементами – потому что если мы один раз реализовали меню и всю логику работы с ним, то легко можем сильно упростить и сделать usable-компоненты, которым потом можно использовать повторно, сократив время на разработку тестов.
No duplicated code
Проблематика в том, что мы видим дубликаты, встречающиеся повсеместно, и мы хотим эти дубликаты устранить.

Так появляется паттерн Page Element, который говорит, что вместо прежней страницы у нас будет улучшенная, на которую вместо полей name, amount и так далее вставляются высокоуровневые виджеты. Первый из них – это форма, которая умеет делать действия, характерные для всех форм, — такие как submit, «введи в поле значение», validate так далее, второй – табличка.
С табличками все обстоит интереснее, поскольку в них есть заголовок, колонки, строки. Есть множество доменных команд, которые присущи всем таблицам без исключения, как бы они ни были реализованы и как бы ни выглядела эта таблица в браузере. Если вы имеете такую табличку, то расположив элементы таким образом, вы очень сильно упрощаете работу с вашей страницей.

С моей точки зрения, следующий паттерн довольно сомнительный, но я знаю точно, что многие его используют.
Loadable Component
Проблематика заключается в том, что когда вы переходите на какую-нибудь страницу, уже давно в том же web-драйвере нет понятия «перезагрузки страниц». Плюс, у нас все больше так называемых одностраничных приложений, в которых такое понятие как «перезагрузка страницы» отсутствует вовсе.
Это значит, что когда вы открываете логическую страницу и собираетесь работать с каким-либо элементом этой страницы, по-хорошему вам следует дождаться и убедиться, что эта страница логически загружена. Получается, что после каждого вашего действия вы должны делать своеобразный wait чего-то, то есть ожидания чего-то. Зачастую такого wait не делают, потому что многие рассчитывают, что за вас это сделает фреймер. Например, в web-драйвере есть понятие implicit wait, и за вас – если что, неявно дождутся того элемента со стороны браузера, с которым вы будете работать.
Некоторые говорят «ОК, мне этого достаточно», но если implicit wait маленький и это не работает для вас, появляется так называемый explicit wait, когда вы основательно ждете чего-то, и получается, что теперь в вашу тестовую логику после каждого такого хорошего действия, которое меняет логическую страницу, дополняется еще wait: что-то сделали – wait, что-то сделали – wait.
Такой шаблон очень сильно загружает вашу тестовую логику, потому что у вас нет в самом описании теста, вы просто говорите «перейди на ту страницу» и уже туда включаете это ожидание.
Для того чтобы этого избежать, вы можете каждую страницу, которую вы делаете, отнаследовать от loadable component и перегрузить метод из loaded, благодаря чему скроете это ожидание и специфицируете его для каждой страницы внутри самой страницы. В этом случае у вас будет инкапсулированная логика в одном месте – если вы одну и ту же страницу будете в пяти местах вызывать и нигде больше этот wait руками писать не придется. Вот для чего придуман и существует этот паттерн.
Почему он спорный? С моей точки зрения, большинство все же полагается на поведение по умолчанию с implicit wait-ами и большинству этого хватает. Так что нужно смотреть, в каком контексте он применим.

Следующий паттерн под названием Strategy нужен, когда мы хотим иметь несколько реализаций одного и того же – либо последовательностей, либо действий. Мы можем подставлять туда эту реализацию в зависимости от контекста.
Это может использоваться, например, в валидации: у вас есть некий абстрактный метод validate для него непосредственно вы применяете эту стратегию. Также это может быть какой-либо вычислительный алгоритм: вы можете использовать сложный или простой алгоритм, но при этом не хотите напрямую вписывать его в ваш код и получить гибкость в подстановке конкретной реализации конкретной стратегии.
В данном конкретном случае – на слайде выше есть стратегия по регистрации пользователя. Первая реализация этой стратегии использует для этого браузер – она открывает страничку и выводит поля, кнопку «зарегистрировать», получая ID на выходе из URL и возвращая нам объект юзера, а вторая идет через API.
Как вы думаете, какая быстрее?
Наверняка вторая: хочу ли я везде прописывать этот код руками, если я потом решил поменять его на 97%? Наверно, нет.
Возможно, его необходимо поменять не везде – ведь где-то действительно нужно проверять регистрацию пользователя, если я не проверю через web, то будет все печально. Поэтому я бы хотел в каких-то местах использовать одну стратегию, а в других – другую стратегию, и я могу это спокойно сделать, потому что сама логика тестов будет полагаться на интерфейс, который не говорит, какая это реализация, и будет использовать ту реализацию, которую я подставлю во время тестов.
За счет этого я получил гибкость и разделение концепции, а также упростил жизнь тем, кому потом нужно будет все это поддерживать.
Паттерны данных – Data Patterns
Как вы видели на изначальной картинке – для чего мы все это делаем — там был треугольник с данными. Мы хотели бы как можно дальше оттащить данные и управление данными от тестовой логики, для того, чтобы убрать количество так называемого boilerplate code – мусорного кода, засоряющего наши тесты. Благодаря этому логика станет еще более прозрачной, ее будет легче поддерживать тем, кто пишет эти автотесты.
Такова мотивация всех паттернов данных.
Value Object
Первый паттерн этой группы – очень простой, думаю, все вы им пользовались, но к моему большому сожалению, я видел много проектов, где этим пренебрегают, и в итоге получается очень сложно.

Суть паттерна такова: если у вас есть несколько объектов, объединенных между собой логически (в данном примере есть registerUser, и мы передаем туда пять параметров – имя, фамилию, возраст, роль и прочее). Я лично видел методы, в которых делали около ста параметров, и спокойно с этим жили, насколько это было удобно – остается только догадываться. Параметры были логически указаны, но нигде этой связи указано не было.
В данном случае это можно трансформировать, введя дополнительный ValueObject, который называется вполне логично user, и который агрегирует в себе всю эту информацию.
Почему ValueObject? Он Immutable: после того, как он создается, его нельзя изменить, потому что в этом его задача, он служит для передачи данных из точки А в точку Б, а не для того чтобы быть модифицируемым или нести сторонние эффекты.
Чтобы упростить создание и работу вот таких пользователей, если вы работаете с Java, вы можете воспользоваться инструментом Lombok, который легко позволит делать компактные элементы, используя только геттеры для получения данных; если вам необходимы конструкторы – точно так же генерируются любые конструкторы в любом количестве, не обязательно писать этот код руками.
Builder
Следующий паттерн – это Builder. Предположим, у нас есть большой объект, и этот объект может быть сконфигурировано совершенно по-разному. Можно пойти первым способом и добавить столько конструкторов, сколько вариаций у вас есть, и каждый раз, когда вы встречаетесь с новой вариацией, вы можете добавлять новый конструктор. В итоге вы будете иметь 100500 конструкторов, и будет совершенно непонятно, когда какой вызывать.

Чтобы упростить это, сделать конструкторы более понятными и добавить возможность автоподсказки того, что еще можно сконфигурировать, используется паттерн Builder, реализация которого выглядит следующим образом.
Мы берем Builder по кластеру, и в данном случае используем доменные методы для конфигурирования этого кластера – добавляем к нему ContactPoints, порт, количество попыток ретрая, конфигурацию метрик, и после этого в конце мы говорим build и в конце получаем наш объект, который далее мы можем использовать в наших автотестах.
Это очень удобно, потому что вам не нужно задавать все необходимые поля – можно задать только те, которые интересны вам на текущий момент, что упрощает конфигурацию объектов, которыми вы манипулируете.
Assert Object/Matchers
Следующий паттерн, о котором говорят все, но применяют его очень мало людей – это Assert Object, или «матчеры». У нас есть классический подход – мы вытащили пользователей и хотим сделать на них какие-то проверки. Классический подход отличается тем, что мы делаем множество различных проверок, и все они относятся к какой-то одной доменной сущности.

За этими проверками – в примере выше три строчки, нет логического названия проверки, мы теряемся, что же мы конкретно проверяем. А проверяем мы то, что в этой конкретной коллекции будет только один пользователь с определенной ролью, но мы должны разделить это на несколько проверок, потому что иначе мы не поймем, что же пошло не так: сначала мы должны убедиться, что в этой коллекции только один пользователь, и затем что у него есть такая роль. Но логически эта информация скрыта он нас, потому что мы имели ее в голове, когда писали этот assert, но теперь эта информация не воспроизводится.
Этот дизайн-паттерн говорит о том, что нам необходимо воплощать наши ассерты в виде повторяющихся конструкций, которые позволят нам не писать такой ассерт в будущем, если он понадобится нам снова – возможно, уже в другом тесте нам потребуется проверить, что есть только один пользователь, но уже с другой ролью, или все пользователи с этой ролью, и так далее.
Мы пытаемся избежать повторного написания кода и попутно закладываем доменную логику. Поэтому предлагается делать это таким образом: во-первых, выделяются группы ассертов, для этого можно использовать либо создание отдельных классов (в данном случае это UserAssert), который делает все возможные ассерты с юзерами, и для того, чтобы это выглядело красиво, делается либо статический метод на самом UserAssert, который говорит assertThat и таким образом возвращает вам этот ассерт, на котором вы можете делать свои дальнейшие проверки. Это выглядит красиво и читается гораздо легче чем было ранее, и все понимают, что код внутри проверки остался точно такой же, только стал доступен для повторного использования.
Можно было бы делать для этого статические методы, это целое отдельное направление, которое реализует библиотека Hamcrest и другие библиотеки Fast assert, которые, пользуясь этим подходом, позволяют вам делать цепочки из ваших ассертов и писать свои собственные ассерты, которые можно использовать повторно.
Для базовых циклов написано уже огромное количество ассертов, писать их с нуля не нужно. Здесь же идет речь о ваших бизнес-ассертах – о тех группировках таких простейших функциональных ассертов базовых типов, которые формулируют вашу бизнес-задачу, что именно вы хотите проверить с точки зрения бизнеса.
Data Registry
Следующий шаблон более интересен. Его проблематика такая: предположим, мы в тестах начинаем использовать данные, и для того, чтобы они были независимы друг от друга, пытаемся каким-то образом отвязать их друг от друга, но в результате можем прийти к тому, что получаются зависимые тесты, которые будут «знать» о логике друг друга. Например, этот тест будет знать, что он использует user 1,2,3, и после этого он говорит «все, user 1,2,3, закреплен за мной и больше никто его не использует», хотя кто-то может попытаться скопипастить его в другое место, не зная о такой проблеме.

Подход Data Registry позволяет вам генерировать уникальные данные и следить за их уникальностью. В данном случае мы используем простейший подход: мы спрашиваем «дай нам уникального пользователя» и используем статический инкрементальный многопоточный счетчик, который постоянно инкрементирует его на единичку, тем самым гарантируя уникальных юзеров.
Ваш конкретный паттерн может быть гораздо сложнее, например, он может брать их из базы данных, из файла, из какого-то predefined набора юзеров, и так далее. Суть в том, что каждый, кто работает со своим тестом, прежде чем начать работу с какими-то уникальными данными, спрашивает у этого Registry юзера или какие-то другие данные, и он не знает самого алгоритма рандомизации, но всегда уверен, что получит эти данные независимо от других тестов. Тем самым возрастает защищенность тестов от ошибок в пересечении по данным.
Object Pool/Flyweight
Следующий паттерн знают и используют ещё меньше людей. Flyweight – это название паттерна, которое пришло из классических паттернов, и решает проблемы с объектами или наборами объектов, которые тяжеловесны в создании. Вместо того, чтобы создавать их каждый раз, мы берём их, пользуемся, и после этого они возвращаются в тот же Pool, откуда мы их взяли.

Благодаря этому паттерну можно реализовать много интересных вещей, например, вы можете реализовать пул браузеров. Многие жалуются – наши web-тесты тормозят, потому что пока браузер поднимется, пока первая страница загрузится, пока скопируется профиль и так далее.
Браузеры не обязательно создавать прямо в тесте, вместо этого можно использовать Background Pool, в котором настроено необходимое вам количество браузеров, и в этом пуле, когда браузер в него возвращается – вы его очищаете, делаете еще что-то, но это все происходит в бэкграунде, в параллельных с выполнением ваших тестов потоках. И только готовый к использованию браузер отдается вашему тесту, когда он запрашивает из браузерного пула новый браузер для себя.
Благодаря этому можно вынести конфигурационную часть и время на конфигурацию браузера из времени выполнения ваших тестов и благодаря этому существенно сократить траты на подготовку браузеров или других ресурсов в самом тесте.
Другой пример, когда вы используете страницы: не обязательно ждать, когда страница откроется, если вы всегда начинаете с одной и той же страницы. Можно иметь пул страниц и запрашивать страницу из него, что означает, что она там уже открыта и ждет вас в каком-то инстансе браузера, и вы уже начинаете свою логику с открытой страницы, а само открытие происходит в скрытом от вас бэкграундном процессе.
Наконец, классический пример более сложного использования этого паттерна – когда вы имеете пул инстансов базы данных. Вместо того, чтобы работать с реальной базой данных, вы поднимаете необходимый набор контейнеров базы данных в необходимом количестве на разных портах, это делается очень просто с Docker или каким-то другим доступным вам инструментом виртуализации, и после того, как вы поработали с базой данных, вы ее «потушили» и в пуле подняли новую. Благодаря этому вы можете постоянно иметь чистую базу данных для работы, нет необходимости делать teardown или очистку базы, собирание и загрузку данных, и так далее.
Data Provider
Следующий паттерн – Data Provider, наверняка знаком всем. Если вы хотите сделать data-driven тесты, и хотели бы, чтобы одна и та же тестовая логика выполнялась с разными данными, для этого вы загружаете свои данные из какого-либо внешнего источника (в данном случае xls), либо из CSV, либо подтягиваете с какого-то сервиса, либо они у вас вшиты прямо здесь.

Это можно сделать либо вот таким корявым способом – под «корявым» я подразумеваю нетипизированные данные, которые представляют из себя простые структуры наподобие массив-массивов или массив-строк, либо же вы можете перейти на более современный подход, который позволяет вам работать на уровне Entity, или на уровне Value Object, про которые мы говорили.

В данном случае вы можете пометить свой метод с помощью аннотации dataProvider, это может быть ваша аннотация или JUnit 5, который позволяет реализовывать такую концепцию, и уже оттуда вернуть набор параметров для использования в тесте.
В самом тесте вы можете указать, что dataProvider-ом является либо метод loadUsers, либо переменная, куда сохраняются эти данные. И все остальное фреймворк делает за вас – он вызывает юзера, подставляя его как параметр сюда.
Очень важный момент – этот паттерн очень круто использовать со вторым паттерном для данных, который мы сегодня уже обсуждали – с Value Object. Если бы мы его не использовали – передавали бы пять параметров того же пользователя там, а здесь была бы очень сложная конструкция – пришлось бы собирать строчку из многих параметров это был бы объект объектов, это был бы кромешный ад при передаче. Такой подход позволяет все это значительно упростить, сделать проще и читабельнее код, и легко повторно использовать.
Technical Patterns
Технические паттерны служат для того, чтобы вынести технические аспекты отдельно от тестовой логики, и зачастую для обеспечения дополнительного низкоуровневого контроля над технической частью.
Decorator
Достаточно известный паттерн в этой области – Decorator. Если вы работаете с какими-либо техническими драйверами (web-драйвер или какой-либо еще) — и хотите добавить к нему, например, логирование или кэширование, или что-то еще. Но при этом ваши тесты не должны об этом знать. В этом случае сама логика теста остается прежней — меняется только техническая реализация.
Поэтому вы предпочитаете пользоваться «принципом капусты» — заворачивая «листок в листок в листок», вы получаете концепцию «драйвер в драйвере в драйвере», о которой ваши тесты не догадываются: они как работали с интерфейсом драйвера, так и продолжают.

Например, мы хотим после клика записывать куда-то в лог. Мы оборачиваем наш основной драйвер EventFiringWebDriver, регистрируем туда слушателя, и, соответственно, наши тесты об этом не знают – они как работали с интерфейсом web-драйвера, так и продолжают.
Для того, чтобы наши тесты действительно об этом не знали, здесь используется вспомогательный паттерн Factory, чтобы этого не было в самой тестовой логике. Чтобы тем, кому действительно нужен браузер, говорил «Factory, дай мне браузер», и ему выдавали браузер (или драйвер). Так же можно воспользоваться пулом и получить уже сконфигурированный браузер из него.
Proxy
Proxy – это паттерн, позволяющий вмешаться в процесс между вами и ещё кем-то, и внедрить туда любую логику, не затрагивая ни вас, ни его.

Этот паттерн может быть полезен тогда, когда, например, вы хотите добавить логирование, вы хотите включить или отключить что-то, вы хотите управлять дополнительно какими-то ресурсами.

В данном случае самый популярный способ – это использование HTTP proxy для ваших тестов, который позволяет гибко настроить, например, black-листы, и сказать, что когда мое приложение пойдет в твиттер, фейсбук и так далее, я верну такие-то закэшированные результаты или верну ничего. Иногда это единственный способ, благодаря которому вы можете проверить, например, какое-нибудь exceptional-поведение ваших внешних сервисов.
Другой пример – вы хотите закэшировать нефункциональные ресурсы, такие как картинки или CSS, которые не влияют на ваши тесты, или же вы хотите параллельно с прогонкой тестов собирать http-трафик для дальнейшего анализа, это позволит обнаружить, например, сколько картинок было не найдено, или сколько ресурсов долго грузились и так далее.
Business Involvement Patterns
Последний набор паттернов, который мы рассмотрим – это паттерны взаимодействия с бизнесом. Мы пытаемся привести product-owners, бизнес-аналитиков и других людей, отвечающих за требования, так близко к автоматизации тестирования, как только можно, для того, чтобы они видели в ней пользу, и они вкладывались в нее не меньше чем мы, потому что мы – единая команда.
Keyword Driven Testing
Для этого используется самый популярный паттерн, который позволяет уйти в тестах как можно дальше от кода: бизнес код не понимает и не должен, но абстрактные команды на человеческих языках он поймет.
Keyword Driven тест использует ключевые слова — команды, которые выглядят понятно для всех участников процесса. В них могут передаваться какие-то данные, и в этом случае ключевые слова реализуются людьми, которые знают технические детали, умеют их реализовать и присоединить к вашему приложению, а тесты может писать кто угодно – бизнес-аналитик, тестировщик без опыта автоматизации, фрейморк это позволяет.

В данной конкретном примере из Robot Framework показано, как он выглядит там. Есть множество платных и бесплатных фреймворков, написанных с использованием этого подхода и позволяющих бизнесу из ключевых слов собирать тесты.
Идея заключается в том, что количество операций в любом приложении конечно. Это значит, что если все операции в приложении реализовать в виде ключевых слов, можно на эти кейворды делать бесконечное количество новых тестовых сценариев, комбинируя их в правильном порядке. Так вы можете обеспечить рабочий инструмент людям, которые хотят вовлекаться.
Многие критикуют этот паттерн, привнеся его и не понимая зачем, потому что их бизнес не хочет вовлекаться. Тесты у них пишут только тестировщики, и, возможно, только автоматизаторы, и для них это в данном случае является оверхедом – использованием паттерна там, где нет проблематики.
Behavior Specification
То же самое касается следующего паттерна – Behavior Specification, который предлагает вместо тестов перейти на описание ожидаемого поведения. Таким образом мы будем описывать фичу в виде поведенческих сценариев.

В данном случае у нас очень простой сценарий: я говорю, что могу сложить два числа, я ввел 50 и 70 в калькулятор, и, нажав сложить и равно, я должен получить 120. Эти тесты не являются «тестами» в чистом виде, это уже более описание поведения, они понятны всем, но, опять же, – паттерн рассчитан на то, что ваш бизнес очень хочет быть вовлеченным в процесс тестирования, например, делать приемочные критерии в виде таких спецификаций, отслеживать, какие из них проходят.
Если ваш бизнес к этому не готов, то проблематики не существует и этот паттерн приведет лишь к тому, что вы будете поддерживать лишь еще один ненужный слой абстракции.
Behavior Driven Development
Обычно паттерн Behavior Specification используют в концепции Behavior Driven Development, которая говорит о том, что сначала мы должны специфицировать все поведение нашей функциональности, после этого мы должны ее реализовать в коде и написать падающие тесты, и в конце мы получим работающие тесты на низком уровне, поведенческие сценарии на высоком уровне, и все будут счастливы.

Как вы понимаете, этот кружок будет бессмысленной тратой времени, если никто другой, кроме вас, технических людей, туда не вовлекается.
Лично я считаю, что если Behavior Driven Development или концепцию Behavior Specification притягивают к unit-тестам или к интеграционным тестам, то это просто бесполезная трата времени.
Steps
Концепция последнего на сегодня паттерна – Steps, интересна вне зависимости от того, используете ли вы Behavior Driven Development, Keyword Driven или Behavior Specification. Когда вы используете логически сценарий, он состоит из шагов. Когда вы реализуете его в коде, зачастую шаги теряются – появляются вызовы каких-то технических деталей, подготовка данных, еще что-то, и очень непросто среди этого вычленить шаги.

Было бы здорово, если бы мы могли эти логические шаги понимать сразу, тогда можно было бы очень быстро понимать, о чем тест и как его модифицировать, это бы значительно упростило поддержку.
Поэтому шаги выглядят следующим образом: у вас есть группы шагов, которые организованы по какому-то принципу, и когда вам необходимы шаги, вы создаете их и используете в своем тесте.
Если вы потом посмотрите на реализацию – в данном случае это реализация напрямую через web-драйвер, они не используют концепцию Page Object, совершенно необязательно мешать эти два паттерна, вы можете ограничиться лишь логическими шагами без посредников. В данном примере получается набор доменных логических команд-шагов, из которых вы можете компоновать ваши тесты.
Когда вы начинаете работать над функциональностью, у вас есть некоторые приемочные критерии. Они могут быть сформулированы явно или неявно, но они в любом случае должны быть. Если у вас их нет, непонятно, как принимать вашу функциональность, не понять, что она сделана хорошо.

У вас есть Page Object или любая другая техническая реализация ваших тестов, и их нужно соединить, для чего и существуют Steps, реализующие логические составляющие ваших тестов.

Если вы задумаетесь над web-драйвер тестом в верхней части слайда, который написан в концепции Steps, в котором каждый шаг вызывается — он логический, его легко прочитать.
Если вы посмотрите на вручную написанный сценарий в нижней части слайда, вы поймете, что это в принципе одно и то же, и если вы используете концепцию Steps, многим это позволяет отказаться от дополнительного инструмента для ручного тестирования, потому что все твои шаги – неважно, автоматизированы они или нет, можно включать в ваш фреймворк или напрямую в код, для этого не нужно использовать дополнительный инструмент. Это дает преимущество, позволяя отслеживать, сколько шагов автоматизировано, кто их автоматизировал, сколько шагов работает или не работает, и так далее.
Нельзя просто так взять и написать классный тест. Один тест написать можно, но сделать, так чтобы по мере того, как количество этих классных тестов росло, как количество людей, которые пишут эти классные тесты, и вы не теряли ни в скорости, ни во времени, которое вы тратите на поддержку этих тестов, ни в каких-то дополнительных ролях, которые вы просто притягиваете за уши, потому что у вас, например, есть какой-то тест-саппорт инженер, задача которого каждый день разбирать проблемы в тестах…

Если вы не хотите всего этого, вы должны понимать, что есть дизайн-паттерны, которые позволят вам в будущем избежать этих проблем. Зная эти дизайн-паттерны, применяя их по месту, понимая проблематику, вы можете сделать ваши тесты лучше быстрее, производительнее и так далее.
Надеюсь, было интересно. Спасибо.
Если вам понравился этот Николая Алименкова, спешим пригласить вас на его очередное выступление в рамках грядущей конференции Heisenbug 2017 Moscow, которая пройдет в Москве 8-9 декабря. На ней Николай расскажет о взаимодействии разработчиков и тестировщиков.
Вам также могут быть интересны и другие доклады, например:
- Truths about technical testing (Alan Page, Unity)
- Тестирование браузерной производительности web приложений (Владимир Ситников, Netcracker)
- Инструменты тестировщика (Юлия Атлыгина, ALM Works)
Комментарии (4)


debose
29.09.2017 22:48+2Отличная статья. До PageObject я сразу дошёл. Концепция из HtmlElements тоже понравилась. Но вот steps и реестры (из того что запомнилось) — это интересно.
sidristij
Вставлю и свою копейку: habrahabr.ru/company/luxoft/blog/281643