
Вчера мне в очередной раз пришлось объяснять почему DataScientist-ы не используют ошибки первого и второго рода и зачем же ввели полноту и точность. Вот прямо заняться нам нечем, лишь бы новые критерии вводить.
И если ошибка второго рода выражается просто:
где ? — это полнота;
то вот ошибка первого рода весьма нетривиально выражается через полноту и точность (см.ниже).
Но это лирика. Самый важный вопрос:
Почему в DataScience используют полноту и точность и почти никогда не говорят об ошибках первого и второго рода?
Кто не знает или забыл — прошу под кат.
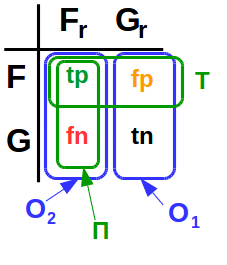
Бизнес-задача
Так как Хабр — это блог IT-шников, постараюсь по минимуму использовать мат.абстракции и рассказывать сразу на примере. Предположим, что мы решаем задачу Fraud-мониторинга в ДБО условного банка Roga & Copyta, сокращённо R&C.
Предположим, что у мы разработали некую автоматизированную экспертную систему (ЭС), определяющую для каждой платёжной транзакции: является ли данная транзакция мошеннической (fraud, F) или легитимной (genuine, G).
Необходимо определить "хорошие" критерии оценки качества системы и дать формулы расчета этих критериев.
Так как Roga & Copyta — это хоть и маленький, но всё же банк, то в нём работают люди меркантильные и ничего кроме денег их не интересует. Поэтому разрабатываемые критерии должны максимально прозрачно показывать: насколько выгодно им использовать нашу ЭС? Может быть выгодно установить ЭС конкурентов?
События и вероятности
Для каждой транзакции могут быть определены четыре события:
- Fr (fraud real) — вероятность того, что транзакция в действительности окажется мошеннической;
- Gr (genuine real) — вероятность того, что транзакция в действительности окажется легитимной;
- F — вероятность того, что ЭС "определит" транзакцию как мошенническую;
- G — вероятность того, что ЭС "определит" транзакцию как легитимную
Очевидно, что Fr и Gr — несовместные события; аналогично F и G — несовместные. По этой причине разумно рассматривать четыре вероятности:
Аббревиатуры читаются так:
- tn — true negative
- fn — false negative
- fp — false positive
- tp — true positive
Мы можем рассматривать условные вероятности:
Так же нам будут интересны и "обратные" условные вероятности:
Например вероятность означает следующее:
Какова вероятность того, что транзакция действительно окажется мошеннической, если ЭС "определила" это событие как мошенническое.
Не следует путать с , которое можно определить словами:
Какова вероятность того, что ЭС "назовёт" транзакцию мошеннической, если данная транзакция действительно мошенническая.
Аналогично можно определить словами и другие условные вероятности.
Вспомним определения
В статистике любят говорить о нулевой гипотезе (H0) и альтернативной (H1) гипотезе. Обычно под нулевой гипотезой определяют "естественное" состояние. В случае фрод-мониторинга "естественным" состоянием является то, что транзакция легитимная. Это действительно разумно, хотя бы по той причине, что количество мошеннических транзакций гораздо меньше количества легитимных.
Поэтому за нулевую гипотезу примем Gr, а за альтернативную Fr.
Ошибки первого (O1) и второго (O2) рода определяются так:
Ошибка первого рода (O1) — это вероятность того, что ЭС "определит" транзакцию как мошенническую, при условии, что она легитимная.
Ошибка второго рода (O2) — это вероятность того, что ЭС "определит" транзакцию как легитимную, при условии, что она мошенническая.
Замечание: часто ошибку первого рода называют false positives а ошибку второго рода как false negatives. В том числе, таковы определения в википедии. Это верно по сути. Но и . Очень многие новички в DataScience делают такую ошибку и путаются.
Полнота (П) и точность (Т) по определению:
Т.е. полнота — это вероятность того, что ЭС "определит" транзакцию мошеннической, при условии, что она действительно мошенническая. А точность — это вероятность того, что транзакция действительно мошенническая, при условии, что ЭС "определила" транзакцию как мошенническую.
Полноту и точность можно выразить через tp, fp, fn следующим образом:
Выводим тупо в лоб.
Для полноты:
Для точности:
Следует заметить, что именно эти формулы очень частно приводят в качестве определения полноты и точности. Тут вопрос во вкусе. Можно сказать, что квадрат — это прямоугольник, у которого все стороны равны и доказать, что ромб с прямым углом — это квадрат. А можно наоборот. Например, когда я учился в школе, у меня квадрат определяли как ромб с прямым углом и доказывали, что прямоугольник с равными сторонами — это квадрат.
Но все же определение полноты как и точности как T мне кажется более правильным. Сразу понятно в чем физический смысл этих величин. Понятно, зачем они нужны.
Бизнес-смысл полноты и точности
Предположим, что для Roga & Copyta мы создали систему с полнотой в 80% и точностью в 10%.
Предположим, что без ЭС банк теряет на мошенничестве 1 миллиард тугриков (?) в год. Это значит, что благодаря ЭС они смогут предотвратить хищение на сумму в 800 миллионов ?. Останется еще 200 миллионов ? — это ущерб банку (или клиентам банка), который не смогла предотвратить ЭС.
А что на счет точности в 10%? Данная величина значит, что из 100 сработок ЭС только 10 будут попадать по цели, а в остальных случаях мы приостановим легитимные транзакции. Хорошо это или плохо?
Во-первых при остановки транзакции банк совершает какие-либо действия. Например звонит клиентам с просьбой подтвердить операции.
Во-вторых заблокировать легитимные транзакции тоже не всегда хорошая идея. Представьте, что вы сидите с девушкой в ресторане, просите счёт, оплачиваете картой… А тут бах… ЭС ошибочно подсчитала что вы — мошенник… Наверное не очень удобно будет перед барышней… Но мы, чтобы не усложнять, пока опустим эту проблему.
Итак, предположим один звонок стоит 1000 ?. Так же предположим что средний чек хакера у нас составляет 100 тысяч ?.
Так как мы предотвращаем мошенничества на 800 миллионов ?, то в среднем у нас будет 8000 правильных мошеннических сработок. Но 8000 — это, судя по точности, лишь 10%; следовательно всего мы позвоним 80000 раз. Умножаем эту цифру на стоимость одного звонка (1000 ?) и получаем аж 80 миллионов ?!
Итоговый ущерб в год для банка R&C равен: 200 + 80 = 280 миллионов ?. Но без ЭС банк терял бы один один миллиард. Следовательно выгода R&C составляет 720 миллионов тугриков.
Следует различать полноту и точность по количеству транзакций и по суммам. Это четыре разные величины. Здесь я "смешал все в кучу", что, конечно не верно! ;)) Будем считать что полнота и точность 80% и 10% как по количеству транзакций, так и по денежным суммам.
Бизнес-смысл ошибок первого и второго рода
Ошибка второго рода элементарно выводится через полноту:
Вывод формулы элементарен (см. следующий параграф)
Поэтому что считать — полноту или упущенный фрод (ошибка второго рода) особой разницы не представляет.
А что на счет ошибки первого рода?
Это вероятность того, что ЭС назовёт мошеннической операцией транзакцию, при условии что она легитимная. Проблема в том, что легитимных транзакций существенно больше мошеннических. Есть банки, в которых более 50 платёжных транзакций в секунду… И это совсем не предел.
R&C — банк небольшой, там всего пять платёжных транзакций в секунду. Давайте посчитаем, сколько это в сутки:
В прошлом параграфе мы узнали, что в R&C 80000 сработок в год, это значит что в сутки в среднем 80000 / 365 = 219,17 сработок. Из них только 10% попали в цель (такова точность), то есть 22. Значит остальные — подлинные: 432000 — 22 = 431978.
Так как полнота 80%, то из этих 22 мы только 4.4 будем упускать.
Значит ошибка первого рода:
Слишком маленькая величина! Бизнес не любит такие числа. Так же сложнее, чем для точности высчитать пользу и ущерб для бизнеса. И есть еще одна проблема:
через ошибку первого рода, можно косвенно понять об объемах платёжных операций в банке!
Что касается точности, то такой проблемы нет. Специалисты из отдела безопасности R&C знают об объемах мошенничества. Они узнают о допустимой нагрузке на контактный центр у самой главной девочки + спрашивают руководство банка о желаемой полноте. Зная абсолютную нагрузку, желаемую полноту и объем фрода можно без труда вычислить приемлемую точность. Эти две цифры вписываются в техническое задание (или тендер).
Разработчику выдают выборку из мошеннических транзакций и легитимных. Если выборка репрезентативна, этих данных достаточно.
"Неправильность" точности с точки зрения чистой математики
Если объем транзакций увеличится в два раза, то точность уменьшится. Если объем мошенничества увеличится в два раза, то точность так же будет больше… С ошибкой первого рода такой проблемы нет, поэтому с точки зрения "чистой математики", эта величина гораздо более "правильная"...
Но на практике, если и резко увеличивается объем мошенничества, то как правило это фрод нового типа и ЭС просто не обучена его ловить… Точность останется той же (а вот полнота уменьшиться, т.к. появится фрод, который мы не умеем ловить). Что касается увеличения количества легитимных транзакций — то это увеличение постепенное и никаких "рывков" не будет.
Поэтому на практике точность — замечательный, понятный для бизнеса критерий оценки качества ЭС.
Вывод ошибок первого рода и второго рода из полноты и точности
Но может быть существует изящная формула вывода ошибки первого рода через точность?
Вот с ошибкой второго рода как все красиво:
К сожалению с O1 так изящно не получится. Вот отношение через точность (Т) и полноту (П):
Эй! Ты что такой ленивый! А ну давай сам попробуй!
Из и
можно составить выражение:
Откуда следует:
Уже из этого отношения легко получить формулу для O1
Заключение
Точность и полнота "не хуже" и "не лучше" чем ошибки первого и второго рода. Всё зависит от задачи. Мы же не едим столовой ложкой торт, а чайной борщ? Хотя это возможно.
Точность и полнота более понятные критерии качества. Ими легче оперировать. С помощью них просто вычислить предотвращённый ущерб в задаче фрод-мониторинга.
Если вы обнаружили описку или грамматическую ошибку — прошу написать в личку.
Комментарии (6)

VT100
16.10.2017 13:12Не стану спорить — просто спрошу:
Разве ошибка первого рода это не «пропуск цели»? И второго, соответственно, — «ложная тревога»? Что является зеркальным отражением:
Ошибка первого рода (O1) — это вероятность того, что ЭС «определит» транзакцию как мошенническую, при условии, что она легитимная.
Ошибка второго рода (O2) — это вероятность того, что ЭС «определит» транзакцию как легитимную, при условии, что она мошенническая.
Замечание: часто ошибку первого рода называют false positives, а ошибку второго рода — как false negatives.
PavelMSTU Автор
16.10.2017 13:57Обычно под нулевой гипотезой определяют «естественное» состояние.
Но вы можете под нулевой гипотезой взять Fr событие.
Тогда да — наоборот. Это дело вкуса.

sunman
18.10.2017 10:41Статья, в целом, полезная, только в ней ошибка — там, где расписаны вероятности ошибок 1-го и 2-го рода в списке вероятных исходов, tp — true positive встречается 2 раза, очевидно, вместо одного из tp должно быть tn — true negative.
Кроме того расчет экономического эффекта от внедрения ЭС сильно смахивает на экономическую часть технического диплома — непроверенные на практике начальные предпосылки дают достаточно сомнительные результаты. Впрочем, возможно, конечных заказчиков именно такими цифрами и надо убеждать
PavelMSTU Автор
18.10.2017 11:24+1По первому абзацу:
Спасибо! поправилАббревиатуры читаются так:
- tn — true negative
- fn — false negative
- fp — false positive
- tp — true positive
P.S> но лучше бы в личку написали ;)
mayorovp
Картинка в начале у вас неправильная, из нее получается что O2 = П, O1 = 1 — П. Очевидно, это не так…
PavelMSTU Автор
Картинка показывает «при условии чего» рассчитывается та или иная величина.