

Привет! По мотивам реализации одной из задач по анализу источников трафика решил написать статью-инструкцию для маркетологов. Это случай, когда маркетологам без Google Analytics API не обойтись. Статья пишется на благо веб-разработчикам, чтобы маркетологи не отвлекали по «всякой фигне».
Знакомимся с технологией на практическом примере. Поехали!
Задача
Есть около 150 000 пользователей, которые зарегистрированы на сайте. Нужно понять, из каких источников изначально пришли 1500 пользователей, которые купили продукт в октябре.
Для привлечения лидов используется модель фримиум, цикл продажи может быть до 1 года.
Из дополнительных настроек, на этапе интеграции Google Analytics, мы подключили UserID и дублировали его значение в Custom Dimension 1 (Scope: User), чтобы с UserID можно было взаимодействовать в отчетах.
Решение
Алгоритм
Для определения первого источника нужно:
- Открыть сервис Query Explorer.
- Пройти авторизацию, выбрать Account, Property и View.
- Составить отчет:
- end-date: дата регистрация пользователя + 5 дней (с запасом на всякий случай)
- start-date: дата регистрации пользователя -25 дней (с запасом, пользователь до регистрации мог совершать взаимодействия с сайтом)
- metrics: ga:sessions
- dimensions:
ga:sourceMedium — источника / канал
ga:dateHourMinute — время, включает дату, часы и минуты. - sort: ga:dateHourMinute — чтобы самая первая сессия отображалась в первой строке.
- filters: ga:dimension1==158384 — ID пользователя.
- Должно получится как-то так:
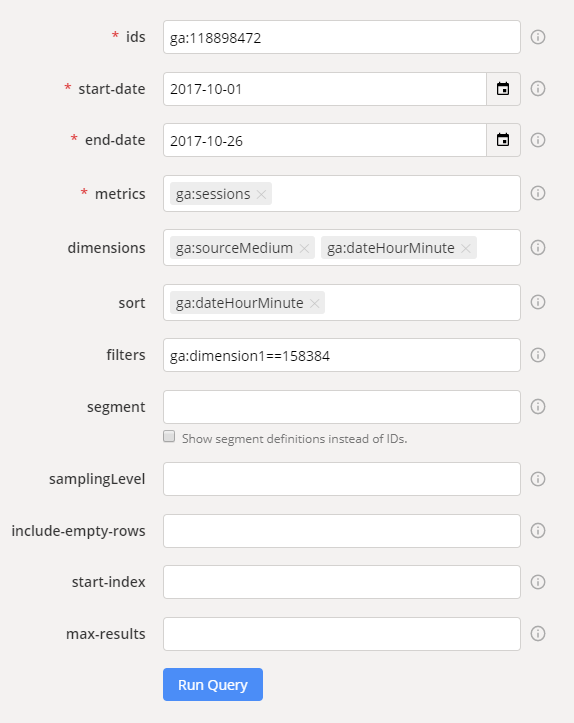
- Запустить запрос, нажимая на Run Query.
Результат
После исполнения запроса должна появиться таблица с результатами:

Т.е. видим, что в заданный период до регистрации первая сессия была из источника yandex / organic.
Для одного пользователя сделали. Но как собрать для 1500, автоматизация?
Автоматизация
Под таблицей с результатами запроса, есть 2 текстовых поля:
Direct link to this Report и API Query URI.
Нас интересует второе поле с проставленной галочкой “Include current access_token ...”.
Содержание поля примерно такое:
https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=2017-10-01&end-date=2017-10-26&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D158384&access_token=ya29.Gl30BMgGpR89kexsBJS8VMIWimIEghKVHubx9iQH7RljCyQNLjX2LLBQ9AyCCRW9K0TjfJEvwe6qY3SIRKbkm8idMZjdygbN647O7JUgXqcGyDt5b63Y2FjDbeQabfA
Если мы откроем ссылку в браузере — увидим результат исполнения запроса в формате JSON:
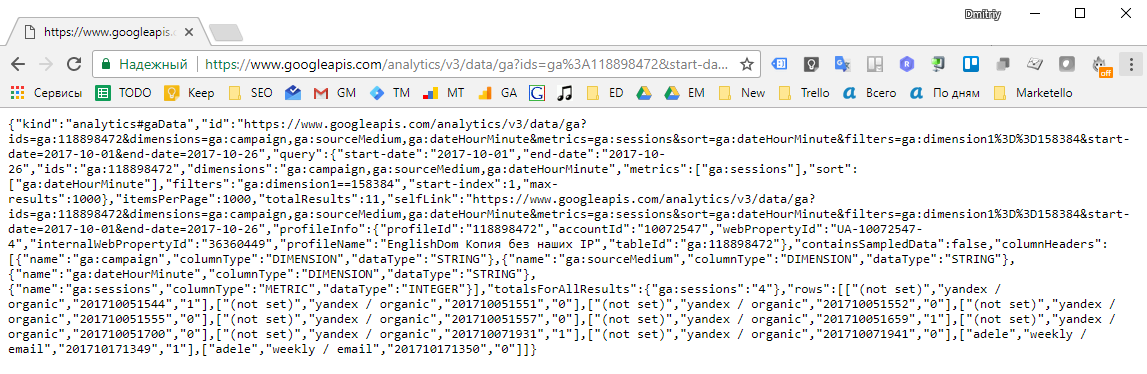
Т.е. подставляя в query url данные dimension1, start-date, end-date — можем получить такую информацию по каждому из пользователей.
Файл с данными пользователей
Я сделал обычный txt файл, который содержит строки вида (UserID start-date end-date):
123456 2017-10-01 2017-10-26
123457 2017-10-02 2017-10-27
Подготовить start-date и end-date можно легко — через Excel или Google Spreadsheets:
start-date:
=date(year(B2),month(B2),day(B2)-25)
end-date:
=date(year(B2),month(B2),day(B2)+5)
Где B2 — ячейка с датой регистрации пользователя.
Делаем скрипт
В качестве языка выбрал Python — просто потому что изучаю его в настоящее время.
Алгоритм работы скрипта:
- Открываем файл с информацией о пользователях.
- Каждую из строк файла делим по “табуляции”.
- Разделенные данные из строки подставляем в Query String, которую мы получили при работе с Query Explorer.
- Получаем информацию по этой ссылке.
- Конвертируем текст ответа в JSON, чтобы можно было взаимодействовать с ним.
- Делаем бекап ответов по каждому из пользователей, который сохранится в users/%userID%.txt
- Попробуем пройтись циклом по разделу “rows”.
- Если получилось — пишем на экран UserID и Source/Medium.
- Если не получилось — пишем просто UserID.
import json
import requests
with open('users_regs.txt') as f:
for line in f:
value = line.split("\t")
source = 'https://www.googleapis.com/analytics/v3/data/ga?ids=ga%3A118898472&start-date=' + value[1] +'&end-date=' + value[2].strip('\n') +'&metrics=ga%3Asessions&dimensions=ga%3AsourceMedium%2Cga%3AdateHourMinute&sort=ga%3AdateHourMinute&filters=ga%3Adimension1%3D%3D' + value[0] +'&access_token=ya29.Gl3wBOWAecjWj4GgW0Gj920Sx2SBtVBkCHZjOsPNu6MWnN1XnsNwwzVzPVBcdVwDf_7lWJd0mege38pP1PSNvc9aBA7wbndUn-h6vqS5bbbEhSOKHp4cjQvVSQiN5R4'
r = requests.get(source)
l = json.loads(r.text)
with open('users/' + value[0]+'.txt', 'w') as outfile:
json.dump(l, outfile)
try:
for row in l["rows"]:
print(value[0] + " " + row[0])
break
except:
print(value[0])
Файл со скриптом назвал ga.py.
Запускаем скрипт через командную строку, наслаждаемся результатом:
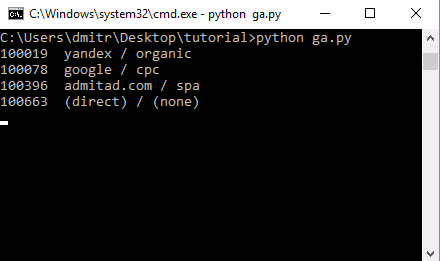
Результаты исполнения скрипта будут выводиться в терминале, можно просто их скопировать для дальнейшей обработки.
Скрипт представлен для примера, вы самостоятельно можете сделать сохранение результатов в единый файл или базу данных.
Если вы будете работать с большим объемом данных — раз в час вам придется генерировать новый токен (открываем снова Query Explorer и нажимаем Run Query) и подставлять в Query String в вашем скрипте.
Успехов!
Бонусы для читателей
Онлайн-курсы
Мы дарим бесплатный доступ на три месяца изучения английского с помощью наших онлайн-курсов. Для этого просто перейдите по ссылке до 31 декабря 2017 года.
Индивидуально по Skype
Будем рады видеть вас на индивидуальных занятиях курса «Английский для IT-специалистов».
Пройдите, бесплатный вводный урок и получите комплексную обратную связь по своему уровню знаний, затем выбирайте преподавателя и программу обучения себе по душе!
Комментарии (5)

brilliant_almazov
31.10.2017 03:25Ваше решение рабочие, но Вы завязаны на тестовом файле, что не хорошо — надо следить за его актуальностью.
Правильный путь (ИМХО) — получить список уникальных пользователей из GA, и уже потом пройтись по этим данным. Такж можно проходиться сразу по нескольким пользователям сразу: ga:dimension1==$userId1,ga:dimension1==$userId2 или регурярное выражение (ga:dimension1=~^$) — думаю, тут все понятно.
Но тут надо понять какое будет сэмплирование данных (если будет), и если будет, то критично ли это для вашего кейса.
ЗЫ: длина фильтра в GA API имеет ограничение по длине.dkomarovskiy Автор
31.10.2017 08:52Вы завязаны на тестовом файле, что не хорошо — надо следить за его актуальностью.
это как пример, если такая информация нужна на постоянно основе — можно и из БД вытягивать список пользователей, которые совершили покупки.
Статья направлена на знакомство с технологией, а не о подробностях интеграции с сайтом.
получить список уникальных пользователей из GA, и уже потом пройтись по этим данным
Лучше брать из БД и запрашивать информацию по каждому из пользователей.
Но тут надо понять какое будет сэмплирование данных (если будет)
Да, это риски. В данном случае лучше по каждому пользователю отдельно пройтись, чтобы избежать сэмплирорвания.
Такж можно проходиться сразу по нескольким пользователям сразу: ga:dimension1==$userId1,ga:dimension1==$userId2 или регурярное выражение (ga:dimension1=~^$)
Можно. :) Но как по мне, это усложнит логику парсинга результатов.
brilliant_almazov
31.10.2017 09:48да, всё верно говорите
Да, это риски. В данном случае лучше по каждому пользователю отдельно пройтись, чтобы избежать сэмплирорвания.
по опыту — часовая статистика не очень профитна, но от кейса к кесйсу всё меняется
Можно. :) Но как по мне, это усложнит логику парсинга результатов
возможно, но как по мне это зло можно опустить
по работе делаем оченннь много запросов к ГА
Cheinkler
Гораздо проще использовать google analytics api: developers.google.com/analytics
dkomarovskiy Автор
В примере используется Google Analytics API, только через сервис Query Explorer (с графическим интерфейсом и простотой получения токена).
Для маркетологов — то, что нужно!