
По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
Найдено в yangteacher.ru/robots.txt
Огороженные сады: банят всех, кроме Google
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php http://www.facebook.com/apps/site_scraping_tos_terms.php)Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
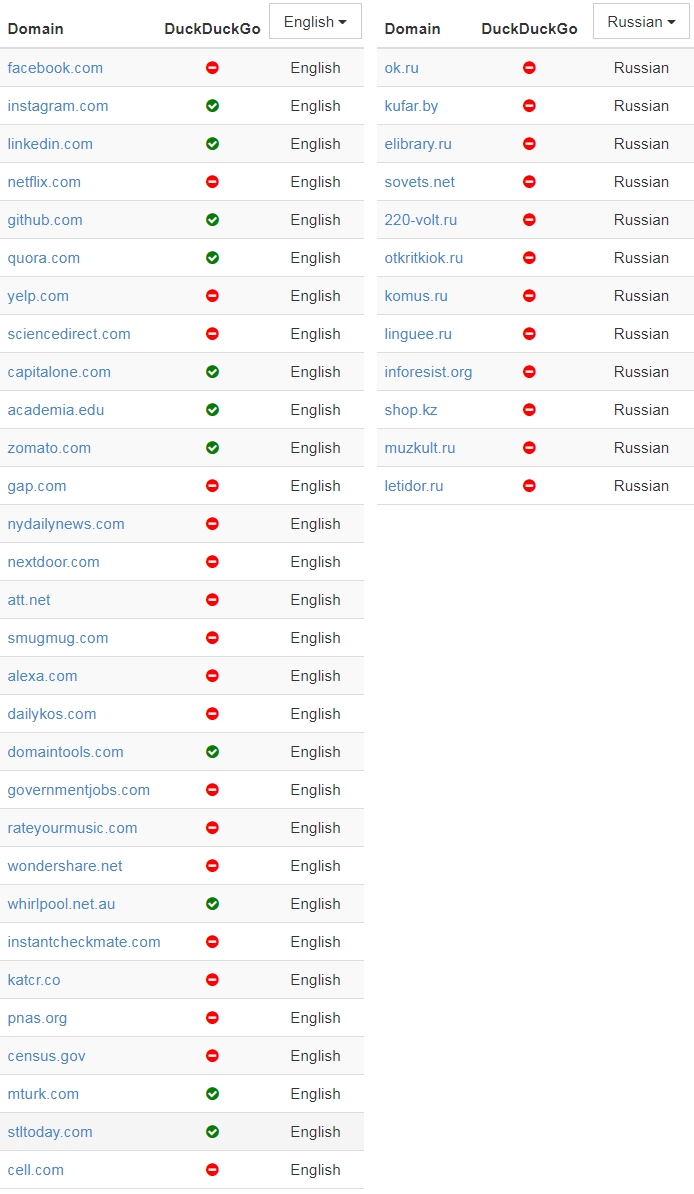
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Боты плохого поведения
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
| user-agent | Тип | Количество |
|---|---|---|
| MJ12bot | SEO | 15156 |
| AhrefsBot | SEO | 14561 |
| Baiduspider | Поисковая система | 11473 |
| Nutch | Поисковая система | 11023 |
| ia_archiver | SEO | 10477 |
| WebCopier | Архивация | 9538 |
| WebStripper | Архивация | 8579 |
| Teleport | Архивация | 7991 |
| Yandex | Поисковая система | 7910 |
| Offline Explorer | Архивация | 7786 |
| SiteSnagger | Архивация | 7744 |
| psbot | Поисковая система | 7605 |
| TeleportPro | Архивация | 7063 |
| EmailSiphon | Спамерский скрапер | 6715 |
| EmailCollector | Спамерский скрапер | 6611 |
| larbin | Неизвестно | 6436 |
| BLEXBot | SEO | 6435 |
| SemrushBot | SEO | 6361 |
| MSIECrawler | Архивация | 6354 |
| moget | Неизвестно | 6091 |
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Объявления о работе
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
Комментарии (28)

bro-dev
07.11.2017 03:12Есть какой то способ искать без учета роботтикст? Какой то ключ в гугле или спец поисковик? чтобы выдавал все результаты игнорируя запреты.

MooNDeaR
07.11.2017 07:30Не очень понимаю, как вы себе это представляете. Всё что выдает поиск — это результат работы поискового бота. Если боту запретить что-то искать на сайте, то и в поиске найти это будет нельзя (теоретически), соответственно, то, о чём вы просите невыполнимо.
bro-dev
07.11.2017 12:15Я себе это представляю очевидным образом, гугл уже был замечен за тем что игнорит робот ткст, это значит он просто на результаты поиска ставит отметку что это было запрещено и не показывать, и именно этот механизм давал сбой, грубо говоря должна быть какая то команда или ключ чтобы он выдал все результаты с учетом запрета, возможно просто в паблике запрещена она, но я уверен что она есть.

webkumo
07.11.2017 13:06Гай, роботс.тхт — это тупо файл в корне сайта. Он ничего сам по себе не может. "Белые" краулеры вроде как стараются его не нарушать, с остальными приходится бороться на уровне серверного ПО (выискивать по user-agent, либо анализировать способ формирования трафика… например 10 страниц в секунду для человека — как-то перебор, а вот робот может попытаться и больше).
bro-dev
07.11.2017 16:12ну так я и спрашиваю есть ли поисковики такие которые выдают результат поиска без учета робот.тхт?
webkumo
07.11.2017 17:36Сомневаюсь, что сколько-нибудь глобальный поисковик напишет, что игнорирует (даже если это так) — банально вредно для бизнеса, так что только вручную искать/проверять.
khim
07.11.2017 20:03Подобная деятельность будет нарушением законов многих стран. Так что подобные вещи глобально невозможны: мелкие компании, которым наплевать на возможные штрафы, не обладают ресурсами, чтобы всё это хранить, крупные — не будут связываться, так как можно улететь на миллионы долларов (вспомните про историю с WiFi)
khim
07.11.2017 19:59гугл уже был замечен за тем что игнорит робот ткст
Когда, кто, где? Единственный известный вариант — это размещение сайта на хостинге «за бакс в месяц», где даже robots.txt отдаётся через раз (тогда гуглобот может robots.txt просто не увидеть) и обновления (когда бот некоторое время пользуется скачанным несколько часов/дней назад robots.txt). Всё. Заведите сами web-сайт да поэспериментируйте.
Данных с сайтов, которые забанили Гуглобота Гугл не получает, соответственно никакого «секретного ключа имени CSI» в природе быть не может…

DenVdmj
07.11.2017 05:51А что вы пишите в юзерагенте в своих скриптах? Я вот не знаю, что там надо писать, так что просто взял первое попавшееся из логов. Оно оказалось гугловским, ну так что с того.
А про robots.txt, так вообще смешно.khim
07.11.2017 20:05Это всё смешно пока вы «неуловимый Джо». Как станете крупнее — так, чтобы иск миллионов так на 10 долларов имел шанс таки выбить из вас эти 10 миллионов — так всё сразу станет куда менее смешно.


pae174
07.11.2017 08:15определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt
Самые плохие найдены не были так как они просто не реагируют на директиву Disallow в /robots.txt, не пишут в user-agent ничего уникального и постоянно меняют свои IP адреса.

FreeManOfPeace
07.11.2017 08:26+1Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы тоже посоветовал заблокировать их.
А потом жалуемся на то что Яндекс плохо ищет не в рунете, и обвиняем его разработчиков.
Сам частично перешёл с гугла на Яндекс ради эксперимента, и когда ищешь какие то темы нормально представленные на русском он даже лучше, но стоит поискать что то на инглише полный мрак и приходится перенаправлять запрос в гугл. Теперь понятно почему.
lperovskaya
07.11.2017 10:43Обратите внимание, что именно фраза про "рекомендую заблокировать" переведена неправильно. В исходной статье: "оба этих поисковика приводят ко мне на сайт пользователей, поэтому я бы не рекомендовал их банить".

m1rko Автор
07.11.2017 11:15Чёрт, как так получилось, исправил. :(
Прошу не искать теории заговора, просто недосмотр.
overweight
07.11.2017 20:02А то, что из Яндекса можно выпилить инфу это нормально? То ли про судью, то ли про депутата какого-то по решению суда удаляли информацию о имевшихся ранее судебных разбирательствах

sumanai
07.11.2017 22:36А все существующие подчиняются DCMA, так что они все не лучше яндекса и выпиливают инфу сотнями тысяч ссылок в неделю, если уже не миллионами.

sergebezborodov
07.11.2017 10:19забудьте вы про топ 1м алексы из того файла, он давно не актуален
blog.majestic.com/development/alexa-top-1-million-sites-retired-heres-majestic-million
я брал маджестик, тоже проводил исследование: www.facebook.com/sergebezborodov/posts/10210475319615839
эти «топ 1м» нужно писать в кавычках, когда в них больше 50 тыс доменов в принципе не резолвятся

esemi
07.11.2017 12:51Про неактуальность топа алексы уже сказали =)
Я аналогично хотел проверить насколько прижился humans.txt по этому топу и результаты получил удручающие: на миллион сайтов только 169 humans.txt файлов и из тех половина — национальные домены гугла =(
Agel_Nash
07.11.2017 14:02Я всегда стараюсь включать этот файл в свои проекты. Есть даже заготовка под него. Но так случилось, что на одном из проектов файла humans.txt не оказалось в продакшине. Зато в robots.txt были строчки:
# User-agent: human
# Goto: /humans.txt
#
# User-agent: hacker
# Goto: /hackers.txt
Через какое-то время после сдачи проекта, клиент присылает мнеаудит от сеошника

AllexIn
07.11.2017 19:04А что не так с аудитом?
Просто интересно, сам я не понимаю в теме ничего.Agel_Nash
07.11.2017 20:05+1— robots.txt поддерживает комментарии, которые можно указывать после символа #
— robots.txt не поддерживает инструкции Goto
Соответственно если в комментариях указано что-то в стиле Goto: /humans.txt, то это никак не означает, что humans.txt должен присутствовать на сервере.
Более того, наличие этого файла дело сугубо индивидуальное и никоим образом не связано с продвижением сайтов. Почему в аудите это отнесли к ошибке — для меня так и осталось загадкой. Но лишь один тот факт, что анализируя robots.txt человек допустил аж 2 ошибки (упустил из виду комментарий и воспринял Goto приписку как инструкцию), можно сделать вывод о его компетентности.

ozgg
07.11.2017 14:10Для начала в каждый популярный фреймворк можно наряду с шаблонным robots.txt добавлять шаблонный humans.txt, тогда про него хотя бы будут знать.
AMDmi3
07.11.2017 14:50Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
На своих сайтах я вижу больше переходов с DDG чем даже с Яндекса, но ни разу не видел в логах их собственного краулера (только DuckDuckGo-Favicons-Bot/1.0 десяток раз в месяц, но это, судя по названию, не то). В Википедии написано что DDG использует массу источников, в том числе Bing, так что предполагаю что по факту заблокированность DDG в robots, к счастью, не сильно мешает его работе.
technik
Очень крутое исследование, спасибо за перевод.
Правда насколько мне известно, большинство так называемых «плохих ботов» просто игнорируют файл robots.txt, поэтому если не стоит защиты на сервере, то чихать они хотели на все эти запреты.