

Qrator Labs выражает благодарность программному комитету ENOG за разрешение опубликовать на Хабре расшифровку круглого стола, посвященного блокировкам запрещенного к распространению контента. Мероприятие проходило в Минске 9-10 октября. Внимание! Текст длинный, тема чувствительная — просьба отнестись серьёзно к комментарию, который вы захотите оставить под публикацией.
ENOG («Евразийская группа сетевых операторов», в оригинале European Network Operators Group) представляет собой региональный форум интернет-специалистов, занимающихся важнейшими аспектами работы интернета. В рамках форума они имеют возможность обмениваться опытом и знаниями по вопросам, присущим Российской Федерации, странам СНГ и Восточной Европы.
Очередность выступлений и темы докладов:
- Техническая сторона блокировок — Алексей Семеняка, RIPE NCC
- Обзор технической ситуации с блокировками в России — Филипп schors Кулин, DIPHOST
- Проблемы deep packet inspection в транспортных сетях — Артем ximaera Гавриченков, Qrator Labs
- Перспективы блокирования контента в условиях дальнейшего развития технологий интернет — Антон Басков, AB Architecture Bureau
- Административные вопросы блокировок — Юрий Каргаполов, UANIC
Блокировки контента, введение
Юрий Каргаполов (модератор дискуссии):
Давайте, наверное, начнем нашу очень необычную, для ENOG, панельную дискуссию. Эта панель связана с тем, что сегодня привыкли называть «блокировками», которые, уже и мы это чувствуем, влияют на качество наших сетей, на качество предоставляемого сервиса. В конечном итоге блокировки влияют на архитектуру сетей, которые мы строим. Накопился некоторый комплекс вопросов, которые особенно актуальны для России. Но, как оказалось, он стал набирать силу и для Украины, и для Белоруссии и для многих других стран региона. Мы до сих пор не понимаем, как на это реагировать адекватно, а потому данная дискуссия будет посвящена попытке понять как реагировать на блокировки, какие выбрать стратегии и как мы можем адекватно ответить на данный вызов.
Техническая сторона блокировок, Алексей Семеняка, RIPE NCC
Видео доклада и слайды презентации
Наша задача — понять, как делать блокировки так или как жить с блокировками так, чтобы получить технически минимальный вред. И, надо сказать, что это не новая проблема — это новая проблема только для региона, но в целом в мире эту булочку жевали уже много раз. Первая дискуссия на достаточно высоком уровне появилась более 15 лет назад, система блокировок, скажем, в Великобритании начала работать масштабно примерно примерно в 2003 году.

Вот список международных организаций, которые выпускали те или иные документы: отчеты, рекомендации, обзоры по тому, как блокируется трафик в интернете. Вы видите, что список начинается с Генеральной Ассамблеи ООН — действительно, есть документ Генассамблеи по блокировкам в разных странах мира. Есть Европейский суд по правам человека, есть Совет Европы, есть ОБСЕ.
Есть и интернет-организации: ISoC, IETF, который выпустил целый RFC 7754 по этому поводу, а на подходе еще и драфт. Мягко говоря, эта проблема не остается без внимания. Есть также EFF, естественно, не оставшийся в стороне — у них тоже важные и интересные документы.
Когда я готовился к сессии, я почитал документы еще и тех организаций, которые приведены на слайде — это порядка 800 страниц. Это огромный объем информации, накопленный к настоящему моменту. Огромное количество проблем уже обсуждено в мире — теперь дошла очередь и до нас.
Моя задача сейчас — озвучить те договоренности, на основе которых мы будем работать в этой дискуссии. Некоторые нулевые аксиомы, с которых мы сейчас начинаем и принимаем их как данность.

Более или менее принятая в мире терминология содержит три понятия: блокировка, фильтрация, цензурирование.
Мы будем говорить о блокировках — по статическим признакам. Это отличается от фильтрации, когда трафик, к примеру, P2P-сетей фильтруется по подписям для обнаружения защищенного авторским правам контента. Это также отличается от цензурирования, что, согласно юридическому определению, является «предварительным согласованием информации перед тем, как сделать её публичной». То есть это ограничение свободы распространения информации.
Какие предпосылки есть у этого обсуждения?

Блокировка является распространенной практикой во всём мире. Мало стран, где она отсутствует, и нет ни одной более-менее развитой страны, где бы она полностью отсутствовала. В том или ином виде во всех странах мира есть какие-то ограничения противоправного контента, размещенного в сетевой среде.
Соответственно, на текущий момент сформулированы общие признаки, считающиеся универсальными в международном праве и позволяющие действительно блокировать контент. Враг номер один — распространение детской порнографии, это причина, по которой контент блокируется практически везде. Это разжигание ненависти, розни, призывы к геноциду и так далее. Это также диффамация. В Европе и в некоторых других странах, но в основном в Европе, на уровне Европейского суда следят за нарушением авторских прав.

На нынешний момент, если сформулировать — и это предпосылка, из которой мы исходим в текущем обсуждении, если сформулировать лучшую практику или лучшую ситуацию, которую можно описать, это:
- Система, в которой блокировки происходят не закрытым, а открытым способом, в результате состязательной процедуры, например, в суде. Где другая сторона может оспорить и привести свою аргументацию того, почему блокировка не должна быть реализована.
- Критерии, по которым осуществляются блокировки, сформулированы заранее и соответствуют тому консенсусу, что есть в обществе. Это не давление на общество, это то, что общество сформулировало для себя как приемлемую норму жизни.
- При этом суд опирается на грамотную экспертизу со стороны профессионального сообщества для предотвращения технически опасных действий — тех, которые несут слишком серьезные последствия и исходят из понимания профессиональных компетенций сетевого сообщества. При этом то, что может быть решено до суда, то есть все меры по досудебному урегулированию, принимаются. Есть система договоренностей между потенциальным обидчиком и потенциально обиженным.
Это та система, в которой мы считаем, что некоторые случаи, когда блокировки являются легитимными, разумными и объяснимыми — в такой системе это можно обсуждать и она может существовать, имеет право на жизнь. Еще раз — мы хотели бы видеть интернет полностью нефильтрованным и прозрачным, однако мы живём в той ситуации, которая есть сегодня в мире — мы пытаемся найти точку минимального вреда. Собственно, эта точка сейчас приведена на экране — та ситуация, к которой необходимо стремиться.

Если мы посмотрим на судебную практику ЕСПЧ, который регулярно рассматривает иски по делам о блокировках, что мало известно в нашем регионе, хотя были иски даже из бывшего СССР и в том числе из России. Хорошей иллюстрацией являются два иска граждан Турции против, собственно, Турции, о блокировках.
Один суд был по поводу вещи, описываемой хорошим термином collateral censorship, когда был заблокирован некий нелегальный ресурс, вместе с ним под запрет попали некоторые ресурсы Google. Суд встал на сторону гражданина и попросил Турцию так не делать. Это совсем недавний кейс, опубликованных результатов дела я ещё не видел.
Во втором случае были заблокированы ресурсы, содержащие контент, защищенный авторским правом — музыка. Суд встал на сторону государства и заявил, что данный случай не является нарушением прав человека. То есть по факту принят дифференцированный подход — это та реальность, которой стоит придерживаться.

European Court of Justice (Европейский суд) в 2001 году принял решение о безусловной блокировке ресурсов за нарушение авторских прав. За последние 16 лет он принял огромное количество частных решений о том, что недопустимо проводить чрезмерную блокировку в связи с тем, что таковая нарушает права человека, и это чётко указано.
При этом формулировки ECJ для национальных судов Европы достаточно мягкие, что создает проблемы в интерпретации, потому что не очень понятно, каковы критерии и как не выйти за эти рамки. Вот используемые формулировки: «принимать разумные меры по блокировке», «в достаточной степени затруднять доступ к запрещенным ресурсам» и «не лишать без необходимости возможности доступа к законной информации». То есть формулировки достаточно расплывчатые, но частных определений при этом достаточно много. Скажем так, проблема четких формулировок даже на этом уровне к нынешнему моменту не решена.

Что делать сетевому сообществу? Это не та вещь, которую мы сегодня сможем решить и не та вещь, которую мы можем сегодня обсуждать. Хотя бы потому, что большинство присутствующих в зале не могут официально представлять свою организацию, не имеют права голоса (в смысле совета директоров) или права подписи.
Но безусловно то, что надо искать формы взаимодействия с государством там, где это возможно. Не всегда возможно, но там, где возможно — надо делать.
Формировать профессиональные объединения, чтобы давление было общим. Чтобы точка зрения была интегрированной. И участвовать как на уровне законодательного процесса, так и на уровне участия в судебных процедурах.
Там, где это возможно, а я понимаю, что страны разные, ситуации тоже разные, поэтому абсолютных обязательств быть не может.

Ну и коротко я сейчас пройдусь по мировой практике, объяснив, как это выглядит. Есть три вектора, которые образуют систему координат:
- Как принимается решение о блокировке?
- Как осуществляется блокировка?
- Какой у блокировки ареал? То есть, среди кого блокируется контент.

Принятие решения.
Самая мягкая ситуация — это когда блокировки не описаны в законодательстве, деятельность в интернете рассматривается как абсолютный аналог офлайновой деятельности и выносится частное решение.
Три разных примера стран, где всё работает именно так, это: Япония, Латвия и Хорватия. Необходимо сказать, что в Латвии очень мало примеров блокировки было — по-моему, лишь единственное решение суда о блокировании фильма, которое ни к чему не привело, потому что фильм был заблокирован в одном месте, но к тому моменту существовал уже примерно в миллионе других мест.
Но у операторов этих стран есть некоторые проблемы с исполнением решений судов, скажем так, потому что никаких правил относительно того, как это делать, единых – нет. Ни на уровне государства, ни на уровне индустрии.

Вторая ситуация — когда блокировки не описаны в законодательстве, но их вопрос решен на уровне профессиональных объединений операторов. Операторы между собой самостоятельно договариваются о том, как они это делают. И на добровольной основе по предоставлению госорганов или судов операторы осуществляют блокирование контента. Так работает практически вся Европа.
Самая продвинутая, в плохом смысле, ситуация с блокировками в, скажем так, традиционной Европе в Великобритании. Но даже там решение принимается ассоциацией, которая была специально для этого создана. Это ассоциация операторов связи, негосударственное объединение.

Следующий тип принятия решения – это когда блокировки есть и они описаны в законодательстве, но осуществляются по решению суда, то есть в результате некой гласной и состязательной процедуры. Примеры приведены на слайде, стоит сказать, что здесь тоже не без «вывертов», например, в Бельгии решение обязательно не только для конечного оператора, но и для транзита. Транзит обязан не передавать какой-то запрещенный контент, что вызывает проблемы. Сетевое бельгийское сообщество уже несколько лет уже пытается объяснить государству, что передачу защищенного копирайтом фильма на транзите отследить практически невозможно — это не работает. Но такой кейс есть и он вызывает определенное напряжение. Хотя, казалось бы, Бельгия достаточно технологически развитая страна с хорошим гражданским обществом.

И последнее — когда блокировки описаны в законодательстве и осуществляются без какой-либо состязательной процедуры. Список стран большой, я специально привёл самые разные страны — как можно видеть, здесь есть Туркменистан, но есть и Эстония, есть Турция, есть Украина, есть Индия. Это тоже, к сожалению, достаточно популярная практика, постоянно вызывающая технические проблемы.

Как работают платформы блокировок? Есть случаи, когда государство требует использовать некоторую централизованную государственную платформу — прогонять трафик через какой-то центр. Яркие примеры: Китай, Саудовская Аравия, Туркменистан.
Есть типовое решение, которое используется основными операторами в стране. Здесь неожиданный пример — Великобритания со системой Clean Feed, которая сначала отлаживалась на British Telecom’е, сейчас ее используют все крупные операторы Великобритании. Как я говорил, при том, что это типовое решение, которое стало стандартом де-факто, ресурсы в этом решении появляются на основе представления общественной организации, в которую входят операторы связи. То есть финальное решение о включении в черный список принимает не государство, а общественная организация.
Или самостоятельная реализация операторами, либо наличие на рынке множества решений и т.д.

Какие механизмы есть?
Самый тяжелый механизм, который недавно использовала Украина массово, то есть большинство операторов блокировало запрещенные ресурсы именно так — это блокировка по автономной системе. То есть все ресурсы автономной системы отправляются в черную дыру.
Следующий способ — это блокировка по IP. Очень популярный способ в России — куча мелких операторов работает именно так. Так работает Турция, так работает Пакистан и многие другие, можно привести разнообразные примеры вроде Бурунди, Конго и так далее. То есть бедные страны Африки тоже очень любят именно такой способ блокирования.
Блокировка на уровне DPI. Здесь возможен разный уровень анализа, начиная с простого анализа host’а в HTTP-заголовке или поля SNI в HTTPS. И кончая достаточно хитрым анализом пакетов. Естественно, чем дальше — тем тяжелее это работает, здесь война меча и щита, потому что все большее количество трафика оказывается зашифрованным, тем не менее Великобритания и Китай идут именно по этому пути.
И достаточно интересный пример — блокировка по DNS. Что это значит? Это значит, что, внимание, только провайдерский DNS направляет пользователя на заглушку. При этом все понимают, что пользователь может прописать четыре восьмерки в хосте DNS’а, и все будет работать — это, скажем так, рассматривается как тот компромисс, который допустим в данном случае. Практически вся континентальная Европа осуществляет блокировки вот таким мягким способом.

И последнее — ареал блокировки.
Это либо все пользователи сети, либо какие-то отдельные группы. Можно посмотреть, как эти группы описаны — например, в Великобритании это группы пользователей «по умолчанию». То есть пользователь может обратиться с просьбой о снятии блокировок с групп ресурсов, куда, для примера, входят вся порнография. Но по умолчанию она отключена — это та система, которая сейчас в процессе внедрения.
В Соединенных Штатах это библиотеки и школы — там есть фильтрация, и достаточно жесткая. Хорватия, Литва, Польша — это только школы. И во Франции был закон о фильтрации в публичных местах, публичного интернета. То есть у себя дома можно получать нефильтрованный интернет, с точностью до тех вещей, о которых я говорил, но в публичных местах интернет должен быть отфильтрован.
На этом моя часть закончена.
Обзор распространенных методов блокирования
Юрий Каргаполов:
Алексей, спасибо за задание некой системы координат относительно того, что происходит с блокировками в мире. Помимо этого, мы бы хотели вам также представить ситуацию, которая происходит в конкретной стране — Российской Федерации. Эту ситуацию мы разберем с помощью Филиппа Кулина, который подробно и детально расскажет о своем опыте в этом вопросе.
Обзор технической ситуации с блокировками в России, Филипп Кулин, DIPHOST
Видео доклада и слайды презентации
Законодательно установлено, что есть некоторый реестр запрещенных сайтов, который наполняется надзорным органом: Прокуратора, Потребнадзор, суд, правообладатели и так далее. Закон постоянно дополняется, чуть ли не на каждой сессии его обсуждения появляются новые государственные органы, которые могут что-то туда, скажем так, предложить. И всё это предоставляется надзорному органу — «Роскомнадзору», который ведет реестр запрещенных ресурсов. По результатам принятия решения «Роскомнадзор» предоставляет реестр операторам связи — провайдерам, они используют его для блокировок. Отмечу, что закон немножко не техничен, нет объекта блокировки — провайдеры как бы делают это сами, есть какие-то рекомендации и играть можно самим.

Как выглядит реестр запрещенных сайтов? Реестр запрещенных сайтов это набор функций, которые провайдеры по своему усмотрению или рекомендациям регулятора должны выполнить. Соответственно, блокируются URL, домен и маска, то есть шаблон. В то же время есть и статические записи, предоставляющие и доменное имя, и IP. Если протокол шифрованный, то тут есть варианты: или провайдер разбирает server indication, то есть заголовок TLS, или он блокирует по IP — такие провайдеры есть и их достаточно много, или true DNS. Тут я опять же отмечу, что у нас предполагается, что DNS полностью перехватывается и подставляет нужный ответ, если ответ из реестра.
Также есть фильтрация по IP полностью и фильтрация по блокам IP, коих не так много, на самом деле.

Как сейчас принято в общем у операторов связи осуществлять фильтрацию по реестру? По рекомендациям и некоторым собственным соображениям.
Первое — выборочная фильтрация IP из реестра или полный перехват DNS и подстановка ответа, или фильтрация всего канала в разрыв. Канал полностью просматривается и фильтруется. Первые два способа могут по разным причинам комбинироваться.

Как контролируется фильтрация?
С конца 2016 года государство бесплатно для операторов связи предоставляет некий прибор «Ревизор». Это такая коробочка, которая до боли напоминает RIPE Atlas и сделана абсолютно на той же базе. Устанавливается на абонентской стороне, то есть имитирует абонента и контролирует качество блокировки по количеству пропусков. То есть просто считает, сколько раз она смогла достичь какого-то запрещенного сайта.
Побочный эффект такого контроля в том, что эта точка сама берет IP-адреса. Перед проверкой она где-то берет адреса тех ресурсов, которые находятся в реестре. Которые могут совпадать, а могут и не совпадать с тем, что написано в реестре. Опять же, DNS не обязан всем отдавать один и тот же IP-адрес и, соответственно, у операторов связи возникает с этим проблема. Второй проблемный момент заключается в том, что оператор несёт ответственность за неограничение доступа, и любой человек, имеющий доступ к управлению доменом, включенным в список запрещенных ресурсов, может управлять IP-адресами, которые испытают деградацию связи, если блокировка не по IP.
В начале лета было множество с этим связанных проблем, вплоть до блокировок банковских платежей, потому что кто-то указал IP процессинговых центров.

Что мы видим в реестре в цифрах?
Тут много цифр, но главное, что интересно — записей на сегодняшний день более 90 000. Они меняются каждый день, и когда я вчера ночью смотрел, было 92 000, сегодня уже, наверное, 93-94 тысячи. Это всех записей в реестре.
Из них наиболее всего интересны блокировки по маске — это когда провайдер должен бегать за каждым доменом и делать шаблон. 1000 доменов убегают, Роскомнадзор это заметил и применил к ним блокировку по маске. Блокировка по блокам IP — это восемь случаев, и там сервисы Blackberry, заблокированные в реестре.

Токсичность реестра — это то, какая ерунда там бывает. Избыточность реестра 13%, что это такое? Есть блокировка по домену, есть блокировка по URL. И если есть блокировка по домену, то бессмысленно держать URL, потому что провайдер уже не будет на них смотреть — он будет смотреть на весь домен. То есть вот таких лишних записей в реестре 13% — он более пухлый, чем надо.
Уникальных IP в реестре 60 000, но на самом деле реально уникальных IP, которые превращаются в домены – 35 000. Реестр ведется в этом плане крайне неаккуратно и там множество лишней информации, не соответствующей действительности.
Еще из интересного — в реестре содержится URL, который не соответствует никаким стандартам. То есть кто-то от руки написал URL, который как-то надо интерпретировать или никак. Подобных URL в реестре целых 2, но они держатся там уже полгода и они, по-моему, там прописались.

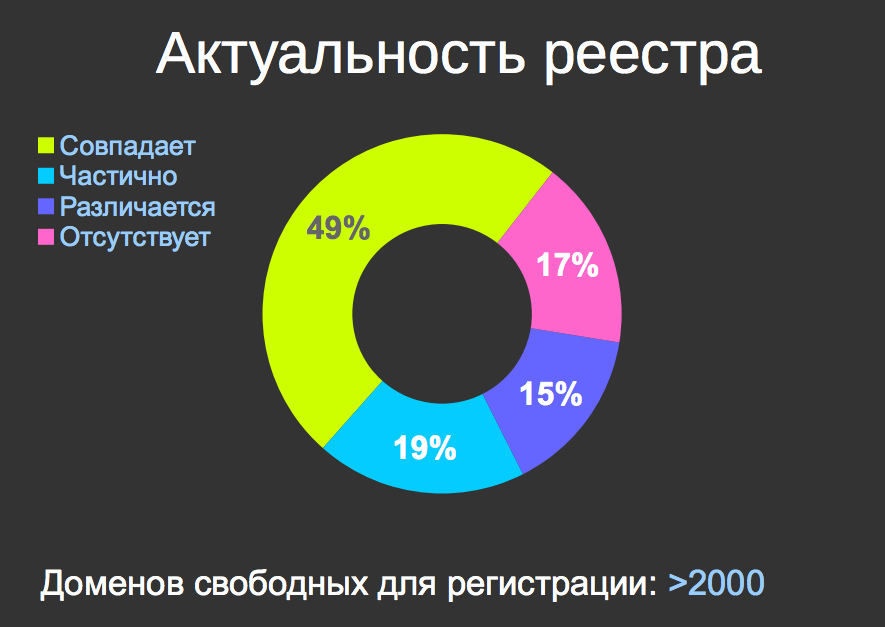
Актуальность реестра. 51% реестра не соответствует действительности — IP-адреса не соответствуют ничему, то есть более половины реестра это полный фарш.
Каждый из вас, подкупив меня или украв мой ноутбук, или сделав предложение, от которого я не смогу отказаться, может получить список доменов, доступных для регистрации, и использовать его для каких-то своих целей, блокируя какие-то произвольные ресурсы в России. Таких доменов больше двух тысяч, прямо вчера я посчитал их специально для нас.
Есть ли убегающие от блокировок домены? Да, такие домены есть. Их больше тысячи, но по факту, когда я посмотрел, что это за домены и почему они убегают, оказалось, что 30% доменов это некие записи CNAME на некие домены в неких CDN, у которых стоит TTL 60 секунд. То есть это не специальное убегание, а в случае с некоторыми CDN зачем-то вот так делают.
И, опять же, это приводит к проблемам у операторов связи, которые вынуждены бегать за этими доменами. Причём никто об этом не знает — я первый человек, говорящий об этом публично.

Соответственно, выводы. Реестр токсичен, неактуален. Если кто-то хочет делать блокировки эффективно, то эффективность страдает. Есть проблема с деградацией связи — есть опыт с банковскими платежами. И чтобы обслуживать реестр, надо затратить силы, время, деньги, но, к сожалению, у надзорного органа таких средств, видимо, нет.

Я описал ситуацию — как ситуация развивается прямо сейчас? За несколько дней до ENOG’а при надзорном органе был создан специальный департамент, который будет заниматься рассмотрением проблем блокировок и ограничения доступа, то есть на это потрачены средства. Сейчас идет активная рекомендация с решением по перехвату всего DNS-трафика и подстановкой соответствующих ответов при совпадении с реестром.
Решение сомнительно — я сразу скажу, это приведет к тому, что будут использовать другой способ. Но все это осознают, включая и надзорное ведомство, поэтому идёт навязывание DPI на всю ширину канала, чтобы не надо было вести в реестре список IP-адресов и актуализировать его. То есть они считают, что это сложно, и перекладывают вопрос обслуживания на провайдеров — это уже звучит в проектах нормативно-правового документа, который уже опубликован.
На этой ноте я передаю микрофон следующему выступающему.
Юрий Каргаполов:
Спасибо, Филипп. Сейчас мы подошли вплотную к техническим решениям, которые предлагаются и о них нам расскажет Артем Гавриченков. Однако, суммируя сказанное к текущему моменту, можно сказать что текущая ситуация не приведет к желаемому властями результату. Это некоторый тупик, о выходах из которого мы попробуем поговорить. Или даже не тупик, а начало пути — предложить решение и далее его обдумывать.
Проблемы deep packet inspection в транспортных сетях, Артем Гавриченков, Qrator Labs
Видео доклада и слайды презентации
Что мы обсудим в докладе, который сейчас начнется – это вопросы возникающие при разработке и внедрении dpi-решений. То есть цель доклада это формирование, может быть, некоторого чеклиста к оборудованию dpi при его внедрении в транспортной транзитной сети.
Этот доклад построен на опыте. Каком опыте? Я уже восемь лет занимаюсь в числе команды сотрудников построением глобальной anycast-сети, задачей которой является (и это типичная задача) deep packet inspection, это защита от ddos-атак.

Глобальная сеть представляет собой кучу точек присутствия по всему миру: от Северной Америки до Юго-Восточной Азии через СНГ и Европу, где каждая точка присутствия представляет это некое железо, причем железо, которое можно купить на рынке. То есть в этом железе нет ничего кастомного.

Кастомный там software, то самое DPI-решение, которое полностью разрабатывается у нас. Этот процесс идет уже восемь лет, это восемь лет дизайна, от выбора железа до настройки софта. То есть дизайн, исследование, развертывание, в том числе на сетях операторов, в том числе у энтерпрайз-заказчиков.

Главной задачей решения является доступность, во всех смыслах. То есть это и анализ трафика, и мониторинг доступности, работоспособности различных сервисов. В конце концов, это и решение по защите от DDoS-атак.

Что представляет собой решение по защите от DDoS-атак на сегодняшний день?
Это анализ, возвращаясь к термину deep packet inspection, анализ трафика на всех уровнях. От примитивного анализа по, допустим, IP-адресам, портам, до отслеживания потоков трафика, сессий, соединений и вплоть до анализа поведения каждого отдельного пользователя с применением различных инструментов big data.

Что мы вынесли из опыта построения такого решения?
Многие из вас, наверное, слышали про термин который вынесен в заголовок этого слайда. Этот термин звучит как «фильтрация пакетов на седьмом уровне» — именно в такой формулировке его можно услышать много где. В эту формулировку закладывается некая гипотеза, которая закладывается и в архитектуру некоторых решений.
Гипотеза следующая — пакетный анализ, то есть анализ каждого отдельного пакета, это мера, достаточная для определения проблем с трафиком, в том числе на седьмом уровне, то есть с третьего по седьмой. Эта гипотеза появилась, в первую очередь, потому, что она очень удобна для построения.

Нужно понимать, что при построении DPI-решений вы сталкиваетесь с целым рядом проблем. Во-первых, если вы хотите из пакета пересобирать TCP-сессию, TLS-сессию и что-то в ней анализировать, то вам нужно на это дело выделять кучу оперативной памяти, это очень сложная задача с поиском каждого отдельного соединения. Растет вычислительная сложность и это нужно делать на каждый пакет, пролетающий мимо.
Далее, сетевые инженеры, которых в зале много и они не дадут мне соврать, очень не любят решения, которые ставятся в сеть, что называется, «в разрыв». Когда весь трафик гоняется через решение по безопасности, потому что сетевые инженеры прекрасно знают, что все эти решения в большинстве случаев ненадежны. Основная задача сетевого инженера это непрерывная доступность — у него SLA, ответственность перед заказчиками по непрерывной работе сервиса, решение по безопасности негативно влияет на доступность сервера: пока оно перезагружается, пока с ним проблемы, и так далее.
Поэтому в основном решение по безопасности, в частности по DPI, работает на копии трафика — где-то в зеркальном порте. И совсем уж желательно, чтобы оно ограничивалось Netflow/IPFIX и больше ничего не делало.

Это очень удобный подход для построения, проблема в том, что уровневая система сети у нас не просто так. Это не чья-то прихоть, уровневая структура сети принципиально важна для ее функционирования. Сеть работает именно на уровнях, пакет — это единица данных именно третьего уровня, уровня протокола IP. Уже на уровне протокола TCP у нас нет понятия «пакет», есть понятие «сегмент» — это разные вещи, каждый, кто сталкивался с mssclamping, это знает.
А на самом деле, на уровне TCP у нас есть сессии, то есть соединения — выше есть TLS-сессии, еще выше имеется уже просто поток данных седьмого уровня. Поэтому игнорирование уровневой структуры сети делает решение теоретически уязвимым. Делало подобное решение уязвимым даже тогда, когда все в интернете передавалось открытым текстом. Впрочем, почему «теоретически».

Три месяца назад на Github’е появился репозиторий с говорящим названием GoodbyeDPI. Этот репозиторий включает в себя ПО, которое предназначено для установки на windows-машину клиента, то есть любого пользователя сети, которое использует ряд примитивных, умных при этом, но все-таки простых техник, таких как:
- Анализ поля Identification протокола IP
- Фрагментация TCP
- Некоторые упражнения с HTTPS-header’ами, в том числе игра с casing, то есть изменение регистра букв в заголовках и тому подобные вещи.
То есть это очень простая техника, которой оказалось достаточно, причем даже не всего комплекса, а одной-двух комбинированных, для того, чтобы обойти абсолютное большинство DPI-решений, уже внедренных на сетях операторов.
И это когда мы говорим про что-то, передающееся в cleartext, как HTTP-заголовки. Но сейчас 2017 год, и у нас есть протокол HTTPS.

Согласно статистике, запущенный в конце 2015-го года бесплатный провайдер TLS-сертификатов Let’s Encrypt выпустил уже порядка 60 миллионов сертификатов.

Согласно телеметрии Firefox, которую публикует Mozilla Foundation, более 60% — две трети, из всей массы сайтов посещаются пользователями данного браузера исключительно по HTTPS.

Соответственно, концепт фильтрации пакетов на седьмом уровне был уязвим даже тогда, когда у нас был cleartext. С современным уровнем и степенью развертывания TLS и с развертыванием механизмов подобным perfect forward secrecy анализ трафика per packet бесполезен даже для целей, которыми мы занимаемся — защиты от DDoS-атак.
Кстати, что такое PFS. Perfect forward secrecy — это концепт, который реализован в эфемерных разновидностях шифра Диффи Хеллмана. Он работает уже сейчас, он работал и в SSL’е — протоколе, которого уже нет, он работает в TLS’е и он обязателен в новой версии TLS 1.3, которая сейчас готовится к релизу.

Суть perfect forward secrecy в том, что установленное TLS-соединение с шифром, например, эфемерными разновидностями Диффи Хеллмана невозможно расшифровать, имея даже приватный ключ. Это невозможно сделать, если вы смотрите на копию трафика — клиент и сервер согласовывают шифры между собой, приватный ключ здесь используется исключительно как подпись этого шифра, соответственно, с его помощью ничего толком не шифруется и расшифровать это нельзя. Это делает невозможной такую красивую ситуацию, когда мы записали трафик за 3 месяца или три года и потом хотим его расшифровать и посмотреть, что там было — благодаря perfect forward secrecy это невозможно.
И по пути perfect forward secrecy ломает уже целый ряд DPI-решений, которые используются для различных целей безопасности, в том числе enterprise уровня.

По нашей статистике, которую я собрал год назад, 70% https-запросов в нашей сети использует pfs. Соответственно, в таких сетях, где используется dpi, не учитывающий это, 70% https-запросов проходит без анализа. Причем это не просто 70% запросов, важно, что 60% легитимных пользователей использует perfect forward secrecy и Диффи Хеллмана. И 90% ботов, потому что злоумышленники превосходно знают о том, что если они используют шифры с поддержкой pfs, то вероятность обойти неправильно или некорректно внедренное dpi-решение сильно повышаются.

Какие задачи DPI-решений существуют на данный момент?
Ну, про защиту от DDoS я сказал уже достаточно и не буду больше к этому возвращаться. Какие еще есть задачи? Это, в целом, quality of service, то есть приоритизация тех или иных поток трафика, исходя из их параметров, из Inspection. В каком-то виде shaping. Далее это родительский контроль, то есть консенсусное ограничение доступа к контенту. Далее это внедрение рекламы на сетях операторов для своих абонентов, вместо той рекламы, которая была бы доступна им, если бы они не были клиентами данного оператора. Далее это enforcement копирайта, то есть блокировка контента, который защищен авторским правом и нелегально распространяется. И, наконец, Lawful Interception.
Все это необходимо делать на транспортной сети и необходимо при этом учитывать, что на данный момент требуется анализ на уровне сессий. Это дает то, что DPI-решение должно учитывать понятие вычислительной сложности, и эта сложность для него чрезвычайно высока.

Простой пример, на котором я не буду останавливаться и приведу ссылку. Очень многие решения DPI предлагают такую удобную функциональность как сопоставление каждого пакета с регулярным выражением. Очень удобно — написал регулярное выражение и все блокируется, все работает.
В регулярных выражениях есть целый ряд проблемных моментов, один из них приведен на слайде вместе со ссылкой, по названию catastrophic backtracking можно понять уровень проблемы. При определенном виде регулярного выражения и определенной строке в него поданной мы имеем квадратичную сложность сопоставления строкой — чем строка длиннее, тем квадратично растет скорость выполнения.
Естественно, целый ряд DPI-решений, которые это используют, никаких предупреждений при формировании сложного регулярного выражения не выдают. И здесь мы при выполнении сталкиваемся со следующей дилеммой — либо необходимо тратить до секунды машинного времени на сопоставление с отдельными пакетами/потоками, то есть скорость соединения, скорость трафика, падает драматически. Либо в какой-то момент необходимо по отсечке останавливать анализ пакета и пропускать его дальше. Зависит от задачи, которая перед нами стоит.

К чему это нас приводит? К тому, что многие полагают, будто DPI-решения это некая серебряная пуля — звучит очень хорошо, глубокий Packet Inspection. Как холодильник, его купил, поставил — он решает проблему, может быть, его нужно как-то настроить, в целом он способен решить свои задачи. На самом деле это не так.

На сегодняшний день DPI это не линейка продуктов, не классификация, а всего лишь общая характеристика целого ряда решений, которые решают совершенно разнообразные задачи, каждое из которых предназначено для решения одной, максимум двух задач. Чем больше задач вы на него кладете, тем хуже оно с ними справляется.
И, естественно, одно-единственное решение не справляется хорошо с каждой задачей DPI. Если оно хорошо работает с родительским контролем, значит, от DDoS-атак оно защищает плохо.

Более того, даже если оно предназначено для решения одной задачи, всегда есть компромисс, некий trade off, между скоростью обработки пакетов (как в случае с catastrophic backtracking) и функциональностью. Соответственно, либо мы получаем функциональность и от этого страдает скорость, либо мы ставим приоритетом скорость, и тогда страдает функциональность.

Другой проблемой DPI-решений является то, что сеть, особенно транзитная сеть, на данный момент предполагает собственную прозрачность для приложений. Приложения рассчитывают на эту прозрачность — передача голоса и видео посетителей, и игровые протоколы, которых в месяц появляется 3 новых, и оверлейные сети, передачи данных внутри enterprise-сетей. Современный веб тоже рассчитывает, что сеть работает так, как написано в RFC. Никакого анализа странного нестандартизованного вида в сети нет. Протоколы HTTP/2, MPTCP, QUIC — все в целом рассчитывают на это.
Более того, современная сеть внедряет протоколы криптографические, TLS 1.3, DNSSEC и прочие, которые все в целом рассчитывают на то, что транзитная сеть является прозрачной. В случае с внедрением DPI это не так, и это не проходит даром.

Результат следующий — ряд приложений страдает от данных проблем. Это слайд от Eric Rescorla с прошедшего в Праге IETF. При тестовом внедрении TLS 1.3 на сети Cloudflare, если я не ошибаюсь, возникли серьезные проблемы — от 1% до 10% трафика в TLS 1.3 терялось из-за «каких-то» middlebox’ов, которые его не умеют и не поддерживают. Соответственно, TLS 1.3 из-за непрозрачности сети сильно ломается, что влияет на безопасность сети и пользователей в целом. TLS 1.3 сейчас дорабатывается, ряд приложений страдают, а другие будут адаптироваться.

Как будет происходить эта адаптация? На круглом столе по безопасности, который прошел на предыдущем ENOG в Санкт-Петербурге, мы узнали, что внедрение, развертывание обновленных прошивок, даже в случае, если в них проблемы безопасности — то есть это обновление безопасности, от момента обнаружения уязвимости до развертывания заплатки тратится от 4 до 6 месяцев. На что тратится это время?
Сначала, от 2 до 3 месяцев, как компания Cisco в данном примере от компании Digital Security, пишет этот фикс. Ускорить это на практике оказывается невозможно — я участвовал в таком процессе и, к сожалению, ускорить это менее чем до двух месяцев невозможно. Далее еще 2-3 месяца, суммарно шесть, занимает развертывание на сети, поскольку главным, о чем я уже говорил, для оператора является сохранить непрерывность работы. Любое обновление может негативно повлиять на работу оборудования, его нужно перезагружать, технические работы — не хочется с этим связываться. Итого мы имеем шесть месяцев.

При этом в случае если у нас есть DPI-решение, оно должно адаптироваться к тому, как эволюционирует сеть на седьмом уровне. Современное приложение: игровое, voice over IP, мобильное приложение, IoT и в том числе malware, использует современные подходы CI и CD, которое позволяет выкатывать новый релиз несколько раз в день.
К чему это приводит? К тому что, в случае если у нас есть DPI-решение, неподдержание им какой-то малвари или определенного типа трафика может не рассматриваться как уязвимость, она может рассматриваться как новая функциональность и может требовать при этом обновление оборудования. При этом те ресурсы, которые будут пытаться обойти эту блокировку, будут выкатывать обновления не раз в 6 месяцев, а несколько раз в день.

Что это такое? Это гонка вооружений, которую вендор или внедренец DPI-решения неизбежно проиграет.

К чему мы приходим? К тому, что решения по DPI, которое рассматривает каждый пакет в отдельности, недостаточно для решения проблем в целом. Для чего оно хорошо работает, так это удовлетворение принципа Парето, закона 80/20. Если вы согласны с тем, что вы потратите 20% процентов усилий на решение 80% проблем — это решение для вас. Сферы применения, такие как родительский контроль, quality of service, та же самая реклама и в целом какая-то блокировка трафика по тем паттернам, о которых говорил ранее Алексей.
Соответственно, с полным пониманием, что пользователь, который захочет это обойти, это обойдет. Если задача стоит по внедрению блокировки 100% определенного контента, то в ситуации когда мы не имеем контроля ни над клиентом (в терминах сетевого взаимодействия), ни над сервером — нужно понимать, что клиент-сервер могут играть в произвольную игру. Они могут, в частности, делать вид что устанавливают соединение, аллоцируя тем самым ресурсы DPI-решения на эту сессию, про которую они забывают. Ни клиент, ни сервер не тратят на это ресурсов — DPI-решение не знает, как это функционирует, поэтому на нем память выделяется, соответственно, при использовании большого числа таких клиентов DPI-решение может просто уйти в отказ. Если оно установлено в разрыв, то отказ произойдет в этот момент на всей сети, чего многие инженеры хотели бы избежать.

К вопросу о безопасности — еще один момент, который необходимо рассматривать при выборе и внедрении DPI-решения заключается в том, что это решение сложное. Сложно дизайнить, сложно строить, внедрять тоже непросто. При этом, скажем так, подходы к безопасности у различных вендоров, я не готов сейчас о них говорить, я не знаю, насколько вендоры, например, обновляют свои решения, проводят какой-то аудит/анализ безопасности.
Что мы можем точно сказать, так это то, что в мире существуют решения, одним из которых является, к примеру, FinFisher, в datasheet’е которых указано предназначение установки через различные «технологические отверстия» на сети оператора, без ведома оператора и для анализа трафика пролетающего мимо. Это решение, которое уже сейчас существует — у меня нет подробностей о том, как именно оно работает, но здесь важно, что люди, занимающиеся подобными вещами, от злоумышленников до определенных компаний, отлично знают, что на сети оператора могут быть сложные вещи.
И если эти вещи начнут разворачиваться на всей сети, они будут туда смотреть, будут искать в них дыры. В случае если это просто какая-то слежка, то для оператора это может быть и не принципиально, но в если это какие-то злоумышленники, которые получат контроль над DPI-решением, развернутым в разрыв на всей сети оператора, последствия сложно даже представить. Это последствия уровня голливудского фильма или футурологического конгресса — что произойдет, что они смогут сделать, скорее всего, практически все.

К чему это все нас приводит? К тому, что вопрос прозрачности и безопасности сети в данном разрезе является основным, принципиальным. И если некое сетевое сообщество или некоторая сетевая структура хочет устанавливать некие непрозрачные решения на транспортную IP-сеть, основной задачей в деле разворачивания такого решения является его, в первую очередь, стандартизация. Выход на те активности, те сообщества, комитеты, которые занимаются стандартизацией с тем, чтобы все участники сети прекрасно понимали, что же происходит в ее середине, что же происходит на транзите. Это RIPE, IETF, ICANN, IEEE и другие сообщества, которые занимаются согласованием требований и учетом требований от всех участников сети: от игровых протоколов до операторов связи со своими требованиями, которые на данный момент при разворачивании DPI-решений часто не учитываются. Их необходимо учитывать, если вы хотите это делать, необходимо делать это всерьез.
Потому что альтернативой является только ненадежный IP-транспорт, приложения, которые обходят ненадежный IP-транспорт, по пути ломая его, и нестабильность критической сетевой инфраструктуры в целом.
Перспективы применения методов блокирования контента
Юрий Каргаполов:
Спасибо, Артем. Твой доклад добавил оптимизма в нашу дискуссию. Мы постарались спланировать панель таким образом, чтобы сейчас Антон Басков дал нам видение будущего — какие могут быть развернуты технологические решения. Попробуем увидеть это будущее вместе.
Перспективы блокирования контента в условиях дальнейшего развития технологий интернет — Антон Басков, AB Architecture Bureau
Видео доклада и слайды презентации
Предположим, что ситуация со временем стала лучше. В реестре уже не 100 000 записей, а его поддержка осуществляется на более или менее нормальном уровне. Предположим, что мы нашли какое-то решение, которое условно работает в текущей ситуации. Что дальше? Как изменится ситуация с течением времени?

При разработке подходов к блокировке противоправного контента у нас всегда остается необходимость выбирать правильный баланс между эффективностью, стоимостью и тем дополнительным сопутствующим ущербом, который приносят блокировки на сети. Что же остается за пределами условно-простых методов реализации блокировок? Какие ситуации мы должны учитывать?
Например, мы должны учитывать случаи, когда контент может прятаться, то есть менять адреса, идентификаторы, делать странные перенаправления — есть множество различных вариантов. Возможна ситуация со скрытием цели, доступом посредством скрытых сетей, ситуация с распределенным контентом, когда часть контента находится внутри сети одного оператора – в таком случае динамически такой трафик будет сложно заблокировать, его придется отправлять до точки фильтрации и возвращать обратно.
Еще мы должны учитывать риски, связанные с созданием глобальных решений в рамках страны. Например, ложные срабатывания, иногда специально наведенные. Например, можно у Филиппа Кулина взять список этих замечательных 2000 доменов, о которых он говорил, и использовать их для блокирования критической инфраструктуры. Также можно, пользуясь тем, что количество решений, которые занимаются блокировками, ограничено, найти уязвимости в одном или нескольких решениях и получить ужасающие проблемы на отдельных сегментах сетей, или в принципе заблокировать работу критической инфраструктуры.
Также хочется отдельно обратить внимание, что важно не только как мы блокируем контент, а что именно мы блокируем, что именно мы понимаем под целью. Для того чтобы понимать цель блокировки, нам необходимо смотреть за живым трафиком, за поведением пользователя, а также иметь распределенную инфраструктуру мониторинга интернет, например, подобную по архитектуре RIPE Atlas.

Конфиденциальность и всеобъемлющий мониторинг – это давняя тема в рамках IETF, и она неразрывно связана с блокировками. При этом, если по поводу блокировок на текущий момент существует 1,5 документа, то тема, связанная с конфиденциальностью и мониторингом, судя по количеству документов, считается более актуальной. Эта тенденция проявилась где-то в 2011 году и активно развивается до текущего момента.
Я бы хотел дать краткий обзор отдельных документов и решений в этой области.

Многие решения, которые делают блокировки трафика по HTTPS, ориентируется на SNI (Server Name Indication). На текущий момент SNI – это передача в plaintext имени хоста, после которого осуществляется необходимое согласование ключей на основе предъявленных сертификатов. На этом уровне мы можем определить, к какому именно ресурсу осуществляется доступ. Именно на основе SNI осуществляется точечная фильтрация ресурсов работающих поверх TLS. В приведённом выше документе описывается два метода шифрования SNI для того, чтобы исключить возможность его анализа, в том числе и впоследствии – записав трафик, мы не сможем узнать, к какому ресурсу обращался интересующий нас пользователь.
Интересно, что в документе рассматривается подход, при котором для получения доступа к конечному ресурсу мы должны обратится к указанному промежуточному узлу, который далее перекинет шифрованный трафик на необходимый хост и, по сути, служит лишь одним из звеньев цепочки, пунктом пропуска трафика. Тем самым, без дополнительного анализа по косвенным данным, мы не сможем узнать, какие ресурсы на самом деле скрываются за промежуточным узлом.

Если говорить о DNS, то, несмотря на «имидж» открытой базы данных, информация о запросах пользователей также может быть крайне полезной для pervasive monitoring. Это не только легкодоступная информация о ресурсах, которые мы посещаем, но также и информация о том, с кем мы общаемся. Когда вы отправляете письмо, отдельные современные клиенты пытаются получить дополнительную информацию о получателе, например, отправляя запрос с хешем адреса электронной почты.
Что же было для сделано для того, чтобы по возможности исключить анализ DNS? Во-первых, это шифрование DNS в рамках TLS и DTLS, для того, чтобы даже косвенно нельзя было понять, по отдельным паттернам, к какому ресурсу осуществлялся доступ. Во-вторых, это подход Query Name Minimisation, основная задача которого – минимизировать количество информации, передаваемой на промежуточные авторитативные сервера резолвером. На текущий момент рекурсивные сервера передают запрос пользователя промежуточные авторитативные сервера, включая корневые, без изменений, что позволяет понять, по каким адресам и с какими запросами обращаются пользователи. На текущий момент эта информация доступна, её достаточно легко можно получить для анализа.
На уровне рекурсивного сервера на текущий момент всё остаётся по прежнему: хоть канал и зашифрован, сам рекурсивный сервер знает обо всех запросах пользователя. Но ситуация тоже меняется, так как есть планы по включению в отдельные протоколы уровня приложений информации DNS, подписанной DNSSEC. Предположим, что мы заходим на страницу сайта, и сервер, понимая, что дальше будут осуществляться запросы внешних ресурсов, уже заранее предлагает нам подписанные ответы. Нам не обязательно обращаться к DNS, мы можем получить необходимую информацию в рамках текущего соединения и использовать её дальнейшем, тем самым минимизируя обращения к рекурсивному серверу. Соответственно, снижается нагрузка на рекурсивный сервер, так часть запросов, по которым можно понять, куда обращался пользователь, предоставляется на уровне приложения.

Существует совершенно шикарная вещь, которая называется Opportunistic IPSec. Она разработана более или менее давно, и современные реализации уже отличаются от изначального RFC. DNSSEC выступает в данном случае триггером, в котором прописывается ключ, и все соединения между узлами сети шифруются на транспортном уровне. Соответственно, промежуточные узлы не смогут не то что получить доступ к данным, но даже напрямую понять, по каким протоколам мы работаем с конечным узлом. Кроме того, этот механизм позволяет защищать нешифрованные соединения унаследованных протоколов.

Если раньше мы думали, что «хорошие ресурсы», которым нечего скрывать, в том числе те, которые не содержат запрещенного контента, работают по HTTP, то есть в plaintext, то на текущий момент это уже не так. С обновлениями программного обеспечения браузеров и HTTP-серверов появляется такой механизм как opportunistic security. Используя механизм альтернативных сервисов, пользователь в более или менее принудительном порядке перенаправляется на HTTP/2 с поддержкой TLS. И тот трафик, который изначально передавался в виде plaintext HTTP, в скором времени станет шифрованным. В Firefox есть поддержка этой технологии с 2015 года. Судя по багтрекеру, Chrome в ближайшем времени (в течение 1-2 месяцев) будет также поддерживать механизм opportunistic security. Остаётся дождаться включения поддержки этого механизма серверами «по умолчанию», и внезапно большая часть нешифрованного трафика окажется зашифрованной.

Если ранее мы говорили о технологиях, так или иначе влияющих на возможность осуществлять блокирование доступа к информации, то нужно понимать, что подобные изменения, препятствующие слежке за пользователями, происходят также и с другими протоколами. Тут можно привести в пример электронную почту. Если ранее соединения между почтовыми серверами использовали механизм opportunistic security, то на текущий же момент появляется триггер в DNS, в котором четко прописано, в каком случае обязательно использовать TLS-соединение и каким сертификатам следует доверять.
То же самое касается и самих писем, передающихся через SMTP-сервера: теперь можно легко узнать, в каком случае мы можем отправить получателю шифрованное сообщение. Уже разработаны специальные фильтры, которые можно поставить на почтовые сервера организации, которые незаметно для пользователя будут по возможности шифровать всю исходящую почту.

Каким будет эффект от внедрения всех вышеописанных протоколов, связанных с шифрованием? Эффективность блокировок, то есть способность обнаружить доступ к запрещенному контенту, будет снижаться, точность блокировок будет также падать из-за неспособности отличить хороший контент от плохого. Сопутствующий ущерб будет только расти.
Тот подход, который сейчас популярен, к примеру, в России, когда мы блокируем контент, после чего о нем забываем, более не работает. Необходимо заниматься не только блокировкой контента, но и самим источником противоправной информации, чтобы подобного контента в принципе не существовало.

Какие методы при этом остаются в распоряжении правоохранительных органов?
Несмотря на то, что количество метаданных, по которым можно анализировать трафик минимизируется, остаются методы статистического, поведенческого анализов — наблюдение за отдельными показателями или наблюдение за поведением пользователей в массе позволяет предсказывать появление новых источников противоправного контента. Приведу такой пример: если человек страдает игровой зависимостью, то он будет продолжать попытки обхода блокировок для того, чтобы зайти в интернет-казино. При этом методы поведенческого и статистического анализа куда менее чувствительны к реализации методов обхода блокировок, хотя и требуют значительных ресурсов для работы, что, учитывая вышеописанные изменения в протоколах, не позволит использовать эти подходы для всеобъемлющей слежки.
Также остаются средства внешнего мониторинга, которые будут совершенствоваться для того, чтобы определять, что именно нужно предпринять для блокировки противоправного контента, т.е. определять, где этот контент находится и как правильно его блокировать, чтобы минимизировать косвенный ущерб.
Не стоит забывать о том, что было еще несколько лет предсказано в RFC, и что, скорее всего, ждет отрасль в дальнейшем — это наличие информаторов, т.е. сотрудничества между крупными и инфраструктурными сервисами и правоохранительными органами. Ими могут быть операторы связи, крупные аналитические и рекламные сервисы типа Google Analytics, Google Adwords, Yandex Metrika, операторы CDN, возможно, разработчики ПО, которые имеют доступ к большему количеству метаданных. К сожалению, данных, к которым имеют доступ эти сервисы, более чем достаточно как для борьбы с противоправным контентом, так и для продолжения всеобъемлющей слежки.

Если говорить о текущем моменте, простых механизмов ограничения доступа (в том числе юридически-правового характера) в большинстве случаев достаточно для того, чтобы усложнить доступ пользователей к противоправному контенту. Нет смысла нарушать принцип Парето, о котором говорил Артем. Заблокировать всё — задача нереальная.
В тех случаях, когда простые механизмы ограничения доступа не будут работать, оперативная работа будет на порядок эффективнее. Конечно, при условии, что она обеспечена необходимыми средствами оперативной разработки, о которых мы говорили выше. Это будет куда эффективнее, чем в тщетных попытках блокировать информацию, организовывать систему тотальной фильтрации в сети.
Также стоит учитывать, что криминал будет всё более и более активно использовать сеть для координации противоправных действий, причем большая часть из них не будет непосредственно связана с условно общедоступным противоправным контентом, на борьбу с которым и рассчитана система блокировок. Так что вывод из всего вышесказанного простой – подход, когда единственным методом борьбы с противоправным контентом являются блокировки, бесперспективен. Не стоит инвестировать миллиарды в бесполезную инфраструктуру, а стоит сосредоточиться на разработке решений, которые помогут правоохранительным органам эффективно работать в мире современных технологий.
Административные вопросы блокировок, Юрий Каргаполов, UANIC
Видео доклада
О чем я хотел сказать, без слайдов.
О том, что я приехал с Украины. Мы начали в стране реализовывать стратегию блокировок. Начали реализовывать на основании двух указов президента, то есть у нас нет законодательной базы в смысле существующего закона, более того, у нас есть интересное нововведение в законе о телекоммуникации, которое говорит о том, что оператор не несет ответственности за содержание контента передающегося по его сетям.
Но между тем наказывать собираются тех, кто не выполняет, а вопиющий пример был такой — когда Яндекс у нас заблокировали и сказали, что нужно заблокировать все сопутствующие Яндексу сервису. Яндекс через два дня ушел в Cloudflare, и нашлись умные товарищи, которые весь Cloudflare отправили в нуль, отдав это по BGP в мир. Мир это съел, не проверив, и отдал дальше.
Когда спохватились, начали откатывать, но выяснилось, что этого украинского аплинка от всех отключили, и треть суток мы сидели с большим количеством отключенных каналов.
Хотел бы сказать еще одну вещь. Кто в 90-х годах занимался IP-телефонией? Вы помните эту ситуацию, когда есть один, есть второй абонент, они звонят друг другу, что-то проходит, что-то не проходит, потому что не во всех роутерах стояли соответствующее ПО и кодеки, этот зоопарк из всего, что только можно, не работал? То, что будет происходить сейчас — искусственное повторение той ситуации с IP-телефонией. Это не прямая аналогия, однако это имеет место быть, чтобы мы осознали момент, где мы находимся.
Если мы понимаем, где мы находимся, то следующий шаг, который стоит сделать, заключается в том, чтобы создать рабочую группу, которая могла бы нормально, без спешки, профессионально обсудить вопрос. Наработать подходы, которые нас уберегут от тех граблей, на которые мы наступали уже неоднократно.
Когда мы готовили эту панельную дискуссию и прогоняли ее, подключив других экспертов, выслушавших нас, мы пришли к выводу, что закончить нам необходимо именно предложением создать рабочую группу. При RIPE, ICANN, ISOC — в общем, рабочую группу, которая бы эти вопросы начала внимательно обсуждать.
Поэтому мы обращаемся и к руководству соответствующих организаций с тем, чтобы они имели в виду — мы будем на них выходить.
Спасибо.
Комментарии (5)

daocrawler
21.11.2017 19:15Если говорить о текущем моменте, простых механизмов ограничения доступа (в том числе юридически-правового характера) в большинстве случаев достаточно для того, чтобы усложнить доступ пользователей к противоправному контенту
Технических — да, с механизмами юридически-правового характера — беда (в РФ), имели некоторый опыт.

ValdikSS
22.11.2017 02:40Часто слышу, как говорят, что блокировок по IP-адресу много. По данным blockcheck, по IP-адресу блокируют 11-13% провайдеров. Я бы не сказал, что это много.

tzlom
22.11.2017 08:17Во первых оценивать количество провайдеров не правильно — надо оценивать количество клиентов.
Во вторых в реестре не у всего есть URL, поэтому по ip блочат все, но некоторые блочат по ip и то, у чего есть URL.ValdikSS
22.11.2017 11:18поэтому по ip блочат все
А вот и нет, и я это определяю эмпирически, без тестов.
Диапазоны адресов Blackberry находятся в реестре. При подключении к некоторым точкам доступа Wi-Fi, мой телефон пытается проверить, есть ли здесь интернет, обращаясь к хосту на одном из заблокированных адресов. Если он определяет, что интернета нет — провайдер блокирует по IP-адресу. Если интернет есть, то не блокирует. Второе случается чаще.
ValdikSS
Идею автоматического шифрования трафика через IPsec поднимали еще в самом начале внедрения IPv6, но быстро от нее отказались.