
Оглавление
Часть 1
1.Введение.
2.Разрезание на части (chunks).
3.Сжатие образов.
3.1.Sparse-файлы.
Часть 2
3.2._sparsechunk-файлы.
4.Создание dat-файлов.
5.Источники информации.
Образы разделов мобильных устройств (МУ), содержащих файловую систему (ФС) ext4, имеют большие размеры, например, размер образа раздела system может достигать нескольких ГБ, а размер образа раздела userdata составляет уже несколько десятков ГБ.
Эти особенности требуют от разработчика прошивок применения «хитростей» при выполнении операций первоначальной загрузки прошивок МУ или установки обновлений, т.к. размеры образов разделов становятся не только соизмеримыми с объемом оперативной памяти МУ, но и значительно их превышают.
Разработчики стоковых (заводских) прошивок для уменьшения размера образов разделов в настоящее время применяют следующие способы:
В основе первого способа лежит уменьшение размера образа за счет разделения его на несколько частей, называемых кусками (chunks), при этом размер каждого куска не должен превышать заранее выбранную допустимую величину. Это позволяет уменьшить размер порции информации, передаваемой в МУ за один сеанс.
При втором способе используется то свойство образа ФС, что он представляет собой разреженный файл [1]. Это позволяет применить кодирование без потери данных, что приводит к уменьшению размера всего образа раздела за счет сокращения объема «пустых» блоков, содержащих или нулевые, или повторяющиеся данные.
Особенность третьего способа состоит в том, что после кодирования из образа удаляются все «пустые» блоки (при установке прошивки) или передаются только изменения образов (при выполнении обновлений).
Думаю, что в качестве повышения квалификации разработчикам custom-прошивок будет интересно ознакомиться с внутренним строением образов такого типа и прояснить некоторые моменты работы с ними…
Этот способ подразумевает, что исходный образ, имеющий ext4-формат, делится на части размером не более заранее заданной величины, называемой границей. Чаще всего, граница имеет значение 128 или 256 Мб. При этом, для обратного восстановления, дополнительно создается, так называемый, файл размещения, описывающий расположение этих частей в исходном образе.
Процесс разрезания образа раздела на части может быть описан таким алгоритмом:
После такого разбиения образа раздела и за счет отсечения нулевых данных происходит существенное уменьшение суммы длин кусков, т.е. общего размера выходного файла.
Процесс восстановления очень прост и производится по следующему алгоритму:
Для примера, давайте рассмотрим процесс восстановления исходного образа раздела, используя прошивку для МУ Lenovo s90 на основе процессора Qualcomm MSM8916 [2], которая содержит файл размещения rawprogram0.xml. А за «границу» части у Qualcomm принято значение 128 Мб.
Файл размещения rawprogram0.xml представляет собой xml-файл, цитата из которого приведена ниже:
Строго говоря, это файл описания разметки памяти МУ на основе чипов Qualcomm. Я не буду описывать все параметры этого файла, т.к. нам потребуются только следующие:
Параметр filename указывает имя файла, содержащего образ или его часть, метка которого представлена параметром label.
Параметр start_sector содержит АБСОЛЮТНОЕ смещение начала файла в памяти МУ.
Т.к. мы не будем прошивать файлы частей в память, а только соберем из них цельный файл-образ раздела, то для размещения каждой части в этом файл-образе нужно использовать относительное смещение. За базу принимается начало образа конкретного раздела, т.е. смещение образа в памяти МУ. Расчет производится по следующей формуле:
В теле прошивки имеется несколько файлов, содержащих ФС ext4:
Давайте попробуем собрать образ раздела cache, т.е. из частей cache_1.img — cache_4.img соберем один файл cache.img. Конкретно, для него выберем из файла размещения rawprogram0.xml, приведенного выше, следующие значения:
Для восстановления необходимо выполнить следующее:
Выполнив все действия, Вы получите файл cache.img, размером 262МБ, содержащий образ раздела cache в виде ФС типа ext4.
Разрезание на части частично решает проблемы разработчиков, уменьшая размер одной части, передаваемой за сеанс передачи при прошивке или обновлении. Тем не менее, общий размер файла не изменяется.
Проблему уменьшения размера образа можно решить путем его сжатия (кодирования). Для этого применяют следующие способы:
Sparse-файлы активно используются, например, в устройстве Moto G фирмы Lenovo, а _sparsechunk-файлы применяются в Moto Z.
Для удаления «пустых» значений, число которых в образах разделов может достигать 90%, сами образы конвертируют (сжимают) в файлы типа Sparse, структура которого описана в [3]. При этом исходный файл рассматривается как массив элементов, представляющих собой четырехбайтовые числа, и просмотр массива выполняется поблочно, т.е. по 4096 байт или по 1024 элемента.
В зависимости от содержимого блоки разделяются на следующие типы:
Разреженный образ раздела с ФС после конвертации в sparse-файл представляет собой последовательность (список) кусков типа Raw и Fill, расположенных вперемежку. Для идентификации и обеспечения обратного преобразования (восстановления образа) все это дополнено заголовком.
Итак, Sparse-файл состоит из:
Несмотря на то, что при конвертации образа Raw-формата в sparse используется только два типа кусков, всего существует 4 типа кусков sparse-файлов, которые будут рассмотрены ниже.
Заголовок имеет следующее строение:
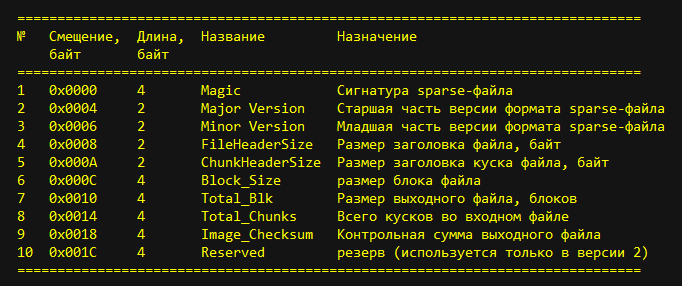
рис.2. Заголовок sparse-файла
Кратко рассмотрим все поля заголовка.
Поле Magic длиной 4 байта, содержит сигнатуру (число 0xed26ff3a) и служит для идентификации sparse-файла как типа файла.
Поля Major Versionи Minor Version длиной по 2 байта, содержат номер версии формата sparse-файла. Сейчас это версия 1.0.
Поле FileHeaderSize длиной 2 байта, содержит размер заголовка sparse-файла в байтах. В настоящее время существует две версии заголовка, отличающихся только его размером: 0х1С (28) байт и 0х20 (32) байта. Соответственно и это поле содержит число или 0х1С, или 0х20.
Поле ChunkHeaderSize длиной 2 байта, содержит размер заголовка кусков sparse-файла. Независимо от типа кусков оно содержит число 0х0С (12).
Поле Block_Size длиной 4 байта, содержит размер блока sparse-файла. Для сжатия в sparse-файл образов ФС типа ext2-ext4 значение этого поля равно 0х1000 (4096).
Поле Total_Blk длиной 4 байта, содержит размер исходного файла (img) в блоках.
Поле Total_Chunks длиной 4 байта, содержит число частей, на которые был разделен исходный (входной) файл. Столько же кусков содержится и в выходном файле (sparse).
Поле Image_Checksum содержит контрольную сумму данных выходного файла (sparse), рассчитанную по алгоритму Crc32 для всего файла (заголовок + данные).
Следом за заголовком располагается область данных, состоящая из списка кусков sparse-файла.
Каждый кусок имеет заголовок куска и данные куска.
Заголовок имеет длину 0х0С (12) байт, как указано в поле ChunkHeaderSize заголовка sparse-файла и содержит следующие поля:

рис.3. Структура заголовка куска
Поле Chunk_Type длиной 2 байта, содержит идентификатор куска и может принимать следующие значения:
Поле Reserved длиной 2 байта, не используется и всегда равно нулю.
Поле Chunk_Size длиной 4 байта, содержит размер исходного куска во входном файле (img), выраженный в блоках.
Поле Total_Size длиной 4 байта, содержит размер полученного куска в выходном sparse-файле, выраженный в байтах. При рассчете учитывается как длина заголовка, так и длина данных куска.
Следом за заголовком располагаются данные, различающиеся в зависимости от типа куска.
Т.к. кусок типа Raw предназначен для хранения неповторяющихся данных, то данные куска полностью совпадают с данными соответствующей ему части входного файла. Имеет наибольший размер, т.к. количество данных может достигать значения выбранной границы.
Кусок типа Fill в качестве данных содержит только одно четырехбайтовое число (4-хбайтовый заполнитель), повторяющееся в соответствующей ему части входного файла. Он заменяет собой всю область, занятую этими повторяющимися данными без их перечисления, что и приводит к их сжатию.
Кусок типа Crc в качестве данных содержит контрольную сумму куска, рассчитанную по алгоритму Crc32 по всем данным куска.
Исключением является кусок типа DontCare, который вообще не содержит данных, но поле Chunk_Size все равно заполняется. Он представляет собой указатель (смещение) на начало следующего куска данных входного файла.
При работе с sparse-файлами выполняются операции кодирования «сырого»(Raw) img-файла в sparse-файл и декодирование sparse -файла в исходный файл.
Кодирование входного Raw-образа раздела sparse-формат производится по следующему алгоритму:
Декодирование sparse-файла в исходный образ производится по следующему алгоритму:
При работе с sparse-файлами чаще всего возникают два вопроса:
Рассмотрим их согласно поступлению…
Для примера рассмотрим процесс восстановления образа раздела oem из sparse-файла МУ Moto Z от Lenovo [4]. Все действия выполняются при помощи hex-редактора, например, WinHex.
Исходный файл oem.img, содержащий сжатый образ раздела oem, имеет размер 69MБ. Посмотрим его заголовок:

рис.4.Заголовок Moto Z
С адреса 0х0000 расположена сигнатура файла, указывающая, что файл имеет тип sparse-файл и состоит из кусков. Сигнатура отмечена синим цветом.
Далее зеленым цветом выделены поля, содержащие версию sparse-файла (1.0).
Затем красным цветом выделены поля FileHeaderSize и ChunkHeaderSize, содержащие размер заголовка файла (0x001C) и размер заголовка куска (0x000C) соответственно.
По смещению 0x000C расположено поле Block_Size, указывающее размер блока sparse-файла. Значение размера блока 0х00001000.
По смещению 0x0010 расположено поле Total_Blk, содержащее размер исходного файла в блоках. Оно выделено желтым цветом и имеет значение 0x0000С021.
По смещению 0x0014 расположено поле Total_Chunks, содержащее число кусков, содержащихся в sparse-файле. Оно выделено фиолетовым цветом и имеет значение 0x0000001F.
По смещению 0x0018 расположено поле Image_Checksum, содержащее контрольную сумму sparse-файла. Это поле содержит 0, что означает, что КС не рассчитывалась и не учитывается при загрузке этого файла в память МУ.
Начиная с адреса 0x001C, расположен заголовок первого куска sparse-файла:

рис.5.Заголовок куска CAC1
Видно, что поле Chunk_Type содержит значение 0xCAC1, выделенное синим цветом. Следующих 2 байта пусты, а затем расположено поле Chunk_Size, отмеченное красным цветом, содержащее число блоков входного файла (0x00000001), закодированных в куске.
Далее расположено поле Total_Size, содержащее длину куска вместе с заголовком, выраженную в байтах (0x0000100C). Оно выделено зеленым цветом. Нам всегда нужен размер без заголовка, поэтому длина только данных: 0х100С — 0х000С = 0х1000.
Сразу за заголовком, начиная с адреса 0x0028 идет массив данных куска.
Итак, для восстановления исходного образа выполним следующие действия:
В результате получится файл, содержащий ФС типа ext4, размером 192МБ.
Для простоты возьмем только что полученный образ oem_ext4.img и попробуем его превратить в sparse-файл. При этом необходимо создать новый файл размера 0х001С (28) байт, поместить в него заголовок sparse-файла и далее последовательно просмотреть исходный файл, деля его на куски и кодируя их, размещать в новом файле все создаваемые sparse-куски. Ну и, конечно, сохранить новый файл под именем, например, oem_sparse.img.
Чтобы заполнить заголовок файла, вписываем в первые 4 байта сигнатуру sparse-файла:

рис.7. Заголовок sparse-файла
Далее последовательно записываем значения:
Оставшиеся поля оставляем свободными, т.к. их значения появятся у нас только после окончательного создания выходного файла.
Давайте теперь рассмотрим как кодировать, т.е. создавать, разные типы кусков.
Любой тип куска имеет заголовок. Поэтому создадим его в первую очередь: создаем в hex-редакторе файл размером 12 байт:

рис.12 Пустой заголовок куска
Далее рассмотрим, как и что заполнять в кусках.
Кусок типа Raw
В первые 2 байта заголовка запишем его тип (CAC1):

рис.13 Тип куска CAC1
Затем в поле вставляем размер данных (0x00000001), выраженное в блоках:

рис.14 Размер в блоках
Ну и, наконец, размер куска в байтах (0x0000100C), т.е. длина заголовка + длина данных:

рис.15 Размер куска САС1
После заголовка вставляем данные, т.е. 0х1000 (4096) байт из исходного файла:

рис.16 Данные куска САС1
Перейдем к созданию следующего куска.
Кусок типа Fill
В первые 2 байта заголовка запишем его тип (CAC2):

рис.17 Тип куска CAC2
Вставляем размер данных куска (0х001D), выраженное в блоках:

рис.18 Размер в блоках САС2
Вставляем размер куска в байтах (0х0010), т.е. длина заголовка + длина данных:

рис.19 Размер куска САС2
Добавляем данные куска. Для CAC2 это элемент-заполнитель (0xFFFFFFFF):

рис.20 Данные куска САС2
Перейдем к созданию следующего куска.
Кусок типа DontCare
В первые 2 байта заголовка запишем его тип (CAC3):

рис.21 Тип куска CAC3
Вставляем значение смещения до следующего куска (0ххххх), выраженное в блоках, по адресу 0х0004 заголовка.
Вставляем размер куска в байтах (0х000С), т.е. просто длина заголовка, т.к. кусок этого типа данных не имеет, по адресу 0х0008 заголовка:

рис.22 Размер куска САС3
Перейдем к созданию следующего куска.
Кусок типа Crc
В первые 2 байта заголовка запишем его тип (CAC4):

рис.23 Тип куска CAC4
Вставляем размер данных куска (0х001D), выраженное в блоках:

рис.24 Размер в блоках САС4
Вставляем размер куска в байтах (0х0010), т.е. длина заголовка + длина данных:

рис.25 Размер куска САС4
Добавляем данные куска. Для CAC4 это контрольная сумма куска, рассчитанная по алгоритму CRC32:

рис.26 Данные куска САС4
Собственно мы уже все разобрали по косточкам: создаем заголовок sparse-куска; и сразу за ним добавляем нужные ему данные.
Теперь процесс кодирования исходного файла в sparse-файл выглядит следующим образом:
Продолжение следует...
1. ru.wikipedia.org/wiki/Разрежённый_файл.
2. s90-a_row_s125_141114_pc_qpst — прошивка устройства Lenovo s90A.
3. system/core/libsparse/sparse_format.h
4. XT1650-03_GRIFFIN_RETEU-EMEA_MPL24.246-17_cid50_subsidy-DEFAULT_regulatory-03_CFC_EMEA.xml.zip — прошивка устройства Lenovo Moto Z.
5. Victara_Retail_China_XT1085_5.1_LPE23.32-53_CFC.xml.zip — прошивка устройства Lenovo Moto X.
Часть 1
1.Введение.
2.Разрезание на части (chunks).
3.Сжатие образов.
3.1.Sparse-файлы.
Часть 2
3.2._sparsechunk-файлы.
4.Создание dat-файлов.
5.Источники информации.
Структура образов разделов, содержащих файловую систему.
1.Введение
Образы разделов мобильных устройств (МУ), содержащих файловую систему (ФС) ext4, имеют большие размеры, например, размер образа раздела system может достигать нескольких ГБ, а размер образа раздела userdata составляет уже несколько десятков ГБ.
Эти особенности требуют от разработчика прошивок применения «хитростей» при выполнении операций первоначальной загрузки прошивок МУ или установки обновлений, т.к. размеры образов разделов становятся не только соизмеримыми с объемом оперативной памяти МУ, но и значительно их превышают.
Разработчики стоковых (заводских) прошивок для уменьшения размера образов разделов в настоящее время применяют следующие способы:
- разделение (разрезание) образа на части (chunks);
- сжатие образа целиком;
- использование dat-файлов.
В основе первого способа лежит уменьшение размера образа за счет разделения его на несколько частей, называемых кусками (chunks), при этом размер каждого куска не должен превышать заранее выбранную допустимую величину. Это позволяет уменьшить размер порции информации, передаваемой в МУ за один сеанс.
При втором способе используется то свойство образа ФС, что он представляет собой разреженный файл [1]. Это позволяет применить кодирование без потери данных, что приводит к уменьшению размера всего образа раздела за счет сокращения объема «пустых» блоков, содержащих или нулевые, или повторяющиеся данные.
Особенность третьего способа состоит в том, что после кодирования из образа удаляются все «пустые» блоки (при установке прошивки) или передаются только изменения образов (при выполнении обновлений).
Думаю, что в качестве повышения квалификации разработчикам custom-прошивок будет интересно ознакомиться с внутренним строением образов такого типа и прояснить некоторые моменты работы с ними…
2.Разрезание на части (chunks)
Этот способ подразумевает, что исходный образ, имеющий ext4-формат, делится на части размером не более заранее заданной величины, называемой границей. Чаще всего, граница имеет значение 128 или 256 Мб. При этом, для обратного восстановления, дополнительно создается, так называемый, файл размещения, описывающий расположение этих частей в исходном образе.
Процесс разрезания образа раздела на части может быть описан таким алгоритмом:
- выбирается значение границы, которое должно удовлетворять следующим критериям:
- кратна размеру блока ФС;
- не превышать допустимый размер файлов для передачи при OTA-обновлении или загрузке в режиме fastboot;
- просматривается образ раздела в RAW-формате и делится на части размером, не превышающим границу;
- из каждой части формируется выходной кусок (chunk) по особым правилам:
- если рассматриваемый кусок содержит данные, в основном отличающиеся от нуля, то они полностью копируются в выходной кусок (chunk типа 1);
- если рассматриваемый кусок содержит только нулевые данные, то выходной кусок будет иметь размер в один блок, состоящий из нулей (chunk типа 2);
- если рассматриваемый кусок содержит немного информации и много нулевых данных, то выходной кусок будет содержать только информационную часть (chunk типа 3);
- размер куска любого типа всегда кратен размеру блока.
- весь процесс разрезания прописывается в файл размещения. В виде атрибутов сохраняются название куска, смещение в прошивке и размер исходного входного куска, соответствующего созданному куску.
После такого разбиения образа раздела и за счет отсечения нулевых данных происходит существенное уменьшение суммы длин кусков, т.е. общего размера выходного файла.
Процесс восстановления очень прост и производится по следующему алгоритму:
- создается новый пустой образ, имеющий размер исходного;
- затем последовательно считываются куски и располагаются в нем согласно информации из файла размещения.
Для примера, давайте рассмотрим процесс восстановления исходного образа раздела, используя прошивку для МУ Lenovo s90 на основе процессора Qualcomm MSM8916 [2], которая содержит файл размещения rawprogram0.xml. А за «границу» части у Qualcomm принято значение 128 Мб.
Файл размещения rawprogram0.xml представляет собой xml-файл, цитата из которого приведена ниже:
<?xml version="1.0" ?>
<data>
<!--NOTE: This is an ** Autogenerated file **-->
<!--NOTE: Sector size is 512bytes-->
...
<program ... filename="cache_1.img" label="cache" ... start_sector="6193152" />
<program ... filename="cache_2.img" label="cache" ... start_sector="6455296" />
<program ... filename="cache_3.img" label="cache" ... start_sector="6455496" />
<program ... filename="cache_4.img" label="cache" ... start_sector="6717440" />
...
</data>
Строго говоря, это файл описания разметки памяти МУ на основе чипов Qualcomm. Я не буду описывать все параметры этого файла, т.к. нам потребуются только следующие:
- filename — название файла;
- label — метка раздела;
- start_sector — смещение файла в памяти, выраженное в секторах по 512 байт.
Параметр filename указывает имя файла, содержащего образ или его часть, метка которого представлена параметром label.
Параметр start_sector содержит АБСОЛЮТНОЕ смещение начала файла в памяти МУ.
Т.к. мы не будем прошивать файлы частей в память, а только соберем из них цельный файл-образ раздела, то для размещения каждой части в этом файл-образе нужно использовать относительное смещение. За базу принимается начало образа конкретного раздела, т.е. смещение образа в памяти МУ. Расчет производится по следующей формуле:
Отн.смещение = абс.смещение_части_раздела — абс.смещение_начала_раздела
В теле прошивки имеется несколько файлов, содержащих ФС ext4:
- cache.img, состоящий из 4 частей (cache_1.img — cache_4.img);
- preload.img, состоящий из 6 частей (preload_1.img — preload_6.img);
- system.img, состоящий из 29 частей (system_1.img — system_29.img).
Давайте попробуем собрать образ раздела cache, т.е. из частей cache_1.img — cache_4.img соберем один файл cache.img. Конкретно, для него выберем из файла размещения rawprogram0.xml, приведенного выше, следующие значения:
- абсолютное смещение начала раздела cache — 6193152;
- начало первой части образа cache имеет абсолютное смещение 6193152, соответственно, относительное смещение равно нулю;
- начало второй части 6455296, соответственно относительное смещение 262144.
- начало третьей части 6455496, соответственно относительное смещение 262344;
- начало четвертой части 6717440, соответственно относительное смещение 524288;
Для восстановления необходимо выполнить следующее:
- открыть любым hex-редактором первую часть, т.е. файл cache_1.img и прочитать значение типа uint32 по адресу 0x0404, которое является размером образа ФС типа ext4 раздела cache, выраженное в блоках. На рис.1 оно отмечено красным цветом:

рис.1. Размер образа раздела cache
- создать новый пустой файл, содержащий ФС типа ext4, размером 0х010600 блоков, т.е. 0х010600 * 0х1000 = 0х010600000 (274 726 912 байт или 262МБ), назвав его cache.img;
- копировать все содержимое первой части и вставить в новый файл, начиная с относительного смещения, рассчитанного выше, т.е. 0х0000;
- открыть файл, содержащий следующую часть файла — это cache_2.img.
- копировать все содержимое этой части и вставить в созданный файл, начиная тоже с относительного смещения второй части (262144), рассчитанного выше;
- повторить предыдущие два действия для всех остальных частей файла cache.img, учитывая их очередность.
Выполнив все действия, Вы получите файл cache.img, размером 262МБ, содержащий образ раздела cache в виде ФС типа ext4.
3.Сжатие образов
Разрезание на части частично решает проблемы разработчиков, уменьшая размер одной части, передаваемой за сеанс передачи при прошивке или обновлении. Тем не менее, общий размер файла не изменяется.
Проблему уменьшения размера образа можно решить путем его сжатия (кодирования). Для этого применяют следующие способы:
- конвертация файла Raw-формата в sparse-файл;
- конвертация файла Raw-формата в _sparsechunk-файлов.
Sparse-файлы активно используются, например, в устройстве Moto G фирмы Lenovo, а _sparsechunk-файлы применяются в Moto Z.
3.1.Sparse-файлы
Для удаления «пустых» значений, число которых в образах разделов может достигать 90%, сами образы конвертируют (сжимают) в файлы типа Sparse, структура которого описана в [3]. При этом исходный файл рассматривается как массив элементов, представляющих собой четырехбайтовые числа, и просмотр массива выполняется поблочно, т.е. по 4096 байт или по 1024 элемента.
В зависимости от содержимого блоки разделяются на следующие типы:
- блоки с повторяющимися элементами, т.е. содержащие нули или одинаковые (повторяющиеся) элементы, т.е. Fill-блоки;
- блоки с информационными элементами, т.е. содержащие различающиеся данные в пределах всего блока, т.е. Raw-блоки.
3.1.1.Структура sparse-файлов
Разреженный образ раздела с ФС после конвертации в sparse-файл представляет собой последовательность (список) кусков типа Raw и Fill, расположенных вперемежку. Для идентификации и обеспечения обратного преобразования (восстановления образа) все это дополнено заголовком.
Итак, Sparse-файл состоит из:
- заголовка файла;
- области данных, т.е. списка кусков.
Несмотря на то, что при конвертации образа Raw-формата в sparse используется только два типа кусков, всего существует 4 типа кусков sparse-файлов, которые будут рассмотрены ниже.
Заголовок sparse-файла
Заголовок имеет следующее строение:
рис.2. Заголовок sparse-файла
Кратко рассмотрим все поля заголовка.
Поле Magic длиной 4 байта, содержит сигнатуру (число 0xed26ff3a) и служит для идентификации sparse-файла как типа файла.
Поля Major Versionи Minor Version длиной по 2 байта, содержат номер версии формата sparse-файла. Сейчас это версия 1.0.
Поле FileHeaderSize длиной 2 байта, содержит размер заголовка sparse-файла в байтах. В настоящее время существует две версии заголовка, отличающихся только его размером: 0х1С (28) байт и 0х20 (32) байта. Соответственно и это поле содержит число или 0х1С, или 0х20.
Поле ChunkHeaderSize длиной 2 байта, содержит размер заголовка кусков sparse-файла. Независимо от типа кусков оно содержит число 0х0С (12).
Поле Block_Size длиной 4 байта, содержит размер блока sparse-файла. Для сжатия в sparse-файл образов ФС типа ext2-ext4 значение этого поля равно 0х1000 (4096).
Поле Total_Blk длиной 4 байта, содержит размер исходного файла (img) в блоках.
Поле Total_Chunks длиной 4 байта, содержит число частей, на которые был разделен исходный (входной) файл. Столько же кусков содержится и в выходном файле (sparse).
Поле Image_Checksum содержит контрольную сумму данных выходного файла (sparse), рассчитанную по алгоритму Crc32 для всего файла (заголовок + данные).
Структура области данных кусков sparse-файла
Следом за заголовком располагается область данных, состоящая из списка кусков sparse-файла.
Каждый кусок имеет заголовок куска и данные куска.
Заголовок имеет длину 0х0С (12) байт, как указано в поле ChunkHeaderSize заголовка sparse-файла и содержит следующие поля:
рис.3. Структура заголовка куска
Поле Chunk_Type длиной 2 байта, содержит идентификатор куска и может принимать следующие значения:
- 0xCAC1 — кусок типа Raw, предназначенный для хранения неповторяющихся данных. Размер куска равен количеству данных в байтах + размер заголовка куска;
- 0xCAC2 — кусок типа Fill описывает повторяющуюся часть входных данных, содержит нулевые или повторяющиеся данные в закодированном виде. Размер куска равен размеру заголовка + 4 байта на элемент-заполнитель;
- 0xCAC3 — кусок типа DontCare совсем не содержит данных. Размер куска равен размеру заголовка куска, т.е. 12 байт;
- 0xCAC4 — кусок типа Crc содержит контрольную сумму файла, рассчитанную по алгоритму Crc32. Размер куска равен размеру заголовка + 4 байта на значение контрольной суммы.
Поле Reserved длиной 2 байта, не используется и всегда равно нулю.
Поле Chunk_Size длиной 4 байта, содержит размер исходного куска во входном файле (img), выраженный в блоках.
Поле Total_Size длиной 4 байта, содержит размер полученного куска в выходном sparse-файле, выраженный в байтах. При рассчете учитывается как длина заголовка, так и длина данных куска.
Следом за заголовком располагаются данные, различающиеся в зависимости от типа куска.
Т.к. кусок типа Raw предназначен для хранения неповторяющихся данных, то данные куска полностью совпадают с данными соответствующей ему части входного файла. Имеет наибольший размер, т.к. количество данных может достигать значения выбранной границы.
Кусок типа Fill в качестве данных содержит только одно четырехбайтовое число (4-хбайтовый заполнитель), повторяющееся в соответствующей ему части входного файла. Он заменяет собой всю область, занятую этими повторяющимися данными без их перечисления, что и приводит к их сжатию.
Кусок типа Crc в качестве данных содержит контрольную сумму куска, рассчитанную по алгоритму Crc32 по всем данным куска.
Исключением является кусок типа DontCare, который вообще не содержит данных, но поле Chunk_Size все равно заполняется. Он представляет собой указатель (смещение) на начало следующего куска данных входного файла.
3.1.2.Алгоритмы работы с sparse-файлами
При работе с sparse-файлами выполняются операции кодирования «сырого»(Raw) img-файла в sparse-файл и декодирование sparse -файла в исходный файл.
Кодирование входного Raw-образа раздела sparse-формат производится по следующему алгоритму:
- Поблочно просматривается входной образ раздела и определяется тип каждого блока.
- Подряд идущие блоки одного типа объединяются в группы. Текущая группа завершается, если происходит смена типа блока, и начинается новая.
Подряд идущие Fill-блоки объединяются в Fill-группы. При этом учитывается повторяющееся значение, которое в пределах одной группы долно быть одно и тоже. Если следом идущий Fill-блок будет иметь другое повторяющееся значение, то создается новая Fill-группа.
Подряд идущие Raw-блоки объединяются в Raw-группы. - Все полученные группы конвертируются в куски (chunks) файла sparse-формата. При этом Raw-группа, содержащая неповторяющиеся данные, полностью, без изменений, копируется в область данных куска Raw. А вся Fill-группа заменяется на один кусок типа Fill, содержащая один повторяющийся элемент в области данных этого куска.
- Заполняется заголовок sparse-файла.
Декодирование sparse-файла в исходный образ производится по следующему алгоритму:
- Создается новый пустой файл, размер которого в блоках берется из поля Total_Blk заголовка sparse-файла.
- Последовательно декодируется каждый кусок списка из области данных sparse-файла, заполняя выходной файл последовательно, начиная с адреса 0x0000. При этом для куска читается заголовок, а затем:
- Данные куска типа Raw полностью копируются из входного файла в выходной.
При этом указатель чтения входного файла и указатель записи выходного файла перемещаются на число копируемых байт. - Для куска типа Fill в выходной файл элемент-заполнитель копируется Total_Size, деленное на 4, раз.
При этом указатель чтения входного файла перемещается на 4 байта заполнителя. Указатель записи выходного файла перемещается на число байт, занятое под заполнители. - Для кусков типа DontCare указатель чтения входного файла не перемещается, а в выходном файле производится перемещение указателя записи на число блоков байт, указанном в поле Chunk_Size куска.
- Данные куска типа Raw полностью копируются из входного файла в выходной.
3.1.3.Примеры работы с sparse-файлами
При работе с sparse-файлами чаще всего возникают два вопроса:
- Как восстановить исходный образ из sparse-файла?
- Как конвертировать исходный образ в sparse-файл?
Рассмотрим их согласно поступлению…
Как восстановить исходный образ из sparse-файла?
Для примера рассмотрим процесс восстановления образа раздела oem из sparse-файла МУ Moto Z от Lenovo [4]. Все действия выполняются при помощи hex-редактора, например, WinHex.
Исходный файл oem.img, содержащий сжатый образ раздела oem, имеет размер 69MБ. Посмотрим его заголовок:
рис.4.Заголовок Moto Z
С адреса 0х0000 расположена сигнатура файла, указывающая, что файл имеет тип sparse-файл и состоит из кусков. Сигнатура отмечена синим цветом.
Далее зеленым цветом выделены поля, содержащие версию sparse-файла (1.0).
Затем красным цветом выделены поля FileHeaderSize и ChunkHeaderSize, содержащие размер заголовка файла (0x001C) и размер заголовка куска (0x000C) соответственно.
По смещению 0x000C расположено поле Block_Size, указывающее размер блока sparse-файла. Значение размера блока 0х00001000.
По смещению 0x0010 расположено поле Total_Blk, содержащее размер исходного файла в блоках. Оно выделено желтым цветом и имеет значение 0x0000С021.
По смещению 0x0014 расположено поле Total_Chunks, содержащее число кусков, содержащихся в sparse-файле. Оно выделено фиолетовым цветом и имеет значение 0x0000001F.
По смещению 0x0018 расположено поле Image_Checksum, содержащее контрольную сумму sparse-файла. Это поле содержит 0, что означает, что КС не рассчитывалась и не учитывается при загрузке этого файла в память МУ.
Начиная с адреса 0x001C, расположен заголовок первого куска sparse-файла:
рис.5.Заголовок куска CAC1
Видно, что поле Chunk_Type содержит значение 0xCAC1, выделенное синим цветом. Следующих 2 байта пусты, а затем расположено поле Chunk_Size, отмеченное красным цветом, содержащее число блоков входного файла (0x00000001), закодированных в куске.
Далее расположено поле Total_Size, содержащее длину куска вместе с заголовком, выраженную в байтах (0x0000100C). Оно выделено зеленым цветом. Нам всегда нужен размер без заголовка, поэтому длина только данных: 0х100С — 0х000С = 0х1000.
Сразу за заголовком, начиная с адреса 0x0028 идет массив данных куска.
Итак, для восстановления исходного образа выполним следующие действия:
- открываем исходный sparse-файл oem.img в hex-редакторе;
- выбираем из заголовка файла значения полей, создаем новый пустой файл размера
и сохраняем под именем, например, oem_ext4.img;Total_Blk * Block_Size = 0x000C021 * 0x1000 = 0х0C021000 байт (192)МБ - переходим к обработке первого куска;
- его тип CAC1, поэтому копируем массив данных (начиная со смещения 0x0028 размером 0х1000) и вставляем в созданный выходной файл;
- переходим к следующему куску. Его тип — CAC2, соответственно заполнитель — 0xFFFFFFFF, а количество заполнителей — 0x1D блоков:

рис.6. Второй кусок CAC2
Вставляем заполнители в созданный файл в количестве
0x001D * 0x1000 = 0x01D000 или 118784 байта - И т.д. будем выполнять описанные действия по декодированию кусков до конца исходного файла.
В результате получится файл, содержащий ФС типа ext4, размером 192МБ.
Как конвертировать исходный образ в sparse-файл?
Для простоты возьмем только что полученный образ oem_ext4.img и попробуем его превратить в sparse-файл. При этом необходимо создать новый файл размера 0х001С (28) байт, поместить в него заголовок sparse-файла и далее последовательно просмотреть исходный файл, деля его на куски и кодируя их, размещать в новом файле все создаваемые sparse-куски. Ну и, конечно, сохранить новый файл под именем, например, oem_sparse.img.
Чтобы заполнить заголовок файла, вписываем в первые 4 байта сигнатуру sparse-файла:
рис.7. Заголовок sparse-файла
Далее последовательно записываем значения:
- номера версии sparse-файла ( занимает 4 байта):

рис.8 Номер версии sparse-файла
- размер заголовка sparse-файла (2 байта):

рис.9 Размер заголовка sparse-файла
- размер заголовка куска (2 байта):

рис.10 Размер заголовка куска
- размер блока в байтах (4 байта):

рис.11 Размер блока
Оставшиеся поля оставляем свободными, т.к. их значения появятся у нас только после окончательного создания выходного файла.
Давайте теперь рассмотрим как кодировать, т.е. создавать, разные типы кусков.
Любой тип куска имеет заголовок. Поэтому создадим его в первую очередь: создаем в hex-редакторе файл размером 12 байт:
рис.12 Пустой заголовок куска
Далее рассмотрим, как и что заполнять в кусках.
Кусок типа Raw
В первые 2 байта заголовка запишем его тип (CAC1):
рис.13 Тип куска CAC1
Затем в поле вставляем размер данных (0x00000001), выраженное в блоках:
рис.14 Размер в блоках
Ну и, наконец, размер куска в байтах (0x0000100C), т.е. длина заголовка + длина данных:
рис.15 Размер куска САС1
После заголовка вставляем данные, т.е. 0х1000 (4096) байт из исходного файла:
рис.16 Данные куска САС1
Перейдем к созданию следующего куска.
Кусок типа Fill
В первые 2 байта заголовка запишем его тип (CAC2):
рис.17 Тип куска CAC2
Вставляем размер данных куска (0х001D), выраженное в блоках:
рис.18 Размер в блоках САС2
Вставляем размер куска в байтах (0х0010), т.е. длина заголовка + длина данных:
рис.19 Размер куска САС2
Добавляем данные куска. Для CAC2 это элемент-заполнитель (0xFFFFFFFF):
рис.20 Данные куска САС2
Перейдем к созданию следующего куска.
Кусок типа DontCare
В первые 2 байта заголовка запишем его тип (CAC3):
рис.21 Тип куска CAC3
Вставляем значение смещения до следующего куска (0ххххх), выраженное в блоках, по адресу 0х0004 заголовка.
Вставляем размер куска в байтах (0х000С), т.е. просто длина заголовка, т.к. кусок этого типа данных не имеет, по адресу 0х0008 заголовка:
рис.22 Размер куска САС3
Перейдем к созданию следующего куска.
Кусок типа Crc
В первые 2 байта заголовка запишем его тип (CAC4):
рис.23 Тип куска CAC4
Вставляем размер данных куска (0х001D), выраженное в блоках:
рис.24 Размер в блоках САС4
Вставляем размер куска в байтах (0х0010), т.е. длина заголовка + длина данных:
рис.25 Размер куска САС4
Добавляем данные куска. Для CAC4 это контрольная сумма куска, рассчитанная по алгоритму CRC32:
рис.26 Данные куска САС4
Собственно мы уже все разобрали по косточкам: создаем заголовок sparse-куска; и сразу за ним добавляем нужные ему данные.
Теперь процесс кодирования исходного файла в sparse-файл выглядит следующим образом:
- создаем в hex-редакторе выходной файл размером 0x001C байт, и заполняем в нем поля заголовка sparse-файла как описано выше;
- открываем исходный файл в hex-редакторе;
- просматриваем 4096 байт (один блок) и определяем тип куска.
- создаем в выходном файле кусок типа САС1;
- просматриваем следующие 4096 байт (один блок) и определяем тип куска.
- создаем в выходном файле кусок типа САС2;
- выполняем поблочный просмотр исходного файла до конца. Все блоки кодируем в куски и складываем их в выходном файле.
- просматриваем выходной файл и объединяем куски одного типа, расположенные последовательно, в одну группу, а куски другого типа — в другую группу. В группе остается один заголовок от первого куска, в котором корректируются значения двух полей:
- Chunk_Size — общий размер группы исходных кусков входного файле (img), выраженный в блоках;
- Total_Size — размер полученной группы в выходном sparse-файле, выраженный в байтах.
- дописываем в поле Total_Blk заголовка размер исходного файла в блоках, а в поле Total_Chunks заголовка файла число кусков;
Продолжение следует...
3.2._sparsechunk-файлы
4.Создание dat-файлов
5.Источники информации
1. ru.wikipedia.org/wiki/Разрежённый_файл.
2. s90-a_row_s125_141114_pc_qpst — прошивка устройства Lenovo s90A.
3. system/core/libsparse/sparse_format.h
4. XT1650-03_GRIFFIN_RETEU-EMEA_MPL24.246-17_cid50_subsidy-DEFAULT_regulatory-03_CFC_EMEA.xml.zip — прошивка устройства Lenovo Moto Z.
5. Victara_Retail_China_XT1085_5.1_LPE23.32-53_CFC.xml.zip — прошивка устройства Lenovo Moto X.