
В последнее время мне довольно много приходится работать с расчетами надежности и рисков, и в этой статье я постараюсь восполнить этот пробел, отталкиваясь от своего предыдущего материала (из цикла о машинном обучении) о пуассоновском случайном процессе и подкрепляя текст вычислениями в Mathcad Express, повторить которые вы сможете скачав этот редактор (подробно о нем тут, обратите внимание, что нужна последняя версия 3.1, как и для цикла по machine learning). Сами маткадовские расчеты лежат здесь (вместе с XPS- копией).
1. Теория: основные характеристики отказоустойчивости
Вроде бы, из самого определения (Mean Time To Failure) понятен его смысл: сколько (конечно, в среднем, поскольку подход вероятностный) прослужит изделие. Но на практике такой параметр не очень полезен. Действительно, информация о том, что среднее время до отказа жесткого диска составляет полмиллиона часов, может поставить в тупик. Гораздо информативнее другой параметр: вероятность поломки или вероятность безотказной работы (ВБР) за определенный период (например, за год).
Для того чтобы разобраться в том, как связаны эти параметры, и как, зная MTTF, вычислить ВБР и вероятности отказа, вспомним некоторые сведения из математической статистики.
Ключевое понятие теории надежности — это понятие отказа, измеряемое, соответственно, интервальным показателем
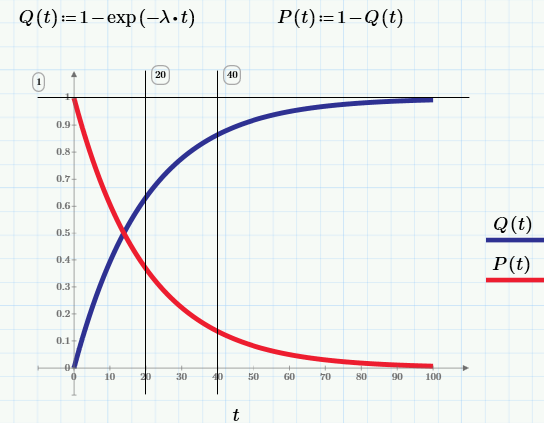
Q(t) = вероятность того, что изделие откажет к моменту времени t.
Соотвественно, вероятность безотказной работы (ВБР, в английской терминологии «reliability»):
P(t) = вероятность того, что изделие проработает без отказа от момента t0=0 до момента времени t.
По определению, в момент t0=0 изделие находится в работоспособном состоянии, т.е. Q(0)=0, а P(0)=1.
Оба параметра — это интервальные характеристики отказоустойчивости, т.к. речь идет о вероятности отказа (или наоборот, безотказной работы) на интервале (0,t). Если отказ рассматривать, как случайное событие, то, очевидно, что Q(t) — это, по определению, его функция распределения. А точечную характеристику можно определить, как
p(t)=dQ(t)/dt = плотность вероятности, т.е. значение p(t)dt равно вероятности, что отказ произойдет в малой окрестности dt момента времени t.
И, наконец, самая важная (с практической точки зрения) характеристика: ?(t)=p(t)/P(t)=интенсивность отказов.
Это (внимание!) условная плотность вероятности, т.е. плотность вероятности возникновения отказа в момент времени t при условии, что до этого рассматриваемого момента времени t изделие работало безотказно.
Измерить параметр ?(t) экспериментально можно путём испытания партии изделий. Если к моменту времени t работоспособность сохранило N изделий, то за оценку ?(t) можно принять процент отказов в единицу времени, происходящих в окрестности t. Точнее, если в период от t до t+dt откажет n изделий, то интенсивность отказов будет примерно равна
?(t)=n/(N*dt).
Именно эта ?-характеристика (в пренебрежении ее зависимостью от времени) и приводится чаще всего в паспортных данных различных электронных компонент и самых разных изделий. Только сразу возникает вопрос: а как вычислить вероятность безотказной работы и при чем здесь среднее время до отказа (MTTF).
А вот при чем.
2. Экспоненциальное распределение
В терминологии, которую мы только что использовали, пока не было никаких предположений о свойствах случайной величины — момента времени, в который происходит отказ изделия. Давайте теперь конкретизируем функцию распределения значения отказа, выбрав в качестве нее экспоненциальную функцию с единственным параметром ?=const (смысл которого будет ясен через несколько предложений).
Дифференцируя Q(t), получим выражение для плотности вероятности экспоненциального распределения:
 ,
, а из него – функцию интенсивности отказов: ?(t)=p(t)/P(t)=const=?.
Что мы получили? Что для экспоненциального распределения интенсивность отказов – есть величина постоянная, причем совпадающая с параметром распределения. Этот параметр и является главным показателем отказоустойчивости и его часто так и называют ?-характеристикой.
Мало того, если теперь посчитать среднее время до первого отказа – тот самый параметр MTTF (Mean Time To Failure), то мы получим, что он равен MTTF=1/ ?.
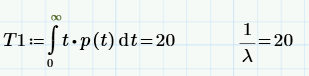
Все это замечательные свойства экспоненциального распределения. Почему мы выбрали в качестве для описания отказов именно его? Да потому что это наиболее простая модель – модель пуассоновского потока событий, которая уже была нами рассмотрена в статье про анализ конверсии сайта. Поэтому-то в теории надежности наиболее часто используется показательное (экспоненциальное) распределение, для которого, как мы выяснили:
- надежность элементов можно оценить одним числом, т.к. ?=const;
- по известной ? довольно просто оценить остальные показатели надежности (например, ВБР для любого времени t);
- ? обладает хорошей наглядностью
- ? нетрудно измерить экспериментально
Но это еще не все, потому, что для экспоненциального распределения особенно легко делать расчет систем, состоящих из множества элементов. Но об этом – в следующей статье (продолжение следует).
Комментарии (27)

dimview
05.04.2015 15:19Вот в этом месте есть загвоздка:
> если в период от t до t+dt откажет n изделий, то интенсивность отказов будет примерно равна
?(t)=n/(N*dt).
Например, у жёстких дисков порядка 1% отказов в год. У отдельных электронных компонентов — ещё меньше. За ограниченное время тестирования ограниченной по размеру тестовой выборки может быть 0 отказов. Поэтому n/N — не очень хороший способ оценивать ?.
Вместо этого лучше Байеса привлекать, например, (n+2)/(N+4) как рекомендует Алан Агрести. Если есть лучше априорное распределение, то формула будет другой, но смысл тот же — ноль отказов в тесте не означает нулевую вероятность отказа.
polybook Автор
05.04.2015 19:09Действительно, так делают редко (но иногда делают). Гораздо более простой способ следует из определения MTTF=среднее время до отказа. Пусть у нас есть серия из N изделий. Мы дожидаемся, пока все они откажут, и записываем время, когда произошел каждый отказ Ti. Очевидно, оценка MTTF=(среднее по Ti)=(суммаTi)/ N.
Есть и другие методы, учитывающие статистику по партии изделий, часть из которых отказала в известные моменты времени, а часть — работает (FRACAS, анализ Вейбулла). Основаны они на том, что оцениваем мы одно число, а статистику имеем кое-какую.
К слову, приведу пример моделирования Монте-Карло отказов партии из N=100 штук. (Показана гистограмма распределения отказов по времени и аппроксимация экспоненциальной плотностью вероятности).

dimview
05.04.2015 19:35> N изделий. Мы дожидаемся, пока все они откажут
Та же проблема. Очень долго придётся ждать, чтобы из партии в 100 изделий с вероятностью отказа 1% в год отказали все.polybook Автор
05.04.2015 20:24«пока все откажут» — конечно, для наглядности. В реальности, делают не так, а следят за партией из N изделий. Пусть за год отказали 5 винчестеров (времена отказов фиксированы), а N-5 работают. Из этих данных и получают оценку ?. Чем дольше наблюдаем — тем лучше оценка.

grossws
05.04.2015 20:32Действительно, так делают редко (но иногда делают). Гораздо более простой способ следует из определения MTTF=среднее время до отказа. Пусть у нас есть серия из N изделий. Мы дожидаемся, пока все они откажут, и записываем время, когда произошел каждый отказ Ti. Очевидно, оценка MTTF=(среднее по Ti)=(суммаTi)/ N.
Только обычно всё-таки делают цензурирование. Т. к. ждать отказ всех устройств в партии может быть слишком дорого. Т. е. выбирают распределение (экспоненциальное, Вейбулла, Гомпертца-Мейкхама), и собирают статистику до наступления какого-то момента времени или выбывания определенного количества устройств.
А дальше используют методы, которые рассчитаны на работу с цензирированной (неполной) выборкой. Например, процедуру Каплана-Мейера.


Vinchi
05.04.2015 17:01Есть еще два нюанса:
1. Плотность вероятности во времени в релаьности совершенно не обязана быть экспоненциальной, а может быть какой угодно. Особенно у сложных устройств.
2. Было бы интересно узнать как реально проводиться расчет времени наработки на отказ. Если бы их испытывали миллионами штук в течение нескольких лет — мы бы долго ждали пока их выпустят на рынок. Скорее всего есть очень много упрощений.polybook Автор
05.04.2015 19:361. Конечно. Если нарисовать типичный график интенсивности отказов, то будет что-то такое:

— Сначала идет приработка изделия — отказов много. бычно в этот период делают испытания — тупо заставляют изделия работать определенное время. Те, что не отказали — идут в продажу.
— Потом — долгий период примерно постоянной интенсивности отказов. Для него экспоненциальное распределение хорошо работает
— Последняя фаза старения — отработавшие изделия отказывают часто. (Но для производителя это несущественно — ему же надо просчитать издержки на гарантийный сервис — вы же понимаете, для чего все эти расчеты — для оптимизации сервиса)
2. Есть специальные методы и специальный софт. Самое простое соображение — нарисовать структурную схему изделия и, зная ?-характеристики комплектующих, вычислить оценку ? для всего изделия.
Прелесть экспоненциального распределения в том, что для получения этой оценки надо просто сложить ? комплектующих (про это будет следующая статья про надежность).
dimview
05.04.2015 19:48+11. Зависимость интенсивности отказов от времени описывает так называемая bathtub curve, похожая на ванну с плоским дном. Постоянная интенсивность — разумное первое приближение, по крайней мере в пределах гарантийного срока службы.
2. Потребительские устройства редко разрабатываются с нуля, поэтому можно использовать данные гарантийных ремонтов от предыдущих поколений. Для систем, где нужна более точная и формальная оценка вероятности отказа (самолёт, ядерный реактор) есть весьма трудоёмкие способы её считать из вероятностей отказов отдельных компонентов. Но для этого нужно, чтоб кто-то предусмотрел и ввёл все возможные отказы и взаимосвязи.


amarao
05.04.2015 17:44А что мы делаем с устройствами, которые не подчиняются этим кривым и распределениям?
polybook Автор
05.04.2015 19:17На то есть специальные методы. Основное развитие они получили в последние 20 лет, когда компьютеры стали мощные, и почти все, что угодно, можно посчитать по Монте-Карло. В наши дни никакой проблемы нет посчитать надежность, если есть исходные данные. Я использую вот этот софт.
Беда в том, что очень редко, когда для изделий (и/или комплектующих) есть что-то большее, чем число ?. Уже хорошо, когда оно есть.amarao
05.04.2015 20:39Вот я про это. Закладываемся на одно, а оно начинает дохнуть по функции F(?,t, L), где t — время, а L — объём обработанных данных.
По моим наблюдениям (эмпирическим) использовать FTBF и всё остальное имеет смысл только для немеханической электроники без ресурса (CPU, RAM, HBA, может быть PSU, может быть MB). Самое о чём все радеют — это HDD/SSD, подчиняются закономерностям, которые не становятся ясными, пока из данной партии не перемрёт достаточно много экземпляров.grossws
05.04.2015 20:53Это значит, что износ не описывается однопараметрическим (как экспоненциальное) распределением и MTBF просто недостаточные данные для оценки реального ресурса. И в реальном кейсе вам придется ждать пока подохнет достаточное количество экземпляров в каждой группе с похожей нагрузкой.
Например, HDD, используемые для преимущественно рандомного доступа, и те же самые диски, используемые для более-менее линейной записи/чтения (WAL или что-нибудь такое) могут иметь ощутимый разброс по статистике отказов. Или имеющие периодическое фоновое чтение и не имеющие. Или установленные в СХД, которое подвергалось или не подвергалось вибрации (например, перемещалось).
polybook Автор
05.04.2015 21:27Наряду с наиболее простым экспоненциальным на практике используется двухпараметрическое распределение Вейбулла.
О зависимости от объема данных. В теории надежности говорят о наработке (время — что в статье — ее частный случай). Для авто наработка скорее измеряется в км, а для винчестера — вполне возможно, в объеме обработанных данных или числе циклов включения-выключения. Вполне возможно, что удастся подобать такую единицу наработки, для которой отказы будут экспоненциальными.amarao
05.04.2015 22:10+1Это все равно не решает главного ужаса индустрии: дохнущей партии. Например, по времени и примерно в одно и то же время. Или через указанный аптайм (подряд, без ребутов). Или к указанной дате. Все расчёты надёжности идут лесом.
grossws
05.04.2015 22:26От этого никто не застрахован. Статистика, всё же, оперирует общим распределением характеристик. А «удачная» партия — это черный лебедь, если масштаб не очень большой.
А если большой и события такого плана закладываются в риски (как, скажем, в авионике), то покупаются компоненты от разных производителей, через разных поставщиков и т. п. Чтобы уменьшить вероятности получить одновременный отказ.amarao
05.04.2015 22:38+1Именно в свете подобного становится куда как менее интересно читать про всякие теории отказа. Теории теориями, а вылетающая полным комплектом стойка жёстких дисков — неприятно.
polybook Автор
05.04.2015 22:50А просто любопытно — когда она вылетает? После того, как гарантия кончилась?
amarao
05.04.2015 23:05Как попало. Если вы хотите драмы в стиле «железки под окончание гарантии планируются» — нет, не этот случай. В условиях ДЦ основным фактором становится либо естественный износ, либо неудачное положение (например, из-за близости к вентилятору или верху/низу стойки большая вибрация, горячие/холодные соседние диски), либо просто нормальные отказы.
В условиях тысяч и десятков тысяч жёстких дисков, их замена — ежедневная рутина.
Если только это не залётный дятел с массовыми отказами.
grossws
05.04.2015 20:38Используем статистические методы, которые не делают таких предположений о вероятности отказа, а оперируют голой статистикой и более слабым предположением, что вероятность отказа является кусочно-постоянной. Как те же медики с 70-х годов.
amarao
05.04.2015 20:39А какое оборудование вы отслеживаете?
grossws
05.04.2015 20:46Я имел ввиду просто статистические подходы к оценке выживаемости. У меня нет в работе систем, где это можно было бы активно применять, а масштабы арендуемого оборудования маловаты для каких-либо оценок.
amarao
05.04.2015 22:14Ну, по практике работы в хостерах, этот вопрос (обычно в контексте «сколько держать резерва») решается экспериментально. Не хватает — делается больше. Хватает и избыток — чуть уменьшается.
grossws
05.04.2015 22:21Ну да. Не угадали или плохая партия — факап или дополнительные затраты на срочную закупку. А если остаток достаточен — повезло. ТАУ оно всегда такое. Риски — одно слово))
PapaBubaDiop
Хорошо изложено. Да еще с живым примером- в каждом абзаце по досадной опечатке, то есть ?=1.
polybook Автор
Спасибо. Честно говоря, не понял, где опечатки.
PapaBubaDiop
Например,
и так далее, сами перечитайте))
polybook Автор
спасибо, поправлю.