
Привет! В этой статье я хочу рассказать о проекте Akumuli, специализированной базе данных для сбора и хранения временных рядов. Я работаю над проектом уже больше четырех лет и достиг высокой стабильности, надежности, и возможно изобрел кое-что новое в этой области.
Временной ряд это упорядоченная во времени последовательность измерений, если говорить максимально просто, это то что можно нарисовать на графике. Временные ряды естественным образом возникают во многих приложениях, начиная с финансов и заканчивая анализом ДНК. Наиболее широкое применение базы данных временных рядов находят в мониторинге инфраструктуры. Там же часто наблюдаются самые серьезные нагрузки.
“Мне не нужна TSDB, у меня уже есть Х”
Х может быть чем угодно, начиная с SQL базы данных и заканчивая плоскими файлами. На самом деле все это действительно можно использовать для хранения временных рядов, с одной оговоркой — у вас мало данных. Если вы делаете 10 000 вставок в свою SQL базу данных — все будет хорошо какое-то время, потом таблица вырастет в размерах настолько, что время выполнения операций вставки увеличится.
Вы начнете их группировать перед вставкой, это поможет, но теперь у вас появилась новая проблема — данные приходится где-то накапливать, а значит можно потерять все что не успело записаться в БД. Следующий шаг — попытаться использовать какую-нибудь хитрую схему, например хранить в одной строке не одно измерение (id + метку времени + значение) а несколько (id + метку времени + значение + значение через 10сек + значение через 20сек + …). Это увеличит пропускную способность на запись, но породит новые проблемы. Место стремительно заканчивается так как сжатие не очень, нужно хранить временные ряды с разным шагом, нужно хранить временные ряды с переменным шагом, нужно считать агрегации (максимальное значение за интервал), нужно сделать из временного ряда с шагом 10 секунд временной ряд с шагом 1 час.
Все эти проблемы преодолимы, нужно просто написать свою TSDB поверх SQL сервера или flat файлов или Cassandra или даже Pandas. На самом деле, многие люди уже прошли этот путь, об этом можно догадаться по количеству уже существующих TSDB, работающих поверх какой-нибудь другой DB. Akumui отличается от них тем, что использует специализированное хранилище на основе оригинальных алгоритмов.
Дизайн
Проблему, которую решает TSDB можно свести к тому что данные записываются в одном порядке а читаются в другом. Представим что у нас есть миллион временных рядов, раз в секунду в каждый из них нужно записать одно значение с текущей меткой времени. Чтобы их быстро записывать, нужно записывать их в том порядке, в котором они приходят. К сожалению, если мы захотим прочитать один час данных одного временного ряда, мы должны будем прочитать все 3600*1000000 точек, отфильтровать большую часть данных и оставить только 3600. Это называется read amplification и это плохо.
К сожалению, примерно это делают очень многие TSDB. Разница лишь в том, что данные а) сжимаются б) разбиваются на блоки небольшого размера, каждый из которых имеет колумнарный формат (т.н. PAX) который позволяет не разбирать все содержимое а сразу перейти к нужным данным.
Я решил пойти по другому пути (впрочем сначала я попробовал PAX) и реализовал колумнарное хранилище в каждой колонке которого хранится отдельный временной ряд. Это позволяет читать только те данные, которые нужны запросу. Современные SSD и NVMe не нуждаются в том, чтобы данные, к которым обращается БД, лежали строго последовательно, но их пропускная способность ограничена, поэтому для БД очень важно читать только то что действительно нужно, а не экономить disk seeks. Раньше все было наоборот, мы меняли пропускную способность на disk seeks, многие структуры данных построены вокруг этого компромисса (привет LSM-tree). Akumuli делает наоборот.
Сжатие
Это самый важный аспект для TSDB, т.к. сжатие сильно влияет на компромиссы, баланс которых лежит в основе дизайна любой БД. Для Akumuli я разработал, как мне кажется, довольно неплохой алгоритм. Он сжимает метки времени и значения используя по сути два разных алгоритма. Я не хочу вдаваться в детали слишком сильно, для этого есть whitepaper, но я постараюсь дать хорошую вводную.
Точки (время + значение) объединяются в группы по 16 и сжимаются вместе. Это позволяет записать алгоритм в виде простых циклов обрабатывающих массивы фиксированной длины, которые компилятор может хорошо оптимизировать и векторизовать. В hot path нет ветвлений, которые branch predictor не может предсказать в абсолютном большинстве случаев.
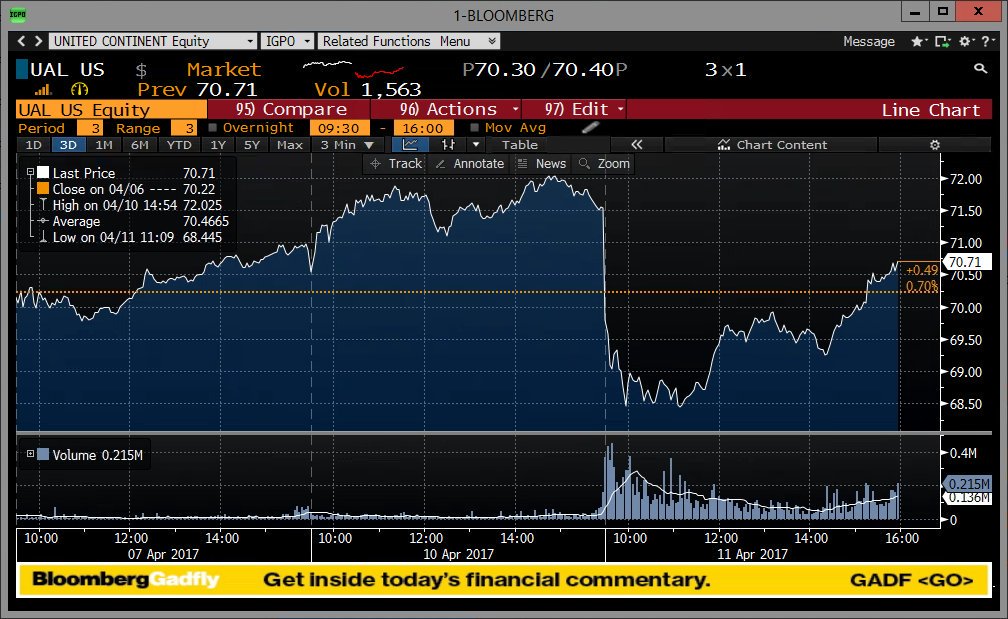
Метки времени сжимаются следующим образом: сначала применяется delta-delta кодировка (сначала считаются дельты, затем из каждой дельты вычитается минимальный элемент), затем это все сжимается с помощью VByte кодировки. VByte кодировка похожа на то что используется в protocol buffers с той лишь разницей, что здесь не требуются побитовые операции, это работает быстрее. Это достигается за счет того, что метки времени объединяются в пары и метаданные каждой пары (control byte) хранятся в одном байте.
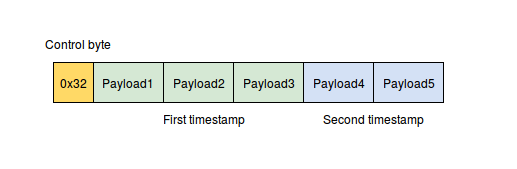
Для сжатия значений используется предиктивный алгоритм, который пытается предугадать следующее значение используя differential finite context method (DFCM) predictor.
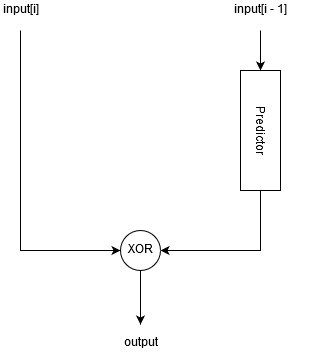
Далее, алгоритм XOR-ит предсказанное и актуальное значения между собой, в результате чего получается строка бит с большим количеством нулей в конце или в начале. Данная строка бит кодируется следующим образом:
- Мы считаем количество нулей в начале и в конце строки, если в начале строки нулей больше, устанавливаем специальный флаг.
- Считаем сколько байт (N) нужно для того, чтобы записать данную битовую строку (с учетом флага).
- Сдвигаем битовую строку влево на 64 — N*8 бит если флаг установлен.
- Записываем в выходной буфер первые N байт битовой строки.
В итоге, у нас есть N байт данных, но помимо этого мы должны сохранить метаданные — значение N и флаг, это четыре бита. Для экономии места я объединяю значения в пары и записываю сначала байт с метаданными для обоих значений (control byte), а затем сами значения.
Помимо этого используется еще один трюк. Если мы имеем дело с “удобными” данными, данный алгоритм может предсказать следующее значение со 100% точностью. В мониторинге такое встречается довольно часто, там иногда значения не меняются на протяжении долгого времени, либо растут с постоянной скоростью. В этом случае, после XOR-а мы будем всегда получать нулевые значения. Для того чтобы не кодировать каждое из них целой половиной байта, в алгоритме есть специальный случай — если все 16 значений можно предсказать, он записывает специальный control byte и больше ничего. Получается, что в этом случае мы тратим на значение меньше бита. Подобный shortcut реализован и для меток времени, для случая если измерения имеют фиксированный шаг.
Данный алгоритм не имеет ветвлений и работает on byte boundary. Скорость сжатия, по моим измерениям, составляет порядка 1Гб/сек.
Storage Engine
Каждый временной ряд представлен на диске в виде отдельной структуры данных. Я называю ее Numeric B+tree, т.к. она предназначена для хранения числовых данных, но по сути, это LSM-дерево сегментами которого являются B+деревья. Обычно (но не обязательно) сегменты (SSTables) реализуются как отсортированные массивы.

Роль MemTable в этом LSM-дереве выполняет единственный лист B+дерева. Когда он заполняется данными, он отправляется на второй уровень, где просто присоединяется к другому B+дереву, состоящему из двух уровней. Когда это дерево заполняется, оно отправляется на третий уровень, присоединяясь к В+дереву состоящему из трех уровней и тд. У меня есть whitepaper подробно описывающий данный процесс.
Такая структура данных позволяет:
- Сливать сегменты не читая их с диска целиком (как это делает обычный LSM-tree). Akumuli не читает данные с диска, чтобы выполнить запись. Благодаря этому читатели не могут замедлить процесс записи израсходовав пропускную способность диска на чтение.
- Иметь очень много независимых деревьев в одном файле. Узлы разных деревьев просто перемежаются на диске друг с другом. Благодаря этому, запись на диск по прежнему происходит последовательно. Чтение одной серии выбирает данные с диска в случайном порядке, но для современных SSD это не проблема.
- Оптимизация для SSD и NVMe дисков. Все операции чтения и записи выровнены по границе блока (что уменьшает write amplification). И запись и чтение могут выполняться параллельно (без чего сложно сатурировать современный SSD). БД готова к появлению byte addressable устройств (вроде Intel Optane SSDs), т.к. умеет отображать данные в память и читать/писать с еще большей гранулярностью.
- Выполнять восстановление после сбоев без использования WAL. Это сложная проблема, детали решения которой раскрыты в статье. Если коротко, то Akumuli не использует WAL и для восстановления после сбоев используются дополнительные ссылки между узлами дерева.
- Multiversion concurrency control позволяет искоренить ошибки синхронизации как класс. И запись и чтение могут выполняться параллельно, читатели/писатели не зависят друг от друга и тд и тп.
У этого подхода есть и недостатки:
- Данные должны записываться в порядке увеличения меток времени.
- При падении можно потерять данные, которые были записаны последними, скажем, последние 5 минут данных мониторинга.
Рано или поздно эти проблемы будут решены, но пока они не решены их следует принимать во внимание.
Обработка запросов
Мне хотелось получить что-то похожее по возможностям на Pandas data frames. В первую очередь, иметь возможность прочитать данные в любом порядке и сгруппировать их как угодно — в порядке увеличения меток времени или наоборот, сначала данные одной серии, затем данные следующей (запрос может возвращать много временных рядов), либо сначала данные всех серий с одной меткой времени, затем данные всех серий в том же порядке со следующей меткой времени и тд. Мой опыт показывает, что это обязательно нужно уметь, т.к. размер запрашиваемых данных может превышать объем ОЗУ у клиента и он просто не сможет переупорядочить их локально, но если данные приходят в правильном порядке, он сможет обработать их по частям.
Помимо этого, хотелось иметь возможность сливать несколько рядов в один, просто объединяя точки, либо join-ить несколько временных рядов по меткам времени, агрегировать данные ряда (min, max, avg, etc), агрегировать с шагом (resample), вычислять всякие функции (rate, abs, etc).
Обработчик запросов, в его текущем виде, имеет иерархическую структуру. На нижнем уровне работают операторы, оператор всегда работает с данными одной колонки, соответствующей одному временному ряду и хранящейся в одном дереве. Операторы, это что-то вроде итераторов. Они реализованы на уровне хранилища и умеют использовать его особенности. В отличии от итераторов, операторы БД умеют не только читать данные, они могут агрегировать и фильтровать, причем эти операции могут выполняться на сжатых данных (не всегда).
Операторы могут пропускать (search pruning) части дерева даже не читая их с диска. Например, если запрос читает данные без downsample преобразования, то будет использован оператор scan, который просто возвращает данные как есть, но если запрос выполняет group aggregate с каким-либо шагом, будет использован другой оператор, который умеет делать downsampling не читая все с диска.
Следующий этап — материализация результатов запроса (Akumuli выполняет только раннюю материализацию). Из данных, которые возвращают операторы, формируются кортежи, основные операции плана (например join) выполняются уже на материализованных данных. Здесь же выполняются всевозможные функции (например rate).
Вся обработка выполняется ленивым образом. Сначала обработчик запросов формирует конвейер из операторов, а затем через него прогоняются данные. Скорость чтения и обработки данных зависит от того, с какой скоростью клиент их читает, т.е. если вы прочитали часть результатов запроса и остановились, запрос перестанет выполняться на сервере. На практике это означает, что клиентское приложение может обрабатывать данные в потоковом режиме, причем эти данные вовсе не обязаны помещаться в ОЗУ клиента или даже сервера.
Тесты
Самое интересное в этом проекте, это тестирование. Тестирование происходит в автоматическом режиме на CI сервере (я использую Travis-CI). В проекте применяются следующие виды тестов:
- Первый этап — модульное тестирование. Модульные тесты отрабатывают примерно за минуту-две, они не трогают диск, поэтому работают довольно быстро. Они редко находят регрессии, но зато когда находят, дают больше всего информации о том, где находится проблема.
- Интеграционные тесты. Это приложение, использующее libakumuli — библиотеку, реализующую систему хранения данных. Оно содержит множество простых тестов с небольшим объемом данных. Задача теста состоит в том, чтобы убедиться в том, что контракты не сломались, т.е. в том что поведение функций API библиотеки не изменилось.
- Функциональные тесты. Эти тесты (их больше 20-ти) написаны на питоне и они работают на самом высоком уровне. Каждый тест это отдельный скрипт, который создает новую БД, запускает сервер БД и что-нибудь делает. Например, у меня есть тест, который просто записывает данные и проверяет что все записалось, есть тест, проверяющий все возможные варианты запросов, тест, убивающий сервер БД через kill -9, чтобы проверить crash recovery и т.д. Это самые важные тесты, которые находят больше всего проблем. Обычно сюда я добавляю регрессии — тесты, которые проверяют уже исправленные проблемы.
- Roundtrip тест. Это простой, на первый взгляд, тест, написанный целиком на bash. Он скачивает с S2 несколько сотен МБ тестовых данных в готовом для записи виде, создает БД, запускает сервер БД, записывает в него тестовые данные, затем он формирует join запрос, который должен выдать все записанные данные ровно в том же формате что и тестовые данные. Если все прошло успешно, оба файла идентичны и тест успешно пройден. Это выполняется дважды, для двух входных форматов данных (RESP и OpenTSDB).
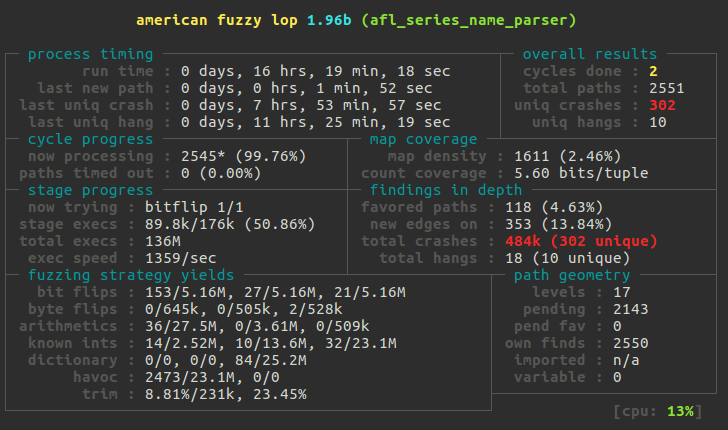
- Fuzz тесты. Эти тесты запускаются вручную. Они проверяют алгоритм сжатия и код, который парсит входные данные, например код разбирающий метки времени и имена временных рядов. Когда pull request затрагивает один из этих участков кода, я запускаю AFL с соответствующим тестом на несколько дней на специально созданном EC2 инстансе в AWS. Eye opening experience!
- Randomized tests. Самая странная разновидность тестов. В некоторых случаях я добавляю специальный код, который делает что-нибудь с очень низкой вероятностью. Например генерирует ошибку при попытке прочитать данные с диска, чтобы не ждать пока она произойдет на самом деле. Из недавнего — я работал над изменением данных в прошлом с использованием shadow pages и для того, чтобы проверить, что запись в прошлое ничего не сломает, я добавил код, который делает то же самое, что делает процедура записи в прошлое ничего при этом не меняя. Этот код вызывался в процессе работы с низкой вероятностью и применялся к случайной точке временного ряда. Собрав БД с этими изменениями я много часов крутил интеграционные тесты на AWS инстансе, пока там что-нибудь не падало, а затем исправлял ошибку и начинал все заново, до тех пор, пока ошибки перестали появляться. Естественно, это не выполняется на CI сервере, мало того, подобный код я всегда удаляю, чтобы он случайно не попал в master.
Benchmarks
Обычно Akumuli может выполнять порядка 0.5 миллионов операций записи в секунду на каждое ядро. Т.е. на двухядерной машине будет порядка 1М, на 4х — 2М и тд. В этой статье я описал процесс тестирования на 32х ядерной машине, там получилось примерно 16 миллионов операций записи в секунду. Для создания такой нагрузки потребовалось четыре машины (m3.xlarge instance). Тестовые данные были подготовлены заранее (максимально приближенные к тому что выдает реальный коллектор, в RESP формате, 16GB в сжатом виде), т.к. для того, чтобы генерировать их на лету, потребовалось бы еще больше вычислительных ресурсов. Я запустил тест через parallel-ssh одновременно на всех машинах и меньше чем через три минуты все было записано. Во время теста БД писала на диск со скоростью 64МБ/сек.
Еще я тестировал скорость чтения вот здесь. Объемы данных там довольно небольшие и все помещается в память, но перед началом тестирования я перезапускал сервер БД и очищал дисковый кэш. Я уверен, что на больших объемах данных и при активной записи в БД Akumuli будет вести себя очень хорошо.
Планы на будущее
В данный момент я работаю над решением проблемы записи в прошлое. Это нужно в том числе и для того, чтобы можно было реализовать репликацию данных и HA. У меня уже есть одна реализация на основе shadow pages, теперь работаю над альтернативным вариантом, использующим WAL. Думаю один из этих двух вариантов попадет в итоге в master, но произойдет это не скоро, т.к. требует серьезного тестирования и железа, а из железа у меня есть только ультрабук, так что привет AWS ES2.
Еще одно направление развития это всевозможные интеграции и инструменты. Я реализовал поддержку протокола OpenTSDB и теперь Akumuli можно использовать вместе с большим количеством коллекторов, вроде collectd. Еще у меня есть плагин для Grafana, который ждет своей очереди на включение в их plugin store. Еще я поглядываю на Redash, правда пока не уверен, что это кому-нибудь может быть нужно.
Akumuli это open source проект, опубликованный под лицензией Apache 2.0. Вы можете найти исходный код здесь. Здесь можно взять docker контейнер с последней стабильной сборкой, а здесь — плагин для графаны. Проекту можно помочь прислав pull-request или bug report.
Комментарии (68)

RomanPokrovskij
02.01.2018 22:36Спасибо за статью и рассказ о требованиях к TS. Вопрос, а такая возможность языка запросов как «верните мне значения от даты, до даты, апроксимированные до N точек (без сглаживания, т.е. оставляя локальные экстремумы)» у вас реализована или это не то что надо ждать от TS DB вообще?
Т.е. если задача «web dashboard графиков временного ряда c server-side zoom'ом » какой продукт (комбинацию продуктов) использовать?
ELazin Автор
02.01.2018 23:39У меня это не реализовано (и я даже не знаю как называется подобный алгоритм), в известных мне TSDB тоже.

little-brother
02.01.2018 23:55Есть алгоритм Largest-Triangle-Three-Buckets. Простой, но хорошо аппроксимирует данные для отображения, не удаляя экстремумы.
По моему мнению для TSDB такая функциональность не требуется.
ELazin Автор
03.01.2018 00:07Этот репозиторий я уже видел, даже в закладки добавил. Думаю что плагин для grafana — самое подходящее место для него.
RomanPokrovskij
03.01.2018 02:32А есть ли название у обобщенной задачи: кэширования в TSDB (или в серверной надстройке) подобных аппроксимаций для нужд оптимизации? Т.е. если известно что инженер всегда открывает данные (на графике) с конкретным treshold'ом, и в 80% углубляется до такого-то treshold'а и только в оставшихся 20% идет глубже, возможно имеет смысл постоянно хранить в TSDB 2 постоянные дополнительные апроксимации?
ELazin Автор
02.01.2018 23:59Тут был комментарий про то что chronix лучше, я его случайно отклонил пытаясь ответить. Так вот, эти ребята ни в одной статье не показали нормальных результатов тестирования производительности, так что я сомневаюсь в том, насколько там все хорошо в реальности. Ну и еще они хранят данные с потерями, поэтому в разделе evaluation у них все так хорошо (там фигурирует скорость чтения и размер на диске ЕМНИП). Естественно они всех рвут по этим параметрам, т.к. сравнивают БД, которой нужно прочитать 1МБ с БД, которой нужно прочитать 10МБ. Проблема в том, что вам может хотеться хранить данные с полной точностью.
vDr78
03.01.2018 01:20
Chronix — это сила!
de.slideshare.net/QAware/chronix-time-series-database-the-new-time-series-kid-on-the-block
Project files & Examples: github.com/ChronixDB

Siemargl
03.01.2018 00:26Нужно адекватно преподнести свое творение в сравнении имеющихся
db-engines.com/en/ranking/time+series+dbms
А в идеале — в этот рейтинг попасть.ELazin Автор
03.01.2018 00:35Сделать так, чтобы этот замечательный ресурс заметил твое существование стоит минимум 500 евро в год, опубликовать статью в их блоге 700 евро и тд.
Siemargl
03.01.2018 00:42Серьезный ценник. (Смайлик не подобрал)
Но сравниваться-то можно и бесплатно.
Насколько я помню, на Хабре в 17м году еще пробегала статья про TS DBMS и более приятно технически проработанная.
Честно говоря меня, как пользователя подобных СУБД, не зацепилоELazin Автор
03.01.2018 00:45Все равно спасибо что прочитали. Буду рад прочитать ту другую статью про TS DBMS.
thatsme
04.01.2018 03:07Я тут погуглил… Ваша БД участвовала в тестировании TSBD с открытым исходным кодом, по скорости записи она 2-ая после DalmatinerDB.
По чтению к сожелению результатов нет.
Caefah
04.01.2018 11:59Спасибо за интересную ссылку. Парадоксально, что пишут «высокопроизводительные» базы на каких-то низкопроизводительных языках программирования. Во всём обзоре в лучшем случае использовался C++. Нет ни одной базы на чистых сях.

phprus
04.01.2018 12:24+1Разница по производительности между хорошим кодом на С и на С++ в среднем равна нулю.
С другой стороны, писать плохой по производительности код на С++ значительно проще, но не факт, что переписывание на С тут хоть как-то поможет (плохой код скорее всего будет переписан в такой же плохой код).Caefah
04.01.2018 13:01Но, почему-то, всегда получается так, что те приложения, для которых требуется беспрецедентно высокая производительность написаны именно на Си. Примеры навскидку: Redis, Postfix, Dovecot, PostgreSQL, SQLite. Их близкие конкуренты, написанные на плюсах, уже несколько меркнут ))) Хоть и нельзя утверждать, что тот же MySQL стал бы лучше PostgreSQL, если бы был переписан на Си.
phprus
04.01.2018 14:0220-30 лет назад компиляторы были другие, а сейчас нет смысла переписывать на другой язык.
ELazin Автор
04.01.2018 12:05+1JFYI, табличку составляли авторы DalmatinerDB. И они ничего не тестировали, а взяли свободно доступные данные из интернета (в случае Akumuli — скорость записи на моем ультрабуке).
Caefah
04.01.2018 12:09То-то у меня подозрения по поводу эрланга возникли… Со своим гарбидж-коллектором и виртуальной машиной оно вообще тормознутое для больших кусков данных, хранящихся в памяти.
ELazin Автор
04.01.2018 12:33Dalmatiner работает забавно (если я правильно их понял). Они просто пишут на диск весь поток, даже без сортировки. Далее, во время чтения интервала (t1, t2) они читают (t1 — delta, t2 + delta) в надежде на то, что все нужные будут там. Сжатие за счет ZFS.

Sartor
03.01.2018 01:04Срочно нужны какие-то вводные статьи, как это пощупать и какие возможности есть из коробки. Очень уж заманчивые характеристики!
ELazin Автор
03.01.2018 01:14+1Вводные статьи есть в wiki проекта. Там есть описание языка запросов и формата входных данных — github.com/akumuli/Akumuli/wiki Эти статьи немного устарели, т.к. там нет описания того как работать с Docker контейнером, но в Docker Hub эта информация есть — hub.docker.com/r/akumuli/akumuli. Разница в том, что Docker контейнер сам создает конфигурацию и файлы БД (если они отсутствуют). Но даже без Docker там с точки зрения операций все очень не трудоемко.
Еще там есть описание языка запросов и форматов входных данных, но записывать данные можно через какой-нибудь коллектор (нужно только использовать протокол OpenTSDB) и читать данные с помощью плагина для графаны. Думаю это то что нужно большинству людей.

ageres
03.01.2018 05:19Продолжайте! И не бойтесь вопросов в стиле «А в чем отличие вашей реализации от уже существующих, например...».

imanushin
03.01.2018 12:13Продолжайте!
ageres, зачем Вы оказываете медвежью услугу?
И не бойтесь вопросов в стиле
Главное — не уверенность, а аргументы. Сейчас ответ читается как "да, я проигрываю комерческим базам и делаю вид, что не заметил в исходном комментарии Click House, так как я проигрываю Open Source решениям тоже".
Ибо получается, что автор сделал серьезный труд, даже внедрил решение, однако будущее его проекта туманно, т.к. придется тягаться с Яндексом на рынке дешевых решений и с кучей других на рынке коммерческих.
А теперь главное — если продолжать работу над Akumuli, то автор опять затратит много сил, добьется того, что уже есть в открытом доступе, и всё равно будет отставать от того же Яндекса.
Всё это, конечно, не отменяет полезность и интересность статьи (за что от меня плюс). Надеюсь, я ошибаюсь, и у автора получится таки найти нишу для Akumuli.
Текущий ответ @ELazin, чтобы не скролитьВ моей базе есть много всего, но это не drop-in replacement для коммерческой БД для хранения тиков, которая стоит столько, что ее стоимость можно узнать только у персонального менеджера, только после того как он соберет всю нужную информацию о твоей компании, чтобы понять сколько денег у тебя можно просить. Сорян.
ELazin Автор
03.01.2018 13:52+1Получилось малость пассивно-агрессивно, извиняюсь, но мой поинт был в том, что это разные продукты, ниши у них абсолютно разные, с тем же успехом можно было сравнивать Akumuli с MySQL, я просто понятия не имею что на это ответить.
ClickHouse это тоже аналитическая БД, его имеет смысл с Vertica сравнивать, это не TSDB, там есть GraphiteMergeTree для метрик, но чтобы с этим разобраться нужно изучать исходники (оно не описано в документации, по крайней мере раньше не было) и судя по всему, создавалось для внутренних нужд. Данные в CH нужно писать батчами, нельзя просто открыть сокет и начать записывать туда данные, все будет слишком медленно. Нужен какой-то сервер, который будет получать данные мониторинга от коллекторов, батчить их и вставлять. Для этого есть graphite-clickhouse и graphouse. Ни одна из этих связок не поддерживат теги.
Сравнивать Akumuli имеет смысл с другими TSDB — OpenTSDB, Graphite, InfluxDB и тд. По сравнению с ними у меня есть преимущество в производительности и простоте операций. Akumuli может работать автономно, не нуждается в администрировании. У меня есть пользователи, которые выбрали Akumuli именно благодаря этому. Им нужна была БД, которая может работать на очень слабом железе, мониторить кучу контроллеров и не нуждаться в администрировании. У меня самого есть кое какой проект, который мониторится с помощью Akumuli на t2.micro инстансе.Andronas
03.01.2018 15:44Скажите, она действительно будет норм работать на не самом мощном железе?
Просто на страничке проекта есть текст «Akumuli is a time-series database for modern hardware.»ELazin Автор
03.01.2018 15:50Я использую t2.micro и EBS volume для мониторинга небольшой системы. Нужно иметь ввиду, что для обработки большого количества точек/сек нужно иметь нормальный процессор или много ядер, если у вас очень много уникальных метрик нужно много памяти (примерно 16-24КБ на метрику). Modern hardware = оптимизация под SSD/NVMe, параллельная запись/чтение и все такое.
ELazin Автор
03.01.2018 13:53А в чем заключается «медвежья услуга»?
imanushin
03.01.2018 14:25А в чем заключается «медвежья услуга»?
Суть в том, что если есть популярное открытое и бесплатное решение (я про Click House), то очень сложно сделать более быстрый аналог. К тому же Click House прекрасно решает в том числе и задачу работы с временными рядами, так как по сути вам надо просто брать определенную проекцию из данных (т.е. создать materialized view для вашей таблицы со своей логикой сортировки).
А в итоге что имеем:
- Есть бесплатное открытое решение, которое улучшается кучей людей и компаний
- Когда новый человек ищет способ решение своей задачи, он зачастую будет руководствоваться тем, какие есть функции в проекте, какая документация, насколько большое сообщество и т.д.
- Ваше решение уже сейчас проигрывает аналогам.
- Если Вы будете продолжать разработку над Akumuli, ваш вклад в "open source" будет неоцененным, так как вы решили задачу, а немало людей пользуются другой такой же программой
- Через N лет вам надоест вкладывать силы в решение, и если вы не успеете собрать community, то проект будет затухать и забываться
То есть по сути серьезный труд остается неоцененным, однако вам говорят, что "всё круто, продолжай". Отсюда моё мнение — как можно раньше признать, что есть более серьезные аналоги, а дальше — попытаться интегрировать ваши алгоритмы в Яндекс (или аналоги), написать статьи об алгоритмах и добавить строчку в резюме.
Да, это шаг назад, однако иначе через 5 лет вам уже сложно будет выдать Akumuli за достижение.
ELazin Автор
03.01.2018 16:03Я еще раз повторю, что CH это не то же самое, с временными рядами он работать может (как и сотни других продуктов), на этом сходство заканчивается. Я действительно не понимаю, при чем тут CH, вы его когда-нибудь использовали для мониторинга? А kdb+?
imanushin
03.01.2018 17:11вы его когда-нибудь использовали для мониторинга
Click House — в соседних командах
А kdb+?
Да, я даже расписал то, как он работает.
ELazin Автор
03.01.2018 18:26Расписать то расписали, но это именно мониторинг? Я просто никогда не встречал kdb+ в мониторинге. Это где же такое есть, если не секрет?

deniszh
03.01.2018 16:10К тому же Click House прекрасно решает в том числе и задачу работы с временными рядами, так как по сути вам надо просто брать определенную проекцию из данных (т.е. создать materialized view для вашей таблицы со своей логикой сортировки).
Materialized view сейчас убивает перформанс КХ напрочь, простите.
Просто проходил мимо.
c4boomb
03.01.2018 18:48Не обращайте внимание.
Slack и Trello, похоже, тоже оказывали медвежью услугу(конкурент Atlassian Jira и HipChat).
phprus
03.01.2018 14:59Главное — не уверенность, а аргументы.
Главный аргумент звучит так:
Akumuli, как публично доступный проект, появился в 2013 году.
Click House, как публично доступный проект — Тремя годами позже (в 2016 году).
В связи с этим Вы либо требуете от автора быть пророком видящим в будущее, либо Ваш вопрос на самом деле не к Akumuli, а к Click House — зачем его стали разрабатывать, если Akumuli уже 3 года как существовал и можно было бы в его разработке участвовать.
Почему-то в подобных вопросах сравнениях люди напрочь забывают, что более известный конкурент мог банально появиться позже и реальный выбор у разработчиков был не между конкурентом и своим решением, а между своим решением и ничем.ELazin Автор
03.01.2018 15:57Насколько я знаю, CH разрабатывается с 2008 года. Просто они его писали для внутренних нужд. В 16-м они его выложили в open-source.
phprus
03.01.2018 16:08А узнали Вы это до 2016 или до 2013 годов?
Конечно же я в курсе, что реальная разработка CH началась раньше, чем выкладка в open-source, но не суть важно, когда она началась. Важно, что в 2013 году тот, кто ставил себе задачу разработать TSDB скорее всего не мог знать о существовании внутренней разработки яндекса CH. Следовательно вопросы в стиле зачем писать свое, если есть CH — это отсылка к видению будущего.ELazin Автор
03.01.2018 16:23Заранее не знал, конечно. Сейчас я не стал бы ничего такого разрабатывать, честно говоря. Очень уж много всего появилось за последние год-два.
Caefah
03.01.2018 16:28Попробуйте переписать на чистый Си. В результате ещё больше увеличите производительность и проект будет выглядеть конкурентоспособнее по сравнению с Click House.
Caefah
03.01.2018 16:05Если вы делаете 10 000 вставок в свою SQL базу данных — все будет хорошо какое-то время, потом таблица вырастет в размерах настолько, что время выполнения операций вставки увеличится.
Пруфлинк в студию, пожалуйста!
Работаю в научной сфере с временными рядами без изысков и экзотики, используя банальную, хорошо настроенную SQLite. На 400 млн строк упомянутой у Вас просадки производительности для insert не наблюдается.
Вообще, хотелось бы увидеть сравнительные тесты разных БД с Вашей разработкой. SQLite в частности.ELazin Автор
03.01.2018 16:25В статье есть ссылка на benchmark. Вставку в sqlite я не тестировал, невозможно заранее сравнить со всем на свете. Просадка производительности для insert это просто educated guess, количество уровней b-tree в sqlite табличке увеличится до определенного уровня и все станет медленнее. 400 млн строк у вас в одной таблице? А какая схема?

xcore78
04.01.2018 03:18Partitioning хорошо помогает, когда у вас откуда-то может появиться 400 млн строк в одной таблице.
Caefah
04.01.2018 13:11Да, 400 млн строк в одной таблице. Во всей БД только одна таблица. Что-то колдовали с опциями для быстрого добавления. Что именно, сейчас не помню. Доберусь до кода — вышлю схему.

port443
04.01.2018 12:06А почему именно SQLite? Это всё же решение для «кофеварок» и небольших задач. Не предполагаете упереться в какое-либо ограничение? Не пробовали что-то более масштабное, типа Postgre или MySQL?
Caefah
04.01.2018 12:39А почему именно SQLite?
Потому, что быстрее просто не удалось найти. Проводился целый ряд исследований под конкретную потребность — хранение временных рядов (среди основных задач). Хочу особенно подчеркнуть, что каждая БД хороша под свои цели. При нагрузочном тестировании рассматривались BerkeleyDB и PostgreSQL в т.ч.
BDB отпала по двум причинам:
1. Она «не SQL» — там своя атмосфера. Дизайн API очень запутанный и странный.
2. Не имеет преимуществ по производительности в сравнении с SQLite.
Производительность PostgreSQL под требуемую задачу не идёт ни в какое сравнение с SQLite. SQLite доступен напрямую как сишная библиотека, которую можно статически собрать с приложением. К PostgreSQL доступ только по сокетам. PostgreSQL хороша для проектов с многопользовательской нагрузкой, с доступом к случайным фрагментам БД и сложными выборками. А для последовательного доступа к данным от имени одного приложения (как в случае с временными рядами) лучше, чем SQLite найти не удалось.
Возможно, где-то MySQL и является преимуществом, но не в научных задачах. По производительности она вообще не конкурент.
Насчёт кофеварок Вы погорячились ) SQLite полноценная БД со своими киллерфичами. Одна из самых быстрых и, кстати, среди прочего, умеет вложенные запросы, in-memory, и много того, чего не умеет MySQL, несмотря на свою «зрелость» и «корпоративную поддержку».ELazin Автор
04.01.2018 12:52А какая у вас схема БД, если не секрет? И с какой скоростью получается читать/записывать?
Caefah
04.01.2018 13:07Пришлю когда доберусь до кода. Не хочу по-памяти восстанавливать, чтобы не ошибиться — там было много нюансов.
Caefah
05.01.2018 01:52Схему привёл в цитатах чуть ниже по тексту. Про скорость, кстати, и упоминать не стану, т.к. на этот показатель сильно влияет CPU, шина и, конечно, дисковая подсистема. Если и приводить цифры, то только в сравнении нескольких БД на одной аппаратной платформе. Но, если честно, это выходит за рамки практических нужд — выбор нативного решения под сишное приложение сильно ограничен, а уж эрланговские и явовские БД кроме чувства брезгливости никаких положительных ассоциаций не вызывают.
В любом случае хочу Вам пожелать успеха в проекте. Продолжайте. Вы делаете полезное дело и пусть конкуренты не смущают — когда-то и про существование Линукс знала пара-тройка энтузиастов ;)
port443
04.01.2018 17:49Нет-нет, я SQLite и сам люблю и применяю нередко. Но не так, как вы. Я как раз и хотел сказать, что это больше встраиваемое/однопользовательское решение (отсюда и производительность). По умолчанию с записью там как раз не очень (особенно на «кофеварках»), так как она параноидально относится к надёжности (при том, что основное место применения — далеко не сервера). Ваше колдовство с настройками скорее всего было в отключении журналирования, и наверняка в группировке записи большими транзакциями.
То, что на «больших» машинах она сильно обгоняет полновесные решения тут вполне понятен, так как она относительно проста.
Мой вопрос как раз был про простоту: достаточно ли её возможностей с учётом дальнейшего развития проекта?
И, да: посмотреть на структуру было бы интересно.Caefah
05.01.2018 01:31Вы совершенно правы. Было и отключение журналирования, и вставка вообще реализована без транзакций, маленькими порциями (если я всё правильно помню).
Т.к. это временной ряд, то при аварийном завершении приложения всегда можно подсмотреть время последней успешной вставки и недостающее подтянуть из внешнего «кеша». Помимо прочего, версия SQLite позволила реализовать consequtive disk access, а в момент старта приложения средствами SQLite производится проверка базы на консистентность pragma integrity_check. В общем, был реализован ряд мер, обеспечивающий и производительность, и надёжность для последовательной записи и обращений к временному ряду. Скорость выборок и вставки вне конкуренции с другими упомянутыми мной БД.
А вот и обещанная схема, она предельна проста. Одна отдельная БД с одной таблицей:
PRAGMA foreign_keys=OFF; PRAGMA synchronous=OFF; PRAGMA journal_mode=OFF; PRAGMA cache_size=524288; PRAGMA page_size=4096; CREATE TABLE timeseries (time TIMESTAMP UNIQUE NOT NULL, responsiveness DOUBLE NOT NULL);ELazin Автор
05.01.2018 12:26Ну, это все же не тоже самое. Тут у вас один большой временной ряд. Можно было бы просто хранить все в файле. В feather файле, например, так у вас было бы сжатие.
Caefah
05.01.2018 13:23Спасибо за информацию про feather, однако нативной поддержки под чистый си найти не удалось.
В моём случае сжатие нецелесообразно. Сэкономить пару гигабайт на диске при современных объёмах резон небольшой, а вот накладные расходы на CPU в момент компрессии/декомпрессии — это уже серьёзный недостаток, когда куча фоновых процессов и математическими расчётами генерируется большая нагрузка. SQLite хранит все данные в бинарном виде с приемлемо малым оверхедом.ELazin Автор
05.01.2018 14:27Я сильно сомневаюсь что тут в CPU что-нибудь упирается. Скорее всего это I/O bound задача и она только выиграет от сжатия.
xcore78
04.01.2018 03:23Позвольте вопрос, почему не in-memory решение, зачем писать на диск в процессе получения данных? Не лучше ли сделать агент, иногда сохраняющий данные на диск (то есть, конечно же, в сеть)?
Причем логика агента может быть любой (вплоть до её полного отсутствия — когда вы не сохраняете и не храните сырые данные).ELazin Автор
04.01.2018 12:17Причина в том, что пользователь хочет durability и хранить много данных. Данные хранятся и кэшируются в памяти, если она есть, никаких проблем в этом нет. Но если периодически синхронизировать in-memory store, то это сожрет пропускную способность диска очень сильно. Допустим у нас есть 1М уникальных временных рядов, пусть каждый из них имеет хотя бы одну не заполненную полностью страницу памяти (скорее всего так и будет всегда). Страница — 4КБ, мы должны будем записать на диск 4ГБ данных чтобы синхронизировать только вот эти вот незаполненные полностью страницы. Каждый раз когда страница изменилась (туда дописали несколько точек и страница стала заполнена не на 10% а на 10.1%) мы пометим ее как грязную и во время следующей синхронизации (допустим по таймеру) снова будем ее записывать.
Ну и второй аспект — нам может не хватать RAM для хранения данных. В принципе, можно хранить временные ряды в Redis, я даже на гитхабе что-то похожее видел. Но это подойдет только для случая когда у пользователя небольшой поток или им нужно хранить только оперативные данные за последний день/час.xcore78
05.01.2018 00:55Объясните, пожалуйста, как вы представляете схему масштабирования.
Когда временных рядов становится больше, вы просто ставите около еще одну такую же монолитную ноду?
Или же архитектура далека от монолитной ноды?ELazin Автор
05.01.2018 12:39Пока только монолитная нода. Можно обеспечить HA, если использовать две ноды и реплицировать трафик на обе. Для того, чтобы реализовать кластеризацию нужно сначала реализовать запись в прошлое. Пока что roadmap такой:
— Запись в прошлое, обновление старых данных и тд.
— Простая репликация, HA с полным набором данных на двух нодах и синхронизацией в случае, если одна из них уходила offline.
— Тут уже можно начинать думать про кластеризацию.
Сама проблема довольно сложна. Непонятно даже как раскидывать метрики между нодами, ведь запросы часто вытаскивают множество метрик и если распределять их случайным образом, то каждый запрос будет задействовать все узлы кластера (разделить на фактор репликации).

imanushin
А в чем отличие вашей реализации от уже существующих, например Click House или KDB?
Ведь для хранения TS уже давно используются колоночные базы данных. Более того, в существующих решениях уже есть немало полезных опций (скажу про KDB):
Более того, у них есть также ряд важных для Enterprise особенностей:
На тему баланса скорости записи и чтения могу посоветовать схему из той же KDB:
Оптимизации для чтения:
И еще раз вопрос: в вашей базе это есть? А если нет — то почему не использовать одно из уже существующих решений (в случае с KDB — она доступна с 2003 года)?
Phizio
>почему не KDB/CH/etc
Видимо, ответ такой:
Потому, что не блокчейн)
Белый лист в тексте как бы мягко намекает на ICO)) И да, это не критика или ирония) дерзайте!
ELazin Автор
Nope
ELazin Автор
В моей базе есть много всего, но это не drop-in replacement для коммерческой БД для хранения тиков, которая стоит столько, что ее стоимость можно узнать только у персонального менеджера, только после того как он соберет всю нужную информацию о твоей компании, чтобы понять сколько денег у тебя можно просить. Сорян.
sshikov
Я бы вообще даже не заводил разговор про такое. Это продукт такого типа, что замена его на другой, даже путь бесплатный и заведомо лучше по характеристикам, все равно будет непростым процессом, который сам по себе стоит денег.
ELazin Автор
Так я и не завожу. Я даже не знаю как можно сравнивать с kdb+.
RomanPokrovskij
А можно спросить почему замена RTDB должна быть непростым делом? Неопытным взглядом подводные камни не видны: это же сервис, cюда шлешь данные, сюда запросы. Запрос, говорят, всегда прост: выдай данные от и до, возможно с какими-то базовыми статистиками (как понимаю с указанием шага). Время от времени прочищаешься. Переписать адаптеры и вся замена.
sshikov
Сразу скажу — у меня практический опыт работы только с OneTick (в пределах трех лет), и там это, мягко говоря, не совсем так. Даже совсем не так. А в целом суть моих соображений проста — это не SQL, при этом даже перенос базы с одного SQL диалекта на другой — штука не всегда простая. А тут со стандартами похуже будет.
Ну и соответственно, переписать адаптеры — может быть нетривиальной задачей с изменением логики обработки.
Я как-то пытался переносить логику работы с OneTick на MS SQL (благо, объемы данных позволяли). Даже на сравнительно небольших потоках, которые MS SQL в принципе переваривает, все не так уж примитивно. И совсем не похоже на оригинал в OneTick.
RomanPokrovskij
А можно пример сложного запроса к OneTick? Хочется узнать что значит «совсем не так». Я могу представить и сложные запросы, например если данные «разбиты на фазы», и шаг статистик надо с началом фазы переначинать. Но на сколько я понял, нет потребности такие фичи в язык запросов вставлять, все это делается на мидллейере. А какие есть?
sshikov
Тут дело не совсем в сложности запроса. Там свой язык запросов, ни с кем не совместимый (хотя ODBC драйвер существует, но SQL весьма специфичный). Функции с одной стороны, как вполне обычные, типа max/min/first/last за период, так и достаточно экзотические. К сожалению, с открытой документаций как-то не очень, я затрудняюсь отослать к какому-либо примеру в интернете.
Кстати, попробуйте на досуге реализовать в виде SQL запроса такую тривиальную в общем-то штуку, как last за произвольный период. И главное посмотрите, как быстро это будет работать.
Что значит "все делается"? Тут есть одна небольшая проблема — при больших объемах вы не можете просто так вытащить нужные вам данные из TDSB "с запасом", и потом их где-то обработать, это слишком много ресурсов потребует.