
В Ethereum для выполнения каждой транзакции требуется определённое количество газа — специальной сущности. Существуют разные пути для снижения затрат. Часть из них уже реализована. Хочу начать с обсуждения вопроса оптимизации стоимости создания смарт-контракта.
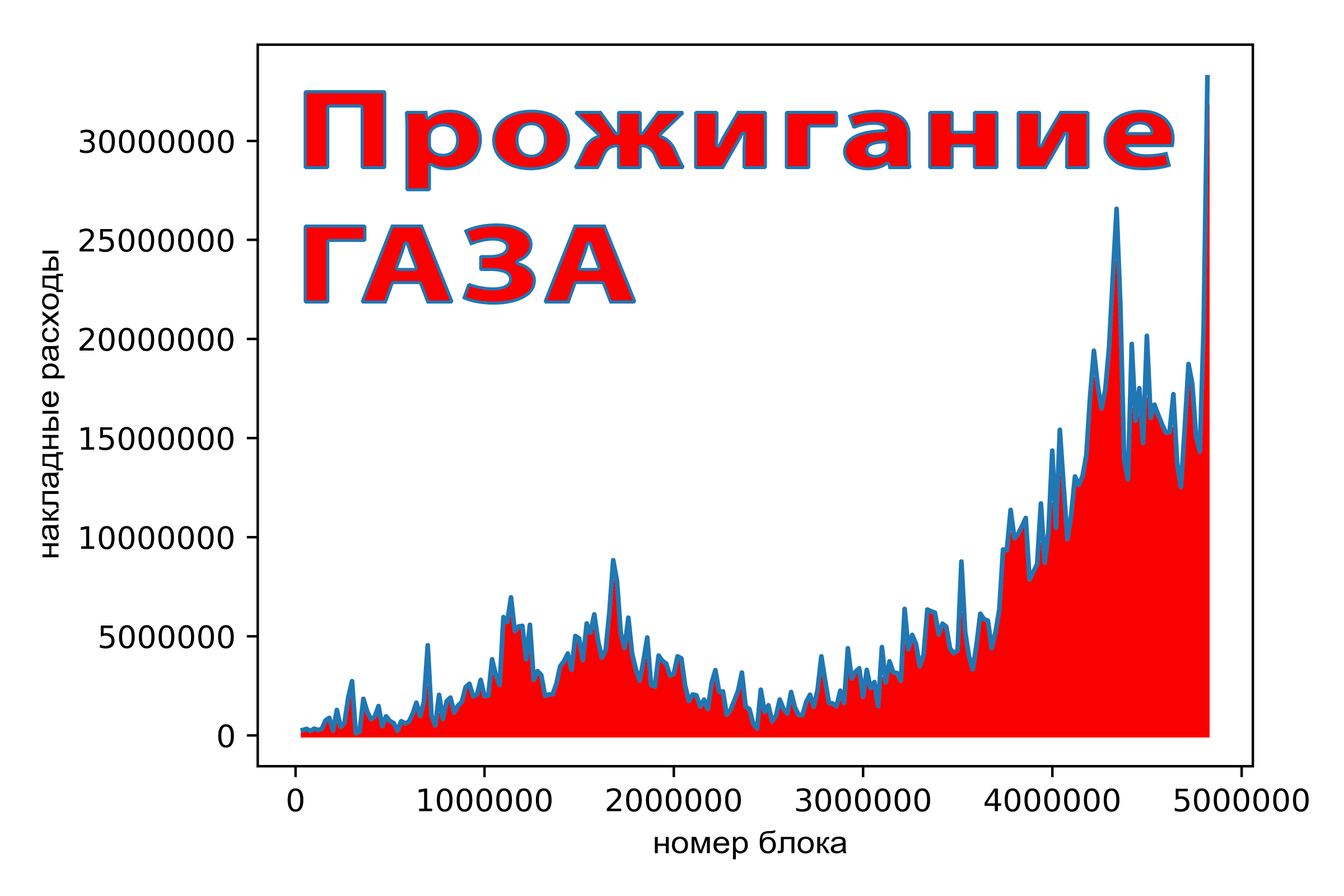
Как видите, можно заметно снизить расход газа, сокращая издержки. Прежде чем займёмся деталями давайте обсудим вопрос оптимизации программ.
Как работают оптимизаторы?
Давайте рассмотрим следующую простую C-программу.

Программе потребуется некоторое время на выполнение, если скомпилировать её без оптимизации. Если же запустить оптимизированную версию программы, то она выполнится моментально. Причина в том, что компилятор обнаружит, что переменная x в функции main() нигде не используется в последующем коде, поэтому вызов функции calculate() можно вообще не выполнять. Вот результат оптимизации:

Давайте немного изменим возвращаемое значение в исходной функции main() следующим образом:

Теперь компилятор будет бессилен помочь нам с оптимизацией. Остаётся лишь ручная оптимизация.
Ручная оптимизация
Сразу отмечу, что ручная оптимизация — это творческий процесс, поскольку есть множество мест и возможностей для улучшений в реальных программах. С другой стороны, мы можем использовать профайлер для поиска узких мест в программе. А когда проблема будет локализована, то можно воспользоваться одним из многих подходов к оптимизации, более эффективными алгоритмами и так далее.
Давайте внимательно посмотрим на функцию calculate() из предыдущего примера. На каждой итерации внутреннего цикла переменная r меняется с 0 на 1 и обратно. Начальное значение 0, поэтому нам достаточно лишь знать, будет ли чётным количество итераций или нет. Если хотя бы один из параметров a или b чётный, то будет чётное количество итераций, поэтому возвращаемое значение будет 0. Таким образом получаем следующую оптимизированную версию функции calculate():

Опасные оптимизации
Оптимизации — это хорошо, поскольку они ускоряют программу, снижают потребление памяти или количество операций ввода-вывода, и т.д. Одновременно с этим оптимизации могут ухудшить производительность или даже оказаться опасными.
Одна из проблем связана с различным окружением и параметрами. Например, программа была оптимизирована для запуска на кластере, а мы используем её на отдельном компьютере. Или программу оптимизировали по скорости и все входные файлы полностью загружаются в оперативную память. Скорее всего, что будут проблемы при нехватке памяти для слишком больших файлов.
Иногда оптимизации могут привести к проблеме с безопасностью. (Тут можно вспомнить и про Spectre с Meltdown.) Во многих программах используется стандартная функция memset() для очистки переменных с конфиденциальной информацией, например, ключами и паролями. Но компиляторы часто просто удаляют эти вызовы, поскольку обновлённые значения переменных не используются в дальнейшем. До недавнего времени функция очистки в проекте OpenSSL выглядела следующим образом:

Конечно, проблема с функцией memset() является исключением из правил. Оптимизаторы генерируют корректный код, и обстоятельства использования могут привести к ошибкам. Но источником некорректного кода являются люди.
Ручные оптимизации очень опасны. Ранее показал оптимизированную версию функции calculate(), но это была некорректная оптимизация. Началось всё с истинного утверждения:
Если хотя бы один из параметров a или b чётный, то будет чётное количество итераций, поэтому возвращаемое значение будет 0.
Это импликация, поэтому при ложном условии следствие может быть любым. Возможна ли ситуация, когда и a, и b нечётные, но количество итераций будет чётным?
Ответ "да". Если значение или a, или b будет отрицательным, то вообще не будет ни одной итерации. Поэтому корректная ручная оптимизация приведёт к следующему коду:

Виртуальная машина Ethereum
Виртуальная машина Ethereum (Ethereum Virtual Machine, EVM) — это основное "железо" платформы Ethereum. В упрощённом виде её архитектура представлена на следующей схеме:

Можно выделить три типа памяти: балансы счетов (balances of accounts), код контрактов (code) и хранилища контрактов (storage). У каждого счёта (личного кошелька или контракта) есть свой собственный баланс в валюте Ethereum (ETH). Для каждого смарт-контракта хранится его код (исполняемая программа для EVM), а также собственная память для хранения переменных. Код контракта не меняется после создания.
Блокчейн Ethereum состоит из множества блоков в определённом порядке. Каждый блок — это набор транзакций и квитанций их выполнения (receipts). Состояние EVM (его память) полностью определяется всем набором предыдущих транзакций. Чтобы получить состояние EVM в момент N надо взять состояние EVM в момент N-1, после чего выполнить все транзакции из блока N. Поэтому, зная все транзакции блокчейна, мы можем определить состояние EVM на любой момент в прошлом. Процесс проиллюстрирован на следующей схеме:
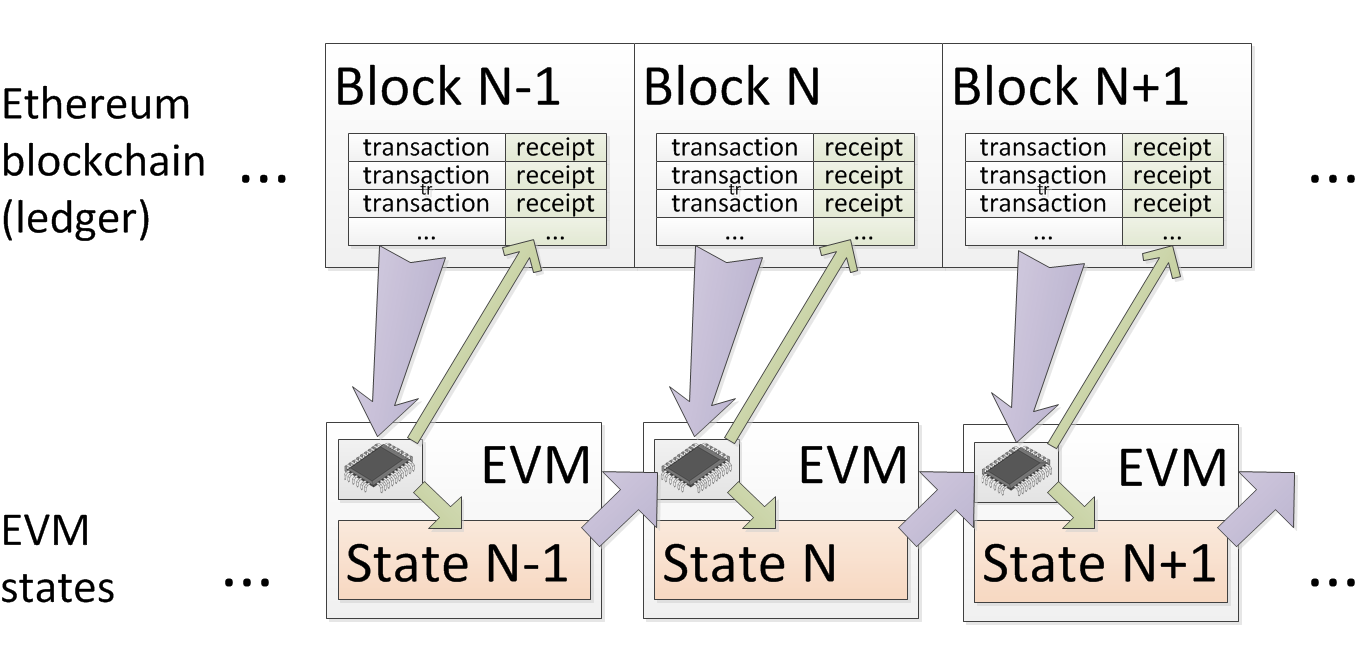
Отмечу, что если зафиксировать состояние EVM в момент M, то есть состояния EVM, которые будут недостижимы в будущем вне зависимости от выполняемых транзакций после блока M.
Рассмотрим два набора транзакций: T and U. Назову эти транзакции "равнозначные", если обработка транзакций T в блоке N приведёт EVM к "идентичному" состоянию, что и обработка U вместо T в том же самом блоке N. Ставлю в кавычки, поскольку допускается разница в балансе отправителя и майнера блока N из-за разницы в затратах газа между наборами транзакций T и U.
Все затраты времени и памяти включены в стоимость газа, поэтому основная цель оптимизации — это снижение затрат газа. Одним из подходов к оптимизации является поиск "равнозначных" транзакций с меньшими затратами газа. Речь идёт про удаление избыточного кода, но не изменении алгоритмов и т.п. Аналогично первому примеру с функцией calculate() выше.
Создание смарт-контрактов
Существует два разных вида транзакций. Сейчас собираюсь обсудить только транзакции создания смарт-контрактов. Транзакция создания контракта выполняет два основных действия в EVM: инициализирует хранилище контракта и сохраняет байт-код. Инициализация хранилища является результатом вызова конструктора контракта с параметрами миграции. Все другие методы контракта сохраняются в коде. Этот процесс изображён на следующей схеме:

Вопрос оптимизации кода контракта оставим для будущих статей. Сегодня сосредоточимся на оптимизации кода развёртывания контракта.
Оптимизация кода развёртывания контракта
В предыдущем разделе мы обсудили, что есть очевидная цель оптимизации — минимизация потребления газа. Одновременно с этим необходимо убедиться, что оптимизированная транзакция "равнозначна" исходной.
Я использовал исходный байт-код развёртывания контрактов, доступный из блокчейна Ethereum. Для этой задачи исходного кода контрактов не требовалось. После этого выполнил трассировку выполнения развёртывания контракта и оставил только требуемый код. Процесс оптимизации кода развётывания можно представить следующим образом:

Предыдущий пример упрощён, хотя используемый подход может быть применим и для более сложных транзакций.
Нижняя оценка
Выполнение каждой отдельной инструкции в EVM имеет свою стоимость в количестве газа. Хотя есть множество путей для достижения одинакового результата, но мы можем легко получить нижнюю оценку. Для этого достаточно просуммировать следующие числа:
- Плата за данные кода развёртывания контракта;
- Плата за создание контракта;
- Количество различных переменных в хранилище, умноженное на стоимость оператора SSTORE;
- Размер байт-кода контракта в словах, умноженный на стоимость записи в память и стоимость инструкции RETURN;
- Количество событий, умноженное на соответствующую стоимость.
Данная нижняя оценка может быть использована в качестве основы и цели оптимизации.
Здесь предполагал, что байт-код контракта будет копироваться из данных транзакции развёртывания. Ситуации генерации байт-кода "на лету" являются исключениями.
Статистика и результаты
Я сделал снимок блокчейна Ethereum на блоке №4841148. На этот момент в блокчейне было 119041944 транзакций, из которых только 1022020 транзакций по созданию контракта. Я сравнил входные данные этих транзакций и обнаружил 111806 уникальных кодов развёртывания контрактов.
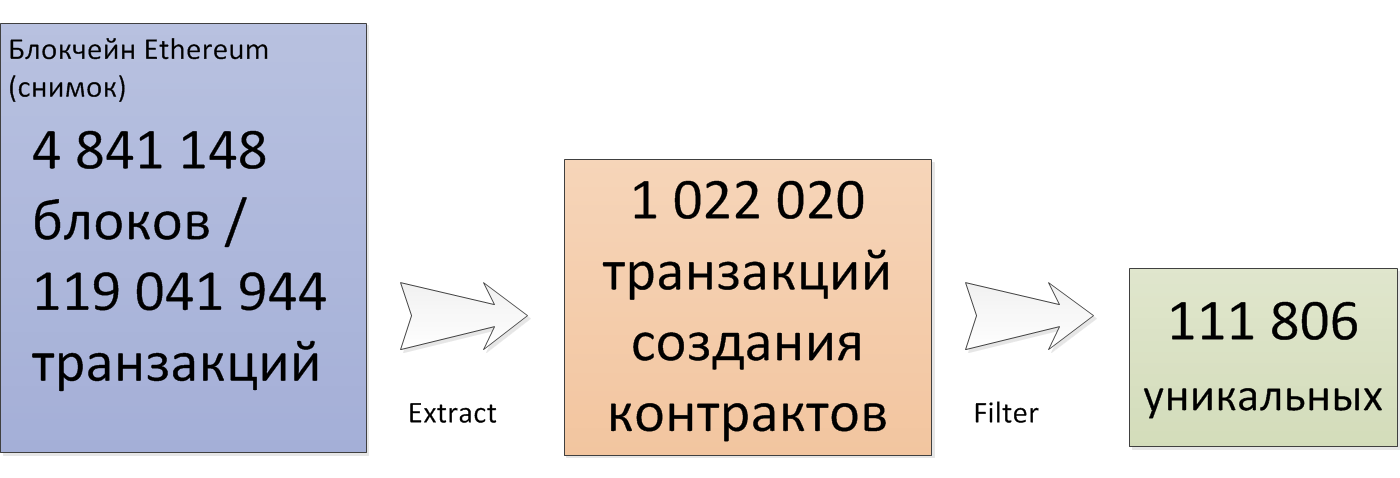
Каждый из уникальных кодов развёртывания запустил в Ganache CLI (бывший TestRPC) и получил квитанцию выполнения и байт-код контракта. Одновременно с этим выполнил наивную оптимизацию, а также посчитал нижнюю оценку. Оптимизированный код был протестирован на локальном блокчейне, после чего результаты сравнивались с исходным кодом. Процесс проиллюстрирован на следующей схеме:

В ходе обработки игнорировал ошибочные транзации и контракты, которые создавали другие контракты. Оптимизатор называю наивным, поскольку он игнорирует любые ранее полученные на стеке значения, создавая каждый раз новые.
Для каждой обработанной транзакции получил три числа: исходные затраты на обработку, затраты для оптимизированной версии и нижнюю оценку. Все значения были посчитаны в текущей стоимости операций. Получились следующие результаты:
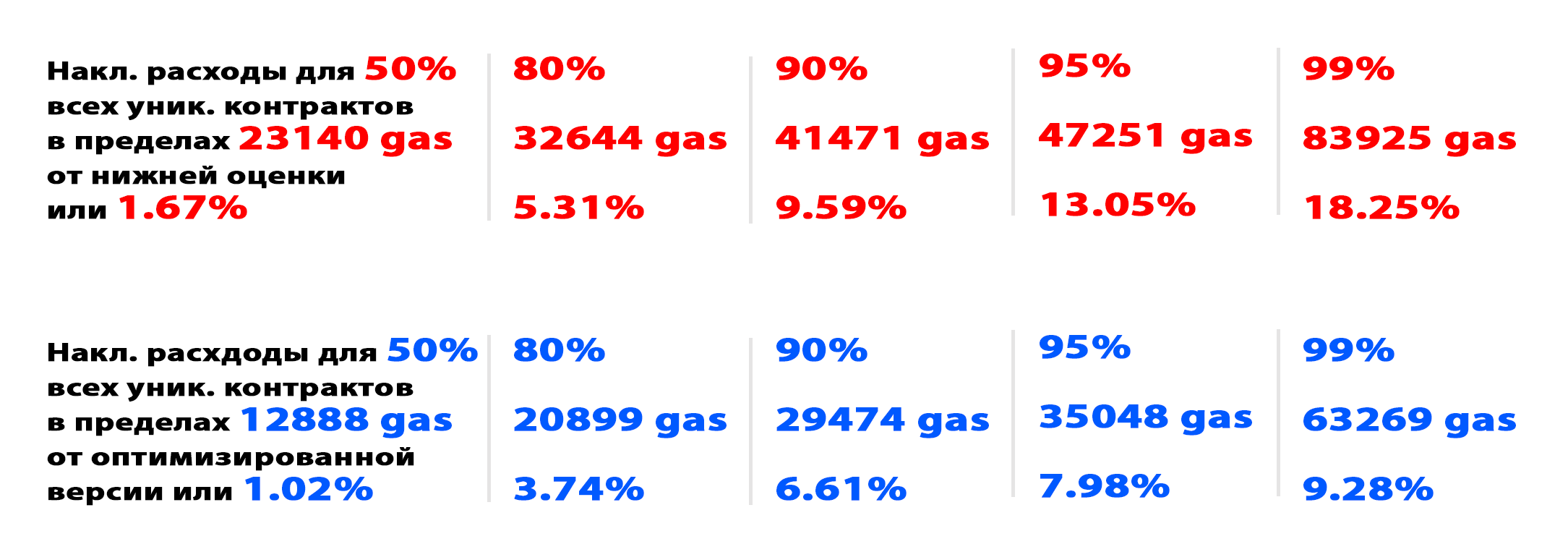
Из таблицы можно увидеть, что даже наивная оптимизация позволяет сэкономить газ. К сожалению, количество не такое уж и большое. С другой стороны, в теории больше 10% газа может быть сэкономлено лишь для 10% контрактов. На практике с наивной оптимизацией мне удалось достичь экономии в 10% лишь для 0.3% контрактов.
Учитывая все эти числа, мы можем вспомнить, что создание контракта — это единовременный процесс, поэтому могу заключить, что оптимизация развёртывания смарт-контрактов не является сейчас важным вопросом для Ethereum. Уверен, что ещё вернусь к этому вопросу в будущем, а сейчас есть ещё много интересных проблем оптимизации, связанных с байт-кодом самих контрактов.
Человеческий фактор
Небольшие ошибки могут перечеркнуть результаты всех предыдущих усилий. Например, 2131132 единиц газа было потрачено для транзакции transaction 0xdfa1..7fbb. Это на 23% больше газа, чем требовалось. Кто-то просто продублировал код развёртывания контракта перед отправкой. В итоге 6Кб данных вообще не использовались.
Что дальше?
Вопрос оптимизации при развёртывании смарт-контрактов появился в качестве побочного результата. Данная тема достаточно проста для понимания, поэтому решил с неё и начать.
Продолжение следует...
Комментарии (8)

alatushkin
02.02.2018 00:48Название «Экономия газа в смарт-контрактах Ethereum» наталкивает на мысль, что статья будет об экономии газа при работе контракта.
Ну а по сути вопроса:
О чем стоит помнить:
1)Экономить на газе можно создавая новые экземпляры контракта из уже загруженного байт-кода. И/или используя в контракте байткод библиотек уже загруженных в эфир. Но тут главное, чтобы не получилось как с Parity
2)Стараться не усложнять. За «грамотное ООП» придется платить.
3)Подумать о том чтобы больше вынести оффчейн. В конечном итоге, когда кто-то с вами вступает в отношения с использованием контракта — скорее всего без действий с вашей стороны всё-равно работать не будет, а значит и офчейн вполне может быть подходящим решением.
4)Чем больше для выполнения метода контракта потребуется газа — тем выше будет gas price. Дело в том что у каждого блока в блокчейне есть лимит газа и как следствие то количество операций которое может быть выполнено. А значит если для выполнения метода вам требуется 10% всего газа блока, то в условии высокой конкуренции (как с недавними криптокотиками, например) — чтобы получить такое количество газа — придется заплатить за него дороже чем участникам с менее прожорливыми транзакциямиXTX Автор
02.02.2018 01:09Название «Экономия газа в смарт-контрактах Ethereum» наталкивает на мысль, что статья будет об экономии газа при работе контракта.
Обязательно доберусь и до этой темы. Там много всего интересного. Будем "поедать слона частями".
О чем стоит помнить:
Полезные замечания. Спасибо. Культура программирования на Solidity всё ещё формируется, и многие учатся лишь на собственных "шишках". К счастью, всё чаще используют наработки и сложившиеся практики.
Думаю, что начинать следует с оценки и подходов к трансформации бизнеса в контексте блокчейна. А в этом вопросе сейчас очень много неизвестных.

ChiefPilot
02.02.2018 11:15Лучше бы и правда газ экономили, который сжигается, чтобы электричество выработать, которое расходуется на все эти расчёты. :) Вот скажите, кто хорошо в этом разбирается: это что же, теперь мы так и будем дальше тратить кучу энергии, чтобы вот эти рассчёты считать в блокчейновых системах?! Я понимаю, что это их обязательное условие — сложность рассчёта, чтобы невозможно (точнее, очень трудно) было подделать несколько предыдущих транзакций, но как-то это не правильно, что столько энергии и вычислительных мощностей уходит просто на то, чтобы участники этих систем могли доверять системе (полагаясь на то, что подделать почти невозможно). Как-то подругому нельзя доверять друг-другу?
alatushkin
02.02.2018 11:44Как-то подругому нельзя доверять друг-другу?
Точнее «не доверять друг другу»)
Не доверять друг-другу «по-другому» можно. Зависит от того сколько именно «недоверия» нам нужно и сколько его мы готовы оплатить.
Больше децентрализации — выше «налог» на недоверие)
Если представить себе «шкалу недоверия» на одном конце которой расположено «абсолютное недоверия» (те самые популярные лозунги «децентрализация»,«анонимность» и прочая анархия), а на другом — «централизация», и разместим на ней все существующие решения, то увидим, что у нас есть
Решения на основе POA(Proof-of-Work) — максимальное недоверие, большие комиссии, большая ресурсоемкость.Эфир, Биткоин и прочее такое.
Решения на основе POA (Proof-of-Authority) — доверие «арбитру». Система при которой есть «главные» узлы, которые проводят транзакции и все остальные желающие — наблюдатели. Полная централизация, низкие комиссии, высокая пропускная способность, Ripple, Visa и т.д.
И Proof-of-Stake — POS — где-то по средине шкалы.ChiefPilot
02.02.2018 12:08Я о том, чтобы расчёт очередного блока не был таким ресурсоёмким. Если я правильно Вас понял, то все приведённые варианты блокчейновых систем отличаются лишь тем — где будет производиться расчёт блока. А сама затратность этого расчёта не меняется. Она может меняться для конкретного участника системы того или иного типа, но не для системы в целом. А я спрашивал о том, нет ли возможности также «не доверять друг-другу», также децентрализовано, но чтобы не нужно было тратить столько энергии и столько вычислительных мощностей? Полная централизация с VISA и проч. тоже не хорошо, но и вот это расходование мощностей для блокчейна это как-то глупо выглядит… Неужели нельзя как-то не менее эффективно защититься от подделки блоков другим, сильно менее ресурсоёмким, способом?
alatushkin
02.02.2018 13:12Это что-то «кармическое»)
«Технически» да — POW от POS от POA, в крупную клетку, отличается только тем кто именно может участвовать в формировании очередного блока.
Но тут вопрос больше психологии и экономики. Пока решения только такие: максимально-децентрализовано, но очень большие издержки, либо ближе к реальности и удобнее пользоваться, но не такие яркие заголовки в СМИ.
И предположу, что массовыми всё же станут более централизованные системы. (И судя по дрифту от POW к POS/POA авторы решений тоже это понимают).
Если, конечно, не найдется принципиально нового решения, которое сбалансировало бы интересы всех участников более «экономным» способом.
hlogeon
Мне в практике достаточно часто попадаются огромные, монолитные контракты, деплой которых не помещается в блок. Это я просто к возможным темам)
XTX Автор
На прошлой неделе Alex Beregszaszi упомянул сжатие в контексте экономии газа, но для больших контрактов это может быть одним из решений github.com/ethereum/solidity/issues/3432
Спасибо за идею темы! Надо будет поискать подобные контракты. А начать можно с построения графа связей между контрактами, если этого уже кто-нибудь не сделал.