

Около месяца назад Google сервис Colaboratory, предоставляющий доступ к Jupyter ноутбукам, включил возможность бесплатно использовать GPU Tesla K80 с 13 Гб видеопамяти на борту. Если до сих пор единственным препятствием для погружения в мир нейросетей могло быть отсутствие доступа к GPU, теперь Вы можете смело сказать, “Держись Deep Learning, я иду!”.
Я попробовал использовать Colaboratory для работы над kaggle задачами. Мне больше всего не хватало возможности удобно сохранять натренированные tensorflow модели и использовать tensorboard. В данном посте, я хочу поделиться опытом и рассказать, как эти возможности добавить в colab. А напоследок покажу, как можно получить доступ к контейнеру по ssh и пользоваться привычными удобными инструментами bash, screen, rsync.
Для начала, почему это интересно
Наличие GPU ускорителя является критическим фактором для скорости обучения deep learning моделей. Без GPU обучение нейросети займет многие часы/дни и не позволит полноценно экспериментировать со структурой сети. Объем видеопамяти так же важен. Больше памяти — можно установить больший размер батча и использовать более сложные модели. На сегодняшний день 13G это хороший объем, если захотите получить примерно столько же у себя на столе, придется покупать GPU уровня GTX 1080 Ti.
Что такое Colaboratory
Это форк популярной среды Jupyter notebook. Ваши ноутбуки доступны через google drive в .ipynb формате и вы можете их запускать у себя локально. Поддерживается Python 2.7 и 3.6. Код исполняется на сервере в docker контейнере. Можно закрыть браузер, все процессы на сервере продолжат работать, позже можно подключиться к серверу снова. Docker контейнер выдается вам во временное пользование на 12 часов. Вы имеете root привилегии, и можете устанавливать и запускать любые программы внутри контейнера. Colaboratory (далее colab) также поддерживает совместную работу над ноутбуком, по типу google docs. Это отличная платформа для начала изучения deep learning, machine learning. Многие бесплатные курсы, например Открытый курс машинного обучения используют Jupyter notebook формат для своих учебных материалов.
Запускаем обучение
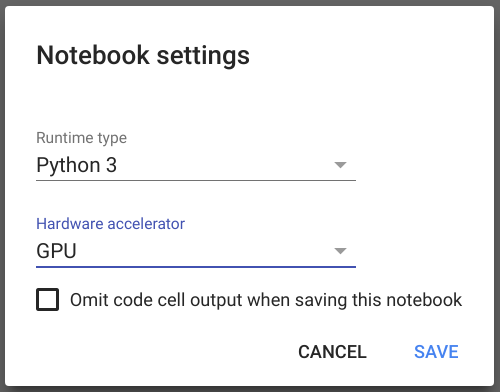
Для создания нового ноутбука перейдите по ссылке. После успешного логина и создания ноутбука в меню выберете Runtime -> Change Runtime Type, в открывшемся диалоге в опции Hardware acceleration установите GPU, далее save.
После этого можно удостовериться, что tensorflow использует GPU. Просто скопируйте этот код в первую ячейку ноутбука и выполните, нажав shift+Enter:
import tensorflow as tf
tf.test.gpu_device_name()Теперь попробуем запустить простую модель tensorflow из примеров, для этого клонируем github репозиторий и запустим скрипт.
! git clone https://github.com/tensorflow/models.git
%run models/samples/core/get_started/premade_estimator.py После выполнения это команды мы увидим как сеть обучиться и сделает первые предсказания. Существует достаточно много материалов описывающих возможности Jupyter, поэтому я не буду подробно на этом останавливаться.
Монтируем google drive
Всё работает отлично, но через 12 часов виртуальную машину у вас заберут и все данные внутри контейнера будут потеряны. Хорошо бы позаботиться о постоянном хранилище. В colab есть примеры как использовать импортировать данные из cloud storage, google sheets. Это предполагает явный вызов операции копирования, а мне бы хотелось иметь возможность примонтировать внешний диск к файловой системе внутри контейнера, тут на помощь приходит google drive и FUSE драйвер для него. Подключить google drive можно выполнив код, по рецепту из статьи
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}После этого вам будет доступна директория куда вы можете записывать данные, без опаски их потерять после остановки контейнера. Вы можете определить параметр model_dir в конфигурации модели, tensorflow будет автоматически восстанавливать состояние модели из последнего checkpoint. Таким образом, вы можете продолжить обучение модели или запустить inference в любой момент.
Tensorboard
Я люблю использовать tensorboard в процессе экспериментов со структурой и параметрами нейросети. Если вы хотите узнать больше об этом инструменте рекомендую посмотреть презентацию. Поэтому, я искал возможность, как можно запустить tensorboard в colab. Ответ нашелся на SO. Через переменную LOG_DIR вам необходимо задать путь к model_dir из конфигурации tensorflow модели, либо к корневой директории внутри которой содержиться множество сохраненных моделей.
LOG_DIR = '/tmp'
get_ipython().system_raw(
'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &'
.format(LOG_DIR)
)
! wget -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
! unzip -o ngrok-stable-linux-amd64.zip
get_ipython().system_raw('./ngrok http 6006 &')
! curl -s http://localhost:4040/api/tunnels | python3 -c "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"После выполнения в последней строчке будет выведен URL, открыв который в браузере, мы увидим привычный нам tensorboard.
Доступ по ssh
Если у вас есть опыт использования Jupyter. То вы вероятно знаете, что выйдя за рамки игрушечных моделей, некоторые преимущества формата jupyter ноутбука становятся его недостатками. Ноутбук превращается в сложно читаемую кашу, результаты вычислений становится трудно воспроизвести. Jupyter ноутбуки остаются отличным инструментом для обучения, визуализации и небольших экспериментов. Однако, в средних по величине проектах, я предпочитаю структурировать python код классическим способом, используя разбиение на модули и классы. Работать на серьезным проектом удобнее в PyCharm / Vim и т.д… Постоянно синхронизировать код через репозиторий, запускать .py файлы не очень удобно через jupyter, использовать для этого привычные инструменты намного комфортнее.
Основываясь на примере запуска tensorboard, я написал код, который открывает ssh туннель в контейнер.
#Generate root password
import secrets, string
password = ''.join(secrets.choice(string.ascii_letters + string.digits) for i in range(20))
#Download ngrok
! wget -q -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
! unzip -qq -n ngrok-stable-linux-amd64.zip
#Setup sshd
! apt-get install -qq -o=Dpkg::Use-Pty=0 openssh-server pwgen > /dev/null
#Set root password
! echo root:$password | chpasswd
! mkdir -p /var/run/sshd
! echo "PermitRootLogin yes" >> /etc/ssh/sshd_config
! echo "PasswordAuthentication yes" >> /etc/ssh/sshd_config
! echo "LD_LIBRARY_PATH=/usr/lib64-nvidia" >> /root/.bashrc
! echo "export LD_LIBRARY_PATH" >> /root/.bashrc
#Run sshd
get_ipython().system_raw('/usr/sbin/sshd -D &')
#Ask token
print("Copy authtoken from https://dashboard.ngrok.com/auth")
import getpass
authtoken = getpass.getpass()
#Create tunnel
get_ipython().system_raw('./ngrok authtoken $authtoken && ./ngrok tcp 22 &')
#Print root password
print("Root password: {}".format(password))
#Get public address
! curl -s http://localhost:4040/api/tunnels | python3 -c "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"Для создания TCP туннеля вам потребуется создать аккаунт на сайте ngrok.com и скопировать authtoken оттуда. В бесплатной версии ngrok два тунеля не поддерживаются, поэтому если http тунель на tensorboard всё еще работает, вам надо его отключить, можно это сделать например перезапустив контейнер, нажав Ctrl+M затем ".".
После запуска тунеля вы увидите в ноутбуке, примерно следующее
Root password: 3KTyBVjtD6zPZX4Helkj
tcp://0.tcp.ngrok.io:15223Теперь с рабочего компьютера вы сможете залогиниться в colab контейнер используя любой ssh клиент и в данном примере хост 0.tcp.ngrok.io, порт 15223. Пример для linux
ssh root@0.tcp.ngrok.io -p15223Бонус для каглеров, для импортирования данных из kaggle и отсылки submit прямо из colaboratory вы можете использовать официальный API клиент, устанавливается командой pip install kaggle.
Комментарии (24)

Imp5
01.02.2018 20:29-2«к Jupyter ноутбукам», «над kaggle задачами», «в docker контейнере» — вот откуда этот порядок слов?
«13G видеопамяти» — может имелось в виду «13<пробел>GB видеопамяти» или «13<пробел>ГБ видеопамяти»?
«tcp тунеля» — тут даже браузер подчёркивает красной волнистой линией.
И полное игнорирование заглавных букв в названиях сервисов.
В личку писать не буду, всё равно почти никто не исправляет.
Goron_Dekar
01.02.2018 21:36порядок слов из документации.

flash_usb
02.02.2018 20:16+1Мы же не говорим «в Samsung телевизорах», «в Metallica альбомах», «в Ford автомобилях». Или уже говорим? :)
AlexAV1000
02.02.2018 13:34Купите себе б/у Nvidia TESLA M2090 за 10 т.р. на авите или еще где и экспериментируйте прямо на своем компе.
de1m
02.02.2018 15:01и во сколько раз она медленнее? Это я просто думаю, что может стоит купить.
AlexAV1000
02.02.2018 17:08Это если вам нужен «вычислитель» с двойной точностью. Поиграть в в бегалки-стрелялки на ней нельзя. :)
ymuv
02.02.2018 16:58По количеству cuda ядер относительно недорогие 1050ti и 1060 и частотах выигрывают в старых Tesla. Искал сравнения, не нашел.
AlexAV1000
02.02.2018 17:05По ядрам сравнения некорректные, 1050ti в вычислениях с двойной точностью — 83 GFlops, 1080ti — 250 GFlops, Tesla M2090 — 667 Gflops. В тесле 6ГБ оперативки с ECC. Тесла — чистый вычислитель или в CUDA или OpenCL.
sergarcada
02.02.2018 13:42Николаса Кейджа можно будет вставить в фильм про супермена на такой машине?
apiksDen
02.02.2018 16:48Идите дальше, Николас Кейдж как раз не был монтажом, просто фильм не стали снимать. Может ли нейросеть сама снять фильм?
sergarcada
02.02.2018 17:30Николас Кейдж как раз не был монтажом
да, но в итоге его в фильм не взяли, а посмотреть хочется.
Но вообще меня интересует такая возможность в принципе. Можно ли использовать предоставленные мощности для таких целей.boblenin
02.02.2018 21:56Не стоит смотреть. Тем более с кейджем. Он умудряется даже призрачного гонщика сделать скучным, а тут изначально персонаж без недостатков.

dbagaev
03.02.2018 00:23Спасибо огромное за статью, у меня как раз закончились мощности на домашнем компьютере, а эти машины считают в раз десять быстрее.
У меня возник вопрос. Я когда пытаюсь показать картинку с помощью matplotlib, получаю вот такую ошибку, вы сталкивались с чем-то подобным?
AttributeError: 'numpy.ndarray' object has no attribute 'mask'
У меня стоит старый matplotlib 1.5.3 и кастомный numpy-1.13.3+mkl, если я обновляюсь к последним версиям из pip-репозитория, то и дома получаю эту ошибку. Как только возвращаюсь к исходным — все в порядке…



htdt
04.02.2018 17:23Поигрался, отличное начинание! Продукт пока что сырой, kernel часто падает и зависает. Для простых экспериментов норм, но не больше.
FreeBa
За 12 часов ничему серьезному сеть научить не получится, даже на такой мощной тесле. Больше маркетинга, чем халявы.
Dumbris Автор
Можно снова запустить, тот же самый ноутбук, подмонтировать google drive и продолжить обучение из последнего checkpointa.
slovak
Этот процесс можно даже автоматизировать простым скриптом по таймеру. Думаю уже кто-то сделал и скоро выложит. Правда лавочку могут и прикрыть.
S_o_T
А учитывая возможность майнить… Точно прикроют :)
Tihon_V
Или научатся эвристическим анализом распознавать большую часть ядер CUDA/OpenCL предназначенных для майнинга. Думаю, что Google — это по силам :)
alhel
Как они будут боротся с майнерами?