
Около года назад я заприметил интереснейшую и увлекательную серию лекций Эдди Мартина, который потрясающе доходчиво, благодаря своей истории и примерам из реальной жизни, а также колоссальному опыту в обучении, позволяет приобрести понимание довольно сложных технологий.

Мы продолжаем цикл из 27 статей на основе его лекций:
01/02: «Понимание модели OSI» Часть 1 / Часть 2
03: «Понимание архитектуры Cisco»
04/05: «Основы коммутации или свитчей» Часть 1 / Часть 2
06: «Свитчи от Cisco»
07: «Область использования сетевых коммутаторов, ценность свитчей Cisco»
08/09: «Основы беспроводной локальной сети» Часть 1 / Часть 2
10: «Продукция в сфере беспроводных локальных сетей»
11: «Ценность беспроводных локальных сетей Cisco»
12: «Основы маршрутизации»
13: «Строение роутеров, платформы маршрутизации от Cisco»
14: «Ценность роутеров Cisco»
15/16: «Основы дата-центров» Часть 1 / Часть 2
И вот шестнадцатая из них.
Что вы думаете о Cisco как о компании? Согласно бизнес-аналитике, наша компания относится к mid-teens — предприятиям с ростом около 15%. Ранее Cisco росла ежегодно на 40%. Я вспоминаю Национальный торговый конгресс, где было заявлено о таком росте, и это стало шоком для многих присутствующих. Однако удерживать такие темпы роста было просто, когда мы были небольшой компанией. Но чем больше мы становимся, тем сложней это делать. Мы захватили 50% рынка свитчей и роутеров, и далее этот сегмент рынка не может расти так стремительно, как это нам нужно. Значит, мы должны стимулировать его рост новой продукцией, формировать потребности рынка в нашей новой продукции.
Я нарисую вертикальную ось – доход, и горизонтальную ось – долю рынка. Мы, как ведущие игроки рынка, находимся вот здесь, наверху.

Однако продажи свитчей не растут более чем на 12% в год. Мы не можем изменить своё место в секторе продажи достаточно стремительно. Значит, мы должны поднимать свои позиции в другой области, области продвинутых технологий! Я обозначу их на графике кругом АТ. Это для Cisco означает миллиарды долларов.
Что же сюда входит? Беспроводные сети WLAN, они обеспечивают нам 10-12-14% от ежегодного оборота в 40 млрд долларов, но только за счёт них обеспечить рост сложно. Мы можем расти сверх нормы только тогда, когда растёт рынок, но если рынок не растёт… Далее следует безопасность, или защита информации, затем видео. Все эти вещи поддерживают наш верхний «шарик», наше положение на рынке, но объём их внедрений не может быть бесконечным.
Поэтому мы должны запустить новый «шарик». Им является MDS 9500.

Но пока мы не создали новый продукт, наш шарик было не запустить. Для этого мы создадим SAN – Storage Area Networks, сети хранения данных.
Мы вложили в них 60-80 миллионов долларов, и они создали рынок сбыта с объёмом примерно 400 миллионов долларов. Мы запускаем на рынок новые технологии, и сейчас дата-центры являются тем, что помогает сохранять наше лидирующее положение. Мы практически каждый месяц придумываем новый продукт – Nexus 9000, Nexus 5000, Nexus 2000, или даже Nexus 1000. И некоторые из них даже не свитчи, а программное обеспечение. Это тот «шарик», который наращивает наш бизнес.
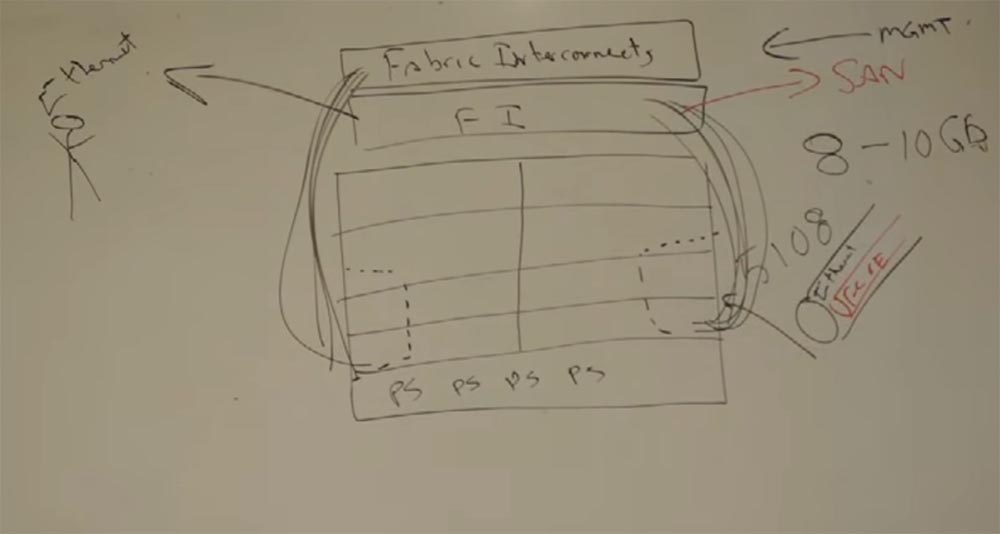
Мы говорим о том, что нужно захватить другой рынок, который создаст для нас другие возможности. Это будут другие типы серверов для сетей – BLADE-серверы. Чем они отличаются от независимых или серверов с виртуализацией? Типовое шасси блейд-сервера имеет 2 блока питания PS для избыточности, модуль управления серверами MGMT для управления серверами внутри, модуль Ethernet для подключения, Cisco по сути продала порты свитча Catalyst IBM, HP и Dell и всем остальным, чтоб они могли выпустить данное решение. Также тут есть хост-адаптер шины HBA и сами «лезвия» серверов – их может быть от 1 до 12 штук. Ценность этого всего в том, что можно получить больше серверов в перерасчёте на количество занимаемых юнитов в шкафу, чем при использовании независимых серверов. Каждое из этих «лезвий» содержит в себе процессор и память RAM и имеют общий источник питания и общий Ethernet модуль. То есть это шасси.

И всё было замечательно, до момента, пока не появилась виртуализация. VMware, о которой мы с Вами говорили в предыдущей лекции. Оказалось, что у блейд-серверов есть один серьезный недостаток. Это нехватка RAM. Предположим, что каждый процессор имеет по 4 ядра, и одно «лезвие» обрабатывают приложение, потребляющие память до 96 ГБ. Её вполне достаточно для работы одного приложения. Но когда сюда пришла виртуализация, выяснилось, что одно приложение нуждается в 48 ГБ, другому требуется 24 ГБ, а третьему 32 ГБ. Всё, математика не сходится, мы не укладываемся в наши 96.
Cisco сказали: «Вот где есть возможность для нас! Мы вернёмся к нулю и построим „блейд“ сервер именно для виртуализации»! И мы это сделали, мы создали шасси серии В, что позволило нам выйти на рынок с объёмом оборота 37 миллиарда долларов. Нам важно добавить новый «шарик» — USC. Если мы через несколько лет будем иметь 10% долю от этого, то это уже будет 3,7 миллиарда долларов.
Сейчас я подробно покажу Вам, что мы сделали. Кстати, большинство из нас разработало именно в этом кампусе компании больше, чем Вы можете себе представить. Итак, нам надо много RAM в наших «лезвиях». Задумайтесь об этом: мы имеем один модуль управления на 12 серверов. Если мы сможем сделать лучше — это также будет хорошо. Cisco вышла на рынок с большим металлическим шасси 5108 – это такой шкаф с коннекторами. Внутри этого шасси мы разместили 8 серверов, именно потому модель называется 5108, максимум 8 слотов здесь, размером с половину ширины, а внизу поместили несколько блоков питания – я нарисую 4 штуки. А самые важные элементы мы поместили снаружи шасси – вот эти два блока оптоволоконных коннекторов FI, Fabric Interconnect. Внутри них размещается платформа управления MGMT, Management Platform, собственная платформа для управления. Сзади серверов размещены порты для соединения с FI, 16 портов по 10 гигабит. Таким образом у нас получилось 160 гигабит коннективности в одном шасси. И внутри каждого коннектора был Ethernet, который необходим был для внешних пользователей, а также Fibre Channel over Ethernet, который подключался к платформе управления MP, откуда мог обмениваться данными с SAN, сетью хранилища данных. Таким образом мы использовали унифицированное подключение, один кабель обеспечивал всё это.
Как я уже говорил, проблема блейд-серверов заключалась в нехватке памяти при обработке многозадачных процессов. Cisco задалась вопросом, можно ли решить эту проблему с помощью новых интегральных схем ASIC и обратились с этим вопросом к Intel.
Каким образом процессор пользуется памятью? Он получает её через контактные выводы DIMM. Cisco задумалась, как можно «перехитрить» этот процесс. Что имеется в виду под словом «перехитрить»?
Что будет, если между процессором и памятью встроить ASIC так, чтобы процессор видел 4 вывода, а в чип приходило 16? Мы предоставим процессору 384 ГБ памяти, если встроим сюда этот чип! То есть вместо 96 ГБ процессор сможет оперировать вчетверо большей памятью! Intel сказали, что это круто и они начнут поддерживать наши чипы.
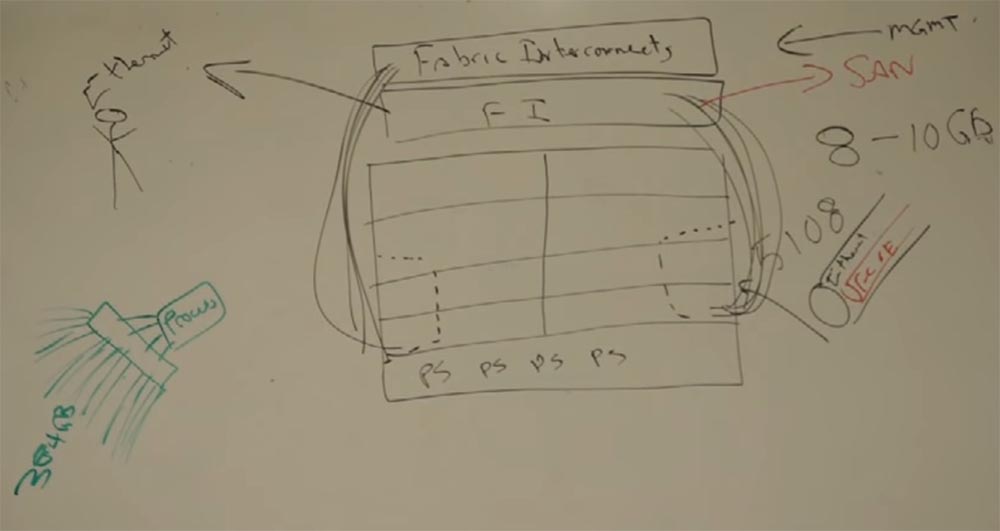
Это называется технологией расширенной памяти EMT (extended memory technology). Это позволяет виртуализировать больше приложений на наших «лезвиях». Это была краткосрочная победа, но пользователи быстро поняли преимущества этого решения и начали работать с нами. По крайней мере рассматривали нас.
Но у нас были и другие преимущества, которые, думаю, были более заманчивые. Помните, я говорил Вам, что мы сотрудничали с компанией VMware, фактически владели их частью, присматривались к их технологиям в их лабораториях. И если я помещаю множество серверы в наше шасси, мне нужны множество сетевых карт, множество VLAN и чтоб мне не ставить целую гроздь этого лучше применить программное решение, которое будет способно обеспечить QoS и всё остальное. Так вот, VMware может создать многозадачный программный свитч со всеми нужными нам функциями на уровне гипервизора, обеспечивающими процесс обмена данными. Но VMware решили, что это слишком сложно для них, и тогда Cisco сказала: «Отдайте это нам, мы специалисты по свитчам, мы знаем, как это сделать»!
Мы вставили в наши серверы программное обеспечение, позволяющее создать виртуальные устройства внутри шасси. Мы назвали его программным свитчем Nexus 1000V. Далее мы решили, что если модуль управления может управлять одним шасси, он сможет делать это с несколькими. Мы разместили внизу ещё шасси с аналогичным содержимым и подключили его к MGMT. Таким образом, можно управлять сразу двадцатью шасси!
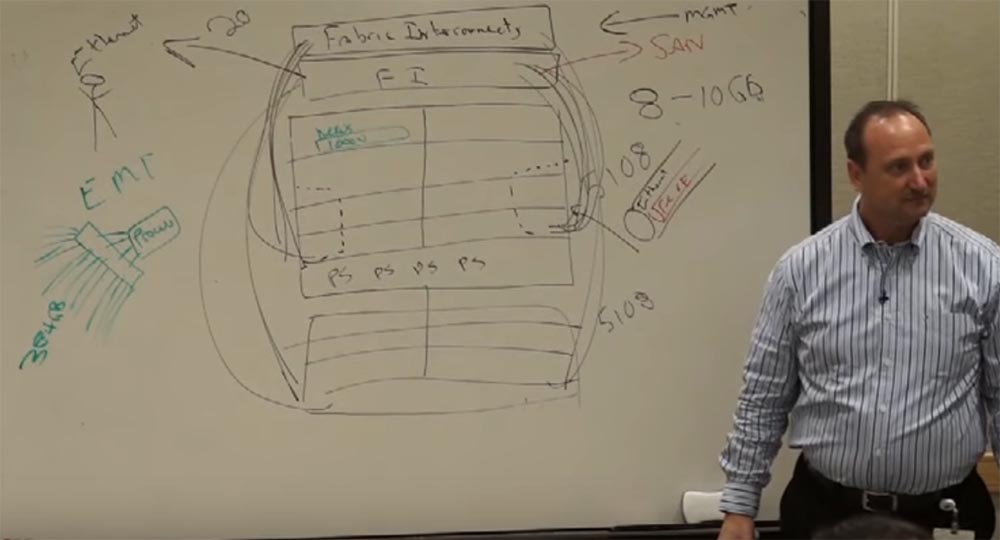
Умножаем 20 на 8 и получаем 160 серверов против 12 серверов, которые могут быть в одном блейд-свитче. Клиентам это тоже понравилось – меньше управляющих интерфейсов, проще управление.
Далее Cisco задумалось над таким вопросом: «Если ты хочешь стать лидером на танцплощадке, лучшим танцором, то ты не должен пускать на эту площадку других танцоров»! Знаете почему VMware выбились в лидеры организации дата-центров? Потому что они лучше нас знали потребности клиентов, все их приложения, мощные сети, необходимые для их работы, и так далее. Фактически мы стали для них подрядчиками, потому что разрабатывали свои устройства для их нужд.
Чтобы исправить ситуацию, Cisco решили разместить внутри нашего управляющего устройства MGMT, Server Profile, который бы позволил управлять серверами, но имел бы 3 определённых секции. В первой из них находятся IT организации со своими MAC-адресами, IP адресами, VLAN, весь софт, который требуется для работы сетевых приложений. То есть, всё, что требуется IT группе клиентов, находится в этом программном обеспечении. Во втором расположены все приложения, которыми пользуются пользователи SAN-группы, а в третьем находятся приложения клиентов, то есть группа пользователей APP.
То есть в нашем ПО имеется 62 разных характеристики и 3 независимых платформы управления. И всё это находится в одном программном модуле, который называется Server Profile, или профиль сервера. Эту программу для серверов мы можем поместить туда, где она нужна, в любом месте. И это тоже понравилось клиентам!
Это означает, что если в одном из серверов нашего шасси работает виртуальная машина, я могу переместить её в любое из 20 шасси, когда захочу и каким угодно образом! И кто нас натолкнул на эту идею? VMware! Они вынудили нас сделать это.
Представьте, что каждый день с 12 ночи до 6 часов утра мы запускаем на сервере приложение, которое использует 2-х ядерный процессор и 24 ГБ памяти. Но после 6 утра, в 8 часов, множество пользователей приходят на работу, задействуют это приложение для своих потребностей, утилизация сервера резко увеличивается, и ему начинает не хватать процессорной мощности и памяти. Что тогда происходит? Платформа управления перемещает это приложение на другой сервер, где в это время свободны 8 ядер и 64 ГБ памяти. Конечно, это очень понравилось нашим клиентам!

Уникальность решения Cisco заключается в том, что мы разработали проект для VMware, то есть скомбинировали «железо» и программы наилучшим образом и воплотили это всё в одном конструктивном решении. И это решение под названием Management Interface является собственностью нашей компании.
Таким образом, если какое-то предприятие в городе или компания, не входящая в число наших постоянных клиентов, будет нуждаться в дополнительных вычислительных мощностях для своих приложений, мы можем предоставить им эту возможность через нашу сеть в течение нескольких секунд.
Если другая компания, например HP, хочет воспользоваться нашими мощностями, но у нё другие коннекторы, адаптеры и прочее, мы просто можем перепрограммировать профиль сервера под их ПО.
Я так объясняю клиентам наши преимущества: «мы предлагаем инновационный подход к оборудованию и софту, который избавляет вас от необходимости периодически наращивать физические мощности Ваших серверов, мы помогаем Вам существенно экономить на развитии сети».
У нас получается та же ситуация, которая была в начале развития IP-телефонии. Компания Nortel Anivia имела все возможности для её развития ещё до того, как Cisco занялись этим, почему же она этого не сделала? Потому что если бы она захотела захватить рынок, то вынуждена была бы тащить туда за собой всё традиционное оборудование.
Как перехватила этот рынок Cisco? В 1999 году она создала программное обеспечение, которое позволило использовать их технологию совершенно по-новому! Они разрабатывали проект IP-телефонии для старой физической архитектуры, а мы разработали проект под новые виртуальные решения. Мы изменили правила игры, стёрли начисто слайд, на котором была изображена старая громоздкая архитектура, ориентированная на «железо». Подумайте, на какой стороне листа бумаги легче рисовать – на том, что заполнен текстом, или на обратной, чистой стороне листа? Наши инновационные решения не пересекались никоим образом с инновациями HP или других игроков рынка, мы шли исключительно собственным путём.
И мы продолжаем им идти. Не думайте, что мы завершили разработку технологии EMT – мы затратили на неё 6-8 месяцев и продолжаем над ней работать! К кому Вы обратитесь на рынке – к тому, кто просто выкачивает из Вас деньги или к тому, кто предлагаем Вам инновации? Мы выходим на рынок, когда наши инновации уже созрели.
Но Cisco хочет делать ещё больше! Помните Nexus? Вернёмся снова к нашим сетям. Как поступает клиент, когда у него есть несколько дата-центров? Он хочет их объединить, чтобы облегчить себе их использование. Предположим, один дата-центр, где расположены приложения, находится в Лос-Анжелесе, а другой в Фениксе, штат Аризона, и там имеется оборудование. Мы хотим перенести сервер, который имеет IP 10.10.10.6, из Лос-Анжелеса в Феникс так, чтобы он имел тот же IP адрес — 10.10.10.6. Зачем нам это нужно? Потому что рядом с этим сервером в первом дата-центре находится сервер 10.10.10.7, который обменивается с 10.10.10.6 приложениями по внутренней сети, а мы не хотим разорвать их связь. Как Cisco решило эту проблему?
Мы подсоединили эти два сервера к свитчу серии 2000, этот свитч к свитчу серии 5000, а его уже к свитчу серии 7000. Мы создали совершенно новую технологию, которую назвали OTV (overlay to transfer transport virtualization) – сетевую оверлейную технологию для дата-центров. Она транспортирует виртуализацию так, что мы можем перенести сервер в 10.10.10.6 другой дата-центр. И когда он хочет обратиться к серверу 10.10.10.7, посылает broadcast, его данные инкапсулируются и перемещаются по сети в Лос-Анжелес таким образом, что 10.10.10.7 думает, что его собрат 10.10.10.6 до сих пор находится рядом с ним!

Таким образом, мы можем объединить 16 дата-центров так, что они будут выглядеть как один, и всё оборудование внутри будет «думать», что находится в одном, а не в разных местах.

Представьте, как эта идея понравилась клиентам! Мы просто размещаем массивы в разных местах и пересылаем между ними данные. В каком ещё случае это может понадобиться клиентам?
Вспомните ураган «Сэнди», который обрушился на Нью-Джерси. Вам понадобился дата-центр в середине страны, за пределами побережья, со всеми его IP-адресами и так далее. И мы переносим его из Нью-Джерси туда, куда Вам требуется. Я не буду ждать, пока ураган разрушит мой дата-центр, но я знаю прогноз, поэтому перенесите половину моих мощностей в безопасное место, а дальше я посмотрю, как будет развиваться ситуация. И если она будет ухудшаться, я попрошу Вас перенести оттуда и вторую половину.
Мы можем использовать такую часть мощности, которая понадобится для обработки конкретного объёма приложений, Server Profile это обеспечит. При этом я не знаю подробно о том, как это работает, я не компетентен в этом, лучше спросите подробности у своего PSS. Как говорил Клинт Иствуд: «Мужчина должен знать свои ограничения». И Cisco затратила на эту технологию сравнительно много денег в короткий промежуток времени, так как она быстро развивалась, мы предложили её рынку в 2009 году. В итоге у нас есть шасси серии В и серверы серии С. Рассмотрим, что такое серверы серии С.
Это отдельно стоящий, автономный сервер, построенный для виртуализации. И опять же, можем ли мы управлять им, посредством инерконнекта с фабрикой? Да, так же как мы могли это сделать с блейд-сервером. Таким образом мы можем управлять, как виртуальными серверами, находящимися на независимых серверах, так и блейдами, и всё по одному интерфейсу. Я нарисую несколько блейд-серверов с оптоволоконным соединениями, несколько шкафов с блейд-серверами, связанными друг с другом через фабрику. Итак, у нас есть несколько стоек серверов, которые управляются фабрикой, способной управлять до 20 шасси. Большая плотность серверов здесь. Тут применяется расширитель фабрики FEX (fabric extender) 2200.

Я уже показывал Вам шасси, в котором расположены модули сетевых карт и супервизоры. А в нашем шасси ещё имеется по 8 серверов. Итак, в первой группе стоек мы устанавливаем оптико-волоконный расширитель соединений FEX серии 2200 для подключения наших серверов-блейдов. Рядом мы создали стойку с серверами, каждый из которых является автономным, и тоже добавили туда FEX 2200. Это называется TOR, Top of Rack Switches. Их много. Фактически они — те же «лезвия», которым нужен супервизор.

Рядом мы установим ещё один шкаф с серверами и TOR FEX 2200. Для того, чтобы обеспечить все три секции шкафов управлением, мы устанавливаем рядом 4-й шкаф, в котором устанавливаем супервизор 5500. Три имеющиеся шкафа с серверами и свитчами мы соединяем с этим супервизором. Это наш мозг.

Он позволяет управлять 16 такими шкафами. Если нам нужно больше, вся система из шкафов, объединённых группами по 4 секции, подсоединяется к супервизору большей мощности серии 7000. Он может управлять 20 или 24 группами. Это позволяет управлять большим количеством соединений с помощью одного интеллектуального устройства. Сами 5500 с помощью оптоволоконных коннекторов FCP соединены с MDS, что ещё больше расширяет наши возможности. Сверху я нарисую свитчи серии Nexus 7000, и теперь мы можем передавать на них 40 Гбит / с Ethernet. Эти свитчи серии 2200 не являются достаточно разумными, поэтому нуждаются в управлении интеллектуального устройства. Таким образом, мы можем обеспечить любую нужную пропускную способность для наших серверов.

Если нужно создать традиционное SAN, мы во второй и третий шкаф должны установить оптоволоконные свитчи, так как мы не будем иметь дела с Ethernet. Замечу, что существует множество способов построения сетевой архитектуры, потому дата-центры не похожи друг на друга.

Cisco строит отношения. Сейчас мы создали «треугольник» услуг, мы создали организацию VCE, которая объединила Cisco, EMC и VMware. Теперь EMC могут продавать дата-центрам свои «коробки», в которых находится их собственное аппаратное и программное обеспечение для хранилищ, а мы интегрируем их продукт в архитектуру дата-центра, придавая ему способность виртуализации серверов и свитчей. Мы называем эту технологию VBlock. Мы получили связь с NetApp, мы создали FlexPod. FlexPod — платформа для построения для дата-центров, готовые архитектурные решения.
Можно сказать, что мы продаём виртуализацию. В другом случае провайдеры со своими независимыми серверами не смогли бы даже думать о том, чтоб предлагать облачные решения клиентам. Они могут продавать всё больше и больше физических серверов, за счёт виртуализации. Это создаёт возможность вплотную подойти к облачной технологии хранения и обработки данных. Завтра мы поговорим о HCS (Hosting Colaboration Solutions) – мы рассмотрим сотрудничество с компаниями, которые не являются поставщиками традиционных услуг, таких как AT&T, IBM, British Telecom.
Вернёмся к нашим шасси серии 7000. Они снабжены сетевыми картами двух разных типов, обеспечивающими приём и передачу данных: F карта на вход, M карта работает на выход. Операционная система Nexus немного отличается от той, что используется в серии 2200. Она была выпущена в декабре 2002 года специально для свитчей, работающих с оптоволоконной связью, MDS 9500 к примеру, который стал свитчем №1 класса «директор» в мире. Отличие заключается в iOS этих серий, но обе основаны на Linux. И вторая помогла обеспечить не только аппаратную избыточность, но и программную. Мы одновременно разрабатываем новое «железо» и новый софт, потому что для работы независимых сервисов нужно своё программное обеспечение. Так, когда Nexus осуществляет передачу данных, он использует BGP, при этом работа на вход не останавливается, потому что здесь установлена вторая сетевая карта. Linux позволяет мне программно перезагрузить сервис. Если это не даёт эффекта, я всегда имею возможность использовать второй аппаратный интерфейс. Так у нас появляется две возможности устранить неполадки — программно или аппаратно. Не все наши iOS базируются на Linux, но все новые семейства Catalyst 6500 и 4500 используют ядро Linux.
Мы обеспечиваем нашу iOS возможностью работать на серверах с ОС типа Linux, поэтому всё наше оборудование совместимо с любыми серверами. Все серии наших свитчей управляются одинаковыми командами, поэтому содержимое командной строки сейчас ничем не отличается от того, что Вы набирали в 1990-х. Лишь внутренний интерфейс различается. И если инженеры из дата-центров привыкли к графическому интерфейсу GUI, они могут его использовать, либо могут использовать командную строку, как я. Основная причина использования ядра Linux заключается в том, что я могу перезапускать сервисы независимо, и если у меня есть проблема с BGP, я просто запущу это на другом сетевом интерфейсе. Вот почему мы не используем Basic или COBOL более, так как Nexus – это ОС следующего поколения. Отмечу, что порт 10 гигабит в серии Nexus стоит дешевле, чем порт такой же пропускной способности в серии Catalyst 6500, тем не менее, если Nexus 7000 cлишком большой для Ваших нужд, то Вы можете использовать Catalyst 6500. И опять же, мы используем Linux, потому что это очень гибкая операционная система для нас, особенно в случаях, когда мы хотим использовать многопроцессорные решения.
Продолжение:
Тренинг FastTrack. «Сетевые основы». «Оборудование для дата-центров». Эдди Мартин. Декабрь, 2012
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Мы продолжаем цикл из 27 статей на основе его лекций:
01/02: «Понимание модели OSI» Часть 1 / Часть 2
03: «Понимание архитектуры Cisco»
04/05: «Основы коммутации или свитчей» Часть 1 / Часть 2
06: «Свитчи от Cisco»
07: «Область использования сетевых коммутаторов, ценность свитчей Cisco»
08/09: «Основы беспроводной локальной сети» Часть 1 / Часть 2
10: «Продукция в сфере беспроводных локальных сетей»
11: «Ценность беспроводных локальных сетей Cisco»
12: «Основы маршрутизации»
13: «Строение роутеров, платформы маршрутизации от Cisco»
14: «Ценность роутеров Cisco»
15/16: «Основы дата-центров» Часть 1 / Часть 2
И вот шестнадцатая из них.
Тренинг FastTrack. «Сетевые основы». «Основы дата-центров». Часть 2. Эдди Мартин. Декабрь, 2012
Что вы думаете о Cisco как о компании? Согласно бизнес-аналитике, наша компания относится к mid-teens — предприятиям с ростом около 15%. Ранее Cisco росла ежегодно на 40%. Я вспоминаю Национальный торговый конгресс, где было заявлено о таком росте, и это стало шоком для многих присутствующих. Однако удерживать такие темпы роста было просто, когда мы были небольшой компанией. Но чем больше мы становимся, тем сложней это делать. Мы захватили 50% рынка свитчей и роутеров, и далее этот сегмент рынка не может расти так стремительно, как это нам нужно. Значит, мы должны стимулировать его рост новой продукцией, формировать потребности рынка в нашей новой продукции.
Я нарисую вертикальную ось – доход, и горизонтальную ось – долю рынка. Мы, как ведущие игроки рынка, находимся вот здесь, наверху.
Однако продажи свитчей не растут более чем на 12% в год. Мы не можем изменить своё место в секторе продажи достаточно стремительно. Значит, мы должны поднимать свои позиции в другой области, области продвинутых технологий! Я обозначу их на графике кругом АТ. Это для Cisco означает миллиарды долларов.
Что же сюда входит? Беспроводные сети WLAN, они обеспечивают нам 10-12-14% от ежегодного оборота в 40 млрд долларов, но только за счёт них обеспечить рост сложно. Мы можем расти сверх нормы только тогда, когда растёт рынок, но если рынок не растёт… Далее следует безопасность, или защита информации, затем видео. Все эти вещи поддерживают наш верхний «шарик», наше положение на рынке, но объём их внедрений не может быть бесконечным.
Поэтому мы должны запустить новый «шарик». Им является MDS 9500.
Но пока мы не создали новый продукт, наш шарик было не запустить. Для этого мы создадим SAN – Storage Area Networks, сети хранения данных.
Мы вложили в них 60-80 миллионов долларов, и они создали рынок сбыта с объёмом примерно 400 миллионов долларов. Мы запускаем на рынок новые технологии, и сейчас дата-центры являются тем, что помогает сохранять наше лидирующее положение. Мы практически каждый месяц придумываем новый продукт – Nexus 9000, Nexus 5000, Nexus 2000, или даже Nexus 1000. И некоторые из них даже не свитчи, а программное обеспечение. Это тот «шарик», который наращивает наш бизнес.
Мы говорим о том, что нужно захватить другой рынок, который создаст для нас другие возможности. Это будут другие типы серверов для сетей – BLADE-серверы. Чем они отличаются от независимых или серверов с виртуализацией? Типовое шасси блейд-сервера имеет 2 блока питания PS для избыточности, модуль управления серверами MGMT для управления серверами внутри, модуль Ethernet для подключения, Cisco по сути продала порты свитча Catalyst IBM, HP и Dell и всем остальным, чтоб они могли выпустить данное решение. Также тут есть хост-адаптер шины HBA и сами «лезвия» серверов – их может быть от 1 до 12 штук. Ценность этого всего в том, что можно получить больше серверов в перерасчёте на количество занимаемых юнитов в шкафу, чем при использовании независимых серверов. Каждое из этих «лезвий» содержит в себе процессор и память RAM и имеют общий источник питания и общий Ethernet модуль. То есть это шасси.
И всё было замечательно, до момента, пока не появилась виртуализация. VMware, о которой мы с Вами говорили в предыдущей лекции. Оказалось, что у блейд-серверов есть один серьезный недостаток. Это нехватка RAM. Предположим, что каждый процессор имеет по 4 ядра, и одно «лезвие» обрабатывают приложение, потребляющие память до 96 ГБ. Её вполне достаточно для работы одного приложения. Но когда сюда пришла виртуализация, выяснилось, что одно приложение нуждается в 48 ГБ, другому требуется 24 ГБ, а третьему 32 ГБ. Всё, математика не сходится, мы не укладываемся в наши 96.
Cisco сказали: «Вот где есть возможность для нас! Мы вернёмся к нулю и построим „блейд“ сервер именно для виртуализации»! И мы это сделали, мы создали шасси серии В, что позволило нам выйти на рынок с объёмом оборота 37 миллиарда долларов. Нам важно добавить новый «шарик» — USC. Если мы через несколько лет будем иметь 10% долю от этого, то это уже будет 3,7 миллиарда долларов.
Сейчас я подробно покажу Вам, что мы сделали. Кстати, большинство из нас разработало именно в этом кампусе компании больше, чем Вы можете себе представить. Итак, нам надо много RAM в наших «лезвиях». Задумайтесь об этом: мы имеем один модуль управления на 12 серверов. Если мы сможем сделать лучше — это также будет хорошо. Cisco вышла на рынок с большим металлическим шасси 5108 – это такой шкаф с коннекторами. Внутри этого шасси мы разместили 8 серверов, именно потому модель называется 5108, максимум 8 слотов здесь, размером с половину ширины, а внизу поместили несколько блоков питания – я нарисую 4 штуки. А самые важные элементы мы поместили снаружи шасси – вот эти два блока оптоволоконных коннекторов FI, Fabric Interconnect. Внутри них размещается платформа управления MGMT, Management Platform, собственная платформа для управления. Сзади серверов размещены порты для соединения с FI, 16 портов по 10 гигабит. Таким образом у нас получилось 160 гигабит коннективности в одном шасси. И внутри каждого коннектора был Ethernet, который необходим был для внешних пользователей, а также Fibre Channel over Ethernet, который подключался к платформе управления MP, откуда мог обмениваться данными с SAN, сетью хранилища данных. Таким образом мы использовали унифицированное подключение, один кабель обеспечивал всё это.
Как я уже говорил, проблема блейд-серверов заключалась в нехватке памяти при обработке многозадачных процессов. Cisco задалась вопросом, можно ли решить эту проблему с помощью новых интегральных схем ASIC и обратились с этим вопросом к Intel.
Каким образом процессор пользуется памятью? Он получает её через контактные выводы DIMM. Cisco задумалась, как можно «перехитрить» этот процесс. Что имеется в виду под словом «перехитрить»?
Что будет, если между процессором и памятью встроить ASIC так, чтобы процессор видел 4 вывода, а в чип приходило 16? Мы предоставим процессору 384 ГБ памяти, если встроим сюда этот чип! То есть вместо 96 ГБ процессор сможет оперировать вчетверо большей памятью! Intel сказали, что это круто и они начнут поддерживать наши чипы.
Это называется технологией расширенной памяти EMT (extended memory technology). Это позволяет виртуализировать больше приложений на наших «лезвиях». Это была краткосрочная победа, но пользователи быстро поняли преимущества этого решения и начали работать с нами. По крайней мере рассматривали нас.
Но у нас были и другие преимущества, которые, думаю, были более заманчивые. Помните, я говорил Вам, что мы сотрудничали с компанией VMware, фактически владели их частью, присматривались к их технологиям в их лабораториях. И если я помещаю множество серверы в наше шасси, мне нужны множество сетевых карт, множество VLAN и чтоб мне не ставить целую гроздь этого лучше применить программное решение, которое будет способно обеспечить QoS и всё остальное. Так вот, VMware может создать многозадачный программный свитч со всеми нужными нам функциями на уровне гипервизора, обеспечивающими процесс обмена данными. Но VMware решили, что это слишком сложно для них, и тогда Cisco сказала: «Отдайте это нам, мы специалисты по свитчам, мы знаем, как это сделать»!
Мы вставили в наши серверы программное обеспечение, позволяющее создать виртуальные устройства внутри шасси. Мы назвали его программным свитчем Nexus 1000V. Далее мы решили, что если модуль управления может управлять одним шасси, он сможет делать это с несколькими. Мы разместили внизу ещё шасси с аналогичным содержимым и подключили его к MGMT. Таким образом, можно управлять сразу двадцатью шасси!
Умножаем 20 на 8 и получаем 160 серверов против 12 серверов, которые могут быть в одном блейд-свитче. Клиентам это тоже понравилось – меньше управляющих интерфейсов, проще управление.
Далее Cisco задумалось над таким вопросом: «Если ты хочешь стать лидером на танцплощадке, лучшим танцором, то ты не должен пускать на эту площадку других танцоров»! Знаете почему VMware выбились в лидеры организации дата-центров? Потому что они лучше нас знали потребности клиентов, все их приложения, мощные сети, необходимые для их работы, и так далее. Фактически мы стали для них подрядчиками, потому что разрабатывали свои устройства для их нужд.
Чтобы исправить ситуацию, Cisco решили разместить внутри нашего управляющего устройства MGMT, Server Profile, который бы позволил управлять серверами, но имел бы 3 определённых секции. В первой из них находятся IT организации со своими MAC-адресами, IP адресами, VLAN, весь софт, который требуется для работы сетевых приложений. То есть, всё, что требуется IT группе клиентов, находится в этом программном обеспечении. Во втором расположены все приложения, которыми пользуются пользователи SAN-группы, а в третьем находятся приложения клиентов, то есть группа пользователей APP.
То есть в нашем ПО имеется 62 разных характеристики и 3 независимых платформы управления. И всё это находится в одном программном модуле, который называется Server Profile, или профиль сервера. Эту программу для серверов мы можем поместить туда, где она нужна, в любом месте. И это тоже понравилось клиентам!
Это означает, что если в одном из серверов нашего шасси работает виртуальная машина, я могу переместить её в любое из 20 шасси, когда захочу и каким угодно образом! И кто нас натолкнул на эту идею? VMware! Они вынудили нас сделать это.
Представьте, что каждый день с 12 ночи до 6 часов утра мы запускаем на сервере приложение, которое использует 2-х ядерный процессор и 24 ГБ памяти. Но после 6 утра, в 8 часов, множество пользователей приходят на работу, задействуют это приложение для своих потребностей, утилизация сервера резко увеличивается, и ему начинает не хватать процессорной мощности и памяти. Что тогда происходит? Платформа управления перемещает это приложение на другой сервер, где в это время свободны 8 ядер и 64 ГБ памяти. Конечно, это очень понравилось нашим клиентам!
Уникальность решения Cisco заключается в том, что мы разработали проект для VMware, то есть скомбинировали «железо» и программы наилучшим образом и воплотили это всё в одном конструктивном решении. И это решение под названием Management Interface является собственностью нашей компании.
Таким образом, если какое-то предприятие в городе или компания, не входящая в число наших постоянных клиентов, будет нуждаться в дополнительных вычислительных мощностях для своих приложений, мы можем предоставить им эту возможность через нашу сеть в течение нескольких секунд.
Если другая компания, например HP, хочет воспользоваться нашими мощностями, но у нё другие коннекторы, адаптеры и прочее, мы просто можем перепрограммировать профиль сервера под их ПО.
Я так объясняю клиентам наши преимущества: «мы предлагаем инновационный подход к оборудованию и софту, который избавляет вас от необходимости периодически наращивать физические мощности Ваших серверов, мы помогаем Вам существенно экономить на развитии сети».
У нас получается та же ситуация, которая была в начале развития IP-телефонии. Компания Nortel Anivia имела все возможности для её развития ещё до того, как Cisco занялись этим, почему же она этого не сделала? Потому что если бы она захотела захватить рынок, то вынуждена была бы тащить туда за собой всё традиционное оборудование.
Как перехватила этот рынок Cisco? В 1999 году она создала программное обеспечение, которое позволило использовать их технологию совершенно по-новому! Они разрабатывали проект IP-телефонии для старой физической архитектуры, а мы разработали проект под новые виртуальные решения. Мы изменили правила игры, стёрли начисто слайд, на котором была изображена старая громоздкая архитектура, ориентированная на «железо». Подумайте, на какой стороне листа бумаги легче рисовать – на том, что заполнен текстом, или на обратной, чистой стороне листа? Наши инновационные решения не пересекались никоим образом с инновациями HP или других игроков рынка, мы шли исключительно собственным путём.
И мы продолжаем им идти. Не думайте, что мы завершили разработку технологии EMT – мы затратили на неё 6-8 месяцев и продолжаем над ней работать! К кому Вы обратитесь на рынке – к тому, кто просто выкачивает из Вас деньги или к тому, кто предлагаем Вам инновации? Мы выходим на рынок, когда наши инновации уже созрели.
Но Cisco хочет делать ещё больше! Помните Nexus? Вернёмся снова к нашим сетям. Как поступает клиент, когда у него есть несколько дата-центров? Он хочет их объединить, чтобы облегчить себе их использование. Предположим, один дата-центр, где расположены приложения, находится в Лос-Анжелесе, а другой в Фениксе, штат Аризона, и там имеется оборудование. Мы хотим перенести сервер, который имеет IP 10.10.10.6, из Лос-Анжелеса в Феникс так, чтобы он имел тот же IP адрес — 10.10.10.6. Зачем нам это нужно? Потому что рядом с этим сервером в первом дата-центре находится сервер 10.10.10.7, который обменивается с 10.10.10.6 приложениями по внутренней сети, а мы не хотим разорвать их связь. Как Cisco решило эту проблему?
Мы подсоединили эти два сервера к свитчу серии 2000, этот свитч к свитчу серии 5000, а его уже к свитчу серии 7000. Мы создали совершенно новую технологию, которую назвали OTV (overlay to transfer transport virtualization) – сетевую оверлейную технологию для дата-центров. Она транспортирует виртуализацию так, что мы можем перенести сервер в 10.10.10.6 другой дата-центр. И когда он хочет обратиться к серверу 10.10.10.7, посылает broadcast, его данные инкапсулируются и перемещаются по сети в Лос-Анжелес таким образом, что 10.10.10.7 думает, что его собрат 10.10.10.6 до сих пор находится рядом с ним!
Таким образом, мы можем объединить 16 дата-центров так, что они будут выглядеть как один, и всё оборудование внутри будет «думать», что находится в одном, а не в разных местах.
Представьте, как эта идея понравилась клиентам! Мы просто размещаем массивы в разных местах и пересылаем между ними данные. В каком ещё случае это может понадобиться клиентам?
Вспомните ураган «Сэнди», который обрушился на Нью-Джерси. Вам понадобился дата-центр в середине страны, за пределами побережья, со всеми его IP-адресами и так далее. И мы переносим его из Нью-Джерси туда, куда Вам требуется. Я не буду ждать, пока ураган разрушит мой дата-центр, но я знаю прогноз, поэтому перенесите половину моих мощностей в безопасное место, а дальше я посмотрю, как будет развиваться ситуация. И если она будет ухудшаться, я попрошу Вас перенести оттуда и вторую половину.
Мы можем использовать такую часть мощности, которая понадобится для обработки конкретного объёма приложений, Server Profile это обеспечит. При этом я не знаю подробно о том, как это работает, я не компетентен в этом, лучше спросите подробности у своего PSS. Как говорил Клинт Иствуд: «Мужчина должен знать свои ограничения». И Cisco затратила на эту технологию сравнительно много денег в короткий промежуток времени, так как она быстро развивалась, мы предложили её рынку в 2009 году. В итоге у нас есть шасси серии В и серверы серии С. Рассмотрим, что такое серверы серии С.
Это отдельно стоящий, автономный сервер, построенный для виртуализации. И опять же, можем ли мы управлять им, посредством инерконнекта с фабрикой? Да, так же как мы могли это сделать с блейд-сервером. Таким образом мы можем управлять, как виртуальными серверами, находящимися на независимых серверах, так и блейдами, и всё по одному интерфейсу. Я нарисую несколько блейд-серверов с оптоволоконным соединениями, несколько шкафов с блейд-серверами, связанными друг с другом через фабрику. Итак, у нас есть несколько стоек серверов, которые управляются фабрикой, способной управлять до 20 шасси. Большая плотность серверов здесь. Тут применяется расширитель фабрики FEX (fabric extender) 2200.
Я уже показывал Вам шасси, в котором расположены модули сетевых карт и супервизоры. А в нашем шасси ещё имеется по 8 серверов. Итак, в первой группе стоек мы устанавливаем оптико-волоконный расширитель соединений FEX серии 2200 для подключения наших серверов-блейдов. Рядом мы создали стойку с серверами, каждый из которых является автономным, и тоже добавили туда FEX 2200. Это называется TOR, Top of Rack Switches. Их много. Фактически они — те же «лезвия», которым нужен супервизор.
Рядом мы установим ещё один шкаф с серверами и TOR FEX 2200. Для того, чтобы обеспечить все три секции шкафов управлением, мы устанавливаем рядом 4-й шкаф, в котором устанавливаем супервизор 5500. Три имеющиеся шкафа с серверами и свитчами мы соединяем с этим супервизором. Это наш мозг.
Он позволяет управлять 16 такими шкафами. Если нам нужно больше, вся система из шкафов, объединённых группами по 4 секции, подсоединяется к супервизору большей мощности серии 7000. Он может управлять 20 или 24 группами. Это позволяет управлять большим количеством соединений с помощью одного интеллектуального устройства. Сами 5500 с помощью оптоволоконных коннекторов FCP соединены с MDS, что ещё больше расширяет наши возможности. Сверху я нарисую свитчи серии Nexus 7000, и теперь мы можем передавать на них 40 Гбит / с Ethernet. Эти свитчи серии 2200 не являются достаточно разумными, поэтому нуждаются в управлении интеллектуального устройства. Таким образом, мы можем обеспечить любую нужную пропускную способность для наших серверов.
Если нужно создать традиционное SAN, мы во второй и третий шкаф должны установить оптоволоконные свитчи, так как мы не будем иметь дела с Ethernet. Замечу, что существует множество способов построения сетевой архитектуры, потому дата-центры не похожи друг на друга.
Cisco строит отношения. Сейчас мы создали «треугольник» услуг, мы создали организацию VCE, которая объединила Cisco, EMC и VMware. Теперь EMC могут продавать дата-центрам свои «коробки», в которых находится их собственное аппаратное и программное обеспечение для хранилищ, а мы интегрируем их продукт в архитектуру дата-центра, придавая ему способность виртуализации серверов и свитчей. Мы называем эту технологию VBlock. Мы получили связь с NetApp, мы создали FlexPod. FlexPod — платформа для построения для дата-центров, готовые архитектурные решения.
Можно сказать, что мы продаём виртуализацию. В другом случае провайдеры со своими независимыми серверами не смогли бы даже думать о том, чтоб предлагать облачные решения клиентам. Они могут продавать всё больше и больше физических серверов, за счёт виртуализации. Это создаёт возможность вплотную подойти к облачной технологии хранения и обработки данных. Завтра мы поговорим о HCS (Hosting Colaboration Solutions) – мы рассмотрим сотрудничество с компаниями, которые не являются поставщиками традиционных услуг, таких как AT&T, IBM, British Telecom.
Вернёмся к нашим шасси серии 7000. Они снабжены сетевыми картами двух разных типов, обеспечивающими приём и передачу данных: F карта на вход, M карта работает на выход. Операционная система Nexus немного отличается от той, что используется в серии 2200. Она была выпущена в декабре 2002 года специально для свитчей, работающих с оптоволоконной связью, MDS 9500 к примеру, который стал свитчем №1 класса «директор» в мире. Отличие заключается в iOS этих серий, но обе основаны на Linux. И вторая помогла обеспечить не только аппаратную избыточность, но и программную. Мы одновременно разрабатываем новое «железо» и новый софт, потому что для работы независимых сервисов нужно своё программное обеспечение. Так, когда Nexus осуществляет передачу данных, он использует BGP, при этом работа на вход не останавливается, потому что здесь установлена вторая сетевая карта. Linux позволяет мне программно перезагрузить сервис. Если это не даёт эффекта, я всегда имею возможность использовать второй аппаратный интерфейс. Так у нас появляется две возможности устранить неполадки — программно или аппаратно. Не все наши iOS базируются на Linux, но все новые семейства Catalyst 6500 и 4500 используют ядро Linux.
Мы обеспечиваем нашу iOS возможностью работать на серверах с ОС типа Linux, поэтому всё наше оборудование совместимо с любыми серверами. Все серии наших свитчей управляются одинаковыми командами, поэтому содержимое командной строки сейчас ничем не отличается от того, что Вы набирали в 1990-х. Лишь внутренний интерфейс различается. И если инженеры из дата-центров привыкли к графическому интерфейсу GUI, они могут его использовать, либо могут использовать командную строку, как я. Основная причина использования ядра Linux заключается в том, что я могу перезапускать сервисы независимо, и если у меня есть проблема с BGP, я просто запущу это на другом сетевом интерфейсе. Вот почему мы не используем Basic или COBOL более, так как Nexus – это ОС следующего поколения. Отмечу, что порт 10 гигабит в серии Nexus стоит дешевле, чем порт такой же пропускной способности в серии Catalyst 6500, тем не менее, если Nexus 7000 cлишком большой для Ваших нужд, то Вы можете использовать Catalyst 6500. И опять же, мы используем Linux, потому что это очень гибкая операционная система для нас, особенно в случаях, когда мы хотим использовать многопроцессорные решения.
Продолжение:
Тренинг FastTrack. «Сетевые основы». «Оборудование для дата-центров». Эдди Мартин. Декабрь, 2012
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Methos
Мне только одному кажется, что пузо у этого товарища немного разъевшееся?
HostingManager Автор
Публичное указание на недостатки человека, в особенности физические, является немного не приличным. С моей точки зрения.
Methos
С чего вы решили, что указание того, что, например, человек «черный», будет означать указание на его недостатки? А ведь за это называли расистом даже. Теперь расистом называют тех черных, которые говорят «ты белый!».
Если бы я сказал, что «человек немного худоват», это тоже его недостатки были бы?
Каждый человек совершенен по себе, у каждого своя комплекция.
Если бы я сказал «пузо у человека отличное и красивое», это было бы его недостаток или достаток?
И чем отличается «пузо полное» от «пузо красивое», или от «пузо худое»?
У каждого своё пузо и именно это я и выразил. Просто голый факт.
А у вас нет чувства юмора.
Ой. Это я тоже указал на ваши недостатки, да?
Простите, это же достоинство!
programmer-tm
Не все следят за своим внешним видом (а у кого-то это не получается в силу физиологии) У нас тема сетевых технологий, а не спорт в каждый дом. И тут есть чего послушать и почитать.