
На рынке много продуктов, подходящих для игровой аналитики: Mixpanel, Localytics, Flurry, devtodev, deltaDNA, GameAnalytics. Но все же многие игровые студии строят свое решение.
Я работал и работаю со многими игровыми компаниями. Я заметил, что по мере роста проектов, в студиях появляется необходимость в продвинутых сценариях аналитики. После того, как несколько игровых компаний заинтересовались данным подходом, было решено задокументировать его в серии из двух статей.
Ответы на вопросы "Почему?", "Как это сделать?" и "Сколько это стоит?" вы найдете под катом.
Почему?
Универсальный комбайн хорош для выполнения простых задач. Но если нужно сделать что-то посложнее, его возможностей не хватает. Например, вышеупомянутые системы аналитики, в разной мере, обладают ограничениями в функционале:
- на количество параметров в событии
- на количество параметров в событиях воронки
- на частоту обновления данных
- на объем данных
- на период расчета данных
- на количество условий воронки
- и другие ограничения в таком же роде
Готовые решения не дают доступ к сырым данным. Например, если нужно провести более детальное исследование. Нельзя забывать и про машинное обучение и предиктивную аналитику. При значительном объеме аналитических данных, можно поиграться со сценариями машинного обучения: предсказание поведения пользователя, рекомендация покупок, персональные предложения и т.д.
Игровые студии часто строят собственные решения не на замену, а в дополнение к уже имеющимся.
Итак, как выглядит своя система аналитики?
Распространенный подход при построении аналитики — это лямбда архитектура, аналитика делится на "горячий" и "холодный" пути. По горячему пути идут данные, которые необходимо обработать с минимальной задержкой (количество игроков онлайн, платежи и т.д.).
По холодному пути идут данные, которые обрабатывают периодически (отчеты за день/месяц/год), а так же сырые данные для долгосрочного хранения.

Например, это полезно при запуске маркетинговых кампаний. Удобно видеть сколько юзеров пришло с кампаний, сколько из них совершили платеж. Это поможет отключить неэффективные каналы рекламы максимально быстро. Учитывая маркетинговые бюджеты игр — это может сэкономить много денег.
К холодному пути относится все остальное: периодические срезы, кастомные отчеты и т.д.
Недостаточная гибкость универсальной системы, как раз, и толкает к разработке собственного решения. По мере того, как игра развивается, необходимость в детальном анализе поведения пользователей возрастает. Ни одна универсальная система аналитики не сравнится с возможностью строить SQL запросы по данным.
Поэтому студии разрабатывают свои решения. Причем, решение, часто, затачивается под конкретный проект.
Студии, разработавшие свою систему, были недовольны тем, что ее приходилось постоянно поддерживать и оптимизировать. Ведь, если проектов много, или они очень большие, то количество собираемых данных растет очень быстро. Своя система начинает все больше тормозить и требовать значительных вкладов по оптимизации.
Как?
Технические риски
Разработка системы аналитики — задача не из простых.
Ниже — пример требований от студии, на которые я ориентировался.
- Хранение большого объема данных: > 3Tb
- Высокая нагрузка на сервис: от 1000 событий в секунду
- Поддержка языка запросов (предпочтительно SQL)
- Обеспечение приемлемой скорости обработки запросов: < 10 min
- Обеспечение отказоустойчивости инфраструктуры
- Обеспечение средств визуализации данных
- Аггрегирование регулярных отчетов
Это — далеко не полный список.
Когда я прикидывал как сделать решение, я руководствовался следующими приоритетами/хотелками:
- быстро
- дешево
- надежно
- поддержка SQL
- возможность горизонтального масштабирования
- эффективная работа с минимум 3Tb данных, опять же масштабирование
- возможность обрабатывать данные real time
Так как активность в играх имеет периодический характер, то решение должно, в идеале, адаптироваться к пикам нагрузки. Например, во время фичеринга, нагрузка возрастает многократно.
Возьмем, например, Playerunknown's Battleground. Мы увидим четко-выраженные пики в течение дня.

Источник: SteamDB
И если посмотреть на рост Daily Active Users (DAU) в течение года, то заметен довольно быстрый темп.

Источник: SteamDB
Не смотря на то, что игра — хит, похожие графики роста я видел и в обычных проектах. В течение месяца количество пользователей вырастало от 2 до 5 раз.
Нужно решение, которое легко масштабировать, но при этом не хочется платить за заранее зарезервированные мощности, а добавлять их, по мере роста нагрузки.
Решение на базе SQL
Решение в лоб — это взять какую-либо SQL БД, направлять туда все данные в сыром виде. Из коробки решает проблему языка запросов.
Напрямую данные с игровых клиентов нельзя направлять в хранилище, поэтому нужен отдельный сервис, который будет заниматься буферизацией событий от клиентов и пересылкой их в БД.
В данной схеме аналитики должны напрямую слать запросы в БД, что чревато. Если запрос тяжелый, БД может встать. Поэтому нужна реплика БД чисто для аналитиков.
Пример архитектуры ниже.

Такая архитектура обладает рядом недостатков:
- Про данные в реальном времени можно сразу забыть
- SQL — мощное средство, но данные ивентов часто не ложатся на реляционную схему, поэтому приходится выдумывать костыли, типа p0-p100500 параметров у событий
- Учитывая объем аналитических данных, собираемых в день, размер БД будет расти как на дрожжах, нужно партиционировать и т.д.
- Аналитик может родить запрос, который будет выполнятся несколько часов, а может даже день, тем самым заблокировав других юзеров. Не давать же каждому свою реплику БД?
- Если SQL on-prem, то нужно будет постоянно заботиться об отказоустойчивости, достаточном объеме свободного места и так далее. Если в облаке — может влететь в копеечку
Решение на базе Apache Stack
Тут стек довольно большой: Hadoop, Spark, Hive, Kafka, Storm, и т.д.
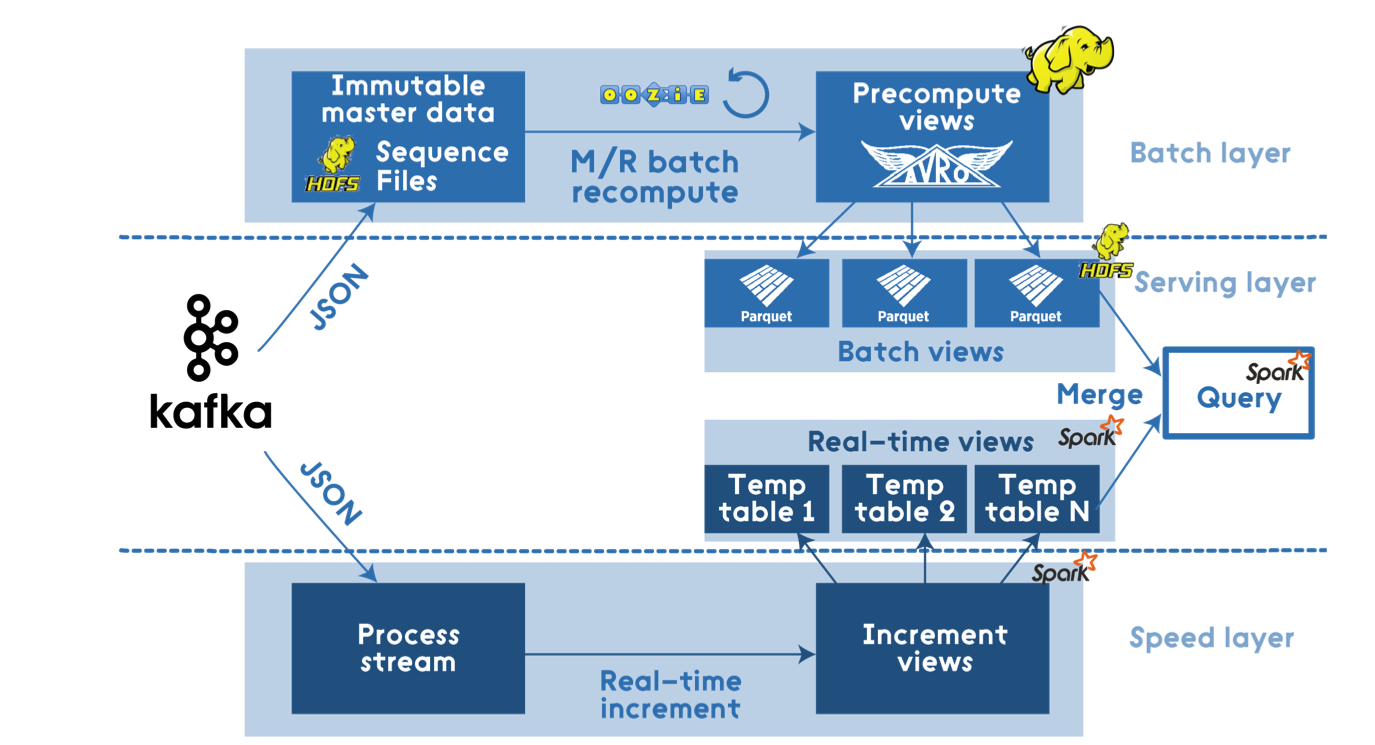
Источник: dzone.com
Такая архитектура точно справится с любыми нагрузками и будет максимально гибкой. Это полноценное решение, которое позволит обрабатывать данные и в реальном времени, и строить зубодробительные запросы по холодным данным.
С ходу подобрать необходимый размер кластера, при отсутствии значительного опыта, нереально. Цена данного решения будет зависеть от количества виртуалок. Как правило, чтобы быть готовым к пиковым нагрузкам, вроде фичеринга, размер кластера берут с запасом. Это может влететь в копеечку.
Плюсы:
- Максимально гибкое решение
- Хорошая масштабируемость
Минусы:
- Поддержка и управление кластером Hadoop осуществляется вручную, масштабирование при пиковых нагрузках может вызвать проблемы
- Высокая стоимость, если кластер не утилизируется на 100%, или не уничтожается по ненадобности
- Сложно подобрать оптимальный размер кластера, если характер нагрузок, в основном, пиковый
Решение на базе облачной платформы
Если использовать Hadoop экосистему на базе облачной платформы типа Azure HDInsight, то, как минимум, боль по поддержке и управлению кластером уйдет. Тем не менее, стоить это будет не дешево, так как биллинг происходит аналогично предыдущему решению, по количеству нод и времени их работы.
Более эффективный подход — взять платформы, биллинг которых происходит по фактически используемым ресурсам.
- Для приема ивентов, Apache Kafka заменить Azure EventHub. Платить за пропускную способность.
- Для обработки данных заменить Apache Kafka/Hive/Spark/Storm на Azure Data Lake Analytics (ADLA) и Azure Stream Analytics
- Azure Data Lake Store (ADLS) — HDFS хранилище для данных
- Power BI/Tableau/др. для визуализации
Что это решает?
- Нет кластера.
- При простое платишь только за хранилище и пропускную способность EventHub
- При выполнении запроса через ADLA платишь только за реальное время исполнения запроса и степень параллелизации
- Не нужно управлять и поддерживать кластер
- Сохраняются все плюшки от Hadoop решения:
- Возможность обрабатывать данные в реальном времени или батчами
- Высокая масштабируемость
- SQL-запросы (U-SQL)
- Возможность писать кастомный код к U-SQL
Конкретные цифры
Все это прекрасно, но давайте больше конкретики. Ниже — пример расчета, который я делал для одной из студий.
Я использовал Azure Pricing Calculator для расчета стоимости.
Рассчитывал цены для работы с холодными данными в регионе West Europe.
Для простоты, я считал только Compute мощности. Я не учитывал хранилище, так как его размер сильно зависит от конкретного проекта.
На данном этапе я включил в таблицу цены для систем буфферизации только для сравнения. Там указаны цены для минимальных кластеров/размеров, с которых можно начать.
Решение "на голых VM" оценивалось ровно с такой же конфигурацией, что предлагает HDInight. Конечно, пожертвовав надежностью, можно уменьшить размер кластера и снизить цену, но это не совсем корректное сравнение.
Стоимость Apache Stack на HDInsight
| Решение | Цена |
|---|---|
| Spark | $670 |
| Kafka | $837 |
| Итого | $1507 |
Стоимость Apache Stack на голых VM
| Решение | Цена |
|---|---|
| Spark | $525 |
| Kafka | $656 |
| Итого | $1181 |
Стоимость решения в Azure
| Решение | Цена |
|---|---|
| Azure Data Lake Analytics | $108 |
| Azure EventHub | $11 |
| Итого | $119 |
Подробнее по расчетам
Spark on Azure HDInsight
Минимальный размер кластера:
2 x Head Nodes (A3 4 cores 7Gb RAM)
1 x Worker Nodes (A3 4 cores 7Gb RAM)
Всего: $670.14 / мес
Заморачиваться с кластером не надо. Облако само заботиться чтобы все работало.
Spark on Bare VMs
Та же самая конфигурация кластера, но развернутая на голых виртуалках $525.6 / мес.
Дешевле, но прибавляется работа по управлению и поддержке кластера.
Если купить Reserved Instances, то можно значительно сэкономить, но не всем это подходит. Да и может быть, что аналитика не нужна будет на год.
Azure EventHub
На этом этапе я делал самый грубый расчет. Исходя от нагрузки 1000 событий / сек = 1 Throughput Unit (TU).
1 TU * $0.015 * 730 ч = $10.95
Azure Data Lake Analytics
Цена в Европе \$2 за Analytics Unit в час.
Analytics Unit — по сути, одна нода. $2/час за ноду дороговато, но биллится это дело поминутно. Обычно Job занимает минимум минуту.
Если Job большой, то нужно больше AU чтобы его распараллелить.
Тут я понял, что пальцем в небо тыкать не очень хорошо. Поэтому предварительно провел небольшой тест. Я сгенерировал json файлы по 100 Мб, всего 1Гб, положил их в стор, запустил простой запрос в Azure Data Lake Analytics по аггрегации данных и посмотрел сколько времени займет обработка 1 Гб. У меня вышло 0.09 AU/h.
Теперь уже можно примерно посчитать сколько будет стоить обработка данных. Предположим, что в месяц у нас накапливается 600 Гб данных. Все эти данные мы должны как минимум 1 раз обработать.
600 Гб * 0.09AU * $2 = $108
Так же к данной цене следует добавить операции к Azure Data Lake Store, но там довольно смешная цена, так как биллинг осуществляется за каждые 10 000 операций.
Итоги по решениям
Были произведены грубые расчеты минимальной конфигурации для аналитики.
Если аналитика молотит запросы 24/7/365, то имеет смысл держать свой кластер. Причем самым выгодным вариантом, по деньгам, будут голые виртуалки с Reserved Instances на год.
Если заморачиваться с поддержкой кластера не хочется, то тут можно выбрать HDInsight. Правда это выйдет примерно ~20% дороже.
Если же запросы выполняются периодически: регулярные срезы данных, кастомные запросы от аналитиков и т.д., — то самый выгодный вариант облачный сервис типа Azure Data Lake Analytics.
Hadoop стек не подойдет для маленьких проектов, или проектов на начальной стадии. А вот облачное решение одинаково хорошо как для маленьких проектов, так и для масштабных.
Нужно учитывать, что для полноценной лямбда-архитектуры необходим Message Broker и хранилище. На данном этапе я не считал их подробно, а взял минимальные цены.
В любом случае, последний вариант мне показался самым простым и выгодным, поэтому я остановился именно на нем.
Игровая аналитика на Azure Event Hub / Azure Data Lake Analytics / Azure Stream Analytics / Power BI
Архитектура
Прикинув все за и против, я взялся за реализацию лямбда архитектуры на Azure. Она выглядит следующим образом:

Azure Event Hub — это очередь, буфер, который способен принимать огромное количество сообщений. Так же есть приятная фича записи сырых данных в хранилище. В данном случае — Azure Data Lake Storage (ADLS).
Azure Data Lake Store — хранилище, базирующееся на HDFS. Используется в связке с сервисом Azure Data Lake Analytics.
Azure Data Lake Analytics — сервис аналитики. Позволяет строить U-SQL запросы к данным, лежащим в разных источниках. Самый быстрый источник — ADLS. В особо сложных случаях, можно писать кастомный код для запросов, на C#. Есть удобный тулсет в Visual Studio, с подробным профайлингом запросов.
Azure Stream Analytics — сервис для обработки потока данных. В данном случае используется для аггрегации "горячих" данных и передачи их для визуализации в PowerBI
Azure Data Factory — довольно спорный инструмент. Позволяет организовывать "пайплайны" данных. В данной конкретной архитектуре, используется для запуска "батчей". То есть запускает запросы в ADLA, вычисляя срезы за определенное время.
PowerBI — инструмент бизнес аналитики. Используется для организации всех дашбордов по игре. Умеет отображать реалтайм данные.
Разбор событий
Холодные данные
После поступления в EventHub, дальше события должны проходить по двум путям: холодному и горячему. Холодный путь ведет в хранилище ADLS. Тут возможно пойти несколькими путями.
EventHub's Capture
Самый простой — использовать Capture фичу EventHub'a. Она позволяет автоматически сохранять сырые данные, поступающие в хаб, в одно из хранилищ: Azure Storage или ADLS. Фича позволяет настроить паттерн именования файлов, правда сильно ограниченный.
Хотя фича и полезная, подойдет она не во всех случаях. Например, мне она не подошла, так как время, используемое в паттерне для файлов, соответствует времени прибытия ивента в EventHub.
По факту, в играх, ивенты могут накапливаться клиентами, а затем посылаться пачкой. В таком случае, ивенты попадут в неправильный файл.
Организация данных в файловой структуре очень важна для эффективности ADLA. Накладные расходы на открытие/закрытие файла довольно велики, поэтому ADLA будет наиболее эффективным при работе с большими файлами. Опытным путем, я выяснил оптимальный размер — от 30 до 50 Мб. В зависимости от нагрузки, может понадобиться разбивать файлы по дням/часам.
Еще одна причина — отсутствтие возможности разложить ивенты по папкам, в зависимости от типа самого ивента. Когда дело дойдет до аналитики, запросы должны будут быть максимально эффективными. Самый оптимальный способ отфильтровать ненужные данные — не читать файлы совсем.
Если события будут смешаны внутри файла по типу (например, события авторизации и экономические события), то часть вычислительных мощностей аналитики будет тратиться на откидывание ненужных данных.
Плюсы:
- Быстро настроить
- Просто работает, без всяких заморочек
- Дешево
Минусы:
- Поддерживает только AVRO формат при сохранении событий в хранилище
- Обладает достаточно ограниченными возможностями по именованию файлов
Stream Analytics (Холодные данные)
Stream Analytics позволяет писать SQL-подобные запросы к потоку событий. Есть поддержка EventHub'a как источника данных и ADLS в качестве вывода. Благодаря этим запросам, в хранилище можно складывать уже трансформированные/агреггированные данные.
Аналогично, обладает скудными возможностями по именованию файлов.
Плюсы:
- Быстрая и простая настройка
- Поддерживает несколько форматов для ввода/вывода событий
Минусы:
(Холодные данные)
- Обладает достаточно ограниченными возможностями по именованию файлов
- Цена
- Отсутствие динамического масштабирования
Azure Functions (Холодные данные)
Наиболее гибкое решение. В Azure Functions есть binding для EventHub, и не надо заморачиваться с разбором очереди. Так же Azure Functions автоматически скалируются.
Именно на этом решении я остановился, так как смог размещать события в папках, соответствующих времени генерации события, а не его прибытия. Так же сами события удалось раскидать по папкам, согласно типу события.
Для биллинга есть две опции:
- Consumption Plan — трушный serverless, платите за используемую память в секунду. При больших нагрузках может быть дороговато
- App Service Plan — в данном варианте у Azure Functions есть сервер, его тип можно выбирать, вплоть до бесплатного, есть возможность автомасштабирования. Именно это опция в моем случае оказалась дешевле.
Плюсы:
- Гибкость в именовании файлов с сырыми данными
- Динамическое масштабирование
- Есть встроенная интеграция с EventHub
- Низкая стоимость решения, при правильно выбранном биллинге
Минусы:
- Необходимо писать кастомный код
Горячие данные
Stream Analytics (Горячие данные)
Опять же Stream Analytics самое простое решение для аггрегации горячих данных. Плюсы и минусы примерно те же, что и для холодного пути. Основной причиной выбора Stream Analytics является автоматическая интеграция с PowerBI. Горячие данные можно отгружать в "реальном" времени.
Плюсы:
- Быстрая и простая настройка
- Имеет множество выводов, включая SQL, Blob Storage, PowerBI
Минусы:
- Поднможество T-SQL, используемое в Stream Analytics, все же имеет свои ограничения, при решении некоторых задач можно упереться в лимиты
- Цена
- Отсутствие динамического масштабирования
Azure Functions (Горячие данные)
Все то же самое, что и в холодных данных. Не буду подробно описывать.
Плюсы:
- Полностью кастомная логика
- Динамическое масштабирование
- Встроенная интеграция с EventHub
- Низкая стоимость решения, при правильно выбранном биллинге
Минусы:
- Необходимо писать кастомный код
- Так как функции stateless, необходимо отдельное хранилище состояния
Считаем цену полного решения
Итак, расчет для нагрузки 1000 событий в секунду.
| Решение | Цена |
|---|---|
| Azure EventHub | $10.95 |
| Azure Stream Analytics | $80.30 |
| Azure Functions | $73.00 |
| Azure Data Lake Store | $26.29 |
| Azure Data Lake Analytics | $108.00 |
В большинстве случаев Stream Analytics может не понадобится, поэтому итого будет от $217 до $297.
Теперь про то как я считал. Расчеты по Azure Data Lake Analytics были выше.
Azure Event Hub — биллится за каждый миллион сообщений, а так же за пропускную способность в секунду.
Расчет Azure Event Hub
Пропускная способность одного throughput unit (TU) 1000 событий / сек или 1МБ/сек, что наступит раньше.
Мы считаем для 1000 сообщений в сек, то есть необходимо 1 TUs. Цена за TU на момент написания статьи $0.015. Принято считать, что в месяце 730 часов.
1 TU * $0.015 * 730 ч = $10.95
Считаем количество сообщений в месяц, с учетом одинаковой нагрузки в течение месяца (ха! такого не бывает):
1000 * 3600 сек * 730 ч = 2 628 000 000 событий
Считаем цену за количество входящих событий. Для Западной Европы, на момент написания статьи, цена была $0.028 за миллион событий:
2 628 000 000 / 1 000 000 * $0.028 = $73.584
Итого $20.44 + $73.584 = $95.024.
Что-то много выходит. Учитывая, что события обычно достаточно мелкие — это не выгодно.
Придется на клиенте написать алгоритм упаковки нескольких событий в одно (чаще всего так и делают). Это не только позволит уменьшить количество событий, но и сократить количество необходимых TUs при дальнейшем росте нагрузки.
Я взял выгрузку реальных ивентов из существующей системы и посчитал средний размер — 0.24KB. Максимально допустимый размер события в EventHub 256KB. Таким образом, мы можем упаковать приблизительно 1000 событий в одно.
Но тут есть тонкий момент: хоть максимальный размер события и 256KB, биллятся они кратно 64KB. То есть максимально упакованное сообщение будет посчитано как 4 события.
Пересчитаем с учетом этой оптимизации.
$73.584 / 1000 * 4 = $0.294
Вот это уже значительно лучше. Теперь посчитаем какая пропускная способность нам нужна.
1000 events per second / 1000 events in batch * 256KB = 256KB/s
Это вычисление показывает и другую важную особенность. Без батчинга ивентов нужно было бы 2.5MB/s, что потребовало бы 3TU. А мы ведь считали что нужен всего 1TU, ведь мы отправляем 1000 ивентов в секунду. Но лимит по пропускной способности наступил бы раньше.
В любом случае, мы можем уложиться в 1 TU вместо 3! И расчеты можно не менять.
Считаем цену для TU.
Итого получаем $20.44 + $0.294 = $20.734.
Сравним с ценой без учета упаковки ивентов: (1 - 20.734/95.024) * 100 = 78.2%.
На 78% выгоднее!
Упаковку событий нужно обязательно учесть при реализации этой архитектуры.
Расчет Azure Data Lake Store
Итак, давайте прикинем примерный порядок роста размера хранилища. Мы уже посчитали, что при нагрузке 1000 событий в секунду, мы получаем 256КБ/сек.
256КБ * 3600 сек * 730 ч = 672 768MB = 657ГБ
Это довольно большая цифра. Скорее всего 1000 событий в секунду будут только часть времени суток, но тем не менее, стоит посчитать худший вариант.
657ГБ * $0.04 = $26.28
Еще ADLS биллится за каждые 10000 транзакций с файлами. Транзакции — это любое действие с файлом: чтение, запись, удаление. К счастью удаление бесплатное =).
Давайте посчитаем чего нам стоит только запись данных. Воспользуемся предыдущими расчетами, мы собираем 2 628 000 000 событий в мес, но мы их упаковываем по 1000 в один ивент, поэтому 2 628 000 событий.
2 628 000 транзакций записи / 10000 транзакций * $0.05 = $13.14
Что-то опять дороговато. Записывать можно батчами, как минимум еще 1000 ивентов в батче. Упаковку нужно делать на уровне клиентского приложения, и батч записи на уровне разбора EventHub.
$13.14 / 1000 = $0.0134
Вот это уже недурно. Но опять же, нужно учесть батчинг при разборе очереди EventHub.
Итого $26.28 + $0.0134 = $26.2934
Расчет Azure Functions
Использование Azure Functions возможно как для холодного, так и для горячего путей. Аналогично, их можно деплоить как одно приложение, так и отдельно.
Я посчитаю самый простой вариант, когда они крутятся как одно приложение.
Итак, у нас нагрузка 1000 событий в секунду. Это не очень много, но и не мало. Ранее я говорил, что Azure Functions могут обрабатывать события в батчах, причем это делают более эффективно, чем обработка событий по отдельности.
Если взять размер батча в 1000 событий, то нагрузка становится 1000 / 1000 = 1 реквест в секунду. Что совсем смешная цифра.
Посему можно деплоить все в одно приложение, и такую нагрузку потянет один минимальный инстанс S1. Его стоимость $73. Можно, конечно, взять и B1, он еще дешевле, но я бы перестраховался, и остановился на S1.
Расчет Stream Analytics
Stream Analytics нужен только для продвинутых реал-тайм сценариев, когда нужна механика скользящего окна. Это довольно редкий сценарий для игр, так как основная статистика рассчитывается на основе окна в день, и сбрасывается при наступлении следующего дня.
Если же вам нужен Stream Analytics, то гайдлайны рекомендуют начать с размера в 6 Streaming Units (SUs), что равно одной выделенной ноде. Далее нужно смотреть нагрузку работы, и скалировать SUs соответственно.
По моему опыту, если запросы не включают DISTINCT, или окно довольно маленькое (час), то достаточно одного SU.
1 SU * $0.110 * 730 hours = $80.3
Итоги
Существующие решения, предлагаемые на рынке, довольно мощные. Но их все равно недостаточно для продвинутых задач, они всегда имеют либо лимиты производительности, либо ограничения по кастомизации. И даже средние игры начинают довольно быстро в них упираться. Это побуждает на разработку собственного решения.
Встав перед выбором стека технологий, я прикинул цену. Мощняцкий Hadoop стек способен справиться с любыми нагрузками, но обходится очень дорого, если машины не загружены на 100% 24/7. Чтобы снизить стоимость, нужно думать как сделать динамическое масштабирование всего этого добра.
Вкладываться в разработку и поддержку инфраструктуры не хочется. Поэтому я рассмотрел облачные платформы. Игровая аналитика требует, в основном, периодических расчетов. Раз в день, например. Поэтому возможность платить только за то, что используешь — как раз в точку.
Но при использовании облачных сервисов нужно очень осторожно подходить к построению решения. Нужно изучать принципы формирования цены и учитывать необходимые оптимизации для снижения стоимости.
В следующей статье я покажу как это все поднять в облаке.
Мне нравится, хочу хочу хочу
Я — часть команды Microsoft, которая помогает партнерам строить интересные и эффективные решения. Мы сейчас ищем еще несколько игровых компаний, с которыми можно сделать подобный проект по аналитике, или придумать новые интересные сценарии. Мы будем рассказывать такие истории уже на примере реальных игр.
Мы не только за слово, но и за дело, поэтому мы готовы, вместе с вашими разработчиками и аналитиками, сесть рука об руку, и разработать такой проект или пилот. Мы поможем подготовить статьи для интересных проектов. Возможны и другие варианты плюшек с нашей стороны.
Контакты
Больше технических деталей:
- Мой канал про игровую разработку: https://t.me/gamedev_architecture
- Telegram: https://t.me/poisonous_john
- E-mail: ivfateev@microsoft.com
Если вы хотите сделать такой же сценарий, или есть интересные идеи:
- Telegram: https://t.me/ivan_kopytov
- E-mail: v-ivanko@microsoft.com
Комментарии (9)


Yo1
15.03.2018 00:19+1как-то не впечатлило. 3 ноды по 4 ядра хадупа явно на два-три порядка более, чем 1к событий/сек прожуют, а тысячу событий просто же в mysql/postgres легко писать можно. выглядит что если цену азур стека пересчитать под более близкую нагрузку к kafka+spark (за $1181) разница будет в тысячи долларов.
плюс возможности kafka+spark+настоящий map-reduce явно другая вселенная в плане возможностей напрограммировать.
в следующей статье хотелось бы обновить расчеты посерьезней нагрузкой, такой с какой имеет смысл влезать в бигдату. с 1к/сек нет смысла так усложнять архитектуру, а рост нагрузки приводит к дополнительным расходам на каждый чих. останутся ли адекватными расходы на азур стек при нагрузках, какие по зубам трем нодам хадуп?
PoisonousJohn Автор
15.03.2018 10:18Спасибо за отзыв! Со многими пунктами согласен. Видимо не удалось передать основную идею запросов от партнеров. Как я и писал 1к в сек — смешная цифра. Но это то, с чего обычно начинают игры на старте. И заканчивают на этапе сансета.
азур стека пересчитать под более близкую нагрузку к kafka+spark (за $1181) разница будет в тысячи долларов.
Давайте пересчитаем =) Какую нагрузку вы считаете оптимальной для такой конфигурации кластера?
а тысячу событий просто же в mysql/postgres легко писать можно.
Можно, но у нас есть конкретные примеры, когда игровым студиям было проблематично поддерживать БД больших размеров (3TB+), и запросы на них выполнялись многими часами.
плюс возможности kafka+spark+настоящий map-reduce явно другая вселенная в плане возможностей напрограммировать.
Можете рассказать поподробнее, в чем вы видите ограничения по возможностям напрограммировать?
3 ноды по 4 ядра хадупа явно на два-три порядка более, чем 1к событий/сек прожуют
с 1к/сек нет смысла так усложнять архитектуру, а рост нагрузки приводит к дополнительным расходам на каждый чих.
Согласен, но задача была посчитать **минимальную** конфигурацию, начиная от 1к событий в сек. Я ориентировался на минимальную архитектуру Apache Stack'a в рамках HDInsight.
У нас были требования таковы, что архитектура должна легко скалироваться от маленькой нагрузки, до реально больших масштабов.
Тут есть специфика игр. На старте игры нет уверенности, что она взлетил, поэтому вкладываться в разработку аналитической системы, администрирования серверов, оплату мощностей, студиям не выгодно. Многие боятся больших цен или сложности поддержки всего этого.
Они хотят начать с малого, платить за то что используют. Но при этом, в случае если игра бомбанет, быть уверенными, что ничего не шлепнется. Быть способными переварить весь возросший объем данных.

arilou_camper
15.03.2018 01:38Подход верный! Но мне кажется, что у вас где-то в рассчётах ошибка или что-то не учтено.
У нас небольшой кластер из 4 серверов под Proxmox стоимостью около 800 евро в месяц (2x12 core CPUs, 64GB RAM, 48TB SATA storage) получает на вход порядка 6000 RPS и генерит где-то 15-20 тыс сообщений в Kafka в секунду. Сервера между собой соединены 1Gbit сетью.
В кластере Kafka развернута на двух контейнерах (да, знаю, что надо три, но мы бедные)), по 4 ядра и 16GB памяти. Входящий трафик на одном где-то 3MB/sec. Написан специальный слушатель, который читает из Kafka и пишет в HDFS (развернутый тоже в контейнере как часть Cloudera Community edition).
Сорри, увлекся. К чему я это пишу — инфраструктура Kafka/Hadoop на самом деле, для вашего объема данных — недорогая. Одного физического сервера за 200 евро в месяц вам бы хватило за глаза, и, как пишут выше, вы бы получили систему, которая масштабируется при необходимости, и вообще «другая вселенная» )
При желании, можно было бы принимать эвенты на nginx, сразу же их ложить в очередь, и с другого конца укладывать в HDFS с пом. Flume, даже не написав ни строчки кода.PoisonousJohn Автор
15.03.2018 10:29Я писал
Решение «на голых VM» оценивалось ровно с такой же конфигурацией, что предлагает HDInight. Конечно, пожертвовав надежностью, можно уменьшить размер кластера и снизить цену, но это не совсем корректное сравнение.
Дело в том, что цена кластера — важный параметр. Но такой же важный параметр и надежность. Что будет, если эта единственная нода упадет? А что если в аналитику идут бизнес-критичные данные, по которым потом рассматривают тикеты пользователей?
Оценка Apache Stack'a была довольно грубой, широкими мазками, так сказать. Я понимал что конфигурация кластера мощнее, что можно это все развернуть руками на виртуалках меньших размеров, но я так же понимал, что студиям придется заниматься администрированием. А как я и говорил раньше, они не очень готовы в это вкладываться.

vkflare
15.03.2018 10:30Слишком сложно и дорого. Такой поток метрик прожует ELK-стэк, развернутый на двух EX41-SSD на хецнере (2 * 34 € ), не особо при этом чихая. Да что там, rdms тоже должны справится, но эластик очевидно выигрывает за счет легкости в добавлении новых ключей и наличия коробочных средств просмотра.
PoisonousJohn Автор
15.03.2018 10:39Слишком сложно и дорого.
А в чем сложность? Все сводится к тому, чтобы поднять через портал пару сервисов, и связать их вместе. Ну в нашем случае еще пару Azure Functions написать — но это опциональный шаг, если нужна гибкость.
Такой поток метрик — довольно детская нагрузка. Среди основных требований — легко масштабироваться. Если игра схватит фичеринг, то легко можно вырасти в 10,20,30 раз.
У меня нет большого опыта с ELK. Но те студии, с которыми мы работали, у которых была своя система аналитики, ELK для игровой аналитики не пользовали. Пользовали для мониторинга.
gaploid
А есть ограничения по обьему даннах в такой конструкции?
PoisonousJohn Автор
Ну это же облако. Там есть свои лимиты на Data Lake Storage аккаунт, но там скорее в деньги упрешься.
Плюс обычно делают, что данные архивируют в другие виды хранилищ, так как дешевле, и не всегда ты ими пользуешься. Так что можно считать, что нет.