
Искусственный интеллект сейчас является одной из самых обсуждаемых тем и главным двигателем цифровой трансформации бизнеса. Стратегия Microsoft в области ИИ включает в себя демократизацию ИИ для разработчиков, т.е. предоставление простых в использовании фреймворков и сервисов для решения интеллектуальных задач. В этой статье рассказывается, как .NET-разработчики могут использовать возможности ИИ в своих проектах: начиная от готовых когнитивных сервисов, работающих в облаке, заканчивая обучением нейросетей на .NET-языках и запуском сложных нейросетевых моделей на компактных устройствах типа Raspberry Pi.
Прототипом статьи послужил доклад Дмитрия Сошникова на конференции DotNext 2017 Moscow. Дмитрий — технологический евангелист компании Майкрософт, занимается популяризацией современных технологий разработки программного обеспечения среди начинающих разработчиков. Специализируется в области интернета вещей, в разработке универсальных приложений Windows, в области функционального программирования и на платформе .NET (F#, Roslyn). Лично провел несколько десятков хакатонов по всей России, помогал многим студенческим стартапам начать свои проекты в различных областях. Доцент, к.ф.-м.н., ведет занятия в МФТИ и МАИ, член Российской ассоциации искусственного интеллекта, летом — ведущий кафедры компьютерных технологий детского лагеря ЮНИО-Р.
Осторожно, трафик! В этом посте присутствует огромное количество картинок — слайдов и скриншотов с видео в формате 720p.
В этой статье мы поговорим об искусственном интеллекте. Почему про него сейчас модно говорить? Потому что это спектр технологий, который очень быстро меняет мир.
Таким примером изменения мира является Макдональдс. И в Америке, и у нас есть МакАвто. У нас там сидит человек, который принимает заказы. А уже лет 20 назад в Америке решили, что человек там не нужен, нужно заменить его оператором, который сидит в Индии — это будет гораздо дешевле. Он будет разговаривать с посетителями по телефону, вбивать это всё в компьютер, заказ будет готовиться, и не нужно будет платить американцу. Сидящий в окошке американец — это очень дорого. Такое решение позволило снизить цены: гамбургеры стали дешевле, люди стали менее здоровыми — всё хорошо. Последний шаг в этом направлении был сделан, когда поняли, что человек там вообще не нужен. Можно взять и заменить его алгоритмом распознавания речи. Такой проект год с лишним назад сделали наши коллеги из американского Microsoft.
В интернете есть ролики, в которых можно постараться разобрать, что слышит человек в окошке Макдональдса, и прочувствовать всю глубину страдания этого человека. Ему ничего не слышно: там шумы, машины проезжают, а он вынужден это распознавать. Оказывается, что ИИ справляется с этим лучше человека, потому что человек устаёт.
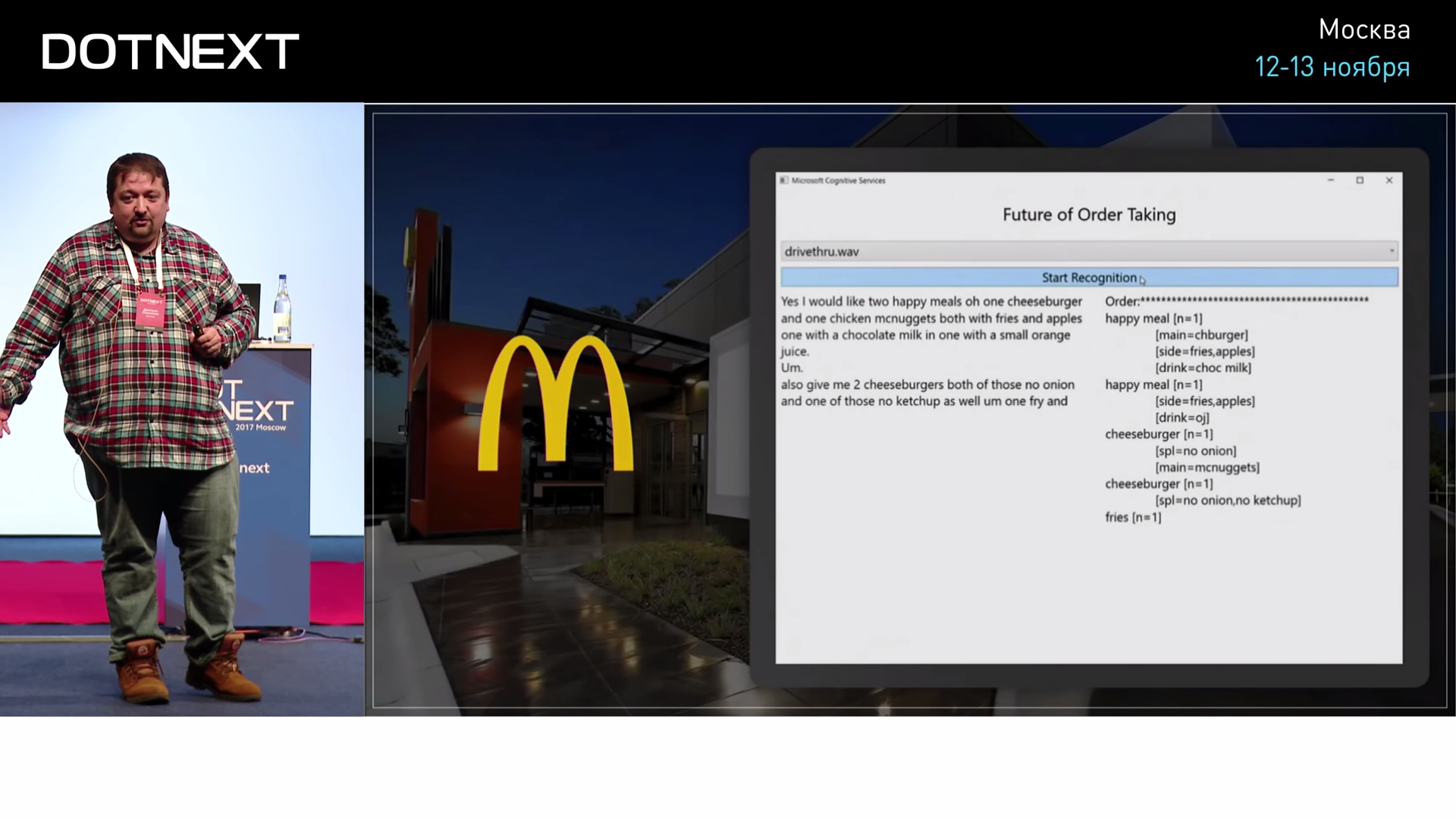
В случае с оформлением заказа беседа с оператором идёт на вполне определённую тему, никто не будет с таким окошком говорить о смысле жизни. Когда понятно меню, когда понятны слова, компьютер распознаёт лучше человека. В 2016 году Microsoft сделал заявление о том, что наконец-то они сделали алгоритм распознавания речи, который работает лучше человека. Его испытали и подтвердили, что действительно лучше.
В 2015 году компьютер стал распознавать определённые изображения — дорожные знаки. Условно, из тысячи картинок компьютер находит дорожные знаки лучше, чем человек. Почему? Наверное, человеку это надоедает где-то на середине, а компьютеру — нет. Но результат есть результат: компьютер лучше нас справляется с такими задачами.
Вот список достижений Microsoft в области ИИ, они впечатляют.

Microsoft находится впереди планеты всей. Сейчас ведутся исследования, как использовать программируемые в облаке чипы FPGA для того, чтобы на них запускать нейронные сети. Спектр решений здесь большой.
Какова в целом стратегия компании? Что вообще Microsoft делает в области ИИ?
Во-первых, естественно, внедряет в продукты. Power BI, HoloLens — к нему очень много сейчас прикручивают распознавания. И в PowerPoint много мест, где используется ИИ. Например, там есть кнопочка «задизайнить слайд за меня», она называется «Design ideas» и предлагает дизайн для простых слайдов. Это результат машинного обучения и применения технологий ИИ. Или если вы вставляете картинку в PowerPoint, к ней генерируется подпись на естественном языке — что на ней изображено. Чтобы потом, если вы будете экспортировать это куда-то в веб, правильно проставлялись соответствующие теги. Казалось бы, мелочь, а приятно.
ИИ внедряется в продукты, проводятся исследования, как можно его эффективнее использовать в облаке, и — самое главное для разработчиков — происходит демократизация ИИ, чтобы им было проще пользоваться.

Есть когнитивные сервисы. Их можно просто использовать для основных задач, которые приходится решать, вроде обработки изображения. Например, мы хотим в свой продукт внедрить такую функциональность, чтобы она автоматически вставляла подпись к картинке. Это несложно — есть готовый облачный сервис: мы передаём ему картинку, он нам возвращает описание на английском языке. Если мы хотим внедрить в свой продукт машинный перевод — тоже всё очень просто: мы пользуемся сервисом Bing Translator, получаем перевод практически с любого языка на любой язык. Эти возможности доступны всем.
В рамках демократизации есть четыре основных направления: когнитивные сервисы, боты, машинное обучение — Azure ML, нейронные сети — Microsoft Cognitive Toolkit. Остановимся на последних двух.
Основная идея машинного обучения в том, чтобы компьютер на данных сам научился что-то делать.
Например, мы хотим научиться распознавать эмоции человека по фотографии. Как это можно сделать?

Если мы будем думать, как написать алгоритм, то понятно, что мы очень быстро зайдём в тупик. Например, мы не совсем знаем, как точно отличить удивление от страха: глаза круглые в обоих случаях. Непонятно, как этот алгоритмически сделать. А если мы возьмём много фотографий, то, наверное, можно по ним как-то автоматически это делать. Как? Во-первых, нам важно по фотографии определить какие-то основные признаки — перейти к каким-то численным показателям. Потому что фотография — это вещь абстрактная, со множеством деталей. Но мы можем, например, распознать положение глаз, положение уголков губ, перейти к численным вещам, которые можно представить в виде таблицы. Далее это можно подать на вход машинному обучению, чтобы алгоритм нашёл в них закономерность и построил модель, которая потом сможет нам делать предсказания. Дальше мы берём лицо, выделяем в нём эти же признаки, подаём на вход модели, и модель нам говорит, что, например, это человек, который на 80% счастлив, на 20% что-то ещё.

Если говорить про терминологию, то искусственный интеллект — это общая тема, в которой мы делаем что-то, что справляется с человеческими задачами. Машинное обучение — это часть ИИ, когда алгоритм пишем не мы, а он сам пишется на основе обработки данных. Нейросети — это один частный случай машинного обучения. А внутри нейросетей различают ещё модный термин «глубокое обучение», когда нейросети глубокие. Вообще сейчас нейронные сети вытесняют остальные алгоритмы, потому что многие сложные задачи решаются именно с помощью этого самого «глубокого обучения».

Что касается инструментов: как живут люди, которые делают глубокое обучение? У них есть два языка: Python и R. Почему Python стал популярным для data scientist’ов? Так случилось, что есть какое-то количество очень хороших библиотек, написанных, естественно, на C++ (потому что иначе они были бы медленными), но к которым есть очень хорошая обёртка на Python. И поэтому оказалось удобно использовать Python как склейку разных библиотек. А поскольку есть уже много библиотек для машинного обучения, то так сложилось, что можно просто их взять и начать использовать.
Для нейронных сетей то же самое. Когда все начали реализовывать свои библиотеки, то подумали: «Все data scientist’ы пишут на Python, поэтому нам тоже нужно делать все библиотеки на Python». Так возникло большое количество библиотек, которые поддерживают Python. Даже Microsoft сделал для нашей библиотеки CNTK поддержку Python, а поддержку .NET долгое время не делал.
С языком R всё ещё интереснее: к R есть готовая Comprehensive R Archive Network, в которой есть куча готовых библиотек на все случаи жизни. Нужно просто выучить этот язык и сто тысяч других библиотек.
А что делать человеку, который с этим никогда не сталкивался?

С одной стороны, можно идти учиться, но не хочется. Поскольку мне приходится работать с нейросетями, при работе с Python я испытываю не то чтобы совсем глубокое отвращение, но мне сложно это делать. Психологически очень сложно после типизированных красивых языков .NET переходить на нетипизированный язык, в котором ошибки не проверяются и выясняются, когда уже всё запускаешь. Ощущение, как будто программируешь без руки.
Давайте посмотрим, какие есть инструменты в мире .NET для того, чтобы решать задачи машинного обучения и тренировки нейронных сетей.

Начнём с вопроса: «А вообще сложно ли написать что-то самому? А вдруг это просто?»
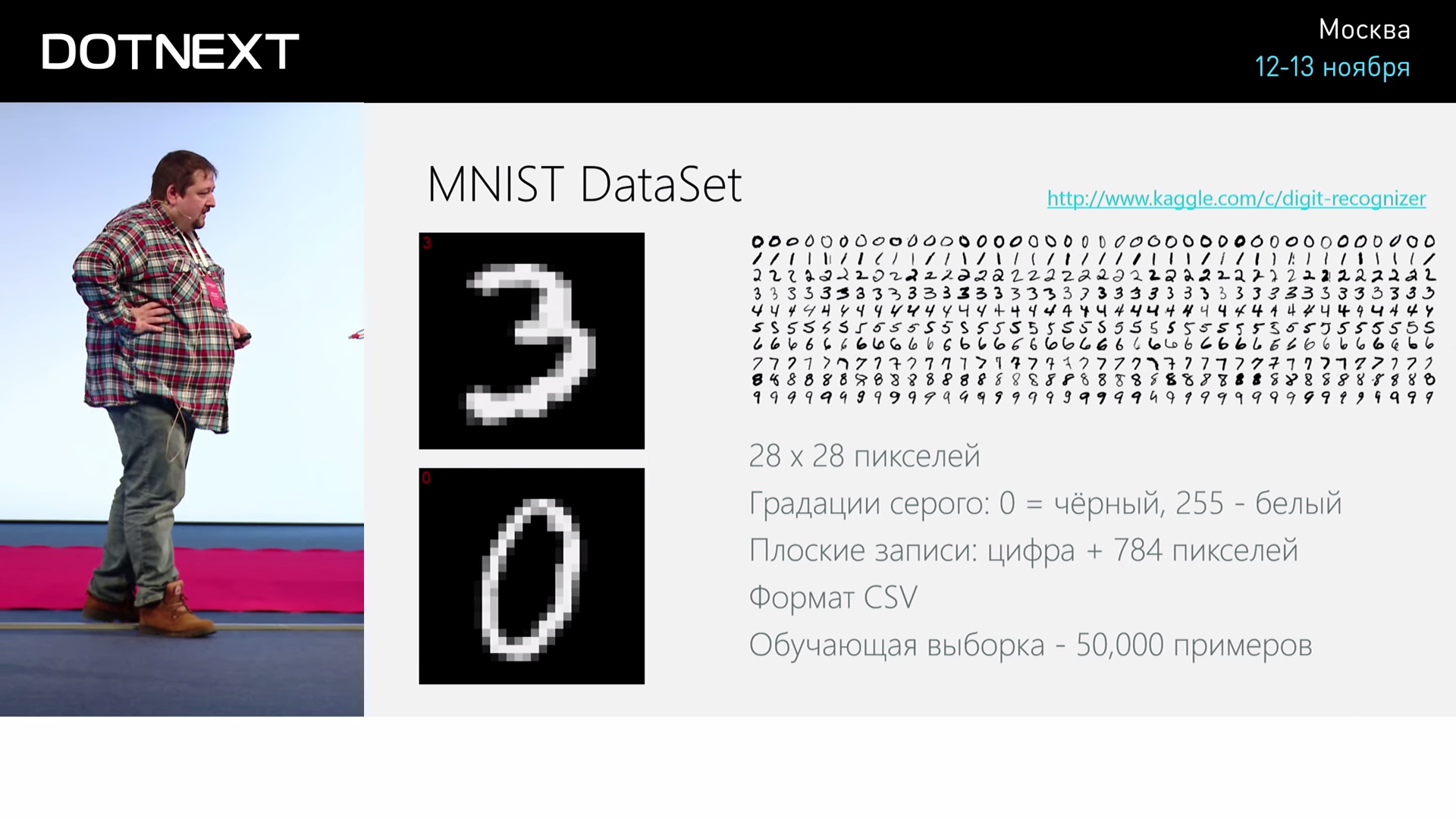
И возьмём такую классическую задачу: распознавание рукописных цифр. Есть готовый датасет где-то из 50000-70000 рукописных цифр, которые писали какие-то сотрудники статистического ведомства США. Эти данные общедоступны и они представлены в виде изображений 28 на 28 пикселей. Эта задача вроде бы не слишком сложная, но, с другой стороны, и не слишком простая, какая-то не совсем игрушечная, не прогнозирование цены на квартиру в Москве. Не очень понятно, как к ней подступиться. Посмотрим, как можно эту задачу решить и насколько эффективно и хорошо можно это сделать.
Какое самое простое решение приходит в голову? Есть у нас 50000 примеров, дальше кто-то написал какую-то цифру и говорит: «А какая это цифра?» Как нам понять, какая? Мы можем просто сравнивать со всеми 50000 и взять ту, которая лучше всего подходит. Как сравнивать? Можно считать разницу яркости в пикселях.

Такой алгоритм называется «K Nearest Neighbours» при K равном 1. Посмотрим, сложно ли его запрограммировать.

Заодно я покажу вам один хороший инструмент, которым пользуются все data scientist’ы, называется Jupyter Notebook. Это очень удобное средство, которое позволяет комбинировать в вебе программный текст с каким-то текстом, написанном на маркдауне. Примерно так это выглядит.
У меня есть ячейка-текст, дальше есть ячейка-код, которую я могу выполнить. Поскольку Jupyter Notebook — это инструмент из мира Python, он хорошо поддерживает Python и R, но можно прикрутить к нему поддержку других языков: C#, F#, даже Prolog. При этом Microsoft сказал: «А давайте эти Jupyter Notebook’и будем в нашем облаке предоставлять готовыми». По хорошему, если вы хотите себе это установить, вам нужно на компьютер поставить Python, Jupyter, запустить это всё и дальше открыть в своём браузере. А Microsoft предоставляет готовые Notebook’и в облаке, вы заходите на notebooks.azure.com — и можете начинать работать: логинитесь со своим Microsoft-аккаунтом и можете создавать эти самые Notebook’и с кодом. Этот код будет выполняться в облаке бесплатно, но с определёнными ограничениями. Например, данные можно брать только из определённых мест: из облака или из GitHub. Эти Notebook’и Microsoft’а поддерживают Python, R и F#. C# — нет, а F# поддерживают. Почему? Потому что F# лучше?
На самом деле, потому что для F# уже есть готовая красивая хорошая поддержка. Для C# есть похожий инструмент, который называется Xamarin Workbook. Это отчасти похожая вещь, она работает локально на вашем компьютере, но тоже позволяет комбинировать код с текстом. Комбинировать код с текстом — это очень здорово, потому что сразу всё понятно, все шаги описаны.
Мы берём эти изображения цифр, которые представлены в виде CSV (Comma-Separated Values). При этом в каждой строке первый элемент — это сама написанная цифра, а остальное — это массив из 784 чисел, каждое из которых это яркость соответствующего пикселя. И эта матрица из цифр разложена в длинную линейку цифр. Я описал на F# функцию, которая берёт эти значения из интернета, считывает и возвращает нам такие длинные строки.
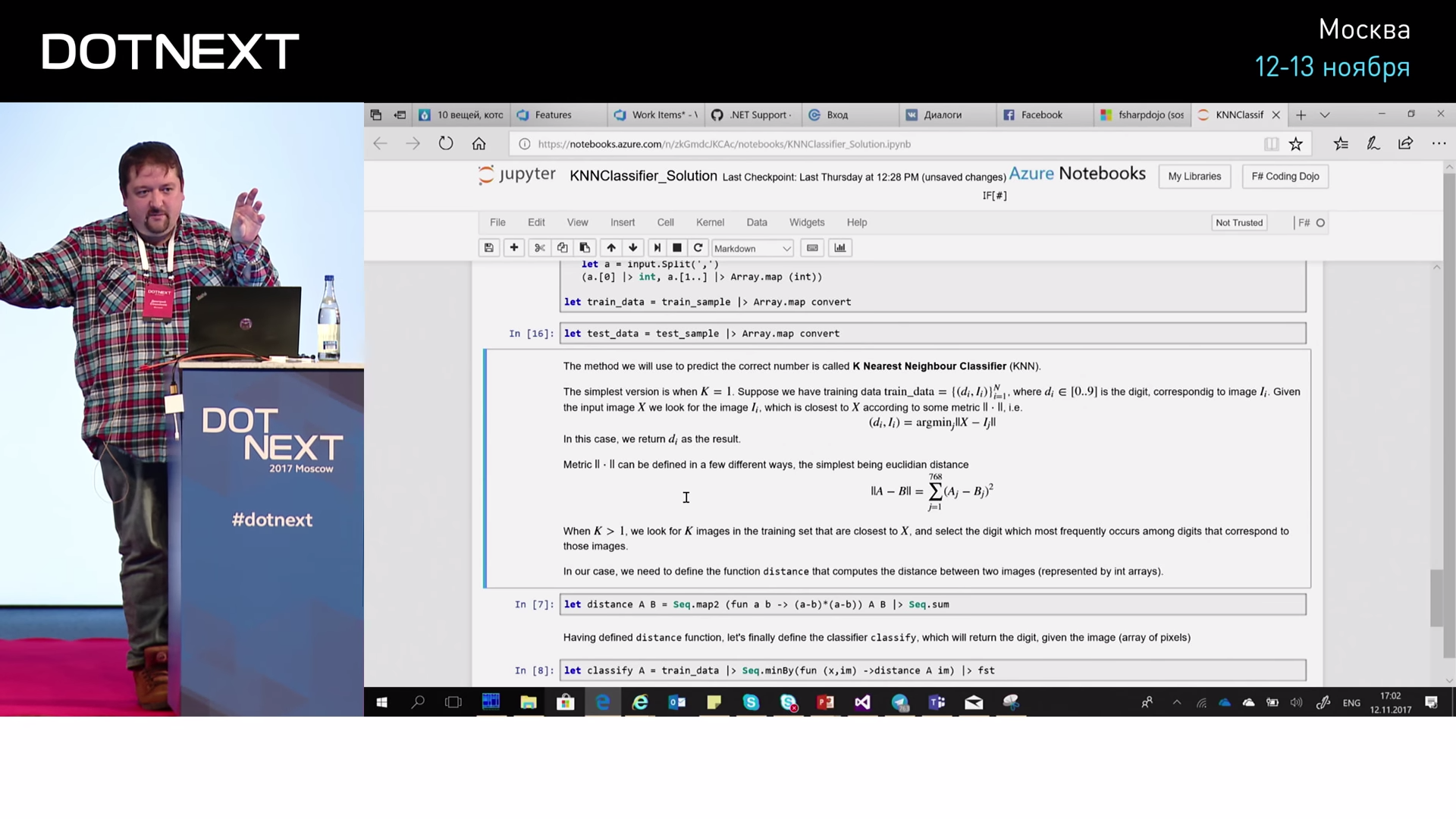
Теперь, чтобы с этим что-то сделать, мы поместим это в массивы и разобъём на две части: у нас будет train_sample — это обучающая выборка, и test_sample — это для проверки. Условно, мы возьмём 50000 обучающих и сколько-то тысяч для проверки. И приведём их к удобному виду: мы представим их в виде пар. В паре у нас будет цифра и массив из оставшихся пикселей. И таких пар много.
Дальше, как нам найти ближайшую? Для того, чтобы найти ближайшую, нам нужно определить расстояние. Для определения расстояния мы опишем функцию distance, которая берёт два массива с изображениями, проходится по этим массивам, считает разность квадратов и потом их сумму. То есть это декартово расстояние, мы просто не извлекаем корень. Оно показывает близость: если массивы одинаковые, оно показывает ноль, если чуть-чуть разные, будет какое-то число. А чтобы найти соответствующую цифру, мы берём все наши train_data — 50000 — дальше ищем, для какого из них расстояние минимальное, и берём соответствующую ему цифру. Код несложный. Дальше запускаем, и всё работает.

Берём тестовые данные. В данном случае я беру верхние три записи и пытаюсь распознать: восьмёрка распознаётся как 8, семёрка как 7, два как 2. Это хорошо, это внушает надежды. Если мы дальше пройдёмся по всей тестовой выборке, получается 94% правильного распознавания. Это, в принципе, очень неплохо.
94% — дальше можно почти ничего не делать, хотя мы написали всего несколько строчек.
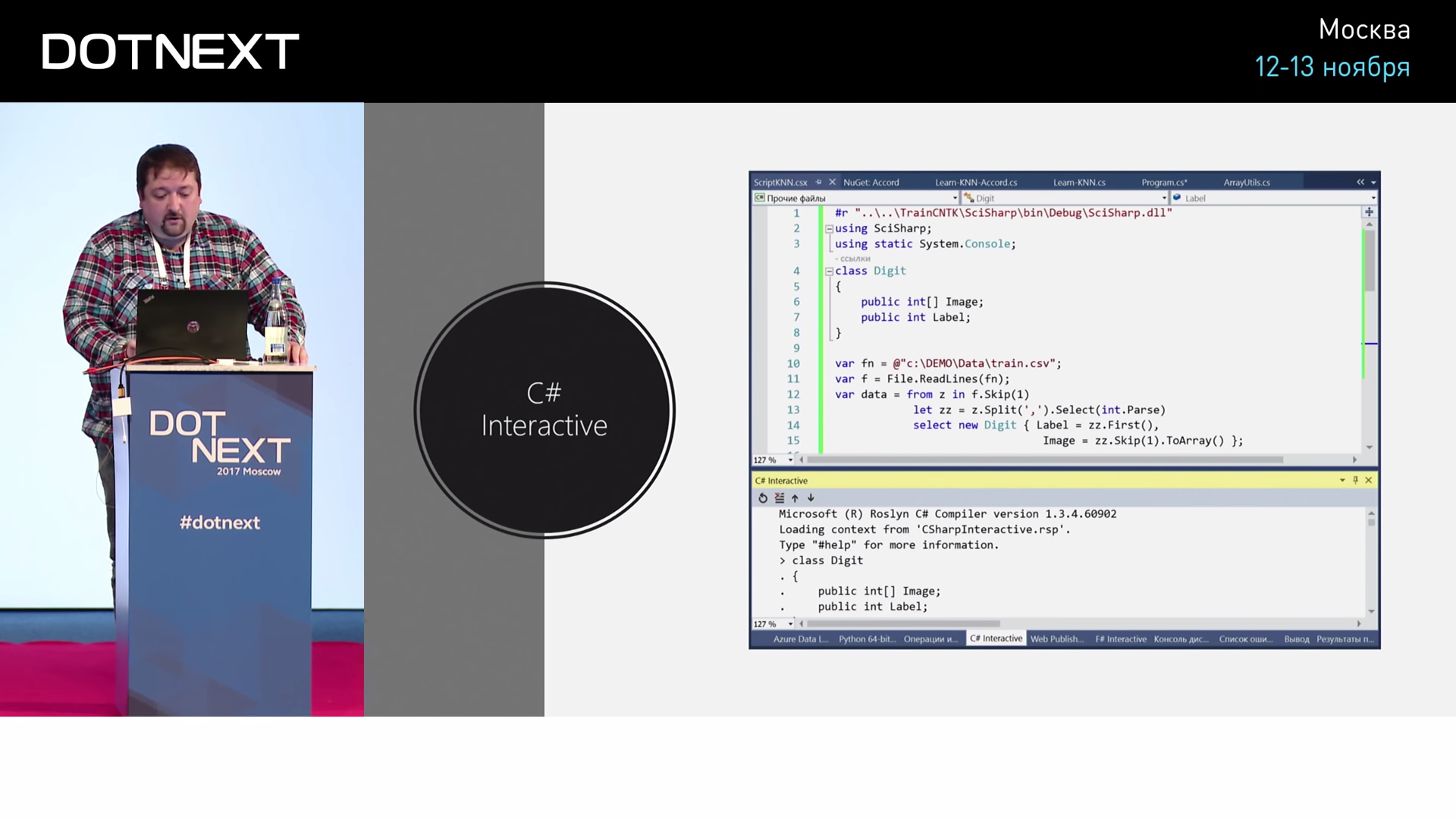
А если мы хотим то же самое сделать на C#?
Покажу, если кто-то не знает. В Visual Studio есть прекрасный инструмент, который называется C# Interactive. Это консоль, в которой можно C# выполнять прямо так: выделил кусочек текста, нажал клавишу и оно в консоли выполняется. Если я хочу то же самое сделать на C#, как это будет выглядеть?
#r "SciSharp.dll"
using SciSharp;
using static System.Console;
class Digit {
public int[] Image;
public int Label;
}
var fn = @"train.csv";
var f = File.ReadLines(fn);
var data = from z in f.Skip(1)
let zz = z.Split(',').Select(int.Parse)
select new Digit {
Label = zz.First(),
Image = zz.Skip(1).toArray();
};
var train = data.Take(10000).toArray();
var test = data.Skip(10000).Take(1000).toArray();
Func<int[ ],int[ ],int> dist = (a, b) =>
a.Zip(b, (x, y) => { return (x - y); } ).Sum();
Func<int[ ], int> classify = (im) =>
train.MindBy(d => dist(d.Image, im)).Label;
int count = 0, correct = 0;
foreach (var z in test)
{
var n = classify(z.Image);
WriteLine("{0} => {1}", z.Label, n);
if (z.Label == n) correct++;
count++;
}Вот и всё. Дальше я могу это запустить и наслаждаться результатом. Цифры распознаются медленно, потому что для каждой цифры нужно просмотреть 50000 записей (в нашем случае — не 50000, а 10000 записей). Поэтому для практического применения такой алгоритм не очень хорошо подходит. Мы его быстро написали, он работает не так плохо, но всё же очень медленно. А вообще хорошо бы, чтобы машинное обучение построило такую модель, которая будет работать быстро, она будет в себя как бы инкапсулировать суть процесса: не каждый раз сравнивать со всеми исходными данными, а найдёт какую-то закономерность. Поэтому, конечно, лучше использовать какие-то другие алгоритмы.

Таким образом, мы плавно переходим к следующему эпизоду.

Чтобы не программировать их самому, нужно посмотреть, а есть ли какие-нибудь готовые библиотеки. И здесь оказывается, что для .NET есть хорошая библиотека под названием Accord.NET.

Для того, чтобы делать машинное обучение, нам нужно уметь хорошо оперировать матрицами, статистикой, разными статистическими функциями. И Accord.NET содержит в себе соответствующие элементы. Там есть фрагмент, который отвечает за статистику, есть алгоритм, который отвечает за генетические алгоритмы, за нейронные сети, обработку звука, изображений. Там же есть полезные функции, которые позволяют строить график. Data scientist’у часто нужно взять и посмотреть, как данные зависят друг от друга.
Для этого я уже буду писать программу, у меня есть такая заготовка, в которой написано WriteLine. Это тот же самый код, который уже был. Он считывает мне все данные, разбивает их на тестовую и обучающую выборку. А дальше я использую Accord.NET для того, чтобы эти цифры нарисовать на экране. Есть такая красивая функция — ImageBox.Show, которая позволяет нарисовать что-нибудь.
#r "SciSharp.dll"
using SciSharp;
using static System.Console;
class Digit {
public int[] Image;
public int Label;
}
var fn = @"train.csv";
var f = File.ReadLines(fn);
var data = from z in f.Skip(1)
let zz = z.Split(',').Select(int.Parse)
select new Digit {
Label = zz.First(),
Image = zz.Skip(1).toArray();
};
var train = data.Take(10000).toArray();
var test = data.Skip(10000).Take(1000).toArray();
for (int i = 0; i < 5; i++) {
ImageBox.show(train[i].Image.Select(x => x / 256.0).toArray(), 28, 28);
}А теперь применим к ним какой-нибудь алгоритм обучения. Для начала тот же самый классификатор KNearestNeighbours. Как это выглядит на Accord?
var classifier = new KNearestNeighbors(1);
classifer.Learn(
(from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(),
(from x in train select x.Label).toArray());Мы просто говорим: «Хотим создать классификатор KNearestNeighbours с K равным единице». К слову, в KNN-алгоритме, что означает это K? В общем случае мы берём не просто ближайшую попавшуюся цифру, а мы берём, например, пять ближайших и среди них выискиваем ту, которая встречается чаще всего. Число 4 может быть похоже три раза на 4 и два раза на 1. И тогда мы берём 4. Увеличение этого класса делает распознавание чуть-чуть получше, но сильно снижает эффективность. Поэтому мы берём 1 и говорим: «Classifier.Learn. Пожалуйста, обучись». И передаём ему наши данные. Данные в этом случае пришлось нарезать, потому что я отдельно должен передать матрицу изображений и отдельно матрицу соответствующих цифр. Так устроен этот Accord, что ему передаётся два массива.
Дальше можно посмотреть, как это работает.
foreach (var z in test)
{
var n = classifer.Decide(z.Image.Select(t=>(double)t)).toArray());
WriteLine("{0} => {1}", z.Label, n);
if (z.Label == n) correct++;
count++;
}Работает это, вроде бы, чуть-чуть быстрее, чем то, что мы видели раньше, но не сильно. Если 5000 цифр так ждать, это будет достаточно долго. Но точность опознавания никак не меняется, потому что мы использовали тот же самый алгоритм. Но писали мы его не сами вручную, а взяли готовую реализацию.
Чем хорош такой подход? Теперь мы можем вместо этого классификатора использовать какой-нибудь другой. Например, я удалю этот классификатор и возьму так называемый классификатор Support vector machine. Это другой класс алгоритмов.
var svm = new MuliclassSupportVectorLearning<Linear>();
var classifier = svm.Lean(
(from x in train select x.Image.Select(z=>(double)z).toArray()).toArray(),
(from x in train select x.Label).toArray());Как они устроены? В терминах машинного обучения эта задача называется задача классификации, когда есть объекты и нужно отнести к одному из 10 классов. И вот Support vector machine берёт эти классы. Если их представить в некотором графическом виде в пространстве состояний, это будет текст, облака каких-то многомерных точек. Представьте себе точки в пространстве с размерностью 784, каждая точка соответствует своей цифре. Их нужно как-то разделить. Идея алгоритма Support vector machine в том, чтобы построить такую плоскость, которая будет максимально отстоять от элементов этих классов, которая будет их лучше всего разделять. Но лучше всего разделять в терминах перпендикуляра опущенного. То есть любая задача классификации — это задача построить плоскость, которая будет лучше всего разделять. Если мы будем смотреть перпендикуляр от ближайшей точки к этой плоскости и минимизировать вот это расстояние, Support vector machine проведёт соответствующую плоскость.
Мы заменили просто две строчки. По сути дела, поменялось название алгоритма.
Запустим, теперь алгоритм будет какое-то время обучаться. Здесь ситуация, в некотором смысле, обратная тому, что мы видели. Если предыдущий алгоритм не обучался, а просто сразу был готов классифицировать цифры, но при этом делал это очень долго, потому что сама работа происходила в процессе классификации, то здесь этот алгоритм сначала обучается. Он подбирает коэффициенты этих гиперплоскостей. И поэтому проходит определённое время, пока он это делает. Зато потом распознавать он начинает очень быстро. Настолько быстро, что мы сможем увидеть за несколько секунд, как эти самые 1000 или 5000 тестовых данных все посчитаются. И мы видим, что точность примерно 91,8%, чуть меньше.

Чем хорош Accord? В нём много разных алгоритмов, и их очень легко пробовать, мы можем заменить один алгоритм на другой, просто заменив конструктор, и дальше принципы их работы достаточно похожи. Если у вас встает задача машинного обучения, то это хороший второй шаг, чтобы начать. Первый шаг — это Azure Machine Learning в облаке у Microsoft, вообще не требующее программирования. Там вы можете просто визуально экспериментировать с данными. А второй шаг для тех, кто знает .NET, — это Accord.NET.

Мы понимаем, что для той области, где в Python используются всякие библиотеки типа SciPy или Scikit-learn, аналог им для мира .NET — это Accord.NET.
Перейдем к нейросетям.

Давайте поговорим немножко вообще про то, что такое нейронные сети. Самое важное, что нужно про них знать, — это что в последние годы многие считают нейросети синонимом вообще ИИ. Когда люди говорят «искусственный интеллект», сразу всплывают в голове нейронные сети. Все когнитивные сервисы Microsoft основаны на нейронных сетях и выглядят как магия. Представьте себе: вы передаёте ей фотографию, а она описывает, что на ней изображено на английском языке. Как это можно сделать? По-моему, это чудо.

Но при этом, с математической точки зрения, мы понимаем, что это чудо — это всего-навсего способ построения некоторой функции, которая оптимально приближает некоторое облако точек в очень многомерном пространстве. То есть получается такая странная ситуация: с одной стороны, с точки зрения математики, ничего странного не происходит. Всё, казалось бы, очень понятно. А с другой стороны, это почему-то решает такие вот интересные задачи.
Я даже в последнее время стал плохо спать по ночам, потому что я начинаю думать: «А мой мозг, он тоже так устроен? Может быть, он тоже всего лишь аппроксимирует функцию?» И это почему-то вгоняет меня в депрессию.
Выглядит всё как магия. Очень важно понимать, что для серьёзных задач, вроде преобразования картинки в текст, нужны очень большие вычислительные ресурсы. Это, скорее всего, либо облако, либо мощные видеокарты, но они уже перестали быть доступными, потому что криптовалютчики уже всё скупили. И это тоже грустно. Но в облаке машины остались.

Как устроена нейронная сеть? Нейронная сеть, в некотором смысле, напоминает по архитектуре человеческий мозг. В человеческом мозгу есть нейроны, которые связаны друг с другом, и вот эти связи в процессе обучения меняют свою проводимость, свои веса. Поэтому, с программной точки зрения, мы получаем такую конструкцию, в которой есть некое количество входов, каждый из которых может иметь какое-то числовое значение. Дальше есть некие промежуточные слои, где мы, например, берём сигнал с этого предыдущего слоя, со входа и суммируем с определёнными весовыми коэффициентами. Получаем здесь какое-то число, дальше суммируем со следующего слоя входа и в результате получаем какой-то выход.
Например, для задачи распознавания на фотографии кошки или собаки. Что мы подаем на вход? На вход мы подаём фотографию. Каждый вход — это будет отдельный пиксель фотографии, а выхода будет два: либо кошка, либо собака. И будет какое-то количество слоёв в середине.
И дальше что нам нужно сделать? Подстроить веса таким образом, чтобы эта нейросеть давала для входа правильный выход. Если мы в начале подадим картинку, очевидно, что она выдаст на выходе какие-то случайные числа. Если коэффициенты там были случайные, то она выдаст какое-то число. А мы скажем: «Нет, пожалуйста, давай подстроим веса так, чтобы это было больше похоже на кошку». И для этого мы используем некоторые алгоритмы.
Есть алгоритм обратного распространения ошибки, который позволяет подстроить веса. Дальше показываем следующий пример — снова подстраиваем веса. И так мы делаем много-много раз для очень большого количества примеров. С точки зрения математики здесь происходят очень простые вещи. Если представить себе, что этот слой выхода этого слоя — это некоторый вектор, то, по сути дела, мы умножаем этот входной вектор x на некоторую матрицу, дальше добавляем какой-то ещё сдвиг и применяем к этому некоторую нелинейную функцию. По сути дела, мы делаем для каждого слоя такое умножение матрицы на вектор. Всё очень просто.
Но зачем мы применяем нелинейную функцию? Отчасти, чтобы получить число в определённом диапазоне. Но есть очень убойный аргумент. Если бы её не было, это всё бы выглядело просто как произведение матриц, а произведение матриц эквивалентно какой-то одной матрице. Если мы берём входной вектор, умножаем на одну матрицу, потом на другую — это как если бы мы просто перемножили две матрицы и потом бы назвали число на это произведение матриц. Поэтому, если бы мы не добавили нелинейную функцию, число слоёв бы не влияло, всё было бы как один слой. А так, за счёт добавления нелинейности, это становится похоже на разложение в ряд. А когда это разложение в ряд, мы можем аппроксимировать произвольную функцию. А если бы этого не было, мы могли бы аппроксимировать только выпуклые линейные многообразия. Поэтому очень важно, что мы добавляем нелинейную функцию. При этом нелинейные функции тоже бывают разные.
Раньше было принято делать такие красивые нелинейные функции, которые называются «сигмоид», сейчас стало модным делать нелинейную функцию в виде линейной функции. То есть наполовину линейной: она линейная больше 0, а меньше 0 она — 0. Почему? Потому что она оказывается эффективной в реализации. Её производная считается легко, хотя это плохая производная. Тем не менее, такие функции часто используют.

Как мы можем реализовать нейронную сеть? Мы можем запрограммировать её вручную, это задача тоже не супер сложная, но не очень приятная. Что ещё важно: поскольку мы хотим обучать потом это всё на графических процессорах, если делать по-хорошему, нужно вдаваться в обучение графических умножений матриц на железе — это всё уже становится сложно.
Поэтому обычно использует какие-то готовые фреймворки. Есть TensorFlow от Google, который является основным конкурентом и которым все в основном пользуются. Есть ещё несколько других.

В Accord тоже есть нейронная сеть, мы можем здесь забацать нейронную сеть, просто взяв и изменив этот алгоритм. Всё будет чуть-чуть по-другому.
var nn = new ActivationNetwork(new SigmoidFunction(0.1), 784, 10);
var learn = new BackPropagationLearning(nn);
nn.Randomize();
WriteLine("StartingLearning");
for (int ep=0; ep<50, ep++) {
var err = learn.RunEpoch((from x in train select x.Image.Select(t=>(double)t/256.0).toArray(),
(from x in train select x.Label.ToOneHot10(10).ToDoubleArray()).toArray()
)
WriteLine($"Epoch={ep}, Error={err}");
}
int count=0, correct=0;
foreach (var v in test) {
var n = nn.Compute(v.Image.Select(t=>(double)t/256.0).toArray());
var z = n.MaxIndex();
WriteLine("{0} => {1}"), z, v.Label);
if (z == v.Label) correct++;
count++;
}
WriteLine("Done, {0} of {1} correct ({2}%)", correct, count, (double)count * 100);С нейросетью есть такая проблема: когда мы её делаем, она не всегда работает очень хорошо, потому что есть разные параметры обучения. В данном случае это ширина этой самой Activation Function. Не очень хорошо, что мы сделали от 0 до 1, может быть, было бы лучше сделать от -1 до 1, чтобы она была в отрицательной зоне. Если бы мы использовали, например, функцию не линейную, а полулинейную, то нам точно важно, чтобы она была в отрицательной зоне. Есть разные тонкости. И первая попытка не всегда оказывается удачной.
На каждом этапе обучения я печатаю ошибку, которая осталась. Она приближает выход к тому, что нужно, но при этом всё равно остаётся какая-то ошибка, и процессе обучения она всё время уменьшается. Однако, иногда она начинает увеличиваться — это верный признак того, что, наверное, что-то пошло не так, и уже стоит останавливать обучение. Есть также проблема переобучения, когда сеть переобучается, она начинает хуже предсказывать.
Например, мы запускаем тест приведенного выше кода, и получаем 88,3%. Это не очень хорошо, но и не очень плохо.
Но пока мы не видим, что нейронные сети гораздо лучше, чем то, что было.
Тем не менее, в Accord можно учить нейронные сети, но не нужно, потому что есть специализированные фреймворки, которые лучше.
Наш Microsoft Cognitive Toolkit, чем он прекрасен? Он может использоваться на GPU, на кластерах компьютеров GPU — во всех возможных случаях. Кроме того, он open source, быстро и активно развивается. Он настолько активно развивается, что, например, до сентября он не позволял обучать нейронные сети на .NET, а сейчас уже позволяет.

Изначально у него было два режима обучения: можно было описать архитектуру сети на специальном языке, который назывался BrainScript, и скормить исходные данные и этот Script утилите в командной строке и сказать: «Пожалуйста, обучи мне нейронную сеть». Это всё происходило в командной строке, и дальше записывался файл модели, который можно было взять и использовать из какого-то своего проекта на C#, на Python, на чём угодно.
Но потом, как бы повинуясь велению моды, перенесли процесс обучения в Python. На самом деле это не так плохо, потому что всё получается более гибким, можно создавать разные хитрые архитектуры сетей, не нужно выучить новый язык BrainScript. Но до сентября 2017 основным режимом использования CNTK было: обучил на Python, а использовать можешь и с .NET.
А вот мы всегда, когда делаем какой-то проект и хотим заказчику показать результат, оборачиваем нейронную сеть в бота. Дальше фотографируем картинку, и сеть выдает результат. Бот пишется на C#, в него легко встроить вычисления нейронной сети, а обучение всегда было на Python и на виртуальной машине в облаке.

Если вы захотите поэкспериментировать с облаком, в облаке есть готовые машины под названием Data Science Virtual Machine. Когда вы её создаёте, получается машина, на которой установлен весь необходимый софт, в основном на Python.

Я чуть-чуть повторюсь: раньше основной режим обучения был такой: либо мы на BrainScript, либо на Python обучаем нейросеть, получаем файл и дальше используем его из с .NET. И всё это работает поверх некой библиотеки на C++. И то, и другое: и обучение, и вычисление.
В сентябре добавили специальные API для поддержки обучения. Почему это стало возможным? Почему у конкурентов такого пока что нет?
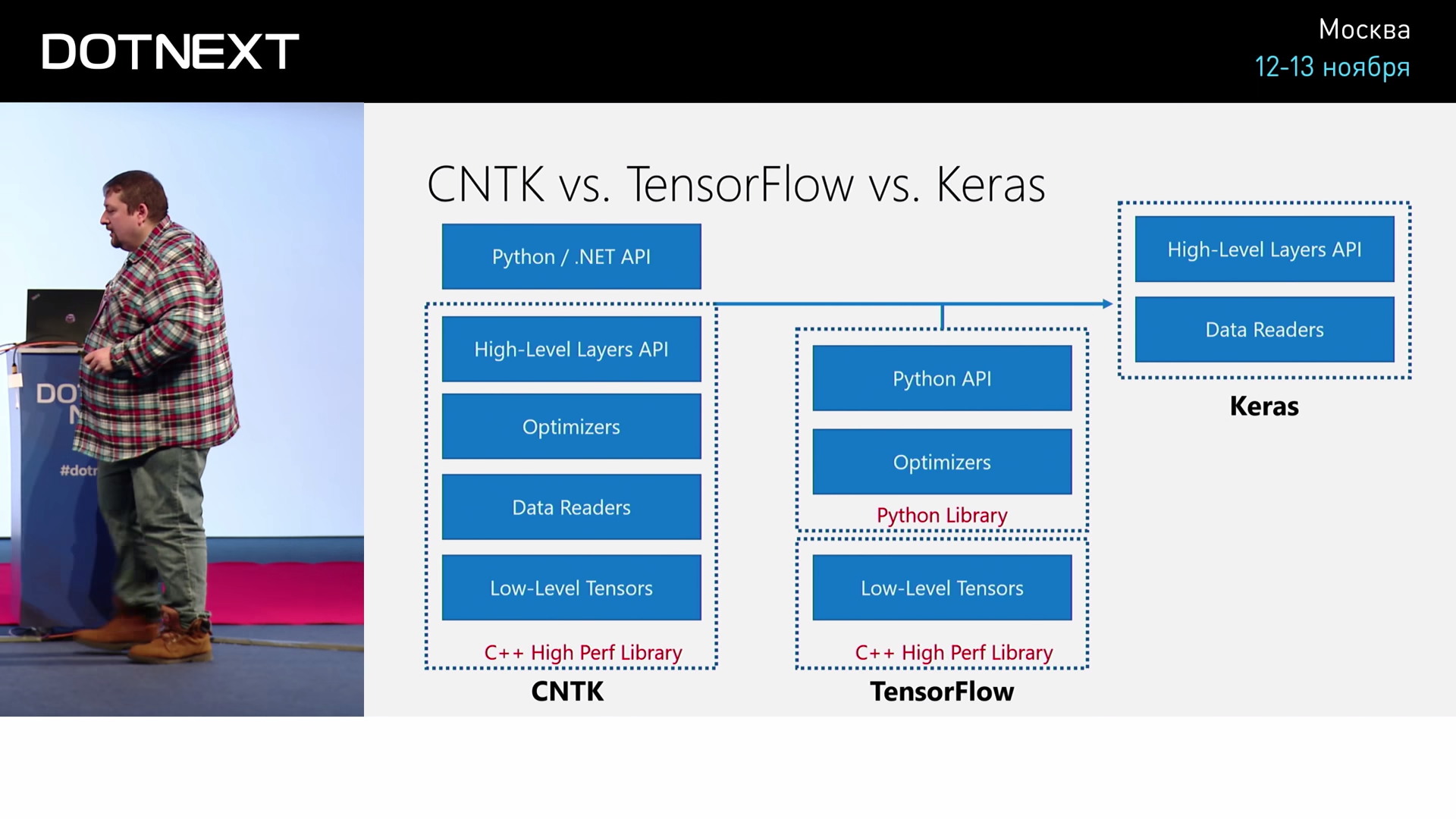
Если посмотреть на то, как устроен CNTK: что вообще включает в себя такая библиотека? В ней есть некий низкий уровень для работы с этими матрицами, которые называются тензорами, потому что нам часто приходится работать с очень многомерными матрицами. Как массивы бывают трехмерными, четырёхмерными и многомерными, так и тензоры. Но только тензоры часто приходится умножать, брать разные срезы, поэтому нужна специальная библиотека, которая умеет это делать.
Также в CNTK входят специальные датаридеры, которые позволяют нам откуда-то брать входные данные. Казалось бы, это очень простая задача: с диска прочитал и всё. Но если мы, например, обучаем модель на распознавание изображений, то нам часто нужно изображение по ходу дела, например, масштабировать. Или нам часто нужно по ходу дела как-то менять изображение. Например, такой часто используемый приём: если мы пишем распознавание котиков на фотографиях, мы будем все выходные данные поворачивать чуть-чуть, чтобы дать больше входных примеров сети, чтобы она видела не одно и то же, а чуть-чуть повёрнутых котиков. Вот эти вот вещи на ходу с данными могут делать как раз датаридеры, в них можно устраивать разные transformations, которые будут на лету данные как-то ещё менять.
Вот это всё входит в состав CNTK. Дальше для обучения нужны оптимайзеры — это некий алгоритм, который будет использовать алгоритм обратного распространения для организации оптимизации весов. Это кажется, что это делается просто, на самом деле, есть разные продвинутые алгоритмы. Простейший алгоритм называется градиентным спуском, но можно использовать, помимо этого, генетические алгоритмы, разные хитрые приёмы, чтобы делать это лучше. Вот эти вещи отвечают за обучение.
Плюс в CNTK есть некая API верхнего уровня, которая позволяет описывать сети очень просто. Не говорить каждый раз, что вот эти матрицы мы хотим перемножить, а говорить: «Хочу такой-то слой сети, такой-то, такой-то слой». Называется Layers API.
Всё это есть в CNTK, написано всё на C++, и поверх этого есть API на Python и на .NET.
Что у конкурентов? У конкурентов есть TensorFlow. TensorFlow состоит из хорошей оптимизированной библиотеки на C++, которая, собственно, работает с тензорами. Алгоритмы оптимизации написаны поверх этого на Python. Соответственно, взять и сказать, что мы будем оптимизировать на другом языке, уже так легко не получится. Поэтому нельзя TensorFlow прикрутить легко процесс обучения на .NET. Есть библиотека, которая позволяет использовать нейросети TensorFlow из C#, но не обучать.
Есть ещё такая популярная в мире нейронных сетей штука под названием Keras. В TensorFlow, как я уже сказал, очень низкоуровневые конструкции для описания нейросетей, а Keras позволяет добавить то, что в CNTK называется Layer API. Это некоторый такой более высокого уровня абстракции инструмент для работы с нейронными сетями.
И поскольку Keras очень популярным стал недавно, CNTK решил его тоже поддержать. Если вы описываете свою нейронную сеть на Keras, вы можете использовать в качестве бэкенда CNTK или TensorFlow, это может быть для каких-то случаев полезно.

Давайте разберем пример, как мы можем на CNTK обучить такую же нашу модель с числами.
Я опять же начну с такой пустой программы, которая только читает данные. Что я здесь сделал? Я только массив сделал не целым, а сразу float, и поделил всё на 256 в процессе чтения массива — сразу сделал так, чтобы у меня были коэффициенты от 0 до 1.
#r "SciSharp.dll"
using SciSharp;
using static System.Console;
class Digit {
public float[] Image;
public int Label;
}
var fn = @"train.csv";
var f = File.ReadLines(fn);
var data = from z in f.Skip(1)
let zz = z.Split(',').Select(int.Parse)
select new Digit {
Label = zz.First(),
Image = zz.Skip(1).Select(x=>x/256f).toArray();
};
var train = data.Take(10000).toArray();
var test = data.Skip(10000).Take(1000).toArray();
Дальше что мы делаем, чтобы писать сеть на CNTK? Нам нужно сначала задать некие параметры сети.
DeviceDescriptor device = DeviceDescriptor.CPUDevice;
int inputDim = 784;
int outputDim = 10;
var inputShape = new NDShape(1, inputDim);
var outputShape = new NDShape(1, outputDim);Во-первых, мы говорим, что хотим обучать всё на CPU. Дальше мы говорим, что входная размерность у нас 784 — это 28 на 28, а выходная размерность — 10, 10 цифр. Дальше мы описываем Shape. Shape — это форма входных данных. Просто описываем некоторую конструкцию под названием NDShape с соответствующими размерностями. Дальше описываем саму сеть.
Variable features = Variable.InputVariable(inputShape, DataType.Float);
Variable label = Variable.InputVariable(outputShape, DataType.Float);
var W = new Parameter(new int[] { outputDim, inputDim }, DataType.Float, 1, device, "w"} );
var b = new Parameter(new int[] { outputDim }, DataType.Float, 1, device, "b"} )
var z = CNTKLib.Times(W, features) + b;Как мы это описываем? У сети есть входной сигнал и выходной сигнал. И как мы её обучаем? Мы подаём входной сигнал, подаём выходной и оптимизируем, чтобы коэффициенты стали правильными. Соответственно, входной сигнал и выходной сигнал называются Variables, это переменные. Поэтому я описываю здесь variable, которая называется features — это входной сигнал, она имеет размерность 768, и выходной сигнал, который называется lable, который имеет размерность 10. И это две переменные. Дальше я описываю параметры. Вспоминаем, что если нейросеть однослойная, то это значит, что выход равен произведению матрицы на вход, плюс некоторый сдвиг.
Соответственно, вот эта матрица — W — это будет матрица размерностью 10 на 768. А сдвиг будет иметь размерность 10, то есть outputDim. Создаю вот эту матрицу и сдвиг. А дальше говорю, что моя сеть, выход — Z, это будет W умножить на вход + b. Я формулу записал просто в виде вызова функции. Всё.
Дальше я говорю: «А теперь, когда я дал на вход и на выход какие-то сигналы, пожалуйста, посчитай ошибку».
var loss = CNTLib.CrossEntropyWithSoftmax(z, label);
var evalError = CNTKLib.ClassificationError(z, label);Соответственно, ошибкой будет некая стандартная функция CrossEntropyWithSoftmax, не вдаваясь в подробности, что это значит. Здесь считается.
Теперь я хочу это всё обучать, для чего делаю некоторую магию. Лучше всего смотреть это на видео). Беру специальный Learner, с помощью него создаю объект под названием Trainer. Trainer будет тренировать с помощью того алгоритма, который определяет Learner, выбираю размер пачки в 60 элементов и говорю: «Trainer.Train».
И дальше всё свершается само.

Ещё раз: как происходит обучение сети по верхнему уровню? Описываем архитектуру в виде умножения матриц, дальше создаём функцию потерь, которую мы будем оптимизировать, и специальный объект оптимизатор и делаем цикл, когда много раз подаём это на вход. Как это выглядит на Python? Точно так же. Но просто на Python чуть-чуть покороче, красиво получается. Поэтому для простых сетей что на Python, что на C# — обучать примерно одинаково.

Можно сделать сложнее. Как улучшить точность? Можно сделать двухслойную сеть. Как в этом случае будет отличаться архитектура сети? Будет две матрицы и некоторый промежуточный слой размерностью 1500, и функция чуть-чуть посложнее. Но мы ожидаем, что теперь точность будет выше. Но и обучается она медленнее, потому что там уже две матрицы. Наш лучший результат был 94% точности.

Для разных задач есть разные архитектуры сетей. Если вы, например, задумаетесь, а как же мне получить описание картинки по фотографии? И вообще — как бы мне сгенерировать текст? Такой обычной сетью этого сделать нельзя, для этого есть специальные рекуррентные сети.

Для анализа изображений тоже есть специальные сети, которые называются «свёрточные сети». Как они устроены? У нас есть изображение, и мы не хотим сразу по всему нему выделять результат. Например, если я хочу котика на фотографии, он может быть в разных местах фотографии. Если я буду по всему изображению обучать сеть, то котик в левом углу и котик в правом углу будут отличаться, будут разными котиками. За них будут отвечать разные веса. Чтобы от этого избавиться, делают окошко, которое бежит по изображению, и это окошко подаётся на вход некоторому фильтру, веса которого тоже обучаются. Это называется свёрточный слой. Мы бежим окошком, обучаем веса и получаем на выходе некоторые признаки, которые подаём на вход следующему слою. Я не буду подробно описывать, но точность повышается до 98%.

Свёрточная сеть выглядит уже чуть-чуть посложнее.

Я задаю параметры этого свёрточного окошечка, дальше идёт первый свёрточный слой. Он задается функцией Convolution. На его выходе делаю ещё некоторое прореживание матрицы из размерности 28 на 28 на 1 — то есть исходный размер изображения 28 на 28 и один цвет — я делаю 14 на 14 на 4. Как будто бы бежит 4 окошечка, каждое из них даёт что-то на выходе, и я потом ещё прореживаю эти выходы, чтобы разрешение упало в два раза, но размерность признаков увеличилась. Дальше я делаю ещё один слой, который из 14 на 14 на 4 делает 7 на 7 на 8. И после этого делаю ещё один полносвязный слой.

Это такая более-менее реальная задача. Если говорить о распознавании кошечек и собак, то эта задача ещё 5 лет назад казалась неразрешимой. Экспертов спрашивали: «Как вы думаете, когда мы сможем, наконец, заставить компьютер распознавать котиков и собачек?» Они говорили: «Не раньше, чем через 20 лет, очень сложно». Потому что правда непонятно, чем они отличаются. И раньше все исследования компьютерного зрения сводились к тому, что сидели люди и думали: «А давайте посчитаем градиенты! А давайте посчитаем такие-то признаки!» И вручную придумывали, какие признаки нужно взять, чтобы отличать кошечек и собак.
А сейчас всё это нейросеть делает сама, поэтому сейчас основные идеи состоят в том, что мы придумываем такую архитектуру сети, которая бы хорошо решала эту задачу, и дальше её обучаем. Но нужно понимать, что я вам сейчас показал свёрточную сеть, в которой три слоя. А в сетях, которые сейчас используются для распознавания такого рода вещей, этих слоёв может быть, если не несколько тысяч, то обычно порядка 500-1500 слоёв, которые нужно обучать. Обучение происходит, естественно, медленно, требуется мощное железо, малейшая ошибка приводит к тому, что сеть не обучается — ошибка не уменьшается. В общем, это такой творческий, очень сложный процесс. Тем не менее, он происходит.
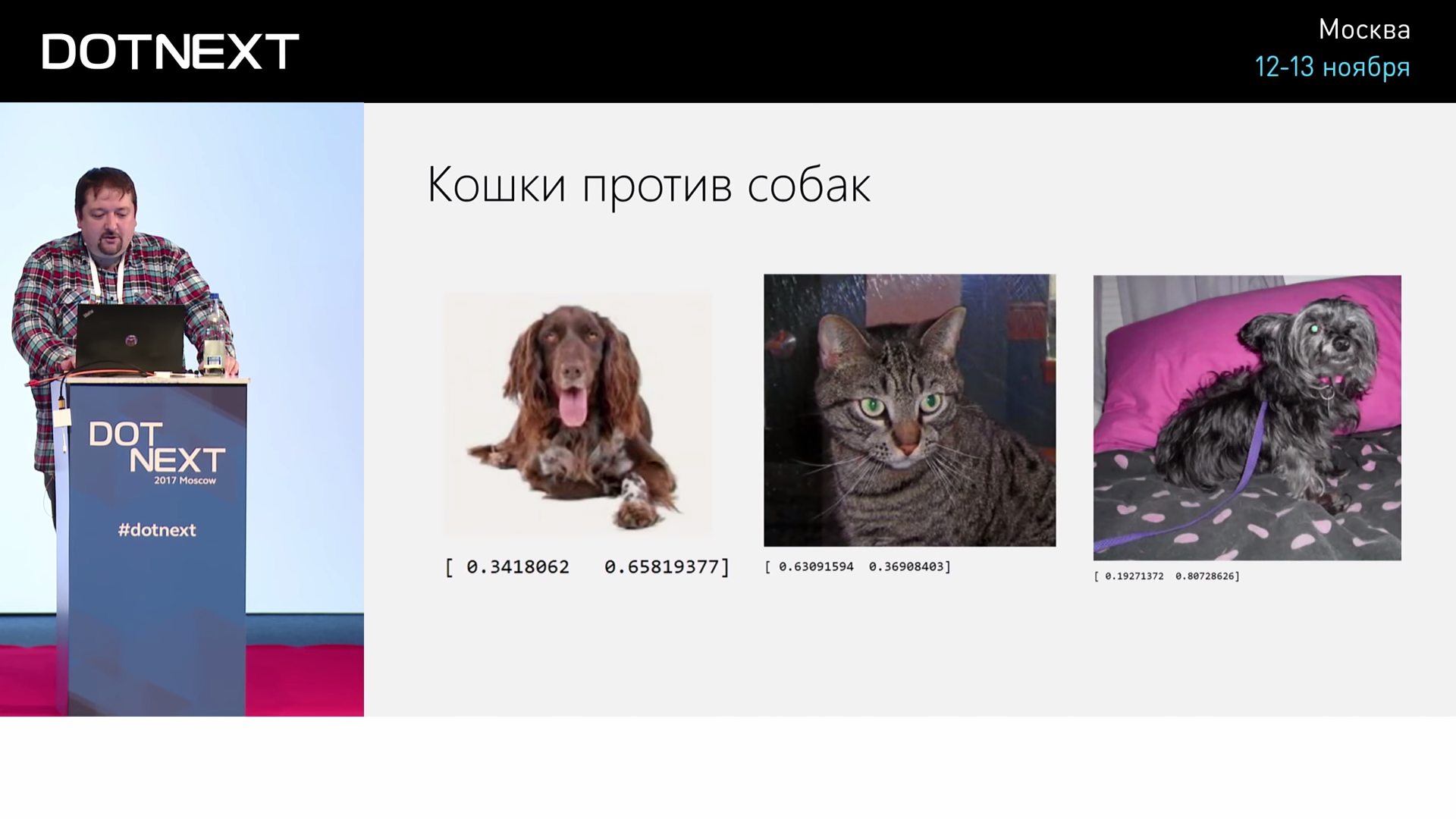
Я на C#, честно признаюсь, этот процесс не проделывал (только на Python), просто написал программу — достаточно простую сеть из 6 слоёв. Это 3 свёрточных слоя, которые с окошком 5 на 5 — это распознавание котиков против собачек по размеру изображения 32 на 32 пикселя. По маленькой картинке. 3 свёрточных слоя и 3 полносвязных слоя.
На Python соответствующая программа позволила мне распознавать собак и кошек, не то чтобы хорошо, но с некой вероятностью больше 50, процентов 75. Вот, кошка, собачка, второе число это собачка. Это 0,8 собачка, это 0,4 собачка, это 0,65 собачка. Но это реальный процесс, там компьютер с графическим процессором поработал 3-4 часа, чтобы этому обучиться.
Что смотреть дальше?
По нейронным сетям:
F# API для CNTK:
Если вас эта тема заинтересовала, есть интенсив по нейронным сетям, который мы делали специально в рамках одной из наших конференций. Он достаточно нудный, потому что это запись выступления со сцены. Четыре часа — всё, что вам нужно знать про нейронные сети. Даже не 4, по-моему, а 6. Но там есть примеры, есть Notebook’и на Python с описанием того, что есть что. По ним можно попытаться разобраться. Не говоря уже про то, что можно посмотреть курс на Coursera или где-то ещё.
Нейронные сети — это тема, которая становится очень актуальной, и в них имеет смысл чуть-чуть разбираться. Для CNTK, помимо того, что я показывал, ещё есть инициатива прикрутить туда F#. Не на C# эти слои описывать, а на F#. Это получается красивее. Но инициатива в самом разгаре, её только начали делать. Есть на GitHub код с идеями, как это правильно сделать. И вообще, как вы поняли, только в сентябре, даже в конце сентября — начале октября 2017 появилась возможность обучать нейросети на C#, поэтому тема достаточно молодая и, конечно, всё будет в этом направлении только улучшаться.

И, наконец, мораль. Что нужно запомнить? На .NET есть достаточно инструментов, чтобы использовать комфортно машинное обучение и нейронные сети. Мы посмотрели на такие инструменты, как Azure Notebooks, на C# Interactive, упомянули ещё Xamarin Workbooks — тоже, возможно, будет полезно в работе. И наконец, для обучения нейросетей есть у Microsoft очень хороший инструмент — CNTK, им можно пользоваться и с C#, им очень хорошо пользоваться в облаке на виртуальных машинах с графическими процессорами, потому что там все сети обучаются быстрее. Если кошки и собачки, то там до 10-15 раз быстрее, это уже достаточно существенный прирост.
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция по .NET — DotNext 2018 Piter. Она пройдет 22-23 апреля 2018 года в Санкт-Петербурге. Какие доклады там бывают — можно посмотреть в нашем архиве на YouTube. На конференции можно будет вживую пообщаться с докладчиками и лучшими экспертами по .NET в специальных дискуссионных зонах после каждого доклада. Короче, заходите, мы вас ждём.
Комментарии (10)

Terras
27.03.2018 20:09За что можно любить мелкомягких, что у них отличные туториалы. Когда после Java-туториалов, где ты сначала разбираешься со всеми конфигурациями, потом понимаешь, что туториал идет по какой-то древней версии, а потом вообще вынужден слушать каких-то лысеющих индусов с их ломанным английским, этот толстячок от мелкомягких заходит на ура.

CrazyFizik
28.03.2018 18:06Проблема даже не в туториалах.
Проблема глубже: архитектурного и идеологического плана.
В Жабе, stack наследуется от Vector, который в свою очередь наследуется от ArrayList. Стек — это просто же просто коллекция в которой последним пришел и первым вышел, все, положил да взял, больше ничего. К чему тогда все это, зачем стэку метода вектора, такая глубокая иерархия наследования — хз. Или написал Long и long, и все, хана, нарвался на упаковку-распаковку. Врожденных дефектов в Жабе море. Богатая история Жабы — с одной стороны достоинство, но учитывая костылестроение — одновременно и проклятие.
А уж туториалы — это уже следствие. Внезапное их устаревание — тоже (хотя .NET генетики тоже не с первого раза дались, но сейчас про костыль ArrayList и не вспомнит уже). А основная масса изменено .NET как правило синтаксический сахар, сама же платформа очень хорошо проработана и жестко стандартизирована (увы, на этом преимущества заканчиваются)


Danov
27.03.2018 23:16Время бежит и этой весной на платформе Windows будет доступен еще один фреймворк WinML:
Windows Machine Learning
Marui
28.03.2018 05:55-1Ожидание — Ух, щас попишем в стиле С++! С нуля! Сами! Хардкор!
Реальность — using; using; using; передать путь к папке. получить вектор результатов, окей.
molnij
28.03.2018 23:44А где можно посмотреть запись того самого 4-6 часового интенсива о котором идет речь в конце? Я по ссылке увидел материалы, но самой трансляции не заметил

ikashnitsky
30.03.2018 03:31Не в обиду Дмитрию =)Посмотрел на первую картинку и подумал, что Давидыча выпустили
Vasyutka
Вот не очень здорово, когда ради использования dotNET приходится углубляться в 45ый framework для deeplearning :(. Лучше обертку для всех существующих, поддерживаемых сообществом, (TF,torch и др.) делали бы и актуальными поддерживали.
А так да, это прямо серьезная проблема: под Windows довольно часто у людей решения крутятся, в которые люди сеточки добавлять хотят. На tensorflow/keras можно быстро соорудить на python скрипт, а дальше начинаются странные архитектурные решения, чтобы с python-ом из dotNET пообщаться
roryorangepants
Во-первых, можно общаться через консоль, вызывая питоновские скрипты прямо из .NET-окружения. Во-вторых, можно извратиться и даже сделать из питоновской модели Windows Service.
Но вообще, конечно, самый простой и адекватный путь — сделать микросервисную архитектуру, за полчаса обернув модель в Docker + Flask, и тогда вообще не надо будет привязываться ни к Windows, ни к .NET-инфраструктуре.