

Редактор данных
Мы добавили журнал запросов, которые редактор данных отправляет в базу. ProgerMan просил в комментариях пару релизов назад :)
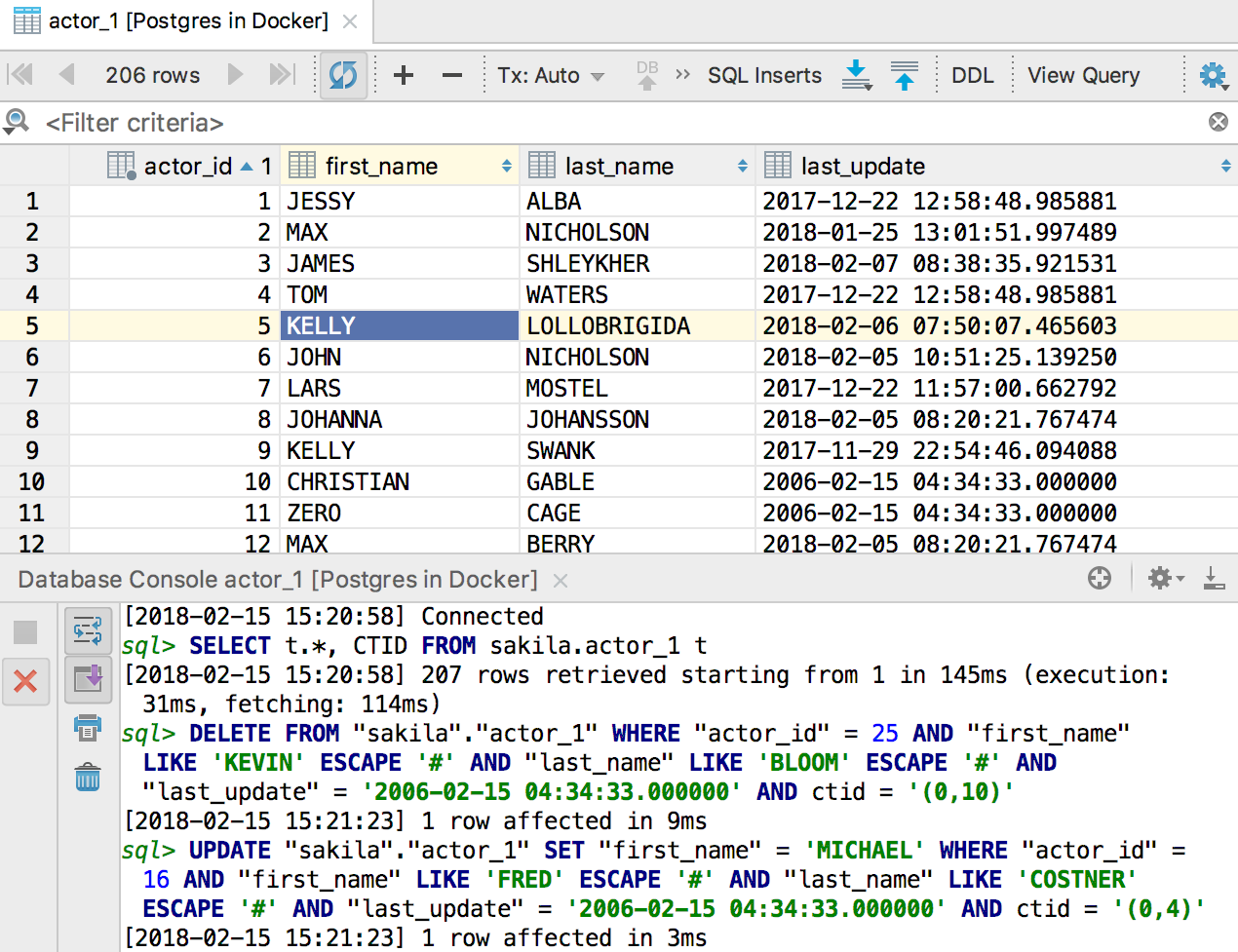
Запуск запросов
Режим «только для чтения»
У нас есть флажок «Read-only» в свойствах источника данных. Он включал этот режим на уровне jdbc-драйвера. Но read-only реализован в разных драйверах с оговорками:
— В SQLite его нельзя переключать для уже созданной коннекции.
— В MySQL он не позволяет запускать запросы, которые начинаются не с символа «S».
— В Oracle, SQL Server и некоторых других базах он вообще не работает :)
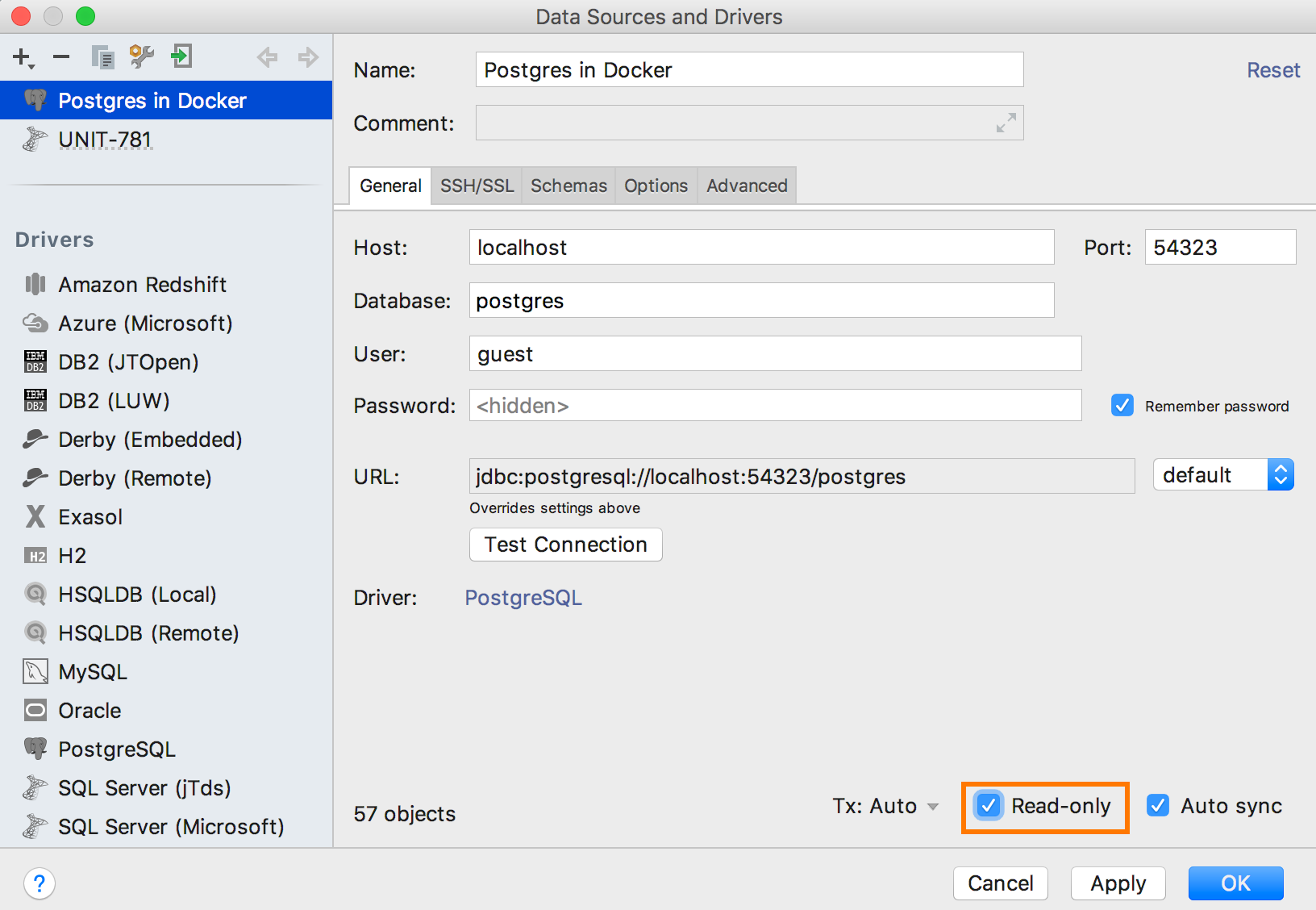
Поэтому мы сделали собственный read-only режим. Он включается вместе с тем, что реализован на уровне драйвера. Для MySQL и SQLite режим на уровне драйвера мы не включаем.
Вот, что делает наш read-only:
Он подсвечивает DDL и DML запросы, предупреждая об их небезопасности.

Если вы всё-таки запустили этот запрос, появится предупреждение. Для особо настойчивых мы показываем кнопку Execute в правой части предупреждения.

Ещё мы строим дерево вызовов функций и процедур, и на каком бы уровне вложенности ваша функция ни вела к модификациям, предупредим об этом.

В сочетании с раскраской источников данных перепутать тестовую базу с живой теперь сложно :) С 2018.1 в цвет источника данных красятся ещё и файлы, которые с ним ассоциированы.
Запуск скриптов
Маленькое приятное улучшение: источник данных, на котором был запущен скрипт из контекстного меню, запоминается и устанавливается по умолчанию для последующих запусков других скриптов.
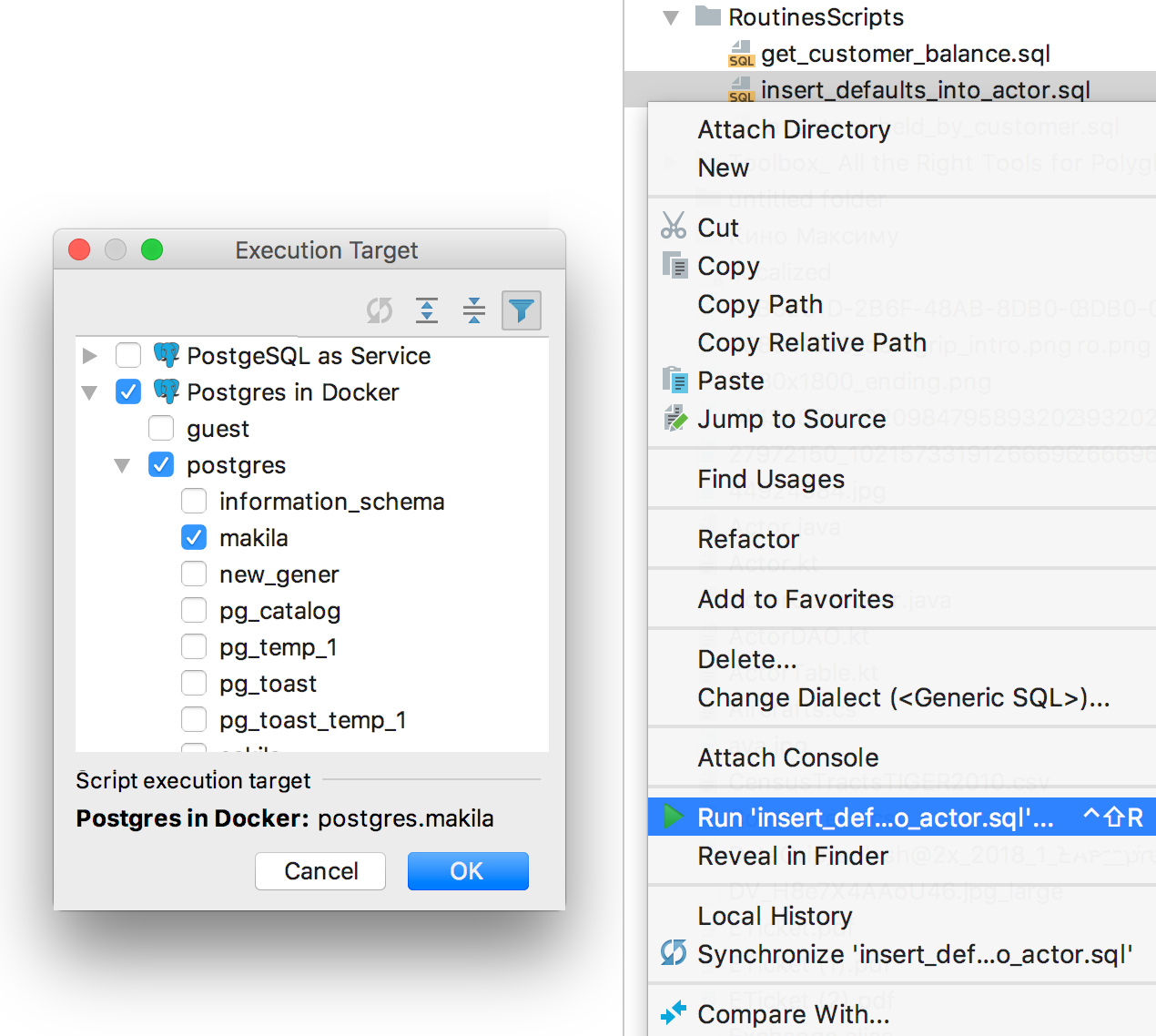
Общие улучшения
Переключение схем
Укажите, как DataGrip будет переключать схемы.
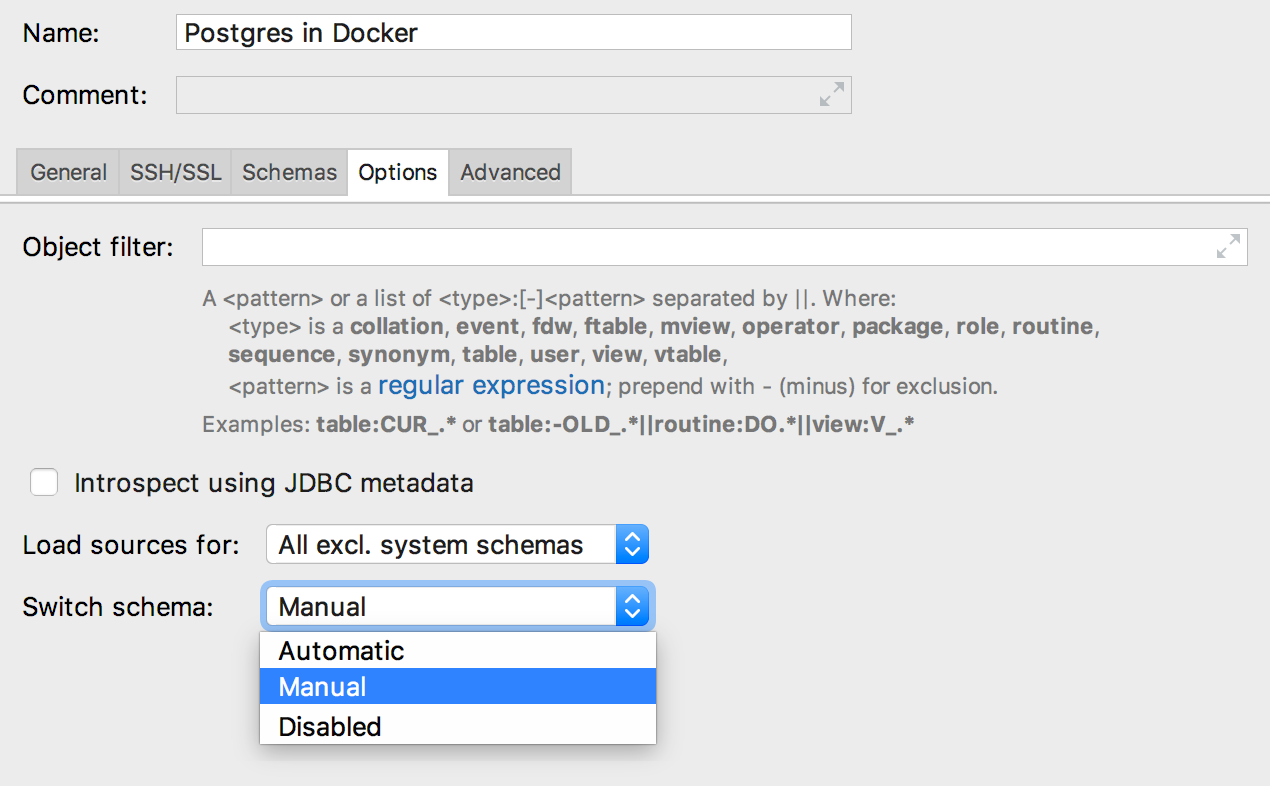
— Automatic. Среда сама будет переключать схемы, если это потребуется для определения правильного контекста. Скажем, если вы переименовываете объект не в текущей схеме, мы переключим схему для внутренней операции.
— Manual. Схемы переключает только пользователь, в правом верхнем углу консоли.
— Disabled. Переключатель вверху не будет работать. Будет полезно для дополнительной защиты при использовании pg_bouncer.
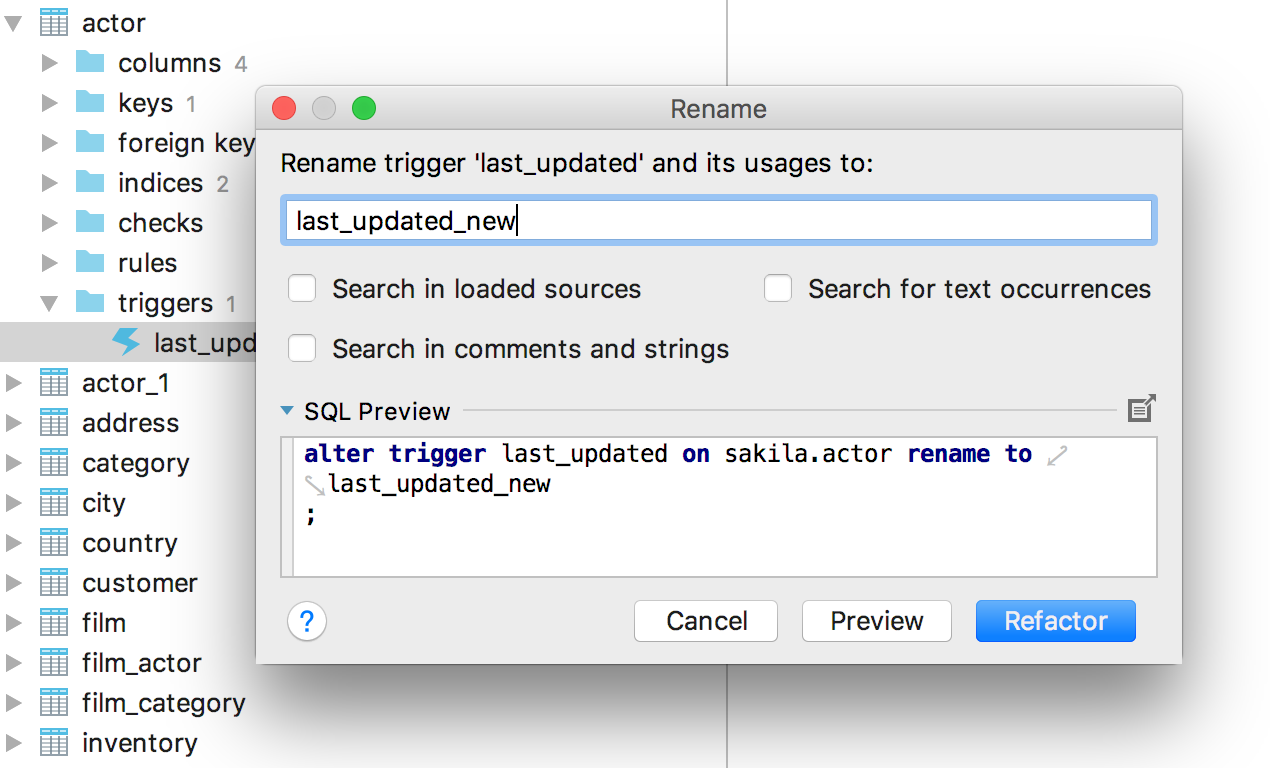
Переименование объектов
С этого релиза мы официально поддерживаем переименование всех объектов, которые интроспектируем. Переименовывайте триггеры в PostgreSQL, события в MySQL, последовательности в Oracle и многие другие объекты, нажав на них Sift+F6 в дереве или в SQL-скрипте.
Навигация
Появилась новая настройка: Prefer data editor over DDL editor. Она влияет на:
— Навигацию к таблице или представлению по Ctrl+N/Сmd+O
— Навигацию к столбцу по Shift+Ctrl+Alt+N/Shift+Cmd+Alt+O
— Двойной щелчок по таблице или столбцу в дереве базы данных.
Если флажок отмечен, в этих случаях вы увидите редактор данных. Если нет — исходный код объекта.
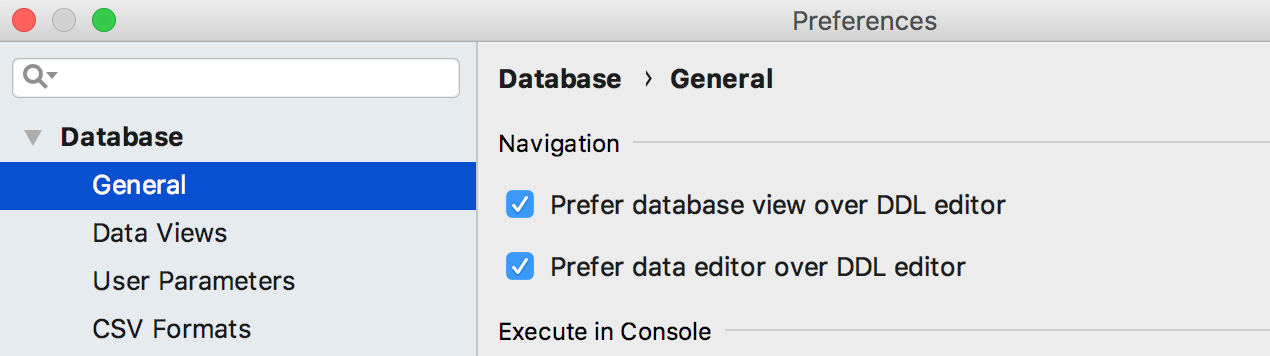
Navigate references to DDL editor переименован в Prefer database view instead of DDL editor. Эта опция влияет на действие Navigate to declaration (Ctrl+B или Ctrl+Клик) из SQL.
Если флажок отмечен, объект подсветится в дереве базы данных. Если нет — откроется исходный код объекта.
Мы объединили два действия — Go to table и Go to class (Ctrl+N/Сmd+O).
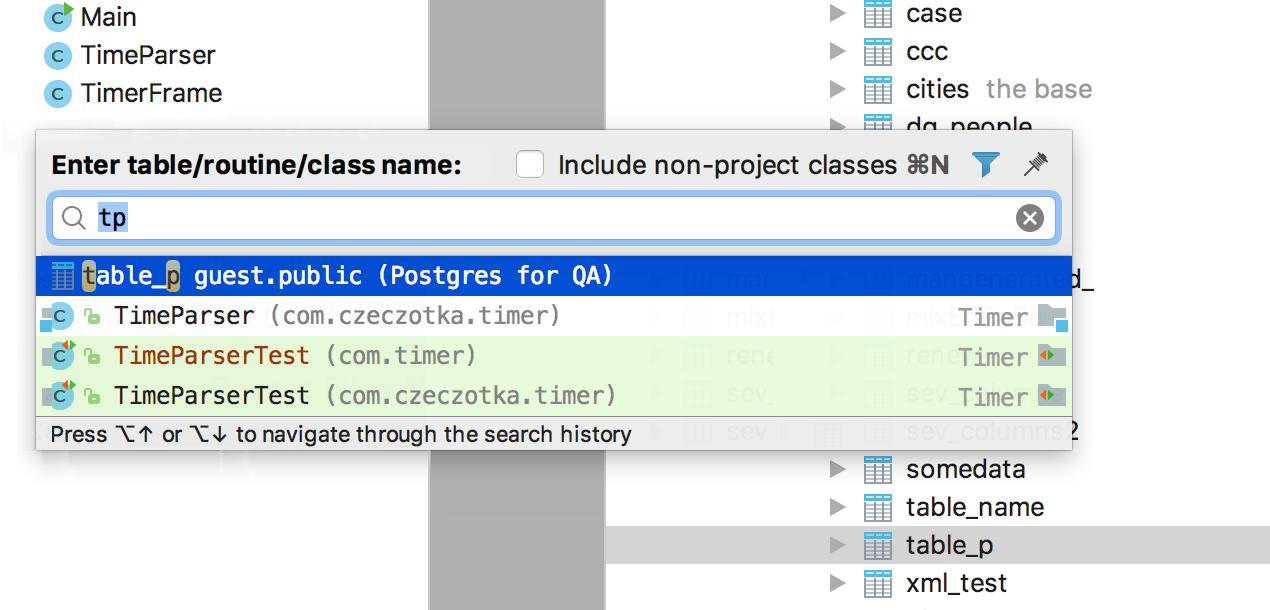
— В DataGrip можно указать имя класса, если вы используете другие поддерживаемые языки.
— В других IDE на платформе IntelliJ с поддержкой баз данных можно указать имя объекта базы и перейти к нему.
Документация для файлов
Это удивительно, но раньше а наших IDE нельзя было быстро узнать размер файла. Поэтому мы добавили основные атрибуты файла в документацию — вызывайте её по Ctrl+Q или F1.
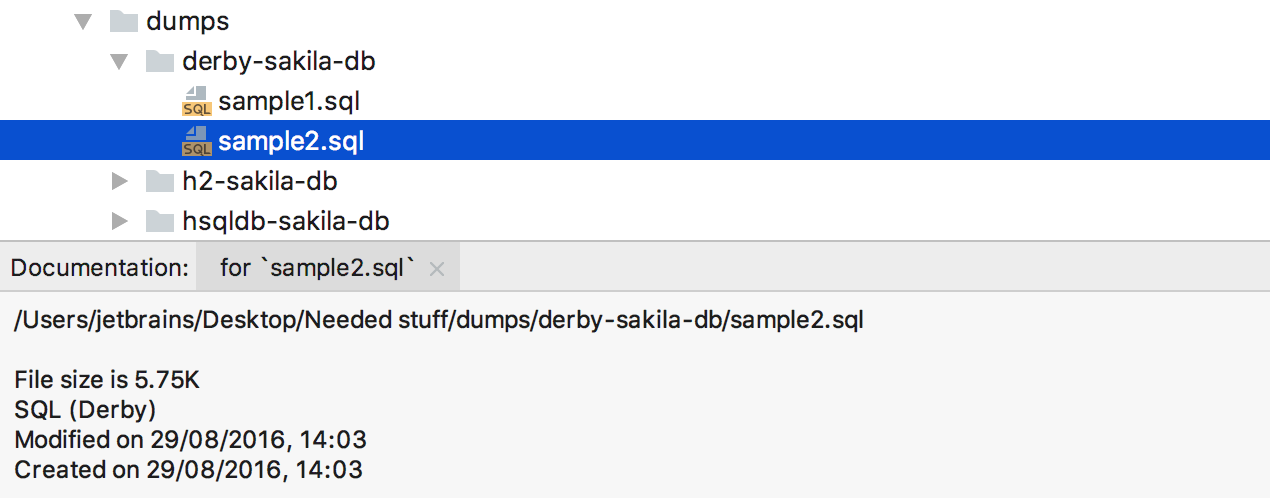
Изображения в фоне
Для изображений в фоне (Preferences/Settings > Appearance > Background images) добавили настройки выравнивания и растягивания.
Дерево базы данных
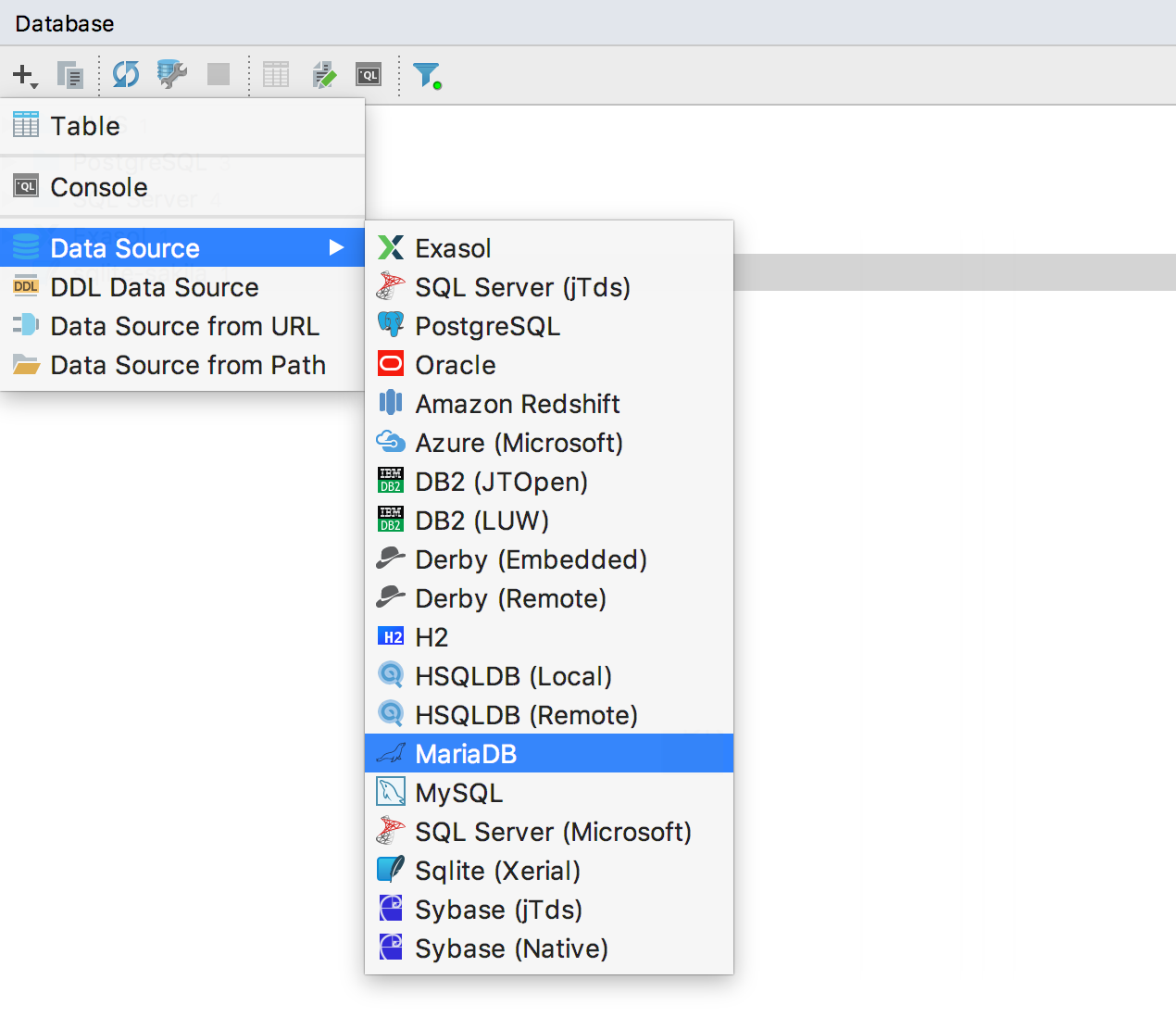
Поддержали MariaDB.
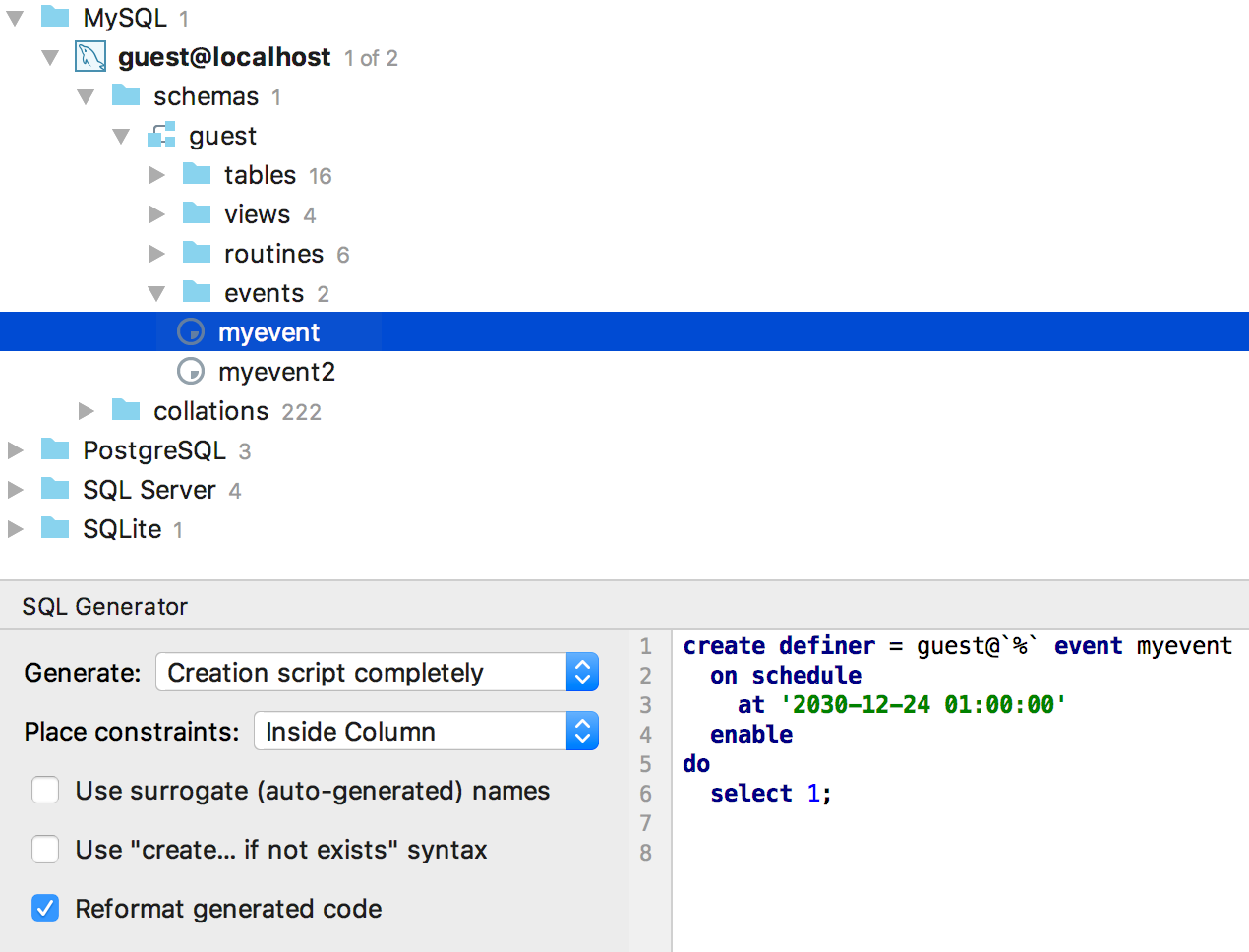
Добавили события для MySQL.
Поддержали внешние схемы в Redshift и виртуальные схемы в Exasol.

Для PostgreSQL 10 поддержали секционированные таблицы.

SQL-редактор
Переходите к следующему и предыдущему использованию объекта в скрипте по Alt+Колесо мышки. Или введите ‘highlighted element usage’ в Find Action (Ctrl+Shift+A).
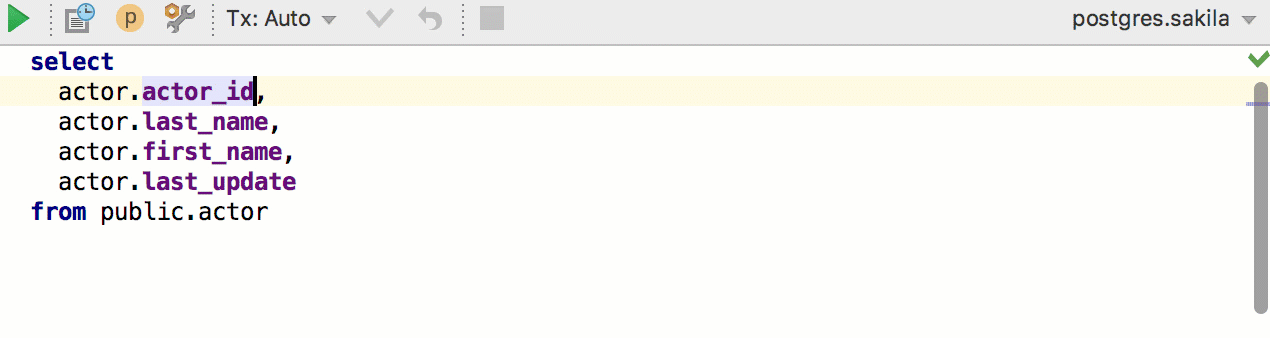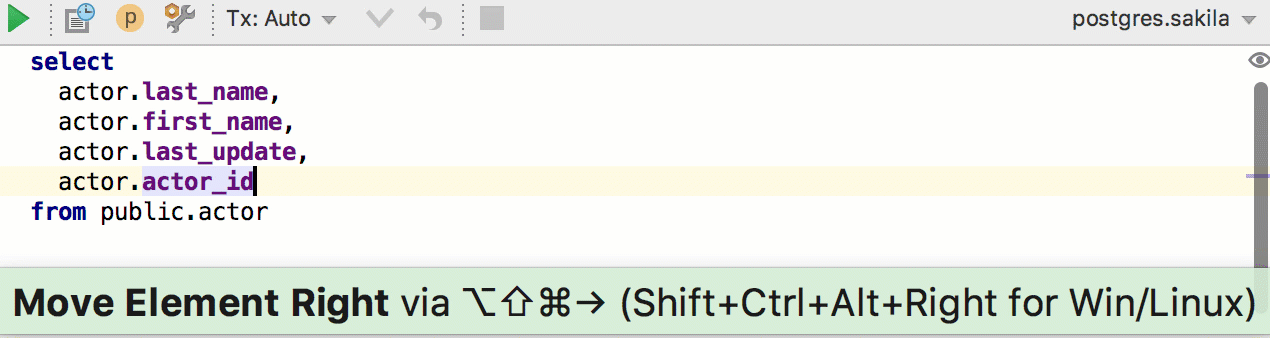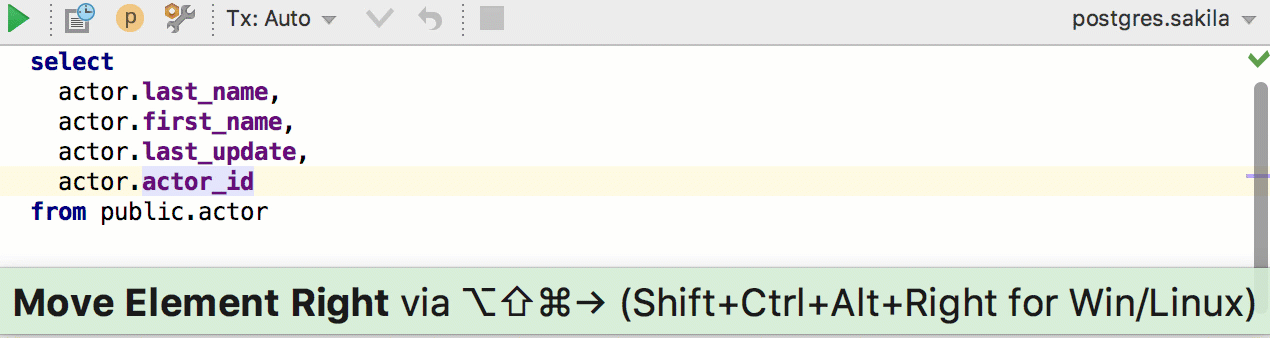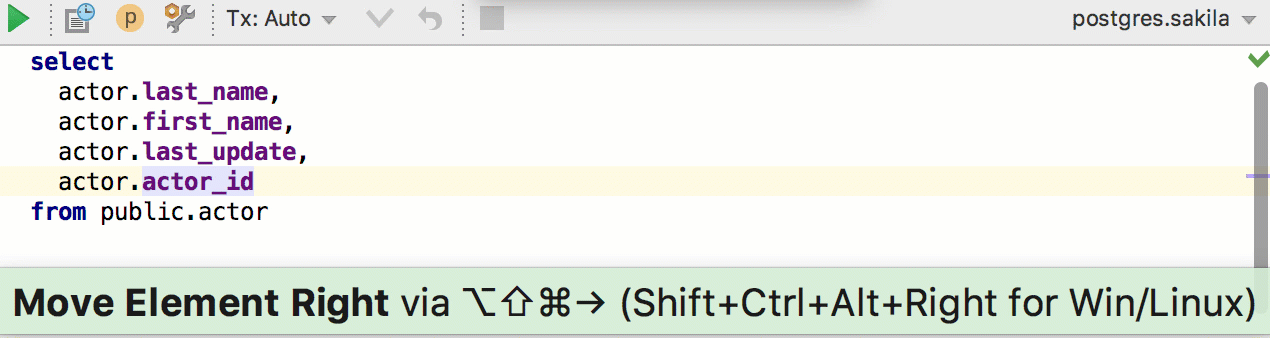
Ещё одно новое действие: Move element left or right. Работает в разных списках, например, полей в INSERT или столбцов в SELECT. Даже если вы любите, когда столбцы написаны один за другим, эта штука пригодится, потому что не будет проблем с запятой. А если использовать Move Line — будут.
Для Oracle и Exasol теперь работает автодополнение для имён файлов.
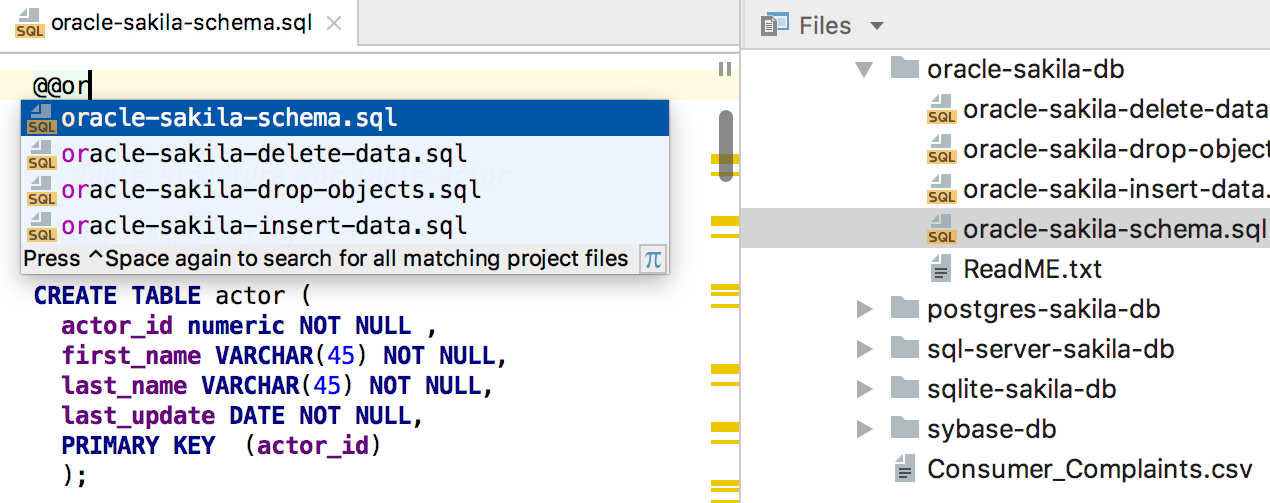
Поддержали CTE в MySQL.
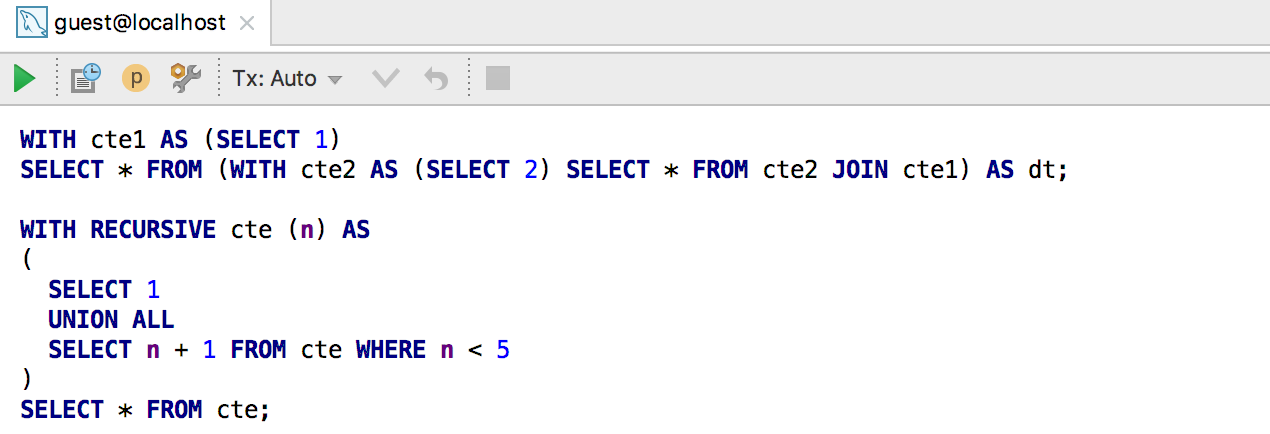
Свернутый код теперь подсвечивается: например, если содержит ошибки или результаты текстового поиска.
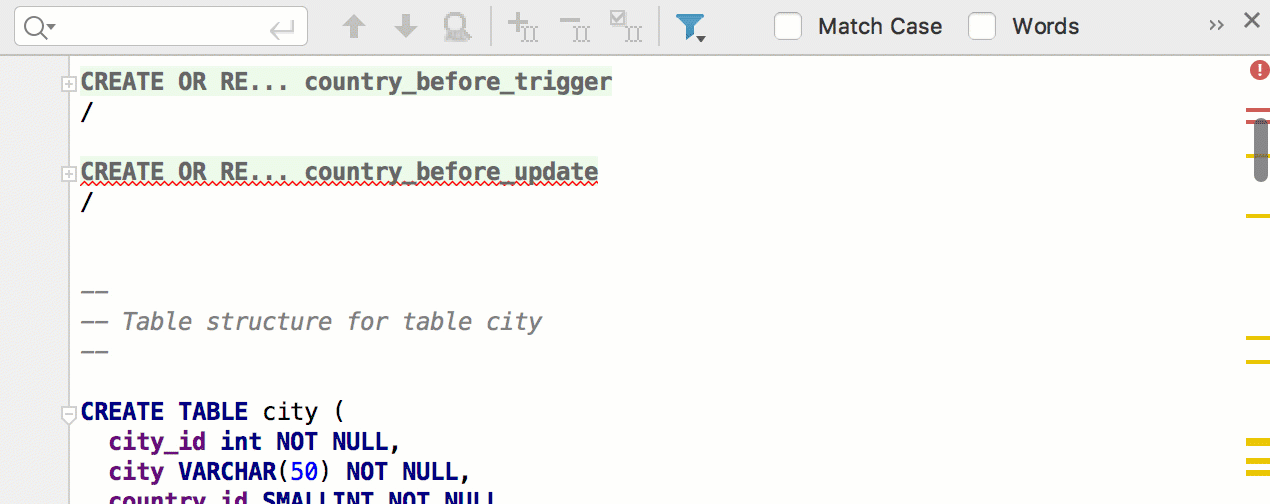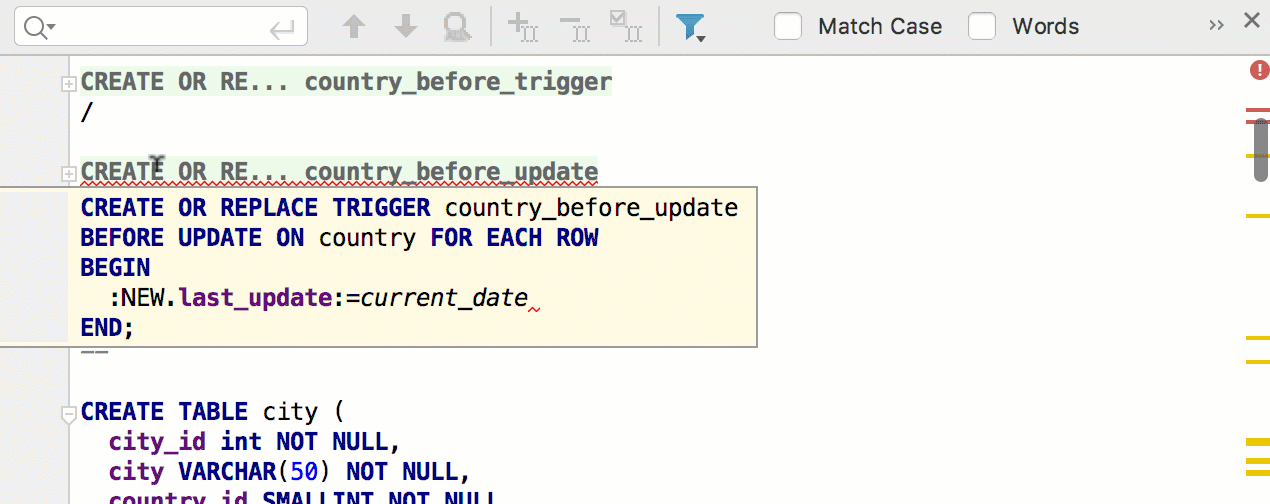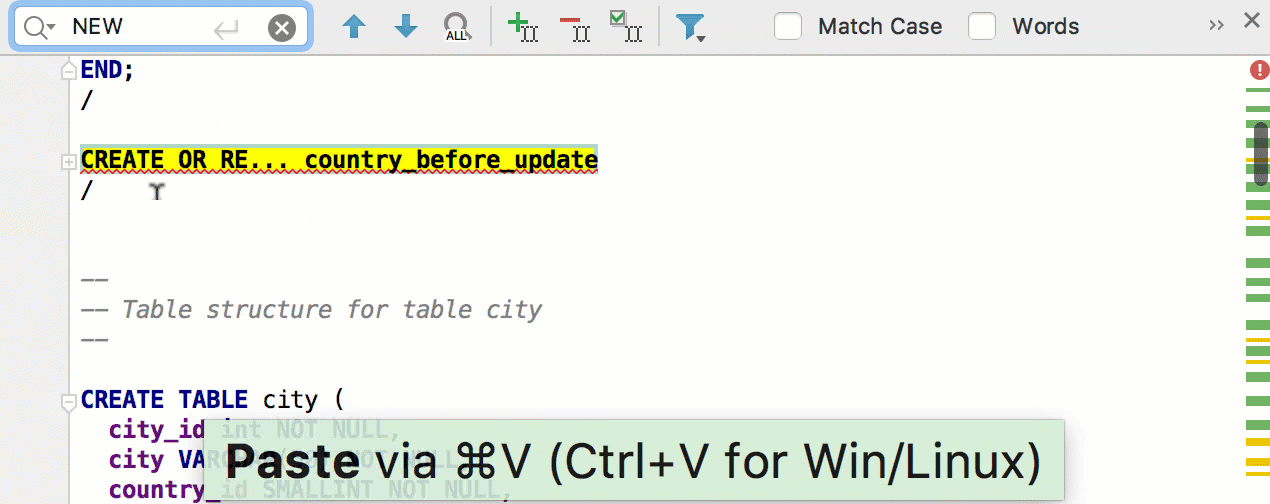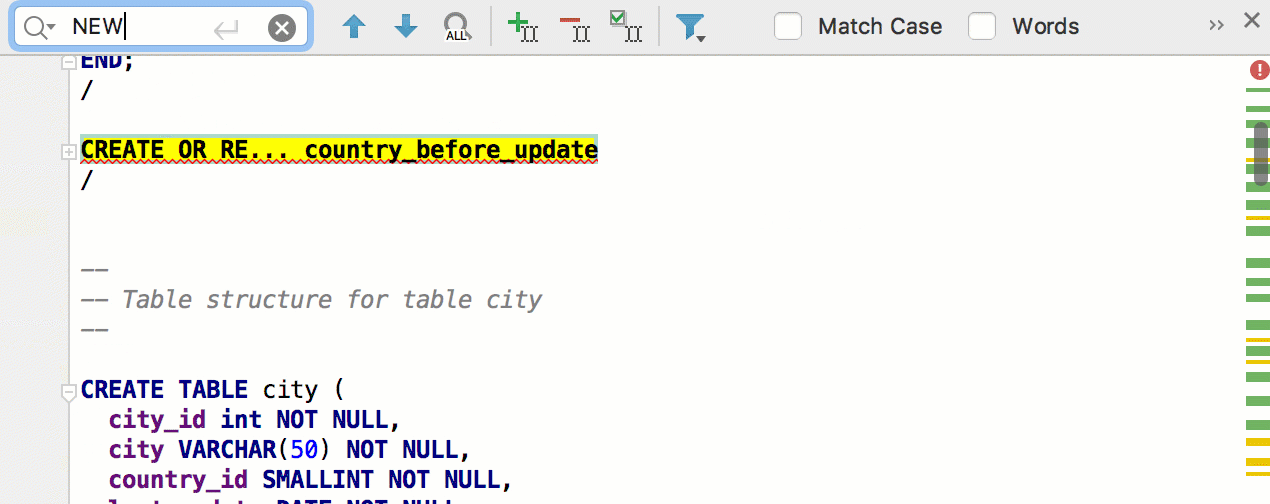
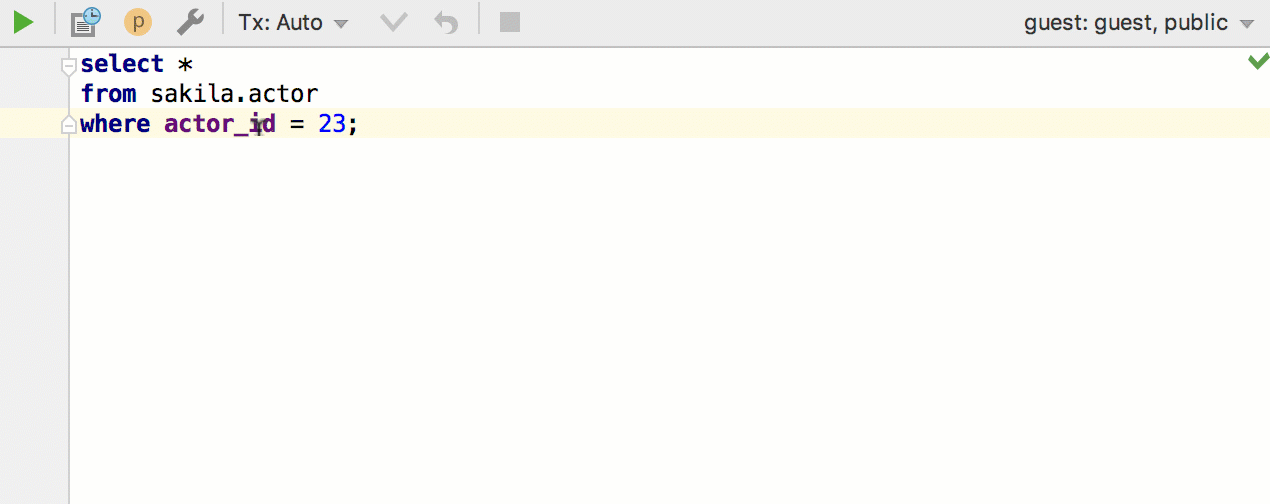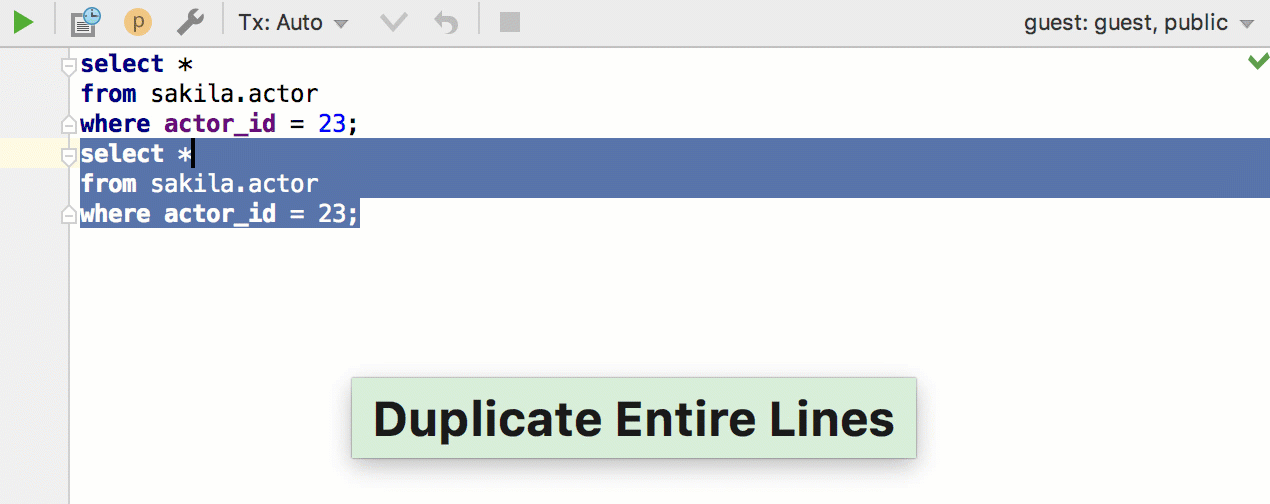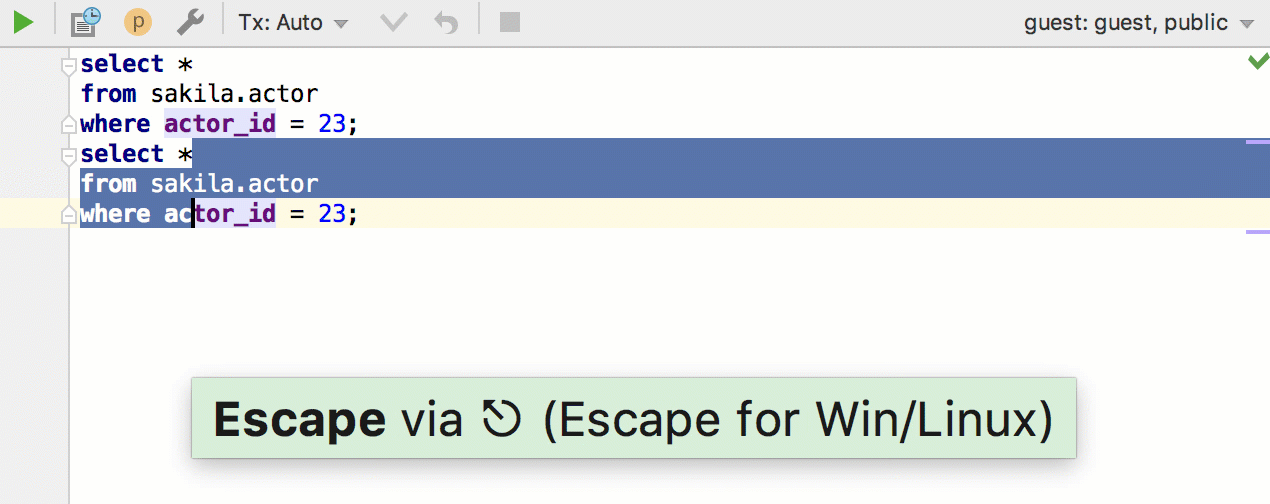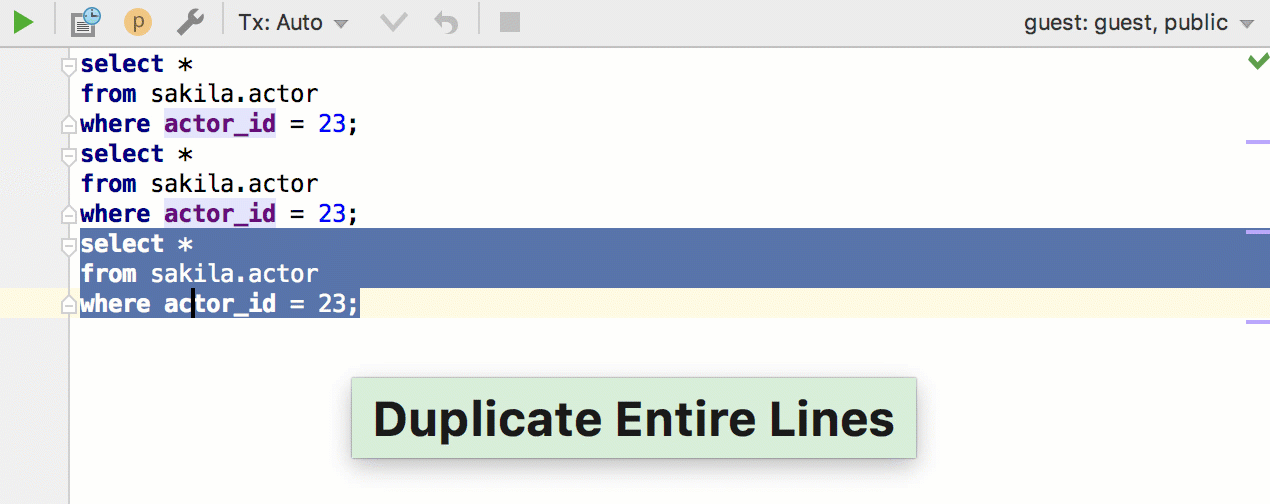
А этот фикс вдохновлён комментарием на Хабре: малоизвестное действие Duplicate Entire Lines теперь работает и в конце файла.
Всякое
— Команды SQLite отныне не порят подсветку кода.
— Поддержали следующие типы в PostgreSQL: point, polygon, line, lseg, box, path, circle, pg_lsn, tsquery, tsvector.
— Форматирование кода не меняет регистр ключевых слов по умолчанию.
— Встроенный SSH-executable поддерживает криптографические алгоритмы.
— DataGrip, как и другие наши IDE, теперь доступен в виде snap-пакета.
— В диалоге Replace in Path поддержали предпросмотр результатов регулярных выражений.
— Плагин The REST client доступен для установки.
Всё! И как всегда: скачать здесь, о багах сообщать сюда, а ещё мы отвечаем на форуме, в Твиттере и здесь, в комментариях.
Спасибо!
Команда DataGrip и JetBrains.
Комментарии (50)

kemsky
05.04.2018 17:46Последний раз когда я пробовал датагрип, он не умел нормально несколько подключений к MS SQL. Эта проблема решена?

moscas Автор
05.04.2018 18:42Хочется ответить «Сейчас стало нормально» :) Но если честно, не понятно, о какой конкретно проблеме речь.
kemsky
05.04.2018 23:04Ну вот попробуйте, подключитесь локально к SQL Server, не указывая базу в подключении, автокомплит работает по-умолчанию на мастер базе, потом как ни выбирай, где не переключай текущую базу на другую, автокомплит работать не начнет. Тоже самое если указать базу при подключении, дальше ее переключить невозможно, автокомплит не понимает, хотя если руками написать запрос то все работает на выбранной базе.
moscas Автор
06.04.2018 12:55Вообще, всё должно работать. У вас база, к которой вы обращаетесь, в дереве отображена? Если да, то скриншот поможет разобраться.
kemsky
06.04.2018 15:18- После подключения https://clip2net.com/s/3TfUo0n
- После выбора базы справа в дропдауне https://clip2net.com/s/3TfUqTA
- После выбора в дереве https://clip2net.com/s/3TfUuC6
Похоже надо обязательно выбирать схему, но интерфейс не слишком на это намекает.
moscas Автор
06.04.2018 18:47Если база уже написана, то Alt+Enter на ее имени предложит добавить ее в дерево :)
moscas Автор
06.04.2018 18:51Но мы согласны, что когда базу выбрали в дропдауне, надо предлагать добавить ее в дерево, потому что очевидно, что пользователь с ней работает. Я открыл тикет: youtrack.jetbrains.com/issue/DBE-6197
kemsky
08.04.2018 02:55Проблема в том, что если схема не выбрана — нет автокомплита. Можно и в дереве выбрать и в дропдауне, только вот работать ничего не будет пока не развернешь дерево до уровня схем и там не выберешь схему (dbo например). Если вы хотя бы раз попробуете сами так сделать все сразу станет ясно.

Sleuthhound
05.04.2018 18:59А кто-нибудь сравнивал сей продукт с DBeaver? Пользуюсь последним последние 6 месяцев для работы с mysql, pg и oracle — все классно. Но хотелось бы сравнения функционала в табличном виде.

Zuzik3500
06.04.2018 11:32Пересел с dbeaver на него (не совсем на него, на пичарм). Используемые бд — аналогичны вашим. Нужно сравнение — думаю вам будет проще написать список того, что нужно вам, а тут уже думаю люди подскажут, поддерживает ли данный продукт необходимые вам функции.
Из личных впечатлений:
- автодополнение в разы лучше
- эспорт/импорт данных — я бы сказал datagrip немного лучше
- интеграция с системой контроля версий которое я в dbeaver не видел (не искал сильно, честно говоря, но из коробки его вроде там нет).
- интерфейс для создания таблиц, по крайней мере для pg — dbeaver значительно больше типов предлагает.
- информация таблице/схеме, разрешения — в datagrip этих данных либо нет, либо представлены в значительно меньшем объеме (пользуюсь пичармом, так что есть небольшая вероятность ошибки).
- был один случай когда datagrip показал неверный ddl для таблицы — была весьма спорная ситуация со значениями по умолчанию в mysql, которую dbeaver обработал правильнее, подробности помню плохо.
- wrapped пакеты процедур и функций dbeaver переваривает значительно лучше
- dbeaver позволяет прокручивать весь список результатов запроса, в datagrip насколько я понимаю только постранично.
- разные мелкие косячки/неудобства у обоих
Все что вспомнил навскидку. Сам, как уже сказал выше, dbeaver оставил в стороне, возвращаюсь к нему только в очень редких случаях. О переходе на datagrip/pycharm не жалею, но базы данных — не основное мое занятие. Было бы основное — скорее всего также использовал бы datagrip. По поводу описанных выше недочетов — в багтрекер не писал, и не просматривал его на этот счет.
moscas Автор
06.04.2018 13:03Спасибо за детальный фидбек. Отвечу на негативные пункты.
интерфейс для создания таблиц, по крайней мере для pg — dbeaver значительно больше типов предлагает.
Мы предлагаем все типы. Единственное, они должны быть в дереве базы данных, то есть, речь, скорее всего, о pg_catalog. Есть мысль сделать так, чтобы пользователь не заботился об этом, но пока нужно явно добавлять схемы в дерево. Новости будут здесь: youtrack.jetbrains.com/issue/DBE-4573
информация таблице/схеме, разрешения — в datagrip этих данных либо нет, либо представлены в значительно меньшем объеме (пользуюсь пичармом, так что есть небольшая вероятность ошибки).
Если речь о grants, то мы действительно их пока не достаём :( Если еще о чем-то, пишите.
был один случай когда datagrip показал неверный ddl для таблицы — была весьма спорная ситуация со значениями по умолчанию в mysql, которую dbeaver обработал правильнее, подробности помню плохо.
Здесь сложно что-то предположить, но есть вероятность того, что исходник поменялся со времен выгрузки его Датагрипом. Если да, то мы планируем сообщать о такой ситуации: youtrack.jetbrains.com/issue/DBE-6185
wrapped пакеты процедур и функций dbeaver переваривает значительно лучше
А что значит лучше?
dbeaver позволяет прокручивать весь список результатов запроса, в datagrip насколько я понимаю только постранично.
Можно и весь сразу результат увидеть, для этого в настройку Page Size надо поставить -1. Тогда не будет никакого пейджинга.Zuzik3500
06.04.2018 23:12По поводу типов — на тикет сегодня наткнулся.
>Если речь о grants, то мы действительно их пока не достаём :( Если еще о чем-то, пишите.
Да, в принципе про них. youtrack.jetbrains.com/issue/DBE-6187.
> wrapped пакеты процедур и функций dbeaver переваривает значительно лучше
>А что значит лучше?
В dbeaver в таких случаях идет CREATE OR REPLACE PACKAGE BODY… wrapped и далее само тело, в wrapped виде, которое можно скопировать и преобразовать в читаемый вид.
У вас — -- auto-generated definition
— No source text available
Немного по теме — youtrack.jetbrains.com/issue/DBE-2310, может если решат его, то и моя проблема исчезнет?
> Можно и весь сразу результат увидеть, для этого в настройку Page Size надо поставить -1. Тогда не будет никакого пейджинга.
У вас либо только по страницам, либо сразу все. У dbeaver — выполнил запрос, 1000 строк. Список из 1000 строк. Просмотрел, подгрузил данные еще — список уже содержит 2000 строк, 3000 строк… Причем без разделения на страницы. Вещь временами удобная, хотя честно говоря — очень временами.

L0NGMAN
06.04.2018 01:12Всёравно приходится открывать HeidiSQL, к тому же в wine :( Как то там функционала по больше и интерфейс понятнее. А хотелось бы всё иметь внутри Data Grip / PHPStorm
moscas Автор
06.04.2018 12:32А можно вас попросить раскрыть? Было бы круто узнать, чего вам не хватает и где интерфейс непонятный.

Caravus
06.04.2018 15:18Я тоже пользуюсь HeidiSQL (для mysql) время от времени, вкину пару копеек:
1) В HeidiSQL есть просмотр «базы данных» и «таблицы», на которой отображается статистика по элементам. Например — очень удобно просматривать объём занимаемого места.
2) Удобный просмотр процессов, статистики, состояния базы.
3) Управление пользователями.
Если хотите — пишите в ЛС, накидаю скринов с реальными данными.
L0NGMAN
06.04.2018 16:10На пример редактировать структуру таблици в DataGrip очен сложно, посмотрите как это реализовано в HeidiSQL. Посмотрите как легко добавить Foreign Key в HeidiSQL и т.д.
moscas Автор
06.04.2018 16:30Кажется, что почти то же самое, но у нас вместо чекбоксов автодополнение: youtu.be/GNKVpyknHhU
L0NGMAN
06.04.2018 16:48Дропдауны юзабельнее. Ещё на пример как мне изменить Table collation? Auto increment value? Row format? Это очен легко в HeidiSQL. Ещё редактировать неудобно в DataGrip из за автодополнении в типах в место дропдаунов. Ещё почти невазможно копировать таблицу с даннимы, часто бросается ошибка «Invalid default value for 'fieldname'», как такое вазможно? Я просто хочу создать клон таблицы с новым именем. HeidiSQL это делает без проблем
moscas Автор
06.04.2018 18:541. По поводу дропдаунов, это концептуальное решение. DataGrip – клавиатурно-ориентированная среда и в нашем представлении автодополнение делает работу быстрее.
2. Table collation, Auto increment value, Row format — над всем этим работаем. Это будет.
3. Про Copy table нужен пример с DDL'ем. И опишите, пожалуйста, как вы копируете.L0NGMAN
07.04.2018 15:521. А что мешает сделать дропдауны с вводом текста и автодополнением?
2. Там ещё много чего нужно, берите пример с HeidiSQL
3. Только DDL не подойдёт, вам и данные нужны наверное. А вообше, если уже сушествует таблица с данными, хоть не валиднимы допустим, MySQL клиент не должен всёравно его копировать? HeidiSQL тык и делает
В целом я бы сказал, мне очен нравится ваши продукты, но хочется вообше не выходить из них, по этому пожалуйста берите всё что удобно и хорошо сделано из других софтов, эта хорошая практика. И HeidiSQL хороший цель для этого

robert_ayrapetyan
06.04.2018 03:39Существует ли какой-то способ закрыть консоль? Я их насоздавал с момента внедрения этой фичи по нескольку десятков в каждой базе, и никак не могу закрыть ни одну…
mors741
06.04.2018 11:32Я пользуюсь таким способом:
В открытой консоли прямо в окне с кодом вызываю контекстное меню (ПКМ) -> Show in Files.
В других ОС может быть Show in что-то другое.
Откроется папка с файлами, соответствующими консолям для данного соединения.
Там их можно удалить.
Кстати говоря, там же можно дать консолям более говорящие имена — у меня, например, всегда висит консоль со скриптом полного удаления схемы Oracle с названием drop_schema.sqlrobert_ayrapetyan
06.04.2018 18:09Спасибо! В IntelliJ Idea получилось через «Copy Path» только обнаружить эту папку.

xtender
06.04.2018 09:53Режим «только для чтения»
В оракле можете просто добавить вызов set transaction read only;
В Oracle, SQL Server и некоторых других базах он вообще не работает :)
Вот, что делает наш read-only

PavelMSTU
06.04.2018 16:43Да, это NoSQL, но когда добавите поддержку Cassandra?
Много проектов BigData «смежные». «Много данных» — в сassandra, «выжимка данных» для Data Science — в MySQL (postgresql и т.д.)
Иметь два инструмента для работы не удобно :(
+ DataGrip красивый! Хочу кассандру в DataGrip!
___
ваш постоянный клиентmoscas Автор
06.04.2018 16:45Пока, к сожалению, можем ответить только номером тикета: youtrack.jetbrains.com/issue/DBE-3515
PavelMSTU
06.04.2018 16:52Да, уже видел. Этот тикет висит с 2013 года. Сейчас 2018.
19 апреля будет уже пять лет!
Скоро юбилей ;)))
Не отвечаю за всех, но мне хотя бы select-ы делать к кассандре — и будет достаточно. Думаю для 80% датасаентистов так же… Проведите исследование — я не один, кому это надо. CQL на порядок примитивнее SQL.
Реально — боль.

Samouvazhektra
А насчёт поддержки NoSql (редис\монга) хотябы отдаленные планы есть? Удобно когда все в одном месте
moscas Автор
Пожалуй, ответ на этот вопрос надо включать в конец каждого поста :)
Он такой: мы думаем об этом, знаем, что это важно. Но в ближайших планах пока нет. Если начнем, скорее всего с Монги. youtrack.jetbrains.com/issue/DBE-41
Hixon10
Скажите, пожалуйста, это связано с каким-то техническими трудностями, или с непонятным объемом рынка? Просто, помнится, что даже во времена 0xDBE все просили Монгу.
moscas Автор
NoSQL базы не очевидно ложатся на нашу архитектуру. То есть за недельку это сделать не получится :) Нужны ресурсы, которых пока нет. Если этот комментарий прочитает человек, который хотел бы заняться поддержкой NoSQL-баз, мы с радостью пригласим его с нами пообщаться.
Samouvazhektra
Что только подчеркивает необходимость этих возможностей. Думаю даже просто возможность зарегистрировать коннекты и интерактивный JumpToConsole с хранением исполняемых запросов привнесет удобство, чтоб не запускать робомонгу и проч. гуи по мелочам
Optik
Может лучше с кассандры? У неё язык запросов близок к sql.
OnYourLips
Имхо лучше elasticsearch и redis.
Потому что они более популярны, просто обычно не являются основной СУБД проекта.
moscas Автор
Да, redis нынче очень популярен. Будем думать.
L0NGMAN
+1000 for Redis and ElasticSearch