
В последнее время стало модным делать разоблачения на задачи. В посте решил привести свои соображения по задачам Одноклассников. Задачи понравились, но уж больно получились неоднозначными, а в отведённое на листочке место всё не уместить. Обсудим?
Внимание! В оригинальной статье можно познакомиться с полным условием задач и порешать их самостоятельно.
Code snippet позаимствован из авторского разбора.
1. Вадим и партицирование музыкальных треков
/**
* @return partition between 0 inclusive
* and partitions exclusive
*/
int partition(Track track, int partitions) {
assert track != null;
assert partitions > 0;
return track.hashCode() % partitions;
}Что не так в алгоритме партицирования объектов Track по серверам?hashCode()
Из условия задачи остаётся непонятным, переопределён ли метод
hashCode() в классе Track или используется реализация из класса Object.Случай первый: метод
hashCode() переопределён. Javadoc выглядит вполне убедительным, а мы же привыкли доверять javadoc'ам, верно? ;) Значит, Вадим должен был позаботиться об отрицательных значениях hashCode (или у кого-то появились Flaky-тесты).В таком случае, к чему же придраться в этом коде? Первое, что бросается в глаза — алгоритм партицирования жёстко связан с количеством серверов. С данной проблемой сталкиваются пользователи различных распределённых хранилищ в отношении количества шардов. Например, эта проблема актуальна для Elasticsearch. Документация на MongoDB тоже напоминает нам об этом.
Выбор количества шардов и алгоритм вычисления shard key — ответственная задача. В приведённых примерах с Elasticsearch и MongoDB изменение количества шардов — осознанное желание. Но если шард-сервер независимо от нашей воли решил почить, то нам на помощь придёт репликация. Ниже схема организации Replica Set для MongoDB:
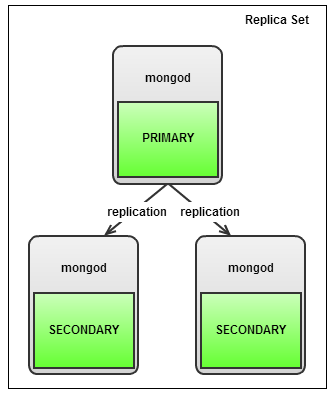
Картинка взята с сайта severalnines.com.
Случай второй: используется метод
Object.hashCode(). Лучше всего об этом скажет javadoc к этому методу (выделен ключевой фрагмент):Whenever it is invoked on the same object more than once duringПоследнее означает, что значение
an execution of a Java application, thehashCodemethod
must consistently return the same integer, provided no information
used inequalscomparisons on the object is modified.
This integer need not remain consistent from one execution of an
application to another execution of the same application.
hashCode того же самого объекта после перезапуска приложения скорее всего будет другим. Объект тот же самый в контексте бизнес-логики (например, получен из базы). Но это ещё полбеды: как следствие, на разных серверах в один момент времени хэши тоже будут скорее всего разными.Нестабильность
hashCode и вероятность появления отрицательных значений может стать причиной Flaky-тестов. Грубо говоря, это тесты, которые на одной кодовой базе по непонятным причинам становятся красными, а в момент их изучения (или сами по себе) внезапно вновь становятся зелёными.Специальный случай: метод
hashCode() полагается на hashCode бизнес-данных (примитивы и строки). Этот случай самый распространённый и от этого не менее интересный!Например, в Intellij IDEA можно сгенерировать методы
hashCode() и equals() для простого data-класса:public class Address {
private final String street;
private final Integer house;
}и получить такую реализацию:
@Override
public int hashCode() {
int result = street != null ? street.hashCode() : 0;
result = 31 * result + (house != null ? house.hashCode() : 0);
return result;
}Так в чём проблема, спросите вы? Пока рано делать выводы, продолжим изучать исходный код (JDK 8):
public final class String {
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
@Override
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
}
public final class Integer {
/**
* Returns a hash code for this {@code Integer}.
*
* @return a hash code value for this object, equal to the
* primitive {@code int} value represented by this
* {@code Integer} object.
*/
@Override
public int hashCode() {
return Integer.hashCode(value);
}
/**
* Returns a hash code for a {@code int} value; compatible with
* {@code Integer.hashCode()}.
*
* @param value the value to hash
* @since 1.8
*
* @return a hash code value for a {@code int} value.
*/
public static int hashCode(int value) {
return value;
}
}Отлично, мы убедились, что результат воспроизводим между перезапусками приложений. Проблема же в том, что мы полагаемся на детали реализации. Нет никаких гарантий, что поведение останется неизменным в будущих версиях Java. Даже несмотря на однозначность javadoc'ов, которым мы доверяем, ведь они касаются только текущей реализации.
Дополнение. Наброс на
String.hashCode() справедлив в меньшей степени. Как верно было отмечено в комментариях, изменение алгоритма сделает тонну скомпилированного кода невалидным, чем вызовет негодование всего Java-сообщества. switch(s) {
case "s":
System.out.println("S");
break;
case "b":
System.out.println("B");
break;
}компилируется в:
int var_ = -1;
switch(s.hashCode()) {
case 98:
if(s.equals("b")) {
var_ = 1;
}
break;
case 115:
if(s.equals("s")) {
var_ = 0;
}
}
switch(var_) {
case 0:
System.out.println("S");
break;
case 1:
System.out.println("B");
}Как видим, в скомпилированном коде зашиваются хэши-константы.
assert
Скажу сразу, что я не очень большой фанат
assert. Речь исключительно про использование assert statement (JLS 14.10).Напомню, что есть два варианта использования:
assert condition [: msg];Если
condition == false, то будет брошена ошибка AssertionError. При этом, если не указано выражение msg, то получим ошибку без detail message, что, на мой взгляд, недопустимо. Во втором случае будет вызван конструктор AssetionError(String detailMessage).Начнём с простого примера:
public class Main {
public static void main(String[] args) {
assert args.length != 0;
assert args.length == 0;
System.out.println("OMG! Is it possible?");
}
}Неожиданно, но на консоль выведется
OMG! Is it possible?, потому что assert не включен по умолчанию:java -ea | -enableassertions Main.Почему я не использую assert
Во-первых, использование короткой записи даёт нам информации чуть больше, чем ничего — без стектрейса не разобраться.
Во-вторых, обратимся к javadoc к
Error:/**
* An {@code Error} is a subclass of {@code Throwable}
* that indicates serious problems that a reasonable application
* should not try to catch. Most such errors are abnormal conditions.
* The {@code ThreadDeath} error, though a "normal" condition,
* is also a subclass of {@code Error} because most applications
* should not try to catch it.
* <p>
* A method is not required to declare in its {@code throws}
* clause any subclasses of {@code Error} that might be thrown
* during the execution of the method but not caught, since these
* errors are abnormal conditions that should never occur.
*
* That is, {@code Error} and its subclasses are regarded as unchecked
* exceptions for the purposes of compile-time checking of exceptions.
*
* @author Frank Yellin
* @see java.lang.ThreadDeath
* @jls 11.2 Compile-Time Checking of Exceptions
* @since JDK1.0
*/
public class Error extends Throwable { /* code omitted */ }
Error indicates serious problems that a reasonable application should not try to catch. Most such errors are abnormal conditions.Error не должны использоваться пользовательским кодом в качестве бизнес-исключений, а их появление должно свидетельствовать о наличии бага. В коде из задачи partitions == 0 больше похоже на бизнесовую проверку, чем на наличие какой-либо ошибки в коде.Например, нет ни одной доступной шарды — вполне себе штатная (обрабатываемая) ситуация. Должен ли за обработку этого случая отвечать метод
partition()? Скорее нет, но это уже другой вопрос.В обоих случаях уместнее использовать
IllegalArgumentException.Заключение
Задача — яркий пример пользы от применения тестов. В тоже время, это и хорошая демонстрация того, как появляются нестабильные тесты.
По использованию
assert придерживаюсь позиции, что не стоит переносить по сути тесты в продакшен-код.Спасибо авторам за разминку для мозгов.
Комментарии (11)

apangin
08.04.2018 09:58hashCode у Integer и String — это не деталь реализации, а часть спецификации. Алгоритм явно прописан в Javadoc.

gnkoshelev Автор
08.04.2018 10:21Строго говоря, ни одна из спецификаций (JLS, JVMS) это не гарантирует. Соглашусь с тем, что на практике проблема скорее всего надуманная.
apangin
08.04.2018 10:40Это гарантирует спецификация платформы Java SE 8/9/10.
JLS, JVMS, Javadoc,… — это части такой спецификации.
habrahabr.ru/company/mailru/blog/321306/#comment_10068620gnkoshelev Автор
08.04.2018 10:43Наверное, я некорректно выразился: нет гарантии совместимости Java 8 SE API и Java X SE API, т.е. описанное в javadoc поведение может поменяться в будущем. Или есть?
apangin
08.04.2018 12:15Точно так же, как и нет гарантий совместимости JVMS 8 и JVMS X. Могут, к примеру, пару байткодов удалить (как уже было с jsr/ret). Гарантии Javadoc в этом смысле не слабее и не сильнее гарантий других спецификаций.

Maccimo
08.04.2018 18:35+3Могут, к примеру, пару байткодов удалить (как уже было с jsr/ret).
Их не удалили, а всего лишь запретили использовать начиная с определённой версии class-файла:
If the class file version number is 51.0 or above, then neither the
jsropcode or thejsr_wopcode may appear in the code array
JVMS9 §4.9.1И в JVMS9 они по-прежнему на месте (§jsr, §ret), и в class-файлах версии 50.0 и ниже они всё так же могут быть использованы.
Пример без проблем был запущен подOpenJDK 64-Bit Server VM 18.3 (build 10+46, mixed mode).apangin
08.04.2018 22:41Спасибо, я в курсе, что HotSpot их поддерживает для старых классов (хотя и не обязан). Суть в том, что с API ровно та же история. Его теоретически могут менять в новых версиях, но на практике предусматривают решения для обратной совместимости. В некоторых случаях даже баги оставляют для поддержки предыдущих версий (см. свойства sun.nio.ch.bugLevel и sun.nio.cs.bugLevel).

fRoStBiT
08.04.2018 10:11+2Отлично, мы убедились, что результат воспроизводим между перезапусками приложений. Проблема же в том, что мы полагаемся на детали реализации. Нет никаких гарантий, что поведение останется неизменным в будущих версиях Java. Даже несмотря на однозначность javadoc'ов, которым мы доверяем, ведь они касаются только текущей реализации.
Этот javadoc документирует данную реализацию, поэтому код вполне может полагаться на неё.
В случае сjava.lang.StringреализацияhashCode()не может взять и поменяться — от неё зависит, например, switch по строкам в уже скомпилированном коде.gnkoshelev Автор
08.04.2018 10:38Верное замечание, спасибо.
Такой исходный код:
switch(s) { case "s": System.out.println("S"); break; case "b": System.out.println("B"); break; }
компилируется в
int var_ = -1; switch(s.hashCode()) { case 98: if(s.equals("b")) { var_ = 1; } break; case 115: if(s.equals("s")) { var_ = 0; } } switch(var_) { case 0: System.out.println("S"); break; case 1: System.out.println("B"); }
apangin
OK, а в чём альтернативность-то? :) Про inconsistent hashing в разборе написано. А assert'ы лишь для того, чтобы показать ограничения на входные данные, не удлиняя сильно условие задачи.
gnkoshelev Автор
На assert явным образом есть отсылка в авторском разборе:
У читателей может сложиться ложное впечатление, что это best practice, не так ли?
А вот тут
ничего нет про поведение
Object.hashCode(), а именно про его невоспроизводимость. Последнее, опять же на мой взгляд, куда большая проблема, чем изменение количество шардов, т.к. их количество может измениться либо вследствие сбоев, либо намеренного изменения (см. отсылки к Elasticsearch или MongoDB), в то время какhashCodeна разных серверах для одних и тех же объектов уже будет давать разные результаты. Это важно.