
Всем привет! В этой статье расскажем, как создавали центр уведомлений — систему, которая решает вопросы качества коммуникации с пользователями в рамках большой и постоянно развивающейся 10-летней системы.
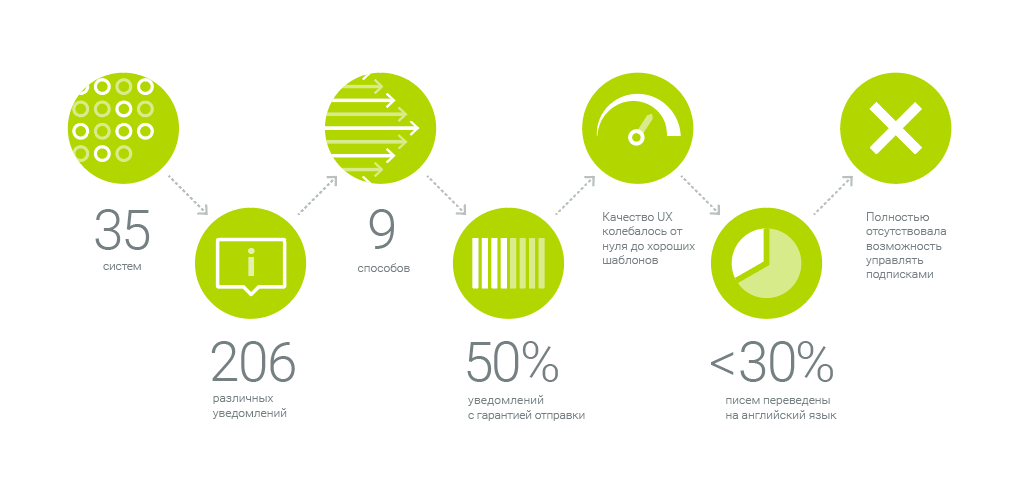
Наша система отправляет 206 различных уведомлений из 35 систем девятью способами. Вот такой фронт работ. Как для этой махины мы создавали единую коммуникационную платформу — центр уведомлений — рассказываем под катом.
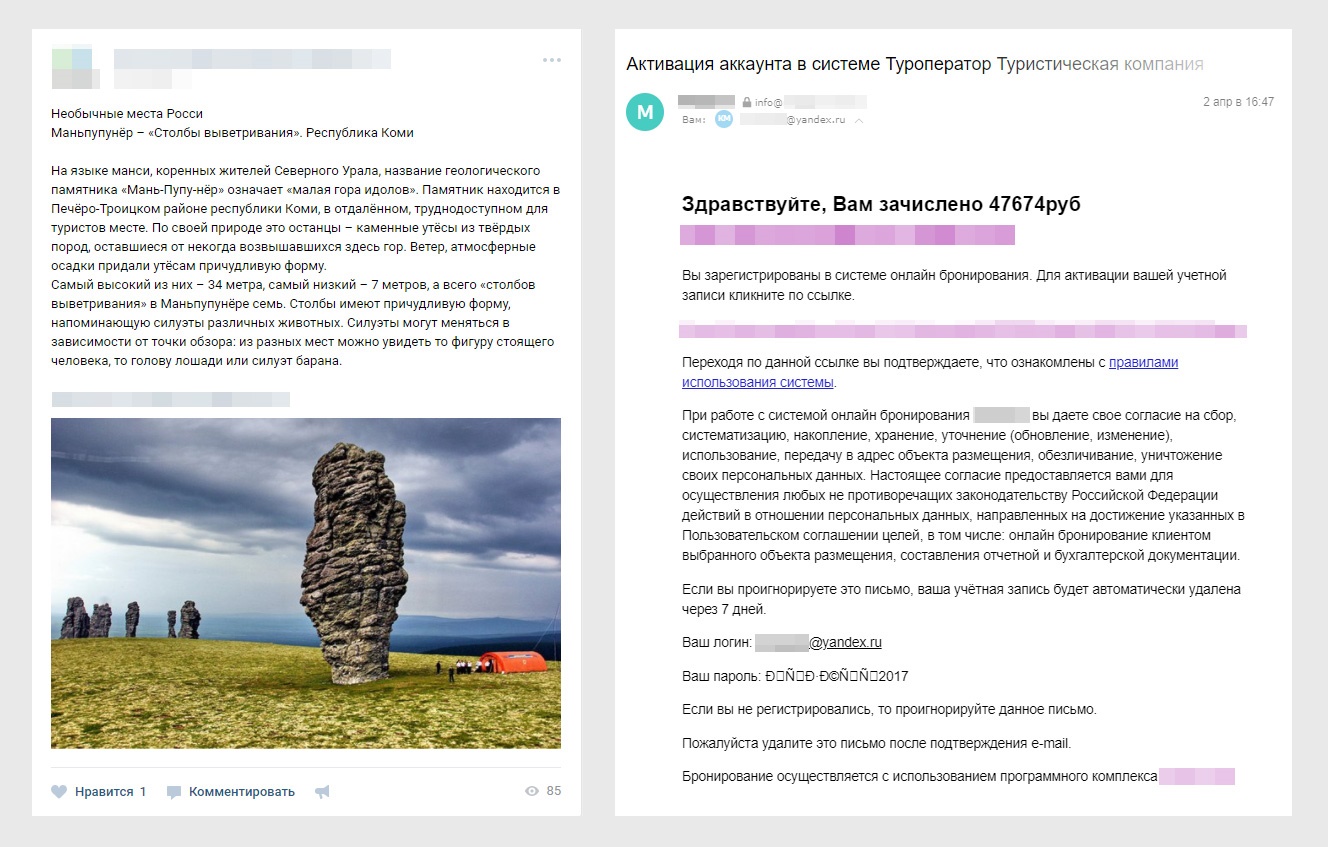
Любые информационные системы развиваются и начинают контактировать с пользователем всё больше и больше. Вспомните любой интернет-магазин, где вы недавно сделали заказ. Он шлёт письма с информацией о заказе, рассылки и пуш-уведомления о новых акциях, смс, а ещё активен в социальных сетях. И наверняка вы замечали, что эти сообщения составлены по-разному. И насколько разным может быть тон и качество – в соцсетях аккуратные тексты и хештеги, а письмо хочется отправить в спам не читая.
Первым делом мы проанализировали все эти сообщения по следующим параметрам:
• кто получатели этих сообщений,
• какая стратегия отправки (немедленно, по расписанию, агрегация),
• есть ли шаблон для сообщения,
• надежность отправки,
• соответствует ли фирменному стилю,
• есть ли поддержка мультиязычности.
Иными словами, мы хотели знать, что мы отправляем и кому. И вот какие результаты мы получили.
Мы поняли, что хотим прийти к единому конвейеру уведомлений, где сообщения доставляются эффективно и сохраняют смысл.
Мы хотим снять с бизнесовых систем нагрузку и ответственность за отправку уведомлений и понимание таких сущностей как «подписки», «локализации» и т.д.
В нашей концепции информационная система должна стать централизованной мини-редакцией с умным конвейером, который по теме/типу сообщения распознает, каким образом, когда, кому и по каким каналам его нужно распространить. И распространяет.
1. Договориться о правилах игры и привести все уведомления к единому качеству. Проанализировать все уведомления и убрать ситуации, когда 5 систем отправляли пользователю одну и ту же информацию, но в разном оформлении. Снимаем с разработчиков бизнес-систем ответственность за UI и грамотность уведомлений, гарантию отправки уведомлений, мониторинг отправки уведомлений. Вместо этого приходим к централизованной системе, где хранятся все шаблоны уведомлений с единым дизайном и функционалом и отдельной команде, которая занимается этими вопросами.
2. Обеспечить своевременную отправку. Иметь возможность настроить, как часто отправлять информацию и какой тип уведомления отправлять. Уметь быстро добавить новое уведомление по запросу бизнеса. Скажем, информацию об отмене заказа нужно доставить как можно быстрее, а про распродажи и новые коллекции можно рассказывать раз в неделю.
3. Обеспечить гарантированную отправку информации. Важное сообщение рассылать самыми оперативно-просматриваемыми каналами — это смс, мессенджеры. Или сразу всеми. Мониторить и дублировать по этим же или другим каналам, если нет реакции.
4. Сохранять единый стиль коммуникации. Создать систему коммуникации — шаблоны писем и сообщений — и придерживаться ее. (Этому служит единый UI и редполитика).
5. Персонализировать коммуникацию. Различать, когда мы общаемся с физическим лицом, а когда с юридическим, в каком часовом поясе он живёт.
6. Бдить, то есть настроить мониторинг и безопасность. Отправлять ссылки на вложения, при открытии которых выполняются проверки безопасности и собирается статистика скачиваний, вместо отправки вложений прямо в письмах. Обеспечить гарантированную отправку, мониторить, что и кому отправлялось.
На рынке есть коробочные решения, которые выполняют часть функций из тех, которые нам нужны. Например, в BizTalk можно вшить уведомления о событиях и настроить специальные пайпы, которые в конечном счете составляют это письмо. В Dynamics CRM и SharePoint есть настройки, которые реагируют на какие-то события. Как правило, это сводится к тому, что кто-то где-то нажал кнопку, и как результат — email отправился. О более сложных вещах, вроде политики агрегации и красивом UI, речи не идёт.
У Azure и AWS много сервисов, которые умеют взять готовый контент и отправить рассылку на почту. Получается, что весь контент для него нужно подготовить вручную. А назначение центра уведомлений — как раз в том, чтобы готовить контент.
Так мы убедились, что в нашем случае не стоит уповать на решение из коробки, где нам останется настроить UI, и система сама куда-то подключится и вытащит всё нужное. Такие вещи не работают из коробки, их нужно делать руками. Коробочные решения в таких случаях подразумевают использование мета-языка и конфигурирования, которые в конечном счете превращаются в проблему настройки. У нас же получилось решение, сделанное под конкретные потребности бизнеса. Его легко настроить и добавлять новые задачи.
У нас есть бизнес-системы — это системы, которые решают главные задачи бизнеса. Они работают отдельно от центра уведомлений и не должны заниматься вопросами коммуникации с пользователями.
В идеале такие системы просто генерируют бизнес-события, необходимые для их работы и взаимодействия с другими системами, а Центр уведомлений просто пристраивается рядом и становится еще одним слушателем этих бизнес-событий, и реагирует на них как на сигналы к действию с минимальным необходимым набором входной информации. Далее Центр уведомлений дополняет события нужной информацией, перерабатывает, и на выходе мы получаем одно или несколько готовых к отправке уведомлений, каждое из которых персонально обращается к заинтересованному пользователю, на нужном языке и со всей необходимой ему информацией.
Технически все это раскладывается в конвейер по переработке информации, который выглядит следующим образом:
Все начинается со сборки событий, которая перехватывает или целенаправленно собирает данные из бизнес-систем и сохраняет их как «сырой» поток событий для дальнейшей обработки.
С точки зрения разработки сборщик событий — это хост-система, разработанная с прицелом на то, что мы можем очень быстро добавить сюда обработку очередного типа событий.
Мы с самого начала отказались от идеи мегасистемы для сборки данных, у которой будет свой метаязык и чудо-UI-настройки, с помощью которых ее можно подключить к чему угодно и собрать что угодно. Вместо этого мы положили в основу системы самый гибкий инструмент из нам доступных — язык программирования, и сосредоточились на том, чтобы обработка очередного бизнес-события сводилась к написанию одного маленького классика, который знает, откуда событие забрать и во что превратить. Дальше этот классик вбрасывается в хост-систему сборки данных и просто начинает работать как еще один элемент конвейера.
В момент сбора данные они приводятся к «канонической форме» — каждое событие получает уникальный идентификатор (либо берется CorrelationId, который уже был назначен событию в бизнес-системе), определяется дата события (DateTime.Now либо дата из пришедших бизнесовых данных, зависит от кейса), тип события и т.д., и все события сохраняются в общий поток событий для дальнейшей обработки. Сборщик не заинтересован непосредственно в данных события, он, образно говоря, оборачивает их в конверт. Форма конверта — каноническая, а содержимое разное.
Как мы писали выше, в момент сбора событий они сохраняются в общий поток для дальнейшей обработки. Решая вопрос того, как хранить данные, мы выбрали широко известный в узких кругах продукт под названием EventStore. Кстати, одним из идеологов EventStore является Greg Young, имя которого неразрывно связано с такими концепциями как CQRS и Event Sourcing.
Согласно определению на главной странице, EventStore это «функциональная база данных с комплексной обработкой событий в JavaScript». Если же попытаться сформулировать в свободной форме, что представляет из себя EventStore, то мы бы сказали, что это очень интересный гибрид базы данных и брокера сообщений.
Преимуществом, взятым от брокеров, является возможность построить реактивную систему, в которой EventStore берет на себя уведомление слушателей о новых событиях, гарантию доставки сообщений, конкурентную обработку, отслеживание, какое из сообщений каким из подписчиков уже прочитано и т.д.
Но, в отличие от брокеров сообщений, данные не удаляются из EventStore после того, как были прочитаны получателем. Это дает возможность не только реактивной работы с атомарными событиями, но и работы с массивами исторических данных, как в БД. К слову, одной из самых продвигаемых фич Event Store является возможность построения temporal queries, позволяющих проводить анализ последовательностей событий во времени, что, как правило, сложно сделать с использованием «традиционных» БД.
В случае с Центром уведомлений, оказались востребованы обе возможности EventStore. Используя реактивную модель подписок, мы реализовали генерацию немедленных уведомлений и обогащение данных о событиях (о нем ниже). А при помощи проекций мы организовали анализ последовательностей событий, с помощью которого можно:
а. генерировать агрегированные события в духе «Сводка о … за неделю/месяц/год»,
б. анализировать последовательности различных типов событий и находить интересные закономерности между ними, отслеживать пики происходящих событий и вообще.
Еще одним вопросом, связанным с хранением данных и вставшим при разработке Центра уведомлений, стала работа с файлами. Нередко нам нужно отправить пользователю в уведомлении какой-либо файл.
Простейший пример: отправка отчета по почте. И самое простое, что можно сделать — прикрепить файл к письму в виде вложения. Но если развивать сценарий, то мы сразу заметим несколько ограничений в таком решении.
Простейшее решение всех этих вопросов — отправить вместо файла ссылку. Так мы и почтовый сервер не нагружаем, и можем мониторить, что происходит с файлом, и даже можем провести проверки безопасности и проверить, что пользователю действительно можно этот файл посмотреть.
С другой стороны, есть в этом и чисто практический смысл. Файл может быть привязан к событию еще с момента, когда событие произошло. Например, когда суть бизнес-события — получен обменный файл от системы бронирования в авиаперевозках за определенную дату. Или файл может быть сгенерирован как результат обработки пачки событий, допустим, за последний месяц.
В общем, файлы могут существовать с самого начала жизни события, и нет смысла «протаскивать» тяжеловесный контент через весь конвейер Центра уведомлений только для того, чтобы в конце его отправить. Можно в самом начале сохранить файл в специальный сервис, а в событии сохранить его идентификатор. А достать файл можно там, где он будет нужен уже при отправке уведомления.
Так и родился у нас еще один очень простой сервис — Blob Storage.В сервис можно сохранить файл через POST-запрос и в ответ получить Guid. Также в сервис можно послать GET-запрос с полученным Guid, а взамен он вернет файл. А все проверки безопасности, сбор статистики и прочее — это уже внутренние дела сервиса Blob Storage.
Итак, на данный момент мы рассмотрели этап сборки событий и то, как мы сохраняем информацию о событиях и файлах. Перейдем к этапу, на котором начинается работа с данными — этапу обогащения.
На вход данного этапа попадают «канонические» события, собранные ранее. На выходе же мы получаем от нуля до N готовых уведомлений, которые уже имеют получателя, текст сообщения на конкретном языке, и уже понятно, по какому каналу (email, telegram, sms и т.д.) уведомление необходимо будет отправить.
На данном этапе исходное событие может быть подвергнуто следующим манипуляциям.
В основном благодаря этой операции весь этап и получил название «обогащение». Простейший пример дополнения данных — в «каноническом» событии нам пришел Id пользователя. На данном этапе мы по Id пользователя находим его ФИО, чтобы иметь возможность обратиться к нему по имени в тексте уведомления, и дополняем исходное событие найденной информацией.
Каждый «обогатитель» — это отдельный маленький класс, который (по аналогии со сборщиками событий) быстро пишется и «вбрасывается» в общий конвейер, который уже подаст всю нужную информацию на вход и сохранит результат, куда нужно.
Здесь все достаточно просто. Подход тот же, что и в обогащении, но классы-агрегаторы запускаются по расписанию, а не реагируют на новые события в потоке. Результатом выполнения таких обработчиков в общем случае является новое событие с другим типом, которое попадает во все тот же канонический поток на основе данных, из которого оно родилось. Далее это новое событие аналогично может подвергнуться обогащению, агрегации и т.д.
После выполнения обогащения наступает последний этап работы с событием:
Уведомление отличается от события тем, что это не просто JSON-данные, а уже совершенно конкретное сообщение с известным получателем, каналом отправки (email, sms и т.д.), и текстом уведомления.
Генерация уведомлений запускается сразу после того, как были применены все необходимые обогащения.
По своей сути, это простой join входящего события с подписками пользователей на данный тип события и прогон исходных JSON-данных через тот или иной шаблонизатор для генерации текста сообщения для указанного в подписке канала. В итоге из одного события мы получаем от 0 до N уведомлений.
Дальше дело за простым — распихать полученные уведомления по соответствующим потокам, откуда их вычитают микросервисы, занимающиеся отправкой писем, sms сообщений и т.д. Но это уже все очевидные и неинтересные вещи, и мы не будем тратить на них внимание читателей.
Последний модуль из тех, что мы рассмотрим — модуль настройки подписок пользователями.
Идея простая — это база данных, которая хранит информацию о том, кто и в каком типе уведомлений заинтересован + UI для настройки.
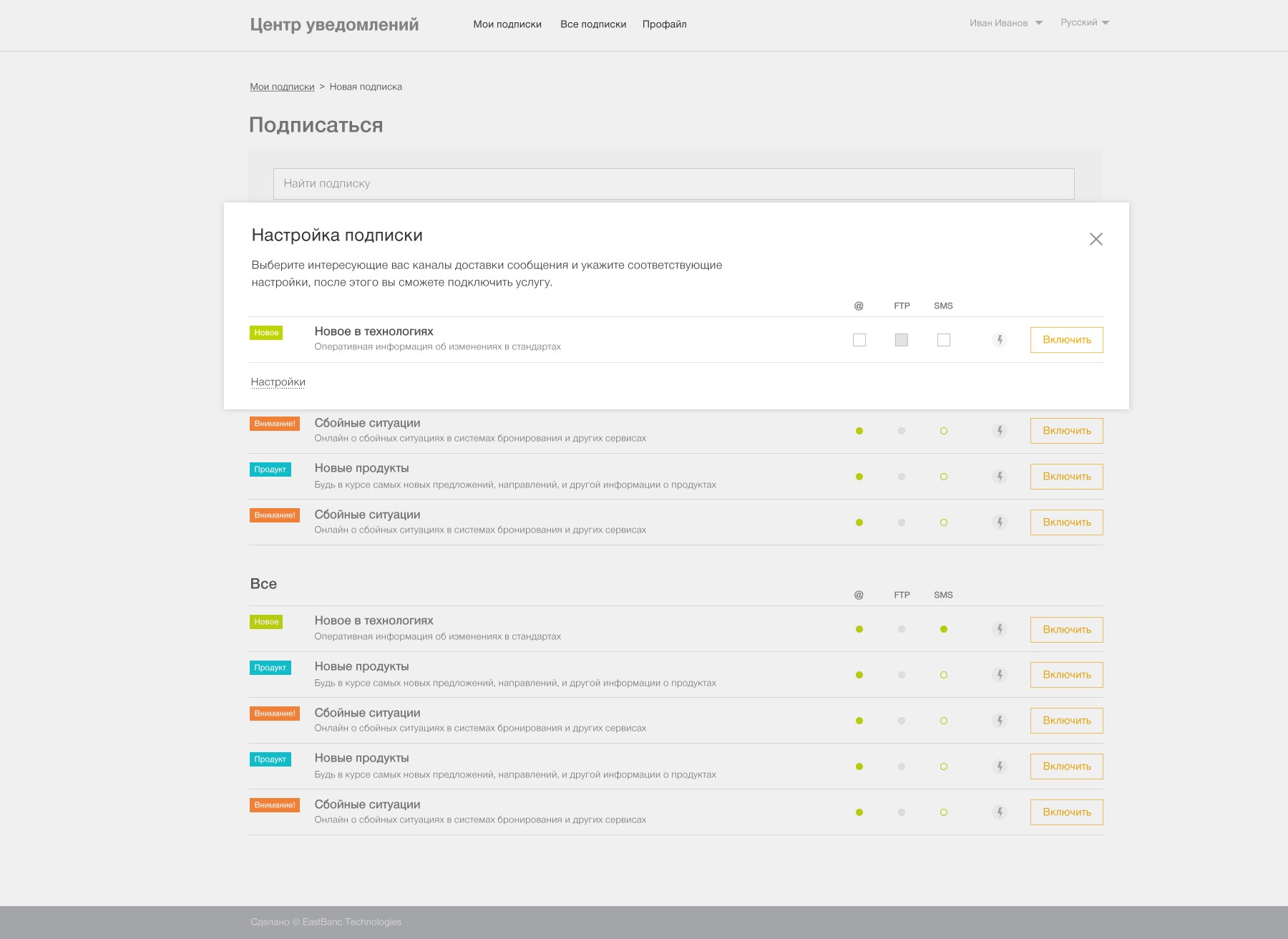
Когда пользователь хочет подписаться, он выбирает интересный ему тип уведомления и открывает окно настроек. Для каждого типа уведомления доступен один или несколько каналов отправки. Тут пользователь указывает минимальное количество настроек: свою почту для email или свой номер телефона для Telegram и при желании выполняет отправку тестового сообщения, чтобы убедиться, что все настроено верно.
На этом всё. Теперь у нас есть подписка пользователя с определенным типом, а в конвейере у нас есть событие с аналогичным типом. Скрещиваем событие и подписку — и на выходе получаем готовое уведомление.
Еще один момент, который мы не рассмотрели ранее, это разграничение доступа. Объясним на примере. Допустим, у нас есть уведомление о том, что контрагенту пора внести оплату за товар. Данное уведомление относится к конкретному контрагенту и получить его должен он один, а не все контрагенты. Соответственно, одного только типа уведомления, описанного выше, недостаточно для того, чтобы определить, для кого конкретно предназначено событие.
Самое простое, но и самое неудачное решение — внести в логику Центра уведомлений понятие контрагента, у которого есть, к примеру, код. И при определении получателей для события отсекать не только по типу события, но и по коду контрагента.
Почему это плохо? Центр уведомлений появился как отдельная система, чтобы избавить бизнес-системы от задачи отправки уведомлений. Но, внося подобные детали в Центр Уведомлений, мы со временем наполним уже Центр Уведомлений кучей знаний из бизнес-систем.
Правильное решение данного вопроса в нашем случае все равно оказалось очень простым, но гибким.
Для авторизации в наших системах мы используем ADFS, то есть авторизация на основе claims. Claim по своей сути это просто пара «идентификатор-значение». Есть заранее определенный набор claims — имя пользователя, набор claims с ролями пользователя и т.д. Ключи этих типов claims заранее известны и стандартны для всех приложений. Также мы используем custom claim providers для присвоения пользователям различных специфичных атрибутов при авторизации.
Например, упомянутый выше код контрагента, если данный пользователь является контрагентом, можно сохранить в виде claim с собственным ключом. Или код региона, в котором находится пользователь. Или владельцем какого девайса он является, IPhone или Android. Мы можем сохранить таким образом любые значимые маркеры.
Это уже половина решения задачи — у нас есть набор claims для каждого пользователя, а значит, и подписки.
Если мы добавим claims к нашим событиям, то мы можем сопоставлять события и подписки не только по типу, но и проверять, что и у события, и у подписки claims с одними и теми же ключами имеют одни и те же значения.
Обратите внимание, понятие «событие, у которого есть claim X со значением Y» — это куда более абстрактная вещь, чем «событие, предназначенное для контрагента Y». Нам не нужно вносить в Центр уведомлений никакой специфики бизнесовых систем.
Вопрос остается в том, где заполнять эти Claims для событий. Поскольку генерация Claims — это все-таки бизнес-специфика в духе «у события о необходимости оплаты должен быть claim контрагента», мы разместили данную логику на этапе сборки данных. Сборщик как минимум знает, откуда брать событие и его структуру. То есть он уже имеет некоторый бизнес-контекст.
На примере события о необходимости внесения оплаты, код контрагента чаще всего находится в контракте бизнес-события о необходимости оплаты, которое сборщик перехватил. Соответственно, сборщик может взять код контрагента из нужного поля контракта и абстрагировать его до понятия «claim с ключом X и значением Y» перед отправкой события в конвейер Центра уведомлений.
Вот так мы решили задачу унификации процессов информирования разных групп пользователей о разных событиях, произошедших в разных модулях системы. Конвейер единый, информирование омниканально, отправка гарантированна и безопасна, а сама платформа открыта к развитию.
Наша система отправляет 206 различных уведомлений из 35 систем девятью способами. Вот такой фронт работ. Как для этой махины мы создавали единую коммуникационную платформу — центр уведомлений — рассказываем под катом.
Любые информационные системы развиваются и начинают контактировать с пользователем всё больше и больше. Вспомните любой интернет-магазин, где вы недавно сделали заказ. Он шлёт письма с информацией о заказе, рассылки и пуш-уведомления о новых акциях, смс, а ещё активен в социальных сетях. И наверняка вы замечали, что эти сообщения составлены по-разному. И насколько разным может быть тон и качество – в соцсетях аккуратные тексты и хештеги, а письмо хочется отправить в спам не читая.
Осознание задачи
Первым делом мы проанализировали все эти сообщения по следующим параметрам:
• кто получатели этих сообщений,
• какая стратегия отправки (немедленно, по расписанию, агрегация),
• есть ли шаблон для сообщения,
• надежность отправки,
• соответствует ли фирменному стилю,
• есть ли поддержка мультиязычности.
Иными словами, мы хотели знать, что мы отправляем и кому. И вот какие результаты мы получили.
Мы поняли, что хотим прийти к единому конвейеру уведомлений, где сообщения доставляются эффективно и сохраняют смысл.
Мы хотим снять с бизнесовых систем нагрузку и ответственность за отправку уведомлений и понимание таких сущностей как «подписки», «локализации» и т.д.
В нашей концепции информационная система должна стать централизованной мини-редакцией с умным конвейером, который по теме/типу сообщения распознает, каким образом, когда, кому и по каким каналам его нужно распространить. И распространяет.
Если быть более конкретным, вот наши главные цели:
1. Договориться о правилах игры и привести все уведомления к единому качеству. Проанализировать все уведомления и убрать ситуации, когда 5 систем отправляли пользователю одну и ту же информацию, но в разном оформлении. Снимаем с разработчиков бизнес-систем ответственность за UI и грамотность уведомлений, гарантию отправки уведомлений, мониторинг отправки уведомлений. Вместо этого приходим к централизованной системе, где хранятся все шаблоны уведомлений с единым дизайном и функционалом и отдельной команде, которая занимается этими вопросами.
2. Обеспечить своевременную отправку. Иметь возможность настроить, как часто отправлять информацию и какой тип уведомления отправлять. Уметь быстро добавить новое уведомление по запросу бизнеса. Скажем, информацию об отмене заказа нужно доставить как можно быстрее, а про распродажи и новые коллекции можно рассказывать раз в неделю.
3. Обеспечить гарантированную отправку информации. Важное сообщение рассылать самыми оперативно-просматриваемыми каналами — это смс, мессенджеры. Или сразу всеми. Мониторить и дублировать по этим же или другим каналам, если нет реакции.
4. Сохранять единый стиль коммуникации. Создать систему коммуникации — шаблоны писем и сообщений — и придерживаться ее. (Этому служит единый UI и редполитика).
5. Персонализировать коммуникацию. Различать, когда мы общаемся с физическим лицом, а когда с юридическим, в каком часовом поясе он живёт.
6. Бдить, то есть настроить мониторинг и безопасность. Отправлять ссылки на вложения, при открытии которых выполняются проверки безопасности и собирается статистика скачиваний, вместо отправки вложений прямо в письмах. Обеспечить гарантированную отправку, мониторить, что и кому отправлялось.
Что с готовыми решениями?
На рынке есть коробочные решения, которые выполняют часть функций из тех, которые нам нужны. Например, в BizTalk можно вшить уведомления о событиях и настроить специальные пайпы, которые в конечном счете составляют это письмо. В Dynamics CRM и SharePoint есть настройки, которые реагируют на какие-то события. Как правило, это сводится к тому, что кто-то где-то нажал кнопку, и как результат — email отправился. О более сложных вещах, вроде политики агрегации и красивом UI, речи не идёт.
У Azure и AWS много сервисов, которые умеют взять готовый контент и отправить рассылку на почту. Получается, что весь контент для него нужно подготовить вручную. А назначение центра уведомлений — как раз в том, чтобы готовить контент.
Так мы убедились, что в нашем случае не стоит уповать на решение из коробки, где нам останется настроить UI, и система сама куда-то подключится и вытащит всё нужное. Такие вещи не работают из коробки, их нужно делать руками. Коробочные решения в таких случаях подразумевают использование мета-языка и конфигурирования, которые в конечном счете превращаются в проблему настройки. У нас же получилось решение, сделанное под конкретные потребности бизнеса. Его легко настроить и добавлять новые задачи.
Собираем конвейер. Архитектура нашего Центра уведомлений
У нас есть бизнес-системы — это системы, которые решают главные задачи бизнеса. Они работают отдельно от центра уведомлений и не должны заниматься вопросами коммуникации с пользователями.
В идеале такие системы просто генерируют бизнес-события, необходимые для их работы и взаимодействия с другими системами, а Центр уведомлений просто пристраивается рядом и становится еще одним слушателем этих бизнес-событий, и реагирует на них как на сигналы к действию с минимальным необходимым набором входной информации. Далее Центр уведомлений дополняет события нужной информацией, перерабатывает, и на выходе мы получаем одно или несколько готовых к отправке уведомлений, каждое из которых персонально обращается к заинтересованному пользователю, на нужном языке и со всей необходимой ему информацией.
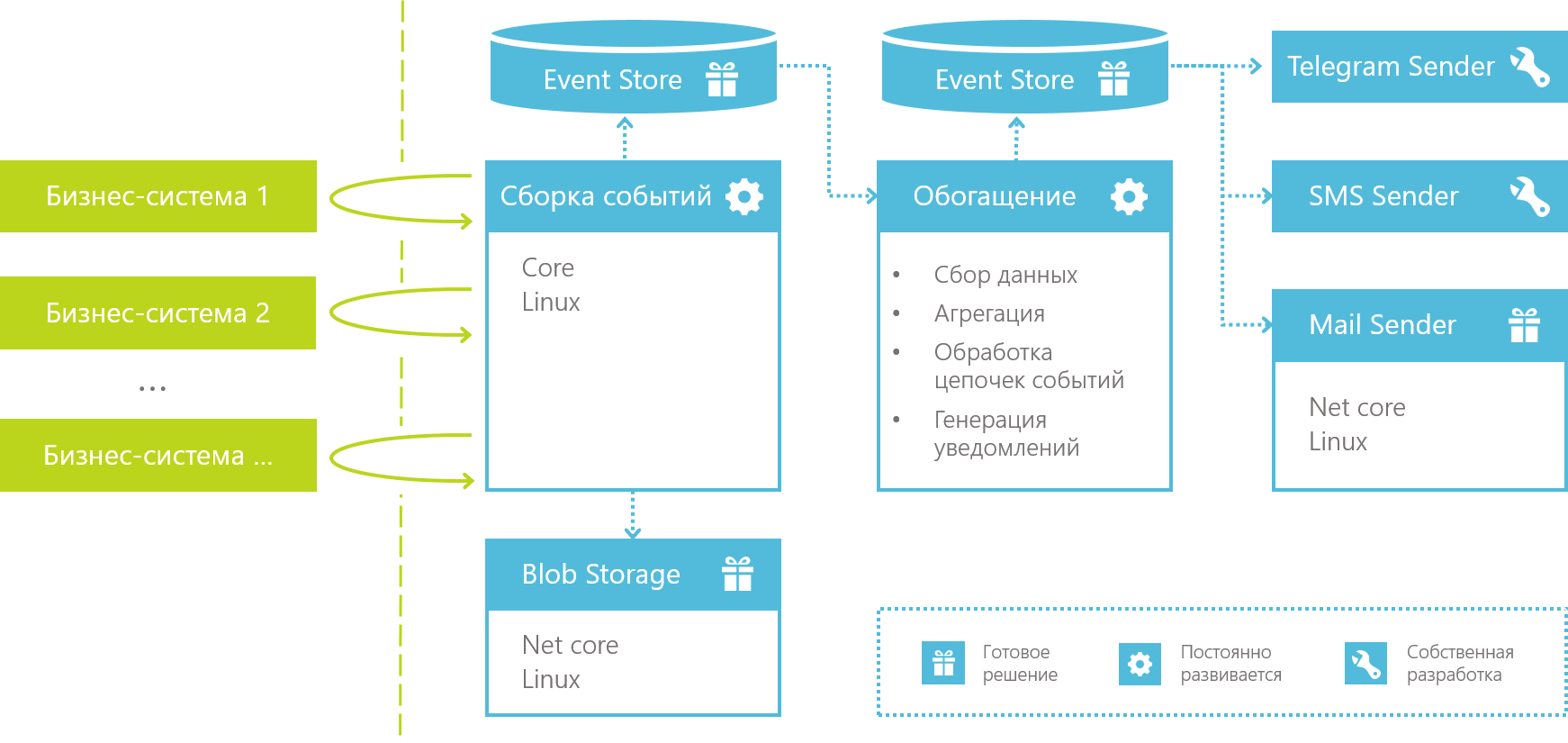
Технически все это раскладывается в конвейер по переработке информации, который выглядит следующим образом:
1. Сборка событий
Все начинается со сборки событий, которая перехватывает или целенаправленно собирает данные из бизнес-систем и сохраняет их как «сырой» поток событий для дальнейшей обработки.
С точки зрения разработки сборщик событий — это хост-система, разработанная с прицелом на то, что мы можем очень быстро добавить сюда обработку очередного типа событий.
Мы с самого начала отказались от идеи мегасистемы для сборки данных, у которой будет свой метаязык и чудо-UI-настройки, с помощью которых ее можно подключить к чему угодно и собрать что угодно. Вместо этого мы положили в основу системы самый гибкий инструмент из нам доступных — язык программирования, и сосредоточились на том, чтобы обработка очередного бизнес-события сводилась к написанию одного маленького классика, который знает, откуда событие забрать и во что превратить. Дальше этот классик вбрасывается в хост-систему сборки данных и просто начинает работать как еще один элемент конвейера.
В момент сбора данные они приводятся к «канонической форме» — каждое событие получает уникальный идентификатор (либо берется CorrelationId, который уже был назначен событию в бизнес-системе), определяется дата события (DateTime.Now либо дата из пришедших бизнесовых данных, зависит от кейса), тип события и т.д., и все события сохраняются в общий поток событий для дальнейшей обработки. Сборщик не заинтересован непосредственно в данных события, он, образно говоря, оборачивает их в конверт. Форма конверта — каноническая, а содержимое разное.
2. Куда сохранять данные? EventStore
Как мы писали выше, в момент сбора событий они сохраняются в общий поток для дальнейшей обработки. Решая вопрос того, как хранить данные, мы выбрали широко известный в узких кругах продукт под названием EventStore. Кстати, одним из идеологов EventStore является Greg Young, имя которого неразрывно связано с такими концепциями как CQRS и Event Sourcing.
Согласно определению на главной странице, EventStore это «функциональная база данных с комплексной обработкой событий в JavaScript». Если же попытаться сформулировать в свободной форме, что представляет из себя EventStore, то мы бы сказали, что это очень интересный гибрид базы данных и брокера сообщений.
Преимуществом, взятым от брокеров, является возможность построить реактивную систему, в которой EventStore берет на себя уведомление слушателей о новых событиях, гарантию доставки сообщений, конкурентную обработку, отслеживание, какое из сообщений каким из подписчиков уже прочитано и т.д.
Но, в отличие от брокеров сообщений, данные не удаляются из EventStore после того, как были прочитаны получателем. Это дает возможность не только реактивной работы с атомарными событиями, но и работы с массивами исторических данных, как в БД. К слову, одной из самых продвигаемых фич Event Store является возможность построения temporal queries, позволяющих проводить анализ последовательностей событий во времени, что, как правило, сложно сделать с использованием «традиционных» БД.
В случае с Центром уведомлений, оказались востребованы обе возможности EventStore. Используя реактивную модель подписок, мы реализовали генерацию немедленных уведомлений и обогащение данных о событиях (о нем ниже). А при помощи проекций мы организовали анализ последовательностей событий, с помощью которого можно:
а. генерировать агрегированные события в духе «Сводка о … за неделю/месяц/год»,
б. анализировать последовательности различных типов событий и находить интересные закономерности между ними, отслеживать пики происходящих событий и вообще.
3. Blob Storage
Еще одним вопросом, связанным с хранением данных и вставшим при разработке Центра уведомлений, стала работа с файлами. Нередко нам нужно отправить пользователю в уведомлении какой-либо файл.
Простейший пример: отправка отчета по почте. И самое простое, что можно сделать — прикрепить файл к письму в виде вложения. Но если развивать сценарий, то мы сразу заметим несколько ограничений в таком решении.
- После отправки мы ничего не знаем о дальнейшей судьбе файла. Открывали ли его вообще, сколько раз, кто открывал.
- С почтой все легко, а вот в СМС-уведомление файл уже не вложишь.
- Дополнительная нагрузка на почтовый сервер при отправке файлов в виде вложений.
- Один и тот же файл может быть интересен множеству пользователей.
Простейшее решение всех этих вопросов — отправить вместо файла ссылку. Так мы и почтовый сервер не нагружаем, и можем мониторить, что происходит с файлом, и даже можем провести проверки безопасности и проверить, что пользователю действительно можно этот файл посмотреть.
С другой стороны, есть в этом и чисто практический смысл. Файл может быть привязан к событию еще с момента, когда событие произошло. Например, когда суть бизнес-события — получен обменный файл от системы бронирования в авиаперевозках за определенную дату. Или файл может быть сгенерирован как результат обработки пачки событий, допустим, за последний месяц.
В общем, файлы могут существовать с самого начала жизни события, и нет смысла «протаскивать» тяжеловесный контент через весь конвейер Центра уведомлений только для того, чтобы в конце его отправить. Можно в самом начале сохранить файл в специальный сервис, а в событии сохранить его идентификатор. А достать файл можно там, где он будет нужен уже при отправке уведомления.
Так и родился у нас еще один очень простой сервис — Blob Storage.В сервис можно сохранить файл через POST-запрос и в ответ получить Guid. Также в сервис можно послать GET-запрос с полученным Guid, а взамен он вернет файл. А все проверки безопасности, сбор статистики и прочее — это уже внутренние дела сервиса Blob Storage.
4. Обогащение данных
Итак, на данный момент мы рассмотрели этап сборки событий и то, как мы сохраняем информацию о событиях и файлах. Перейдем к этапу, на котором начинается работа с данными — этапу обогащения.
На вход данного этапа попадают «канонические» события, собранные ранее. На выходе же мы получаем от нуля до N готовых уведомлений, которые уже имеют получателя, текст сообщения на конкретном языке, и уже понятно, по какому каналу (email, telegram, sms и т.д.) уведомление необходимо будет отправить.
На данном этапе исходное событие может быть подвергнуто следующим манипуляциям.
Дополнение исходного набора данных
В основном благодаря этой операции весь этап и получил название «обогащение». Простейший пример дополнения данных — в «каноническом» событии нам пришел Id пользователя. На данном этапе мы по Id пользователя находим его ФИО, чтобы иметь возможность обратиться к нему по имени в тексте уведомления, и дополняем исходное событие найденной информацией.
Каждый «обогатитель» — это отдельный маленький класс, который (по аналогии со сборщиками событий) быстро пишется и «вбрасывается» в общий конвейер, который уже подаст всю нужную информацию на вход и сохранит результат, куда нужно.
Агрегация, обработка последовательностей событий, анализ во времени
Здесь все достаточно просто. Подход тот же, что и в обогащении, но классы-агрегаторы запускаются по расписанию, а не реагируют на новые события в потоке. Результатом выполнения таких обработчиков в общем случае является новое событие с другим типом, которое попадает во все тот же канонический поток на основе данных, из которого оно родилось. Далее это новое событие аналогично может подвергнуться обогащению, агрегации и т.д.
После выполнения обогащения наступает последний этап работы с событием:
5. Генерация уведомлений
Уведомление отличается от события тем, что это не просто JSON-данные, а уже совершенно конкретное сообщение с известным получателем, каналом отправки (email, sms и т.д.), и текстом уведомления.
Генерация уведомлений запускается сразу после того, как были применены все необходимые обогащения.
По своей сути, это простой join входящего события с подписками пользователей на данный тип события и прогон исходных JSON-данных через тот или иной шаблонизатор для генерации текста сообщения для указанного в подписке канала. В итоге из одного события мы получаем от 0 до N уведомлений.
Дальше дело за простым — распихать полученные уведомления по соответствующим потокам, откуда их вычитают микросервисы, занимающиеся отправкой писем, sms сообщений и т.д. Но это уже все очевидные и неинтересные вещи, и мы не будем тратить на них внимание читателей.
6. Подписки
Последний модуль из тех, что мы рассмотрим — модуль настройки подписок пользователями.
Идея простая — это база данных, которая хранит информацию о том, кто и в каком типе уведомлений заинтересован + UI для настройки.
Когда пользователь хочет подписаться, он выбирает интересный ему тип уведомления и открывает окно настроек. Для каждого типа уведомления доступен один или несколько каналов отправки. Тут пользователь указывает минимальное количество настроек: свою почту для email или свой номер телефона для Telegram и при желании выполняет отправку тестового сообщения, чтобы убедиться, что все настроено верно.
На этом всё. Теперь у нас есть подписка пользователя с определенным типом, а в конвейере у нас есть событие с аналогичным типом. Скрещиваем событие и подписку — и на выходе получаем готовое уведомление.
7. Разграничение доступа
Еще один момент, который мы не рассмотрели ранее, это разграничение доступа. Объясним на примере. Допустим, у нас есть уведомление о том, что контрагенту пора внести оплату за товар. Данное уведомление относится к конкретному контрагенту и получить его должен он один, а не все контрагенты. Соответственно, одного только типа уведомления, описанного выше, недостаточно для того, чтобы определить, для кого конкретно предназначено событие.
Самое простое, но и самое неудачное решение — внести в логику Центра уведомлений понятие контрагента, у которого есть, к примеру, код. И при определении получателей для события отсекать не только по типу события, но и по коду контрагента.
Почему это плохо? Центр уведомлений появился как отдельная система, чтобы избавить бизнес-системы от задачи отправки уведомлений. Но, внося подобные детали в Центр Уведомлений, мы со временем наполним уже Центр Уведомлений кучей знаний из бизнес-систем.
Правильное решение данного вопроса в нашем случае все равно оказалось очень простым, но гибким.
Для авторизации в наших системах мы используем ADFS, то есть авторизация на основе claims. Claim по своей сути это просто пара «идентификатор-значение». Есть заранее определенный набор claims — имя пользователя, набор claims с ролями пользователя и т.д. Ключи этих типов claims заранее известны и стандартны для всех приложений. Также мы используем custom claim providers для присвоения пользователям различных специфичных атрибутов при авторизации.
Например, упомянутый выше код контрагента, если данный пользователь является контрагентом, можно сохранить в виде claim с собственным ключом. Или код региона, в котором находится пользователь. Или владельцем какого девайса он является, IPhone или Android. Мы можем сохранить таким образом любые значимые маркеры.
Это уже половина решения задачи — у нас есть набор claims для каждого пользователя, а значит, и подписки.
Если мы добавим claims к нашим событиям, то мы можем сопоставлять события и подписки не только по типу, но и проверять, что и у события, и у подписки claims с одними и теми же ключами имеют одни и те же значения.
Обратите внимание, понятие «событие, у которого есть claim X со значением Y» — это куда более абстрактная вещь, чем «событие, предназначенное для контрагента Y». Нам не нужно вносить в Центр уведомлений никакой специфики бизнесовых систем.
Вопрос остается в том, где заполнять эти Claims для событий. Поскольку генерация Claims — это все-таки бизнес-специфика в духе «у события о необходимости оплаты должен быть claim контрагента», мы разместили данную логику на этапе сборки данных. Сборщик как минимум знает, откуда брать событие и его структуру. То есть он уже имеет некоторый бизнес-контекст.
На примере события о необходимости внесения оплаты, код контрагента чаще всего находится в контракте бизнес-события о необходимости оплаты, которое сборщик перехватил. Соответственно, сборщик может взять код контрагента из нужного поля контракта и абстрагировать его до понятия «claim с ключом X и значением Y» перед отправкой события в конвейер Центра уведомлений.
Итого
Вот так мы решили задачу унификации процессов информирования разных групп пользователей о разных событиях, произошедших в разных модулях системы. Конвейер единый, информирование омниканально, отправка гарантированна и безопасна, а сама платформа открыта к развитию.