
29 мая прошла Yet another Conference 2018 — ежегодная и самая большая конференция Яндекса. На YaC этого года было три секции: о технологиях маркетинга, умном городе и информационной безопасности. По горячим следам мы публикуем один из ключевых докладов третьей секции — от Юрия Леонычева tracer0tong из японской компании Rakuten.
— Я работаю в международной корпорации Rakuten. Хочу поговорить о нескольких вещах: немного о себе, о нашей компании, о том, как оценивать стоимость атак и понять, нужно ли вам вообще делать fraud prevention. Хочу рассказать, как мы наш fraud prevention собрали и какие модели, которые мы использовали, дали хорошие результаты на практике, как они отработали и что вообще можно сделать, чтобы предотвратить фрод-атаки.

О себе кратко. Работал в компании Яндекс, занимался безопасностью веб-приложений, и в Яндексе тоже когда-то делал систему для предотвращения фрод-атак. Умею разрабатывать распределенные сервисы, у меня немного математического бэкграунда, который помогает с использованием машинного обучения на практике.
Компания Rakuten не очень широко известна в РФ, но думаю, вы все знаете ее по двум причинам. Из более чем 70 наших сервисов в России известен Rakuten Viber, и если тут есть футбольные фанаты, возможно, вы знаете, что наша компания — генеральный спонсор футбольного клуба «Барселона».
Поскольку у нас очень много сервисов, есть свои платежные системы, свои кредитные карты, множество reward-программ, мы постоянно подвергаемся атакам злоумышленников. И естественно, у нас всегда есть запрос от бизнеса на системы защиты от фрода.
Когда бизнес просит нас сделать систему защиты от фрода, мы всегда сталкиваемся с некоторой дилеммой. С одной стороны, есть запрос на то, чтобы был высокий conversion rate, чтобы пользователю было удобно аутентифицироваться на сервисах, совершать покупки. А с нашей стороны, со стороны безопасников, хочется, чтобы было меньше жалоб, меньше аккаунтов было взломано. И мы со своей стороны хотим сделать цену атаки высокой.
Если вы будете покупать fraud prevention-систему или попытаетесь сделать ее сами, вам в первую очередь нужно оценить затраты.

Как мы считали, нужен ли нам fraud prevention? Мы опирались на то, что у нас от фрода есть некоторые виды финансовых потерь. Это прямые потери — деньги, которые вы вернете своим клиентам, если они были похищены злоумышленниками. Это затраты на службу техподдержки, которая будет общаться с пользователями, разрешать конфликтные вопросы. Это возврат товаров, которые очень часто доставляются по ненастоящим адресам. И есть прямые затраты на разработку системы. Если вы сделали систему защиты от фрода, развернули ее на каких-то серверах, вы будете платить за инфраструктуру, за разработку ПО. И есть третий очень важный аспект ущерба от атакующих — упущенная прибыль. Она состоит из нескольких компонентов.
По нашим подсчетам, есть очень важный параметр — lifetime value, LTV, то есть деньги, которые пользователь тратит в наших сервисах, существенно уменьшаются. Потому что в половине случаев фрода пользователи просто уходят с вашего сервиса и не возвращаются.
Также мы платим деньги за рекламу, и если пользователь ушел, они потеряны. Это customer acquisition cost, CAC. И если у нас много автоматизированных пользователей, не являющихся реальными людьми — мы имеем ненастоящие цифры monthly active users, MAU, которые тоже влияют на бизнес.
Давайте посмотрим с другой стороны, со стороны атакующих.
Некоторые докладчики говорили, что атакующие активно используют ботнеты. Но какой бы метод они ни использовали, им все равно нужно инвестировать деньги, заплатить за атаку, они тоже тратят какие-то средства. Наша задача, когда мы делаем систему fraud prevention, найти такой баланс, чтобы атакующий потратил слишком много денег, а мы потратили меньше. Это делает атаку на нас невыгодной, и злоумышленники просто уходят ломать другой сервис.

Для наших сервисов по ущербу мы поделили атаки на четыре типа. Это таргетированные, когда пытаются взломать один аккаунт, одну учетную запись. Атаки, совершенные одним пользователем или небольшой группой лиц. Или более опасные для нас атаки массированные и нетаргетированные, когда атакующие нападают на множество учетных записей, кредитных карт, телефонных номеров и т. д.

Расскажу, что происходит, как на нас нападают. Основной самый очевидный тип атак, про который все знают, это переборы паролей. В нашем случае злоумышленники пытаются перебирать телефонные номера, пытаются валидировать номера кредитных карт. Некоторое разнообразие присутствует.
Массовая регистрация аккаунтов, для нас она очевидна вредна. Позже приведу пример.
Что регистрируют? Фейковые учетные записи, какие-то несуществующие товары, пытаются спамить в сообщениях обратной связи. Думаю, это для многих коммерческих компаний актуально и сходно.
Есть еще неочевидные для e-commerce, но очевидные для Яндекса проблемы — атаки на рекламный бюджет, click fraud. Ну или просто кража персональных данных.

Приведу пример. У нас была довольно интересная атака на сервис, который продает электронные книги, там была возможность для любого пользователя зарегистрироваться и свое электронное произведение начать продавать, такая возможность поддержки начинающих писателей.
Злоумышленник зарегистрировал одну легальную мастер учетную запись, и несколько тысяч ненастоящих миньон-аккаунтов. И сгенерировал фальшивую книгу, просто из случайных предложений, никакого смысла в ней не было. Он ее выложил на маркетплейс, и у нас была маркетинговая компания, у каждого миньона был, условно, 1 доллар, который он мог потратить на книгу. И эта фейковая книга стоила 1 доллар.
Был организован набег миньонов — фейковых аккаунтов. Они все купили эту книжку, книжка подскочила в рейтингах, стала бестселлером, злоумышленник поднял цену до условных 10 долларов. А так как книга стала бестселлером, ее начали покупать обычные люди, и на нас посыпались жалобы о том, что мы продаем какой-то некачественный товар, книгу с бессмысленным набором слов внутри. Злоумышленник получил профит.
Тут нет девятого пункта, его позже арестовала полиция. Так что профит не пошел впрок.
Основная цель всех злоумышленников в нашем случае потратить как можно меньше своих денег и как можно больше забрать наших.

Есть атакующие, один человек, которые просто бизнес-логику пытаются обойти. Но отмечу, что такие атаки мы для себя не считаем приоритетными, потому что по соотношению количества взломанных аккаунтов и украденных денег они несут для нас низкий риск. А основной проблемой для нас являются ботнеты.

Это массивные распределенные системы, они нападают на наши сервисы со всей планеты, с разных континентов, но у них есть некоторые особенности, которые облегчают борьбу с ними. Как и во всякой большой распределенной системе, узлы ботнета выполняють более-менее одинаковые задачи.
Другая важная вещь — сейчас, как многие коллеги отмечали, ботнеты распространяются на всяких умных устройствах, домашних роутерах, умных колонках и т. д. Но эти устройства имеют низкие аппаратные спецификации и не могут выполнять сложные сценарии.
С другой стороны, для злоумышленника аренда ботнета для простого DDoS достаточно дешевая, для перебора паролей к учетным записям тоже. Но если требуется реализация какой-то бизнес логики специально для вашего приложения или сервиса, разработка и поддержка ботнета становится очень дорогой. Обычно же злоумышленник просто арендует часть готового ботнета.
У меня всегда атака ботнетов ассоциируется с парадом Пикачу в Йокогаме. У нас 95% вредоносного трафика исходит от ботнетов.
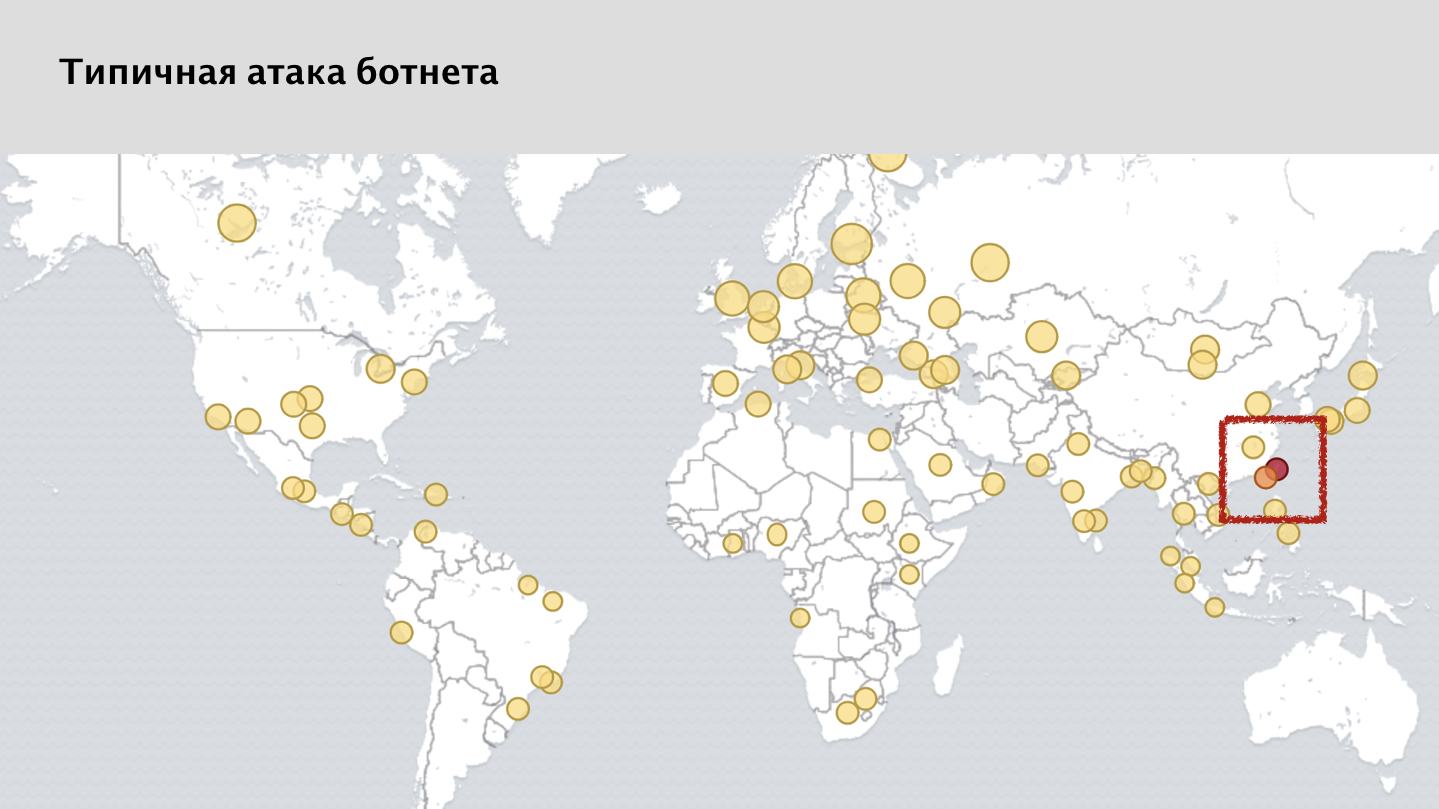
Если посмотреть на скриншот нашей системы мониторинга, вы увидите множество желтых пятен — это заблокированные запросы от различных узлов. И здесь внимательный человек может заметить, что я вроде сказал, что атака равномерно распределена по земному шару. Но на карте есть явная аномалия, красное пятно в районе Тайваня. Это довольно любопытный случай.
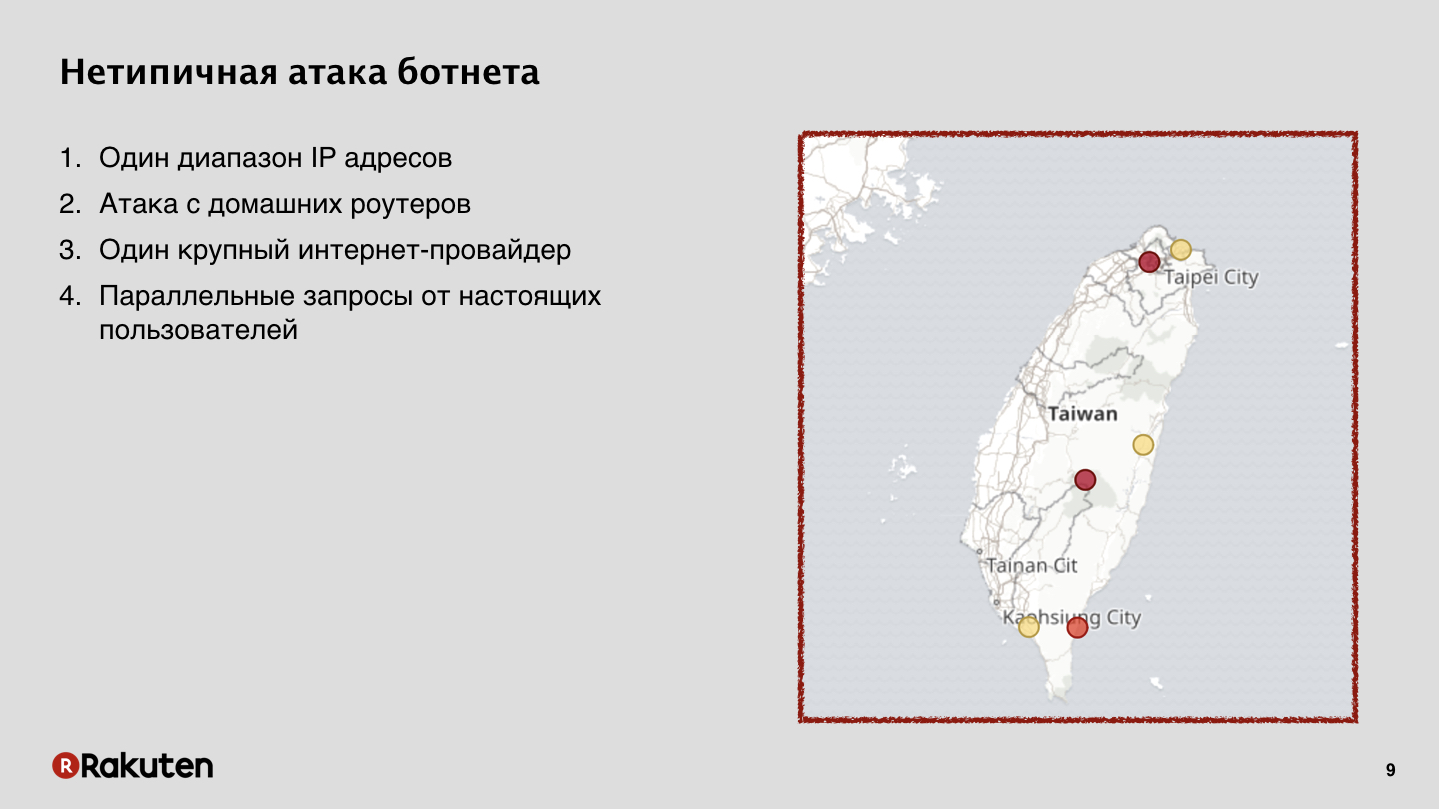
Эта атака исходила от домашних роутеров. В Тайване был взломан крупный интернет-провайдер, который предоставлял интернет для большей части жителей острова. И для нас это была очень большая проблема, связанная с тем, что очень много легальных пользователей в то же время, когда происходила атака, с тех же IP-адресов ходили и работали с нашими сервисами. Мы эту атаку остановили успешно, но это было очень сложно.
Если говорить о скоупе, о поверхности, о том, что мы защищаем. Если у вас маленький e-commerce веб-сайт или маленький региональный сервис, у вас особых проблем нет. У вас есть сервер, может, несколько, или виртуальные машины в облаке. Ну и пользователи, плохие, хорошие, которые к вам приходят. Защищать особой проблемы здесь нет.
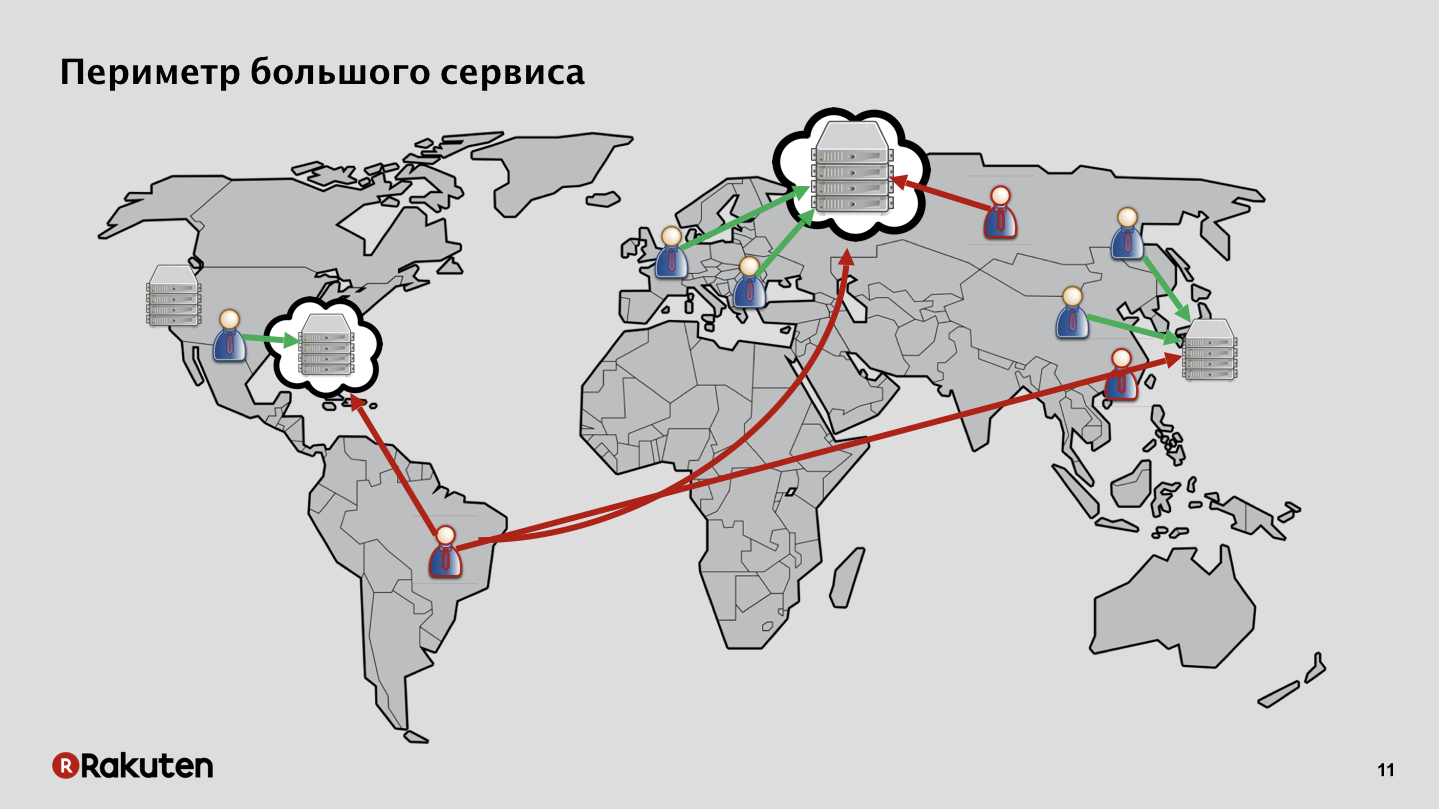
В нашем случае все сложнее, поверхность атаки огромная. У нас есть сервисы, развернутые в наших собственных дата-центрах, в Европе, в Юго-Восточной Азии, в США. У нас пользователи тоже на разных континентах, причем как хорошие, так и плохие. Плюс некоторые сервисы развернуты в облачной инфраструктуре, причем не нашей собственной.
При таком количестве сервисов и такой обширной инфраструктуре защищаться очень тяжело. Плюс многие наши сервисы поддерживают различные виды клиентских приложений и интерфейсов. Например, у нас есть сервис Rakuten TV, который работает на умных телевизорах, и для него защита совершенно специальная.

Если подытожить проблему, огромное количество пользователей циркулируют в вашей системе, как люди у магазина на перекрестке в Шибуе. И среди этого множества людей надо выявить и поймать злоумышленников. При этом дверей у вас в магазине очень много, и людей еще больше.
Итак, из чего и как мы собрали нашу систему?
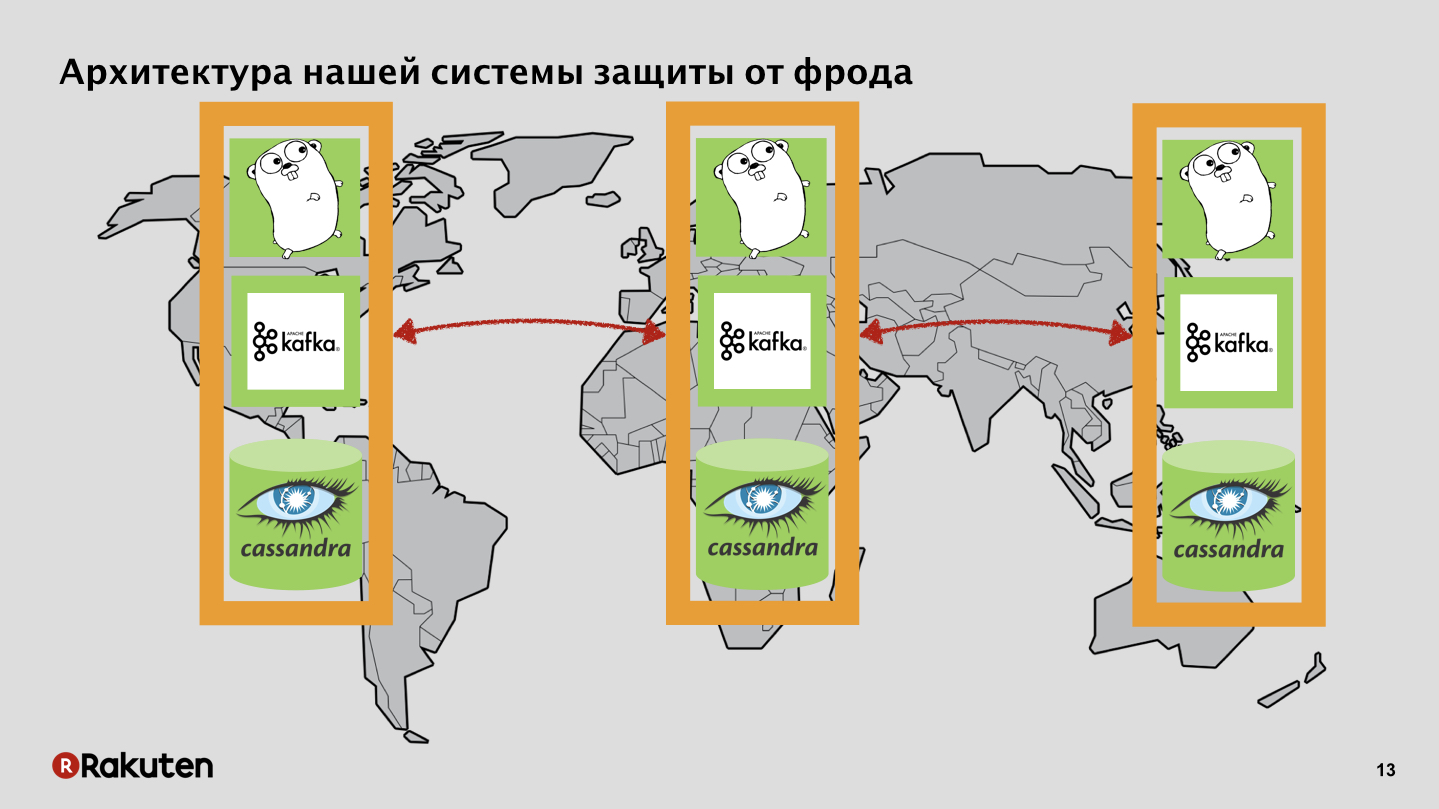
Нам удалось использовать только open source компоненты, это было достаточно дешево. Использовали силу множества «сусликов». Значительная часть ПО была написана на языке Golang. Использовали очереди сообщений и БД. Для чего нам это было нужно? Мы преследовали две цели: сбор данных о поведении пользователей и расчет репутации, проведение каких-то действий, чтобы распознать, хороший пользователь или плохой.
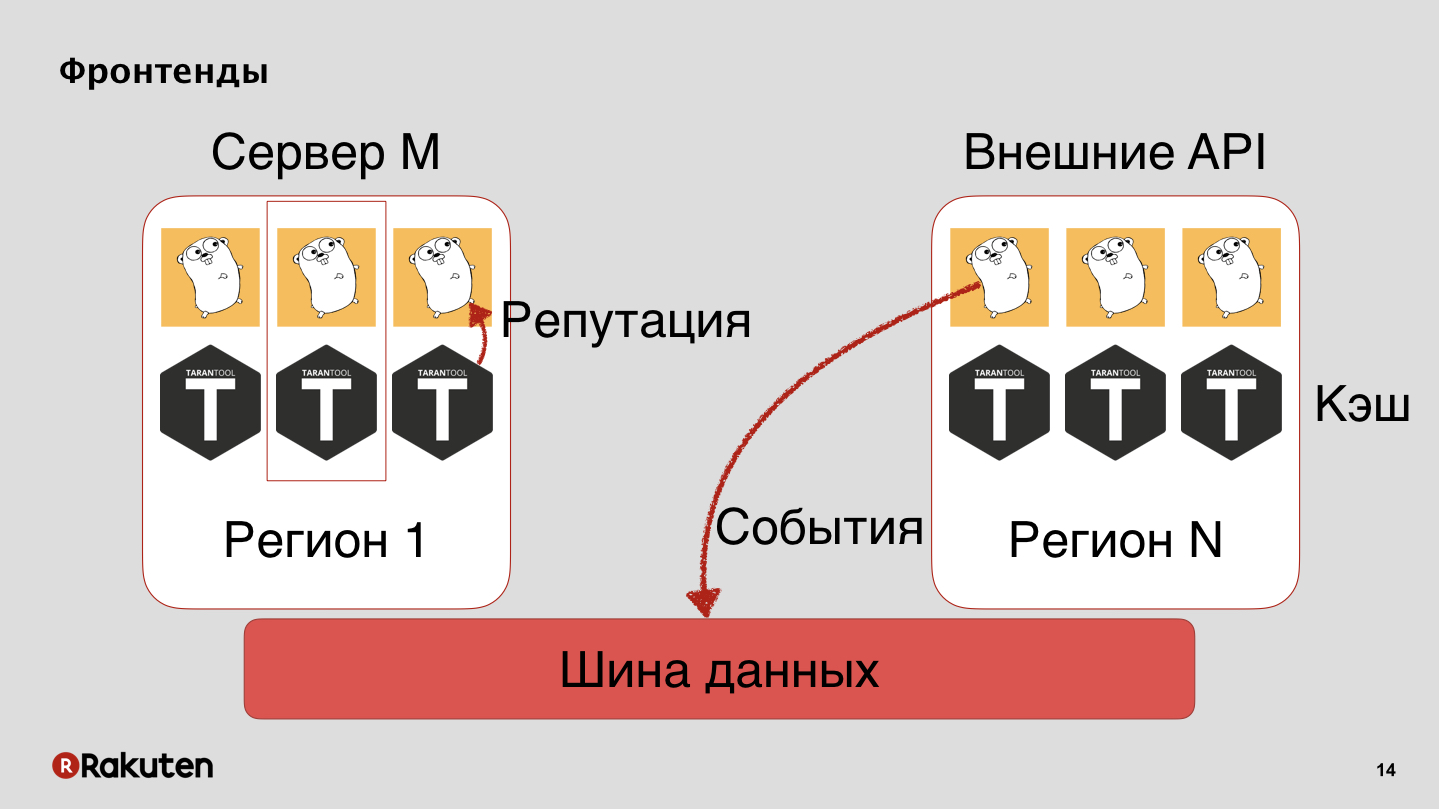
У нас в системе множество уровней, фронтенды мы используем, написанные на Golang, а как кэширующую базу — Tarantool. Наша система развернута во всех регионах, где находятся наши бизнесы. События мы передаем по шине данных, из нее же получаем репутацию.
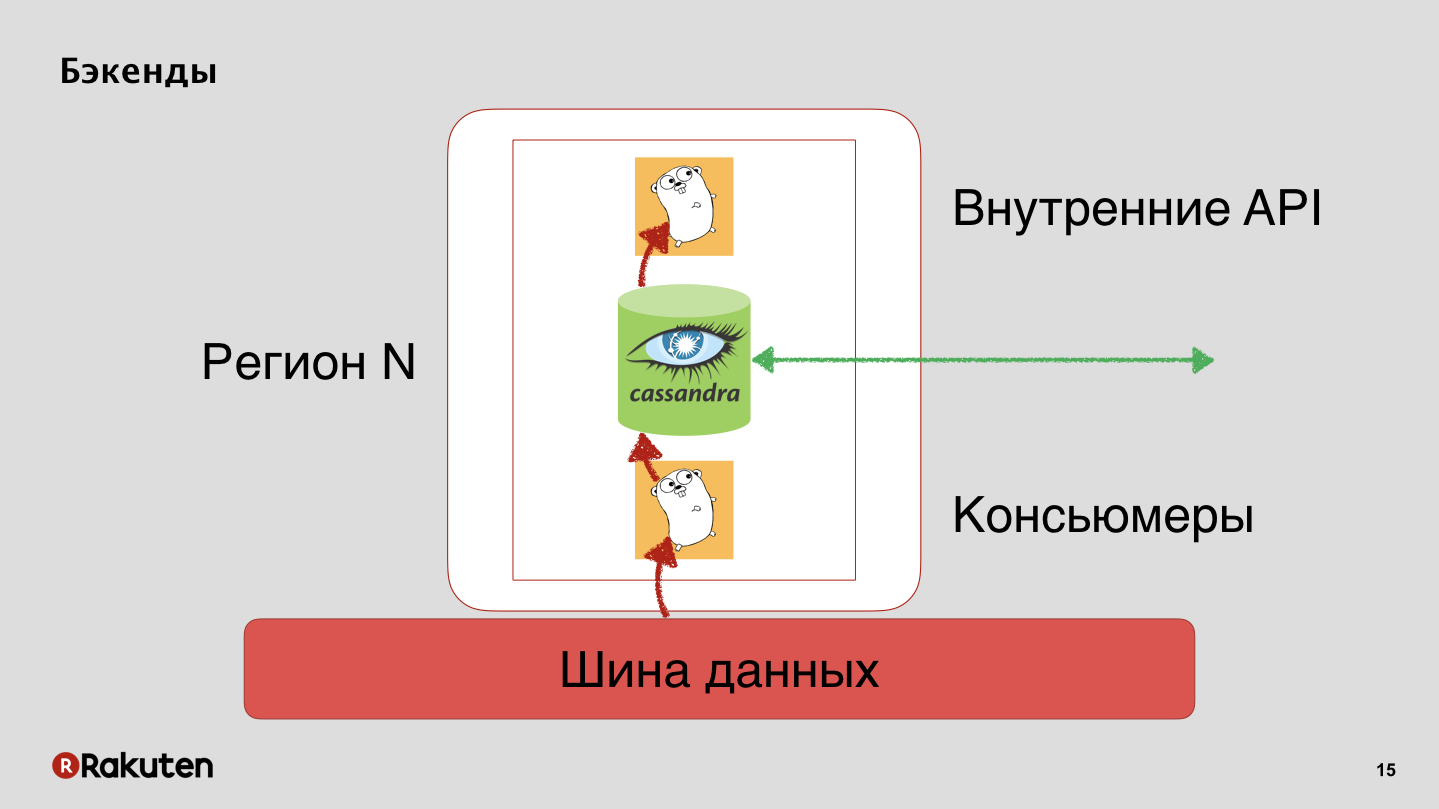
У нас есть бэкенды, которые также реплицируют состояние репутации пользователей с помощью Cassandra.
Шина данных, ничего секретного, Apache Kafka.
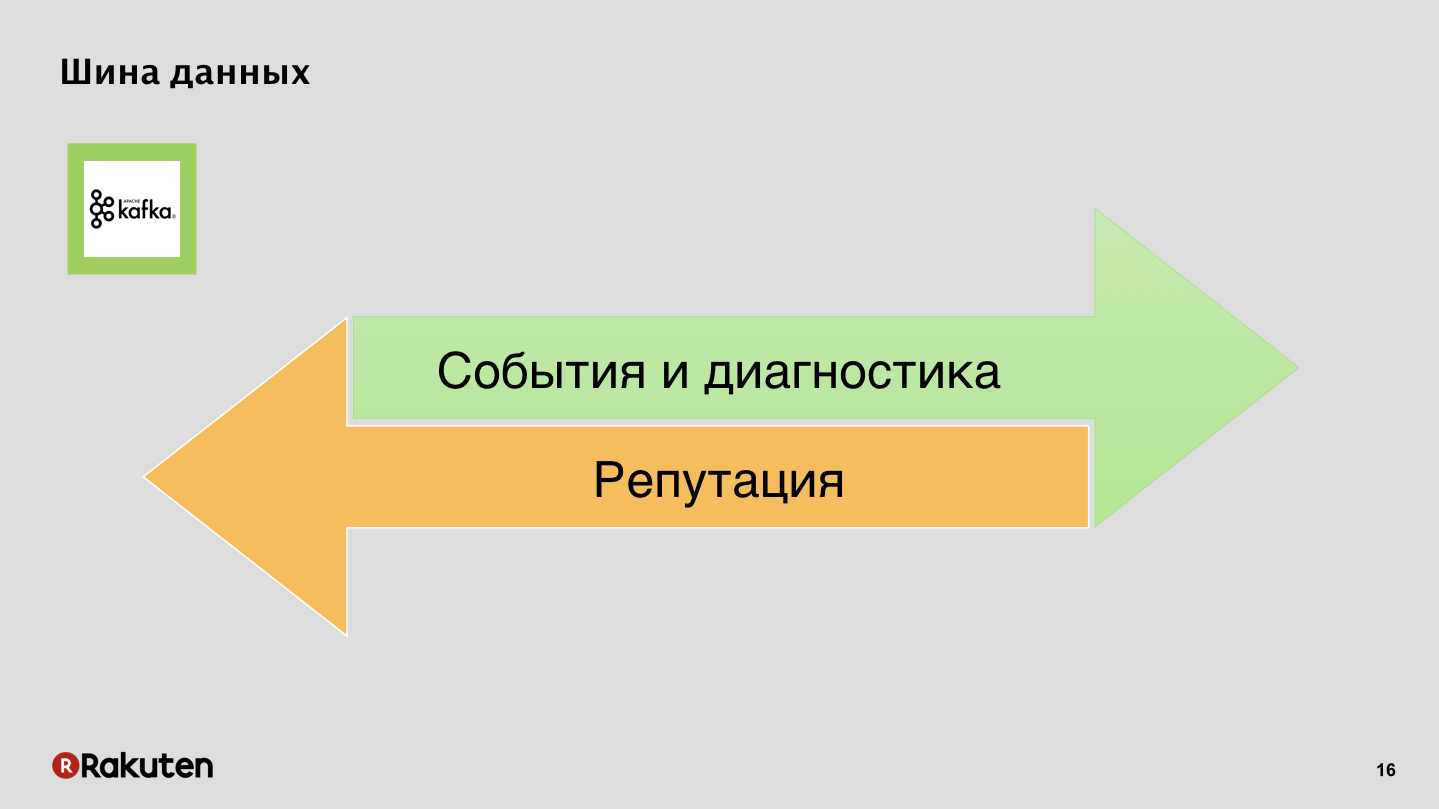
События и логи в одну сторону, репутация в другую.
И естественно, у системы есть мозг, который считает, плохой это пользователь или хороший, плохая это активность или хорошая. Мозг построен на Apache Storm, и самое интересное — что происходит там внутри.
Но сначала расскажу, как мы собираем данные и как блокируем злоумышленников.
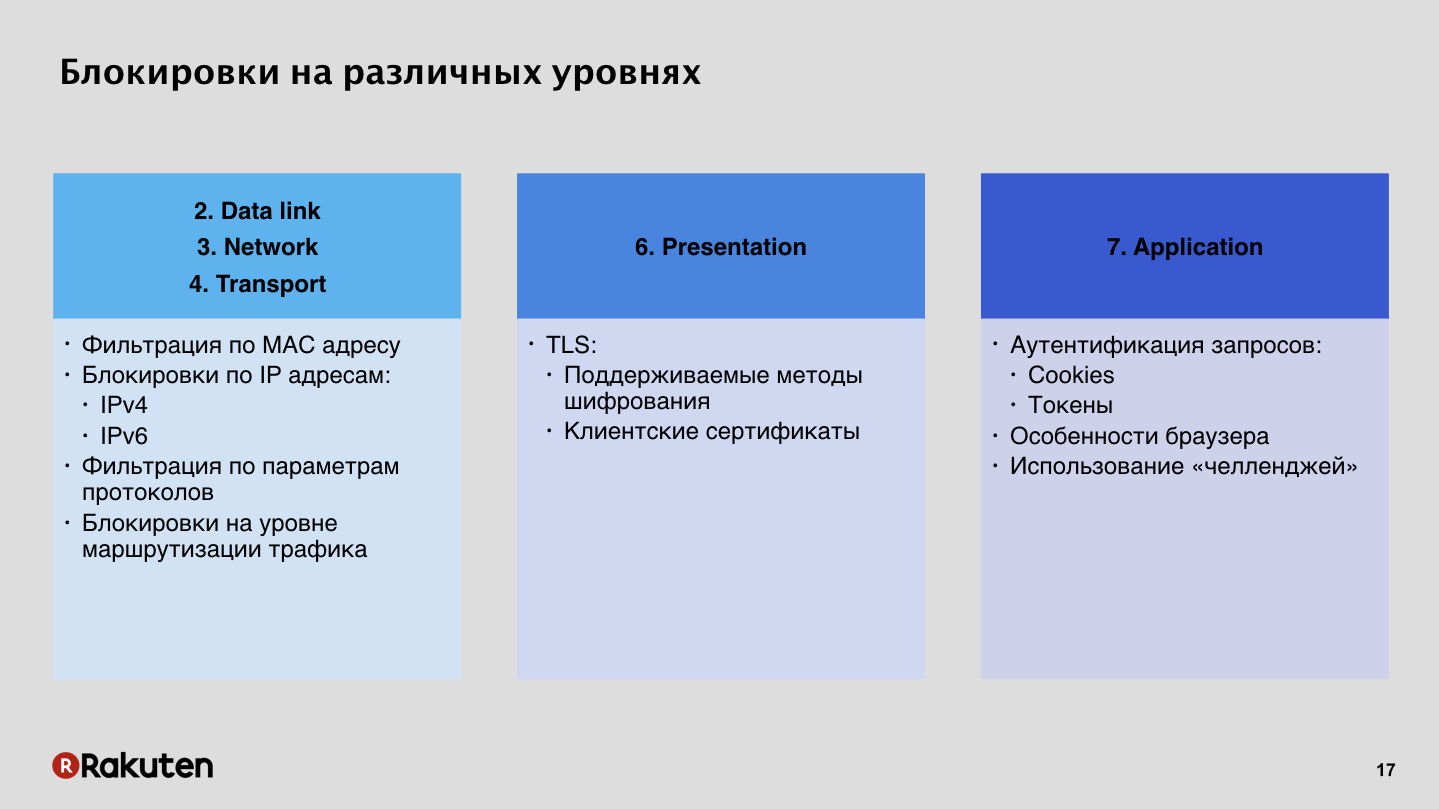
Здесь существует множество подходов. Про некоторые из них уже говорили коллеги из Яндекса в своем первом докладе. Как блокировать злоумышленников? Антон Карпов сказал, что файрволы — это плохо, они нам не нравится. Действительно можно блокировать по IP-адресам, тема для России очень актуальная, но этот метод нам не подходит совершенно. Мы предпочитаем использовать более высокоуровневые блокировки, на седьмом уровне, на уровне приложения, с помощью аутентификации запросов с помощью токенов, сессионные кук.
Почему? Давайте посмотрим сначала на блокировки на низком уровне.
Это дешевый способ, все знают, как им пользоваться, у всех на серверах стоят файрволы. Куча инструкций в интернете, никаких проблем заблокировать пользователя по IP нет. Но когда вы блокируете пользователя на низком уровне, у него нет возможности как-то обойти вашу систему защиты, если это было ложное срабатывание. Современные браузеры более-менее пытаются какое-то красивое сообщение об ошибке показать пользователю, но все равно человек никак вашу систему не может обойти, потому что не может обычный пользователь произвольно менять свои IP-адреса. Поэтому мы считаем, что этот способ не очень хорош и недружелюбен. И плюс IPv6 шагает по планете, если у вас есть какие-то таблицы заблокированных, то через какое-то время поиск адресов по таким таблицам будет занимать очень продолжительное время, и будущего за такими блокировками нет.

Наш метод — блокировки на верхнем уровне. Мы предпочитаем аутентифицировать запросы, потому что для нас это возможность очень гибко адаптироваться к бизнес-логике наших приложений. У таких методов есть достоинства и недостатки. Недостаток — высокая цена разработки, большое количество ресурсов, которые вам придется вложить в инфраструктуру, ну и архитектура таких систем при всей своей кажущейся простоте все-таки сложная.
Вы слышали на предыдущих докладах про различные методы, основанные на биометрии, сборе данных. Мы тоже об этом, естественно, думаем, но тут очень легко нарушить приватность пользователя, собрав не те данные, которые пользователь хочет вам доверить.
Как мы аутентифицируем? В нашем случае ничего экстраординарного нет, но один метод хочу упомянуть. Кроме традиционных видов — капчи и одноразовых паролей — мы используем Proof of Work, PoW. Нет, мы не майним биткоины на компьютерах пользователей. Мы используем PoW, чтобы замедлить атакующего и иногда даже заблокировать полностью, заставив его решить очень сложную задачу, на которую он потратит очень много времени.
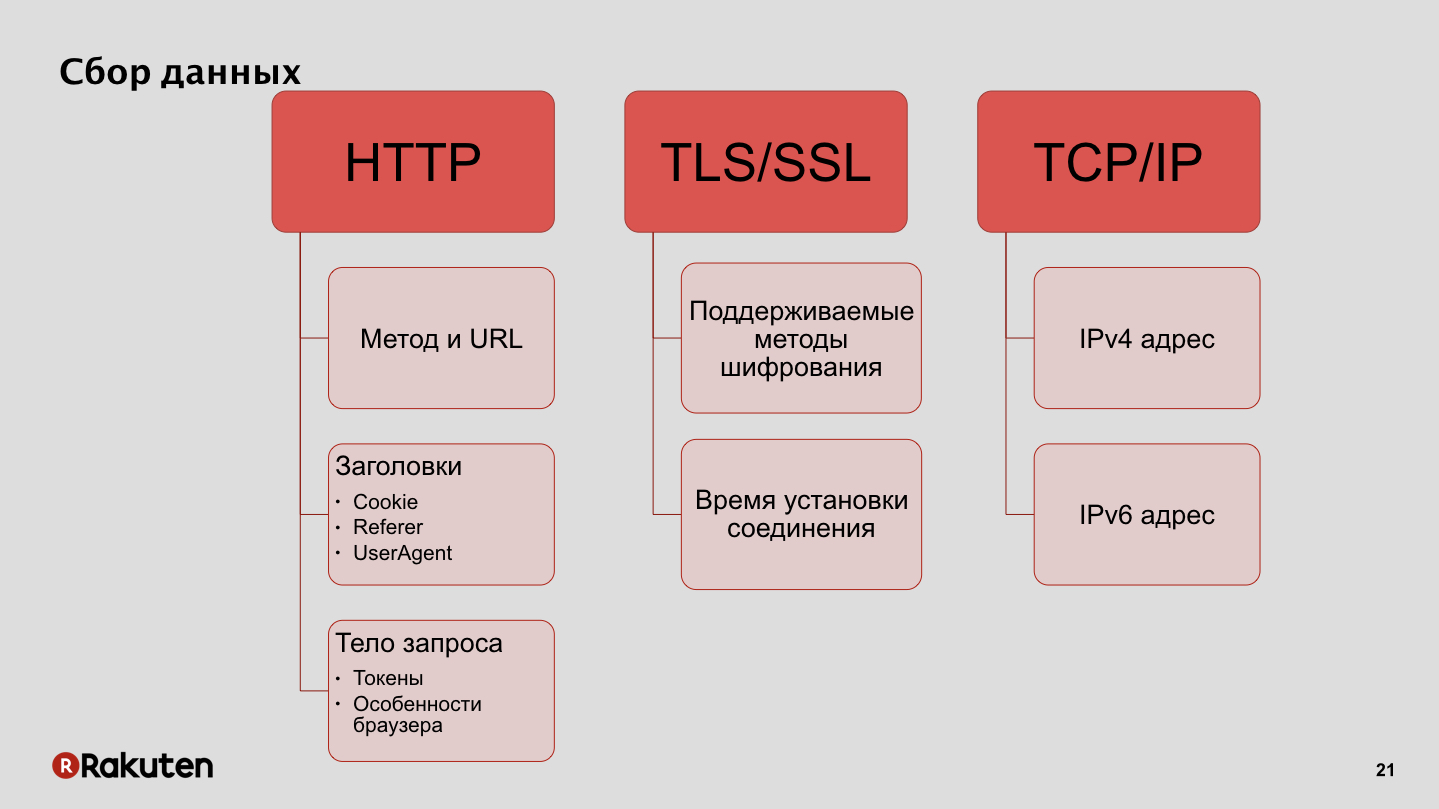
Как мы собираем данные? Мы используем IP-адреса как одну из фич, также одним из источников данных для нас являются протоколы шифрования, поддерживаемые клиентами, и время установления соединения. Также данные, которые мы собираем с пользовательских браузеров, особенности этих браузеров, ну и токены, которые мы используем для аутентификации запросов.
Как обнаруживать злоумышленников? Наверное, вы ожидаете, что я скажу, что мы построили огромную нейросеть и сразу же всех поймали. На самом деле нет. Мы использовали многоуровневый подход. Это связано с тем, что у нас много сервисов, очень большие объемы трафика, и если попытаться на такие объемы трафика поставить сложную вычислительную систему, скорее всего она будет очень дорогой и будет замедлять работу сервисов. Поэтому мы начали с банального простого метода: мы стали считать, сколько запросов приходит от различных адресов, от различных браузеров.

Такой метод очень примитивный, но позволяет отсеивать глупые массивные атаки типа DDoS, когда у вас ярко выраженные аномалии появляются в трафике. В таком случае вы абсолютно уверены, что это злоумышленник, и можете его заблокировать. Но этот метод годен только на начальном уровне, потому что он предотвращает только самые грубые атаки.
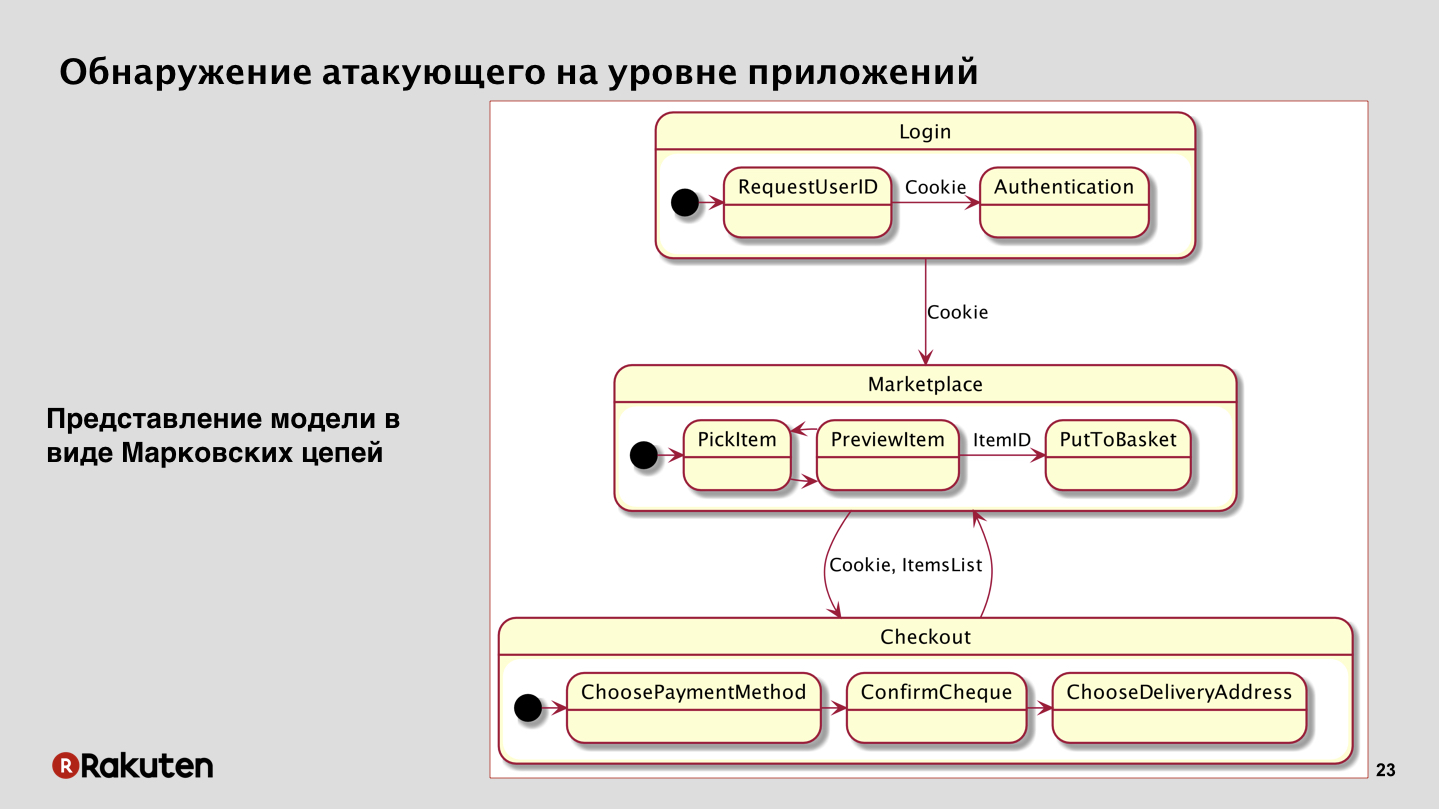
После этого мы пришли к следующему методу. Мы решили ориентироваться на то, что у нас есть бизнес-логика приложений, и злоумышленник никогда не может просто прийти на ваш сервис и своровать деньги. Если он его не взломал, конечно. В нашем случае, если посмотреть на самую упрощенную схему какого-то абстрактного маркетплейса, мы увидим, что пользователь должен залогиниться вначале, предъявить свои credentials, получить сессионные куки, потом перейти в маркетплейс, поискать там товары, положить их в корзину. После этого он переходит к оплате покупки, выбирает адрес, метод оплаты, и в конце концов он нажимает «оплатить», и наконец-то происходит покупка товара.
Вы видите, что злоумышленник должен сделать множество шагов. И эти переходы между состояниями, между сервисами напоминают одну математическую модель — это цепи Маркова, которые здесь тоже можно использовать. В принципе, в нашем случае они показали очень хорошие результаты.

Могу привести упрощенный пример. Грубо говоря, есть момент, когда пользователь аутентифицируется, когда он выбирает покупки и совершает оплату, и например, очевидно, как может злоумышленник себя аномально повести, он может несколько раз пытаться логиниться с разными учетными записями. Или он может добавлять не те товары в корзину, которые обычные пользователи покупают. Или совершает какое-то аномально большое количество действий.
В цепях Маркова обычно рассматривают состояния. Мы для себя решили также добавить время к этим состояниям. Злоумышленники и нормальные пользователи во времени ведут себя совершенно по-разному, и это также помогает их разделять.
Цепи Маркова — достаточно простая математическая модель, их очень легко считать на лету, поэтому они позволяют добавить еще один уровень защиты, отсеять еще часть трафика.
Следующий этап. Мы поймали злоумышленников глупых, поймали злоумышленников среднего ума. Теперь остались самые умные. Для хитрых злоумышленников нужны дополнительные фичи. Что мы можем сделать?
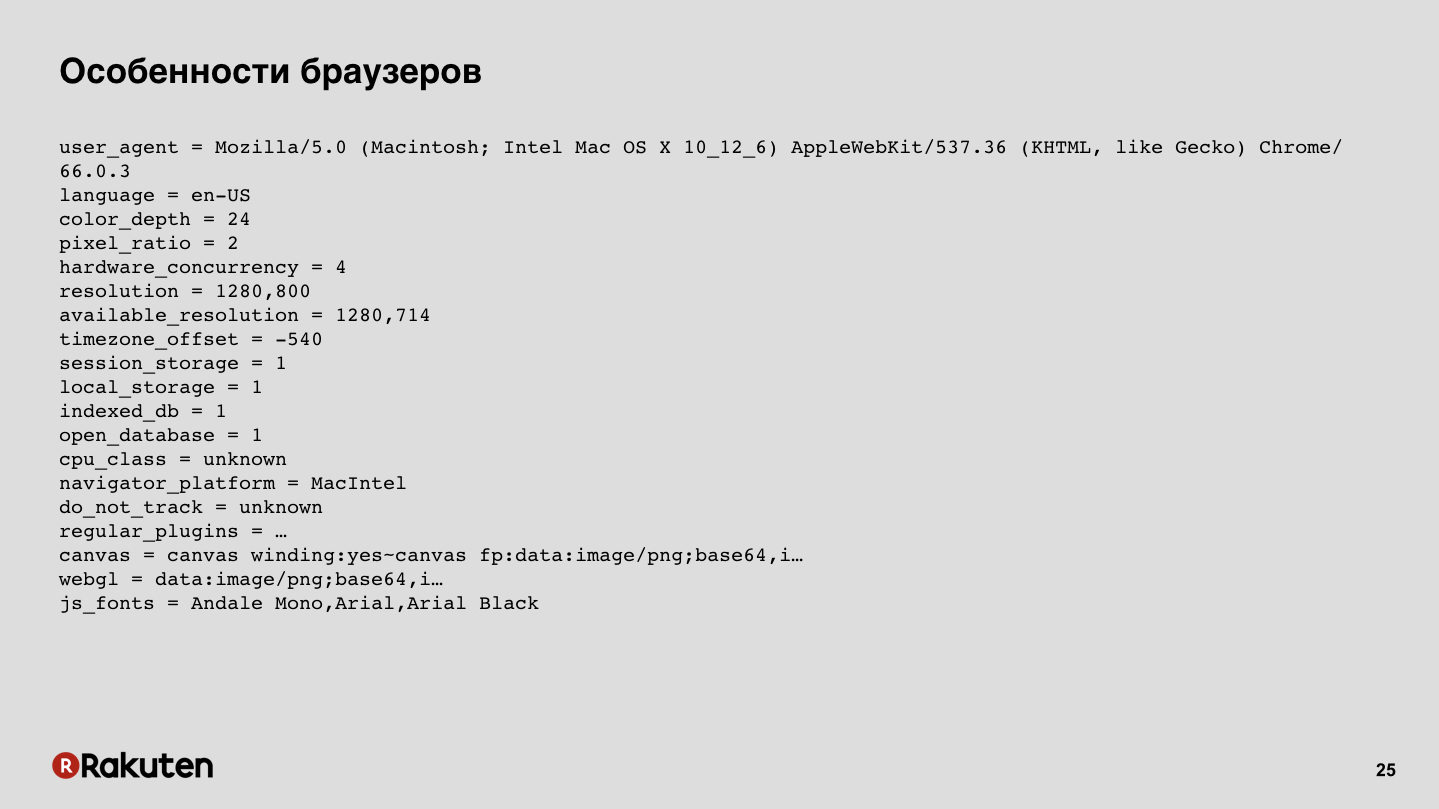
Мы можем собрать какие-то отпечатки с браузеров. Сейчас браузеры — это достаточно сложные системы, у них много поддерживаемых фич, они запускают JS, у них есть различные низкоуровневые возможности, и все это можно собрать, все эти данные. На слайде — пример вывода одной из опенсорсных библиотек.
Плюс вы можете собрать данные о том, как пользователь взаимодействует с вашим сервисом, как он двигает мышь, как совершает касания на мобильном устройстве, как скроллит экран. Такие вещи собирает, например, Яндекс.Метрика. В нашем случае мы пришли к тому, что можем сопоставлять текущее поведение пользователя с поведением, которое мы запомнили заранее.
Мы перешли к сравнению пользовательских действий с профилем, который у нас уже есть. Что такое профиль? Мы знаем, что люди часто покупают и когда, какой у человека домашний провайдер, в каких регионах он бывал, когда он путешествует. Все эти данные накапливаются долгое время, и после этого вы можете начать использовать профиль. Здесь уже мы применили machine learning, но использовали простые decision tree, поскольку это один из самых легко интерпретируемых человеком алгоритмов. Decision tree порождает конструкции вида if-else, занимает небольшое место в памяти, и вы можете строить деревья для каждого пользователя отдельно. Работают они быстро, вы можете сопоставлять поведение пользователей с профилем почти в реальном времени. Если что-то не так, вы можете показать пользователю какой-то челлендж — например, запросить двухфакторную аутентификацию при покупке, и тем самым остановить злоумышленника.
Например, у нас есть пользователь, который основную часть времени проводит в Таиланде и Японии, покупает какую-то бытовую электронику, пользуется, допустим, японским провайдером Softbank, использует наш маркетплейс. Если у нас есть такое дерево, мы можем по текущей активности прикинуть и посмотреть, что же пользователь делает. Если он опять купил какую-то электронику, находясь в Японии, в этом ничего необычного нет, и мы можем на это внимания не обращать.
Но если вдруг пользователь заходит, к примеру, из Бразилии и внезапно начинает покупать предоплаченные карты iTunes в большом количестве — мы понимаем, что это какая-то аномальная активность, человек так никогда не делал.
На этом уровне защиты мы уже понимаем очень четко, что это действительно злоумышленник, можем отклонять транзакции и платежи, совершать более активные действия.

В целом я описал логику работы системы. Считаю ли я, что она идеально работает? Чтобы победить злоумышленников, нам предстоит пройти еще долгий путь. Тем не менее, уже сейчас мы блокируем миллионы вредоносных запросов каждый день, и размеры ботнетов увеличились до достаточно больших, до десятков тысяч узлов. Со своей стороны мы понимаем, что для атакующих уже достаточно дорого платить за такие ботнеты.
В нашей системе есть возможность гибких улучшений. Мы сейчас работаем над некоторыми опциями, стараемся начать блокировать атаки как можно ближе к реальному времени. Мы стараемся адаптировать нашу систему к различным пользовательским интерфейсам. Но вот мое персональное мнение: не нужно надеяться только на систему защиты от фрода. Нужно также улучшать, добавлять различные методы аутентификации и тем самым защищаться с разных сторон.
Как мы аутентифицируем? В нашем случае ничего экстраординарного нет, но один метод хочу упомянуть. Кроме традиционных видов — капчи и одноразовых паролей — мы используем Proof of Work, PoW. Нет, мы не майним биткоины на компьютерах пользователей. Мы используем PoW, чтобы замедлить атакующего и иногда даже заблокировать полностью, заставив его решить очень сложную задачу, на которую он потратит очень много времени.
— Я работаю в международной корпорации Rakuten. Хочу поговорить о нескольких вещах: немного о себе, о нашей компании, о том, как оценивать стоимость атак и понять, нужно ли вам вообще делать fraud prevention. Хочу рассказать, как мы наш fraud prevention собрали и какие модели, которые мы использовали, дали хорошие результаты на практике, как они отработали и что вообще можно сделать, чтобы предотвратить фрод-атаки.
О себе кратко. Работал в компании Яндекс, занимался безопасностью веб-приложений, и в Яндексе тоже когда-то делал систему для предотвращения фрод-атак. Умею разрабатывать распределенные сервисы, у меня немного математического бэкграунда, который помогает с использованием машинного обучения на практике.
Компания Rakuten не очень широко известна в РФ, но думаю, вы все знаете ее по двум причинам. Из более чем 70 наших сервисов в России известен Rakuten Viber, и если тут есть футбольные фанаты, возможно, вы знаете, что наша компания — генеральный спонсор футбольного клуба «Барселона».
Поскольку у нас очень много сервисов, есть свои платежные системы, свои кредитные карты, множество reward-программ, мы постоянно подвергаемся атакам злоумышленников. И естественно, у нас всегда есть запрос от бизнеса на системы защиты от фрода.
Когда бизнес просит нас сделать систему защиты от фрода, мы всегда сталкиваемся с некоторой дилеммой. С одной стороны, есть запрос на то, чтобы был высокий conversion rate, чтобы пользователю было удобно аутентифицироваться на сервисах, совершать покупки. А с нашей стороны, со стороны безопасников, хочется, чтобы было меньше жалоб, меньше аккаунтов было взломано. И мы со своей стороны хотим сделать цену атаки высокой.
Если вы будете покупать fraud prevention-систему или попытаетесь сделать ее сами, вам в первую очередь нужно оценить затраты.
Как мы считали, нужен ли нам fraud prevention? Мы опирались на то, что у нас от фрода есть некоторые виды финансовых потерь. Это прямые потери — деньги, которые вы вернете своим клиентам, если они были похищены злоумышленниками. Это затраты на службу техподдержки, которая будет общаться с пользователями, разрешать конфликтные вопросы. Это возврат товаров, которые очень часто доставляются по ненастоящим адресам. И есть прямые затраты на разработку системы. Если вы сделали систему защиты от фрода, развернули ее на каких-то серверах, вы будете платить за инфраструктуру, за разработку ПО. И есть третий очень важный аспект ущерба от атакующих — упущенная прибыль. Она состоит из нескольких компонентов.
По нашим подсчетам, есть очень важный параметр — lifetime value, LTV, то есть деньги, которые пользователь тратит в наших сервисах, существенно уменьшаются. Потому что в половине случаев фрода пользователи просто уходят с вашего сервиса и не возвращаются.
Также мы платим деньги за рекламу, и если пользователь ушел, они потеряны. Это customer acquisition cost, CAC. И если у нас много автоматизированных пользователей, не являющихся реальными людьми — мы имеем ненастоящие цифры monthly active users, MAU, которые тоже влияют на бизнес.
Давайте посмотрим с другой стороны, со стороны атакующих.
Некоторые докладчики говорили, что атакующие активно используют ботнеты. Но какой бы метод они ни использовали, им все равно нужно инвестировать деньги, заплатить за атаку, они тоже тратят какие-то средства. Наша задача, когда мы делаем систему fraud prevention, найти такой баланс, чтобы атакующий потратил слишком много денег, а мы потратили меньше. Это делает атаку на нас невыгодной, и злоумышленники просто уходят ломать другой сервис.
Для наших сервисов по ущербу мы поделили атаки на четыре типа. Это таргетированные, когда пытаются взломать один аккаунт, одну учетную запись. Атаки, совершенные одним пользователем или небольшой группой лиц. Или более опасные для нас атаки массированные и нетаргетированные, когда атакующие нападают на множество учетных записей, кредитных карт, телефонных номеров и т. д.
Расскажу, что происходит, как на нас нападают. Основной самый очевидный тип атак, про который все знают, это переборы паролей. В нашем случае злоумышленники пытаются перебирать телефонные номера, пытаются валидировать номера кредитных карт. Некоторое разнообразие присутствует.
Массовая регистрация аккаунтов, для нас она очевидна вредна. Позже приведу пример.
Что регистрируют? Фейковые учетные записи, какие-то несуществующие товары, пытаются спамить в сообщениях обратной связи. Думаю, это для многих коммерческих компаний актуально и сходно.
Есть еще неочевидные для e-commerce, но очевидные для Яндекса проблемы — атаки на рекламный бюджет, click fraud. Ну или просто кража персональных данных.
Приведу пример. У нас была довольно интересная атака на сервис, который продает электронные книги, там была возможность для любого пользователя зарегистрироваться и свое электронное произведение начать продавать, такая возможность поддержки начинающих писателей.
Злоумышленник зарегистрировал одну легальную мастер учетную запись, и несколько тысяч ненастоящих миньон-аккаунтов. И сгенерировал фальшивую книгу, просто из случайных предложений, никакого смысла в ней не было. Он ее выложил на маркетплейс, и у нас была маркетинговая компания, у каждого миньона был, условно, 1 доллар, который он мог потратить на книгу. И эта фейковая книга стоила 1 доллар.
Был организован набег миньонов — фейковых аккаунтов. Они все купили эту книжку, книжка подскочила в рейтингах, стала бестселлером, злоумышленник поднял цену до условных 10 долларов. А так как книга стала бестселлером, ее начали покупать обычные люди, и на нас посыпались жалобы о том, что мы продаем какой-то некачественный товар, книгу с бессмысленным набором слов внутри. Злоумышленник получил профит.
Тут нет девятого пункта, его позже арестовала полиция. Так что профит не пошел впрок.
Основная цель всех злоумышленников в нашем случае потратить как можно меньше своих денег и как можно больше забрать наших.
Есть атакующие, один человек, которые просто бизнес-логику пытаются обойти. Но отмечу, что такие атаки мы для себя не считаем приоритетными, потому что по соотношению количества взломанных аккаунтов и украденных денег они несут для нас низкий риск. А основной проблемой для нас являются ботнеты.
Это массивные распределенные системы, они нападают на наши сервисы со всей планеты, с разных континентов, но у них есть некоторые особенности, которые облегчают борьбу с ними. Как и во всякой большой распределенной системе, узлы ботнета выполняють более-менее одинаковые задачи.
Другая важная вещь — сейчас, как многие коллеги отмечали, ботнеты распространяются на всяких умных устройствах, домашних роутерах, умных колонках и т. д. Но эти устройства имеют низкие аппаратные спецификации и не могут выполнять сложные сценарии.
С другой стороны, для злоумышленника аренда ботнета для простого DDoS достаточно дешевая, для перебора паролей к учетным записям тоже. Но если требуется реализация какой-то бизнес логики специально для вашего приложения или сервиса, разработка и поддержка ботнета становится очень дорогой. Обычно же злоумышленник просто арендует часть готового ботнета.
У меня всегда атака ботнетов ассоциируется с парадом Пикачу в Йокогаме. У нас 95% вредоносного трафика исходит от ботнетов.
Если посмотреть на скриншот нашей системы мониторинга, вы увидите множество желтых пятен — это заблокированные запросы от различных узлов. И здесь внимательный человек может заметить, что я вроде сказал, что атака равномерно распределена по земному шару. Но на карте есть явная аномалия, красное пятно в районе Тайваня. Это довольно любопытный случай.
Эта атака исходила от домашних роутеров. В Тайване был взломан крупный интернет-провайдер, который предоставлял интернет для большей части жителей острова. И для нас это была очень большая проблема, связанная с тем, что очень много легальных пользователей в то же время, когда происходила атака, с тех же IP-адресов ходили и работали с нашими сервисами. Мы эту атаку остановили успешно, но это было очень сложно.
Если говорить о скоупе, о поверхности, о том, что мы защищаем. Если у вас маленький e-commerce веб-сайт или маленький региональный сервис, у вас особых проблем нет. У вас есть сервер, может, несколько, или виртуальные машины в облаке. Ну и пользователи, плохие, хорошие, которые к вам приходят. Защищать особой проблемы здесь нет.
В нашем случае все сложнее, поверхность атаки огромная. У нас есть сервисы, развернутые в наших собственных дата-центрах, в Европе, в Юго-Восточной Азии, в США. У нас пользователи тоже на разных континентах, причем как хорошие, так и плохие. Плюс некоторые сервисы развернуты в облачной инфраструктуре, причем не нашей собственной.
При таком количестве сервисов и такой обширной инфраструктуре защищаться очень тяжело. Плюс многие наши сервисы поддерживают различные виды клиентских приложений и интерфейсов. Например, у нас есть сервис Rakuten TV, который работает на умных телевизорах, и для него защита совершенно специальная.
Если подытожить проблему, огромное количество пользователей циркулируют в вашей системе, как люди у магазина на перекрестке в Шибуе. И среди этого множества людей надо выявить и поймать злоумышленников. При этом дверей у вас в магазине очень много, и людей еще больше.
Итак, из чего и как мы собрали нашу систему?
Нам удалось использовать только open source компоненты, это было достаточно дешево. Использовали силу множества «сусликов». Значительная часть ПО была написана на языке Golang. Использовали очереди сообщений и БД. Для чего нам это было нужно? Мы преследовали две цели: сбор данных о поведении пользователей и расчет репутации, проведение каких-то действий, чтобы распознать, хороший пользователь или плохой.
У нас в системе множество уровней, фронтенды мы используем, написанные на Golang, а как кэширующую базу — Tarantool. Наша система развернута во всех регионах, где находятся наши бизнесы. События мы передаем по шине данных, из нее же получаем репутацию.
У нас есть бэкенды, которые также реплицируют состояние репутации пользователей с помощью Cassandra.
Шина данных, ничего секретного, Apache Kafka.
События и логи в одну сторону, репутация в другую.
И естественно, у системы есть мозг, который считает, плохой это пользователь или хороший, плохая это активность или хорошая. Мозг построен на Apache Storm, и самое интересное — что происходит там внутри.
Но сначала расскажу, как мы собираем данные и как блокируем злоумышленников.
Здесь существует множество подходов. Про некоторые из них уже говорили коллеги из Яндекса в своем первом докладе. Как блокировать злоумышленников? Антон Карпов сказал, что файрволы — это плохо, они нам не нравится. Действительно можно блокировать по IP-адресам, тема для России очень актуальная, но этот метод нам не подходит совершенно. Мы предпочитаем использовать более высокоуровневые блокировки, на седьмом уровне, на уровне приложения, с помощью аутентификации запросов с помощью токенов, сессионные кук.
Почему? Давайте посмотрим сначала на блокировки на низком уровне.
Это дешевый способ, все знают, как им пользоваться, у всех на серверах стоят файрволы. Куча инструкций в интернете, никаких проблем заблокировать пользователя по IP нет. Но когда вы блокируете пользователя на низком уровне, у него нет возможности как-то обойти вашу систему защиты, если это было ложное срабатывание. Современные браузеры более-менее пытаются какое-то красивое сообщение об ошибке показать пользователю, но все равно человек никак вашу систему не может обойти, потому что не может обычный пользователь произвольно менять свои IP-адреса. Поэтому мы считаем, что этот способ не очень хорош и недружелюбен. И плюс IPv6 шагает по планете, если у вас есть какие-то таблицы заблокированных, то через какое-то время поиск адресов по таким таблицам будет занимать очень продолжительное время, и будущего за такими блокировками нет.
Наш метод — блокировки на верхнем уровне. Мы предпочитаем аутентифицировать запросы, потому что для нас это возможность очень гибко адаптироваться к бизнес-логике наших приложений. У таких методов есть достоинства и недостатки. Недостаток — высокая цена разработки, большое количество ресурсов, которые вам придется вложить в инфраструктуру, ну и архитектура таких систем при всей своей кажущейся простоте все-таки сложная.
Вы слышали на предыдущих докладах про различные методы, основанные на биометрии, сборе данных. Мы тоже об этом, естественно, думаем, но тут очень легко нарушить приватность пользователя, собрав не те данные, которые пользователь хочет вам доверить.
Как мы аутентифицируем? В нашем случае ничего экстраординарного нет, но один метод хочу упомянуть. Кроме традиционных видов — капчи и одноразовых паролей — мы используем Proof of Work, PoW. Нет, мы не майним биткоины на компьютерах пользователей. Мы используем PoW, чтобы замедлить атакующего и иногда даже заблокировать полностью, заставив его решить очень сложную задачу, на которую он потратит очень много времени.
Как мы собираем данные? Мы используем IP-адреса как одну из фич, также одним из источников данных для нас являются протоколы шифрования, поддерживаемые клиентами, и время установления соединения. Также данные, которые мы собираем с пользовательских браузеров, особенности этих браузеров, ну и токены, которые мы используем для аутентификации запросов.
Как обнаруживать злоумышленников? Наверное, вы ожидаете, что я скажу, что мы построили огромную нейросеть и сразу же всех поймали. На самом деле нет. Мы использовали многоуровневый подход. Это связано с тем, что у нас много сервисов, очень большие объемы трафика, и если попытаться на такие объемы трафика поставить сложную вычислительную систему, скорее всего она будет очень дорогой и будет замедлять работу сервисов. Поэтому мы начали с банального простого метода: мы стали считать, сколько запросов приходит от различных адресов, от различных браузеров.
Такой метод очень примитивный, но позволяет отсеивать глупые массивные атаки типа DDoS, когда у вас ярко выраженные аномалии появляются в трафике. В таком случае вы абсолютно уверены, что это злоумышленник, и можете его заблокировать. Но этот метод годен только на начальном уровне, потому что он предотвращает только самые грубые атаки.
После этого мы пришли к следующему методу. Мы решили ориентироваться на то, что у нас есть бизнес-логика приложений, и злоумышленник никогда не может просто прийти на ваш сервис и своровать деньги. Если он его не взломал, конечно. В нашем случае, если посмотреть на самую упрощенную схему какого-то абстрактного маркетплейса, мы увидим, что пользователь должен залогиниться вначале, предъявить свои credentials, получить сессионные куки, потом перейти в маркетплейс, поискать там товары, положить их в корзину. После этого он переходит к оплате покупки, выбирает адрес, метод оплаты, и в конце концов он нажимает «оплатить», и наконец-то происходит покупка товара.
Вы видите, что злоумышленник должен сделать множество шагов. И эти переходы между состояниями, между сервисами напоминают одну математическую модель — это цепи Маркова, которые здесь тоже можно использовать. В принципе, в нашем случае они показали очень хорошие результаты.
Могу привести упрощенный пример. Грубо говоря, есть момент, когда пользователь аутентифицируется, когда он выбирает покупки и совершает оплату, и например, очевидно, как может злоумышленник себя аномально повести, он может несколько раз пытаться логиниться с разными учетными записями. Или он может добавлять не те товары в корзину, которые обычные пользователи покупают. Или совершает какое-то аномально большое количество действий.
В цепях Маркова обычно рассматривают состояния. Мы для себя решили также добавить время к этим состояниям. Злоумышленники и нормальные пользователи во времени ведут себя совершенно по-разному, и это также помогает их разделять.
Цепи Маркова — достаточно простая математическая модель, их очень легко считать на лету, поэтому они позволяют добавить еще один уровень защиты, отсеять еще часть трафика.
Следующий этап. Мы поймали злоумышленников глупых, поймали злоумышленников среднего ума. Теперь остались самые умные. Для хитрых злоумышленников нужны дополнительные фичи. Что мы можем сделать?
Мы можем собрать какие-то отпечатки с браузеров. Сейчас браузеры — это достаточно сложные системы, у них много поддерживаемых фич, они запускают JS, у них есть различные низкоуровневые возможности, и все это можно собрать, все эти данные. На слайде — пример вывода одной из опенсорсных библиотек.
Плюс вы можете собрать данные о том, как пользователь взаимодействует с вашим сервисом, как он двигает мышь, как совершает касания на мобильном устройстве, как скроллит экран. Такие вещи собирает, например, Яндекс.Метрика. В нашем случае мы пришли к тому, что можем сопоставлять текущее поведение пользователя с поведением, которое мы запомнили заранее.
Мы перешли к сравнению пользовательских действий с профилем, который у нас уже есть. Что такое профиль? Мы знаем, что люди часто покупают и когда, какой у человека домашний провайдер, в каких регионах он бывал, когда он путешествует. Все эти данные накапливаются долгое время, и после этого вы можете начать использовать профиль. Здесь уже мы применили machine learning, но использовали простые decision tree, поскольку это один из самых легко интерпретируемых человеком алгоритмов. Decision tree порождает конструкции вида if-else, занимает небольшое место в памяти, и вы можете строить деревья для каждого пользователя отдельно. Работают они быстро, вы можете сопоставлять поведение пользователей с профилем почти в реальном времени. Если что-то не так, вы можете показать пользователю какой-то челлендж — например, запросить двухфакторную аутентификацию при покупке, и тем самым остановить злоумышленника.
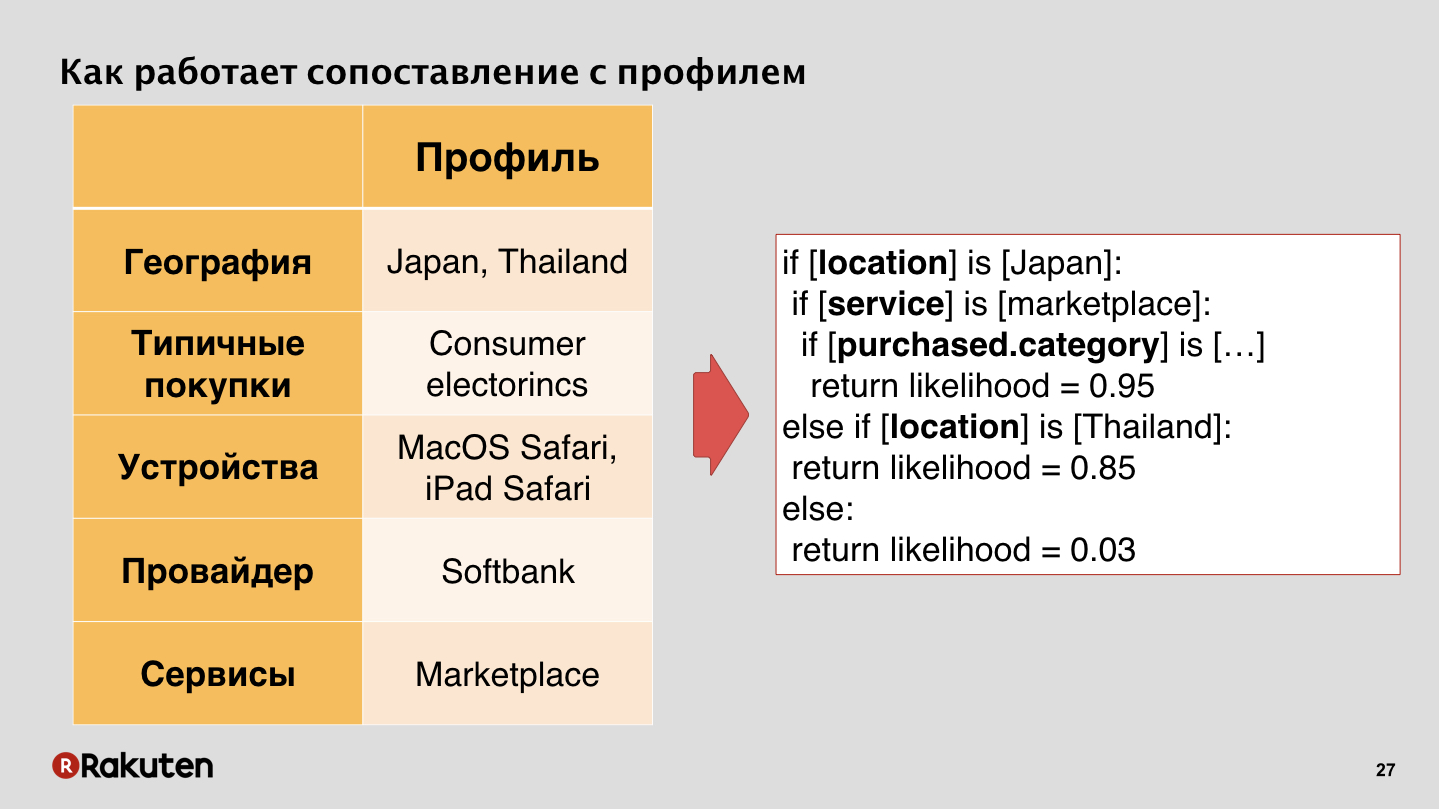
Например, у нас есть пользователь, который основную часть времени проводит в Таиланде и Японии, покупает какую-то бытовую электронику, пользуется, допустим, японским провайдером Softbank, использует наш маркетплейс. Если у нас есть такое дерево, мы можем по текущей активности прикинуть и посмотреть, что же пользователь делает. Если он опять купил какую-то электронику, находясь в Японии, в этом ничего необычного нет, и мы можем на это внимания не обращать.
Но если вдруг пользователь заходит, к примеру, из Бразилии и внезапно начинает покупать предоплаченные карты iTunes в большом количестве — мы понимаем, что это какая-то аномальная активность, человек так никогда не делал.
На этом уровне защиты мы уже понимаем очень четко, что это действительно злоумышленник, можем отклонять транзакции и платежи, совершать более активные действия.
В целом я описал логику работы системы. Считаю ли я, что она идеально работает? Чтобы победить злоумышленников, нам предстоит пройти еще долгий путь. Тем не менее, уже сейчас мы блокируем миллионы вредоносных запросов каждый день, и размеры ботнетов увеличились до достаточно больших, до десятков тысяч узлов. Со своей стороны мы понимаем, что для атакующих уже достаточно дорого платить за такие ботнеты.
В нашей системе есть возможность гибких улучшений. Мы сейчас работаем над некоторыми опциями, стараемся начать блокировать атаки как можно ближе к реальному времени. Мы стараемся адаптировать нашу систему к различным пользовательским интерфейсам. Но вот мое персональное мнение: не нужно надеяться только на систему защиты от фрода. Нужно также улучшать, добавлять различные методы аутентификации и тем самым защищаться с разных сторон.
Комментарии (6)

3aicheg
04.06.2018 05:48
tracer0tong
04.06.2018 09:35Жалко, что не английская версия, пригодилось бы.
3aicheg
04.06.2018 09:50Я могу нарисовать и английскую версию (что угодно, лишь бы не работать) — но туда же не втащишь каламбур с «защитой от Фродо»?
foxyrus
На днях искал гироскутер, отфильтровал по параметрам, отсортировал по отзывам, нашел подходящий market.yandex.ru/product/14235032
Почитал отзывы, вроде живые люди, но потом присмотрелся: все отзывы от пользователей без аватарок, все отзывы с 5 балаллами.
Дальше больше: если посмотреть отзывы отдельно взятого пользователя, то он ставил товарам только 5 баллов, большинство товаров от Noname или ОЕМ производителей. Если перейти в один из товаров, который обозревал этот покупателей, то найдем точно такие же отзывы с 5 баллами от других ботов…
Вот за 5 минут нашел ботов:
market.yandex.ru/user/koioivoko/reviews
market.yandex.ru/user/tirohot/reviews
market.yandex.ru/user/koioivoko/reviews
market.yandex.ru/user/bertolopka/reviews
market.yandex.ru/user/bursovaandruxa/reviews
market.yandex.ru/user/v.jakin/reviews
market.yandex.ru/user/sereja.bartasevitch/reviews
market.yandex.ru/user/laskol90/reviews
market.yandex.ru/user/chirvanout/reviews
market.yandex.ru/user/gremlinseriy/reviews
market.yandex.ru/user/LikaMoro/reviews
Так что Яндексу есть куда еще работать…
coalesce
Предположу что это живой человек у которого такая работа, регистрировать новые аккаунты и отзывы пачками оставлять.
tracer0tong
Дело в том, что я не рассказывал про Яндекс в своей презентации.