
"Исследование рынка вакансий аналитиков" — так звучала вполне реальная задача одного вполне реального ведущего аналитика одной ни большой, ни маленькой фирмы. Рисерчер парсил десятки описаний вакансий с hh вручную, раскидывая их по запрашиваемым скиллам и увеличивая счетчик в соответствующей колонке спредшита.
Я увидела в этой задаче неплохое поле для автоматизации и решила попытаться справиться с ней меньшей кровью, легко и просто.
Меня интересовали следующие вопросы, затронутые в данном исследовании:
- средний уровень зарплат бизнес- и системных аналитиков,
- наиболее востребованные умения и личные качества на этой позиции,
- зависимости (если есть) между определенными навыками и уровнем зп.
Спойлер: легко и просто не получилось.

Подготовка данных
Если мы хотим собрать кучу данных о вакансиях, то логично hh не ограничиваться. Однако, для чистоты эксперимента простоты начнем с этого ресурса.
Сбор
Для сбора данных воспользуемся поиском по вакансиям через hh API.
Искать буду с помощью простого текстового запроса "systems analyst", "business analyst" и "product owner", потому как активности и зоны ответственности у этих позиций, как правило, пересекаются.
Для этого нужно сформировать запрос вида https://api.hh.ru/vacancies?text="systems+analyst" и распарсить полученный JSON.
Чтобы в выборку попали максимально релевантные вакансии, искать будем только в заголовках вакансий, добавив в запрос параметр search_field=name.
Здесь можно посмотреть, какие поля вакансий возвращаются по этому запросу. Я выбрала следующие:
- название вакансии
- город
- дата публикации
- зарплата — верхняя и нижняя границы
- валюта, в которой указана зарплата
- gross — T/F
- компания
- обязанности
- требования к кандидату
Кроме того, я хочу дополнительно проанализировать скиллы, которые указываются в разделе "Ключевые навыки", но этот раздел доступен только в полном описании вакансии. Поэтому я также сохраню ссылки на найденные вакансии, чтобы впоследствии достать список скиллов для каждой из них.
# без этих товарищей никуда :)
library(jsonlite)
library(curl)
library(dplyr)
library(ggplot2)
library(RColorBrewer)
library(plotly)
hh.getjobs <- function(query, paid = FALSE)
{
# Makes a call to hh API and gets the list of vacancies based on the given search queries
df <- data.frame(
query = character() # мой исходный запрос
, URL = character() # ссылка на вакансию
, id = numeric() # id вакансии
, Name = character() # название вакансии
, City = character()
, Published = character()
, Currency = character()
, From = numeric() # ниж. граница зарплатной вилки
, To = numeric() # верх. граница
, Gross = character()
, Company = character()
, Responsibility = character()
, Requerement = character()
, stringsAsFactors = FALSE
)
for (q in query)
{
for (pageNum in 0:99) {
try(
{
data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\""
, q
, "\"&search_field=name"
, "&only_with_salary=", paid
,"&page="
, pageNum))
df <- rbind(df, data.frame(
q,
data$items$url,
as.numeric(data$items$id),
data$items$name,
data$items$area$name,
data$items$published_at,
data$items$salary$currency,
data$items$salary$from,
data$items$salary$to,
data$items$salary$gross,
data$items$employer$name,
data$items$snippet$responsibility,
data$items$snippet$requirement,
stringsAsFactors = FALSE))
})
print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\""))
}
}
names <- c("query", "URL", "id", "Name", "City",
"Published", "Currency", "From", "To",
"Gross", "Company", "Responsibility", "Requirement")
colnames(df) <- names
return(df)
}В функции hh.getjobs() на вход принимается вектор интересующих нас поисковых запросов и уточнение, интересуют нас только вакансии с указанной зарплатой или все подряд (по умолчанию берем второй вариант). Создается пустая dafa frame, а затем используется функция fromJSON() пакета jsonlite, которая принимает на вход URL и возвращает структурированный list. Далее из узлов этого списка мы достаем интересующие нас данные и заполняем соответствующие поля data frame.
По умолчанию данные отдаются постранично, по 20 элементов на каждой странице. Максимально по одному запросу можно получить 2000 вакансий. Все полученные данные мы записываем в df.
Лайфхак 1: совершенно не факт, что по нашему запросу найдется 2000 вакансий, и начиная с какого-то момента нам будут приходить пустые страницы. В этом случае R ругается и выпрыгивает из цикла. Поэтому содержимое внутреннего цикла заботливо обернем в try().
Лайфхак 2: во внутренний цикл также имеет смысл добавить вывод в консоль текущего статуса сбора данных, потому как дело это небыстрое. Я сделала так:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))После заполнения данными столбцы переименовываются так, чтобы с ними было удобно работать, и возвращается полученная data frame.
Эту и другие вспомогательные функции я буду хранить в отдельном файле functions.R, чтобы не захламлять основной скрипт, который пока выглядит так:
source("functions.R")
# Step 1 - get data
# 1.1 get vacancies (short info)
jobdf <- hh.getjobs(query = c("business+analyst"
, "systems+analyst"
, "product+owner"),
paid = FALSE)Теперь из полного описания вакансий вытащим experience и key_skills.
Функции hh.getxp передаем data frame, проходимся по сохраненным ссылкам на вакансии, и из полного описания достаем значение требуемого опыта работы. Полученное значение сохраняем в новом столбце.
hh.getxp <- function(df)
{
df$experience <- NA
for (myURL in df$URL) {
try(
{
data <- fromJSON(myURL)
df[df$URL == myURL, "experience"] <- data$experience$name
}
)
print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df)))
}
return(df)
}Описание новой вспомогательной функции отправляется в functions.R, а основной скрипт теперь обращается к ней:
# s.1.2 get experience (from full info)
jobdf <- hh.getxp(jobdf)
# 1.3 get skills (from full info)
all.skills <- hh.getskills(jobdf$URL)В фрагменте выше мы также формируем новую data frame all.skills вида "id вакансии — навык":
hh.getskills <- function(allurls)
{
analyst.skills <- data.frame(
id = character(), # id вакансии
skill = character() # название скилла
)
for (myURL in allurls) {
data <- fromJSON(myURL)
if (length(data$key_skills) > 0)
analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills))
print(paste0("Filling in "
, which(allurls == myURL, arr.ind = TRUE)
, " out of "
, length(allurls)))
}
names(analyst.skills) <- c("id", "skill")
analyst.skills$skill <- tolower(analyst.skills$skill)
return(analyst.skills)
}Препроцессинг
Посмотрим, сколько всего данных удалось собрать:
> length(unique(jobdf$id))
[1] 1478
> length(jobdf$id)
[1] 1498Почти полторы тысячи вакансий! Выглядит неплохо. И по всей видимости, несколько вакансий попались в результатах поиска дважды — по разным запросам. Поэтому первым делом оставим только уникальные записи: jobdf <- jobdf[unique(jobdf$id),].
Для того, чтобы сравнивать зарплаты аналитиков на рынке труда, мне нужно
1) убедиться, что все имеющиеся данные по зарплатам представлены в единой валюте,
2) выделить в отдельную data frame те вакансии, для которых зарплата указана.
Рассмотрим каждую из подзадач детальнее. Предварительно можно выяснить, какие в принципе валюты встречаются в наших данных с помощью table(jobdf$Currency). В моем случае помимо рублей фигурировали доллары, евро, гривны, казахские тенге и даже узбекские сумы.
Чтобы перевести значения зарплат в рублевые, нужно узнать актуальный курс валют. Узнавать будем у Центробанка:
quotations.update <- function(currencies)
{
# Parses the most up-to-date qutations data provided by the Central Bank of Russia
# and returns a table with currency rate against RUR
doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp")
quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE)
quotationsdf <- select(quotationsdf, -Name)
quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode)
quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal)
quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value))
quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal
quotationsdf <- quotationsdf %>% select(CharCode, Value)
return(quotationsdf)
}Чтобы курсы корректно обрабатывались в R, нужно убедиться, что десятичная часть отделена точкой. Кроме того, стоит обратить внимание на колонку Nominal: где-то он равен 1, где-то 10 или 100. Это значит, один фунт стерлингов стоит ~85 рублей, а, скажем, за сотню армянских драмов можно купить ~13 рублей. Для удобства дальнейшей обработки я привела значения к номиналу 1 относительно рубля.
Теперь можно и переводить. Наш скрипт делает это с помощью функции convert.currency(). Актуальный курс валют в ней берется из таблицы quotations, куда мы сохранили данные из XML, предоставляемой Центробанком. Также на вход функция принимает целевую валюту для конвертации (по умолчанию RUR) и таблицу с вакансиями, значения зарплатных вилок в которой необходимо привести к единой валюте. Функция возвращает таблицу с обновленными зарплатными цифрами (уже без столбца Currency, за ненадобностью).
С белорусскими рублями пришлось повозиться: после получения весьма странных данных в несколько подходов, я провела небольшой рисерч и узнала, что начиная с 2016 года в Беларуси используется новая валюта, которая отличается не только курсом, но и аббревиатурой (теперь не BYR, а BYN). В справочниках hh до сих пор используется аббревиатура BYR, про которую XML от Центробанка ничего не знает. Поэтому в функции convert.currency() я не самым изящным образом сначала заменяю аббревиатуру на актуальную, и только затем перехожу непосредственно к конвертации.
Выглядит все это следующим образом:
convert.currency <- function(targetCurrency = "RUR", df, quotationsdf)
{
cond <- (!is.na(df$Currency) & df$Currency == "BYR")
df[cond, "Currency"] <- "BYN"
currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency]))
# Нижний порог зарплатной вилки (если указан)
if (!is.null(df$From))
{
for (currency in currencies)
{
condition <- (!is.na(df$From) & df$Currency == currency)
try(
df$From[condition] <-
df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency]
)
}
}
# Верхний порог зарплатной вилки (если указан)
if (!is.null(df$To))
{
for (currency in currencies)
{
condition <- !is.na(df$To) & df$Currency == currency
try(
df$To[condition] <-
df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency]
)
}
}
return(df %>% select(-Currency))
}Также можно учесть, что некоторые данные по зарплатам представлены в значениях gross, то есть на руки сотрудник будет получать несколько меньше. Чтобы рассчитать зарплату net для резидентов РФ, нужно вычесть из указанных цифр 13% (для нерезидентов вычитается 30%).
gross.to.net <- function(df, resident = TRUE)
{
if (resident == TRUE)
coef <- 0.87
else
coef <- 0.7
if (!is.null(df$Gross))
{
if (!is.null(df$From)) # Нижний порог зарплатной вилки (если указан)
{
index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,])))
df$From[index] <- df$From[index] * coef
}
if (!is.null(df$To)) # Верхний порог зарплатной вилки (если указан)
{
index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,])))
df$To[index] <- df$To[index] * coef
}
df <- df %>% select(-Gross)
}
return(df)
}Делать этого я, конечно, не буду, потому что в таком случае стоит учитывать налоги в разных странах, а не только в России, либо в исходный поисковой запрос добавлять фильтр по стране.
Последним шагом перед анализом разделю найденные вакансии на три категории: джунов, миддлов и сеньоров и запишу полученные позиции в новый столбец. К старшим позициям будем относить те, в названиях которых присутствует слово "старший" и его синонимы. Аналогичным образом найдем стартовые позиции по ключевым словам "junior" и синонимам, а к миддлам отнесем всех, кто между:
get.positions <- function(df)
{
df$lvl <- NA
df[grep(pattern = "lead|senior|старший|ведущий|главный",
x = df$Name, ignore.case = TRUE), "lvl"] <- "senior"
df[grep(pattern = "junior|младший|стажер|стажёр",
x = df$Name, ignore.case = TRUE), "lvl"] <- "junior"
df[is.na(df$lvl), "lvl"] <- "middle"
return(df)
}В основной скрипт добавляем блок подготовки данных.
# Step 2 - prepare data
# 2.1. Convert all currencies to target currency
# 2.1.1 get up-to-date currency rates
quotations <- quotations.update()
# 2.1.2 convert to RUR
jobdf <- convert.currency(df = jobdf, quotationsdf = quotations)
# 2.2 convert Gross to Net
# jobdf <- gross.to.net(df = jobdf)
# 2.3 define segments
jobdf <- get.positions(jobdf)Анализ
Как упоминалось выше, я собираюсь анализировать следующие аспекты полученных данных:
- средний уровень зарплат BA/SA,
- наиболее востребованные умения и личные качества на этой позиции,
- зависимости (если есть) между определенными навыками и уровнем зп.
Средний доход BA/SA
Как выяснилось, компании неохотно указывают верхнюю или нижнюю границу зарплаты.
В нашей data frame jobdf эти значения находятся в колонках To и From соответсвенно. Я хочу найти средние значения и записать их в новый столбец Salary.
Для кейсов, где зарплата указана полностью, это легко сделать с помощью функции mean(), отфильтровав все остальные записи, где данные по вилке отсутствуют полностью или частично. Но в этом случае от нашей исходной выборки, которая и так невелика, осталось бы менее 10%. Поэтому я вычисляю коэффициент Подгониана, который подсказывает, насколько в среднем отличаются значения To и From в вакансиях, где указана полная вилка, и с его помощью примерно заполняю недостающие данные в кейсах, где пропущенно только одно значение.
select.paid <- function(df, suggest = TRUE)
{
# Returns a data frame with average salaries between To and From
# optionally, can suggest To or From value in case only one is specified
if (suggest == TRUE)
{
df <- df %>% filter(!is.na(From) | !is.na(To))
magic.coefficient <- # shows the average difference between max and min salary
round(mean(df$To/df$From, na.rm = TRUE), 1)
df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient
df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient
}
else
{
df <- na.omit(df)
}
df$salary <- rowMeans(x = df %>% select(From, To))
df$salary <- ceiling(df$salary / 10000) * 10000
return(df %>% select(-From, -To))
}Это "мягкая" фильтрация данных, которая в функции select.paid() задается параметром suggest = TRUE. Альтернативно мы можем указать suggest = FALSE при вызове функции и просто выпилить все строки, где зарплатные данные хотя бы частично отсутствуют. Однако с использованием мягкой фильтрации и волшебнго коэффициента мне удалось сохранить в выборке почти четверть от исходного набора данных.
Переходим к визуальной части:

На этом графике можно визуально оценить плотность распределения зарплат BA/SA в двух столицах и в регионах. Но что если конкретизировать запрос и сравнить, сколько получают миддлы и сеньоры в столицах?
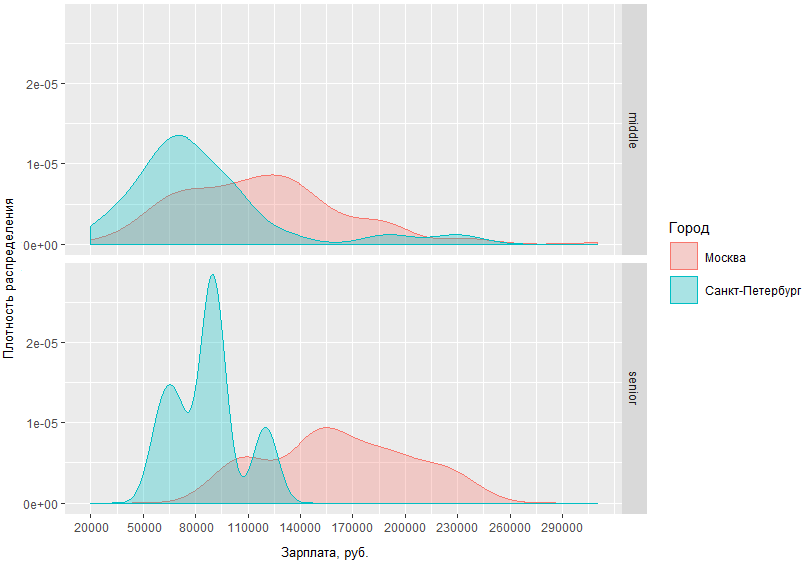
Из полученного графика видно, что разница в зарплатных ситуациях у миддлов и сеньоров в Москве и Питере не слишком различается. Так, в Санкт-Петербурге мидлы получают, как правило, в районе 70 т.р., в то время как в Москве пик плотности приходится на ~120 т.р., а разница в доходах старших специалистов уровня в Москве и Санкт-Петербурге отличается в среднем на 60 тысяч.
Также мы можем взглянуть, например, на московские зарплаты аналитиков в разрезе должности:

Можно сделать вывод, что а) на сегодняший день в Москве гораздо больший спрос на специалистов-аналитиков начального уровня, и б) в то же время, верхний порог зарплат таких специалистов ограничен куда более четко, чем у миддлов и сеньоров.
Еще одно наблюдение: средняя зп московских специалистов среднего и высокого уровня имеет довольно большую площадь пересечения. Это может говорить о том, что на рынке довольно размытая граница между этими двумя ступенями.
Полный код для графиков под катом.
# Step 3 - analyze salaries
# 3.1 get paid jobs (with salaries specified)
jobs.paid <- select.paid(jobdf)
# 3.2 plot salaries density by region
ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) +
geom_density(alpha=.3) +
scale_fill_discrete(guide = guide_legend(reverse=FALSE)) +
scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = "Зарплата, руб.",
breaks = round(seq(min(jobs.paid$salary),
max(jobs.paid$salary), by = 30000),1)) +
scale_y_continuous(name = "Плотность распределения") +
theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
# 3.3 compare salaries for middle / senior in capitals
ggplot(jobs.paid %>% filter(region %in% c("Москва", "Санкт-Петербург"),
lvl %in% c("senior", "middle")),
aes(salary, fill = region, colour = region)) +
facet_grid(lvl ~ .) +
geom_density(alpha = .3) +
scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = "Зарплата, руб.",
breaks = round(seq(min(jobs.paid$salary),
max(jobs.paid$salary), by = 30000),1)) +
scale_y_continuous(name = "Плотность распределения") +
scale_fill_discrete(name = "Город") +
scale_color_discrete(name = "Город") +
guides(fill=guide_legend(
keywidth=0.1,
keyheight=0.1,
default.unit="inch")
) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10))
# 3.4 plot salaries in Moscow by position
ggplotly(ggplot(jobs.paid %>% filter(region == "Москва"), aes(salary, fill = lvl, color = lvl)) +
geom_density(alpha=.4) +
scale_fill_brewer(palette = "Set2") +
scale_color_brewer(palette = "Set2") +
theme_light() +
scale_y_continuous(name = "Плотность распределения") +
scale_x_continuous(labels = function(x) format(x, scientific = FALSE),
name = "Зарплата, руб.",
breaks = round(seq(min(jobs.paid$salary),
max(jobs.paid$salary), by = 30000),1)) +
theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))Анализ навыков (Key skills)
Переходим к ключевой цели исследования — определить наиболее востребованные навыки для BA/SA. Для этого проведем анализ тех данных, что в явном виде указаны в специальном поле вакансии — key skills.
Наиболее популярные навыки
Ранее мы получили отдельную data frame all.skills, куда записали пары "id вакансии — навык". Найти наиболее часто встречающиеся скиллы несложно с помощью функции table():
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq"))
htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]),
rnames = FALSE, header = c("Skill", "Freq"),
align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")Получится примерно следующее:

Здесь Freq — это количество вакансий, в поле "key_skills" которых указан соответствующий навык из столбца Skill.
"Но это еще не все!"(ц) Совершенно очевидно, что одни и те же скиллы запросто могут встречаться в разных вакансиях в синонимичных выражениях.
Я составила небольшой словарь синонимов названий скиллов и разделила их по категориям.
Словарь представляет собой csv-файл со столбцами category — одно из следующего: Activities, Tools, Knowledge, Standards и Personal; skill — основное название навыка, которое я буду использовать вместо всех найденных синонимов; syn1, syn2,… syn13 — собственно возможные вариации для каждого навыка. Некоторые строки могут содержать пустые столбцы синонимов.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13
tools;axure;;;;;;;;;;;;;
tools;lucidchart;;;;;;;;;;;;;
standards;archimate;;;;;;;;;;;;;
standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;;
personal;teamwork;team player;работа в команде;;;;;;;;;;;
activities;wireframing;mockup;mock-up;мокап;мок-ап;wireframe;прототип;ui;ux/;/ux;;;;Сначала импортируем словарь, а затем раскидаем скиллы заново на основе имеющихся эквивалентностей:
# Analyze skills
# 4.1 import dictionary
dict <- read.csv(file = "competencies.csv", header = TRUE,
stringsAsFactors = FALSE, sep = ";", na.strings = "",
encoding = "UTF-8")
# 4.2 match skills with dictionary
all.skills <- categorize.skills(all.skills, dict)Под катом можно посмотреть начинку функции categorize.skills().
categorize.skills <- function(analyst_skills, dictionary)
{
analyst_skills$skill.group <- NA
analyst_skills$category <- NA
for (myskill in dictionary$skill)
{
category <- dictionary[dictionary$skill == myskill, "category"]
mypattern <- paste0(na.omit(t(dictionary %>%
filter(skill == myskill) %>%
select(starts_with("syn")))), collapse = "|")
if (nchar(mypattern) > 1)
mypattern <- paste0(c(myskill, mypattern), collapse = "|")
else
mypattern <- myskill
try(
{
analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill
analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category
}
)
}
return(analyst_skills)
}Я добавляю к исходной data frame с навыками столбец category и skill. group — для категории и обобщающего названия навыка соответсвенно. Затем я прохожусь по импортированному словарю и из каждой строчки синонимов составляю паттерн для функции grep(). Добавляя каждое непустое значение колонки к строке, я разделяю их чертой, чтобы получить условие "или". Так, для всех скиллов из исходной таблицы, в которые входит паттерн uml|activity diagram|use case diagram|ucd|class diagram, я запишу в колонку skill.group значение "uml". И так будет с каждым!.. скиллом из исходной data frame.
Повторно запросив топ наиболее популярных навыков можно увидеть, что расстановка сил несколько поменялась:
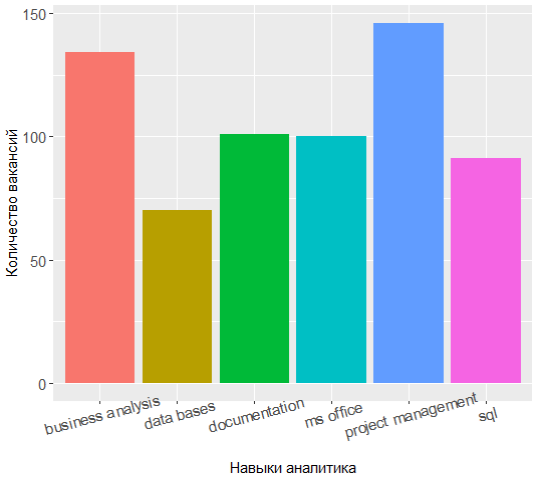
В тройке лидеров теперь управление проектами, бизнес-анализ и документирование, а знание UML сместили из топ-7.
Довольно интересно пройтись по категориям и выяснить, какие навыки наиболее востребованы в каждой из них.
Например, для категории Knowledge дело обстоит следующим образом:
tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl),
by = "id", sort = FALSE)
tmp <- na.omit(tmp)
ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>%
select(skill.group)))) +
geom_bar(colour = "#666666", stat = "identity",
aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) +
scale_y_continuous(name = "Число вакансий") +
theme(legend.position = "none",
axis.text = element_text(size = 12)) +
coord_flip()
Из графика видно, что наибольшим спросом пользуются знания в области баз данных, методологий разработки ПО и 1С. Далее идут знания в области CRM, ERP-систем и основы программирования.
В том, что касается стандартов, действительно большим спросом пользуется знание SQL и UML, на пятки им наступает нотация ARIS, а вот ГОСТы занимают всего лишь шестое место.
ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>%
select(skill.group)))) +
geom_bar(colour = "#666666", stat = "identity",
aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) +
scale_y_continuous(name = "Число вакансий") +
theme(legend.position = "none",
axis.text = element_text(size = 12)) +
coord_flip()
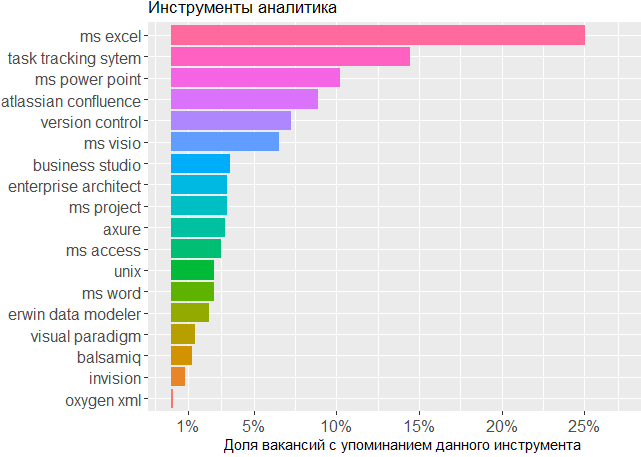
Что касается используемых тулов, — мы лишний раз видим подтверждение тому, что основным инструментом аналитика является голова. Без линейки MS Office и таск-трекинговых систем не обойтись, а в остальном мало кого волнует, в каком именно редакторе аналитик создает свои схемы или набрасывает макеты интерфейсов.
ggplot(tmp %>% filter(category == "tools")) +
geom_histogram(colour = "#666666", stat = "count",
aes(skill.group, fill = skill.group)) +
scale_y_continuous(name = "Число вакансий") +
theme(legend.position = "none",
axis.text = element_text(size = 12)) +
coord_flip()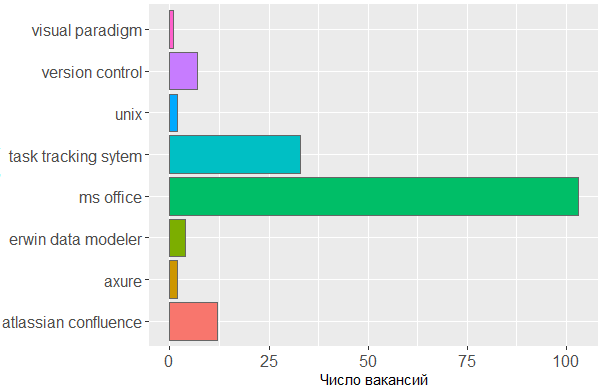
Влияние навыков на доход
Наконец, проанализируем, в каком диапазоне зарплат фигурируют упоминания различных навыков. Поскольку ранее мы уже убедились, как сильно влияет город на цифру, указанную в вакансии, мы будем рассматривать влияние навыков в разрезе городов.
Для начала соединим интересующие нас столбцы из таблиц по вакансиям jobs.paidи скиллам all.skills, чтобы было удобнее строить графики на основе полученной data frame.
# 4.4 vizualize paid skills
tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City),
by = "id", sort = FALSE))Получится таблица следующего вида:
> head(tmp)
id skill skill.group category salary lvl City
2 25781585 android mobile os knowledge 90000 middle Владимир
3 25781585 проектный менеджмент project management activities 90000 middle Владимир
5 25781585 управление проектами project management activities 90000 middle Владимир
6 25781585 ios mobile os knowledge 90000 middle Владимир
7 25750025 aris aris standards 70000 middle Москва
8 25750025 бизнес-анализ business analysis activities 70000 middle МоскваИз городов я решила отфильтровать Москву и Питер, т.к. по ним больше всего данных. Сначала взглянем на активности:
ggplotly(ggplot(tmp %>% filter(category == "activities"),
aes(skill.group, salary)) +
coord_flip() +
geom_count(aes(size = ..n.., color = City)) +
scale_fill_discrete(name = "Город") +
scale_y_continuous(name = "Зарплата, руб.") +
scale_size_area(max_size = 11) +
theme(legend.position = "bottom", axis.title = element_blank(),
axis.text.y = element_text(size=10, angle=10)))
Из графика можно сделать вывод, что в вакансиях BA/SA конкретизация предстоящих активностей и требуемых навыков уменьшается прямо пропорционально увеличению зарплаты.
Теперь проанализируем личные качества желаемых кандидатов:
ggplot(tmp %>% filter(category == "personal", City %in% c("Москва", "Санкт-Петербург")),
aes(tools::toTitleCase(skill), salary)) +
coord_flip() +
geom_count(aes(size = ..n.., color = skill.group)) +
scale_y_continuous(breaks = round(seq(min(tmp$salary),
max(tmp$salary), by = 20000),1),
name = "Зарплата, руб.") +
scale_size_area(max_size = 10) +
theme(legend.position = "none", axis.title = element_text(size = 11),
axis.text.y = element_text(size=10, angle=0))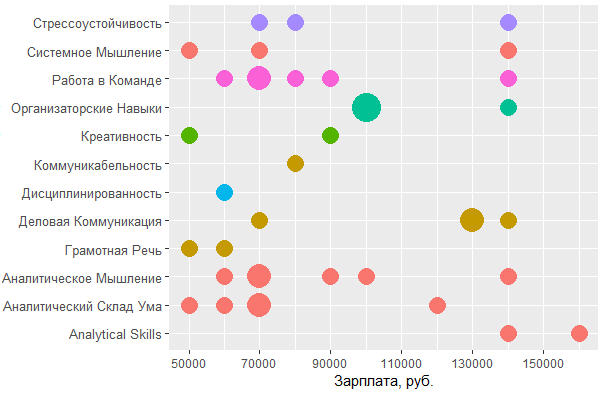
Что касается используемых инструментов, начиная от пакета MS Office и заканчивая софтом для составления диаграмм и создания мокапов, — здесь данных оказалось слишком мало, чтобы на их основании делать какие-то выводы о связи между владением определенным инструментом и уровнем дохода. Более того, чем выше зарплата, обозначенная в вакансии, тем меньше внимания уделяется конкретным инструментам в арсенале аналитика.
В том, что касается стандартов, картина немного отличается: умение обращатсья с нотациями UML и ARIS, а также знания SQL стабильно востребованы (в своих пропорциях) при разных уровнях зарплат, а вот знание IDEF — уже не такой популярный запрос, который и вовсе отсутствует на "максималках".
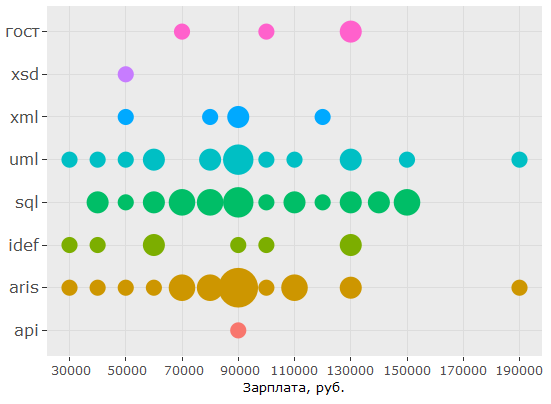
Анализ текста вакансий
На самом деле, эту часть статьи и работы я хотела отложить на следующий раз, но в ходе исследования стало понятно, что без анализа текста решительно не обойтись. Дело в том, что из найденных по исходному запросу 1478 вакансий лишь четверть содержали в себе упоминания хоть каких-нибудь навыков в поле key_skills. Это означает, что при публикации вакансий самая интересная и полная информация все-таки лежит в ее полном описании.
Импорт и подготовка описаний
Посмотрим, как выглядит типичное описание вакансии в нашей исходной data frame:
> jobdf$Responsibility[[1]]
[1] "Training course in business analysis. ? Define needs of the user/client, understand the problem which needs to be solved. ? "
> jobdf$Requirement[[1]]
[1] "At least 6 months' experience in business analysis. ? Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ? "Текст, очевидно, не полный. Поэтому пришлось снова пробежаться по исходным URL'ам найденных вакансий, чтобы вытащить необходимую информацию.
hh.get.full.desrtion <- function(df)
{
df$full.description <- NA
for (myURL in df$URL) {
try(
{
data <- fromJSON(myURL)
if (length(data$description) > 0)
{
df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description
}
print(paste0("Filling in "
, which(df$URL == myURL, arr.ind = TRUE)
, " out of "
, length(df$URL)))
}
)
}
df$full.description <- tolower(df$full.description)
return(df)
}Полное описание вакансии может содержать юникод-символы списка, html-теги и пр., от чего можно избавиться с помощью уже знакомой нам стандартной функции gsub:
remove.Html <- function(htmlString) { #remove html tags
return(gsub("<.*?>", "", htmlString))
}Это, впрочем, не является обязательнм шагом, поскольку сравнивать тексты вакансий я собираюсь все с тем же словарем, составленным вручную. Следующая функция принимает на вход data frame и словарь (также в виде df), пробегается по столбцу с полным описанием вакансии, ищет совпадения со словарем и формирует новую df вида "id, skill.group, category".
skills.from.desc <- function(df, dictionary)
{
sk <- data.frame(
id = numeric()
, skill.group = character()
, category = character()
)
for (myskill in dictionary$skill)
{
category <- dictionary[dictionary$skill == myskill, "category"]
mypattern <- paste0(na.omit(t(dictionary %>%
filter(skill == myskill) %>%
select(starts_with("syn")))), collapse = "|")
if (nchar(mypattern) > 1)
{
mypattern <- paste0(c(myskill, mypattern), collapse = "|")
}
else
{
mypattern <- myskill
}
cond = grep(x = df$full.description, pattern = mypattern)
tmp <- data.frame(
id = df[cond, "id"],
skill.group = rep(myskill, length(cond)),
category = rep(category, length(cond))
)
sk <- rbind(sk, tmp)
}
return(sk)
}Снова о самых востребованных навыках
# 5 text analysis
# 5.1 get full descriptions
jobdf <- hh.get.full.description(jobdf)
jobdf$full.description <- remove.Html(tolower(jobdf$full.description))
sk.from.desc <- skills.from.desc(jobdf, dict)Проверим, что получается?
> head(sk.from.desc)
id skill.group category
1 25638419 axure tools
2 24761526 axure tools
3 25634145 axure tools
4 24451152 axure tools
5 25630612 axure tools
6 24985548 axure tools
> tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq"))
> htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")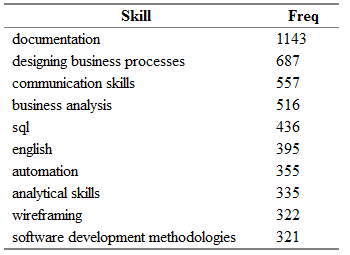
Да, вот теперь баланс сил точно сместился! Project management, который неожиданно лидировал при анализе полей key_skills, теперь не входит даже в десятку (и в двадцатку тоже).
Если говорить об общем кругозоре, наиболее востребованными теперь представляются знания в области автоматизации процессов, в то время как при анализе полей key_skills эти знания даже не вошли в топ-5.
На следующем графике представлены области знаний, отсортированные в порядке убывания по частоте упоминания вакансиях аналитиков. Поскольку в этот раз мы анализируем тексты всех найденных 1478 вакансий, а не ограничиваемся теми, в которых заполнены key_skills, полученную картину можно считать достаточно достоверной, чтобы представить результат в процентах.
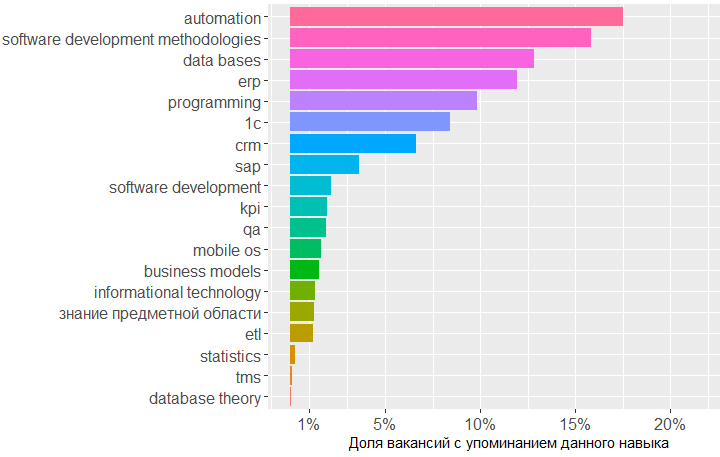
Что касается выбора инструментов, то из графика создается впечатление, что средний сферический BA в вакууме большую часть времени проводит в экселе, таск-трекере и составляет по итогам красивые презентации.
И снова о деньгах
Проверим, как распределились различные навыки и знания на шкале доходности.
Для построения графиков сформируем новую data frame из перечня скиллов, полученных из описания вакансий, и таблицы вакансий с указанными зарплатами. При этом сразу оставим только те записи, которые относятся к Москве и Санкт-Петербургу.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>%
filter(City %in% c("Москва", "Санкт-Петербург")) %>%
select(id, salary, lvl, City),
by = "id", sort = FALSE))> head(tmp)
id skill.group category salary lvl City
1 25243346 uml standards 160000 middle Москва
2 25243346 requirements management activities 160000 middle Москва
3 25243346 designing business processes activities 160000 middle Москва
4 25243346 communication skills personal 160000 middle Москва
5 25243346 mobile os knowledge 160000 middle Москва
6 25243346 ms visio tools 160000 middle МоскваСледующим графиком я хочу отразить, упоминания каких навыков чаще всего встречаются в описаниях вакансий на позиции джунов, миддлов и сеньоров соответственно, а также на какие деньги может рассчитывать счастливый обладатель тех или иных навыков.
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) +
geom_count(aes(color = salary, size = ..n..)) +
scale_size_area(max_size = 13) +
theme(legend.position = "right",
legend.title = element_text(size = 10),
axis.title = element_blank(),
axis.text.y = element_text(size=10)) +
coord_flip() +
scale_color_continuous(labels = function(x) format(x, scientific = FALSE),
breaks = round(seq(min(tmp$salary), max(tmp$salary),
by = 70000),1),
low = "blue",
high = "red", name = "Зарплата, руб."))Что мы видим из этого графика?
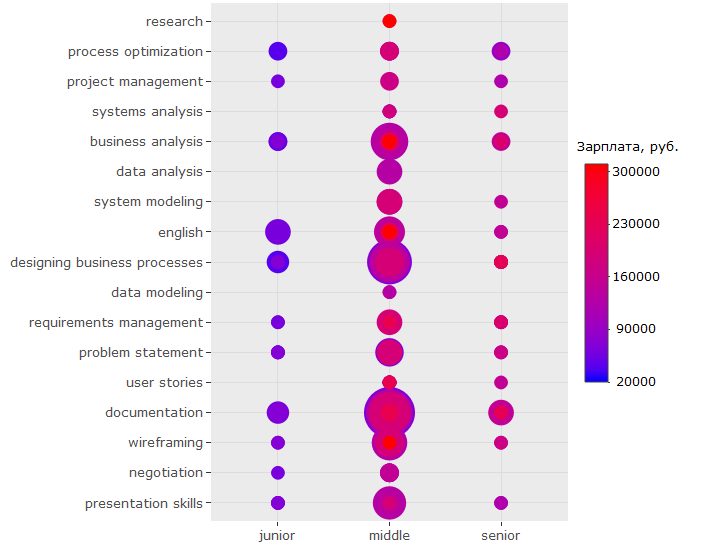
Во-первых, то, что наибольшее количество вакансий включают требования в области дизайна бизнес-процессов и документирования. (Это больше похоже на правду, хоть и отличается от результата, полученного нами в первой части исследования, где уверенно лидировал навык управления проектами.)
Во-вторых, несмотря на это, наиболее "денежными" занятиями является непосредственно бизнес-анализ, создание макетов интерфейсов и проведение исследований.
В части стандартов картина также прояснилась и стала более правдоподобной, чем при анализе голых key_skills.
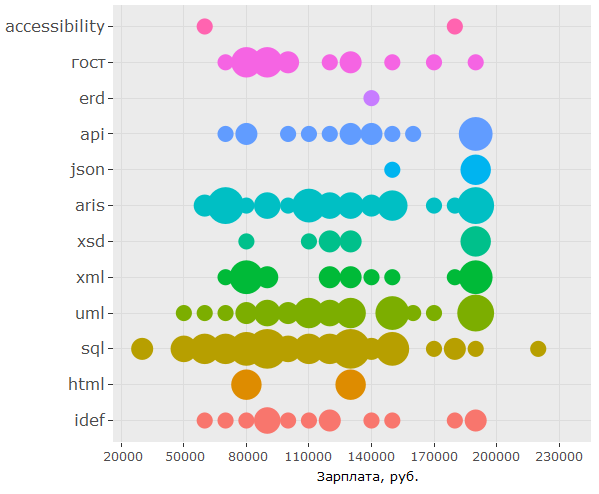
Глядя на график, можно сделать вывод, что на самом деле в зарплатном сегменте свыше 150 т.р. есть необходимость в специалистах со знанием не только UML или ARIS, но и IDEF, и ГОСТов, однако спрос на знание ГОСТов заметно ниже — в этой части первоначальный вывод подтверждается.
Некоторые изменения наблюдаются и в области личностных качеств аналитика:

Из графика видно, что по-прежнему лидируют аналитические и коммуникативные навыки, но при этом креативность, которая в перечне key_skills едва упоминалась, в описаниях вакансий встречается гораздо чаще. Более того, в зарплатном сегменте свыше 150 т.р. это качество ценится больше, чем умение работать в команде и даже способность организовать работу других.
А как же бесценный опыт?
Например, вот так выглядит плотность распределения зарплат в Москве для специалистов-аналитиков с различным стажем:

Интересно, почему на графике так много вакансий, где требуется специалист с более чем шестилетним опытом, но при этом область подозрительно смещена влево? Казалось бы, связь между опытом работы и стоимостью сотрудника должна быть самая прямая. К тому же, обратите внимание, что график затрагивает только столичный рынок вакансий. Я могу предположить, что в бoльшей части таких вакансий (лежащих в красной области графика) требуемый опыт работы указан из оптимизма нестрого.
Для сравнения, в Санкт-Петербурге разделение куда более выраженное:

Кое-какие выводы
Проведенный анализ ключевых навыков и текстов вакансий BA/SA показал, что
- качество такого анализа во многом зависит от словаря категорий навыков. В процессе работы я несколько раз обновляла и дополняла таблицу навыков и инструментов, но и сейчас классификация неидеальна;
- потолок зарплаты аналитика в Москве (и в целом в России) составляет приблизительно 200 т.р. Все, что выше этой цифры, встречается весьма эпизодически и требует нетипичных скиллов вроде знания статистики или специфической предметной области;
- на рынке вакансий довольно размытая граница между миддлами и сеньорами;
- главный инструмент аналитика — по-прежнеу голова (выбор тулов, как правило, остается на усмотрение аналитика и не влияет на доход)
- поле
key_skillsв вакансиях на hh заполняется через раз, и на основе только него нельзя делать выводы о наиболее востребованных навыках аналитика; - анализ текста вакансий, в свою очередь, оказался достовернее и полезнее, поскольку данных в результате парсинга описаний было собрано в пять(!) раз больше;
- чтобы прийти к успеху во всех отношениях, аналитику стоит наиболее активно прокачивать навык бизнес-анализа, создания добротного UX и английский язык;
- нельзя недооценивать коммуникативные навыки. Впрочем, их значимость снижается где-то после отметки в 150 т.р.;
- в том, что касается стандартов, заслуживает упоминания SQL, а также нотации UML & ARIS. Для меня видеть такую популярность языка запросов довольно неожиданно, т.к. за несколько лет мне не приходилось активно его использовать. И это, пожалуй, единственный вывод данного исследования, который противоречит
здравому смыслуличному опыту.
Комментарии (5)

Ethera Автор
10.06.2018 09:34Он попадает в enterprise architect вместе со sparx ea. На графике «Инструменты аналитика» можно проследить, что enterprise architect наступает на пятки business studio, но ни один из них не набирает 5% упоминаний.
lostpassword
Можете уточнить, что такое «аналитик»? Финиасовый аналитик? Бизнес-аналитик? Аналитик в сфере разработки ПО?
Robodub
Ну если в требованиях к вакансиям рассматриваются wireframing, aris, idef, uml и т.д. Надо понимать речь о бизнес и системных аналитиках.
lostpassword
Мне из этих аббревиатур только UML знаком, да и то лишь понаслышке.
Поэтому и спросил.