

«Божественный» код — громкий термин, который может показаться желтым заголовком, но всё же именно о таком коде будет идти речь: из каких частей он состоит и как его писать. Это история о моих стараниях сделать так, чтобы задачи не возвращались с code review с пометкой: «Всё хе*ня — переделать».
У меня нет профильного образования, и учиться программированию приходилось на практике, через ошибки, ссадины и ушибы. Непрерывно работая над улучшением качества написанного кода, я вырабатывал некоторые правила, которым он должен соответствовать. Хочу ими поделиться.
GOD’S code — акроним из акронимов — код, написанный в соответствии с принципами Grasp, Object calisthenics, Demeter’s law и Solid. Кому-то они знакомы все, кто-то встречался лишь с некоторыми, но мы рассмотрим каждую составляющую акронима. Я не ставлю своей целью детально погрузиться в каждую группу правил, так как на просторах интернета они уже много раз освещались. Вместо этого предлагаю выжимку из собственного опыта.
GRASP
Девять шаблонов для назначения ответственностей классам и объектам. Для удобства запоминания я разделяю их на две подгруппы:
- В первую подгруппу можно выделить правила, позволяющие писать атомарные модули, которые хорошо тестируются и изменяются. Эти правила не столько про ответственность, а, скажем так, про свойства модулей: слабая связанность, сильное сцепление, полиморфизм, устойчивость к изменениям. Для себя я перекрываю эти правила SOLID’ом, об этом подробнее — в соответствующей части.
- Вторая подгруппа — это уже более чёткие шаблоны, которые говорят нам о том, кто создаёт объекты («создатель» — собирательное название для фабричных паттернов), каким образом понизить связанность между модулями (используя паттерны «контроллер» и «посредник»), кому делегировать отдельные обязанности (информационный эксперт) и что делать, если я люблю DDD и одновременно low coupling (чистая выдумка).
Подробнее можно почитать здесь.
Объектная калистеника
Набор правил оформления кода, очень похожих на свод законов codeStyle. Их также девять. Я расскажу о трёх, которые стараюсь соблюдать в повседневной работе (немного видоизменённых), об остальных можно почитать в первоисточнике.
- Длина метода — не более 15 LOC, количество методов в классе — не более 15, количество классов в одном пространстве имён — не более 15. Суть в том, что длинные простыни кода очень сложно читать и понимать. К тому же, длинные классы и методы являются сигналом о нарушении SRP (об этом ниже).
- Максимум один уровень вложенности на метод.
public function processItems(array items) { // 0 foreach (items as item) { // 1 for (i = 0; i < 5; i++) { // 2 … process item 5 times … } } }
В этом примере пятикратную обработкуitemуместно вынести в отдельный метод.
public function processItems(array items) { // 0 foreach (items as item) { // 1 this.processItem(item); } } public function processItem(Item item) { // 0 for (i = 0; i < 5; i++) { // 1 … process item 5 times … } }
Опять-таки, цель — иметь возможность понять, что делает метод, кинув на него один взгляд и не компилируя код в голове. - Не использовать
elseтам, где он не нужен.
public function processSomeDto(SomeDtoClass dto) { if (predicat) { throw new Exception(‘predicat is failed’); } else { return this.dtoProcessor.process(dto); } }
И брюки превращаются:
public function processSomeDto(SomeDtoClass dto) { if (predicat) { throw new Exception(‘predicat is failed’); } return this.dtoProcessor.process(dto); }
В результате приходится читать меньше кода, к тому же выпрямляем поток выполнения.
Закон Деметры
Жёсткая версия слабой связанности из GRASP’a. Накладывает ограничения на то, с кем может взаимодействовать текущий модуль.
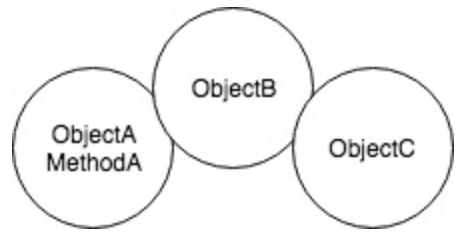
Возьмём три объекта: А содержит B, В содержит С. Рассмотрим объект А. Метод А объекта А может иметь доступ только к методам и свойствам:
- Самого объекта А.
- Объекта, который передан в качестве параметра методу А.
- Объекта В.
- Объектов, которые непосредственно созданы внутри метода А.
И всё. Проще говоря, объект А взаимодействует только с непосредственными соседями. Взаимодействие типа
this.objectB.objectC.getSomeStuff() является нарушением Закона Деметры, потому что из объекта А мы обращаемся к методу объекта С, который не является непосредственным соседом объекта А.Есть пара интересных следствий. Во-первых, использование фабрик приводит к нарушению Закона Деметры. Посудите сами:
public function methodA()
{
spawnedObject = this.factory.spawn();
spawnedObject.performSomeStuff();
}Равносильно:
public function methodA()
{
this.factory.spawn().performSomeStuff();
}Для решения этой проблемы можно выделить некую обёртку, единственным назначением которой будет создание объекта с помощью фабрики и передача его на обработку куда-либо дальше.
public function methodA()
{
this.processor.process(this.factory.spawn());
}Второе интересное следствие: DTO/Entity. Многим довольно часто приходится собирать или использовать контейнеры данных.
public function methodA(SomeDtoClass dto)
{
dto.getAddress().getCity();
}Если следовать букве Закона Деметры, это будет нарушением, так как мы обратились к соседу соседа. Но на практике с контейнером данных допускают послабление, считая его как единое целое, и, соответственно, обращение к методу
getCity DTO Address в нашем случае считается обращением к части контейнера dto.Принципы SOLID
SRP, OCP, LSP, ISP, DIP — я лишь вкратце коснусь их, потому как в Википедии и на Хабре они описаны довольно подробно.
SRP — принцип единственной ответственности. Один программный модуль — одна задача, одна причина для изменения. Перекликается с High Cohesion из GRASP’a.
Пример: у нас есть контроллер, задача которого — быть связующим звеном между бизнес-логикой и представлением (MVC). Если мы засунем какую-либо часть бизнес-логики в контроллер, то автоматически нарушим SRP.
public function indexAction(RequestInterface request): ResponseInterface
{
requestDto = this.requestTransformer.transform(request);
responseDto = this.requestProcessor.process(requestDto);
return this.responseTransformer.transform(responseDto);
}В данном примере контроллер не выполняет никакой бизнес-логики или логики преобразования, а делегирует её другим модулям, выполняя лишь одну функцию — быть связующим звеном. Нарушение данного принципа приведёт к тому, что при необходимости внесения изменений в одной функциональности, мы увеличиваем риски затронуть другую функциональность, расположенную по соседству, но которую менять мы совершенно не планировали.
OCP — принцип открытости-закрытости. Пишем код так, чтобы не приходилось его изменять, а лишь расширять.
Если в выполнении кода нужно сделать какую-либо развилку, то обычно используется if/switch. А если нужно добавить ещё одну ветку, то текущий код изменяется. И это нехорошо. Работает — не трогай. Добавляй новое и тестируй новое, а старое пусть себе работает.
Для решения подобной задачи имеет смысл создать некоторый resolver, который настраивается набором ветвей и выбирает нужную.
final сlass Resolver implements ResolverInterface
{
private mapping;
public function Resolver(array mapping)
{
this.mapping = mapping;
}
public function resolve(Item item)
{
return this.mapping[item.getType()].perform(item);
}
}Не забудьте про обработку ошибок, её я опустил. Дам совет: если принять за правило, что все классы могут быть либо final, либо abstract, то следовать этому принципу будет гораздо проще.
LSP — принцип подстановки Барбары Лисков. Корнями уходит в контрактное программирование и говорит о том, как нам правильно строить наследование.
Постулаты таковы:
- Производные классы не должны усиливать предусловия (не должны требовать большего от своих клиентов).
- Производные классы не должны ослаблять постусловия (должны гарантировать, как минимум, то же, что и базовый класс).
- Производные классы не должны нарушать инварианты базового класса (инварианты базового класса и наследников суммируются).
- Производные классы не должны генерировать исключения, не описанные базовым классом (методы подкласса не могут генерировать никаких дополнительных исключений, кроме тех, которые сами являются подклассами исключений, генерируемых методами надкласса).
class ParentClass { public function someMethod(string param1) { // some logic } } class ChildClass extends ParentClass { public function someMethod(string param1, string param2) { if (param1 == '') { throw new ExtraException(); } // some logic } }
В данном примере
someMethod класса ChildClass требует большего от клиентов (param2), и к тому же предъявляет определённые требования к param1, которых не было в родительском классе. То есть нарушаются правила наследования, в результате мы не сможем без дополнительных ухищрений заменять использование ParentClass на ChildClass.ISP — принцип разделения интерфейсов. Говорит о том, что не стоит засовывать все возможные методы в один интерфейс. Иными словами, если мы реализуем в классе интерфейс, и при этом часть методов обязательны к реализации, но нам они не нужны, — значит, стоит разделить этот интерфейс.
interface DuckInterface
{
public function swim(): void;
public function fly(): void;
}
class MallardDuck implements DuckInterface
{
public function swim(): void
{
// some logic
}
public function fly(): void
{
// some logic
}
}
class RubberDuck implements DuckInterface
{
public function swim(): void
{
// some logic
}
public function fly(): void
{
// can't fly :(
}
}RubberDuck реализует интерфейс DuckInterface. Но, насколько мне известно, резиновые утки не летают, поэтому интерфейс DuckInterface имеет смысл разделить на два интерфейса FlyableInterface и SwimableInterface, и реализовывать уже их.DIP — принцип инверсии зависимостей. Суть его в том, чтобы вынести все внешние зависимости за пределы модуля и завязаться на абстракции, а не подробности (то бишь на интерфейсы и абстрактные классы, а не конкретные классы). Одним из признаков нарушения этого принципа является наличие ключевого слова
new в классе. class DIPViolation
{
public function badMethod()
{
someService = new SomeService(445, 'second params');
// operations with someService
}
}Когда мы инстанцируем какой-либо сервис непосредственно внутри нашего класса, то в будущем будем иметь большие проблемы с покрытием этого кода модульными тестами. Также мы увеличиваем связанность между классами. Пример выше следует отрефакторить следующим образом:
class DIP
{
private $service;
public function DIP(SomeServiceInterface $someService)
{
$this->someService = $someService;
}
public function goodMethod()
{
// operations with someService
}
}Итак, в данной статье, я постарался собрать воедино правила, которыми руководствуюсь, чтобы писать более удобочитаемый и «ремонтопригодный» код. Надеюсь, вам понравилось это маленькое приключение в принципы хорошего кода. И когда в следующий раз вы услышите, что код, который вы написали, просто «божественен», вы будете знать, что именно это значит :)
Комментарии (167)

mayorovp
26.06.2018 10:41По поводу закона Деметры и фабрик я несогласен категорически.
Фабрика — это абстрагированный конструктор. А значит, объект который фабрика вернула, должен считаться созданным в вызвавшем фабрику методе.
Более того, слепое следование рассуждениям из статьи может привести к очень кривому коду. Допустим, объект который вернула фабрика нужно закрывать. Как это будет выглядеть в простом случае?
foo = factory.create(); foo.bar(); foo.close();
Но если бездумно следовать закону Деметры — то вызовы bar и close придется вынести в отдельный метод… который в итоге будет закрывать объект не им открытый.
AxisPod
26.06.2018 11:10Вариантов море
1. RAII, в этом случае конструктор объекта создаст внутренние и close в этом случае адекватен, в рамках управляемого кода, в рамках же того же C++ вместо close будет деструктор.
2. DI, здесь close не будет сам закрывать, а просто дёрнет сервис для закрытия внутреннего объекта.
3. Я частенько в своём коде ипользую некие IGuard объекты, следящие за ресурсами, которые сами знают что и как делать.
Если же вы говорите вообще как close в противопоставление factory.create(), то здесь вы не ресурс уничтожаете, вы говорите, что надо бы вычистить внутренее состояние объекта, а не сам объект и это нормально.
В итоге в C# используем IDisposable для этих целей, по нему же и описание ловим и работаем так
using (var foo = factory.Creat()) { foo.bar(); }
В C++ используем std::unique_ptr как результат фабрики, само удалиться, тут по хорошему работать только с RAII.
И ничего для закрытия вручную не дёргаем.mayorovp
26.06.2018 11:29Ну, под капотом using — обычный вызов Dispose, а под капотом RAII — деструктора. Не вижу причин почему генерируемый компилятором код имеет право нарушать правила.
sys_int64
26.06.2018 20:14Ага, посмотри что компилятор генерирует, он может такое нагенерировать ради оптимизации кода, что нарушит все ваши правила, и не важно какой чистый и продуманный код вы напишете.
c3037 Автор
26.06.2018 11:35Не поймите неправильно, я ни в коем случае никого не призываю бездумно следовать тому, что описано в статье. Стоит помнить, что Закон Деметры, как и любой другой принцип стоит применять в меру и не вдаваться в крайности. Я описал следствия, которые действительно имеют место быть. Если в каком-то случае пренебрежение его использованием позволит улучить кодовое решение, то разумнее это сделать.
Aquahawk
26.06.2018 11:49+15Критика подхода ограничения размера метода.
Просто ужасные советы если отнести к производительности. Напишите в таком виде алгоритм который осуществляет свёртку изображения по ядру произвольного размера. У вас там будет 4 вложенных фора в любом случае. А если несколько свёрток за раз по одному исходнику так 5.
Да и вообще есть миллион ситуаций где нельзя размазывать код. Сложные вещи останутся сложными. Вы можете спрятать эту сложность в тонне классов и кода, но лучше не станет. Станет ещё сложнее новичку увидеть и так сложный алгоритм сквозь размазню методов. Бить нужно логически так как бъётся алгоритм, так чтобы было читаемо и логически понятно что делается и как. А это приходит с опытом. А то бывает смотришь, всё вылизано по кодстайлам, куча маленьких методов, всё туда-сюда передаётся, идилия просто, каждый метод прозрачен как слеза младенца. Но хрен поймёшь что весь этот океан делает. Я не призываю всё сляпывать. Я призываю думать и обеспечивать прозрачность архитектуры и понятность алгоритмов, и это не правилом 15ти строк делается.Artyomcool
26.06.2018 16:57Чтобы правильно нарушать правила, нужно для начала научиться им следовать. Бить логически — сложно, это думать надо, и как вы правильно заметили — иметь опыт. С чего-то нужно начинать, чтобы этот опыт заполучить. Вероятно, новичку было бы полезно иметь набор простых советов из разряда «15 строк и не больше». Со временем придет понимание, что это далеко не всегда верно.
Касательно же производительности: в современном программировании производительность за пределами асимптотики нужна крайне редко. И даже в этом случае сначала было бы неплохо написать код понятным, а уже потом аккуратно профилировать и оптимизировать.Aquahawk
26.06.2018 23:43+1Не согласен. Применять практику не понимая зачем она странно. Имхо нужно упасть с велосипеда чтобы понять как ехать. В IT правда для этого надо поработать 2-3 года на одном проекте, чтобы самому оценить как работают твои же решения. Вот тогда появляется червячок мысли о том как читать книги по паттернам и на что на самом деле смотреть и как читать между строк.
Druu
27.06.2018 05:10+1Чтобы правильно нарушать правила, нужно для начала научиться им следовать. Бить логически — сложно, это думать надо, и как вы правильно заметили — иметь опыт.
Так чтобы научиться чему-то — надо это что-то делать. Если человек с самого начала будет бить бездумно методы, потому что "кодстайлы", то логическому разделению он никогда не научится.
Вероятно, новичку было бы полезно иметь набор простых советов из разряда «15 строк и не больше»
Совет должен выглядеть как: "если метод длиннее 15 строк, то стоит обратить на него внимание, и возможно вынести часть логики, если это будет разумно". И ни в коем случае не должен выглядеть как: "15 строк и не больше".
gandjustas
26.06.2018 17:05+1Люди забывают, что надо сначала написать работающий код, выпустить его в продакшн, а потом уже применять эту фигню, когда развитие кода станет сложным или понадобится фиксить баги.
arTk_ev
26.06.2018 17:16+1ага, вот из-за таких людей в каждом проекте огромное количество лапши. И из-за этого разработка замедляется в сотни раз или становится в принципе невозможной.
Поработайте на поддержке старого проекта, сразу появится ответственность за свой говно-код и понимание цены умственной лени.gandjustas
26.06.2018 17:42+1Проекты с огромным количеством лапши приносят деньги, в том числе программистам, проекты с красивым кодом, которые никогда не выходят в продакшн — закрываются.
Код должен сначала работать и зарабатывать, а потом быть "красивым". Если он плохо работает — надо улучшать, если появляются большие затраты на поддержку — надо улучшать.
Улучшать код до того, как он заработал — непозволительная трата денег заказчика.
Никто не говорит, что улучшать код не надо. Работаешь на поддержке — улучшай код, а не создавай еще больше лапши, кто тебе мешает?
Я, вот, работал на проектах поддержки, который писали более 5 лет до этого, и я улучшал код.
arTk_ev
26.06.2018 18:45+4
Но git помнит ваши имена ))
Если вы бы работали на поддержке, то бы знали, что любой рефакторинг запрещен в принципе, даже обычное переименование. И говно-код занимает больше времени, он даже больше по объему. И разве не проще сразу писать нормальный рабочий код?gandjustas
27.06.2018 01:00Я работал на поддержке если что.
Даже больше скажу, сейчас у меня хобби-проект — моды к компьютерной игре. В модах есть унаследованный код, которому больше 5 лет, код других моддеров, который надо иногда править и обновлять (обновления о наших правках не знают ничего). Из инструментов — только текстовый редактор с подсветкой синтаксиса. Тестирования как такового нет, каждый тестовый цикл это запуск игры и около 3 минут ожидания.
И ниче: правим, рефакторинг делаем, добавляем и (о ужас!) убираем код. Около 300к строк.
Neikist
27.06.2018 07:49Эм… Ну хз, у нас вот в принципе по максимуму запрещено менять любой код с модификаторами public, только в совсем крайних случаях можно. И это продукт с исходным кодом который клиентам отдается. А запрещено поскольку клиент мог сделать себе доработки которые на этот код опираются. А уж на поддержке и вовсе жуть может быть.
gandjustas
27.06.2018 18:13+1Подобные запреты и есть основной источник лапши. Если код перестал удовлетворять требованиям, то его надо менять, а не хранить как священную корову.
zenkz
27.06.2018 19:16Давно уже придумали интерфейсы и SOLID-принципы… Клиенты не должны делать доработки внутри общего кода. Если у вас происходит такое, то вам срочно нужно от этого отказываться, т.к. это постоянный источник плохого качества кода и трудноуловимых багов… В идеальном случае клиенту предоставляется интерфейс/API для взаимодействия… А всё что внутри модуля может меняться постоянно и это нормально…
pesh1983
27.06.2018 10:39А представляете, как было бы замечательно, если бы код был понятнее и его поддержка занимала в 2 раза меньше времени, например. На самом деле, очень важно найти золотую середину: не писать лютый говнокод, но и не стараться добиться идеальной структуры кода, который даже не работает ещё. Все упирается естественно в ресурсы, в том числе времени, но важно помнить, что сэкономив время сейчас и набросав говнокод, его поддержка потом может съесть больше времени, чем вы выиграли на данном этапе. Так что важен баланс
gandjustas
27.06.2018 18:19-1Было бы замечательно если бы все были богатыми и здоровыми.
А по поводу "середины" — лучше самый лютый говнокод, который работает, чем "идеальная архитектура", которая не работает.
А теперь самая важные фишка о которой все забывают:
1) "Идеальная архитектура" и "говнокод" это эмоциональные оценки. К формальным характеристикам сложности, связности, читаемости, скорости работы и плотности багов отношения не имеют.
2) "Идеальная архитектура" и "говнокод" это не противоположные стороны спектра. Может быть "говнокод" при почти "идеальной архитектуре".GeekberryFinn
27.06.2018 18:58+1«Идеальная архитектура» и «говнокод» это не противоположные стороны спектра. Может быть «говнокод» при почти «идеальной архитектуре»
Может. Потому что «идеальная архитектура» это идеальное разбиение программы на модули. И внутри модуля может иметься говнокод, но, разница не в этом, а в том что
— «идеальная архитектура» — при чистке говнокода ничего не ломается;
— «дерьмовая архитектура» — при чистке говнокода ломается ВСЁ и приходится лепить множество заплат;
— бывают и промежуточные состояния архитектуры.
pesh1983
27.06.2018 19:07Вы невнимательно читали. Я не писал ничего про архитектуру), я также не писал, что идеальный нерабочий код лучше, чем рабочий говнокод. А писал я про баланс. Если ваш бизнес не выделяет достаточно времени, чтобы писать нормальный код, то это может быть отправдано в следующих случаях: 1. У руководства есть понимание, что мы сейчас пишем быстро говнокод и в дальнейшем, если мы планируем поддерживать этот код, мы его причешем, перепишем и так далее. 2. Вы не планируете поддерживать написанный код, например, пишете прототип. Во всех остальных случаях руководство скорее всего не понимает проблему наличия говнокода и руководствуется планами только на ближайшую перспективу. Это, кстати, довольно распространенный подход. Хотя конечно, еще возможно, что денег много, и ничего страшного, если поддержка и внедрение фичей будут занимать больше времени. Ну тут, как говорится, "кто платит, тот и музыку заказывает", you are the boss)
gandjustas
27.06.2018 19:16Давайте считать, что срок фиксирован и всегда недостаточный, чтобы сделать все хорошо. Делать сразу, чтобы код был SOLID или написать быстро, чтобы работало, а потом поправить там, где архитектура совсем неочень получилась?
Я замерял, второй вариант получается быстрее. Получившийся код недостаточно соответствует канонам "правильной архитектуры". Но пользователю пофиг.
GeekberryFinn
27.06.2018 19:22-1а потом поправить...
Если архитектура дерьмовая, то поправить что-то не сломав другое — не получится, в результате придётся лепить много заплат из-за «одно — лечим, другое — калечим».
При правильной архитектуре — можно вносить изменения ничего не ломая.gandjustas
27.06.2018 19:25Поправить всегда можно. Код это же не кирпичи в стене нижнего этажа.
GeekberryFinn
27.06.2018 19:27Если всегда, то почему при починке говнокода лезут новые баги и глюки?
gandjustas
27.06.2018 19:32У кого лезут? У меня не лезут.
Neikist
28.06.2018 07:00Если не лезут — это как раз значит что архитектура более менее. Возможно вы просто не видели настоящее отсутствие архитектуры. Ну либо вы тратите например 5X времени вместо X.
gandjustas
28.06.2018 18:32Я много чего видел, в том числе то, что вы можете назвать "настоящее отсутствие архитектуры".
Ну либо вы тратите например 5X времени вместо X.
Чтобы потратить Х вместо 5Х при поддержке в "будущем" надо потратить 20Х на сейчас. "будущее" в кавычках, потому что оно может и не наступить.
Neikist
28.06.2018 19:45Я много чего видел, в том числе то, что вы можете назвать «настоящее отсутствие архитектуры».
Либо не видели, либо вы гений который может в голове одновременно держать десятки тысяч строк кода на которые могут повлиять совсем небольшие исправления самым неочевидным образом, либо баги и глюки все же лезут.gandjustas
29.06.2018 03:49Утрировать можно до бесконечности. В реальной жизни количество связей, которые может создавать строка кода, ограничено сверху.
В реальной жизни можно сгруппировать код так, чтобы в каждом блоке количество связей было минимально.
Имея такую группировку можно вынести
сильносвязные куски кода в отдельные модули слабосвязанные между собой.
Проблема только в том, что такие действия требуют усилий по чтению и пониманию кода, а иногда и политической воли, чтобы внести изменения. А усилия и ответственность — не о, чего хотят программисты.
Neikist
29.06.2018 07:36+1В реальной жизни можно сгруппировать код так, чтобы в каждом блоке количество связей было минимально.
Имея такую группировку можно вынести
сильносвязные куски кода в отдельные модули слабосвязанные между собой.
Ну так это уже можно сказать приемлемая архитектура, пусть еще и не хорошая.
zenkz
27.06.2018 19:58Неужели писать код по SOLID настолько дольше?!
Или вы как в Delphi — весь код в button1_click пишите? Конечно важно как можно быстрее выдать продукт рынку, но через 1-2 года поддержка этого кода и добавление новых фич будет стоить компании в разы дороже, чем если бы сразу написать хотя бы приблизительно соблюдая SOLID
Когда нужно быстро — я всё равно делю код на классы (хотя бы уровня структура данных — контроллер/accessor — UI), для контроллеров делаю интерфейсы и резолвлю их через ServiceLocator/DI — если этого не делать, то потом юнит тесты замучаешься писать… Да и код по слоям разделён хотя бы…gandjustas
27.06.2018 20:10Неужели писать код по SOLID настолько дольше?!
Зависит от степени упоротости в применении принципов SRP и DIP. В частности у меня был код, который в 10 строках читал данные из двух источников и записывал один. Чтение из каждого источника было одной строкой.
Посоны, которые делали по SOLID на каждую строку фиганули по классу. Потом выделили интерфейс, обратили зависимости. Потом из класса сделали базовый и два наследника, один тестовый, а второй обращался к системе. В итоге две строки превратились в двадцать две. Это не считая тестов.
Естественно две строки были написаны за 5 минут (вместе с проверкой), а 4 класса и инверсия зависимостей потребовали почти полдня работы.
Или вы как в Delphi — весь код в button1_click пишите?
Сейчас везде по дефолту MVC и MVVM, батонкликов не найдешь.
Когда нужно быстро, я беру готовый шаблон, который дает фреймворк и фигачу код прямо в точке вызова. Когда код начинает делать то, что нужно — рефакторю до вменяемого состояния.
GeekberryFinn
27.06.2018 20:16Сейчас везде по дефолту MVC и MVVM, батонкликов не найдешь.
А что там сейчас?
(так вышло, что с Дельфи перешёл на Оракл, и про то как сейчас не в курсе)
zenkz
27.06.2018 21:28Ну ваш пример с SOLID — жесть конечно. Нарушает мои любимые принципы KISS и YAGNI. Чем больше кода напишите, чем тяжелее поддерживать. В данном случае те товарищи слишком буквально поняли SRP и вместо разделения ответственности стали плодить сущности… А YAGNI принцип нарушается, т.к. скорее всего никто не будет добавлять новые источники данных, а значит все эти интерфейсы будут лежать мёртвым грузом в проекте. Я бы рассмотрел эту задачу как конвертер, а значит обойтись одним интерфейсом IDataConverter, который умеет считать (не важно из скольки источников) и записать… Код бы стал на 4 строчки длинее и появилась бы возможность легко написать юнит тесты…
gandjustas
27.06.2018 23:09Почему же не поняли? Очень даже поняли, потом долго рассказывали что теперь в конфиге можно источники данных подменить, не трогая остальную логику.
С источниками данных, кстати, не самая большая проблема была. Просто самая показательная.
Neikist
28.06.2018 07:03Сейчас везде по дефолту MVC и MVVM, батонкликов не найдешь.
Хахаха, вы серьезно? Как раз куча примеров когда все как раз в события формы лепится.
pesh1983
27.06.2018 21:15Мне правда жаль, что у вас всегда недостаточно времени для качественного выполнения своей работы. Это в большинстве случаев проблема менеджмента. Поменяйте работу, поверьте, есть компании, в которых и планирование адекватное, и при этом даже ЗП хорошую платят, ну и проекты уж точно не скучные. А пользователю действительно пофиг, как вы правильно заметили. Ему ж не придётся поддерживать говнокод. А вам придётся, ну или вашим коллегам.
zenkz
27.06.2018 19:21«Идеальная архитектура» — это конечно субъективное понятие, а вот «говнокод» — вполне измеримое. Мои любимые принципы разработки: DRY, KISS and YAGNI. Т.е. любое изменение в коде должно происходить в одном месте (т.е. без необходимости использовать текстовый поиск и замену кода во многих файлах), код должен легко читаться и позволять понять его назначение, весь неиспользуемый код должен быть удалён. Для меня эти принципы важнее SOLID и прочих — и если они нарушаются — это и есть говнокод…
gandjustas
27.06.2018 01:06+1Если бы было проще писать "нормальный рабочий код", то его писали все. Но раз "нормального рабочего кода" оказывается в итоге крайне мало, то видимо не проще.
Не проще, потому что люди сначала долго рисуют диаграммы классов (иногда в голове), разделяют интерфейсы, инвертируют зависимости, делают так, чтобы код соответствовал OCP, SRP и еще каким-то аббревиатурам, а потом сроки подходят и срочно лепится абы-какой код, чтобы все взлетело.
Достаточно сделать просто в обратном порядке — сначала чтобы работало, а потом чтобы было красиво. Но для этого требуется скилл и выдержка.
sic
27.06.2018 02:49Тут еще проблема, что поди все это объясни людям. У меня аж в трех компаниях подобная практика была, что сначала я пишу по задаче PoC код, причем и на планированиях отмечаю, что это proof of conect и в комментариях все помечаю, и в связной информации в системах контроля версий, трекерах и прочее, и каждый раз на меня смотрят «оО у нас так плохо и джуниоры не пишут». Разумеется, к PoC требований ну почти никаких, запросто бывает и полотнище размером в 1 метод на 1000 строк, и копипаста из интернетов, заместо каких-то уже библиотечных функций, и все константы не вынесены, ну не знаю, чем еще напугать, регистр переменных и идентификаторов рандомный, но зато, в среднем, это раз в 10 быстрее, чем писать сразу нормально, и отрефакторить это нормально займет не более трети времени от «сразу писать нормально».
Но нет. «А как же мы будем юнит тесты писать?» «У нас к каждому спринту юнит тесты — это обязательная часть acceptance criteria.»
И пофиг, что большинство фич идет с отстованием в три спринта, пофиг, что несмотря на юнит тесты продакшн все равно постоянно падает (поэтому релизится то, что когда-то считалось не очень падающим), и пофиг, что бизнес через раз говорит, что ну, знаете, а эта фича не очень-то нам и нужна будет.
MVP? Такого слова большинство коллег и не слышало. А менеджеры работают так, что если большинству что-то не нравится, значит — это что-то плохое.Neikist
27.06.2018 07:51-1А теперь два вопроса. В вашем коде при необходимости что то поправить сколько людей с ходу разберутся? И приводите ли вы его в порядок? А то может и падает то из за такого кода.
pesh1983
27.06.2018 21:04У вас фигово процессы настроены. То, что вы не укладываетесь в сроки, в большинстве — результат плохого планирования. Мудрый менеджер возьмёт оценку программиста, умножит ее на 2 и ещё добавит половину, и даже такую оценку стоит брать во внимание с учётом других факторов, которые могут не зависеть от сроков выполнения задачи. А юнит тесты хороши, как вспомогательный инструмент, как гарантия,, что реализованный код работает правильно на данном этапе, ну и для устранения регрессий, но уж точно не как гарантия того, что ваш код и все остальное будет работать в продакшене в связке. Для этого есть ревью кода, процедура приемки со стороны QA, стейджинг и много всего ещё по желанию. А если у вас все это есть, но проекты продолжают падать в проде, значит у вас где-то что-то не отрабатывает как надо, поскольку до прода непротестированный проект при хорошо поставленных процессах просто не доедет) Даже с лютым говнокодом и без тестов можно жить, если есть правильно поставленная проверка QA на стейджинге) Не так конечно хорошо, как с тестами и не так быстро, потому что количество возвратов и багфиксов возрастает, но в целом можно. А вот наоборот — нет.
arTk_ev
26.06.2018 19:22-2С математической точки зрения, лапша-код куда более интереснее для меня, с недавних пор). Так что не утверждаю, что такой код объективно хуже.
sshmakov
26.06.2018 20:21+2Раскройте тайну, что интересного в лапше с математической точки зрения? Мне тоже интересно.
arTk_ev
26.06.2018 20:36натуральный Deus ex machina. Нынче вновь становятся популярны теория Хаоса и синергетика.
Думаю у каждого были интересные и весьма неожиданные баги. И в теории, можно получить такую систему, которая будет производить только положительные баги)
arTk_ev
26.06.2018 16:18Задача программиста — упрощать сложную(системная сложность) систему и внедрить метод управления.
Для проектирования архитектуры и вообще главный принцип — это KISS и декомпозиция модулей.
Упрощение — это минимизация количества связей и возможных состояний системы. Для этого применяют инкапсуляцию и шаблоны проектирования, SOLID.
Для минимизации состояний используют минимизацию ветвления кода(все if) и декомпозицию методов(маленькие простые вложенные методы)
Для управления систем, чаще всего, используют классическую пирамиду власти из кибернетики.
Для понимания как нужно строить архитектуру и откуда берутся баги, нужно прочитать системный анализ. Прочитать можно за пару дней, никаких доп. знаний не нужно.
gandjustas
26.06.2018 16:58+1Излишняя приверженность "правильной" архитектуре и коду стала сродни преждевременно оптимизации. Люди занимаются этой фигней еще до того, как код начал вообще работать.
c3037 Автор
26.06.2018 19:39-1Позволю себе не согласиться. Не вижу ничего плохого в том, что бы думать об архитектуре в момент написания кода. У кода, как и бизнеса, есть одно постоянное свойство — меняться. Да, разумеется, иногда нужно по-быстрому сделать MVP и выпустить его в продакт, но по моему опыту нет ничего более вечного, чем временное. Если конечно у вас не конвеерное производство MVP, то закладывание возможности изменений принесёт больше пользы, чем времени отнимет. К тому же, следование описанным принципам со временем уже просто откладывается на подкорке и каких-то особых усилий не требует — проверено на себе и коллегах.
gandjustas
27.06.2018 00:54Плохо то, что программисты не могут остановиться. Улучшать код можно почти до бесконечности. А если кода еще нет, то мыслительный процесс может вообще не остановиться.
Многократно себя ловил на мысли о том, что начинаю улучшать код до его написания, что приводит к тому, что я не могу начать писать.
Код всегда можно поменять, поэтому закладывание возможностей обычно требует больше времени из-за продумывания, чем правка кода, когда возможность понадобится.
Neikist
27.06.2018 07:52то закладывание возможности изменений принесёт больше пользы, чем времени отнимет.
Код всегда можно поменять, поэтому закладывание возможностей обычно требует больше времени из-за продумывания, чем правка кода, когда возможность понадобится.
Не видите некоторого противоречия? Не закладывания возможностей, а закладывания возможности изменения кода. Это все таки разные вещи.gandjustas
27.06.2018 18:23Не вижу. В обоих случаях это добавление кода, который не нужен сейчас, но возможно понадобится в будущем.
Плотность багов величина почти постоянная, поэтому чем больше кода, тем больше ошибок. Чем больше кода, тем больше требуется времени на поддержку.GeekberryFinn
27.06.2018 18:34Нет, это не добавление кода «который не нужен сейчас, но возможно понадобится в будущем», а создание возможности легко добавить такой код в случае необходимости не сломав ничего.
Что достигается продуманной архитектурой = без кривого прибивания гвоздями «тяп-ляп и в продакшн».gandjustas
27.06.2018 18:38Каким образом достигается "создаются возможности"? Из воздуха? Или есть некоторый код, который за это "создание возможностей" отвечает?
GeekberryFinn
27.06.2018 18:54Продуманное разбиение программы на модули, которые возможно изменять и дополнять не ломая всего остального. То есть не создаётся «который не нужен сейчас, но возможно понадобится в будущем», а создаётся код который сейчас нужен и используется для взаимодействия между модулями.
есть некоторый код, который за это «создание возможностей» отвечает?
По сути да, но этот код не висит мёртвым грузом «который не нужен сейчас, но возможно понадобится в будущем», а реально используется и работает.
Это как разъёмные соединения — вместо жёсткого прибивания гвоздями.
И если, что-то нужно изменить, то достаточно изменить конкретный модуль, а не лепить поверх всего заплату.gandjustas
27.06.2018 19:20Если вы умеете не писать дополнительный код и получать дополнительные возможности, не затрачивая при этом дополнительное время, то конечно надо этим пользоваться.
Но в жизни не встречал ни разу такого. Скорее было обратное. Ради "дополнительных возможностей" люди тратили в 10 раз больше времени, писали в 4 раза больше кода (а в совокупности с тестами в 8 раз больше), делали "идеальную" SOLID архитектуру, но код был нерабочим. Тупо не делал то, что нужно.
GeekberryFinn
27.06.2018 19:04-1добавление кода, который не нужен сейчас, но возможно понадобится в будущем
Или есть некоторый код, который за это «создание возможностей» отвечает?
Если у вас на машине стоит трансмиссия — то это не «добавление кода, который не нужен сейчас, но возможно понадобится в будущем», а реально работающий механизм, который за «создание возможностей» отвечает.
Если у вас на машине колёса — жёстко приколочены к оси по принципу «тяп-ляп и в продакшн», то вам чтобы на машине повернуть придётся поверх уже имеющихся колёс лепить «заплату» из дополнительных колёс, которые могут поворачиваться.gandjustas
27.06.2018 19:21Доказательство по аналогии ущербно изначально. Потому что надо сначала доказать верность аналогии.
GeekberryFinn
27.06.2018 19:26-1Вы gandjustas сначала приписали другим "добавление кода, который не нужен сейчас, но возможно понадобится в будущем".
А когда вам сказали о том, что вы не правы и это не так — начали придумывать отмазки!
Слив засчитываем?
Druu
28.06.2018 06:45Если у вас на машине колёса — жёстко приколочены к оси по принципу «тяп-ляп и в продакшн», то вам чтобы на машине повернуть придётся поверх уже имеющихся колёс лепить «заплату» из дополнительных колёс, которые могут поворачиваться.
Если у вас требования ВНЕЗАПНО меняются с "приколотить колеса намертво" к "обеспечить возможность руления", то какие-то архитектурные недостатки (возможные) — наименьшая из ваших проблем. И уж точно не надо пытаться эту проблему решать архитектурными костылями.
JobberNet
28.06.2018 07:57Увы, на практике часто такое встречается, когда клиент захотел именно именно такую «мелкую фичу», и искренне считает, что это «легко сделать».
А «приколотить колёса намертво» — это не требования клиента, которому на такие «мелочи» — глубоко пофиг, а изначальная архитектура доставшаяся в качестве легаси.
mayorovp
28.06.2018 08:55Бывает что и из воздуха. Например, при использовании сторонней библиотеки или фреймворка.
sys_int64
26.06.2018 20:21Конечно излишнаяя приверженность — это плохо, но забивать на нее тоже нельзя, вообще сильно зависит от размеров проекта, если проект очень большой, то тут сразу лучше начать адекватно разрабатывать архитектуру, если проект постоянно меняется, то правильная архитектура поможет быстро выпилвать устаревший функциаонал и внедрить новый, легко протестировать все это итд. Если же проект не большой, то сильно можно и не заморачиваться и возможно получится все удержать в голове. По поводу преждевременной оптимизации — лучше бы люди все же иногда задумывались бы об оптимизациях, а то последнее время все полюбили это правило и вообще не оптимизируют ничего, что относительно простые программы тормозят на весьма не плохом железе.
sic
27.06.2018 00:56+2Тут главное не запутаться. Излишней приверженности правильной архитектуры не бывает, ибо архитектура практически всегда, для любого приложения будет морфироваться в худшую сторону со временем. Ну кроме приложений «написал и выбросил», но имхо к ним вообще не может быть никаких требований кроме надежности/безопасности.
Другое дело, что стилистика написания кода к архитектуре имеет лишь условное отношение. И излишняя декомпозиция на ранних этапах, да, зло, не меньшее, чем преждевременная оптимизация. Хотя бы потому, что декомпозировать всегда проще, чем объединить уже разбитые (и особенно сомнительно) сущности.
А об оптимизациях, ну вот в восновном все и тормозит, ибо из-за слепых требований к объему методов, простоты форматов, у нас в доброй части приложений, чтобы 2+2 сложить, в 15 LOC методе эти данные сначала из JSON парсятся, потом обратно запихиваются, и чтоб скучно не было, это все еще сидит под жирным мьютексом, ибо чего плодить объекты синхронизации. Зато SRP, OCP, LSP, ISP, DIP, и прочее, что нужно каждому сеньору потрогать в продакшн на уровне эксперимента, чтобы потом понять, что в принципе, программирование никогда об этом и не было.
JobberNet
27.06.2018 08:47Излишняя приверженность «правильной» архитектуре и коду стала сродни преждевременно оптимизации.
Ошибки лучше предотвращать на стадии проектирования, чем потом выяснить что архитектура настолько кривая, что лучше бы переписать весь проект с нуля. :(Neikist
27.06.2018 09:20Именно, вспоминаются исследования приводимые макконелом в «Совершенный код», которые показывали что стоимость ошибок на каждом этапе: выявление требований->проектирование->конструирование повышается в разы, а то и на порядок.
Druu
27.06.2018 10:14+1Ошибки лучше предотвращать на стадии проектирования, чем потом выяснить что архитектура настолько кривая, что лучше бы переписать весь проект с нуля. :(
Очень часто лучше быстро получить готовый продукт, а потом переписать его с нуля, чем долго заниматься проектированием, а потом выяснить, что вы уже опоздали на последний поезд и не сможете конкурировать с имеющимися решениями.
Neikist
27.06.2018 10:57А тут вступает в игру другой фактор. Часто после того как накидали что то для проверки концепта — это что то остается в таком виде поскольку «Ну переписать это же ресурсы нужны, а у вас вон уже продукт есть, давайте быстро еще фичи.» И похрен что все страдают как из-за непродуманной бизнес логики, так и из за говнокода в который изменения просто страшно вносить. Ибо «что за тесты такие? Это же ресурсы нужны».
Druu
27.06.2018 12:18А тут вступает в игру другой фактор. Часто после того как накидали что то для проверки концепта — это что то остается в таком виде поскольку «Ну переписать это же ресурсы нужны, а у вас вон уже продукт есть, давайте быстро еще фичи.»
Вот видите. Продукт оказался востребованным, есть бюджет, есть требование новых фич. А если бы планировали — то никто бы новых фич не требовал, потому что продукт оказался бы нафиг никому не нужен к тому моменту, как вы там чего-то допланировали :)
Я в общем веду к тому, что "проектирование", "следование архитектуре" и т.п. вещи — это все не бесплатно, всегда есть трейдофф и всегда есть конкретная ситуация с конкретными требованиями. В одних ситуациях можно посидеть и попланировать, в других — надо иметь собранные на коленке и регулярно выбрасываемые прототипы. Каждой задаче — свое решение, универсального рецепта нет.
Ну и:
И похрен что все страдают как из-за непродуманной бизнес логики, так и из за говнокода в который изменения просто страшно вносить.
Вы страдаете, конечно, но в итоге вносите. Вам за это деньги и платят. И пофиг заказчику на ваши страдания, ему главное чтобы вы фичи вовремя внедряли.
Neikist
27.06.2018 12:25А вот тут есть еще пара но. Таким образом шла разработка второй версии продукта, когда первой уже было лет 7, и она нормально продавалась. И страдаю не я, страдают пользователи и заказчики из за того что фичи долго внедряются и новые ломают старые из за кучи костылей и отсутствия тестов. Собственно этой второй версии уже почти 4 года и почти ничего не меняется.
Druu
27.06.2018 12:32А вот тут есть еще пара но. Таким образом шла разработка второй версии продукта, когда первой уже было лет 7, и она нормально продавалась.
Но ведь вторая версия не просто так появилась? В ней, видимо, возникла какая-то необходимость. Решили реализовать какой-то функционал, который давал бы конкурентное преимущество, так? Вы можете гарантировать, что если бы вторая версия с соответствующим функционалом появилась с задержкой, то продукт был бы так же успешен?
В общем, суть в том, что часто бывают рассуждения вида: "вот сразу не делали все по науке, не учли роста, а теперь приходится жрать кактус", но они не учитывают, что очень часто именно тот факт, что делали вначале "херакс-херакс и в продакшн", и позволил "вырасти" и жрать теперь кактус.
Neikist
27.06.2018 12:46Я не пойму, вы всерьез считаете что если все время разработчиков тратится на исправление ошибок и ком только растет — это нормально? Что когда из соседних отделов людей выдергивать приходится на латание ошибок? И иногда еще фичи добавляются (если не добавить — вообще вздернут клиенты).
Окей, выпустили MVP, оценили что нужно, самое критичное реализовали, может пора уже и что нибудь поправить? Хотя бы избавиться от методов на тысячи строк, конструкций if… else вложенных в одной процедуре по 7-10 уровней, от функций сигнатура которых больше чем наполовину состоит из флагов которые передаются через 5 уровней вызова чтобы где нибудь влепить очередной костыль в if… else, и подобного?Druu
27.06.2018 13:09Я не пойму, вы всерьез считаете что если все время разработчиков тратится на исправление ошибок и ком только растет — это нормально?
Слушайте, тут не существует такого понятия как "нормально". Вы выбираете из нескольких альтернатив, у каждой есть свои плюсы и свои минусы. Их следует оценивать объективно, а не так, что: "у этой альтернативы есть определенные минусф, по-этому мы выбираем другую, не важно какую". Понимаете?
Что толку от грамотного планирования и затрат на контроль за архитектурой, если в итоге ваш проект просто не доживет до того момента, когда плохая архитектура могла бы оказать какое-либо влияние?
Окей, выпустили MVP, оценили что нужно, самое критичное реализовали, может пора уже и что нибудь поправить?
Может, и пора. Но, очевидно, есть и еще какие-то задачи (они всегда есть, согласитесь). Есть какой-то актор, ответственный за определение приоритета задач. Он не выбрал рефакторинг и исправление архитектуры. Возможно ли такое, что он основывался на каких-то объективных факторах?
Я не говорю, что плохая аритектура, недостаток планирования и некачественный код лучше, чем хорошая архитектура, грамотное планирование и качественный код. Очевидно, не лучше. Я говорю о том, что все имеет свою цену и вполне возможно, что в данный момент — она, ну, слишком велика. Возможно же?
Neikist
27.06.2018 14:44А вообще с таких проектов просто будут разбегаться те кто хочет разрабатывать с учетом хороших практик. В принципе если компания на это решилась — ну, окей.
Druu
27.06.2018 14:47В принципе если компания на это решилась — ну, окей.
Ну так оно и происходит. Кто-то оценивает варианты и приходит к тому, что можно просто зп накинуть (ну или нанимать не таких квалифицированных кадров, сойдут и послабее). Всмысле, оно же не само, всегда есть ответственное лицо, принявшее соответствующее решение (ну если только это не вы с друзьяшками решили стартапик пилить и чот там навскидку прикинули, тогда да, ответственного лица нет).
JobberNet
27.06.2018 13:15+1ведь вторая версия не просто так появилась? В ней, видимо, возникла какая-то необходимость. Решили реализовать какой-то функционал, который давал бы конкурентное преимущество, так?
Видел вторую версию отличавшуюся от первой версии лишь наличием новомодного интерфейса, а все внутренности состоящие из многократно залатанного легаси так и остались.
JobberNet
27.06.2018 11:02Кисло с нуля переписывать запутанное легаси в десятки тысяч строк, где заплатка сидит на заплатке и заплаткой погоняет. :(
Druu
27.06.2018 12:14> Кисло с нуля переписывать запутанное легаси в десятки тысяч строк, где заплатка сидит на заплатке и заплаткой погоняет. :(
Если переписывать с нуля — запутанность и количество заплаток не играет ровным счетом никакой роли :)JobberNet
27.06.2018 12:34Увы, бывает, что играет. У меня были случаи, когда клиенты сами спрашивали по какому алгоритму работает программа, и чтобы им ответить приходилось копаться в заплатках. А произошло это потому что люди причастные к созданию — уже ушли.
Druu
27.06.2018 12:36Это, конечно, печальная ситуация, но мне так кажется, что плохой код и архитектура в данном случае — не главные проблемы (хотя и проблемы, конечно).
gandjustas
27.06.2018 19:34Проблема в том, что процесс проектирования кода, для соответствия принципам SOLID и GRASP не уменьшает количество ошибок.
GeekberryFinn
27.06.2018 19:40Потому что такие принципы часто, увы, бездумно превращают в «культ Карго», вместо того чтобы сначала сесть и продумать архитектуру.
Druu
28.06.2018 06:48Тут интересно отметить следующую штуку — вот в стандартах нередко вводятся понятия вроде: "обязательно к исполнению", "очень рекомендовано к исполнению", "рекомендовано к исполнению" (с четким описанием этих понятий). И, с-но, те или иные вещи маркируются соответствующими понятиями.
По логике-то ко всем принципам надо относиться тем же самым образом — есть какие-то вещи которые необходимо исполнять, есть которые можно нарушать в определенных случаях, есть "просто рекомендации", но нет же! Все всё воспринимают как: "шаг вправо/влево — расстрел, подпрыгивание на месте — попытка улететь".
TigraSan
26.06.2018 18:22+4Меня все чаще смущает поголовный отказ от
public function processSomeDto(SomeDtoClass dto) { if (predicat) { throw new Exception(‘predicat is failed’); } else { return this.dtoProcessor.process(dto); } }
И если этот пример я еще могу понять, так как в реальности это скорее всего было бы так:
public function processSomeDto(SomeDtoClass dto) { if (predicat) { throw new Exception(‘predicat is failed’); } if (anotherPredicat) { throw new Exception(‘another predicat is failed’); } return this.dtoProcessor.process(dto); }
И это хорошо, это точки выхода, которые легко вынести в что-либо вроде
public function processSomeDto(SomeDtoClass dto) { this.validateParams() return this.dtoProcessor.process(dto); }
Но основной посыл всегда — отказаться от else, если работать будет так же без него. А это имхо, зло.
Ибо следующие два варианта работают одинаково, но читаются абсолютно по разному. И активно продвигается первый вариант, с чем в корне не согласен
function abs(int num){ if(num < 0){ return -num } return num } function abs(int num){ if(num < 0){ return -num } else { return num } }
Одно дело точки выхода, другое дело акцент на разных поведениях и при рефакторинге, когда нет этого самого else — намного проще допустить ошибку
deej
28.06.2018 09:18Это две разные ситуации. В случае с Exception — это "отсекающие" условия. В вашем примере уместнее оставить else.
slonopotamus
26.06.2018 21:03Максимум один уровень вложенности на метод.
То есть цикл с break/continue вы написать не можете?
c3037 Автор
26.06.2018 21:40-2Как вы верно отметили
внутри цикла будет нарушением одного из принципов объектной калистеники. Но когда такая необходимость действительно возникает, я предпочитаю не впадать в крайности и не бросаться исключениями, а сознательно нарушить это правило и оставить как есть. Цель данного правила в том, что бы не усложнить код, а избавиться от многоуровневых лесенок. Для себя вы можете взять не цифру 1, а более. Я в практике стараюсь использовать 1 уровень. И каждое его превышение обосновать.if (predicat) { break; }slonopotamus
26.06.2018 21:59+4Печалька с ограничением вложенности и длины методов — падает code locality в исходнике. Вместо обозримого метода, пусть на 25 вместо 15 строк получаем пяток функций, а это лишние прыганья по коду туда-сюда, мучительное выдумывание этим функциям названий. Опять же, при необходимости поменять входные аргументы на глубоком уровне приходится менять все сигнатуры по пути, просовывать новые аргументы через все уровни, в результате дифф разбухает. В общем я готов поспорить с тем что искусственные ограничения на вложенность или длину функций являются безусловным добром.
sic
27.06.2018 00:34+2Кроме того, как с подобными ограничениями можно реализовать хоть какой либо алгоритм? Если не нарушать принцип локальности, то элементарно посчитав количество вложенных for можно сразу сделать предположения о сложности алгоритма, но если размазать их на кучу вложенных методов с одним циклом, то… да что тут говорить, на реальной практике команда программистов в компании где я работал не замечала 3 года, что у них один из алгоритмов работы с данными имеет кубическую сложность, и элементарно приводится к O(nlogn), но как догадаться, если все размазно на методы по 15 LOC?
Кроме того, неизбежно, если мы пишем многопоточный код (а мы ведь пишем?) будет уйма проблем с синхронизацией/блокировкой. Запихивать блокировку в каждый 15 LOC метод жирновато, не правда ли? И дело не в том, что рекурсивные мьютиксы как-то плохо с этим справляются, вовсе нет, но если слишком часто отпускать блокировки, то в большинстве нетривиальных ситуаций мы лишь потеряем огромное время, если у нас больше одного связанного логикой объекта блокировки.
Понятно, что панацеи тут нет, но стратегия использовать любое количество LOC (любое — значит действительно любое) для метода у которого ровно одна ответственность, и никакая его внутренняя часть не решает никакой понятной и самодостаточной задачи для меня намного более предпочтительна, чем шинковать методы по любым правилам длины. Сейчас сложно найти редактор, который не умеет по уровням вложенности сворачивать, кроме того.
Druu
27.06.2018 05:03+2Для решения этой проблемы можно выделить некую обёртку, единственным назначением которой будет создание объекта с помощью фабрики и передача его на обработку куда-либо дальше.
Но зачем?
Следование тем или иным принципам должно снижать количество проблем, а не создавать новые проблемы, которые потом приходится героически преодолевать (аналогично с вложенностью и ограничениями на длину методов — это не решает никаких проблем, но создает новые, в результате чего качество кода существенно падает).
Akon32
27.06.2018 12:11Максимум один уровень вложенности на метод.
Есть такое понятие "цикломатическая сложность". Упрощённо — количество ветвлений и циклов в методе + 1. Во времена изучения мною
этого вашегоООП рекомендовалась цикломатическая сложность не более 4-5 на метод.
Позднее, я сталкивался с написанием алгоритмов с цикломатической сложностью порядка 100 (специфическая обработка полилиний в ГИС). Это было реализовано примерно тридцатью методами с цикломатической сложностью в основном 4-6, иногда до 10.
В статье же предлагается ограничить цикломатичекую сложность значением около двух ("около" — потому что вложенность и цикломатическая сложность не эквивалентны). Для достаточно сложных алгоритмов это предложение звучит бредово.
Более того, с ограничением "1 уровень вложенности" даже линейный поиск не написать.
for(...){if(...){return ...}}— уже два уровня вложенности.Druu
27.06.2018 12:22-1Есть такое понятие "цикломатическая сложность".
Оно работает только для структурной парадигмы. В ООП (из-за виртуальных вызовов) или ФП (из-за лямбд) цикломатическая сложность не определена. Точнее, если попытаться определить ее хоть сколько-нибудь разумным образом, то она будет выходить бесконечной.
mayorovp
27.06.2018 13:26Цикломатическая сложность вычисляется для одной функции, а не для программы целиком (потому что для программы целиком она не определена при наличии простейшей рекурсии).
А в пределах одной функции что виртуальный вызов, что вызов лямбды — это всего лишь еще один оператор.Druu
27.06.2018 14:31Цикломатическая сложность вычисляется для одной функции, а не для программы целиком (потому что для программы целиком она не определена при наличии простейшей рекурсии).
Это не важно. Если в ф-и есть виртуальный вызов или лямбда — цикломатическая сложность не определена.
А в пределах одной функции что виртуальный вызов, что вызов лямбды — это всего лишь еще один оператор.
Правда? Вот вам два куска кода:
function test(x: number, y: number) { if (x > y) { console.log('bigger'); } else { console.log('lesser'); } }
и:
function yobaIf<T>(pred: boolean, then: () => T, els: () => T) { return pred ? then() : els(); } function test(x: number, y: number) { yobaIf(x > y, () => console.log('bigger'), () => console.log('lesser')); }
какова цикломатическая сложность ф-и test в первом случае и какова во втором? если она в обоих случаях одинаковая — то ответьте, считаете ли вы способ расчета цикломатической сложности, при котором она в указанных ф-ях одинакова, "сколько-нибудь разумным", учитывая что после простейшей механической замены ифов на лямбды (продемонстрированной выше) цикломатическая сложность любой ф-и становится равной единице?
mayorovp
27.06.2018 14:50А еще если всю функцию простейше-механически перенести в другую оставив один вызов — то цикломатическая сложность тоже станет равной единице, но это почему-то никого не удивляет…
Druu
27.06.2018 15:01А еще если всю функцию простейше-механически перенести в другую оставив один вызов — то цикломатическая сложность тоже станет равной единице
Так я ничего здесь не переносил. Вся логика осталась в ф-и test, и она вообще говоря не изменилась, я только поменял синтаксис. Есть вообще языки, где if — функция (хаскель, например). По-вашему, в хаскеле любая ф-я имеет нулевую цикломатическую сложность? Какая цикломатическая сложность у программы на языке нетипизированного лямбда-исчисления? комбинаторной логики? на форте? Почему бы тогда просто не определить, что "цикломатическая сложность равна единице для любой ф-и", раз для языков с виртуальными ф-ми и лямбдами она все равно всегда единица? Вы вообще понимаете, что цикломатическая сложность рассчитывается не на программном коде а на графе потока управления, который для вышеприведенных ф-й test одинаковый?
mayorovp
27.06.2018 15:05Что же до вашего примера — то у измененной функции test на языке javascript формальная цикломатическая сложность — 1, общая же 3 (поскольку функций-то три), что даже больше чем у исходной или даже 5 если считать yobaIf.
Если же рассматривать эту функцию как программу на «птичьем языке» построенном над javascript — то ее цикломатическая сложность остается 2, ведь в этом языке yobaIf — условный оператор.
К Хаскелю понятие «цикломатическая сложность» не применимо потому что там нет алгоритмов в традиционном понимании этого слова.Druu
27.06.2018 15:21Что же до вашего примера — то у измененной функции test на языке javascript формальная цикломатическая сложность — 1
Почему 1? как вы посчитали?
общая же 3 (поскольку функций-то три), что даже больше чем у исходной или даже 5 если считать yobaIf
Почему три? Это вы как посчитали?
на самом деле, в обоих случаях — ровно 2, т.к. у вас в графе 5 узлов, 5 ребер и 1 компонента связности
К Хаскелю понятие «цикломатическая сложность» не применимо потому что там нет алгоритмов в традиционном понимании этого слова.
В смысле, нет? Конечно же, есть, точно такие же алгоритмы, как и везде. Вы имеете ввиду, что там нету процедур и ф-и все чистые? Так это как раз вычислению цикломатичесой сложности никак не мешает. Если запретить в хаскеле лямбды и ввести if спецформой, то прекрасно там все будет считаться.
Неприменимо оно к хаселю именно потому, что лямбды там по факту есть. И точно так же оно неприменимо ко всем остальным языкам с лямбдами, потмоу что вы не можете по ф-и построить ее control flow. Именно по-этому при определении цикломатической сложности строго оговаривается, что исследуемая функция — структурная.mayorovp
27.06.2018 15:24Я бы все-таки ослабил это требование до требования императивности.
Druu
27.06.2018 15:40Я бы все-таки ослабил это требование до требования императивности.
Так дело не в императивности, отсутствие императивности расчету цикломатической сложности никак не мешает, мешает наличие лямбд. Из-за лямбд не получается построить граф потока управления локально. В струутурной ф-и вы любой другой ф-й вызов заменяете на узел графа и все. В случае ф-и test вы этого сделать не можете, т.к. внутренне устройство yobaIf влияет на связи между узлами, которые являются составляющими графа потока управления самой test! Не зная реализации yobaIf вы не можете построить граф для test.
Ну вы попробуйте сами логически рассудить — вот вы согласны, что в чистом бестиповом лямбда-исчислении цикломатическая сложность "не считается", так? Но ведь любую ф-ю, которую вы можете написать на чистой бестиповой лямбде вы можете написать точно так же в js! получается каким-то магическим образом одна и та же ф-я, написания одним и тем же образом при помощи одних и тех же примитивов и, в принципе, даже, в принципе, в одном и том же синтаксисе (ну нам же никто не мешает в лямбда-исчислении сделать синтаксис со стрелками вместо lambda-x.t?), то есть просто один и тот же терм (!) с той же самой семантикой (!) не имеет цикломатической сложности в рамках чистой лямбды, но сразу эту сложность преобретает, когда мы говорим: "а, так это написнао на js!"!
Вам не кажется это странным?mayorovp
27.06.2018 15:51Чистые безтиповые лямбды не являются императивными независимо от того на каком языке написаны.
Druu
27.06.2018 15:58Чистые безтиповые лямбды не являются императивными независимо от того на каком языке написаны
То есть цикломатическая сложность для чистых ф-й не считается, вы так предлагаете? Вы сформулируйте четко, чтобы не было непоняток.
Akon32
27.06.2018 15:40В ООП (из-за виртуальных вызовов) или ФП (из-за лямбд) цикломатическая сложность не определена. Точнее, если попытаться определить ее хоть сколько-нибудь разумным образом, то она будет выходить бесконечной.
Если виртуальный метод делает что-то в соответствии с его спецификацией, то не важно, виртуальный он или нет. Виртуальность (или не виртуальность) вызываемого метода не меняет число путей, по которым может идти выполнение вызывающего кода.
Или у вас есть пруфы, что цикломатическая сложность по определению не может использоваться с виртуальными методами?
Для ФП, наверно, эта метрика действительно не определена из-за отсутствия графа потока управления.
Также не вполне ясно, как считать её для всяких там цепочек map — filter — reduce или list comprehensions, которые сегодня есть в ООП-языках.
Но речь шла о процедурном и ООП-коде, а не о хаскеле.
Druu
27.06.2018 15:45-1Виртуальность (или не виртуальность) вызываемого метода не меняет число путей, по которым может идти выполнение вызывающего кода.
Вообще-то зависит. Если у вас вызывается какой-то метод (виртуальный) и есть десяток классов в которых он реализован, то у вас 10 путей исполнения. А если 5 реализаций — то всего 5 путей исполнения.
Или у вас есть пруфы, что цикломатическая сложность по определению не может использоваться с виртуальными методами?
Конечно, она может использоваться, но она не будет показывать что-либо осмысленное. Вы можете все if-ы заменить виртуальными вызовами через диспатч по таблице виртуальных ф-й и станет у вас везде единичная сложность. Какой смысл в такой метрике?
Для ФП, наверно, эта метрика действительно не определена из-за отсутствия графа потока управления.
Дык и виртуальный вызов и лямбда — это одного характера вещи. Лямбда-исчисление эмулируется на ООП (ну, как и наоборот).
Так что у вас если нету лямбд но есть ооп, то вы все ранво можете писть "как на хаскеле" (ну как на лиспе скорее, что не существенно в рамках дискуссии :))mayorovp
27.06.2018 15:52Если у вас вызывается какой-то метод (виртуальный) и есть десяток классов в которых он реализован, то у вас 10 путей исполнения...
… за пределами оцениваемого кода.
Druu
27.06.2018 16:01… за пределами оцениваемого кода.
Но без которых не получится достроить граф. Вы же понимаете, что какая-нибудь лямбда в шарпожавах — это семантически тот же анонимный класс, реализующий интерфейс типа IRunnable? То есть я пишу на ООП себе лямбды, потом на этих лямбдах — пишу себе yobaIf и потом ломаю этим yobaIf вам расчет сложности. Вопрос же здесь в том, до каких пор можно использовать лямбды/ооп, чтобы "все было хорошо"? Ну вот когда мы уже до yobaIf дошли, то так уже, очевидно, нельзя, весь расчет смысл теряет, а где граница?
И тут сразу чтобы определиться — на самом-то деле я могу и не реализовывать лямбды в явном виде, а воспроизвести логику yobaIf неявно.
По всей видимости, граница там, где вы передаете лямбду аргументом. А передача лямбды аргументом — это ведь то же самое, что передача объекта, реализующего некоторый интерфейс. То есть пролегает эта граница практически сразу.
mayorovp
27.06.2018 16:02Да без проблем достраивается граф! Виртуальный вызов — это один оператор. Что он делает внутри — уже не важно.
Druu
27.06.2018 16:06-1Да без проблем достраивается граф! Виртуальный вызов — это один оператор. Что он делает внутри — уже не важно.
Нет, не достраивается. Если у вас есть ф-я А, в которой вы передаете некоторый объект, реализующий интерфейс B, в ф-ю C, то все реализации интерфейса B — узлы графа для А. При этом вы не знаете связей между узлами, не заглядывая в С. Ну, то есть, да, что в самом виртуальном вызове — не важно, важно, когда вы передали объект с возможностью виртуального вызова куда-то там.
Akon32
27.06.2018 16:07+1Если у вас вызывается какой-то метод (виртуальный) и есть десяток классов в которых он реализован, то у вас 10 путей исполнения. А если 5 реализаций — то всего 5 путей исполнения.
Метрика рассчитывается только для написанного метода. Иначе, при использовании вашего подхода, нужно учитывать все пути во вложенных вызовах. Боюсь тогда даже представить цикломатическую сложность функции
void pf(float n){printf("%.3f\n", n);}
или какой-нибудь функции, содержащей recv().
Лямбда-исчисление эмулируется на ООП (ну, как и наоборот).
Естественно. Но я не уверен насчёт применимости метрики цикломатической сложности к коду, содержащему несколько map (т.е. циклов) в строчке. С одной стороны, код простой, с другой — в нём куча условий и циклов.
Druu
27.06.2018 16:11-1Естественно. Но я не уверен насчёт применимости метрики цикломатической сложности к коду, содержащему несколько map (т.е. циклов) в строчке.
Ну то есть вы согласны, что если в коде используется ф-я, в которую вы передаете другую ф-ю, то сложность ломается, т.к. по факту эта ф-я может быть семантически эквивалентна ветвлению или циклу, или чему-то еще более сложному.
Но передача ф-и аргументом в принципе ничем не отличается от передачи объекта, реализующего IRunnable.
То есть — если у вас есть ф-я, которая принимает ф-ю или ф-я, которая принимает объект с виртуальными методами, то все ломается. Но если исключить такие передачи то у вас фактически и останется чистое структурное программирование :)Akon32
27.06.2018 16:54Ну то есть вы согласны, что если в коде используется ф-я, в которую вы передаете другую ф-ю, то сложность ломается, т.к. по факту эта ф-я может быть семантически эквивалентна ветвлению или циклу, или чему-то еще более сложному.
Вообще-то, нет. Я считаю сложность для вызывающей функции. Её код (
call *%rax) никак не меняется от того, сколько имплементаций есть у переданной функции. Из вызывающей функции все вызываемые выглядят одинаковыми чёрными ящиками, независимо от их числа или реализаций. Поэтому вызов на сложность не влияет.
Мне это кажется более логичным, чем ваш вариант. Но это больше вопрос определений.
Akon32
27.06.2018 17:00Upd.: switch(...){...} и (*f)(); могут иметь схожие графы потока управления, но вызов функции имеет одну и ту же семантику для всех её реализаций, все они выполняются одинаково для вызывающего кода. А ветки в switch — это разные варианты, их все нужно тестировать отдельно. Я вижу в этом разницу.
Druu
28.06.2018 06:53Вообще-то, нет. Я считаю сложность для вызывающей функции. Её код (call *%rax) никак не меняется от того, сколько имплементаций есть у переданной функции.
Дык а как вы считаете сложность вызывающей ф-и, если не можете построить ее граф без ф-и вызываемой?
function test(x: number, y: number) { yobaIf(x > y, f, g); }
откуда вы знаете, какие дуги соединяют узлы yobaif, f и g, если не знаете реализации yobaIf?
Из вызывающей функции все вызываемые выглядят одинаковыми чёрными ящиками
Только в том случае, если вызываемая ф-я не принимает объектов и лямбд. Если она принимает — то она уже не черный ящик, т.к. она меняет (потенциально) граф потока управления той ф-и, из которой вызывается. Вот в чем проблема.
Upd.: switch(...){...} и (*f)(); могут иметь схожие графы потока управления, но вызов функции имеет одну и ту же семантику для всех её реализаций, все они выполняются одинаково для вызывающего кода.
ну можно написать так, что (*f)() будет выполняться для вызывающего кода точно так же как switch. В чем тогда разница?
mayorovp
28.06.2018 08:56откуда вы знаете, какие дуги соединяют узлы yobaif, f и g, если не знаете реализации yobaIf?
Внутренних дуг между ними — нет. Это известно.
Druu
28.06.2018 09:17> Внутренних дуг между ними — нет. Это известно.
Откуда? Если у меня yobaIf(pred, f, g) { f(); g(); }, то будет граф yobaIf -> f -> g, то есть как раз внутренняя дуга.mayorovp
28.06.2018 09:28Это внешние дуги
Druu
28.06.2018 10:20что значит «внешние»? не бывает никаких внешних дуг у графа. Есть узлы yobaIf, f, g. Все дуги, которые соединяют эти узлы, принадлежат графу, который содержит эти узлы. У вас после узла yobaIf выполнение переходит на узел f а потом на узел g. С-но дуги графу принадлежат, иначе как управление-то переходит?
Akon32
28.06.2018 10:33Не понимаю, почему вы делаете именно такое различие между виртуальной функцией (учитываете граф вызываемой функции) и обычной (не учитываете графа вызываемой функции). Особенно когда речь идёт о метрике вообще другой функции, вызывающей. И если учитывать, что статическая функция из стандартной dll может иметь десяток реализаций.
ну можно написать так, что (*f)() будет выполняться для вызывающего кода точно так же как switch. В чем тогда разница?
Примеры:
1:obj->f();Druu
28.06.2018 11:47Не понимаю, почему вы делаете именно такое различие между виртуальной функцией (учитываете граф вызываемой функции) и обычной (не учитываете графа вызываемой функции).
Тут вышло недопонимание, речь не о вызове obj->f() речь о вызове p(obj), внутри которой уже, в свою очередь как-то вызывается (или не вызывается, мы не знаем) obj->f(). Чтобы построить граф ф-и, в которой совершен вызов p(obj) нам надо знать, как, с-но, внутри р происходят вызовы методов obj.
Akon32
28.06.2018 12:03Мне кажется, вы рассматриваете граф путей выполнения с точки зрения процессора или анализа производительности (но я всё равно не понимаю, почему вы делаете исключение именно для вирт.функций).
Однако метрика "цикломатическая сложность" применяется для оценки сложности кода с точки зрения написания и понимания, а не выполнения процессором. Поэтому вызов функции не добавляет сложности вообще, независимо от его виртуальности.Druu
28.06.2018 12:19-1Однако метрика "цикломатическая сложность" применяется для оценки сложности кода с точки зрения написания и понимания, а не выполнения процессором. Поэтому вызов функции не добавляет сложности вообще, независимо от его виртуальности.
Именно потому, что цикломатическая сложность применяется для оценки сложности мы не можем не учитывать факт наличия виртуальных вызовов и лямбд внутри ф-и.
Вот я взял ф-ю с большой сложностью, заменил там все ифы и циклы на виртуальные вызовы или лямбды. Код при этом изменился только синтаксически и совсем немного. Цикломатическая сложность стала 1. Что вам это число показывает в данном случае? Ф-я же проще не стала, она, может, сложнее стала, но точно не проще.
То есть, вы конечно можете придумать какой-то способ расчета цикломатической сложности. И считать его для чего угодно. Но вы не можете придумать никакого способа сделать этот расчет так, чтобы он случае виртуальных/вызовов лямбд давал какую-то адекватную информацию о реальной сложности ф-й.
Если ф-и структурные, вы можете сказать: "ага, вот тут цм 5, а тут цм — 15. первая функция норм, а вторая — сложная, надо подумать, может ее переписать?". В случае анализа в ООП/ФП у вас вполне может оказаться, что сложность ф-и с цм 5 выше чем сложность ф-и с цм 15, а когда вы перепишите цм 15 в цм1 то в итоге может оказаться что вы сложность не уменьшили а просто замели под ковер, спрятав за лямбдами/виртуальными вызовами, то есть сделали еще хуже чем было. Я вот об этом говорю.
Оценка по цм работает в структурном программировании, потому что там граф потока управления нагляден. В ООП/ФП вы можете куски графа управления тасовать и перекидывать туда-сюда.
То есть когда кто-то в ФП/ООП считает цикломатическую сложность и что-то рефакторит, чтобы ее уменьшить — это просто карго-культ, человек не понимает, что он делает.Akon32
28.06.2018 12:39+1Если не ошибаюсь, есть рефакторинг "выделение виртуального метода", то есть вместо switch делается виртуальный вызов. И считается, что это уменьшает сложность кода (особенно когда таких switch было много по всему коду).
Уточните, пожалуйста, про невозможность подсчёта цикломатической сложности при наличии виртуальных вызовов — это вы сами придумали или это где-то описано в литературе? Было бы интересно почитать. Ваша аргументация ясна, но не могу с ней полностью согласиться.
Druu
28.06.2018 13:38-1И считается, что это уменьшает сложность кода (особенно когда таких switch было много по всему коду).
Но на самом-то деле не уменьшает, вот в чем штука :)
Уточните, пожалуйста, про невозможность подсчёта цикломатической сложности при наличии виртуальных вызовов — это вы сами придумали или это где-то описано в литературе?
Это прямое следствие из определения цикломатической сложности. Явно оно, конечно, нигде не написано, в силу своей очевидности, но известно любому знакомому с основами cs человеку, который когда-то цикломатическую сложность пытался смчитать :)
Можете сами взять определение, попробовать посчитать и наглядно убедиться, что ничего не получается :)Neikist
28.06.2018 13:45+1Но на самом-то деле не уменьшает, вот в чем штука :)
Но ведь на самом деле уменьшает сложность понимания текущего метода. В текущем методе больше не нужно отслеживать разные ветки switch, мы их в другой метод скрываем.Druu
28.06.2018 14:23Но ведь на самом деле уменьшает сложность понимания текущего метода.
Так ведь нет.
В текущем методе больше не нужно отслеживать разные ветки switch, мы их в другой метод скрываем.
С чего бы? У вас остается тот же самый свитч, просто вы ветки исполнения разбрасываете по всему коду вместо того, чтобы держать их в одном месте.
Это упрощает понимание в том случае, если ветки одинаковы по семантике, то есть все ветки свитча делают одно и то же действие, параметризованное параметром свитча, но без возможности записать это в виде ф-и от параметра в силу ограниченной выразительности конкретного ЯП.
Если же у вас какой-то алгоритм, который в разных ветках свитча предпринимает семантически разные действия, то вы только все усложните, т.к. вам чтобы понять алгоритм придется по куску все ветки свитча собрать.Neikist
28.06.2018 14:34С чего бы? У вас остается тот же самый свитч, просто вы ветки исполнения разбрасываете по всему коду вместо того, чтобы держать их в одном месте.
Эм… Почему? Из текущей процедуры он исчезает. И в текущей процедуре, не включая вызываемые процедуры, количество путей выполнения снижается.
Akon32
28.06.2018 14:22Можете сами взять определение, попробовать посчитать и наглядно убедиться, что ничего не получается :)
Много раз считал.
На английской вики есть ссылки на исследования, в которых метрика цикломатической сложности успешно применяется в ООП-проектах.
Не вижу больше смысла спорить с тем, что вам "очевидно".
Druu
28.06.2018 14:30Много раз считал.
Значит, неправильно считали. Вот вам ф-я:
function someFunction(arg: ISomeInterface) { justFunctiion(); arg.someMerhod(); }
Если вы считали цикломатическую сложность, то должны знать, что дуга в flow графе обозначает переход на инструкцию. Начинаете вы с начала ф-и, start, в случае justFunction все понятно — вы переходите на start JustFunction, а на какую инструкцию вы переходите при вызове someMethod()?
в которых метрика цикломатической сложности успешно применяется в ООП-проектах.
Конечно, применяется. Необразованными людьми, не понимающими, что такое цикломатическая сложность. Обычный каргокульт.
Neikist
28.06.2018 14:36А какая разница? Для понимания текущей функции нам это неважно. Мы знаем эта функция делает justFunctiion, а также делегирует someMerhod на arg, все.
Druu
28.06.2018 14:39-1А какая разница? Для понимания текущей функции нам это неважно. Мы знаем эта функция делает justFunctiion, а также делегирует someMerhod на arg, все.
Мы сейчас не про понимание ф-и, а про вычисление цикломатической сложности. Если нет конца дуги — нет флоу графа, нет флоу графа — цикломатическая сложность не рассчитывается. Ф-я, конечно, может при этом быть простой, кто спорит-то.
Neikist
28.06.2018 15:14Мы говорим сейчас про цикломатическую сложность конкретного метода, с чего эта ветка и началась, а именно с того что ее нужно на метод ограничивать. А для ее расчета нам важно только сколько ветвлений собственно в этом методе, исключая вызывающие и вызываемые методы.
Druu
28.06.2018 15:21-1А для ее расчета нам важно только сколько ветвлений собственно в этом методе, исключая вызывающие и вызываемые методы.
Для ее расчета нам важно, сколько путей в соответствующем cfg. А cfg у этой ф-и не существует. Нельзя посчитать пути в графе, которого не существует.
Akon32
28.06.2018 14:45+1Нарисуйте, пожалуйста, блок-схему этой функции.
Druu
28.06.2018 15:04-1Вы хотели меня подловить? Не выйдет, я прекрасно знаю, что блок-схемы нельзя написать для кода, их можно написать для алгоритма или процесса. По-этому наличие блок-схемы совсем не ведет к наличию графа потока управления.
К слову, при рефакторингах типа выделения ф-и и т.д. алгоритм (и, с-но, блокхсема) не меняется.
michael_vostrikov
28.06.2018 10:27+1Мне кажется, все проще.
Например, если исходный код не содержит никаких точек ветвления или циклов, то сложность равна единице, поскольку есть только единственный маршрут через код.
Сложность простой функции 1. Лямбда это функция. Если в функции определяется другая функция, ее сложность увеличивается на 1.
Druu
28.06.2018 11:49-1Сложность простой функции 1. Лямбда это функция. Если в функции определяется другая функция, ее сложность увеличивается на 1.
Ну прекрасно, я объявил ф-и где-то в другом месте и только их использую, то есть:
yobaIf(pred, f, g), где f и g — определеные где-то там ф-и. Или даже: yobaIf(pred, f(x), g(x)), где х — обычная переменная (не ф-я), а f и g возвращают ф-и. Какая в данном случае сложность?michael_vostrikov
28.06.2018 13:36В обоих случаях либо 1 либо 3. С одной стороны, путь выполнения один — вызов yobaIf с аргументами. С другой, аргументы сами являются ссылками на выполняемый код, то есть являются возможными путями выполнения. Думаю, логично будет считать, что сложность 3, так как пути выполнения обозначаются здесь.
Druu
28.06.2018 13:41Думаю, логично будет считать, что сложность 3, так как пути выполнения обозначаются здесь.
А почему именно 3? откуда вы знаете что там столько путей выполнения? Может, их 1? или 23? Откуда вообще взялось число три, как вы его получили?
michael_vostrikov
28.06.2018 13:53Один тело самой функции, один первый callback, один второй callback. Число путей выполнения это те, которые задаются здесь. То, что задается снаружи функции, при оценке сложности того что внутри нас не интересует.
Druu
28.06.2018 14:35-1Один тело самой функции, один первый callback, один второй callback.
Так какая разница сколько колбеков? Это же не пути выполнения, это узлы в графе, и внутри вашей ф-и никаких путей между этими узлами не задано. 2 в данном случае — это просто случайное число. Можно так же было бы сказать, что их 100 или 42, ничем не хуже числа. А чтобы узнать, сколько между этими узлами путей — вам уже нужно заглянуть в реализацию вызываемой ф-и.
michael_vostrikov
28.06.2018 15:11Это возможные пути выполнения. Как и ветки в if. Вы же не знаете в момент анализа, какая из веток выполнится.
Внутри нашей функции они связываются оператором вызова другой функции. 2 это число кусков кода, которые могут выполняться. Очевидно, 100 или 42 числа хуже, так как они не показывают число кусков кода.
Внутри анализируемой функции у них один путь — в вызываемую функцию.Druu
28.06.2018 15:17Это возможные пути выполнения.
Еще раз, это не пути выполнения — а узлы. Точки, между которыми можно пути проложить. Или не проложить. Вы понимаете разницу между путем в графе и узлом в графе?
Вы же не знаете в момент анализа, какая из веток выполнится.
Так это и не ветки. Может, никакая вообще не выполнится. Может, выполнятся обе. В том или ином порядке. Может — каждая по нескольку раз.
Очевидно, 100 или 42 числа хуже, так как они не показывают число кусков кода.
А какое отношение число кусков кода имеет к количеству путей через эти куски кода? То есть, отношение определенно есть, но какое? Вы сможете сформулировать?
Внутри анализируемой функции у них один путь — в вызываемую функцию.
Если путь один, то почему вы считаете 2? Что-то я утратил нить повествования. Вы можете четко и ясно определить ваш способ расчета? Вы пути считаете или не пути? Если пути, то какие и в чем?
michael_vostrikov
28.06.2018 18:13Вы понимаете разницу между путем в графе и узлом в графе?
Я понимаю разницу между понятным кодом и не очень. Нужно брать метрику, которая это отражает, а не гнаться за формальными определениями. Но пока с определением цикломатической сложности проблем нет.
"Цикломатическая сложность части программного кода — количество линейно независимых маршрутов через программный код."
Функция это линейно независимый маршрут? Да. Ссылка на нее находится в программном коде функции? Да. Значит каждую можно считать за 1.
И самое главное что проблема с вынесением if в функцию исчезает. Раньше были куски кода в фигурных скобках, которые считались за 1, и теперь они есть.
Может, никакая вообще не выполнится. Может, выполнятся обе.
if (inputA == inputB)
if (inputC == inputD)
Ровно то же самое. Не будем их считать?
А какое отношение число кусков кода имеет к количеству путей через эти куски кода?
Они сами по себе линейно независимые куски, которые присутствуют в коде функции. Их я и считаю.
McAaron
27.06.2018 14:52Это какой язык? Код похож на с++, но это не c++, поскольку в с++ нет никаких «методов» (В ISO/IEC 14882 нет такого термина).
dim2r
28.06.2018 12:32-1Я когда эту литературу читаю, то все время вхожу в когнитивный диссонанс изза неточных переводов. Например Inversion — в английском имеет больше смыслов, чем в русском.
ссылка на словарь. Больше по смыслу подходят «перестановка; изменение порядка;»mayorovp
29.06.2018 08:35Это вы про Dependency inversion principle?
Почему вы считаете что «перестановка зависимостей» является более точным переводом чем «инверсия зависимостей»?
cynovg
При том, что SOLID сам по себе является аббревиатурой, состоящей из аббревиатур и включающий в себя Demetra's law — все это выглядит странно. Осталось только каким-то образом сократить GOD'S code и включит его в SOLID, так сказать для рекурсии.
c3037 Автор
Рад, что вы оценили игру слов =)
igor_suhorukov
По хорошему, вместо игры слов лучше использовать в сборке проекта continuous code quality подход с применением статического анализа кода и проверок следования стилю кодирования. Тогда упрощается и процедура ревью кода — код который нарушает правила просто не собирается в бранче на CI сервере. Есть ещё фреймворк, которые проверяют базовые архитектурные соглашения и точно так же "рушат" сборку при нарушениях.
c3037 Автор
Я согласен с тем, что continuous code quality классная вещь, вот только мне как разработчику для ускорения своей работы полезно знать правила по которым проходит оценка качества кода.
igor_suhorukov
Безусловно, понимать нужно и, например, Sonar показывает что нарушено, почему это плохо и очень часто как нужно было делать, чтобы реализация была правильной с точки зрения этого правила. А плагин к вашей IDE позволит получать предупреждения в процессе написания кода.
dopusteam
Разве SOLID включает в себя Demetra's law?
cynovg
Вы правы, а я — нет
totally_nameless
То есть архетиктура акронима не удовлетворяет требованиям, которые он содержит :)