
[Советуем почитать] Предыдущие 15 частей цикла
Часть 1: Обзор движка, механизмов времени выполнения, стека вызовов
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
Часть 2: О внутреннем устройстве V8 и оптимизации кода
Часть 3: Управление памятью, четыре вида утечек памяти и борьба с ними
Часть 4: Цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
Часть 5: WebSocket и HTTP/2+SSE. Что выбрать?
Часть 6: Особенности и сфера применения WebAssembly
Часть 7: Веб-воркеры и пять сценариев их использования
Часть 8: Сервис-воркеры
Часть 9: Веб push-уведомления
Часть 10: Отслеживание изменений в DOM с помощью MutationObserver
Часть 11: Движки рендеринга веб-страниц и советы по оптимизации их производительности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 12: Сетевая подсистема браузеров, оптимизация её производительности и безопасности
Часть 13: Анимация средствами CSS и JavaScript
Часть 14: Как работает JS: абстрактные синтаксические деревья, парсинг и его оптимизация
Часть 15: Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
При проектировании веб-приложения чрезвычайно важно выбрать подходящие средства для локального хранения данных. Речь идёт о механизме, который позволит надёжно хранить информацию, будет способствовать снижению объёма данных, передаваемых между серверной и клиентской частями приложения, и при этом не ухудшит скорость реакции приложения на воздействия пользователя. Хорошо продуманная стратегия локального кэширования данных является центральным звеном в разработке мобильных веб-приложений, которые могут работать без подключения к интернету. Современные пользователи всё чаще и чаще относятся к подобным возможностям как к чему-то привычному и ожидаемому.

Сегодня, в переводе 16 части серии материалов, посвящённых всему, что связано с JavaScript, мы поговорим о механизмах хранения данных на стороне клиента, которые могут использоваться в веб-разработке, и о выборе системы хранения данных для конкретного проекта.
Модель данных
Модель данных определяет внутреннюю организацию хранимых данных. Она воздействует на все аспекты устройства веб-приложения, в ней заложены решения, часто компромиссные, от которых зависит эффективность приложения и возможность системы хранения решать поставленные перед ней задачи. Не существует некоего «самого лучшего» подхода к проектированию моделей данных, нет универсальных решений, подходящих для всех приложений. Выбор модели данных основан на особенностях и потребностях конкретного приложения. Рассмотрим несколько основных моделей хранения данных, из которых можно выбрать что-то подходящее для конкретного проекта.
- Модель хранения структурированных данных. При использовании этой модели данные хранятся в таблицах с заранее заданными полями. Такой подход характерен для систем управления базами данных, основанных на SQL. Такие системы хорошо приспособлены для работы с ними с помощью запросов. Известным примером структурированного браузерного хранилища данных является IndexedDB (хотя это — NoSQL СУБД).
- Модель хранения данных типа ключ/значение. Хранилища для данных, организованных в виде пар ключ/значение, и связанные с ними NoSQL СУБД, дают разработчику возможность хранить неструктурированные данные и извлекать их из хранилища по их уникальным ключам. Такие хранилища похожи на хэш-таблицы в том смысле, что они позволяют организовать доступ к индексированным данным непрозрачных типов. Удачным примером хранилища значений типа ключ/значение является API Cache в браузере и серверная СУБД Apache Cassandra.
- Модель хранения данных в виде последовательностей байтов. При использовании этой простой модели данные хранятся в виде последовательностей байтов переменной длины. Задача внутренней организации этих данных целиком решается на уровне приложения. Эта модель используется в файловых системах и в других иерархически организованных хранилищах данных наподобие облачных систем хранения данных.
Методики постоянного хранения данных, доступных браузеру
Методы хранения данных, используемые в веб-приложениях, можно проанализировать с точки зрения времени постоянного хранения таких данных.
- Хранение данных в рамках сессии. Данные этой категории хранятся лишь до тех пор, пока существует конкретная веб-сессия или активна вкладка браузера. В качестве примера механизма хранения данных сессий можно привести API SessionStorage.
- Хранение данных на устройстве без привязки к времени жизни сессии. Эти данные хранятся на конкретном устройстве и в промежутках между сессиями, например, при закрытии вкладки браузера со страницей веб-приложения, не удаляются. В качестве примера механизма хранения данных веб-приложений на устройствах можно привести API Cache.
- Постоянное хранение данных с использованием глобального хранилища. Этот подход предусматривает хранение данных, которые не теряются между сессиями и не привязаны к конкретному устройству. Такие данные могут совместно использоваться различными устройствами пользователями. В результате, это — самый надёжный и долгосрочный способ хранения данных. Такие данные нельзя сохранить на самом устройстве, что означает, что для организации такой схемы хранения данных нужно использовать какое-нибудь серверное хранилище. Мы не будем в это углубляться, так как наша основная задача заключается в рассмотрении способов хранения данных веб-приложений на устройствах.
Оценка систем хранения данных на стороне клиента
В наши дни существует немало браузерных API, которые позволяют организовать хранение данных. Мы рассмотрим некоторые из них и сравним их для того, чтобы упростить вам выбор подходящего API.
Для начала, однако, остановимся на нескольких общих вопросах, которые стоит принять к сведению перед выбором конкретной технологии для хранения данных. Конечно, в первую очередь нужно понять то, как ваше приложение будет использоваться, как будет организована его поддержка, как планируется его развивать. При этом, если даже у вас есть чёткие ответы на эти вопросы, вы, в итоге, можете выйти на несколько вариантов систем хранения данных, из которых нужно будет выбрать наиболее подходящий. Вот на что стоит обратить внимание, выбирая систему хранения данных:
- Поддержка браузерами. Тут следует учесть тот факт, что лучше всего отдавать предпочтение стандартизированным, развитым API. Они, во-первых, отличаются достаточно длительным сроком существования, а во-вторых — их поддерживает много браузеров. Подобные API, кроме того, обычно имеют хорошую документацию и активное сообщество разработчиков.
- Поддержка транзакций. Иногда важно, чтобы при работе с хранилищем наборы связанных операций обладали бы свойством атомарности, то есть, чтобы выполнение набора операций либо завершалось успешно, при успешном выполнении всех операций, либо, при отказе хотя бы одной из них, завершалось бы с ошибкой. Базы данных традиционно поддерживают эту возможность, задействуя модель транзакций, при использовании которой связанные обновления данных могут быть сгруппированы в произвольные блоки.
- Синхронная или асинхронная работа. Некоторые API хранения данных являются синхронными, в том смысле, что операции сохранения или загрузки данных из таких API блокируют активный поток до завершения соответствующего запроса. Использование синхронных API может привести к блокировке главного потока, что может выразиться в «тормозах» пользовательского интерфейса. Поэтому, если это возможно, старайтесь использовать асинхронные API.
Сравнение систем хранения данных
В этом разделе мы рассмотрим некоторые из существующих систем хранения данных, доступных веб-разработчикам, и сравним их по описанным выше показателям.
| API |
Модель данных |
Методика хранения |
Поддержка браузерами |
Поддержка транзакций |
Синхронное или асинхронное |
|---|---|---|---|---|---|
| FileSystem |
Последовательность байтов |
Устройство |
52% |
Нет |
Асинхронное |
| LocalStorage |
Ключ/значение |
Устройство |
93% |
Нет |
Синхронное |
| SessionStorage |
Ключ/значение |
Сессия |
93% |
Нет |
Синхронное |
| Cookie |
Структурированные данные |
Устройство |
100% |
Нет |
Синхронное |
| Cache |
Ключ/значение |
Устройство |
60% |
Нет |
Асинхронное |
| IndexedDB |
Гибридная модель |
Устройство |
83% |
Да |
Асинхронное |
Теперь поговорим подробнее об этих способах хранения данных.
API FileSystem

Благодаря использованию API FileSystem веб-приложения могут работать с выделенной областью локальной файловой системы пользователя. Приложение может просматривать содержимое хранилища, создавать файлы, выполнять операции чтения и записи.
Это API состоит из следующих основных частей:
- Механизмы для управления файлами и для чтения файлов:
File/Blob,FileList,FileReader
- Механизмы для создания файлов и записи в них данных:
Blob,FileWriter
- Механизмы для работы с директориями и с файловой системой:
DirectoryReader,FileEntry/DirectoryEntry,LocalFileSystem
API
FileSystem не является стандартным, поэтому его не следует использовать в продакшне, так как оно будет работать не у всех пользователей. Различные реализации этого API могут сильно различаться, кроме того, весьма вероятно то, что в будущем оно может измениться.Интерфейс
filesystem этого API используются для представления файловой системы. Доступ к соответствующим объектам можно получить через свойство filesystem. Некоторые браузеры предлагают дополнительные API для создания файловых систем и управления ими.Этот интерфейс не даёт веб-странице доступ к файловой системе пользователя. Вместо этого он позволяет работать с чем-то вроде виртуального диска, который находится в «песочнице», создаваемой браузером. Если вашему приложению нужен доступ к файловой системе пользователя, вам понадобится использовать другие механизмы.
Веб-приложение может запросить доступ к виртуальной файловой системе, выполнив вызов
window.requestFileSystem():// Примечание: Здесь используются префиксы Google Chrome 12:
window.requestFileSystem = window.requestFileSystem || window.webkitRequestFileSystem;
window.requestFileSystem(type, size, successCallback, opt_errorCallback)Если вы вызываете
requestFileSystem() в первый раз, то для вашего приложения будет создано новое хранилище. Важно помнить, что это — изолированное хранилище, то есть, одно веб-приложение не может работать с хранилищем, созданным другим приложением.После того, как вы получите доступ к файловой системе, вы сможете выполнять большинство стандартных операций с файлами и директориями.
API
FileSystem серьёзно отличается от других подобных систем, используемых веб-приложениями, так как оно нацелено на решение задач хранения данных на клиенте, которые не очень хорошо решаются средствами баз данных. В целом, это — приложения, которые работают с большими фрагментами бинарных данных, либо обмениваются данными с внешними по отношению к браузеру приложениями.Среди вариантов использования API
FileSystem можно отметить следующие:- Системы выгрузки данных. Когда пользователь выбирает файл или папку, которые нужно выгрузить на какой-нибудь сервер, эти данные копируются в локальное изолированное хранилище, после чего, по частям, отправляются на сервер.
- Приложения, оперирующие большими объёмами мультимедийных данных — игры, музыкальные проигрыватели.
- Приложения для редактирования звука и изображений, работающие без подключения к интернету или использующие локальный кэш большого объёма для ускорения работы. Данные, с которыми работают такие приложения, представляют собой последовательности байтов, которые могут иметь довольно большой объём. Хранилище для таких данных должно поддерживать возможность их записи и чтения.
- Оффлайновые видеопроигрыватели. Таким программам надо загружать большие файлы, которые можно просматривать без подключения к интернету. Это может понадобиться и при потоковой передаче данных, и для организации удобной системы перемещения по файлу.
- Оффлайновые почтовые клиенты. Такие программы могут загружать файлы, вложенные в электронные письма, и сохранять их локально.
Вот как обстоят дела с поддержкой API
FileSystem браузерами.
Поддержка API FileSystem браузерами
API LocalStorage

API LocalStorage, или локальное хранилище, позволяет работать с объектом Storage объекта Document с учётом принципа одинакового источника. Данные не теряются между сессиями. API
LocalStorage похоже на API SessionStorage, сессионное хранилище, разница заключается в том, что данные в сессионном хранилище удаляются после того, как сессия страницы завершится, а данные в локальном хранилище хранятся постоянно.Обратите внимание на то, что данные, размещённые в локальном или в сессионном хранилище привязаны к источнику страницы, который определяется комбинацией протокола, хоста и порта.
Вот сведения о поддержке API
LocalStorage различными браузерами.
Поддержка API LocalStorage браузерами
API SessionStorage
API SessionStorage позволяет работать с объектом Storage сессии. API
SessionStorage похоже на API LocalStorage, о котором мы говорили выше. Разница между ними, как уже было сказано, заключается во времени хранения данных, а именно, в случае с SessionStorage данные хранятся столько, сколько длится сессия. Длится она до тех пор, пока открыт браузер, при этом она сохраняется после перезагрузки страницы. Открытие страницы в новой вкладке или окне приведёт к инициированию новой сессии, это отличается от поведения сессионных куки-файлов. При этом, работая и с SessionStorage, и с LocalStorage, надо помнить о том, что данные в таких хранилищах привязаны к источнику страницы. Вот сведения о поддержке API
SessionStorage различными браузерами:Поддержка API SessionStorage браузерами
API Cookie

Cookie (куки, веб-куки, браузерные куки) — это небольшие фрагменты информации, которые сервер отправляет браузеру. Браузер может их сохранять и отправлять серверу, используя их при формировании запросов к нему. Обычно они используются для идентификации конкретного экземпляра браузера, от которого поступают запросы. Например — для того, чтобы пользователь, после входа в систему, оставался бы в ней. Куки — это нечто вроде системы хранения информации о состоянии сеанса связи для протокола HTTP, который рассматривает каждый запрос, даже приходящий из одного и того же браузера, как совершенно независимый от других.
Куки используются для решения трёх основных задач:
- Управление сессией. На использовании куки основаны такие механизмы, как системы входа в веб-приложения, корзины покупателей в интернет-магазинах, хранение очков, набранных в браузерных играх. Речь идёт о хранении всего того, что нужно знать серверу во время работы с ним пользователя.
- Персонализация. Куки применяются для хранения данных о предпочтениях пользователя, о выбираемых им темах оформления сайта, и о прочих подобных вещах.
- Наблюдение за пользователем. С помощью куки выполняется запись и анализ поведения пользователя.
В своё время куки применялись как хранилище данных общего назначения. Хотя это и вполне нормальный способ использования куки, особенно, когда они были единственным способом хранения данных на клиенте, в наше время применять их в таком качестве не рекомендуется, отдав предпочтение более современным API. Куки отправляются с каждым запросом, поэтому они могут ухудшить производительность (особенно — на мобильных устройствах).
Существует два вида куки:
- Сессионные куки. Они удаляются после завершения сессии. Веб-браузеры могут использовать технику восстановления сессии, благодаря которой большинство сессионных куки хранятся постоянно, в результате сессии сохраняются даже после закрытия и повторного запуска браузера и открытия соответствующей страницы.
- Постоянные куки. Постоянные куки не теряют актуальности после завершения сессии. Они имеют определённый срок хранения, который определяется либо некоей датой (атрибут
Expires), либо неким периодом времени (атрибутMax-Age).
Обратите внимание на то, что конфиденциальную или другую важную информацию не следует хранить в куки-файлах или передавать в HTTP-куки, так как весь механизм работы с куки, по своей сути, небезопасен.
Если говорить о поддержке куки, то их, как вы, вероятно, уже поняли, поддерживают все браузеры.
API Cache

Интерфейс Cache предоставляет механизм хранения данных для кэшируемых пар объектов Request / Response. Этот интерфейс определён в тех же спецификациях, что и сервис-воркеры, но доступен он не только воркерам. Интерфейс
Cache доступен и в области видимости объекта window, его необязательно использовать только с сервис-воркерами.Некий источник может иметь несколько именованных объектов
Cache. Разработчик несёт ответственность за реализацию того, как его скрипт (например — в сервис-воркере) поддерживает кэш в актуальном состоянии. Элементы, сохранённые в кэше, не обновляются до тех пор, пока не будет сделан явный запрос на их обновление, срок их хранения не истекает, их можно лишь удалить из кэша. Для того чтобы открыть именованный объект кэша, можно воспользоваться командой CacheStorage.open(), после чего можно, обращаясь к нему, вызывать команды управления кэшем.Кроме того, разработчик ответственен за периодическую очистку кэша. У каждого браузера имеется жёстко заданное ограничение на размер кэша, который выделяется конкретному источнику. Узнать примерное значение квоты кэширования можно, воспользовавшись API StorageEstimate.
Браузер делает всё, что в его силах, для того, чтобы поддерживать определённый объём доступного пространства кэша, но он может удалить кэш для некоего источника. Обычно браузер либо удаляет весь кэш, либо совершенно его не касается. Пользуясь кэшами, не забывайте о том, чтобы различать их в соответствии с версиями ваших скриптов, например, включая версию скрипта в имя кэша. Делается это для того, чтобы обеспечить безопасную работу различных версий скриптов с кэшем. Подробности об этом можно посмотреть здесь.
Интерфейс CacheStorage представляет хранилище для объектов Cache. Вот задачи, за решение которых отвечает этот интерфейс:
- Предоставление списка всех именованных кэшей, с которыми может работать сервис-воркер, или другой тип воркера. Работать с кэшем можно и через объект window.
- Поддерживает установление соответствия между строковыми именами и соответствующими объектами типа
Cache.
Для того чтобы получить экземпляр объекта
Cache, воспользуйтесь командой CacheStorage.open().Для того чтобы узнать, является ли некий объект Request ключом какого-либо объекта
Cache, которым управляет CacheStorage, воспользуйтесь методом CacheStorage.match().Обратиться к
CacheStorage можно через глобальное свойство caches.API IndexedDB

API IndexedDB — это СУБД, которая позволяет хранить данные средствами браузера. Так как это позволяет создавать веб-приложения, обладающие возможностями работы со сложными наборами данных даже без подключения к интернету, такие приложения могут одинаково хорошо себя чувствовать и при наличии соединения с сервером, и без него. IndexedDB находит применение в приложениях, которым нужно хранить большие объёмы данных (например, такое приложение может быть чем-то вроде каталога фильмов некоей службы, выдающей их напрокат), и которым необязательно поддерживать постоянное соединение с сетью для нормальной работы (например — это почтовые клиенты, менеджеры задач, записные книжки, и так далее).
Здесь мы уделим IndexedDB немного больше внимания, чем остальным технологиям хранения данных на клиенте, так как, с одной стороны, другие API известны более широко, а с другой — так как СУБД IndexedDB становится всё более популярной из-за постоянного роста сложности веб-приложений.
?Внутренние механизмы IndexedDB
API
IndexedDB позволяет сохранять в базу и читать из неё данные объектов с использованием «ключа». Все изменения, вносимые в базу данных, происходят в транзакциях. Как и большинство подобных решений, IndexedDB следует политике одного источника. В результате приложение может получить доступ только к данным, относящимся к собственному домену, но не к данным из других доменов.IndexedDB — это асинхронное API, которое можно использовать в большинстве контекстов, в том числе — в веб-воркерах. Раньше существовала и синхронная версия этого API, предназначенная для веб-воркеров, но её убрали из спецификации из-за того, что она была не особенно интересна веб-разработчикам.У
IndexedDB был конкурент в лице базы данных WebSQL, но работа над этим стандартом была прекращена W3C много лет назад. В то время, как и IndexedDB и WebSQL являются решениями для хранения данных на клиенте, их функционал различается. WebSQL — это реляционная СУБД, а IndexedDB — это система, основанная на индексированных таблицах.Не стоит приступать к работе с IndexedDB, основываясь на идеях, вынесенных из опыта работы с другими СУБД. Вместо этого полезно будет внимательно ознакомиться с документацией по этой базе данных и использовать при работе с ней те методы, на которые она рассчитана. Вот краткий обзор основных концепций IndexedDB:
- Базы данных IndexedDB хранят данные в формате ключ/значение. Значения могут быть сложно структурированными объектами, а ключи могут быть свойствами таких объектов. Индексы можно создавать на основе любого свойства объекта, что способно ускорить поиск данных и упростить их сортировку. Ключи, кроме того, являются двоичными объектами.
- СУБД IndexedDB построена на базе транзакционной модели. Все операции, выполняемые с базой данных, всегда происходят в контексте транзакции. В результате, например, нельзя выполнять команды или открывать курсоры за пределами транзакций. Кроме того, транзакции подтверждаются автоматически, вручную их подтверждать нельзя.
- API IndexedDB, по большей части, является асинхронным. Это API не предоставляет запрошенные данные, просто возвращая их в ответ на какую-то команду. Вместо этого при запросе данных нужно передать соответствующему методу функцию обратного вызова. Синхронный подход не используется ни для сохранения данных в базу, ни для их загрузки из неё. Вместо этого приложение выполняет запрос к базе данных, описывающий требуемую операцию. После завершения операции возникает событие, оповещающее приложение о том, что операцию либо удалось выполнить, либо нет. Этот подход не особенно отличается от работы API XMLHttpRequest, или многих других механизмов JavaScript.
- В IndexedDB используется множество запросов. Запросы — это объекты, которые принимают события об успешном или неуспешном завершении операции. У них есть свойства
onsuccessиonerror, которым можно назначать прослушиватели соответствующих событий, а так же — свойстваreadyState,result,errorCode, анализируя которые можно узнать о состоянии запроса.
- IndexedDB — это объектно-ориентированная база данных. Это не реляционная СУБД, таблицы которой представляют собой коллекции строк и столбцов. Эта фундаментальная особенность влияет на то, как проектируют и создают приложения, использующие IndexedDB.
- IndexedDB не использует SQL. В этой СУБД применяются запросы к индексам, возвращающие курсоры, которые используются для работы с наборами данных, являющимися результатами запросов. Если вы не знакомы с NoSQL-системами, взгляните на этот материал.
- К IndexedDB-хранилищам применяется политика одного источника. Источник — это комбинация домена, протокола и порта URL документа, в котором выполняется скрипт. Каждый источник может работать только с собственным набором баз данных, при этом у каждой базы данных есть уникальное имя, идентифицирующее её в пределах баз одного источника.
?Ограничения IndexedDB
Система IndexedDB разработана в расчёте на то, что её возможностей должно хватить для решения большинства задач хранения данных на стороне клиента. Понятно, что она не является универсальной системой, подходящей для любых сценариев использования. Вот несколько ситуаций, на которые она не рассчитана:
- Сортировка данных с учётом особенностей различных языков. Не во всех языках строки сортируют одинаково, и IndexedDB не поддерживает сортировку с учётом особенностей различных языков. При этом, хотя база данных не может выполнять подобную сортировку, информацию, полученную из базы, можно сортировать средствами приложения.
- Синхронизация. API не проектировалось с учётом возможности синхронизации локальной базы с сервером. Такая синхронизация, конечно же, возможна, но соответствующие механизмы разработчику придётся реализовывать самостоятельно.
- Полнотекстовый поиск. API IndexedDB не поддерживает чего-то вроде оператора LIKE из SQL.
Кроме того, работая с IndexedDB, учитывайте то, что браузер может удалить базу данных в следующих случаях:
- Пользователь отдал команду на удаление данных. Многие браузеры имеют разделы настроек, в которых есть средства, позволяющие пользователю удалить все данные, сохранённые для некоего веб-сайта, включая куки, закладки, сохранённые пароли, и данные IndexedDB.
- Браузер работает в анонимном режиме. Такие режимы называются в разных браузерах по-разному. В Chrome это «режим инкогнито», в Firefox — «приватный режим». После завершения анонимной сессии браузер удалит базу данных.
- Переполнение диска или достижение некоего заданного лимита.
- Повреждение данных.
В целом, можно отметить, что разработчики браузеров стремятся к тому, чтобы не удалять базы данных IndexedDB без крайней необходимости.
Вот сведения о поддержке IndexedDB в различных браузерах.
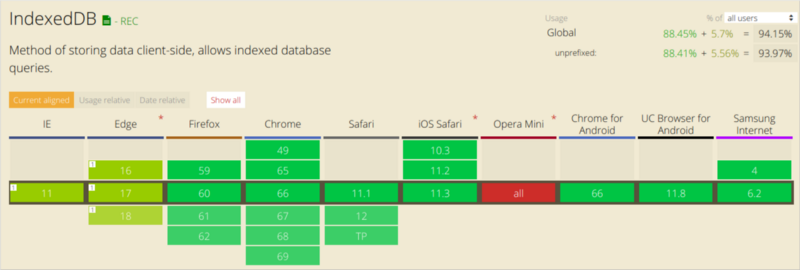
Поддержка IndexedDB различными браузерами
Выбор системы хранения данных
Как уже было сказано, учитывая потребности приложения, лучше всего выбирать те системы хранения данных, которые обладают широкой поддержкой браузеров и работают в асинхронном режиме, что позволяет минимизировать их воздействие на пользовательский интерфейс. Эти критерии вполне естественным образом ведут к следующим технологиям:
- Для оффлайнового хранения информации используйте API Cache. Оно доступно в любом браузере, поддерживающем сервис-воркеры, которые необходимы для создания веб-приложений, умеющих работать без подключения к интернету. API Cache — это идеальный выбор для хранения неких ресурсов, связанных со страницей.
- Для хранения данных, формирующих состояние приложения, или некоей информации, создаваемой пользователями, используйте IndexedDB. Эту технологию, в сравнении с кэшированием, поддерживает больше браузеров, что расширяет возможности пользователей приложений, основанных на IndexedDB, по работе в оффлайне.
Итоги
Автор этого материала говорит, что в компании SessionStack используют различные API для хранения данных. Например, библиотека, интегрируемая в веб-приложения для сбора данных об их работе, использует куки и сессионное хранилище. Приложение, которое предназначено для воспроизведения того, что происходило на странице, использует куки-файлы для целей аутентификации пользователей.
Уважаемые читатели! Какими технологиями хранения данных на стороне клиента вы пользуетесь в своих веб-приложениях?
