
В нашей компании СберТех (Сбербанк Технологии) на данный момент используется HDFS 2.8.4 так как у него есть ряд преимуществ, таких как экосистема Hadoop, быстрая работа с большими объемами данных, он хорош в аналитике и многое другое. Но в декабре 2017 года Apache Software Foundation выпустила новую версию открытого фреймворка для разработки и выполнения распределённых программ — Hadoop 3.0.0, которая включает в себя ряд существенных улучшений по сравнению с предыдущей основной линией выпуска (hadoop-2.x). Одно из самых важных и интересующих нас обновлений это поддержка кодов избыточности (Erasure Coding). Поэтому была поставлена задача сравнить данные версии между собой.
Компанией СберТех на данную исследовательскую работу было выделено 10 виртуальных машин размером по 40 Гбайт. Так как политика кодирования RS(10,4) требует минимум 14 машин, то протестировать ее не получится.
На одной из машин будет расположен NameNode помимо DataNode. Тестирования будет проводиться при следующих политиках кодирования:
А также, используя репликацию с фактором репликации равным 3.
Размер блока данных был выбран равным 32 Мб.
Были проведены тесты на скорость передачи данных. Данные перебрасывались с локальной файловой системы на распределенную файловую систему. Размер используемого в данном тесте файла — 292.2 Мбайт.
Были получены следующие результаты:
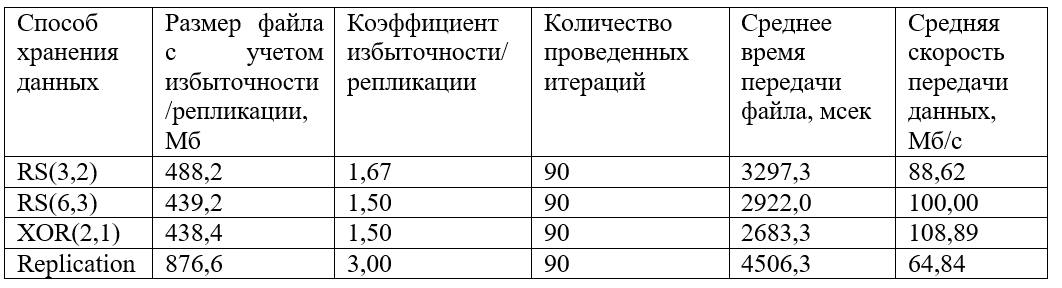
Также построен график сгруппированных полученных значений времени передачи файла:

А также, график сгруппированных полученных значений скорости передачи данных:
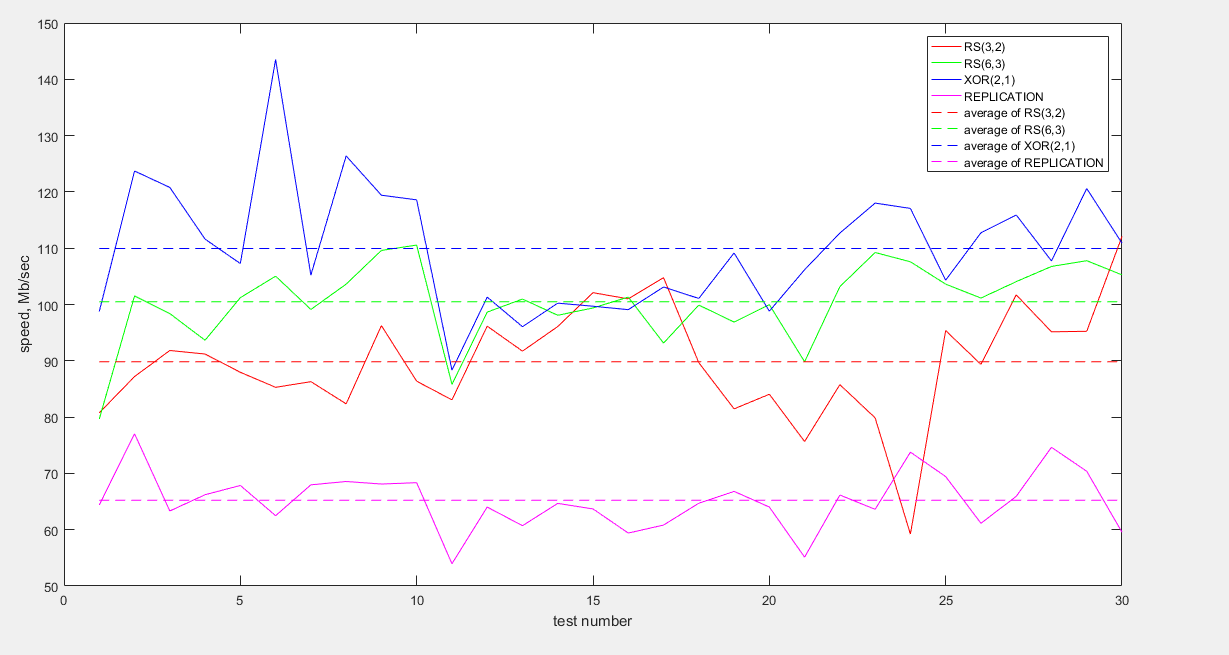
Как видно по графику, быстрее всего данные передаются с кодировкой XOR(2,1). Кодировки RS(6,3) и RS(3,2) показывают похожее поведение хоть и среднее значение скорости у RS(6,3) немного выше. Репликация сильно проигрывает в скорости (примерно в 1,5 раз меньше чем XOR и в 1,5 раза меньше чем RS).
Что касается эффективности хранения, XOR(2,1) и RS(6,3) самые выгодные способы хранения, избыточных данных всего 50%. Репликация, с коэффициентом реплицирования 3, снова проигрывает, храня 200% избыточных данных.
При проведении предыдущего теста состояние серверов отслеживалось с помощью инструмента для мониторинга Grafana.
Ниже приведен график показывающий нагрузку на центральный процессор при проведении тестов передачи данных:
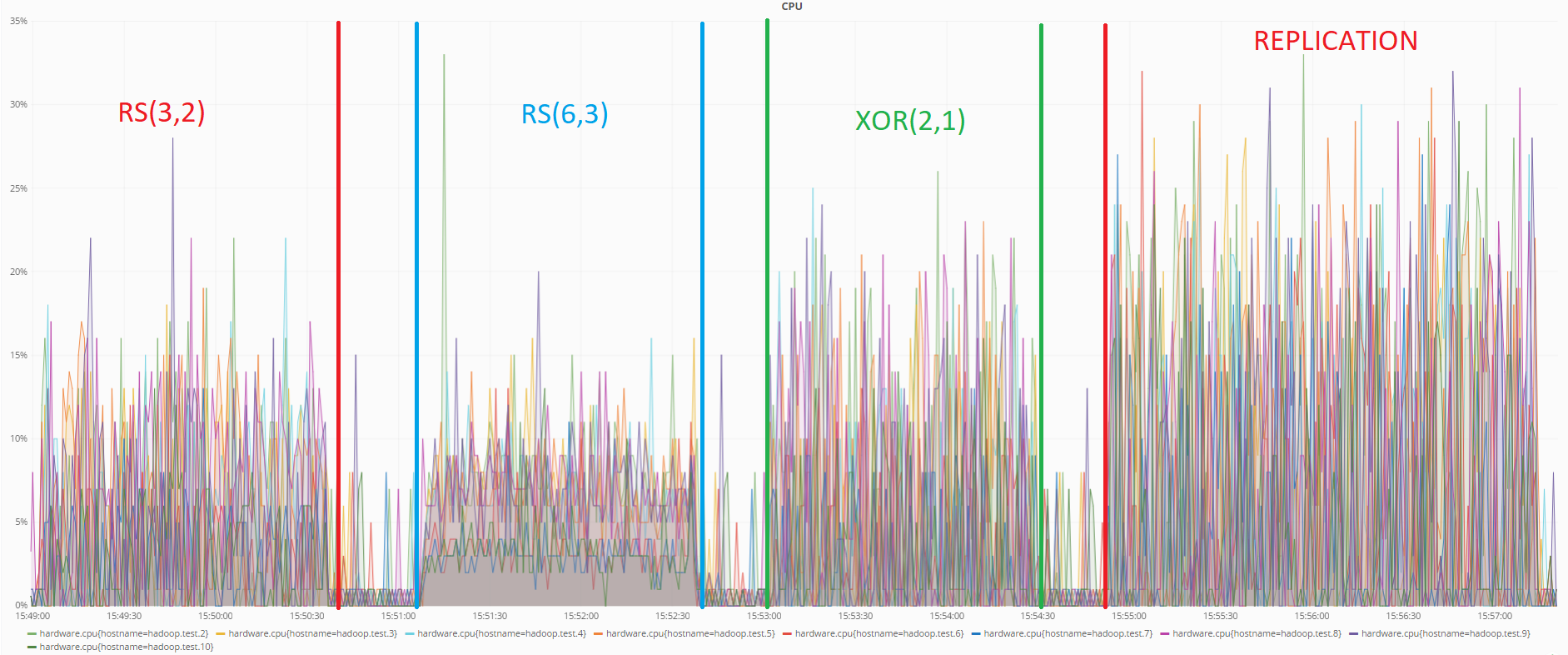
Как видно по графику, в данном тесте также меньше всего ресурсов потребляет кодировка RS(6,3). Репликация показывает опять самый худший результат.
Для проведения данного теста были загружено некоторое количество данных на распределенную файловую систему Hadoop. Затем были опущены две машины с DataNode.
Ниже представлены графики состояния машин в момент восстановления данных при кодировке RS(6,3) и при использовании репликации:
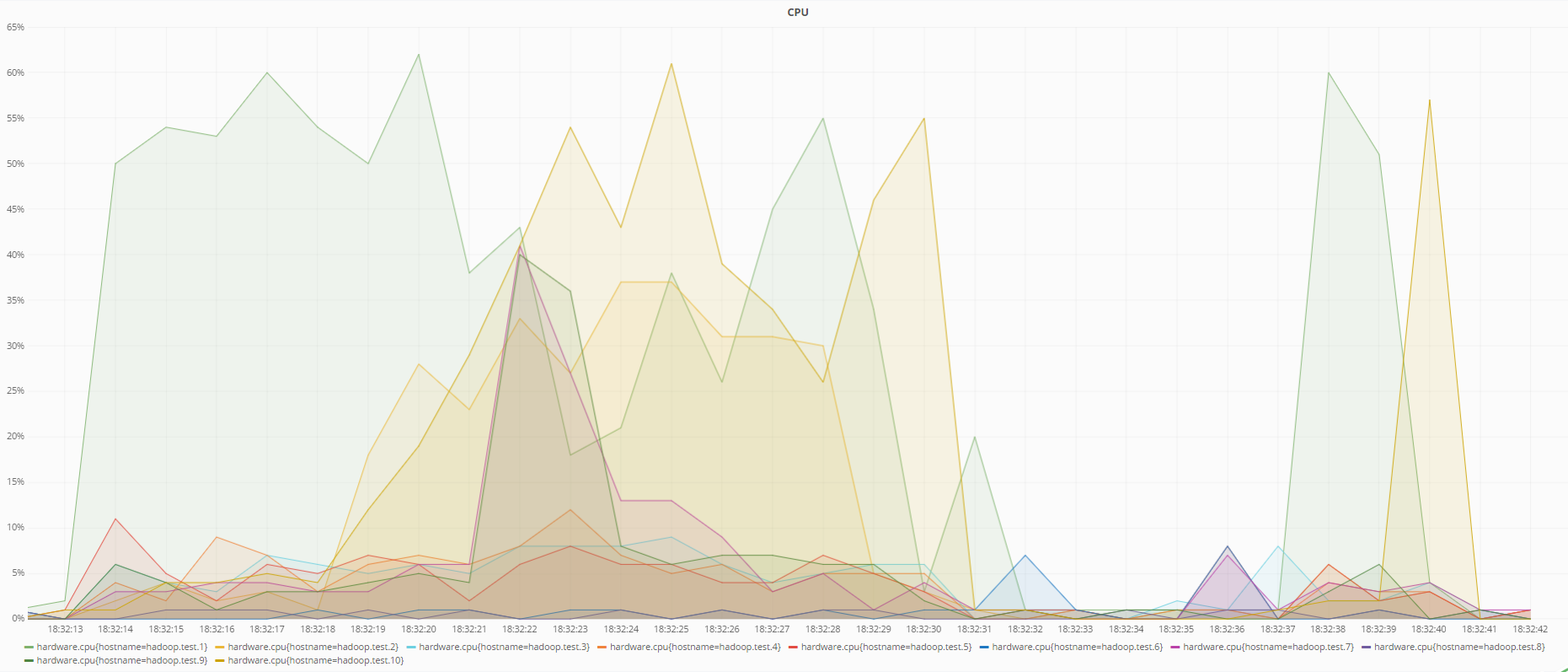
Состояние процессора при восстановлении данных при использовании кодировки RS(6,3)

Состояние процессора при восстановлении данных при использовании репликации
Как видно по графикам, кодировка RS(6,3) нагружает процессор больше, чем репликация при восстановлении данных, что логично, ведь для того чтобы восстановить потерянные данные используя избыточные коды, необходимо рассчитать обратную матрицу избыточности, что потребляет больше ресурсов, чем просто перезаписать данные с других DataNode в случае репликации.
Самым надежным способом хранения является кодировка RS(6,3) так, как она позволяет потерять до трех машин без потери данных, а репликация с коэффициентом репликации равным 3, поддерживает выход из строя до 2 машин. XOR (2, 1) является самым ненадежным способом хранения данных так, как позволяет потерять максимум одну машину.
Основными целями использования распределенной файловой системы в СберТех являются:
По результатам проведенного анализа сделаны следующие выводы:
В связи с этим сделан вывод, что HDFS 3 является рациональной заменой для HDFS 2.
Компанией СберТех на данную исследовательскую работу было выделено 10 виртуальных машин размером по 40 Гбайт. Так как политика кодирования RS(10,4) требует минимум 14 машин, то протестировать ее не получится.
На одной из машин будет расположен NameNode помимо DataNode. Тестирования будет проводиться при следующих политиках кодирования:
- XOR(2,1)
- RS(3,2)
- RS(6,3)
А также, используя репликацию с фактором репликации равным 3.
Размер блока данных был выбран равным 32 Мб.
Проведение исследования
Тест на скорость передачи данных
Были проведены тесты на скорость передачи данных. Данные перебрасывались с локальной файловой системы на распределенную файловую систему. Размер используемого в данном тесте файла — 292.2 Мбайт.
Были получены следующие результаты:
Также построен график сгруппированных полученных значений времени передачи файла:
А также, график сгруппированных полученных значений скорости передачи данных:
Как видно по графику, быстрее всего данные передаются с кодировкой XOR(2,1). Кодировки RS(6,3) и RS(3,2) показывают похожее поведение хоть и среднее значение скорости у RS(6,3) немного выше. Репликация сильно проигрывает в скорости (примерно в 1,5 раз меньше чем XOR и в 1,5 раза меньше чем RS).
Что касается эффективности хранения, XOR(2,1) и RS(6,3) самые выгодные способы хранения, избыточных данных всего 50%. Репликация, с коэффициентом реплицирования 3, снова проигрывает, храня 200% избыточных данных.
Тест на производительность
При проведении предыдущего теста состояние серверов отслеживалось с помощью инструмента для мониторинга Grafana.
Ниже приведен график показывающий нагрузку на центральный процессор при проведении тестов передачи данных:
Как видно по графику, в данном тесте также меньше всего ресурсов потребляет кодировка RS(6,3). Репликация показывает опять самый худший результат.
Потребление ресурсов при восстановлении данных
Для проведения данного теста были загружено некоторое количество данных на распределенную файловую систему Hadoop. Затем были опущены две машины с DataNode.
Ниже представлены графики состояния машин в момент восстановления данных при кодировке RS(6,3) и при использовании репликации:
Состояние процессора при восстановлении данных при использовании кодировки RS(6,3)
Состояние процессора при восстановлении данных при использовании репликации
Как видно по графикам, кодировка RS(6,3) нагружает процессор больше, чем репликация при восстановлении данных, что логично, ведь для того чтобы восстановить потерянные данные используя избыточные коды, необходимо рассчитать обратную матрицу избыточности, что потребляет больше ресурсов, чем просто перезаписать данные с других DataNode в случае репликации.
Результаты тестирования:
- В скорости передачи данных лучше всего использовать кодировку XOR(2,1) или RS(6,3)
- При передаче данных менее всего процессор нагружает кодировка RS(6,3) и RS(3,2)
- При восстановлении данных менее всего процессор нагружает использование репликации
- Самым компактным способом хранения данных являются кодировки RS(6,3) и XOR(2,1)
Самым надежным способом хранения является кодировка RS(6,3) так, как она позволяет потерять до трех машин без потери данных, а репликация с коэффициентом репликации равным 3, поддерживает выход из строя до 2 машин. XOR (2, 1) является самым ненадежным способом хранения данных так, как позволяет потерять максимум одну машину.
Заключение
Основными целями использования распределенной файловой системы в СберТех являются:
- Обеспечение высокой надежности
- Минимизация затрат на содержание серверов для хранения данных
- Обеспечение инструментов для анализа данных
По результатам проведенного анализа сделаны следующие выводы:
- HDFS 3 выигрывает по надежности перед HDFS 2.
- HDFS 3 выигрывает по минимизации затрат на содержание серверов, так как более компактнее хранит данные.
- HDFS 3 имеет тот же набор инструментов для анализа данных, что и HDFS 2.
В связи с этим сделан вывод, что HDFS 3 является рациональной заменой для HDFS 2.
Используемые источники:
Комментарии (3)

acmnu
30.07.2018 17:46Очень медленно вся остальная обвязка переходит на поддержку Hadoop 3.
Barsegyans Автор
31.07.2018 10:48Сейчас проходит beta тестирование Cloudera 6, которая поддерживает Hadoop 3. Затянули конечно
Barsegyans Автор
В HDFS все реплики хранятся на разных машинах.