
Некоторое время назад передо мной была поставлена задача написать процедуру, которая выполняет прореживание котировок рынка Форекс (точнее, данных таймфреймов).
Формулировка задачи: данные поступают на вход с интервалом в 1 секунду в таком формате:
Необходимо обеспечить пересчёт и синхронизацию данных в таблицах: 5 сек, 15 сек, 1 мин, 5 мин, 15 мин, и т.д.
Описанный формат хранения данных имеет название OHLC, или OHLCV (Open, High, Low, Close, Volume). Он применяется часто, по нему сразу можно построить график «Японские свечи».
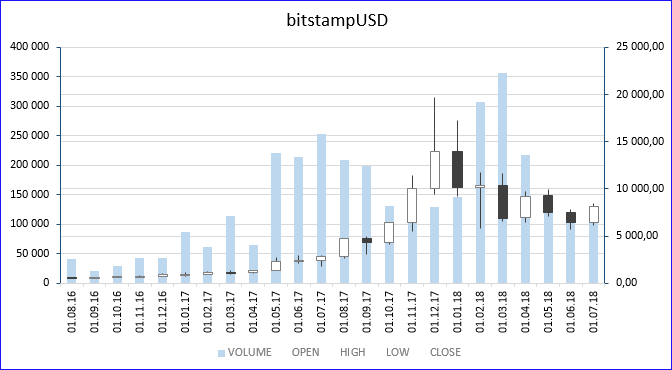
Под катом я описал все варианты, какие смог придумать, как можно прореживать (укрупнять) полученные данные, для анализа, например, зимнего скачка цены биткоина, а по полученным данным вы сразу построите график «Японские свечи» (в MS Excel такой график тоже есть). На картинке выше этот график построен для таймфрейма «1 месяц», для инструмента «bitstampUSD». Белое тело свечи означает рост цены в интервале, чёрное — снижение цены, верхний и нижние фитили означают максимальную и минимальную цены, которые достигались в интервале. Фон — объём сделок. Хорошо видно, что в декабре 2017 цена вплотную приблизилась к отметке 20К.
Решение будет приведено для двух движков БД, для Oracle и MS SQL, что, в некотором роде, даст возможность сравнить их на этой конкретной задаче (обобщать сравнение на другие задачи мы не будем).
Тогда я решил задачу тривиальным способом: расчёт верного прореживания во временную таблицу и синхронизация с целевой таблицей — удаление строк, которые существуют в целевой таблице, но не существуют во временной и добавление строк, которые существуют во временной таблице, но не существуют в целевой. На тот момент Заказчика решение удовлетворило, и задачу я закрыл.
Но сейчас я решил рассмотреть все варианты, потому что указанное выше решение содержит одну особенность — его трудно оптимизировать для двух случаев сразу:
Это связано с тем, что в процедуре придётся соединять целевую таблицу и временную таблицу, а присоединять нужно к большей меньшую, а не наоборот. В указанных выше двух случаях большая/меньшая меняются местами. Оптимизатор будет принимать решение о порядке соединения на основании статистики, а статистика может быть устаревшая, и решение может быть принято неверное, что приведёт к значительной деградации производительности.
В этой статье я опишу методы разового прореживания, которое может пригодиться читателям для анализа, например, зимнего скачка цены биткоина.
Процедуры онлайн-прореживания можно будет скачать с github по ссылке внизу статьи.
К делу… Моя задача касалась прореживания с таймфрейма «1 сек» до следующих, но здесь я рассматриваю прореживания с уровня транзакций (в исходной таблице поля STOCK_NAME, UT, ID, APRICE, AVOLUME). Потому что такие данные выдаёт сайт bitcoincharts.com.
Собственно, прореживание c уровня транзакций до уровня «1 сек» выполняется такой командой (оператор легко транслируется в прореживание с уровня «1 сек» до верхних уровней):
На Oracle:
Функция avg () keep (dense_rank first order by UT, ID) работает так: поскольку запрос с группировкой GROUP BY, то каждая группа рассчитывается независимо от других. В пределах каждой группы строки сортируются по UT и ID, нумеруются функцией dense_rank. Поскольку далее идет функция first, то выбирается та строка, где dense_rank вернула 1 (иными словами, выбирается минимальное) — выбирается первая транзакция внутри интервала. Для этого минимального UT, ID, если бы там было несколько строк, считалось бы среднее. Но в нашем случае там будет гарантированно одна строка (из-за уникальности ID), поэтому получившееся значение сразу возвращается как AOPEN. Несложно заметить, что функция first заменяет собой две агрегатные.
На MS SQL
Здесь нет функций first/last (есть first_value/last_value, но это не то). Поэтому придётся соединять таблицу саму с собой.
Запрос отдельно приводить не буду, но его можно посмотреть ниже в процедуре dbo.THINNING_HABR_CALC. Конечно, без first/last он не настолько изящен, но работать будет.
Как же эту задачу можно решить одним оператором? (Здесь, под термином «один оператор» подразумевается не то, что оператор будет один, а то, что не будет циклов, «дёргающих» данные по одной строчке.)
Я перечислю все известные мне варианты решения этой задачи:
Забегая вперёд скажу, что этот тот редкий случай, когда процедурное решение PPTF оказывается самым эффективным на Oracle.
Скачаем файлы транзакций с сайта http://api.bitcoincharts.com/v1/csv
Я рекомендую выбрать файлы kraken*. Файлы localbtc* сильно зашумлены — содержат отвлекающие строки с нереалистичными ценами. Все kraken* содержат порядка 31M транзакций, я рекомендую исключить оттуда krakenEUR, тогда транзакций становится 11М. Это наиболее удобный объём для тестирования.
Выполним скрипт в Powershell для генерации управляющих файлов для SQLLDR для Oracle и для генерации запроса импорта для MSSQL.
Создадим таблицу транзакций на Oracle.
На Oracle запустите файл LoadData-Oracle.bat, предварительно исправив параметры подключения в начале скрипта Powershell.
Я работаю на виртуальной машине. Загрузка всех файлов 11M транзакций в 8 файлах kraken* (я пропустил файл EUR) заняла порядка 1 минуты.
И создадим функции, которые будут выполнять усечение дат до границ интервалов:
Рассмотрим варианты. Сначала приведен код всех вариантов, далее скрипты для запуска и тестирования. Сначала задача описана для Oracle, далее — для MS SQL
Весь набор транзакций умножается декартовым произведением на набор из 10 строк с числами от 1 до 10. Это нужно, чтобы из одной строки транзакции получить 10 строк с усечёнными до границ 10 интервалов датами.
После этого строки группируются по номеру интервала и усечённой дате и выполняется приведённый выше запрос.
Создадим VIEW:
В этом варианте мы итерационно прореживаем с транзакций до уровня 1, с уровня 1 до уровня 2, и так далее
Создадим таблицу:
Вы можете создать индекс по полю STRIPE_ID, но экспериментальным путём установлено, что на объёме 11М транзакций без индекса получается выгоднее. При больших количествах ситуация может измениться. А можно партиционировать таблицу, раскомментирвав блок в запросе.
Создадим процедуру:
Для симметрии создадим простое VIEW:
Метод отличается брутальной прямолинейностью подхода, и заключается в отказе от принципа «Не повторяй себя». В данном случае — отказ от циклов.
Вариант приводится здесь только для полноты картины.
Забегая вперёд скажу, что по производительности на данной конкретной задаче занимает второе место.
Вариант с User Defined Aggregated Function здесь приводить не буду, но его можно посмотреть на github.
Создадим функцию (в пакете):
Создадим VIEW:
Вариант итерационно рассчитывает прореживание для всех 10 уровней можно с помощью фразы MODEL clause с фразой ITERATE.
Вариант тоже непрактичный, поскольку он оказывается медленным. На моём окружении 1000 транзакций по 8 инструментам рассчитываются за 1 минуту. Большая часть времени тратится на вычисление фразы MODEL.
Здесь я привожу этот вариант лишь для полноты картины и как подтверждение того факта, что на Oracle почти все сколь угодно сложные вычисления возможно выполнить одним запросом, без использования PL/SQL.
Одной из причин низкой производительности фразы MODEL в этом запросе является то, что поиск по критериям справа производится для каждого правила, которых у нас 6. Первые два правила вычисляются довольно быстро, потому что там прямая явная адресация, без джокеров. В остальных четырёх правилах есть слово any — там вычисления производятся медленнее.
Второе затруднение в том, что приходится рассчитывать референсную модель. Она нужна потому, что список dimension должен быть известен до вычисления фразы MODEL, мы не можем рассчитывать новые измерения внутри этой фразы. Возможно, это можно обойти с помощью двух фраз MODEL, но я не стал это делать из-за низкой производительности большого числа правил.
Добавлю, что можно было бы не рассчитывать UT_OPEN и UT_CLOSE в референсной модели, а использовать те же функции avg () keep (dense_rank first/last order by) непосредственно во фразе MODEL. Но так получилось бы ещё медленнее.
Из-за ограничения производительности я не буду включать этот вариант в процедуру тестирования.
Запрос, описанный ниже, потенциально был бы самым эффективным и потреблял бы количество ресурсов, равное теоретическому минимуму.
Но ни Oracle, ни MS SQL не позволяют записать запрос в такой форме. Полагаю, это продиктовано стандартом.
Этот запрос соответствует следующей части документации Oracle:
If a subquery_factoring_clause refers to its own query_name in the subquery that defines it, then the subquery_factoring_clause is said to be recursive. A recursive subquery_factoring_clause must contain two query blocks: the first is the anchor member and the second is the recursive member. The anchor member must appear before the recursive member, and it cannot reference query_name. The anchor member can be composed of one or more query blocks combined by the set operators: UNION ALL, UNION, INTERSECT or MINUS. The recursive member must follow the anchor member and must reference query_name exactly once. You must combine the recursive member with the anchor member using the UNION ALL set operator.
Но противоречит следующему абзацу документации:
The recursive member cannot contain any of the following elements:
The DISTINCT keyword or a GROUP BY clause
An aggregate function. However, analytic functions are permitted in the select list.
Таким образом, в recursive member агрегаты и группировка недопустимы.
Проведём сначала для Oracle.
Выполним процедуру расчёта для метода CALC и запишем время её выполнения:
Результаты расчёта по четырём методам находятся в четырёх view:
Время выполнения по всем методам уже замерены мной и приведены в таблице в конце статьи.
Для остальных VIEW выполним запросы и запишем время выполнения:
где XXXX — SIMP, CHIN, PPTF.
Эти VIEW рассчитывают дайджест набора. Для расчёта дайджеста нужно выполнить fetch всех строк, и с помощью дайджеста можно сравнить наборы между собой.
Также сравнить наборы можно с помощью пакета dbms_sqlhash, но это намного медленнее, потому что требуется сортировка исходного набора, да и расчёт хэша выполняется небыстро.
Также в 12c есть пакет DBMS_COMPARISON.
Можно одновременно проверить корректность всех алгоритмов. Посчитаем дайджесты таким запросом (при 11М записей на виртуальной машине это будет относительно долго, порядка 15 минут):
Мы видим, что дайджесты совпадают, значит все алгоритмы выдали одинаковые результаты.
Теперь воспроизведём всё то же самое на MS SQL. Я тестировал на версии 2016.
Предварительно создайте базу DBTEST, после этого в ней создайте таблицу транзакций:
Загрузим скачанные данные.
На MSSQL создайте файл format_mssql.bcp:
И запустите скрипт LoadData-MSSQL.sql в SSMS (этот скрипт был сгенерирован единственным powershell скриптом, приведенным в разделе этой статьи для Oracle).
Создадим две функции:
Приступим к реализации вариантов:
Выполните:
Отсутствующие функции first/last реализованы двойным самосоединением таблиц.
Создадим таблицу, процедуру и view:
Варианты 3 (CHIN) и 4 (UDAF) я не реализовывал на MS SQL.
Создадим табличную функцию и view. Эта функция является просто табличной, а не parallel pipelined table function, просто вариант сохранил своё историческое название от Oracle:
Выполним расчёт таблицы QUOTES_CALC для метода CALC и запишем время выполнения:
Результаты расчёта по трём методам находятся в трёх view:
Для двух VIEW выполним запросы и запишем время выполнения:
где XXXX — SIMP, PPTF.
Теперь можно сравнить результаты расчёта по трём методам для MS SQL. Это можно сделать одним запросом. Выполните:
Если три строки совпадают по всем полям — результат расчёта по трём методам идентичный.
Я настоятельно советую на этапе тестирования использовать маленькую выборку, потому, что производительность этой задачи на MS SQL невысокая.
Если вы располагаете только движком MS SQL, и хотите рассчитывать больший объём данных, то можно попробовать следующий метод оптимизации: можно создать индексы:
Результаты замера производительности на моей виртуальной машине, следующие:
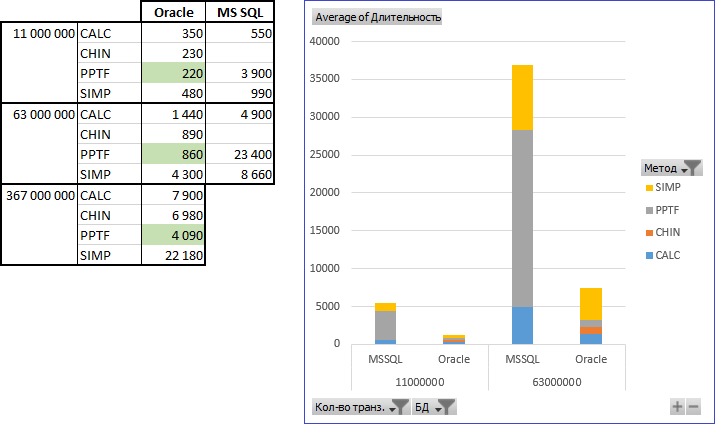
Скрипты можно скачать с github: Oracle, схема THINNING — скрипты этой статьи, схема THINNING_LIVE — онлайн-скачивание данных с сайта bitcoincharts.com и онлайн-прореживание (но этот сайт в онлайн-режиме отдаёт данные только за последние 5 дней), и скрипт для MS SQL тоже по этой статье.
Вывод:
Эта задача решается быстрее на Oracle, чем на MS SQL. С ростом количества транзакций разрыв становится всё более существенным.
На Oracle наиболее оптимальным оказался вариант PPTF. Здесь процедурный подход оказался выгоднее, такое случается нечасто. Остальные методы показали тоже приемлемый результат — я тестировал даже объём 367М транзакций на виртуальной машине (метод PPTF рассчитал прореживание за полтора часа).
На MS SQL наиболее производительным оказался метод итерационного расчёта (CALC).
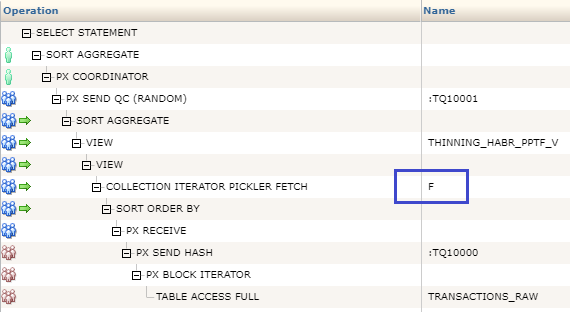
Почему же метод PPTF на Oracle оказался лидером? Из-за параллельности выполнения и из-за архитектуры — функция, которая создана как parallel pipelined table function, встраивается в середину плана запроса:
Формулировка задачи: данные поступают на вход с интервалом в 1 секунду в таком формате:
- Название инструмента (код пары USDEUR и пр.),
- Дата и время в формате unix time,
- Open value (цена первой сделки в интервале),
- High value (максимальная цена),
- Low value (минимальная цена),
- Close value (цена последней сделки),
- Volume (громкость, или объём сделки).
Необходимо обеспечить пересчёт и синхронизацию данных в таблицах: 5 сек, 15 сек, 1 мин, 5 мин, 15 мин, и т.д.
Описанный формат хранения данных имеет название OHLC, или OHLCV (Open, High, Low, Close, Volume). Он применяется часто, по нему сразу можно построить график «Японские свечи».
Под катом я описал все варианты, какие смог придумать, как можно прореживать (укрупнять) полученные данные, для анализа, например, зимнего скачка цены биткоина, а по полученным данным вы сразу построите график «Японские свечи» (в MS Excel такой график тоже есть). На картинке выше этот график построен для таймфрейма «1 месяц», для инструмента «bitstampUSD». Белое тело свечи означает рост цены в интервале, чёрное — снижение цены, верхний и нижние фитили означают максимальную и минимальную цены, которые достигались в интервале. Фон — объём сделок. Хорошо видно, что в декабре 2017 цена вплотную приблизилась к отметке 20К.
Решение будет приведено для двух движков БД, для Oracle и MS SQL, что, в некотором роде, даст возможность сравнить их на этой конкретной задаче (обобщать сравнение на другие задачи мы не будем).
Тогда я решил задачу тривиальным способом: расчёт верного прореживания во временную таблицу и синхронизация с целевой таблицей — удаление строк, которые существуют в целевой таблице, но не существуют во временной и добавление строк, которые существуют во временной таблице, но не существуют в целевой. На тот момент Заказчика решение удовлетворило, и задачу я закрыл.
Но сейчас я решил рассмотреть все варианты, потому что указанное выше решение содержит одну особенность — его трудно оптимизировать для двух случаев сразу:
- когда целевая таблица пуста и нужно добавить много данных,
- и когда целевая таблица большая, и необходимо добавлять данные маленькими порциями.
Это связано с тем, что в процедуре придётся соединять целевую таблицу и временную таблицу, а присоединять нужно к большей меньшую, а не наоборот. В указанных выше двух случаях большая/меньшая меняются местами. Оптимизатор будет принимать решение о порядке соединения на основании статистики, а статистика может быть устаревшая, и решение может быть принято неверное, что приведёт к значительной деградации производительности.
В этой статье я опишу методы разового прореживания, которое может пригодиться читателям для анализа, например, зимнего скачка цены биткоина.
Процедуры онлайн-прореживания можно будет скачать с github по ссылке внизу статьи.
К делу… Моя задача касалась прореживания с таймфрейма «1 сек» до следующих, но здесь я рассматриваю прореживания с уровня транзакций (в исходной таблице поля STOCK_NAME, UT, ID, APRICE, AVOLUME). Потому что такие данные выдаёт сайт bitcoincharts.com.
Собственно, прореживание c уровня транзакций до уровня «1 сек» выполняется такой командой (оператор легко транслируется в прореживание с уровня «1 сек» до верхних уровней):
На Oracle:
select
1 as STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, 1) as UT
, avg (APRICE) keep (dense_rank first order by UT, ID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_rank last order by UT, ID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
group by STOCK_NAME, TRUNC_UT (UT, 1);
Функция avg () keep (dense_rank first order by UT, ID) работает так: поскольку запрос с группировкой GROUP BY, то каждая группа рассчитывается независимо от других. В пределах каждой группы строки сортируются по UT и ID, нумеруются функцией dense_rank. Поскольку далее идет функция first, то выбирается та строка, где dense_rank вернула 1 (иными словами, выбирается минимальное) — выбирается первая транзакция внутри интервала. Для этого минимального UT, ID, если бы там было несколько строк, считалось бы среднее. Но в нашем случае там будет гарантированно одна строка (из-за уникальности ID), поэтому получившееся значение сразу возвращается как AOPEN. Несложно заметить, что функция first заменяет собой две агрегатные.
На MS SQL
Здесь нет функций first/last (есть first_value/last_value, но это не то). Поэтому придётся соединять таблицу саму с собой.
Запрос отдельно приводить не буду, но его можно посмотреть ниже в процедуре dbo.THINNING_HABR_CALC. Конечно, без first/last он не настолько изящен, но работать будет.
Как же эту задачу можно решить одним оператором? (Здесь, под термином «один оператор» подразумевается не то, что оператор будет один, а то, что не будет циклов, «дёргающих» данные по одной строчке.)
Я перечислю все известные мне варианты решения этой задачи:
- SIMP (simple, простой, декартово произведение),
- CALC (calculate, итерационное прореживание верхних уровней),
- CHIN (china way, громоздкий запрос для всех уровней сразу),
- UDAF (user-defined aggregate function),
- PPTF (pipelined and parallel table function, процедурное решение, но всего с двумя курсорами, фактически, два оператора SQL),
- MODE (model, фраза MODEL),
- и IDEA (ideal, идеальное решение, которое не может работать сейчас).
Забегая вперёд скажу, что этот тот редкий случай, когда процедурное решение PPTF оказывается самым эффективным на Oracle.
Скачаем файлы транзакций с сайта http://api.bitcoincharts.com/v1/csv
Я рекомендую выбрать файлы kraken*. Файлы localbtc* сильно зашумлены — содержат отвлекающие строки с нереалистичными ценами. Все kraken* содержат порядка 31M транзакций, я рекомендую исключить оттуда krakenEUR, тогда транзакций становится 11М. Это наиболее удобный объём для тестирования.
Выполним скрипт в Powershell для генерации управляющих файлов для SQLLDR для Oracle и для генерации запроса импорта для MSSQL.
# MODIFY PARAMETERS THERE
$OracleConnectString = "THINNING/aaa@P-ORA11/ORCL" # For Oracle
$PathToCSV = "Z:\10" # without trailing slash
$filenames = Get-ChildItem -name *.csv
Remove-Item *.ctl -ErrorAction SilentlyContinue
Remove-Item *.log -ErrorAction SilentlyContinue
Remove-Item *.bad -ErrorAction SilentlyContinue
Remove-Item *.dsc -ErrorAction SilentlyContinue
Remove-Item LoadData-Oracle.bat -ErrorAction SilentlyContinue
Remove-Item LoadData-MSSQL.sql -ErrorAction SilentlyContinue
ForEach ($FilenameExt in $Filenames)
{
Write-Host "Processing file: "$FilenameExt
$StockName = $FilenameExt.substring(1, $FilenameExt.Length-5)
$FilenameCtl = '.'+$Stockname+'.ctl'
Add-Content -Path $FilenameCtl -Value "OPTIONS (DIRECT=TRUE, PARALLEL=FALSE, ROWS=1000000, SKIP_INDEX_MAINTENANCE=Y)"
Add-Content -Path $FilenameCtl -Value "UNRECOVERABLE"
Add-Content -Path $FilenameCtl -Value "LOAD DATA"
Add-Content -Path $FilenameCtl -Value "INFILE '.$StockName.csv'"
Add-Content -Path $FilenameCtl -Value "BADFILE '.$StockName.bad'"
Add-Content -Path $FilenameCtl -Value "DISCARDFILE '.$StockName.dsc'"
Add-Content -Path $FilenameCtl -Value "INTO TABLE TRANSACTIONS_RAW"
Add-Content -Path $FilenameCtl -Value "APPEND"
Add-Content -Path $FilenameCtl -Value "FIELDS TERMINATED BY ','"
Add-Content -Path $FilenameCtl -Value "(ID SEQUENCE (0), STOCK_NAME constant '$StockName', UT, APRICE, AVOLUME)"
Add-Content -Path LoadData-Oracle.bat -Value "sqlldr $OracleConnectString control=$FilenameCtl"
Add-Content -Path LoadData-MSSQL.sql -Value "insert into TRANSACTIONS_RAW (STOCK_NAME, UT, APRICE, AVOLUME)"
Add-Content -Path LoadData-MSSQL.sql -Value "select '$StockName' as STOCK_NAME, UT, APRICE, AVOLUME"
Add-Content -Path LoadData-MSSQL.sql -Value "from openrowset (bulk '$PathToCSV\$FilenameExt', formatfile = '$PathToCSV\format_mssql.bcp') as T1;"
Add-Content -Path LoadData-MSSQL.sql -Value ""
}
Создадим таблицу транзакций на Oracle.
create table TRANSACTIONS_RAW (
ID number not null
, STOCK_NAME varchar2 (32)
, UT number not null
, APRICE number not null
, AVOLUME number not null)
pctfree 0 parallel 4 nologging;
На Oracle запустите файл LoadData-Oracle.bat, предварительно исправив параметры подключения в начале скрипта Powershell.
Я работаю на виртуальной машине. Загрузка всех файлов 11M транзакций в 8 файлах kraken* (я пропустил файл EUR) заняла порядка 1 минуты.
И создадим функции, которые будут выполнять усечение дат до границ интервалов:
create or replace function TRUNC_UT (p_UT number, p_StripeTypeId number)
return number deterministic is
begin
return
case p_StripeTypeId
when 1 then trunc (p_UT / 1) * 1
when 2 then trunc (p_UT / 10) * 10
when 3 then trunc (p_UT / 60) * 60
when 4 then trunc (p_UT / 600) * 600
when 5 then trunc (p_UT / 3600) * 3600
when 6 then trunc (p_UT / ( 4 * 3600)) * ( 4 * 3600)
when 7 then trunc (p_UT / (24 * 3600)) * (24 * 3600)
when 8 then trunc ((trunc (date '1970-01-01' + p_UT / 86400, 'Month') - date '1970-01-01') * 86400)
when 9 then trunc ((trunc (date '1970-01-01' + p_UT / 86400, 'year') - date '1970-01-01') * 86400)
when 10 then 0
when 11 then 0
end;
end;
create or replace function UT2DATESTR (p_UT number) return varchar2 deterministic is
begin
return to_char (date '1970-01-01' + p_UT / 86400, 'YYYY.MM.DD HH24:MI:SS');
end;
Рассмотрим варианты. Сначала приведен код всех вариантов, далее скрипты для запуска и тестирования. Сначала задача описана для Oracle, далее — для MS SQL
Вариант 1 — SIMP (Тривиальный)
Весь набор транзакций умножается декартовым произведением на набор из 10 строк с числами от 1 до 10. Это нужно, чтобы из одной строки транзакции получить 10 строк с усечёнными до границ 10 интервалов датами.
После этого строки группируются по номеру интервала и усечённой дате и выполняется приведённый выше запрос.
Создадим VIEW:
create or replace view THINNING_HABR_SIMP_V as
select STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID) as UT
, avg (APRICE) keep (dense_rank first order by UT, ID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_rank last order by UT, ID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
, (select rownum as STRIPE_ID from dual connect by level <= 10)
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID);
Вариант 2 — CALC (вычисляемый итерационно)
В этом варианте мы итерационно прореживаем с транзакций до уровня 1, с уровня 1 до уровня 2, и так далее
Создадим таблицу:
create table QUOTES_CALC (
STRIPE_ID number not null
, STOCK_NAME varchar2 (128) not null
, UT number not null
, AOPEN number not null
, AHIGH number not null
, ALOW number not null
, ACLOSE number not null
, AVOLUME number not null
, AAMOUNT number not null
, ACOUNT number not null
)
/*partition by list (STRIPE_ID) (
partition P01 values (1)
, partition P02 values (2)
, partition P03 values (3)
, partition P04 values (4)
, partition P05 values (5)
, partition P06 values (6)
, partition P07 values (7)
, partition P08 values (8)
, partition P09 values (9)
, partition P10 values (10)
)*/
parallel 4 pctfree 0 nologging;
Вы можете создать индекс по полю STRIPE_ID, но экспериментальным путём установлено, что на объёме 11М транзакций без индекса получается выгоднее. При больших количествах ситуация может измениться. А можно партиционировать таблицу, раскомментирвав блок в запросе.
Создадим процедуру:
create or replace procedure THINNING_HABR_CALC_T is
begin
rollback;
execute immediate 'truncate table QUOTES_CALC';
insert --+ append
into QUOTES_CALC
select 1 as STRIPE_ID
, STOCK_NAME
, UT
, avg (APRICE) keep (dense_rank first order by ID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_rank last order by ID)
, sum (AVOLUME)
, sum (APRICE * AVOLUME)
, count (*)
from TRANSACTIONS_RAW a
group by STOCK_NAME, UT;
commit;
for i in 1..9
loop
insert --+ append
into QUOTES_CALC
select --+ parallel(4)
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, i + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from QUOTES_CALC a
where STRIPE_ID = i
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, i + 1);
commit;
end loop;
end;
/
Для симметрии создадим простое VIEW:
create view THINNING_HABR_CALC_V as
select * from QUOTES_CALC;
Вариант 3 — CHIN (китайский код)
Метод отличается брутальной прямолинейностью подхода, и заключается в отказе от принципа «Не повторяй себя». В данном случае — отказ от циклов.
Вариант приводится здесь только для полноты картины.
Забегая вперёд скажу, что по производительности на данной конкретной задаче занимает второе место.
Большой запрос
create or replace view THINNING_HABR_CHIN_V as
with
T01 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select 1
, STOCK_NAME
, UT
, avg (APRICE) keep (dense_rank first order by ID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_rank last order by ID)
, sum (AVOLUME)
, sum (APRICE * AVOLUME)
, count (*)
from TRANSACTIONS_RAW
group by STOCK_NAME, UT)
, T02 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T01
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T03 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T02
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T04 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T03
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T05 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T04
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T06 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T05
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T07 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T06
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T08 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T07
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T09 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T08
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
, T10 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select
STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T09
group by STRIPE_ID, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1))
select * from T01 union all
select * from T02 union all
select * from T03 union all
select * from T04 union all
select * from T05 union all
select * from T06 union all
select * from T07 union all
select * from T08 union all
select * from T09 union all
select * from T10;
Вариант 4 — UDAF
Вариант с User Defined Aggregated Function здесь приводить не буду, но его можно посмотреть на github.
Вариант 5 — PPTF (Pipelined and Parallel table function)
Создадим функцию (в пакете):
create or replace package THINNING_PPTF_P is
type TRANSACTION_RECORD_T is
record (STOCK_NAME varchar2(128), UT number, SEQ_NUM number, APRICE number, AVOLUME number);
type CUR_RECORD_T is ref cursor return TRANSACTION_RECORD_T;
type QUOTE_T
is record (STRIPE_ID number, STOCK_NAME varchar2(128), UT number
, AOPEN number, AHIGH number, ALOW number, ACLOSE number, AVOLUME number
, AAMOUNT number, ACOUNT number);
type QUOTE_LIST_T is table of QUOTE_T;
function F (p_cursor CUR_RECORD_T) return QUOTE_LIST_T
pipelined order p_cursor by (STOCK_NAME, UT, SEQ_NUM)
parallel_enable (partition p_cursor by hash (STOCK_NAME));
end;
/
create or replace package body THINNING_PPTF_P is
function F (p_cursor CUR_RECORD_T) return QUOTE_LIST_T
pipelined order p_cursor by (STOCK_NAME, UT, SEQ_NUM)
parallel_enable (partition p_cursor by hash (STOCK_NAME))
is
QuoteTail QUOTE_LIST_T := QUOTE_LIST_T() ;
rec TRANSACTION_RECORD_T;
rec_prev TRANSACTION_RECORD_T;
type ut_T is table of number index by pls_integer;
ut number;
begin
QuoteTail.extend(10);
loop
fetch p_cursor into rec;
exit when p_cursor%notfound;
if rec_prev.STOCK_NAME = rec.STOCK_NAME
then
if (rec.STOCK_NAME = rec_prev.STOCK_NAME and rec.UT < rec_prev.UT)
or (rec.STOCK_NAME = rec_prev.STOCK_NAME and rec.UT = rec_prev.UT and rec.SEQ_NUM < rec_prev.SEQ_NUM)
then raise_application_error (-20010, 'Rowset must be ordered, ('||rec_prev.STOCK_NAME||','||rec_prev.UT||','||rec_prev.SEQ_NUM||') > ('||rec.STOCK_NAME||','||rec.UT||','||rec.SEQ_NUM||')');
end if;
end if;
if rec.STOCK_NAME <> rec_prev.STOCK_NAME or rec_prev.STOCK_NAME is null
then
for j in 1 .. 10
loop
if QuoteTail(j).UT is not null
then
pipe row (QuoteTail(j));
QuoteTail(j) := null;
end if;
end loop;
end if;
for i in reverse 1..10
loop
ut := TRUNC_UT (rec.UT, i);
if QuoteTail(i).UT <> ut
then
for j in 1..i
loop
pipe row (QuoteTail(j));
QuoteTail(j) := null;
end loop;
end if;
if QuoteTail(i).UT is null
then
QuoteTail(i).STRIPE_ID := i;
QuoteTail(i).STOCK_NAME := rec.STOCK_NAME;
QuoteTail(i).UT := ut;
QuoteTail(i).AOPEN := rec.APRICE;
end if;
if rec.APRICE < QuoteTail(i).ALOW or QuoteTail(i).ALOW is null then QuoteTail(i).ALOW := rec.APRICE; end if;
if rec.APRICE > QuoteTail(i).AHIGH or QuoteTail(i).AHIGH is null then QuoteTail(i).AHIGH := rec.APRICE; end if;
QuoteTail(i).AVOLUME := nvl (QuoteTail(i).AVOLUME, 0) + rec.AVOLUME;
QuoteTail(i).AAMOUNT := nvl (QuoteTail(i).AAMOUNT, 0) + rec.AVOLUME * rec.APRICE;
QuoteTail(i).ACOUNT := nvl (QuoteTail(i).ACOUNT, 0) + 1;
QuoteTail(i).ACLOSE := rec.APRICE;
end loop;
rec_prev := rec;
end loop;
for j in 1 .. 10
loop
if QuoteTail(j).UT is not null
then
pipe row (QuoteTail(j));
end if;
end loop;
exception
when no_data_needed then null;
end;
end;
/
Создадим VIEW:
create or replace view THINNING_HABR_PPTF_V as
select * from table (THINNING_PPTF_P.F (cursor (select STOCK_NAME, UT, ID, APRICE, AVOLUME from TRANSACTIONS_RAW)));
Вариант 6 — MODE (model clause)
Вариант итерационно рассчитывает прореживание для всех 10 уровней можно с помощью фразы MODEL clause с фразой ITERATE.
Вариант тоже непрактичный, поскольку он оказывается медленным. На моём окружении 1000 транзакций по 8 инструментам рассчитываются за 1 минуту. Большая часть времени тратится на вычисление фразы MODEL.
Здесь я привожу этот вариант лишь для полноты картины и как подтверждение того факта, что на Oracle почти все сколь угодно сложные вычисления возможно выполнить одним запросом, без использования PL/SQL.
Одной из причин низкой производительности фразы MODEL в этом запросе является то, что поиск по критериям справа производится для каждого правила, которых у нас 6. Первые два правила вычисляются довольно быстро, потому что там прямая явная адресация, без джокеров. В остальных четырёх правилах есть слово any — там вычисления производятся медленнее.
Второе затруднение в том, что приходится рассчитывать референсную модель. Она нужна потому, что список dimension должен быть известен до вычисления фразы MODEL, мы не можем рассчитывать новые измерения внутри этой фразы. Возможно, это можно обойти с помощью двух фраз MODEL, но я не стал это делать из-за низкой производительности большого числа правил.
Добавлю, что можно было бы не рассчитывать UT_OPEN и UT_CLOSE в референсной модели, а использовать те же функции avg () keep (dense_rank first/last order by) непосредственно во фразе MODEL. Но так получилось бы ещё медленнее.
Из-за ограничения производительности я не буду включать этот вариант в процедуру тестирования.
with
-- построение первого уровня прореживания из транзакций
SOURCETRANS (STRIPE_ID, STOCK_NAME, PARENT_UT, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select 1, STOCK_NAME, TRUNC_UT (UT, 2), UT
, avg (APRICE) keep (dense_rank first order by ID)
, max (APRICE)
, min (APRICE)
, avg (APRICE) keep (dense_rank last order by ID)
, sum (AVOLUME)
, sum (AVOLUME * APRICE)
, count (*)
from TRANSACTIONS_RAW
where ID <= 1000 -- увеличьте значение для каждого интсрумента здесь
group by STOCK_NAME, UT)
-- построение карты PARENT_UT, UT для 2...10 уровней и расчёт UT_OPEN, UT_CLOSE
-- используется декартово произведение
, REFMOD (STRIPE_ID, STOCK_NAME, PARENT_UT, UT, UT_OPEN, UT_CLOSE)
as (select b.STRIPE_ID
, a.STOCK_NAME
, TRUNC_UT (UT, b.STRIPE_ID + 1)
, TRUNC_UT (UT, b.STRIPE_ID)
, min (TRUNC_UT (UT, b.STRIPE_ID - 1))
, max (TRUNC_UT (UT, b.STRIPE_ID - 1))
from SOURCETRANS a
, (select rownum + 1 as STRIPE_ID from dual connect by level <= 9) b
group by b.STRIPE_ID
, a.STOCK_NAME
, TRUNC_UT (UT, b.STRIPE_ID + 1)
, TRUNC_UT (UT, b.STRIPE_ID))
-- конкатенация первого уровня и карты следующих уровней
, MAINTAB
as (
select STRIPE_ID, STOCK_NAME, PARENT_UT, UT, AOPEN
, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT, null, null from SOURCETRANS
union all
select STRIPE_ID, STOCK_NAME, PARENT_UT, UT, null
, null, null, null, null, null, null, UT_OPEN, UT_CLOSE from REFMOD)
select STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT
from MAINTAB
model
return all rows
-- референсная модель содержит карту уровней 2...10
reference RM on (select * from REFMOD) dimension by (STRIPE_ID, STOCK_NAME, UT) measures (UT_OPEN, UT_CLOSE)
main MM partition by (STOCK_NAME) dimension by (STRIPE_ID, PARENT_UT, UT) measures (AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
rules iterate (9) (
AOPEN [iteration_number + 2, any, any]
= AOPEN [cv (STRIPE_ID) - 1, cv (UT)
, rm.UT_OPEN [cv (STRIPE_ID), cv (STOCK_NAME), cv (UT)]]
, ACLOSE [iteration_number + 2, any, any]
= ACLOSE [cv (STRIPE_ID) - 1, cv (UT)
, rm.UT_CLOSE[cv (STRIPE_ID), cv (STOCK_NAME), cv (UT)]]
, AHIGH [iteration_number + 2, any, any]
= max (AHIGH)[cv (STRIPE_ID) - 1, cv (UT), any]
, ALOW [iteration_number + 2, any, any]
= min (ALOW)[cv (STRIPE_ID) - 1, cv (UT), any]
, AVOLUME [iteration_number + 2, any, any]
= sum (AVOLUME)[cv (STRIPE_ID) - 1, cv (UT), any]
, AAMOUNT [iteration_number + 2, any, any]
= sum (AAMOUNT)[cv (STRIPE_ID) - 1, cv (UT), any]
, ACOUNT [iteration_number + 2, any, any]
= sum (ACOUNT)[cv (STRIPE_ID) - 1, cv (UT), any]
)
order by 1, 2, 3, 4;
Вариант 6 — IDEA (ideal, идеальный, но неработоспособный)
Запрос, описанный ниже, потенциально был бы самым эффективным и потреблял бы количество ресурсов, равное теоретическому минимуму.
Но ни Oracle, ни MS SQL не позволяют записать запрос в такой форме. Полагаю, это продиктовано стандартом.
with
QUOTES_S1 as (select 1 as STRIPE_ID
, STOCK_NAME
, TRUNC_UT (UT, 1) as UT
, avg (APRICE) keep (dense_rank first order by ID) as AOPEN
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, avg (APRICE) keep (dense_rank last order by ID) as ACLOSE
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
-- where rownum <= 100
group by STOCK_NAME, TRUNC_UT (UT, 1))
, T1 (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
as (select 1, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT
from QUOTES_S1
union all
select STRIPE_ID + 1
, STOCK_NAME
, TRUNC_UT (UT, STRIPE_ID + 1)
, avg (AOPEN) keep (dense_rank first order by UT)
, max (AHIGH)
, min (ALOW)
, avg (ACLOSE) keep (dense_rank last order by UT)
, sum (AVOLUME)
, sum (AAMOUNT)
, sum (ACOUNT)
from T1
where STRIPE_ID < 10
group by STRIPE_ID + 1, STOCK_NAME, TRUNC_UT (UT, STRIPE_ID + 1)
)
select * from T1
Этот запрос соответствует следующей части документации Oracle:
If a subquery_factoring_clause refers to its own query_name in the subquery that defines it, then the subquery_factoring_clause is said to be recursive. A recursive subquery_factoring_clause must contain two query blocks: the first is the anchor member and the second is the recursive member. The anchor member must appear before the recursive member, and it cannot reference query_name. The anchor member can be composed of one or more query blocks combined by the set operators: UNION ALL, UNION, INTERSECT or MINUS. The recursive member must follow the anchor member and must reference query_name exactly once. You must combine the recursive member with the anchor member using the UNION ALL set operator.
Но противоречит следующему абзацу документации:
The recursive member cannot contain any of the following elements:
The DISTINCT keyword or a GROUP BY clause
An aggregate function. However, analytic functions are permitted in the select list.
Таким образом, в recursive member агрегаты и группировка недопустимы.
Тестирование
Проведём сначала для Oracle.
Выполним процедуру расчёта для метода CALC и запишем время её выполнения:
exec THINNING_HABR_CALC_TРезультаты расчёта по четырём методам находятся в четырёх view:
- THINNING_HABR_SIMP_V (будет выполнять расчёт, вызывая сложный SELECT, поэтому будет выполняться долго),
- THINNING_HABR_CALC_V (отобразит данные из таблицы QUOTES_CALC, поэтому выполнится быстро),
- THINNING_HABR_CHIN_V (тоже будет выполнять расчёт, вызывая сложный SELECT, поэтому будет выполняться долго),
- THINNING_HABR_PPTF_V (будет выполнять функцию THINNING_HABR_PPTF).
Время выполнения по всем методам уже замерены мной и приведены в таблице в конце статьи.
Для остальных VIEW выполним запросы и запишем время выполнения:
select count (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from THINNING_HABR_XXXX_V
где XXXX — SIMP, CHIN, PPTF.
Эти VIEW рассчитывают дайджест набора. Для расчёта дайджеста нужно выполнить fetch всех строк, и с помощью дайджеста можно сравнить наборы между собой.
Также сравнить наборы можно с помощью пакета dbms_sqlhash, но это намного медленнее, потому что требуется сортировка исходного набора, да и расчёт хэша выполняется небыстро.
Также в 12c есть пакет DBMS_COMPARISON.
Можно одновременно проверить корректность всех алгоритмов. Посчитаем дайджесты таким запросом (при 11М записей на виртуальной машине это будет относительно долго, порядка 15 минут):
with
T1 as (select 'SIMP' as ALG_NAME, a.* from THINNING_HABR_SIMP_V a
union all
select 'CALC', a.* from THINNING_HABR_CALC_V a
union all
select 'CHIN', a.* from THINNING_HABR_CHIN_V a
union all
select 'PPTF', a.* from THINNING_HABR_PPTF_V a)
select ALG_NAME
, count (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from T1
group by ALG_NAME;
Мы видим, что дайджесты совпадают, значит все алгоритмы выдали одинаковые результаты.
Теперь воспроизведём всё то же самое на MS SQL. Я тестировал на версии 2016.
Предварительно создайте базу DBTEST, после этого в ней создайте таблицу транзакций:
use DBTEST
go
create table TRANSACTIONS_RAW
(
STOCK_NAME varchar (32) not null
, UT int not null
, APRICE numeric (22, 12) not null
, AVOLUME numeric (22, 12) not null
, ID bigint identity not null
);
Загрузим скачанные данные.
На MSSQL создайте файл format_mssql.bcp:
12.0
3
1 SQLCHAR 0 0 "," 3 UT ""
2 SQLCHAR 0 0 "," 4 APRICE ""
3 SQLCHAR 0 0 "\n" 5 AVOLUME ""
И запустите скрипт LoadData-MSSQL.sql в SSMS (этот скрипт был сгенерирован единственным powershell скриптом, приведенным в разделе этой статьи для Oracle).
Создадим две функции:
use DBTEST
go
create or alter function TRUNC_UT (@p_UT bigint, @p_StripeTypeId int) returns bigint as
begin
return
case @p_StripeTypeId
when 1 then @p_UT
when 2 then @p_UT / 10 * 10
when 3 then @p_UT / 60 * 60
when 4 then @p_UT / 600 * 600
when 5 then @p_UT / 3600 * 3600
when 6 then @p_UT / 14400 * 14400
when 7 then @p_UT / 86400 * 86400
when 8 then datediff (second, cast ('1970-01-01 00:00:00' as datetime), dateadd(m, datediff (m, 0, dateadd (second, @p_UT, cast ('1970-01-01 00:00:00' as datetime))), 0))
when 9 then datediff (second, cast ('1970-01-01 00:00:00' as datetime), dateadd(yy, datediff (yy, 0, dateadd (second, @p_UT, cast ('1970-01-01 00:00:00' as datetime))), 0))
when 10 then 0
when 11 then 0
end;
end;
go
create or alter function UT2DATESTR (@p_UT bigint) returns datetime as
begin
return dateadd(s, @p_UT, cast ('1970-01-01 00:00:00' as datetime));
end;
go
Приступим к реализации вариантов:
Вариант 1 — SIMP
Выполните:
use DBTEST
go
create or alter view dbo.THINNING_HABR_SIMP_V as
with
T1 (STRIPE_ID)
as (select 1
union all
select STRIPE_ID + 1 from T1 where STRIPE_ID < 10)
, T2 as (select STRIPE_ID
, STOCK_NAME
, dbo.TRUNC_UT (UT, STRIPE_ID) as UT
, min (1000000 * cast (UT as bigint) + ID) as AOPEN_UT
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, max (1000000 * cast (UT as bigint) + ID) as ACLOSE_UT
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW, T1
group by STRIPE_ID, STOCK_NAME, dbo.TRUNC_UT (UT, STRIPE_ID))
select t.STRIPE_ID, t.STOCK_NAME, t.UT, t_op.APRICE as AOPEN, t.AHIGH
, t.ALOW, t_cl.APRICE as ACLOSE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T2 t
join TRANSACTIONS_RAW t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.AOPEN_UT / 1000000 = t_op.UT and t.AOPEN_UT % 1000000 = t_op.ID)
join TRANSACTIONS_RAW t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.ACLOSE_UT / 1000000 = t_cl.UT and t.ACLOSE_UT % 1000000 = t_cl.ID);
Отсутствующие функции first/last реализованы двойным самосоединением таблиц.
Вариант 2 — CALC
Создадим таблицу, процедуру и view:
use DBTEST
go
create table dbo.QUOTES_CALC
(
STRIPE_ID int not null
, STOCK_NAME varchar(32) not null
, UT bigint not null
, AOPEN numeric (22, 12) not null
, AHIGH numeric (22, 12) not null
, ALOW numeric (22, 12) not null
, ACLOSE numeric (22, 12) not null
, AVOLUME numeric (38, 12) not null
, AAMOUNT numeric (38, 12) not null
, ACOUNT int not null
);
go
create or alter procedure dbo.THINNING_HABR_CALC as
begin
set nocount on;
truncate table QUOTES_CALC;
declare @StripeId int;
with
T1 as (select STOCK_NAME
, UT
, min (ID) as AOPEN_ID
, max (APRICE) as AHIGH
, min (APRICE) as ALOW
, max (ID) as ACLOSE_ID
, sum (AVOLUME) as AVOLUME
, sum (APRICE * AVOLUME) as AAMOUNT
, count (*) as ACOUNT
from TRANSACTIONS_RAW
group by STOCK_NAME, UT)
insert into QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
select 1, t.STOCK_NAME, t.UT, t_op.APRICE, t.AHIGH, t.ALOW, t_cl.APRICE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T1 t
join TRANSACTIONS_RAW t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.UT = t_op.UT and t.AOPEN_ID = t_op.ID)
join TRANSACTIONS_RAW t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.UT = t_cl.UT and t.ACLOSE_ID = t_cl.ID);
set @StripeId = 1;
while (@StripeId <= 9)
begin
with
T1 as (select STOCK_NAME
, dbo.TRUNC_UT (UT, @StripeId + 1) as UT
, min (UT) as AOPEN_UT
, max (AHIGH) as AHIGH
, min (ALOW) as ALOW
, max (UT) as ACLOSE_UT
, sum (AVOLUME) as AVOLUME
, sum (AAMOUNT) as AAMOUNT
, sum (ACOUNT) as ACOUNT
from QUOTES_CALC
where STRIPE_ID = @StripeId
group by STOCK_NAME, dbo.TRUNC_UT (UT, @StripeId + 1))
insert into QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT, AOPEN, AHIGH, ALOW, ACLOSE, AVOLUME, AAMOUNT, ACOUNT)
select @StripeId + 1, t.STOCK_NAME, t.UT, t_op.AOPEN, t.AHIGH, t.ALOW, t_cl.ACLOSE, t.AVOLUME, t.AAMOUNT, t.ACOUNT
from T1 t
join QUOTES_CALC t_op on (t.STOCK_NAME = t_op.STOCK_NAME and t.AOPEN_UT = t_op.UT)
join QUOTES_CALC t_cl on (t.STOCK_NAME = t_cl.STOCK_NAME and t.ACLOSE_UT = t_cl.UT)
where t_op.STRIPE_ID = @StripeId and t_cl.STRIPE_ID = @StripeId;
set @StripeId = @StripeId + 1;
end;
end;
go
create or alter view dbo.THINNING_HABR_CALC_V as
select *
from dbo.QUOTES_CALC;
go
Варианты 3 (CHIN) и 4 (UDAF) я не реализовывал на MS SQL.
Вариант 5 — PPTF
Создадим табличную функцию и view. Эта функция является просто табличной, а не parallel pipelined table function, просто вариант сохранил своё историческое название от Oracle:
use DBTEST
go
create or alter function dbo.THINNING_HABR_PPTF ()
returns @rettab table (
STRIPE_ID bigint not null
, STOCK_NAME varchar(32) not null
, UT bigint not null
, AOPEN numeric (22, 12) not null
, AHIGH numeric (22, 12) not null
, ALOW numeric (22, 12) not null
, ACLOSE numeric (22, 12) not null
, AVOLUME numeric (38, 12) not null
, AAMOUNT numeric (38, 12) not null
, ACOUNT bigint not null)
as
begin
declare @i tinyint;
declare @tut int;
declare @trans_STOCK_NAME varchar(32);
declare @trans_UT int;
declare @trans_ID int;
declare @trans_APRICE numeric (22,12);
declare @trans_AVOLUME numeric (22,12);
declare @trans_prev_STOCK_NAME varchar(32);
declare @trans_prev_UT int;
declare @trans_prev_ID int;
declare @trans_prev_APRICE numeric (22,12);
declare @trans_prev_AVOLUME numeric (22,12);
declare @QuoteTail table (
STRIPE_ID bigint not null primary key clustered
, STOCK_NAME varchar(32) not null
, UT bigint not null
, AOPEN numeric (22, 12) not null
, AHIGH numeric (22, 12)
, ALOW numeric (22, 12)
, ACLOSE numeric (22, 12)
, AVOLUME numeric (38, 12) not null
, AAMOUNT numeric (38, 12) not null
, ACOUNT bigint not null);
declare c cursor fast_forward for
select STOCK_NAME, UT, ID, APRICE, AVOLUME
from TRANSACTIONS_RAW
order by STOCK_NAME, UT, ID; -- THIS ORDERING (STOCK_NAME, UT, ID) IS MANDATORY
open c;
fetch next from c into @trans_STOCK_NAME, @trans_UT, @trans_ID, @trans_APRICE, @trans_AVOLUME;
while @@fetch_status = 0
begin
if @trans_STOCK_NAME <> @trans_prev_STOCK_NAME or @trans_prev_STOCK_NAME is null
begin
insert into @rettab select * from @QuoteTail;
delete @QuoteTail;
end;
set @i = 10;
while @i >= 1
begin
set @tut = dbo.TRUNC_UT (@trans_UT, @i);
if @tut <> (select UT from @QuoteTail where STRIPE_ID = @i)
begin
insert into @rettab select * from @QuoteTail where STRIPE_ID <= @i;
delete @QuoteTail where STRIPE_ID <= @i;
end;
if (select count (*) from @QuoteTail where STRIPE_ID = @i) = 0
begin
insert into @QuoteTail (STRIPE_ID, STOCK_NAME, UT, AOPEN, AVOLUME, AAMOUNT, ACOUNT)
values (@i, @trans_STOCK_NAME, @tut, @trans_APRICE, 0, 0, 0);
end;
update @QuoteTail
set AHIGH = case when AHIGH < @trans_APRICE or AHIGH is null then @trans_APRICE else AHIGH end
, ALOW = case when ALOW > @trans_APRICE or ALOW is null then @trans_APRICE else ALOW end
, ACLOSE = @trans_APRICE, AVOLUME = AVOLUME + @trans_AVOLUME
, AAMOUNT = AAMOUNT + @trans_APRICE * @trans_AVOLUME
, ACOUNT = ACOUNT + 1
where STRIPE_ID = @i;
set @i = @i - 1;
end;
set @trans_prev_STOCK_NAME = @trans_STOCK_NAME;
set @trans_prev_UT = @trans_UT;
set @trans_prev_ID = @trans_ID;
set @trans_prev_APRICE = @trans_APRICE;
set @trans_prev_AVOLUME = @trans_AVOLUME;
fetch next from c into @trans_STOCK_NAME, @trans_UT, @trans_ID, @trans_APRICE, @trans_AVOLUME;
end;
close c;
deallocate c;
insert into @rettab select * from @QuoteTail;
return;
end
go
create or alter view dbo.THINNING_HABR_PPTF_V as
select *
from dbo.THINNING_HABR_PPTF ();
Выполним расчёт таблицы QUOTES_CALC для метода CALC и запишем время выполнения:
use DBTEST
go
exec dbo.THINNING_HABR_CALC
Результаты расчёта по трём методам находятся в трёх view:
- THINNING_HABR_SIMP_V (будет выполнять расчёт, вызывая сложный SELECT, поэтому будет выполняться долго),
- THINNING_HABR_CALC_V (отобразит данные из таблицы QUOTES_CALC, поэтому выполнится быстро)
- THINNING_HABR_PPTF_V (будет выполнять функцию THINNING_HABR_PPTF).
Для двух VIEW выполним запросы и запишем время выполнения:
select count (*) as CNT
, sum (STRIPE_ID) as S_STRIPE_ID, sum (UT) as S_UT
, sum (AOPEN) as S_AOPEN, sum (AHIGH) as S_AHIGH, sum (ALOW) as S_ALOW
, sum (ACLOSE) as S_ACLOSE, sum (AVOLUME) as S_AVOLUME
, sum (AAMOUNT) as S_AAMOUNT, sum (ACOUNT) as S_ACOUNT
from THINNING_HABR_XXXX_Vгде XXXX — SIMP, PPTF.
Теперь можно сравнить результаты расчёта по трём методам для MS SQL. Это можно сделать одним запросом. Выполните:
use DBTEST
go
with
T1 as (select 'SIMP' as ALG_NAME, a.* from THINNING_HABR_SIMP_V a
union all
select 'CALC', a.* from THINNING_HABR_CALC_V a
union all
select 'PPTF', a.* from THINNING_HABR_PPTF_V a)
select ALG_NAME
, count (*) as CNT, sum (cast (STRIPE_ID as bigint)) as STRIPE_ID
, sum (cast (UT as bigint)) as UT, sum (AOPEN) as AOPEN
, sum (AHIGH) as AHIGH, sum (ALOW) as ALOW, sum (ACLOSE) as ACLOSE, sum (AVOLUME) as AVOLUME
, sum (AAMOUNT) as AAMOUNT, sum (cast (ACOUNT as bigint)) as ACOUNT
from T1
group by ALG_NAME;
Если три строки совпадают по всем полям — результат расчёта по трём методам идентичный.
Я настоятельно советую на этапе тестирования использовать маленькую выборку, потому, что производительность этой задачи на MS SQL невысокая.
Если вы располагаете только движком MS SQL, и хотите рассчитывать больший объём данных, то можно попробовать следующий метод оптимизации: можно создать индексы:
create unique clustered index TRANSACTIONS_RAW_I1 on TRANSACTIONS_RAW (STOCK_NAME, UT, ID);
create unique clustered index QUOTES_CALC_I1 on QUOTES_CALC (STRIPE_ID, STOCK_NAME, UT);
Результаты замера производительности на моей виртуальной машине, следующие:
Скрипты можно скачать с github: Oracle, схема THINNING — скрипты этой статьи, схема THINNING_LIVE — онлайн-скачивание данных с сайта bitcoincharts.com и онлайн-прореживание (но этот сайт в онлайн-режиме отдаёт данные только за последние 5 дней), и скрипт для MS SQL тоже по этой статье.
Вывод:
Эта задача решается быстрее на Oracle, чем на MS SQL. С ростом количества транзакций разрыв становится всё более существенным.
На Oracle наиболее оптимальным оказался вариант PPTF. Здесь процедурный подход оказался выгоднее, такое случается нечасто. Остальные методы показали тоже приемлемый результат — я тестировал даже объём 367М транзакций на виртуальной машине (метод PPTF рассчитал прореживание за полтора часа).
На MS SQL наиболее производительным оказался метод итерационного расчёта (CALC).
Почему же метод PPTF на Oracle оказался лидером? Из-за параллельности выполнения и из-за архитектуры — функция, которая создана как parallel pipelined table function, встраивается в середину плана запроса:
Drunik
Любая задача быстрее решается тем инструментом, которым лучше владеешь. Бегло посмотрел код на MSSQL — мне кажется там много где можно докрутить — типы курсоров, оконные функции, детерминирование функции TRUNC_UT и т.д. А вообще задача довольно простая — зачем так много вариантов перебирать и сравнивать сервера — что в итоге хотели получить?
yaroslabat Автор
Но если запрос выполняется час или день — полагаю, у каждого
разработчика БД или DBA возникнет вопрос, а можно ли его оптимизировать?
Просто есть опыт 4.5 года и на MS SQL, запустил и там. Цели «сравнить» не было
Возможно код, возможно сервер, но кроме оконных функций
Drunik
Оконные функции использовать можно в подобных запросах — в этом случае можно не делать соединения таблицы самой с собой — иногда это выгодно. Вопрос производительности — это уже другой вопрос.
Скорее всего на практике вам не потребуются все данные, а только определённый объём за период и по определённому таймфрейму — это может привести совсем к другим показателям.
И очень странные результаты тестирования варианта CALC — как может вариант, где всё заранее посчитано и сложено в таблицу медленнее какого-то другого?
И ещё вот тут — min (1000000 * cast (UT as bigint) + ID) — маловато будет смещение для 11 млн записей. Да и не нужно такие сложности — достаточно просто min(ID) сделать.
yaroslabat Автор
Тут, также как в DWH. Действительно, в каждый конкретный момент времени нам требуется небольшой кусочек данных, но за день окажется что мы опросили большую часть всего объёма, и некоторые части — многократно (и многократно же их рассчитывали). Чтобы не тратить время на многократный расчёт — мы загружаем в хранилище все данные, за весь период, и рассчитав однократно.
Почему? Он не медленнее, он быстрее всего на MS SQL.
?
Можешь связаться со мной, обсудим, отвечу на вопросы
Это моя ошибка. Я исправлю. Просто ранее это поле называлось не ID, а SEQ_NUM, и в нём хранился порядковый номер транзакции внутри секунды. Там окна 10^6 было с запасом. Но потом я отказался от этого поля, потому что требовался дополнительный оператор, который пройдёт по всей таблице и заполнит это поле на основании ID
Drunik
Хороших результатов с оконными функциями я не добился на MSSQL, так что в данном случае особенно выкладывать думаю нечего и тратить на это время тоже — использование внутри функции расчёта таймфрейма для PARTITION BY несколько раз для каждой цены свечки — не самый хороший вариант:
Тут наверное нужно делать предварительный расчёт даты/времени в отдельных колонках таблицы для каждого таймфрейма и потом уже пользоваться ими в запросе.
Вобщем не самый оптимальный вариант.
Что касается скорости метода CALC — то я имел в виду ORACLE — он оказался чуть ли не на последнем месте — просто не хватило индексов в таблице?