
Прим. перев.: Автор оригинальной статьи — Nicolas Leiva — архитектор решений Cisco, который решил поделиться со своими коллегами, сетевыми инженерами, о том, как устроена сеть Kubernetes изнутри. Для этого он исследует простейшую её конфигурацию в кластере, активно применяя здравый смысл, свои познания о сетях и стандартные утилиты Linux/Kubernetes. Получилось объёмно, зато весьма наглядно.

Помимо того факта, что руководство Kubernetes The Hard Way от Kelsey Hightower просто работает (даже на AWS!), мне понравилось, что сеть поддерживается в чистоте и простоте; и это замечательная возможность понять, какова роль, например, Container Network Interface (CNI). Сказав это, добавлю, что сеть Kubernetes в действительности не очень-то интуитивно понятна, особенно для новичков… а также не забывайте, что «такой вещи, как сети для контейнеров, попросту не существует».
Хотя уже есть неплохие материалы по этой теме (см. ссылки здесь), я не смог найти такого примера, что объединил бы всё необходимое с выводами команд, которые так любят и ненавидят сетевые инженеры, демонстрируя, что же на самом деле происходит за кулисами. Поэтому я и решил собрать информацию из множества источников — надеюсь, это поможет и вам лучше разобраться, как всё связано друг с другом. Эти знания важны не только для того, чтобы проверить себя, но и для упрощения процесса диагностики проблем. Можете последовать приведенному примеру в своём кластере из Kubernetes The Hard Way: все IP-адреса и настройки взяты оттуда (по состоянию коммитов на май 2018 года, до использования контейнеров Nabla).
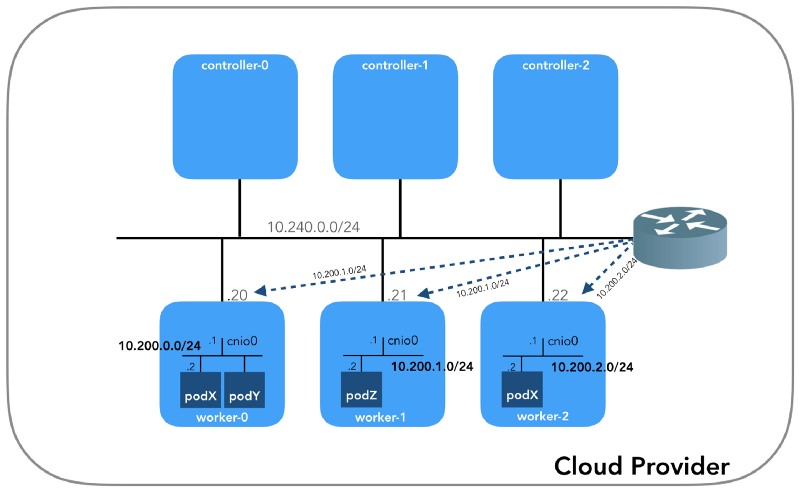
А начнём мы с конца, когда у нас есть три контроллера и три рабочих узла:
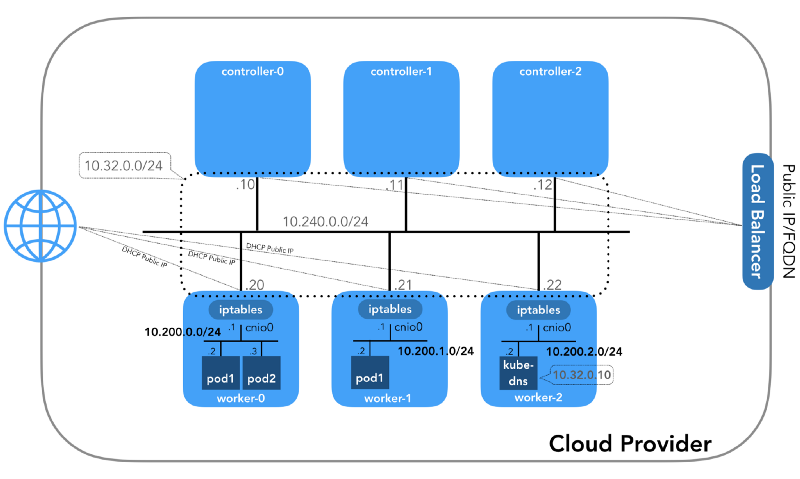
Вы можете заметить, что здесь также есть как минимум три частные подсети! Немного терпения, и все они будут рассмотрены. Помните, что, хоть мы и ссылаемся на очень специфичные IP-префиксы, они попросту взяты из Kubernetes The Hard Way, так что имеют лишь локальную значимость, а вы вольны выбрать для своего окружения любой другой блок адресов в соответствии с RFC 1918. Для случая с IPv6 будет отдельная статья в блоге.
Это внутренняя сеть, частью которой являются все узлы. Определяется флагом
(
(
Каждый экземпляр будет иметь два IP-адреса: частный от сети узла (контроллеры —
Все узлы должны быть способны пинговать друг друга, если политики безопасности верны (и если
Это сеть, в которой живут поды. Каждый рабочий узел использует подсеть этой сети. В нашем случае —
Чтобы понять, как всё настроено, сделаем шаг назад и посмотрим на сетевую модель Kubernetes, которая требует следующего:
Реализация всего этого возможна разными способами, и Kubernetes передаёт сетевую настройку плагину CNI.
Linux предоставляет семь различных пространств имён (
Спустимся на землю и посмотрим, как всё это относится к кластеру. Во-первых, сетевые плагины в Kubernetes разнообразны, и плагины CNI — одни из них (почему не CNM?). Kubelet на каждом узле говорит исполняемой среде контейнера, какой сетевой плагин использовать. Container Network Interface (CNI) находится между исполняемой средой контейнера и сетевой реализацией. А уже плагин CNI настраивает сеть.
Реальные бинарники плагина CNI находятся в
Обратите внимание, что параметры вызова
Первым делом Kubernetes создаёт сетевое пространство имён для пода, ещё до вызова каких-либо плагинов. Это реализуется с помощью специального контейнера
Используемый конфиг для CNI указывает на применение плагина

Также будет настроена veth-пара для подключения пода к только что созданному мосту:
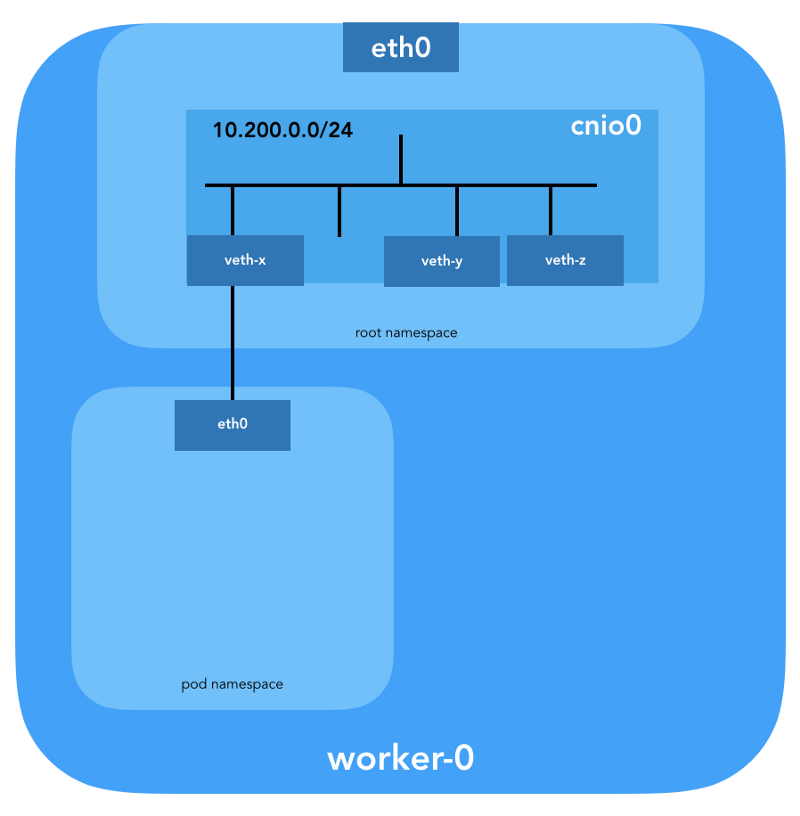
Для назначения L3-информации, такой как IP-адреса, вызывается плагин IPAM (
И последняя важная деталь: мы запросили маскарадинг (

Теперь мы готовы настраивать поды. Посмотрим на все сетевые пространства имён одного из рабочих узлов и проанализируем одно из них после создания deployment'а
С помощью опции
Также вывести список всех сетевых пространств имён можно с помощью
Чтобы увидеть все процессы, запущенные в сетевом пространстве
Видно, что помимо
Теперь посмотрим, что расскажет об этом поде
Больше подробностей:
Мы видим название пода —
Зная пространство имён containerd (
… и
ID контейнера
Помните, что процессы с PID 27331 и 27355 запущены в сетевом пространстве имён
… и:
Теперь мы точно знаем, какие контейнеры запущены в этом поде (

Как же этот под (
Для этих целей воспользуемся
… и
Таким образом подтверждается, что IP-адрес, полученный ранее через
Видим, что
Чтобы убедиться в этом окончательно, посмотрим:
Отлично, с виртуальным линком теперь всё понятно. С помощью
Итак, картина выглядит следующим образом:
Как мы на самом деле пересылаем трафик? Посмотрим на таблицу маршрутизации в сетевом пространстве имён пода:
По меньшей мере известно, как добраться до корневого пространства имён (
Мы знаем, как пересылать пакеты на VPC Router (у VPC есть «скрытый» [implicit] роутер, который обычно имеет второй адрес из основного пространства IP-адресов подсети). Теперь: знает ли VPC Router, как добраться до сети каждого пода? Нет, не знает, поэтому предполагается, что маршруты будут настроены плагином CNI или же вручную (как в руководстве). По всей видимости, AWS CNI-plugin делает именно это за нас в AWS. Помните, что есть множество плагинов CNI, а мы рассматриваем пример простейшей сетевой конфигурации:
Командой
(
Получим:
Пинги от одного контейнера к другому должны быть успешными:
Для понимания движения трафика можно посмотреть на пакеты с помощью
IP источника с пода 10.200.0.21 транслируется в IP-адрес узла 10.240.0.20.
В iptables можно увидеть, что счётчики увеличиваются:
С другой стороны, если убрать
Пинг всё ещё должен проходить:
И в данном случае — без использования NAT:
Итак, мы проверили, что «все контейнеры могут общаться с любыми другими контейнерами без использования NAT».
Возможно, вы заметили в примере с
Есть разные способы публикации сервиса; типом по умолчанию является
(
Как именно?.. Снова
Как только пакеты создаются процессом (
Следующие цели соответствуют TCP-пакетам, отправленным на 53-й порт у 10.32.0.10, и транслируются получателю 10.200.0.27 с 53-м портом:
То же самое для UDP-пакетов (получатель 10.32.0.10:53 > 10.200.0.27:53):
Есть и другие типы
Под теперь доступен из интернета как
Пакет пересылается от worker-0 к worker-1, где находит своего получателя:
Идеальна ли такая схема? Возможно, нет, но она работает. В данном случае запрограммированные правила
Другими словами, адрес для получателя пакетов с портом 31088 транслируется в 10.200.1.18. Порт тоже транслируется, с 31088 на 80.
Мы не затронули другой тип сервисов —
Могло показаться, что здесь множество информации, однако мы лишь затронули верхушку айсберга. В будущем я собираюсь рассказать про IPv6, IPVS, eBPF и пару интересных актуальных плагинов CNI.
Читайте также в нашем блоге:
Помимо того факта, что руководство Kubernetes The Hard Way от Kelsey Hightower просто работает (даже на AWS!), мне понравилось, что сеть поддерживается в чистоте и простоте; и это замечательная возможность понять, какова роль, например, Container Network Interface (CNI). Сказав это, добавлю, что сеть Kubernetes в действительности не очень-то интуитивно понятна, особенно для новичков… а также не забывайте, что «такой вещи, как сети для контейнеров, попросту не существует».
Хотя уже есть неплохие материалы по этой теме (см. ссылки здесь), я не смог найти такого примера, что объединил бы всё необходимое с выводами команд, которые так любят и ненавидят сетевые инженеры, демонстрируя, что же на самом деле происходит за кулисами. Поэтому я и решил собрать информацию из множества источников — надеюсь, это поможет и вам лучше разобраться, как всё связано друг с другом. Эти знания важны не только для того, чтобы проверить себя, но и для упрощения процесса диагностики проблем. Можете последовать приведенному примеру в своём кластере из Kubernetes The Hard Way: все IP-адреса и настройки взяты оттуда (по состоянию коммитов на май 2018 года, до использования контейнеров Nabla).
А начнём мы с конца, когда у нас есть три контроллера и три рабочих узла:
Вы можете заметить, что здесь также есть как минимум три частные подсети! Немного терпения, и все они будут рассмотрены. Помните, что, хоть мы и ссылаемся на очень специфичные IP-префиксы, они попросту взяты из Kubernetes The Hard Way, так что имеют лишь локальную значимость, а вы вольны выбрать для своего окружения любой другой блок адресов в соответствии с RFC 1918. Для случая с IPv6 будет отдельная статья в блоге.
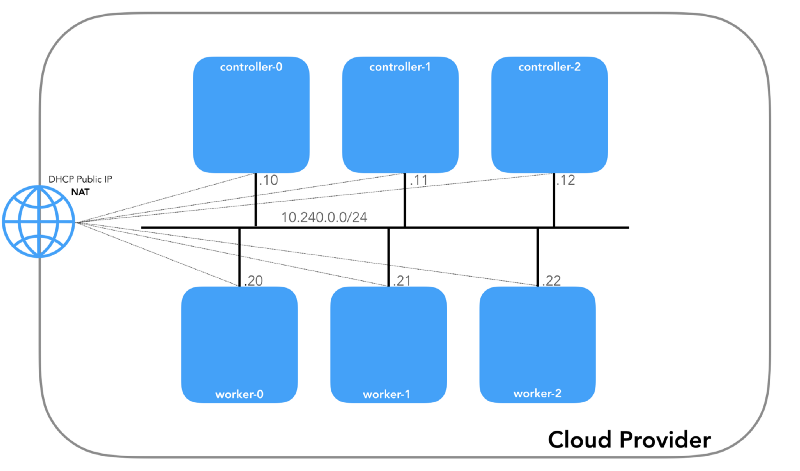
Сеть узла (10.240.0.0/24)
Это внутренняя сеть, частью которой являются все узлы. Определяется флагом
--private-network-ip в GCP или опцией --private-ip-address в AWS при выделении вычислительных ресурсов.Инициализация узлов контроллера в GCP
for i in 0 1 2; do
gcloud compute instances create controller-${i} # ...
--private-network-ip 10.240.0.1${i} # ...
done(
controllers_gcp.sh)Инициализация узлов контроллера в AWS
for i in 0 1 2; do
declare controller_id${i}=`aws ec2 run-instances # ...
--private-ip-address 10.240.0.1${i} # ...
done(
controllers_aws.sh)Каждый экземпляр будет иметь два IP-адреса: частный от сети узла (контроллеры —
10.240.0.1${i}/24, воркеры — 10.240.0.2${i}/24) и публичный, назначенный облачным провайдером, о котором мы поговорим попозже, как доберёмся до NodePorts.GCP
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING
worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING
...AWS
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /'
10.240.0.10 34.228.XX.XXX controller-0
10.240.0.21 34.173.XXX.XX worker-1
...Все узлы должны быть способны пинговать друг друга, если политики безопасности верны (и если
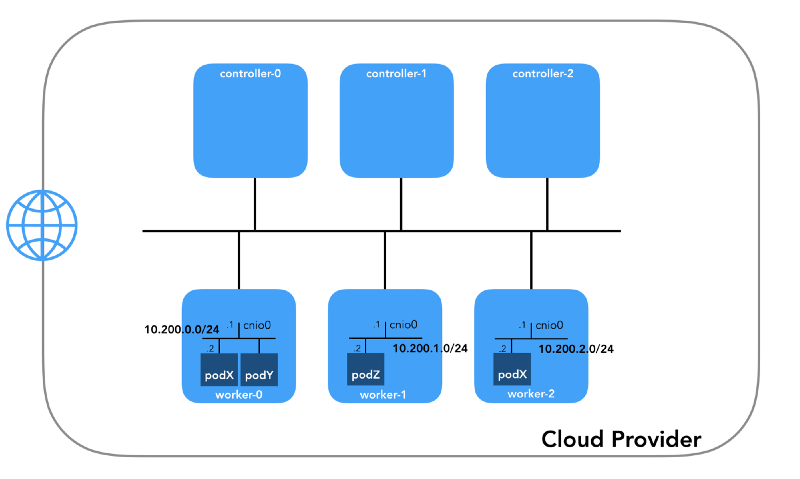
ping установлен на хост).Сеть подов (10.200.0.0/16)
Это сеть, в которой живут поды. Каждый рабочий узел использует подсеть этой сети. В нашем случае —
POD_CIDR=10.200.${i}.0/24 для worker-${i}.Чтобы понять, как всё настроено, сделаем шаг назад и посмотрим на сетевую модель Kubernetes, которая требует следующего:
- Все контейнеры могут общаться с любыми другими контейнерами без использования NAT.
- Все узлы могут общаться со всеми контейнерами (и наоборот) без использования NAT.
- IP, который видит контейнер, должен быть таким же, как его видят другие.
Реализация всего этого возможна разными способами, и Kubernetes передаёт сетевую настройку плагину CNI.
«Плагин CNI отвечает за добавление сетевого интерфейса в сетевом пространстве имён контейнера (например, один конец veth-пары) и выполнение необходимых изменений на хосте (например, подключение второго конца veth к мосту). Затем он должен назначить IP интерфейсу и настроить маршруты соответственно разделу «IP Address Management» путём вызова нужного плагина IPAM». (из Container Network Interface Specification)
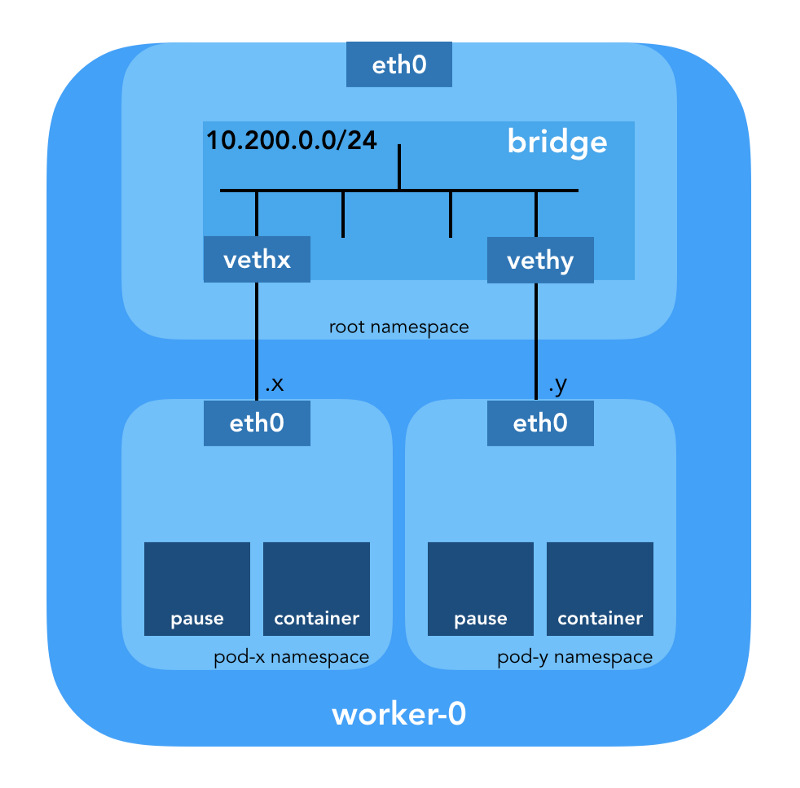
Сетевое пространство имён
«Пространство имён оборачивает глобальный системный ресурс в абстракцию, которая видна процессам в этом пространстве имён таким образом, что у них есть свой изолированный экземпляр глобального ресурса. Изменения в глобальном ресурсе видны другим процессам, входящим в это пространство имён, но не видны иным процессам». (из man-страницы namespaces)
Linux предоставляет семь различных пространств имён (
Cgroup, IPC, Network, Mount, PID, User, UTS). Сетевые (Network) пространства имён (CLONE_NEWNET) определяют сетевые ресурсы, которые доступны процессу: «У каждого сетевого пространства имён есть свои сетевые устройства, IP-адреса, таблицы IP-маршрутизации, директория /proc/net, номера портов и так далее» (из статьи «Namespaces in operation»).Виртуальные Ethernet-устройства (Veth)
«Виртуальная сетевая пара (veth) предлагает абстракцию в виде „трубы“, которую можно использовать для создания туннелей между сетевыми пространствами имён или же для создания моста к физическому сетевому устройству в ином сетевом пространстве. Когда пространство имён освобождается, все находящиеся в нём veth-устройства уничтожаются». (из man-страницы network namespaces)
Спустимся на землю и посмотрим, как всё это относится к кластеру. Во-первых, сетевые плагины в Kubernetes разнообразны, и плагины CNI — одни из них (почему не CNM?). Kubelet на каждом узле говорит исполняемой среде контейнера, какой сетевой плагин использовать. Container Network Interface (CNI) находится между исполняемой средой контейнера и сетевой реализацией. А уже плагин CNI настраивает сеть.
«Плагин CNI выбирается передачей опции командной строки--network-plugin=cniв Kubelet. Kubelet считывает файл из--cni-conf-dir(по умолчанию это/etc/cni/net.d) и использует конфигурацию CNI из этого файла для настройки сети каждого пода». (из Network Plugin Requirements)
Реальные бинарники плагина CNI находятся в
--?cni-bin-dir (по умолчанию это /opt/cni/bin).Обратите внимание, что параметры вызова
kubelet.service включают в себя --network-plugin=cni:[Service]
ExecStart=/usr/local/bin/kubelet \ --config=/var/lib/kubelet/kubelet-config.yaml \ --network-plugin=cni \ ...Первым делом Kubernetes создаёт сетевое пространство имён для пода, ещё до вызова каких-либо плагинов. Это реализуется с помощью специального контейнера
pause, который «служит „родительским контейнером“ для всех контейнеров пода» (из статьи «The Almighty Pause Container»). Затем Kubernetes выполняет плагин CNI для присоединения контейнера pause к сети. Все контейнеры пода используют сетевое пространство имён (netns) этого pause-контейнера.{
"cniVersion": "0.3.1",
"name": "bridge",
"type": "bridge",
"bridge": "cnio0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"ranges": [
[{"subnet": "${POD_CIDR}"}]
],
"routes": [{"dst": "0.0.0.0/0"}]
}
}Используемый конфиг для CNI указывает на применение плагина
bridge для конфигурации программного моста Linux (L2) в корневом пространстве имён под названием cnio0 (имя по умолчанию — cni0), который выступает в роли шлюза ("isGateway": true).Также будет настроена veth-пара для подключения пода к только что созданному мосту:
Для назначения L3-информации, такой как IP-адреса, вызывается плагин IPAM (
ipam). В данном случае используется тип host-local, «который хранит состояние локально на файловой системе хоста, чем обеспечивает уникальность IP-адресов на одном хосте» (из описания host-local). Плагин IPAM возвращает эту информацию предыдущему плагину (bridge), благодаря чему могут быть настроены все указанные в конфиге маршруты ("routes": [{"dst": "0.0.0.0/0"}]). Если gw не указан, он берётся из подсети. Маршрут по умолчанию тоже настраивается в сетевом пространстве имён подов, указывая на мост (который настраивается как первый IP подсети пода).И последняя важная деталь: мы запросили маскарадинг (
"ipMasq": true) трафика, исходящего из сети подов. В действительности нам здесь не нужен NAT, но таков конфиг в Kubernetes The Hard Way. Поэтому для полноты картины я должен упомянуть, что записи в iptables плагина bridge настроены для этого конкретного примера. Все пакеты из пода, получатель которых не входит в диапазон 224.0.0.0/4, будет за NAT'ом, что не совсем соответствует требованию «все контейнеры могут общаться с любыми другими контейнерами без использования NAT». Что ж, мы ещё докажем, почему NAT не нужен…Маршрутизация пода
Теперь мы готовы настраивать поды. Посмотрим на все сетевые пространства имён одного из рабочих узлов и проанализируем одно из них после создания deployment'а
nginx отсюда. Воспользуемся lsns с опцией -t для выбора нужного типа пространства имён (т.е. net):ubuntu@worker-0:~$ sudo lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026532089 net 113 1 root /sbin/init
4026532280 net 2 8046 root /pause
4026532352 net 4 16455 root /pause
4026532426 net 3 27255 root /pauseС помощью опции
-i к ls мы можем найти их номера inode:ubuntu@worker-0:~$ ls -1i /var/run/netns
4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af
4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c
4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0Также вывести список всех сетевых пространств имён можно с помощью
ip netns:ubuntu@worker-0:~$ ip netns
cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2)
cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1)
cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)Чтобы увидеть все процессы, запущенные в сетевом пространстве
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (4026532426), можно выполнить, например, такую команду:ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p
PID TTY STAT TIME COMMAND
27255 ? Ss 0:00 /pause
27331 ? Ss 0:00 nginx: master process nginx -g daemon off;
27355 ? S 0:00 nginx: worker processВидно, что помимо
pause в этом поде мы запустили nginx. Контейнер pause делит пространства имён net и ipc со всеми остальными контейнерами пода. Запомним PID от pause — 27255; мы ещё вернёмся к нему.Теперь посмотрим, что расскажет об этом поде
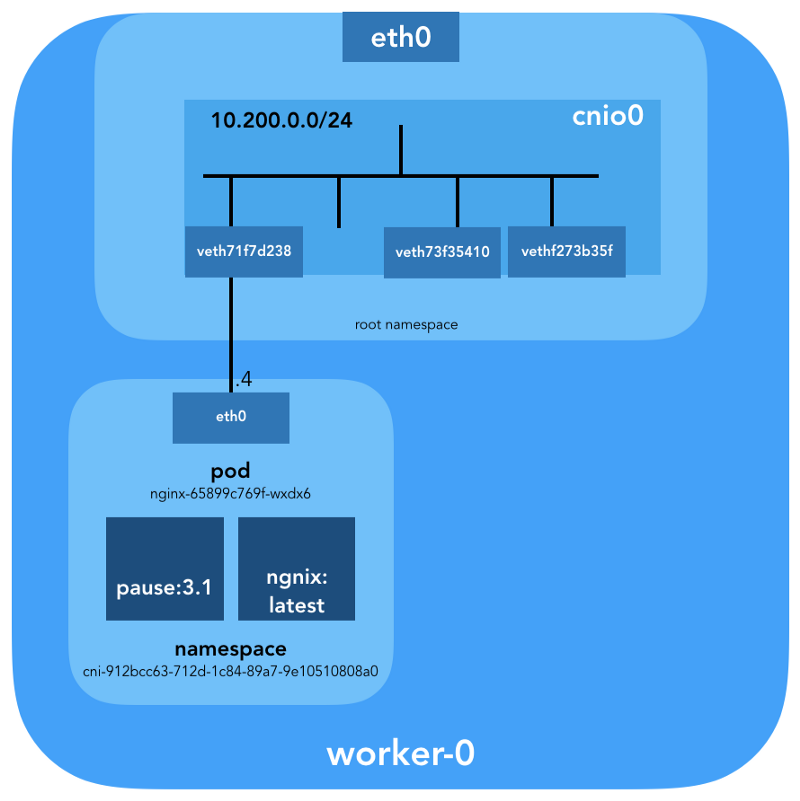
kubectl:$ kubectl get pods -o wide | grep nginx
nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0Больше подробностей:
$ kubectl describe pods nginx-65899c769f-wxdx6Name: nginx-65899c769f-wxdx6
Namespace: default
Node: worker-0/10.240.0.20
Start Time: Thu, 05 Jul 2018 14:20:06 -0400
Labels: pod-template-hash=2145573259
run=nginx
Annotations: <none>
Status: Running
IP: 10.200.0.4
Controlled By: ReplicaSet/nginx-65899c769f
Containers:
nginx:
Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7
Image: nginx
...Мы видим название пода —
nginx-65899c769f-wxdx6 — и ID одного из его контейнеров (nginx), но про pause — пока что ни слова. Копнём глубже рабочий узел, чтобы сопоставить все данные. Помните, что в Kubernetes The Hard Way не используется Docker, поэтому для получения подробностей о контейнере мы обращаемся к консольной утилите containerd — ctr (см. также статью «Интеграция containerd с Kubernetes, заменяющая Docker, готова к production» — прим. перев.):ubuntu@worker-0:~$ sudo ctr namespaces ls
NAME LABELS
k8s.ioЗная пространство имён containerd (
k8s.io), можно получить ID контейнера nginx:ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux… и
pause тоже:ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause
0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linuxID контейнера
nginx, заканчивающийся на …983c7, совпадает с тем, что мы получили от kubectl. Посмотрим, получится ли выяснить, какой pause-контейнер принадлежит поду nginx:ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls
TASK PID STATUS
...
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNINGПомните, что процессы с PID 27331 и 27355 запущены в сетевом пространстве имён
cni-912bcc63–712d-1c84–89a7–9e10510808a0?ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6
{
"ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6",
"Labels": {
"io.cri-containerd.kind": "sandbox",
"io.kubernetes.pod.name": "nginx-65899c769f-wxdx6",
"io.kubernetes.pod.namespace": "default",
"io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382",
"pod-template-hash": "2145573259",
"run": "nginx"
},
"Image": "k8s.gcr.io/pause:3.1",
...… и:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7
{
"ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7",
"Labels": {
"io.cri-containerd.kind": "container",
"io.kubernetes.container.name": "nginx",
"io.kubernetes.pod.name": "nginx-65899c769f-wxdx6",
"io.kubernetes.pod.namespace": "default",
"io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382"
},
"Image": "docker.io/library/nginx:latest",
...Теперь мы точно знаем, какие контейнеры запущены в этом поде (
nginx-65899c769f-wxdx6) и сетевом пространстве имён (cni-912bcc63–712d-1c84–89a7–9e10510808a0):- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7); - pause (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6).
Как же этот под (
nginx-65899c769f-wxdx6) подключён к сети? Воспользуемся полученным ранее PID 27255 от pause для запуска команд в его сетевом пространстве имён (cni-912bcc63–712d-1c84–89a7–9e10510808a0):ubuntu@worker-0:~$ sudo ip netns identify 27255
cni-912bcc63-712d-1c84-89a7-9e10510808a0Для этих целей воспользуемся
nsenter с опцией -t, определяющей целевой PID, и -n без указания файла, чтобы попасть в сетевое пространство имён целевого процесса (27255). Вот что скажет ip link show:ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0… и
ifconfig eth0:ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link>
ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet)
RX packets 540 bytes 42247 (42.2 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 177 bytes 16530 (16.5 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Таким образом подтверждается, что IP-адрес, полученный ранее через
kubectl get pod, настроен на интерфейсе eth0 пода. Этот интерфейс — часть veth-пары, один из концов которой в поде, а второй — в корневом пространстве имён. Чтобы узнать интерфейс второго конца, воспользуемся ethtool:ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0
NIC statistics:
peer_ifindex: 7Видим, что
ifindex пира — 7. Проверим, что он в корневом пространстве имён. Это можно сделать с помощью ip link:ubuntu@worker-0:~$ ip link | grep '^7:'
7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group defaultЧтобы убедиться в этом окончательно, посмотрим:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex
7Отлично, с виртуальным линком теперь всё понятно. С помощью
brctl посмотрим, кто ещё подключён к Linux-мосту:ubuntu@worker-0:~$ brctl show cnio0
bridge name bridge id STP enabled interfaces
cnio0 8000.0a580ac80001 no veth71f7d238
veth73f35410
vethf273b35fИтак, картина выглядит следующим образом:
Проверка маршрутизации
Как мы на самом деле пересылаем трафик? Посмотрим на таблицу маршрутизации в сетевом пространстве имён пода:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show
default via 10.200.0.1 dev eth0
10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4По меньшей мере известно, как добраться до корневого пространства имён (
default via 10.200.0.1). Теперь посмотрим таблицу маршрутизации хоста:ubuntu@worker-0:~$ ip route list
default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100
10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1
10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20
10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100Мы знаем, как пересылать пакеты на VPC Router (у VPC есть «скрытый» [implicit] роутер, который обычно имеет второй адрес из основного пространства IP-адресов подсети). Теперь: знает ли VPC Router, как добраться до сети каждого пода? Нет, не знает, поэтому предполагается, что маршруты будут настроены плагином CNI или же вручную (как в руководстве). По всей видимости, AWS CNI-plugin делает именно это за нас в AWS. Помните, что есть множество плагинов CNI, а мы рассматриваем пример простейшей сетевой конфигурации:
Глубокое погружение в NAT
Командой
kubectl create -f busybox.yaml создадим два идентичных контейнера busybox с Replication Controller:apiVersion: v1
kind: ReplicationController
metadata:
name: busybox0
labels:
app: busybox0
spec:
replicas: 2
selector:
app: busybox0
template:
metadata:
name: busybox0
labels:
app: busybox0
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always(
busybox.yaml)Получим:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1
busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0
...Пинги от одного контейнера к другому должны быть успешными:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15
PING 10.200.1.15 (10.200.1.15): 56 data bytes
64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms
64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms
--- 10.200.1.15 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.440/0.484/0.528 msДля понимания движения трафика можно посмотреть на пакеты с помощью
tcpdump или conntrack:ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15
icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1IP источника с пода 10.200.0.21 транслируется в IP-адрес узла 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15
icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1В iptables можно увидеть, что счётчики увеличиваются:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
...
5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */
Zeroing chain `POSTROUTING'С другой стороны, если убрать
"ipMasq": true из конфигурации плагина CNI, можно увидеть следующее (эта операция выполняется исключительно для образовательных целей — не рекомендуем менять конфиг на работающем кластере!):$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0
busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1
...Пинг всё ещё должен проходить:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13
PING 10.200.1.6 (10.200.1.6): 56 data bytes
64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms
64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms
--- 10.200.1.6 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.427/0.471/0.515 msИ в данном случае — без использования NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13
icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1Итак, мы проверили, что «все контейнеры могут общаться с любыми другими контейнерами без использования NAT».
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13
icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1Сеть кластера (10.32.0.0/24)
Возможно, вы заметили в примере с
busybox, что IP-адреса, выделенные для пода busybox, были разными в каждом случае. Что, если бы мы хотели сделать эти контейнеры доступными для связи со стороны других подов? Можно было бы взять текущие IP-адреса пода, но они изменятся. По этой причине нужно настроить ресурс Service, который будет проксировать запросы ко множеству недолговечных подов.«Service в Kubernetes — абстракция, определяющая логическую совокупность подов и политику, по которой к ним можно обращаться». (из документации Kubernetes Services)
Есть разные способы публикации сервиса; типом по умолчанию является
ClusterIP, настраивающий IP-адрес из CIDR-блока кластера (т.е. доступного только из кластера). Одним из таких примеров является DNS Cluster Add-on, настроенный в Kubernetes The Hard Way.# ...
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.32.0.10
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
# ...(
kube-dns.yaml)kubectl показывает, что Service помнит об endpoint'ах и делает их трансляцию:$ kubectl -n kube-system describe services
...
Selector: k8s-app=kube-dns
Type: ClusterIP
IP: 10.32.0.10
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.200.0.27:53
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.200.0.27:53
...Как именно?.. Снова
iptables. Пройдёмся по правилам, созданным для этого примера. Их полный список можно увидеть командой iptables-save.Как только пакеты создаются процессом (
OUTPUT) или приходят на сетевой интерфейс (PREROUTING), они проходят через следующие цепочки iptables:-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICESСледующие цели соответствуют TCP-пакетам, отправленным на 53-й порт у 10.32.0.10, и транслируются получателю 10.200.0.27 с 53-м портом:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H
-A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53То же самое для UDP-пакетов (получатель 10.32.0.10:53 > 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG
-A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53Есть и другие типы
Services в Kubernetes. В частности, в Kubernetes The Hard Way рассказано про NodePort — см. Smoke Test: Services.kubectl expose deployment nginx --port 80 --type NodePortNodePort публикует сервис на IP-адресе каждого узла, размещая его на статический порт (он и называется NodePort). К сервису NodePort можно обратиться и извне кластера. Проверить выделенный порт (в данном случае — 31088) можно с помощью kubectl:$ kubectl describe services nginx
...
Type: NodePort
IP: 10.32.0.53
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 31088/TCP
Endpoints: 10.200.1.18:80
...Под теперь доступен из интернета как
http://${EXTERNAL_IP}:31088/. Здесь EXTERNAL_IP — публичный IP-адрес любого рабочего экземпляра. В этом примере я использовал публичный IP-адрес worker-0. Запрос получается узлом с внутренним IP-адресом 10.240.0.20 (публичным NAT'ом занимается облачный провайдер), однако сервис в действительно запущен на другом узле (worker-1, что можно увидеть по IP-адресу endpoint'а — 10.200.1.18):ubuntu@worker-0:~$ sudo conntrack -L | grep 31088
tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1Пакет пересылается от worker-0 к worker-1, где находит своего получателя:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80
tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1Идеальна ли такая схема? Возможно, нет, но она работает. В данном случае запрограммированные правила
iptables таковы:-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA
-A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H
-A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80Другими словами, адрес для получателя пакетов с портом 31088 транслируется в 10.200.1.18. Порт тоже транслируется, с 31088 на 80.
Мы не затронули другой тип сервисов —
LoadBalancer, — который делает сервис публично доступным с помощью балансировщика нагрузки облачного провайдера, но статья уже и без того получилась большой.Заключение
Могло показаться, что здесь множество информации, однако мы лишь затронули верхушку айсберга. В будущем я собираюсь рассказать про IPv6, IPVS, eBPF и пару интересных актуальных плагинов CNI.
P.S. от переводчика
Читайте также в нашем блоге:
- «Иллюстрированное руководство по устройству сети в Kubernetes»;
- «Сравнение производительности сетевых решений для Kubernetes»;
- «Эксперименты с kube-proxy и недоступностью узла в Kubernetes»;
- «Улучшая надёжность Kubernetes: как быстрее замечать, что нода упала»;
- «Play with Kubernetes — сервис для практического знакомства с K8s»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров».
Комментарии (3)

shurup
31.08.2018 13:00В качестве дополнения к статье, специально для тех, кому кому хочется погрузиться на «следующий уровень» (в сторону плагинов CNI, на которые не раз ссылается автор), — «Kubernetes Networking: How to Write Your Own CNI Plug-in with Bash».
И ещё одним дополнением станет наш (компании «Флант») практический материал на тему сетей в Kubernetes, публикацию которого ожидаем в течение ~недели. Stay tuned!
celebrate
Спасибо за статью! А вот мне например нужно создать в Кубере подобие изолированных вланов, т.е. чтобы сервисы внутри влана могли между собой общаться, а между вланами — нет. Как мне такого достичь в Кубере?
de1m
Нужно использовать Network Policy (это что-то типа фаерволла). Так-же, если надо, то можно зашивровать соединение, для этого можно использовать cni плагин weave.