
 Глубокое обучение — Deep learning — это набор алгоритмов машинного обучения, которые моделируют высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований. Согласитесь, эта фраза звучит угрожающе. Но всё не так страшно, если о глубоком обучении рассказывает Франсуа Шолле, который создал Keras — самую мощную библиотеку для работы с нейронными сетями. Познакомьтесь с глубоким обучением на практических примерах из самых разнообразных областей. Книга делится на две части, в первой даны теоретические основы, вторая посвящена решению конкретных задач. Это позволит вам не только разобраться в основах DL, но и научиться использовать новые возможности на практике. Эта книга написана для людей с опытом программирования на R, желающих быстро познакомиться с глубоким обучением на практике, и является переложением бестселлера Франсуа Шолле «Глубокое обучение на Python», но использующим примеры на базе интерфейса R для Keras.
Глубокое обучение — Deep learning — это набор алгоритмов машинного обучения, которые моделируют высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований. Согласитесь, эта фраза звучит угрожающе. Но всё не так страшно, если о глубоком обучении рассказывает Франсуа Шолле, который создал Keras — самую мощную библиотеку для работы с нейронными сетями. Познакомьтесь с глубоким обучением на практических примерах из самых разнообразных областей. Книга делится на две части, в первой даны теоретические основы, вторая посвящена решению конкретных задач. Это позволит вам не только разобраться в основах DL, но и научиться использовать новые возможности на практике. Эта книга написана для людей с опытом программирования на R, желающих быстро познакомиться с глубоким обучением на практике, и является переложением бестселлера Франсуа Шолле «Глубокое обучение на Python», но использующим примеры на базе интерфейса R для Keras. Об этой книге
Книга «Глубокое обучение на R» адресована статистикам, аналитикам, инженерам и студентам, обладающим навыкам программирования на R, но не обладающим существенными знаниями в области машинного и глубокого обучения. Эта книга является переработанным вариантом предыдущей книги — «Глубокое обучение на Python», содержащим примеры, которые используют интерфейс R для Keras. Цель этой книги — дать сообществу R руководство, содержащее все необходимое, от базовой теории до продвинутых практических приложений. Вы увидите более 30 примеров программного кода с подробными комментариями, практическими рекомендациями и простыми обобщенными объяснениями всего, что нужно знать для использования глубокого обучения в решении конкретных задач.
В примерах используются фреймворк глубокого обучения Keras и библиотека TensorFlow как внутренний механизм. Keras — один из популярнейших и быстро развивающихся фреймворков глубокого обучения. Он часто рекомендуется как наиболее удачный инструмент для начинающих изучать глубокое обучение. Прочитав эту книгу, вы будете понимать, что такое глубокое обучение, для решения каких задач может привлекаться эта технология и какие ограничения она имеет. Вы познакомитесь со стандартным процессом интерпретации и решения задач машинного обучения и узнаете, как бороться с типичными проблемами. Вы научитесь использовать Keras для решения практических задач от распознавания образов до обработки естественного языка: классификации изображений, прогнозирования временных последовательностей, анализа эмоций и генерация изображений и текста и много другого.
Отрывок. 5.4.1. Визуализация промежуточных активаций
Визуализация промежуточных активаций заключается в отображении карт признаков, которые выводятся разными сверточными и объединяющими уровнями в сети в ответ на определенные входные данные (вывод уровня, результат функции активации, часто называют его активацией). Этот прием позволяет увидеть, как входные данные разлагаются на различные фильтры, полученные сетью в процессе обучения. Обычно для визуализации используются карты признаков с тремя измерениями: шириной, высотой и глубиной (каналы цвета). Каналы кодируют относительно независимые признаки, поэтому для визуализации этих карт признаков предпочтительнее строить двумерные изображения для каждого канала в отдельности. Начнем с загрузки модели, сохраненной в разделе 5.2:
> library(keras)
> model <- load_model_hdf5("cats_and_dogs_small_2.h5")
> model________________________________________________________________
Layer (type) Output Shape Param #
==============================================================
conv2d_5 (Conv2D) (None, 148, 148, 32) 896
________________________________________________________________
maxpooling2d_5 (MaxPooling2D) (None, 74, 74, 32) 0
________________________________________________________________
conv2d_6 (Conv2D) (None, 72, 72, 64) 18496
________________________________________________________________
maxpooling2d_6 (MaxPooling2D) (None, 36, 36, 64) 0
________________________________________________________________
conv2d_7 (Conv2D) (None, 34, 34, 128) 73856
________________________________________________________________
maxpooling2d_7 (MaxPooling2D) (None, 17, 17, 128) 0
________________________________________________________________
conv2d_8 (Conv2D) (None, 15, 15, 128) 147584
________________________________________________________________
maxpooling2d_8 (MaxPooling2D) (None, 7, 7, 128) 0
________________________________________________________________
flatten_2 (Flatten) (None, 6272) 0
________________________________________________________________
dropout_1 (Dropout) (None, 6272) 0
________________________________________________________________
dense_3 (Dense) (None, 512) 3211776
________________________________________________________________
dense_4 (Dense) (None, 1) 513
================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0Далее выберем входное изображение кошки, не являющееся частью обучающего набора.

Листинг 5.25. Отображение тестового изображения
plot(as.raster(img_tensor[1,,,]))Для извлечения карт признаков, подлежащих визуализации, создадим модель Keras, которая принимает пакеты изображений и выводит активации всех сверточных и объединяющих уровней. Для этого используем функцию keras_model из фреймворка Keras, которая принимает два аргумента: входной тензор (или список входных тензоров) и выходной тензор (или список выходных тензоров). В результате будет получен объект модели Keras, похожей на модели, возвращаемые функцией keras_sequential_model(), с которыми вы уже знакомы; эта модель отображает заданные входные данные в заданные выходные данные. Особенностью моделей
этого типа является возможность создания моделей с несколькими выходами (в отличие от keras_sequential_model()). Более подробно функция keras_model обсуждается в разделе 7.1.


Если передать этой модели изображение, она вернет значения активации слоев в исходной модели. Это первый пример модели с несколькими выходами в данной книге: до сих пор все представленные выше модели имели ровно один вход и один выход. Вообще, модель может иметь сколько угодно входов и выходов. В частности, данная модель имеет один вход и восемь выходов: по одному на каждую активацию уровня.

Возьмем для примера активацию первого сверточного слоя для входного изображения кошки:
> first_layer_activation <- activations[[1]]
> dim(first_layer_activation)
[1] 1 148 148 32Это карта признаков 148 ? 148 с 32 каналами. Попробуем отобразить некоторые из них. Сначала определим функцию для визуализации канала.
Листинг 5.28. Функция визуализации канала
plot_channel <- function(channel) {
rotate <- function(x) t(apply(x, 2, rev))
image(rotate(channel), axes = FALSE, asp = 1,
col = terrain.colors(12))
}Теперь отобразим второй канал активации первого уровня оригинальной модели (рис. 5.18). Похоже, что этот канал представляет детектор контуров.
Листинг 5.29. Визуализация второго канала
plot_channel(first_layer_activation[1,,,2])Теперь взглянем на седьмой канал (рис. 5.19), но имейте в виду, что у вас каналы могут отличаться, потому что обучение конкретных фильтров не является детерминированной операцией. Этот канал немного отличается и, похоже, что он выделяет радужку кошачьих глаз.
Листинг 5.30. Визуализация седьмого канала
plot_channel(first_layer_activation[1,,,7])
Теперь построим полную визуализацию всех активаций в сети (листинг 5.31). Для этого извлечем и отобразим каждый канал во всех восьми картах активаций, поместив результаты в один большей тензор с изображениями (рис. 5.20–5.23).
Листинг 5.31. Визуализация всех каналов для всех промежуточных активаций
image_size <- 58
images_per_row <- 16
for (i in 1:8) {
layer_activation <- activations[[i]]
layer_name <- model$layers[[i]]$name
n_features <- dim(layer_activation)[[4]]
n_cols <- n_features %/% images_per_row
png(paste0("cat_activations_", i, "_", layer_name, ".png"),
width = image_size * images_per_row,
height = image_size * n_cols)
op <- par(mfrow = c(n_cols, images_per_row), mai = rep_len(0.02, 4))
for (col in 0:(n_cols-1)) {
for (row in 0:(images_per_row-1)) {
channel_image <- layer_activation[1,,,(col*images_per_row) + row + 1]
plot_channel(channel_image)
}
}
par(op)
dev.off()
}

Вот несколько замечаний к полученным результатам.
- Первый слой действует как коллекция разных детекторов контуров. На этом этапе активация сохраняет почти всю информацию, имеющуюся в исходном изображении.
- По мере подъема вверх по слоям активации становятся все более абстрактными, а их визуальная интерпретация все более сложной. Они начинают кодировать высокоуровневые понятия, такие как «кошачье ухо» или «кошачий глаз». Высокоуровневые представления несут все меньше информации об исходном изображении и все больше — о классе изображения.
- Разреженность активаций увеличивается с глубиной слоя: в первом слое все фильтры активируются исходным изображением, но в последующих слоях остается все больше и больше пустых фильтров. Это означает, что шаблон, соответствующий фильтру, не обнаруживается в исходном изображении.
Мы только что рассмотрели важную универсальную характеристику представлений, создаваемых глубокими нейронными сетями: признаки, извлекаемые слоями, становятся все более абстрактными с глубиной слоя. Активации на верхних слоях содержат все меньше и меньше информации о конкретном входном изображении, и все больше и больше о цели (в данном случае о классе изображения — кошка или собака). Глубокая нейронная сеть фактически действует как конвейер очистки информации, которая получает неочищенные исходные данные (в данном случае изображения в формате RGB) и подвергает их многократным преобразованиям, фильтруя ненужную информацию (например, конкретный внешний вид изображения) и оставляя и очищая нужную (например, класс изображения).
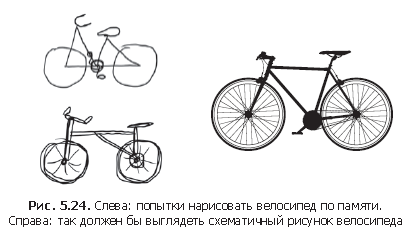
Примерно так же люди и животные воспринимают окружающий мир: понаблюдав сцену в течение нескольких секунд, человек запоминает, какие абстрактные объекты присутствуют в ней (велосипед, дерево), но не запоминает всех деталей внешнего вида этих объектов. Фактически при попытке нарисовать велосипед по памяти, скорее всего, вам не удастся получить более или менее правильное изображение, даже при том, что вы могли видеть велосипеды тысячи раз (см. примеры на рис. 5.24). Попробуйте сделать это прямо сейчас, и вы убедитесь в справедливости сказанного. Ваш мозг научился полностью абстрагировать видимую картинку, получаемую на входе, и преобразовывать ее в высокоуровневые визуальные понятия, фильтруя при этом неважные визуальные детали затрудняя тем самым их запоминание.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Deep Learning with R