
Поясню ещё раз суть всех вещей простым языком.
Пользователь имеет видеорегистратор, например, популярной модели QCM-08DL. Ему нужна видеозапись за определённую дату и время. Он может её извлечь либо на флешку, либо через web-интерфейс видеорегистратора (DVR) на компьютер. Извлечённый файл с видеозаписью (расширение .264) откроется только в программе-плеере, которая прилагается с DVR. Плеер весьма неудобный. Его ещё можно открыть, в плеере VLC, поставив режим RAW H264 в настройках демультиплексирования (настройки для опытных пользователей). Но при этом нормальному воспроизведению мешают, видимо, блоки аудиопотоков, которые интерпретируются как видео, а звуковое сопровождение отсутствует. А для того, чтобы видео открыть в любом плеере, файл .264 нужно его предварительно преобразовать в какой-либо популярный формат, например, avi. Программа для преобразования также прилагается с DVR. Но она также очень неудобная. Когда речь идёт об одном или нескольких файлах, проблем нет. Однако когда ставится задача получить доступ ко всем видеозаписям на жёстком диске, а уж тем более их все преобразовать в популярный формат, штатный инструментарий практически не пригоден.

Задача о доступе ко всем файлам решена. Этому и была посвящена прошлая публикация. Приступим к решению второй задачи. Мне уже давали «дельные советы»: достаточно в имени файла переименовать расширение с «264» на «avi», и всё попрёт, мол, нечего заморачиваться. Но это самая распространённая ошибка любого рядового пользователя, который, как правило, не разбирается в соответствующих вопросах.
В прошлой публикации я уже писал кратко про структуру исходного файла .264. Напомню.
Основная информация с аудио и видео потоками берёт начало по смещению 65536 байт. Блоки видеопотока начинаются с 8-байтового заголовка «01dcH264» (встречается также «00dcH264»). Следующие за ним 4 байта описывают размер текущего блока видеопотока в байтах. Через 4 байта нулей (00 00 00 00) начинается сам блок видеопотока. Блоки аудиопотоков имеют заголовок «03wb» (хотя, по моим наблюдениям, первый символ заголовка в некоторых случаях был необязательно «0»). После – 12 байт информации, которую я пока не разгадал. А начиная с 17-ого байта – аудиопоток фиксированной длины 160 байт. Какие-либо метки в конце файла отсутствуют.
Прокомментирую вышесказанное. Всё, что находится до смещения 65536 байт, оказалось неразгаданным и ненужным. Со смещения 65536 байт до первого заголовка потока есть небольшой промежуток, содержимое которого также не разгадано, и, тем более, как было мной проверено, оно не встречается в выходном файле avi после конвертации штатной программой.
Каждый блок видеопотока представляет собой один кадр. Первый символ в заголовке блоков видеопотока необязательно «0». Его назначение я не разгадывал, ибо, как я выяснил, оно не является ключевым в решении поставленной задачи. Второй символ заголовка видеопотока может быть как «1», так и «0». Во втором случае содержание блока видеопотока представляет собой так называемый опорный кадр. А в первом случае содержание блока видеопотока представляет собой закодированный сжатый кадр, который зависит от опорного кадра. Размер содержимого опорного кадра значительно больше размера содержимого сжатого вспомогательного кадра. Период следования опорных кадров, скорее всего, зависит от настроек степени сжатия в DVR. Но в моём случае период следования составил 1 кадр/сек.
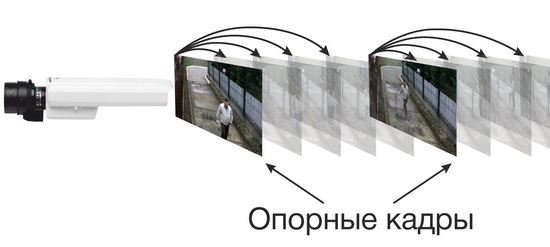
Штатная программа для перепаковки видео из контейнера «264» в контейнер «avi» давала разные результаты по поводу частоты кадров. В случае с видео, которые были записаны в режиме высокого разрешения (704*576) частота кадров составила 20 кадров/сек. А в случае с низким разрешением (352*288) – 25 кадров/сек. Эту информацию выдаёт утилита «MediaInfo» Она же выдаёт то, что размер видео при любом случае единый: 720*576, причём размер видеопотока (эта же утилита сообщает) — 704*576 или 352*288. Большинство плееров разворачиваются именно под размер видеопотока. Однако встречался мне плеер, который некорректно отображал полуэкранный режим при воспроизведении файла 352*288. Я хотел исправить этот незначительный недостаток штатного перепаковщика, заглянув в байты содержания видеопотока и вытащив оттуда информацию о размере кадра. Но на скорую руку этого мне сделать не удалось. Вышесказанное продемонстрировано на рисунке ниже.

Теперь по поводу частоты кадров. Как я выяснил, штатный перепаковщик не обращается ни к какому полю заголовка контейнера «264». Он судит о частоте кадров путём подсчёта соотношения количества блоков видео и аудиопотоков. И это значение при расчёте даже не округляется до целого значения, что видно из рисунка выше (обведено зелёным цветом). Как я выяснил, число блоков аудиопотока на единицу времени всегда и везде (в любом файле) фиксированное, а именно 25 блоков в секунду. Если исследовать файл видео с частотой 20 кадров/сек., то опорный кадр (блок) встречается через каждые 19 сжатых кадров, а для случая 25 кадров/сек. – через каждые 24 сжатых кадра.
Продолжим изучать структуру заголовка видеопотока. С первыми восьми байтами мы разобрались: это метка опорного или сжатого кадра плюс ключевое слово «H264». Следующие четыре байта, описывают, как я выяснил, не точный, а приблизительный размер содержимого видеопотока. А штатный перепаковщик перебрасывает полностью все байты этого содержимого, а затем получившийся размер записывает в соответствующие поля avi-контейнера. И это значение отличается от значения, указанного в соответствующем поле исходного .264 файла.
Двенадцать байт информации после заголовка блока аудиопотока я разгадал частично. Во всяком случае, ключевыми элементами являются 4 последних байта, после которых начинается аудиопоток. Это два 16-разрядных числа, которые описывают начальные параметры итерационной схемы декодирования из ADPCM в PCM. Декодирование увеличивает размер аудиопотока в 4 раза. Я ещё заранее при детальном исследовании файлов выяснил, что штатный перепаковщик декодирует аудио, но содержимое видео оставляет без изменений.
Не имея глубоких знаний, я долго пытался разгадывать, какой именно алгоритм декодирования применён в моём случае. Интуитивно уже догадывался, что применён метод сжатия ADPCM. Точнее, не интуитивно, а с грамотным подходом, опираясь на тот факт, что аудиопоток сжат ровно в 4 раза. А при открытии фрагмента в Adobe Audition как RAW в различных форматах (и сравнивая такой же фрагмент после перепаковки штатной программой), очень похожий (но не точный) по звучанию результат мне выдал ADPCM. Для разбора алгоритма сжатия мне помогла информация на сайте wiki.multimedia.cx/index.php/IMA_ADPCM. Здесь я узнал о двух начальных параметрах декодирования, а потом «методом тыка» догадался, что эти начальные параметры записаны в 4-х байтах перед началом аудиопотока. Опишу работу алгоритма и приведу грубую математическую интерпретацию (под спойлером).
Анализируя код алгоритма на Си, можно увидеть две таблицы. Они приведены ниже.
int ima_index_table[] =
{
-1, -1, -1, -1, 2, 4, 6, 8
};
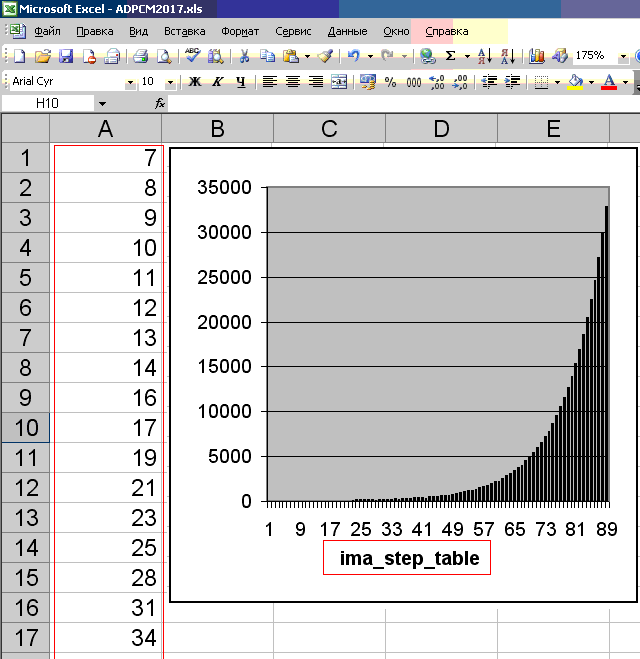
int ima_step_table[] =
{
7, 8, 9, 10, 11, 12, 13, 14,
16, 17, 19, 21, 23, 25, 28, 31,
34, 37, 41, 45, 50, 55, 60, 66,
73, 80, 88, 97, 107, 118, 130, 143,
157, 173, 190, 209, 230, 253, 279, 307,
337, 371, 408, 449, 494, 544, 598, 658,
724, 796, 876, 963, 1060, 1166, 1282, 1411,
1552, 1707, 1878, 2066, 2272, 2499, 2749, 3024,
3327, 3660, 4026, 4428, 4871, 5358, 5894, 6484,
7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899,
15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794,
32767
};
Эти два «волшебных» массива, можно сказать, представляют собой табличные функции, в аргументы которых подставляются соответственно те самые два начальных параметра. В процессе итерации с каждым шагом параметры пересчитываются и подставляются в эти таблицы вновь. Сначала посмотрим, как это реализуется в коде.
Объявляем необходимые, в том числе и вспомогательные переменные.
int current1;
int step;
int stepindex1;
int diff;
int current;
int stepindex;
int value; //Значение входного сэмпла;
Перед началом итерации нужно присвоить переменной current начальный параметр , а переменной stepindex — . Это делается за пределами рассматриваемого алгоритма, поэтому я не отражаю это кодом. Далее следуют преобразования, которые выполняются по кругу (в цикле).
value = read(input_sample); //Псевдокод считывания входного сэмпла;
current1 = current;
stepindex1 = stepindex;
step = ima_step_table[stepindex1];
diff = step>>3;
if(value & 1){
diff += step >> 2;
}
if(value & 2){
diff += step >> 1;
}
if(value & 4){
diff += step;
}
if(value & 8){
current1 -= diff;
if(current1 < -32768){ //Лимит, если "зашкалит";
current1 = -32768;
}
}else{
current1 += diff;
if(current1 > 32767){ //Лимит, если "зашкалит";
current1 = 32767;
}
}
//На этом этапе известно значение выходного сэмпла: это переменная current1;
stepindex1 += ima_index_table[value & 7];
if(stepindex1 < 0){ //Тоже "лимит";
stepindex1 = 0;
}
if(stepindex1 > 88){ //Тоже "лимит";
stepindex1 = 88;
}
output_sample = curent1; //Псевдокод вывода выходного сэмпла;
current = current1;
stepindex = stepindex1;
Во вспомогательную переменную step из массива ima_step_table записывается значение по индексу stepindex1. Для первой итерации это начальный параметр , для дальнейших итераций это пересчитанный параметр . Затем значение из этого массива делится на 8 (видимо, нацело) операцией битового сдвига вправо, и результатом этого деления инициализируется переменная diff. Затем происходит анализ трёх младших битов значения входного сэмпла и, в зависимости от их состояний, переменная diff может быть скорректирована тремя слагаемыми. Слагаемые представляют собой аналогичное целочисленное деление значения diff на 4 (>>2), на 2 (>>1) или diff без изменений (пусть это будет деление на 1 для обобщения). Затем анализируется старший (знаковый) бит значения входного сэмпла. В зависимости от его состояния к переменной current1 прибавляется или вычитается переменная diff, которая была сформирована перед этим. Это и будет значение выходного сэмпла. Для корректности значения ограничиваются сверху и снизу. Затем stepindex1 корректируется путём прибавления значения из массива ima_index_table по индексу значения входного сэмпла с обнулённым знаковым битом. Значения stepindex1 также подвергаются лимиту. В самом конце перед повторением этого алгоритма значениям current и stepindex присваиваются только что пересчитанные значения current1 и stepindex1, и алгоритм повторяется заново.
Можно попробовать разобраться, чтобы приблизительно понять, как формируется переменная diff. Пусть . Это значения переменной step на каждом i-ом шаге итерации, как значения функции (массива) аргумента , где . Для удобства обозначим сишную переменную diff как . Следуя логике рассуждений, описанных выше, имеем: где — младшие 3 бита числа . Приводя к общему знаменателю, преобразуем это выражение к более удобному виду: Последнее преобразование основано на том, что, в неком смысле, младшие три бита (0 или 1) числа с представленными коэффициентами есть нечто иное, как запись абсолютного значения этого числа, а старший бит числа будет соответствовать знаку всего выражения. Далее по формуле вычисляется новое значение сэмпла на основе старого. Кроме того, вычисляется новое значение переменной : Модуль в формуле указывает на то, что переменная попадает в функцию без учёта старшего знакового бита, что и отражено в коде. А функция — это значение массива ima_index_table с индексом, соответствующий аргументу.
В описании формул я пренебрёг операциями ограничения сверху и снизу. Итого, итерационная схема выглядит приблизительно так:
Сильно глубоко в теорию кодирования/декодирования ADPCM я не вникал. Однако, табличные значения массива ima_step_table (из 89 штук), судя по отражению их на графике (см. рис. ниже), описывают вероятностное распределение сэмплов относительно нулевой линии. На практике обычно так: чем сэмпл ближе к нулевой линии, тем он чаще встречается. Следовательно, ADPCM основан на вероятностной модели, и далеко не любой исходный набор 16-битных сэмплов PCM может быть корректно преобразован в 4-битные сэмплы ADPCM. А вообще говоря, ADPCM — это PCM с переменным шагом квантования. Как раз, видимо, данный график отражает этот самый переменный шаг. Он выбран грамотно, на основе закона распределения аудиоданных на практике.
Теперь перейдём к описанию структуры avi контейнера. На самом деле, он представляет собой сложную иерархическую структуру.
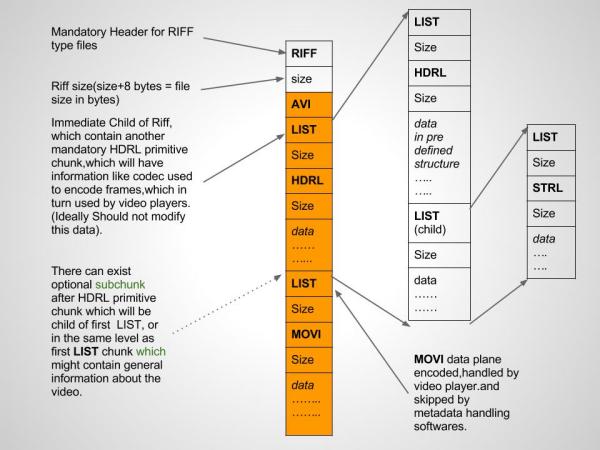
Но, упростив задачу для частного случая, я представил структуру avi в линейном виде. Итого получилось так: файл avi состоит из большого заголовка, нулевых байтов пропуска (JUNK), области потоков аудио и видео (с их заголовками и размерами содержимого), и списка индексов. Последний служит, в частности, для прокрутки видео в плеере. Без этого списка прокрутка не будет работать (проверял). Он представляет собой только оглавление, где перечислены ключевые названия блоков потока (совпадающими с названиями в заголовках блока), соответствующие размеры содержимого и значения смещений (адреса) относительно начала области потоков.
Теперь можно перейти к разработке программы. Конкретное описание задачи следующее.
В корне раздела X: имеется каталог «DVR». В данном каталоге содержится множество непустых подкаталогов (и только подкаталогов) с именами, которые соответствуют неким датам. В каждом из таких подкаталогов имеется множество файлов с различными именами и расширением «264». Требуется в разделе Y: создать каталог «DVR», а в нём те же самые подкаталоги, как и в разделе X:. Каждый из таких подкаталогов заполнить файлами с теми же соответствующими именами, но с расширениями не «264», а «avi». Данные avi-файлы нужно получить из исходных 264-файлов путём их обработки, которая, так или иначе, повторяет алгоритм уже имеющийся программы. Обработка заключается в прямой перепаковке потоков видео, перепаковке с декодированием потоков аудио, форматировании файла avi. Программа должна запускаться из командной строки следующим образом: «264toavi.exe X: Y:», где «264toavi.exe» — имя программы, «X:» — исходный раздел, «Y:» — раздел назначения.
На самом деле, для упрощения задачи, можно было написать программу, которая занималась бы только преобразованием (перепаковкой) одного файла, сделав дня неё два аргумента: имя входного файла и имя выходного файла. А затем, чтобы реализовать именно групповую перепаковку, можно написать командный батник (bat), используя другие инструменты, например, Excel. Но мной была реализована полноценная программа, весьма громоздкая. Вряд ли исходный код заслужил бы внимания у читателей. Опишу структуру программного кода.
Программа написана на языке Си в среде разработки «Dev-C++» с элементами WinAPI. В программе реализованы три большие вспомогательные функции: функция формирования первоначального заголовка avi, функция декодирования сэмпла аудио и функция сканирования исходного файла «264» по словам. Словами я называю порцию из 4-х байт. Было замечено, что размеры заголовков и содержимого всех потоков кратны четырём байтам. Функция сканирования может возвращать пять значений: 0 – если это обычные 4 байта видеопотока для перепаковки, 1 – если это заголовок блока видеопотока опорного кадра, 2 – если это заголовок блока видеопотока сжатого кадра, 3 – если это заголовок блока аудиопотока, 4 – если это «испорченный» блок, который нужно игнорировать при перепаковке. Очень-очень редко, но такое встретилось. Испорченный блок (как я его назвал) представляет собой заголовок вида «\0\0\0\0H264», где «\0» — нулевой байт. Блоки такого вида штатный перепаковщик игнорирует. Разумеется, содержимое такого блока может оказаться вполне рабочим, но я подобные блоки игнорирую для максимального приближения своей программы к штатной.
В основной функции, кроме организации каталогов, происходит считывание входного файла функцией сканирования. В зависимости от того, что возвратила эта функция, происходят дальнейшие действия. Если это заголовки видеопотоков, то формируются в выходной avi файл соответствующие заголовки. Там они именуются по-другому: «00db» — это заголовок блока видеопотока опорного кадра, а «00dc» — для сжатого кадра. После операции перепаковки (переписывания слов) перед новым вновь встретившимся заголовком происходит расчёт размера перепакованного содержимого и запись этого значения в поле, которое следует сразу за заголовком только что обработанного потока. Если при сканировании встретился заголовок аудиопотока, то формируется в выходной avi файл имя заголовка «03wb» и тут же в цикле происходит декодирование аудиопотока из ADPCM в PCM одновременно с записью декодированного содержимого в avi файл. Одновременно со всем вышесказанным происходит фиксирование краткой информации (оглавления) во временный файл индексов «index». Функцию сканирования можно было не делать, а всё писать в основной функции. Но тогда программа бы получилась очень громоздкой и практически сложно читаемой.
В конце всей операции, когда кончился входной файл «264», прежде чем перейти на новый файл, программа грамотно завершает все операции. Сначала корректируются определённые поля в заголовке avi файла, значения которых зависят от размеров и количества прочитанных потоков, а затем к почти готовому файлу avi присоединяется содержимое временного файла «index», который затем удаляется. После этих операций выходной avi файл готов к воспроизведению.
Во время работы программы в командной строке происходит текстовая визуализация, которая отображает текущий каталог, файл, а также номер блока видеопотока, приходящийся на опорный кадр и соответствующий момент времени видео в минутах и секундах. А если входной файл имеет не произвольное имя, а исходное (содержащее номер канала, дату и время начала записи), то происходит более интерактивная визуализация, основанная на арифметике даты-времени.
При тестировании и отлаживании программы основные проблемы у меня возникали при работе с декодированием звука. Простая арифметика работала некорректно, если я при объявлении переменных в функции декодирования неграмотно расставлял типы. Из-за этого, некоторые блоки аудиопотоков были битыми, а на слух наблюдались щелчки. Несколько не совсем понятных полей заголовка исходного файла 264, которые я не смог разгадать, оказались нечувствительными к результату. В отличие от штатной программы моя программа не выкидывает из операции перепаковки последний незавершённый блок потока. Хотя, его отсутствие никакой практической роли не сыграет. Ещё штатная программа, в отличие от моей, оставляет за собой «мусор» в небольшом количестве (это содержимое последнего потока) в самом конце avi файла после индексов. При всём при этом видео воспроизводится практически одинаково. А перепаковку программа осуществляет за тот же промежуток времени, что и штатная программа.
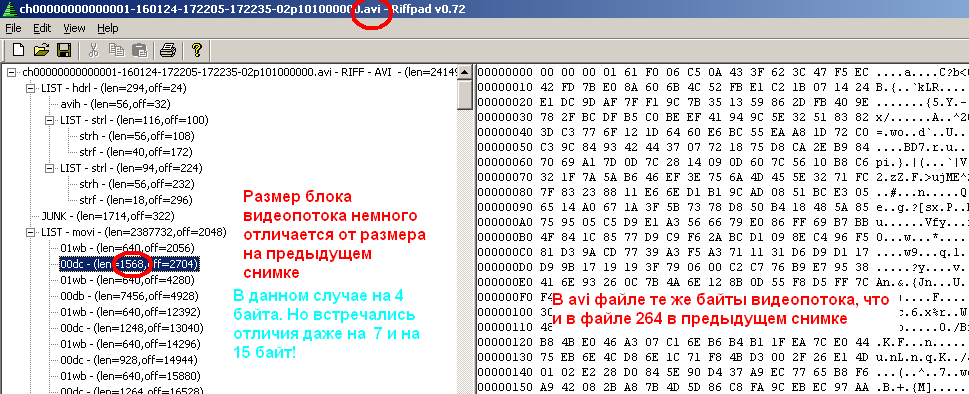
В заключение я приведу иллюстрации, демонстрирующие структуру организации потоков в файле .264 (в шестнадцатеричном редакторе WinHex) на примере одного из файлов и вид программы RiffPad с открытым в нём перепакованным файлом avi. Данная программа мне очень упростила процесс изучения структуры avi файла. Она наглядно демонстрирует иерархическую структуру, показывает байтовое содержимое каждого члена структуры и даже умно интерпретирует содержимое заголовков в виде списка параметров. На картинке, в частности, продемонстрирован тот факт, что содержимое видеопотока переписывается без изменений.

Комментарии (25)

BugM
03.09.2018 16:41+2Автор вообще в курсе существования ffmpeg?
Для решения конкретной задачи конвертации кроме него вообще ничего не нужно.
Ну или статью надо было называть «Автор изучил формат хранения видео и решил написать об этом. При этом популярные контейнеры (mp4, mkv) автор не осилил.»Videoman
03.09.2018 18:31Для записи не спорю, а вот интересно, как бы ffmpeg помог автору в случае чтения. По описанию битового потока, там явно проприетарный формат контейнера собранный на коленках.
BugM
03.09.2018 18:55-1ffmpeg умный. Он ну очень много форматов и контейнеров знает. И он очень хорошо демуксеры подбирает для любого говна.
Я не встречал файлов которые он не сумел бы распознать и перепаковать в нормальный контейнер.andreymal
03.09.2018 19:54+1У меня завалялось «любое говно» тоже с видеорегистратора, внутри которого вроде бы H.264, и ffmpeg его не осиливает, вываливая тонну ошибок. Воспроизвести его осиливает только плеер, идущий в комплекте с видеорегистратором. (Поделиться файлом не могу, там секретики)
BugM
03.09.2018 23:03Если даже это принять на веру. В конце концов все в жизни бывает. Тогда надо понять почему он не понимает этот формат и сделать препроцессор который превратит файлик во что-то понимаемое ffmpeg. Или в крайнем случае сделать свой демуксер. Это не так сложно.
Это избавит от проблем создания муксера и добавит поддержку любых выходных форматов. Ну и велосипед заметно уменьшится в размерах.
А вообще не надо связывать с железками которые пишут видео в собственный проприетарный формат. Просто не надо.andreymal
03.09.2018 23:10сделать препроцессор который превратит файлик во что-то понимаемое ffmpeg
Вроде бы об этом и пост?)
А вообще не надо связывать с железками которые пишут видео в собственный проприетарный формат. Просто не надо.
На практике нередко бывает, что выбора по каким-то причинам просто не было
BugM
03.09.2018 23:14Нет. Статья о полном велосипеде. От начала и до конца и демуксим и муксим сами.
Значит задача плохо поставлена. Железка стоила ~10к рублей. Реверсинжиниринг + написание кода + тесты + ловля багов которые в таком будут точно выйдет больше месяца трудозатрат. Оно того не стоит. Дешевле железки обновить.
Videoman
03.09.2018 21:57+1К сожалению там нет никакой «магии», поверьте. Так получилось, что из-за текущих проектов мне приходится очень плотно сидеть в исходниках ffmpeg. На самом деле, форматов там очень даже счетное количество, множество из которых старые, никому не нужные, богом забытые экзотические форматы всяких редакторов, консолей, приставок и т.д. Все его «распознавание» — это вызов функции Probe() для каждого муксера для тестового набора данных и поиск заранее известных сигнатур. У меня с легкостью получалось записывать контейнеры ffmpeg-ом которые он же не мог прочитать и наоборот. Редкие или кастомные форматы он не в состоянии читать.
BugM
03.09.2018 22:59Магии нет. Есть очень хороший анализатор форматов и контейнеров. Простой ну и тем лучше. Важно что работает хорошо. Поддержка древних и забытый форматов это то что и надо автору статьи. Какой-то левый формат. Есть большой шанс что он как раз и будет одним из тех старых экзотических форматов.
Videoman
03.09.2018 23:24Анализатор у ffmpeg не плохой, но он не распарсит формат которого он не знает. Как вы оцениваете шанс, что любой придуманный вами из головы формат случайно совпадет с одним из известных (примерно сотня) ffmpeg-у форматом? То, что иногда ffmpeg удается считать незнакомый ему файл это не его заслуга, а разработчиков MPEG 1,2,4. Дело в том, что поток MPEG запросто может обходится без контейнера, так как он сам им и является, по сути и он приспособлен для передачи по ненадежным каналам связи. Это приводит к тому, что незнакомый файл воспринимается как «битый» MPEG-поток в котором ffmpeg, без проблем находит хорошо подобранные стандартные сигнатуры.
BugM
03.09.2018 23:27Я адекватно оцениваю шанс на наличие стандартного формата в железке. Пусть экзотического, но стандартного. Разработчикам железок самим же дешевле взять стандартный формат и не делать велосипед. Ну максимум заголовок могут свой дописать. Смысл контейнер свой делать?
Videoman
03.09.2018 23:44Не будет там стандартного формата, т.к. просто не существует формата, который одновременно:
1. Поддерживал бы возможность дозаписи
2. Поддерживал бы при этом растущий индекс
3. Был бы при этом надежным (транзакционным) в случае зависания или сбоя
Это я вам говорю с уверенностью, т.к. уже второй раз за сою карьеру разрабатываю систему записи видео-потоков 24/7, в которой приходится использовать свой проприетарный способ хранения из-за того, что стандартного просто не существует в природе. Если вы подскажет мне стандартный формат который бы отвечал всем трем требованиям одновременно, то я был бы вам очень благодарен.BugM
03.09.2018 23:53fmp4 ну или m2ts чем не устраивают? Недописанный конец фрагмента это не страшно. Даже сам фрагмент будет читаемым.
Videoman
04.09.2018 00:09m2ts сразу отпадает в случае если скорость носителя или сети слишком медленная ( <= 100Mb) для бинарного поиска по пакетам по большим файлам, т.к. нет поддержки индекса.
fmp4- используется в MPEG DASH, но сильно стандартным вне Web я бы его не стал называть. Ffmpeg, относительно, недавно научился правильно его записывать. Не проигрывается очень многими сплитерами. Для настоящей транзакционности его не достаточно, т.к. необходим еще один файл который бы описывал бы сами фрагменты.
На само деле MPEG DASH — наиболее близкий к желаемому стандарт, но и он, к сожалению, слишком комплексный и сложный, имеет кучу проблем и косяков если его использовать в режиме отличном от Read-Only.BugM
04.09.2018 00:49m2ts можно резать на кусочки и обеспечивать индекс любыми внешними средствами. hls вполне справляется и проще некуда.
Так я и предложил новый модный формат и добрый старый. Выбирать по вкусу. Один проверен временем и поддерживается всем, второй новый больше возможностей внутри, но с поддержкой пока не очень.
А то что они для веба оба, так с чем работаю что знаю то и предлагаю.Videoman
04.09.2018 10:49m2ts можно резать на кусочки и обеспечивать индекс любыми внешними средствами. hls вполне справляется и проще некуда.
Можно много чего делать, но это уже не будет являться стандартным решением, которые мы тут обсуждаем. Как вы собираетесь резать открытые GOP-ы? А если источником вы не управляете?
HLS, при всем уважении к нему, не является стандартным форматом обмена видео, а является одним из многих протоколов стриминга в сети.
Так я и предложил новый модный формат и добрый старый. Выбирать по вкусу. Один проверен временем и поддерживается всем, второй новый больше возможностей внутри, но с поддержкой пока не очень.
Fragmented MPEG-4 далеко не новый формат, просто от из-за своей кривизны не использовался нигде, пока разработчики MPEG-DASH не обратили на него внимание. Все эти Web-протоколы (MPEG-DASH, HLS, Smooth Streaming) не создавались для удобства решения тех задач которые мы обсуждаем. Они создавались для обхода проблемы лицензирования для разных браузеров.
А то что они для веба оба, так с чем работаю что знаю то и предлагаю.
Еще раз, стандартного контейнера (именно контейнера) для видео — простого, поддерживающего легкую дозапись, поддерживающего растущий индекс, и обеспечивающего надежность в случае сбоев — не существует. Именно в таких случаях всегда приходится изобретать «велосипед», хоть и используя отдельные стандартные «блоки».BugM
04.09.2018 14:27У вас философские вопросы в основном. Понятно что с ключевыми кадрами 1 раз на часовое видео ничего резать не выйдет. Я когда такое видео увидел был в шоке.
Зато HLS проще некуда и задачу навигации RO клиента за медленным каналом выполняет на ура.
Если быть совсем честным, то задачу писать на диск ролики с видеорегистратора решает обычный mp4. Сам регистратор режет ролики на заранее настроенные промежутки и обзывает по времени. Все задачи решаются полностью. Совместимо со всем. Дуракоустойчиво. Никаких велосипедов. Найти нужный отрезок или склеить что можно типовыми средствами абсолютно примитивно.Videoman
04.09.2018 14:53У вас философские вопросы в основном.
Ну я вообще-то овечаю вам на ваше же утвержение:Разработчикам железок самим же дешевле взять стандартный формат и не делать велосипед. Ну максимум заголовок могут свой дописать. Смысл контейнер свой делать?
Не понимая какие задачи и проблемы решали разработчики нельзя ничего точно утверждать.Понятно что с ключевыми кадрами 1 раз на часовое видео ничего резать не выйдет.
И с нормальными ключевыми кадрами (раз в секунду) может ничего не выйти. Вы же не знаете какой у них там H.264 поток. Может быть там встроенный чип, который генерирует поток с B-кадрами и открытыми GOP-ами, где есть ссылки на предыдущие кадры. Как в этом случае вы будете разбивать фалы на куски?
andreymal
04.09.2018 14:54А если отрезок по какой-то причине окажется не дописан? Вышеупомянутый ffmpeg читать урезанные mp4-файлы лично у меня тоже упорно отказывается, например
Hardcoin
03.09.2018 17:01Технически статья интересная. Практический вывод — не покупать регистратор QCM-08DL, т.к. он пишет файлы в неподдерживаемом виде.
Самое забавное — что производитель регистратора тоже это понимает, раз предлагает программу конвертации в комплекте.
Videoman
03.09.2018 18:19+2Ну у них не очень богатый выбор был:
Всякие: AVI, MPEG4 и MOV отпадают, так как в случае потери питания данные превратятся в тыкву.
Из стандартных остаются TS или сырой H264. C ними проблема в том, что нет заголовков, где-бы отражалась информация о длительности и индексах. Возможно, без этого, напрямую с флешь-памяти проблематично переходить на произвольную позицию в случае перемотки. Пришлось изобретать «велосипед».
mrxakerrus
03.09.2018 22:51+1Большинство людей утверждают что автор поста просто не знаком с ffmpeg, но я подтверждаю что ffmpeg не всегда способен распознать структуру файла, например я работал с тем, чтобы с IP камер Bovotech (ActiveCam и прочих ему) преобразовать структуру файлов, которые он записывает на флешку и заверяю что ffmpeg не справлялся с этой задачей, в итоге я разобрался с тем чтобы распарсить файл на аудио+видео и затем уже через ffmpeg накладывал дорожки и сделал это кстати даже лучше, чем приложение от вендора камер, которое смещало аудио и не всегда корректно воспроизводило файл если fps на камере при записи было скажем 10 кадров в секунду.
P.S на регистраторе первыми байтами идут характеристики файла, длительность и все прочее, включая параметр по которому видео записывалось, либо по детекции, либо постоянная запись, либо там еще много всяких приблуд и т.д. И если этот регистратор связан с облаком xm, то на него есть SDK, в котором можно скачивать файл в avi формате вместе с дорожкой звука, либо можно на китайских форумах нарыть документацию(она точно есть)
hssergey
Решал похожую задачу через mkvmerge. Система обрабатывала загруженный файл на сервере. Командная строка для вызова была вида:
После обработки файл без проблем открывался как в vlc, так и через opencv.