
 В наш век облачных сервисов, AWS Lambda и прочих
В наш век облачных сервисов, AWS Lambda и прочих TL;DR> объединение, балансировка, rr limit, вот это вот всё.
Собственно, текст далее не про то, что это вообще возможно или ноу-хау какое-то. Интернет полон статьями для чайников (вот здесь ставим галочки, затем Next, Next, Done) о том, как подать дисковую ёмкость по iSCSI. Пишу как раз для того, чтобы исключить «ошибки выживших» и поделиться моментами, когда «всё пойдёт не так» (а оно пойдёт, Мерфи был прав), и при попытке нагрузить решение оно просто падает.
Итак, мы попробуем раздушить наш «бытовой гипервизор» внешним дисковым массивом, подключенным по сети. Поскольку у нас всё крутится вокруг «недорого», пусть это будет FreeNAS и 4 SATA-диска, которые обслуживает средненький 3 ГГц 45-нм проц. Смотрим на Ebay, и за сравнимые с б/у RAID-контроллером деньги тащим оттуда пару сетевых карточек i350-T4. Это четырёхпортовые гигабитные адаптеры от Intel. По ним и будем связывать хранилку с гипервизором.
Немножко посчитаем. Средняя скорость передачи данных среднего SATA диска — 160-180 МБ/сек при ширине интерфейса в 6 Гбит/с. Фактически, реальная скорость передачи данных с HDD не превышает 2 Гбит/с. Не такая уж большая цифра, учитывая, что связь мы планируем по 4м гигабитным портам (как именно превратить 4x1Гбит в 4 Гбит — обсудим далее). Намного хуже все со скоростями произвольного доступа — здесь всё падает чуть ли не до уровня дискет.
Учитывая, что профиль дисковой нагрузки от множества гостевых ОС — далёк от линейного, хотелось бы видеть более веселые цифры. Для исправления ситуации в файловой системе гипервизора ( VMFS v6) размер блока составляет 1 МБ, что способствует уплотнению множества случайных операций и ускоряет доступ к данным на виртуальных дисках. Но даже с этим одного физического диска будет недостаточно для обработки операций ввода-вывода от всех «гостей».
Сразу оговорюсь — всё дальнейшее имеет смысл, если у вас адаптеров для «сети хранения» больше двух. ESXi с бесплатной однопроцессорной лицензией умеет подключаться, кроме локальных дисков, к хранилищам двух типов — NFS и iSCSI. NFS предполагает доступ файлового уровня и тоже по-своему хорош. На нем можно развернуть гостей, нетребовательных к дисковой производительности. Бэкапить их — одно удовольствие, т.к. можно открыть эту же NFS шару ещё куда-либо и копировать снапшоты вм. В общем, с одним сетевым интерфейсом (если это не 10GE, конечно) — NFS ваш выбор.
У iSCSI есть ряд преимуществ перед NFS. Для того, чтобы реализовать их в полной мере, мы уже подготовились — заложив для сети хранения аж 4 гигабитных порта. Как обычно происходит расширение пропускной способности сети при известной скорости интерфейсов? Правильно, агрегацией. Но для полной утилизации агрегированного канала нужен целый ряд условий, и это подходит больше для связи коммутаторов между собой либо для сетевого аплинка гипервизора. Реализация протокола iSCSI предусматривает такую функцию, как multipathing (дословно, много путей) — возможность подключения одного и того же тома через разные сетевые интерфейсы. Само собой, про возможность балансировки нагрузки там тоже есть, хотя основное назначение — отказоустойчивость сети хранения. (Справедливости ради, NFSv4.1 поддерживает session trunking на базе совершеннейшей магии типа RDMA и MPTCP, но это попытка переложить проблемы файлового доступа
Итак, для начала опубликуем наш таргет. Считаем, что FreeNAS установлен, IP-адрес управления исправно отгружает нам web-интерфейс, массив и zvol на нём мы нарезали в полном соответствии с нашими внутренними убеждениями. В нашем случае это 4 х 500ГБ диска, объединённых в raidz1 (что даёт всего 1,3 ТиБ эффективной ёмкости), и zvol размером в 1 ТБ ровно. Настроим сетевые интерфейсы i350, для простоты принимаем, что все будут принадлежать разным подсетям.

Затем настраиваем iSCSI-шару методом «Next, Next, Done». При настройке портала не забываем добавить туда все сетевые интерфейсы, выделенные для iSCSI. Выглядеть должно примерно так, как на картинках.


Чуть больше внимания потребуется уделить настройке extent — при презентации тома необходимо форсировать размер блока 512 байт. Без этого инициатор ESXi вообще отказывался опознавать презентованные тома. Для верности лучше отключить проброс размеров физ блока (которого на zvol нет и быть не может) и включить режим поддержки Xen.
С FreeNAS пока всё.
На стороне ESXi немного сложнее с настройкой сети. Опять же, считаем, что сам гипервизор установлен и также управляется по отдельному порту. Потребуется выделить 4 интерфейса VM Kernel, принадлежащих 4м разным порт-группам в 4х разных виртуальных коммутаторах. Каждому из этих коммутаторов выделяем свой физический порт аплинка. Адреса vmk# берём, разумеется, в соответствующих подсетях, аналогично настройке портов хранилища. Порядок настройки адресов, в общем случае, важен — либо мы соединяем карточки «порт-в-порт» без коммутатора, либо отдаём разные линки в разные сети (ну, это если по-взрослому), поэтому физическое соответствие портов имеет значение.
Особое внимание при настройке сети под iSCSI уделяем параметру MTU. Это как раз тот случай, когда «размер имеет значение» — берём максимум, который позволяют установить все компоненты сети. Если карточки соединены напрямую, можно указать mtu 9000 на обоих сторонах, на ESXi и FreeNAS. Впрочем, нормальные коммутаторы это значение поддержат. Пингуем, видим, что сеть у нас в норме, и пакеты требуемого размера проходят. Отлично. Поджигаем инициатор.
Включаем iSCSI, добавляем IP-адреса в динамическую секцию настройки (Storage -> Adapters -> Configure iSCSI -> Dynamic targets). После сохранения будет выполнен опрос iSCSI порталов по этим адресам, инициатор определит, что за каждым из них стоит один и тот же том, и подключится к нему по всем доступным адресам (тот самый multipath). Дальше нам потребуется создать datastore на появившемся устройстве.
После этого можно раскатать виртуальную машинку и замерить, что у нас получилось.

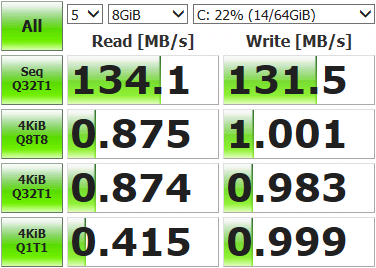
Не такие уж впечатляющие результаты. Открываем консоль хранилища, выводим текущее состояние сети и запускаем тесты.
root@freenas:~ # systat -ifstat /0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10
Load Average
Interface Traffic Peak Total
lo0 in 0.319 KB/s 0.893 KB/s 3.041 MB
out 0.319 KB/s 0.893 KB/s 3.041 MB
alc0 in 0.478 KB/s 1.233 KB/s 3.934 MB
out 0.412 KB/s 1.083 KB/s 2.207 MB
igb3 in 0.046 KB/s 0.105 KB/s 181.434 KB
out 0.073 KB/s 0.196 KB/s 578.396 KB
igb2 in 0.046 KB/s 0.105 KB/s 120.963 KB
out 0.096 KB/s 0.174 KB/s 517.221 KB
igb1 in 4.964 MB/s 121.255 MB/s 10.837 GB
out 6.426 MB/s 120.881 MB/s 3.003 GB
igb0 in 0.046 KB/s 0.105 KB/s 139.123 KB
out 0.073 KB/s 0.210 KB/s 869.938 KB
Утилизирован лишь один сетевой порт из четырёх (igb1). Происходит это потому, что механизм балансировки, предусмотренный по умолчанию для multipath, с каждым пакетом данных выбирает один и тот же адаптер. Нам же надо задействовать из все.
Подключаемся к гипервизору по SSH и командуем.
Для начала глянем, какой ID у луна с multipath, и как он работает:
[root@localhost:~] esxcfg-mpath -b
naa.6589cfc000000b478db42ca922bb9308 : FreeNAS iSCSI Disk (naa.6589cfc000000b478db42ca922bb9308)
[root@localhost:~] esxcli storage nmp device list -d naa.6589cfc000000b478db42ca922bb9308 | grep PSP
Path Selection Policy: VMW_PSP_MRUПолитика выбора путей — MRU, то бишь most recently used. Все данные идут в один и тот же порт, перевыбор пути происходит только при недоступности сетевого соединения. Меняем на round-robin, при которой все интерфейсы меняются по очереди после какого-то числа операций:
[root@localhost:~] esxcli storage nmp device set -d naa.6589cfc000000b478db42ca922bb9308 -P VMW_PSP_RRПерезагружаем ESXi, открываем мониторинг, запускаем тесты. Видим, что нагрузка распределяется по сетевым адаптерам равномерно (как минимум, пиковые значения, лишнее поскипано), результаты теста тоже повеселее.
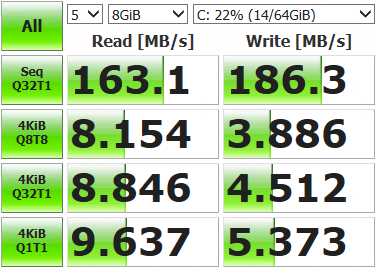
Interface Peak
igb3 in 43.233 MB/s
out 46.170 MB/s
igb2 in 42.806 MB/s
out 45.773 MB/s
igb1 in 43.495 MB/s
out 45.489 MB/s
igb0 in 43.208 MB/s
out 46.079 MB/sЕсть некоторые отклонения по портам, это возникает из-за лимитов Path Selection Policy — числа операций либо байт, после которого происходит переключение на другой порт. По умолчанию 1000 IOPS, то есть если обмен данными уложился в 999 операций — он пройдет через один сетевой порт. Можно менять, сравнивать и подбирать подходящее значение. Можно не менять, дефолта достаточно для большинства задач.
Делаем замеры, тестируем, работаем. Полученные результаты ощутимо превосходят возможности одиночного диска, так что теперь наши виртуальные машинки могут не толкаться локтями на операциях ввода-вывода. Итоговые значения скоростей и отказоустойчивость массива будут зависеть от железа и того, как выполнена конфигурация тома.
Комментарии (55)

amarao
17.09.2018 15:39Скажите, а когда вы увеличивали MTU до 9000, вы основывались на интуиции или на данных? Я вот посмотрел на данные, посмотрел, да и выключил jumbo. С TSO/GRO быстрее получается.

b0sun Автор
17.09.2018 16:33Про offload я чё-то и не вспомнил, хотя симптом вполне предполагал копать туда: на некоторых нагрузках четырехпортовый i350 просто топит проц в прерываниях. Спасибо, надо будет сравнить.
Насчёт jumbo — основывался на рекомендациях (в т.ч. самой VMWare), с учётом сказанного выше — действительно, был некоторый эффект.amarao
17.09.2018 16:56jumbo увеличивает latency на большинстве типов сетевого оборудования. А TSO/GRO ликвидирует оверхед по числу прерываний. Остаётся оверхед на заголовки пакетов, но он микроскопический.
Nizametdinov
17.09.2018 17:56Зачем вопрос вторичный. Я вот про халявную версию ESXi задумался, не накатить ли на домашний сервак, уже статья не мимо.
Firz
17.09.2018 20:43NFS предполагает доступ файлового уровня и тоже по-своему хорош. На нем можно развернуть гостей, нетребовательных к дисковой производительности.
Как вариант, для подключения гостей, можно и Samba использовать, у нее так же есть multichannel с помощью нескольких интерфейсов, причем настраивать вообще ничего не нужно(ну кроме включения самого multichannel в конфиге, если не включен). Правда тоже не супер универсально, та же mac os, к слову, до сих пор multichannel не умеет.
ximik13
18.09.2018 11:25Что мешает решать вопрос с RAID (сохранностью данных) на уровне самих виртуальных машин? Почти все современные OS умеют софт-рэйд. На VM с двумя vmdk, раскиданными на два локальных физических диска (датастора), можно организовать тот же Raid1. При наличии большего количества локальных дисков и типов используемых OS можно и другие типы софт-RAID сделать. Необходимость в железке под FreeNAS отпадает.
Что касается описанного в статье подключения по iSCSI, то хорошо бы обратиться к статьям VMware.
1) Выключить DelayedACK: https://kb.vmware.com/s/article/1002598
2) Adjusting Round Robin IOPS limit from default 1000 to 1: https://kb.vmware.com/s/article/2069356
3) Setting the Maximum Outstanding Disk Requests for virtual machines: https://kb.vmware.com/s/article/1268b0sun Автор
18.09.2018 12:04Да, очереди и уменьшение (для слабого железа) iscsivmk_LunQDepth чуток помогают. С мыслями соберусь — напишу ещё по этому поводу.
Что мешает решать вопрос с RAID (сохранностью данных) на уровне самих виртуальных машин?
Никогда не считал этот вариант приемлемым.
ximik13
18.09.2018 12:12Никогда не считал этот вариант приемлемым.
А причины есть?
У меня домашние сервисы на HP Microserver Gen8 несколько лет именно в таком режиме и крутятся. Два диска и VMware на microSD. Все что совсем не хочется потерять живет на софт рэйд (для обеспечения доступности в случае потери физ. диска) + периодический авто-бэкап на стационарник.b0sun Автор
18.09.2018 12:28Дома-то оно, может, и нормально, когда больше ничего нету. Но вообще это идёт вразрез с самой концепцией виртуализации. Обеспечение ресурсов, в т.ч. отказоустойчивых — это уровень гипервизора, не гостей.
ximik13
18.09.2018 12:35Ну тут скорее от задач зависит. Так что я не совсем согласен про противоречие концепции виртуализации. Если хочется избежать лишних трат во внепромышленной эксплуатации, то почему нет? В разрезе виртуализации, проблем при одиночном хосте тоже нет. На одной физ. машине размещается несколько виртуальных, повышая утилизацию и экономя средства на железо. С переносимостью виртуалок в другое место проблем тоже особых не будет. Без кластера и покупки лицензий в online этого не сделать, да и вряд ли будет такая потребность. С простоем сервисов перенести на другое железо совсем не проблема. Как-то так.
igrblkv
19.09.2018 10:14Я из статьи понял, что наш «бытовой гипервизор» как-раз и относится к «домашней» виртуализации — был не прав? Речь про энтерпрайз, что-ли?
PS: И если не затруднит — и это не секрет какой-нибудь — можно конфиг Вашего «бытового гипервизора» узнать? Особенно мать интересует…b0sun Автор
19.09.2018 11:29Да ну какой «энтерпрайз». Так, тестовый стенд в SOHO. Железо под ESXi: GA-X150M-pro / E3-1240-v6 / 64GB. Железо под FreeNAS: GA-G41M-s2pt / E5450 / 8GB / 4x Hitachi CLA362 500GB. И собирался NAS как раз под объединение дисковой ёмкости во внешнем RAIDе, пощупать-попробовать. Результаты вполне устроили, выбор сделан в пользу этой схемы, пойдёт в работу — железо будет другое.
ievgen
18.09.2018 13:05В статье и комментариях было упоминание про HCL. в связи с этим вопрос: а почему тогда вообще в качестве гипервизора был выбран ESXi? А не proxmox например?
b0sun Автор
18.09.2018 15:10Вопрос личных предпочтений и интересов. Провернуть те же изыскания в Proxmox я бы сходу не рискнул, пожалуй. Плюс, его на md надо ещё натянуть… VMWare мне привычнее.
Так-то и Hyper-V — тоже вполне подходит ))ximik13
19.09.2018 08:21ESXi на маленьких конфигурациях все же менее прожорлив. Да и танцев с бубуном нет с ним. Когда сервер всего один. С Hyper-V все несколько тяжелее и сложенее.
Tabletko
19.09.2018 09:57Hyper-V на маленьких конфигурациях тоже не сложен. Плюсом есть кластер, репликация, миграция и бекапы родными средствами
ximik13
19.09.2018 15:24Плюсом есть кластер, репликация, миграция и бекапы родными средствами
И это на одном физическом сервере? :)
ximik13
19.09.2018 15:37Hyper-V на маленьких конфигурациях тоже не сложен.
Ну и почитав вот тут: https://serveradmin.ru/ustanovka-i-nastroyka-windows-hyper-v-server-2016/ не назвал бы установку и настройку Hyper-V абсолютно интуитивно понятной и простой :). В ESXi настройка сводиться практически к прохождению одного простого визарда и ожиданию окончания установки.
Tabletko
19.09.2018 16:08То что описано в статье, если вы хотите странного — управление Hyper-V Server 2016 в рабочей группе без домена с отдельной рабочей станции. Устанавливая обычную редакцию WS с включённой ролью гиппервизора вы получаете то же самое, но без геморроя описанного в статье. Вся установка и настройка Hyper-V сводится к установке WS 2016, включению роли Hyper-V и настройке виртуального коммутатора.
igrblkv
19.09.2018 17:04Только в первом случае Вы лицензионно чисты, а во втором — должны купить WS2016, но при этом имеете права поставить два WS 2016 в качестве виртуальных.
Т.е. геморрой будет потом и с такими процентами, что лучше сразу, но без них!..
igrblkv
19.09.2018 15:48И это на одном физическом сервере? :)
Если железо позволяет, то можно поставить гипервизор, а в нем еще два-три гипервизора и софтСХД. Для тестовой среды — вполне ок и ВМваря так умеет. Вот конкретно про ESXi, конечно, сомневаюсь…ximik13
19.09.2018 15:57Где памяти-то столько взять на домашнем сервере? И дискового пространства под
виндуHyper-V? :)
А про ESXi не сомневайтесь :). Вложенная виртуализация давно поддерживается.igrblkv
19.09.2018 16:18Где памяти-то столько взять на домашнем сервере?
Столько — это сколько?
Тут конфиг обсуждается с 64 гигами — это мало под тестовую среду?
Вложенная виртуализация давно поддерживается.
Именно на бесплатном ESXi? «Бесплатном» в соответствии с лицензией, а не «не хочу — не плачу, всё и так работает»? Ну ок, но перекосы странные, кмк…
igrblkv
19.09.2018 16:34А про ESXi не сомневайтесь :). Вложенная виртуализация давно поддерживается.
Вот не зря сомневался — тут пишут что:
1) Вложенная виртуализация не для энтерпрайза! (за единственным исключением)
2) Таки не бесплатно: требуются дополнительные лицензии даже в случае бесплатного ESXi.ximik13
20.09.2018 09:32Лицензии для постоянного использования вложенных гипервизоров нужны. А вот на сделать лабу и поиграться я думаю дефолтного двухмесячного триала должно быть достаточно.
Ну и согласен, что погорячился. Но тем не менее оффициально не поддерживается и не работает — это не одно и то же.
https://www.vmgu.ru/news/vmware-nested-esxi-content-library
ievgen
19.09.2018 17:14то, что вопрос личных предпочтений это верно. Но справедливости ради kvm (proxmox) это linux и у него лист совместимости с аппаратным обеспечение заметно шире ESXi. И на md его ставить не обязательно. может работать так же как и esxi с флэшки. Но лучше конечно на рейд. пусть и софтовый. тогда голову можно не забивать тем что флешка может внезапно умереть.
b0sun Автор
20.09.2018 12:11С вашего позволения, на все неотвеченные вопросы здесь, внизу напишу.
У нас у всех разные представления о простоте. Кто-то вот, к примеру, в 2018 году всё ещё локально дисковую ёмкость подключает и собирает в md… Кстати, All Proxmox VE versions does not support the Linux Software RAID (mdraid), как у них написано. А ESXi принятый по iSCSI том — вполне себе поддерживает, куча рекомендаций, best practices, опять же… Кто-то вообще уже до следующего этапа дорос, SDS и vSAN домашний. Кто-то предлагает многоуровневую вложенную виртуализацию и софтрейд внутри неё — пусть
делаетпробует, не возбраняется ).
По поводу "в здравом уме никто не будет..." А у вас везде всё строго задублировано, кластеризовано и вендор готов в три часа доставить запчасть со склада? Рад, отлично. Если любого из перечисленных пунктов нет — решение мало чем отличается от того же FreeNAS, Nexenta, чего-то linux-based или вообще самостроя. Есть риск отказа, есть RTO, когда оно измеримо, определяемо и принято всеми сторонами процесса — уже вполне себе такой энтерпрайз.
igrblkv
Вообще не очень понятно ради чего это всё? Попробовать быстрый сетевой диск, но не разориться на 10G-карточки?
У меня где-то валяется парочка двухпортовых FC-карточек, доставшихся совсем за копейки, на которых можно получить те-же 4Гбит/с, но при этом можно построить почти взрослую SAN-сеть…
Опять-же, с точки зрения «недорого» — RAID или HB[A]-контроллер выйдет всяко дешевле отдельной конфигурации под FreeNAS с ZFS, которая и проц и память кушает как не в себя…
Ну а так, если бороться за скорость и дешевизну — то проще с иБея назаказывать б/у SSD интел/самсунг/микрон из старых серий…
b0sun Автор
Всё, из чего состоит FreeNAS — просто "валялось под ногами", а в процессе вылезли некоторые интересные вещи, которыми буду делиться. Ну и сама сеть — решающий выбор, на 10G нет особо задач. Так что FC не взял бы даже даром, а уж найти FC-коммутаторы "для "почти взрослой SAN"… Карточку RAID проще, тут согласен. Однако я бы предпочёл иметь возможность повторить технологию размазывания своих данных по нескольким шпинделям. Иначе результат не заставит себя ждать. Так что карточек должно быть больше, чем 1шт, а ZFS пул при необходимости восстановления — спокойно собирается в любом аппаратном окружении.
igrblkv
Argentalas
Ничего не понял, еще раз, почему не собрать локальный RAID10? И быстрее, и дешевле, и проще… А то что валялось под ногами под бэкапы и тп.
b0sun Автор
Потому, что
— локальный RAID можно только с контроллером, который есть в hardware compatibility list
— контроллер без запитанного кэша — деньги на ветер;
— контроллер без второго контроллера — данные на ветер;
— к хранилке по сети можно легко и непринуждённо подключить ещё один гипервизор
— к бэкапам надо относиться ответственно и на что попало их не складывать ))
igrblkv
т.е., хранилку собрать из того, что «валялось под ногами» — это ОК, а бэкапы туда складывать — уже "надо относиться ответственно и на что попало их не складывать"? Ну ОК, норм, чё…
b0sun Автор
Если говорить о возможности — то не обязательно тоже по 4м портам, и уж тем более не обязателен управляемый 16п-коммутатор. Для тестов вполне достаточно любого гигабитного, отданного целиком под сеть хранения. Я больше скажу — вот та сборка на E5450 просто не тянет 4 порта, поэтому можно спокойно располовинить адаптер хранилки на два потребителя.
igrblkv
PS: Мне всегда казалось, что если надо подключиться к коммутатору через несколько сетевых портов — то обязателен, как минимум, Web-управляемый коммутатор с тимингом. Есть другие варианты?
b0sun Автор
А что ему, коммутатору, сделается? Нормальный коммутатор даже просадки скорости не даёт. Это не магия, это обычный multipath. В статье эти настройки даже с иллюстрациями, кстати.
Да, для прода лучше управляемые свитчи, и то, для нарезки VLAN по подсетям путей и изоляции SAN-трафика.
igrblkv
В статье как-бы всё напрямую, т.е. порт в порт, подключено и как-бы:
Попробуйте это всё в один виртуальный коммутатор засунуть, а потом рассказать про multipath получившийся…ximik13
Вы немного путаете теплое с мягким. MPIO разруливается на стороне OS сервера. В данном случае гипервизора. И коммутаторы тут как бы остаются не при чем. Правда и сетевую карту лучше иметь с поддержкой iSCSI инициаторов, а не использовать софтовый.
И что касается тиминга и агрегации, то в случае iSCSI они скорее вредны, чем полезны. Так как MPIO гарантированно равномерно разложит нагрузку по всем активным физическим путям, в отличии от агрегированных интерфейсов.
igrblkv
Однако, я прочитал MPIO vs LACP и согласен, В данном случае, при необходимости подключения третьего устройства (т.е. два гипервизора к одному СХД) и при необходимости железного коммутатора вместо тиминга, агрегации
или 4х разных виртуальных коммутаторовможно воспользоваться VLAN'ами (т.е. получить те-же 4-е разных виртуальных коммутатора на одном железном) — ЧТО потребует, опять-таки, управляемый коммутатор, а не дешевый гигабитный д-линк за 500 рублей!PS: Если неправ — прошу поделиться ссылками на почитать в чем неправ.
ximik13
Вот тут нужно опять же разделить мух и котлеты. Я не имею ничего принципиально против управляемых коммутаторов :). Но если по теме статьи, цель автора, как я его понял, была собрать стенд для экспериментов. И в данном случае чем проще и дешевле, тем лучше. Можно для третьего сервера и еще одну сетевую карту воткнуть. И с неуправляемым коммутатором я тут особых проблем не вижу. Ну будет с его точки зрения подключено какое-то количество неизвестных ему устройств, каждое из которых имеет свой mac и IP. Ну обмениваются они по TCP/IP какими-то пакетами. С какого IP и физ.интерфейса слать следующий пакет решается на стороне multipath I/O на сервере.
Если же говорить о нормальном продуктиве, то не думаю, что кто-то в здравом уме решиться использовать FreeNAS под хранения виртуалок, т.к. точкой отказа тут сразу будет сам сервер/компьютер, на котором это поднято. Если использовать для сети хранения данных iSCSI, то опять же для отказоустойчивости нужны будут минимум две отдельных физических фабрики. Каждая из которых состоит как минимум из одного коммутатора. В идеале в этих фабриках не должен бегать трафик пользователей (от серверов к клиентам), а значит VLAN не понадобятся.
Почему отдельные коммутаторы и две фабрики под iSCSI? Причин может быть несколько. Начиная от упрощения конфигурирования, обслуживания и замены неисправных до улучшения общей производительности, за счет отсутствия пользовательского трафика. Наиболее простой пример, если накосячить с изменением конфигурации и прервать доступ пользователей к серверам, то будет не приятно, но не смертельно. А вот если на ходу случайно у гипервизора оторвать датастор с виртуалками, то есть не нулевая вероятность, что не все виртуальные машины и сервисы на них смогут пережить такое отношение.
igrblkv
ximik13
Я просто пытался расширить ваш кругозор, простите глупого :).
Все ухожу дальше кроваво энтерпрайзить… :)
igrblkv
За кругозор — спасибо!
За энтерпрайз — нет!
Ну и энтерпрайз бывает очень сильно разный: у кого-то банк, а у кого-то минимаркет — и время приемлимого простоя у каждого своё!
PS: Я не думаю что кто-то в энтерпрайзе будет поднимать хранилище ВМ через iSCSI на FreeNAS — есть другие бесплатные решения именно для энтерпрайза.
b0sun Автор
Бесплатные для энтерпрайза — только костыли, не? Всё оплачивается, либо это прямые расходы на решение и от вендора, либо косвенные на сотрудников, которые умеют в "бесплатные костыли", либо убытки от простоев.
igrblkv
Ну так-то разве есть разница между оплачивать своего гуру или чужого? В любом случае придется оплачивать сотрудника(-ов). Но свои, обычно, дешевле…
b0sun Автор
В конкретном случае профит multipath как раз в одновременной утилизации всех линков. Я намеренно не пишу "агрегации", дабы не вводить Вас в заблуждение. LACP здесь вообще никаким боком не стоял.
P.S. выше вот уже написали по существу.
igrblkv
Там-же и ответил, но так-же хочу повторить и здесь, что, с моей точки зрения, всё-равно понадобится управляемый коммутатор, только для VLAN'ов, а не тиминга/агрегации, в случае подключения второго гипервизора к СХД через коммутатор…
PS: Если неправ — прошу поделиться ссылками на почитать в чем неправ.
Argentalas
То что контроллер не продублирован это да, но у вас и мать не продублирована, и вообще, тут же речь о подешевле, а не о high availability, failover и тд.
Еще, я тут погуглил и внезапно осознал, что ESXi не может в software RAID. Не знал.
А представляете, был бы KVM можно было бы просто mdadm и сеть не собирать…
igrblkv
То-же в недоумении, весьма странная позиция: что-бы попробовать бесплатно, надо прикупить чуть-чуть энтерпрайз-железа…
А на матери как-раз софтрейд есть на 6 SATA-портов.