
Любите ли вы книги так, как люблю их я…
Детство и юность, проведенная в маленьком городе, где в районной библиотеке из энциклопедий был лишь «Большой энциклопедический словарь» приучила к бережному, практически благоговейному отношению к любой технической книге. Я понимаю, почему люди пережившие блокаду все время держали дома запас продуктов. Первое время, получив доступ к более или менее скоростному интернету все время хотелось скачивать новые книги и сохранять их на жестком диске, сохранять, сохранять :). Потом появился twirpx и я понял, что книги, как и знания, должны участвовать в постоянном круговороте, иначе они мертвы. Стоило один раз отсканировать монографию своего научного руководителя и услышать десятки отзывов скачавших, как лавину уже было не остановить. Я заметил, что сегодня поделившись редкой книгой, завтра я увижу две, а то и три не менее редких, которыми поделились другие.

В годы студенчества из-за довольно узкой специализации, библиотека была практически вторым домом. Но библиотека библиотеке, как водится, рознь и при прочих равных гораздо удобнее читать (а также распознавать и сразу копировать в курсовую) странички, пусть и цифровые, но сидя дома. Поэтому сначала был планшетный сканер Mystek BearPaw2400, тонкий, с питанием от USB, но ужасно медленный. С уменьшением стоимость цифровых камер (и ростом разрешения) его заменил отличный быстрый фотоаппарат Canon PowerShot A720IS (имхо, один из лучших в линейке PowerShot-ов). Именно с его помощью я прочувствовал всю мощь оптической стабилизации :). Вопрос со скоростью сканирования был решен, но в угоду спешке пострадало качество. Чтобы не ходить по пятьдесят раз и не перефотографировать испорченные/пересвеченные/недосвеченные и т.п. страницы было решено решать возникшие проблемы программно.
Опыт, наработанный в результате изысканий (и десятков отсканированных книг) вылился в целые серии статей, посвященных особенностям обработки сырого книжного материала и доводки его до состояния «неплохой djvu копии». В том числе причиной написания были вопросы друзей и знакомых «а как это djvu сделать вообще, мне вот дали хорошую книгу на пару дней». Ниже привожу, на всякий случай ссылки:
Увлечение сканирование пришлось на то время, когда только начинал наполнятся twirpx и нормально работал avaxhome. Отсканировав около полусотни книг, постепенно начали выкристализоваться алгоритмы, которые бы позволяли получать материал удобный для чтения на 10" планшете (не говоря уже про монитор компьютера) достаточно высокого качества и при этом экономить время, которое затрачивается на обработку одной книги.
Честно скажу, мне несколько раз очень хотелось сделать настоящий книжный сканер, вроде описанного на Хабре (Книжный сканер своими руками), или еще лучше такой как cделал крутой немецкий дедок (видео ч.1, ч.2, ч.3). Но мысли о самоделках посещают тогда, когда есть уйма свободного времени для размышлений (и материал, и инструмент и т.д., и т.п.). Чаще же всего этого под рукой нет, а книга нужна. И нужна срочно, да еще и в приемлемом качестве.
Поэтому уже довольно давно я пользуюсь несложным программно-аппаратным комплексом, который позволяет мне создавать довольно качественные копии книг за короткое время. К примеру на обработку одной 300 страничной книги (начиная от фотографирования и заканчивания кодированием в djvu) уходит примерно час, с использованием ПК на базе AMD Athlon II X4 640/16 Gb RAM/4 Tb SATA 3.0 HDD.

В джентельменский набор железа мобильного цифрового книгопечатника входят следующие позиции:
1) Смартфон Nokia PureView 808
2) Подвижный штатив-струбцина
3) Крепление для смартфона
4) Bluetooth пульт управления Coco CC-PC101
Смартфон от Nokia выбран за свою надежность и максимальный размер матрицы. Ну и люблю я его очень :) (и на Хабре ему пели дифирамбы). Из недостатков можно отметить то, что в отличие от Android-смартфонов мне пришлось довольно долго искать подходящий пульт, который бы заработал с моим телефоном. В итоге я остановился на Coco CC-PC101. Притом этот пульт работает только с программой CameraPro (cтандартное приложение его не подхватывает). При использовании Android подойдет любой копеечный пульт с Aliexpress.

Подвижная штанга, с помощью которой можно регулировать высоту смартфона над книгой — обычнаяселфи-палка палка-себяшка, но с наличием в нижней части стандартной резьбы 1/4" для прикручивания к струбцине/любой другой стойке. На aliexpress много вариантов, мне по цене/параметрам понравился "монопод для GoPro Hero 5 4 3"

Крепление для смартфона тоже первое попавшееся с резьбами 1/4", не самое дешевое (в отличие от проволочных вариантов), но мне понравилось своей формой. И пока никаких проблем с ним нет.
Штатив-струбцина — советского производства УТМ ЛСНХ. Чистый дюралюминий, настоящая радость для инженера, ну и просто очень надежный инструмент с множеством регулировок.

Смартфон у меня достаточно тяжелый, + вес телескопической штанги, поэтому пластиковым китайским струбцинкам я не доверяю. Но они имеют место быть.
Сам процесс фотографирования особой сложностью не отличается. Книга располагается так, чтобы попадать в фокус камеры и с помощью пульта происходит фокусировка/съемка. Перевернули страниц — «фокусировка/съемка». При этом располагать книгу я стараюсь так, чтобы были видны все края (это нужно для выравнивания изгиба страниц в программе ScanTailor). Несколько хвалебных слов о ней. Раньше мне приходилось использовать либо довольно капризную (часто вылетала с ошибкой) и платную программу BookRestorer, либо «косноязычную» ScanKromsator (хотя более чем уверен, что у нее найдутся свои фанаты :) ). Но слава богу появилась ScanTailor и жизнь таких вот как я «книгопечатников» сильно упростилась. Вот что говорит Википедия по этому поводу:
После окончания работы программы в папке out будут готовые страницы. Их загружаем в любой конвертер DJVU (выбирать можно на сайте). Я использую DEE — Document Express Editor v6.0.1 Build 1320 LE (for NT) (Light Edition for NT) за маленький размер и шуструю работу. В принципе, после DEE книжку можно закидывать на любимую читалку/смартфон и использовать по назначению. Если время и силы позволяют — можно добавить OCR-слой и оглавление. Эти процедуры подробно описаны в моих статья, на которые я ссылался в начале статьи.
Надеюсь мой опыт будет полезен всем тем, кто фотографирует книги на телефон и читает их потом с картинок в галерее :)
P.S.: На Хабре была статья (Оцифровка всемирного книжного наследия с помощью смартфонов). Там где:
Детство и юность, проведенная в маленьком городе, где в районной библиотеке из энциклопедий был лишь «Большой энциклопедический словарь» приучила к бережному, практически благоговейному отношению к любой технической книге. Я понимаю, почему люди пережившие блокаду все время держали дома запас продуктов. Первое время, получив доступ к более или менее скоростному интернету все время хотелось скачивать новые книги и сохранять их на жестком диске, сохранять, сохранять :). Потом появился twirpx и я понял, что книги, как и знания, должны участвовать в постоянном круговороте, иначе они мертвы. Стоило один раз отсканировать монографию своего научного руководителя и услышать десятки отзывов скачавших, как лавину уже было не остановить. Я заметил, что сегодня поделившись редкой книгой, завтра я увижу две, а то и три не менее редких, которыми поделились другие.
В годы студенчества из-за довольно узкой специализации, библиотека была практически вторым домом. Но библиотека библиотеке, как водится, рознь и при прочих равных гораздо удобнее читать (а также распознавать и сразу копировать в курсовую) странички, пусть и цифровые, но сидя дома. Поэтому сначала был планшетный сканер Mystek BearPaw2400, тонкий, с питанием от USB, но ужасно медленный. С уменьшением стоимость цифровых камер (и ростом разрешения) его заменил отличный быстрый фотоаппарат Canon PowerShot A720IS (имхо, один из лучших в линейке PowerShot-ов). Именно с его помощью я прочувствовал всю мощь оптической стабилизации :). Вопрос со скоростью сканирования был решен, но в угоду спешке пострадало качество. Чтобы не ходить по пятьдесят раз и не перефотографировать испорченные/пересвеченные/недосвеченные и т.п. страницы было решено решать возникшие проблемы программно.
Опыт, наработанный в результате изысканий (и десятков отсканированных книг) вылился в целые серии статей, посвященных особенностям обработки сырого книжного материала и доводки его до состояния «неплохой djvu копии». В том числе причиной написания были вопросы друзей и знакомых «а как это djvu сделать вообще, мне вот дали хорошую книгу на пару дней». Ниже привожу, на всякий случай ссылки:
- Цифровое «книгопечатание». Книга за 5 минут. Часть 1, часть 2
- Цифровое «книгопечатание» Пошаговое руководство по оцифровке книг. Часть 1, часть 2, часть 3
- Цифровое «книгопечатание». Фотоаппарат вместо сканера Статья
Увлечение сканирование пришлось на то время, когда только начинал наполнятся twirpx и нормально работал avaxhome. Отсканировав около полусотни книг, постепенно начали выкристализоваться алгоритмы, которые бы позволяли получать материал удобный для чтения на 10" планшете (не говоря уже про монитор компьютера) достаточно высокого качества и при этом экономить время, которое затрачивается на обработку одной книги.
Честно скажу, мне несколько раз очень хотелось сделать настоящий книжный сканер, вроде описанного на Хабре (Книжный сканер своими руками), или еще лучше такой как cделал крутой немецкий дедок (видео ч.1, ч.2, ч.3). Но мысли о самоделках посещают тогда, когда есть уйма свободного времени для размышлений (и материал, и инструмент и т.д., и т.п.). Чаще же всего этого под рукой нет, а книга нужна. И нужна срочно, да еще и в приемлемом качестве.
Поэтому уже довольно давно я пользуюсь несложным программно-аппаратным комплексом, который позволяет мне создавать довольно качественные копии книг за короткое время. К примеру на обработку одной 300 страничной книги (начиная от фотографирования и заканчивания кодированием в djvu) уходит примерно час, с использованием ПК на базе AMD Athlon II X4 640/16 Gb RAM/4 Tb SATA 3.0 HDD.
То же самое, но снятое под другим углом :)
В джентельменский набор железа мобильного цифрового книгопечатника входят следующие позиции:
1) Смартфон Nokia PureView 808
2) Подвижный штатив-струбцина
3) Крепление для смартфона
4) Bluetooth пульт управления Coco CC-PC101
Смартфон от Nokia выбран за свою надежность и максимальный размер матрицы. Ну и люблю я его очень :) (и на Хабре ему пели дифирамбы). Из недостатков можно отметить то, что в отличие от Android-смартфонов мне пришлось довольно долго искать подходящий пульт, который бы заработал с моим телефоном. В итоге я остановился на Coco CC-PC101. Притом этот пульт работает только с программой CameraPro (cтандартное приложение его не подхватывает). При использовании Android подойдет любой копеечный пульт с Aliexpress.
Работает принцип 'книга поменьше-штатив пониже'

Подвижная штанга, с помощью которой можно регулировать высоту смартфона над книгой — обычная
Крепление для смартфона тоже первое попавшееся с резьбами 1/4", не самое дешевое (в отличие от проволочных вариантов), но мне понравилось своей формой. И пока никаких проблем с ним нет.
Штатив-струбцина — советского производства УТМ ЛСНХ. Чистый дюралюминий, настоящая радость для инженера, ну и просто очень надежный инструмент с множеством регулировок.
Смартфон у меня достаточно тяжелый, + вес телескопической штанги, поэтому пластиковым китайским струбцинкам я не доверяю. Но они имеют место быть.
Сам процесс фотографирования особой сложностью не отличается. Книга располагается так, чтобы попадать в фокус камеры и с помощью пульта происходит фокусировка/съемка. Перевернули страниц — «фокусировка/съемка». При этом располагать книгу я стараюсь так, чтобы были видны все края (это нужно для выравнивания изгиба страниц в программе ScanTailor). Несколько хвалебных слов о ней. Раньше мне приходилось использовать либо довольно капризную (часто вылетала с ошибкой) и платную программу BookRestorer, либо «косноязычную» ScanKromsator (хотя более чем уверен, что у нее найдутся свои фанаты :) ). Но слава богу появилась ScanTailor и жизнь таких вот как я «книгопечатников» сильно упростилась. Вот что говорит Википедия по этому поводу:
Scan Tailor (англ. scan — сканировать, tailor — портной) — компьютерная программа для обработки изображений, полученных при помощи сканера. Является кроссплатформенной программой и работает под управлением операционых систем Microsoft Windows, Linux и Mac OS X. Высокий уровень программы был отмечен по итогам первого конкурса «Лучший свободный проект России» в 2009 году, проводимым журналом Linux FormatОсновной плюс программы — это автоматическая обрезка, чистка и распрямление строк. Притом распрямление работает по тому же принципу, что и у японского «робота для сканирования книг» о котором писали на Хабре (Японский сканер оцифровывает книгу в 250 страниц за минуту). Позволю себе выдержку из этой статьи:
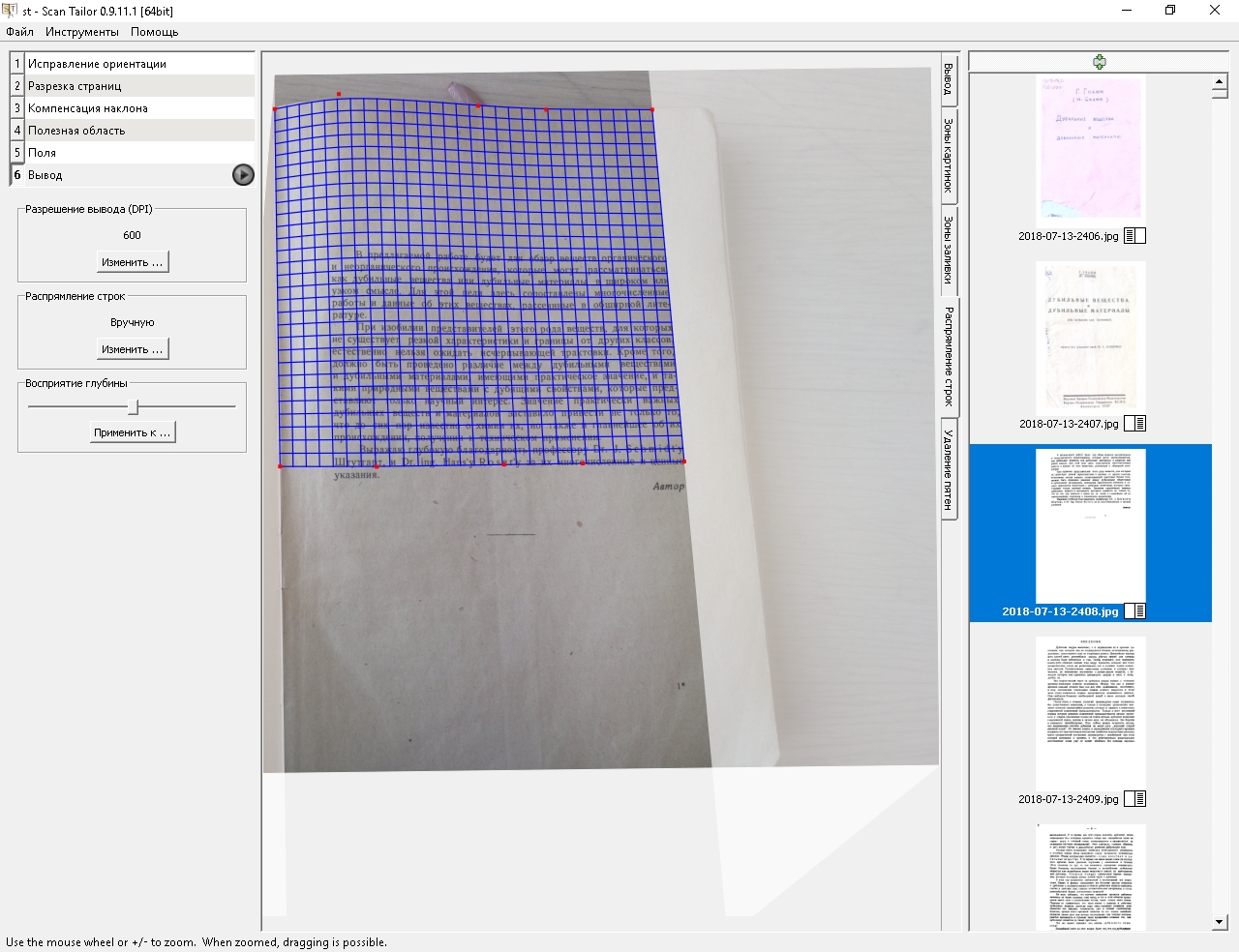
Открытая книга фотографируется с использованием лазеров (они формируют сетку на поверхности). При этом фотографирование производится сразу с нескольких ракурсов, после чего происходит автоматическое объединение всех трех кадров. Разработчики утверждают, что их способ позволяет избежать искажений, обычно проявляющихся при стандартном сканировании.. Тот же принцип используется и в ScanTailor, только расположение разметочной сетки на странице регулируется самим пользователем. Я выравниваю сетку по краям страниц (для этого при съемке они должны быть видны).
Пример страницы без распрямления строк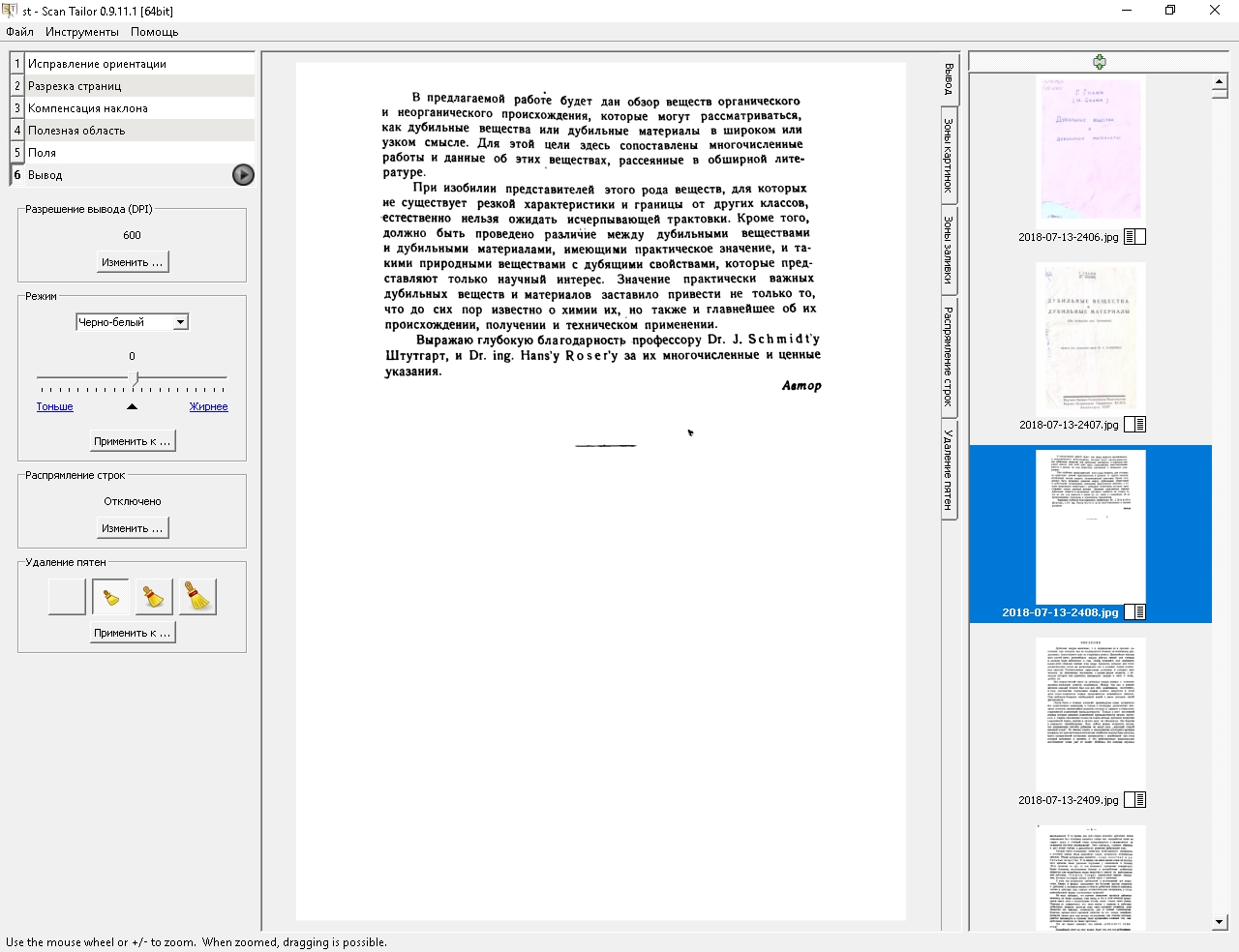
Пример страницы с использованием распрямления строк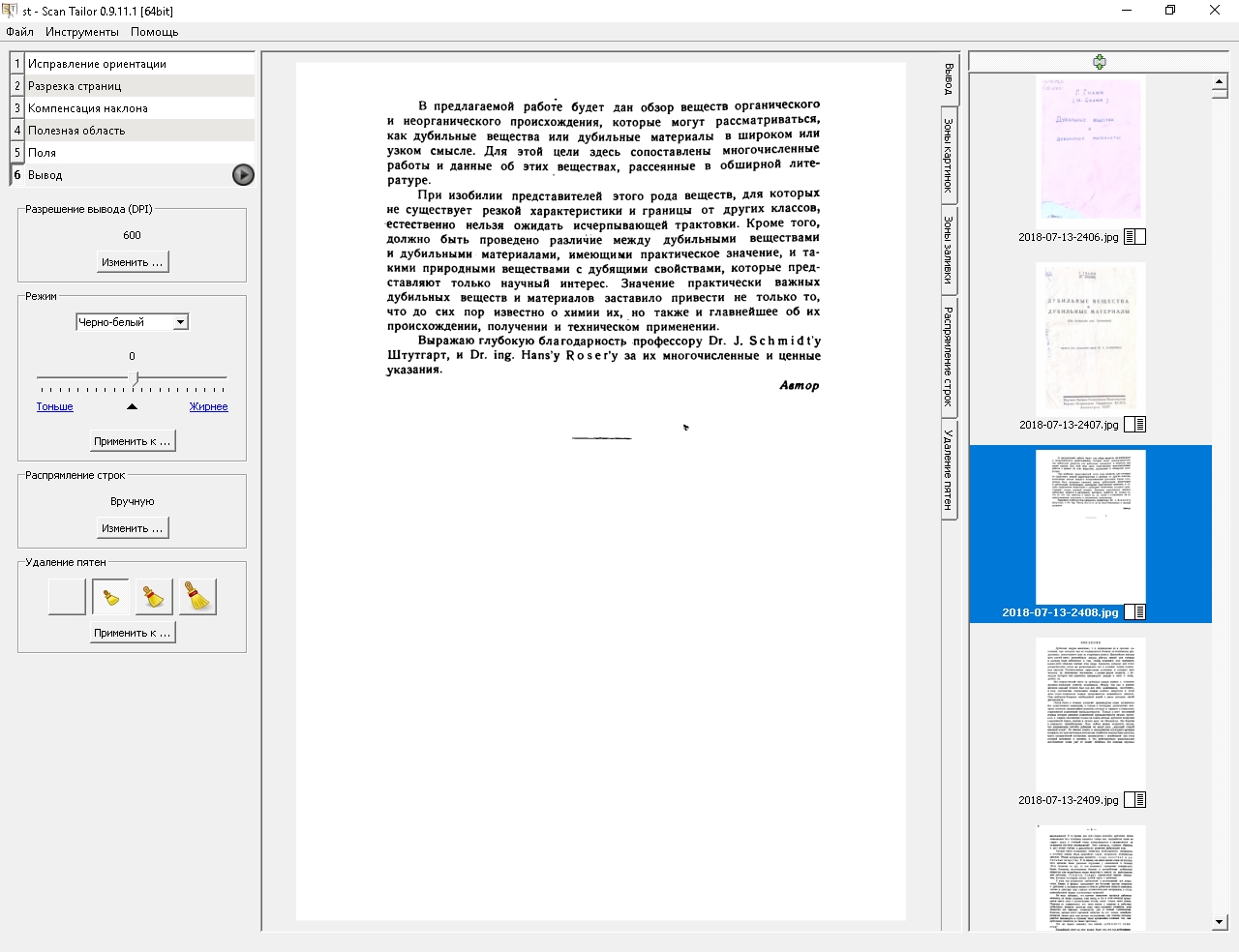
После окончания работы программы в папке out будут готовые страницы. Их загружаем в любой конвертер DJVU (выбирать можно на сайте). Я использую DEE — Document Express Editor v6.0.1 Build 1320 LE (for NT) (Light Edition for NT) за маленький размер и шуструю работу. В принципе, после DEE книжку можно закидывать на любимую читалку/смартфон и использовать по назначению. Если время и силы позволяют — можно добавить OCR-слой и оглавление. Эти процедуры подробно описаны в моих статья, на которые я ссылался в начале статьи.
Надеюсь мой опыт будет полезен всем тем, кто фотографирует книги на телефон и читает их потом с картинок в галерее :)
P.S.: На Хабре была статья (Оцифровка всемирного книжного наследия с помощью смартфонов). Там где:
Литару провёл несколько тестов и выяснил, что таким образом один пользователь, приноровившись, сможет за пять-десять минут оцифровать 600-страничную книгу. Сам он в 2004 году для дипломной работы вручную оцифровал тридцать тысяч страниц материалов из более чем семисот документов, используя обычную цифровую камеру и дешёвую настольную лампу. Большую часть этой работы Литару выполнил в течение пятнадцати часов в один из выходных дней.Так это, дорогой Калев Литару, если читаешь Хабр — напиши мне, может чего посоветую :)
vconst
Если пользовался нормальным планшетником, то весь хитрый софт выравнивания — не нужен. И пачка картинок — это полуфабрикат книги. Для полноценной электронной копии, ее надо распознать. И тут очень быстро становится понятно, почему планшетник для этих целей намного предпочтительнее.
Javian
Есть настолько ценные и редкие книги, что автору, который хотя бы переснимет в djvu, надо сказать большое спасибо. Лучше хоть какая книга, чем никакая.
Конечно для навигации и поиска еще необходимо распознавание.
К слову самые сложные книги, которые в мягком переплете — их невозможно развернуть полностью ( на 180 градусов) для сканирования.
steanlab Автор
К сожалению вы правы, насчет мягкого переплета. В таком случае я лично фотографирую по одному листу.
noksel
Пользуюсь одним популярным приложением на Android для документов. Обрезает, чистит, выравнивает при съёмке под наклоном, но нет функционала с разметочной сеткой(выравнивание изгиба страниц ). Не встречали для Android такого?
steanlab Автор
К сожалению, не встречал. У меня в качестве боевого коня — Nokia 808 с Symbian Belle на борту, там тем более ничего подобного нет. Но вполне возможно, что я просто не осведомлен. ScanTailor-open source, а значит движок выравнивания на гитхабе скорее всего отследить можно. Может быть есть аналогичные проекты для Android.
klirichek
Ну, там как бы нет отдельного движка. Это часть самого скан-тейлора.
(его наверное можно декомпозировать и выделить в отдельную либу, но этим же кто-то должен специально заняться)
steanlab Автор
Извиняюсь, под «движком распрямления» — подразумевал «кусок кода» из ST
nick0x01
Есть спец.сканера для книг, позволяющие не ломать переплет книги, с одной стороны от края до области сканирования где-то 5-6 мм, что позволяет сканировать страницу практически полностью.
steanlab Автор
а каков ценник для таких сканеров?
nick0x01
Ниже zartarn пишет, что с рук 5k рублей. Новый Plustek OpticBook 3800 (след. поколение) 20k рублей. Крайне удобный сканер для книг, после сканирования фактически даже постобработка не нужна (я только в scantailor'е делаю подрезку страниц с выравниванием по центру если нужно). И есть программируемые копки для сканирования с нужным профилем (цвет/серый/чб), что ускоряет процесс.
Barafu_Albino_Cheetah
3 — 6 тыс. руб. новый. Гуглить iScan.
nick0x01
Этот сканер совсем из другой категории.
vconst
Если у автора так высок процент редких книг — это оправдывает сооружение книжного фотосканера, но этот из мобильника — явно не для них.
steanlab Автор
Редкая книга редкой книге рознь. Есть редкие новые книги небольшого тиража, а есть книги из библиотечного хранилища редкой книги. Последние я никогда не возьмусь сканировать без щадящего спец.оборудования. Хотя в принципе, реставрировать книги доводилось.
vconst
Ну тогда — колхоз наше все :) Ящики, штативы, стекла. Текстовая область должна быть таки расплющена стеклом. ФР хорошая прога, но иногда его не поймешь, на ровном месте может заглючить. Но чем ровнее скан — тем меньше проблем.
steanlab Автор
Со стеклом — согласен. Когда работал с Powershot A720IS то разворот прижимал стеклом от шкафа. Отличный вариант, но времязатратный. Поэтому в один прекрасный момент я для себя взвесил все за/против и пришел к алгоритму, описанному в статье.
klirichek
Если только они уже не поломаны одним из предыдущих читателей.
Тогда технически всё довольно просто — срезаем целиком клеевой корешок (гильотинным ножом), оцифровываем стопку страниц, затем делаем новый корешок (гибкий при засыхании ПВА практически идеален). На крайний случай (если книга не очень ценная) можно даже переплести спиралью.
И да, это всё если книга УЖЕ испорчена. Либо если точно известно, что разломается при первом же открытии.
steanlab Автор
Мне было бы очень тяжело решиться так обкорнать даже «потенциально испорченную книгу». Потому что в большинстве случаев все реставрируется при желании. В моем понимании «испорченная/поврежденная» — та, страницы которой требуют наращивания в листодоливочной машине:
steanlab Автор
И за сколько на нормальном планшетнике вы отсканируете 300 страниц?
А насчет полноценной копии и OCR. А в бумажных книгах OCR есть? Хотя добавить текстовый слой — работа не пыльная (см. ссылки в тексте на мои ранние статьи, там этот вопрос освещается). Просто зачем он, если читаешь на смартфоне и ничего копировать не нужно никуда. Да и вообще, замечательно распознается выровненный текст с фотографий (особенно если сфотографировать на полных 40 МПикс камеры :) ). Очень редко проблемы такого плана возникают (только может если фотографировать на веб-камеру :) или очень плохое состояние самой книги)
nick0x01
Не знаю про vconst. У меня на книгу в 300 страниц уходит от 40 минут до 1,5 часов.
synedra
OCR нужен для ctrl+F. Ну и гиперссылок хотя бы в оглавлении.
kalapanga
Добавлю. И не только для этого! Автору статьи везёт — он либо ещё достаточно молод, либо природа наградила его подходящим зрением, что он читает сканированные тексты на смартфоне. Мне для этого нужен минимум планшет на 10 дюймов, и то, я буду так читать только в случае какой-то крайней необходимости. И никакие мегапиксели при съёмке здесь не помогут. Поэтому нужен не просто текстовый слой для дежавю, а другой формат книги, содержащий текст в виде текста (какие-нибудь всем известные epub, fb2) для подгонки текста под экран, изменения размера шрифта и т.д. Безусловно, трудозатраты возрастают существенно, кроме сканирования и распознавания добавляется ещё вычитка. Но это будет действительно «электронная книга».
Ограничиваться сканированием нужно только для исторически значимых изданий, где ценно всё — шрифт, цвет, вплоть до заметок на полях. Но в таких случаях и для сканирования используется что-нибудь получше, чем смартфон.
p.s. Выше уже сказали, что лучше сканированная книга, чем никакой. С этим не поспоришь — согласен!
steanlab Автор
Про планшет на 10" — я упомянул в тексте. Действительно, наиболее удобный вариант для постраничного чтения. Но, но, в случае обилия чертежей/схем и т.п. ценность сугубо текстового формата снижается и к тому же добавляется такой фактор как качество фотографий тех самых схем и чертежей.
klirichek
Не просто существенно, а СУЩЕСТВЕННО!
Это в крайнем варианте равно полностью перевёрстке книги.
Поэтому djvu/pdf со скрытым ocr-слоем — это самый универсальный вариант в плане трудозатрат/удобства.
Rikkitik
Мне как-то раз пришлось сканировать, распознавать и перевёрстывать редкий профлит, попавший в мои руки в виде пачки перекошенных недоразворотов (разворот больше А4, страница меньше, книга толстая). Ох и развлечение… Но оригинал пришлось тоже сохранить: чтобы оформить ссылку в работе по ГОСТу, надо знать номер страницы, которую цитируешь, а в итоговом тексте почти все номера были утрачены в угоду удобству чтения (да и не на всех листах они были изначально).
steanlab Автор
Гиперссылки (области реагирующие на щелчек по тексту) в оглавлении привязываются к страницам. OCR там не нужен.
vconst
Текст в электронном виде — совершенно необходим. Даже не вижу смысла это обсуждать.
Скорость сканирования не так важна, как последующая возня со сканами в ФайнРидере. Если это сканы с планшетника, где ты уже наловчился точно выравнивать обе страницы разворота, полностью расплющивая текстовые области на странице — то все очень быстро и просто. Размечается текстовая область в шаблоне и погнали. А если это фотоскан, с минимальными искажениями — то проще забить и пересканить на планшетнике, потому что на исправление ошибок уйдет дикое количество времени и все равно все не выловить.
Более менее современный планшетник сканит разворот, ну… может секунд за 30, если учесть перелистывание, перекладывание книги. 300 страниц это 150 разворотов, час-полтора времени. Зато ФР потом практически не требует вмешательства, все по шаблону и без ошибок.
klirichek
Планшетник жалко гонять ради оцифровки ширпотреба (если уж вдруг стало "надо"). Там ж механика, она изнашивается...
vconst
Ни разу еще не видел «изношенного сканера». А на некоторых виденных мной — сканировали десятилетиями. Если не ронять и не бить — ничего им не сделается. Сейчас можно купить недорого очень хорошие бу сканеры, даже профи А3. Они еще нас переживут.
klirichek
Ну, я вот один умудрился износить. Хороший был, старенький HP Scanjet 2400.
К тому же фотоаппаратом/камерой — это существенно быстрее.
И если "соседская бабушка попросила оцифровать Донцову" — то вряд ли стоит морочиться со сканером (если не соседская, а своя, любимая — то да).
vconst
Ну и стоит такой офисный старичок — от 500 до 1000 рублей. Найти посвежее и еще лет 10 прослужит. Поднять бюджет до 5к и можно взять профи полиграфический А3, неубиваемый в принципе.
klirichek
Это абсолютно никак не повлияет на то, что переснять — существенно быстрее.
(даже не "старичок", а "модный молодёжный" планшетник не сравнится по скорости с "перелистнул и щёлкнул")
vconst
Переснять быстрее, но потом эта экономия выльется в такие дикие проблемы с распознованием, что проще убить, чем прокормить. Если снимать — то уж тогда делать полноценный фотосканер.
steanlab Автор
Попробуйте просто сфотографировать страницу с максимальным разрешением, обработать в ScanTailor и скормить FineReader 11-12. И такую же процедуру проведите с обычным сканом с планшетника. У меня разница получалась в десяток-полтора слов. А разница в трудозатратах — намного весомее.
vconst
Разница очень весома — скан с планшетника переваривается ФР без дополнительной обработки и результат гораздо стабильнее, ошибок распознавания практически нет, если шрифт в книге не убитый.
klirichek
Правильно. Поэтому и не надо ничего распознавать.
Максимум — автоматический скрытый OCR-слой для возможности поиска. Но там настроек по минимуму; качество не важно (на то он и скрытый).
vconst
А этот «скрытый OCR-слой» — откуда возьмется?
Чтобы этот слой появился — надо книжку распознать. Если распознавать сканы — то они отправляются сразу в ФР, без обработки, где распознаются по шаблону, без вмешательства человека, ошибок или нет вообще, или минимум.
steanlab Автор
А3 пока еще стоят достаточно серьезных денег. Я вот, к примеру, работая с картами даже и не думаю их фотографировать. Несу в библиотеку где можно поработать с A3 и A2 (!) сканером. Но это только карты. Всякие инструмент для своего дела.
vconst
Прошвырнулся на Авито и навскидку нашел несколько А3 от 5к до 10к. А2 это уже — космос…
steanlab Автор
Не, пока не доступны рядовому пользователю однозначно. Если только всю жизнь этим не заниматься. Реально продуктивнее — арендовать у библиотек (НЕ копи центров :) ).
Я правда тоже грешен, имею протяжной маленький дорожный сканер для старых фото (это к тому, что мы полностью от сканеров не отказываемся)
vconst
Вопрос уместности. Если прям ппц как надо А3, то 5к и он ваш, надо только поискать. Если хватает А4, то все гораздо доступнее.
steanlab Автор
Разговор тут про планшетники, а мне сегодня человек взахлеб расказывал (увидев мою статью на Хабре) про то, какая замечательная вещь вот такой Fujitsu ScanSnap SV600
vconst
Ну, это не просто железяка, там и софт в комплекте, который «выравнивает» страницы. Что характерно, при поиске А3 сканеров на ибеях-амазонах — таких машин в выдаче большинство. Надо тестить, но выглядит вполне работоспособно. И стоит…
steanlab Автор
Да, стоит конечно нормально :(. Но оказалось что такой сканер стоит в совсем ж заурядном учреждении. Честно, был даже немного шокирован. В центральных библиотеках такого не видел… Мда
vconst
Узкоспециализированная железка, ниши очень маленькая. Аналоги на Ибее стоят порядка ста баксов, но не думаю, что это полноценная замена.
steanlab Автор
Да, Fujitsu не похожа на фирму однодневку, я бы не гнался за дешевыми аналогами. Но в серии ScanSnap (я так понимаю шустрых протяжных и иже с ними сканеров) только SV600 выделяется своим, хм, внешним видом. Надеюсь в ближайшее время оценить качество сканирования и обработки (выравнивания особенно) разворота. Оценить «софты» уж очень хочется.
vconst
Есть возможность потестить это чудо? :) Будет интересно почитать об этом.
steanlab Автор
Скажите, на чем сделать акцент — постараюсь сделать! Можно по пунктам.
steanlab Автор
нашел обзор и подумал, что лучше уж я как-нибудь со ScanTailor. Честно не понял, за что там такая цена…
vconst
Упс…
Обычная офисная машинка для секретутки на ресепшн. Книги сканирует криво, компенсации изгиба нет и текст не ровный. Своих денег не стоит, даже учитывая что на ибее уже по 450-700 баксов. Еще и разрешение низкое.
klirichek
Ну, это только с точки зрения перфекциониста.
Можно ещё сказать, что документ из кучи страниц с распознанным текстом — это суррогат книги. А для полноценной надо взять электронный макет из издательства, и откадрировать по формату (выкинуть разные метки обрезки/цветопробы и т.д.). И да, иллюстрации там должны быть исключительно в высшем разрешении и если сжаты, то только lossless.
В общем, предела совершенству нет :).
С практической точки зрения для подавляющего большинства задач получение "электронной книги" — это излишние и не нужные трудозатраты. Пусть это будет просто "электронный скан", но прямо здесь и сейчас. (и да, разные плюшки вроде интерактивных оглавлений/указателей и поиска по Ctrl+F из скрытого слоя OCR никто не отменяет; если это можно сделать автоматически в один проход — пусть компьютер сделает. Но вручную вычитывать, перевёрстывать, подбирать шрифты — это уж извольте). На эту работу уйдёт 20% времени, которое ушло бы на "полноценную электронную книгу". Зачем тратить остальные 80%?
Ну, разве что если это хобби, и этим заниматься нравится. Либо если это профессия, и это занятие оплачивается (тогда скорее всего и рабочая лицензия/подписка на FineReader есть под рукой).
А с точки зрения быстрого электронного скана — не нужен ни планшетник, ни finereader, всё делается легко и быстро открытым софтом.
steanlab Автор
согласен, основная цель книги — информация. перфекционизм со шрифтами/кеглем и проч. — это вроде аудиофилии или «теплого лампового звука» (см. Лукоморье).
vconst
На надо загоняться. Какая верстка, зачем вообще нужна эта дичь?? Откуда вы все это берете? Тут никто не говорил ни о чем подобном — вы яростно спорите сами с собой.
Достаточно текста без ошибок, а каким шрифтом его читать — каждый пусть выбирает сам. Текст без ошибок быстрее всего получить со сканов.
klirichek
Ну а я о том, что даже просто "текст без ошибок" — это уже роскошь.
Обычная отсканированная книга — как правило ограничивается многостраничным файлом с отсканированными картинками. С оригинальным (растровым) видом.
Если доводить до "текста без ошибок", то изготовление массового варианта (скан с оглавлением) займёт в нём 10-20% времени; остальное уйдёт на распознавание и исправление ошибок. За очень редким исключением (серый текст без иллюстраций на одном языке).
На "просто почитать" править все ошибки нет надобности.
На "писать работу и ссылаться на книгу" — как раз практичнее скан, а не электронный текст. Потому что сохраняется естественная пагинация (а вот в электронном тексте она выглядит уже искусственно натянутой).
vconst
Роскошь — это золоченый переплет, тисненая кожа и прочие заморочи, требующие много денег и времени. А офисный планшетник за полторы тыщи и пакетная обработка в ФР, отнимающая только процессорное время.
Если сканер не полные дрова и оператор наловчился хорошо прижимать книгу в нужном месте — ошибок будет минимум. Без всяких дополнительных заморочек, бесплатно.
А вот «сохранение естественного вида книги», стопка многомеговых сканов в контейнере дежавю или пдф — считаю бесполезным излишеством. Все это сильно затрудняет чтение.
zartarn
Вы как всегда так категоричны). Иногда приходится ссылаться в книгах на конкретные страницы, с фб2/epub Это нормально не сделать. А читать А4 12 размером шрифта прекрасно читаетсяна планшетах с 8'' экраном, без каких либо проблем.
vconst
Ну конечно, я категоричен. А комментарий выше, где рассказывается о полноценное переверстке книги — не категоричен ни разу :) Причем — никто об этой переверстке и не упоминал, кроме автора комментария.
Здоровенные планшеты — встречаются намного реже смартов и небольших планшетов, небольших читалок. Так что — это не самое распространенное средство для чтения. Если книга нужна только для ссылок на нее, тогда хватит и пустых сканов, но это встречается еще реже, чем большие планшеты.
zartarn
НУ да, это вы хотите заниматься вычиткой и переверсткой технической литературы в кривой epub/fb2. Что лишне, достаточно OCR для поиска под изображением о чем выше и говорилось. Какова вероятность что вы потеряете каконибудь штрих, или распознаете большую прописную как обычную буквы и потеряете обозначение? Техническую литературу только в виде обработаных сканов и стоит оставлять. С художкой творите что хотите.
Особенно книги по программированию в FB2/Epub настолько читаемые что ух…
vconst
Я говорил о том, что если сканировать на планшетнике, то ошибок будет гораздо меньше, чем при распознавании с фото.
zartarn
Это то к чему? я про вашу фразу
Или мы друг друга не так поняли тут? :)
vconst
Что непонятно в процитированном? Сканы в голом виде сохраняют естественный вид книги, но я считаю это лишним.
tim2018
Домик из двух стекол 90 градусов, две камеры. Лучший вариант
steanlab Автор
Посмотрите видео упомянутые в этой статье, тем где «аппарат немецкого деда». Имхо — самый лучший вариант. Я под это даже себе две Canon Powershot SX100 купил. Но цейтнот, коммандировки. Лежат, короче, ждут своего часа.
QuAzI
Аппарат у деда классный, руки прямые, но «энергосберегайки» эти дают ужаснейший свет, ещё и мерцать могут (некоторые камеры пытаются сгладить мерцание, но качество всё равно хромает), плюс источник света получается точечный (где-то будет пересвет, где-то недосвет, где-то блик). Стёкла при раскладке книги в V скорее всего тоже лишние, для выравнивания достаточно небольшого V-образного треугольника-вкладыша посередине. Если смайстырить насадку на объектив из зеркал вида / ? \ то можно обойтись одной хорошей камерой. Разрешающей способности при хорошем свете (чтобы не зернило и без шевелёнок) хватит более чем у большинства современных железок. Есть варианты как покрутить вспышку камеры «в потолок» или надеть на неё что-нибудь матовое, чтобы получить равномерное заполнение.
Что касается мыльниц Canon, есть смысл попробовать CHDK накатить, вроде там должна быть опция предварительного поднятия шторки — так будет снимать чуть дольше, но в условиях плохого света меньше будет сказывается шевелёнка на больших выдержках. Ну и делать штатив максимально тяжёлым и устойчивым. Эффект шевелёнки может проявляться даже если снимаете с пультом, достаточно хорошего сквозняка, пройти мимо стола (если пол не бетонный) и, опять же, срабатывающей шторки в камере.
В общем есть над чем подумать, чтобы оцифровать свой скарб
klirichek
Ну дык это ж не истина в последней инстанции.
Я, например, если надумаю повторять — сразу возьму светодиодный свет, причём с линейным драйвером.
Стёкла при раскладке — они дёшево и сердито решают проблему точной фиксации (разные мелкие вкладыши — да, можно. Насадку на объектив — тоже можно. Но это всё добавляет лишних деталей к модели "тук-тук — и в продакшн").
В общем, "немецкий дед" сделал те самые необходимые 20% работы, которые дают 80% результата.
Дальше получится лучше, но уже качественных улучшений не будет.
amaksr
С 90 градусами будет постоянная помеха в виде отражения другой страницы в районе соединения стекол. Угол надо делать тем больше, чем ближе фотоаппарат к странице.
prohfessor
А как сейчас относятся библиотекари к сканированию книг? Лет 8 назад, в московских архивах было строго-настрого запрещено фотографировать. Либо переписывайте вручную, либо заказывайте пересьемку в библиотеке. И ладно бы с неадекватной ценой. Это же еще и время — 2-3 дня, что сильно критично в командировках.
В 1998 году (помните кризис?) выиграл грант Сороса на создание сайта. Нам на двоих выдали 7000$. Несмотря на советы друзей, потратить эти деньги на что-нибудь полезное (квартиру там купить, или машину), на свои 3500$ купил цифровой фотоаппарат и ноутбук. Тогда еще ограничений по фотографированию в архивах еще не было. До сих пор помню, как на меня, со слезами на глазах, смотрели завсегдатаи архивов, переписывавшие все вручную. Сайт, кстати, до сих пор живой :-) info.irk.ru/kbrr/index2.htm
steanlab Автор
Библиотекари относятся нормально. По крайней мере в общих фондах. В «редкой книге» пересъемка естественно запрещена
n_demitsuri
Теперь в РГБ, например, официально можно фотографировать.
Tropolinarius
Не могу не сказать Вам и Соросу спасибо.
argonavtt
1 фото выглядит как начала того самого фильма
steanlab Автор
:) :) :)
Бигборды такие по всему Минску
fomiash
Должно быть вы не в курсе, по каким причинам книжные магазины переполнены односезонной макулатурой… Как раз по причине быстрой оцифровки чего-нибудь стоящего и безвоздмезного (сейчас я радею за авторов) появления в сети. Поэтому есть два варианта для новых авторов.
1) Много (минимум книга в год) и быстро (сейчас многие издательства не принимают размеры произведений менее 12 авторских листов (12*40 000 знаков с пробелами)). Качество на уровне Донцовой соответственно.
2)В стол, очень медленно, как хобби после основной работы.
В общем если бы не это отступление
то можно было бы подумать, что вы призываете к пиратству) Тоже надеюсь, данное отступление заставит их подумать, что статья бесполезна для их нужд.
steanlab Автор
Что вы, что вы, какое пиратство :) Лайфхак для гика и только :)
В моей практике очень много интересной технической литературы времен СССР. Там авторы были достаточно адекватными и ничего против наличия в сети интернет скан-копии своей книги не имеют.
klirichek
Кроме книг на бумажных носителях бывает много ещё чего интересного.
Например, ноты…
И там да, либо в фотошопе почистить шум, выровнять свет и конвертнуть в 1-бит (и распечатать), либо именно как вы сказали — сфотографировать на телефон, и перенабрать в лилипонде (увы, качественных "файнридеров" для нот не придумали)
fomiash
Ну если только такие ноты, которые у метро раздают бесплатно. Не встречал. Обычно всё, что листается — имеет производителя, авторские права и прочее. Даже брошюрки, где люди в обнимку со зверьём лесным. Если автор/издательство не приняли решение выкладывать в общий доступ, то скорее всего на то есть причины, частично их я описал выше. Отсылка на пользу сканирования старой литературы нисколько не оправдывает инструменты для упразднения новой.
k2m30
Богоугодное дело
klirichek
Хм… "за 5-10 минут оцифровать 600-страничную книгу" — по-моему это фантастика.
За секунду (а тем более за пол-секунды) надо сделать и сохранить снимок, потому что дальше — тут же следующий.
Поверю, если всё уже настроено и выставлено, нужно только листать и нажимать спуск (например, педалью). Но в эти 10 минут, я так понимаю, ещё и подготовка к процессу входит...
steanlab Автор
klirichek: можно настроить автоматический автоспуск каждую секунду, главное приноровиться так переворачивать страницы. Нужен однозначно какой-то фиксирующий уголок для книги.
klirichek
Да, с автоспуском возможно и выйдет.
Но вряд ли чаще, чем раз в секунду (а если перед этим ещё и готовить рабочее место, то надо ещё чаще). Итого 600 страниц — 600 секунд. Это 10 минут чистой съёмки.
Но вот в 5 минут уложиться — ооочень сомневаюсь.
(я последний раз аврально без всяких уголков делал — просто двумя руками держал книгу; в качестве штатива — табурет, фотал на смарт, он лежал на табурете, камера выглядывала за край. Листал и держал руками, спуск на экране нажимал носом...)
steanlab Автор
Что за книга была? :) Или из спортивного интереса?
klirichek
Да, всякие философские книжки на английском и немецком из зарубежной библиотеки.
Штук 5, на полторы тыс. страниц.
Надо было срочно, шеф попросил. "У меня завтра самолёт, мне эти книжки нужно везти-возвращать, а они хорошие". Поэтому ресурс камеры 2x на xiaomi mi 6 пришлось уменьшить на два килоснимка. А потом scantailor, pdfbeads и в конечном итоге вышло 45мб материала. Что для >1000 страниц вполне неплохо!
steanlab Автор
Да, для 1000+ 45 Мб в PDF действительно отличный вариант.
И насчет ресурса камеры — вот поэтому я зеркалку и не использую :)
amaksr
О, я тоже когда-то делал книжный сканер. Проблема выравнивания, фокусировки и устранения искажений толстых книг была решена тем, что книга лежала в люльке на резинках, а опускаемое на нее V-образное стекло опускалось всегда в постоянную позицию. Все это фотографировалось 2-мя мыльницами, доработанными проводными кнопками, загружалось в самописный софт, которые давал на выходе PDF с исходным изображением + совмещенный с ним невидимый OCR-слой. И да, скорость оцифровки могла запросто доходить до 1 страницы в секунду.
klirichek
1 страница в секунду — это в смысле уже готовая (с ocr-слоем) страница в финальном pdf, или просто снятие первички?
amaksr
Снятие первички. Обсчет pdf-а теоритически можно было делать параллельно, но на тот момент не было надобности экономить минуты, поэтому считалось все уже после, в автоматическом режиме.
zartarn
OpticBook 3600 недавно за 5к отдавали. Взял бы да сканировать в таких объемах больше не нужно. Коретка в обе стороны проезжает быстрее чем ты успеваешь поднять книгу и перевернуть страницу
Так же ничто не мешает спилить край у обычного сканера, надо только найти подходящий где это можно сделать. На авито встречались.
А где тут DIY? Телефон к штативу прикрутили?
У ScanKromsator порог вхождения, но возможности шире чем у ScanTailor. Так же ScanTailor есть несколько версий о чем Вы даже не упомянули — на данный момент активно развивается Advanced.
А это вообще кусок мамонта, профили от него уже 100 лет как раскурили, и есть DjVu Small Mod куда легче и удобнее.
steanlab Автор
zartarn спасибо огромное за замечания (особенно, про DjVu Small Mod). Отчасти поэтому и написал на Хабр, чтобы услышать актуализированные мнения.
Ну и это, а чем вам мой телефон не нравится? Размер матрицы то у него, как у мыльницы :) Не говоря уж про ручные настройки в CameraPro. (/зеркалкой не фотографировал/). По вашей ссылке не нашел ничего нового, что бросило бы камень в огород моего метода. Ну кроме отсутствия света, дааа %) НО! Ключевой момент с цитируемого сайта:
Моя статья относится именно к сканированию Ч/Б технических книг, и здесь разрешение снимка наверное самый главный фактор.
Насчет twirpx. Максимум что мне приходилось переделывать — резать сплошные страницы. Ну и еще перегонять сугубо текстовые книги из PDF в FB2.
zartarn
Да, если вы сканируете художку и подобное, где пропашвий штрих/точка не критичны, то да, можно фоткать.
Если есть формулы то я бы не стал, DjVu кодеры и на хороших то сканах их порой съедать могут. И да, тут свет более важен, чем контрастнее тем лучше будет. Если что то редкое и возможность только сфоткать, я бы максимум приводил к единообразному размеру и в PDF, чтоб как можно меньше потерь было.
По сканкрамсатору есть большущий сборный туториал о том что вообще в нем можно сделать (но к сожалению там звук плох) www.youtube.com/channel/UCa_qTE3APItrURNZol13t8g но это просто кладезь. Ни в одной туториале нет этого всего). Инструмент сильно сложнее. ST делался для домохозяек с минимумом настроек, а SK с точностью до наоборот.
По приведению сканов в порядок в фотошопе, и вообще фотошоп как инструмент для работы со сканами, есть отдельный хороший плейлист www.youtube.com/playlist?list=PLtX2JBh28dABhvKs2ae3P0bod31I_dMWO
klirichek
фотошоп для сканов?..
Ну, если один-два-десять, норм.
Если сотни однотипных страниц — да ну нафиг…
Тогда уж декомпозировать задачу, и скриптовать в ImageMagick.
zartarn
Ну как на видео видно — вполне себе. Тем более если сканы однотипные, макросами все неплохо автоматизируется.
Я так то тоже не сторонник, просто для общего развития подкинул, что и так можно. Автор роликов вполне немало книг таким образом сделал :) А так, есть у меня сканы в загашнике, там либо SK, либо в фотошопе мучаться, еще не решил. Когда нибудь может займусь.
П.С. Раз уж тут, не допиливали скрипт? :)
klirichek
Вот сейчас до конца года 20 дней отпуска надо утилизовать.
Скорее всего этим и займусь. Тем более, благодаря распродаже "день друга" есть практически халявная RubyMine.
(возможно, даже пост сделаю. Для очень многих "электронных архивариусов" djvu стал своего рода священной коровой. И то, что в pdf нынче можно сделать практически то же самое, для многих оказывается открытием).
steanlab Автор
С нынешними объемами жестких дисков, все можно гнать в «Фото» (из моего любимого DEE наиболее lossless )
zartarn
Раз уж вы фотографируете, купите стекло, да несколько шпилек, и сделайте нечто подобное. Один раз выставляете фокус, а потом только со страницы на страницу переставляете да фоткаете. Делал себе нечто подобное когда художку цифровал.
steanlab Автор
zartarn отличная приспособа, но книги бывают разных размеров, + не всегда надо фоткать постранично (в плане целесообразности затрат времени). Лично вне штатив и телескопическая штанга очень нравится в плане удобства, единственное, что пока не придумал замену стеклу…
zartarn
t*2 не такая большая плата, за минимум искажений. Проще один раз сделать исходники хорошие, чем потом мучаться вытягивать.
Конструкция копеешная и легко повторяема, в разобранном виде занимает минмиум места.
П.С.: комплектный профиль «Фото» в DEE достаточно печальный. Лучше уж в jpeg2000 и в PDF собрать.
steanlab Автор
zartarn: предлагаю в вашу конструкцию рацпредложение, вместо шпилек — трубки LOC-LINE. Жесткость достаточная + четкость регулирования высоты (замена телескопической штанге). Как вам такой вариант? :)
zartarn
Картинки под спойлер прячьте.
Жестькость недостаточная, за стекло поднимать неудобно. А на шпильках, если вы видете фото, имеется ручка. за ручку всю конструкцию поднимаем, переставляем, перелистываем, прижимаем когда надо сильнее. С данным вариантом так не прокатит.
steanlab Автор
Вы работали с такими трубками? У меня из них собран монтажный столик «третья рука». Запросто поднимается вместе с закрепленными платами. Очень жесткий пластик.
SandroSmith
vconst
ПДФ можно прочитать в чем угодно, хоть дефолтными средствами, хоть в браузере, хоть в бесплатном и общедоступном Адоб Ридере. Его можно затолкать в распознавалку, хоть в ФР, хоть в любой онлайновый сервис.
Дежавю старое чудовище, которое навскидку не пойми чем посмотреть, ни одна современная программа или сервис с ним нормально не работает.
zartarn
Для винды — WinDjvu, для андроидов почти сразу в первой же строке поиска. 2 нормальные читалки, кушают и PDF и DjVu.
PDF — 1993, DjVu — 1996, ну и кто древнее?
PDF Не менее старое чудовище, еще и с кучей версией формата и со своими проблемами. Адобридер тоже то еще монструозное неповоротливое чудище.
«Хоть в браузере» — это надо уточнять в каких, не все такими же пользуются.
Я молчу про удобный софт для готовки PDF и все прелести при создании CS.
Вы хоть представляете отличие обычного PDF и A-PDF?
Я в вашем же стиле могу продолжать еще долго. Всё это очень субъективно.
vconst
А кроме винды и андроида есть макинтошы, иос и линукс. Каким бы чудовищем ни был ПДФ, он поддерживается почти везде на уровне системы, есть тонны сервисов для работы с ним онлайн, в том числе распознавание текста или его редактирование.
А для дежавю есть полторы штуки калечного софта, ваяемого на коленке парой энтузиастов, половина из которого уже годами не обновляется. Онлайн-сервисы при виде дежавю начинают ругаться неведомыми словами.
Если я выложу на файлопомойку или отправлю по почте кому угодно ПДФ — его просмотрят без всякого труда. Даже если человек не работает с пдф каждый день, он, как минимум, в курсе существования этого формата, любой поисковик наведет его на тысячи способов работы с пдф. Если человеку далекому от истории электронного книгоделания (то есть любому, ибо не факт что хотя-бы 1 из 1000 понимает в этой теме), отправить дежавю — то файл будет выкинут в помойку.
Я искренне изумлен, что кому-то надо объяснять такие очевидные вещи.
zartarn
На линуксе DjVu Тоже из коробки, в том же самый Ubuntu.
Слишком громкие слова. В винде только в 10ке в Edge стало открываться сразу, но не все Edge оставляют.
Опять слишком громкие слова.
но которые из года в год прекрасно выполняют свою функцию.
а с DjVu значит нет? ну загуглите «разобрать PDF на страницы», найдете десяток сайтов которые отдадут жепег и всё, и только на Н-ой страницы выдачи встретите как это сделать на пк (причем под виндой, про мак линукс я вообще молчу).
Значит человеку он изначально не нужен был. Обычно в помойку полетит «ужасноприготовленый файл» независимо о формата, но никак не из за формата.
Большинство читает книги в doc, и что, теперь все остальные форматы в помойку?
Вы пол флибусты в свое время заспамили своими объяснениями «очевидных вещей», но почему то вам там не рады (и не только там). Неужто все вокруг неправы один Вы Д'Артаньян?)
vconst
Есть простой факт.
С ПДФ работать легко и просто. Куча программ генерит ПДФы из коробки, этот формат без всяких проблем понимается облачными сервисами, Дропбокс, Гуглодиск, всякие Ворды-Эксели любят его почти как родного. ПДФ вызывает никаких сложностей в плане открыть-посмотреть.
Количество программ и сервисов понимающих Дежавю — на много-много порядков меньше. Вот и все.
И перестаньте хамить.
zartarn
На самом деле, мне абсолютно плевать кому что там удобно. То, что я сканирую, я сканирую в первую очередь для себя и так как мне удобно. И мне удобнее DjVu — буду его делать. Если будет доделан скрипт который пересобирает DjVu в качественный PDF (DjVuToy с малоцветкой порой ужас что творит), буду прикладывать к DjVu и PDF'ку, чтоб не заливали потом на либген херню сделаную через виртуальный принтер. Если нет исходников, из сканов собрать заметно хороший PDF сложнее чем DjVu.
vconst
zartarn
А я нигде не топил за «дежавю наше все и за ним будущее», это вы реагировали на мои слова как будто я топлю. Я всего лишь говорил что у пдф проблемы тоже имеются, и с дежавю работать проще и удобнее. Ну и как следствие хороший DjVu из сканов больше чем хороших PDF. (я не говорю про случаи когда тот или иной формат исопльзуют просто как контейнер).
А вот вы во всех темах на хабре посвещеные сканированию книг ведете себя как огалтелый фанатик ;).
vconst
zartarn
ZverDVD в свое время по умолчанию ставил WinDjVu и неплохо так популязовал это дело. О формате уже знает достаточно много, и люди наконец то научились у гугла спрашивать о расширениях файлов. Последний раз я встречал вопрос «Как открыть», лет 5 назад)). К epub'ам было больше вопросов до Win10
vconst
ZverDVD
А, так вот в чем дело. Нет, я с этой адово помойной сборкой никогда не имел дела. Не ко мне.
steanlab Автор
Тот самый обычный человек абсолютно так же удалит и PDF, не пытаясь с ним разобраться. Особенно если у него Win 7 на борту, а то и ХP (зачем обычному человеку новые windows, работает и хорошо, а сисадмин обычному человеку ставить новое не будет, дабы себе не усложнять жизнь с обучением работе).
vconst
Ну давайте еще Хрю вспомним, пожалуемся, что DOS 3.3 его не понимает.
Еще раз…
PDF — формат, который постоянно на слуху. Сложно найти человека, который про него не слышал и не сталкивался. Его хоть и давно придумали, но распространенность и поддержка у него практически абсолютная.
Если человеку придет ПДФ — то веб-морда гмейла его предложит открыть прямо в самом движке, а также сохранить его на гуглодиске, который пдфы показывает без всяких костылей — сам. Почтовые клиенты давно уже отлично показывают пдфы собственными встроенными средствами и тд и тп тд тп.
Дежавю и близко не приближается к популярности и распространенности пдф.
steanlab Автор
Я не спорю с кросс-платформенностью pdf и очень уважительно к этому формату отношусь. И да, pdf можно прочитать везде, начиная от Symbian и WinCE и заканчивая всевозможными unix-ами. Но практически везде утилиты (особенно opensource) — одинаково переваривают и pdf, и djvu. Почему? :)
Кстати подумал про openwrt. Можно ли прочесть pdf на роутере через SSH, через framebuffer какой или т.п.?
vconst
Есть такие то странные программы для чтения ПДФ из текстовой консоли, но зачем?
Опенсорц это хорошо, но поддержка в Ворде или Гуглодрайве куда важнее.
steanlab Автор
zartarn Поддерживаю вас в защиту DJVU. Несмотря на «однокнопочность создания», которая пришла с последними офисами и «де-факто для документооборота», экспорт тот же самый простенький нужной страницы сделать очень тяжело. В отличие от «древнего» DJVU. Иногда именно это решает.
vconst
Бликовать будет. Уже на этой превьюшке видны блики и отражения.
zartarn
vconst всегда такой vconst %) При освещении сбоку все хорошо и без бликов.
vconst
zartarn
Увы, кажется Вы продолжаете %) Все решается освещением! И блики и отражения и прочее. И не просто силой его, а еще и положением. Вы кажется вообще не в теме фотосъемки.
Я это делал года 3 назад, примеров не осталось, но всё хорошо было. на флибусеках мои сканы обрабатывали, никто и не знал что они на камеру)).
П.С.: про сканы в голом виде в djvu/pdf — надо руки отрывать)
vconst
//рукалицо
Не может взрослый человек не знать, чем отличается отражение от блика. Никакими заморочками со светом — нельзя убрать отражения самой растопырки и камеры на ней. Вообще и никак. И эти отражения видны на фото. Если кому-то кажется, что они не видны — продолжать бесполезно.
Скан с планшетника на порядки уменьшает количество ошибок распознавания, в отличии от фотографий.
Сканы в голом виде — это то, о чем написана эта статья.
zartarn
Если вы не умеете фоткать без бликов и отражений, не значит что другие не умеют.
Что скан с обычного самого дешевого сканера будет лучше — это неоспоримо, тут и говорить не о чем. Но мы обсждаем все тут именно фотографирование.
С статье не в голом видео, а после скантейлора.
vconst
Откройте то фото стеклоштатива, которое постили выше и найдите в нем отражения камеры и распорок. Их видно? Да. Можно сделать снимок так, чтобы их не было видно? Нет.
zartarn
Вы это серьезно? Да? лол.
Фото сделано с другой камеры внешне, под другим углом, при никаком освещении. Конечно тут видно что там в стекле что то отражается. Фото всего лишь чтоб показать конструкцию.
Можно сделать снимок с закрепленой камерой так чтоб ничего из этого небыло на снимке страницы. Еще раз, то что вы не умеете, и не волокете в данной теме ничего, это не значит что другие такие же.
vconst
Может хватит уже?
Сделать снимок так, чтобы камера не отражалась в зеркале — можно только двумя способами: снять со стороны и потом выправить в фотошопе геометрию; снять со стороны с объективом позволяющим манипулировать наклоном и сдвигом. Ну или просто адово выфотошопливать камеру из картинки. В этом девайсе нет ничего подобного.
Снять зеркало так, чтобы в нем не отражалась камера, фокальная плоскость которой находится параллельно плоскости зеркала, а ее проекция по нормали попадает на зеркало — физически невозможно.
DIXI
zartarn
Как всегда передергиваете.
Чтоб стекло было зерклом, надо соблюдать условия, которые вполне можоно обойти.
vconst
Не в этом случае.
RumataEstora
steanlab Автор
ну это ж краундфаундинг, там и не такое писали %)